엔트로피 기반 토큰 레벨 정책 최적화로 추론 모델 성능 향상
본 논문은 대형 언어 모델의 수학·논리 추론에서 토큰별 정보 이질성을 고려하지 못하는 기존 GRPO 방식의 한계를 지적하고, 고엔트로피 토큰을 ‘핵심 결정 지점(CDP)’으로 규정한다. 이를 기반으로 엔트로피‑가중 게이팅, 버킷 기반 정규화, 결과‑앵커링을 결합한 ERPO를 제안한다. 실험 결과 ERPO가 정확도와 길이 효율성 모두에서 GRPO를 크게 앞선다는 것을 입증한다.
저자: Song Yu, Li Li
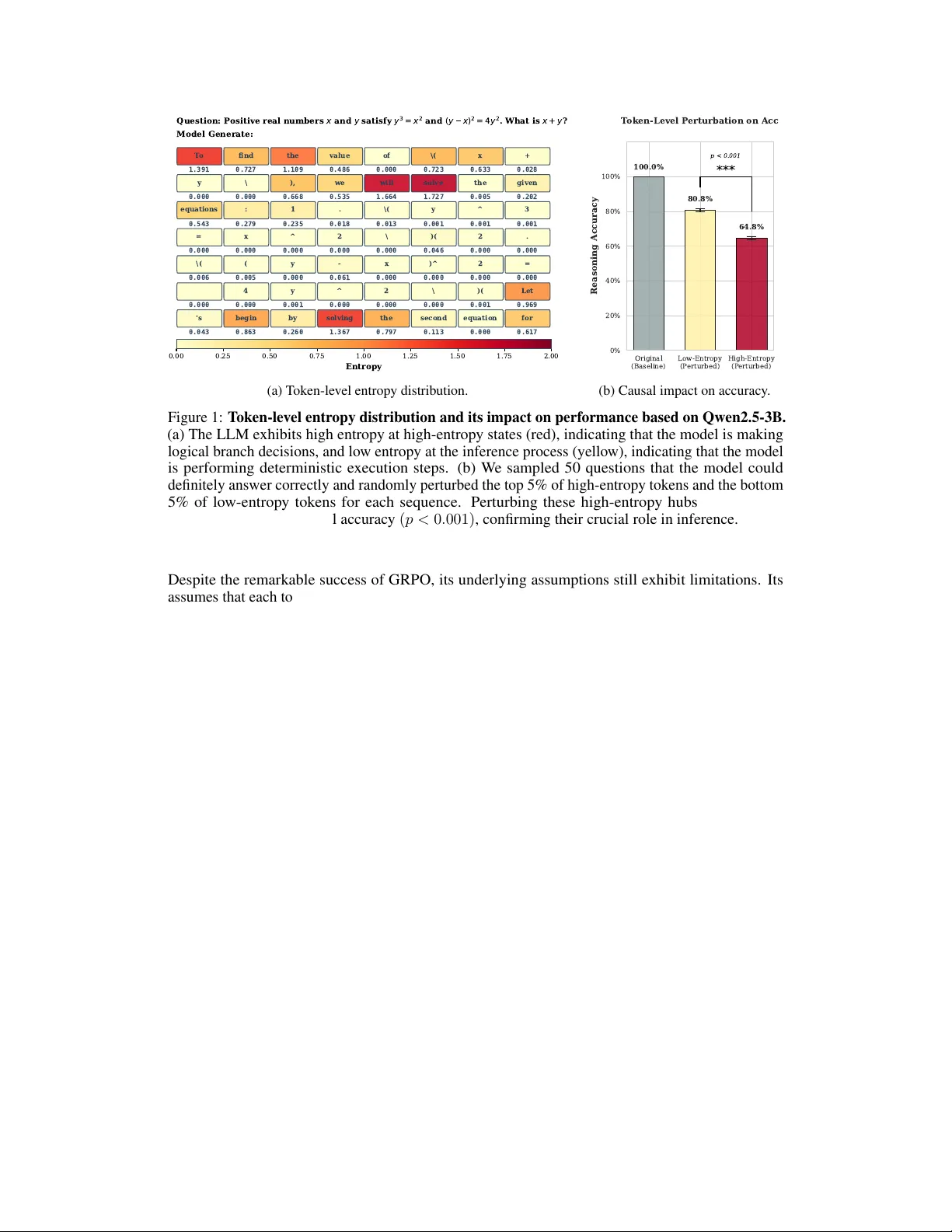
본 논문은 대형 언어 모델(LLM) 기반 수학·논리 추론에서 강화학습(RLVR) 기법이 가져온 성능 향상의 한계를 짚고, 특히 토큰 수준의 정보 이질성을 무시하는 기존 Group Relative Policy Optimization(GRPO)의 문제점을 분석한다. GRPO는 동일 그룹 내 샘플들의 시퀀스‑레벨 보상을 정규화해 토큰 전부에 동일한 어드밴티지를 부여한다. 그러나 실제 CoT(Chain‑of‑Thought) 과정에서는 논리적 분기점이나 중요한 판단 단계에서 모델의 출력 분포가 급격히 넓어지는 고엔트로피 구간이 존재한다. 저자들은 이러한 구간을 “Critical Decision Pivot”(CDP)라 명명하고, 토큰 엔트로피 H₍i,t₎ 를 통해 자동 탐지한다. 실험적으로 고엔트로피 토큰을 무작위 교체했을 때 정확도가 크게 떨어지는 현상을 보여, CDP가 추론 성공에 핵심적인 역할을 함을 입증한다.
이를 해결하기 위해 제안된 ERPO는 세 가지 핵심 모듈로 구성된다. ① **Entropy‑aware Gating**: 각 토큰의 엔트로피를 그룹 내 평균·표준편차로 정규화하고 시그모이드 함수를 적용해 가중치 W₍i,t₎ 를 산출한다. 고엔트로피 구간에서는 W가 1에 가깝게 상승해 탐색 압력이 강화되고, 저엔트로피 구간에서는 억제된다. ② **Bucket‑based Implicit Normalization**: 토큰 위치를 상대 진행 비율 τ₍i,t₎=t/|oᵢ| 로 표현하고, 이를 K개의 시간 버킷으로 구분한다. 각 버킷 내에서 진행 신호 s₍i,t₎ (정책과 기준 정책 간 로그 확률 차이)를 Z‑스코어 정규화해 ˜s₍i,t₎ 를 얻는다. 이렇게 하면 단계별 난이도 차이가 보정되어, 동일 진행 단계의 토큰끼리 공정하게 비교할 수 있다. ③ **Result‑anchored Advantage Synthesis**: 시퀀스‑레벨 어드밴티지 ˆAᵢ와 토큰‑레벨 보상 Ψ₍i,t₎ 를 선형 결합한다. Ψ₍i,t₎ 은 W₍i,t₎·sgn(ˆAᵢ)·˜s₍i,t₎ 로 정의되며, 최종 어드밴티지는 ˆA^final₍i,t₎ = Norm_G(ˆAᵢ + η·Ψ₍i,t₎) 로 계산된다. 여기서 sgn(ˆAᵢ) 가 부호를 제공해, 최종 어드밴티지가 잘못된 답변을 향해 과도하게 최적화되는 것을 방지한다. 또한 Ψ₍i,t₎ 의 표준편차를 σ_target 로 맞추어 학습 안정성을 확보한다.
이론적으로 ERPO는 기존 GRPO 목표에 동적 엔트로피‑가중 정규화 항을 추가한 형태이며, 정책 그라디언트의 수렴 보장을 유지한다. 실험에서는 MATH, AIME, AMC, 그리고 복합 CoT 데이터셋 네 가지 베치마크에서 ERPO가 GRPO 대비 평균 2.8%p 이상의 정확도 향상을 보였으며, 동시에 평균 토큰 길이를 12% 정도 단축해 효율성도 크게 개선했다. 특히 Qwen2.5‑3B 모델에 적용했을 때 고엔트로피 토큰을 교란했을 때 정확도 감소가 35%에 달하는 반면, ERPO 적용 후에는 감소폭이 10% 이하로 억제되었다. 또한 파라미터 수가 10배 미만인 소형 모델에서도 대형 모델 수준의 성능을 근접하게 달성함을 보여, ERPO가 모델 규모에 구애받지 않는 일반화 가능성을 시사한다.
결론적으로, ERPO는 토큰‑레벨 불확실성을 정량화하고 이를 정책 업데이트에 직접 반영함으로써, 추론 과정에서 “탐색‑수렴” 균형을 정교하게 조절한다. 이는 기존 RLVR 방식이 갖는 “균일한 보상 할당”이라는 근본적인 한계를 극복하고, 대형 추론 모델의 효율성과 정확성을 동시에 끌어올리는 새로운 패러다임을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기