CoT2-Meta: Budgeted Metacognitive Control for Test-Time Reasoning
Recent test-time reasoning methods improve performance by generating more candidate chains or searching over larger reasoning trees, but they typically lack explicit control over when to expand, what to prune, how to repair, and when to abstain. We i…
Authors: Siyuan Ma, Bo Gao, Zikai Xiao
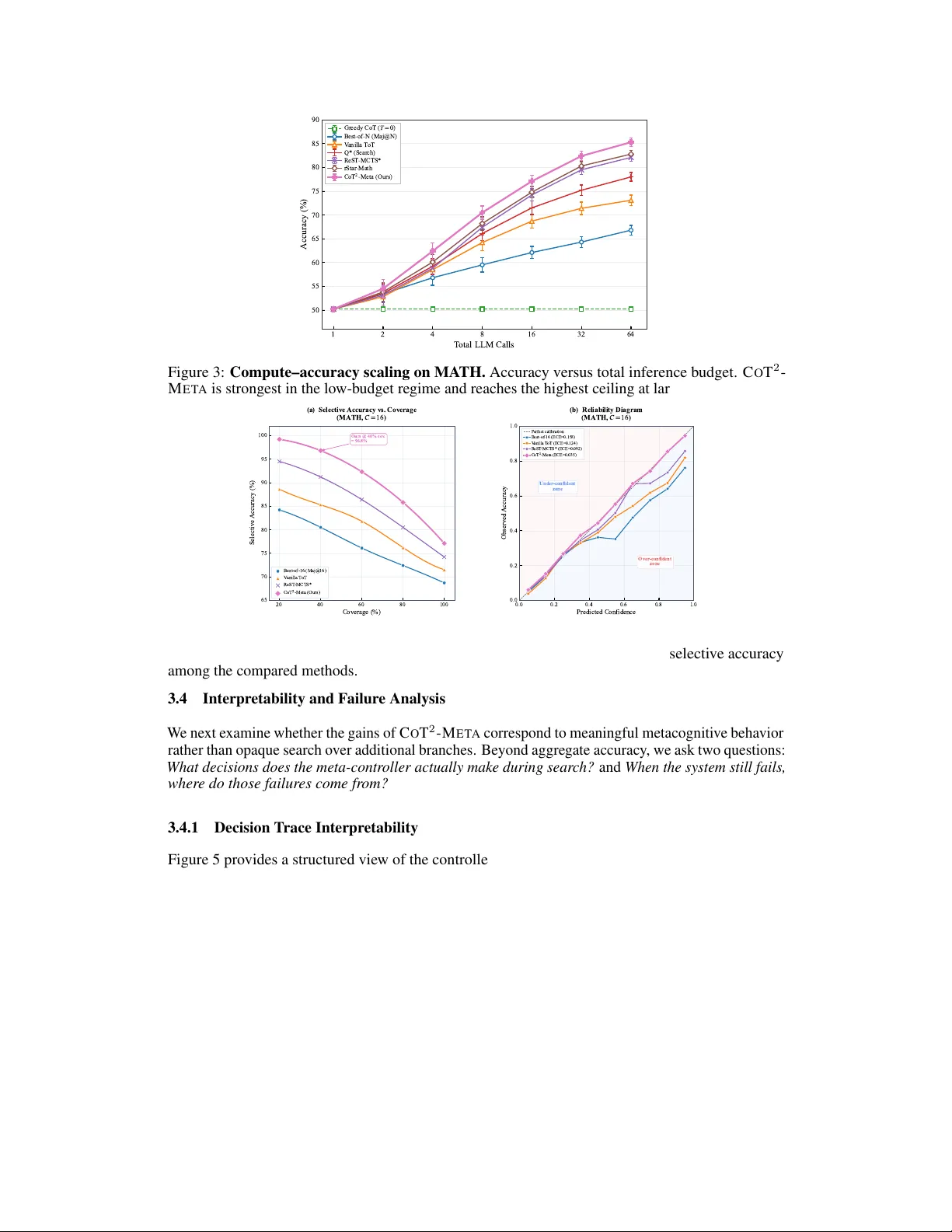
CoT 2 -Meta: Budgeted Metacognitiv e Contr ol f or T est-T ime Reasoning Siyuan Ma Nanyang T echnological Univ ersity MASI0004@e.ntu.edu.sg Bo Gao Carnegie Mellon Uni versity Zikai Xiao Zhejiang Univ ersity Hailong W ang Sun Y at-Sen Uni versity Xinlei Y u National Univ ersity of Singapore Rui Qian Fudan Univ ersity Jiayu Qian City Univ ersity of Hong K ong (Dongguan) Luqi Gong Zhejiang Lab Y ang Liu Nanyang T echnological Univ ersity Abstract Recent test-time reasoning methods improv e performance by generating more candidate chains or searching o ver lar ger reasoning trees, b ut they typically lack explicit control ov er when to expand, what to prune, how to repair , and when to abstain. W e introduce C O T 2 - M E T A , a training-free metacognitive reasoning framew ork that combines object-lev el chain-of-thought generation with meta- lev el control ov er partial reasoning trajectories. The framework integrates four components: strategy-conditioned thought generation, tree-structured search, an online process oracle for step-le v el reasoning e valuation, and a meta-controller that allocates computation through e xpansion, pruning, repair , stopping, and fallback decisions. Under matched inference b udgets, C O T 2 - M E T A consistently outperforms strong single-path, sampling-based, and search-based baselines, including ReST -MCTS. On the def ault backbone, it achie ves 92.8 EM on M A T H , 90.4 accuracy on G P Q A , 98.65 EM on G S M 8 K , 75.8 accurac y on B B E H , 85.6 accuracy on M M M U - P R O , and 48.8 accuracy on H L E, with gains over the strongest non- C O T 2 - M E T A baseline of +3.6, +5.2, +1.15, +2.0, +4.3, and +4.3 points, respectiv ely . Beyond these core results, the framework remains effecti ve across a broader 15-benchmark suite spanning knowledge and QA, multi-hop reasoning, coding, and out-of-distribution ev aluation. Beyond aggregate accuracy , we show that the gains are not reducible to brute- force compute: C O T 2 - M E T A yields better compute scaling, improved calibration, stronger selective prediction, and targeted repair behavior under token-matched comparisons. Additional analyses show that the framework generalizes across backbone families while decision-trace audits and failure taxonomies re v eal inter- pretable controller behavior and localized remaining failure modes. These results suggest that e xplicit metacogniti v e control is a practical design principle for reliable and compute-efficient test-time reasoning systems. Preprint. a a a a Thought Generator + Strategy Switch Strategy is chosen by the meta- controller. a a Input: Problem (optional: imag e textified) Constraint: Budgeted calls/ toke ns Output Target: Answer + Trace Task Input + Budget Frontier selection (UCB/MCTS-style) ToTSearcher (Meta-level Search) Expand node generate next thought step rewards ( r i ...r t ) earliest error idx V pro c (process value) ProcessOracleV2(Process Reward) semantic incoherence contradict ionnvalid operation Meta-state + Metacognitive Pruning depth strategy id reward stats error position Z z ∈ R 32 (meta-state) combined_value = a .V out + (1-a ).V proc Decision :Prune Path X(Low Value), Keep Path Y Pruning Log Top-k Verification + Final Output Budget-matched improvement under sam e C calls. Best reasoning path (trace) Final answer Diagnostics (why pruned /which strategy used) Figure 1: CoT 2 -Meta as r easoning over reasoning . The inner layer performs object-le vel reasoning, while the outer layer performs metacogniti ve control o ver partial trajectories. The meta-controller decides when to expand, prune, repair , stop, or abstain under a bounded b udget. 1 Introduction Large language models (LLMs) benefit substantially from additional test-time compute on complex reasoning tasks. Chain-of-thought (CoT) prompting, self-consistency , and related scaling strategies show that more inference-time reasoning can impro ve final performance W ang et al. [2022], Zhou et al. [2022]. More recent methods extend single-path reasoning to structured exploration, including tree-based search, graph-based search, and process-reward-guided deliberation Y ao et al. [2023], Besta et al. [2024], Zhang et al. [2024]. Ho we ver , most still treat extra compute mainly as more gener ation rather than better contr ol : they e xpand search more broadly , but typically do not explicitly decide when a partial trajectory should be expanded, pruned, repaired, or terminated Y ao et al. [2023], Zhang et al. [2024]. As a result, computation is often wasted on weak branches, while fluent but incorrect trajectories may persist too long. A parallel line of work shows that reliable reasoning requires more than final-answer correctness. V erifier-based methods and process supervision highlight the importance of intermediate reasoning quality Cobbe et al. [2021], Lightman et al. [2023], Pronesti et al. [2026], Kim and Y un; related studies sho w that outcome accurac y can mask fla wed reasoning processes Pronesti et al. [2026], while LLM confidence is often poorly calibrated unless explicitly modeled or controlled Guo et al. [2017], Jiang et al. [2021], Kapoor et al. [2024]. More broadly , metareasoning and computation-selection research frames deliberation as a decision problem under limited resources: the question is not only how to reason, but also which computations are worth performing, and when Russell and W efald [1991], Hay et al. [2014]. These observations moti vate systems that reason not only through trajectories, but also about ho w reasoning should proceed. W e introduce C O T 2 - M E TA , a b udgeted metacogniti ve reasoning frame work that separates object-level r easoning from meta-level contr ol . An LLM generates candidate reasoning steps that form a tree of partial trajectories, while a controller e v aluates process quality , maintains a compact meta-state, and decides whether to expand , prune , r epair , stop , or abstain . This casts test-time reasoning as sequential control ov er trajectories rather than passiv e sample-and-rerank. Our design follo ws two principles. First, useful test-time scaling should be selective : computation should be allocated according to intermediate quality and uncertainty rather than spent uniformly across trajectories Ma et al. [2026], Snell et al. [2024], Singhi et al. [2025]. Second, confidence should be actionable : the same signals used to assess trustworthiness should also gov ern whether the system continues searching, in vok es repair, or declines to answer . Accordingly , C O T 2 - M E TA integrates process e v aluation, meta-state construction, confidence-aw are routing, and decision logging into a single inference-time loop. Empirically , C O T 2 - M E TA consistently outperforms strong baselines under matched compute b udgets. On the default backbone, it improves ov er the strongest non- C O T 2 - M E TA baseline by +3 . 6 on M A T H , +5 . 2 on G P Q A , +1 . 15 on G S M 8 K , +2 . 0 on B B E H , +4 . 3 on M M M U - P R O , and +4 . 3 on H L E . The method also remains ef fectiv e across a broader 15-benchmark suite spanning knowledge and QA, multi-hop QA, coding, and out-of-distribution ev aluation, with gains that persist across 2 backbone families under compute-normalized e v aluation and are accompanied by better calibration, stronger selectiv e prediction, more ef fectiv e repair , and interpretable decision traces. Contributions. (1) W e introduce C O T 2 - M E TA , a unified inference-time framew ork for process- aware metacognitive control over reasoning trajectories. (2) W e show consistent gains across a 15-benchmark suite spanning reasoning, multimodal reasoning, kno wledge and QA, multi-hop QA, coding, and out-of-distrib ution ev aluation under strict compute normalization. (3) W e sho w that these gains arise from stronger reasoning control rather than brute-force extra compute alone. 2 Method W e present C O T 2 - M E TA , a budgeted metacogniti ve reasoning frame work that e xplicitly separates object-level reasoning from meta-level contr ol . At the object level, a backbone language model generates candidate reasoning steps. At the meta lev el, a controller ev aluates partial trajectories, maintains a compact state representation, and decides whether to expand, prune, repair , stop, or abstain. This design turns test-time reasoning from pure text generation into a sequential control problem ov er reasoning trajectories. 2.1 Problem F ormulation Let x denote an input problem. A reasoning trajectory is a sequence of intermediate thoughts τ t = ( z 1 , z 2 , . . . , z t ) , where each z i is a coherent reasoning unit such as a sub-deriv ation, decomposition step, verification step, or intermediate conclusion. The final output is either an answer ˆ y or an abstention decision ∅ . W e assume access to an object-lev el generator G θ ( z t +1 | x, τ t , s t ) , where s t denotes the current control conte xt, including the acti ve reasoning strate gy and any meta- lev el signals exposed to the generator . Unlike standard chain-of-thought prompting, which follo ws a single trajectory , we consider a search space over multiple trajectories org anized as a reasoning tree. Let T denote the ev olving reasoning tree and let F t be its frontier at step t . Each frontier node corresponds to a partial reasoning trajectory . The system operates under a finite inference budget C , which counts all generation, ev aluation, repair , and control calls. The goal is to maximize answer quality while respecting this budget: max π E [ U ( ˆ y , x )] s.t. Cost( π ; x ) ≤ C, where π is the meta-control policy and U ( ˆ y , x ) is a utility that rewards correct high-confidence answers and can optionally penalize unsafe ov erconfident predictions. This formulation dif fers from con ventional test-time scaling in tw o ways. First, the system does not spend compute uniformly across all trajectories. Second, the controller can choose not only which branc h to expand , b ut also whether further reasoning is worthwhile at all . Hence, the problem is not merely “generate more thoughts, ” but rather: under a limited budget, how should computation be allocated acr oss gener ation, evaluation, r epair , and stopping decisions? 2.2 CoT 2 -Meta Framework Figure 2 shows the overall architecture of C O T 2 - M E TA . The framew ork separates object-level r easoning from meta-le vel contr ol through four components: a thought generator , a tree-structured search space, an online process oracle, and a meta-controller . T ogether , they cast inference-time reasoning as closed-loop control ov er partial trajectories rather than single-pass chain generation. Giv en an input x and a partial trajectory τ t , the thought generator proposes next-step thoughts under strategy tags such as Direct , Decompose , and V erify . Each generated thought is appended to the reasoning tree, whose nodes store the local thought, parent state, depth, strategy tag, and control metadata. This explicit representation enables branch-le vel e xpansion, pruning, repair , and termination. 3 Frontier Management UCB Path Selection (based on V combined ) Pruning Decision (Threshold Check) Search Controller (Meta-Agent Controller) Step-level Signals (Semantic, Logical Error Correction) Global Metrics (Total Process Reward, Earliest Error idx) Final Answer Check Process Oracle V2:Monitoring Build 32-dim Vector M i (Encodes: Strategy, Rewards, Error loc, Depth,etc.) Meta-State Encoder: Representation Decision Logs (PathSelection & Pruning) Meta-level: Cognition & Control 1.Select Node & Strategy s i 5.Prune Command if V
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment