Temporal Credit Is Free
Recurrent networks do not need Jacobian propagation to adapt online. The hidden state already carries temporal credit through the forward pass; immediate derivatives suffice if you stop corrupting them with stale trace memory and normalize gradient s…
Authors: Aur Shalev Merin
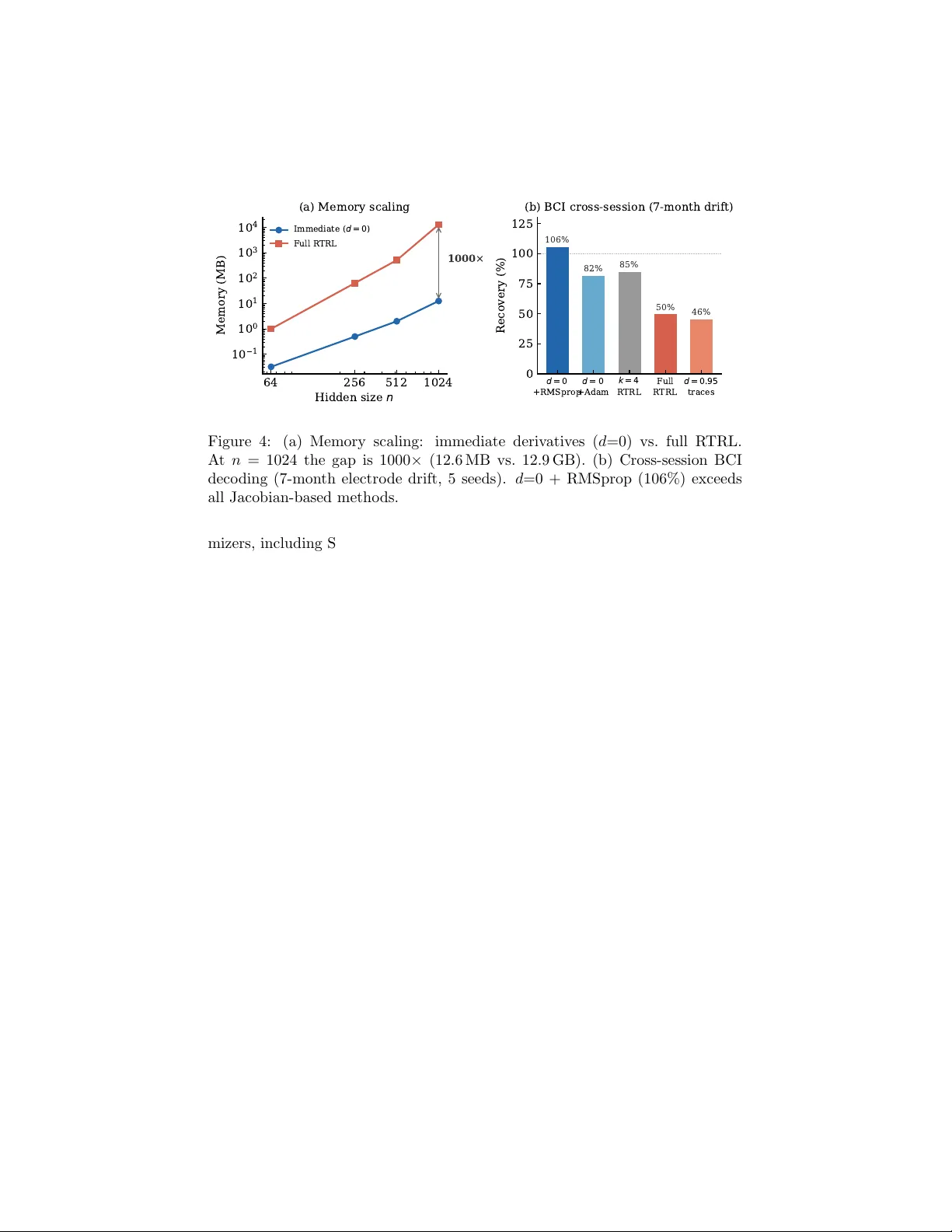
T emp oral Credit Is F ree Aur Shalev Merin Marc h 2026 Abstract Recurren t net w orks do not need Jacobian propagation to adapt online. The hidden state already carries temporal credit through the forward pass; immediate deriv ativ es suffice if you stop corrupting them with stale trace memory and normalize gradient scales across parameter groups. An arc hitectural rule predicts when normalization is needed: β 2 is required when gradien ts m ust pass through a nonlinear state update with no output b ypass, and unnecessary otherwise. Across ten arc hitectures, real primate neural data, and streaming ML b enchmarks, immediate deriv ativ es with RMSprop match or exceed full R TRL, scaling to n = 1024 at 1000 × less memory . 1 In tro duction T raining recurren t net works online means assigning credit across timesteps: ho w did past inputs affect the curren t error? The standard answ er, real-time recur- ren t learning [Williams and Zipser, 1989], propagates a Jacobian tensor forward through the netw ork’s dynamics at O ( n 4 ) cost p er step. Thirt y y ears of work since then has tried to mak e this cheaper. Ev ery approac h assumes the Jacobian term carries gradien t information y ou cannot get an y other w a y . W e revisit that assumption. It is not needed. The hidden state already carries temp oral credit through the forw ard pass. The immediate deriv ativ e, computed through that state, is enough for online adaptation. Eligibilit y traces fail for t w o reasons: the standard decay rate (0.95) ov erw eigh ts stale gradients by 85 × relativ e to the true propagation factor, and without p er-parameter normalization, recurrent weigh t up dates get dro wned out by output gradien ts that are 100 × larger. Adam’s β 2 partially compensates for bad deca y (18% recov ery vs 0% for SGD), but full adaptation requires b oth corrections (T able 1). W e mak e four claims, each tested indep enden tly: • Eligibility traces fail b ecause of t w o miscalibrations, not b ecause they lac k the Jacobian. The standard decay (0.95) ov erweigh ts stale gradien ts b y 85 × relative to the measured self-propagation factor, and uniform learning rates cannot bridge the 100 × gradien t scale gap betw een recurrent and output parameters. 1 T able 1: Reco very (%) on sine frequency-shift task ( n = 64, 5 seeds). Reco very is defined as ( M frozen − M post ) / ( M frozen − M R TRL ), where M is p ost-shift MSE; v alues ab o ve 100% mean the metho d outperforms full R TRL. Tw o factors in- teract: trace deca y and optimizer. Adam partially compensates for bad deca y (18%) but full adaptation requires both corrections. SGD Adam λ = 0 . 95 (standard) 0% 18% λ = 0 . 0 (ours) − 1% 102 % • Correcting b oth (zero decay , β 2 normalization) recov ers full R TRL perfor- mance without any Jacobian computation. On c haotic dynamics and real BCI data, it b eats full R TRL in both accuracy and stabilit y . • An architectural rule predicts when β 2 is needed: it is necessary when adaptation m ust flo w through a nonlinear or m ultiplicative state update, and unnecessary when the architecture provides a parallel output path. The rule holds across nine architectures (T able 3) plus a ten th (LeWM transformer) ev aluated via gradien t diagnostics. • The metho d scales to n = 1024 at 1000 × less memory than R TRL (12.6 MB vs 12.9 GB). Online LoRA adaptation with β 2 ac hieves 21–134% recov ery on five pretrained language models from 124M to 7B parameters, single- pass, no replay . Rank-16 adapters reach 136.8% recov ery . SGD with iden tical adapter capacit y sho ws zero adaptation everywhere. 2 Bac kground Online learning in recurren t netw orks requires computing the gradient of a streaming loss with resp ect to mo del parameters at eac h timestep. Real-time recurren t learning [Williams and Zipser, 1989] do es this b y maintaining a sen- sitivit y tensor P t = ∂ h t /∂ θ , updated recursiv ely as P t = J t P t − 1 + ∂ h t ∂ θ direct , (1) where J t = ∂ h t /∂ h t − 1 is the state Jacobian. The J t P t − 1 term propagates credit from past timesteps. Computing it costs O ( n 4 ) p er step for a netw ork with n hidden units, which has limited R TRL to small net works and motiv ated thirt y y ears of appro ximation methods. Eligibilit y traces [Murray , 2019, Bellec et al., 2020] av oid this cost by replac- ing J t with a scalar or diagonal appro ximation: e t = λ e t − 1 + ∂ h t ∂ θ direct . (2) 2 The deca y λ (t ypically 0.95) is meant to appro ximate the fading influence of past timesteps. This reduces cost to O ( n 2 ) but discards most of the recurrent comp onen t of the gradien t. The resulting traces are biologically motiv ated and computationally c heap, but they fail to adapt to distribution shifts in practice, a failure typically attributed to the missing Jacobian term. Adam [Kingma and Ba, 2015] maintains a p er-parameter running estimate of squared gradient magnitudes: v t = β 2 v t − 1 + (1 − β 2 ) g 2 t . Eac h parameter up- date is then normalized b y √ v t , whic h equalizes effective learning rates across parameters with different gradien t scales. In standard usage this is a training con venience. In recurren t net works, where nonlinear activ ations compress re- curren t gradients to be orders of magnitude smaller than output gradients, this normalization has a more specific role that w e iden tify in Section 4. 2.1 Related work Since Williams and Zipser [1989], online recurrent learning has fo cused on com- puting or approximating the Jacobian pro duct J t P t − 1 : exact metho ds at O ( n 4 ) [Williams and Zipser, 1989], rank-1 compression at O ( n 2 ) [T allec and Ollivier, 2017], optimal Kroneck er-sum approximation at O ( n 3 ) [Benzing et al., 2019], graph-structured sparsit y for weigh t-sparse netw orks [Menick et al., 2021], diag- onal recurrence exploited for efficiency [Zucc het et al., 2023], and architectural elimination of inter-neuron recurrence [Irie et al., 2024]. Marschall et al. [2020] pro vide a unified taxonomy . These metho ds span four orders of magnitude in cost but share an assumption: the J t P t − 1 term carries gradient information that cannot be reco vered from the immediate deriv ative alone. Murra y [2019] and Bellec et al. [2020] to ok a different approac h, dropping J t and retaining only immediate deriv atives with a scalar or diagonal deca y . This is equiv alen t to our deca y > 0 baseline. Their methods are neurally plausible and cheap, but neither identified the t wo factors that mak e immediate deriv a- tiv es sufficien t: Murray uses λ = 0 . 9, whic h o verw eights stale gradien ts relativ e to the true propagation factor, and neither method uses p er-parameter gradi- en t normalization. With these corrections (deca y = 0, β 2 ), the approach they pioneered matc hes or exceeds full R TRL. P er-parameter adaptiv e learning rates [Kingma and Ba, 2015] are w ell un- dersto od for batch training. Their role in online recurren t learning has not b een examined. W e show that second-moment normalization is not a training con- v enience in this setting but a necessary correction for a sp ecific architectural problem: the gradient scale mismatch that nonlinear recurrences create b e- t ween parameter groups. This connection betw een optimizer design and online recurren t adaptation is, to our knowledge, new. Concurrent w ork on test-time training [Sun et al., 2024, Aky ¨ urek et al., 2026] adapts mo del weigh ts during in- ference via gradien t up dates, ac hieving context compression and long-sequence efficiency . These methods use Adam but do not examine why p er-parameter normalization is necessary . Our findings explain why: without β 2 , the gradient scale mismatch b etw een parameter groups prev ents adaptation (SGD achiev es 0% reco very across all configurations tested). 3 3 The trace deca y mismatc h The standard explanation for wh y eligibilit y traces fail is that they discard the Jacobian term J t P t − 1 , losing the recurrent comp onen t of the gradient. W e prop ose a simpler explanation: the trace decay is miscalibrated. The starting p oin t was an accident. In prior w ork on sparse Jacobian trans- p ort [Shalev Merin, 2026], a sweep ov er sparsity lev els found that propagating a single random Jacobian column ( k = 1) recov ers 86% of full R TRL p erformance at n = 64. Due to the ring mask implementation, k = 1 pro duces an empty propagation mask, meaning it computes only the immediate deriv ative with zero Jacobian propagation. If zero temp oral propagation recov ers most of the signal, wh y do standard eligibility traces, whic h also lack full Jacobian propagation, fail? In a trained v anilla RNN with hidden size 64, we measured the p er-neuron self-propagation factor: diag(1 − h 2 t ) · diag( W hh ), av eraged o ver timesteps. This is the rate at whic h eac h neuron’s o wn past v alue influences its presen t through its recurren t self-connection. The measured v alue is approximately 0.01 per step. (The sp ectral radius of the full Jacobian D t W hh is higher, t ypically 0.37–0.93, b ecause cross-neuron interactions con tribute additional propagation. But scalar trace decay is a p er-neuron approximation: it applies one λ to eac h neuron’s trace indep enden tly , without mo deling cross-neuron coupling. The diagonal, not the sp ectral radius, is the right quantit y to compare it against.) With λ = 0 . 95, information from 10 steps ago is w eighted at 0 . 95 10 ≈ 0 . 60 b y the trace, while its true p er-neuron influence is 0 . 01 10 ≈ 10 − 20 . The p er-step o verw eighting is 85 × (0 . 95 / 0 . 01), and the cum ulative gap grows exp onentially with horizon. This is not a subtle discrepancy . At timestep 500 in a trained netw ork, the accum ulated trace ( λ = 0 . 95) is 6.7 times larger in magnitude than the immedi- ate deriv ative and p oin ts in a differen t direction (cosine similarit y 0.577). The trace do es not pro vide useful temp oral credit. It provides stale gradient infor- mation at wildly incorrect scale. The immediate deriv ative, computed through h t − 1 whic h already encodes the full history of inputs through the forw ard pass , is both more accurate and more relev an t. Figure 1 shows the consequence. W e sw eep trace deca y from 0.001 to 0.95 on a sine frequency-shift task at tw o scales ( n = 64, n = 256, five seeds each), all with Adam ( β 1 = 0 . 9, β 2 = 0 . 999). At b oth scales, deca y v alues from 0.001 to 0.5 pro duce successful adaptation (102–130% recov ery at n = 64, 163–200% at n = 256). Recov ery exceeding 100% indicates the adapted mo del outp erforms the full R TRL reference on the target distribution, whic h o ccurs when full R TRL is itself unstable or when the simpler gradient acts as implicit regularization. Deca y 0.95 pro duces exactly 0% recov ery on every seed at every scale. The transition b et ween w orking and failing is sharp: decay 0.7 shows high v ariance (77 ± 56% at n = 64), indicating seed-dependent threshold behavior, while deca y 0.5 works reliably (130 ± 8%). The entire region below 0.5 is a safe plateau; the standard default of 0.95 sits on the wrong side of a cliff. The optimal decay v alue is not zero ev erywhere. A t n = 64, decay 0.5 outp erforms decay 0.001 b y 28 p ercentage p oin ts (130% vs 102%), likely due 4 1 0 3 1 0 2 1 0 1 1 0 0 T r a c e d e c a y 0 50 100 150 Recovery (%) standard default ( a ) n = 6 4 1 0 3 1 0 2 1 0 1 1 0 0 T r a c e d e c a y 0 100 200 300 standard default ( b ) n = 2 5 6 Figure 1: Reco very vs. trace decay on a sine frequency-shift task (5 seeds, mean ± 1 std). The standard default ( λ = 0 . 95) pro duces 0% recov ery at b oth scales. V alues below 0.5 form a safe plateau. The optimal deca y decreases with netw ork size: at n = 256, all v alues ≤ 0 . 5 are statistically indistinguishable. to a mild regularization effect from residual trace memory . A t n = 256, this adv antage disappears: error bars ov erlap across the en tire d ≤ 0 . 5 range. The optimal deca y decreases with net work size, and at scales that matter for practice ( n = 256 and ab o ve), zero is indistinguishable from any other v alue in the safe range. W e recommend zero as the default b ecause it requires no tuning and w orks at every scale tested. Its interpretation is direct: use the immediate deriv ative and let the hidden state carry temp oral information through the forw ard pass. The pattern holds on real data. On cross-session BCI data from primate reac hing exp erimen ts, using Adam, deca y 0.0 achiev es 74% recov ery , decay 0.5 ac hieves 82%, and decay 0.95 ac hieves 46%. On BCI data, small nonzero de- ca y provides a marginal benefit (82% vs 74%), consistent with slow er neural dynamics where short-term trace memory is helpful at 50 ms time bins. Zero deca y still passes the adaptation threshold on all seeds. On a c haracter-level language task (Shak esp eare to Python domain shift), decay 0.0 matc hes BPTT to three decimal places (cross-en trop y 2.716 vs 2.718). On chaotic dynamics (Lorenz attractor), decay 0.0 reco v ers 113% while deca y 0.95 recov ers 0%. The pattern is consistent: low or zero deca y w orks, the standard v alue fails. 4 The role of gradien t normalization Correcting the trace deca y is necessary but not sufficien t. With decay set to zero, SGD reco vers − 1% (T able 1), no b etter than a frozen mo del. The immediate deriv ative is now correct in direction, but SGD cannot use it. The problem is gradien t scale. In a trained v anilla RNN ( n = 64), we measured the mean gradien t norm for 5 SGD SGD+ mom. 1 - o n l y RMSprop 2 - o n l y Adam 50 0 50 100 150 200 Recovery (%) ( a ) O p t i m i z e r i s o l a t i o n ( d = 0 . 0 ) Sine Delayed N o 2 H a s 2 W h h W o u t 1 0 3 1 0 2 1 0 1 Gradient norm 1 0 0 × (b) Gradient scale Figure 2: (a) Optimizer isolation with immediate deriv atives ( λ = 0). Only metho ds with second-momen t normalization ( β 2 ) adapt. Momen tum ( β 1 ) adds nothing. (b) Gradien t norms by parameter group in a trained v anilla RNN ( n = 64), sho wing the 100 × scale mismatch b et w een recurrent and output w eights. T able 2: Optimizer isolation: recov ery (%) with immediate deriv atives ( λ = 0). Only methods with β 2 adapt; momen tum alone adds nothing. Optimizer Sine Dela y ed ( t +50) SGD − 34 − 58 SGD + momentum 12 − 59 Adam β 1 -only − 34 − 58 RMSprop ( α = 0 . 99) 91 179 Adam β 2 -only 33 167 Adam (full) 102 147 eac h parameter group during online adaptation. The recurrent w eight gradien ts ( ∂ L/∂ W hh ) are appro ximately 100 times smaller than the output weigh t gradi- en ts ( ∂ L/∂ W out ). This is a direct consequence of the activ ation function: the tanh deriv ative (1 − h 2 t ) compresses gradients flo wing through the recurrence, while the output path is a direct linear pro jection with no compression. SGD applies the same learning rate to both groups, so recurrent w eight updates are 100 times smaller in effective magnitude than output up dates. The netw ork adapts its output mapping but cannot adjust its dynamics. T able 2 isolates the mec hanism using BPTT with a window of one step. This computes the same immediate deriv ativ e as λ = 0 traces but through PyT orch autograd, which includes gradien t clipping and the full single-step computation graph. The difference is substantial: with autograd, SGD learns pre-shift (MSE ≈ 0 . 03) but fails to adapt ( − 34%), while with man ual traces SGD never learns 6 at all (pre-shift MSE ≈ 0 . 5, recov ery − 1% in T able 1). The autograd results are more informative because they isolate the adaptation failure from the training failure. W e trained v anilla RNNs under six optimizer configurations so that the only v ariable is the optimizer. The pattern is unambiguous. Every con- figuration with second-momen t normalization ( β 2 ) adapts. Every configuration without it fails. Momentum ( β 1 ) av erages gradient direction ov er time, which is the closest thing to temporal credit assignment that an optimizer provides. It adds nothing: β 1 -only recov ery ( − 34%) is iden tical to raw SGD ( − 34%). The mec hanism is p er-parameter scale normalization, not temp oral av eraging of any kind. RMSprop ( α = 0 . 99) outperforms full Adam on the dela yed task (179% vs 147%), confirming that β 2 alone, without momentum or bias correction, is the activ e component. The Adam-to-SGD con trol (switc hing optimizer at the shift with a pre-trained mo del) c onfirms this is ab out adaptation, not training: SGD ac hieves only 6% recov ery with a fully conv erged mo del, while Adam achiev es 100% and β 2 -only ac hieves 93%. With miscalibrated deca y ( λ = 0 . 95), even Adam achiev es only 18% recov ery: β 2 partially comp ensates for stale traces but cannot fully ov ercome them. A p ossible ob jection is that β 2 ’s running second moment ( v t = β 2 v t − 1 + (1 − β 2 ) g 2 t , with an effective windo w of ∼ 1000 steps at β 2 = 0 . 999) is itself a form of temp oral credit propagation through a differen t c hannel. W e can test this directly . W e trained a mo del to conv ergence with Adam, then switched the optimizer to SGD at the distribution shift, k eeping all mo del parameters iden- tical. If the trained mo del’s gradient qualit y is sufficient and only the optimizer matters at adaptation time, SGD should work with a conv erged mo del even if it cannot train from scratch. It do es not: recov ery is 6%. The same switc h to Adam yields 100%, and to β 2 -only yields 93%. The mismatc h is not ab out what the mo del learned during training. It is ab out what the optimizer do es at each adaptation step: normalizing g t / √ v t equalizes effectiv e learning rates across parameter groups with different gradient scales. This is scale calibration, not credit assignmen t. The gradient scale mismatc h in v anilla RNNs arises specifically from tanh compression. An y nonlinear activ ation that differen tially compresses gradien ts through the state up date should pro duce a similar mismatch. W e test this prediction across architectures in the next section. 5 Cross-arc hitecture generalization The trace decay and gradien t scale findings were established on v anilla RNNs. If the underlying cause is arc hitectural (nonlinear activ ations compressing recur- ren t gradients), the same pattern should app ear in any architecture with non- linear state up dates and disappear in architectures that pro vide an alternative adaptation path. W e tested this across ten architectures. T able 3 summarizes the results. The arc hitectural rule can b e stated precisely: p er-parameter gradient nor- malization is necessary for online adaptation when tw o conditions hold simulta- 7 T able 3: Cross-architecture β 2 requiremen t on sine frequency-shift task (5 seeds unless noted, BPTT w =1 gradients; see Section 4 for comparison with man ual traces). Architectures without an output b ypass sho w large Adam/SGD gaps; arc hitectures with a bypass show no gap or inv erted b eha vior. ‡ R WKV sho ws in verted b eha vior on Lorenz: all β 2 -con taining optimizers diverge, only SGD surviv es (see text). Arc hitecture Adam/ β 2 SGD Grad. ratio Bypass V anilla RNN 102% − 34% 100 × None LSTM 99.7% 59.4% ∼ 31 × None CTRNN 89.8% − 0 . 1% (=frozen) 278 × None xLSTM (sLSTM) 91.5% 60.0% ∼ 24 × None R WKV ‡ adapts 0% (=frozen) ∞ (zero rec.) None RetNet 93% − 17% ∼ 64 × None V anilla GR U adapts adapts 5–19 × Up date gate SSM (S4) adapts adapts < 6 × C / D output Blo c k-GRU+MLP adapts 50 × better 50000 × MLP output neously . First, the recurrent state update in volv es a nonlinear or m ultiplicative transformation that compresses gradients. Second, there is no parallel output path with sufficient capacity for the mo del to adapt without updating the com- pressed recurrence. When either condition is absen t, SGD suffices. Six arc hitectures confirm the rule on stable tasks (sine frequency-shift). V anilla RNN, LSTM, CTRNN, xLSTM, R WKV, and RetNet all hav e nonlinear or multiplicativ e state up dates and no parallel output path. In eac h case, SGD either fails entirely or p erforms dramatically w orse than Adam, and gradient norm measuremen ts confirm the same pattern: recurrent parameter gradien ts are 100 × to 50,000 × smaller than output parameter gradien ts. The compres- sion source v aries across architectures (tanh saturation in RNNs and CTRNNs, sigmoid gating in LSTMs and xLSTM, multiplicativ e key-v alue interaction in R WKV and RetNet), but the consequence is the same. β 2 normalizes the mis- matc h. SGD cannot. On chaotic dynamics (Lorenz), the rule holds for most architectures but t wo sho w task-dependent b eha vior. xLSTM’s exp onen tial gating allo ws SGD to adapt on Lorenz (100% recov ery , 5 seeds) despite failing on sine (60%, 24 × w orse than RMSprop). R WKV exhibits an in version: on Lorenz, all three β 2 - con taining optimizers (Adam β 2 -only , full Adam, RMSprop) div erge on ev ery seed, while SGD is the only optimizer that surviv es (293% recov ery , zero v ari- ance). Gradient norms explain the mec hanism: under SGD, R WKV’s recurrent gradien ts are literally zero, so SGD effectively freezes the recurrence and adapts only through the output predictor, which has sufficien t capacit y for the Lorenz task. When β 2 normalizes these near-zero recurrent gradien ts, it amplifies them through the m ultiplicative k · v interaction, creating unstable updates on c haotic dynamics. The architectural rule correctly predicts the β 2 requiremen t on sta- 8 40 20 0 20 40 60 80 100 Recovery (%) V anilla RNN LSTM CTRNN xLSTM R WKV RetNet V anilla GRU S SM (S4) Block -GRU +MLP A d a m / 2 SGD Has bypass Figure 3: Adam/ β 2 (circles) vs. SGD (squares) recov ery across ten architectures. Red background: no output b ypass ( β 2 required). Green background: has output bypass (SGD suffices or is b etter). The gap b et ween dots is the β 2 requiremen t. ble tasks; on chaotic dynamics, multiplicativ e state updates can mak e gradien t normalization destabilizing. Standard LSTM is w orth examining separately b ecause its cell state pro- vides a gradient high wa y for backpropagation through time, whic h is the classic mec hanism for a v oiding v anishing gradients. One might exp ect this high wa y to also bypass the gradien t scale mismatch. It do es not. The sigmoid gates (input, forget, output) still compress recurren t gradients, producing a 31 × mismatch b et ween recurren t and output parameter norms. SGD reco very is 59% on sine and 8% on Lorenz (5 seeds, near-zero v ariance). The cell state helps with long- range credit in BPTT but do es not help with gradien t scale normalization in online adaptation. Gated recurrences compress gradients regardless of in ternal memory structure. RetNet has a linear decay built in to its recurrence, which looks like it should pro vide a gradient path that a v oids nonlinear compression. It does not help. The k ey-v alue outer product in RetNet’s state update compresses recurrent gra- dien ts regardless of the linear decay factor. On Lorenz, SGD recov ery is − 17%: not just failing but actively harmful, pro ducing worse p erformance than a frozen mo del. The linear deca y preserves state magnitude but does not preserve gra- dien t magnitude through the m ultiplicative interaction. Three architectures break the pattern. V anilla GRUs adapt under all op- timizers, including SGD. The up date gate z t = σ ( W z x t + U z h t − 1 ) creates a linear interpolation h t = (1 − z t ) ⊙ h t − 1 + z t ⊙ ˜ h t that provides a gradien t path b ypassing the nonlinear candidate computation. The gradient ratio is 5–19 × , small enough for SGD to handle. State space mo dels (S4 v ariant, trained from scratch) adapt under all opti- 9 64 256 512 1024 H i d d e n s i z e n 1 0 1 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 Memory (MB) 1 0 0 0 × (a) Memory scaling I m m e d i a t e ( d = 0 ) Full R TRL d = 0 +RMSprop d = 0 +Adam k = 4 R TRL Full R TRL d = 0 . 9 5 traces 0 25 50 75 100 125 Recovery (%) 106% 82% 85% 50% 46% (b) B CI cross-session (7-month drift) Figure 4: (a) Memory scaling: immediate deriv atives ( d =0) vs. full R TRL. A t n = 1024 the gap is 1000 × (12.6 MB vs. 12.9 GB). (b) Cross-session BCI deco ding (7-month electro de drift, 5 seeds). d =0 + RMSprop (106%) exceeds all Jacobian-based metho ds. mizers, including SGD. The reason is arc hitectural: SSMs hav e a direct output path through the C and D matrices that b ypasses the recurrent state up date ( A , B ) entirely . Gradient norms confirm this. Recurren t parameter gradien ts are near zero, but the model does not need to up date them. Adaptation hap- p ens through the output matrices, whose gradien ts are large and direct. The blo c k-diagonal GRU arc hitecture used in DreamerV3 [Hafner et al., 2024] sho ws a similar bypass through a different mechanism. A tw o-lay er MLP with SiLU activ ation sits b et ween the GRU output and the prediction, pro viding enough capacit y for the mo del to learn a new output mapping from unc hanged GRU states. On Lorenz, SGD outp erforms Adam b y 50 × . The MLP output path pro vides direct, well-scaled gradients that do not b enefit from per-parameter normalization; b oth momen tum and second-momen t normalization degrade per- formance on this architecture. The MLP receives 50,000 times more gradient than the GRU in ternals. W e also measured gradien t uniformity in a pretrained transformer world mo del (LeWM; Maes et al. [2026]), a six-la y er transformer with 16 attention heads and AdaLN conditioning. Within the predictor la yers, gradien t norms v ary by less than 6 × across lay ers, even through 20 autoregressive rollout steps. Residual connections preven t the differen tial compression that mak es β 2 neces- sary in recurren t arc hitectures. This confirms that the β 2 requiremen t is specific to architectures where gradien ts m ust pass through nonlinear state updates with no b ypass. 6 Scaling and real-w orld v alidation T able 4 summarizes the metho d comparison across all tested domains. Im- mediate deriv atives with Adam or RMSprop match or exceed Jacobian-based 10 T able 4: Head-to-head comparison: immediate deriv ativ es ( d =0) vs. Jacobian- based methods across domains. All v alues are recov ery (%) unless noted. “–” indicates not tested in that configuration. † Language ro w rep orts cross-entrop y (lo wer is b etter); b oth methods matc h to three decimal places. Domain d =0 + Adam d =0 + RMSprop k =4 R TRL F ull R TRL Sine ( n =64) 102 73 125 100 Dela yed ( t +50) 147 179 130 100 Lorenz (c haotic) 113 – – 100 BCI (real data) 82 106 85 50 Language (CE ↓ ) † 2.716 – 2.708 – n =1024 378 – – can’t run metho ds on every task, at O ( n 2 ) cost instead of O ( n 3 ) or O ( n 4 ). The mec hanism was established on small net works and synthetic tasks. F our questions follow: do es it scale, do es it w ork on real data, can it compete with existing methods, and does it extend to pretrained models? Scaling. With decay set to zero, the metho d stores only the immediate deriv a- tiv e p er parameter, requiring O ( n 2 ) memory . F ull R TRL maintains the Jaco- bian sensitivity tensor at O ( n 3 ), and sparse R TRL ( k = 4) reduces the constant but not the scaling. A t n = 64, the difference is mo dest (32 KB vs 1 MB). A t n = 1024, immediate deriv atives require 12.6 MB while full R TRL requires 12.9 GB and cannot run on a single GPU. The ratio is 1000 × . Reco very at n = 1024 is 378 ± 76% (five seeds), where the high recov ery p ercen tage reflects the full R TRL reference being unstable at this scale; absolute p ost-shift MSE is more informativ e and sho ws consistent adaptation across all seeds. Decay 0.95 at n = 1024 pro duces 0.54 MSE uniformly across seeds, indistinguishable from a frozen mo del. Real neural data. W e tested cross-session BCI deco ding using primate reach- ing data [O’Doherty et al., 2017], with seven months of real electro de drift b et ween sessions. Ninet y-six electro de channels w ere reduced to 40 PCA di- mensions fit on the source session only . Switching from Adam (82% recov ery in Section 3) to RMSprop ( α = 0 . 99) impro ves reco very to 106 ± 18% across fiv e seeds, with the adapted deco der performing comparably to or exceeding the original deco der on its own session. All five seeds exceed 84%. F or comparison, sparse R TRL ( k = 4) achiev es 85% and full R TRL achiev es only 50%, with t wo of fiv e seeds partially diverging. RMSprop outp erforms Adam on this task (106% vs 82%), consisten t with its shorter effectiv e memory window ( ∼ 100 steps at α = 0 . 99 vs ∼ 1000 steps at β 2 = 0 . 999) b eing better suited to the timescale of neural drift at 50 ms bins. 11 T able 5: Online LoRA adaptation across pretrained LMs (rank-4 adapters, code- to-Wikip edia shift). Adam β 2 adapts at ev ery scale; SGD shows zero adaptation regardless of mo del size or architecture. Mo del Params Adam β 2 SGD GPT-2 124M 21.6% 0.0% Mam ba-130M 130M 51.6% 0.1% Tin yLlama 1.1B 31.6% 0.1% Mam ba-1.4B 1.4B 133.5% 2.4% Qw en2 7B 31 . 3 ± 7 . 3% 0 . 0 ± 0 . 4% Streaming ML b enc hmarks. Online RNNs with deca y 0.0 and Adam can outp erform tree-based streaming metho ds on tasks dominated by con tinuous drift. On a head-to-head comparison using the Hyp erplane generator from the Riv er library [Mon tiel et al., 2021] with parameters matc hing Gomes et al. [2017] (200K samples, 10 features, gradual drift), the RNN ac hieves 0.925 accuracy v ersus Adaptive Random F orest at 0.842 (+8 . 3 pp). T ree ensembles retain their adv antage on tasks requiring spatial partitioning (RandomRBF) and real-world tabular data (Electricity), where gradient-based adaptation cannot compensate for trees’ structural inductive bias. Pretrained language mo dels. The same β 2 requiremen t app ears in pre- trained models through LoRA adapters. W e adapted five pretrained LMs on- line on domain shifts using LoRA adapters with single-pass pro cessing and no repla y . T able 5 sho ws the results across a 56 × scale range. F rom 124M to 7B, SGD achiev es zero adaptation across all mo dels, adapter sizes, and learning rates tested. Adam β 2 ac hieves 21–134% recov ery at rank-4; with rank-16 adapters and 40K tokens, GPT-2 recov ery reaches 136.8% (cross- en tropy 2.744, down from 3.493 frozen). Unlike the from-scratc h arc hitectures in Section 5, the β 2 requiremen t here arises from depth-induced gradien t atten- uation through the frozen backbone rather than nonlinear activ ation compres- sion. Direct measuremen t of LoRA gradien t norms on Mamba confirms this: across 24 lay ers and 3 matrix t yp es, the gradient magnitude ratio betw een the largest group (L23 dt pro j, norm 1.35) and smallest (L15 x pro j, norm 0.026) is 51.8 × . Last-lay er gradien ts are 12 × larger than mid-net work gradients, consis- ten t with depth attenuation. The pattern spans b oth SSM-based (Mamba) and transformer-based (GPT-2, Tin yLlama, Qw en2) architectures, confirming that depth atten uation, not an y particular arc hitecture, drives the mismatch. T o test whether online LoRA adaptation handles multiple sequential domain shifts, we streamed Code → Wiki → Co de → Wiki through GPT-2 with a rank-4 adapter. Adam β 2 adapts to ev ery shift (39% and 26% recov ery on successive Wiki segments) while SGD shows zero adaptation across all four segments. The adapter does not forget: Code B cross-en trop y (1.608) is low er than Code A (1.796), indicating the adapter improv es on return to a previously seen domain. 12 Wiki readaptation is faster on second exposure (shock cross-entrop y 2.612 vs 3.048), and the lo wer reco very percentage on Wiki B (26% vs 39%) reflects a smaller gap to close, not w orse adaptation. No replay buffer, no task boundaries, single-pass. T est-time adaptation in vision. The β 2 requiremen t dep ends on which pa- rameters are adapted, not just whether adaptation happens. On CIF AR-10-C test-time adaptation (WideResNet-28-10, 15 corruption types at severit y 5, 3 seeds), adapting only batch normalization affine parameters via entrop y mini- mization [W ang et al., 2021] shows a 2.6 percentage p oint gap betw een Adam and SGD. BN parameters are the same type at ev ery lay er, so gradien t scales are roughly uniform and β 2 adds little. Replacing BN with LoRA adapters at ev ery conv olutional lay er widens the Adam–SGD gap to 7.6 pp (51.1% vs 43.5% reco very). β 2 -only matches Adam (52.3%), and β 1 -only falls b etw een (46.0%). LoRA gradients span 28 lay ers with a 5–6 × norm ratio betw een shallow est and deep est, enough for β 2 to matter. The same architectural rule from Section 5 predicts the result: homogeneous parameters tolerate SGD; heterogeneous pa- rameters across depths require per-parameter normalization. 7 Discussion Tw o misc alibrations in standard eligibilit y traces, once corrected, remo v e the need for Jacobian propagation in online recurrent learning. What looked lik e a temp oral credit assignment problem was a gradient scaling problem. The hidden state carries temporal information through the forward pass. The im- mediate deriv ativ e, computed through that state, points in a useful direction for adaptation. The missing piece was gradient scale normalization, not a b etter Jacobian appro ximation. This connects to a structural prop erty of recurren t netw orks identified in prior work [Shalev Merin, 2026]. The parameter Jacobian of trained RNNs is near-isotropic: its singular v alues are approximately uniform, with condition n umbers b et w een 2.6 and 6.5 at n = 64 and scaling as n 0 . 216 . This isotrop y is not learned but inherited from random Gaussian initialization and appro ximately preserv ed by training. Because the gradient information is spread roughly evenly across directions in parameter space, any single direction, including the imme- diate deriv ative, captures most of the relev ant signal. Isotropy explains wh y the Jacobian term adds so little: when all directions carry similar information, there is no privileged subspace that temp oral propagation could reveal. Wh y w as this not noticed earlier? Three factors reinforced eac h other. First, nob ody measured the actual self-propagation factor. Murra y’s RFLO used λ = 0 . 9, Bellec’s e-prop used mem brane time constants, and 0.95 b ecame conv ention. Computing diag(1 − h 2 t ) · diag( W hh ) is trivial, but nob o dy did it. Second, Adam did not exist until 2014 [Kingma and Ba, 2015]. The R TRL literature began in 1989. F or 25 y ears, every one used SGD, and SGD genuinely cannot do online adaptation with immediate-only gradien ts (T able 1). The conclusion “y ou need 13 temp oral propagation” was correct for SGD. The field did not revisit it after p er-parameter normalization b ecame standard. Third, these errors reinforced eac h other: if y ou b eliev e temp oral propagation is essential, you will not examine wh y immediate-only plus SGD fails. When immediate-only plus SGD does fail, y ou conclude temporal propagation is essen tial. Nob o dy tried the combination that breaks the cycle: immediate-only plus Adam. These findings hav e clear limits. First, all from-scratch exp erimen ts use single-la yer netw orks. In t wo-la yer RNNs, p er-la yer Jacobians remain isotropic (condition num b ers 1.7 and 2.5), but the cross-la y er Jacobian is highly anisotropic (condition num b er 3773). Sparse or immediate gradien ts within eac h la yer are accurate, but credit assignmen t from the output lay er back through the input la yer’s recurrence hits a structural bottleneck. Extending the β 2 finding to deep recurren t net w orks is an op en problem. Second, the tasks tested inv olv e tem- p oral dep endencies up to 50 steps. Our claim is about gradient computation, not ab out long-range credit assignment. If the hidden state do es not retain information from step t − k due to v anishing gradien ts, no gradient metho d re- co vers it. Longer-range credit requires architectural solutions such as attention, gating, or structured state spaces, not b etter gradient approximations. Third, direct online up dates to pretrained foundation mo dels pro duce near-zero adap- tation regardless of optimizer. The β 2 finding applies to pretrained mo dels only through parameter-efficient adapters like LoRA, where the adapter’s smaller parameter count allo ws individual up dates to ha ve meaningful magnitude. This has b een confirmed from 124M to 7B parameters (T able 5). F ourth, at n = 256 and abov e, recov ery p ercen tage shows high v ariance ( ± 64%) driv en by insta- bilit y in the full R TRL reference rather than in the metho d itself. Absolute p ost-shift MSE is more stable across seeds at these scales. Op en questions remain. Deep recurren t net w orks require addressing the cross-la yer anisotropy b ottleneck. Whether immediate deriv atives remain suffi- cien t under non-gradient learning rules (e.g., predictive co ding) is un tested. The LoRA results at 7B suggest online adaptation of foundation models is feasible, but the practical engineering (up date frequency , adapter rank, stabilit y ov er long streams) has not been explored. F or any single-la yer recurren t architecture trained online, the practical rec- ommendation is: set trace decay to zero and use Adam or RMSprop. This matc hes or exceeds full R TRL at a fraction of the cost and without any Jaco- bian computation. F or pretrained mo dels, LoRA with Adam ac hieves online domain adaptation that SGD cannot. References Ekin Aky ¨ urek, Mehul Damani, Linlu Lin, Sai V emprala, Dale Sc huurmans, and Ashish Kap o or. In-place test-time training for language mo dels. In ICLR , 2026. Guillaume Bellec, F ranz Scherr, Anand Subramoney , Elias Ha jek, Darjan Sala j, 14 Rob ert Legenstein, and W olfgang Maass. A solution to the learning dilemma for recurren t net works of spiking neurons. Natur e Communic ations , 11(1): 3625, 2020. F rederik Benzing, Marcelo Matheus Gauy , Asier Mujik a, Anders Martinsson, and Angelik a Steger. Optimal Kroneck er-sum approximation of real time recurren t learning. arXiv pr eprint arXiv:1902.03993 , 2019. Heitor M Gomes, Alb ert Bifet, Jesse Read, Jean Paul Barddal, F abr ´ ıcio Enem- brec k, Bernhard Pfharinger, Geoff Holmes, and T alel Ab dessalem. Adaptive random forests for ev olving data stream classification. Machine L e arning , 106 (9):1469–1495, 2017. Danijar Hafner, Jurgis Pasuk onis, Jimmy Ba, and Timoth y Lillicrap. Mastering div erse domains through world mo dels. Natur e , 625:118–126, 2024. Kazuki Irie, R´ ob ert Csord´ as, and J ¨ urgen Sc hmidhuber. Exploring the promise and limits of real-time recurren t learning. arXiv pr eprint arXiv:2305.19044 , 2024. Diederik P Kingma and Jimm y Ba. Adam: A metho d for stochastic optimiza- tion. arXiv pr eprint arXiv:1412.6980 , 2015. ´ Eloi Maes, Quentin Le Lidec, Damien Scieur, Y ann LeCun, and Randall Balestriero. Learning world models with large language mo del bac kb ones. arXiv pr eprint arXiv:2603.19312 , 2026. Ow en Marsc hall, Kyungh yun Cho, and Cristina Sa vin. A unified framew ork of online learning algorithms for training recurrent neural netw orks. Journal of Machine L e arning R ese ar ch , 21(135):1–34, 2020. Jacob Menick, Jac k Rae, and Simon Osindero. A practical sparse appro ximation for real time recurrent learning. arXiv pr eprint arXiv:2104.09750 , 2021. Jacob Montiel, Max Halford, Saulo Martiello Mastelini, Geoffrey Bolmier, Raphael Sourb er, Robin V aysse, Adil Zouitine, Heitor Murilo Papadopou- los, et al. River: mac hine learning for streaming data in Python. Journal of Machine L e arning R ese ar ch , 22(110):1–8, 2021. James M Murray . Lo cal online learning in recurren t netw orks with random feedbac k. eLife , 8:e43299, 2019. Joseph E O’Dohert y , Mariana M B Cardoso, Joseph G Makin, and Philip N Sab es. Nonh uman primate reaching with multic hannel sensorimotor cortex electroph ysiology . Zeno do , 2017. DOI: 10.5281/zenodo.3854034. Aur Shalev Merin. Random sparse Jacobian transp ort in recurren t netw orks. arXiv pr eprint arXiv:2603.15195 , 2026. 15 Y u Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Y ann Dub ois, Xinlei Chen, Xiaolong W ang, Sanmi Kumbhar, et al. Learning to (learn at test time): RNNs with expressive hidden states. In NeurIPS , 2024. Coren tin T allec and Y ann Ollivier. Un biased online recurrent optimization. arXiv pr eprint arXiv:1702.05043 , 2017. Dequan W ang, Ev an Shelhamer, Shaoteng Liu, Bruno Olshausen, and T revor Darrell. T ent: F ully test-time adaptation by entrop y minimization. In ICLR , 2021. Ronald J Williams and David Zipser. A learning algorithm for contin ually running fully recurrent neural netw orks. Neur al Computation , 1(2):270–280, 1989. Nicolas Zucc het, Simon Sc hug, Johannes von Oswald, Dominic Zhao, and Jo˜ ao Sacramen to. Online learning of long-range dep endencies. A dvanc es in Neur al Information Pr o c essing Systems , 2023. 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment