실시간 MRI 기반 음성‑조음 역변환: 오디오 임베딩과 데이터 양의 영향
본 연구는 실시간 MRI(RT‑MRI) 영상에서 자동 추출한 조음기 윤곽선을 이용해 음성 신호를 조음 움직임으로 역변환하는 방법을 제안한다. Bi‑LSTM 모델에 MFCC, LCC, HuBERT 임베딩을 입력으로 사용하고, 데이터 양을 10분부터 3.5시간까지 변화시켜 성능을 평가하였다. 평균 RMSE는 1.48 mm(픽셀 크기 1.62 mm)로, 전체 성대‑입술 구간을 포함한 완전한 조음역변환이 가능함을 보여준다.
저자: Sofiane Azzouz, Pierre-André Vuissoz, Yves Laprie
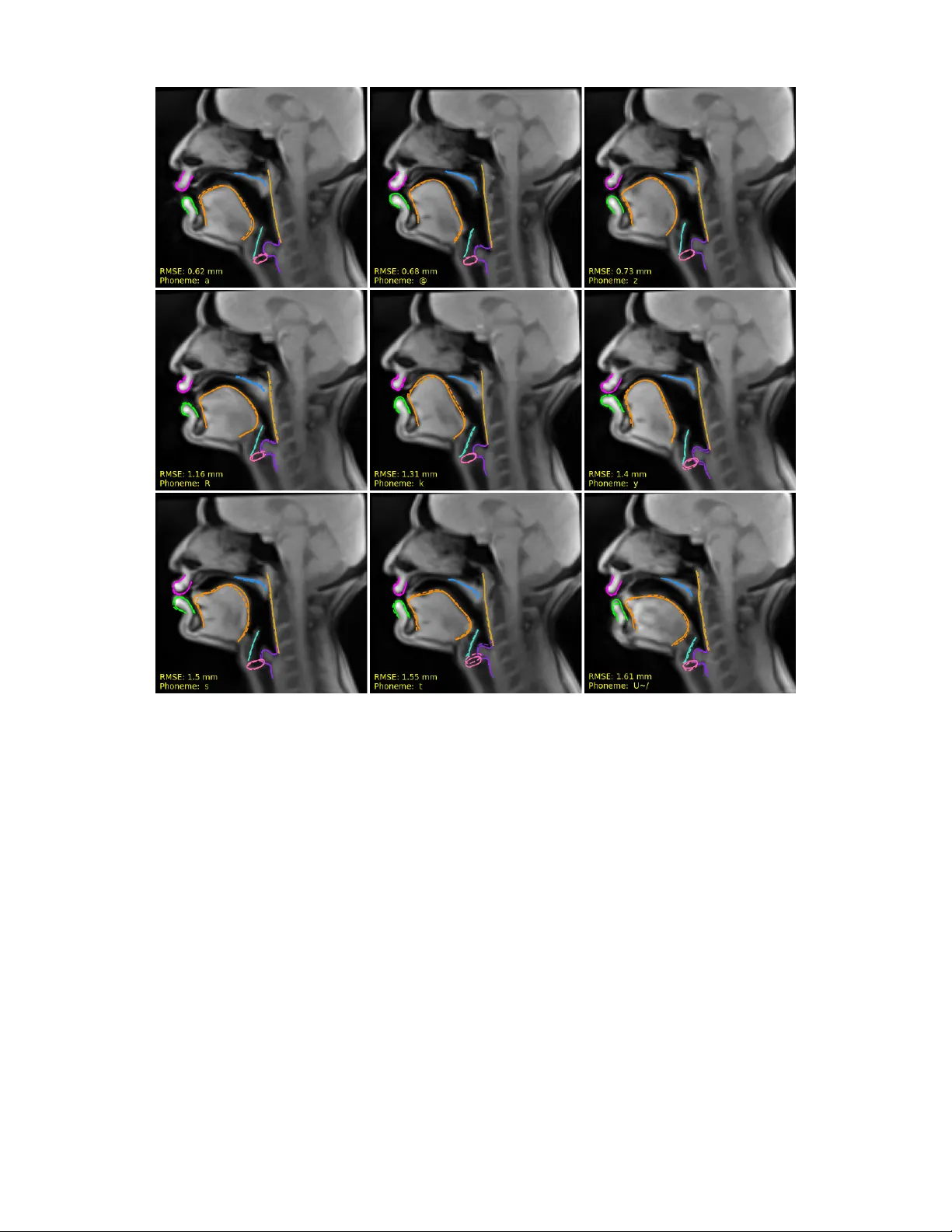
본 논문은 음성 신호를 이용해 전체 성도(성대부터 입술까지)의 조음 형태를 복원하는 ‘음성‑조음 역변환’ 문제에 접근한다. 기존 연구는 주로 전자기식 조음계(EMA)를 사용했으며, 이는 센서 수가 제한되고 전방 조음만을 측정한다는 근본적인 한계가 있다. 이러한 제약을 극복하고자 저자들은 실시간 MRI(RT‑MRI) 데이터를 활용한다. RT‑MRI는 전신 조음 정보를 제공하지만, 이미지 자체를 직접 학습에 사용하면 픽셀 수준의 잡음과 고해상도 요구 등 여러 문제점이 있다. 따라서 저자들은 자동 윤곽선 추적(RCNN 기반)으로 8개의 주요 조음기와 2개의 기준 랜드마크를 50점씩 2차원 좌표로 변환하고, 이를 정규화하여 모델 입력으로 사용한다. 이 과정에서 추적 오차는 평균 1 mm 수준으로, 실제 조음 움직임을 높은 정확도로 포착한다.
음성 입력 특징으로는 세 가지를 비교한다. 첫째, 전통적인 MFCC는 음성 인식에서 널리 쓰이며, 주파수 축을 멜 스케일로 변환해 기본 주파수 영향을 억제한다. 둘째, 선형 주파수 스케일을 사용하는 LCC는 형태학적 정보(포먼트) 보존에 유리하다. 셋째, 최신 자기지도 학습 모델인 HuBERT는 대규모 다중언어 데이터로 사전학습된 고차원 임베딩을 제공한다. 실험에서는 HuBERT‑Base(768 차원)와 HuBERT‑Large를 비교했으며, Base 모델이 가장 효율적이었다.
모델은 5‑계층 Bi‑LSTM 구조를 채택한다. 입력 특징은 300‑유닛 전결합 레이어 두 개를 거쳐, 양방향 LSTM 레이어 두 개(각 300 유닛)로 전달된다. 최종 출력은 100 × 8 차원의 텐서(각 조음기의 X·Y 좌표 50점씩)이며, 손실은 모든 좌표에 대한 평균 제곱 오차(MSE) 합으로 정의한다. 이 설계는 조음 과정에서 앞선 음소와 뒤따르는 음소 간의 상호작용을 동시에 모델링할 수 있게 한다.
데이터는 프랑스어 여성 화자 1명에 대해 2,100문장(약 3.5시간)으로 구성된다. 각 세션은 80초 길이의 4,000 프레임(50 fps)으로 촬영되며, 해상도는 136 × 136 픽셀, 픽셀 간격 1.62 mm이다. 음성은 16 kHz 광학 마이크로 녹음 후, 기존 연구(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기