Merge and Conquer: Instructing Multilingual Models by Adding Target Language Weights
Large Language Models (LLMs) remain heavily centered on English, with limited performance in low-resource languages. Existing adaptation approaches, such as continual pre-training, demand significant computational resources. In the case of instructed…
Authors: Eneko Valero, Maria Ribalta i Albado, Oscar Sainz
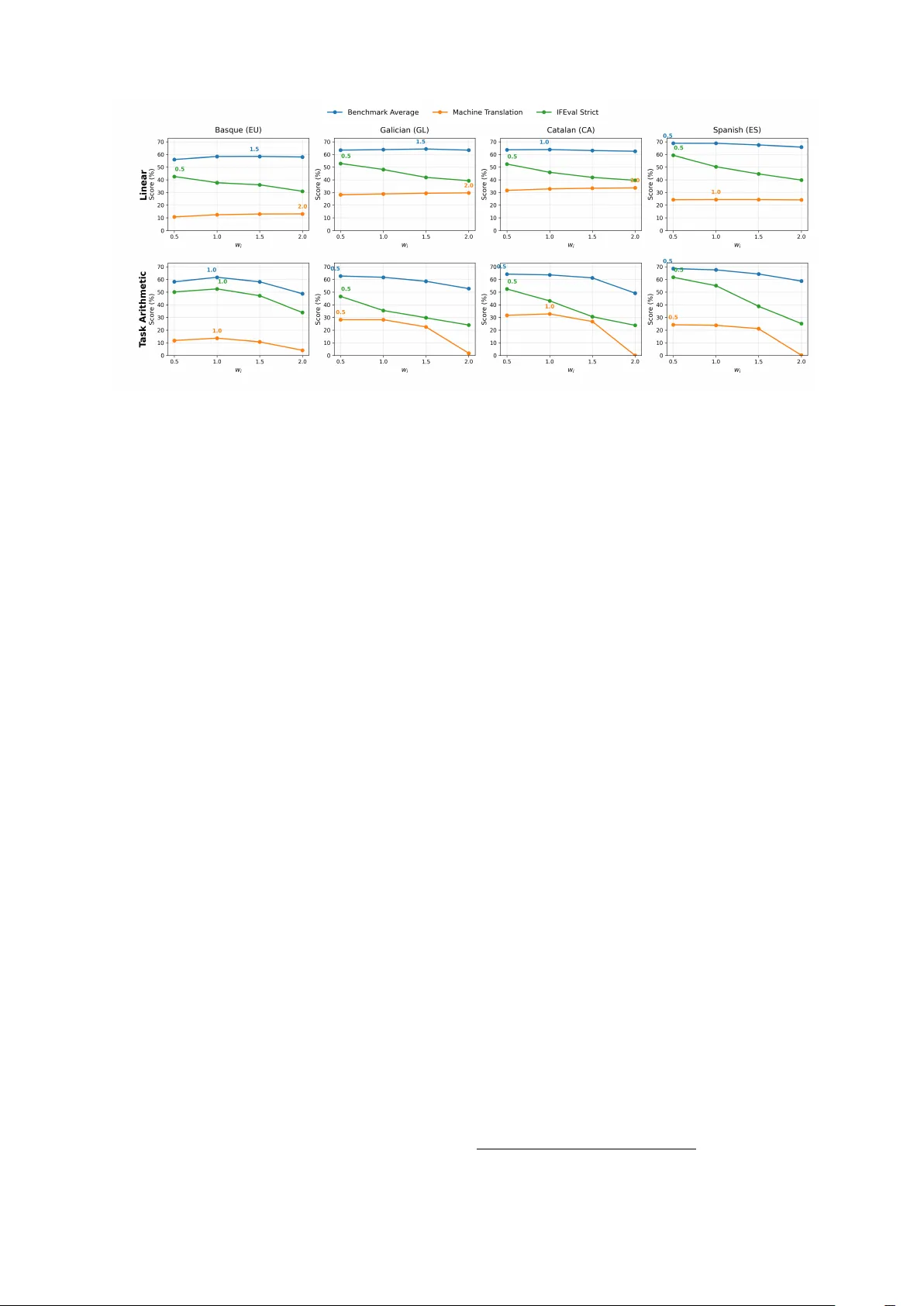
Merge and Conquer : Instructing Multilingual Models by Adding T arget Languag e Weights Eneko V alero, Maria Ribalta i Albado, Oscar Sainz, N aiara Perez, German Rigau HiTZ Center - Ix a, University of the Basque Country UPV/EHU {name.surname}@ehu.eus Abstract Large Language Models (LLMs) remain hea vily centered on English, with limited per formance in low-resource languages. Existing adaptation approaches, such as continual pre-training, demand significant computational resources. In the case of instructed models, high-quality instruction data is also required, both of which are of ten inaccessible for low-resour ce language communities. Under these constraints, model merging offers a lightweight alternativ e, but its potential in low-resource contexts has not been systematically explored. In this work, we explor e whet her it is possible to transfer language knowledge to an instruction-tuned LLM by merging it with a language-specific base model, thereby eliminating the need of language-specific instructions and repeated fine-tuning processes whenever stronger instructed variants become av ailable. Through experiments covering four Iberian languages (Basque, Catalan, Galician, and Spanish) and two model families, we show that merging enables effective instruction-following behavior in new languages and even supports multilingual capability through the combination of multiple language-specific models. Our results indicate that model merging is a viable and efficient alternative to traditional adaptation methods for low-resource languages, achieving competitiv e per formance while greatly reducing computational cost. Ke ywords: Evaluation Methodologies, Language Modeling, Less-Resourced/Endangered Languages, Mul- tilinguality 1. Introduction Recent advances in Large Language Models (LLMs) have significantly improv ed their multilin- gual capabilities. Modern LLMs, particularly those deploy ed as commercial products, are generally expect ed to under stand and generate te xt in high- resource languages such as English, Chinese, and Spanish. Howe ver , this performance does no t ext end uniforml y across all languages. For low- resource languages, especially those with limited online presence, LLMs continue to exhibit substan- tial performance degradation, ev en in state-of-the- ar t models ( Moroni et al. , 2025 ; Baucells et al. , 2025 ; Grandury et al. , 2025 ). This disparity can be attributed to both the scarcity of training data and the limited economic incentiv es to suppor t these languages, resulting in inconsistent and of ten unreli- able behavior from frontier models. In an attempt to improv e the LLM capabilities for cer tain languages, sev eral works hav e presented different approaches, mainly based on continual pre-training, to adapt al- ready trained LLMs to low-r esource languages ( Etx- aniz et al. , 2024b ; Üstün et al. , 2024 ). The emergence of instruction-tuned and aligned LLMs has fur ther raised the bar for low-resource model dev elopment. Be yond requiring large-scale corpora in the target language, these models also depend on high-quality instruction–response pairs to guide beha vior during fine-tuning. For lo w- resource languages, already constrained by limited te xtual data, curating such instruction datasets is par ticularly challenging, and, in some cases, prac- tically infeasible. Fortunately , recent work demon- strat es that combining target-language cor pora with English-language instructions can yield competitiv e models for low-resource languages ( Sainz et al. , 2025 ). Howe ver , this approach introduces a new bottleneck: each time a more capable instructed model is released, the target language community must repeat the adaptation process through contin- ued pretraining or fine-tuning. As with data av ail- ability , computational resources are of ten scarce in these communities, fur ther limiting their ability to keep pace with rapid advancements in LLM dev el- opment. Motiv ated by the goal of enhancing LLM capa- bilities in low-resour ce languages while simultane- ously reducing the substantial computational cost typically required, this paper e xplores the use of model merging techniques as a more compute ef- ficient alternativ e to joint pre-training ( Sainz et al. , 2025 ). Specificall y , we investig ate whether it is possible to teach a new language to an already instructed LLM through weight merging. That is, we aim for a model as proficient in the target lan- guage as the language-specific base model, while maintaining the instruction following capabilities of the instructed variant. This approach allows adapt- ing any newly released and potentiall y stronger in- structed variant of a base LLM to a target language, while requiring the base model to be trained on that language only once . Our e xperiments, con- ducted on four languages with varying resource lev els (namely , Basque, Galician, Catalan, and Spanish) and across two model families, demon- strate that this is indeed feasible. Moreov er , we show that a single LLM can acquire multiple lan- guages by merging sev eral language-specific mod- els. In addition, to evaluat e the instruction-follo wing competence of the merged models, we ext ended the IFEval ( Zhou et al. , 2023 ) benchmar k currently av ailable to Spanish and Catalan, to Basque and Galician languages. In sum, this paper mak es the following contri- butions. First, we demonstrate that it is possible to dev elop language-specific instructed LLMs by merging language-specific base models with gen- eral instructed models. Second, we conduct an in-depth analysis of the behavior of various merg- ing techniques and hyperparamet er configurations within our setup. Finally , we release both base and instructed models for Basque, Galician, Catalan, and Spanish developed during our experiments; and, the Basque version of the IFEval dataset. 1 2. Related Work Dev eloping LLMs for under -resourced languages remains a major challenge due to the extensiv e data and computational requirements that are needed to pre-train and post-train models from scratch. As a result, most research has moved to- wards multilingual pretraining, where a single model is exposed to data from many languages ( Le Scao et al. , 2022 ; Shliazhk o et al. , 2024 ). While this strat- egy provides broad cov erage, the percentage of data destined to low-resource languages is usu- ally insignificant, and of ten results in poor per for - mance ( González et al. , 2026 ; Bao et al. , 2023 ). This imbalance is clear in large-scale web corpora: according to Common Crawl statistics, 2 English alone accounts for nearly half of the available te xt, whereas Basque represents barely 0.03%, placing it under the low-resource categor y . This unev en dis- tribution explains the limited per formance of multilin- gual LLMs on Iberian languages despite their broad cov erage. As obser v ed in recent work, Spanish en- joy s abundant resources, while Basque, Galician, and Catalan remain largely under -represented, lim- iting their ability to benefit from the capabilities obser v ed in state-of-the-art LLMs ( Etxaniz et al. , 2024b ; de Dios-Flores et al. , 2024 ). Consequently , multilingual pretraining alone prov es insufficient when it comes to low-resource languages. 1 https://hf.co/collections/HiTZ/ merge- and- conquer 2 https://commoncrawl.github.io/ cc- crawl- statistics/plots/languages Multilingual instruction tuning has become a main strategy for instructing models to low-resource lan- guages, complementing the pretraining stage with language-specific instructions. T o address the scarcity of native instruction data, researchers hav e proposed several approaches such as translating exis ting datasets, generating synthetic ex amples, or leveraging English-centric corpora for cr oss- lingual transfer . For instance, A ya ( Üstün et al. , 2024 ) extends instruction tuning to o ver 100 lan- guages, more than half of which are low-resource, through large multilingual finetuning. Other works improv e data quality via translation-based meth- ods like ( Nguyen et al. , 2024a ), which builds high- quality instruction-response pairs through iterativ e translation and rewriting. In the Iberian conte xt, Bao et al. ( 2023 ) present a curated Galician model, and t he Salamandra initiative ( Gonzalez-A girre et al. , 2025 ) integrat es resources for Catalan, Gali- cian, Spanish, and Basque. Alternativel y , Sainz et al. ( 2025 ) explored systematically all possible approaches to instruct or adapt a LLM for a specific low-resource language. They pro ved that joint in- struction tuning, ev en with just English instructions, and continual pre-training substantially outper forms traditional approaches. Howev er , while these ef- forts show a promising performance, they remain computationally e xpensive because they must be repeated with ev er y new model release. Model merging has recently emerged as an al- ternativ e to traditional multi-task learning, offering an efficient wa y to combine model capabilities from different experts without additional training ( Y ang et al. , 2026a ). These approaches interpolate pa- ramet ers between two or more models using differ - ent methods. T ask Arithmetic builds task vectors from fine-tuned models and combines them addi- tively ( Ilharco et al. , 2023 ), while D ARE drops and rescales delta parameters to reduce inter fer ence during merging ( Y u et al. , 2024a ), and TIES prunes redundant parameters across models ( Y adav et al. , 2023 ). Resear ch on low-resource multilingual sce- narios is still emerging and remains limited with few works showing promising results ( T ao et al. , 2024 ; Huang et al. , 2024 ; Pipatanakul et al. , 2025 ). More recently , Cao et al. ( 2025 ) and Sarasua et al. ( 2025 ) applied the T ask Arithmetic merging approach to transfer instruction-following capabilities to contin- ued pre-trained models, with the latter placing spe- cial emphasis on low-resource languages such as Basque. Nev er theless, these works do not pro vide a systematic analysis and evaluation of the different alternativ es within the merging paradigm for low- resource languages. In contrast, our study focuses on a broad experimental characterization of lan- guage transfer via merging across four Iberian lan- guages, model families, sizes, and merging strat e- gies, and evaluat es both language competence Language Documents Llama 3.1 Qwen3 Basque (eu) 4.2M 3.5B 3.5B Galician (gl) 8.9M 3.5B 3.5B Catalan (ca) 3.8M 3.7B 3.8B Spanish (es) 3.8M 3.4B 3.5B English (en) 0.5M 0.3B 0.3B T able 1: Cor pus sizes for each language in docu- ments, Llama 3.1 tok ens and Qwen3 tok ens. (through multiple-choice benchmar ks and machine translation) and instruction-following behavior (IFE- val). 3. Methodology Adapting an instructed LLM to a target language using merging techniques follows a straightforward methodology . First, a base model must be trained to be proficient in the target language. Then, this newly trained base model is merged with an e x- isting instructed model using a merging technique. This section describes the construction of the com- ponents used in our experiments. We begin by detailing the av ailable resources, follow ed by the procedures for training the base LLMs and per form- ing the model merging. 3.1. Continued pr e-training W e trained language-adapted base models for four Iberian languages: Basque, Galician, Catalan and Spanish. T o train language-specific base LLMs, we followed the methodology proposed by Etxaniz et al. ( 2024b ), who used a Basque corpus compris- ing appro ximately 4.2 billion tokens. T o enable fair comparisons across languages, we limited the cor - pus size for all the languages to roughly the same number of tokens. T able 1 presents the corpus statistics in terms of document counts, as well as to- ken counts for Llama 3.1 and Qwen 3 (correspond- ing to the models used in our experiments; § 4 ). As expect ed, token counts vary slightly depending on the tok enizer , but remain comparable in ov erall size. Note that we included a small-sized English corpus, which was first prov en essential to av oid catastrophic forge tting in Etxaniz et al. ( 2024b ), and later confirmed in Elhady et al. ( 2025 ). Corpus collection. For Basque, we use the pretraining data from the Latxa corpus ( Etxaniz et al. , 2024b ), which consists of 4.3M documents and 1.2B words (mainly massiv e web-cra wl con- tent, news pieces, and ency clopedic te xt). In the case of Galician, we rely on the CorpusNÓS cor - pus ( de Dios-Flores et al. , 2024 ) of 9.7M documents and 2.1B words drawn from web crawls and public administrations, among others. Spanish and Cata- lan data are taken from the massive, multilingual CulturaX corpus ( Nguyen et al. , 2024b ). Given the substantially larger size of CulturaX compared to the Basque and Galician resources, we imple- mented a series of strategies to obtain a more tar - geted subset. F or Spanish, we retained only docu- ments whose URLs contain a top-lev el domain indi- cating origin in Spain (namely , .es , .eus , .cat , or .gal ). In addition, both Spanish and Catalan data were filter ed using the Dolma toolkit ( Soldaini et al. , 2024 ), with the pre-implement ed Gopher ( Rae et al. , 2021 ) and C4 ( Raffel et al. , 2020 ) heuristics. For the English subset, we sam pled 500k documents from the FineWeb corpus ( P enedo et al. , 2024 ). Model tr aining. W e trained the models with a sequence length of 8,196 tokens and an effective batch size of 256 instances, corresponding to a total of approximat ely 2 million tok ens per optimiza- tion step. T raining employed a cosine learning rate scheduler with a warm-up ratio of 0.1 and a peak learning rate of 1 × 10 − 5 . Experiments were conducted on the CINEC A Leonardo high- performance computing cluster , utilizing 32 nodes, each equipped with 4 NVIDIA A100 GPUs (64 GB memory). For distributed training, we adopted Fully Sharded Data Parallel ( Zhao et al. , 2023 ), which shards model parameters, optimizer states, and activations across all GPUs to maximize memor y efficiency and scalability . 3.2. Model merging Model merging ref ers to the process of combining two or more models, typically sharing the same base architecture and initialization, into a single unified model whose paramet ers θ merge are derived from the paramet er sets { θ 1 , θ 2 , · · · , θ n } of individ- ual e xper t models. F ormally , the sim plest instance of model merging can be expressed as a weight ed linear interpolation of model paramet ers, i.e., θ merge = n X i =1 w i θ i , where the scalar weights w i sum to one ( Worts- man et al. , 2022 ). While such naive interpolation methods can already transfer useful knowledge between models, more sophisticated approaches e xplicitly address parameter alignment, conflict res- olution, or parameter impor tance weighting to miti- gate per formance degradation when models hav e diver ged substantially during training ( Ilharco et al. , 2023 ; Y u et al. , 2024a ). These methods aim to appro ximate the effect of multi-task training with- out requiring access to the original fine-tuning data, making them particularly valuable for domains or languages where annotated resources are scarce. In this work, we ev aluate several merging strategies across two complementar y experimental settings: monolingual merging and multilingual merging . Monolingual Merging. In the monolingual set- ting, we study how different merging techniques per form when adapting a model to a new language while preser ving previously learned capabilities. Specifically , we analyze the impact of various merg- ing algorithms and their associated hyperparame- ters on the transf er efficiency and stability of the resulting model. This allows us to assess the ext ent to which model merging can ser ve as an alterna- tive to conventional fine-tuning when incorporating additional linguistic knowledge. Multilingual Merging. In the multilingual setting, we investigat e how multiple monolingual expert models can be effectivel y combined to produce a single multilingual, instruction-tuned LLM. W e ex- amine how different merge ratios and strat egies influence the balance between languages, ev alu- ating whether specific methods fa vor stronger per- language specialization or instead yield more uni- form cross-lingual per formance. This analysis pro- vides insights into the ability of merging techniques to fuse diverse linguistic com pet encies into a uni- fied model without the need for costly joint training. 4. Experimental Setup T o thoroughly ev aluate our hypotheses, we con- ducted experiments across multiple languages (Basque, Galician, Catalan, and Spanish), diverse model families (§ 4.1 ), various merging methods (§ 4.2 ), and several benchmarks (§ 4.3 ). The fol- lowing sections provide a detailed description of our experimental setup. 4.1. Models and baselines Our experimental design requires that both the base and instructed variants of each model fam- ily be publicly av ailable. Consequently , we se- lected two widely used and representative model families: Llama 3.1 ( Grattafiori et al. , 2024 ) and Qwen 3 ( Y ang et al. , 2025 ). Llama 3.1 is a well- established model family within the community , known for its strong multilingual per formance and widespread adoption. In contrast, Qwen 3 e xempli- fies the recent emergence of model families that are not predominantly centered on English, reflecting a growing shif t tow ards more linguistically diverse large language models. Given our computational constraints and the high cost associated with large- scale training, we opted to focus on moderate-sized language models. Specifically , we used the 8B vari- ants of both Llama 3.1 and Qwen 3, as well as the 14B variant of Qwen 3, striking a balance between performance and feasibility for our experiments. Regarding the baselines, we considered two main points of comparison. The first are the ex- isting instructed variants of the chosen model fam- ilies (namely , Llama 3.1 Instruct and Qwen 3 In- struct) which ser v e as our non–language-adapt ed but instructed baselines, allowing us to measure how much the instruction following capabilities are retained af ter merging. Our second baseline is the language-adapt ed but not instructed baseline, which allows us to test the language proficiency transfer of the methods. Additionally , we compare our approach to the current state-of-the-art method for low-resource language adaptation, which jointly combines continued pre-training and instruction tuning in a single training phase ( Sainz et al. , 2025 ). Specifically , we compare our approach against their best model release for Basque. 3 Moreo ver , we include in the com parison Salamandra and ALIA models ( Gonzalez-Agirre et al. , 2025 ), two LLMs specifically trained for our target Iberian languages. 4.2. Merge techniques Sev eral model merging techniques hav e been pro- posed in the literature. In this work, we focus on four representative and conceptually simple ap- proaches: Linear Merging , T ask Arithmetic , D ARE and Breadcrumbs . Linear Merging. The Linear method ( Wortsman et al. , 2022 ) is the most straightforward approach to model merging. It consists in per forming a weighted av erage of the parameters from multiple models, assigning a specific coefficient to each. This tech- nique can be viewed as an extension of the idea behind model soups, where model weights are inter - polated to combine knowledge from different check- points or fine-tuned variants. M Linear ( { θ i } N i =1 , θ base ) = w base · θ base + N X i =1 w i · θ i , where w base + N X i =1 w i = 1 . (1) T ask Arithmetic. The T ask Arithmetic method, introduced by Ilharco et al. ( 2023 ), is based on the notion of task v ectors . For a given task t i , the task vect or τ i is defined as the difference between the task -specific model and the base model, i.e., τ i = θ i − θ base . These task vect ors capture the paramet er updates associated with adapting the 3 https://huggingface.co/HiTZ/ Latxa- Llama- 3.1- 8B- Instruct base model to a specific task. Model merging is then performed by adding a weighted combination of these vect ors to the base model: M T A ( { θ i } N i =1 , θ base ) = θ base + N X i =1 w i · ( θ i − θ base ) . (2) TIES. The T rim and Elect (TIES) method ( Y adav et al. , 2023 ) offer s an alternativ e to the standard computation of the task vector τ i . It addresses two main challenges: update redundancy and parame- ter sign disagreement. The fir st issue is mitigated by setting to 0 those values in τ i that fall below the top k %, through the application of a mask m k i to the task vector τ i . T o handle sign conflicts, the method computes an aggregat e elected sign vect or γ m by taking the sign of the av erage values across the different task v ectors. Finally , only the paramet ers consistent with the elected sign are retained for the final task vect or ˆ τ i . Formally , τ ′ i = m k i ⊙ τ i , γ m,p = sgn n X t =1 τ ′ i,p ! , A p = { t ∈ [ n ] | sgn ( τ ′ i,p ) = γ m,p } , ˆ τ i,p = 1 |A p | X t ∈A p τ ′ i,p (3) In our experiments, we did not use the TIES method directly , but applied it in conjunction of the D ARE and Breadcrumbs methods defined below . D ARE. The Drop And REscale (D ARE) method ( Y u et al. , 2024b ) aims to sparsify task vect ors in order to reduce interference be- tween tasks during model merging. Similar to T ask Arithmetics, it operates on the difference between a fine-tuned model and its base model, defined as τ i . Howe ver , it proposes to randomly drop a proportion p of its parameters and rescale the remaining ones by a factor of 1 1 − p to preser ve the expect ed magnitude. F ormally , DARE produces a sparsified task vector : τ D ARE i = (1 − Z i ) ⊙ ˆ τ i 1 − p , (4) where Z i is a binary mask sampled element-wise from a Bernoulli distribution with parameter p , and ⊙ denotes element-wise multiplication. The merged model is then obtained as: M D ARE ( { θ i } N i =1 , θ base ) = θ base + N X i =1 w i · τ D ARE i . (5) Model Breadcrumbs. Dav ari and Belilo vsky ( 2025 ) provides a deterministic alternative to D ARE by filtering both negligible and e xtreme parame- ter updates in the task vectors. For each lay er of a task vector τ i , v alues below a low er threshold (small per turbations) and abov e an upper thresh- old (outliers) are masked out, retaining only the mid-range updates that are considered most infor - mative. F ormally , let f ( τ i ) denote this la yer -wise filtering operation; the merged model is computed as: M BC ( { θ i } N i =1 , θ base ) = θ base + N X i =1 w i · f ( ˆ τ i ) , f L ( ˆ τ i ) = ( ˆ τ L i , if γ L ≤ | ˆ τ L i | ≤ β L , 0 , otherwise. (6) 4.3. Ev aluation benchmarks W e conducted our evaluations using the LM Eval- uation Harness framework ( Gao et al. , 2024 ). Each model variant was tested on a suite of benchmarks on five languages: Basque, Gali- cian, Catalan, Spanish, and English. Our ev alu- ation setup includes multiple-choice benchmarks together with machine translation and instruction- following datasets. W e incor porated machine trans- lation and instruction-following as they are te xt gen- eration tasks, allowing us to better assess the mod- els’ language generation capabilities. In total, we conducted evaluations in 14 different benchmarks and their language variants, if av ailable. All of the results are obtained by prompting the models with 5 ex amples (i.e., 5-shot ev aluation). Multiple-choice benchmarks. Our evaluation framework includes tasks from multiple categories to assess a range of language understanding and generation capabilities. F or r eading com- prehension , we used Belebele ( Bandarkar et al. , 2024 ) and EusReading ( Etxaniz et al. , 2024b ); the former is available in all ev aluation languages, while the latter is specific to Basque. T o evalu- ate common sense reasoning , we employ ed XS- toryCloze ( Lin et al. , 2022 ), which is also avail- able in all our target languages. Linguistic profi- ciency in Basq ue was assessed using EusProfi- ciency ( Etxaniz et al. , 2024b ), while linguistic ac- ceptability was ev aluated using language-specific variants of CoLA ( W arstadt et al. , 2019 ): Gal- CoLA ( Baucells et al. , 2025 ) for Galician, Cat- CoLA ( Bel et al. , 2024b ) for Catalan, and Es- CoLA ( Bel et al. , 2024a ) for Spanish. F or miscella- neous know ledge , we used BertaQA ( Etxaniz et al. , 2024a ), EusT rivia and EusExams ( Etxaniz et al. , 2024b ) in Basque, and OpenBookQA ( Mihaylo v et al. , 2018 ) for Galician, Catalan, and Spanish. Lastly , to evaluate paraphrasing capabilities , we used Paráfrases ( Baucells et al. , 2025 ) in Gali- cian. For all the classification tasks we hav e used accuracy as our ev aluation metric. Machine T ranslation. We include machine trans- lation as a text generation task to better as- sess model performance in low-resource lan- guages, where grammatical correctness is of ten lacking ( Sainz et al. , 2025 ). F or this purpose, we use the Flores benchmar k ( Goy al et al. , 2022 ) and group languages into two categories: high resource (Spanish, English) and low resource (Basque, Galician, Catalan). We e valuate trans- lation in both directions: { es , en } → { eu , gl , ca } and { eu , gl , ca , es , en } → { es , en } . All results are reported using BLEU scores, av eraged across the target languages. Instruction-following. We fur ther ev aluated the instruction-following capabilities of the generated models, as the ability to accurately interpret and ex ecute user prompts in practical scenarios consti- tutes an essential aspect of model quality . T o this end, we employ ed the IFEval benchmark ( Zhou et al. , 2023 ), which is specifically designed to auto- matically measure instruction adherence across a diverse set of tasks, including the inclusion or ex- clusion of k eywords, the use of cer tain punctuation marks and capitalization patterns, and similar for - mal requirements. IFEval was originally proposed for English, and subsequent work introduced trans- lated and post-edit ed versions for Catalan 4 and Spanish. 5 As par t of this study , we extended the benchmark to Basque using GPT -4o, followed by manual revision by native speakers to ensure se- mantic fidelity , fluency , and naturalness. Instances that did not translate directly due to linguistic or cultural differences were adapted accordingly . The metadata and IFEval codebase were also modified to ensure correct evaluation in each of the sup- por ted languages. Note that we e xcluded the task type response_language from our ev aluation (5% of the instances), due to discrepancies across the language-specific versions of the dataset. 5. Results In this section, we first discuss the main findings (§ 5.1 ), beginning with the per formance of the language-adapted base models, followed by the monolingual and multilingual merging strategies, and finally their instruction-following capabilities. W e then repor t additional experimental analyses 4 https://huggingface.co/datasets/ projecte- aina/IFEval_ ca 5 https://huggingface.co/datasets/ BSC- LT/IFEval_ es Model EU GL CA ES EN Llama 3.1 8B 47 . 37 58 . 91 59 . 14 66 . 36 72 . 80 Llama 3.1 8B eu 60 . 63 56 . 19 56 . 77 64 . 37 74 . 85 Llama 3.1 8B gl 43 . 94 59 . 59 56 . 89 63 . 44 71 . 08 Llama 3.1 8B ca 44 . 13 54 . 64 60 . 91 64 . 64 70 . 91 Llama 3.1 8B es 45 . 51 57 . 81 58 . 56 65 . 88 72 . 13 Qwen3 8B 51 . 02 61 . 80 62 . 81 68 . 57 75 . 27 Qwen3 8B eu 67 . 56 60 . 47 60 . 72 66 . 13 78 . 30 Qwen3 8B gl 48 . 66 62 . 57 61 . 76 66 . 09 74 . 47 Qwen3 8B ca 49 . 63 59 . 56 64 . 60 66 . 78 74 . 79 Qwen3 8B es 50 . 79 62 . 24 63 . 57 67 . 11 75 . 58 Qwen3 14B 55 . 57 63 . 37 66 . 55 70 . 98 77 . 06 Qwen3 14B eu 70 . 77 61 . 10 62 . 86 69 . 52 80 . 36 Qwen3 14B gl 53 . 66 66 . 09 64 . 83 68 . 89 77 . 05 Qwen3 14B ca 54 . 22 61 . 09 68 . 06 69 . 37 77 . 19 Qwen3 14B es 55 . 90 63 . 62 65 . 91 70 . 48 77 . 51 T able 2: Base model language adaptation results. Bold indicates best among the same model archi- tecture and underline indicates best overall. (§ 5.2 ), e xamining the impact of different merging methods and merge propor tions. The results are organized in a top-down manner . W e star t by com paring the models obtained using the best-performing merging approach, Linear , with the best hyperparamet ers ( w i = 1 . for monolingual merging and w i = . 25 for multilingual merging), and subsequently present the dev elopment analyses in greater detail. 5.1. Main r esults Base models results. T able 2 compares the language-adapted base models against their corre- sponding non-adapted base baselines on multiple- choice benchmarks. Ov erall, the language- adapted versions clearly outper form the baseline in their target languages , with the ex ception of the Spanish, an already high-resource language. The biggest improv ements are found in Basque, which is expect ed due to the low amount of resources and the low er baseline results. W e can conclude that the language-adapted models achieve consis- tently better per formance than the original base models and, therefore, can be used to teach the target languages to the instructed variants. Monolingual merge results. T able 3 com pares the performance of language-specific merged mod- els ( merge- ) with the original instruct models ( instruct ) across multiple-choice benchmarks and machine translation tasks. The results show that monolingual merges generally improve per for - mance in their target language relativ e to the non- adapted instruct baseline ( merge- vs. instruct ), with the clearest gains observed for lower -resource languages (EU/GL/C A), while results for Spanish are more mixed. In machine translation, monolin- gual merged models also tend to improve transla- Benchmark average Machine T ranslation Model EU GL CA ES EN *-EU *-GL *-CA *-ES *-EN Llama 3.1 8B joint-EU 61 . 75 58 . 13 57 . 81 64 . 59 73 . 71 15 . 03 25 . 71 29 . 00 23 . 86 35 . 42 Salamandra 2B Instruct 27 . 95 37 . 11 43 . 18 34 . 68 37 . 13 6 . 69 25 . 27 28 . 41 21 . 69 31 . 50 Salamandra 7B Instruct 44 . 94 53 . 60 56 . 55 52 . 79 57 . 27 11 . 31 29 . 94 34 . 12 25 . 46 37 . 67 ALIA 40B Instruct 60 . 64 64 . 98 64 . 68 62 . 93 66 . 04 15 . 78 29 . 86 33 . 10 26 . 56 37 . 85 Llama 3.1 8B Instruct 49 . 29 60 . 11 61 . 56 68 . 22 73 . 87 7 . 18 26 . 55 30 . 12 24 . 01 35 . 49 Llama 3.1 8B merge-EU 58 . 36 61 . 41 60 . 61 67 . 87 75 . 08 12 . 27 26 . 14 29 . 91 23 . 97 37 . 46 Llama 3.1 8B merge-GL 47 . 56 63 . 94 59 . 96 68 . 23 73 . 56 6 . 37 28 . 91 27 . 81 23 . 76 36 . 69 Llama 3.1 8B merge-CA 48 . 26 59 . 84 63 . 99 67 . 87 73 . 48 6 . 85 24 . 49 32 . 92 23 . 79 36 . 77 Llama 3.1 8B merge-ES 40 . 46 60 . 26 60 . 62 68 . 87 74 . 24 7 . 65 26 . 91 30 . 84 24 . 46 36 . 71 Llama 3.1 8B merge-multi 51 . 66 62 . 23 61 . 72 68 . 46 74 . 06 8 . 42 27 . 19 31 . 10 24 . 31 37 . 02 Qwen3 8B Instruct 44 . 06 56 . 51 59 . 37 64 . 04 69 . 84 3 . 51 24 . 39 27 . 78 23 . 05 33 . 09 Qwen3 8B merge-EU 55 . 81 55 . 80 60 . 94 65 . 80 72 . 67 9 . 39 24 . 60 27 . 64 24 . 06 34 . 57 Qwen3 8B merge-GL 38 . 98 58 . 84 59 . 77 65 . 22 71 . 47 2 . 74 27 . 35 25 . 22 23 . 37 33 . 19 Qwen3 8B merge-CA 39 . 29 56 . 27 62 . 66 65 . 90 71 . 10 3 . 11 24 . 01 31 . 29 23 . 46 33 . 78 Qwen3 8B merge-ES 41 . 03 56 . 74 60 . 26 65 . 91 72 . 44 3 . 49 25 . 00 28 . 00 23 . 90 33 . 32 Qwen3 8B merge-multi 44 . 85 56 . 64 61 . 34 65 . 65 72 . 19 4 . 45 26 . 02 28 . 83 23 . 80 33 . 86 Qwen3 14B Instruct 52 . 09 62 . 39 62 . 14 67 . 87 71 . 82 5 . 40 25 . 87 29 . 11 24 . 20 35 . 10 Qwen3 14B merge-EU 63 . 26 62 . 66 64 . 62 68 . 88 75 . 78 11 . 78 26 . 45 29 . 99 25 . 19 36 . 86 Qwen3 14B merge-GL 53 . 96 66 . 27 64 . 46 69 . 30 74 . 28 5 . 46 29 . 21 29 . 52 24 . 55 36 . 10 Qwen3 14B merge-CA 53 . 85 63 . 28 66 . 84 69 . 39 74 . 50 5 . 49 25 . 92 32 . 40 24 . 54 36 . 22 Qwen3 14B merge-ES 53 . 52 64 . 02 64 . 90 69 . 98 74 . 78 5 . 86 27 . 04 30 . 02 24 . 78 36 . 21 Qwen3 14B merge-multi 56 . 37 64 . 15 65 . 17 69 . 47 74 . 77 7 . 14 27 . 63 30 . 91 24 . 88 36 . 45 T able 3: Main experimental results on multiple-choice benchmarks (Accuracy) and machine translation (BLEU). Bold indicates best among the same backbone model and underline indicates best o verall. tion quality in their target language compared to the instruct baselines, mirroring the trends obser ved in the benchmark ev aluation. When com pared with the state-of-t he-ar t language adaptation approach (Llama 3.1 8B joint-EU ), the Basque merged mod- els achiev e comparable per formance in the target language across both benchmarks and translation tasks, while e xhibiting substantially smaller perfor - mance degradation in other languages, resulting in more consist ent and stable over all per formance and highlighting the promise of the merging ap- proach. Finally , similarly strong improv ements are obser v ed across the different backbone models, fur ther demonstrating the robustness of the model- merging strat egy . Multilingual results. T able 3 also reports the re- sults for the multilingual merged models (listed as model merge-multi ). Com pared with the monolingual merged variants, the multilingual models gener - ally provide more balanced per formance across languages, although their performance typically remains below that of the target-language monolin- gual models. Nevertheless, relative to the instruct baseline, they show clear improv ements in almost ev er y language across all bac kbone models. Over - all, these results indicate that (1) model merging is a promising approach for enabling an instructed LLM to acquire compet ence in multiple languages, and (2) there remains significant room for improv e- Model EU GL CA ES Llama 3.1 8B joint-EU 46 . 82 2 . 0 48 . 36 2 . 6 46 . 71 0 . 7 57 . 06 0 . 2 Salamandra 2B Instruct 23 . 87 0 . 9 24 . 78 0 . 7 25 . 20 0 . 7 25 . 15 0 . 9 Salamandra 7B Instruct 32 . 79 1 . 5 35 . 12 0 . 7 34 . 93 2 . 8 33 . 50 2 . 0 ALIA 40B Instruct 35 . 41 0 . 3 38 . 40 0 . 7 41 . 17 0 . 4 43 . 48 1 . 6 Llama 3.1 8B Instruct 40 . 22 1 . 2 58 . 66 1 . 7 52 . 03 0 . 7 63 . 83 0 . 9 Llama 3.1 8B merge-* 39 . 98 1 . 1 47 . 86 1 . 3 46 . 96 1 . 2 50 . 08 0 . 7 Llama 3.1 8B merge-multi 34 . 08 1 . 4 47 . 74 1 . 0 45 . 03 1 . 9 51 . 59 0 . 4 Qwen3 8B Instruct 54 . 05 2 . 1 75 . 97 0 . 5 74 . 59 0 . 9 80 . 66 0 . 9 Qwen3 8B merge-* 43 . 38 1 . 1 63 . 06 0 . 1 59 . 45 0 . 8 66 . 83 0 . 2 Qwen3 8B merge-multi 39 . 98 1 . 6 62 . 85 0 . 4 61 . 51 0 . 7 66 . 75 1 . 1 Qwen3 14B Instruct 62 . 81 0 . 9 79 . 00 0 . 9 76 . 81 0 . 3 82 . 92 0 . 4 Qwen3 14B merge-* 61 . 35 0 . 6 65 . 75 1 . 7 66 . 00 1 . 1 71 . 43 1 . 1 Qwen3 14B merge-multi 56 . 45 1 . 0 66 . 25 1 . 0 67 . 25 1 . 9 72 . 26 0 . 9 T able 4: Strict instruction-lev el accuracy on IFEval (mean ± SD ov er 3 runs). For each test language, {model} merge-* denotes the corresponding mono- lingual variant adapted to that language. ment in transferring language competence between models. Instruction-following results. T able 4 presents the instruction-following per formance across Basque, Galician, Catalan, and Spanish. In contrast to the consistent gains obser ved in static benchmar ks and translation tasks, model merging yields rather mixed results in this setting. These findings can be interpret ed from two complementar y perspectives. On the one hand, both monolingual and multilingual merges retain Method EU GL CA ES Avg Benchmark average Linear 58 . 36 63 . 94 63 . 99 68 . 87 63 . 79 T ask Arithmetic 61 . 48 61 . 67 63 . 62 67 . 61 63 . 59 D ARE 61 . 23 61 . 55 63 . 70 66 . 29 63 . 19 Breadcrumbs 61 . 53 61 . 22 63 . 89 67 . 54 63 . 55 Machine translation Linear 12 . 27 28 . 91 32 . 92 24 . 46 24 . 64 T ask Arithmetic 13 . 62 28 . 26 32 . 76 23 . 78 24 . 61 D ARE 12 . 35 27 . 90 32 . 65 23 . 39 24 . 07 Breadcrumbs 13 . 35 00 . 19 00 . 42 22 . 46 09 . 11 Instruction Following Linear 39 . 98 47 . 86 46 . 96 50 . 08 46 . 22 T ask Arithmetic 50 . 73 35 . 04 42 . 10 54 . 59 45 . 62 D ARE 50 . 77 35 . 33 42 . 10 23 . 56 37 . 94 Breadcrumbs 46 . 45 29 . 93 28 . 85 51 . 15 39 . 09 T able 5: Merge method comparison. Results are reported using Llama 3.1 8B merge-* , where each language is evaluat ed with their specialized e xper t. instruction-following capabilities to some extent, suggesting that the merging process successfully transfers these abilities to the language-adapted base models alongside the improvements ob- ser v ed in the benchmar ks. On the other hand, the fact that the merged models do not sur pass the instruct baseline indicates that improv ements in language proficiency do not necessarily translate into stronger instruction-follo wing capabilities when using the merging approach. The gap becomes ev en more evident when compared with the state- of-the-art joint adaptation method. Nev er theless, as discussed later in § 5.2 , instruction-follo wing per formance varies substantially depending on the merging method used. 5.2. F ur ther analyses results Bey ond the main e xperiments, this section pro vides complementar y analyses that inv estigate ke y pre- liminary factors influencing our results. W e first ex amine the effect of the various merging strate- gies employ ed, followed by an analysis of the influ- ence of the weighting parameter w i in the context of monolingual merges. Merge method comparison. During our experi- mental phase, we evaluat ed the various merging methods described in § 4.2 . T able 5 presents the re- sults obtained by each method for each language with its corresponding specialized e xper t across three scenarios: benchmarks, machine transla- tion, and instruction following. Overall, although the Linear method appears to per form best across most language–task pairs, there is no clear one- size-fits-all method . For e xample, for the lowest- resource language (Basque), the Linear method is the worst-performing approach, while the remain- Method EU GL CA ES Avg Benchmark average Linear 55 . 81 58 . 84 62 . 66 65 . 91 60 . 80 T ask Arithmetic 55 . 71 57 . 26 58 . 14 63 . 55 58 . 66 D ARE 52 . 39 55 . 97 55 . 42 61 . 94 56 . 43 Breadcrumbs 56 . 38 59 . 35 61 . 33 65 . 41 60 . 62 Machine translation Linear 9 . 39 27 . 35 31 . 29 23 . 90 22 . 98 T ask Arithmetic 12 . 65 29 . 27 32 . 23 23 . 36 24 . 38 D ARE 12 . 22 28 . 89 32 . 09 23 . 22 24 . 11 Breadcrumbs 0 . 11 3 . 86 0 . 61 22 . 55 6 . 78 Instruction Following Linear 43 . 38 63 . 06 59 . 45 66 . 83 58 . 18 T ask Arithmetic 55 . 92 76 . 21 77 . 69 81 . 04 72 . 72 D ARE 61 . 02 75 . 26 77 . 19 81 . 08 73 . 64 Breadcrumbs 27 . 69 35 . 95 32 . 12 51 . 92 36 . 92 T able 6: Merge method comparison. Results are reported using Qwen3 8B merge-* , where each lan- guage is ev aluated with their specialized expert. ing methods achieve comparable per formance. For the machine translation task, where text genera- tion is required, we obser ve that the Breadcr umbs method per forms par ticularly poorly , leading to a complete collapse of the model for Galician and Catalan. Finally , instruction-following capabilities e xhibit the greatest v ariability across methods, with no clear pattern indicating which method performs best. Moreov er , af ter conducting the same analy- sis on the other models, see T able 6 , we conclude that there is no universally best method ; instead, performance of the merging method must be as- sessed on a case-by-case basis for each language and model pair . Merge proportion im pact. Af ter evaluating the impact of different merging methods, we next ex- plored the effect of the merge propor tion w i . For this analysis, we restricted the setup to two meth- ods: Linear and T ask Arithmetic . These were se- lected because they showed the strongest ov erall performance in the previous analysis. The Linear method represents the simplest interpolation ap- proach, while T ask Arithme tic ser ves as the base- line for several more advanced merging techniques. Figure 1 presents the proportion sweep across the four Iberian languages (Basque, Galician, Cata- lan, and Spanish), repor ting Benchmark A verage, Machine T ranslation, and Instruction Follo wing per - formance. The best w i value for each configuration is annotated in the figure. As expected, for both approaches, increas- ing w i increases the influence of the language- adapted base model and therefore tends to de- grade instruction-following capabilities. Howev er , the behavior differs across t he o ther two axes, Benchmark Av erage and Machine T ranslation. For the Linear method, the trade-off is relatively smooth: Figure 1: Proportion sweep ablation for Llama 3.1 8B merges across Iberian languages (EU, GL, C A, ES), comparing Linear (top row) and T ask Arithmetic (bott om row). Each subplot shows the effect of varying the merge propor tion w i on Benchmark Av erage, Machine T ranslation, and IFEval Strict. performance on benchmarks and machine trans- lation does not exhibit a sharp degradation as w i increases. In contrast, with T ask Arithmetic , the model rapidly collapses once w i e xceeds a cer tain threshold (typically w i ≥ 1 . 5 ). Interestingly , the ef- fect of w i on benchmark per formance and machine translation appears to be strongly correlat ed. Fi- nally , although the optimal w i value varies across languages, the general trends remain consistent : selecting a value in the range w i ∈ [0 . 5 , 1 . 0) typi- cally yields robust per formance. 6. Conclusions In this work, we show that model merging is a feasible alternative to continual pre-training for ex- tending instructed LLMs to low-resource languages. Our experiments across Basq ue, Galician, Cata- lan, and Spanish show that merging can success- fully transf er the target language proficiency from specialized base models into instructed variants. As a result, the obtained language-adapted and instruction-following models show substantial per - formance gains on benchmarks and machine trans- lation tasks while maintaining instruction following capabilities, par ticularly for under -represented lan- guages such as Basque. Among the methods ev al- uated, Linear and T ask Arithmetic hav e shown to be the best performing alternativ es o verall, con- firming that ev en sim ple paramet er -space merging strat egies can effectiv ely “teach” new languages to instruction-tuned models. Bey ond raw per formance, merging offers an ef- ficient path for multilingual expansion that av oids the heavy computational cost of re-training and fine-tuning cycles. The approach lowers hardware requirements, enabling smaller research groups to adapt frontier models to their own languages. Still, instruction-follo wing abilities remain par tly sensitive to merging, emphasizing the need for techniques that preserve alignment during language transfer . F uture work should explor e merge alignment, inv es- tigate stability across model families, and design language-specific merging algorithms to fur ther im- prov e instruction re tention. Overall, our findings suggest that model merging bridges the gap between efficiency and multilin- gual cov erage, pro viding a promising direction for building more accessible language models. As par t of the contributions of this work, we publicly release the continued pre-trained base models and the Basque and Galician IFEval variants. 6 7. Limitations Despite the promising results, this work has sev - eral limitations. Our study is restrict ed to a lim- ited number of model f amilies and sizes of up to 14B parame ters, as well as to a small set of Iberian languages—namely Basque, Catalan, Gali- cian, and Spanish. Extending these e xperiments to larger model scales and additional languages would help to fur ther validat e and generalize our findings. Mor eover , our analysis focuses e xclu- sively on instruction-tuned models, while model merging techniques could also be valuable in other conte xts, such as judge LLMs, reward models, or safety and guard models. 6 https://huggingface.co/collections/HiTZ/merge-and- conquer Acknowledgments This work has been funded by the Spanish Ministry of Science, Inno vation, and Universities (Project HumanAIze, grant number AIA2025-163322-C61), by the Basque Government (IKER-GAITU project) and the Ministerio para la T ransformación Digital y de la F unción Pública - F unded by EU – Ne xtGener - ationEU within the framew ork of the project Desar - rollo de Modelos ALIA. The models were trained on the Leonardo supercomputer at CINECA under the EuroHPC Joint Under taking, project EHPC-EXT - 2024E01-042. We also acknowledge the suppor t of the HiTZ Chair of Ar tificial Intelligence and Lan- guage T echnology (TSI100923-2023-1), funded by MTDFP , Secretaría de Estado de Digitalización e Inteligencia Ar tificial, ENIA, and by the European Union-Ne xt Generation EU / PRTR. W e thank Sofía García González for post-editing the Galician trans- lation of IFEval. 8. Bibliographical References T akuya Akiba, Makot o Shing, Y ujin T ang, Qi Sun, and David Ha. 2025. Evolutionary optimization of model merging recipes . Nature Machine Intel- ligence , 7(2):195–204. Jinze Bai, Shuai Bai, Y unfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Y ang Fan, Wenbin Ge, Y u Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi T an, Sinan T an, Jianhong T u, Peng Wang, Shijie W ang, Wei W ang, Shengguang Wu, Benfeng Xu, Jin Xu, An Y ang, Hao Y ang, Jian Y ang, Shusheng Y ang, Y ang Y ao, Bowen Y u, Hongyi Y uan, Zheng Y uan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. 2023. Qwen technical repor t . T echnical repor t. Lucas Bandarkar , Davis Liang, Benjamin Muller , Mikel Ar tetx e, Satya Nara yan Shukla, Donald Husa, Naman Goyal, Abhinandan Krishnan, Luke Zettlemoy er , and Madian Khabsa. 2024. The belebele benchmark: a parallel reading com- prehension dataset in 122 language variants . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V ol- ume 1: Long Papers) , pages 749–775, Bangkok, Thailand. Association for Computational Linguis- tics. Eliseo Bao, Anxo Perez, and Javier P arapar . 2023. Conv ersations in galician: a large language model for an underrepresent ed language . ArXiv , abs/2311.03812. Irene Baucells, Javier Aula-Blasco, Iria de Dios- Flores, Silvia Paniagua Suárez, Naiara Perez, Anna Salles, Susana Sotelo Docio, Júlia F al- cão, Jose Javier Saiz, Robiert Sepulveda T orres, Jerem y Barnes, Pablo Gamallo, Aitor Gonzalez- Agirre, German Rigau, and Mar ta Villegas. 2025. IberoBench: A benchmark for LLM ev aluation in Iberian languages . In Proceedings of the 31st Inter national Conference on Computational Lin- guistics , pages 10491–10519, A bu Dhabi, U AE. Association for Com putational Linguistics. Núria Bel, Mar ta Punsola, and V alle Ruiz- Fernández. 2024a. EsCoLA: Spanish corpus of linguistic acceptability . In Proceedings of the 2024 Joint Inter national Confer ence on Compu- tational Linguistics, Language Resources and Ev aluation (LREC-COLING 2024) , pages 6268– 6277, T orino, Italia. ELRA and ICCL. Núria Bel, Mar ta Punsola, and V alle Ruiz- Fernández. 2024b. Catcola, catalan corpus of linguistic acceptability . Procesamient o del Lenguaje Natur al , 73(0):177–190. Sheng Cao, Mingrui W u, Kar thik Prasad, Y uandong Tian, and Zechun Liu. 2025. Param ∆ f or direct mixing: P ost-train large language model at zero cost . In The Thir teent h International Conf erence on Learning Repr esentations . ICLR 2025 poster . MohammadReza Dav ari and Eugene Belilovsky . 2025. Model breadcrumbs: Scaling multi-task model merging with sparse masks. In Computer Vision – ECCV 2024 , pages 270–287, Cham. Springer Nature Switzerland. Iria de Dios-Flores, Silvia Paniagua Suárez, Cristina Carbajal Pérez, Daniel Bardanca Outeir - iño, Marcos Garcia, and Pablo Gamallo. 2024. CorpusNÓS: A massive Galician cor pus for train- ing large language models . In Proceedings of the 16th International Conf erence on Computational Processing of Portuguese - V ol. 1 , pages 593– 599, Santiago de Compostela, Galicia/Spain. As- sociation for Com putational Lingustics. Ahmed Elhady , Eneko Agirre, and Mikel Ar te txe. 2025. Emergent abilities of large language mod- els under continued pre-training for language adaptation . In Proceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (V olume 1: Long Papers) , pages 32174– 32186, Vienna, Austria. Association for Compu- tational Linguistics. BigScience W orkshop et al. 2023. Bloom: A 176b- paramet er open-access multilingual language model . Julen Etxaniz, Gorka Azkune, Aitor Soroa, Oier Lopez de Lacalle, and Mikel Ar tetx e. 2024a. Ber taqa: How much do language models know about local culture? In Adv ances in Neural Inf or - mation Processing Sys tems , volume 37, pages 34077–34097. Curran Associates, Inc. Julen Etxaniz, Oscar Sainz, Naiara P erez, Itziar Aldabe, German Rigau, Eneko Agirre, Aitor Or - mazabal, Mikel Ar tetx e, and Aitor Soroa. 2024b. Latxa: An open language model and evaluation suite for Basq ue . In Proceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (V olume 1: Long P apers) , pages 14952–14972, Bangkok, Thailand. Asso- ciation for Com putational Linguistics. Leo Gao, Jonathan T ow , Baber Abbasi, Stella Biderman, Sid Black, Anthony DiP ofi, Charles Fost er , Laurence Golding, Jeffre y Hsu, Alain Le Noac’h, Haonan Li, K yle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Re ynolds, Hailey Schoelkopf, Aviy a Sko wron, Lintang Sutawika, Eric T ang, Anish Thite, Ben W ang, Kevin W ang, and Andy Zou. 2024. The language model ev aluation harness . Charles Goddard, Shamane Siriwardhana, Malikeh Ehghaghi, Luke Me yers, Vladimir Karpukhin, Brian Benedict, Mark McQuade, and Jacob So- lawe tz. 2024. Arcee’s MergeKit : A toolkit for merging large language models . In Proceedings of the 2024 Conference on Empirical Me thods in Natural Language Processing: Industry T rack , pages 477–485, Miami, Florida, US. Association for Com putational Linguistics. José A. González, Ian Borrego-Obrador , Ál- varo Romo Herr ero, Areg Mikael Sar vazy an, Mara Chinea-Rios, Angelo Basile, and Marc F ranco-Salvador . 2026. Iberbench: Llm eval- uation on iberian languages . Computer Speech & Language , 96:101899. Aitor Gonzalez-Agirre, Marc Pàmies, Joan Llop, Irene Baucells, Severino Da Dalt, Daniel T amayo, José Javier Saiz, Ferr an Espuña, Jaume Prats, Javier Aula-Blasco, Mario Mina, Iñigo Pikabea, Adrián Rubio, Alex ander Shvets, Anna Sallés, Iñaki Lacunza, Jorge Palomar , Júlia F alcão, Lucía T ormo, Luis V asq uez-Reina, Montserrat Marimon, Oriol P areras, V alle Ruiz-F ernández, and Mar ta Villegas. 2025. Salamandra technical report . T echnical repor t, Barcelona Supercom- puting Center . Naman Goyal, Cynthia Gao, Vishra v Chaudhar y , P eng-Jen Chen, Guillaume W enzek, Da Ju, San- jana Krishnan, Marc’Aurelio Ranzato, Francisco Guzmán, and Angela F an. 2022. The FL ORES- 101 ev aluation benchmark for low-resource and multilingual machine translation . T ransactions of the Association for Computational Linguistics , 10:522–538. María Grandur y , Javier Aula-Blasco, Júlia F al- cão, Clémentine Fourrier , Miguel González Saiz, Gonzalo Martínez, Gonzalo Santamaria Gomez, Rodrigo Agerri, Nuria Aldama Gar - cía, Luis Chiruzzo, Javier Conde, Helena Gomez Adorno, Mar ta Guerrero Nieto, Guido Ive tta, Natàlia López Fuertes, Flor Miriam Plaza- del Arco, María- T eresa Mar tín- V aldivia, He- lena Montoro Zamorano, Carmen Muñoz Sanz, P edro Reviriego, Leire Rosado Plaza, Alejan- dro V aca Serrano, Estrella V allecillo-Rodríguez, Jorge V allego, and Irune Zubiaga. 2025. La leaderboard: A large language model leader - board for Spanish varieties and languages of Spain and Latin America . In Proceedings of the 63rd Annual Meeting of the Association for Com- putational Linguistics (V olume 1: Long P apers) , pages 32482–32524, Vienna, Austria. Associa- tion for Com putational Linguistics. Aaron Grattafiori, Abhimanyu Dubey , Abhinav Jauhri, Abhinav Pande y , Abhishek Kadian, Ah- mad Al-Dahle, Aiesha Letman, Akhil Mathur , Alan Schelten, Alex V aughan, Amy Y ang, Angela F an, Anirudh Goyal, Anthony Har tshorn, Aobo Y ang, Archi Mitra, Archie Sra vankumar , Ar tem K orenev , Ar thur Hinsv ark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, A va Spataru, Baptiste Roziere, Bethany Biron, Binh T ang, Bobbie Chern, Charlott e Caucheteux, Chay a Nay ak, Chloe Bi, Chris Marra, Chris McConnell, Christian Keller , Christophe T ouret, Chuny ang W u, Corinne W ong, Cristian Can- ton Ferr er , Cyrus Nikolaidis, Damien Allonsius, Daniel Song, Danielle Pintz, Danny Liv shits, Danny Wyatt, David Esiobu, Dhruv Choud- hary , Dhruv Mahajan, Diego Garcia-Olano, Diego P erino, Dieuwke Hupkes, Egor Lakomkin, Ehab AlBadawy , Elina Lobanov a, Emily Di- nan, Eric Michael Smith, Filip Radeno vic, F ran- cisco Guzmán, F rank Zhang, Gabriel Synnaeve, Gabrielle Lee, Georgia Lewis Anderson, Govind Thattai, Graeme Nail, Gregoire Mialon, Guan P ang, Guillem Cucurell, Hailey Nguyen, Han- nah Kore vaar , Hu Xu, Hugo T ouvron, Iliy an Zarov , Imanol Arrieta Ibarra, Isabel Kloumann, Ishan Misra, Ivan Evtimo v , Jack Zhang, Jade Copet, Jaewon Lee, Jan Geffer t, Jana V ranes, Jason Park, Jay Mahadeokar , Jeet Shah, Jelmer van der Linde, Jennifer Billoc k, Jenny Hong, Jeny a Lee, Jeremy F u, Jianfeng Chi, Jianyu Huang, Jiaw en Liu, Jie W ang, Jiecao Y u, Joanna Bitton, Joe Spisak, Jongsoo Park, Joseph Rocca, Joshua Johnstun, Joshua Saxe, Junteng Jia, Kaly an V asuden Alwala, Kar thik Prasad, Kar - tike ya Upasani, Kate Plawiak, Ke Li, Kennet h Heafield, Ke vin Stone, Khalid El-Arini, Krithika Iyer , Kshitiz Malik, Kuenle y Chiu, Kunal Bhalla, Kushal Lakhotia, Lauren R antala- Y ear y , Lau- rens van der Maaten, Lawrence Chen, Liang T an, Liz Jenkins, Louis Martin, Lovish Madaan, Lubo Malo, Lukas Blecher , Lukas Landzaat, Luke de Oliveira, Madeline Muzzi, Mahesh P asupuleti, Mannat Singh, Manohar Paluri, Marcin Kardas, Maria T simpoukelli, Mathew Oldham, Mathieu Rita, May a Pa vlov a, Melanie Kambadur , Mike Lewis, Min Si, Mitesh K umar Singh, Mona Has- san, Naman Goy al, Narjes T orabi, Nikola y Bash- lyko v , Nikola y Bogoy chev , Niladri Chatterji, Ning Zhang, Olivier Duchenne, Onur Çelebi, Patrick Alrassy , P engchuan Zhang, P engwei Li, Petar V a- sic, Pet er Weng, Prajjwal Bharga va, Pratik Dubal, Prav een Krishnan, Punit Singh Koura, Puxin X u, Qing He, Qingxiao Dong, Raga van Srinivasan, Raj Ganapathy , Ramon Calderer , Ricardo Sil- veira Cabral, Robert Stojnic, Roberta Raileanu, Rohan Maheswari, Rohit Girdhar , Rohit Pat el, Romain Sauvestr e, Ronnie Polidoro, Roshan Sumbaly , Ross T aylor , Ruan Silva, Rui Hou, Rui W ang, Saghar Hosseini, Sahana Chennabas- appa, Sanjay Singh, Sean Bell, Seohyun So- nia Kim, Sergey Edunov , Shaoliang Nie, Sha- ran Narang, Sharath Rapar th y , Sheng Shen, Shengye W an, Shruti Bhosale, Shun Zhang, Simon V andenhende, Soumy a Batra, Spencer Whitman, Sten Sootla, Stephane Collot, Suchin Gururangan, Sydne y Borodinsky , T amar Her - man, T ara Fo wler , T arek Sheasha, Thomas Geor - giou, Thomas Scialom, T obias Speckbacher , T odor Mihaylo v , T ong Xiao, Ujjwal Karn, V edanuj Goswami, Vibhor Gupta, Vignesh Ramanathan, Viktor Kerk ez, Vincent Gonguet, Virginie Do, Vish V ogeti, Vítor Albiero, Vladan P etrovic, Wei- wei Chu, Wenhan Xiong, W enyin F u, Whitney Meers, Xavier Mar tinet, Xiaodong W ang, Xiao- fang W ang, Xiaoqing Ellen T an, Xide Xia, Xin- feng Xie, X uchao Jia, Xue wei W ang, Y aelle Goldschlag, Y ashesh Gaur , Y asmine Babaei, Yi Wen, Yiwen Song, Y uchen Zhang, Y ue Li, Y uning Mao, Zacharie Delpierre Couder t, Zheng Y an, Zhengxing Chen, Zoe Papakipos, Aaditya Singh, Aayushi Srivasta va, Abha Jain, Adam K elsey , Adam Shajnfeld, Adith ya Gangidi, Adolfo Victoria, Ahuva Goldstand, Ajay Menon, Ajay Sharma, Alex Boesenberg, Alex ei Baevski, Allie Feins tein, Amanda Kallet, Amit Sangani, Amos T eo, Anam Y unus, Andrei Lupu, Andres Al- varado, Andrew Caples, Andrew Gu, Andrew Ho, Andrew Poult on, Andrew Ryan, Ankit Ram- chandani, Annie Dong, Annie Franco, Anuj Goy al, Aparajita Saraf, Arkabandhu Chowd- hury , Ashley Gabriel, Ashwin Bharambe, As- saf Eisenman, Azadeh Y azdan, Beau James, Ben Maurer , Benjamin Leonhardi, Bernie Huang, Beth Loyd, Beto De Paola, Bharga vi Paran- jape, Bing Liu, Bo Wu, Bo yu Ni, Braden Han- cock, Bram Wasti, Brandon Spence, Brani Sto- jko vic, Brian Gamido, Britt Montalvo, Carl Park er , Carly Bur ton, Catalina Mejia, Ce Liu, Chang- han W ang, Changkyu Kim, Chao Zhou, Chester Hu, Ching-Hsiang Chu, Chris Cai, Chris Tin- dal, Christoph Feicht enhofer , Cynthia Gao, Da- mon Civin, Dana Beaty , Daniel Kre ymer , Daniel Li, David Adkins, David Xu, Davide T estuggine, Delia David, Devi Parikh, Diana Lisko vich, Di- dem Foss, Dingkang Wang, Duc Le, Dustin Hol- land, Edward Dowling, Eissa Jamil, Elaine Mont- gomery , Eleonora Presani, Emily Hahn, Emily W ood, Eric- T uan Le, Erik Brinkman, Esteban Ar- caute, Evan Dunbar , Ev an Smothers, F ei Sun, Felix Kreuk, F eng Tian, Filippos Kokkinos, Firat Ozgenel, F rancesco Caggioni, Fr ank Kana yet, F rank Seide, Gabriela Medina Florez, Gabriella Schwarz, Gada Badeer , Georgia Swee, Gil Halpern, Grant Herman, Grigor y Sizov , Guangyi, Zhang, Guna Lakshminara yanan, Hakan Inan, Hamid Shojanazeri, Han Zou, Hannah W ang, Hanwen Zha, Haroun Habeeb, Harrison Rudolph, Helen Suk, Henry Aspegren, Hunter Goldman, Hongyuan Zhan, Ibrahim Damlaj, Igor Moly- bog, Igor T ufano v , Ilias Leontiadis, Irina-Elena V eliche, Itai Gat, Jake Weissman, James Ge- boski, James Kohli, Janice Lam, Japhet Asher , Jean-Baptiste Gay a, Jeff Marcus, Jeff T ang, Jen- nifer Chan, Jenny Zhen, Jerem y Reizenstein, Jerem y T eboul, Jessica Zhong, Jian Jin, Jingyi Y ang, Joe Cummings, Jon Car vill, Jon Shep- ard, Jonathan McPhie, Jonathan T orres, Josh Ginsburg, Junjie W ang, Kai W u, Kam Hou U, Karan Saxena, Kar tika y Khandelwal, Kata youn Zand, Kath y Matosich, Kaushik V eeraragha van, K elly Michelena, K eqian Li, Kiran Jagadeesh, Kun Huang, Kunal Chawla, K yle Huang, Lailin Chen, Lakshy a Garg, Lav ender A, Leandro Silv a, Lee Bell, Lei Zhang, Liangpeng Guo, Licheng Y u, Liron Moshko vich, Luca W ehrstedt, Ma- dian Khabsa, Manav Av alani, Manish Bhatt, Mar tynas Mankus, Matan Hasson, Matthew Lennie, Matthias Reso, Maxim Groshev , Maxim Naumov , May a Lathi, Meghan K eneally , Miao Liu, Michael L. Seltzer , Michal V alko, Michelle Restrepo, Mihir Patel, Mik Vyatsk ov , Mikay el Samv elyan, Mike Clar k, Mike Macey , Mike Wang, Miquel Juber t Hermoso, Mo Metanat, Moham- mad Rast egari, Munish Bansal, Nandhini San- thanam, Natascha P arks, Natasha White, Na vy- ata Baw a, Nay an Singhal, Nick Egebo, Nicolas Usunier , Nikhil Mehta, Nikola y Pa vlovich Lapt ev , Ning Dong, Norman Cheng, Oleg Chernoguz, Olivia Hart, Omkar Salpekar , Ozlem Kalinli, P arkin K ent, Parth Parekh, Paul Saab, P avan Balaji, P edro Rittner , Philip Bontrager , Pierre Roux, Piotr Dollar , Polina Zvy agina, Prashant Ratanchandani, Pritish Y uvraj, Qian Liang, Rachad Alao, Rachel Rodriguez, Rafi A yub, Raghot ham Mur thy , Raghu Nay ani, Rahul Mitra, Rangaprabhu Parthasarathy , Ra ymond Li, Re- bekkah Hogan, Robin Batte y , Rocky W ang, Russ Howes, Ruty Rinott, Sachin Mehta, Sachin Siby , Sai Ja yesh Bondu, Samyak Datta, Sara Chugh, Sara Hunt, Sargun Dhillon, Sasha Sidorov , Sa- tadru Pan, Saurabh Mahajan, Saurabh V erma, Seiji Y amamoto, Sharadh Ramaswam y , Shaun Lindsa y , Shaun Lindsay , Sheng Feng, Shenghao Lin, Shengxin Cindy Zha, Shishir Patil, Shiva Shankar , Shuqiang Zhang, Shuqiang Zhang, Sinong W ang, Sneha Agarwal, Soji Sajuyigbe, Soumith Chintala, St ephanie Max, Stephen Chen, Stev e Kehoe, Stev e Satter field, Sudar - shan Govindaprasad, Sumit Gupta, Summer Deng, Sungmin Cho, Sunny Virk, Suraj Sub- ramanian, Sy Choudhur y , Sydney Goldman, T al Remez, T amar Glaser , T amara Best, Thilo K oehler , Thomas Robinson, Tianhe Li, Tianjun Zhang, Tim Matthews, Timo thy Chou, Tzook Shaked, V arun V ontimitta, Victoria Aja yi, Vic- toria Montanez, Vijai Mohan, Vinay Satish Ku- mar , Vishal Mangla, Vlad Ionescu, Vlad P oenaru, Vlad Tiberiu Mihailescu, Vladimir Ivano v , Wei Li, W enchen W ang, Wen wen Jiang, Wes Bouaziz, Will Constable, Xiaocheng T ang, Xiaojian W u, Xiaolan W ang, Xilun Wu, Xinbo Gao, Y aniv Klein- man, Y anjun Chen, Y e Hu, Y e Jia, Y e Qi, Y enda Li, Yilin Zhang, Ying Zhang, Y ossi Adi, Y oungjin Nam, Y u, Wang, Y u Zhao, Y uchen Hao, Y undi Qian, Y unlu Li, Y uzi He, Zach Rait, Zachar y De- Vito, Zef Rosnbrick, Zhaoduo Wen, Zhenyu Y ang, Zhiwei Zhao, and Zhiyu Ma. 2024. The llama 3 herd of models . Shih-Cheng Huang, Pin-Zu Li, Y u-chi Hsu, Kuang- Ming Chen, Y u T ung Lin, Shih-Kai Hsiao, Richard T sai, and Hung-yi Lee. 2024. Chat v ector: A simple approach to equip llms with instruction following and model alignment in new languages . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 10943–10959, Bangkok, Thailand. Association for Computa- tional Linguistics. Gabriel Ilharco, Marco T ulio Ribeiro, Mitchell Worts- man, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali F arhadi. 2023. Editing models with task arith- metic . In The Elev enth International Conference on Learning Repr esentations . ICLR 2023 poster . Alber t Q. Jiang, Alex andre Sablayrolles, Antoine Roux, Ar thur Mensch, Blanche Sav ar y , Chris Bamford, Dev endra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gi- anna Lengyel, Guillaume Bour , Guillaume Lam- ple, Lélio Renard Lav aud, Lucile Saulnier , Marie- Anne Lachaux, Pierre Stock, Sandeep Subrama- nian, Sophia Y ang, Szymon Antoniak, T ev en Le Scao, Théophile Ger ve t, Thibaut Lavril, Thomas W ang, Timothée Lacroix, and William El Say ed. 2024. Mixtral of e xper ts . T even Le Scao, Thomas W ang, Daniel Hess- low , Stas Bekman, M Saiful Bari, Stella Bider - man, Hady Elsahar , Niklas Muennighoff, Jason Phang, Ofir Press, Colin Raffel, Vict or Sanh, Sheng Shen, Lintang Sutawika, Jaesung T ae, Zheng Xin Y ong, Julien Launay , and Iz Beltagy . 2022. What language model to train if you hav e one million GPU hour s? In Findings of the As- sociation for Computational Linguistics: EMNLP 2022 , pages 765–782, Abu Dhabi, Unit ed Arab Emirates. Association for Computational Linguis- tics. Xi Victoria Lin, T odor Mihaylo v , Mikel Ar tetx e, Tianlu W ang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ra- makanth Pasunuru, Sam Shleifer , Punit Singh K oura, Vishra v Chaudhar y , Brian O’Horo, Jeff W ang, Luke Zettlemoy er , Zornitsa Kozare va, Mona Diab, V eselin Stoy anov , and Xian Li. 2022. Fe w-shot learning with multilingual generative language models . In Proceedings of the 2022 Confer ence on Empirical Me thods in Natur al Language Processing , pages 9019–9052, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics. T odor Miha ylo v , P eter Clark, T ushar Kho t, and Ashish Sabharwal. 2018. Can a suit of armor conduct electricity? a new dataset for open book question answering . In Proceedings of the 2018 Confer ence on Empirical Methods in Natural Lan- guage Processing , pages 2381–2391, Brussels, Belgium. Association for Com putational Linguis- tics. Luca Moroni, Javier Aula-Blasco, Simone Conia, Irene Baucells, Naiara Perez, Silvia Paniagua Suárez, Anna Sallés, Malte Ostendorff, Júlia F al- cão, Guijin Son, Aitor Gonzalez-Agirr e, Rober to Navigli, and Mar ta Villegas. 2025. Multi-LMentry: Can multilingual LLMs solve elementar y tasks across languages? In Proceedings of the 2025 Confer ence on Empirical Methods in Natu- ral Language Processing , pages 34126–34157, Suzhou, China. Association for Computational Linguistics. Thao Nguyen, Jeffre y Li, Sewoong Oh, Ludwig Schmidt, Jason E. W eston, Luke Zettlemoy er , and Xian Li. 2024a. Better alignment with in- struction back -and-forth translation . In Findings of the Association for Computational Linguis- tics: EMNLP 2024 , pages 13289–13308, Miami, Florida, USA. Association for Computational Lin- guistics. Thuat Nguyen, Chien V an Nguy en, Viet Dac Lai, Hieu Man, Nghia T rung Ngo, F ranck Dernon- cour t, Ryan A. Rossi, and Thien Huu Nguyen. 2024b. CulturaX: A cleaned, enormous, and multilingual dataset for large language models in 167 languages . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evalua- tion (LREC-COLIN G 2024) , pages 4226–4237, T orino, Italia. ELRA and ICCL. OpenAI. 2023. Gpt-4 technical report . T echnical report, OpenAI. Guilherme P enedo, Hynek K ydlíček, Loubna Ben allal, Anton Lozhko v , Margaret Mitchell, Colin Raffel, Leandro V on Werra, and Thomas W olf. 2024. The fineweb datasets: Decanting the web for the finest te xt data at scale . In The Thir ty -eight Confer ence on Neur al Information Processing Sys tems Datasets and Benchmarks T rack . Kunat Pipatanakul, Pittawat T aveekitw orachai, Pot- sawee Manakul, and Kasima Tharnpipitchai. 2025. Adapting language-specific llms to a rea- soning model in one day via model merging – an open recipe . Jack W Rae, Sebastian Borgeaud, T rev or Cai, Katie Millican, Jordan Hoffmann, F rancis Song, John Aslanides, Sarah Henderson, Roman Ring, Su- sannah Y oung, et al. 2021. Scaling language models: Methods, analysis & insights from train- ing gopher . arXiv preprint arXiv :2112.11446 . Colin Raffel, Noam Shazeer , Adam Rober ts, Katherine Lee, Sharan Narang, Michael Matena, Y anqi Zhou, Wei Li, and P eter J. Liu. 2020. Ex- ploring the limits of transfer learning with a uni- fied te xt-to-te xt transformer . Journal of Machine Learning Research , 21(140):1–67. Oscar Sainz, Naiara P erez, Julen Etxaniz, Joseba Fernandez de Landa, Itziar Aldabe, Iker García- Ferr ero, Aimar Zabala, Ekhi Azurmendi, Ger - man Rigau, Eneko Agirre, Mikel Ar te txe, and Aitor Soroa. 2025. Instructing large language models for low-resource languages: A system- atic study for Basque . In Proceedings of the 2025 Confer ence on Empirical Methods in Natu- ral Language Processing , pages 29136–29160, Suzhou, China. As sociation for Computational Linguistics. Ixak Sarasua, Ander Corral, and Xabier Saralegi. 2025. DIPLomA: Efficient adaptation of in- structed LLMs to low-resource languages via post-training delta merging . In Findings of the As- sociation for Computational Linguistics: EMNLP 2025 , pages 24898–24912, Suzhou, China. As- sociation for Com putational Linguistics. Oleh Shliazhko, Alena Fenogeno va, Maria Tikhonov a, Anastasia Kozlo va, Vladislav Mikhailov , and T atiana Shavrina. 2024. mGPT: Fe w-shot learners go multilingual . T ransactions of the Association for Computational Linguistics , 12:58–79. Luca Soldaini, Rodney Kinney , Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur , Ben Bogin, Khyat hi Chandu, Jennifer Dumas, Y anai Elazar , V alentin Hofmann, Ananya Jha, Sachin K umar , Li Lucy , Xinxi L yu, Nathan Lam- ber t, Ian Magnusson, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Cr ystal Nam, Matthew Pe ters, A bhilasha Ravichander , K yle Richardson, Zejiang Shen, Emma Strubell, Nis- hant Subramani, Oyvind T afjord, Evan Walsh, Luke Zettlemoy er , Noah Smith, Hannaneh Ha- jishirzi, Iz Beltagy , Dirk Groene veld, Jesse Dodge, and K yle Lo. 2024. Dolma: an open corpus of three trillion tokens for language model pretraining research . In Proceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (V olume 1: Long P apers) , pages 15725–15788, Bangkok, Thailand. Asso- ciation for Com putational Linguistics. Mingxu T ao, Chen Zhang, Quzhe Huang, Tianyao Ma, Songfang Huang, Dongyan Zhao, and Y an- song Feng. 2024. Unlocking the potential of model merging for low-resource languages . In Findings of the Association for Computational Linguistics: EMNLP 2024 , page 8705–8720. As- sociation for Com putational Linguistics. Gemini T eam and Google. 2023. Gemini: A family of highly capable multimodal models . T echnical report. Ahmet Üstün, Viraat Ar yabumi, Zheng Y ong, W ei- Yin K o, Daniel D’souza, Gbemileke Onilude, Neel Bhandari, Shivalika Singh, Hui-Lee Ooi, Amr Ka yid, F reddie V argus, Phil Blunsom, Sha yne Longpre, Niklas Muennighoff, Marzieh Fadaee, Julia Kreutzer , and Sara Hooker . 2024. Ay a model: An instruction finetuned open-access multilingual language model . In Proceedings of the 62nd Annual Meeting of the Association f or Computational Linguistics (V olume 1: Long Pa- pers) , pages 15894–15939, Bangk ok, Thailand. Association for Com putational Linguistics. Alex Warstadt, Amanpreet Singh, and Samuel R. Bowman. 2019. Neural network acceptability judgments . T ransactions of the Association for Computational Linguistics , 7:625–641. Mitchell Wortsman, Gabriel Ilharco, Samir Y a Gadre, Rebecca Roelofs, Raphael Gontijo- Lopes, Ari S. Morcos, Hongseok Namkoong, Ali F arhadi, Y air Carmon, Simon Kornblith, and Lud- wig Schmidt. 2022. Model soups: Av eraging weights of multiple fine-tuned models improv es accuracy without increasing infer ence time . In Proceedings of the 39th International Confer - ence on Machine Learning , volume 162 of Pro- ceedings of Machine Learning Resear ch , pages 23965–23998. PMLR. Sean W u, Michael Koo, Lesley Blum, Andy Black, Liyo Kao, Fabien Scalzo, and Ira Kur tz. 2023. A comparative study of open-source large lan- guage models, gpt-4 and claude 2: Multiple- choice test taking in nephrology . Prateek Y adav , Derek T am, Leshem Choshen, Colin A Raffel, and Mohit Bansal. 2023. Ties- merging: Resolving interference when merging models . In Adv ances in Neural Information Pro- cessing Sys tems , volume 36, pages 7093–7115. Curran Associates, Inc. An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bow en Y u, Chang Gao, Chengen Huang, Chenxu Lv , Chu- jie Zheng, Da yiheng Liu, F an Zhou, Fei Huang, F eng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong T ang, Jian Y ang, Jianhong T u, Jianwei Zhang, Jianxin Y ang, Jiaxi Y ang, Jing Zhou, Jingren Zhou, Juny ang Lin, Kai Dang, K eqin Bao, Ke xin Y ang, Le Y u, Lianghao Deng, Mei Li, Mingfeng X ue, Mingze Li, Pei Zhang, P eng W ang, Qin Zhu, Rui Men, Ruize Gao, Shixuan Liu, Shuang Luo, Tianhao Li, Tianyi T ang, W enbiao Yin, Xingzhang Ren, Xinyu Wang, Xin yu Zhang, X uancheng Ren, Y ang F an, Y ang Su, Yichang Zhang, Yinger Zhang, Y u Wan, Y uqiong Liu, Zekun Wang, Zeyu Cui, Zhenru Zhang, Zhipeng Zhou, and Zihan Qiu. 2025. Qwen3 technical repor t . T echnical report. Enneng Y ang, Li Shen, Guibing Guo, Xingwei W ang, Xiaochun Cao, Jie Zhang, and Dacheng T ao. 2026a. Model merging in llms, mllms, and bey ond: Methods, theories, applications, and oppor tunities . A CM Comput. Surv . , 58(8). Enneng Y ang, Li Shen, Guibing Guo, Xingwei W ang, Xiaochun Cao, Jie Zhang, and Dacheng T ao. 2026b. Model merging in llms, mllms, and bey ond: Methods, theories, applications, and oppor tunities . A CM Computing Surve y s , 58(8). Le Y u, Bowen Y u, Haiyang Y u, Fei Huang, and Y ongbin Li. 2024a. Language models are super mario: Absorbing abilities from homologous mod- els as a free lunch . In Proceedings of the 41st Inter national Conference on Machine Learning , ICML ’24. JMLR.org. Le Y u, Bowen Y u, Haiyang Y u, Fei Huang, and Y ongbin Li. 2024b. Language models are super mario: absorbing abilities from homologous mod- els as a free lunch. In Proceedings of the 41st Inter national Conference on Machine Learning , ICML ’24. JMLR.org. Y anli Zhao, Andrew Gu, Rohan V arma, Liang Luo, Chien-Chin Huang, Min Xu, Less W right, Hamid Shojanazeri, Myle Ott, Sam Shleifer , Alban Des- maison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Y uchen Hao, Ajit Math- ews, and Shen Li. 2023. Pytorch FSDP: Experi- ences on scaling fully sharded data parallel . Pro- ceedings of the VLDB Endowment , 16(12):3848– 3860. Jeffre y Zhou, Tianjian Lu, Swaroop Mishra, Sid- dhar tha Brahma, Sujoy Basu, Yi Luan, Denn y Zhou, and Le Hou. 2023. Instruction-follo wing ev aluation for large language models . A. Additional results Benchmark average Machine T ranslation Model EU GL CA ES EN *-EU *-GL *-CA *-ES *-EN Llama 3.1 8B joint-EU 61 . 75 58 . 13 57 . 81 64 . 59 73 . 71 15 . 03 25 . 71 29 . 00 23 . 86 35 . 42 Salamandra 2B Instruct 27 . 95 37 . 11 43 . 18 34 . 68 37 . 13 6 . 69 25 . 27 28 . 41 21 . 69 31 . 50 Salamandra 7B Instruct 44 . 94 53 . 60 56 . 55 52 . 79 57 . 27 11 . 31 29 . 94 34 . 12 25 . 46 37 . 67 ALIA 40B Instruct 60 . 64 64 . 98 64 . 68 62 . 93 66 . 04 15 . 78 29 . 86 33 . 10 26 . 56 37 . 85 Llama 3.1 8B Instruct 49 . 29 60 . 11 61 . 56 68 . 22 73 . 87 7 . 18 26 . 55 30 . 12 24 . 01 35 . 49 Llama 3.1 8B merge-EU 61 . 48 57 . 93 57 . 40 66 . 42 74 . 83 13 . 62 25 . 06 28 . 14 23 . 61 34 . 33 Llama 3.1 8B merge-GL 45 . 11 61 . 67 58 . 42 67 . 05 71 . 86 5 . 08 28 . 26 25 . 29 21 . 61 33 . 19 Llama 3.1 8B merge-CA 45 . 84 57 . 71 63 . 62 67 . 03 72 . 39 5 . 64 22 . 95 32 . 76 22 . 93 32 . 17 Llama 3.1 8B merge-ES 46 . 71 59 . 36 59 . 91 67 . 61 72 . 84 6 . 52 25 . 47 28 . 93 23 . 78 34 . 45 Llama 3.1 8B merge-multi 53 . 31 60 . 19 61 . 61 67 . 93 73 . 59 8 . 38 26 . 00 28 . 72 24 . 07 34 . 96 Qwen3 8B Instruct 44 . 06 56 . 51 59 . 37 64 . 04 69 . 84 3 . 51 24 . 39 27 . 78 23 . 05 33 . 09 Qwen3 8B merge-EU 55 . 71 52 . 57 56 . 29 64 . 10 72 . 15 12 . 65 21 . 84 25 . 64 22 . 70 34 . 09 Qwen3 8B merge-GL 42 . 05 57 . 26 55 . 62 61 . 71 69 . 58 2 . 66 29 . 27 23 . 00 21 . 66 32 . 85 Qwen3 8B merge-CA 39 . 73 48 . 97 58 . 14 58 . 90 69 . 53 2 . 74 19 . 79 32 . 23 22 . 05 32 . 95 Qwen3 8B merge-ES 39 . 61 50 . 96 54 . 39 63 . 55 70 . 65 3 . 17 24 . 41 26 . 95 23 . 36 33 . 07 Qwen3 8B merge-multi 45 . 90 54 . 85 58 . 67 62 . 91 70 . 26 5 . 69 26 . 22 28 . 89 23 . 43 33 . 89 Qwen3 14B Instruct 52 . 09 62 . 39 62 . 14 67 . 87 71 . 82 5 . 40 25 . 87 29 . 11 24 . 20 35 . 10 Qwen3 14B merge-EU 65 . 19 59 . 20 60 . 11 65 . 58 74 . 40 13 . 90 24 . 31 27 . 61 24 . 49 35 . 81 Qwen3 14B merge-GL 50 . 53 63 . 92 59 . 04 65 . 50 71 . 78 4 . 60 29 . 30 26 . 48 23 . 33 34 . 67 Qwen3 14B merge-CA 51 . 15 58 . 62 64 . 25 64 . 33 71 . 45 4 . 31 22 . 07 32 . 10 23 . 66 35 . 03 Qwen3 14B merge-ES 51 . 29 61 . 46 62 . 11 67 . 26 72 . 67 5 . 14 25 . 88 28 . 90 24 . 39 35 . 11 Qwen3 14B merge-multi 56 . 15 61 . 80 62 . 08 66 . 35 72 . 72 7 . 90 27 . 16 30 . 32 24 . 45 35 . 82 T able 7: Additional results for T ask Arithmetic merges on multiple-choice benchmar ks (Accuracy) and machine translation (BLEU). We repor t baseline models together with T ask Arithmetic merge variants for Llama 3.1 8B, Qwen3 8B, and Qwen3 14B. Bold indicates the best result among merged variants of the same backbone model, and underline indicates the best ov erall result. Benchmark av erage Machine T ranslation Model EU GL CA ES EN *-EU *-GL *-CA *-ES *-EN Llama 3.1 8B joint-EU 61 . 75 58 . 13 57 . 81 64 . 59 73 . 71 15 . 03 25 . 71 29 . 00 23 . 86 35 . 42 Salamandra 2B Instruct 27 . 95 37 . 11 43 . 18 34 . 68 37 . 13 6 . 69 25 . 27 28 . 41 21 . 69 31 . 50 Salamandra 7B Instruct 44 . 94 53 . 60 56 . 55 52 . 79 57 . 27 11 . 31 29 . 94 34 . 12 25 . 46 37 . 67 ALIA 40B Instruct 60 . 64 64 . 98 64 . 68 62 . 93 66 . 04 15 . 78 29 . 86 33 . 10 26 . 56 37 . 85 Llama 3.1 8B Instruct 49 . 29 60 . 11 61 . 56 68 . 22 73 . 87 7 . 18 26 . 55 30 . 12 24 . 01 35 . 49 Llama 3.1 8B merge-EU nearswap 60 . 43 56 . 19 56 . 77 64 . 37 74 . 85 14 . 56 24 . 81 28 . 60 23 . 59 36 . 61 Llama 3.1 8B merge-GL linear 47 . 56 63 . 94 59 . 96 68 . 23 73 . 56 6 . 37 28 . 91 27 . 81 23 . 76 36 . 69 Llama 3.1 8B merge-CA linear 48 . 26 59 . 84 63 . 99 67 . 87 73 . 48 6 . 85 24 . 49 32 . 92 23 . 79 36 . 77 Llama 3.1 8B merge-ES linear 40 . 46 60 . 26 60 . 62 68 . 87 74 . 24 7 . 65 26 . 91 30 . 84 24 . 46 36 . 71 Llama 3.1 8B merge-multi linear 51 . 66 62 . 23 61 . 72 68 . 46 74 . 06 8 . 42 27 . 19 31 . 10 24 . 31 37 . 02 Qwen3 8B Instruct 44 . 06 56 . 51 59 . 37 64 . 04 69 . 84 3 . 51 24 . 39 27 . 78 23 . 05 33 . 09 Qwen3 8B merge-EU ta 55 . 71 52 . 57 56 . 29 64 . 10 72 . 15 12 . 65 21 . 84 25 . 64 22 . 70 34 . 09 Qwen3 8B merge-GL ta 42 . 05 57 . 26 55 . 62 61 . 71 69 . 58 2 . 66 29 . 27 23 . 00 21 . 66 32 . 85 Qwen3 8B merge-CA ta 39 . 73 48 . 97 58 . 14 58 . 90 69 . 53 2 . 74 19 . 79 32 . 23 22 . 05 32 . 95 Qwen3 8B merge-ES linear 41 . 03 56 . 74 60 . 26 65 . 91 72 . 44 3 . 49 25 . 00 28 . 00 23 . 90 33 . 32 Qwen3 8B merge-multi ta 45 . 90 54 . 85 58 . 67 62 . 91 70 . 26 5 . 69 26 . 22 28 . 89 23 . 43 33 . 89 Qwen3 14B Instruct 52 . 09 62 . 39 62 . 14 67 . 87 71 . 82 5 . 40 25 . 87 29 . 11 24 . 20 35 . 10 Qwen3 14B merge-EU ta 65 . 19 59 . 20 60 . 11 65 . 58 74 . 40 13 . 90 24 . 31 27 . 61 24 . 49 35 . 81 Qwen3 14B merge-GL ta 50 . 53 63 . 92 59 . 04 65 . 50 71 . 78 4 . 60 29 . 30 26 . 48 23 . 33 34 . 67 Qwen3 14B merge-CA linear 53 . 85 63 . 28 66 . 84 69 . 39 74 . 50 5 . 49 25 . 92 32 . 40 24 . 54 36 . 22 Qwen3 14B merge-ES linear 53 . 52 64 . 02 64 . 90 69 . 98 74 . 78 5 . 86 27 . 04 30 . 02 24 . 78 36 . 21 Qwen3 14B merge-multi linear 56 . 37 64 . 15 65 . 17 69 . 47 74 . 77 7 . 14 27 . 63 30 . 91 24 . 88 36 . 45 T able 8: Additional results showing the best-per forming merge configuration per language and backbone on multiple-choice benchmarks (Accuracy) and machine translation (BLEU). For each merged model, we report the strongest variant among the explored merge methods. Bold indicates the best result among merged variants of the same backbone model, and underline indicates the best over all result.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment