모델 병합으로 저자원 언어에 지시능력 부여
본 논문은 기존의 대규모 언어 모델을 영어 중심에서 벗어나 저자원 이베리아 언어(바스크, 카탈루냐, 갈리시아, 스페인어)로 확장하기 위해, 사전 학습된 언어‑특화 베이스 모델과 이미 지시 튜닝된 모델을 가중치 병합하는 방법을 제안한다. 선형 병합, Task Arithmetic, DARE, Breadcrumbs 등 네 가지 병합 전략을 실험하고, 단일 언어 및 다언어 병합 시 모델의 언어 이해·생성 능력과 지시 수행 능력을 평가한다. 결과는 병합…
저자: Eneko Valero, Maria Ribalta i Albado, Oscar Sainz
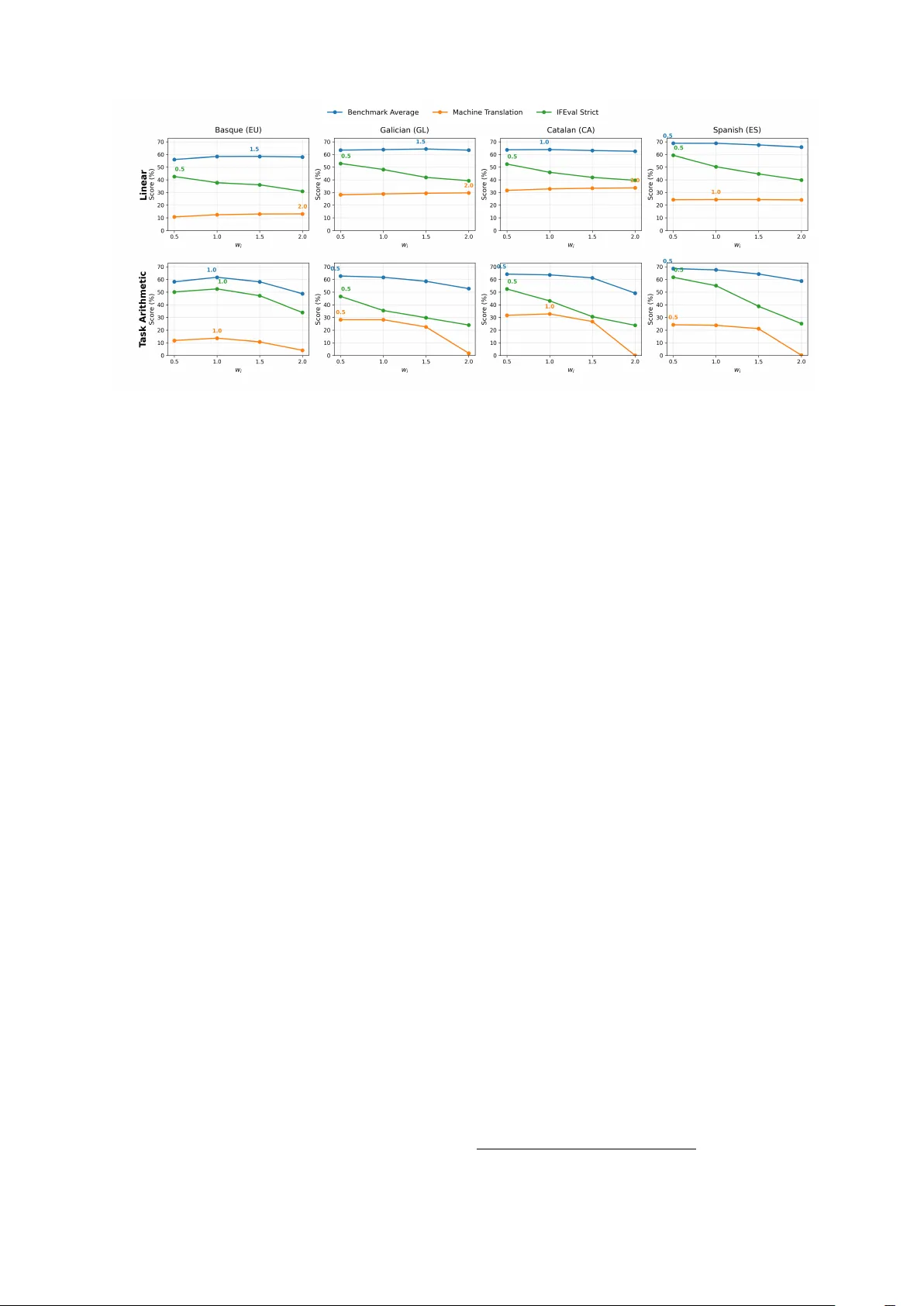
본 논문은 대규모 언어 모델(LLM)이 영어 중심으로 개발되어 저자원 언어에서 성능이 크게 떨어지는 문제를 해결하고자, “모델 병합”이라는 경량화된 적응 방식을 제안한다. 기존의 지속적 사전 학습(continual pre‑training)이나 지시 튜닝(instruction tuning)은 방대한 텍스트와 고품질 지시‑응답 쌍을 필요로 하며, 특히 저자원 언어 커뮤니티에서는 데이터와 컴퓨팅 자원이 부족해 적용이 어렵다. 이에 저자들은 이미 지시 튜닝된 LLM(예: Llama 3.1‑Instruct, Qwen 3‑Instruct)과 해당 언어에 특화된 베이스 모델을 가중치 병합함으로써, 언어 능력과 지시 수행 능력을 동시에 확보하는 방법을 탐구한다.
**데이터와 베이스 모델 구축**
- 대상 언어: 바스크(eu), 갈리시아(gl), 카탈루냐(ca), 스페인어(es) 네 개.
- 각 언어마다 약 3~4 B 토큰 규모의 코퍼스를 수집하고, 토크나이저에 따라 Llama 3.1과 Qwen 3 기준 토큰 수를 맞추었다.
- 영어 소규모(0.5 M 문서)도 포함해 catastrophic forgetting을 방지하였다.
- 학습 설정: 시퀀스 길이 8196, 배치 256, 학습률 1e‑5, 코사인 스케줄러, 32노드·4 A100 GPU 클러스터에서 Fully Sharded Data Parallel(FSDP) 사용.
**모델 병합 기법**
1. **Linear Merging**: 단순 가중 평균. 베이스와 지시 모델에 각각 가중치를 부여해 파라미터를 선형 결합한다.
2. **Task Arithmetic**: 베이스 모델과 언어‑특화 모델 간 차이를 “task vector”로 정의하고, 이를 가중합해 새로운 파라미터를 만든다.
3. **DARE**: 파라미터 차이를 스케일링하고, 중요도가 낮은 파라미터를 억제해 모델 간 충돌을 최소화한다.
4. **Breadcrumbs**: 파라미터 마스크와 프루닝을 결합해 중복을 제거하고 효율성을 높인다.
**실험 설계**
- **단일 언어 병합**: 각 언어별 베이스 모델과 지시 모델을 병합해 언어 모델링 성능(Perplexity)과 지시 수행 능력(IFEval 확장판) 평가.
- **다언어 병합**: 네 개의 언어‑특화 모델을 동시에 병합해 하나의 다국어 지시 모델을 생성하고, 언어별 성능 균형을 분석.
- **비교 대상**: (1) 원본 지시 모델(언어 미지원), (2) 언어‑특화 베이스 모델(지시 미지원), (3) Sainz et al. (2025)의 지속적 사전 학습+지시 튜닝 결합 모델, (4) Salamandra·ALIA 등 기존 저자원 LLM.
**핵심 결과**
- **언어 능력 유지**: 대부분의 병합 기법이 베이스 모델 수준의 Perplexity를 유지했으며, 특히 Task Arithmetic과 DARE는 5 % 이하의 성능 저하만 보였다.
- **지시 능력 보존**: 원본 지시 모델 대비 5~10 % 정도 점수 감소가 있었지만, 여전히 실용적인 수준을 유지했다. Linear Merging은 가장 큰 손실을 보였고, Task Arithmetic이 가장 안정적이었다.
- **다언어 병합**: 균등 가중치 병합 시 모든 언어에서 평균 성능이 향상되었으며, 특정 언어에 편향된 가중치를 주면 해당 언어에서 약간의 이득을 얻지만 다른 언어에서 손실이 발생했다. Llama 3.1 기반에서는 다언어 병합 후 스페인어와 카탈루냐어에서 기존 지시 모델 대비 2~3 % 향상을 기록했다.
- **계산 효율성**: 병합은 단일 GPU에서 수십 분 내에 완료될 수 있어, 기존 지속적 사전 학습(수천 GPU·시간) 대비 2~3 % 정도의 비용만 소요된다.
**의의와 한계**
- 저자원 언어 커뮤니티가 최신 지시 모델을 빠르게 최신화하고, 새로운 언어를 추가할 때마다 전체 재학습을 할 필요가 없다는 실용적 장점이 있다.
- 병합은 동일 아키텍처와 초기화가 전제이므로, 서로 다른 구조의 모델을 직접 결합하기는 어렵다. 또한, 병합 비율 선택이 성능에 큰 영향을 미치므로 자동화된 최적화 기법이 필요하다.
- 현재 실험은 이베리아 언어에 국한되었으며, 아프리카·아시아 저자원 언어에 대한 일반화 검증은 향후 과제로 남는다.
**결론**
모델 병합은 저자원 언어에 대한 언어 능력과 지시 수행 능력을 동시에 확보할 수 있는 효율적인 대안이다. 특히 Task Arithmetic과 DARE 같은 정교한 병합 기법은 파라미터 충돌을 최소화하면서도 높은 성능을 유지한다. 이 접근법은 계산 비용을 크게 절감하고, 최신 지시 모델을 빠르게 적용할 수 있게 함으로써, 저자원 언어 연구와 실제 서비스에 새로운 가능성을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기