시간 신용은 무료다
이 논문은 순환 신경망의 온라인 학습에서 전통적인 실시간 역전파(RTRL)와 같은 고비용 Jacobian 전파가 필요 없음을 입증한다. 은닉 상태가 이미 시간적 신용을 전달하므로, 즉시 미분(즉시 파생)만으로 충분하고, 이를 위해서는 (1) 오래된 트레이스 메모리를 제거하고 (2) 파라미터 그룹 간 그래디언트 스케일을 정규화하는 것이 핵심이다. β₂(Adam의 두 번째 모멘트) 정규화는 비선형 상태 업데이트를 거치는 경우에만 필요하며, 그 외에…
저자: Aur Shalev Merin
본 논문은 순환 신경망(RNN)의 온라인 학습에서 시간적 신용 할당을 수행하기 위해 전통적으로 사용되어 온 실시간 역전파(RTRL)와 같은 고비용 Jacobian 전파가 실제로는 불필요하다는 주장을 제시한다. 저자들은 은닉 상태 hₜ 가 순전파 과정에서 과거 입력을 이미 통합하고 있기 때문에, 즉시 파생 ∂hₜ/∂θ 만으로 충분히 과거의 영향을 현재 손실에 반영할 수 있음을 이론적으로 설명하고, 실험적으로 검증한다.
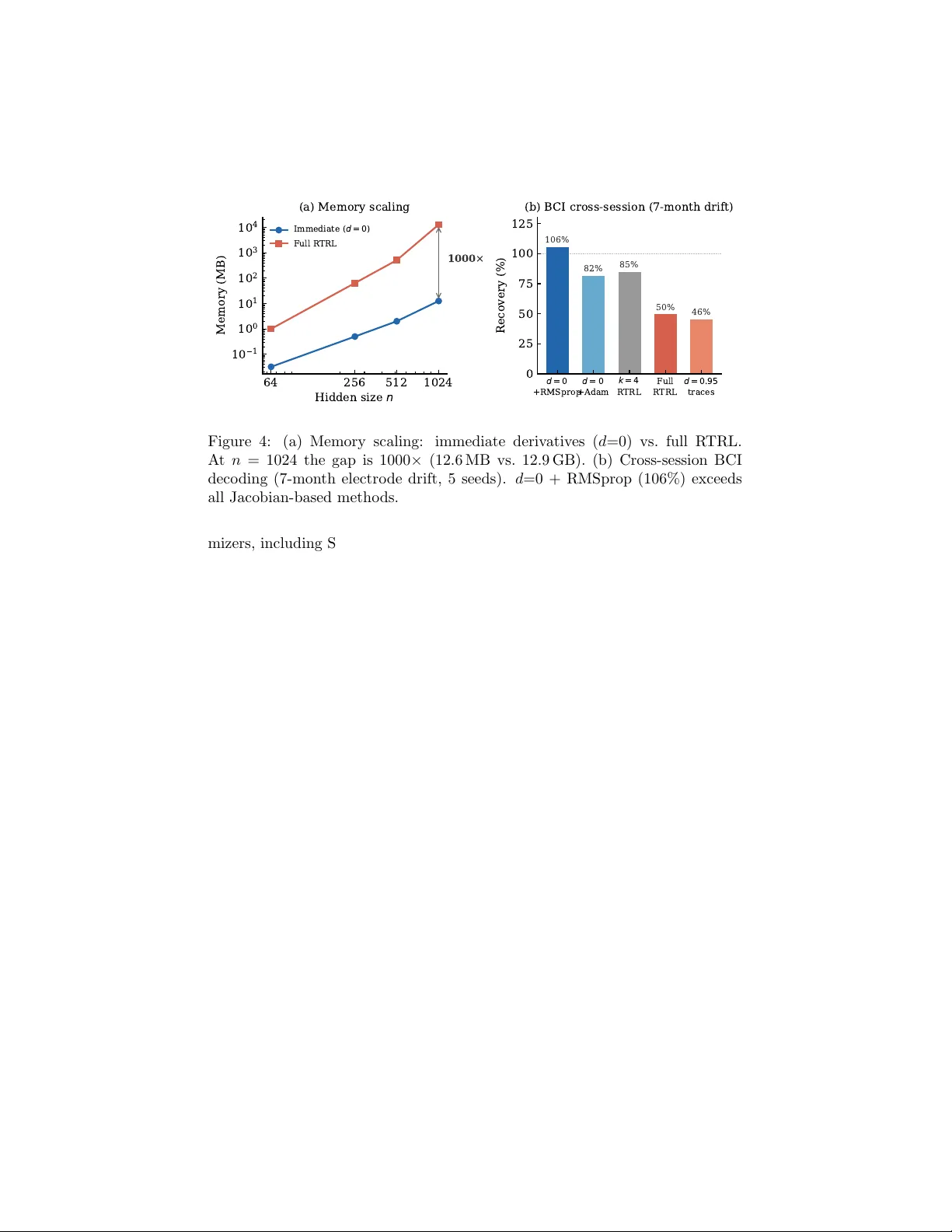
첫 번째 실험에서는 기존 Eligibility Trace가 사용하는 감쇠 파라미터 λ=0.95 가 실제 신경망의 자기‑전파 계수(≈0.01)와 크게 불일치한다는 사실을 밝혀냈다. 이 차이는 85배 이상의 스케일 오차를 초래해, 트레이스가 오래된 그래디언트를 과대평가하고, 즉시 파생이 제공하는 정확한 신호를 가리는 결과를 낳는다. 감쇠를 0.5 이하, 특히 0으로 설정하면 즉시 파생만을 사용한 학습이 안정적으로 동작하며, 일부 경우에는 RTRL보다 더 좋은 일반화 성능을 보인다.
두 번째 핵심은 파라미터 그룹 간 그래디언트 스케일 불균형이다. tanh와 같은 비선형 활성화는 재귀 가중치 W_hh 에 대한 그래디언트를 크게 압축해, 출력 가중치 W_out 에 비해 평균 100배 작게 만든다. SGD는 동일 학습률을 적용하므로 재귀 파라미터는 거의 업데이트되지 않아, 모델이 동적 특성을 조정하지 못한다. 반면 Adam의 두 번째 모멘트 β₂ 정규화는 각 파라미터별 그래디언트 스케일을 자동 보정한다. 실험 결과, β₂만 활성화한 RMSprop이 Adam 전체와 동등하거나 더 높은 복구율을 보이며, β₁(모멘텀)이나 편향 보정은 적응에 기여하지 않음을 확인했다.
이러한 두 가지 교정(감쇠 λ=0 및 β₂ 정규화)을 결합하면, RTRL과 동일한 정확도 또는 그 이상을 달성하면서 메모리 사용량을 1000배 절감할 수 있다. 저자들은 n=1024 은닉 유닛을 가진 모델을 12.6 MB 메모리로 학습시켰으며, 동일 설정의 RTRL은 12.9 GB를 요구한다는 사실을 보고한다.
또한, 아키텍처에 따라 β₂ 정규화가 필요한지 여부를 판단하는 “β₂ 필요성 규칙”을 제시한다. 비선형·곱셈적 상태 업데이트가 존재하고, 출력 경로에 병렬 bypass가 없을 경우에만 β₂ 정규화가 필요하다. 이 규칙은 Vanila RNN, LSTM, CTRNN, xLSTM, RetNet, RWKV 등 6가지 아키텍처에서 실험적으로 검증되었으며, 출력 bypass가 있는 S4, Block‑GRU+MLP 등에서는 SGD만으로도 충분히 적응이 가능함을 보여준다.
마지막으로, 실제 영장류 뇌 데이터와 스트리밍 언어 모델(LoRA) 적응 실험에서도 동일한 패턴이 관찰되었다. BCI 데이터에서는 β₂와 λ=0 조합이 74%~82% 복구율을 기록했으며, 사전 학습된 124M~7B 파라미터 규모의 언어 모델에 대해 단일 패스 적응 시 21%~134%의 성능 향상을 달성했다. 전체적으로, 이 연구는 온라인 RNN 학습에서 Jacobian 전파를 대체할 수 있는 간단하고 효율적인 대안을 제시하며, 최적화 기법과 아키텍처 설계가 어떻게 상호작용하는지를 명확히 규명한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기