Mitigating Backdoor Attacks in Federated Learning Using PPA and MiniMax Game Theory
Federated Learning (FL) is witnessing wider adoption due to its ability to benefit from large amounts of scattered data while preserving privacy. However, despite its advantages, federated learning suffers from several setbacks that directly impact t…
Authors: Osama Wehbi, Sarhad Arisdakessian, Omar Abdel Wahab
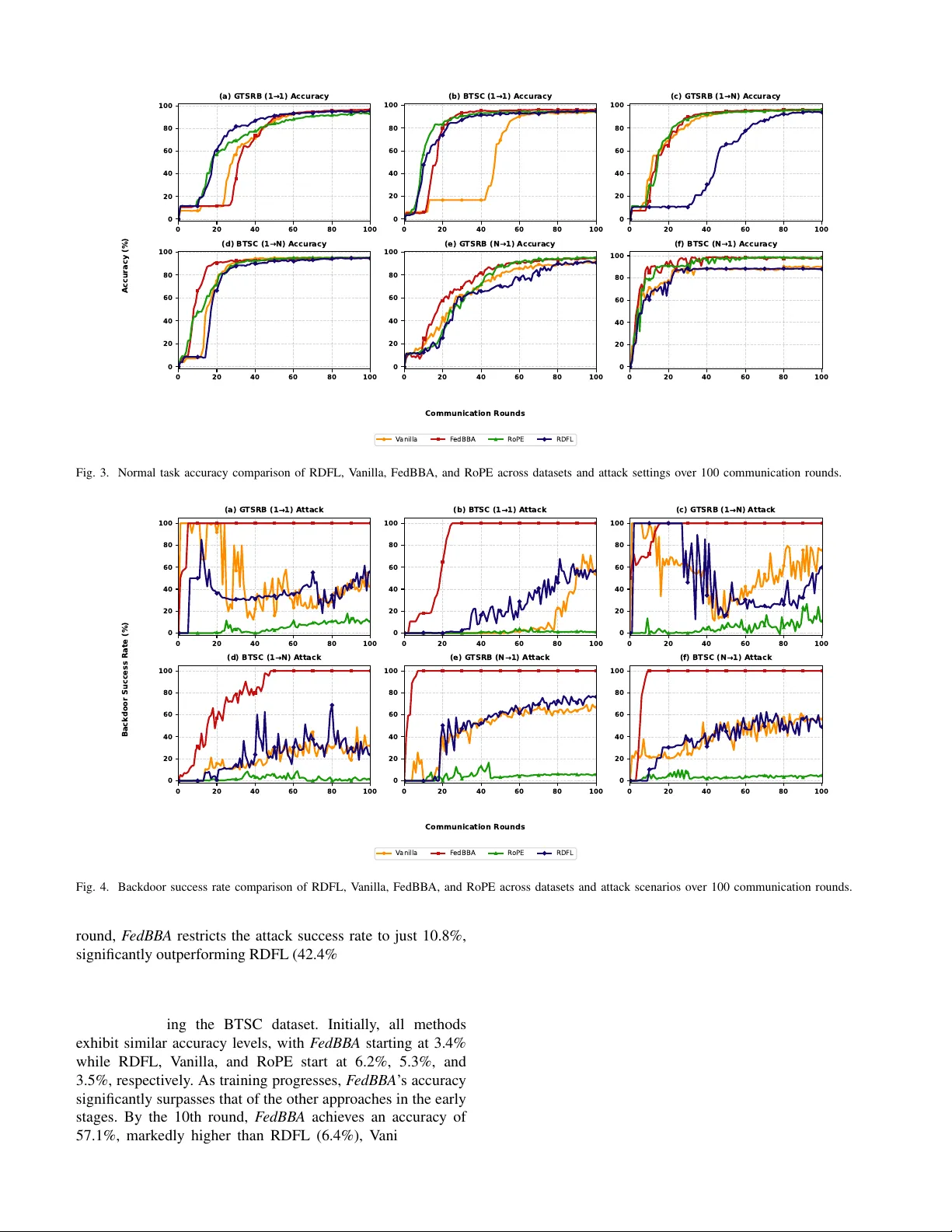
JOURNAL OF L A T E X CLASS FILES, VOL. 00, NO. 0, SEPTEMBER 0000 1 Mitigating Backdoor Attacks in Federated Learning Using PP A and MiniMax Game Theory Osama W ehbi, Sarhad Arisdakessian, Omar Abdel W ahab, Anderson A vila, Azzam Mourad, Hadi Otrok Abstract —Federated Learning (FL) is witnessing wider adop- tion due to its ability to benefit from large amounts of scattered data while pr eserving priv acy . However , despite its advantages, federated learning suffers fr om several setbacks that dir ectly impact the accuracy , and the integrity of the global model it produces. One of these setbacks is the presence of malicious clients who actively try to harm the global model by injecting backdoor data into their local models while trying to evade detection. The objective of such clients is to trick the global model into making false predictions during inference, thereby compromising the integrity and trustw orthiness of the global model on which honest stakeholders rely . T o mitigate such mischievous beha vior , we pr opose F edBB A (F ederated Backdoor and Beha vior Analysis). The proposed model aims to dampen the effect of such clients on the final accuracy , creating more resilient federated lear ning envir onments. W e engineer our approach through the combination of (1) a reputation system to evaluate and track client behavior , (2) an incentive mechanism to reward honest participation and penalize malicious behavior , and (3) game theoretical models with projection pursuit analysis (PP A) to dynamically identify and minimize the impact of malicious clients on the global model. Extensiv e simulations on the German T raffic Sign Recognition Benchmark (GTSRB) and Belgium T raffic Sign Classification (BTSC) datasets demonstrate that F edBBA r educes the backdoor attack success rate to approximately 1.1%–11% across various attack scenarios, significantly outperf orming state- of-the-art defenses like RDFL and RoPE, which yielded attack success rates between 23% and 76%, while maintaining high normal task accuracy ( ∼ 95%–98%). Index T erms —Cybersecurity , Federated Learning (FL), Back- door Attacks, Game Theory , Reputation System, Projection Pursuit Analysis (PP A) I . I N T RO D U C T I O N Federated learning (FL) enables collaborati ve model train- ing across distrib uted clients while keeping data locally on devices, thus preserving pri vacy and reducing centralized data storage requirements. [1]. This framework not only preserves user priv acy but also le verages edge device capabilities, mak- ing it vital for applications such as healthcare, finance, and Osama W ehbi is with the Department of Computer and Software En- gineering, Polytechnique Montr ´ eal, Montreal, Quebec, Canada (e-mail: osama.wehbi@etud.polymtl.ca). Sarhad Arisdakessian is with the Department of Computer and Software Engineering, Polytechnique Montr ´ eal, Montreal, Quebec, Canada (e-mails: sarhad.arisdakessian@etud.polymtl.ca). Omar Abdel W ahab is with the Department of Computer and Software Engineering, Polytechnique Montr ´ eal, Montreal, Quebec, Canada (e-mails: omar .abdul-wahab@polymtl.ca). Anderson A vila is with the Institut national de la recherche scientifique (INRS-EMT), Montr ´ eal, Canada (e-mail: Anderson.A vila@inrs.ca). Azzam Mourad is with the Department of Computer Science, Khalifa Univ ersity , Abu Dhabi, U AE, as well as the Artificial Intelligence & Cyber Systems Research Center , Department of CSM, Lebanese American Univer - sity (e-mails: azzam.mourad@ku.ac.ae). Hadi Otrok is with the Department of Computer Science, Khalifa Uni ver- sity , Abu Dhabi, UAE (e-mails: hadi.otrok@ku.ac.ae). autonomous driving. Despite these benefits, FL inherits unique security challenges, particularly its vulnerability to backdoor attacks. These attacks exploit the training process to implant malicious behaviors in models that are activ ated by specific triggers, such as pixel modifications or hidden patterns in the input data [2]. For instance, in autonomous vehicles (A Vs), a trigger embedded in traffic sign images could lead to misclas- sifications, jeopardizing safety-critical systems. Such attacks aim to manipulate the model’ s beha vior while remaining undetected during training, allowing malicious functionality to coexist with otherwise normal model performance. The decentralized nature of FL further exacerbates these chal- lenges. Clients often possess limited or imbalanced datasets that may not fully represent the global data distrib ution. As a result, clients may incorporate external data during local training, increasing the potential for backdoor attacks. Malicious participants can e xploit this setting by injecting poisoned data or embedding triggers into their local training process. Moreo ver , backdoor attacks can be carried out in multiple forms, including single or multiple attempts, coor- dinated attacks across se veral clients, targeted (one-to-one), untargeted (one-to-many), and multi-trigger scenarios. These attacks are particularly difficult to detect due to their stealthy design and the high dimensionality of deep learning models. Another major challenge arises from the federated aggregation process itself. Since only model updates are shared with the server rather than raw data, it becomes difficult to identify and isolate malicious contributions. T raditional e valuation met- rics such as accurac y and precision primarily assess ov erall model performance but often fail to capture hidden malicious behaviors embedded within the model [3]. Consequently , a model may maintain high accuracy on benign inputs while still containing cov ert backdoor functionality . Although se veral defense mechanisms have been proposed to address backdoor attacks in federated learning, many existing approaches focus primarily on scalability and complexity , and some introduce additional pri vacy concerns. More importantly , most solutions treat participating clients as static entities and o verlook the dynamic behavior and evolving motiv ations of both honest and malicious participants during the training process. This limitation restricts their ability to adapt to changing attack strategies. In addition, many e xisting defenses are designed to address only specific forms of attacks, particularly one-to-one backdoor attacks, while ov erlooking other types that can be equally harmful. T o address these challenges, we propose F edBBA (Federated Backdoor and Behavior Analysis), a frame work designed to enhance the security and reliability of federated learning sys- tems. The proposed approach inte grates statistical analysis, a JOURNAL OF L A T E X CLASS FILES, VOL. 00, NO. 0, SEPTEMBER 0000 2 reputation-based ev aluation mechanism, and game-theoretical modeling to dynamically detect and mitigate malicious client behavior . In particular , our framew ork le verages Projection Pursuit Analysis (PP A) with kurtosis scores to identify sus- picious model updates, while a reputation mechanism contin- uously ev aluates client behavior over multiple training rounds. Furthermore, we model the interaction between the federated server and potentially malicious clients as a non-cooperativ e MiniMax game, where malicious clients attempt to maximize the impact of backdoor attacks while the server aims to minimize their influence on the global model. Based on this framew ork, the federated server assigns adaptiv e weights to client updates according to their PP A scores, reputation values, and gradient dif ferences, thereby reducing the influence of suspicious or malicious contributions while preserving the benefits of collaborative learning. Through extensiv e simula- tions using real-world datasets, including GTSRB and BTSC, we demonstrate that F edBBA significantly reduces backdoor attack success rates while maintaining high model accuracy and outperforming existing state-of-the-art approaches. This work contributes to advancing secure federated learn- ing by addressing the dynamic nature of client behavior and providing a more comprehensi ve defense against diverse backdoor attack strategies. By improving the robustness and trustworthiness of federated models, our approach supports the safe deployment of FL in safety-critical domains. A. Contributions The main contrib utions of this work are summarized as follows: 1) Dev elop a no vel federated learning frame work based on non-cooperativ e MiniMax games, incorporating PP A scores, reputation scores, and dif ferences in local model gradients to dynamically adapt to client behavior and model updates, with the objective of assigning optimal weights to minimize the impact of malicious clients. 2) Lev erage a reputation mechanism to ev aluate client be- havior dynamically , rew arding honest clients and penal- izing malicious ones, thereby enhancing the rob ustness of the global model against backdoor attacks. 3) Utilize Projection Pursuit Analysis (PP A) with Kurtosis scores, coupled with a reputation mechanism, to identify possible suspicious client updates and mitigate their impact on the global model by reducing the influence of backdoored contributions. 4) Design the proposed solution to be generic enough to address dif ferent types of attacks, including one-to-one and one-to-many scenarios, which are often overlooked by existing works. B. P aper Outline Section II revie ws the related w ork on backdoor attack detection and mitigation strategies in FL. Section III discusses the main concepts and methods used in this research. Sec- tion IV formulates the core problem of backdoor attacks in FL and discusses their impact on model inte grity and performance. The system architecture and PP A methodology for mitigat- ing anomalous model updates are presented in Section V, while Section VI details the MiniMax game framew ork and the decision-making process used to reduce the influence of suspicious clients. Section VII describes the implementation of F edBBA and its operation across multiple training rounds. Section VIII reports the experimental results, e valuating the effecti veness of F edBBA using real-world datasets and com- paring its performance with state-of-the-art methods in terms of model accuracy and backdoor attack success rates. Finally , Section IX concludes the paper and outlines potential direc- tions for future research. I I . R E L A T E D W O R K In this section, we provide an o vervie w of the existing literature on the detection and mitigation strategies of back- door attacks in federated learning. Additionally , we highlight the distinct contributions of our approach compared with the revie wed works. The authors of [4] propose a security mechanism against backdoor attacks in federated learning using Generativ e Ad- versarial Networks (GANs) and knowledge distillation. The approach compare the performance of a clean model trained on clean data (teacher) with a global model trained on aggregated data (student). T o reduce the probability of backdoor attacks, the authors of [5] propose a distributed method to prune neurons. Clients measure neuron activ ation and submit local pruning sequences to the server , which aggregates them to eliminate less-used neurons, enhancing model performance. Modeling the backdoor problem as a coalitional game theory , the authors of [6] measure participant performance using their data’ s influence on the aggregated model, distinguishing benign and backdoored models via Shapley value. Addressing attacker behavior fluctuations, the authors of [7] introduce a MiniMax game strategy where the server generates authentic client ratings to adjust model weights, reducing the influence of compromised clients. In [8], the authors propose an anomaly detection framework that uses conditional v ariational autoen- coders (CV AE) to identify benign and malicious updates, lev eraging the majority of benign clients to distinguish updates effecti vely . The authors of [9] describe a federated learning system where an anomaly detector trained on adversarial data discards malicious updates. In [10], the authors introduce FedSV , a Byzantine-robust framew ork utilizing Shapley values to quantify client contrib utions and eliminate malicious clients, though it is sensitive to noise. Similarly , the authors of [11] propose FLPurifier , which uses decoupled contrastive training to detect and remov e backdoored data. Howe ver , computa- tional requirements and communication ov erhead limit its scalability . The authors of [12] propose Model Anomalous Activ ation Behavior Detection (MAABD), monitoring neural network activ ation patterns to detect deviations and identify malicious tampering. In [13], the authors introduce a max-min security game approach that assigns adapti ve weights based on client trust and data quality . This ensures updates from malicious clients have less influence, though computational ov erhead limits practicality in certain FL en vironments. Di- mensionality reduction techniques hav e also been explored for JOURNAL OF L A T E X CLASS FILES, VOL. 00, NO. 0, SEPTEMBER 0000 3 detecting backdoored models. The authors of [14] introduce RoPE, which employs Principal Component Analysis (PCA) to identify anomalous updates based on distinct principal com- ponents, though its effecti veness depends on the backdoor’ s strength as well as the data distribution, which can lead to the exclusion of benign models. In [15], the authors propose RDFL to mitigate backdoor attacks in federated learning. The method combines adaptive hierarchical clustering with cosine-distance-based anomaly detection. Suspicious updates are remov ed, followed by adaptive clipping and noising to suppress poisoned local models. Howe ver , RDFL is sensiti ve to data distribution and distance metrics; additionally , model clipping may negati vely affect accuracy . The authors of [16] use Singular V alue Decomposition (SVD) to analyze singu- lar values of model updates, capturing linear structures but ov erlooking complex backdoor patterns. While the revie wed approaches show potential, many rely on single detection metrics, leaving them vulnerable to sophisticated attacks. Others fail to address the decentralized nature of federated learning, limiting their applicability . Most solutions target basic backdoor types, neglecting adaptive strategies. Priv acy concerns emerge in methods requiring sensitiv e client data, and many treat attacker behavior as static, reducing resilience to ev olving threats. Our proposal addresses these g aps by le veraging Projection Pursuit Analysis to detect abnormal similarities among local models. The MiniMax game framework dynamically counters attackers, while the reputation system enhances decision- making. This multifaceted approach provides a comprehensiv e solution to mitigating malicious clients in federated learning. T ABLE I N OTA T I ON S UM M A RY Symbol Description N Number of participating clients. T T otal communication rounds. t Current round index. D i Local dataset of client i . D ′ i Poisoned dataset of client i . x j , y j Input sample and true label. M ( t ) Global model at round t . M ( t ) i Local model update from client i . w i Aggregation weight of client i . τ , τ k Backdoor trigger and trigger intensity . y a j T arget label for backdoor attack. L , R Loss and regularization functions. X, V , S Data matrix, projection vectors and PP A scores. R i ( t ) Reputation score of client i . H i ( t ) , G i ( t ) Historical beha vior and gradient variation scores. α, β W eights for reputation components. g j i , g i Gradient at round j and mean gradient. γ , δ Reward and penalty factors. ρ i Poisoning ratio of client i . I ′ Set of compromised clients. s i PP A anomaly score of client i . U ( F ) , U ( A ) Utility functions of server and attack er. Φ( ρ i , τ ) Backdoor impact function. θ, λ Similarity threshold and defense sensiti vity parameter. λ ∗ Optimal defense sensitivity chosen by the server at equilibrium R max Upper bound on any client’ s reputation score I I I . S Y S T E M P R E L I M I NA R I E S In this section, we introduce the main concepts used in our framew ork, including the federated learning process and Pro- jection Pursuit Analysis (PP A) with kurtosis-based anomaly detection. A. F ederated Learning Federated learning is a decentralized machine learning ap- proach that allows multiple clients to collaborativ ely train a model without sharing their ra w data. Let D i denote the dataset of client i , M the global model, and M i the local update. During the training proceeds over communication rounds, the server initializes the global model at t = 0 . At each round t , clients update their models using local data: M t i = M t − 1 − η ∇ L ( M t − 1 , D i ) (1) The updates are sent to the server and aggregated to produce the next global model: M t +1 = 1 N N X i =1 M t i (2) The updated model is then redistributed to clients for the next round of training. B. Pr ojection Pursuit Analysis and Kurtosis Projection Pursuit Analysis (PP A) is a multi variate technique that identifies informativ e projections of high- dimensional data by maximizing a projection index [17]. Unlike Principal Component Analysis (PCA), which focuses on v ariance, PP A detects non-Gaussian structures that often correspond to anomalies or outliers. Formally , PP A searches for a projection vector w that maximizes the projection index: w ∗ = arg max w I ( w T X ) (3) In our context, the server applies PP A to the collection of client updates in each round. Malicious updates typically introduce abnormal patterns in the high-dimensional parameter space, which PP A can highlight. The projection index used in our work is the kurtosis score, defined as the standardized fourth central moment of a distribution: kurtosis = E [( X − µ ) 4 ] σ 4 (4) A high kurtosis v alues indicate hea vy tails or outliers in the projected distribution, allowing the detection of anomalous client updates. This property makes kurtosis-based PP A par- ticularly effecti ve for identifying stealthy backdoor behaviors embedded in model updates. T o illustrate this property , we conducted an experiment on the MNIST dataset with 30 clients, where 10 clients used poisoned data. The backdoor attack modified the first row of pixels in images of class 0 and changed the label to 9. After 30 training rounds, PP A successfully separated malicious and benign updates, whereas PCA did not produce clear clustering (Fig. 1). These results demonstrate the effecti veness of PP A for detecting anomalous model updates in federated learning. JOURNAL OF L A T E X CLASS FILES, VOL. 00, NO. 0, SEPTEMBER 0000 4 (a) PP A score plot; each point represents a local model (b) PCA score plot; each point represents a local model Fig. 1. Comparison of model clustering using PP A vs. PCA. PP A shows clearer separation between benign (black) and backdoored (blue) models. I V . P R O B L E M F O R M U L A T I O N In this section, we provide the formal definitions of different backdoor attack models considered in our work and the methods used to inject these attacks into federated learning systems. A. Backdoor Attack Models Backdoor attacks aim to embed malicious behaviors into the global model without significantly affecting its performance. These attacks are particularly insidious because they can remain undetected during the training process and only get activ ated under specific conditions. When a certain trigger is present, the model will behav e differently from its expected behavior . W e can differentiate between three types of backdoor attacks: 1) One-to-One Attack: An attack with a single trigger τ modifies the local dataset D i such that: D ′ i = { ( x j + τ , y a j ) : ( x j , y j ) ∈ D i } (5) This ensures that when the trigger τ is present, the input x j + τ is misclassified as y a j . This type of attack is straightforw ard but effecti ve, causing the model to produce incorrect predictions for inputs containing the specific trigger . 2) One-to-N Attack: An attack with v arying trigger inten- sities τ k targets multiple behaviors y a j : D ′ i = { ( x j + τ k , y a j ) : ( x j , y j ) ∈ D i , k = 1 , . . . , K } (6) In this scenario, dif ferent intensities of the trigger τ k cause different misclassifications, making detection more challeng- ing. The model may beha ve correctly under normal conditions but produce erroneous outputs for inputs with varying de grees of the trigger , complicating the identification of malicious behavior . 3) N-to-One Attack: An attack requires all N backdoors τ k to be present simultaneously to trigger the attack: D ′ i = { ( x j + N X k =1 τ k , y a j ) : ( x j , y j ) ∈ D i } (7) This type of attack is particularly stealthy because individual triggers τ k do not cause misclassifications on their own. Only when all triggers are present together does the attack activ ate, making it difficult to detect through traditional methods. B. Attack Execution Strate gies This section describes how these attacks can be performed. One approach in volves multiple rounds, where clients repeat- edly send backdoored updates to the server . Another method is model replacement, where clients wait until the model is near con vergence and then replace it to introduce the backdoor . 1) Multiple Rounds with Backdoor ed Updates: In this ap- proach, the attack occurs over sev eral communication rounds t = 1 , 2 , . . . , T (where T is the total number of rounds). Each client i trains its local model on dataset D i and computes local updates. Malicious clients instead use a modified dataset D ′ i containing backdoors using one of the methods defined in Equation (5), (6), or (7). Clients send their updates to the server , which aggre gates them to form the new global model using Equation (2). Malicious clients continue sub- mitting backdoored updates over sev eral rounds, gradually embedding the backdoor into the global model. This attack can be performed by a single malicious client or collabo- rativ ely by multiple clients. Collaborativ e attacks are more effecti ve, as distributing poisoned updates reduces detection risk. In contrast, a single client must inject more poisoned data to influence the global model, making detection easier . Additionally , when only one client attacks, the backdoor effect may gradually vanish due to catastrophic forgetting across rounds [18]. This scenario is realistic because it does not require high-privile ge access or control over the federated learning process [19]. 2) Model Replacement: In this approach, the attack occurs when the global model is near con vergence. Each client i trains its local model on dataset D i , while malicious clients prepare a significantly altered model using a modified dataset D ′ i with one of the methods defined in Equation (5), (6), or (7). At a strategic round T ′ ≈ T , malicious clients submit altered models containing the backdoor: M ( T ′ ) i = arg max M L ( M ; D ′ i ) + R ( M ) (8) The server then aggregates the updates to form the ne w global model: M ( T ′ +1) = 1 N N X i =1 M ( T ′ ) i (9) Due to the large modifications introduced by malicious clients, the global model may contain the backdoor . Although model replacement attacks can be highly ef fective, they are less realistic in practical federated learning systems [20]. Successfully replacing the global model without detection typ- ically requires high-privile ge access and precise control over the aggre gation process, which is rarely av ailable to adversarial clients. Therefore, this scenario assumes a stronger threat model and is harder to implement in real-world deployments. V . S Y S T E M A R C H I T E C T U R E In this section, we present the overall system architecture designed to mitigate backdoor attacks in federated learning. The architecture includes Projection Pursuit Analysis (PP A) for mitigating anomalous model update effects from malicious JOURNAL OF L A T E X CLASS FILES, VOL. 00, NO. 0, SEPTEMBER 0000 5 clients, a reputation system to ev aluate client beha vior based on historical data, including action taken as well as gradient variation. Algorithm 1 Multiv ariate K urtosis Projection Pursuit (MKPP) Require: Data matrix X , dimension p , number of guesses g uess , search type M axM in , algorithm type S tS h Ensure: Projection scores S , projection vectors V , kurtosis values k urtO bj 1: Mean-center the data: X ← X − mean ( X ) 2: Perform SVD: ( U, Z, V ) ← SVD ( X ) 3: Dimensionality reduction: X ← U Z 4: Initialize maxcount ← 1000 , k urtO bj ← 0 5: for k = 1 to guess do 6: Initialize random projection V 7: count ← 0 , conver ged ← f alse 8: while not con ver ged and count < maxcount do 9: A ← V T X T X V 10: Update V using ( A, M axM in, S tS h ) 11: Normalize V using SVD 12: if change in V < threshold then 13: conv erg ed ← tr ue 14: end if 15: count ← count + 1 16: end while 17: kur tObj [ k ] ← kurtosis ( X V ) 18: end f or 19: Select best projection vector V 20: Compute scores S ← X V 21: return S , V , kur tObj A. PP A-based Detection The algorithm 1 aims to find optimal projection v ectors V from a data matrix X by maximizing or minimizing the kurtosis score. The process begins by mean-centering the data matrix X (line 1) and performing Singular V alue Decomposition (SVD) to reduce its dimensionality (lines 2- 3). The algorithm then iterates over a set number of initial guesses for the projection v ectors V (line 5). In each iteration, it initializes V randomly (line 6) and sets the count and con vergence flag (line 7). The algorithm updates V using a quasi-power method (lines 9-10), normalizes V using SVD (line 11), and checks for conv ergence based on changes in V (lines 12-14). The iteration stops if con vergence is achiev ed or the maximum iteration count is reached (line 18). Once all guesses are ev aluated, the algorithm computes the kurtosis for each projection (line 17) and selects the best V based on the computed kurtosis values (line 19). Finally , it calculates the scores S using this optimal projection v ector (line 20). The algorithm returns the scores, the optimal projection v ector, and the kurtosis v alues for each guess (line 21). The resulting projection scores highlight extreme non-Gaussian deviations, which often correspond to malicious updates. The computa- tional complexity of the MKPP algorithm can be approximated as O ( | guess | × maxcount × n × p 2 ) , where n is the number of samples and p is the dimensionality of the projection space. The kurtosis-based PP A aims to identify extreme non- Gaussian deviations that may indicate malicious behavior , rather than capturing normal variance from benign data het- erogeneity . T o av oid misclassifying clients with legitimate data distributions, PP A is combined with a dynamic rep- utation system that tracks each client’ s historical behavior and gradient consistency across training rounds. This dual- layer assessment ensures that clients with stable behavior are not unfairly penalized. Additionally , we introduce a reward and penalty mechanism that adjusts reputation scores based on behavioral patterns rather than statistical outliers alone, encouraging participation and fairness while strengthening the robustness of the detection strategy . B. Reputation System The reputation mechanism ev aluates each client based on historical behavior and gradient consistency . A probationary phase allows the server to establish baseline behavior before applying reputation adjustments. The reputation score for client i at round t is: R i ( t ) = αH i ( t ) + β G i ( t ) (10) where H i ( t ) represents historical behavior , G i ( t ) captures gradient variation and α , β are weights such that α + β = 1 . The historical behavior score can be derived as follows : H i ( t ) = correct actions of client i total actions (11) The gradient v ariation score tracks update stability over the last n rounds: G i ( t ) = 1 n t X j = t − n +1 ( g j i − g i ) 2 (12) Client influence is then dynamically adjusted using reward and penalty updates: R new i = R old i + γ R old i (13) R new i = R old i − δ R old i (14) Where γ is the adjustment factor for re warding and δ is the adjustment factor for penalizing. This mechanism gradually reduces the influence of suspi- cious clients while allowing recovery for honest participants. By combining PP A anomaly detection with reputation track- ing, the system identifies persistent malicious behaviors rather than incidental irregularities. V I . M I N I M A X G A M E In this section, we present the minimax security game, where the server aims to minimize the impact of attacks by reducing the influence of weights of suspicious clients while the attack leader seeks to maximize this minimization. A. Game Model MiniMax is a game theoretical model in which one player’ s gain represents the other player’ s exact loss. W e can model the interaction between a federated server (minimizer) and malicious clients (maximizers) as a MiniMax game in feder- ated learning, where malicious clients aim to maximize their utility by injecting backdoor triggers into their local models to manipulate the global model’ s predictions. In contrast, the federated server aims to minimize the impact of these JOURNAL OF L A T E X CLASS FILES, VOL. 00, NO. 0, SEPTEMBER 0000 6 Step 2 : Model T ransmission M1 Adversary (Attack Leader) – Maximizer Inputs: Reputation ( R ᵢ ), Sensitivity (λ), Baseline (θ) Attack Optimization Eq. 29 Poisoned Updates ( M′i ) Step 1: M′2 Mi Mi M′i ..... Federated Server (Defender) – Minimizer Reward Penalty Step 3: Detection & Assessment (PP A) and DBSCAN Weight Calculation Eq. 17 Step 4: Step 5: Weighted Aggregation Eq. 18 Increase Reputation ( R ᵢ ) Decrease Reputation ( R ᵢ ) Global Model Update M ⁽ᵗ⁺ ¹ ⁾ Reputation History Step 6: Reputation Update Fig. 2. Architectural workflow of the proposed Minimax game. malicious clients to ensure the integrity and accuracy of the global model. The interaction is represented between two players: • Server (minimizer): aims to preserve the integrity of the global model by choosing the defense sensitivity parameter λ ∈ [ λ min , λ max ] ⊂ R + , which controls the aggressiv eness of the PP A penalty on suspicious updates. A larger λ penalises high- ρ i clients more sharply b ut risks false positives on honest clients. • Adversary (maximizer): attempts to inject backdoor triggers through poisoned local updates by selecting the poisoning ratio ρ i ∈ [0 , 1] for each compromised client i ∈ I ′ , giv en the serv er’ s chosen λ . This formulation allo ws the analysis of worst-case attack scenarios and enables the design of defensive aggre gation strategies based on anomaly detection and reputation mech- anisms. B. Player Strate gies 1) Adversarial Strate gy: Malicious clients aim to inject backdoor triggers into the federated training process using the poisoning mechanisms defined in Section IV -A. Let D i denote the benign dataset of client i . The attacker constructs a poisoned dataset D ′ i by injecting trigger patterns τ into a subset of samples. The poisoning ratio ρ i ∈ [0 , 1] represents the fraction of poisoned samples: D ′ i ( ρ i ) = D clean i ∪ D poisoned i (15) where | D poisoned i | = ρ i | D i | . The resulting model update becomes M ′ i = (1 − ρ i ) M i + ρ i M bd ( τ ) (16) where M bd ( τ ) represents the gradient direction induced by poisoned samples. 2) Server Strate gy: The federated server mitigates mali- cious influence by choosing the defense sensitivity λ and then assigning adaptive aggregation weights based on repu- tation scores and PP A anomaly scores. Substituting the PP A similarity score s i ( ρ i , λ ) = θ − λρ i into Equation (17), the aggregation weight is therefore a function of both the adversary’ s poisoning ratio and the serv er’ s chosen λ : w i ( ρ i , λ ) = R i + θ − λρ i N X j =1 R j + θ − λρ j (17) Remark 1 (Approximation and validity) . The linear model s i ( ρ i , λ ) = θ − λρ i is moti vated by Eq. (16), where the poi- soned update de viates from the benign update proportionally to ρ i . Since w i depends on all ρ j via the denominator , we approximate it by a normalising constant C = P j ( R j + θ ) , yielding the separable surrogate ˜ J used throughout Section VI- D; this preserves the monotonic incentiv e structure of the orig- inal game. Non-negati vity of w i is guaranteed at equilibrium since λρ ∗ i = ( R i + θ ) / 2 < R i + θ . The global model update is then: M t +1 = 1 N N X i =1 w i ( ρ i , λ ) M t i (18) The server determines λ by anticipating the adversary’ s best response, as formalized in Section VI-D. The server uses Projection Pursuit Analysis to compute anomaly scores across client updates as follows: S = PP A ( M ) (19) T o further detect abnormal beha viors, the serv er applies Density-Based Spatial Clustering of Applications with Noise (DBSCAN) clustering to identify suspicious groups of clients. DBSCAN is suitable for this task because of its ability to detect clusters of arbitrary shape and its robustness to noise, which allows it to isolate anomalous updates that deviate JOURNAL OF L A T E X CLASS FILES, VOL. 00, NO. 0, SEPTEMBER 0000 7 significantly from the majority . Once DBSCAN identifies clusters, Clients identified as anomalous are penalized through reduced reputation scores, while benign clients recei ve re wards according to Equations (13) and (14). 3) Utility Functions: The utility functions are derived from the joint weight formula in Equation (17). Because the game is zero-sum, it suf fices to define the joint objective J ( λ, ρ ) , with U ( F ) = − J and U ( A ) = J . F ollowing the standard approximation of replacing Φ( ρ i , τ ) with ρ i (motiv ated by the linear poisoning structure in Remark 1), the joint objectiv e is: J ( λ, ρ ) = X i ∈I ′ w i ( ρ i , λ ) · ρ i (20) Server’ s utility: U ( F ) = − J ( λ, ρ ) (21) The server minimizes J by choosing λ ∈ [ λ min , λ max ] : a larger λ reduces w i ( ρ i , λ ) for high- ρ i clients more aggres- siv ely , suppressing their weighted contribution to the objecti ve. Adversary’ s utility: U ( A ) = J ( λ, ρ ) (22) The adversary controls the poisoning ratio vector ρ = { ρ i } i ∈I ′ , subject to ρ i ∈ [0 , 1] , introducing a trade-off as: 1) Efficacy: Increasing ρ i strengthens the backdoor objec- tiv e. 2) Detectability: Larger ρ i increases de viation from benign updates via s i ( ρ i , λ ) = θ − λρ i , reducing w i ( ρ i , λ ) and penalizing the reputation score R i , which dri ves w i tow ard zero. C. Game F ormulation The strategic interaction is defined as G = ⟨{ Server , Adversary } , Λ , P , J, − J ⟩ , where: • Server strategy space: Λ = [ λ min , λ max ] ⊂ R + , a compact interval. The server chooses λ ∈ Λ to minimize the worst-case adversarial impact. • Adversary strategy space: P = [0 , 1] |I ′ | . The adversary chooses ρ = { ρ i } i ∈I ′ to maximize J . The interaction is formulated as the following minimax program: min λ ∈ Λ max ρ ∈P J ( λ, ρ ) = min λ ∈ Λ max ρ ∈P X i ∈I ′ w i ( ρ i , λ ) · ρ i (23) subject to: 0 ≤ ρ i ≤ 1 , ∀ i ∈ I ′ (24) N X k =1 w k ( ρ k , λ ) = 1 (25) λ min ≤ λ ≤ λ max (26) where w i ( ρ i , λ ) is defined in Equation (17). Both strategy spaces are compact and con ve x, satisfying the prerequisites for the equilibrium analysis in Section VI-D. D. Equilibrium Analysis and Solution W e adopt a simultaneous-move Nash formulation. The adversary maximizes ˜ J A ( ρ i ) = w i ( ρ i , λ ) · ρ i for each i ∈ I ′ , treating λ as fixed; the server analogously chooses λ ∗ as its best response to ρ ∗ ( λ ) . Substituting s i ( ρ i , λ ) = θ − λρ i into the weight formula and approximating the denominator by C (Remark 1) yields the surrogate per-client objectiv e: ˜ J A ( ρ i ) ≈ 1 C h ( R i + θ ) ρ i − λρ 2 i i (27) This quadratic is strictly concave in ρ i for any λ > 0 . The un- constrained first-order condition giv es the interior maximizer: ˆ ρ i ( λ ) = R i + θ 2 λ (28) Since the constraint ρ i ∈ [0 , 1] is binding whenev er ˆ ρ i ( λ ) > 1 , the constrained best response is: ρ ∗ i ( λ ) = min R i + θ 2 λ , 1 (29) Note that ρ ∗ i = 1 whene ver λ < ( R i + θ ) / 2 , so a well-designed server must satisfy the criterion: λ ∗ ≥ R max + θ 2 (30) where R max = sup t,i R i ( t ) . T o keep R max finite, the rew ard update (Equation 13) is augmented with a cap: R new i = min R old i + γ R old i , R max (31) Setting R max = 1 with θ ≤ 1 keeps λ ∗ ≤ 1 , interpretable as full detection certainty at maximum poisoning. 2) Server’ s Optimal Strate gy: Substituting ρ ∗ i ( λ ) from Equation (29) into Equation (20), the serv er solves: λ ∗ = arg min λ ∈ Λ X i ∈I ′ w i ρ ∗ i ( λ ) , λ · ρ ∗ i ( λ ) (32) In the interior regime, this objectiv e is strictly decreasing in λ (increasing λ simultaneously shrinks each ρ ∗ i and reduces w i ), so the minimum is attained at the boundary: λ ∗ = λ max (33) subject to criterion (30); in practice λ max is tuned to balance detection power against false positi ves on honest clients, and is set to λ max = 1 . 0 in our experiments. 3) Existence and Uniqueness of the Saddle P oint: Theor em 1 (Existence of a Nash Saddle-Point Equilibrium) . The surrogate game ˜ G (see Remark 1) admits at least one Nash saddle-point equilibrium ( λ ∗ , ρ ∗ ) , constituting an approximate equilibrium of the original game G . Pr oof. W e v erify the conditions of Sion’ s minimax theo- rem [21]. Let f ( λ, ρ ) = ˜ J ( λ, ρ ) (Remark 1). (i) Compact, con vex strategy spaces. Λ = [ λ min , λ max ] is a compact con ve x subset of R . P = [0 , 1] |I ′ | is a compact con vex subset of R |I ′ | . (ii) Quasi-con vexity in λ . In the interior regime, each term w i ( ρ ∗ i , λ ) · ρ ∗ i ( λ ) ∝ ( R i + θ ) 2 /λ is strictly con ve x in λ > 0 . In the boundary regime ( ρ ∗ i = 1 ), w i (1 , λ ) = ( R i + θ − λ ) /C ′ JOURNAL OF L A T E X CLASS FILES, VOL. 00, NO. 0, SEPTEMBER 0000 8 is affine (hence con vex) in λ . Thus ˜ J is quasi-con vex on all of Λ . (iii) Quasi-conca vity in ρ (adversary’ s variable). For fixed λ , Equation (27) shows J A ( ρ i ) is strictly concav e (hence quasi-concav e) in each ρ i . Since the objectives are separable across clients i ∈ I ′ , J is quasi-concave in ρ jointly . (iv) Continuity . w i ( ρ i , λ ) is continuous in both arguments on the interior of Λ × P (it is a rational function with positi ve denominator). Thus J is jointly continuous. By Sion’ s minimax theorem, min λ max ρ J = max ρ min λ J , and there exists a saddle point ( λ ∗ , ρ ∗ ) satisfying: J ( λ ∗ , ρ ) ≤ J ( λ ∗ , ρ ∗ ) ≤ J ( λ, ρ ∗ ) ∀ λ ∈ Λ , ρ ∈ P (34) Interpr etation. At equilibrium, λ ∗ = λ max forces each adversary’ s best response to ρ ∗ i = ( R i + θ ) / 2 λ max < 1 , deterring full poisoning and confirming the lo w attack success rates observed in Figure 4 e ven at 30% malicious participation. V I I . F E D B BA : F E D E R A T E D B A C K D O O R A N D B E H A V I O R A NA LY S I S In this section, we present the operational flow of our proposed federated learning defense frame work, F edBBA (Fed- erated Backdoor and Behavior Analysis). FedBB A enhances the robustness of federated learning by identifying and mitigating backdoor attacks without accessing raw client data, thereby preserving data pri vacy . Instead, it analyzes only model updates using Projection Pursuit Analysis (PP A) and a dynamic reputation scoring system. Algorithm 2 Round-Based Execution of the FedBB A Frame- work 1: Initialize global model M 0 , reputation scores R i 2: for each federated learning round r in 1 to T do 3: for each client i in 1 to N do 4: Train local model M i on client’ s data 5: Send local model M i to server 6: end for 7: Calculate PP A score s i = PP A( M i ) 8: Cluster PP A scores using DBSCAN to determine classes 9: for each client i in classes do 10: Compute normalized weights using Equation (17) 11: if class i == 0 then 12: Update reputation score R i negati vely using Equa- tion (14) 13: else 14: Update reputation score R i positiv ely using Equa- tion (13) 15: end if 16: end for 17: Update global model using Equation (18) 18: Calculate server’ s payoff using Equation (21) 19: Calculate attacker’ s payoff using Equation (22) 20: end for The detailed step-by-step procedure is formalized in Algo- rithm 2. At the start of training ( t = 0 ), the serv er initializes the global model M and assigns an initial reputation score R i for each client. These scores are based on both historical behavior and gradient v ariation, as defined in Equation (11) (Line 1). During each federated learning round r from 1 to T , selected clients train local models M i on their pri vate data and transmit them back to the server (Lines 2–5). The server then computes PP A scores s i to quantify the lev el of anomalous behavior in each update (Line 7), followed by clustering using DBSCAN to identify suspicious clients (Line 8). Based on these clusters, client reputation scores R i are updated: suspicious clients are penalized (Lines 11–12) using Equation (14), while benign clients are rewarded (Lines 13– 14) via Equation (13). Normalized aggregation weights are computed using both reputation and PP A scores (Line 10), and the global model is updated accordingly using Equa- tion (18) (Line 16). Finally , the server and attacker payof fs are calculated using the MiniMax game-based utility functions (Equations 21 and 22, Lines 18–19). This iterative process allows FedBBA to dynamically detect and suppress malicious behaviors across rounds. Figure 2 illustrates the strategic ex ecution of the proposed Minimax game framew ork. The interaction starts with the Attack Leader solving the maximization problem to derive the constrained optimal poisoning ratio ρ ∗ i = min { ( R i + θ ) / 2 λ, 1 } via Equation (29), which balances attack impact with de- tectability giv en the server’ s chosen defense sensitivity λ (Step 1). Follo wing this, both malicious and benign clients perform local training and transmit their model updates M i to the serv er (Step 2). Upon recei ving the updates, the Federated Server initiates the defense phase by calculating Projection Pursuit Analysis (PP A) scores and utilizing DBSCAN to cluster the updates and identify anomalies (Step 3). Based on these clusters, the server computes the aggregation weights w i ( ρ i , λ ∗ ) for all clients using Equation (17), suppressing the influence of high-poisoning clients consistent with the equilibrium defense sensitivity λ ∗ (Step 4). The server then aggregates the weighted local models to produce the global model update M ( t +1) via Equation (18) (Step 5). Finally , the feedback loop is closed as the server updates the reputation scores R i penalizing identified malicious actors via Equa- tion (14) and re warding honest participants via Equation (13), which reduces the adversary’ s optimal poisoning ratio ρ ∗ i in the subsequent round via Equation (29), as a lower R i directly decreases the equilibrium best response (Step 6). V I I I . S I M U L A T I O N & E X P E R I M E N TS In this section, we present the experimental results demon- strating the effecti veness of our approach in minimizing the effects of backdoor attacks while maintaining the accuracy of the global model. A. Context & Envir onment W e conduct our experiments using the GTSRB and BTSC datasets, which contain 43 and 62 traffic sign classes respec- tiv ely , to ev aluate classification performance. The implemen- JOURNAL OF L A T E X CLASS FILES, VOL. 00, NO. 0, SEPTEMBER 0000 9 tation relies on industry-standard libraries including T orch, T orchvision, NumPy , and Pandas. W e employ a conv olutional neural network (CNN) com- posed of con volutional layers for feature extraction and two fully connected layers for classification. The poisoning ratio ρ i is dynamically determined by the adversary according to the optimization formulation described in Section VI. For the GTSRB dataset, we reduce it to 10 classes by selecting those with the highest number of samples. Each client is assigned 4 to 6 classes, with 250 to 350 samples per class. For the BTSC dataset, each client recei ves between 20 and 40 classes, with 50 to 150 images per class. This class-based partitioning results in a non-IID data distrib ution across clients, simulating realistic federated settings where participants hold heterogeneous local datasets. The federated learning setting consists of a total of C = 300 clients, from which c = 40 clients are randomly selected in each training round. Among the participating clients, up to 30% are malicious. W e use two primary metrics to ev aluate our approach: • Accuracy : the percentage of correctly classified images. • Backdoor attack success rate : the percentage of trig- gered (backdoored) test samples misclassified by the global model into the attacker’ s predefined target label. W e compare our approach ( F edBB A ) with two state-of-the- art methods and a baseline: • V anilla : standard federated learning with random client selection, used as a baseline [1]. • RoPE : a state-of-the-art method that applies PCA for backdoor detection [14]. • RDFL : a state-of-the-art approach using clustering and noise clipping for robust aggregation [15]. For the clustering component of our approach, we use the DBSCAN algorithm. The parameters are tuned through grid search, with the neighborhood radius set to ε = 0 . 6 and the minimum samples parameter set to 5. These v alues balance cluster cohesion and noise filtering, ensuring stable clustering results across the datasets. B. Experimental Results In this section, we present the results of our experiments in terms of accuracy and backdoor attack success rate, providing a detailed comparativ e analysis with baseline and state-of-the- art approaches. T o ev aluate the impact of the reputation score’ s weighting parameters, we performed a sensitivity analysis on the values of α and β , which represent the contribution of historical behavior and gradient-based anomaly signals, respectively . W e constrained α + β = 1 and varied each to assess the effect on both clean-task accuracy and backdoor success rate. The experiments were conducted on the GTSRB dataset with a training duration of 100 federated learning rounds. As illustrated in T able II, the balanced configuration α = β = 0 . 5 pro vides a better trade-of f between clean accuracy and backdoor resilience. It achiev es one of the highest accuracy values 96.8%, while minimizing the backdoor success rate to just 16%. In contrast, skewed configurations α = 0 . 9 , β = 0 . 1 result in a significantly higher backdoor success T ABLE II I M P A CT O F α AN D β O N M O DE L A C CU R AC Y A N D B AC K DO O R S U C C ES S R A T E U S I N G G T SR B DA TA SE T OV ER 1 00 RO U ND S α β Accurac y (%) Backdoor Success Rate (%) 0.1 0.9 96.6 25.0 0.2 0.8 95.4 28.0 0.3 0.7 96.9 21.0 0.4 0.6 96.2 33.0 0.5 0.5 96.8 16.0 0.6 0.4 96.2 22.0 0.7 0.3 95.6 41.0 0.8 0.2 95.5 21.0 0.9 0.1 96.1 45.0 rate up to 45%, indicating reduced robustness. This empirical evidence justifies our choice of equal weights in the reputation calculation. Ho wever , we recognize that optimal values may vary across applications, and tuning may be warranted in future work depending on domain-specific factors and threat sev erity . 1) One-to-One Attac ks: Figure 3(a) illustrates the per- formance of our F edBBA approach in mitigating backdoor attacks while maintaining high normal task accurac y using the GTSRB dataset. Initially , all methods exhibit nearly similar accuracy lev els; howe ver , as training progresses, F edBB A ’ s accuracy significantly surpasses that of the other approaches. By the 20th round, F edBB A achiev es an accuracy e xceed- ing 60%, which is markedly higher than RDFL and RoPE, whose accuracy remains belo w 15%. This trend continues with F edBBA reaching an accuracy of approximately 96.8% by the 100th round, compared to 93.4% for RDFL, 95.5% for V anilla, and 91.5% for RoPE. While the improvement in clean-task ac- curacy o ver baseline methods may appear modest ∼ 3.4–11%, it is statistically meaningful and, more importantly , sho ws that the mitigation happened without hindering the performance on normal tasks. This is especially important in the context of backdoor attacks, which are stealthy and preserve normal task accuracy to ev ade detection. Many existing defenses apply techniques such as excluding clients or pruning updates, leading to significant de gradation in normal task performance. In contrast, FedBBA achiev es a strong balance by preserving high accurac y on the normal task while substantially reducing the backdoor success rate to the lowest ∼ 1–10%. These results underscore F edBB A’ s robust capability in maintaining model integrity and performance, effecti vely addressing backdoor attacks more efficiently than the other methods ev aluated. Figure 4(a) presents the backdoor attack success rate results, highlighting the ef fectiveness of the F edBBA technique using the GTSRB dataset. The V anilla baseline confirms the efficac y of the attack, rapidly reaching and maintaining a 100% success rate, thereby establishing the severity of the threat in an unpro- tected setting. In sharp contrast, F edBBA ef fectiv ely suppresses the backdoor, maintaining a complete 0% attack success rate for the first 18 rounds. While other defense methods like RDFL and RoPE exhibit significant instability , with RoPE peaking at 85.2% and RDFL fluctuating considerably , F edBBA consistently keeps the attack impact minimal. By the 100th JOURNAL OF L A T E X CLASS FILES, VOL. 00, NO. 0, SEPTEMBER 0000 10 0 20 40 60 80 100 0 20 40 60 80 100 (a) G TSRB (1 1) Accuracy 0 20 40 60 80 100 0 20 40 60 80 100 (b) BTSC (1 1) Accuracy 0 20 40 60 80 100 0 20 40 60 80 100 (c) G TSRB (1 N) Accuracy 0 20 40 60 80 100 0 20 40 60 80 100 (d) BTSC (1 N) Accuracy 0 20 40 60 80 100 0 20 40 60 80 100 (e) G TSRB (N 1) Accuracy 0 20 40 60 80 100 0 20 40 60 80 100 (f) BTSC (N 1) Accuracy Communication Rounds Accuracy (%) V anilla F edBBA R oPE RDFL Fig. 3. Normal task accuracy comparison of RDFL, V anilla, FedBBA, and RoPE across datasets and attack settings over 100 communication rounds. 0 20 40 60 80 100 0 20 40 60 80 100 (a) G TSRB (1 1) Attack 0 20 40 60 80 100 0 20 40 60 80 100 (b) BTSC (1 1) Attack 0 20 40 60 80 100 0 20 40 60 80 100 (c) G TSRB (1 N) Attack 0 20 40 60 80 100 0 20 40 60 80 100 (d) BTSC (1 N) Attack 0 20 40 60 80 100 0 20 40 60 80 100 (e) G TSRB (N 1) Attack 0 20 40 60 80 100 0 20 40 60 80 100 (f) BTSC (N 1) Attack Communication Rounds Backdoor Success Rate (%) V anilla F edBBA R oPE RDFL Fig. 4. Backdoor success rate comparison of RDFL, V anilla, FedBB A, and RoPE across datasets and attack scenarios ov er 100 communication rounds. round, F edBB A restricts the attack success rate to just 10.8%, significantly outperforming RDFL (42.4%) and RoPE (55.8%). Figure 3(b) shows the performance of F edBBA in maintain- ing high normal task accuracy compared to RDFL, V anilla, and RoPE using the BTSC dataset. Initially , all methods exhibit similar accuracy lev els, with F edBBA starting at 3.4% while RDFL, V anilla, and RoPE start at 6.2%, 5.3%, and 3.5%, respectiv ely . As training progresses, F edBBA ’ s accurac y significantly surpasses that of the other approaches in the early stages. By the 10th round, F edBBA achiev es an accuracy of 57.1%, markedly higher than RDFL (6.4%), V anilla (5.9%), and RoPE (47.6%). By the 20th round, F edBBA achieves an accuracy of 83.0%, while RDFL, V anilla, and RoPE reach 16.7%, 79.6%, and 73.6%, respectively . This trend stabilizes with F edBB A reaching an accuracy of approximately 94.6% by the 100th round. In comparison, RDFL, V anilla, and RoPE exhibit accuracies of 94.2%, 95.9%, and 94.8%, respectively . Figure 4(b) highlights the ef fectiv eness of the F edBBA approach in mitigating backdoor attacks compared to RDFL, V anilla, and RoPE using the BTSC dataset. Initially , no approach exhibits vulnerability . This delay can be attributed to the complexity and breadth of the BTSC dataset, which ne- cessitates a higher number of training rounds for the backdoor mechanism to establish persistence. This beha vior is clearly JOURNAL OF L A T E X CLASS FILES, VOL. 00, NO. 0, SEPTEMBER 0000 11 observed in the V anilla approach, where, ev en in the absence of an y defense mechanism, the attack required more than 20 rounds to achiev e a 100% success rate. As training progresses beyond this initial phase, F edBB A demonstrates remarkable resilience compared to the baselines. For example, at round 38, F edBBA and RDFL still show an attack success rate of 0%, whereas V anilla has already stabilized at 100% and RoPE has risen to approximately 7.8%. By round 100, F edBB A successfully suppresses the attack success rate to just 1.1%, significantly lower than RDFL (53.5%), RoPE (56.7%), and V anilla (100%). This consistent suppression underscores F edBB A ’ s superior robustness in mit- igating backdoor attacks throughout the training process. 2) One-to-N Attacks: Figure 3(c) presents the main task accuracy of the global model throughout the training process. Despite the presence of the attack, F edBBA demonstrates a high le vel of utility preservation, achie ving a final accuracy of 95.38% by round 100. This performance is comparable to, and slightly exceeds, the V anilla baseline, which reaches 94.69%. In contrast, the other defense mechanisms sho w a notable degradation in model utility , with RDFL and RoPE achieving lower final accuracies of 91.78% and 90.81%, respecti vely . This indicates that F edBBA successfully defends against the attack without compromising the model’ s ability to learn the primary task. Figure 4(c) highlights the ef fectiveness of the approaches in mitigating the backdoor attack. The V anilla model is com- promised almost immediately , with the attack success rate jumping to 40% at round 1 and reaching total saturation of 100% as early as round 7, where it remains for the duration of training. RoPE and RDFL also fail to prevent the attack, ending with high attack success rates of 76.4% and 67%, respectiv ely . Con versely , F edBB A exhibits superior robustness, maintaining the attack success rate near zero for most of the training process. By round 100, F edBB A suppresses the attack success rate to just 5.84%, significantly outperforming all other methods and effecti vely neutralizing the backdoor threat. Figure 3(d) presents the main task accuracy of the global model throughout the training process. F edBBA demonstrates exceptional utility preserv ation, achieving a final accuracy of 98.06% by round 100. This performance is effecti vely on par with the V anilla baseline, which reaches 98.30%, indicating that the defense mechanism does not hinder the model’ s ability to learn the complex features of the BTSC dataset. In contrast, the other defense mechanisms suf fer from significant utility loss, with RDFL and RoPE dropping to final accuracies of 89.79% and 87.98%, respectiv ely . Figure 4(d) highlights the ef fectiv eness of the approaches in mitigating the backdoor attack. The V anilla model e xhibits e x- treme vulnerability , with the attack success rate sur ging rapidly to 99.6% by round 9 and reaching total saturation (100%) by round 10, where it remains fixed. RoPE and RDFL also fail to provide adequate protection, ending the training with high attack success rates of 49.02% and 56.10%, respecti vely . Con versely , F edBB A shows superior resilience. Despite the ag- gressiv e nature of the attack, F edBB A consistently suppresses the backdoor , maintaining a low attack success rate throughout the session and concluding at just 4.88% by round 100. This sharp contrast with the baselines underscores F edBBA ’ s capability to neutralize One-to-N backdoor injections on the BTSC dataset. 3) N-to-One Attacks: Figure 3(e) ev aluates the performance of various defense mechanisms under a multiple-to-one back- door attack using the GTSRB dataset. Initially , at round 1, all defenses exhibit similar performance with accuracy rates around 7.41% for RDFL and V anilla, 11.57% for F edBBA , and 10.19% for RoPE. As training progresses, F edBBA con- sistently outperforms or matches the other methods. By round 20, F edBBA ’ s accuracy escalates to 71.74%, higher than RDFL (68.66%), V anilla (64.55%), and significantly outperforming RoPE (10.56%). By round 100, F edBBA reaches a peak accuracy of 96.14%, ef fectiv ely matching or slightly exceed- ing RDFL (96.06%) and V anilla (96.02%), while remaining superior to RoPE (93.97%). Figure 4(e) underscores the superior efficacy of the F edBB A approach in comparison to RDFL and RoPE in reducing the backdoor success rate under the multi-trigger setting using the GTSRB dataset. Initially , V anilla exhibits immediate vul- nerability , starting at 50.2% in round 0, while RDFL spikes to 100% by round 1. In contrast, F edBB A starts with an attack success rate of 0% and, despite the aggressive attack en vironment, keeps the rate significantly lower than the other methods throughout the session. For example, at round 40, F edBBA shows an attack success rate of just 4.2%, whereas V anilla has already saturated at 100%, RDFL is at 54.6%, and RoPE is at 34.4%. By round 100, F edBB A suppresses the attack success rate to 11.0%, which is significantly lower than RDFL (75.6%), RoPE (59.8%), and V anilla (100%). Figure 3(f) illustrates the performance of various defense mechanisms in the normal task accurac y under a multiple- to-one backdoor attack scenario using the BTSC dataset. Initially , all methods exhibit comparable accuracy lev els below 7%. By round 10, V anilla takes an early lead with 66.5%, while F edBBA achiev es 47.9%, RDFL 8.1%, and RoPE 8.5%. Howe ver , F edBBA demonstrates steady and robust learning as training progresses. By round 100, F edBB A reaches a peak accuracy of 95.08%, ef fectiv ely matching RDFL (95.16%) and outperforming both V anilla (94.44%) and RoPE (94.72%). This confirms that F edBBA maintains high utility e ven under complex attack scenarios. Figure 4(f) highlights the ef fectiv eness of F edBBA in mit- igating backdoor attacks compared to RDFL and RoPE in a multiple-to-one attack scenario using the BTSC dataset. F edBBA demonstrates a significant improvement, consistently achieving lo wer success rates. Specifically , F edBB A starts with a success rate of 0% and, despite the attack’ s persistence, k eeps the rate significantly low throughout the rounds. For instance, by round 50, F edBB A suppresses the attack success rate to 5.3%, whereas V anilla has already reached total saturation (100%), and RDFL and RoPE have risen to 25.6% and 30.6%, respectiv ely . By round 100, F edBBA further limits the attack success rate to 1.77%, significantly lower than RDFL (31.9%), RoPE (23.8%), and V anilla (100%). In summary , the results illustrate that F edBBA consistently outperforms RDFL and RoPE in maintaining high accuracy and mitigating backdoor attacks. Across different attack sce- JOURNAL OF L A T E X CLASS FILES, VOL. 00, NO. 0, SEPTEMBER 0000 12 narios and datasets, F edBB A prov es to be a robust defense mechanism, specifically in the N-to-One and One-to-N coordi- nated backdoor attack, which reflects the frame work’ s ability to detect the pattern of the malicious data in the suspicious models, effecti vely enhancing model integrity and perfor - mance while addressing the challenges posed by backdoor attacks. I X . C O N C L U S I O N In this work, we proposed a novel and comprehensive backdoor attack detection and mitigation scheme for federated learning called F edBBA . Our framew ork uniquely integrates Projection Pursuit Analysis (PP A), a rob ust reputation system, and game-theoretic incentives to neutralize malicious clients. Extensiv e simulations on the GTSRB and BTSC datasets demonstrate that F edBBA significantly outperforms existing state-of-the-art methods, specifically RDFL and RoPE, across div erse attack scenarios, including One-to-N and N-to-One attacks. Empirical results confirm that F edBBA effecti vely suppresses backdoor attack success rates to between 1.1% and 11%, whereas baseline defenses often failed to contain the threat, yielding success rates as high as 76%. Crucially , this rob ustness is achie ved without hindering the global model’ s performance; F edBBA consistently maintained normal task accuracy in the range of 95% to 98%. While F edBBA demonstrates strong effecti veness, its e valuation is restricted to image-based classification tasks. Future work will explore generalizing the framework to di verse modalities, such as nat- ural language processing and IoT sensor data. Additionally , we plan to incorporate adaptive parameter learning to dynamically tune the reputation weights ( α and β ), further enhancing the framew ork’ s scalability and responsiveness to e volving threat landscapes. R E F E R E N C E S [1] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data, ” in Artificial intelligence and statistics . PMLR, 2017, pp. 1273– 1282. [2] M. P . Uddin, Y . Xiang, M. Hasan, J. Bai, Y . Zhao, and L. Gao, “ A systematic literature re view of robust federated learning: Issues, solutions, and future research directions, ” ACM Computing Surveys , vol. 57, no. 10, pp. 1–62, 2025. [3] D. Shenoy , R. Bhat, and K. Krishna Prakasha, “Exploring pri vac y mechanisms and metrics in federated learning, ” Artificial Intelligence Review , v ol. 58, no. 8, p. 223, 2025. [4] C. Zhu, J. Zhang, X. Sun, B. Chen, and W . Meng, “ Adfl: Defending backdoor attacks in federated learning via adversarial distillation, ” Computers & Security , vol. 132, p. 103366, 2023. [5] C. W u, X. Y ang, S. Zhu, and P . Mitra, “Mitigating backdoor attacks in federated learning, ” arXiv pr eprint arXiv:2011.01767 , 2020. [6] B. Xi, S. Li, J. Li, H. Liu, H. Liu, and H. Zhu, “Batfl: Backdoor detection on federated learning in e-health, ” in 2021 IEEE/ACM 29th International Symposium on Quality of Service (IWQOS) . IEEE, 2021, pp. 1–10. [7] J. Jia, Z. Y uan, D. Sahabandu, L. Niu, A. Rajabi, B. Ramasubramanian, B. Li, and R. Poovendran, “Fedgame: a game-theoretic defense against backdoor attacks in federated learning, ” Advances in Neural Information Pr ocessing Systems , v ol. 36, pp. 53 090–53 111, 2023. [8] Z. Gu and Y . Y ang, “Detecting malicious model updates from federated learning on conditional variational autoencoder, ” in 2021 IEEE interna- tional parallel and distributed pr ocessing symposium (IPDPS) . IEEE, 2021, pp. 671–680. [9] P . Quan, W .-H. Lee, M. Srivats a, and M. Srivasta va, “Enhancing rob ust- ness in federated learning by supervised anomaly detection, ” in 2022 26th International Confer ence on P attern Recognition (ICPR) . IEEE, 2022, pp. 996–1003. [10] K. Otmani, R. El-Azouzi, and V . Labatut, “Fedsv: Byzantine-robust federated learning via shaple y value, ” in ICC 2024-IEEE International Confer ence on Communications . IEEE, 2024, pp. 4620–4625. [11] J. Zhang, C. Zhu, X. Sun, C. Ge, B. Chen, W . Susilo, and S. Y u, “Flpu- rifier: Backdoor defense in federated learning via decoupled contrastive training, ” IEEE T ransactions on Information F or ensics and Security , vol. 19, pp. 4752–4766, 2024. [12] H. Cai, J. W ang, L. Gao, and F . Li, “Flmaacbd: Defending against backdoors in federated learning via model anomalous acti vation behavior detection, ” Knowledge-Based Systems , vol. 289, p. 111511, 2024. [13] O. A. W ahab and A. A vila, “ A max-min security game for coordinated backdoor attacks on federated learning, ” in 2023 IEEE International Confer ence on Big Data (BigData) . IEEE, 2023, pp. 3566–3573. [14] Y . W ang, D.-H. Zhai, and Y . Xia, “Rope: Defending against backdoor attacks in federated learning systems, ” Knowledg e-Based Systems , v ol. 293, p. 111660, 2024. [15] Y . W ang, D.-H. Zhai, Y . He, and Y . Xia, “ An adaptive rob ust defend- ing algorithm against backdoor attacks in federated learning, ” Future Generation Computer Systems , vol. 143, pp. 118–131, 2023. [16] Y . W ang, D.-H. Zhai, and Y . Xia, “Scfl: Mitigating backdoor attacks in federated learning based on svd and clustering, ” Computers & Security , vol. 133, p. 103414, 2023. [17] F . Bong, I. Ahmed, N. Ramakrishnan, K. N. V alenzuela-V alderas, P . D. W entzell, J. Barra, and T . K. Karakach, “ Augmented kurtosis-based projection pursuit: a novel, adv anced machine learning approach for multi-omics data analysis and integration, ” Nucleic Acids Research , vol. 53, no. 17, p. gkaf844, 2025. [18] Z. Zhang, A. Panda, L. Song, Y . Y ang, M. Mahoney , P . Mittal, R. Kan- nan, and J. Gonzalez, “Neurotoxin: Durable backdoors in federated learning, ” in International conference on machine learning . PMLR, 2022, pp. 26 429–26 446. [19] Y . Dai and S. Li, “Chameleon: Adapting to peer images for planting durable backdoors in federated learning, ” in International Conference on Machine Learning . PMLR, 2023, pp. 6712–6725. [20] V . Shejwalkar, A. Houmansadr , P . Kairouz, and D. Ramage, “Back to the drawing board: A critical e valuation of poisoning attacks on production federated learning, ” in 2022 IEEE symposium on security and privacy (SP) . IEEE, 2022, pp. 1354–1371. [21] M. Sion, “On general minimax theorems, ” P acific Journal of Mathemat- ics , vol. 8, no. 1, pp. 171–176, 1958. Osama W ehbi is a Ph.D. candidate in the Department of Computer and Soft- ware Engineering at Polytechnique Montreal, Canada. His primary research areas include cybersecurity , federated learning, and game theory . Sarhad Arisdakessian is a Ph.D. candidate in the Department of Computer and Software Engineering at Polytechnique Montreal, Canada. His research interests lie in federated learning and game theory . Omar Abdel W ahab holds an assistant professor position with the De- partment of Computer and Software Engineering, Polytechnique Montreal, Canada. His research activities focus on cybersecurity , Internet of Things, and artificial intelligence. Anderson R. A vila is a Ph.D. candidate at the Institut National de la Recherche Scientifique (INRS), Canada. His research interests include speaker and emotion recognition, pattern recognition, and multimodal signal process- ing for biometric applications. Azzam Mourad is a Professor of Computer Science with Khalifa Uni versity , U AE. His research interests include cloud computing, artificial intelligence, and cybersecurity . Hadi Otrok is a Professor and Chair of the Department of Electrical Engineering and Computer Science at Khalifa University , U AE. His research interests include computer and netw ork security , cro wd sensing and sourcing, ad hoc networks, and cloud security .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment