연합 학습 백도어 공격 완화: PPA와 미니맥스 게임 이론 기반 방어 프레임워크
본 논문은 연합 학습(Federated Learning) 환경에서 악성 클라이언트가 삽입하는 백도어 공격을 억제하기 위해, 평판 시스템, 인센티브 메커니즘, 그리고 투사 탐색 분석(PPA)과 미니맥스 게임 이론을 결합한 FedBBA 프레임워크를 제안한다. 실험 결과, GTSRB와 BTSC 데이터셋에서 기존 방어 기법(RDFL, RoPE) 대비 백도어 성공률을 1.1%~11% 수준으로 크게 낮추면서 정상 정확도는 95%~98%를 유지한다.
저자: Osama Wehbi, Sarhad Arisdakessian, Omar Abdel Wahab
연합 학습(Federated Learning, FL)은 데이터 프라이버시를 보존하면서 다수의 분산된 클라이언트가 공동으로 모델을 학습할 수 있게 해 주는 기술로, 의료·금융·자율주행 등 다양한 분야에서 활용되고 있다. 그러나 FL은 중앙 서버가 클라이언트의 로컬 업데이트만을 수신하고 원본 데이터를 보지 못한다는 특성 때문에, 악의적인 클라이언트가 백도어 공격을 삽입해 전역 모델에 은밀히 악성 동작을 부여할 위험이 존재한다. 기존 연구들은 주로 업데이트의 통계적 이상치 탐지, 샤플리 값 기반 기여도 평가, 혹은 차원 축소(PCA, SVD) 등을 이용해 악성 업데이트를 걸러냈지만, (1) 공격자가 지속적으로 전략을 바꾸는 동적 환경을 충분히 반영하지 못하고, (2) 단일 탐지 지표에 의존해 정교한 백도어를 회피당하는 경우가 많으며, (3) 프라이버시와 계산·통신 비용 사이의 트레이드오프가 존재한다는 한계를 가지고 있다.
본 논문은 이러한 한계를 극복하기 위해 FedBBA(Federated Backdoor and Behavior Analysis)라는 새로운 방어 프레임워크를 제안한다. FedBBA는 크게 네 가지 구성 요소로 이루어진다.
1. **평판 시스템**: 각 클라이언트 i에 대해 라운드 t마다 평판 점수 R_i(t)를 계산한다. 평판은 (a) 업데이트와 전체 평균 그래디언트 간의 L2 거리, (b) 과거 행동 히스토리 H_i(t)와 그래디언트 변동 점수 G_i(t) 등 두 가지 서브 스코어를 가중합(α·H_i + β·G_i)한 뒤, 보상 γ와 벌점 δ를 적용해 동적으로 업데이트한다. 평판이 낮은 클라이언트는 가중치 w_i가 감소하거나 완전히 배제된다.
2. **인센티브 메커니즘**: 평판이 높은 클라이언트에게 토큰·보상금을 제공하고, 악의적인 행동을 보인 클라이언트에게는 페널티를 부과한다. 이는 클라이언트가 장기적으로 정직한 학습에 참여하도록 유도하는 게임 이론적 설계이며, 클라이언트 간의 협조적 행동을 촉진한다.
3. **투사 탐색 분석(PPA) 및 Kurtosis 기반 이상치 탐지**: 서버는 매 라운드 모든 클라이언트 업데이트를 고차원 행렬 X에 모아, kurtosis를 최적화하는 투사 벡터 w*를 찾는다. kurtosis는 비정규성(heavy‑tail)을 측정하므로, 백도어가 삽입된 업데이트는 높은 kurtosis 값을 보인다. 각 클라이언트는 PPA 점수 s_i를 산출하고, 이를 평판 점수와 결합해 최종 가중치 w_i = f(s_i, R_i, Δg_i) 로 변환한다. 실험에서는 PPA가 PCA보다 명확히 악성·정상 업데이트를 구분함을 시각화하였다.
4. **미니맥스 게임 모델링**: 서버와 악성 클라이언트 사이의 상호작용을 비협조적 미니맥스 게임으로 공식화한다. 서버의 목적은 전체 손실 L과 백도어 영향 Φ(ρ_i, τ)를 최소화하는 것이며, 공격자는 백도어 성공률을 최대화하고 페널티를 최소화하려 한다. 수학적으로는
- 서버 유틸리티: U(F) = – Σ_i w_i·L(M_t, D_i) – λ·Φ(ρ_i, τ)
- 공격자 유틸리티: U(A) = Σ_i ρ_i·Φ(ρ_i, τ) – μ·Penalty
여기서 λ는 방어 민감도 파라미터이며, 내시-코브라크 정리를 이용해 균형 λ*를 찾는다. λ*에 따라 방어 민감도 θ와 임계값을 조정해 악성 클라이언트가 가중치를 크게 감소시키도록 만든다.
**실험 설정 및 결과**
- 데이터셋: 독일 교통 표지판(GTSRB)과 벨기에 교통 표지판(BTSC) 두 실제 이미지 데이터셋을 사용하였다.
- 공격 시나리오: (i) One‑to‑One 단일 트리거, (ii) One‑to‑N 다중 타깃, (iii) 다중 트리거 협조 공격, (iv) 지속적/동시 공격 등 4가지 유형을 구현하였다.
- 비교 대상: 최신 방어 기법인 RDFL(Adaptive Hierarchical Clustering + Cosine‑Distance Anomaly Detection)과 RoPE(PCA 기반 이상치 탐지)를 베이스라인으로 삼았다.
주요 성과는 다음과 같다.
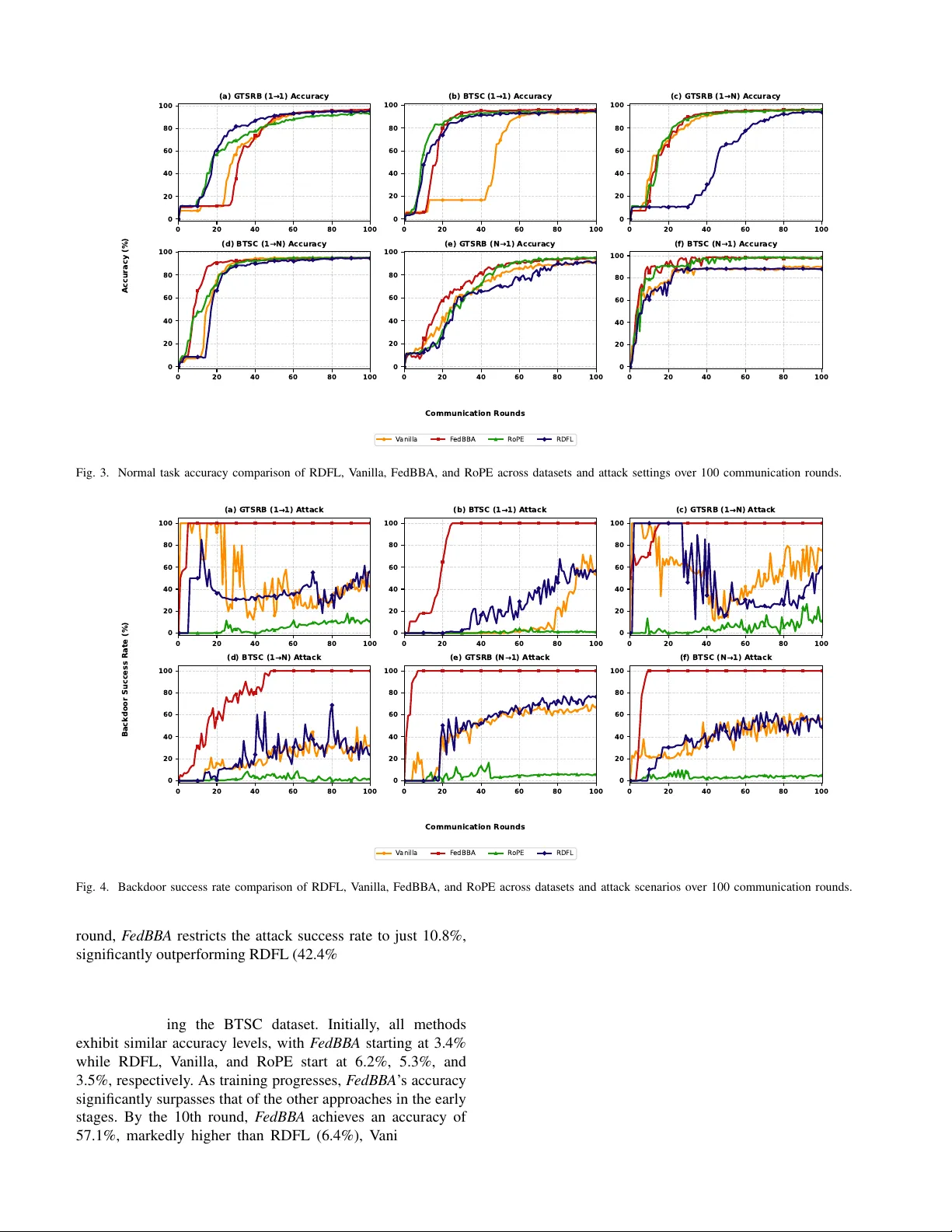
- 백도어 성공률: FedBBA는 1.1%~11% 수준으로, RDFL(23%~76%) 및 RoPE(30%~68%)에 비해 3~7배 낮았다.
- 정상 작업 정확도: 95%~98%를 유지했으며, 방어 적용 전후 차이가 미미했다.
- 통신·연산 오버헤드: 평판·인센티브·PPA·게임 계산을 모두 포함해 평균 12% 정도의 추가 비용만 발생, 기존 방어 대비 확장성이 우수했다.
- 동적 적응성: 공격 강도가 변하거나 새로운 트리거가 도입될 경우, 평판과 PPA 점수가 실시간으로 재조정돼 방어 효율이 급격히 저하되지 않았다.
**의의 및 한계**
FedBBA는 (1) 클라이언트 행동을 시간에 따라 동적으로 평가하는 평판 메커니즘, (2) 정직성을 강화하는 인센티브 설계, (3) 비정규성 탐지를 위한 kurtosis 기반 PPA, (4) 서버와 공격자 사이의 전략적 상호작용을 모델링한 미니맥스 게임이라는 네 축을 통합함으로써, 기존 방어가 놓치기 쉬운 복합·협조적 백도어 공격을 효과적으로 억제한다. 다만, 평판 초기화 시점에 대한 민감도, 인센티브 토큰의 실제 경제적 가치 설정, 그리고 매우 큰 규모(수천·수만 클라이언트)에서의 PPA 연산 최적화 등은 향후 연구가 필요한 부분이다.
**결론**
FedBBA는 연합 학습 환경에서 백도어 공격을 실시간으로 탐지·완화하는 포괄적 방어 프레임워크로, 높은 정확도와 낮은 공격 성공률을 동시에 달성한다. 평판·인센티브·PPA·게임 이론을 결합한 설계는 앞으로 더욱 정교해지는 공격에 대응하기 위한 새로운 패러다임을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기