ERPO: Token-Level Entropy-Regulated Policy Optimization for Large Reasoning Models
Reinforcement learning from verifiable rewards (RLVR) has significantly advanced the reasoning capabilities of large language models. However, standard Group Relative Policy Optimization (GRPO) typically assigns a uniform, sequence-level advantage to…
Authors: Song Yu, Li Li
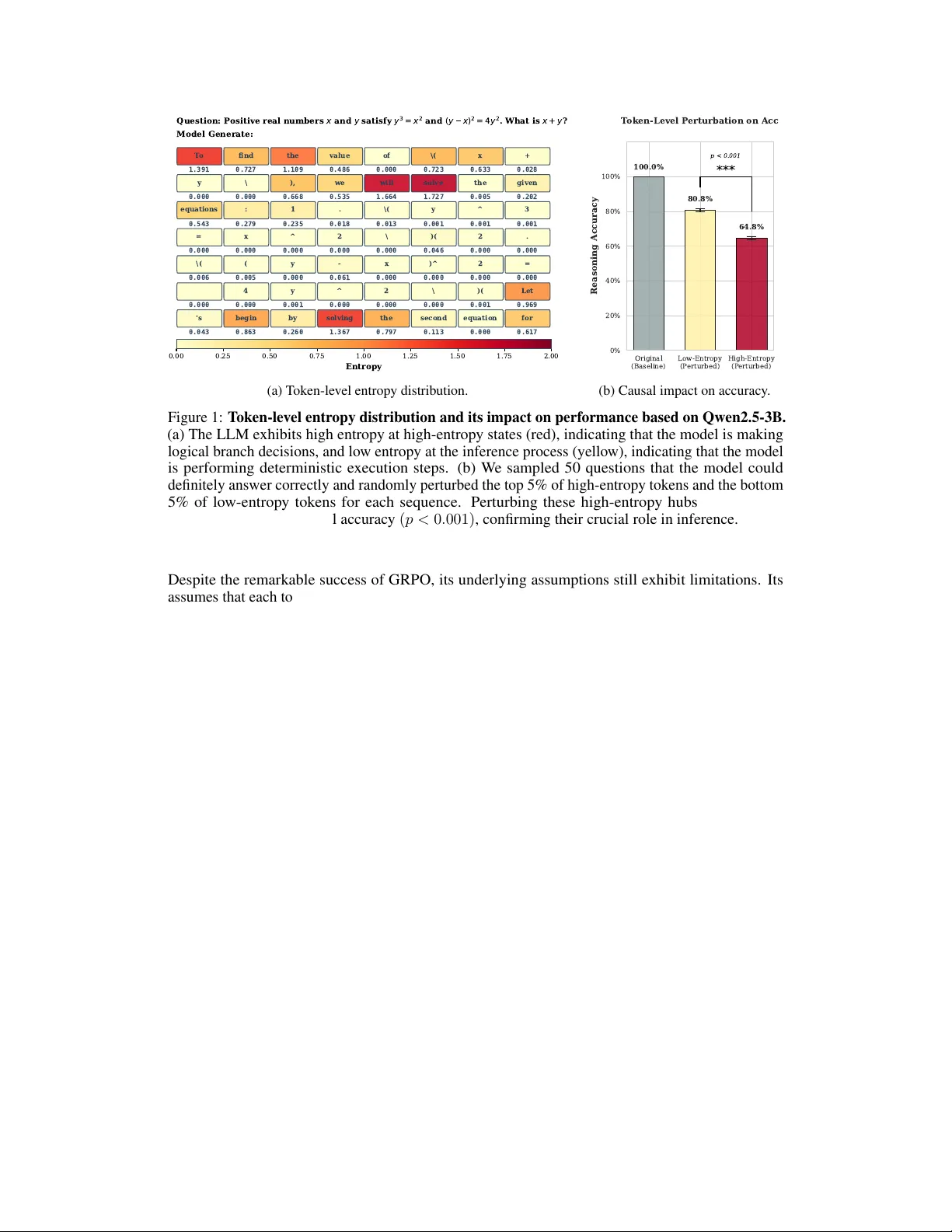
ERPO: T oken-Le vel Entr opy-Regulated P olicy Optimization f or Large Reasoning Models Song Y u, Li Li ∗ School of Computer and Information Science Southwest Univ ersity Chongqing, China 400715 yusong0929@email.swu.edu.cn lily@swu.edu.cn Abstract Reinforcement learning from verifiable rew ards (RL VR) has significantly adv anced the reasoning capabilities of large language models. Howe ver , standard Group Relativ e Policy Optimization (GRPO) typically assigns a uniform, sequence-le vel adv antage to all tokens, thereby o verlooking the intrinsic information heterogeneity along reasoning chains. W e show that this coarse-grained credit assignment leads to premature entropy collapse and encourages the model to generate redundant, low-quality reasoning paths. Through systematic empirical analysis, we identify Critical Decision Pi vots (CDPs): transient high-entropy states where the polic y’ s trajectory is most sensiti ve to perturbations. These piv ots represent the "forks in the road" where ef fectiv e multi-path exploration is most crucial yet often suppressed by uniform advantage signals. Building on these insights, we propose Entropy- Regulated Polic y Optimization (ERPO), which transitions the optimization focus from coarse sequences to fine-grained token dynamics. ERPO introduces three synergistic components: (i) Entropy-aware Gating, which adaptively amplifies exploration at CDPs to facilitate di verse path discov ery; (ii) Bucket-based Implicit Normalization, which mitigates difficulty bias by aligning token progress win- do ws; and (iii) Result-anchored Adv antage Synthesis, which re-weights token-le vel signals via outcome-dri ven anchors. Extensiv e experiments on competiti ve math- ematical benchmarks (e.g., MA TH, AIME) demonstrate that ERPO significantly outperforms GRPO. Notably , ERPO not only boosts reasoning accuracy but also yields significantly more concise and rob ust deri vation paths, establishing a ne w efficienc y-accuracy frontier for lar ge reasoning models. 1 Introduction W ith the advancement of large language models (LLMs), reinforcement learning has emerged as a central paradigm for post-training base models in complex agent tasks [ 1 ]. OpenAI’ s o1 [ 2 ] demonstrates the capability of solving complex logical problems through Chain-of-Thought (CoT), while the release of DeepSeek-R1 [ 3 ] marks the significant ef fectiveness of reinforcement learning with verifiable re wards (RL VR) [ 4 ] in enhancing model reasoning abilities, powered by Group Relativ e Policy Optimization [ 5 ] (GRPO). GRPO removes the critic network and adopts intra- group relati ve adv antages for gradient updates, substantially reducing computational o verhead and improving training ef ficiency [6]. ∗ Corresponding Author . Preprint. Under revie w . Q u e s t i o n : P o s i t i v e r e a l n u m b e r s x a n d y s a t i s f y y 3 = x 2 a n d ( y x ) 2 = 4 y 2 . W h a t i s x + y ? Model Generate: T o 1.391 find 0.727 the 1.109 value 0.486 of 0.000 \( 0.723 x 0.633 + 0.028 y 0.000 \ 0.000 ), 0.668 we 0.535 will 1.664 solve 1.727 the 0.005 given 0.202 equations 0.543 : 0.279 1 0.235 . 0.018 \( 0.013 y 0.001 ^ 0.001 3 0.001 = 0.000 x 0.000 ^ 0.000 2 0.000 \ 0.000 )( 0.046 2 0.000 . 0.000 \( 0.006 ( 0.005 y 0.000 - 0.061 x 0.000 )^ 0.000 2 0.000 = 0.000 0.000 4 0.000 y 0.001 ^ 0.000 2 0.000 \ 0.000 )( 0.001 Let 0.969 's 0.043 begin 0.863 by 0.260 solving 1.367 the 0.797 second 0.113 equation 0.000 for 0.617 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 2.00 Entropy (a) T oken-level entrop y distribution. Original (Baseline) Low-Entropy (P erturbed) High-Entropy (P erturbed) 0% 20% 40% 60% 80% 100% Reasoning Accuracy 100.0% 80.8% 64.8% *** p < 0.001 T oken-Level P erturbation on Acc (b) Causal impact on accuracy . Figure 1: T oken-lev el entropy distrib ution and its impact on performance based on Qwen2.5-3B. (a) The LLM exhibits high entrop y at high-entropy states (red), indicating that the model is making logical branch decisions, and low entropy at the inference process (yellow), indicating that the model is performing deterministic execution steps. (b) W e sampled 50 questions that the model could definitely answer correctly and randomly perturbed the top 5% of high-entrop y tokens and the bottom 5% of lo w-entropy tokens for each sequence. Perturbing these high-entropy hubs resulted in a significant decrease in final accuracy ( p < 0 . 001) , confirming their crucial role in inference. Despite the remarkable success of GRPO, its underlying assumptions still exhibit limitations. Its assumes that each token shares the sequence-lev el advantage, implying an inherent premise that each token in the reasoning sequence contrib utes equally to the final adv antage. Howe ver , in actual CO T reasoning processes, the informational value of tok ens demonstrates significant heterogeneity: when models encounter logical branches or critical decision points, token distributions exhibit high entropy characteristics [ 7 ]. At such junctures, models require substantial randomness and exploration to identify correct reasoning paths. During deterministic logical expansion phases, token distrib utions tend to con verge. At this stage, redundant deriv ations often lead to inefficient generation and may ev en introduce extraneous computational overhead [ 8 , 9 ]. Existing verifiable re ward designs, such as length penalties or KL div ergence, are typically token-agnostic. This penalization suppresses exploration when models are hesitating, yet fails to ef fectiv ely compress redundancy when models are confident. T o systematically inv estigate this heterogeneity , we conducted a multi-stage empirical analysis rev ealing fundamental differences in le xical importance. W e first observed significant heterogeneity in the predicti ve dynamics of LLMs during complex reasoning processes. By visualizing the lexical entropy of inference trajectories (e.g., on the AMC dataset), we identified specific high entrop y token [ 10 ] at which the model exhibits higher predictiv e entropy . This stands in stark contrast to deterministic computational steps that maintain near-zero entropy in Figure 1a. W e define these high- entropy re gions as Critical Decision Piv ots (CDPs). Unlike fixed logical k eywords, CDPs represent the model’ s reasoning frontier where the polic y is most uncertain and sensitive to perturbations. W e then determined the causal significance of these tokens through a lar ge-scale perturbation study . By performing controlled truncation and random replacement on 2460 samples from the MA TH dataset, we rev ealed a significant sensitivity gap: perturbing high-entropy token leads to a sharp 35.2% drop in inference accuracy [ 11 ], while the model remains highly robust to perturbations of lo w-entropy steps in Figure 1b. This suggests that high-entropy states are not merely ’confused’ steps but represent irreplaceable structural transitions where any de viation leads to a cascading failure of the reasoning chain. Howe ver , standard reinforcement learning methods such as GRPO [ 5 ] ignore this, imparting a uniform adv antage throughout the sequence and diluting the crucial re ward signal with gradient noise from redundant labels. Our empirical analysis confirms that disrupting these ’hesitation points’ leads to a disproportionate drop in reasoning accuracy , regardless of whether the token is a formal logical operator or a complex 2 structural transition. Based on these insights, we propose Entropy-Regulated Relativ e Advantage (ERPO), a nov el reinforcement learning paradigm designed to refine credit assignment in comple x reasoning tasks. The core of ERPO lies in its ability to transform sparse, sequence-le vel outcomes into dense, token-le vel signals by integrating Implicit Process Rewards with a dynamic entropy- gating mechanism. ERPO prioritizes exploration at these CDPs to fortify the most fragile links in the reasoning chain. By selectively amplifying the advantage signal at high-entropy tokens while dampening it during deterministic computations, ERPO ensures that the gradient update is concentrated on the most causal steps of the inference chain. In summary , our main contrib utions are as follows: • W e identify CDPs in LLM reasoning via token-level entropy and propose ERPO, which integrates implicit PRM signals and relati ve position bucketing for fine-grained credit assignment without additional rew ard training. • W e introduce an adaptive gating function that dynamically adjusts rew ard density based on local predicti ve uncertainty , balancing exploration at critical junctions with stability in deriv ation steps. • Experiments on four datasets show ERPO outperforms GRPO, achie ving a superior Pareto frontier between reasoning accuracy and sequence length redundancy , while riv aling or ev en surpassing models tens of times its size in parameter count. 2 Preliminaries W e begin by formalizing the probabilistic framework of LLMs [ 12 ], followed by an overvie w of RL VR. Then, we delineate the GRPO algorithm, providing the necessary background for our proposed method. LLMs. Specifically , gi ven an input prompt x , an LLM π θ sequentially generates a T -token response y = ( y 1 , ..., y T ) : π θ ( y | x ) = T Y t =1 π θ ( y t | x , y 0 is a hyperparameter scaling the sensitivity to policy deviation. Intuitiv ely , s i,t acts as an intrinsic motiv ator that re wards tokens reflecting a refined understanding over the base 4 model. This term enables fine-grained credit assignment by distinguishing the relati ve contrib ution of individual tok ens within a long CoT sequence, effecti vely mitigating the sparse re ward challenge in RL VR. 3.2 Entropy awar e Gating While H i,t provides a raw measure of uncertainty , to effecti vely lev erage this signal for optimization, we introduce an adapti ve gating function W i,t that translates local predicti ve uncertainty into a relativ e importance weight. W e perform intra-group entropy calibration to account for v arying task complexities. Specifically , for each token o i,t in a prompt group G , we compute the gated weight: W i,t = σ γ · H i,t − µ H, G σ H, G + δ , (8) where µ H, G and σ H, G denote the moving mean and standard de viation of entropy within the current group, respectiv ely . σ ( · ) is the sigmoid function and γ is a scaling factor . Essentially , W i,t acts as a diagnostic probe that surfaces the logic junctions where multiple reasoning paths div erge, ensuring that the gradient signal is concentrated on these high stakes decision points. 3.3 Bucketing Implicit Advantage As shown in Figure 1a, the inference phase exhibits temporal heterogeneity . LLMs typically in volv e dif ferent stages, from step planning and logical branching to stepwise deri v ation and finally numerical verification. The implicit progress values of these steps cannot be directly compared horizontally . T o ensure fairness, we propose relati ve position binning. W e first define the relativ e progress of a token o i,t as τ i,t = t/ | o i | , where | o i | is the sequence length. The reasoning process is then partitioned into K discrete temporal buckets B 1 , . . . , B K , each representing a synchronized progress window . W ithin each prompt group G , we perform intra-group buck et normalization to isolate the relativ e quality of a token from its temporal position: ˜ s i,t = s i,t − µ k, G σ k, G + δ , ∀ ( i, t ) ∈ B k , (9) where µ k, G and σ k, G are the mean and standard deviation of the signals belonging to bucket k across all G sequences in the group. By judging a token’ s advantage only against its peers at the same reasoning stage, its filters out task variance and pro vides a pure measure of token-le vel contribution, effecti vely aligning the optimization signal with the model’ s multi stage reasoning trajectory . 3.4 Final Advantages Synthesis W e synthesize the refined process signals with the global sequence-lev el adv antage. A primary concern in this fusion is ensuring that the process-lev el feedback does not lead to re ward hac king , where the model might optimize for high-confidence tokens that ultimately lead to incorrect answers. W e introduce an Outcome Anchoring mechanism, where the sign of the sequence-le vel advantage acts as a directional guardrail. Specifically , we compute the calibrated process re ward Ψ i,t and synthesize it into the final advantage as follo ws: ˆ A final i,t = Norm G ˆ A group i + η · Ψ i,t , with Ψ i,t = σ target · W i,t · sgn ( ˆ A i ) · ˜ s i,t std ( ˆ Ψ activ e ) + δ , (10) where Norm G ( · ) denotes the intra-group Z-score normalization to preserve the relati ve optimization property of GRPO. σ target and η are parameters, respectively . This strategy ensures that ˆ A final i,t is unbiased and well calibrated, ensuring that even highly confident pi votal tok ens are penalized if they ultimately lead to a fallacious conclusion. 3.5 Theoretical Analysis W e analyze whether ERPO preserv es the theoretical guarantees of policy gradient methods and prev ents pathological behaviors such as re ward hacking. 5 Algorithm 1: ERPO: Entropy-Regulated Polic y Optimization Require: Initial policy π θ , reference policy π ref ; learning rate α lr ; group size G ; number of buck ets K ; gating factor γ ; scaling constants β progress , η , σ target . Ensure: Optimized policy parameters θ . 1 f or iteration n = 1 , . . . , N do 2 Sample prompt x ∼ D and generate G responses { o 1 , . . . , o G } ∼ π θ ( · | x ) ; 3 Compute verifiable re wards { r 1 , . . . , r G } and group advantages ˆ A group i via standard GRPO; /* Token-level Diagnostic Metrics */ 4 for eac h r esponse o i and token t do 5 H i,t ← − P v ∈V π θ ( v | x, o i,t of the current policy being optimized, preserving the causality of the trajectory . 4 Experiments 4.1 Experimental Setup Datasets and Evaluation Benchmarks. For reinforcement learning, we utilized the MA TH dataset [ 16 ], specifically filtering problems with difficulty levels 3 to 5. This curated subset ensures the model is exposed to high entropy reasoning tasks. T o ev aluate generalization and peak reasoning capabilities, we conducted testing on four prestigious competitive mathematics benchmarks: AMC23 [17], AIME24 [18], AIME25 [19], and the Minerva [20]. Model Configurations. W e implemented ERPO across three scales of the Qwen2.5 series [ 21 ]: 1.5B, 3B, and 7B. T o ensure training efficienc y , we employed Low-Rank Adaptation (LoRA) [ 22 ] with a rank r = 32 and α lora = 64 , targeting all linear layers to provide sufficient capacity for complex reasoning updates. T raining Specifications. The models were trained for a single epoch using the TRL framework [ 23 ], with the maximum sequence length set to 2048 to accommodate CoT deriv ations. W e utilized a global batch size of 16, with G = 8 rollouts per prompt. The learning rate was fixed at 5 × 10 − 6 with a 0 . 1 warmup ratio and a cosine decay schedule. Optimization was performed using AdamW with a weight decay of 0 . 001 , integrated with DeepSpeed for memory ef ficiency . Detailed settings are provided in Appendix. 4.2 Baselines T o ev aluate the ef fectiveness of ERPO, we benchmark our approach against the follo wing baseline configurations: Base Model. The model without any fine-tuning, serving as the fundamental performance lo wer bound. 7 T able 1: Performance ev aluation of Qwen2.5 models across reasoning benchmarks. Acc (%) and Fmt (%) denote sample accuracy and boxed rate. Benchmarks are ordered by difficulty: AMC23, Minerva, AIME24, and AIME25. Bold values indicate the best performance within each parameter scale. AMC 23 Minerva AIME 24 AIME 25 A verage Model Acc Fmt Acc Fmt Acc Fmt Acc Fmt Acc Fmt Commer cial Baselines DeepSeek-R1-671B-0528 33.91 33.91 11.41 34.38 13.54 13.54 11.04 11.04 17.48 23.22 Qwen3-235B-A22B-Instr . 47.81 55.00 17.66 92.34 24.58 29.58 16.88 20.21 26.73 49.28 1.5B Scale Qwen2.5-1.5B Base 0.78 27.97 0.31 27.97 0.21 28.33 0.00 26.67 0.33 27.74 Qwen2.5-1.5B SFT 8.13 98.28 1.41 84.84 0.83 95.42 0.42 93.13 2.70 92.92 Qwen2.5-1.5B GRPO 25.31 95.31 4.06 93.44 3.54 87.08 2.08 94.17 8.75 92.50 Qwen2.5-1.5B ERPO 27.19 95.31 4.22 97.81 3.75 90.00 2.08 94.17 9.31 94.32 3B Scale Qwen2.5-3B Base 14.84 72.66 3.13 62.66 2.08 75.83 1.46 78.96 5.38 72.53 Qwen2.5-3B SFT 10.63 99.38 2.03 74.69 0.83 95.42 0.83 95.63 3.58 91.28 Qwen2.5-3B GRPO 32.81 97.03 7.34 97.03 5.21 87.71 3.33 93.96 12.17 93.93 Qwen2.5-3B ERPO 37.50 96.72 8.91 98.91 7.08 92.50 2.92 97.92 14.10 96.51 7B Scale Qwen2.5-7B Base 23.75 86.09 4.38 77.03 3.54 82.50 1.25 83.54 8.23 82.29 Qwen2.5-7B SFT 17.03 96.88 4.84 71.88 1.46 88.75 1.46 94.79 6.20 88.08 Qwen2.5-7B GRPO 47.50 97.19 12.50 98.91 11.25 93.75 6.46 94.17 19.43 96.01 Qwen2.5-7B ERPO 49.53 98.13 13.28 98.75 12.92 94.79 7.08 96.25 20.70 96.98 SFT Model. A supervised fine-tuned version of the base model using the same MA TH training set, representing the gain from standard cross entropy loss on reasoning chains. Instruct Model. The of ficial models, which hav e undergone lar ge-scale general instruction tuning and alignment. GRPO. The most critical baseline to isolate the specific contributions of our proposed entropy-gated credit assignment and temporal buck eting under identical rollout and reward configurations. 4.3 Overall P erformance and Benchmarking Comparison with Large-Scale Models. According to the results in T able 1, ERPO achieves a dominant position across various parameter scales. Specifically , our 7B model reaches a lev el of per- formance that surpasses much larger commercial models, including DeepSeek-R1-0528 (671B) and Qwen3-235B-A22B-Instruct. This indicates that token-le vel credit assignment ef fectiv ely compen- sates for smaller parameter counts by maximizing the reasoning potential of each layer . Furthermore, the format consistency rate (Fmt) also sho ws a steady improv ement across all benchmarks. The Generalization Gap in SFT . W e observe that certain SFT models perform worse than their corresponding base models after fine-tuning. This phenomenon stems from the fact that our SFT phase is conducted on the relativ ely simple MA TH dataset, while the ev aluation benchmarks like AIME25 are significantly more difficult. SFT tends to force the model to mimic specific e xpert solution paths, which limits its ability to generalize to out-of-distrib ution problems. In contrast, ERPO encourages autonomous exploration, allo wing the model to de velop rob ust internal logic rather than simple pattern matching. 8 T able 2: Comprehensiv e pass @ k ( k ∈ { 2 , 4 , 8 , 16 } ) performance e valuation. Bold values indicate the best performance within each parameter scale (1.5B, 3B, and 7B). AMC 23 Minerva AIME 24 AIME 25 Model @2 @4 @8 @16 @2 @4 @8 @16 @2 @4 @8 @16 @2 @4 @8 @16 Commer cial Baselines DeepSeek-R1-671B-0528 47.62 58.72 66.19 72.50 16.35 20.94 23.78 25.00 21.03 28.07 32.14 33.33 17.33 23.68 28.82 33.33 Qwen3-235B-A22B-Instr . 54.35 59.66 63.00 65.00 19.50 21.44 23.40 25.00 27.03 28.32 30.00 33.33 20.03 22.21 24.22 26.67 1.5B Scale Qwen2.5-1.5B Base 1.56 3.12 6.25 12.50 0.62 1.25 2.50 5.00 0.42 0.83 1.67 3.33 0.00 0.00 0.00 0.00 Qwen2.5-1.5B SFT 14.90 25.41 39.17 55.00 2.48 3.96 5.66 7.50 1.67 3.33 6.67 13.33 0.83 1.67 3.33 6.67 Qwen2.5-1.5B GRPO 36.67 49.09 62.92 75.00 6.92 10.40 13.62 17.50 6.19 10.06 15.56 23.33 4.11 8.00 15.11 26.67 Qwen2.5-1.5B ERPO 38.25 49.62 61.46 72.50 6.21 8.53 11.92 17.50 6.81 11.40 17.08 23.33 3.72 6.12 9.21 13.33 3B Scale Qwen2.5-3B Base 25.29 38.60 52.48 67.50 5.44 8.62 12.24 15.00 3.92 6.95 11.21 16.67 2.72 4.76 7.43 10.00 Qwen2.5-3B SFT 18.31 28.64 40.35 52.50 3.77 6.56 10.38 15.00 1.64 3.17 5.89 10.00 1.67 3.33 6.67 13.33 Qwen2.5-3B GRPO 46.00 59.57 71.73 80.00 10.94 14.58 17.56 20.00 8.58 12.81 18.44 26.67 6.31 11.40 19.29 30.00 Qwen2.5-3B ERPO 49.79 61.91 71.11 77.50 13.25 17.73 22.57 27.50 11.22 16.43 23.40 33.33 5.56 10.07 16.56 23.33 7B Scale Qwen2.5-7B Base 38.15 54.06 67.42 77.50 7.75 12.46 17.60 22.50 6.19 10.06 15.56 23.33 2.50 5.00 10.00 20.00 Qwen2.5-7B SFT 28.56 43.31 59.20 70.00 8.17 12.31 16.47 20.00 2.86 5.50 10.11 16.67 2.83 5.36 9.67 16.67 Qwen2.5-7B GRPO 60.81 71.62 79.25 82.50 17.83 24.15 30.54 35.00 16.28 21.49 27.09 33.33 10.97 16.93 24.29 33.33 Qwen2.5-7B ERPO 63.40 75.22 84.21 90.00 17.92 23.10 28.29 32.50 17.89 22.45 27.38 33.33 12.08 18.60 26.44 36.67 4.4 Multi-Sample Scaling Analysis Perf ormance Gains in Pass@k. As demonstrated in T able 2, the number of solved problems increases for all models as the sampling count k rises. Howe ver , the improvement is significantly more pronounced for models trained with reinforcement learning (GRPO and ERPO). By optimizing the reasoning process, ERPO e xpands the ef fecti ve search space of the policy . This allows our smaller models to partially e xceed the performance of models with ten times more parameters when ev aluated under high-throughput sampling conditions. 4.5 Scale-Dependent T raining Dynamics Con vergence and P erformance on 3B and 7B Scales. The training curves in Figure 2 sho w that ERPO achie ves higher final accuracy and faster conv ergence than the GRPO baseline on the 3B and 7B scales. The entropy-regulated mechanism immediately provides beneficial guidance to these larger models, which possess more stable logical representations. Initial Exploration Lag in 1.5B Models. On the 1.5B scale, we observe that ERPO initially underperforms GRPO before rising sharply in the later stages. Our analysis suggests that the entropy- regulation mechanism introduces significant perturbations to smaller models, which ha ve less stable latent states. This causes the model to spend more time on e xploration in the early phase. Howe ver , once correct reasoning paths are captured, the performance increases rapidly , eventually surpassing GRPO as seen in the late steps of Figure 2a. This explains why ERPO might sho w lower metrics on certain dif ficult tasks like AIME25 within 1 epoch, and we anticipate that extended training would yield ev en greater gains. 4.6 Policy Stability and Inf ormation Metrics Entropy and Reward Ev olution. Figure 3 visualizes the core training metrics. Although ERPO’ s rew ard is initially lower than GRPO’ s due to the emphasis on exploration, it ev entually exceeds the baseline. Crucially , ERPO maintains a healthy entropy le vel between 0.2 and 0.4 in the late stages, whereas GRPO suffers from entropy collapse. This preservation of diversity is key to pre venting mode collapse. Gradient and Divergence Stability . The gradient norms of ERPO remain stable throughout the process, showing no signs of gradient explosion. While our KL diver gence is slightly higher than that of standard GRPO—reflecting a more aggressiv e departure from the base model—it remains 9 0 300 600 900 Steps 0.00 0.08 0.16 0.24 Accuracy (%) AMC23 0 300 600 900 Steps 0.000 0.015 0.030 Minerva 0 300 600 900 Steps 0.000 0.015 0.030 AIME24 0 300 600 900 Steps 0.000 0.006 0.012 0.018 AIME25 ERPO (Ours) GRPO (Baseline) (a) T raining dynamics of 1.5B models. 0 300 600 900 Steps 0.16 0.24 0.32 Accuracy (%) AMC23 0 300 600 900 Steps 0.02 0.04 0.06 0.08 Minerva 0 300 600 900 Steps 0.02 0.04 0.06 AIME24 0 300 600 900 Steps 0.01 0.02 0.03 AIME25 ERPO (Ours) GRPO (Baseline) (b) T raining dynamics of 3B models. 0 300 600 900 Steps 0.24 0.32 0.40 0.48 Accuracy (%) AMC23 0 300 600 900 Steps 0.03 0.06 0.09 0.12 Minerva 0 300 600 900 Steps 0.03 0.06 0.09 0.12 AIME24 0 300 600 900 Steps 0.02 0.04 0.06 AIME25 ERPO (Ours) GRPO (Baseline) (c) T raining dynamics of 7B models. Figure 2: Comparison of training efficienc y and generalization performance between GRPO (Baseline) and ERPO (Ours) across three model scales (1.5B, 3B, 7B). Each row presents the sample accurac y (%) on AMC23, Minerva, AIME24, and AIME25 benchmarks, smoothed with EMA ( α = 0 . 2 ). well-controlled without the sharp spikes observed in the baseline. This suggests that ERPO maintains a more consistent optimization trajectory . 4.7 Inference Efficiency and Computational Ov erhead Reasoning Conciseness. A major adv antage of ERPO is shown in Figure 4(a), where our models achiev e higher accuracy while maintaining shorter sequence lengths. By encouraging exploration at high entropy points and suppressing redundancy at lo w-entropy steps, ERPO pre vents the model from becoming ov erly verbose in straightforward reasoning steps. Evolution of Generation Length. Figure 4c sho ws that while our generation length is slightly higher during the initial exploration phase, it drops significantly belo w the GRPO length in the later stages while maintaining superior accuracy . This characteristic improv es the overall quality of the reasoning chains. T raining Efficiency and Future Gains. As shown in Figure 4b, the total training time for ERPO is comparable to GRPO with almost no increase. This is because the additional diagnostic signals used by ERPO are computationally inexpensi ve to deriv e. W e e xpect that as training continues, ERPO will 10 0 300 600 900 Steps 0.0 0.4 0.8 V alue Reward 0 300 600 900 Steps 0.0 0.1 0.2 0.4 1.0 5.0 Entropy 0 300 600 900 Steps 0 1 2 Grad Norm 0 300 600 900 Steps 0.0 0.2 0.4 KL Divergence GRPO (Baseline) ERPO (Ours) Figure 3: T raining dynamics of ERPO vs. GRPO. W e visualize the (a) Re ward, (b) Entropy , (c) Grad Norm, and (d) KL Div ergence. Note that the Entropy axis uses a symlog scale to highlight the significant dif ference in the late training stage ( 0 . 4 vs. 0 . 05 ), demonstrating that ERPO ef fectiv ely prev ents mode collapse. All curves are smoothed with EMA ( α = 0 . 12 ) while raw data is sho wn in light colors. become ev en more efficient than GRPO because the decreasing rollout length directly translates into higher training throughput. 5 Conclusion In this work, we have presented ERPO, an entropy-regulated policy optimization framework de- signed to address the challenges of sparse and coarse-grained rewards in reinforcement learning for mathematical reasoning. By inte grating token-le vel uncertainty diagnostics with a temporal buck eting mechanism, ERPO successfully transforms global sequence-le vel feedback into a dense, process-aware guidance signal. This approach allows the model to prioritize exploration at critical decision piv ots while suppressing redundant computations in straightforward reasoning steps. Our empirical ev aluation across multiple model scales and competitive benchmarks demonstrates that ERPO significantly outperforms standard GRPO and traditional supervised fine-tuning. Beyond pure accuracy , ERPO achiev es a superior balance between performance and inference efficiency . By encouraging concise reasoning paths, ERPO models generate shorter sequences while maintaining higher precision, ef fectiv ely reducing the computational footprint of long-form thought deri vations. Giv en that the diagnostic signals used in ERPO are computationally inexpensiv e, the frame work maintains a training efficienc y comparable to vanilla GRPO. Future work will explore the application of ERPO to e ven more comple x multi-modal reasoning tasks and in v estigate the long-term scaling laws of entropy-re gulated exploration o ver extended training horizons. References [1] Long Ouyang, Jeffrey W u, Xu Jiang, Diogo Almeida, Carroll W ainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Ale x Ray , et al. T raining language models to follow instructions with human feedback. Advances in neur al information pr ocessing systems , 35:27730–27744, 2022. [2] OpenAI. Learning to reason with llms. https://openai.com/index/ learning- to- reason- with- llms/ , 2024. Accessed: 19 March 2026. [3] Daya Guo, Dejian Y ang, Haowei Zhang, Junmei Song, Ruo yu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi W ang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint , 2025. [4] Nathan Lambert, Jacob Morrison, V alentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V alidad Miranda, Alisa Liu, Nouha Dziri, Xinxi L yu, et al. T ulu 3: Pushing frontiers in open language model post-training. In Second Confer ence on Language Modeling , 2024. 11 AMC 23 Minerva AIME 24 AIME 25 Mathematical Reasoning Benchmarks 0 200 400 600 800 1000 A verage Generation T okens 755.7 652.8 887.4 872.3 776.5 679.0 949.8 953.7 Best Checkpoint T oken Efficiency (Qwen2.5-7B) ERPO GRPO Base (static) (a) Best checkpoint token ef ficiency . GRPO ERPO Algorithm 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 Duration (Hours) 14.02h 14.46h T otal T raining Time (b) T otal training time. 0 250 500 750 1000 Checkpoint Steps 700 800 900 1000 1100 A vg Generation T okens AMC 23 0 250 500 750 1000 Checkpoint Steps Minerva 0 250 500 750 1000 Checkpoint Steps AIME 24 0 250 500 750 1000 Checkpoint Steps AIME 25 GRPO ERPO (c) Evolutionary trends of a verage generation tokens during training (EMA, α = 0 . 12 ). Figure 4: Comprehensi ve ef ficiency and training dynamics analysis for Qwen2.5-7B. T op ro w: (a) compares reasoning conciseness at the best checkpoints; (b) e v aluates computational overhead. Bottom row: (c) displays the stability of token generation length across four benchmarks. ERPO achiev es superior performance with significantly more concise reasoning paths and comparable training time to GRPO. [5] Zhihong Shao, Peiyi W ang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y ang W u, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint , 2024. [6] Y ang Y ue, Zhiqi Chen, Rui Lu, Andre w Zhao, Zhaokai W ang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? In The Thirty-ninth Annual Confer ence on Neural Information Pr ocessing Systems , 2025. [7] Shenzhi W ang, Le Y u, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xiong-Hui Chen, Jianxin Y ang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens dri ve ef fectiv e reinforcement learning for llm reasoning. In The Thirty-ninth Annual Confer ence on Neural Information Pr ocessing Systems , 2025. [8] Haoyu Liu and Le Xiao. Re-grpo: Lev eraging hard negati ve cases through large language model guided self training. Neur ocomputing , page 132543, 2025. [9] Mz Dai, Shixuan Liu, and Qingyi Si. Stable reinforcement learning for ef ficient reasoning. In NeurIPS 2025 W orkshop on Efficient Reasoning , 2025. [10] Zhihao Dou, Qinjian Zhao, Zhongwei W an, Dinggen Zhang, W eida W ang, T owsif Raiyan, Benteng Chen, Qingtao Pan, Y ang Ouyang, Zhiqiang Gao, et al. Plan then action: High-lev el planning guidance reinforcement learning for llm reasoning. arXiv preprint , 2025. [11] Y ang Li, Zhichen Dong, Y uhan Sun, W eixun W ang, Shaopan Xiong, Y ijia Luo, Jiashun Liu, Han Lu, Jiamang W ang, W enbo Su, et al. Attention illuminates llm reasoning: The preplan- 12 and-anchor rhythm enables fine-grained policy optimization. arXiv preprint , 2025. [12] T om Bro wn, Benjamin Mann, Nick Ryder , Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry , Amanda Askell, et al. Language models are few-shot learners. Advances in neur al information pr ocessing systems , 33:1877–1901, 2020. [13] John Schulman, Filip W olski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov . Proximal policy optimization algorithms. arXiv pr eprint arXiv:1707.06347 , 2017. [14] John Schulman. Approximating KL div ergence. http://joschu.net/blog/kl- approx. html , March 2020. Accessed: 2026-03-20. [15] Amrith Setlur , Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, and A viral Kumar . Rew arding progress: Scaling automated process verifiers for llm reasoning. In ICLR , 2025. [16] Dan Hendrycks, Collin Burns, Saurav Kada vath, Akul Arora, Stev en Basart, Eric T ang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv pr eprint arXiv:2103.03874 , 2021. [17] Y ifan Zhang and T eam Math-AI. American mathematics competitions (amc) 2023. https: //huggingface.co/datasets/math- ai/amc23 , 2023. [18] Y ifan Zhang and T eam Math-AI. American in vitational mathematics examination (aime) 2024. https://huggingface.co/datasets/math- ai/aime24 , 2024. [19] Y ifan Zhang and T eam Math-AI. American in vitational mathematics examination (aime) 2025. https://huggingface.co/datasets/math- ai/aime25 , 2025. [20] Aitor Lewk owycz, Anders Andreassen, David Dohan, Ethan Dyer , Henryk Michalewski, V inay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quan- titativ e reasoning problems with language models. Advances in neural information pr ocessing systems , 35:3843–3857, 2022. [21] Qwen T eam. Qwen2.5 technical report, 2025. [22] Edward J Hu, Y elong Shen, Phillip W allis, Zeyuan Allen-Zhu, Y uanzhi Li, Shean W ang, Lu W ang, and W eizhu Chen. Lora: Low-rank adaptation of lar ge language models. In International Confer ence on Learning Repr esentations , 2022. [23] Leandro v on W erra, Y ounes Belkada, Le wis T unstall, Edward Beeching, T ristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. TRL: T ransformers Rein- forcement Learning, 2020. A A ppendix / supplemental material 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment