Learning unified control of internal spin squeezing in atomic qudits for magnetometry
Generating and preserving metrologically useful quantum states is a central challenge in quantum-enhanced atomic magnetometry. In multilevel atoms operated in the low-field regime, the nonlinear Zeeman (NLZ) effect is both a resource and a limitation…
Authors: C. Z. Cao, J. Z. Han, M. Xiong
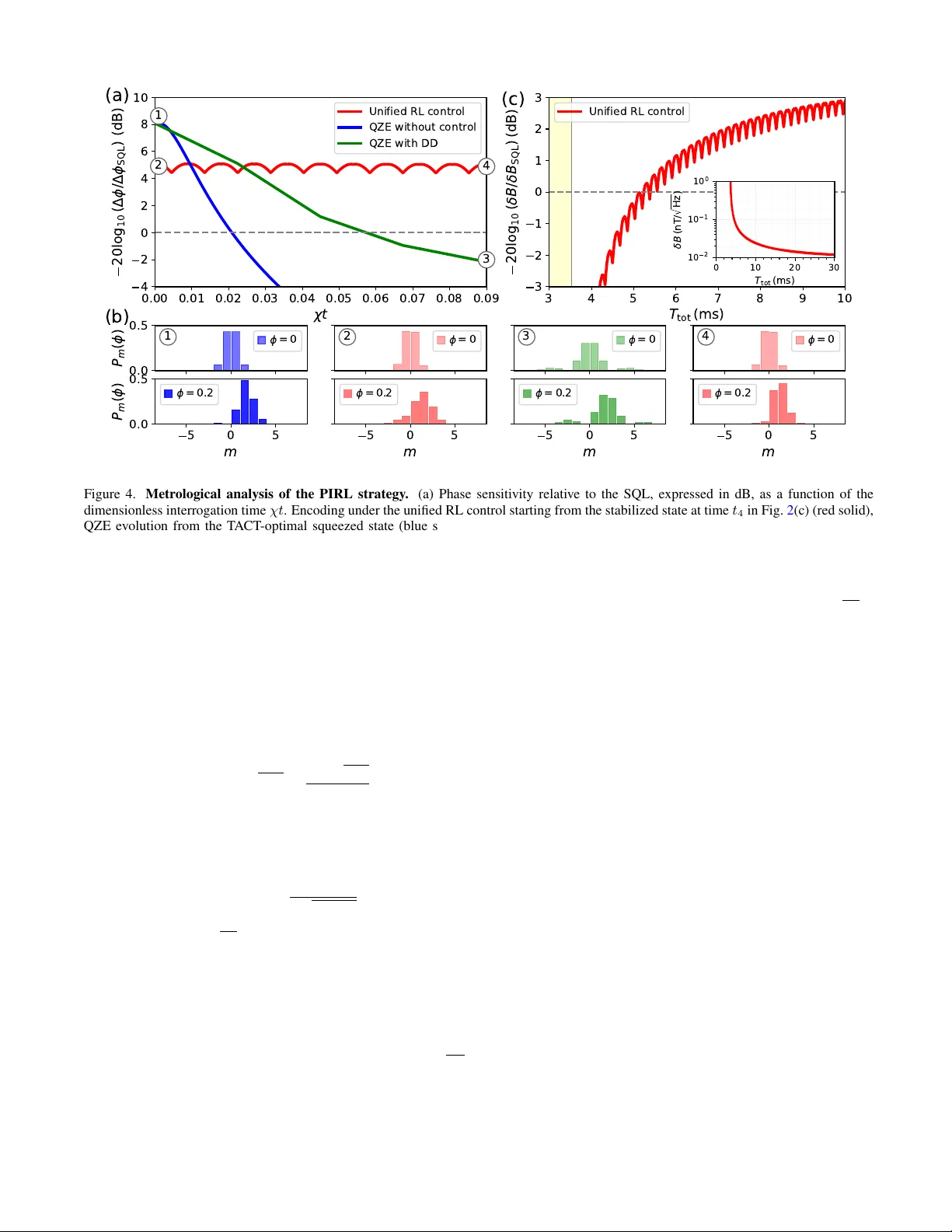
Learning unified contr ol of internal spin squeezing in atomic qudits f or magnetometry C. Z. Cao, 1 , ∗ J. Z. Han, 2, 1 , ∗ M. Xiong, 1 M. Deng, 3 L. W ang, 4 X. Lv, 4 , † and M. Xue 1, 5 , ‡ 1 Colle ge of Physics, Nanjing University of Aer onautics and Astr onautics, Nanjing 211106, China 2 China Mobile (Suzhou) Softwar e T echnology Co., Ltd., Suzhou, 215163, China 3 Y ichang T esting T echnique R&D Institute, Specialized W eak Magnetic Metering Station of NDM, Y ichang 443003, China 4 Shanghai Institute of Optics and Fine Mechanics, Chinese Academy of Sciences, Shanghai 201800, China 5 K ey Laboratory of Aerospace Information Sensing and Physics (NUAA), MIIT , Nanjing 211106, China (Dated: March 31, 2026) Generating and preserving metrologically useful quantum states is a central challenge in quantum-enhanced atomic magnetometry . In multilevel atoms operated in the low-field regime, the nonlinear Zeeman (NLZ) ef- fect is both a resource and a limitation. It nonlinearly redistributes internal spin fluctuations to generate spin- squeezed states within a single atomic qudit, yet under fixed readout it distorts the measurement-relev ant quadra- ture and limits the accessible metrological gain. This challenge is compounded by the time dependence of both the squeezing axis and the ef fectiv e nonlinear action. Here we sho w that physics-informed reinforcement learn- ing can transform NLZ dynamics from a source of readout degradation into a sustained metrological resource. Using only e xperimentally accessible low-order spin moments, a trained agent identifies, in the f = 21 / 2 mani- fold of 161 Dy , a unified control polic y that rapidly prepares strongly squeezed internal states and stabilizes more than 4 dB of fixed-axis spin squeezing under always-on NLZ ev olution. Including state-preparation overhead, the learned protocol yields a single-atom magnetic sensitivity of 13 . 9 pT / √ Hz , corresponding to an advan- tage of approximately 3 dB beyond the standard quantum limit. Our results establish learning-based control as a practical route for conv erting unav oidable intrinsic nonlinear dynamics in multilevel quantum sensors into operational metrological advantage. I. INTR ODUCTION Atomic magnetometry is a leading platform for precision sensing, with applications in fundamental physics [ 1 – 5 ], bio- magnetic detection [ 6 – 9 ], and magnetic navigation [ 10 – 12 ]. State-of-the-art experiments ha ve demonstrated high sensi- tivities in realistic operating regimes [ 13 – 15 ]. Quantum- enhanced magnetometry can further surpass the standard quantum limit (SQL) by exploiting nonclassical spin correla- tions [ 16 – 18 ]. In multilev el atoms, such correlations need not rely on interparticle entanglement, but can instead be gener- ated within the internal degrees of freedom of a single spin- f system, equiv alently viewed as a symmetric ensemble of 2 f spin- 1 / 2 constituents [ 19 , 20 ]. Recent experiments hav e established the internal Hilbert space of multilevel atoms as a metrological resource. Atomic qudits can host nonclassical internal states, including non- Gaussian and cat-like states generated by controllable nonlin- ear dynamics such as light-induced tensor shifts, yielding en- hanced magnetic sensiti vity and e ven near-Heisenber g-limited performance under suitable control [ 21 – 24 ]. In these settings, howe v er , the nonlinearity is externally engineered and can be switched or shaped, so that state preparation can be cleanly separated from metrological interrogation. In realistic lo w-field sensing regimes, by contrast, the rel- ev ant nonlinearity is often intrinsic. The quadratic Hamilto- nian ∝ ˆ f 2 z , arising from the nonlinear Zeeman (NLZ) ef fect, is the single-atom counterpart of the familiar one-axis-twisting ∗ These authors contributed equally to this work. † xudonglv@siom.ac.cn ‡ mxue@nuaa.edu.cn (O A T) interaction in many-body spin systems [ 25 ]. It nat- urally generates internal spin squeezing, but simultaneously rotates the squeezing axis and driv es ov ertwisting on experi- mentally relev ant timescales [ 26 ]. As a result, the same dy- namics that create nonclassical correlations can also degrade the metrological gain accessible under fixed readout. This dif- ficulty is most acute when the relev ant nonlinearity is intrin- sic to the sensing process and therefore remains always on throughout both squeezing generation and signal interroga- tion. A prototypical example is Earth-field-range magnetom- etry , where the NLZ ef fect is ev er present and has motiv ated a range of compensation, spin-locking, and staged-control approaches that either suppress its influence or recover part of the metrological gain through fixed dynamical-decoupling pulse structures and separate squeezing-generation and stabi- lization stages [ 27 – 36 ]. Because the NLZ dynamics cannot be turned off, howe ver , the optimal control is intrinsically nonseparable: squeezing generation and stabilization must be interleav ed in time to preserve the measurement-rele vant quadrature. The resulting task is therefore inherently adaptiv e. Use- ful control actions must be selected step by step during the nonlinear e volution from experimentally limited informa- tion, while their impact on fixed-readout metrological perfor- mance is not directly evident in the high-dimensional Hilbert space. This structure makes the problem a natural target for reinforcement learning and related learning-based ap- proaches [ 37 , 38 ]. In contrast to dynamical-decoupling-based strategies, which typically optimize within predefined pulse structures and staged control protocols, reinforcement learn- ing can interact directly with the controlled dynamics and dis- cov er pulse patterns tailored to the underlying system. Here we address this challenge using physics-informed reinforce- ment learning (PIRL) [ 39 ]. W e consider a protocol in which 2 Figure 1. Physics-inf ormed reinfor cement-learning framework for control of internal spin dynamics in an atomic qudit. (a) W e consider a single 161 Dy atom with nuclear spin i = 5 / 2 and electronic angular momentum j = 8 , focusing on the hyperfine manifold with f = 21 / 2 . In a magnetic field, the multile vel Zeeman structure acquires a quadratic component, giving rise to an always-on nonlinear Zeeman (NLZ) interaction ∝ ˆ f 2 z . (b) Control problem. Starting from an initial coherent spin state, the qudit ev olves under repeated cycles