시각 예산을 학습하는 입력 측 적응 프레임워크 ResAdapt
ResAdapt은 영상 질문응답·시간 정렬 등 멀티모달 추론 작업에서, 프레임별 시각 해상도를 동적으로 할당하는 입력‑측 적응 기법이다. 가벼운 Allocator가 질의와 저해상도 특징을 기반으로 베타 분포를 통해 각 프레임에 할당량을 예측하고, 이를 리사이징 연산에 적용한다. 정책 학습은 Cost‑Aware Policy Optimization(CAPO)으로, 정확도와 시각 토큰 비용을 동시에 최적화하며, 시간 유사도 정규화로 중복 할당을 억제…
저자: Huanxuan Liao, Zhongtao Jiang, Yupu Hao
본 논문은 멀티모달 대형 언어 모델(MLLM)이 비디오와 같은 고해상도·장시간 입력을 처리할 때 직면하는 “시각 토큰 폭증” 문제를 해결하고자 한다. 기존 접근법은 크게 두 가지로 나뉜다. 모델‑측 방법은 인코더 후 단계에서 토큰을 병합·프루닝하거나 압축하지만, 이미 손실된 세부 정보를 복구할 수 없으며, 토큰 레이아웃을 변경해 최적화된 어텐션 커널을 방해한다. 출력‑측 방법은 질의에 따라 반복적으로 프레임을 재조회하거나 줌인하는 에이전트를 두어 다중 라운드 지연을 초래하고, 초기 저해상도 뷰가 결정적인 단서를 놓칠 위험이 있다. 저자는 이러한 한계가 “인코딩 전 픽셀 양”에 있음을 강조하고, 입력‑측에서 시각 예산을 동적으로 할당하는 프레임워크 ResAdapt을 제안한다.
ResAdapt의 구조는 크게 세 부분으로 구성된다. (1) **Allocator**: 가벼운 시각‑텍스트 인코더와 시계열 어텐션 디코더를 사용해 각 프레임에 대한 베타 분포 파라미터(α_t, β_t)를 예측한다. 베타 샘플 a_t∈(0,1)를 s_min과 s_max 사이의 스케일 값 s_t로 변환한다. 이 스케일은 리사이징 연산 O에 전달돼 프레임을 저해상도·고해상도 중 하나로 변환한다. (2) **Operator**: 논문에서는 bilinear 리사이징을 사용했으며, 프레임당 토큰 수는 s_t²에 비례한다. (3) **Backbone MLLM**: 변환된 프레임 시퀀스를 기존 토큰 인터페이스 그대로 입력받아, 한 번의 전방 패스로 질의에 대한 답변을 생성한다. 따라서 백본 구조나 최적화된 추론 엔진을 그대로 유지한다.
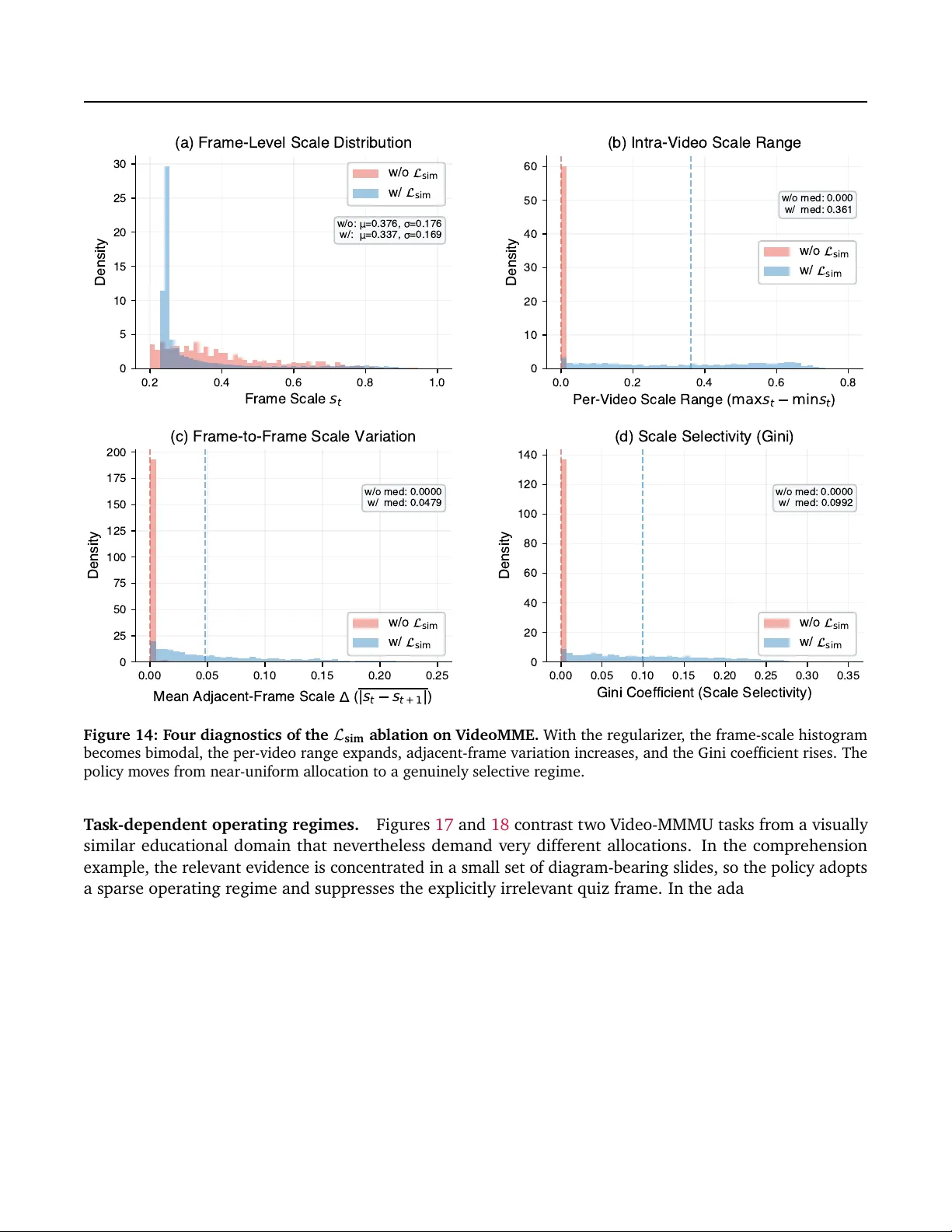
학습 목표는 정확도 Q(x, y)와 시각 비용 C(s) 사이의 라그랑주식 트레이드오프를 최적화하는 것이다. 이를 위해 저자는 Cost‑Aware Policy Optimization(CAPO)이라는 강화학습 기반 방법을 설계한다. 주요 아이디어는 다음과 같다. (i) **Proxy Cost**: 실제 토큰 수 ρ(s)는 s_t²에 따라 급격히 변해 학습이 불안정해지므로, 평균 스케일 \bar{s}를 이용한 부드러운 비용 c(s) = (\bar{s} - s_min)/(s_max - s_min) 를 내부 최적화에 사용한다. (ii) **Dynamic Cost Pivot** τ_dyn = κ_mix·\bar{c}_group + (1-κ_mix)·τ_fix 으로, 현재 배치의 평균 비용과 고정 목표 비용을 혼합해 정책이 과도하게 최소 예산에 수렴하는 것을 방지한다. (iii) **Asymmetric Shaping**: 정답 여부 u에 따라 보상 S를 비대칭적으로 조정한다. 정답이면 비용 피벗보다 낮은 경우 보너스를 주고, 오답이면 비용 초과에 대한 페널티를 크게 부여한다. (iv) **Temporal Similarity Regularizer**: 인접 프레임 간 특징 유사도에 기반해 고예산 할당을 억제한다. 이는 중복된 시각 정보를 줄여 전체 비용 효율을 높인다.
실험은 다양한 데이터셋과 백본을 대상으로 수행되었다. 비디오 QA에서는 NExT‑QA, MSVD‑QA, MSRVTT‑QA 등에서 10%~30% 토큰 유지율(≈10% 시각 보존)에서도 기존 모델‑측 토큰 압축 방법보다 높은 정확도를 기록했다. 특히, 16배 더 많은 프레임을 동일 비용으로 처리했을 때 15% 이상의 상대적 성능 향상이 관찰되었다. 시간 정렬(Temporal Grounding) 작업에서도 동일한 경향을 보였으며, 이미지 기반 추론(ScienceQA)에서도 저예산 상황에서 경쟁력을 유지했다. Ablation 연구에서는 CAPO 없이 베타 샘플링만 사용했을 때 정책이 최소 예산으로 수렴하는 현상이 나타났으며, 동적 피벗과 비대칭 보상이 없을 경우 비용‑정확도 트레이드오프가 크게 악화됨을 확인했다. 또한, 시간 유사도 정규화가 없을 경우 인접 프레임에 중복 할당이 발생해 전체 효율이 떨어지는 것을 실험적으로 입증했다.
결론적으로 ResAdapt은 입력‑측에서 시각 예산을 학습적으로 할당함으로써, 고해상도·장시간 멀티모달 입력을 효율적으로 처리한다. 백본을 변경하지 않고도 기존 최적화된 인퍼런스 파이프라인과 호환되며, 비용‑정확도 프론티어에서 경쟁력 있는 위치를 차지한다. 향후 연구에서는 다양한 연산자(프레임 선택, 영역 기반 크롭 등)와 더 복잡한 시나리오(다중 카메라, 실시간 스트리밍)에도 적용 가능성을 탐색할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기