내부 스핀 압축을 위한 통합 제어와 원자 퀀텀 센서 메타로노미 향상
본 논문은 비선형 제우머 효과(NLZ)를 활용해 원자 퀀텀 비트(f=21/2) 내부에서 스핀 압축을 생성·안정화하는 물리‑정보 강화학습(PIRL) 방법을 제시한다. 저차 스핀 모멘트만을 관측값으로 사용해 학습된 정책은 초기 급속 압축 후 교대형 R_y 펄스를 통해 압축 축을 고정시켜 4 dB 이상의 고정축 스핀 압축을 유지한다. 전체 프로토콜을 포함한 감도는 13.9 pT/√Hz이며, 표준 양자 한계 대비 약 3 dB의 메타로노미 이득을 제공한…
저자: C. Z. Cao, J. Z. Han, M. Xiong
본 논문은 저자들이 원자 퀀텀 비트(f=21/2)에서 비선형 제우머(NLZ) 효과가 내재된 상황을 메타로노미 자원으로 전환하기 위해 물리‑정보 강화학습(PIRL) 접근법을 제시한 연구이다. 서론에서는 원자 자기계측의 최신 동향과 양자 향상된 메타로노미의 필요성을 언급하고, 다중 레벨 원자에서 내부 자유도를 이용한 스핀 압축이 최근 실험적으로 입증되었지만, 실제 저자속(지구 자기장) 환경에서는 NLZ가 항상 켜져 있어 압축 축이 회전하고 과도한 뒤틀림이 발생해 고정된 읽기축에 대한 메타로노미 이득이 급격히 감소한다는 문제점을 제시한다. 기존의 보상·스핀‑잠금·단계적 제어 방법은 NLZ를 억제하거나 별도 단계로 압축과 측정을 분리했지만, NLZ를 끌 수 없는 현실에서는 연속적인 제어가 필수적이다.
이에 저자들은 NLZ와 전이 마이크로파 회전이 교대로 적용되는 스토크라스틱 모델을 정의하고, 이를 강화학습 문제로 변환한다. 시스템 해밀토니안은 H_QZE = χ f_z²와 제어 항 H_ctrl = λ( f_x cosφ + f_y sinφ ) 로 구성되며, 시간은 N_t 개의 작은 구간 δt 로 이산화된다. 각 구간에서 에이전트는 R_μ(β) 회전(μ∈{x,y}, β∈{±π/2,±π/3,±π/4}) 혹은 무동작을 선택한다. 관측값은 ⟨f_x⟩/f, ⟨f_y⟩/f, ⟨f_z⟩/f, ⟨f_x²⟩/f², ⟨f_y²⟩/f² 로 제한해 실험적 측정 가능성을 확보하고, 차원 독립성을 확보한다.
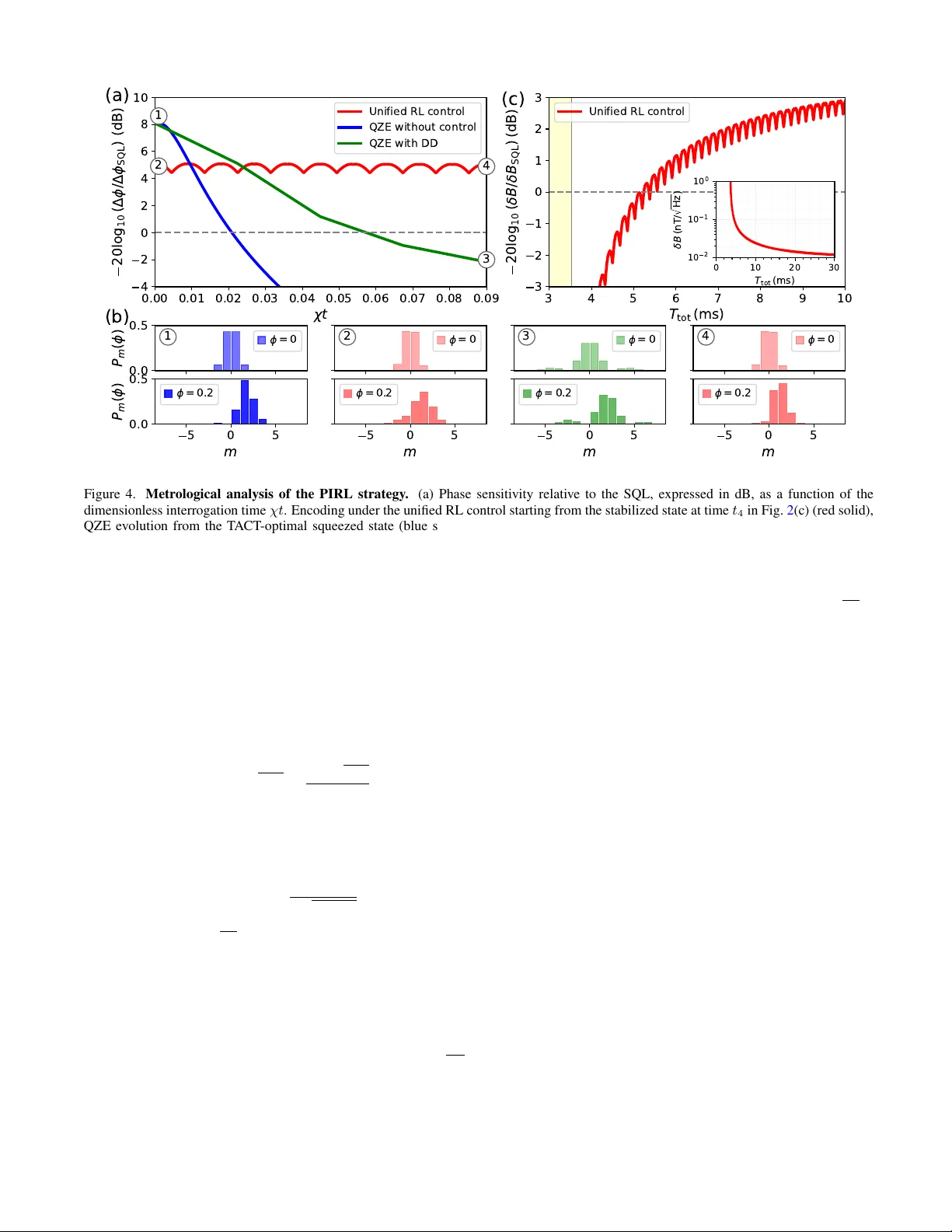
보상 설계는 두 단계 목표를 반영한다. 첫 단계에서는 Wineland 파라미터 ξ²가 목표값 ξ²_ref(이론적 TACT 최적값) 이하가 될 때까지 log ξ² 감소량을 보상하고 펄스 사용 비용 c(a_k)를 차감한다. 목표 달성 시점 k*에서는 ζ·e^{−κk*} 보너스를 주어 빠른 도달을 장려한다. 두 번째 단계에서는 고정축 압축 ξ_y²를 직접 최소화하는 보상(−α log ξ_y²)을 적용해 측정에 최적화된 상태를 유지한다. 이러한 보상 구조는 에이전트가 압축‑생성 및 압축‑안정화라는 두 단계 전략을 자연스럽게 학습하도록 만든다.
학습에는 PPO 기반 Actor‑Critic 네트워크를 사용했으며, 정책 네트워크는 관측값을 입력받아 행동 확률을 출력하고, 가치 네트워크는 기대 누적 보상을 추정한다. 학습 결과는 명확한 두 단계 구조를 보인다. 초기 3개의 R_y(±π/2) 쌍 펄스는 NLZ에 의한 과도한 뒤틀림을 억제하면서 OAT에 근접한 −8 dB 수준의 압축을 빠르게 달성한다. 이후 R_x(π/3) 펄스로 압축 축을 y축에 가깝게 회전시킨 뒤, 추가적인 R_y(−π/4) 펄스로 두 상태 사이의 비대칭을 보정한다. 최종적으로는 R_y(±π/2) 교대 펄스가 주기적으로 적용되어, 토글링 프레임에서 ˆf_z²와 ˆf_x²가 번갈아 작용함으로써 효과적인 생성자는 ˆf_y²가 된다. 이는 ˆf_y²가 고정축 압축을 담당하도록 만들며, 과도한 축 회전을 억제한다는 점에서 기존의 R_x 보정 방식과 근본적으로 다르다.
시뮬레이션을 통해 고정축 스핀 압축 ξ_y²가 −4 dB 수준을 지속적으로 유지함을 확인했으며, 전체 프로토콜(준비 단계 포함)의 단일 원자 감도는 13.9 pT/√Hz, 즉 표준 양자 한계 대비 약 3 dB의 메타로노미 이득을 제공한다. 또한, 학습된 정책은 저차 모멘트만을 사용해도 충분히 높은 성능을 달성했으며, 정책 자체가 물리적으로 해석 가능한 구조를 가지고 있어 실험 구현이 용이함을 강조한다. 논문은 이러한 학습 기반 제어가 다중 레벨 원자 센서에서 불가피한 비선형 동역학을 활용해 실용적인 메타로노미 향상을 이루는 실질적인 경로임을 제시한다. 마지막으로, 향후 연구 방향으로는 다중 원자 집합체에 대한 확장, 잡음 및 비이상성 고려, 그리고 실시간 피드백과 결합한 하이브리드 제어 전략을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기