Acoustic-to-articulatory Inversion of the Complete Vocal Tract from RT-MRI with Various Audio Embeddings and Dataset Sizes
Articulatory-to-acoustic inversion strongly depends on the type of data used. While most previous studies rely on EMA, which is limited by the number of sensors and restricted to accessible articulators, we propose an approach aiming at a complete in…
Authors: Sofiane Azzouz, Pierre-André Vuissoz, Yves Laprie
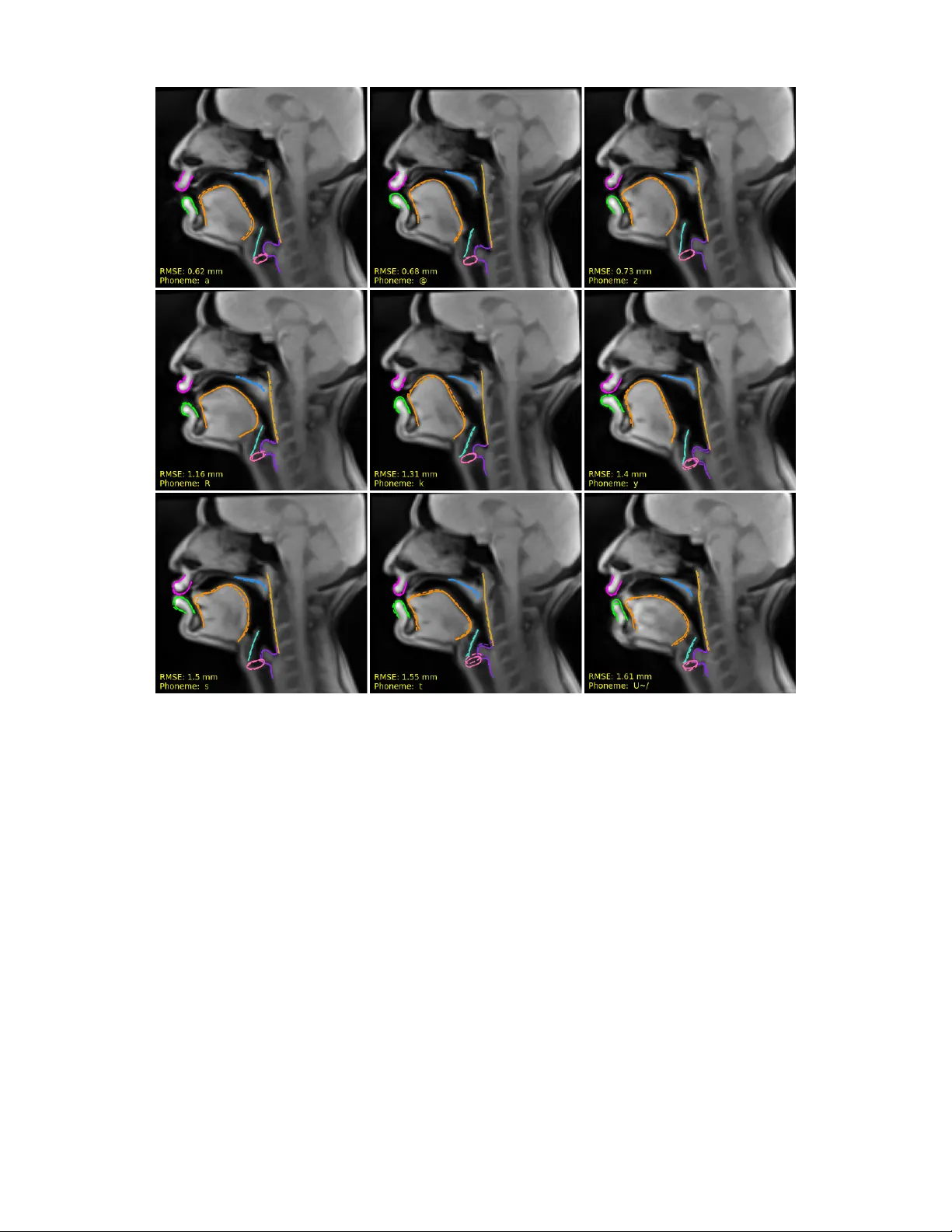
1 Acoustic-to-articulatory In v ersion of the Complete V ocal T ract from R T -MRI with V arious Audio Embeddings and Dataset Sizes Sofiane Azzouz, Pierre-Andr ´ e V uissoz, Yv es Laprie Abstract —Articulatory-to-acoustic in version str ongly depends on the type of data used. While most pre vious studies rely on EMA, which is limited by the number of sensors and restricted to accessible articulators, we propose an appr oach aiming at a complete in version of the v ocal tract, from the glottis to the lips. T o this end, we used approximately 3.5 hours of RT -MRI data fr om a single speaker . The innovation of our approach lies in the use of articulator contours automatically extracted fr om MRI images, rather than relying on the raw images themselves. By focusing on these contours, the model prioritizes the essential geometric dynamics of the vocal tract while discarding redundant pixel-level inf ormation. These contours, alongside denoised audio, were then processed using a Bi-LSTM architectur e. T wo experi- ments were conducted: (1) the analysis of the impact of the audio embedding, for which three types of embeddings were evaluated as input to the model (MFCCs, LCCs, and HuBER T), and (2) the study of the influence of the dataset size, which we varied from 10 minutes to 3.5 hours. Evaluation was performed on the test data using RMSE, median error , as well as T ract V ariables, to which we added an additional measur ement: the larynx height. The average RMSE obtained is 1.48 mm, compared with the pixel size (1.62 mm). These results confirm the feasibility of a complete vocal-tract inv ersion using RT -MRI data. Index T erms —Acoustic to articulatory in version, speech pr o- duction, rt-MRI. I . I N T RO D U C T I O N Articulatory-to-acoustic inv ersion consists in recovering the shape of the vocal tract from the speech signal. Early work on in v ersion was based on an analysis-by-synthesis paradigm. One of the first examples is W akita’ s in v erse filtering approach [1], which imposes a highly constrained model in the form of an all-pole model to enable in v ersion, with the advantage of limiting the use of articulatory data. Indeed, W akita points out that it is difficult to acquire data, that this poses risks for subjects (as the data was obtained through X-rays), and that the techniques av ailable at the time did not allow for the transverse dimension (perpendicular to the mid-sagittal plane) to be determined. The entire history of articulatory acoustic in v ersion is a kind of compromise between the complexity of an analysis model and the existence of data to adjust or replace the model. F ollo wing W akita, the analytical approach was improv ed in terms of both acoustic numerical simulations and the geometric model of the vocal tract. Recent modeling techniques are based on acoustic sim- ulations that take into account vocal folds, aerodynamics, and the acoustic properties of the vocal tract. They aim to Sofiane Azzouz and Yves Laprie are with the Univ ersit ´ e de Lorraine, CNRS, Inria, F-54000 Nancy , France (e-mail : sofiane.azzouz@loria.fr , yves.laprie@loria.fr). Pierre-Andr ´ e V uissoz is with the Uni versit ´ e de Lorraine, Inserm, IADI U1254, F-54000 Nancy , France (e-mail : pa.vuissoz@chru-nancy .fr). achiev e a formulation that is suf ficiently efficient in terms of computation time and fidelity to physics. Advances in acoustic simulations now make it possible to produce high-quality speech, as demonstrated by the V ocalT ractLab system [2]. The shape of the vocal tract and its temporal ev olution must be specified as input for these simulations. The first technique uses geometric primiti ves, cylinders whose center and radius can change, and planes in the case of a three-dimensional model [3]. This technique has the advantage of being simple, but it does not guarantee the realism of the geometric shape. A second technique consists of using medical images of the vocal tract (X-ray images in the 1970s and, since then, 2D MRI images or 3D MRI volumes), which guarantees greater realism but presents the difficulty of switching from one speaker to another . Recently , Gao and Birkholz [4] hav e used Birkholz’ s articulatory synthesizer to propose an articulatory copy synthesis system, the principle of which is to search for the parameters of the articulatory synthesis model that generate a speech signal close to the input speech. The principle is therefore very similar to articulatory acoustic in version, and the resynthesized speech appears to be of very good quality . Despite these advances, there is still a discrepancy between the underlying geometric analysis model and the actual speaker , which compromises the geometric accuracy of the inv ersion. The second approach in volves dispensing with an analysis model and establishing a direct link between the signal and the geometry of the vocal tract. W ith the advent of new techniques for acquiring articulatory data, first microbeam X- ray technology (abandoned due to the risks posed by X-rays), and especially EMA (ElectroMagnetic Articulography), it has become possible to acquire a sufficient volume of data to perform machine learning [5], [6]. Unfortunately , this data only covers a few points (3 or 4 on the tongue, 1 on the soft palate, 1 on the lower central incisor , and 2 on the lips), but it is possible to record speech for a little over 30 minutes. This technique has become widely used because, unlike the microbeam technique, it does not pose any radiological risks. On the other hand, the fact that the sensors are connected to the measuring de vice by wires slightly alters speech articulation, and these sensors often come off after about 30 minutes. The second weakness is that the articulatory information is very limited, since only the positions of seven points are known, and these points are located at the front part of the vocal tract, pro viding no information about the pharynx and larynx. Finally , if several acquisition sessions are made, it is impossible to guarantee that the sensors will be glued in the same place. In practice, e v aluations generally focus on distances between two sensors, or between a sensor and a reference contour such as the palate. 2 This data has been used for training stochastic and neural approaches. The weakness of stochastic techniques is that temporal modeling, which is essential for speech, is insuf- ficient. This explains why neural network based approaches quickly supplanted stochastic models. The architecture of neural netw orks has ev olved from multilayer networks [7] to recurrent networks, LSTMs or Bi-directional Gated Recurrent Units [8]–[10] which ha ve become the standard in recent years. Howe ver , these studies only provide partial information about the vocal tract, as they only concern the anterior part of the oral cavity , whereas it is well known that the length of the vocal tract —and therefore the position of the larynx— has a strong influence on resonance frequencies, and that there are compensation mechanisms in v olving the lower part of the vocal tract. Despite their interest in terms of taking the temporal dimension into account, the use of in version trained on EMA data is not realistic, because, from an application point of vie w , it is essential that the entire vocal tract be cov ered. Only dynamic MRI data can meet this requirement, but this necessitates high-quality data to provide reliable geometric information in suf ficient quantity [11], good spatial resolution images and high-quality denoised speech signal despite the strong noise generated by the MRI machine [12], [13]. Real- time Magnetic Resonance Imaging (rt-MRI) was introduced as an alternativ e to EMA, with the first recorded corpus described in [14]. Deep learning approaches ha v e been applied to these data [15]. Howe v er , the use of rt-MRI remains limited due to several constraints: difficulty in acquiring sufficiently large datasets, low signal quality after denoising, lack of robust contour-tracking tools, and relativ ely low spatial resolution (68x68 pixels with a voxel size of 2.9 x 2.9 x 5mm 3 or more recently 84x84 pixels with a vox el size of 2.4 × 2.4 x 6 mm 3 in [11]), along with certain MRI-related artefacts. There are two ways to perform in version. The first is implicit in v ersion, which in volv es recovering an MRI image. [15], [16] use an LSTM-based approach to recover the image, while [17] uses a diffusion model used in image synthesis. In both cases, the e v aluation is performed on the image pix els, either in terms of distance or in terms of global or local correlation. In [17] correlation focuses on a few regions of interest to the vocal tract and not the entire image. In all cases, the e v aluation does not take into account any information about the position of the articulators themselves. The first weakness is that the assessment therefore does not take into account any information relating to articulators. The second weakness is that e xploiting the inv ersion results requires a post-processing step. For example, to use the in v ersion as input for articulatory synthesis, the contours of the articulators must be extracted from the images reconstructed during the inv ersion. These images are marred by in version errors and are therefore less easy to interpret and segment automatically . The second avenue of research consists of working on the contours of the articulators, which must therefore be extracted automatically from the images. The adv antage is that the in v ersion result is directly usable since the in v ersion provides the contours of the articulators from the signal. Our work has shown that it is possible to extract the contours automatically with a high degree of reliability [18]. W e chose the second approach, which has the adv antage of pro viding information that is easy to use as articulatory feedback in educational applications or speech rehabilitation, for e xample. In our study , we used an rt-MRI dataset with good spatial resolution (136×136 pixels), good quality denoised speech signal of higher quality than most existing rt-MRI datasets. Furthermore, in contrast to previous studies that inv ert complete R T -MRI images, we opted for automatic contour tracking to extract the shapes of individual articulators, and performed in v ersion only on these contours rather than on the full image. W e use this high-quality database for both image and sound to assess the geometrical accuracy of in version. Until now , the articulatory variables used to characterize the v ocal tract from a phonetic point of view ha ve not taken into account the v ertical position of the larynx, which plays an essential role in modifying the length of the vocal tract and, consequently , its resonance frequencies. The reason for this is that it is impossible to reliably locate the position of the larynx using EMA data. As we use high-quality MRI data and contours, we hav e added this new articulatory variable to our work. W e also use a lar ge single-speak er database, which allo ws us to study in detail v arious aspects of training, such as the impact of dataset size on in version performance — using subsets of 10 minutes, 30 minutes, 1 hour, 2 hours, and the full dataset. In this paper, we propose a complete v ocal tract inv ersion approach from the glottis to the lips, striving to work under optimal conditions on a single speaker , in order to achie ve the lo west possible error rate for MRI data. Furthermore, we precisely determine the minimal amount of data required to obtain reliable and reproducible results for one speaker . I I . D A TA SE T A. corpus The corpus was recorded at the Centre Hospitalier R ´ egional de Nancy . It consists of recordings from a single female French speaker and contains 2,100 sentences, corresponding to approximately 3.5 hours of speech. The dataset is structured into 153 acquisitions, each lasting 80 seconds and containing 4,000 images acquired at a rate of 50 images per second. Each image corresponds to a 8 mm slice in the mid-sagittal plane and has a resolution of 136×136 pixels and a pixel spacing of 1.62 mm. The corresponding audio was recorded using an optical microphone at 16 kHz and then denoised with the algorithm proposed in [19]. The audio quality of denoised speech is close to clean speech (an example audio file is provided in the Supplementary Material). In addition, we also hav e precise phonetic segmentations. The AST ALI software [20] was used to perform a forced alignment, which was then carefully manually corrected by an e xpert. The corrections focused on the boundaries between sounds, most often for plosiv es. In addition, we separated the closure of voiceless plosi v es from the burst because the articulatory position changes significantly between the two parts. W e did not apply this correction to voiced plosiv es because it is often more difficult to distinguish between the two parts. 3 B. Image r e gistr ation Our data was recorded over six different sessions. In order to ensure that the speaker maintains the same posture we made a blocking foam perfectly adapted to the MRI antenna and the speaker’ s head. Despite these precautions, it is impossible for the speaker to maintain exactly the same posture during the six recording sessions and e ven during the same session, which could lead to misaligned images. T o overcome this difficulty , we realigned the images for each acquisition. A mask cov ering only the static part of the head (see Fig. 1) was created, after which rigid transformations were applied within a ±4-pixel translation range and ±4° rotation range. The transformation yielding the highest normalized cross- correlation with a reference image was then selected. Fig. 1. mask of the reference image. The green region represents the static part of the vocal tract C. Choice of input r epresentation W e explored sev eral types of speech signal modeling at the input of in version. T raditionally , MFCCs are used for in version because they have long provided the best results for automatic speech recognition [21]. One of the strengths of MFCCs is that they neutralize the influence of the fundamental frequency and attenuate dif ferences between speakers by using a non-linear frequency scale. Here, we use data from a single speaker and we thus also used linear cepstral coef ficients (LCCs) [22], which use a linear frequency scale. This should be an advantage because the formants that depend directly on the vocal tract shape are preserv ed. Self-supervised learning (SSL) models hav e recently demonstrated their ef fecti v eness in v arious speech processing tasks, particularly in articulatory acoustic in version. In [23], sev eral SSL models — such as HuBER T [24], W av2V ec2 [25], and W a vLM [26] — were compared to traditional ap- proaches based on hand-crafted acoustic features, such as Mel- frequency cepstral coef ficients (MFCCs), for the in version task on EMA data. The results showed that HuBER T outperformed all other methods. Similarly , [27] conducted experiments on XRMB data and compared the representations extracted by HuBER T to those based on MFCCs, confirming HuBER T’ s superiority through higher correlations between acoustic and articulatory signals. In this work we will therefore only com- pare the results obtained with MFCCs, LCCs, and HuBER T 1 . D. Data pr epr ocessing Unlike other works using full MRI images, the proposed method recovers the contours of articulators. The vocal tract is represented by the contours of eight articulators or cartilages: the upper lip, lower lip, tongue, soft palate midline (v elum), pharyngeal wall, epiglottis, arytenoid cartilage, and vocal folds (glottis). Additionally , two landmarks are included that do not contribute directly to the inv ersion—the lower incisor and upper incisor . Howe v er , the upper incisor is utilized in the calculation of the T ract V ariables (TVs), inspired by articulatory phonology [28]. All contours, as shown in Fig. 2, were obtained using an automatic tracking approach based on RCNN [29], dev eloped by our team. This approach, which maintains a tracking error of approximately 1.00 mm, is av ailable as open-source code 2 . Each articulator contour consists of 50 points with X and Y coordinates. The contours were normalized following the approach used in [8]. For each contour point a moving av erage was computed over the 30 preceding and following frames. This average was subtracted from the coordinates, and the result di vided by the corresponding standard de viation for each session. Three different representations were used as input features: MFCCs, LCCs, and HuBER T embeddings. The MFCCs were computed together with their first-order ( ∆ ) and second-order ( ∆∆ ) deri v ati v es, using 13 coef ficients, a windo w size of 25 ms, and a hop length of 10 ms. The LCCs were extracted using the first 30 linear cepstral coef ficients with the same window and hop sizes. F or HuBER T , we compared both the Base and Large architectures; the best results were obtained using the Base model. While the standard HuBER T was trained on English multi-speaker data, the literature indicates that the multilingual fine-tuned version, mHuBER T -147 [30], yields very similar results, what our preliminary tests hav e confirmed for inv ersion. Therefore, this study utilizes only the HuBER T -Base representation. HuBER T processes 16 kHz audio and generates 768-dimensional embeddings at a frame 1 https://huggingface.co/docs/transformers/model doc/hubert 2 https://github .com/vribeiro1/vocal- tract- se g Fig. 2. Segmentation of articulators contour tracked in two images of the rt-MRI film: Arytenoid cartilage, Epiglottis, Lo wer lip, V ocal folds, Soft palate midline, T ongue, Upper lip, Pharyngeal wall 4 rate of 50 Hz. All features (MFCCs, LCCs, and HuBER T) were normalized per session by subtracting their mean and dividing by their standard deviation. I I I . M E T H O D S A. Model ar chitectur e Our model is based on a bidirectional LSTM (Bi-LSTM) architecture [31], [32], which has demonstrated strong per- formance for this specific task. The choice of a Bi-LSTM is motiv ated by its inherent ability to capture bidirectional temporal dependencies, which are crucial for modeling the anticipatory and carryov er coarticulation effects [33] in speech production. The architecture consists of fi ve layers and takes acoustic feature vectors as input, passes through two dense layers with 300 units each, followed by two bidirectional LSTM layers, each consisting of 300 units (see Fig. 3). The output is generated by a dense layer , producing a tensor of size 100 × 8 (number of articulators), where 100 represents the contour coordinates (50 for the X coordinates and 50 for the Y coordinates). In our previous work [32], we tested sev eral v ariants of this model, including an 8-layer version, and we concluded that this model is sufficient to perform this task. B. Loss function Since acoustic-to-articulatory in version is a regression task, the Mean Squared Error (MSE) is the most commonly used loss function. MSE = 1 n n X i =1 ( y i − ˆ y i ) 2 (1) where n represents the total number of the contour points, y i and ˆ y i represent the true and predicted v alues of the output for example i , respectively . W e use the sum of the Mean Squared Error for all the contours of each frame to minimize the distance between the predicted and the ground-truth articulatory positions. C. Evaluation First, the data were denormalized by multiplying with the standard deviation and adding the mean used to normalize each articulator . we ev aluated the model using the average RMSE. For each image, we computed the mean RMSE for each articulator, by considering its 100 coordinates. Then, we calculated the mean error across all articulators, which giv es us the image-level RMSE. After obtaining the RMSE for each image, we computed the median as well as the overall mean RMSE across all images. These values are expressed in millimeters (mm). RMSE = v u u t 1 n n X i =1 ( y i − ˆ y i ) 2 (2) I V . A RT I C U L ATO RY T R A J E C T O R I E S The acoustic impact of a geometric error depends on the distance between the two walls of the vocal tract, usually a fixed wall, such as the palate, and a mobile articulator , such as the tongue. The smaller this distance, and therefore the greater the constriction, the greater the acoustic impact, which determines the realization of a phonetic feature. An articulator is critical for a phoneme if it corresponds to a minimum distance, i.e. a constriction, and the tract variables (VT) of articulatory phonology [28] correspond to the points or regions of the vocal tract that play a critical phonetic role for one or more phonemes. Unlike global metrics such as RMSE applied to articulatory contours, TVs thus allow for targeted e v aluation of the articulatory gestures specific to each phoneme. These distances provide a more functionally meaningful assessment Fig. 3. Architecture of the model 5 of articulatory in v ersion quality , as they reflect constrictions formed in the vocal tract and the y are directly linked to con- striction re gions in the vocal tract. They were defined within the framework of gestural phonology , sho wn in the Fig. 4, and the tract variables with their corresponding constrictors are presented in T able I. Unlike EMA data, we do not have fixed points directly located on the critical articulators required for computing the TVs. In our case, for each TV , we selected a set of points on the two articulators in order to approximate as closely as possible the anatomical reference points. W e ha ve added the larynx height (see Fig. 4 and subsec- tion IV -B) as a ne w variable that we believe to be important. It does not correspond to a constriction, b ut has a significant acoustic impact on resonance frequencies. A. V elum movement The velum is elongated in shape, and we chose to use its midline because it of fers greater robustness in terms of tracking and modeling. The main mov ement of the velum corresponds to an opening/closing that allows or prevents airflow into the nasal cavities. An initial idea is to measure the distance between the lower end of the midline, i.e. the velum tip, and the pharyngeal wall, but this has two weaknesses. The first is that the distance between this point and the pharyngeal wall is never zero since it is in the middle of the Fig. 4. V isual Representation of the V arious V ocal Tract V ariables (TVs) represented by dashed lines : LP , LA, LD, TTCD, TBCD, TRCL, TRCD, LH velum and therefore does not contact this wall. The second weakness is that the velum thickness is minimal at this point, which reduces the image contrast and consequently reduces the robustness of the tracking. T o estimate the dynamics of velum opening and closing we thus characterize velopharyngeal mov ement more com- prehensiv ely by defining a subset of 25 points along the midline, starting at the velum tip and extending posteriorly (see Fig. 5). This re gion was chosen because it corresponds anatomically to the portion of the v elum most directly in v olved in the velopharyngeal closure gesture, thereby providing a detailed representation of its motion during both lowering (opening) and raising (closing) phases. A principal component analysis (PCA) was applied to these 25 midline points across the entire dataset including all silences, with all articulatory coordinates centered and normalized prior to analysis to ensure that differences in absolute position do not bias the results. Similarly to [34] the first principal component PC1, which accounted for 57% of the total v ariance in our dataset (59% in [34]), was interpreted as representing the primary degree of freedom corresponding to the opening/closing gesture of the velum. For each frame in the dataset, the degree of velum opening or closure was quantified by projecting the 25-point midline configuration onto PC1. This projection, i.e. the dot prod- uct between the PC1 loading vector and the current velum configuration, yielded a scalar score that we term the PC1 score. The polarity of PC1 was defined such that positiv e scores indicate motion in the opening direction (velopharyn- geal port enlar ging), whereas negativ e scores indicate motion in the closing direction (velopharyngeal port constricting). Thus, in the context of our analysis, large positi ve PC1 scores correspond to maximal opening, large ne gati ve scores to maximal closure, and values near zero to intermediate or neutral positions (see Fig. 5). By reducing the velopharyngeal movement to this single physiologically interpretable dimension, we were able to track the temporal evolution of the gesture with high precision. B. Larynx height In addition to the vocal tract variables (TVs) already studied in the literature [28], we introduced a new metric that consists of measuring the larynx height. T ABLE I V O C A L T R AC T V AR I A B LE S A ND T H EI R A SS O C I A T E D C O N S TR I C TO R D I S T A N CE S . VT V ariable Definition / Distance LA Lip Aperture V ertical distance between the upper and lower lips (mouth opening) LP Lip Protrusion Forward displacement of the lips along the anterior-posterior axis LD Lip Constriction Degree Distance between the lower lip and the upper teeth TTCD T ongue T ip–Palate Distance Distance between the tongue tip and the hard palate TBCD T ongue Body–Palate Distance Distance between the tongue body and the hard palate TRCD T ongue Root Constriction Degree Distance between the tongue root and the posterior pharyngeal wall TRCL T ongue Root Constriction Location Position along the vocal tract where the tongue root occurs VEL V elic Opening Distance Distance between the velum and the posterior pharyngeal wall LH Larynx height V ertical distance between the glottis and the hard palate 6 Fig. 5. Example of two velopharyngeal port opening configurations: open (4.69) and closed (–9.68). Original points, Projected points. It is defined as the distance from the glottis to the hard palate right extremity (see Fig. 6), used as the reference. This measurement is particularly important for character- izing the vertical dimensions of the vocal tract, which hav e a direct influence on the resonance frequencies of the vocal tract. T o perform this calculation, we first defined the center of the glottis as the geometric centroid of its contour points. The distance was then measured from this center to a specific reference point on the hard palate (see Fig. 6), ensuring that this measurement was taken along an axis parallel to the pharyngeal wall. This orientation guarantees anatomical relev ance and provides better consistency with the vocal tract structures. T o our knowledge, previous studies ha ve nev er succeeded in measuring this specific v ariable of the vocal tract directly inside the vocal tract due to the limitations of electromagnetic articulography (EMA), which makes it impossible to position a sensor at the lev el of the larynx. The only option w as to deduce the position of the larynx from video images of the speaker’ s head [35], which necessarily introduces a high degree of inaccuracy . Furthermore, on the MR imaging side sev eral technical challenges have pre vented this analysis: either the anatomical contours were not segmented accurately , or the anatomical structures were not suf ficiently visible due to insufficient image resolution. Introducing this ne w vocal tract v ariable is a major advan- tage, since it provides a better understanding of the impact of v ocal tract dimensions on the acoustic characteristics of speech, particularly on vocal resonances, or formants, which are fundamental for v o wel perception and identification. C. Calcul of TVs Unlike EMA data, which consist of discrete sensor points, our data comprise full articulatory contours. Before computing the tract variables, all contours were first denormalized. T o estimate the relev ant distances, we selected a specific range of points on each articulator and calculated the minimum Eu- clidean distance between these regions. This approach allo ws us to approximate constriction locations without relying on individual point measurements. Distances were computed for each tract variable (TV) and each frame independently , for both the original and predicted contours. Fig. 6. V isual Representation of the Larynx height LH Upper incisor with hard palate The Pearson correlation, as shown in ( 3), was then used to quantify the relationship between each TV extracted from the original contours and those derived from the predicted contours, for all TVs. Pearson = P n i =1 ( x i − ¯ x )( y i − ¯ y ) p P n i =1 ( x i − ¯ x ) 2 , p P n i =1 ( y i − ¯ y ) 2 (3) For velum mov ement, in addition to the Pearson correlation, we also used another metric. Since we consider any positive value as open and an y negati v e v alue as closed, we represented these states as 1 and –1, respectively . T o ev aluate the agree- ment between the original and predicted TVs in this case, we used accuracy , as defined in ( 4): Accuracy = Number of correct predictions T otal number of predictions (4) Accuracy provided better results than the Pearson correla- tion, which is why we decided to keep and report only the accuracy scores. D. Experiments Our primary objective is to successfully perform the in- version of the complete v ocal tract contour under the best possible conditions. T o this end, we conducted two distinct experiments. The first experiment aimed to e v aluate the impact of different acoustic input representations on the model’ s performance. Three types of inputs were considered. First, the Mel-Frequency Cepstral Coefficients (MFCCs), which are widely used in articulatory in version studies and generally yield e xcellent results. Second, LCCs, which pro vide higher - quality acoustic information. Indeed, some spectral peaks can be attenuated in MFCCs due to Mel-scale filtering and compression. LCCs, being more directly related to the spectral en v elope of the vocal tract, enable the model —particularly in a single-speaker scenario— to establish a more direct mapping between acoustic features and articulatory trajectories. Finally , we ev aluated a self-supervised learning (SSL) embedding obtained from the HuBER T model, which has demonstrated promising results in pre vious studies [27], even outperform- ing MFCC-based representations. T rained to predict masked 7 acoustic representations, HuBER T produces rich and contex- tual embeddings capable of capturing fine-grained temporal and spectral information, making it particularly well-suited for complex tasks such as acoustic-to-articulatory inv ersion. The second experiment focused on in v estigating the influ- ence of dataset size on model performance. W e examined whether similar results could be achie ved using smaller subsets of datasets. T o this end, the model was trained on datasets of increasing duration: the full 3.5-hour corpus, 2 hours, 1 hour, 30 minutes, and 10 minutes. In this experiment, the LCCs features were used as the model input and ev aluations were conducted against the same complete test set. E. Model par ameters All models were trained for 300 epochs with a batch size of 10, using the Adam optimizer with an initial learning rate of 0.001. T o av oid overfitting early stopping w as applied with a patience of 10 epochs on the validation data, halting training if no improv ement was observed. Our dataset contains 450,000 images after removing silence.W e randomly di vided our dataset by acquisitions into 80% for training, 10% for validation, and 10% for testing. All experiments were run with the same training configura- tion and train-validation-test splits to ensure a fair comparison. The entire implementation was done using PyT orch. F . Statistical Significance of the Results T o ev aluate whether the performance dif ference between different results is statistically significant, we accounted for the temporal dependency inherent in consecuti v e frames. The original test set contained 45,000 frames; ho wever , consecutiv e frames are highly correlated. T o ensure the independence of observations required for statistical testing, we aggre gated the results by calculating the mean score for consecutiv e frames within the same phone. This process resulted in a reduced but more robust sample of n = 10 , 871 independent observations. Since the distribution is not normal (as tested with the D’Agostino test), the W ilcoxon Signed-Rank T est was used with a significance threshold of α = 0 . 05 . V . R E S U LT S First, we verified that our model does not o verfit. For instance, the LCC-based model achiev ed an error of 1.48 mm on the test set, which is lower than the validation error of 1.63 mm. This slightly superior performance on the test set suggests that the model did not overfit. All training runs con verged in fewer than 150 epochs for both experiments, and all reported differences were tested for statistical significance using Wilcoxon test to ensure that the observed performance variations between embeddings and dataset sizes were meaningful. The first experiment compared the model’ s performance when trained with three different types of acoustic embed- dings: MFCCs, LCCs, and HuBER T . As sho wn in T able II, LCC-based model achieved the best ov erall performance across all articulators, with an average RMSE of 1.48 mm and a median error of 1.27 mm, follo wed by HuBER T -based model (RMSE = 1.49 mm, median = 1.31 mm) and MFCC- based model (RMSE = 1.51 mm, median = 1.30 mm). When examining each articulator indi vidually , LCC-based model outperformed the other embeddings for six articulators and tied with HuBER T -based model for one — the epiglottis — where both reached an RMSE of 1.49 mm and a median of 1.31 mm. HuBER T -based model slightly surpassed LCC-based model for the tongue, with RMSE and median values of 2.20 mm and 1.99 mm, compared to 2.28 mm and 2.04 mm for LCC-based model. Ov erall, MFCC-based model consistently yielded the lowest performance across all articulators. Fig. 7 shows a boxplot for the LCC-based model, illustrating the v ariability of the mean RMSE for each frame. It also indicates the distribution of outliers. Fig. 8 presents the Pearson correlations between ground- truth and predicted articulatory variables. HuBER T -based model achieved the highest correlations for most variables, ex- cept for LD, where it tied with LCC-based model (correlation = 0.91). Overall, HuBER T -based model’ s correlations ranged from 0.88 to 0.92, followed by LCC-based model (0.86–0.91) and MFCC-based model (0.84–0.91). Fig. 10 shows examples of predicted and ground-truth contours using LCC-based model as input, with mean RMSE T ABLE II C O MPA R IS O N O F R MS E ( MM ) A ND M E DI A N E R RO R ( MM ) F OR D I FFE R E NT I N PU T F EAT UR E S : M F C C S , L CC S , A N D H U B E R T E M B E DD I N G S . MFCC-based model HuBER T -based model LCC-based model Articulator RMSE Median RMSE Median RMSE Median Arytenoid 1.63 ∗ ± 1.02 1.38 1.63 ± 1.00 1.39 1.60 ± 1.00 1.35 Epiglottis 1.52 ∗ ± 0.88 1.33 1.49 ∗ ± 0.84 1.31 1.49 ± 0.85 1.31 Lower lip 1.53 ∗ ± 0.83 1.35 1.48 ± 0.80 1.31 1.47 ± 0.81 1.30 Pharyngeal 1.08 ± 0.58 0.96 1.09 ± 0.56 0.98 1.07 ± 0.57 0.94 V elum 1.34 ± 0.67 1.21 1.35 ± 0.65 1.23 1.33 ± 0.66 1.20 T ongue 2.33 ∗ ± 1.17 2.10 2.20 ∗ ± 1.12 1.99 2.28 ± 1.14 2.04 Upper lip 1.15 ∗ ± 0.55 1.03 1.20 ∗ ± 0.58 1.09 1.11 ± 0.53 1.01 V ocal folds 1.49 ∗ ± 0.84 1.31 1.47 ∗ ± 0.76 1.33 1.46 ± 0.80 1.30 Mean 1.51 ∗ ± 0.91 1.30 1.49 ∗ ± 0.87 1.31 1.48 ± 0.89 1.27 ∗ Significant dif ference compared to the LCC-based model result ( p < 0 . 05 ) based on a W ilcoxon test. 8 Fig. 7. Boxplot of mean RMSE per frame for the LCC-based model, showing outlier ranges. The red curve shows the distribution of # outliers. The right axis gives the number of outliers as a function of the error in mm. values ranging from 0.62 mm to 1.61 mm. The second experiment ev aluated the impact of dataset size on model performance using LCC-based model as input. Fig. 9 shows the decrease in the mean RMSE from 1.75 mm to 1.48 mm, the mean median from 1.51 mm to 1.27 mm, as well as the tongue RMSE from 2.78 mm to 2.28 mm as the amount of training data increases from 10 minutes to 3.5 hours. T able III further indicates that, when examining indi vidual articulators, the 3.5-hour dataset produced the lo west RMSE and median values. Performance followed a clear hierarchical trend, with errors increasing as dataset size decreased from 2 hours to 1 hour , 30 minutes, and finally 10 minutes, which yielded the highest errors overall. V I . D I S C U S S I O N A. Comparative Analysis of Input F eatures T able II presents the results of the first experiment, which aims to compare different acoustic representations used as model inputs: MFCCs, LCCs, and HuBER T embeddings. The results sho w that LCC-based model provide the best performance, both globally (a v eraged over all articulators) and individually , except for the tongue, where HuBER T -based model achieves slightly better results. HuBER T -based model ranks second, while MFCC-based model yield the lowest performance. These results and their ranking can be explained by the specific nature of the information captured by each type of representation. LCCs are computed directly from the linear spectrum of the signal, without relying on the Mel scale, which is perceptually based. In the context of a single speaker , this spectral richness allows the model to learn a more direct mapping between acoustic features, especially spectral prominences corresponding to resonance frequencies, and articulatory trajectories. Indeed, for a given resonance cavity , the resonance frequencies are ev enly spaced, so it is Fig. 8. Correlation between the predicted and target trajectories for each measured tract variable. 9 T ABLE III C O MPA R IS O N O F R MS E ( MM ) A ND M E DI A N ( M M ) B Y VARY I N G T H E S I ZE O F T H E D A TA S ET . 10 minutes 30 minutes 1 hour 2 hours 3.5 hours Articulator RMSE Median RMSE Median RMSE Median RMSE Median RMSE Median Arytenoid 1,82 ∗ ± 1.07 1,57 1.73 ∗ ± 1.03 1.48 1.70 ∗ ± 1.01 1.45 1.65 ∗ ± 1.01 1.41 1.60 ± 1.00 1.35 Epiglottis 1.81 ∗ ± 1.00 1.61 1.67 ∗ ± 0.93 1.48 1.61 ∗ ± 0.92 1.41 1.57 ∗ ± 0.88 1.38 1.49 ± 0.85 1.31 Lower lip 1.83 ∗ ± 0.99 1.61 1.78 ∗ ± 0.97 1.57 1.59 ∗ ± 0.86 1.40 1.52 ∗ ± 0.83 1.34 1.47 ± 0.81 1.30 pharyngeal 1.22 ∗ ± 0.66 1.08 1.15 ∗ ± 0.61 1.03 1.16 ∗ ± 0.61 1.04 1.10 ∗ ± 0.58 0.98 1.07 ± 0.57 0.94 V elum 1.55 ∗ ± 0.77 1,40 1.52 ∗ ± 0.72 1.39 1.43 ∗ ± 0.71 1.29 1.37 ∗ ± 0.68 1.24 1.33 ± 0.66 1.20 T ongue 2.78 ∗ ± 1.36 2.50 2.60 ∗ ± 1.27 2.33 2.48 ∗ ± 1.24 2.22 2.37 ∗ ± 1.20 2.11 2.28 ± 1.14 2.04 Upper lip 1.27 ∗ ± 0.60 1.15 1.21 ∗ ± 0.57 1.10 1.19 ∗ ± 0.56 1.08 1.16 ∗ ± 0.56 1.04 1.11 ± 0.53 1.01 V ocal folds 1,72 ∗ ± 0.95 1.52 1.62 ∗ ± 0.88 1.43 1.58 ∗ ± 0.86 1.40 1.52 ∗ ± 0.82 1.34 1.46 ± 0.80 1.30 Mean 1,75 ∗ ± 1,05 1.51 1.66 ∗ ± 0.99 1.43 1.59 ∗ ± 0.95 1.37 1.53 ∗ ± 0.92 1.32 1.48 ± 0.89 1.27 ∗ Significant dif ference compared to the 3.5 hours dataset result ( p < 0 . 05 ) based on a Wilcoxon test. Fig. 9. Comparison of tongue RMSE, mean RMSE, and median error by varying the dataset size. normal that LCCs corresponding to a linear frequency scale giv e better results. In other words, LCCs establish a more linear and physically interpretable relationship between the acoustic signal and the vocal tract geometry . Howe v er , this gain in robustness for a single speaker would disappear if multiple speakers had to be taken into account. HuBER T embeddings, deriv ed from self-supervised learn- ing, encode rich and conte xtual representations of the speech signal. By being trained to predict masked acoustic segments, HuBER T captures temporal dependencies and preserves fine acoustic variations that are directly related to articulatory con- figurations. Thus, although the results obtained with HuBER T - based model are highly satisf actory , they remain slightly belo w those of cepstral coefficients for the specific task of acoustic- to-articulatory in version. Finally , MFCCs—although widely used in speech process- ing—are based on a perceptual frequency scale (the Mel scale) and logarithmic compression. This design, oriented tow ard human auditory perception rather than the physical production of speech, attenuates high-frequency components that contain essential cues for accurately reconstructing articulatory move- ments. As a result, MFCC-based model show lower in v ersion accuracy compared to the other representations. According to Fig. 8, strong correlations are observed, ex- ceeding 84% for all tract v ariables. Among the three types of acoustic representations, HuBER T -based model consistently outperforms the others, achie ving the highest correlations across all variables. This superiority can be explained by the fact that, although it shows slightly higher RMSE and median values compared to LCC-based model, HuBER T -based model is able to accurately predict the contours of the articulators most in volv ed in the production of the tar get phoneme. Howe ver , it sometimes produces larger errors for articula- tors that are less in v olved in the same sound, as discussed in subsection VI-B. This behavior is consistent with the nature of the model: HuBER T , based on self-supervised learning, extracts conte xtual and phonetically rich representations, while LCC-based model, grounded in a physical and deterministic modeling of the acoustic signal, maintain a more direct cor - respondence with articulatory reality . Regarding MFCC-based model, although they show solid performance, their correlations remain slightly lower than those obtained with LCC-based model and HuBER T -based model. They effecti vely capture low-le v el acoustic properties through Mel-scale filtering and logarithmic compression, but their representational capacity remains limited for modeling articulatory dynamics and coarticulation effects. It is not possible to compare our results with those in the literature because we hav e complete contours, whereas others only use information from a fe w points. Howe v er , regarding the correlation of articulatory variables, we obtain an ov erall correlation of 90%, compared to 81% in the case of [27]. T ABLE IV N U MB E R O F O UT L I E RS B Y T Y P E Outlier type # Image ambiguity 7 Global shift 8 T racking error 2 Critical articulator correct 29 In version error 54 10 Fig. 10. Illustration of inference images. The dotted lines represent the predicted values, while the solid lines correspond to the ground truth. B. Outliers During our tests, we did not limit ourselves to ev aluating the global average RMSE; we also examined the mean RMSE for each frame indi vidually (see Fig. 7). This analysis revealed that, for certain frames, the av erage RMSE reached very high values—exceeding 6 mm—compared to the global averages of 1.48 mm for LCC- based model T o identify these outliers, we computed the standard deviation (STD) and considered any value above the third quartile (Q3) as an outlier . W e examined the 100 images with the most significant in v ersion outliers to better understand the origin of these errors. This in vestigation revealed fi ve categories of outliers, summarized in T able IV, with the number of images corre- sponding to each category . Fig. 11 provides an illustration of each category . The fiv e categories are: 1) Images that are ambiguous due to MRI technical con- straints during acquisition [12]. It is impossible to deter- mine the contours and therefore to ev aluate the in version. 2) All articulator contours are shifted. The speaker’ s posi- tion has changed slightly , resulting in a slight translation of the position of all their articulators. The in v ersion therefore generates contours that are all shifted, leading to a significant outlier ev en though the overall shape of the vocal tract is correct. 3) The position of the critical articulator is correct, but the positions of the other articulators are incorrect. This concerns almost exclusi v ely stops and the uvular consonant / K /. 4) The contours produced by automatic tracking are incor- rect, and the result of the in version is closer to the actual shape of the v ocal tract. 5) The in version is incorrect, and one or more articulators are not in the expected position. This analysis shows that inv ersion errors account for just ov er half of the outliers. Cate gories 1 to 3 correspond to the process of forming the MRI images themselves, automatic contour tracking, or a small change in the speaker’ s posture. These three cate gories account for 17% of the outliers. Cate- gory 4 is interesting because the critical articulator is correctly 11 Fig. 11. Illustration of each of the 5 types of outliers. From top to bottom and left to right: image ambiguity (tongue), global shift, tracking error (tongue), correct critical articulator (correct lip position), in version error (tongue) in v erted. It accounts for 29% of cases. This mainly concerns plosiv es and, in some cases, nasal vo wels. For /p/, for example (Fig. 11) (first image of the second row), the position of the lips is correct, but that of the other articulators is not. In this case, only the position of the lips is decisiv e, and the speaker can anticipate the position of the other articulators to minimize their articulatory effort. The last category is that of in v ersion errors. The position of one or more articulators is incorrect. For vo wels, it is possible to achie ve the same target in terms of formants with different shapes, e ven if this articulatory variability depends on the vowels [36], but we did not use acoustic simulation to verify that the in verted shapes could giv e the same acoustic parameters because, from a phonetic point of view , they seem very far from the expected result. In summary , it is interesting to note that almost half of the outliers can be explained by problems other than the in version process itself. C. Impact of Dataset Size on Model P erformance The results of the second experiment indicate that the 3.5- hour dataset produced the best overall performance for all articulators. Both the root mean square error (RMSE) and median error increase monotonically as the training duration decreases, with accuracy declining substantially for datasets smaller than 1 hour . Notably , the mar gin of impro vement diminishes as the dataset gro ws; for instance, the difference in RMSE between the 10-minute and 30-minute subsets was 0 . 09 mm, whereas the difference between the 3.5-hour and 2-hour datasets was only 0 . 05 mm. This suggests that while increasing data volume consistently reduces error , performance has not yet stabilized, implying that even larger datasets may be required for full model con v ergence. Interestingly , the 1- hour subset achie v ed an average RMSE of 1 . 59 mm—which is on the same order of magnitude as the pixel size ( 1 . 62 mm)—indicating that the model performs reasonably well ev en with a moderately sized dataset. This highlights the model’ s robustness and suggests that a 1-hour dataset may be sufficient for practical applications where data collection is costly or difficult to achieve. V I I . C O N C L U S I O N T o our knowledge, this is the first study to achieve an RMSE of 1.48 mm and a median error of 1.27 mm across all vocal-tract articulators — from the glottis to the lips — using R T -MRI images. In comparison, our previous work [32] reported 1.65 mm and 1.47 mm, respectiv ely . These findings demonstrate the feasibility of performing a complete vocal- tract in version from R T -MRI data. W e also analyzed the articulatory v ariables for which HuBER T -based model achiev ed the highest correlation scores, all exceeding 88%, demonstrating its strong capacity to model articulatory dynamics. In particular , the Larynx Height (LH) variable provides new insights into characterizing the vertical dimensions of the vocal tract, which have often been over - looked in prior studies. In terms of dataset size, to our knowledge, this is the largest R T -MRI corpus available for a single speaker , compared to those reported in the literature. This allo wed us to conclude that our model trained with one hour of speech produced very satisfactory results, with only a very slight decrease in performance compared to three hours of data, i.e., 0.03 mm in RMSE. 12 In addition, we ev aluated the robustness of the model by testing it on speech recorded in a clean en vironment [37], following a training phase conducted exclusiv ely on denoised speech. This study confirms the model’ s ability to adapt to changes in the acoustic characteristics of the input signal. It is worth noting that the model was trained exclusiv ely on a single speaker , which may limit its generalization to unseen speakers. Future work will focus on developing a speaker- independent model, where the potential of HuBER T -based model representations could be further demonstrated. Beyond its theoretical significance in speech science, acous- tics to articulatory inv ersion holds great potential for practical applications in speech synthesis, automatic speech recognition, clinical phonetics, and silent speech interfaces. This study aims to establish a robust and bidirectional link between articulatory gestures and their acoustic manifestations. Furthermore, it seeks to characterize the specific role of each articulator, providing insights that could help compensate for potential perturbations affecting individual articulatory mechanisms. R E F E R E N C E S [1] H. W akita, “Direct estimation of the vocal tract shape by in verse filtering of acoustic speech waveforms, ” IEEE Tr ansactions on Audio and Electroacoustics , vol. 21, no. 5, pp. 417–427, 1973. [2] P . Birkholz, “Modeling consonant-vo wel coarticulation for articulatory speech synthesis, ” PLOS one , vol. 8, no. 4, 2013. [3] P . Birkholz and D. Jackel, “ A three-dimensional model of the v ocal tract for speech synthesis, ” in 15th International Congr ess of Phonetic Sciences - ICPhS’2003, Barcelona, Spain , Aug 2003, pp. 2597–2600. [4] Y . Gao, P . Birkholz, and Y . Li, “ Articulatory copy synthesis based on the speech synthesizer vocaltractlab and conv olutional recurrent neural networks, ” IEEE/ACM T ransactions on A udio, Speech, and Langua ge Pr ocessing , vol. 32, pp. 1845–1858, 2024. [5] A. Wrench and W . Hardcastle, “ A multichannel articulatory database and its application for automatic speech recognition, ” in Proceedings of the 5th Seminar on Speech Production: Models and Data , 01 2000. [6] K. Richmond, P . Hoole, and S. King, “ Announcing the electromagnetic articulography (day 1) subset of the mngu0 articulatory corpus, ” in Pr oceedings of the 12th Interspeec h Conference , 08 2011, pp. 1505– 1508. [7] K. Richmond, “ A trajectory mixture density network for the acoustic- articulatory in version mapping, ” in Proceedings of the Annual Confer- ence of the International Speech Communication Association, INTER- SPEECH , vol. 2, 09 2006. [8] M. Parrot, J. Millet, and E. Dunbar , “Independent and Automatic Evaluation of Speaker-Independent Acoustic-to-Articulatory Reconstruction, ” in Pr oceedings of INTERSPEECH 2020, 21st Annual Confer ence of the International Speech Communication Association , ser . Proceedings of INTERSPEECH 2020, 21st Annual Conference of the International Speech Communication Association, Shanghai / V irtual, China, Oct. 2020, pp. 3740–3744. [Online]. A v ailable: https://hal.science/hal- 03087264 [9] A. Illa and P . Ghosh, “Closed-set speaker conditioned acoustic-to- articulatory inversion using bi-directional long short term memory network, ” The Journal of the Acoustical Society of America , vol. 147, pp. EL171–EL176, 02 2020. [10] C. Mcghee, K. Knill, and M. Gales, “Highly intelligible speaker - independent articulatory synthesis, ” in Pr oceedings of 25th Conference Interspeech , 09 2024, pp. 3375–3379. [11] Y . Lim, A. T outios, Y . Bliesener , Y . T ian, S. Ling ala, C. V az, T . Sorensen, M. Oh, S. Harper, W . Chen, Y . Lee, J. T ¨ oger , M. Llorens Monteserin, C. Smith, B. Godinez, L. Goldstein, D. Byrd, and S. Narayanan, “ A multispeaker dataset of raw and reconstructed speech production real- time mri video and 3d volumetric images, ” Scientific Data , vol. 8, 07 2021. [12] K. Isaie v a, Y . Laprie, J. Lecl ` ere, I. Douros, J. Felblinger , and P .-A. V uissoz, “Multimodal dataset of real-time 2d and static 3d mri of healthy french speakers, ” Scientific Data , vol. 8, 10 2021. [13] K. Maekawa, “Introduction to the real-time articulatory movement database - version 2.1, ” National Institute for Japanese Language and Linguistics, T ech. Rep., 2025. [14] V . Ramanarayanan, S. Tilsen, M. Proctor, J. T ¨ oger , L. Goldstein, K. S. Nayak, and S. Narayanan, “ Analysis of speech production real-time mri, ” Computer Speech & Language , vol. 52, pp. 1–22, 2018. [15] T . Csap ´ o, “Speak er dependent acoustic-to-articulatory in v ersion using real-time MRI of the v ocal tract, ” in Proc. INTERSPEECH 2020 – 21 st Annual Confer ence of the International Speech Communication Association , Shanghai, 10 2020, pp. 3720–3724. [16] A. Oura, H. Kikuchi, and T . Kobayashi, “Preprocessing for acoustic-to- articulatory inversion using real-time mri movies of japanese speech, ” in Pr oceedings of 25th Conference Interspeech , 09 2024, pp. 1550–1554. [17] H. Nguyen, S. F oley , K. Huang, X. Shi, T . Feng, and S. Narayanan, “Speech2rtmri: Speech-guided diffusion model for real-time mri video of the vocal tract during speech, ” 2024. [Online]. A vailable: https://arxiv .org/abs/2409.15525 [18] V . Ribeiro, K. Isaie va, J. Leclere, J. Felblinger , P .-A. V uissoz, and Y . Laprie, “Automatic segmentation of vocal tract articulators in real-time magnetic resonance imaging, ” Computer Methods and Pr ogr ams in Biomedicine , vol. 243, no. 2, p. 107907, Jan. 2024. [Online]. A v ailable: https://inria.hal.science/hal- 04376938 [19] A. Ozerov , E. V incent, and F . Bimbot, “ A general flexible framework for the handling of prior information in audio source separation, ” IEEE T r ansactions on A udio Speech and Langua ge Pr ocessing , vol. 20, 05 2012. [20] D. Fohr , O. Mella, and D. Jouvet, “De l’importance de l’homog ´ en ´ eisation des conv entions de transcription pour l’alignement automatique de corpus oraux de parole spontan ´ ee, ” in 8es Journ ´ ees Internationales de Linguistique de Corpus (JLC2015) , 2015. [21] Z. K. Abdul and A. K. Al-T alabani, “Mel frequency cepstral coefficient and its applications: A revie w , ” IEEE Access , vol. 10, pp. 122 136– 122 158, 2022. [22] L. R. Rabiner, Digital processing of speech signals . Pearson Education India, 1978. [23] C. J. Cho, P . W u, A. Mohamed, and G. K. Anumanchipalli, “Evidence of vocal tract articulation in self-supervised learning of speech, ” in ICASSP 2023-2023 IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2023, pp. 1–5. [24] W .-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdinov , and A. Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units, ” IEEE/ACM transactions on audio, speech, and language pr ocessing , vol. 29, pp. 3451–3460, 2021. [25] A. Bae vski, Y . Zhou, A. Mohamed, and M. Auli, “wa v2vec 2.0: A framework for self-supervised learning of speech representations, ” Advances in neural information processing systems , vol. 33, pp. 12 449– 12 460, 2020. [26] S. Chen, C. W ang, Z. Chen, Y . W u, S. Liu, Z. Chen, J. Li, N. Kanda, T . Y oshioka, X. Xiao et al. , “W avlm: Large-scale self-supervised pre- training for full stack speech processing, ” IEEE Journal of Selected T opics in Signal Processing , vol. 16, no. 6, pp. 1505–1518, 2022. [27] A. A. Attia, Y . M. Siriwardena, and C. Espy-W ilson, “Improving speech in version through self-supervised embeddings and enhanced tract variables, ” in 2024 32nd Eur opean Signal Processing Conference (EUSIPCO) . IEEE, 2024, pp. 306–310. [28] C. P . Browman and L. Goldstein, “ Articulatory phonology: An overvie w , ” Phonetica , vol. 49, no. 3-4, pp. 155–180, 1992. [29] V . Ribeiro, K. Isaiev a, J. Leclere, J. Felblinger, P .-A. V uissoz, and Y . Laprie, “ Automatic segmentation of vocal tract articulators in real- time magnetic resonance imaging, ” Computer Methods and Pro grams in Biomedicine , vol. 243, p. 107907, 11 2023. [30] M. Z. Boito, V . Iyer , N. Lagos, L. Besacier, and I. Calapodescu, “mhubert-147: A compact multilingual hubert model, ” arXiv pr eprint arXiv:2406.06371 , 2024. [31] S. Azzouz, P .-A. V uissoz, and Y . Laprie, “Complete reconstruction of the tongue contour through acoustic to articulatory in version using real- time mri data, ” in ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2025, pp. 1–5. [32] ——, “Reconstruction of the complete vocal tract contour through acoustic to articulatory in version using real-time mri data, ” in Pr oc. Interspeech 2025 , 2025, pp. 978–982. [33] E. Farnetani and D. Recasens, “Coarticulation and connected speech processes, ” The handbook of phonetic sciences , vol. 371, p. 404, 1997. [34] C. Cunha, P . Hoole, D. V oit, J. Frahm, and J. Harrington, “The physiological basis of the phonologization of vowel nasalization: A real- 13 time mri analysis of american and southern british english, ” Journal of Phonetics , vol. 105, p. 101329, 2024. [35] P . Hoole and C. Kroos, “Control of larynx height in vo wel production, ” 11 1998. [36] B. Potard, Y . Laprie, and S. Ouni, “Incorporation of phonetic constraints in acoustic-to-articulatory in version, ” Journal of the Acoustical Society of America , vol. 123, no. 4, pp. 2310–2323, 2008. [Online]. A vailable: https://inria.hal.science/inria- 00112226 [37] S. Azzouz, P .-A. V uissoz, and Y . Laprie, “ Acoustic-to-articulatory in- version of clean speech using an mri-trained model, ” arXiv pr eprint arXiv:2603.11845 , 2026.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment