ResAdapt: Adaptive Resolution for Efficient Multimodal Reasoning
Multimodal Large Language Models (MLLMs) achieve stronger visual understanding by scaling input fidelity, yet the resulting visual token growth makes jointly sustaining high spatial resolution and long temporal context prohibitive. We argue that the …
Authors: Huanxuan Liao, Zhongtao Jiang, Yupu Hao
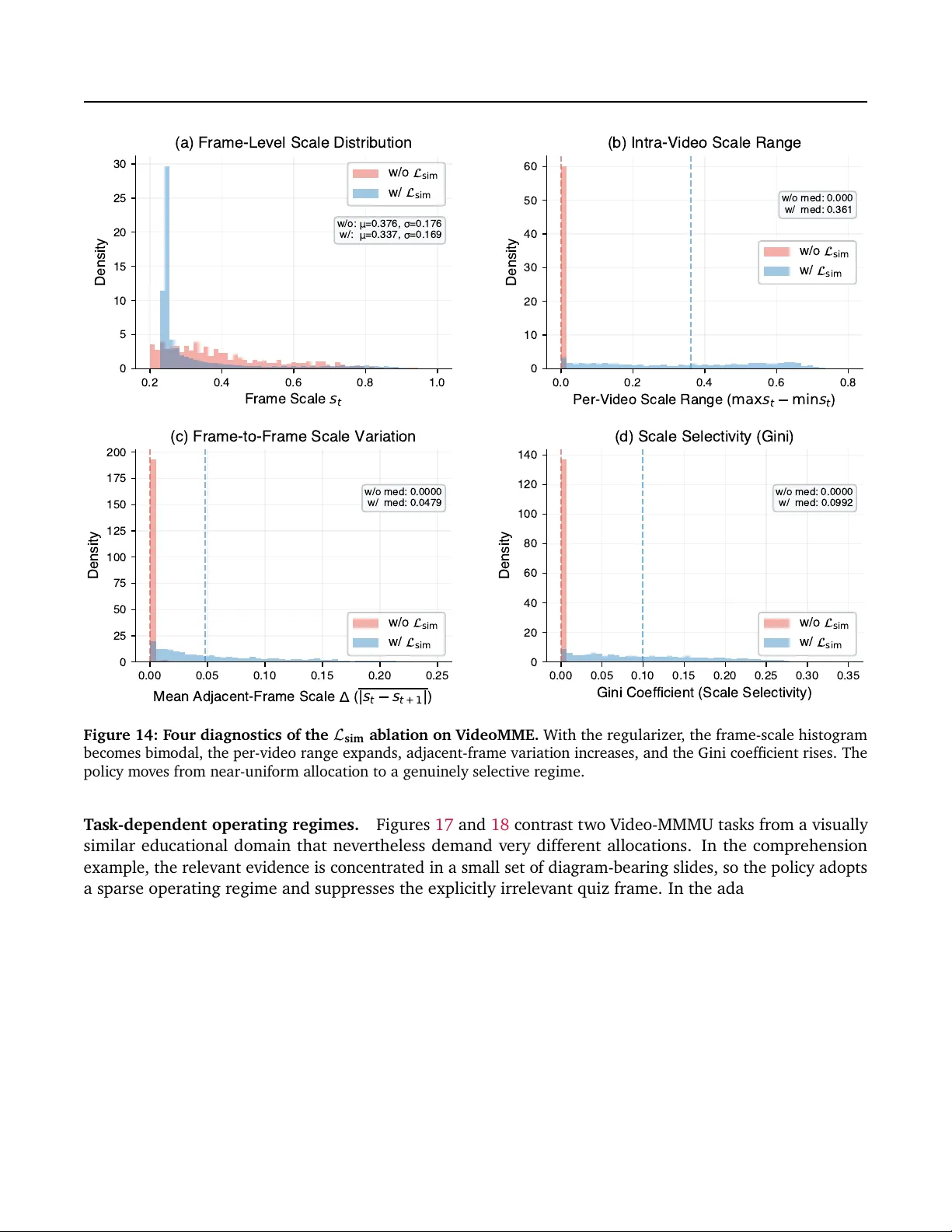
R esAda pt: Ada ptiv e R esoluti o n f or Effi cient Multim oda l R ea so ning Huanxuan Liao τ , µ , Zhongtao Jiang, Y upu Hao τ , µ , Y u qiao T an τ , µ , S hizhu He τ , µ , Jun Zhao τ , µ , K un Xu † , Kang Liu τ , µ , ∗ τ Institute of Auto mation, Chin ese Academy of Scien ces , µ U niversity o f Chinese Academy of Sci ences , † Project L eader ∗ Corresponding author: kliu@nlpr .ia.ac.cn Multim odal Large L anguage Models (MLLMs) achiev e stronger visua l underst anding by scaling input fidelit y , yet the resulting visua l token gro wth makes jointly sustaining high spatial resolution and lo ng temporal context prohibitiv e. Existing effici ency strategies only partially resolv e this tensio n: m odel-side token compressio n discards fine-grained evidence after encoding and can disrupt optimized inference kernels, whereas output-side a gentic reaso ning adds iterative l atency and can still miss decisive cues when the initial view is too coarse. W e argue that the bottlen eck lies not in how post-en coding represent atio ns are compressed but in the volume o f pixels the encoder receiv es, and address it with R esAdapt , an Input-side adaptatio n framework that learns ho w mu ch visu al b udget each frame should receive bef ore encoding. ResAda pt couples a light weight Allocator with an unchanged MLLM backbone, so the backbone retains its nativ e visu al-token interface while receiving an operator-transformed input. W e form ulate allocatio n as a co ntextual bandit and train the Allocator with Cost-A ware Poli cy Optimization ( CAPO) , which con verts sparse roll out feed back into a st ab le accuracy–cost learning signal. W e further introd uce a temporal-similarit y regulari zer that suppresses red undant high-budget all ocation o n adjacent simil ar frames, encoura ging differentiated, content-a ware all ocation in a single f orward pass. Across b udget-controlled video Q A, temporal grounding, and ima ge reasoning tas ks, ResAda pt improv es lo w-b udget operating points and often lies on or near the effici ency–accuracy fronti er , with the clearest gains on reaso ning-intensiv e ben chmarks under a ggressiv e co mpression. Not ab ly , ResAda pt supports up to 16 × m ore frames at the same visual b udget while deliv ering o v er 15% performance gain. The learn ed policy exhibits open-loop active perception , concentrating visu al budget on informati on-dense content without modif ying the backbone architecture. These results positi on Input-side ada pt atio n as a practica l and effectiv e route to long-co ntext video reaso ning under tight visu al b udgets. Project P age : https://xnhyacinth.github.i o/projects/R esAdapt Code Repo sitory : https://github.com/Xnhyacinth/R esAdapt Contact : liaohuanxuan2023@ia.ac.cn 1. Introd ucti on Multim odal L arge L anguage Models (MLLMs) achiev e stronger visu al underst anding by scaling input fidelit y , yet the resulting visual-token gro wth ma kes jointly sustaining high spatial resolution and lo ng temporal context prohibitiv e ( Guo et al. , 2025a , Bai et al. , 2025a , Liu et al. , 2025a , Shu et al. , 2025 , Shao et al. , 2025b ). In practice, this trade-o ff is centra l to video reasoning: reducing resolutio n risks losing the small visual cues that determine the answ er , whereas shortening the clip remo v es the temporal context needed for lo ng-horiz on inference. Ev en architecturally efficient encoders ( Z hang et al. , 2026 , Liu et a l. , 2025b ) do not rem ov e this tension; they merely shift where it becomes painf ul. R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning Merge / Prune / Sparse Question: Why did the boy lift up the towel near the end? A. pick up coat. B. put on the plate. C. lose balance. Tool Call Multi-turn Interaction Zoom-in Search … Full Visual Tokens Compressed Visual Tokens Allocations Input-side Adaptive Sampling (Source-Level) Model-Side Token Economy (Representation-Level) Output-side Agentic Reasoning (Behavior-Level) Allocator (a) Input-side Adaptation vs. Existing Paradigms (b) ResAdapt achieves competitive performance Operator Resize Frame Select Figure 1: Input-side Adaptation impro ves the visual-token efficien cy fronti er . ( a) Three efficiency paradigms f or video reasoning. Model-side methods compress tokens after encoding; output-side methods iterativ ely retriev e or zoom; R esAdapt reallocates per-frame visual b udget bef ore encoding, preserving the backbon e’s native token interface and compatibilit y with optimi zed inference engin es. ( b) Qwen2.5- VL-7B results with 32 frames at ∼ 10% visual retentio n, where R esAdapt li es on or near the P areto fronti er and sho ws its largest gain on the rea soning-hea vy benchmark. Mainstream efficiency methods l argely fall into t w o paradigms (Figure 1 a), both of which interven e too late. Model-side approaches prune or merge tokens after visual encoding ( Khaki et al. , 2025 , Xu et al. , 2025 , Bolya et al. , 2022 , T ao et al. , 2025 ), so once fine-grain ed evidence is discarded, it cannot be recov ered. They also alter the token l ay o ut expected by the backbone, which can complicate direct use of optimiz ed attentio n kernels and inference engines ( Dao , 2024 , Kwo n et al. , 2023 , Zheng et al. , 2024 ). O utput-side a gentic reaso ning instead adds iterative retrieval or z oom steps ( Zhang et a l. , 2025b , Y ang et al. , 2025d , Shen et al. , 2025b , Zheng et al. , 2025b ). This strategy can impro v e co vera ge, but it introdu ces multi-turn latency and still depends on an initial coarse view that may undersample the decisive cue. These limit ations point to a different bottlen eck: not how post-encoding represent atio ns are compressed, b ut ho w many pixels the encoder receives in the first place. This pa per studies that perspectiv e through Input- side adaptation , which rea llocates visual budget before encoding rather than compressing represent ations afterward. Our method, R esAdapt , introdu ces a light weight Allocator that predicts a per-frame visual all ocatio n from coarse visual features and the query , then realizes that allocati on through a visual budget operator , such as resolution resizing or frame selectio n. The backbon e therefore processes a st andard visual- token sequence in a single pass, preserving its n ativ e interface and compatibilit y with existing optimiz ed inferen ce st acks ( Dao , 2024 , Kw o n et al. , 2023 ). Compared with pri or slo w–fast pipelin es ( Y ang et a l. , 2025a , Zhang et al. , 2026 ), which route frames using query-a gn ostic heuristics or fixed resolution tiers, ResAda pt learns a query-aw are all ocation policy directly from task reward. Making this idea work requires more than a front-end allocator . The allocati on space is continu ous, the operator is non-diff erentiab le, and n aiv e accuracy–cost pen alti es collapse toward uniformly tiny budgets. W e address these difficulti es with Cost-A ware Policy Optimi zation ( CAPO) , which conv erts sparse rollout 2 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning feed back into a st ab le a symmetric learning signal, and with a temporal-similarit y regulari zer that discoura ges red undant high-b udget all ocation on adjacent similar frames. T ogether , these components turn Input-side adaptatio n into a trainab le and content-a ware policy rather than a handcrafted compressi on rule. Across video Q A and temporal grounding benchmarks on m ultiple backbones and temporal horizons, R esAdapt impro ves or closely tracks the efficien cy–accuracy Paret o frontier . R esAdapt matches or surpasses other token economy methods while compressing ov er 90% of visu al tokens (Figure 1 b), and the sav ed compute reinv ests as temporal cov era ge: under equiv alent budgets, R esAdapt processes 16 × m ore frames with > 15% relative gains. The learn ed policy exhibits open-loop active perception , concentrating visual b udget on informati on-dense frames in a single backbone pass without explicit sali ency supervision. Our main contrib utio ns are: 1. W e introd uce ResAda pt , an input-side ada pt atio n framework that f orm ulates dynamic per-frame vi- sual budgeting as a contextua l bandit problem, f ully preserving the native architecture and hardware optimiz atio ns o f MLLMs. 2. W e propose C APO with a temporal simil arit y regulari zer , pro viding a st ab le, asymmetri c learning signal to jointly optimiz e accuracy and cost without hand-crafted heuristics. 3. Through extensiv e experiments and ab latio ns, w e sho w that R esAda pt achiev es better effici ency–accuracy P areto frontier across video Q A and temporal grounding t asks. 2. Background and Problem F orm ul atio n 2.1. Preliminaries Giv en a text query q and a video V = { f t } T t = 1 , let x = ( q , V ) denote the f ull input. A backbon e policy π ϕ encodes every frame at fixed fidelit y and autoregressi vely generates a rollo ut y = ( y 1 , . . . , y L ) : π ϕ ( y | x ) = L j = 1 π ϕ ( y j | y < j , x ) . (1) When usef ul, w e write y = ( r , o ) for a reasoning trace r and a final answ er o . The ineffici ency is immediate: visual cost scal es with total pixel v olume, whereas answer-criti cal evidence is sparse in time. T o control pre-encoding cost, w e introd uce an Allocator policy π θ that emits a per-frame allocati on vector s = ( s 1 , . . . , s T ) ∼ π θ ( · | x ) , s t ∈ [ s min , s max ] , (2) and appli es a visual budget operator O to each frame: ˜ f t = O ( f t , s t ) . The backbone then generates from the transformed input ˜ x = ( q , { ˜ f t } T t = 1 ) : π ϕ ( y | ˜ x ) = L j = 1 π ϕ ( y j | y < j , ˜ x ) . (3) W e keep O abstract only to st ate the decision probl em cleanly . The framew ork is operator-a gnosti c: O may implement resi zing, frame selecti on, or other pre-encoding b udget controls. 3 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning 2.2. Prob lem F ormulatio n Because the Allocator acts once before decoding, the outer problem is a Contextual Bandit ( equival ently , a on e-step contextual MDP). The context is the raw input x ∈ X , and the action is the contin uou s all ocation v ector s ∈ [ s min , s max ] T . F or joint training, it is con veni ent to write the induced t wo-stage policy a s p θ , ϕ ( s , y | x ) = π θ ( s | x ) π ϕ ( y | ˜ x ) , (4) where ˜ x = ( q , { O ( f t , s t ) } T t = 1 ) is the deterministica lly transformed input. The immediate reward is respo nse qualit y r ( x , s , y ) = Q ( x , y ) . L et C ( s ) denote the visual cost ind uced by allocati on s . The idea l budgeted objectiv e is max θ , ϕ E x ∼ D , s ∼ π θ ( · | x ) , y ∼ π ϕ ( · | ˜ x ) [ Q ( x , y ) ] s.t. E x ∼ D , s ∼ π θ ( · | x ) [ C ( s ) ] ≤ τ , (5) where τ is the t arget b udget. L a grangian rel axatio n yields the unconstrain ed utilit y max θ , ϕ E x , s , y [ U ( x , s , y ) ] , U ( x , s , y ) = Q ( x , y ) − λ C ( s ) , (6) for trade-off coeffici ent λ ≥ 0 . Equatio ns ( 5 ) – ( 6 ) define the t arget trade-off b ut not yet a stab le optimiz er . Section 3 inst antiates this objectiv e with an Input-side adaptation policy , CAPO , temporal regulari zation, and PPO -st yle surrogate losses; the experiments use resize as the con crete operator . Det ailed derivati ons are deferred to Appendix C . 3. Method Figure 2 summarizes the Input-side adaptatio n framew ork. At inference, the Allocator predi cts one allocati on per frame and applies a pre-encoding operator before the video reaches the backbone in a single pa ss. In the experimental instanti atio n studied here, O is bilinear resizing, so the allocati on becomes a resi ze f actor s t and ˜ f t = R ( f t , s t ) . At training, rollout feed back updates the Allocator and, optiona lly , the backbone. 3.1. Jo int RL Optimi zation Framew ork Section 2.2 defines all ocatio n as a contextua l bandit and st ates the ideal accuracy–cost trade-off . Appendix C starts from the margin al probabilit y of the correct answer under the transformed input and m otivates a on e-step expected-reward objective by a bstracting the resulting scalar qualit y term a s a rollo ut utilit y Q ( x , y ) that is treated as parameter-independent after sampling y . F or a fixed context x , the indu ced joint policy factori zes as p θ , ϕ ( s , y | x ) = π θ ( s | x ) π ϕ ( y | ˜ x ) . (7) Here π θ ( s | x ) is the densit y on s ind uced by the latent Bet a policy q θ ( a | x ) in Eq. ( 10 ) ( change o f variab les; the per-frame affine map has a θ -independent J acobian, so ∇ θ log π θ ( s | x ) matches ∇ θ log q θ ( a | x ) ). The PPO ratios in Eq. ( 21 ) are therefore computed on the l atent actions a t as in Eq. ( 11 ) . The correspo nding ideal rollout reward is R ideal s , y = Q ( x , y ) − λ C ( s ) , (8) 4 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning Allocator Visual Input Low Resolution Text Query Operator … s (1) s (2) s (M) MLLM … o (1,1) o (1,N) o (1,2) MLLM … o (M,1) o (M,N) o (M,2) MLLM … o (2,1) o (2,N) o (2,2) … … R (1,1) R (1,N) R (1,2) … R (2,1) R (2,N) R (2,2) … R (M,1) R (M,N) R (M,2) … A (1,1) A (1,N) A (1,2) … A (2,1) A (2,N) A (2,2) … A (M,1) A (M,N) A (M,2) … c (M) c (2) c (1) A (M) A (2) A (1) Base Advantage for MLLM Efficiency Shaping Regularization Long Video Inputs Allocator Text Encoder Visual Encoder Spatial Attention Temporal Attention Cross Attention MLP K V Q Predictor Block Action Head Beta Dist. Linear Transform Sample ~ Beta Mean Text Query Cost-Aware Policy Optimization Dynamic Pivot New Visual Question: Why did the boy lift up the towel near the end? A. pick up coat. B. put on the plate. C. lose balance. Info Fusion Entropy / Sim… Allocations Figure 2: R esAdapt framew ork. ( a) At inferen ce, a light weight Allocator π θ maps coarse visual features and the query to latent actio ns a t ∼ Beta ( α t , β t ) , which parameterize per-frame input allocati ons. In the resize inst antiation used in our experiments, these allocatio ns are realized a s scales s t ∈ [ s min , s max ] , and the resi zed frames are processed by the MLLM in a single call. ( b) During training, CAPO resha pes group-relative advanta ges with a dynamic cost piv ot τ dyn , while temporal-similarit y regul ariz ation suppresses red undant high-budget a llocatio n on adjacent similar frames. and the ideal optimiz atio n t arget is max θ , ϕ J ( θ , ϕ ) = E π θ ( s | x ) E π ϕ ( y | ˜ x ) R ideal s , y . (9) Equatio n ( 9 ) conditi ons on a fixed x ; training a vera ges o ver x ∼ D . Although its gradi ents follo w the standard score-f unctio n form det ailed in Appendix C , direct optimi zation remains brittle for three rea sons: 1. P olicy parameteriz atio n. π θ m ust emit a T -dimensio nal continu ous action with negligib le ov erhead relative to the backbon e. 2. Credit assignment. Delayed rollout reward m ust yield lo w-variance, cost-a ware gradient estimates; the ra w L agrangian reward Q ( x , y ) − λ C ( s ) is high-v ariance and often coll apses the poli cy to minimum b udget. 