of free NLZ e volution and agent-selected transverse rotations R µ ( β ) with µ ∈ { x, y } . At each step, the agent receives an observation o k ∈ O consisting of experimentally accessible low-order spin moments, chooses an action a k ∈ A from a discrete set of realizable rotations, and is trained to maximize the cumulative reward G defined from physically motiv ated squeezing metrics. This defines a unified control problem under always-on nonlinear dynamics. resonant transverse microw ave rotations are interleav ed with intrinsic nonlinear dynamics, and train an agent to select con- trol operations using only experimentally accessible lo w-order spin moments. Guided by a reward that captures both overall squeezing and measurement-relev ant fixed-axis performance, the learned unified policy rapidly generates strong internal spin squeezing while stabilizing the measurement-relev ant quadrature under continuous ev olution. It also rev eals a sim- ple and physically interpretable pulse structure that suppresses ov ertwisting while preserving useful quantum correlations. II. MODEL AND REINFORCEMENT -LEARNING FRAMEWORK A. Intrinsic nonlinear dynamics and squeezing metrics W e consider an atomic qudit encoded in the d = 2 f + 1 Zee- man states | f , m ⟩ ( m = − f , . . . , f ) within a single hyperfine manifold in the presence of a magnetic field, which defines the quantization z axis, as illustrated in Fig. 1 (a) for 161 Dy with f = 21 / 2 . The internal spin operators are denoted by { ˆ f x , ˆ f y , ˆ f z } . In the weak-field regime, the hyperfine–Zeeman structure within a fixed manifold is described by the effecti ve single-atom Hamiltonian ( ℏ = 1 ) ˆ H B ≃ Ω L ˆ f z + χ ˆ f 2 z , (1) where Ω L is the Larmor frequency and χ denotes the quadratic Zeeman ef fect (QZE) coefficient (see Appendix A ). In the rotating frame that remov es the Larmor precession, the dynamics reduce to ˆ H QZE = χ ˆ f 2 z , (2) which is formally equiv alent to the OA T Hamiltonian, here acting on the internal (2 f +1) -dimensional manifold of a sin- gle spin. Starting from a coherent spin state (CSS) polarized along x , | ψ 0 ⟩ = | f , m x = f ⟩ , the always-on quadratic term shears the spin distrib ution in the plane transverse to the mean spin, thereby generating a spin-squeezed state (SSS). Howe ver , continued nonlinear evolution rotates the squeezing axis and induces overtwisting, so that the metrological gain under a fixed readout rapidly degrades. This competition between squeezing generation and its subsequent distortion underlies the need for acti ve control, as schematically illustrated in Fig. 1 (b). T o quantify squeezing during the e volution of a single spin- f relativ e to a spin-coherent state, we use the W ineland pa- rameter [ 40 ] ξ 2 = 2 f min ⊥ [(∆ f ⊥ ) 2 ] |⟨ ˆ f ⟩| 2 , (3) for which ξ 2 = 1 for a CSS. Since our sensing protocol uses a fixed readout axis, we further introduce ξ 2 y = 2 f (∆ f y ) 2 |⟨ ˆ f x ⟩| 2 , (4) which quantifies the metrological usefulness of squeezing specifically for readout along y . B. Reinfor cement-learning contr ol framework The single-atom spin- f manifold is controlled by a trans- verse micro wav e drive. In the rotating frame of Eq. ( 2 ) and under the rotating-wav e approximation, the dynamics are de- scribed by ˆ H QZE + ˆ H ctrl with ˆ H ctrl = λ ( ˆ f x cos ϕ + ˆ f y sin ϕ ) , where λ is the Rabi frequency and ϕ sets the rotation axis in the transverse xy plane. For numerical optimization, we discretize the control into a sequence of piecewise-constant pulses. The total duration T is divided into N t intervals of 3 length δ t = T / N t . In the k th interval, the control is fully specified by the rotation angle β k = R ( k +1) δ t kδ t λ dt . W e de- note the corresponding instantaneous transverse rotation by ˆ R µ ( β k ) = e − iβ k ˆ f µ , where µ labels the rotation axis deter- mined by the phase ϕ . Each control step then consists of a spin rotation followed by free ev olution under the QZE Hamiltonian, | ψ k +1 ⟩ = e − iχδ t ˆ f 2 z ˆ R µ ( β k ) | ψ k ⟩ . (5) This stroboscopic form makes e xplicit ho w transverse control rotations are interleaved with the intrinsic nonlinear dynamics, as illustrated in Fig. 1 (b). The agent selects actions from a discrete set of experimen- tally natural rotations, A = I , R µ ( β ) µ ∈ { x, y } , β ∈ {± π 2 , ± π 3 , ± π 4 } , (6) where I denotes no control pulse. While this symmetric parametrization is con venient, the two rotation channels play distinct physical roles. Pairs of opposite-angle R y rotations enable symmetric toggling-frame control that compensates the nonlinear rotation induced by the QZE [ 41 , 42 ]. By con- trast, R x pulses primarily act as corrective rotations that reori- ent the squeezed state to ward the measurement-rele vant axis. For this purpose, positive rotation angles are already suf ficient in practice, as confirmed by the optimized pulse sequences discussed below . T o av oid an exponential dependence on the Hilbert-space dimension and to remain within e xperimentally feasible read- out, the agent observes only lo w-order spin moments, O = {⟨ ˆ f x ⟩ /f , ⟨ ˆ f y ⟩ /f , ⟨ ˆ f z ⟩ /f , ⟨ ˆ f 2 x ⟩ /f 2 , ⟨ ˆ f 2 y ⟩ /f 2 } , (7) which can be obtained from measurements of spin projections and their variances, and suffice to track the mean-spin di- rection and transverse fluctuations relev ant to squeezing and readout [43–46] . Importantly , these features are normalized by f , rendering the input representation independent of the Hilbert-space dimension and enabling transfer of the learned policy across dif ferent spin manifolds. The control objectiv e is unified but, due to the nonlinear dynamics, the optimal strategy naturally separates into two regimes: rapid squeezing generation follo wed by stabilization of the measurement-relev ant quadrature. In the PIRL frame- work, this structure is encoded directly into a scalar rew ard r k built from the ph ysically rele vant squeezing metrics ξ 2 and ξ 2 y . The agent is trained to maximize the cumulative re ward G = N t − 1 X k =0 γ k RL r k , (8) where γ RL ∈ (0 , 1) is the discount factor , the cumulative re- ward captures long-term control performance beyond instan- taneous gains. T o implement this objective, we design a curriculum-style rew ard with a state-dependent switching time defined as the first-hitting time k ⋆ ≡ inf { k ≥ 0 : ξ 2 ( k ) ≤ ξ 2 ref } , (9) namely , the first step at which the W ineland squeezing param- eter reaches a prescribed threshold. The reference value ξ 2 ref is fixed throughout training and chosen as the optimal squeezing benchmark attainable under ideal two-axis counter-twisting (T A CT) dynamics [ 25 , 41 ]. The reward function is then de- fined as r k = log ξ 2 ( k − 1) − log ξ 2 ( k ) − c ( a k ) , k < k ⋆ , ζ e − κk ⋆ − c ( a k ) , k = k ⋆ , − α log ξ 2 y ( k ) − c ( a k ) , k > k ⋆ , (10) where the first term rew ards rapid squeezing generation, the second provides a one-time bonus fa voring earlier threshold crossing, and the third promotes post-threshold stabilization by directly optimizing the fixed-axis squeezing ξ 2 y , which is the quantity most relev ant for metrological performance un- der our fixed readout. In other w ords, once the squeezing lev el reaches the tar get threshold, the re ward switches from a state- preparation objective to a readout-aware sensing objectiv e. The cost term c ( a k ) penalizes pulse usage, with a k ∈ A\{ I } . Here ζ sets the bonus scale, κ its temporal decay with the hitting time k ⋆ , and α the weight assigned to post-threshold stabilization (see Appendix B ). W e optimize the cumulative reward using Proximal Policy Optimization (PPO) [ 47 – 49 ], an Actor –Critic policy-gradient method [ 50 , 51 ] well suited to sequential decision problems with delayed re wards. A policy network selects actions from the observation set O of low-order spin moments, while a value network estimates the e xpected return. This architecture enables stable model-free learning without an explicit dynam- ical model and is therefore well suited to discovering a single unified policy for squeezing generation and long-time stabi- lization [ 52 – 56 ]. III. LEARNED CONTR OL STRA TEGY , ST ABILIZA TION MECHANISM, AND METR OLOGICAL GAIN A. Learned pr otocol structure W e no w analyze the control protocol learned by the agent. Although the reward is defined in terms of physically moti- vated squeezing metrics, the resulting policy exhibits a clear two-stage structure, in direct correspondence with the pulse sequence in Fig. 2 (a): an initial preparation stage that rapidly generates spin squeezing, followed by a stabilization stage that preserves the measurement-relev ant quadrature, as quan- tified in Fig. 2 (b). During the preparation stage, the pulse sequence con- sists of three paired R y ( ± π / 2) operations. These paired pulses suppress QZE-induced overtwisting and accelerate squeezing generation, enabling the system to reach ξ 2 ( t 3 ) = − 8 . 19 dB at time t 3 , comparable to the optimal T A CT bench- mark of − 8 . 07 dB and below the QZE (O A T) benchmark of − 7 . 17 dB . The spin W igner distributions in Fig. 2 (c) illustrate how these pulses reshape the spin-fluctuation distrib ution and counteract the distortion accumulated during the intervening QZE ev olution. 4 a b c t 1 f x f y f z f x f y f z t 2 t 3 t 5 t 4 Figure 2. Learned pulse protocol from PIRL. (a) Control pulse sequence selected by the PIRL agent. Colored bars denote discrete transverse rotations applied at each control step. (b) T ime e volution of the Wineland squeezing parameter ξ 2 ( t ) (red solid) and the fixed-axis squeezing parameter ξ 2 y ( t ) (green solid) as functions of the dimensionless time χt . Gray solid and dotted curv es denote the QZE (O A T) e volution and the effecti ve T ACT benchmark, respectiv ely . The vertical gray line near χt ≃ 0 . 15 marks the reward-defined switching time t r . (c) Spin Wigner distributions at representati ve times t 1 – t 5 indicated in panel (b), cov ering the squeezing-generation and stabilization stages. Once the squeezing reaches the reference threshold ξ 2 ref , the agent applies the isolated R x ( π / 3) pulse at time t 3 in Fig. 2 (a), rotating the state toward an orientation where the fixed-axis squeezing ξ 2 y is close to its minimum. The control objectiv e then switches from squeezing generation to stabi- lization. Importantly , the learned protocol does not enter the final periodic cycle immediately after this rotation. Instead, as indicated by the additional R y ( − π / 4) pulse in Fig. 2 (a), the agent first rebalances the two states visited within one control period before settling into the subsequent alternating sequence of R y ( ± π / 2) pulses. This intermediate adjustment is essential. Although the state at t 3 already has a value of ξ 2 y close to the minimum of ξ 2 , a direct transition into a simple alternating R y ( ± π / 2) cycle would map a state oriented near the x axis close to the north or south pole, causing the other state visited in the same stabilization cycle to acquire a much larger value of ξ 2 y . The resulting protocol would therefore produce large oscil- lations of the measurement-relev ant squeezing. Instead, the learned policy balances the values of ξ 2 y between the two al- ternating states, primarily through the intermediate rotation close to R y ( − π / 4) . This mechanism is visualized by the W igner distributions at times t 4 and t 5 in Fig. 2 (c), which correspond to two successiv e states within the stabilized cy- cle. The corresponding fixed-axis squeezing values, ξ 2 y ( t 4 ) = − 4 . 03 dB and ξ 2 y ( t 5 ) = − 5 . 11 dB , show that the learned pol- icy maintains metrologically relev ant squeezing while keep- ing the cycle-to-cycle oscillation bounded. As a result, the fixed-axis squeezing exhibits only weak and bounded oscilla- tions throughout the stabilization stage, despite the continued action of the QZE term. The learned stabilization strategy dif fers qualitatively from the repeated- R x correction protocol of Ref. [ 36 ]. Instead, the PIRL agent identifies a mechanism based on alternating trans- verse R y rotations. Consider one elementary control cycle of duration dt = 2 δ t , e − iχδ t ˆ f 2 z R y ( − π / 2) e − iχδ t ˆ f 2 z R y ( π / 2) . (11) Under the two opposite R y pulses, the second free-ev olution interval is transformed as R y ( − π / 2) e − iχδ t ˆ f 2 z R y ( π / 2) = e − iχδ t ˆ f 2 x , (12) because R y ( − π / 2) ˆ f 2 z R y ( π / 2) = ˆ f 2 x . (13) One cycle therefore becomes e − iχδ t ˆ f 2 z e − iχδ t ˆ f 2 x = e − iχdt ( ˆ f 2 z + ˆ f 2 x )+ 1 2 ( χδ t ) 2 [ ˆ f 2 x , ˆ f 2 z ]+ O (( χδ t ) 3 ) . 5 0.00 0.05 0.10 0.15 0.20 0.25 0.30 t 0.0 0.2 0.4 0.6 0.8 1.0 F idelity CSS RL O A T T A CT Figure 3. Fidelity-based evidence for the toggling-frame stabi- lization mechanism. Fidelity ev olution for sev eral reference states. Solid and dashed curves denote ev olution under ˆ f 2 y and ˆ f 2 z , respec- tiv ely . The reference states are the coherent spin state | f , m x = f ⟩ , the PIRL state at t 3 , and the O A T and T A CT states at their respecti ve minima of ξ 2 . For the O A T and T ACT states, an additional R x rota- tion is applied so that ξ 2 y = ξ 2 . For the parameters used here, χδ t ∼ 10 − 3 , so the higher-order terms are negligible and the dynamics is well captured by the leading term. Using ˆ f 2 x + ˆ f 2 z = f ( f + 1) − ˆ f 2 y , we find that the ef fectiv e generator is proportional to − ˆ f 2 y , up to an irrelev ant constant. The alternating R y ( ± π / 2) pulses therefore suppress the direct distortion produced by ˆ f 2 z twist- ing and redirect the nonlinear ev olution into a form more com- patible with preserving the fixed-axis squeezing ξ 2 y . Since the effecti v e dynamics is dominated by a ˆ f 2 y -type term, its action is weak on states with small variance along ˆ f y . This picture is supported by the fidelity analysis in Fig. 3 . Under ˆ f 2 z ev olution, states with smaller ξ 2 y —and hence stronger anti-squeezing along ˆ f z —show faster fidelity decay , indicating greater susceptibility to QZE-induced distortion. By contrast, ev olution under ˆ f 2 y preserves both the PIRL- and T A CT -generated squeezed states much more effecti vely , con- sistent with the vie w that the learned protocol stabilizes the measurement-relev ant squeezed quadrature. B. Phase sensitivity and metr ological gain W e no w e v aluate the metrological performance of the PIRL protocol under fixed projecti ve readout of ˆ f y . In the stabiliza- tion regime, signal encoding proceeds under the learned peri- odic control cycle, which keeps the readout-relev ant squeez- ing axis stable throughout the interrogation. During the sensing stage, a weak signal is encoded as a small phase ϕ accumulated over an encoding time T e . The encoded state is | ψ enc ⟩ = N e Y k =1 h e − i ( χ ˆ f 2 z + ϕ T e ˆ f z ) δ t R y (( − 1) k π / 2) i | ψ t 4 ⟩ , (14) where | ψ t 4 ⟩ is the stabilized state at time t 4 in Fig. 2 (c), and N e = ⌈ T e /δ t ⌉ is the number of control steps during encoding. After encoding, the phase is read out from the spin projection ˆ f y . For small ϕ , the phase sensitivity is quantified by (∆ ϕ ) 2 = (∆ ˆ f y ) 2 | ∂ ϕ ⟨ ˆ f y ⟩| 2 , which equals the in verse classical Fisher information in the linear-response re gime [ 57 ]. Figure 4 (a) compares the SQL-relativ e phase sensitivity ∆ ϕ SQL / ∆ ϕ as a function of the dimensionless interrogation time χt . As references, we consider QZE ev olution from the T A CT -optimal squeezed state (blue), and the R x -pulse stabi- lization protocol (see Appendix C ) of Ref. [ 36 ] applied to the same initial state (green). The unified RL protocol (red) starts from the stabilized state at time t 4 in Fig. 2 (c). At short inter- rogation times, the blue and green curv es perform slightly bet- ter than the red one, because they start from the more strongly squeezed T A CT -optimal probe. This initial adv antage is short- liv ed: as the interrogation time increases and QZE-induced distortion accumulates, the freely ev olving squeezed probe (blue) drops below the SQL already around χt ≈ 0 . 02 , while the optimized R x protocol (green) remains above the SQL only up to about χt ≈ 0 . 05 before degrading rapidly . By con- trast, the unified RL protocol (red) keeps ∆ ϕ SQL / ∆ ϕ > 1 ov er a broad range of interrogation times, with only weak residual oscillations. Thus, once QZE-induced distortion be- comes appreciable, the stability provided by the unified RL control outweighs the larger initial squeezing of the reference probes. Figure 4 (b) shows the corresponding readout distributions P m ( ϕ ) . Panels 1 and 2 compare the initial probe states used for the free-QZE reference (blue) and the unified RL protocol (red), respectively , before ( ϕ = 0 , top) and after ( ϕ = 0 . 2 , bot- tom) phase encoding. Although the RL-prepared probe (red) is slightly less squeezed than the T A CT -optimal state (blue), its readout distrib ution remains narrow and close to Gaus- sian. Panels 3 and 4 sho w the corresponding distributions at χt ≈ 0 . 09 for the R x -pulse stabilization protocol (green) and the unified RL protocol (red), respectively . At this e volution time, the optimized R x protocol (green) produces a strongly distorted, non-Gaussian distribution, whereas the PIRL proto- col (red) preserves a narrow , approximately Gaussian profile. Accordingly , the error-propagation formula remains reliable for PIRL, but becomes inadequate once the readout statistics are strongly distorted. For a realistic 161 Dy atomic qudit in a bias magnetic field at the Earth-field scale, B 0 = 50 µ T , the rele vant param- eters are χ = (2 π ) 8 . 112 Hz and the gyromagnetic ratio γ = (2 π ) 13 . 24 GHz / T . T o quantify performance under a finite time budget, we conv ert the phase uncertainty into a magnetic-field sensitivity . Neglecting the readout time, the 6 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 t 4 2 0 2 4 6 8 10 2 0 l o g 1 0 ( / S Q L ) ( d B ) 1 2 3 4 (a) Unified RL contr ol QZE without contr ol QZE with DD 3 4 5 6 7 8 9 10 T t o t ( m s ) 3 2 1 0 1 2 3 2 0 l o g 1 0 ( B / B S Q L ) ( d B ) (c) Unified RL contr ol 0 10 20 30 T t o t ( m s ) 1 0 2 1 0 1 1 0 0 B ( n T / H z ) 0.0 0.5 P m ( ) 1 (b) = 0 5 0 5 m 0.0 0.5 P m ( ) = 0 . 2 2 = 0 5 0 5 m = 0 . 2 3 = 0 5 0 5 m = 0 . 2 4 = 0 5 0 5 m = 0 . 2 Figure 4. Metrological analysis of the PIRL strategy . (a) Phase sensitivity relativ e to the SQL, expressed in dB, as a function of the dimensionless interrogation time χt . Encoding under the unified RL control starting from the stabilized state at time t 4 in Fig. 2 (c) (red solid), QZE ev olution from the T ACT -optimal squeezed state (blue solid), and the same initial state under the R x -pulse stabilization protocol of Ref. [ 36 ] (green solid). The black dashed line denotes the SQL. (b) Readout distributions P m ( ϕ ) for representative probe states and control protocols. Panels 1 and 2 show the distributions before ( ϕ = 0 , top) and after ( ϕ = 0 . 2 , bottom) phase encoding for the initial states used in the blue and red curves of panel (a), respectively . Panels 3 and 4 show the corresponding distributions at χt ≈ 0 . 09 for the green and red curves in panel (a), respectiv ely . (c) Single-atom magnetic-field sensitivity relative to the SQL, expressed in dB, as a function of the total protocol time T tot . The shaded region indicates the preparation time T p , and the inset shows the absolute sensiti vity δ B ( T tot ) in nT / √ Hz . total protocol time is T tot = T p + T e , where T p is the fixed preparation time and T e is the encoding time. The single-atom magnetic-field sensitivity is δ B = ∆ B p T tot = ∆ ϕ √ T tot γ T e . (15) As a benchmark, we use the coherent-spin-state (CSS) stan- dard quantum limit (SQL), defined in the absence of QZE and with no preparation ov erhead, so that T tot = T e and δ B SQL ( T tot ) = 1 γ √ 2 f T tot , (16) where ∆ ϕ CSS = 1 / √ 2 f . Figure 4 (c) shows the SQL-relativ e magnetic-field sensi- tivity δ B SQL /δ B as a function of T tot . Because of the fi- nite preparation overhead, the unified RL protocol (red) is initially belo w the SQL. After the preparation cost is amor- tized, ho wev er , it surpasses the SQL at T tot ≈ 5 . 5 ms and continues to improve at longer times. The inset shows the absolute sensitivity δ B ( T tot ) , which reaches 13 . 9 pT / √ Hz at T tot = 30 ms , corresponding to an adv antage of approx- imately 3 dB beyond the standard quantum limit. For fixed χ , increasing T tot corresponds to stronger accumulated QZE effects, so the continued improvement demonstrates that the learned protocol preserves metrologically useful correlations ov er extended interrogation times. IV . SUMMAR Y AND OUTLOOK W e hav e shown that a unified RL control can con vert the intrinsic QZE nonlinearity of an atomic qudit from a metrological liability into a useful sensing resource. Under always-on nonlinear dynamics, the learned control rapidly generates strong internal spin squeezing and then stabilizes the measurement-relev ant quadrature through a simple pulse structure dominated by transverse rotations. This yields sus- tained phase sensitivity and, after accounting for the finite preparation ov erhead, a net magnetic-field sensiti vity beyond the SQL. Beyond its numerical performance, the learned strategy also admits a transparent physical interpretation. The stabi- lization stage is dominated by alternating R y ( ± π / 2) pulses, which ef fecti vely redirect the bare ˆ f 2 z nonlinear e v olution into a form more compatible with preserving the fixed-readout squeezing. In this sense, the unified RL control does not merely discover a black-box pulse sequence, but rather iden- tifies a physically meaningful control mechanism tailored to the always-on nonlinear dynamics. 7 The control principle is not restricted to the specific 161 Dy example studied here. Across dif ferent spin- f systems, inde- pendently trained agents consistently recov er the same qual- itativ e structure: a rapid squeezing stage followed by a sta- bilization stage under continued QZE evolution, although the detailed pulse sequences depend nontri vially on f . This indi- cates that the underlying mechanism is generic, while its op- timal implementation remains system dependent. Detailed re- sults for dif ferent spin- f systems are provided in Appendix D . More broadly , the present framew ork relies only on exper - imentally accessible low-order moments and realizable con- trol operations, and is therefore compatible with other high- spin atoms and, in principle, with more general effecti ve-spin models, including collective atomic ensembles. This opens a natural route tow ard combining internal squeezing control with interatomic entanglement generation in many-atom sen- sors, where additional metrological gain may become av ail- able [ 58 – 61 ]. It is also compatible with emerging platforms offering spatially resolved readout, which may enable paral- lelized and site-resolved quantum sensing [ 62 – 65 ]. Finally , the present w ork suggests a broader learning-based perspectiv e on quantum sensing with intrinsic nonlinear dy- namics. Here the re ward is b uilt from squeezing-based figures of merit, but the same framework can be extended to opti- mize sensing performance more directly . For example, when the signal has a prior distrib ution, one may train the controller against Bayesian posterior objectives rather than squeezing it- self, thereby shifting the target from state preparation to end- to-end metrological performance [ 66 – 68 ]. A CKNO WLEDGEMENTS W e thank Dr . Q. Liu for helpful discussions and insight- ful inputs. This work was supported by the National Natu- ral Science Foundation of China (No. 12304543), the Quan- tum Science and T echnology - National Science and T ech- nology Major Project (No. 2021ZD0302100), the Natural Science Foundation of Jiangsu Province (Nos. BK20250404 and BG2025017), the Y outh Science and T echnology T alent Support Program of Jiangsu Province (Nos. JSTJ-2024-507, JSTJ-2025-600 and JSTJ-2025-829), the Frontier T echnology Research Program of Suzhou (No. SYG202322), and the Post- graduate Research & Practice Innov ation Program of NU AA (No. xcxjh20252107). D A T A A V AILABILITY The data that support the findings of this study are publicly av ailable at [URL]. Additional information is av ailable from the corresponding author upon reasonable request. Appendix A: Gr ound-State Hyperfine Structure of Dy Atoms In the presence of an external magnetic field, the internal structure of a Dy atom is gov erned by the combined hyper - fine interaction between the electronic and nuclear angular momenta and their Zeeman couplings to the field. Denoting the nucleus and electron angular momenta by i and j , the full Hamiltonian is giv en by [ 69 ] ˆ H = A ˆ i · ˆ j + B 3 2 ˆ i · ˆ j 2 ˆ i · ˆ j + 1 − i ( i + 1) − j ( j + 1) 2 i (2 i − 1) j (2 j − 1) + g j µ B ˆ j z B + g i µ N ˆ i z B . (A1) where h is the Planck constant, A and B are the magnetic- dipole and electric-quadrupole hyperfine coefficients, g j and g i are the electron and nuclear Land ´ eg factors, and µ B and µ N are Bohr and nuclear magnetons, respectiv ely , B is the- magnetic field intensity . In this work, the leading magnetic field is assumed to be aligned along the laboratory z axis. W e focus on the isotope 161 Dy , whose ground state has j = 8 and i = 5 / 2 . The hyperfine interaction splits the ground state into manifolds labeled by the total angular momentum f . In this work, we restrict attention to the ground-state hy- perfine manifold with f = 21 / 2 . The large-spin adv antage of atomic spin systems has already enabled the realization of non-Gaussian and cat-like states for quantum-enhanced magnetometry with sensitivities approaching the Heisenberg limit [ 21 , 22 , 24 ]. In the weak-field re gime, the Zeeman ef fect is non- negligible to but smaller than the hyperfine splitting. As a con- sequence, the energy spectrum within a fixed hyperfine man- ifold exhibits nonlinear dependence on the magnetic quan- tum number m . After numerically diagonalizing Eq. ( A1 ) in the | f , m ⟩ basis for a given magnetic-field strength B , the eigenenergies E m can be accurately fitted by a quadratic ex- pansion, E m ≃ ℏ Ω L m + χm 2 , (A2) where Ω L is the Larmor frequency and χ is the QZE coeffi- cient, also referred to as the NLZ coefficient or quantum-beat revi v al frequency . For atoms with j = 1 / 2 , both Ω L and χ can be ob- tained analytically from the Breit–Rabi formula [ 70 ]. How- ev er , for high-spin atoms such as 161 Dy with j > 1 / 2 , no closed-form e xpression exists, and the numerical fit- ting is essential. For the leading magnetic field in Earth- field strengths around B 0 = 50 µ T , we obtain Ω L = (2 π ) 661 . 9 kHz , χ = (2 π ) 8 . 112 Hz . The Larmor frequency satisfies Ω L = γ B 0 , which corresponds to the gyromagnetic ratio γ = (2 π )13 . 24 GHz / T [ 71 ]. The internal dynamics are therefore well described by the Hamiltonian ˆ H = ℏ Ω L ˆ f z + χ ˆ f 2 z , (A3) where ˆ f z is the z -component of the total angular-momentum operator for a single atom. The quadratic term ∝ ˆ f 2 z giv es rise to intrinsic O A T dynamics, which plays a central role in both the generation of spin squeezing and the QZE-induced degra- dation of metrological performance discussed in the main text. 8 Appendix B: PPO algorithm W e train the PIRL agent using PPO, kno wn as an actor - critic algorithm. The agent is parameterized by a policy net- work π θ as an actor parameterized by θ , and a value network V w as a critic parameterized by w . The system state at the k th time step is the full quantum state | ψ k ⟩ of the atom, which ev olves deterministically ac- cording to the controlled Schr ¨ odinger dynamics in Eq. ( 5 ). Instead of accessing the full state, the agent receiv es an ob- servation o k defined in Eq. ( 7 ) at each discrete control step k , consisting of first moments and selected second moments of the spin operator . Based on o k , the policy samples an action a k from the discrete action set in Eq. ( 6 ), corresponding to experimentally accessible transverse rotations. The environ- ment then ev olves the underlying quantum state from | ψ k ⟩ to | ψ k +1 ⟩ , yielding the next observ ation o k +1 and a scalar re ward r k in Eq. ( 10 ). T ransitions ( o k , a k , r k , o k +1 ) are collected into a trajectory buf fer and used for subsequent updates. The value network outputs the state value V w ( o k ) , which estimates the expected return from observ ation o k ; these v alue estimates are then used to compute the generalized advantage estimation (GAE), ˆ A k = N t − k − 1 X l =0 ( γ RL ˆ λ ) l r k + l + γ RL V w ( o k + l +1 ) − V w ( o k + l ) , (B1) where γ RL ∈ (0 , 1) is the discount factor and ˆ λ is a hyperpa- rameter that controls the bias–variance trade-of f. The policy network is updated by maximizing the clipped objectiv e function L actor ( θ ) = E k h min η k ( θ ) ˆ A k , clip( η k ( θ ) , 1 − ϵ, 1 + ϵ ) ˆ A k i , (B2) with the probability ratio η k ( θ ) = π θ ( a k | o k ) π θ old ( a k | o k ) . (B3) The hyperparameter ϵ sets the clipping range for the policy ratio, which decreases the updating speed of the policy and improv es the learning stability . The value network is updated by minimizing the mean-squared error , L critic ( w ) = E k h min( V w ( o k ) − G k ) 2 i , (B4) with the discounted return G k = N t − k − 1 X l =0 γ l RL r k + l . (B5) The total loss minimized during training is L total = − L actor ( θ ) + c 1 L critic ( w ) − c 2 S ( π θ ) , (B6) where c 1 , c 2 are the hyperparameters that balance the three terms, and S ( π θ ) is the policy entropy that promotes explo- ration. Parameters are updated over multiple epochs for each batch of collected trajectories. T able I. Parameters used for PPO training and en vironment design. Parameter V alue PPO Actor learning rate 3 × 10 − 4 Critic learning rate 1 × 10 − 3 Discount factor γ 0 . 9999 GAE parameter ˆ λ 0 . 96 Clip parameter ϵ 0 . 2 V alue-loss weight c 1 0 . 5 Entropy weight c 2 0 . 01 Minibatch size 512 Update epochs 8 Max train steps 8 × 10 6 Buffer size 17920 Actor network MLP (128 , 128) Critic network MLP (128 , 128) En vironment / r eward spin f 21/2 T otal steps N t 70 T otal time χT 0 . 314 Bonus scale ζ 5 . 0 Decay rate κ 0 . 05 Stabilization weight α 0 . 05 Action penalty c ( a k ) 0 . 001 In our PIRL framework, the rew ard function is well de- signed to guide the agent to achiev e both spin squeezing and stabilization. For this purposes,we choose ξ 2 ( t ) and ξ 2 y ( t ) as the reward metrics, and introduce hyperparameters ζ , κ, α to stabilize and accelerate the training process. T o discourage the agent from taking unnecessary actions, we include a small penalty term c ( a k ) in the reward function. The parameters used for training in the Results section are listed in T able I . Appendix C: Spin stabilization with DD pulses As a reference strategy for comparison with the PIRL pro- tocol, we consider a spin-stabilization scheme which incorpo- rates a dynamic decoupling (DD) sequence optimized by ma- chine learning [ 36 ]. In this scheme, the initial state is chosen as the T ACT -optimal squeezed state after an additional R x ro- tation such that ξ 2 y = ξ 2 . Same as the PIRL protocol, the encoding time T e is predefined and discretized with time step δ t = T e / N e . At each discrete time step of duration δ t , the system first an instantaneous rotation about the x axis and is then subjected to undergoes QZE ev olution. The state update at the k th step is | ψ k +1 ⟩ = e − iχdt ˆ f 2 z e − iβ k ˆ f x | ψ k ⟩ , (C1) where β k is the rotation angle applied at the k th step. For a fair comparison with the discrete PIRL protocol, we use the same time step δ t . The rotation angle β k is arbitrary theoretically , while considering the running speed of the algorithm, β k is set to be nπ / 48 , and the domain is set to [0 , π / 3] . In contrast 9 to PIRL, this scheme is formulated as a con ventional param- eter optimization problem over the finite set { β k } . The op- timization is performed using the differential ev olution (DE) algorithm [ 72 – 74 ]. The cost function is defined as the a verage value of the fixed-axis squeezing parameter during the encod- ing stage, C = 1 N e N e X k =1 ξ 2 y ( k ) , (C2) where N e is the total number of discrete steps in the encoding stage. Appendix D: Adaptability acr oss different spin- f systems T o assess the adaptability of the PIRL framew ork, we in- dependently train the agent for a range of spin- f systems and compare the resulting squeezing performance and character- istic time scales. In all cases, the learned protocol e xhibits the same qualitati ve two-stage structure: it first generates squeez- ing close to the ef fectiv e T ACT benchmark and then stabilizes the fixed-axis squeezing ξ 2 y within a narrow oscillation win- dow under continued QZE ev olution, typically through alter- nating R y ( ± π / 2) pulses. Quantitativ ely , the stabilized value of ξ 2 y decreases ov erall with increasing f . For f = 25 / 2 , cor- responding to a metastable state of Dy [ 75 ], the protocol sta- bilizes ξ 2 y at − 5 . 14 dB ; for the larger spin f = 16 , it reaches − 6 . 31 dB , approaching the regime relev ant to collective-spin squeezing in larger effectiv e-spin systems. The associated time scales show that the PIRL protocol enters the stabilized- ξ 2 y regime earlier than the ef fectiv e T A CT model reaches its optimal squeezing. Overall, these results sho w that the learned strategies are not simple copies of a single pulse pattern: while the stabilization stage is generally dominated by alternating R y ( ± π / 2) pulses, the squeezing stage and the onset of stabi- lization vary noticeably with f , highlighting the adv antage of adaptiv e learning-based control. [1] D. F . Jackson Kimball, J. Dudley , Y . Li, D. P atel, and J. V aldez, Constraints on long-range spin-gravity and monopole-dipole couplings of the proton, Physical Re view D 96 , 075004 (2017) . [2] Z. W ang, X. Peng, R. Zhang, H. Luo, J. Li, Z. Xiong, S. W ang, and H. Guo, Single-species atomic comagnetometer based on rb 87 atoms, Physical Re view Letters 124 , 193002 (2020) . [3] M. A. Fedderke, P . W . Graham, D. F . Jackson Kimball, and S. Kalia, Earth as a transducer for dark-photon dark-matter de- tection, Physical Re view D 104 , 075023 (2021) . [4] M. A. Fedderke, P . W . Graham, D. F . Jackson Kimball, and S. Kalia, Search for dark-photon dark matter in the super- mag geomagnetic field dataset, Physical Revie w D 104 , 095032 (2021) . [5] A. Arza, M. A. Fedderke, P . W . Graham, D. F . Jackson Kim- ball, and S. Kalia, Earth as a transducer for axion dark-matter detection, Physical Re view D 105 , 095007 (2022) . [6] T . Sander , J. Preusser , R. Mhaskar, J. Kitching, L. T rahms, and S. Knappe, Magnetoencephalography with a chip-scale atomic magnetometer , Biomedical optics express 3 , 981 (2012) . [7] K. Kamada, D. Sato, Y . Ito, H. Natsuka wa, K. Okano, N. Mizu- tani, and T . K obayashi, Human magnetoencephalogram mea- surements using newly developed compact module of high- sensitivity atomic magnetometer, Japanese Journal of Applied Physics 54 , 026601 (2015) . [8] K. He, S. W an, J. Sheng, D. Liu, C. W ang, D. Li, L. Qin, S. Luo, J. Qin, and J.-H. Gao, A high-performance compact magnetic shield for optically pumped magnetometer-based magnetoen- cephalography , Revie w of Scientific Instruments 90 (2019) . [9] R. Zhang, W . Xiao, Y . Ding, Y . Feng, X. Peng, L. Shen, C. Sun, T . Wu, Y . Wu, Y . Y ang, et al. , Recording brain activities in unshielded earth’ s field with optically pumped atomic magne- tometers, Science Advances 6 , eaba8792 (2020) . [10] A. Canciani and J. Raquet, Absolute positioning using the earth’ s magnetic anomaly field, NA VIGA TION: Journal of the Institute of Navigation 63 , 111 (2016) . [11] A. Canciani and J. Raquet, Airborne magnetic anomaly navi- gation, IEEE T ransactions on aerospace and electronic systems 53 , 67 (2017) . [12] A. Gnadt, Machine learning-enhanced magnetic calibration for airborne magnetic anomaly navigation, in AIAA SciT ech 2022 forum (2022) p. 1760. [13] R. Zhang, D. Kanta, A. Wickenbrock, H. Guo, and D. Budker , Heading-error-free optical atomic magnetometry in the earth- field range, Physical Re view Letters 130 , 153601 (2023) . [14] W . Xiao, M. Liu, T . W u, X. Peng, and H. Guo, Femtotesla atomic magnetometer employing diffusion optical pumping to search for exotic spin-dependent interactions, Physical Revie w Letters 130 , 143201 (2023) . [15] L. Lei, T . Wu, and H. Guo, Sensitivity of quantum magnetic sensing, National Science Revie w 12 , nwaf129 (2025) . [16] L. Pezze, A. Smerzi, M. K. Oberthaler , R. Schmied, and P . Treutlein, Quantum metrology with nonclassical states of atomic ensembles, Revie ws of Modern Physics 90 , 035005 (2018) . [17] J. Huang, M. Zhuang, and C. Lee, Entanglement-enhanced quantum metrology: From standard quantum limit to heisen- berg limit, Appl. Phys. Re v . 11 , 031302 (2024) . [18] V . Montenegro, C. Mukhopadhyay , R. Y ousefjani, S. Sarkar, U. Mishra, M. G. Paris, and A. Bayat, Review: Quantum metrology and sensing with many-body systems, Phys. Rep. 1134 , 1 (2025) . [19] T . Fernholz, H. Krauter , K. Jensen, J. F . Sherson, A. S. Sørensen, and E. S. Polzik, Spin Squeezing of Atomic Ensem- bles via Nuclear-Electronic Spin Entanglement, Phys. Re v . Lett. 101 , 073601 (2008) . [20] Z. Kurucz and K. Mølmer, Multilevel holstein-primakof f ap- proximation and its application to atomic spin squeezing and ensemble quantum memories, Phys. Re v . A 81 , 032314 (2010) . [21] T . Chalopin, C. Bouazza, A. Evrard, V . Makhalov , D. Dreon, J. Dalibard, L. A. Sidorenko v , and S. Nascimbene, Quantum- enhanced sensing using non-classical spin states of a highly magnetic atom, Nature communications 9 , 4955 (2018) . [22] A. Evrard, V . Makhalov , T . Chalopin, L. A. Sidorenk ov , J. Dal- ibard, R. Lopes, and S. Nascimbene, Enhanced magnetic sensi- tivity with non-gaussian quantum fluctuations, Phys. Rev . Lett. 122 , 173601 (2019) . 10 [23] T . Satoor, A. Fabre, J.-B. Bouhiron, A. Evrard, R. Lopes, and S. Nascimbene, P artitioning dysprosium’ s electronic spin to re- veal entanglement in nonclassical states, Phys. Rev . Res. 3 , 043001 (2021) . [24] Y . Y ang, W .-T . Luo, J.-L. Zhang, S.-Z. W ang, C.-L. Zou, T . Xia, and Z.-T . Lu, Minute-scale schr ¨ odinger-cat state of spin-5/2 atoms, Nature Photonics 19 , 89 (2025) . [25] M. Kitagawa and M. Ueda, Squeezed spin states, Physical Re- view A 47 , 5138 (1993) . [26] M. A. Norcia and F . Ferlaino, Dev elopments in atomic control using ultracold magnetic lanthanides, Nature Physics 17 , 1349 (2021) . [27] V . Acosta, M. Ledbetter , S. Rochester , D. Budker , D. Jack- son Kimball, D. Hovde, W . Gawlik, S. Pustelny , J. Za- chorowski, and V . Y ashchuk, Nonlinear magneto-optical rota- tion with frequency-modulated light in the geophysical field range, Physical Revie w A—Atomic, Molecular, and Optical Physics 73 , 053404 (2006) . [28] D. Budker and M. Romalis, Optical magnetometry , Nature physics 3 , 227 (2007) . [29] S. Seltzer, P . Meares, and M. Romalis, Synchronous optical pumping of quantum reviv al beats for atomic magnetometry , Physical Revie w A—Atomic, Molecular , and Optical Physics 75 , 051407 (2007) . [30] K. Jensen, V . Acosta, J. Higbie, M. Ledbetter , S. Rochester , and D. Budker , Cancellation of nonlinear zeeman shifts with light shifts, Physical Re view A—Atomic, Molecular , and Opti- cal Physics 79 , 023406 (2009) . [31] W . W asile wski, K. Jensen, H. Krauter , J. J. Renema, M. Balabas, and E. S. Polzik, Quantum noise limited and entanglement-assisted magnetometry , Physical Revie w Letters 104 , 133601 (2010) . [32] G. Bao, A. Wick enbrock, S. Rochester , W . Zhang, and D. Bud- ker , Suppression of the nonlinear zeeman effect and heading error in earth-field-range alkali-vapor magnetometers, Physical revie w letters 120 , 033202 (2018) . [33] P . Y ang, G. Bao, L. Chen, and W . Zhang, Coherence protec- tion of electron spin in earth-field range by all-optical dynamic decoupling, Physical Re view Applied 16 , 014045 (2021) . [34] W . Lee, V . Lucivero, M. Romalis, M. Limes, E. Foley , and T . K ornack, Heading errors in all-optical alkali-metal-vapor magnetometers in geomagnetic fields, Physical Revie w A 103 , 063103 (2021) . [35] G. Bao, D. Kanta, D. Antypas, S. Rochester , K. Jensen, W . Zhang, A. W ickenbrock, and D. Budker , All-optical spin locking in alkali-metal-vapor magnetometers, Physical Revie w A 105 , 043109 (2022) . [36] P . Y ang, G. Bao, J. Chen, W . Du, J. Guo, and W . Zhang, Quan- tum locking of intrinsic spin squeezed state in earth-field-range magnetometry , npj Quantum Information 11 , 36 (2025) . [37] X. Meng, Y . Zhang, X. Zhang, S. Jin, T . W ang, L. Jiang, L. Xiao, S. Jia, and Y . Xiao, Machine learning assisted vec- tor atomic magnetometry , Nature Communications 14 , 6105 (2023) . [38] J. Duan, Z. Hu, X. Lu, L. Xiao, S. Jia, K. Mølmer , and Y . Xiao, Concurrent spin squeezing and field tracking with machine learning, Nature Physics 21 , 909 (2025) . [39] C. Banerjee, K. Nguyen, C. Fookes, and M. Raissi, A sur- ve y on physics informed reinforcement learning: Revie w and open problems, Expert Systems with Applications 287 , 128166 (2025) . [40] D. J. W ineland, J. J. Bollinger , W . M. Itano, F . Moore, and D. J. Heinzen, Spin squeezing and reduced quantum noise in spec- troscopy , Physical Revie w A 46 , R6797 (1992) . [41] Y . Liu, Z. Xu, G. Jin, and L. Y ou, Spin squeezing: Transforming one-axis twisting into two-axis twisting, Physical re view letters 107 , 013601 (2011) . [42] F . Chen, J.-J. Chen, L.-N. W u, Y .-C. Liu, and L. Y ou, Extreme spin squeezing from deep reinforcement learning, Physical Re- view A 100 , 041801 (2019) . [43] K. C. Cox, G. P . Gre ve, J. M. W einer, and J. K. Thompson, De- terministic squeezed states with collective measurements and feedback, Physical re view letters 116 , 093602 (2016) . [44] O. Hosten, N. J. Engelsen, R. Krishnakumar , and M. A. Ka- sevich, Measurement noise 100 times lowe r than the quantum- projection limit using entangled atoms, Nature 529 , 505 (2016) . [45] E. Pedrozo-Pe ˜ nafiel, S. Colombo, C. Shu, A. F . Adiyatullin, Z. Li, E. Mendez, B. Braverman, A. Kawasaki, D. Akamatsu, Y . Xiao, et al. , Entanglement on an optical atomic-clock transi- tion, Nature 588 , 414 (2020) . [46] J. M. Robinson, M. Miklos, Y . M. Tso, C. J. Kennedy , T . Both- well, D. Kedar , J. K. Thompson, and J. Y e, Direct comparison of two spin-squeezed optical clock ensembles at the 10- 17 level, Nature Physics 20 , 208 (2024) . [47] J. Schulman, F . W olski, P . Dhariwal, A. Radford, and O. Klimov , Proximal policy optimization algorithms, arXiv preprint arXiv:1707.06347 (2017) . [48] Y . W ang, H. He, and X. T an, Truly proximal policy optimiza- tion, in Uncertainty in artificial intelligence (PMLR, 2020) pp. 113–122. [49] Y . Gu, Y . Cheng, C. P . Chen, and X. W ang, Proximal policy optimization with policy feedback, IEEE Transactions on Sys- tems, Man, and Cybernetics: Systems 52 , 4600 (2021) . [50] V . K onda and J. Tsitsiklis, Actor -critic algorithms, Adv ances in neural information processing systems 12 (1999) . [51] I. Grondman, L. Busoniu, G. A. Lopes, and R. Babuska, A sur - ve y of actor-critic reinforcement learning: Standard and natural policy gradients, IEEE T ransactions on Systems, Man, and Cy- bernetics, part C (applications and revie ws) 42 , 1291 (2012) . [52] M. Bukov and F . Marquardt, Reinforcement learning for quan- tum technology , arXiv preprint arXiv:2601.18953 (2026) . [53] J. Y ao, L. Lin, and M. Bukov , Reinforcement learning for many- body ground-state preparation inspired by counterdiabatic driv- ing, Physical Re view X 11 , 031070 (2021) . [54] S. Li, Y . Fan, X. Li, X. Ruan, Q. Zhao, Z. Peng, R.-B. Wu, J. Zhang, and P . Song, Rob ust quantum control using reinforce- ment learning from demonstration, npj Quantum Information 11 , 124 (2025) . [55] R. Porotti, A. Essig, B. Huard, and F . Marquardt, Deep rein- forcement learning for quantum state preparation with weak nonlinear measurements, Quantum 6 , 747 (2022) . [56] R. Porotti, D. T amascelli, M. Restelli, and E. Prati, Coherent transport of quantum states by deep reinforcement learning, Communications Physics 2 , 61 (2019) . [57] A. J. Hayes, S. Dooley , W . J. Munro, K. Nemoto, and J. Dun- ningham, Making the most of time in quantum metrology: con- current state preparation and sensing, Quantum Science and T echnology 3 , 035007 (2018) . [58] Z. Kurucz and K. Mølmer, Multilevel holstein-primakof f ap- proximation and its application to atomic spin squeezing and ensemble quantum memories, Physical Re view A—Atomic, Molecular , and Optical Physics 81 , 032314 (2010) . [59] L. M. Norris, C. M. Trail, P . S. Jessen, and I. H. Deutsch, En- hanced squeezing of a collective spin via control of its qudit subsystems, Physical re view letters 109 , 173603 (2012) . [60] Y . Zhang, S. Jin, J. Duan, K. Mølmer , G. Zhang, M. W ang, and Y . Xiao, Cooperativ e squeezing of internal and collective spins in an atomic ensemble, Phys. Re v . Lett. 135 , 213604 (2025) . 11 [61] Z. Hu, Y . Zhang, J. Duan, M. W ang, and Y . Xiao, Enhancing collectiv e spin squeezing via one-axis twisting echo control of individual atoms (2026), arXi v:2602.14036 [quant-ph] . [62] S. Antonijevic and S. W imperis, Refocussing of chemical and paramagnetic shift anisotropies in 2h nmr using the quadrupolar-echo experiment, Journal of Magnetic Resonance 164 , 343 (2003) . [63] R. Shani v , N. Akerman, T . Manovitz, Y . Shapira, and R. Ozeri, Quadrupole shift cancellation using dynamic decoupling, Phys- ical Revie w Letters 122 , 223204 (2019) . [64] T . Na Narong, H. Li, J. T ong, M. Due ˜ nas, and L. Hollberg, Quantum states imaging of magnetic field contours based on autler-to wnes effect in ytterbium atoms, Phys. Rev . Lett. 134 , 193201 (2025) . [65] Y .-W . Zhang, D.-S. Xiang, R. Liao, H.-X. Liu, B. Xu, P . Zhou, Y . Zhou, K. Zhang, and L. Li, Microwa ve electrometry with quantum-limited resolutions in a rydberg-atom array , Phys. Rev . Lett. 136 , 110802 (2026) . [66] R. Kaubruegger , D. V . V asilyev , M. Schulte, K. Hammerer, and P . Zoller, Quantum variational optimization of ramsey interfer- ometry and atomic clocks, Phys. Re v . X 11 , 041045 (2021) . [67] Q. Liu, M. Xue, M. Radzihovsky , X. Li, D. V . V asilyev , L.-N. W u, and V . V uleti ´ c, Enhancing dynamic range of sub- standard-quantum-limit measurements via quantum deamplifi- cation, Phys. Re v . Lett. 135 , 040801 (2025) . [68] Z. Ma, C. Han, Z. T an, H. He, S. Shi, X. Kang, J. W u, J. Huang, B. Lu, and C. Lee, Adaptiv e cold-atom magnetometry mitigat- ing the trade-off between sensitivity and dynamic range, Sci- ence Advances 11 , eadt3938 (2025) . [69] A. Corney , Atomic and Laser Spectroscopy (Oxford Univ ersity Press, 2006). [70] G. Breit and I. I. Rabi, Measurement of nuclear spin, Physical Revie w 38 , 2082 (1931) . [71] M. Lu, N. Q. Burdick, and B. L. Lev , Quantum degenerate dipo- lar fermi gas, Physical Re view Letters 108 , 215301 (2012) . [72] R. Storn and K. Price, Differential e volution–a simple and effi- cient heuristic for global optimization over continuous spaces, Journal of global optimization 11 , 341 (1997) . [73] N. B. Lovett, C. Crosnier, M. Perarnau-Llobet, and B. C. Sanders, Differential evolution for many-particle adaptive quantum metrology , arXiv preprint arXiv:1304.2246 (2013) . [74] X. Y ang, J. Li, and X. Peng, An impro ved dif ferential e volution algorithm for learning high-fidelity quantum controls, Science Bulletin 64 , 1402 (2019) . [75] D. Budker , D. DeMille, E. D. Commins, and M. S. Zolotorev , Experimental in vestigation of excited states in atomic dyspro- sium, Phys. Re v . A 50 , 132 (1994) .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment