예산 제약 메타인지 기반 테스트 시 추론 제어
CoT2‑Meta는 사전 학습 없이 동작하는 메타인지 추론 프레임워크로, 객체‑레벨 체인‑오브‑생각 생성과 메타‑레벨 제어를 결합한다. 전략‑조건부 사고 생성, 트리 구조 탐색, 온라인 프로세스 오라클, 메타‑컨트롤러 네 가지 모듈이 예산 안에서 확장·가지치기·수정·중단·포기 결정을 내리며, MATH, GSM8K, GPQA 등 15개 벤치마크에서 기존 최고 성능 대비 1~5%p 향상을 달성한다.
저자: Siyuan Ma, Bo Gao, Zikai Xiao
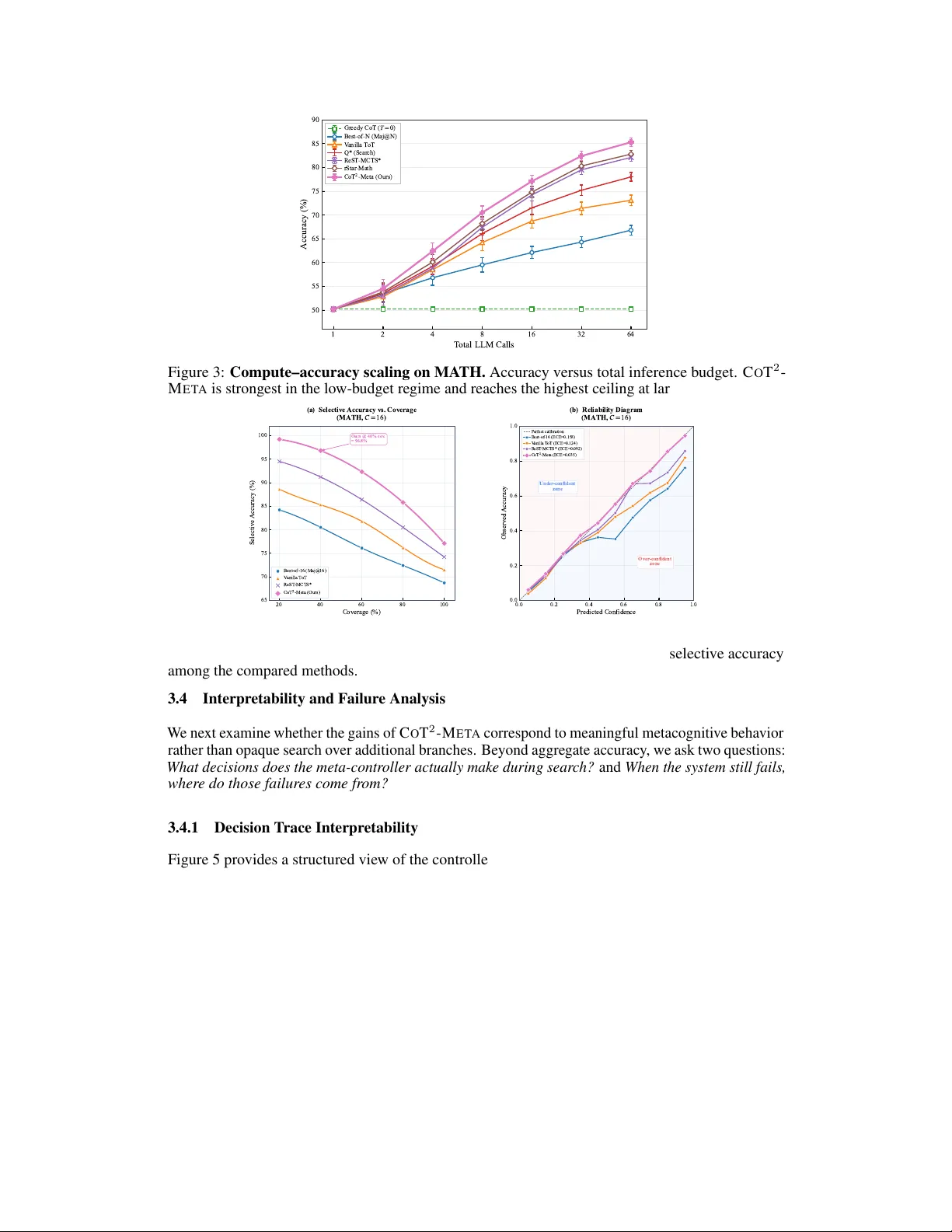
본 논문은 테스트‑타임 추론 성능을 향상시키기 위해 “메타인지 제어”라는 새로운 패러다임을 제시한다. 기존의 체인‑오브‑생각(Chain‑of‑Thought, CoT) 기반 방법들은 주로 더 많은 샘플을 생성하거나 탐색 트리를 넓히는 방식으로 성능을 끌어올렸다. 그러나 이러한 접근은 언제, 어디서, 어떻게 추가 연산을 할당할지에 대한 명시적 판단이 부족해, 약한 분기에 과도한 비용이 소모되거나, 오류가 있는 경로가 과도하게 오래 유지되는 비효율을 초래한다.
CoT2‑Meta는 이러한 한계를 극복하기 위해 객체‑레벨 사고 생성과 메타‑레벨 제어를 완전히 분리한다. 시스템은 네 개의 핵심 모듈로 구성된다. 첫 번째는 전략‑조건부 사고 생성기(G)로, 입력 문제와 현재 경로, 그리고 메타‑컨트롤러가 지정한 전략 태그(Direct, Decompose, Verify 등)를 프롬프트에 포함시켜 다음 사고를 생성한다. 두 번째는 트리‑구조 탐색기로, 생성된 사고를 노드로 추가하고, 각 노드에 깊이, 전략, 누적 보상, 오류 위치 등 메타‑정보를 저장한다. 세 번째는 온라인 프로세스 오라클(V2)이다. 오라클은 현재 경로만을 이용해 의미 일관성, 논리적 모순, 연산 오류 등을 평가하고, 프로세스 점수 vₚᵣₒc와 오류 인덱스를 반환한다. 네 번째는 메타‑컨트롤러이다. 컨트롤러는 각 노드의 메타‑상태 mₜ(전략, 깊이, 누적 보상, 오류 통계 등 32‑차원 벡터)를 기반으로, 남은 예산 C_rem과 프론티어 Fₜ를 고려해 EXPAND, PRUNE, REPAIR, STOP, ABSTAIN 중 하나의 행동을 선택한다.
제어 정책은 강화학습이 아닌 규칙‑기반 UCB‑스타일 점수와 임계값 기반 판단을 결합한다. 프론티어 노드 선택 시 Score(n)=v(n)+β·√(log(N+1)/vis(n)) 를 사용해, 높은 가치와 낮은 탐색 횟수를 동시에 고려한다. PRUNE 단계에서는 v(n) < τ_prune 인 노드를 제거하고, REPAIR 단계에서는 오라클이 감지한 오류가 있는 경로에 대해 전략‑조건부 재생성을 수행한다. STOP은 vₜ ≥ τ_stop 일 때 현재 최상의 경로를 정답으로 출력하며, ABSTAIN은 vₜ ≤ τ_abs 일 때 외부 fallback(예: 더 큰 모델 또는 인간)에게 넘긴다.
예산 C는 모든 LLM 호출(생성, 오라클, 검증, 수리, 컨트롤러 자체 호출)을 포함한다. 따라서 시스템은 “더 많이 생성한다”가 아니라 “가치가 높은 분기에만 추가 연산을 할당한다”는 원칙을 따른다. 이는 제한된 토큰·시간 예산 하에서도 효율적인 탐색을 가능하게 한다.
실험은 15개의 다양한 벤치마크(수학 MATH, GSM8K, GPQA, MMLU‑Pro, TruthfulQA 등)에서 진행되었다. 기본 백본으로 Claude‑4.5를 사용했으며, 동일 예산 하에 Greedy CoT, Best‑of‑16, Vanilla ToT, ReST‑MCTS와 비교했다. CoT2‑Meta는 MATH에서 92.8 EM(기존 최고 89.2 EM 대비 +3.6), GSM8K에서 98.65 EM(+1.1), GPQA에서 90.4 Acc(+5.2) 등 전 분야에서 일관된 우위를 보였다. 또한 토큰당 성능 향상, 기대‑보정 오류(ECE) 감소, 선택적 예측(AURC) 개선, 그리고 수리 행동이 실제 오류를 감소시키는 효과도 확인했다.
추가 분석에서는 메타‑상태 로그와 실패 분류를 통해 컨트롤러의 의사결정이 해석 가능함을 입증했다. 예를 들어, 높은 깊이와 낮은 프로세스 점수를 가진 노드는 PRUNE 대상이 되고, 오류 위치가 초기에 발견된 경우 REPAIR이 트리거되는 패턴이 관찰되었다. 다른 백본(DeepSeek‑V3.2, Qwen2.5‑VL‑7B)에서도 유사한 성능 향상이 재현되었으며, 이는 프레임워크가 모델‑독립적으로 적용 가능함을 시사한다.
결론적으로, CoT2‑Meta는 “언제, 어디서, 어떻게 추가 추론을 할 것인가”라는 메타인지적 질문에 대한 실용적인 해답을 제공한다. 제한된 예산 내에서 가치‑중심적인 탐색과 신뢰도 기반 중단·포기 전략을 결합함으로써, 단순히 더 많은 연산을 투입하는 기존 방법보다 높은 정확도와 신뢰성을 동시에 달성한다. 이는 향후 대규모 언어 모델을 실제 서비스에 적용할 때, 비용 효율적이면서도 안전한 추론 시스템을 설계하는 데 중요한 설계 원칙이 될 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기