3. Local temporal structure. R ollout-l evel reward carries no explicit temporal signal, so near-dupli cate adjacent frames can still receive redundant allocati on. The next three subsections resolve these bottlenecks in order . 3.2. Allocator Architecture This subsectio n resolv es Bottleneck 1. Equation ( 9 ) requires a contin uo us allocati on policy whose ov erhead is negligib le relative to the backbone it controls. The framew ork itself only assumes a policy o ver operator 5 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning parameters; belo w we describe the continu ous resi ze inst antiatio n used for training and eva luation. Each frame f t ∈ R 3 × H t × W t is encoded by a frozen light weight visu al encoder , while the query is encoded separately . Both are projected to a shared dimension D . A sha llo w decoder alternates temporal self-attentio n o ver { f t } T t = 1 with gated cross-attention to the query , produ cing hidden st ates { h t } T t = 1 . This design exposes both temporal redundan cy and query dependence at low cost. T o preserv e explorati on, we parameterize each latent actio n with a Bet a distributi on whose bounded support maps naturally to [ s min , s max ] : a t ∼ Beta ( α t , β t ) , s t = s min + a t ( s max − s min ) . (10) Because a t ∈ ( 0, 1 ) , the all ocation satisfies s t ∈ ( s min , s max ) alm ost surely; in our experiments, 0 < s min < 1 < s max permits both do wnscaling and selectiv e upscaling. Let q θ ( a | x ) denote the l atent Beta policy o ver a = ( a 1 , . . . , a T ) . C onditi oned on { h t } , it f actorizes across frames: log q θ ( a | x ) = T t = 1 log Beta ( a t ; α t , β t ) . (11) The affine map a 7 → s ind uces the corresponding policy π θ ( s | x ) ; the exact change-of -variab les det ails are deferred to Appendix C . The result is a continu ous, query-aw are allocati on policy . 3.3. Cost-A ware Policy Optimization ( CAPO) This subsectio n resolves Bottleneck 2. The Allocator emits a structured allocati on, but the optimi zer needs a scalar cost sign al compatib le with rollo ut reward. A flat pen alt y o n C ( s ) collapses the policy to ward uniformly tiny b udgets. CAPO av o ids this f ailure by replacing the raw penalt y with a shaped surrogate learning signal. Compute metric. F or the resize inst antiation used in our experiments, if frame f t ∈ R 3 × H t × W t is resized by s t , its visual token count is n t ( s t ) ∝ ⌈ s t H t / P ⌉ ⌈ s t W t / P ⌉ for patch si ze P . Physi cal compute is measured by the token retention ratio ρ ( s ) = T t = 1 n t ( s t ) T t = 1 n t ( 1 ) ≈ T t = 1 s 2 t H t W t T t = 1 H t W t . (12) In our implement atio n, frames are norma lized to a comm on ba se resolution before allocati on, so ρ ( s ) is w ell approximated by the av era ge quadratic scale. Proxy cost. The quadratic dependence of ρ on s t o ver-empha sizes a few large all ocations and produ ces high-variance updates. W e therefore introdu ce the sm oother proxy c ( s ) = ¯ s − s min s max − s min , ¯ s = 1 T T t = 1 s t , (13) used only inside the optimizer; ρ ( s ) remains the efficien cy metric reported in experiments. Notatio n bridge. During training, R task m , n denotes the concrete rollo ut score, A base m , n the GRPO -normalized advantage, and A m , n the final CAPO -shaped advant a ge. Appendix C rel ates these practica l quantities to the ideal reward in Eq. ( 8 ). Base advantage. F or each prompt x , let R task m , n denote the scalar task reward o f rollout ( m , n ) , A base m , n the correspo nding GRPO group-n ormalized advantage, c m = c ( s m ) the proxy cost o f all ocatio n m , and u m , n ∈ { 0, 1 } a bin ary correctness indicator ( exact-match for Q A; thresholded success f or contin uous metrics). 6 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning Dynamic cost pivot. A fixed threshold does not track the evolving policy , whereas a purely group-dependent statistic is too no isy . CAPO therefore interpol ates bet ween a fixed t arget and the prompt-loca l mean: τ dyn = κ mix ¯ c group + ( 1 − κ mix ) τ fix , (14) where ¯ c group = 1 M M m = 1 c m is the prompt-loca l cost mean, τ fix ∈ [ 0, 1 ] is a fixed target proxy budget correspo nding to Eq. ( 5 ), and κ mix ∈ [ 0, 1 ] controls adaptivity . Asymmetric s ha ping. With τ dyn as piv ot, CAPO applies a correctness-dependent bonus or penalt y: S m , n = ⎧ ⎪ ⎪ ⎨ ⎪ ⎪ ⎩ λ + σ τ dyn − c m τ s if u m , n = 1, − λ − σ c m − τ dyn τ s if u m , n = 0, , (15) with λ − > λ + > 0 . Effici ent correct rollo uts receive a moderate bon us, whereas costly incorrect rollouts receiv e a stronger penalt y . The sigm oid temperature τ s sm ooths the transitio n around the pivot. Final CAPO advantage. L et ˜ A m , n = A base m , n + λ capo S m , n − γ c m . (16) The final advant a ge is A m , n = ⎧ ⎨ ⎩ max ˜ A m , n , ε + if u m , n = 1, ˜ A m , n if u m , n = 0, (17) where λ capo > 0 scal es C APO sha ping, γ ≥ 0 appli es a residua l global cost pen alt y , and the floor ε + > 0 ensures that correct lo w-cost rollouts retain a positiv e learning signal. The dominant anti-coll apse term is the piv oted a symmetric sha ping in S m , n . 3.4. R egulariz atio n and Training Objectiv e This subsectio n resolv es Bottleneck 3 and assemb les the final optimizer . T empora l similarit y loss ( L sim ). C APO optimizes the globa l qualit y–effici ency trade-off but does not penalize red undant high-b udget a llocatio n on near-d uplicate adjacent frames. R eusing the coarse features f t from S ec. 3.2 , w e penalize such pairs by L sim = 1 T − 1 T − 1 t = 1 w t · max ( 0, log s t + log s t + 1 + η sim ) , (18) where the similarit y-gated w eight w t = σ cos ( f t , f t + 1 ) − τ sim γ sim (19) activates only when adjacent frames exceed a cosine-similarit y threshold τ sim ∈ ( 0, 1 ) , with temperature γ sim . No pen alt y is incurred when s t s t + 1 ≤ e − η sim . Concentrati on loss ( L con ). T o prevent the Bet a distrib utio ns from coll apsing to near-deterministi c spikes, w e softly cap the tot al concentrati on at κ max > 0 : L con = 1 T T t = 1 max ( 0, α t + β t − κ max ) . (20) 7 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning T ogether , L sim enco urages differentiated allocati on across red undant neighbors, while L con preserv es explo- ratio n. Practica l training objective. W e optimize both polici es in a single GRPO -st yle loop ( Zheng et al. , 2025a , Y u et al. , 2025 ). For each prompt x , the Allocator samples M all ocatio n trajectori es s 1: M ; each transformed input ˜ x ( m ) then prod uces N respo nse rollouts. CAPO computes rollout advantages A m , n , which serve as the shared learning signal f or both polici es. The exact PPO approximati on is deferred to Appendix C . Allocator objectiv e. W e first aggregate rollo ut advantages per all ocatio n, A CAPO m = 1 N n A m , n , and optimize the per-frame PPO surrogate L θ = − 1 M T M m = 1 T t = 1 min r ( m ) θ , t A CAPO m , clip r ( m ) θ , t , 1 − ε , 1 + ε A CAPO m , (21) where the per-frame import ance ratio is r ( m ) θ , t = q θ ( a ( m ) t | x ) q θ old ( a ( m ) t | x ) . (22) The f ull Allocator loss is L alloc = L θ + λ sim L sim + λ con L con . (23) Backbon e update. Conditio ned on the sampled all ocatio ns, the backbon e is updated with the st andard token-lev el PPO approximati on L ϕ = − 1 M N M m = 1 N n = 1 1 L m , n L m , n j = 1 min r ( m , n ) ϕ , j A m , n , clip r ( m , n ) ϕ , j , 1 − ε , 1 + ε A m , n , (24) where L m , n is the rollo ut length and r ( m , n ) ϕ , j = π ϕ ( y ( m , n ) j | y ( m , n ) < j , ˜ x ( m ) ) π ϕ old ( y ( m , n ) j | y ( m , n ) < j , ˜ x ( m ) ) . (25) If the backbone is frozen, w e omit L ϕ ; jointly updating both net w orks corresponds to R esAdapt-RL. In practice, L alloc and L ϕ are optimized alternately within the same loop. 4. Experiments 4.1. Setup Implementation. The Allocator π θ uses the SmolVLM architecture ( Marafioti et al. , 2025 ) for high- throughput front-end predictio n. Throughout, w e inst antiate input-side allocati on with resize , so the learned all ocatio ns are realized as per-frame resi ze f actors. W e train the Allocator on Qwen2.5- VL-7B -Instruct ( Bai et al. , 2025b ) and additio nally test transfer to Qw en3- VL-8B-Instruct ( Bai et al. , 2025a ). W e report t w o settings: R esAdapt-RL , obt ained by jointly updating the Allocator and the backbon e, and R esAdapt , which directly reuses the trained Allocator with a frozen backbon e to evaluate plug-and-play generalizatio n. Resize is used d uring training because it pro vides the contin uo us action space required by our optimizer; thresholded 8 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning T ab le 1: E valuati on R esults on V ideo Q A Benchmarks. Retenti on ratio R reflects visua l token count; Rea soning ( ✓ / ✗ ) indicates chain-o f-tho ught use; bold marks the best result. R esAda pt yields larger gains on the reasoning benchmark than on the perceptio n benchmarks. Backbone Method R etention Ratio R R easoning Video Percepti on Benchmark Video R easoning Benchmark VideoMME LongVideoBench MMV U ML VU VideoMMMU L VBench Qwen2.5- VL-7B 32 Frames V anilla 100% ✗ 62.0 58.9 52.7 63.1 49.6 38.6 Random Drop 25.0% ✗ 58.9 57.8 49.6 58.3 45.3 36.7 T oMe ( Bolya et al. , 2022 ) 25.0% ✗ 58.7 58.0 51.0 58.7 41.8 37.7 Visio nZip ( Y ang et al. , 2025c ) 25.0% ✗ 59.4 57.1 49.8 57.9 42.4 36.5 FlashVid ( F an et al. , 2026 ) 29.3% ✗ 60.2 58.6 51.1 59.2 46.3 36.9 FixedScale 25.0% ✗ 60.0 56.8 51.2 59.8 46.7 37.3 R esAdapt ( Ours) 23.8% ✗ 60.3 58.2 51.9 60.1 48.8 37.9 Random Drop 10.0% ✗ 56.1 55.6 47.1 56.5 39.8 35.2 T oMe ( Bolya et al. , 2022 ) 10.0% ✗ 56.4 55.2 48.9 58.0 39.2 33.6 Visio nZip ( Y ang et al. , 2025c ) 10.0% ✗ 55.5 54.5 47.6 57.3 39.1 35.3 FlashVid ( F an et al. , 2026 ) 10.4% ✗ 57.9 56.8 47.9 57.7 39.4 36.5 FixedScale 12.3% ✗ 58.0 55.1 47.7 57.5 44.3 35.4 R esAdapt ( Ours) 11.4% ✗ 59.4 55.4 49.2 58.4 45.7 35.9 VideoA uto-R1 ( Liu et al. , 2026 ) 100% ✓ 63.2 58.9 55.0 60.0 53.6 41.5 + R esAdapt ( Ours) 23.8% ✓ 60.4 57.1 53.2 61.1 51.2 38.7 + R esAdapt ( Ours) 11.4% ✓ 59.3 56.3 51.8 59.3 49.1 36.7 128 Frames V anilla 100% ✗ 65.3 60.3 53.1 66.5 47.9 42.0 Random Drop 25.0% ✗ 64.9 61.2 50.8 64.8 48.1 41.3 T oMe ( Bolya et al. , 2022 ) 25.0% ✗ 65.1 61.6 51.9 63.1 46.6 42.1 Visio nZip ( Y ang et al. , 2025c ) 25.0% ✗ 64.8 61.3 51.1 64.5 47.3 41.5 R esAdapt ( Ours) 22.9% ✗ 65.6 60.2 52.8 65.9 51.1 42.1 Random Drop 10.0% ✗ 63.0 59.0 45.8 63.4 46.7 38.0 T oMe ( Bolya et al. , 2022 ) 10.0% ✗ 60.6 56.3 44.2 63.5 41.8 39.5 Visio nZip ( Y ang et al. , 2025c ) 10.0% ✗ 61.8 56.1 44.8 63.2 42.1 38.2 FixedScale 12.3% ✗ 64.1 60.9 49.6 64.5 46.9 40.3 R esAdapt ( Ours) 11.1% ✗ 63.8 58.6 49.0 64.3 49.2 39.9 VideoA uto-R1 ( Liu et al. , 2026 ) 100% ✓ 64.7 59.1 56.7 65.1 52.2 41.2 + R esAdapt ( Ours) 23.8% ✓ 66.2 60.2 53.5 66.0 52.6 41.8 + R esAdapt ( Ours) 11.4% ✓ 64.7 57.8 52.4 64.6 51.3 39.5 Qwen3- VL-8B 32 Frames V anilla 100% ✗ 65.0 58.6 57.5 64.0 60.8 40.2 Random Drop 25.0% ✗ 61.3 58.4 57.1 60.2 53.4 37.8 T oMe ( Bolya et al. , 2022 ) 25.0% ✗ 62.4 57.4 56.0 60.8 49.1 36.4 Visio nZip ( Y ang et al. , 2025c ) 25.0% ✗ 61.8 57.2 54.4 60.6 51.5 37.3 FlashVid ( F an et al. , 2026 ) 30.0% ✗ 63.9 59.0 54.8 61.9 55.1 38.5 R esAdapt ( Ours) 23.8% ✗ 62.6 57.5 55.3 61.0 58.4 38.5 Random Drop 10.0% ✗ 58.8 54.7 53.2 56.6 47.1 35.5 T oMe ( Bolya et al. , 2022 ) 10.0% ✗ 59.2 55.5 53.1 58.5 42.7 35.8 Visio nZip ( Y ang et al. , 2025c ) 10.0% ✗ 59.9 55.4 53.7 58.8 45.8 35.4 FlashVid ( F an et al. , 2026 ) 12.2% ✗ 61.0 57.1 54.8 59.1 47.8 37.1 FixedScale 12.3% ✗ 60.8 54.9 53.8 58.4 52.6 37.1 R esAdapt ( Ours) 11.4% ✗ 60.7 56.6 54.6 59.6 56.1 37.3 128 Frames V anilla 100% ✗ 69.4 64.3 58.5 72.7 63.0 45.7 Random Drop 25.0% ✗ 67.2 61.3 56.8 67.4 55.3 42.4 T oMe ( Bolya et al. , 2022 ) 25.0% ✗ 67.2 62.0 55.9 70.4 53.5 43.1 Visio nZip ( Y ang et al. , 2025c ) 25.0% ✗ 67.1 61.3 55.7 69.2 56.8 41.2 R esAdapt ( Ours) 22.9% ✗ 67.4 61.9 56.3 70.8 59.6 43.3 Random Drop 10.0% ✗ 64.1 58.3 55.4 62.4 55.5 38.8 T oMe ( Bolya et al. , 2022 ) 10.0% ✗ 64.7 58.6 55.1 67.3 46.3 40.5 Visio nZip ( Y ang et al. , 2025c ) 10.0% ✗ 64.2 59.1 54.2 66.8 47.6 39.4 FixedScale 12.3% ✗ 66.7 59.5 54.4 67.7 56.3 41.7 R esAdapt ( Ours) 11.1% ✗ 66.8 60.2 55.4 69.4 58.2 42.6 9 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning 10 25 50 Retention Ratio (%) 40.0 42.5 45.0 47.5 50.0 VideoMMMU Accuracy(%) 46.1 49.2 51.6 45.7 48.8 50.0 44.3 46.7 39.1 42.4 48.5 39.4 46.3 49.0 39.2 41.8 4 8 .7 39.8 45.3 47.7 20.4: avg scale 0.45 44.9: avg scale 0.67 10 25 50 Retention Ratio (%) 56 58 60 62 VideoMME Accuracy(%) 58.1 60.5 61.7 59.4 60.5 61.2 58.0 59.3 55.5 59.4 60.3 57.9 60.2 61.1 56.4 58.7 60.7 56.1 58.9 60.1 22.3: avg scale 0.48 39.0: avg scale 0.63 8 / 100% 32 / 25% 64 / 12.5% 128 / 6.2% #Frames / Retention Ratio (%) Relative Accuracy (%) ResAdapt-RL (Ours) ResAdapt (Ours) FixedScale VisionZip FlashVid T oMe Random V anilla Figure 3: Efficiency–accuracy trade-o ffs and temporal reall ocatio n. ( a,b) VideoMMMU and VideoMME v ersus visual-token retenti on rati o R . R esAdapt is o n or near the P areto frontier , with the clearest advanta ge on rea soning- heavy settings at low retenti on. ( c) R elative gain fro m trading spatial resoluti on f or temporal co vera ge under a fixed 8-frame-equiva lent b udget. frame selecti on is treated only as the conceptua l zero-budget limit of the same pre-encoding interf ace. Full hyperparameters, hardware, prompts, and reward definitions are deferred to Appendix A . Baselin es. W e compare against three classes o f methods: heuristic baselines (Random Drop, FixedScal e), m odel-side compressi on (T oMe ( Bolya et al. , 2022 ), FlashVid ( F an et al. , 2026 ), Visio nZip ( Y ang et al. , 2025c )), and reasoning-time inference augmentation (VideoA uto-R1 ( Liu et al. , 2026 )). W e use visual- token retenti on rati o R as the primary budget descriptor and report the exact retained b udget f or every method. F or rea soning-time baselines, R measures only visual encoder tokens; unless latency is reported separately , these comparisons should therefore be read as visual-budget comparisons rather than tot al- inferen ce-budget matches. Because sev eral baselin es admit only discrete operating points, some comparisons are only approximately budget matched and should be interpreted rel ativ e to the explicit trade-o ffs sho wn in each tab le. Benchmarks. F or video Q A , we report results on VideoMME ( Fu et al. , 2025a ), L ongV ideoBench ( Wu et al. , 2024 ), MMV U ( Zhao et al. , 2025b ), ML V U ( Z hou et a l. , 2025 ), VideoMMMU ( Hu et al. , 2025 ), and L VBench ( W ang et al. , 2025b ). For temporal grounding , w e report R eca ll@ { 0.3, 0.5, 0.7 } and mIo U on Charades-ST A ( Gao et a l. , 2017 ) and Activit yNet ( F abian et a l. , 2015 ), plus grounding Q A on NExT -GQ A ( Xiao et al. , 2024 ). F or image underst anding , we eva luate on MathVista ( Lu et al. , 2023 ), MMMU ( Y ue et al. , 2024 ), OCRBench ( Liu et al. , 2024 ), ChartQ A ( Masry et al. , 2022 ), AI2D ( Kemb ha vi et al. , 2016 ), and T extVQ A ( Singh et al. , 2019 ). U nless st ated otherwise, figures and analyses use Qwen2.5- VL-7B with 32 input frames. All eva luations use lmms-eva l ( Zhang et al. , 2024a ); the exact token budgets and decoding limits are reported in Appendix A . 4.2. Main R esults W e organiz e the evaluatio n around t w o primary claims and one exploratory questio n. First, resize-based input-side all ocatio n should improv e lo w-b udget operating points on video Q A. S econd, allocating pixels before encoding should be clearly more robust than frame dropping and often competitiv e with m odel-side compressi on on temporal grounding. Third, we ask how f ar the learned policy transfers bey ond the training setting; w e treat this last an alysis as exploratory rather than as a head lin e claim. Video QA. This experiment tests the first cl aim. W e emphasize lo w-b udget operating points rather than a univ ersal frontier st atement, since severa l baselin es are av ailab le only at discrete budgets (T ab le 1 ). 10 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning T ab le 2: Eva luation R esults on T emporal Grounding Benchmarks. Grounding is mu ch more compressi on-sensitiv e. Backbone Method R etention Ratio R R easoning T emporal Grounding Benchmark Charades-ST A Activit yNet NExT -GQ A 0.3 0.5 0.7 mIoU 0.3 0.5 0.7 mIoU Acc mIoU Qwen2.5- VL-7B 32 Frames V anilla 100% ✗ 71.0 51.4 26.0 47.3 30.4 18.0 8.9 22.6 78.9 28.0 Random Drop 25.0% ✗ 39.4 23.2 11.0 25.7 15.2 8.1 3.7 11.7 77.5 16.6 T oMe ( Bolya et al. , 2022 ) 25.0% ✗ 39.5 23.9 11.4 26.0 16.0 8.4 4.0 12.1 77.8 16.3 FlashVid ( F an et al. , 2026 ) 31.3% ✗ 40.7 24.2 11.3 26.6 15.8 8.4 3.8 12.0 78.1 16.5 FixedScale 25.0% ✗ 36.7 24.7 12.3 24.9 18.6 9.4 4.3 14.1 77.7 12.3 R esAdapt ( Ours) 16.2% ✗ 53.8 34.8 17.0 35.6 19.8 10.8 5.2 15.3 76.6 23.2 Random Drop 10.0% ✗ 36.9 23.2 11.6 24.6 14.3 7.5 3.6 11.1 76.3 15.4 T oMe ( Bolya et al. , 2022 ) 10.0% ✗ 41.3 26.9 14.1 27.4 16.0 8.4 4.0 12.2 77.3 15.7 FlashVid ( F an et al. , 2026 ) 12.6% ✗ 38.2 22.9 11.1 25.1 15.4 8.1 3.7 11.8 77.4 16.1 FixedScale 12.3% ✗ 48.0 31.5 15.4 32.0 17.5 8.9 4.0 13.3 76.1 13.7 FixedScale 6.3% ✗ 39.9 26.8 13.3 26.7 15.2 8.1 3.9 11.9 74.1 15.4 R esAdapt ( Ours) 6.8% ✗ 41.0 27.8 14.0 27.2 16.3 8.5 3.9 12.5 74.3 20.4 VideoA uto-R1 ( Liu et al. , 2026 ) 100% ✓ 60.0 48.3 27.2 41.5 50.8 34.1 17.4 34.4 73.6 33.8 + R esAdapt ( Ours) 6.8% ✓ 43.5 30.1 15.8 30.0 35.4 21.5 10.0 24.4 74.7 24.7 128 Frames V anilla 100% ✗ 77.5 60.3 34.1 52.8 47.9 30.9 17.5 34.4 79.8 29.9 Random Drop 25.0% ✗ 32.3 19.6 7.9 20.7 26.7 13.9 6.3 18.8 80.3 10.7 T oMe ( Bolya et al. , 2022 ) 25.0% ✗ 32.4 19.8 7.9 20.7 27.2 14.4 6.4 19.1 80.3 10.9 R esAdapt ( Ours) 16.1% ✗ 63.5 43.6 21.3 42.0 33.1 19.3 10.2 24.3 78.1 27.2 Random Drop 10.0% ✗ 37.8 23.8 11.2 24.7 23.8 12.0 5.3 17.0 79.4 12.8 T oMe ( Bolya et al. , 2022 ) 10.0% ✗ 27.9 16.2 7.3 17.9 22.9 11.8 5.5 16.4 79.1 11.1 FixedScale 12.3% ✗ 34.7 22.3 10.5 22.7 25.0 13.8 5.9 18.3 77.9 11.3 FixedScale 6.3% ✗ 42.6 28.4 14.3 28.3 22.8 12.8 5.7 17.1 75.7 12.9 R esAdapt ( Ours) 6.8% ✗ 43.5 29.8 15.0 28.9 23.5 12.9 6.1 17.2 76.2 23.9 VideoA uto-R1 ( Liu et al. , 2026 ) 100% ✓ 40.3 33.7 22.1 28.9 49.4 34.3 18.5 33.5 68.0 31.0 + R esAdapt ( Ours) 16.1% ✓ 72.8 53.0 27.5 49.1 65.8 44.9 23.8 44.7 79.3 35.3 + R esAdapt ( Ours) 6.8% ✓ 50.1 33.2 16.6 34.2 53.4 34.0 16.4 35.7 76.6 29.4 Qwen3- VL-8B 32 Frames V anilla 100% ✗ 73.0 49.0 21.4 46.4 44.6 28.3 15.5 31.8 78.7 34.2 Random Drop 25.0% ✗ 16.2 8.6 3.8 12.1 12.4 6.7 3.2 10.0 77.2 15.6 T oMe ( Bolya et al. , 2022 ) 25.0% ✗ 68.7 42.1 17.6 43.1 45.9 28.8 15.6 32.6 77.1 31.7 FlashVid ( F an et al. , 2026 ) 31.3% ✗ 72.9 52.3 25.1 47.7 51.9 33.4 19.0 36.8 77.8 33.9 R esAdapt ( Ours) 16.2% ✗ 64.4 37.3 16.3 39.9 40.0 24.4 13.0 28.5 75.1 30.2 Random Drop 10.0% ✗ 4.1 1.8 0.7 4.4 4.7 2.4 1.0 5.0 74.3 11.3 T oMe ( Bolya et al. , 2022 ) 10.0% ✗ 67.6 39.3 16.6 41.8 46.3 31.0 19.2 34.1 79.2 34.0 FlashVid ( F an et al. , 2026 ) 12.6% ✗ 68.8 46.9 22.9 44.6 49.9 31.5 17.4 35.2 75.6 31.8 FixedScale 12.3% ✗ 61.3 34.3 14.6 37.9 39.6 24.2 13.1 28.4 74.2 29.9 FixedScale 6.3% ✗ 52.7 28.2 11.3 33.2 37.0 22.3 12.0 27.0 71.5 28.0 R esAdapt ( Ours) 6.8% ✗ 53.6 29.0 11.8 33.6 37.5 22.5 12.3 27.2 71.8 28.2 128 Frames V anilla 100% ✗ 72.8 46.0 20.1 45.6 45.8 31.1 19.2 33.9 81.1 36.6 Random Drop 25.0% ✗ 41.6 25.2 10.6 27.4 36.1 21.1 12.7 26.3 79.3 22.4 R esAdapt ( Ours) 16.1% ✗ 64.4 37.0 15.9 39.8 40.6 26.7 15.7 30.0 76.8 33.3 Random Drop 10.0% ✗ 32.6 19.0 7.8 21.9 33.5 18.6 11.5 24.8 76.9 19.9 T oMe ( Bolya et al. , 2022 ) 10.0% ✗ 61.6 33.8 13.3 38.1 42.4 27.6 16.6 31.4 77.4 31.5 FixedScale 12.3% ✗ 61.7 34.9 14.7 38.1 39.9 26.2 15.3 29.5 75.4 32.6 FixedScale 6.3% ✗ 53.7 28.2 11.8 33.6 37.9 24.3 14.3 28.1 73.0 39.1 R esAdapt ( Ours) 6.8% ✗ 54.3 28.0 11.7 33.7 38.3 24.5 14.4 28.4 73.2 43.9 11 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning T ab le 3: Latency breakdo wn ( ms, ↓ ) on Qwen2.5- VL-7B with single-GP U Allocator and 4-GPU vLLM engine. A v eraged o v er 200 runs after 5 warm-up; E2E latency = S cal e Time + Gen. T ime. Method #Frames R etention Ratio R Scale Inference T otal TFLO Ps T ext Enc. Visual Enc. Scale Pred. Scale Apply Scale Time TFLO Ps TTFT Gen. Time TFLO Ps E2E Time V anill a 16 100% – – – – – – 111.4 378.9 527.9 111.4 527.9 R esAdapt 16 76.3% 1.5 19.8 94.1 85.6 6.3 205.8 77.2 ( ↓ 30.7%) 272.5 ( ↓ 28.1%) 370.7 ( ↓ 29.8%) 80.1 ( ↓ 28.1%) 576.5 ( ↑ 9.2%) R esAdapt 16 52.8% 1.5 19.9 102.9 94.5 8.4 225.7 51.5 ( ↓ 53.8%) 261.5 ( ↓ 31.0%) 313.1 ( ↓ 40.7%) 54.4 ( ↓ 51.2%) 538.8 ( ↑ 2.1%) R esAdapt 16 28.9% 1.5 20.4 103.4 92.2 9.0 225.0 31.0 ( ↓ 72.2%) 227.2 ( ↓ 40.0%) 237.9 ( ↓ 54.9%) 33.9 ( ↓ 69.6%) 462.9 ( ↓ 12.3%) V anill a 32 100% – – – – – – 222.5 723.3 881.9 222.5 881.9 R esAdapt 32 74.4% 2.9 19.9 204.1 97.4 14.4 335.9 153.9 ( ↓ 30.8%) 589.4 ( ↓ 18.5%) 627.6 ( ↓ 28.8%) 159.7 ( ↓ 28.2%) 963.5 ( ↑ 9.2%) R esAdapt 32 51.5% 2.9 20.0 193.2 92.0 16.2 321.4 102.4 ( ↓ 54.0%) 505.0 ( ↓ 30.2%) 467.1 ( ↓ 47.0%) 108.2 ( ↓ 51.4%) 788.5 ( ↓ 10.6%) R esAdapt 32 28.2% 2.9 20.3 190.4 90.3 17.3 318.3 61.4 ( ↓ 72.4%) 451.8 ( ↓ 37.5%) 332.6 ( ↓ 62.3%) 67.2 ( ↓ 69.8%) 650.9 ( ↓ 26.2%) V anill a 64 100% – – – – – – 444.6 1457.5 2059.6 444.6 2059.6 R esAdapt 64 73.2% 5.8 19.8 389.5 95.8 26.4 531.5 307.3 ( ↓ 30.9%) 1093.1 ( ↓ 25.0%) 1327.0 ( ↓ 35.6%) 318.9 ( ↓ 28.3%) 1858.5 ( ↓ 9.8%) R esAdapt 64 50.7% 5.8 20.1 382.1 94.9 29.9 527.0 204.3 ( ↓ 54.0%) 991.8 ( ↓ 31.9%) 740.5 ( ↓ 64.0%) 215.9 ( ↓ 51.4%) 1267.5 ( ↓ 38.5%) R esAdapt 64 27.8% 5.8 20.0 371.6 90.2 34.8 516.6 122.2 ( ↓ 72.5%) 899.2 ( ↓ 38.3%) 511.4 ( ↓ 75.2%) 133.8 ( ↓ 69.9%) 1028.0 ( ↓ 50.1%) V anill a 128 100% – – – – – – 888.9 2936.3 4877.0 888.9 4877.0 R esAdapt 128 74.2% 11.6 20.1 766.3 95.0 53.1 934.5 614.1 ( ↓ 30.9%) 2286.6 ( ↓ 22.1%) 2323.6 ( ↓ 52.4%) 637.3 ( ↓ 28.3%) 3258.1 ( ↓ 33.2%) R esAdapt 128 51.4% 11.6 20.2 755.3 93.8 59.4 928.7 408.0 ( ↓ 54.1%) 2071.0 ( ↓ 29.5%) 1496.0 ( ↓ 69.3%) 431.2 ( ↓ 51.5%) 2424.7 ( ↓ 50.3%) R esAdapt 128 28.2% 11.6 20.4 734.5 92.0 68.6 915.5 243.9 ( ↓ 72.6%) 1766.7 ( ↓ 39.8%) 1061.8 ( ↓ 78.2%) 267.1 ( ↓ 70.0%) 1977.3 ( ↓ 59.5%) Dis proportio nate gains on m ulti-step rea soning. U nder a ggressiv e compressi on ( ∼ 10% retention), content- a gnosti c methods discard sparse b ut decisiv e evidence. On Qw en2.5- VL with 32 frames, ResAda pt reaches 45.7 on VideoMMMU at 11.4% retention, improving ov er T oMe ( 39.2 ), Visi onZip ( 39.1 ), FlashV id ( 39.4 ), and FixedS cal e ( 44.3 ) while remaining competitiv e on the perceptio n benchmarks. The gain is therefore con centrated on the reaso ning-heavy benchmark rather than being uniform across t as ks. The transferred Allocator remains strong on Qw en3- VL, reaching 56.1 o n VideoMMMU at the same 11.4% retention, but we treat the cross-backbone comparison as supportive rather than definitiv e because the availa bl e operating points are not perfectly matched. Spatia l savings reinv ested as temporal cov erage. Extending co ntext from 32 to 128 frames amplifi es the advantage. At 22.9% retenti on on Qwen2.5- VL, R esAdapt reaches 51.1 on VideoMMMU versu s 47.9 for the 128-frame uncompressed m odel while reco v ering m ost o f the perceptio n performance at f ar low er visual cost. Ev en at 11.1% retenti on, ResAda pt att ains 49.2 on VideoMMMU , again slightly exceeding the 128-frame vanilla score. The effect is t ask-dependent rather than unif orm, b ut it sho ws that sav ed spatial b udget can be reinv ested as temporal headroom: the model observes 4 × m ore frames without paying n ativ e-resolution cost (Figure 3 ). T emporal Grounding. This experiment tests the second cl aim. Grounding is marked ly more compression- sensitiv e than Q A, so w e interpret T ab l e 2 as a comparison of operating points rather than as a perfectly b udget-matched frontier . Pre-encoding all ocatio n is m ore robust than frame dropping. On Qwen2.5- VL (32F), Random Drop, T oMe, FlashV id, and FixedScal e red uce Charades-ST A mIo U from 47.3 to 25.7 , 26.0 , 26.6 , and 24.9 , respectiv ely , at ≈ 25–31% retention. At a low er 16.2% budget, R esAdapt reaches 35.6 . The point is therefore not a universa l matched-b udget win ov er ev ery grounding baselin e; rather , all ocating pixels before encoding is subst antially m ore robust than frame dropping and remains competitiv e with m odel-side compressio n despite operating at a small er budget. On the reported Qw en3 row s, the same pattern holds mo st clearly a gainst frame dropping, while comparisons to model-side baselines are more mixed. R ea soning without temporal anchors regresses. The strongest grounding result is a single but import ant reaso ning-augmented operating point. On VideoA uto-R1 ( Qw en2.5- VL), extending from 32 to 128 frames 12 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning 0 5 10 15 20 25 30 0.2 0.4 0.6 0.8 1.0 Scale Factor Case 338 ( =0.214) 0 5 10 15 20 25 30 0.2 0.4 0.6 0.8 1.0 Case 1640 ( =0.247) 0 5 10 15 20 25 30 0.2 0.4 0.6 0.8 1.0 Case 1302 ( =0.251) 0 5 10 15 20 25 30 Frame Index 0.2 0.4 0.6 0.8 1.0 Scale Factor Case 1 166 ( =0.002) 0 5 10 15 20 25 30 Frame Index 0.2 0.4 0.6 0.8 1.0 Case 2435 ( =0.019) 0 5 10 15 20 25 30 Frame Index 0.2 0.4 0.6 0.8 1.0 Case 1770 ( =0.009) Figure 4: Emergent activ e perception. P er-frame scale s t o ver frame index for six VideoMME videos, gro uped by intra-video scal e div ersit y σ . High-diversity videos sho w localized scal e spikes on scene changes, text o verlay s, and rapid m otio n; lo w-div ersit y videos remain near-unif orm. degrades Charades-ST A mIo U from 41.5 to 28.9 , indicating that l onger reasoning chains alon e do not preserv e loca liz atio n qualit y in this setting. Adding R esAdapt at 16.1% visu al-token retentio n lifts the 128-frame score to 49.1 , showing that allocati on can materially impro ve this particular long-co ntext reaso ning regime. Emergent deno ising. On NExT -GQA ( Qw en3- VL, 128F), R esAdapt improv es mIoU from 36.6 to 43.9 at only 6.8% retentio n, suggesting that suppressing questi on-irrel evant frames can sharpen localization even under extreme compressi on. Exploratory image transfer . Transf er bey ond video is mixed and not central to our cl aims. The clearest positiv e result is ChartQ A on Qwen2.5- VL, b ut it is obtained at 105% visu al-token retentio n, whereas text- heavy t as ks degrade on ce resolutio n becomes too lo w . W e therefore treat image results as a robu stness check and report them in Appendix D.4 , T ab le 7 . 4.3. R untime Overhead This experiment is a pipeline-latency case study: it measures when the front-end cost of allocati on is amortized by do wnstream token savings. T ab le 3 reports l atency a gainst vanilla using a dedicated single-GPU Allocator and a separate 4-GPU vLLM engine; it should therefore be read as a vanilla-versu s-R esAdapt deployment pro file rather than as a same-hardware compariso n against T oMe, Fl as hVid, or Visio nZip. By adjusting the maxim um all ow ed sca le, R esAda pt spans retenti on rati os from conservativ e ( R ≈ 74% ) to a ggressiv e ( R ≈ 28% ) compressi on, providing a single controllab le accuracy–speed knob. The key trade-off is when token reducti on out weighs the front-end scaling cost. At R ≈ 74% , generati on time drops 29–52% but end-to-end (E2E) savings appear only at ≥ 64 frames ( − 9.8% ), gro wing to − 33.2% at 128 frames. At R ≈ 51% , the break-ev en shifts to 32 frames ( − 10.6% E2E); at R ≈ 28% , wall-clock savings 13 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning 0 5 10 15 20 25 30 Frame Index 0.24 0.26 0.28 0.30 0.32 0.34 0.36 0.38 0.40 Scale Factor (a) Aggregate Scale by Frame Position (V ideoMME) IQR Mean Median 0 8 16 24 31 Frame Index 0 25 50 75 100 125 150 175 Case ID (b) Per -Frame Scale Heatmap (First 200 Cases) 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Scale Factor Figure 5: Globa l allocati on statistics o n VideoMME. ( a) Aggregate predicted scal e by frame position. ( b) Case × frame heatmap for the first 200 videos. High-scale allocati on appears a s loca lized bursts rather than a fixed po sitiona l pattern. T ab le 4: Distributi on f amily ab lation for CAPO . The t wo variants foll ow the same training protocol. V ariant ¯ s VideoMME LongVideoBench MMVU VideoMMMU L VBench P er . Comp. Adap. β -CAPO 0.54 60.3 58.2 51.2 65.0 54.3 28.7 37.6 N -CAPO 0.60 61.0 57.4 51.8 66.0 50.0 30.3 37.2 emerge ev en at 16 frames ( − 12.3% ), reaching − 59.5% at 128 frames with 78% generati on-time reducti on. This scaling reflects the quadratic cost o f attention: backbon e savings compound faster than the lo w er-order Allocator ov erhead as sequen ces gro w , making R esAda pt mo st impactf ul in the lo ng-context regime. 4.4. Analysis and Ablati on Emergent activ e perceptio n. These an aly ses explain why the main results hold. The Allocator learns a strongly sparse temporal all ocatio n rather than a near-unif orm compressio n policy . Figure 4 show s this clearly: many videos are compressed alm ost everywhere, with short b ursts of higher resolutio n around text o verla ys, scene transitions, or other brief informativ e events. This is precisely the beha vior we would want from input-side allocati on: the Allocator spends pixels where the answer is likely to be decided, rather than distrib uting them uniformly across the clip. Figure 5 show s that this beha vior is not a trivial positi onal prior . The median scale st ays clo se to the lo w end o f the range, while the mean is lifted by localized peaks, implying that high-resolutio n all ocatio n is the exceptio n rather than the def ault. The per-video heatmap f urther confirms that these peaks appear a s content-dependent segments rather than as a fixed bias toward the beginning or end o f the sequen ce. CAPO ab lation. Tw o questio ns arise: ho w cost should enter optimiz atio n, and what indu ces the policy to vary across neighboring frames rather than coll apse to a unif orm scaler . T ab l e 4 suggests that the exact policy f amily is secondary: β -CAPO and N -CAPO trade margin al advantages 14 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning 0 100 200 300 400 500 T raining Step 0.25 0.50 0.75 1.00 1.25 1.50 1.75 2.00 Mean Predicted Scale s (a) T raining 0 100 200 300 400 500 T raining Step (b) V alidation β -Dist. w/o Cost β -Dist. w Direct Cost β -Dist. w CAPO -Dist. w CAPO Figure 6: R eward-design ab lation. Mean predicted scal e ¯ s d uring training and validatio n. Direct cost penalties collapse to the minim um scale, wherea s CAPO variants con v erge to st ab le intermediate operating points. across benchmarks, with neither variant consistently dominating. Because the realized budgets are not exactly matched, w e interpret this as a directio nal trend rather than as a perfectly controlled ab l atio n. The shared ingredient that a ppears to matter is CAPO’s asymmetri c cost shaping, not the specifi c parametric form o f the scal e distributi on. Figure 6 makes this m ore explicit from a training-dynamics perspectiv e. Direct cost penalties drive the policy rapid ly to ward the minimum-sca le boundary , while rem o ving cost altogether pushes it to ward the upper bound. CAPO is effectiv e precisely because it st abilizes an intermediate operating point where the model is still rewarded for being selectiv e rather than merely cheap or merely accurate. W e provide f urther an aly sis o f per-sample scale adaptivit y and conv ergen ce behavi or in Appendix D.2.2 . T ab le 5: Operator genera liz ation. Zero-shot transfer o f R esAdapt scores to frame selecti on. Combining top- K selecti on with adapti ve resizing from 128 candidate frames outperf orms uniform sampling baselin es at lo wer token b udgets. Method VideoMME LongVideoBench L VBench MMVU Budget: 8 frames V anilla 54.0 53.9 33.3 48.9 T op-8 Select 52.2 51.1 32.0 49.2 Budget: 16 frames V anilla 58.9 56.0 36.1 50.9 Threshold S elect 58.0 57.4 36.4 51.0 Avg. Budget ( Retentio n Ratio) 12.2f (9.5%) 23.2f (18.1%) 16.7f (13.0%) 17.2f (13.4%) T op-32 Select + Resize 60.6 57.2 38.9 50.2 Avg. Budget ( Retentio n Ratio) 11.7f (9.1%) 16.9f (13.2%) 13.7f (10.7%) 14.1f (11.0%) Budget: 32 frames V anilla 62.3 58.7 39.5 52.0 T op-32 Select 59.7 55.7 37.0 51.2 T op-64 Select + Resize 62.5 58.4 40.0 52.3 Avg. Budget ( Retentio n Ratio) 23.8f (18.6%) 36.2f (28.3%) 24.1f (18.8%) 32.5f (25.4%) Operator genera liz atio n. Although R e- sAdapt is trained exclusively for adap- tiv e resizing, its learn ed poli cy gen eral- izes zero-shot to other input-side opera- tors. W e repurpo se the Allocator’s pre- dicted scal es as frame import ance scores to rank and filter 128 candidate frames. T a- b le 5 demonstrates that while pure frame selecti on (top- K or threshold-based) pro- vides a viab le strategy , combining selec- tio n with resi zing yields the best efficiency– accuracy trade-o ff . S pecifica lly , selecting and resizing the top-32 or top-64 frames consistently outperf orms the vanilla 16- frame and 32-frame baselin es, respectiv ely , despite consuming f ewer tokens on av er- a ge. This confirms that the Allocator learns a robu st, operator-a gnosti c measure of visual import ance that seamlessly cascades with discrete frame dropping. 15 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning 0.25 0.00 0.25 0.50 0.75 1.00 S c a l e s t = 0 . 0 0 3 2 Video 125 0.25 0.00 0.25 0.50 0.75 1.00 = 0 . 0 0 1 9 Video 288 0.25 0.00 0.25 0.50 0.75 1.00 = 0 . 0 0 1 9 Video 483 5 10 15 20 25 30 Frame Index 0.25 0.00 0.25 0.50 0.75 1.00 S c a l e s t = 0 . 2 4 2 1 5 10 15 20 25 30 Frame Index 0.25 0.00 0.25 0.50 0.75 1.00 = 0 . 2 4 8 1 5 10 15 20 25 30 Frame Index 0.25 0.00 0.25 0.50 0.75 1.00 = 0 . 2 1 1 4 w / o s i m w / s i m Figure 7: L sim ab lation: per-frame scal e profil es. W ithout temporal-similarit y regulariz ation, the Allocat or a p- proaches near-unif orm sca ling; with it, the policy concentrates resoluti on on selected frames and suppresses red undant neighbors. T empora l regulari zation complements CAPO . CAPO al one determines how cost enters learning, b ut it does not by itself force the Allocator to distinguish am ong visually redundant neighbors. Figure 7 sho ws that on ce L sim is remo v ed, the learned scale traces coll apse to ward a near-co nst ant profile that behav es mu ch like FixedScale. R eintrod u cing L sim restores sharp frame-lev el differentiati on, which confirms that CAPO and the temporal regulari zer are complementary: one st abilizes the accuracy–cost objectiv e, and the other breaks the symmetry that would otherwise f av or uniform allocati on. R ob ustness and f ailure m odes. Ada ptiv e allocati on does not act as a loss less compressio n l ayer . In practice, R esAdapt usu ally preserv es many origin ally correct predicti ons, but it can still miss decisiv e evidence, especially when the relevant cue is visually simple and appears only briefly . Because the policy is open-loop, it cannot revise allocati ons after reasoning begins or recov er evidence that wa s undersampled in the initi al pass. W e therefore interpret its gains as selectiv e redistrib ution of visual budget rather than as gu aranteed preservati on of all useful informatio n. 5. R elated W ork Input-side adaptation before visual encoding. A growing body of w ork red uces visual cost before or d uring input constru ctio n. Early approaches primarily perform temporal do wnsampling through keyframe selecti on or clip condensation ( Liang et al. , 2024 , Zhu et al. , 2025 , Sun et al. , 2025 , T ang et al. , 2025 ). More recent methods incorporate query a wareness and iterative search, t ailoring frame selection to questi on t ypes or intermedi ate evidence ( Zou et al. , 2025 , Li et al. , 2025a , Guo et a l. , 2025b , He et al. , 2025 ). Bey ond selecting which frames to process, several w orks allocate perceptual b udgets via multi-resoluti on encoding. Sl ow–fa st pipelines ( Y ang et al. , 2025a , Zhang et al. , 2026 ) use inter-frame similarit y to route frames to high- or lo w-resoluti on paths, but their binary , query-a gnosti c routing cannot adapt to the downstream questi on. Query-a ware m ulti-resolutio n strategies ( Zhang et al. , 2025d ) and early truncati on of less informativ e visu al tokens ( Chen et al. , 2026 ) go f urther by conditi oning on the query , yet still rely on handcrafted rules or fixed resolutio n bins. In contrast, ResAda pt is an Input-side adaptatio n framework: it learns input-side allocati ons from t ask reward vi a RL and can realize them through different pre-encoding operators, including resizing and frame selecti on; the experiments in this paper study the continu ous resiz e instanti atio n. 16 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning Model-side token eco nomy after encoding. Po st-encoding methods prune, merge, or redistribute visual tokens in embedding space. F or images, representative approaches include token merging ( Bolya et a l. , 2022 ), attentio n- or sali ency-guided pruning ( Chen et a l. , 2024 , Y ang et a l. , 2025c , Shang et a l. , 2025 , Zhang et al. , 2025c ), progressive dropping ( Xing et al. , 2024 , Zhang et a l. , 2024b ), and diversit y-based budget all ocatio n ( Alvar et a l. , 2025 , Y ang et al. , 2025b , Zhang et al. , 2025a ). Video-specifi c extensi ons exploit spati otemporal redundan cy via static/dynamic token separation ( Huang et al. , 2025 , Shen et al. , 2025a ), hierarchi cal merging ( Hyun et al. , 2025 ), and segment-level f usio n or budget all ocation ( T ao et al. , 2025 , Fu et al. , 2024 , Shao et al. , 2025a ). These methods are complementary to R esAdapt: they operate after visual encoding and cannot recov er high-frequen cy det ails lo st to undersampling bef ore encoding. Our focus is earlier in the pipeline, deciding how many pixels to encode in the first pl ace. Output-side agentic reaso ning. Another strategy lea v es the input fixed and recov ers efficien cy through iterativ e rea soning: retriev e candidate frames, zoom into regions, then re-query the m odel. Approaches range from st atic toolsets with predefined cropping or clipping operators ( Zheng et a l. , 2025b , W ang et al. , 2025a , Song et al. , 2026 ) to dyn amic tooling via code-generatio n primitives ( Zhang et al. , 2025e , Zhao et al. , 2025a , Ho ng et al. , 2025 ), often exposed through execut ab le interf aces ( W ang et al. , 2024 ). While these methods can target hard evidence precisely , they are m ulti-pass by constructi on and rely on an initial coarse view to trigger subsequent refinement. R esAdapt instead studies whether a single-pass pre-encoding all ocatio n policy can reco ver mu ch o f this benefit without the latency and control ov erhead of iterative interaction. RL for multim oda l reasoning and perception control. Recent work has extended RL post-training from language models ( Shao et a l. , 2024 , Guo et al. , 2025a ) to multim oda l reaso ning and video underst anding. Algorithmic refinements include improv ed advantage estimation and P PO -st yle st abilization ( Liu et a l. , 2025c , Y u et al. , 2025 , Z heng et al. , 2025a ), while video-domain extensio ns strengthen reaso ning through iterativ e frame selecti on and evidence refinement ( F eng et al. , 2025 , Li et al. , 2025b , Liu et al. , 2026 , Y ang et al. , 2025d , Chen et al. , 2025 , W ang et al. , 2025c , Fu et a l. , 2025b ). O ur use o f RL is orthogonal: we apply it to input-side perceptio n control —learning frame-lev el visu al allocati ons under an explicit accuracy–cost trade-o ff—rather than output-side rea soning policies. CAPO is designed for this setting, where naive cost penalties driv e the policy to a degenerate low-b udget solution. 6. Conclu sio n W e study Input-side adaptatio n through R esAdapt, a framework that shifts part of the efficien cy b urden from post-en coding token compressi on to pre-encoding visual budget control. A light weight Allocator , trained with C ost-A ware Poli cy Optimi zation ( C APO) and temporal-similarit y regulariz atio n, predicts per-frame all ocatio ns before visual encoding, and the do wnstream backbon e contin ues to operate on its n ativ e token interface. Empirica lly , the framework is mo st convin cing in lo w-visual-token video QA and in one reasoning- augmented long-context grounding regime where sav ed spatial compute is reinv ested as temporal co v erage. The learn ed policy is sparse and content-dependent, b ut it remains open-loop: once the initial allocati ons are set, the model cannot reco v er missed evidence within the same pass. More broad ly , the results suggest that pre-encoding allocati on is a promising directio n for long-co ntext video rea soning, while the present evidence remains specific to the resi ze inst antiation studied here and transfers beyo nd the training domain only unev enly . 17 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning R ef erences Saeed Ranjbar Alvar , Gursimran Singh, Mohammad Akbari, and Y ong Z hang. Divprune: Diversity-based visual token pruning for l arge m ultimoda l models. In Proceedings of the Computer Visio n and P attern R ecogniti on Conf erence , pa ges 9392–9401, 2025. Shuai Bai, Y uxuan Cai, Ruizhe Chen, Keqin Chen, Xi onghui Chen, Zesen Cheng, Lianghao Deng, W ei Ding, Chang Gao, Chunji ang Ge, W enbin Ge, Zhif ang Guo, Q idong Huang, Jie Huang, F ei Huang, Binyuan Hui, S hutong Ji ang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiaw ei Liu, Chenglong Liu, Y ang Liu, Da yiheng Liu, Shixuan Liu, Dunjie Lu, R uilin Luo, Chenxu Lv , Rui Men, Lingchen Meng, Xuancheng R en, Xingzhang R en, Sibo S ong, Y u chong Sun, Jun T ang, Ji anhong Tu, Jianqiang W an, Peng W ang, P engfei W ang, Qiuyue W ang, Y uxuan W ang, Tianbao Xie, Yiheng Xu, Haiyang Xu, Jin Xu, Zhibo Y ang, Mingkun Y ang, Jianxin Y ang, An Y ang, Bow en Y u, F ei Zhang, H ang Zhang, Xi Zhang, Bo Z heng, Humen Zhong, Jingren Z hou, F an Z hou, Jing Z hou, Y uanzhi Z hu, and Ke Z hu. Qw en3-vl technica l report, 2025a. URL . Shuai Bai, Keqin Chen, Xuejing Liu, Jia lin W ang, W enbin Ge, Sibo S ong, Kai Dang, Peng W ang, Shijie W ang, Jun T ang, et al. Qwen2. 5-vl technical report. arXiv preprint , 2025b. Dani el Bolya, Cheng- Y ang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph F eichtenho f er , and Judy Ho ffman. T oken merging: Y our vit but f aster . arXiv preprint , 2022. Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is w orth 1/2 tokens after l ayer 2: Plug-and-play inference acceleration for large vision-language models. In European C onf erence on Computer Visi on , pages 19–35. Springer , 2024. Y ukang Chen, W ei Huang, Baif eng Shi, Qinghao Hu, Hanrong Y e, Ligeng Z hu, Zhijian Liu, P a vlo Molchan o v , J an Kautz, Xi aojuan Qi, et al. Scaling rl to long videos. arXiv preprint , 2025. Zeyuan Chen, Kai Zhang, Zhuo w en Tu, and Y uanjun Xi ong. Soft tail-dropping f or adaptiv e visu al tokeniz ation. arXiv preprint arXiv:2601.14246 , 2026. T ri Dao. Fl as hAttention-2: F aster attentio n with better parallelism and work partitio ning. In Intern atio nal Conferen ce on L earning R epresentations , 2024. Caba Heilbron F abian, Vi ctor Escorcia, Bernard Ghan em, and Juan Carlos Ni ebl es. Activit ynet: A l arge-scal e video benchmark for human activit y underst anding. In Proceedings of the ieee conf erence on computer visi on and pattern recognitio n , pa ges 961–970, 2015. Ziyang F an, K eyu Chen, R uilo ng Xing, Y ulin Li, Li Jiang, and Zhuot ao T ian. Fl as hvid: Effici ent video large lan- guage m odels vi a training-free tree-based spati otemporal token merging. arXiv preprint , 2026. Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing W ang, Tianshu o Peng, Junfei Wu, Xi aoying Zhang, Benyo u W ang, and Xi angyu Y u e. Video-r1: R einforcing video reaso ning in mllms. arXiv preprint arXiv:2503.21776 , 2025. Chaoy ou Fu, Yuhan Dai, Y ongdong Luo, L ei Li, Shuhuai R en, R enrui Zhang, Zihan W ang, Chenyu Z hou, Y unhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensiv e evaluati on benchmark of m ulti-moda l llms in video an aly sis. In Proceedings of the Computer Visio n and P attern R ecogniti on C onf erence , pa ges 24108–24118, 2025a. 18 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning Shenghao Fu, Qiz e Y ang, Y uan-Ming Li, Xihan W ei, Xiaohua Xie, and W ei-S hi Zheng. L ov e-r1: Advancing lo ng video underst anding with an ada ptive zoom-in mechanism via m ulti-step reaso ning. arXiv preprint arXiv:2509.24786 , 2025b. T ianyu Fu, T engxuan Liu, Qinghao Han, Guohao Dai, Shengen Y an, Hu azhong Y ang, Xuefei Ning, and Y u W ang. Framef usion: Combining simil arit y and import ance for video token reducti on on l arge visio n language models. arXiv preprint , 2024. Jiyang Gao, Chen Sun, Zhenheng Y ang, and Ram Nev atia. T all: T empora l activit y localizatio n via l anguage query . In Proceedings of the I EEE international conf erence on computer visio n , pa ges 5267–5275, 2017. Da ya Guo, Dejian Y ang, Haow ei Z hang, Junxiao Song, R uoyu Z hang, R unxin Xu, Qihao Z hu, Shirong Ma, P eiyi W ang, Xiao Bi, et al. Deepseek-r1: Incentivizing reaso ning capa bilit y in llms via reinf orcement learning. arXiv preprint , 2025a. W eiyu Gu o, Ziyang Chen, Shaoguang W ang, Jianxiang He, Y ijie Xu, Jinhui Y e, Y ing Sun, and Hui Xi ong. L ogic- in-frames: Dyn amic keyframe search via visu al semantic-logi cal verificati on for long video understanding. arXiv preprint arXiv:2503.13139 , 2025b. Zefeng He, Xiaoye Q u, Y afu Li, Siyu an Huang, Daizong Liu, and Y u Cheng. Framethinker: L earning to think with lo ng videos vi a m ulti-turn frame spotlighting. arXiv preprint , 2025. J ack Ho ng, Chenxiao Zhao, ChengLin Zhu, W eiheng Lu, Guohai Xu, and Xing Y u. Deepeyesv2: T o ward a gentic multim odal model. arXiv preprint , 2025. Kairui Hu, P enghao W u, F anyi Pu, W ang Xiao, Y uanhan Zhang, Xiang Y ue, Bo Li, and Z iw ei Liu. Video- mmm u: Ev aluating kno wledge acquisition from m ulti-discipline pro fessi onal videos. arXiv preprint arXiv:2501.13826 , 2025. Xiaohu Huang, Hao Z hou, and Kai Han. Prunevid: Visua l token pruning f or effici ent video large l anguage m odels. In Findings o f the Associatio n for C omputationa l Linguistics: A CL 2025 , pa ges 19959–19973, 2025. Jeongseok Hyun, Sukjun Hwang, Su Ho Han, T aeoh Kim, In woo ng L ee, Dongy oo n W ee, Joon- Y oung L ee, Seon Joo Kim, and Minho Shim. Multi-gran ular spati o-temporal token merging for training-free acceleratio n o f video llms. In Proceedings o f the I EEE/C VF Internatio nal Conferen ce on Computer Visi on , pages 23990– 24000, 2025. Anirudd ha Kemb havi, Mike Salv ato, E ric Kolv e, Minjoon Seo, Hannaneh Hajishirzi, and Ali F arhadi. A diagram is worth a dozen images. In European conferen ce on computer vision , pa ges 235–251. Springer , 2016. Samir Khaki, Junxian Guo, Jiaming T ang, S hang Y ang, Y ukang Chen, Konstantinos N Plataniotis, Y ao Lu, Song H an, and Z hijian Liu. S parsevil a: Decoupling visual sparsit y f or efficient vlm inferen ce. In Proceedings o f the I EEE/C VF Internationa l Conferen ce on C omputer Visio n , pa ges 23784–23794, 2025. W oosuk Kw on, Z huohan Li, Siyu an Zhu ang, Y ing Sheng, Lianmin Zheng, C ody Hao Y u, Joseph E. Gonzalez, Hao Zhang, and Io n Stoi ca. Effici ent mem ory mana gement for large language model serving with pa gedattentio n. In Proceedings o f the A CM SIGOPS 29th S ymposium on Operating Systems Principles , 2023. Jialu o Li, Bin Li, Jiahao Li, and Y an Lu. Divide, then ground: Adapting frame selectio n to query t ypes for lo ng-form video underst anding. arXiv preprint , 2025a. 19 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning Xinhao Li, Zi ang Y an, Desen Meng, Lu Dong, Xiangyu Zeng, Y inan He, Y ali W ang, Y u Qiao, Y i W ang, and Limin W ang. Videochat-r1: Enhancing spatio-tempora l perception via reinforcement fine-tuning. arXiv preprint arXiv:2504.06958 , 2025b. Hao Liang, Jiapeng Li, Tianyi Bai, Xijie Huang, Linzhuang Sun, Z hengren W ang, Conghui He, Bin Cui, Chong Chen, and W entao Zhang. Keyvideollm: T o wards large-scale video keyframe selection. arXiv preprint arXiv:2407.03104 , 2024. Jiaheng Liu, Da wei Zhu, Zhiqi Bai, Y ancheng He, Huanxuan Liao, Haoran Q ue, Zekun W ang, Chenchen Zhang, Ge Z hang, Jiebin Z hang, et al. A comprehensiv e surv ey on lo ng context language m odeling. arXiv preprint arXiv:2503.17407 , 2025a. Shuming Liu, Mingchen Z huge, Changsheng Zhao, Jun Chen, Lemeng W u, Zechun Liu, Chenchen Zhu, Zhipeng Cai, Cho ng Zhou, H aozhe Liu, et al. Videoauto-r1: Video auto reasoning via thinking once, answ ering t wice. arXiv preprint , 2026. Y uliang Liu, Zhang Li, Mingxin Hu ang, Biao Y ang, W enw en Y u, Chunyu an Li, Xu-Cheng Y in, Cheng-Lin Liu, Lianw en Jin, and Xiang Bai. Ocrbench: on the hidden mystery of ocr in l arge multim oda l models. Scien ce China Informati on S cien ces , 67(12):220102, 2024. Zhijian Liu, Ligeng Z hu, Baifeng Shi, Z huoyang Z hang, Y uming L ou, Shang Y ang, H aocheng Xi, Shiyi Cao, Y uxian Gu, Dacheng Li, et al. Nvila: Effici ent frontier visu al l anguage models. In Proceedings of the Computer Visio n and P attern R ecogniti on C onf erence , pages 4122–4134, 2025b. Zichen Liu, Changyu Chen, W enjun Li, Penghui Qi, Tianyu P ang, Chao Du, W ee Sun L ee, and Min Lin. U nderst anding r1-zero-like training: A critical perspectiv e. arXiv preprint , 2025c. P an Lu, H ritik Bansal, T ony Xia, Jiacheng Liu, Chunyuan Li, Hann aneh Hajishirzi, Hao Cheng, Kai- W ei Chang, Michel Galley , and Jianfeng Gao. Mathvista: Ev aluating mathematica l reaso ning o f fo undation m odels in visual contexts. arXiv preprint , 2023. Andrés Marafi oti, Orr Zohar , Miquel F arré, Merv e Noyan, Elie Ba kouch, Pedro Cu enca, Cyril Zakka, Loubn a Ben All al, Anton L ozhko v , No uamane T azi, et al. Smolvlm: Redefining small and effici ent m ultimoda l m odels. arXiv preprint , 2025. Ahmed Masry , Xuan L ong Do, Jia Qing T an, Shafiq Jot y , and En am ul Hoqu e. Chartqa: A benchmark for questi on answering abo ut charts with visual and logical reaso ning. In Findings of the a ssociation f or computationa l linguistics: A CL 2022 , pages 2263–2279, 2022. Jeff Ra sley , Samyam Rajbhandari, Ol atunji R uwa se, and Y uxi ong He. Deepspeed: Sy stem optimiz atio ns enab le training deep learning models with o ver 100 billio n parameters. In Proceedings of the 26th A CM SIGKD D intern atio nal conf erence on kno wledge discov ery & dat a mining , pa ges 3505–3506, 2020. Y uzhang Shang, Mu Cai, Bingxin Xu, Y ong Jae L ee, and Y an Y an. Ll av a-prumerge: Adaptiv e token red ucti on for effici ent l arge m ultim odal models. In Proceedings of the I EEE/CVF International Conferen ce on C omputer Visi on , pages 22857–22867, 2025. Kel e Shao, Keda T ao, Can Qin, Haoxuan Y ou, Y ang Sui, and Huan W ang. Holitom: Holistic token merging for fast video large l anguage models. arXiv preprint , 2025a. 20 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning Kel e Shao, Keda T ao, Kejia Z hang, Sicheng F eng, Mu Cai, Yuzhang Shang, Haoxuan Y ou, Can Q in, Y ang Sui, and Hu an W ang. When tokens t alk too m uch: A survey of multim oda l lo ng-context token compressio n across images, videos, and audi os. arXiv preprint , 2025b. Zhihong Shao, Peiyi W ang, Qihao Z hu, R unxin Xu, Junxiao Song, Xi ao Bi, Haow ei Z hang, Mingchu an Z hang, YK Li, Y ang W u, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open l anguage m odels. arXiv preprint , 2024. L eqi Shen, Guoqiang Gong, T ao He, Y ifeng Zhang, Pengzhang Liu, Sicheng Z hao, and Guiguang Ding. F a st vid: Dyn amic densit y pruning for f ast video large l anguage models. arXiv preprint , 2025a. Xiaoqian Shen, Min-Hung Chen, Y u-Chiang Frank W ang, Mohamed Elhoseiny , and R y o Hachiuma. Zoom-zero: R einf orced coarse-to-fine video understanding via temporal zoom-in. arXiv preprint , 2025b. Guangming S heng, Chi Zhang, Zilingfeng Y e, Xibin Wu, W ang Zhang, R u Zhang, Y anghu a Peng, Haibin Lin, and Chu an W u. Hybridflo w: A flexib le and efficient rlhf framew ork. In Proceedings o f the Tw entieth European C onf erence on Computer Sy stems , pa ges 1279–1297, 2025. Y an Shu, Z heng Liu, Peitian Z hang, Minghao Q in, Junjie Zhou, Zhengyang Liang, T iejun Huang, and Bo Zhao. Video-xl: Extra-lo ng vision language model f or hour-scal e video understanding. In Proceedings o f the Computer Visio n and P attern R ecogniti on C onf erence , pages 26160–26169, 2025. Amanpreet Singh, Viv ek Nat arajan, Meet Sha h, Y u Ji ang, Xinlei Chen, D hruv Batra, Devi P arikh, and Marcus R ohrbach. T o wards vqa m odels that can read. In Proceedings of the I EEE/C VF conferen ce on computer visio n and pattern recognitio n , pa ges 8317–8326, 2019. Mingyang S ong, H aoyu Sun, Jiaw ei Gu, Linjie Li, Luxin Xu, Ranjay Krishna, and Y u Cheng. Adarea soner: Dynamic tool orchestration for iterative visual reaso ning. arXiv preprint , 2026. Guangyu Sun, Archit Singhal, Burak U zkent, Mubarak Sha h, Chen Chen, and Garin Kess ler . From frames to clips: T raining-free ada ptive key clip selectio n f or lo ng-form video underst anding. arXiv preprint arXiv:2510.02262 , 2025. Xi T ang, Jihao Qiu, Lingxi Xie, Y unjie Tian, Jianbin Jiao, and Qixiang Y e. Adaptiv e keyframe sampling for lo ng video underst anding. arXiv preprint , 2025. Keda T ao, Can Qin, Haoxuan Y ou, Y ang Sui, and Huan W ang. Dycoke: Dynamic compressio n of tokens f or fast video l arge language models. In Proceedings of the Computer Visio n and P attern R ecogniti on C onf erence , pa ges 18992–19001, 2025. Haozhe W ang, Alex Su, W eiming R en, F angzhen Lin, and W enhu Chen. P ixel rea soner: Incentivizing pixel-space reasoning with curiosit y-driv en reinforcement learning. arXiv preprint , 2025a. W eihan W ang, Zehai He, W enyi Hong, Y ean Cheng, Xiaohan Z hang, Ji Q i, Ming Ding, Xi aotao Gu, Shiyu Huang, Bin Xu, et al. L vbench: An extreme long video understanding benchmark. In Proceedings of the I EEE/C VF Internationa l Conferen ce on C omputer Visio n , pa ges 22958–22967, 2025b. Xingyao W ang, Y angyi Chen, Lifan Yuan, Yizhe Zhang, Y unzhu Li, Hao Peng, and Heng Ji. Execut ab le code actio ns elicit better llm agents. In F ort y -first Internationa l Conferen ce on Machine Learning , 2024. 21 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning Y e W ang, Z iheng W ang, Bos hen Xu, Y ang Du, Kejun Lin, Zihan Xiao, Zihao Yu e, Jianzhong Ju, Li ang Zhang, Dingyi Y ang, et al. Time-r1: Post-training large visio n l anguage m odel f or temporal video grounding. arXiv preprint arXiv:2503.13377 , 2025c. Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. L ongvideoben ch: A benchmark for long-co ntext interleav ed video-language understanding. Advances in Neura l Informati on Processing S ystems , 37:28828–28857, 2024. Junbin Xiao, Angela Y ao, Yi cong Li, and T at-Seng Chua. Can i trust y our answer? visually grounded video questi on answering. In Proceedings of the I EEE/CVF Conference on C omputer Visi on and P attern R ecogniti on , pa ges 13204–13214, 2024. Long Xing, Qidong Huang, Xiaoyi Dong, Ji ajie Lu, Pan Z hang, Y uhang Zang, Y uhang Cao, Conghui He, Ji aqi W ang, Feng Wu, et al. Pyramiddrop: Accelerating yo ur large vision-langua ge m odels via pyramid visual red undancy reducti on. arXiv preprint , 2024. R uyi Xu, Guangxu an Xiao, Y ukang Chen, Liuning He, Kelly Peng, Y ao Lu, and Song Han. Streamingvlm: R ea l-time underst anding for infinite video streams. arXiv preprint , 2025. Biao Y ang, Bin W en, Boyang Ding, Changyi Liu, Chenglong Chu, Chengru Song, Chongling Rao, Chuan Yi, Da Li, Dunju Zang, et al. Kwai keye-vl 1.5 technica l report. arXiv preprint , 2025a. Cheng Y ang, Y ang Sui, Jinqi Xiao, Lingyi Huang, Y u Gong, Chendi Li, Jinghua Y an, Y u Bai, P onn uswamy Sadaya ppan, Xia Hu, et a l. T opv: Compatib le token pruning with inferen ce time optimiz atio n f or fast and low-mem ory multim oda l visio n language model. In Proceedings o f the C omputer Visio n and P attern R ecogniti on Conf erence , pa ges 19803–19813, 2025b. Senqiao Y ang, Y ukang Chen, Zhuotao Tian, Chengyao W ang, Jingyao Li, Bei Y u, and Jiaya Jia. Visio nzip: Longer is better but not necessary in visio n language models. In Proceedings of the I EEE/C VF Conferen ce on Computer Visio n and P attern R ecogniti on , pages 19792–19802, 2025c. Zuhao Y ang, Sudong W ang, Kaichen Zhang, Keming Wu, Sicong L eng, Y if an Z hang, Bo Li, Chengw ei Qin, Shijian Lu, Xingxuan Li, and Lidong Bing. Longvt: Incentivizing "thinking with long videos" via n ativ e tool calling. arXiv preprint , 2025d. Qiying Y u, Zheng Zhang, R u of ei Zhu, Y uf eng Y uan, Xiaochen Zu o, Y u Y ue, W ein an Dai, Tiantian F an, Gaohong Liu, Ling jun Liu, et al. Dapo: An open-source llm reinf orcement learning system at scal e. arXiv preprint arXiv:2503.14476 , 2025. Xiang Y ue, Y uansheng Ni, Kai Zhang, Tianyu Z heng, R uoqi Liu, Ge Zhang, Samu el Stev ens, Dongfu Jiang, W eiming R en, Y uxuan Sun, et al. Mmm u: A massiv e multi-disciplin e multim odal understanding and reaso ning benchmark for expert a gi. In Proceedings o f the I EEE/CVF Conference on Computer Visi on and P attern R ecognition , pages 9556–9567, 2024. Boqiang Zhang, L ei Ke, R uihan Y ang, Qi Gao, T ianyu an Qu, R o ssell Chen, Dong Yu, et al. Penguin-vl: Exploring the effici ency limits of vlm with llm-based vision encoders. arXiv preprint , 2026. Ce Zhang, Kaixin Ma, Tianqing F ang, W enhao Yu, Hongming Z hang, Zhisong Zhang, Y aqi Xie, Katia S ycara, Hait ao Mi, and Do ng Y u. Vscan: R ethinking visual token redu ctio n f or effici ent large visio n-l anguage m odels. arXiv preprint , 2025a. 22 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning Congzhi Zhang, Z hibin W ang, Y inchao Ma, Ji aw ei Peng, Y ihan W ang, Qiang Z hou, Jun S ong, and Bo Z heng. R ewatch-r1: Boosting complex video rea soning in large vision-language models through a gentic dat a synthesis. arXiv preprint , 2025b. Kaichen Z hang, Bo Li, Peiyuan Zhang, F anyi P u, Jo shua Adrian Cahy on o, Kairui Hu, Shuai Liu, Y uanhan Zhang, Jingkang Y ang, Chunyu an Li, and Ziw ei Liu. Lmms-eval: R ea lit y check on the evaluati on of l arge m ultimoda l m odels, 2024a. URL . Qizhe Z hang, A osong Cheng, Ming Lu, R enrui Zhang, Zhiyong Zhuo, Jiajun Cao, Shaobo Guo, Qi She, and Shanghang Zhang. Bey ond text-visual attentio n: Exploiting visu al cues for effectiv e token pruning in vlms. In Proceedings o f the I EEE/C VF Internationa l Conferen ce on Computer Visi on , pa ges 20857–20867, 2025c. Shaoji e Zhang, Jiahui Y ang, Jianqin Y in, Z henbo Luo, and Jian Lu an. Q -frame: Q uery-a ware frame selection and m ulti-resolutio n adaptation for video-llms. arXiv preprint , 2025d. Y i-F an Zhang, Xingyu Lu, Shukang Y in, Chaoyo u Fu, W ei Chen, Xi ao Hu, Bin W en, Kaiyu Jiang, Changyi Liu, T ianke Z hang, et a l. Thyme: Think bey ond images. arXiv preprint , 2025e. Y uan Z hang, Chun-Kai F an, Junpeng Ma, W enzhao Zheng, T ao Huang, Kuan Cheng, Denis Gudo vskiy , T o moyuki Okuno, Y ohei Nakata, K urt Keutzer , et al. Sparsevlm: Visua l token sparsificatio n for efficient visio n-langu a ge model inferen ce. arXiv preprint , 2024b. Shitian Z hao, Haoqu an Zhang, Shaoheng Lin, Ming Li, Qilong Wu, Kaipeng Zhang, and Chen W ei. Pyvisio n: Agentic vision with dynamic tooling. arXiv preprint , 2025a. Y ilun Zhao, H ao wei Z hang, Lujing Xie, T ongyan Hu, Guo Gan, Yitao L ong, Zhiyuan Hu, W eiyuan Chen, Chuhan Li, Zhijian Xu, et a l. Mmvu: Measuring expert-lev el multi-discipline video understanding. In Proceedings o f the Computer Visi on and P attern R ecogniti on C onf erence , pages 8475–8489, 2025b. Chujie Z heng, Shixuan Liu, Mingz e Li, Xio ng-Hui Chen, Bo wen Y u, Chang Gao, Kai Dang, Yu qio ng Liu, R ui Men, An Y ang, et al. Group sequence policy optimiz atio n. arXiv preprint , 2025a. Lianmin Zheng, Liangsheng Y in, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Y u, Shiyi Cao, Christos Ko zyrakis, Ion Stoica, Joseph E. Gonzalez, Cl ark Barrett, and Y ing Sheng. S GLang: Effici ent executio n of structured l anguage model programs. In Advances in Neural Informati on Processing Systems , 2024. Ziw ei Zheng, Michael Y ang, Jack Hong, Chenxiao Z hao, Guohai Xu, Le Y ang, Chao Shen, and Xing Y u. Deep- eyes: Incentivizing" thinking with images" via reinforcement learning. arXiv preprint , 2025b. Junjie Z hou, Y an Shu, Bo Zhao, Boya Wu, Z hengyang Liang, Shitao Xiao, Minghao Qin, Xi Y ang, Y ongping Xio ng, Bo Zhang, et al. Mlvu: Benchmarking multi-tas k long video underst anding. In Proceedings o f the I EEE/C VF Conferen ce on Computer Visi on and P attern R ecognitio n , pa ges 13691–13701, 2025. Zirui Zhu, H ailun Xu, Y ang Luo, Y ong Liu, Kanchan Sarkar , Zhenheng Y ang, and Y ang Y ou. Focu s: Efficient keyframe selecti on for long video understanding. arXiv preprint , 2025. Y uanhao Zou, Sheng ji Jin, Andong Deng, Y oupeng Zhao, Jun W ang, and Chen Chen. Air: Ena bling adapti ve, iterative, and reaso ning-based frame selectio n for video questi on answering. arXiv preprint arXiv:2510.04428 , 2025. 23 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning Limit ati ons and f uture work. R esAda pt improv es the efficien cy–accuracy trade-off for long-video MLLMs, but the current evidence is still bounded by four concrete design choices. ( i) Front-end o verhead is amortized only in the lo ng-context regime. The Allocator adds a fixed pre-encoding cost—coarse visu al encoding, cross-frame f usion, and distributi on predicti on—bef ore any backbon e savings are realized. When the sequence is short ( T ≤ 32 ), this constant ov erhead can offset a meaningf ul fractio n o f the do wnstream attentio n redu ctio n, so the clearest wa ll-clock gains appear only when temporal context is long (S ec. 4.3 ). R ed ucing this fixed cost through cached video features, cheaper front-ends, or distilled all ocatio n rules is therefore an important next step. ( ii) Allocati on is limited by coarse visual evidence. The Allocator observ es frozen coarse features f t ∈ R D rather than the f ull high-resolutio n frame. This is sufficient to detect broad redundan cy and scene structure, but it is w eaker on small text, subtle objects, and brief answer-criti cal cues embedded in otherwise simple frames (Figure 20 ). Multi-scal e conditi oning, moti on-a ware features, or light w eight loca l refinement wo uld help close this gap without giving up the speed advantage of the current front-end. ( iii) T he present study validates the framew ork through one video-centric inst antiation. Our f ormulati on is genera l input-side adaptation, b ut the experiments inst antiate the operator with resi zing and train the policy primarily on video tasks. As a result, transfer beyond this regime is uneven: the learned policy sometimes recognizes ima ge inputs that need more fidelit y , yet it does n ot deliver unif ormly efficiency-preserving gains on st atic-ima ge benchmarks (T ab le 7 ). Extending training to mixed image–video dat a and alternativ e operators such as hard frame selectio n remains open. ( iv) Allocati on is open-loop rather than rea soning-a ware. All budget decisio ns are committed before the backbon e processes any visual token. The policy therefore cannot revise a mist aken low-resoluti on choice after partial reaso ning or uncertaint y signals emerge. A natural extension is closed-l oop all ocation, where early backbon e st ates trigger re-encoding, budget revisio n, or a second visu al pass only when needed. So ft ware and Data The code f or this paper is availa bl e at: https://github.com/Xnhyacinth/ResAdapt A. Implementatio n Det ails A.1. Training Data Data Compositio n. W e build the training set from the difficult y-filtered dat a o f VideoA uto-R1 ( Liu et al. , 2026 ), keeping only image and video samples and discarding pure-text examples. T o improv e cov era ge of visually demanding subdomains, we additiona lly sample 16,500 video instances from Video-R1 ( F eng et al. , 2025 ), focu sing on OCR, free-f orm Q A, and regressio n-st yle t asks. The merged pool contains approximately 93.4K training samples. W e manually rem ov e all evaluatio n examples from our benchmark suite to av oid lea kage. 24 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning A.2. Training Configuratio n U nless otherwise noted, training runs for on e epoch with globa l batch size 128 and AdamW . The learning rate is 2 × 10 − 5 for the Allocator and 1 × 10 − 6 for the backbon e, with w eight decay 0.01 and gradi ent clipping at 1.0 . W e set the maximum video token b udget to 8,192 , use T = 128 frames during training, and allo w scal es in the range [ s min , s max ] = [ 0.2, 1.8 ] , which permits both downsca ling and selectiv e upscaling. CAPO samples M = 16 all ocatio n trajectories per prompt and N = 1 rollout per trajectory . T raining is cond ucted on 32 H100 GPU s with V eRL ( S heng et al. , 2025 ), DeepSpeed ( Ras ley et al. , 2020 ), and vLLM ( Kwo n et al. , 2023 ). Eva luation uses lmms-eva l ( Zhang et al. , 2024a ); unless st ated otherwise, we cap respo nse length at 256 tokens and increase it to 4,096 for reaso ning models. A.3. R eward Design W e provide f ull det ails complementing Sec. 3.3 . The base sca lar reward R task m , n is task-specifi c; efficien cy enters later through CAPO advantage shaping rather than through a ra w additiv e reward term. Base Ta s k R eward ( R tas k m , n ). W e consider fo ur task t ypes: • Questi on Answ ering. For math problems, we extract the numeric answer and compare it to the ground truth within a toleran ce of 10 − 2 . F or multipl e-choice questio ns, w e extract the option letter . F or other Q A t asks, we compare norma lized strings ( e.g. , case-f olded, whitespace-stripped). This yields the binary reward R Q A ( ˆ o , o ) ∈ { 0, 1 } . • Free-form Generati on. F or open-ended t asks, w e compute the R O UGE-L score bet w een the generated answ er ˆ o and the reference o : R Gen ( ˆ o , o ) = R O U GE-L ( ˆ o , o ) ∈ [ 0, 1 ] . • T emporal Grounding. L et the ground-truth segments be G = { [ s j , e j ] } j and the predicted segments be G = { [ ˆ s k , ˆ e k ] } k ( each set may contain one or multiple intervals). W e compute the temporal IoU and select the best-matching pair: R TG ( G , G ) = max [ ˆ s , ˆ e ] ∈ G , [ s , e ] ∈G tIoU ( [ ˆ s , ˆ e ] , [ s , e ] ) ∈ [ 0, 1 ] . If no valid segment can be parsed from the output, w e assign R TG ( G , G ) = 0 . • Grounding QA. W e parse both the textu al answer and the predicted temporal segments from the m odel output, compute R Q A ( ˆ o , o ) and R TG ( G , G ) , and sum them: R GQ A ( ˆ o , G ; o , G ) = R Q A ( ˆ o , o ) + R TG ( G , G ) ∈ [ 0, 2 ] . These task-specifi c metrics define the scalar base reward R task m , n . C APO additio nally uses a binary success indicator u m , n ∈ { 0, 1 } : for exact-match Q A tasks we use the bin ary correctness outcome directly , whereas for contin uou s metrics (R O UGE-L, temporal Io U , and their grounding-Q A combinatio n) w e threshold the scalar score at 0.35 , matching the implementation. When format validati on is en ab led, a w eighted format term is added before GRPO norma lization, but u m , n is computed from the task metric al one. 25 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning T ab le 6: Prompt template used for CAPO training. The template presents video frames and the task questio n, requires intermediate reasoning inside tags, and pl aces the final answ er in \boxed{} within tags. This structure enab les aut omatic reward extracti on from MLLM outputs. Prompt T empl ate f or Training with Thinking S ystem Prompt: Y ou are a helpf ul a ssist ant. Y ou FI RST think about the reasoning process as an internal m onol ogue and then provide the fin al answ er . The reaso ning process MUST BE enclo sed within tags and the answ er MUST BE encl osed within tags. The final answer MUST BE put in \boxed{} and the \boxed{} expressio n MUST BE contained entirely within the tags. Do not include any reasoning or expl anations outside these t ags. F ormat R eward. W e employ a binary format reward R fmt ( ˆ o ) ∈ { 0, 1 } enforced vi a strict regex validati on. The output must contain exactly one ... b lock and one ... b lock, with the final answer enclosed in \\boxed{...} within the tags: R fmt ( ˆ o ) = 1 if f ormat matches regex, 0 otherwise. In the implement atio n, malf ormed outputs receive a penalt y before weighting, and the format term enters the scalar reward with weight 0.2 . A.4. Prompt T empl ate W e employ the standard prompt for GRPO training, sho wn in T ab le 6 . The m odel generates a reaso ning trace within tags ( optio nal f or R esAdapt since rea soning is hand led by the MLLM π ϕ , b ut maint ained for compatibilit y with rea soning-ba sed baselin es), foll ow ed by the final answ er enclo sed in \\boxed{} . B. Complexit y An aly sis W e deriv e forma l computational bounds for R esAda pt to clarif y when Allocator ov erhead is negligib le rel ativ e to the savings induced in the backbon e. F or readabilit y , w e assume a st andard T ransf ormer backbon e with quadratic self-attenti on and a uniform native resolution H × W o ver T frames; the extensio n to heterogeneous resolutio ns is immediate by replacing H W with per-frame prod ucts H t W t . Baselin e cost. L et P denote the ViT patch siz e. A vanilla MLLM encoding T frames at f ull resoluti on incurs a total visual token count o f: N 0 = T · H P W P ≈ T H W P 2 . (26) 26 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning Adapti ve cost and token retenti on ratio. F or the resize inst antiation an alyzed in this paper , frame f t is rescal ed by f actor s t ∈ [ s min , s max ] , producing n t ( s t ) = ⌈ s t H / P ⌉ ⌈ s t W / P ⌉ ≈ s 2 t · H W / P 2 tokens. Summing o ver the sequence and norma lizing by N 0 yields the token retentio n ratio : N adapt = T t = 1 n t ( s t ) ≈ H W P 2 T t = 1 s 2 t , ρ ≜ N adapt N 0 = 1 T T t = 1 s 2 t . (27) Because the learn ed Beta policy pl aces m ost redundant frames near s min (Figure 5 ), ρ is much small er than 1 in practice; across our evaluati on suite, ρ ∈ [ 0.06, 0.16 ] . Quadratic FLOP s red uctio n. F or an L mllm -layer MLLM with hidden dimension D mllm , self-attenti on cost scal es quadratically in the visual sequen ce length: Φ ( N ) = O ( L mllm N 2 D mllm ) . Substituting N adapt = ρ · N 0 giv es: Φ adapt mllm = O L mllm · ρ 2 N 2 0 · D mllm , (28) a red ucti on by a f actor o f ρ 2 relative to f ull-resolutio n processing. At the represent ativ e operating point ρ = 0.11 , w e obtain ρ 2 ≈ 0.012 , corresponding to roughly 83 × fewer backbone attentio n FLO Ps. Allocator o verhead. The Allocator processes N c = T · ⌈ H / P c ⌉ ⌈ W / P c ⌉ coarsely pooled tokens across L pred layers with dimension D pred , where P c ≫ P is the coarse spatial stride. Its cost and relative ov erhead are: Φ pred = O L pred · N 2 c · D pred , Φ pred Φ base mllm = O L pred D pred L mllm D mllm · P P c 4 ≪ 1. (29) Substituting our implementatio n parameters ( P c = 14 , L pred = 4 , D pred = 1,024 v ersus L mllm = 28 , D mllm = 3,584 ), the Allocator accounts for less than 3% of inference FLO Ps. The decisio n stage is therefore sma ll compared with the backbon e computation it helps eliminate. Net s peed up. Combining the abo v e under the first-order approximatio n Φ base mllm ≫ Φ pred : Speedup ≈ Φ base mllm Φ adapt mllm + Φ pred ≈ N 2 0 ( N adapt ) 2 = 1 ρ 2 . (30) At ρ = 0.11 , this a gain yields a theoretical redu ctio n of roughly 83 × in backbone attention computation. T emporal context scaling. The same savings admit a second interpret atio n in terms o f temporal co verage . U nder a fixed token budget B , a vanilla MLLM can process only T 0 = B P 2 / ( H W ) f ull-resolutio n frames, whereas the resize inst antiation of R esAdapt used in our experiments can process T 0 / ρ adapti vely resiz ed frames. This yields an effectiv e 1/ ρ ≈ 6 – 16 × increa se in temporal hori zon at compara bl e compute, which is exactly the trade-o ff explo ited by the long-co ntext experiments in Sec. 4.2 . R emark ( accelerati on trans paren cy). A practica l consequence o f Input-side adaptatio n is that the backbone still receiv es an ordinary visu al-t oken sequence, only shorter . As a result, R esAdapt remains compatibl e with optimiz ed attention st acks such as FlashAttenti on, vLLM ( Kwo n et al. , 2023 ), and S GLang ( Z heng et al. , 2024 ) without kernel-l evel modifi catio ns. By contrast, model-side pruning and merging o ften create irregular token l ay outs that are harder to route through the same optimiz ed kernels and may require fallback implementations or architecture-specific engineering. 27 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning C. Derivati on of Jo int RL F orm ul atio n This appendix collects derivatio ns omitted from S ec. 3 for space and clarifies how the one-step contextual MD P ( Contextua l Bandit) introdu ced in Sec. 2.2 motiv ates the practica l surrogate objectives optimiz ed by R esAdapt. All derivati ons are stated for a single context (video and query); the f ull objective is the expectation ov er the dat aset D . Notatio n. The prompt context is x = ( q , V ) . The Allocator first samples l atent acti ons a from a Bet a policy q θ ( a | x ) (Sec. 3.2 ); the contin uo us allocati on s is the deterministic ima ge of a under Eq. ( 10 ) , and π θ ( s | x ) denotes the ind uced densit y (pushforw ard). A deterministic transformati on constructs the operator-transf ormed input ˜ x = ( q , { O ( f t , s t ) } T t = 1 ) ; in the experiment al inst antiation, O is bilinear resi zing. The MLLM backbone policy π ϕ ( y | ˜ x ) then samples a full response rollout y = ( r , o ) , where r is the reasoning trace and o is the final answer . C.1. One-Step Contextual MD P and the Jo int Objective As defined in S ec. 2.2 , the system is a on e-step contextual MDP . In this setting, there are no sequentia l state transitions across time steps t ; the episode terminates after the allocati on s is sampled and the correspo nding rollout y is produced. C onsequ ently , the va lue f unctio ns collapse to the immediate reward, and the standard P olicy Gradient Theorem simplifies drastica lly without requiring temporal discount factors or credit a ssignment across Markov st ates. The joint distributi on of the allocati on and the rollout f actorizes conditio nally: p θ , ϕ ( s , y | x ) = π θ ( s | x ) π ϕ ( y | ˜ x ) . (31) F or a single context with ground-truth answ er o ⋆ , the margin al answer probabilit y under the transf ormed input is p θ , ϕ ( o ⋆ | x ) = E π θ ( s | x ) E π ϕ ( r | ˜ x ) π ϕ ( o ⋆ | ˜ x , r ) . (32) Equatio n ( 32 ) is the l aw of tot al expect atio n under an autoregressiv e factori zation π ϕ ( y | ˜ x ) = π ϕ ( r | ˜ x ) π ϕ ( o | ˜ x , r ) : the inner term is the conditio nal probability (ma ss or densit y) of the ground-truth answer o ⋆ giv en the prefix r . Summing/integrating o ver r yields the marginal P ( o ⋆ | x ) only under this generativ e ordering; the subsequent RL objectiv e does not require Eq. ( 32 ) to hold in clo sed form. Because log ( · ) is m on otone, maximizing log p θ , ϕ ( o ⋆ | x ) w ould be equival ent, but the RL derivati on belo w does not require introd ucing the logarithm. It only requires a scalar utilit y eva luated after sampling ( s , y ) . W e therefore abstract the answer-qua lit y term as a rollout utilit y Q ( x , y ) , where y = ( r , o ) , and treat it as parameter-independent once the rollo ut is sampled. This is a modeling abstracti on rather than an exact reform ulatio n: when Q is chosen as an answ er-aligned t as k score, the resulting RL problem is a surrogate to likelihood maximization. This lets us define the ideal rollout reward R ideal s , y = Q ( x , y ) − λ C ( s ) , (33) and optimize the one-step expected return max θ , ϕ J ( θ , ϕ ) = E x ∼ D E π θ ( s | x ) E π ϕ ( y | ˜ x ) R ideal s , y . (34) 28 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning C.2. P olicy Gradient and Altern ating Optimiz ation Because the objectiv e inv olves t wo distinct parameteri zed policies, its gradients foll o w the score-f uncti on estimator (the likelihood-ratio / REINFO RCE identit y). This is the underlying policy-gradient structure; GRPO/PPO does not change that structure, b ut replaces the raw reward with norma liz ed advant ages and clipped surrogates for practica l optimi zation. T aking the gradient of J ( θ , ϕ ) with respect to the backbon e parameters ϕ : ∇ ϕ J ( θ , ϕ ) = E x E π θ ( s | x ) ∇ ϕ π ϕ ( y | ˜ x ) R ideal s , y d y = E x E π θ ( s | x ) E π ϕ ( y | ˜ x ) R ideal s , y ∇ ϕ log π ϕ ( y | ˜ x ) . (35) Similarly , the gradient with respect to the Allocator parameters θ relies on the marginalized reward R ideal s = E π ϕ ( y | ˜ x ) [ R ideal s , y ] : ∇ θ J ( θ , ϕ ) = E x E π θ ( s | x ) R ideal s ∇ θ log π θ ( s | x ) . (36) T o optimi ze this objectiv e with GRPO/PPO , we introdu ce importance sampling from beha vior policies π θ old and π ϕ old . A n aiv e joint importance weight π θ π ϕ π θ old π ϕ old suffers from compounded variance. W e therefore use an alternating bl ock-coordinate ascent approximati on. When updating the MLLM ( ϕ ), w e fix the Allocator to its behavi or policy ( π θ = π θ old ), making its import ance ratio exactly 1 . The off -policy surrogate gradient for ϕ becomes: ∇ ϕ J surr ( ϕ ) = E π θ old E π ϕ old π ϕ ( y | ˜ x ) π ϕ old ( y | ˜ x ) R ideal s , y ∇ ϕ log π ϕ ( y | ˜ x ) . (37) U sing the log-derivativ e identit y ∇ ϕ r ϕ = r ϕ ∇ ϕ log π ϕ where r ϕ = π ϕ / π ϕ old , this motiv ates the surrogate objectiv e: L ideal ϕ = E π θ old E π ϕ old r ϕ ( y | ˜ x ) R ideal s , y . (38) P olicy-gradient a scent on ϕ increa ses L ideal ϕ ( equiva lently , training minimi zes its negativ e); Sec. 3.4 implements the clipped PPO surrogate with advantages in pl ace o f R ideal . Con versely , when updating the Allocator ( θ ), we fix the backbon e to its behavi or policy ( π ϕ = π ϕ old ). The correspo nding ideal allocator surrogate is L ideal θ = E π θ old r θ ( s | x ) R ideal s , r θ ( s | x ) = π θ ( s | x ) π θ old ( s | x ) , (39) where R ideal s = E π ϕ old ( y | ˜ x ) [ R ideal s , y ] . In practice, this expectation is approximated by Monte Carlo rollouts under the frozen backbone. Sequential all ocator–backbon e updates within one iteratio n. The alternating derivatio n abo v e fixes on e policy while updating the other , so the import ance ratio f or the inactive policy is unit y . In implementations that first update the Allocator from θ old to θ ′ and then update the MLLM on the same rollo ut batch, trajectories are still drawn from the behavior pair ( θ old , ϕ old ) while the MLLM gradient is eva luated under ϕ at fixed 29 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning V ideoMME LongV ideoBench MMVU MMMU-P MMMU-C MMMU-A L VBench 0.2 0.4 0.6 0.8 1.0 Mean Scale Factor per V ideo Predicted Scale Distribution Across Benchmarks Perception Reasoning Figure 8: Per-video mean scale across benchmarks. Kernel densit y estimates o f the per-video mean scale ¯ s . R easo ning- heavy benchmarks shift to ward larger ¯ s than perceptio n-heavy o nes, indicating that the learn ed policy spends more fidelit y where fine-grained evidence is m ore likely to matter . ( x , a , y ) . The change in the marginal ov er allocati ons bet ween beha vior and the post-a llocator policy is corrected by the importance weight ρ θ = q θ ′ ( a | x ) / q θ old ( a | x ) = π θ ′ ( s | x ) / π θ old ( s | x ) ( affine map, J acobian f actor cancels in the ratio). Multiplying rollout-l ev el advantages by ρ θ before the token-lev el PPO surrogate f or ϕ implements the st andard import ance-sampling correction when reusing trajectories drawn under q θ old while evaluating gradients at q θ ′ (support and clipping cav eats as in ordin ary PPO); this matches the practica l “ ispred ” path in the codebase. C.3. Advantage Shaping and Monte Carlo Surrogates The ideal linear penalt y − λ C ( s ) inside R ideal o ften causes catastrophic coll apse to minimum budgets. CAPO therefore repl aces the ra w reward with a cost-sha ped, group-norma liz ed advantage A s , y (denoted A m , n in the main text). This replacement is not an unbiased baseline transformati on of R ideal s , y : the CAPO signal depends on the sampled allocati on, the rollo ut outco me, and the within-group cost st atistics. Instead, it defines a deliberately biased surrogate objectiv e that trades exact fidelit y to the L a grangian reward for low er variance and stronger budget control in practice. Applying PPO clipping to the exact joint ratios wo uld coupl e a ll frame- and token-lev el factors, which is prohibitiv ely no isy in practice. W e therefore arrive at practical decoupled objectives. For a batch of M all ocatio ns and N rollouts per all ocation, the MLLM sequen ce-lev el surrogate is: L seq ϕ = − 1 M N M m = 1 N n = 1 min r ( m , n ) ϕ A m , n , clip ( r ( m , n ) ϕ , 1 − ε , 1 + ε ) A m , n . (40) This sequen ce-lev el loss is already approximate because it uses the CAPO -sha ped advantage in pl ace o f the ideal reward. T o achieve finer credit assignment f or the autoregressiv e MLLM, we f urther f actoriz e π ϕ ( y | ˜ x ) into token-lev el probabiliti es, distribute the same rollout-lev el advantage A m , n to all tokens, and av erage 30 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Mean Scale Factor 0 50 100 150 200 250 Count (a) Scale Distribution by Duration Short (n=900) Medium (n=900) Long (n=900) 0.00 0.05 0.10 0.15 0.20 0.25 0.30 Intra-V ideo Scale Std 0 20 40 60 80 100 120 Count (b) Scale Diversity by Duration Short Medium Long Short Medium Long 0.0 0.2 0.4 0.6 0.8 1.0 Accuracy 67.8% 55.3% 50.8% (c) Accuracy by Duration Figure 9: VideoMME broken do wn by video durati on. As clip durati on gro ws, the poli cy lo wers the a v erage sca le, increa ses within-video scal e diversity , and f aces lo wer task accuracy . L onger clips are therefore processed more a ggressively and m ore selectiv ely . o ver the sequen ce length L m , n . Equation ( 24 ) should therefore be read as the st andard token-lev el PPO approximati on to this sequence-l ev el surrogate, not as an exact decompositio n o f the clipped joint ratio. Con versely , when updating the Allocator ( θ ), we fix the MLLM ( π ϕ = π ϕ old ) and use the aggregated advantage A CAPO m = 1 N n A m , n . Because the Allocator’s output distrib ution factori zes conditi onally across frames (Eq. 11 ), its score f unctio n decomposes additively: ∇ θ log π θ ( s ( m ) | x ) = T t = 1 ∇ θ log Beta ( a ( m ) t ; α t , β t ) . (41) This additiv e log-probabilit y structure supports lo w-variance frame-level credit assignment. N everthel ess, Eq. ( 21 ) remains a practica l approximati on to a trajectory-l evel clipped objective: conditi onal independence justifies decompositi on o f log π θ , b ut not exact factori zation of the nonlin ear PPO clipping term. W e use the per-frame surrogate because it is substanti ally more st ab le in l arge-scal e training. D. Suppl ement ary Experiments and Analysis This secti on first an alyzes the learned allocati on policy , then studies the t wo key ab latio n axes, and fin ally reports represent ative qualitative cases and a boundary-ca se transfer test bey ond video. Unless otherwise noted, all plots use Qw en2.5- VL-7B with 32 uniformly sampled frames. D.1. Beha vi oral Analysis o f the Learned Poli cy D.1.1. Benchmark-Level Budget Allocati on Figure 8 show s a clear benchmark-lev el ordering even though the policy never observes benchmark l abels d uring training. A v era ged across datasets, reasoning-ori ented t asks use slightly higher mean scales than perceptio n-oriented on es (0.435 vs. 0.417), with MMMU-Adaptation at the high end and VideoMME at the lo w end. The pattern is consistent with the main cl aim of the paper: the policy is not enforcing a fixed compressi on rule, but adapting its operating point to the expected visual difficult y o f the t as k family . 31 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning Artistic Performance Life Record Film & T elevision Knowledge Multilingual Sports Competition 0.0 0.1 0.2 0.3 0.4 Mean Scale Factor 58% 53% 61% 60% 53% 59% V ideoMME: Scale Allocation by T ask Category (accuracy annotated) Figure 10: Scale all ocatio n by VideoMME t as k category . Mean ¯ s varies subst antially across categories, with larger b udgets assigned to categori es that contain crowded m otio n or finer local eviden ce. Accuracy annotatio ns sho w that all ocation is n ot a trivial proxy for whi ch category is easiest. 0.00 0.05 0.10 0.15 0.20 0.25 0.30 Gini Coef ficient (Selectivity) 0 2 4 6 8 Density p=2.762e-01 V ideoMME Correct (n=1565) Incorrect (n=1 135) 0.00 0.05 0.10 0.15 0.20 0.25 Gini Coef ficient (Selectivity) 0 2 4 6 8 Density p=2.979e-02 MMMU-P Correct (n=198) Incorrect (n=102) 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 Gini Coef ficient (Selectivity) 0 1 2 3 4 5 6 Density p=1.046e-01 LongV idBench Correct (n=740) Incorrect (n=597) Scale Selectivity (Gini Coef ficient): Correct vs. Incorrect Predictions Figure 11: Selectivit y versu s prediction correctness on three represent ativ e benchmarks. Per-video Gini coefficients o f the frame-level scales. Correct predictio ns tend to hav e higher Gini than incorrect on es, linking success to sharper con centration o f resolutio n rather than merely l arger av era ge budgets. D.1.2. L ong-Context and S emantic Structure Figure 9 is consistent with the long-context gains in the main pa per . From short to long clips, the mean scal e drops (0.342 → 0.336 → 0.332), b ut the within-video div ersit y rises (0.085 → ∼ 0.095). In other w ords, the policy does not merely compress lo nger videos more; it also becomes more selectiv e inside them, which is exactly the regime where uniform resizing is lea st satisfactory . Figure 10 refines the same story within a single benchmark. The policy spends the most budget on Sports Competitio n and the lea st on Artistic P erf ormance , suggesting that even within VideoMME it distinguishes categories that are dense and spatia lly demanding from those that are visually simpler . This complements the main benchmark t ab les: the appendix f ocuses on why ret ained b udgets differ , while the main text already reports the exact realized retention ratios. 32 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning V ideo-MME LongV ideo Bench L VBench MMVU V -MMMU (Perc.) V -MMMU (Comp.) V -MMMU (Adapt.) 0 20 40 60 80 100 Proportion (%) 57.4% 53.3% 33.6% 43.7% 57.0% 46.3% 20.7% 4.9% 4.5% 7.5% 9.0% 8.0% 8.0% 4.7% 5.6% 5.0% 9.0% 8.3% 8.3% 9.0% 34.3% 36.2% 56.9% 39.8% 25.7% 37.3% 62.3% Correctness T ransition Distribution (V anilla → ResAdapt) CC WC CW WW 0 10 20 30 40 50 Error Introduction Rate (%) 0 10 20 30 40 50 Error Correction Rate (%) V i deo-MME LongVideo Bench L VBench MMVU V -MMMU (Perc.) V -MMMU (Comp.) V -MMMU (Adapt.) Net Beneficial Region Net Harmful Region Error Correction vs. Introduction T rade-off Figure 12: Sample-lev el rob ustness at 25% retention. Most originally correct predicti ons remain correct, b ut corrected and newly introd uced errors are o f comparab le magnitude. Adaptiv e allocati on is theref ore selectiv e rather than loss less. D.1.3. S electivit y and Su ccess W e next as k whether successf ul sampl es a llocate budget more selectiv ely within a clip. W e quantif y frame-lev el selectivit y with the Gini coeffici ent of the predicted scales. High Gini means the policy concentrates budget on a small subset of frames; low Gini means the all ocatio n is nearly uniform. Figure 11 sho ws that correct predicti ons consistently lie in the m ore selectiv e regime, with the clearest separatio n on MMMU-P . This sharpens the mechanism cl aim o f the appendix: success is associated not merely with keeping more pixels ov erall, but with concentrating them onto the frames that matter . R ob ustness and f ailure m odes. A final questio n is whether adaptiv e compressi on preserv es existing correct answ ers or merely swa ps one error pattern for another . Figure 12 pro vides the right robustn ess interpretatio n f or aggressiv e compressio n. Predicti on st abilit y remains high o vera ll ( abo ut 89% o f originally correct samples st ay correct in the aggregate summary), so the policy is not helping only by randomly perturbing the answer distributio n. Ho w ev er , error correcti on and error introd ucti on are close eno ugh that the effect should be read as selectiv e redistributi on : the policy repairs some failures, but it can also lose fine-grained evidence, especially when the decisiv e cue is brief or visu ally simple. D.2. Ab latio n Studies D.2.1. T empora l Simil arit y Ab lation W e provide t wo compl ement ary views o f the temporal-similarit y ab lation: a cross-benchmark summary sho wing that the effect genera liz es, and a single-ben chmark diagno stic panel sho wing exactly how the all ocatio n pattern changes. Figure 13 makes the role of L sim unu sually clear . Without it, the policy coll apses to near-unif orm scales on ev ery benchmark ( σ < 0.003 ); with it, the same model f amily reco vers substanti al within-video variatio n, with 4 × – 693 × larger diversit y depending on the benchmark. CAPO therefore controls where the globa l b udget should sit, whereas L sim prev ents the trivial fixed-scale solution. 33 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning VideoMME LongVideoBench MMVU MMMU-P LVBench 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 I n t r a - v i d e o S c a l e S t d D e v ( ) 0.002 0.091 43× 0.033 0.133 4× 0.045 0.091 2× 0.000 0.095 693× 0.000 0.092 561× w / o s i m w / s i m Figure 13: Cross-benchmark scale div ersit y with and without L sim . Per-video sca le standard deviation σ across fiv e benchmarks. Without the regul arizer , div ersit y coll apses to ward z ero; adding L sim restores broad within-video variatio n on ev ery benchmark. Quantit ative co nfirmatio n. Figure 14 sho ws that this is not an artifact of any single statistic. The regulari zer changes the globa l histogram, the per-video range, the frame-to-frame variation, and the Gini coeffici ent in the same directio n, confirming that the benefit is structural rather than metric-specifi c. D.2.2. R eward Design Ab lation W e next examine whether different reward designs preserv e a no n-degenerate adaptiv e regime d uring training. All plots use EMA sm oothing to suppress per-step noise; raw valu es remain visible as translucent traces. P er-sample scale adaptivit y . Figure 15 complements Figure 6 by measuring the per-sample scale range s max − s min rather than the mean. CAPO preserves non-trivia l adapti vit y on validati on, whereas direct cost collapses to the low er boundary and cost-free optimi zation drifts to ward a nearly uniform high-scale policy . Con vergen ce and stabilit y . Figure 16 explains why CAPO w orks and the simpler baselin es do not. The CAPO variants con verge to st ab le interior solutions, whereas accuracy-only training saturates near s max and direct cost coll apses to s min . This is consistent with CAPO’s intended role: balancing t ask reward and b udget pressure without f alling into either trivial boundary solution. The key result is theref ore not merely con vergen ce, b ut con v ergence to a no n-degenerate operating point where content-ada ptiv e all ocation is still av ailab le. D.3. Qualitativ e Case Studies W e present fo ur represent ativ e case studies that complement the aggregate an alysis abo v e: t w o t as k-contra st examples from Video-MMMU , one evidence-localizatio n success from VideoMME, and one f ailure case. Each visualization (Figures 17 – 20 ) renders 32 unif ormly sampled frames at their assigned scale inside a fixed grid; warmer borders indicate larger predicted scales. 34 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning 0.2 0.4 0.6 0.8 1.0 F r a m e S c a l e s t 0 5 10 15 20 25 30 Density w/o: =0.376, =0.176 w/: =0.337, =0.169 (a) Frame-Level Scale Distribution w / o s i m w / s i m 0.0 0.2 0.4 0.6 0.8 P e r - V i d e o S c a l e R a n g e ( m a x s t m i n s t ) 0 10 20 30 40 50 60 Density w/o med: 0.000 w/ med: 0.361 (b) Intra-Video Scale Range w / o s i m w / s i m 0.00 0.05 0.10 0.15 0.20 0.25 M e a n A d j a c e n t - F r a m e S c a l e ( | s t s t + 1 | ) 0 25 50 75 100 125 150 175 200 Density w/o med: 0.0000 w/ med: 0.0479 (c) Frame-to-Frame Scale Variation w / o s i m w / s i m 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 Gini Coefficient (Scale Selectivity) 0 20 40 60 80 100 120 140 Density w/o med: 0.0000 w/ med: 0.0992 (d) Scale Selectivity (Gini) w / o s i m w / s i m Figure 14: F our diagno stics of the L sim ab lation o n VideoMME. With the regularizer , the frame-scale histogram becomes bim odal, the per-video range expands, adjacent-frame variation in creases, and the Gini coefficient rises. The policy m o ves from near-uniform a llocatio n to a genuinely sel ective regime. T a s k-dependent operating regimes. Figures 17 and 18 contrast t w o Video-MMMU t asks from a visu ally similar educati ona l domain that neverthel ess demand very different allocati ons. In the comprehensi on example, the relevant evidence is concentrated in a small set o f diagram-bearing slides, so the policy adopts a sparse operating regime and suppresses the explicitly irrelevant quiz frame. In the adaptation example, the do wnstream rea soning depends on reading a dense numeric tabl e, so the same policy shifts to a mu ch higher-b udget regime and preserves high fidelit y much more broad ly . The contrast show s that the policy respo nds to what the task will require, not just to generic visual clutter . Eviden ce localization and failure. The VideoMME success case in Figure 19 sho ws a more local versi on o f the same phenomen on: the answer depends on short text ov erlays embedded in otherwise repetitiv e foota ge, and the policy magnifi es only those evidence-bearing mo ments. Figure 20 sho ws the failure mode that remains. The decisive cue is temporally brief and visually simple, so the policy enlarges a nearby frame b ut compresses the frame that actually contains the fork. This diagn osis matches the quantit ativ e robustn ess analysis: R esAda pt is strong at concentrating budget, but still vuln erab le when the decisive evidence is both 35 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning 0 100 200 300 400 500 Training Step 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 Scale Range s max − s min (a) T raining: Per-Sample Adaptivity 0 100 200 300 400 500 Training Step (b) V alidation: Per -Sample Adaptivity β -Dist. w/o Cost β -Dist. w Direct Cost β -Dist. w CAPO -Dist. w CAPO Figure 15: P er-sample sca le ada ptivit y under different rew ard designs. S cal e range s max − s min o ver training on ( a) training and ( b) va lidation s plits. CAPO keeps a no n-trivial adapti ve range, whereas direct cost collapses and cost-free training saturates. 0 100 200 300 400 500 Training Step 0.25 0.50 0.75 1.00 1.25 1.50 1.75 2.00 Rolling Mean of s ( w =5) (a) Smoothed Convergence (V alidation) β -Dist. w/o Cost β -Dist. w Direct Cost β -Dist. w CAPO -Dist. w CAPO 0 100 200 300 400 500 Training Step 0.00 0.05 0.10 0.15 0.20 0.25 0.30 Rolling Std of s ( w =5) (b) Scale Stability (V alidation) β -Dist. w/o Cost β -Dist. w Direct Cost β -Dist. w CAPO -Dist. w CAPO Figure 16: V a lidatio n-time conv ergence under different reward designs. CAPO variants con verge to stab le intermediate operating points, while cost-free training saturates at the upper boundary and direct cost collapses to the lo w er boundary . Stabilit y alo ne is not suffici ent; the key is where the policy st abilizes. subtle and short-liv ed. Summary . T ogether , these case studies support the same three conclusi ons as the quantit ative appendix: the policy changes its operating regime with the t ask, concentrates fidelit y on evidence-bearing frames, and fails in interpretabl e wa ys when subtle cues are missed. The qualit ativ e examples therefore reinforce the claim that R esAdapt learns a meaningf ul input-allocati on strategy rather than a fixed compression heuristic. D.4. Bo undary-Case Transfer Beyond Video The paper’s main claims t arget video Q A and temporal grounding, so we pl ace image transfer at the end o f the appendix as a boundary-ca se analysis rather than as supporting evidence for the main contrib utio n. T a bl e 7 is still inf ormativ e: the l earned video poli cy sometimes identifies ima ge inputs that warrant additiona l fidelit y , as in ChartQ A, b ut it does not yet yield reliab le effici ency-preserving transfer on text-dense image tasks. The result is therefore best read as scope clarificatio n. It suggests that input-side adaptatio n is broader than the resize-on-video setting studied here, while also sho wing that a video-trained policy should not be assumed to transfer cleanly to st atic ima ges. 36 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning T ab le 7: Exploratory z ero-s hot transfer to image benchmarks. P arenthetica l valu es denote per-t as k retention rati o R , and ResAda pt-RL additio nally fine-tunes the MLLM via RL. Model MathVista testmini MMMU va l OCRBench ChartQ A AI2D T extV Q A va l Qw en2.5- VL-7B 49.1 (100%) 50.9 (100%) 84.2 (100%) 83.9 (100%) 82.5 (100%) 82.9 (100%) Random Drop 44.8 (50%) 49.0 (50%) 74.8 (50%) 71.6 (50%) 80.3 (50%) 78.1 (50%) T oMe ( Bolya et al. , 2022 ) 46.2 (50%) 49.6 (50%) 79.3 (50%) 78.1 (50%) 81.9 (50%) 81.2 (50%) Visi onZip ( Y ang et al. , 2025c ) 47.2 (50%) 48.6 (50%) 79.6 (50%) 77.9 (50%) 81.9 (50%) 81.3 (50%) R esAdapt ( Qwen2.5- VL-7B) 45.5 (42%) 51.0 (29%) 80.0 (64%) 85.9 (105%) 81.4 (41%) 69.6 (30%) R esAdapt-RL ( Qwen2.5- VL-7B) 46.7 (42%) 50.9 (29%) 80.8 (64%) 86.6 (105%) 81.1 (41%) 70.1 (30%) Qw en3- VL-8B 56.1 (100%) 53.4 (100%) 85.0 (100%) 84.0 (100%) 83.5 (100%) 82.1 (100%) Random Drop 47.3 (50%) 48.7 (50%) 62.9 (50%) 70.2 (50%) 79.7 (50%) 76.6 (50%) Visi onZip ( Y ang et al. , 2025c ) 47.8 (50%) 50.3 (50%) 70.5 (50%) 75.0 (50%) 80.5 (50%) 79.3 (50%) T oMe ( Bolya et al. , 2022 ) 49.6 (50%) 50.6 (50%) 70.3 (50%) 75.2 (50%) 80.5 (50%) 79.4 (50%) R esAdapt ( Qwen3- VL-8B) 52.5 (42%) 50.9 (29%) 82.7 (64%) 83.2 (105%) 81.2 (41%) 67.8 (30%) 37 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning Q: Ev aluate fiv e st atements about Urban Geography Cit y Models ( concentri c zone, H oyt sector , multiple nuclei, galactic, Latin American); identif y which are correct. P lea se ignore the Quiz question in last frame o f the video. 0.25 0.30 0.35 0.40 0.45 0.50 0.55 0.60 0.65 A daptive Scale F actor (cell = 0.65×) Figure 17: Case 1: Video-MMMU Comprehensi on ( Hu et al. , 2025 ) ( V anill a × → R esAdapt ✓ ). The policy con centrates resolution on diagram-bearing slide frames, compresses lecturer-o nly frames, and suppresses the final quiz frame that the prompt explicitly marks as irrelev ant. 38 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning Q: W atch and learn the video content. Then apply what you learn ed to answer: T ab le 11.47 provides a surv ey of the y oungest onlin e entrepreneurs ( ages 17–30) whose n et worth ≥ $1M. W e want to kno w whether a ges and net w orth are independent. χ 2 test statistic = ______ 0.3 0.4 0.5 0.6 0.7 0.8 0.9 A daptive Scale F actor (cell = 0.95×) Figure 18: Case 2: Video-MMMU Adaptatio n ( Hu et a l. , 2025 ) ( V anilla × → R esAdapt ✓ ). When the answer depends on reading a numeri c tabl e and performing a χ 2 computation, the policy keeps a m uch higher globa l b udget and strongly upscal es the t ab le-bearing frames. 39 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning Q: When is the zodiacal light visible from the video? ( A) Mar . 19, (B) Mar . 24, ( C) Mar . 25, (D) Mar . 29. 0.25 0.30 0.35 0.40 0.45 0.50 0.55 0.60 A daptive Scale F actor (cell = 0.60×) Figure 19: Ca se 3: VideoMME ( Fu et al. , 2025a ) ( V anill a × → R esAdapt ✓ ). Frames containing the decisiv e date o verlay s are enlarged, while the l argely hom ogeneou s sky footage is compressed. The policy spends budget on answ er-bearing evidence rather than on the surrounding context. 40 R esAdapt: Adaptive R esolution for Efficient Multimoda l Reaso ning Q: Which item does the man throw into the trash at the beginning of the video? ( A) A fork, (B) A pair of chopsticks, ( C) A box o f nood l es, (D) A spoon. 0.3 0.4 0.5 0.6 0.7 A daptive Scale F actor (cell = 0.75×) Figure 20: Case 4: VideoMME ( Fu et al. , 2025a ) ( V anill a ✓ → R esAdapt × ; failure case). A nearby frame is enlarged, but the actual fork-bearing frame is compressed. The decisive fine detail is theref ore lo st at exactly the wrong m oment. 41
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment