Transcription and Recognition of Italian Parliamentary Speeches Using Vision-Language Models
Parliamentary proceedings represent a rich yet challenging resource for computational analysis, particularly when preserved only as scanned historical documents. Existing efforts to transcribe Italian parliamentary speeches have relied on traditional…
Authors: Luigi Curini, Alfio Ferrara, Giovanni Pagano
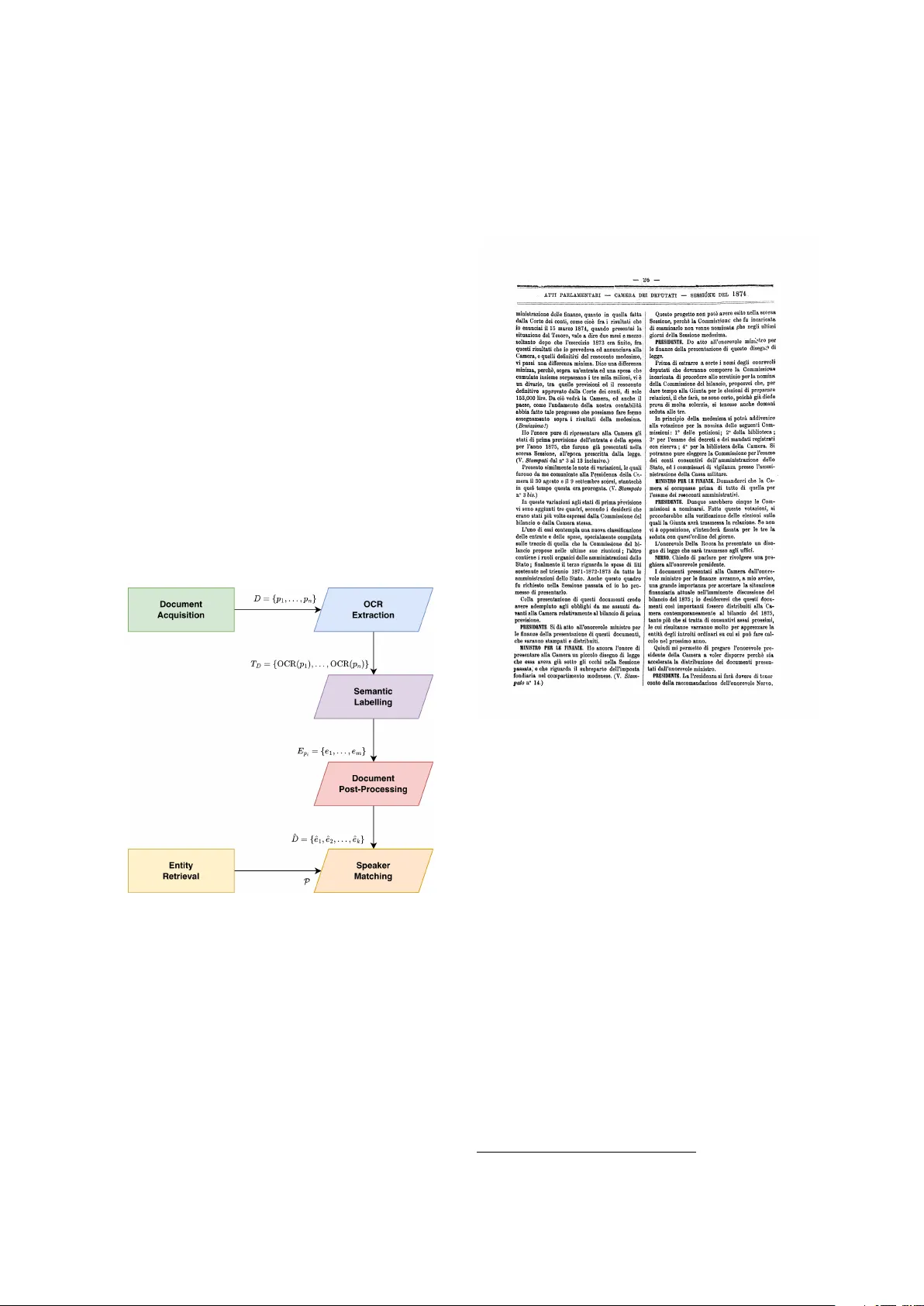
T ranscription and Recognition of Italian Parliamentar y Speeches Using Vision-Language Models Luigi Curini 1 , Alfio Ferrara 2 , Giov anni Pagano 1 , Sergio Picascia 3 ∗ 1 Università degli Studi di Milano, Depar tment of Social and Political Sciences Via Conser vatorio, 7 - 20122 Milano (Italy) luigi.curini@unimi.it, giovanni.pagano@unimi.it 2 Università degli Studi di Milano, Depar tment of Literary Studies, Philology and Linguistics Via Festa del P erdono, 7 - 20122 Milano (Italy) alfio.ferrara@unimi.it 3 Università degli Studi di Milano, Depar tment of Computer Science Via Celoria, 18 - 20133 Milano (Italy) sergio.picascia@unimi.it Abstract P arliamentar y proceedings r epresent a rich ye t challenging resource for computational analysis, par ticularly when preserved only as scanned historical documents. Existing effor ts to transcribe Italian parliamentar y speeches hav e relied on traditional Optical Character Recognition pipelines, resulting in transcription errors and limited semantic annotation. In this paper , we propose a pipeline based on Vision-Language Models for the automatic transcription, semantic segmentation, and entity linking of Italian parliamentary speeches. The pipeline employ s a specialised OCR model to extract text while preserving reading order , followed by a large-scale Vision-Language Model that performs transcription refinement, element classification, and speaker identification by jointly reasoning ov er visual lay out and textual content. Extracted speakers are then linked to the Chamber of Deputies knowledge base through SP ARQL queries and a multi-strategy fuzzy matching procedure. Evaluation against an established benchmark demonstrates substantial improvements both in transcription quality and speaker tagging. Ke ywords: vision language models, document layout analysis, Italian parliamentary speeches 1. Introduction P arliamentar y proceedings constitute one of the most valuable documentar y sources for the study of political, linguistic, and social change. In the Ital- ian context, these records chronicle nearly two cen- turies of transformativ e events. The stenographic reports produced by both chambers of the Italian P arliament, the Camera dei Deputati and the Sen- ato della Repubblica, provide a uniquely detailed account of these dev elopments through the verba- tim transcription of political discourse. Sev eral initiatives hav e sought to make these records av ailable in machine-readable form. Cross- national projects such as ParlaMint ( Erjavec et al. , 2022 ) hav e assembled comparable parliamen- tary corpora across European countries, while Italy-specific effor ts, including IPSA ( F rasnelli and P almero Aprosio , 2024 ) and ItaParlCorpus ( Cov a , 2025 ), have produced large-scale datasets span- ning extensiv e historical periods. Howev er , these resources predominantly rely on traditional Optical Character Recognition (OCR) pipelines follow ed by rule-based heuristics for te xt cleaning and speaker attribution. While effective to a degree, such ap- proaches face well-document ed limitations when applied to historical documents, contributing to tran- scription errors and unreliable speaker identifica- tion. The latter issue is especially acute for the earlier por tion of the corpus (pre-1948), where high- quality annotated data remains scarce. Speaker identification in Italian parliamentar y documents is challenging because the typographic conv entions used to mark speakers var y consid- erably across legislatures and historical periods. Additional variability arises from the treatment of homonymous members, for whom both surname and first name are pro vided, and from the occa- sional inclusion of the speak er’s institutional role alongside the surname. T aken together , these in- consistencies make rule-based speaker attribution brittle and difficult to generalise across the full his- torical span of the corpus. The recent emergence of Vision-Language Mod- els (VLMs) offer s a promising alternative to pipeline- based methods. VLMs jointly process visual and te xtual information through unified architectures, enabling end-to-end reasoning about document lay out, content, and semantics. Specialised mod- els such as dots.ocr ( Li et al. , 2025 ) hav e demonstrated strong per formance on document lay out analysis and te xt recognition, while general- purpose models like Qwen2.5-VL ( Bai et al. , 2025 ) provide com plementary capabilities in semantic understanding and conte xtual inference. T o date, howe ver , the potential of these models for the digi- tisation and annotation of historical parliamentar y documents remains largely unexplor ed. In this paper , we present a pipeline for the auto- matic transcription, semantic segmentation, and en- tity linking of Italian parliamentar y speeches based on Vision-Language Models. Unlike previous ap- proaches, our method lev erages the visual lay out of documents alongside their te xtual content, enabling more accurate transcription and richer semantic annotation. W e evaluat e the proposed pipeline against IPSA on its released benchmark, assessing both OCR q uality and speaker tagging accuracy . The remainder of this paper is organised as fol- lows. Section 2 reviews prior work on parliamentary corpora and vision-language models. Section 3 describes the proposed pipeline in detail. Sec- tion 4 presents the experimental evaluation and dis- cusses the results. Finally , Section 5 summarises the contributions and outlines directions for future work. 2. Related W ork This section reviews prior work relev ant to our con- tribution, organised into two main areas: parliamen- tary corpora with a focus on Italian resources, and vision-language models for document understand- ing and OCR. 2.1. Italian Parliamentar y Resources P arliamentar y debates constitute a v aluable re- source for political science, linguistics, and compu- tational social science research. The syst ematic collection and annotation of parliamentar y proceed- ings has been pursued across numerous countries, resulting in large-scale corpora that enable studies of political discourse, policy prefer ences, and leg- islative behaviour . Cross-national initiatives have sought to harmonise parliamentary data across countries. The ParlaMint project ( Erja vec et al. , 2022 ) assembled comparable corpora from 29 Eu- ropean countries, containing ov er one billion words and covering at least the period 2015–2022, with linguistic annotations following the Univ ersal De- pendencies framework. Similarly , the P arlSpeech dataset ( Rauh and Schwalbach , 2020 ) provides full- te xt cor pora from various advanced democracies, though notably ex cluding Italy . The digitisation and analysis of Italian parliamen- tary proceedings has receiv ed increasing attention in recent years. IPSA ( Fr asnelli and P almero Apro- sio , 2024 ) represents the most comprehensiv e ef- fort to date, providing ov er 1.2 billion tokens of par - liamentar y debates from both the Camera dei Dep- utati and the Senato della Repubblica, spanning from 1848 to 2022. The corpus was constructed by applying T esseract OCR to scanned documents, follow ed by rule-based heuristics for te xt cleaning and speaker tagging through fuzzy string matching against lis ts of parliamentarians. The ItaParlCorpus dataset ( Cov a , 2025 ) offers a machine-readable collection of Camera dei Deputati speeches from 1948 to 2022, encompassing 470 million words with metadata including speaker identification and par ty affiliation. P arlaMint-It ( Alzetta et al. , 2024 ) contributes a manually re vised treebank of Italian parliamentary debates annotated according to the Universal Dependencies framew ork, addressing the underrepresentation of parliamentar y language varie ties in syntactic resour ces. The IMP A QTS corpus ( Cominetti et al. , 2024 ) takes a multimodal approach, collecting 2.65 million tokens of politi- cal discourse from 1946 to 2023 with pragmatic annotations capturing im plicit content. Despite these adv ances, e xisting Italian parlia- mentary cor pora share common limitations: they predominantly rel y on traditional OCR pipelines that struggle with historical document quality , employ rule-based approaches for speaker identification that cannot lever age visual lay out cues, and lack fine-grained semantic annotations linking speak- ers to authoritative knowledge bases. Our work addresses these limitations by proposing a vision- language model pipeline that jointly performs tran- scription, semantic segmentation, and entity link - ing. 2.2. Vision-Language Models Vision-Language Models (VLMs) are AI syst ems designed to jointly process visual and textual infor - mation ( Zhang et al. , 2024 ). These models typically employ a dual-encoder architecture, where sepa- rate encoders transform images and te xt into vector embeddings that are subseq uently projected into a shared latent space. The aligned multimodal representations are then processed by a T rans- former decoder , where visual embeddings ser ve as conditioning conte xt for text generation. This architectur e enables VLMs to perform a wide range of tasks requiring joint reasoning over images and te xt, including visual question answering, image captioning, and document understanding. Optical Character Recognition has traditionally relied on pipeline approaches combining image preprocessing, lay out analysis, character segmen- tation, and recognition ( Islam et al. , 2017 ). T esser - act ( Smith , 2007 ) remains widely used due to its e xtensive language suppor t and cost-effectiveness. Howe ver , traditional OCR systems face significant challenges with historical documents, including de- graded print quality , non-standard typefaces, and complex multi-column lay outs. The application of VLMs to document understanding and OCR rep- resents a paradigm shift from pipeline-based ap- proaches to end-to-end syst ems capable of jointly reasoning about visual lay out and textual content. Recent benchmarks ha ve e valuat ed VLMs on OCR tasks across different document types ( Ouyang et al. , 2025 ). Among end-to-end models, specialised OCR-focused VLMs such as dots.ocr ( Li et al. , 2025 ) hav e achieved strong results by combining lay out analysis with te xt recognition in a unified framework. dots.ocr performs document lay out analysis to identify ele- ment bounding bo xes and categories, followed by te xt transcription respecting logical reading order . General-purpose VLMs hav e also demonstrat ed competitive OCR per formance when appropriately prompted. Qwen2.5-VL-72B ( Bai et al. , 2025 ) achiev es results comparable t o specialised syst ems while offering additional capabilities for semantic understanding. The combination of these com plementary capabilities, accurate transcription from specialised OCR models and semantic understanding from large VLMs, enables richer annotation of parliamentar y documents than previousl y achiev able with traditional approaches. 3. Methodology Figure 1: Pipeline diagram showing the six stages with data flow between components. This section presents the methodology dev el- oped for the automatic transcription and semantic labelling of Italian parliamentar y session reports. The proposed pipeline transforms digitised parlia- mentary documents into structured, semantically annotated data, enabling downstream analyses on political discour se studies. The pipeline comprises six sequential stages: (1) Document Acquisition, (2) OCR Extraction, (3) Semantic Labelling, (4) Docu- ment Post-Processing, (5) Entity Re trieval, and (6) Speaker Matching. Figure 1 provides a schematic ov er view of the complete processing pipeline. T o illustrat e the transformations applied at each stage, we introduce a running e xample drawn from an actual parliamentar y session. Figure 2 presents an ex cerpt from a document page 1 that will be traced through the pipeline, demonstrating how raw visual in put is progressiv ely transformed into struc- tured data. Figure 2: Excerpt from the stenogr aphic report of the session held on Nov ember 27th 1874, Legisla- ture 12 of the Kingdom of Italy . This page ex cerpt ser v es as the running example throughout this sec- tion. 3.1. Document Acquisition For each legislature in the history of the Italian Par - liament, we re trieved the complete list of sessions ( sedute ). Each session, which can be thought of as a parliamentary meeting, is uniq uely identified by a URI and associated with the specific date on which it took place. The majority of sessions are documented by a single PDF file containing the official verbatim repor t of the proceedings ( reso- conto stenog rafico ). These repor ts tend to follow a consistent structure: they contain v erbatim tran- scriptions of parliamentary debates, with speaker names indicated at the beginning of each inter ven- tion, typically accompanied by their institutional role 1 https://storia.camera.it/regno/ lavori/leg12/sed004.pdf#page=6 when applicable (e.g., BIANC HI LEONARDO, MINIS- TER OF PUBLIC EDUC A TION ). For the session held on Nov ember 27th 1874, belonging to Legislature 12 of t he Kingdom of Italy , the following metadata was retriev ed from the parliamentary portal: legislature URI ( http://dati.camera.it/ocd/legislatura.rdf/regno_12 ), ses- sion URI ( http://dati.camera.it/ocd/seduta.rdf/sr12004 ), date ( 1874-11-27 ), and document URL ( http://storia.camera.it/r egno/lavori/leg12/sed004.pdf ). 3.2. OCR Extraction The digitised parliamentary reports present sev - eral challenges for automatic te xt extraction. The documents exhibit a two-column layout, variable print quality depending on the historical period, and occasional multilingual content. Preliminary ex- periments with traditional OCR engines, such as T esseract, re vealed significant limitations when fac- ing these issues. T o address these challenges, we employ ed dots.ocr ( Li et al. , 2025 ), a specialised vision- language model designed for document under - standing tasks. For each page p i in a document D = ⟨ p 1 , p 2 , . . . , p n ⟩ , the model receiv es the page image and a prompt requesting document lay out analysis and textual transcription in reading order . The model identifies the bounding bo xes of the ele- ments in the page, labels these elements according to the corresponding category in the page lay out, and transcribes their te xtual content respecting the logical reading sequence. The output of this stage undergoes a fur ther pro- cessing to extr act only the te xtual content, discard- ing lay out labels. This design decision was moti- vat ed by obser ved inconsistencies in the labelling conv entions applied by the model across pages. The semantic classification of elements was there- fore delegated to the subsequent processing stage, where a more capable model could lev erage both vi- sual and te xtual information for consistent labelling. Formally , let OCR ( p i ) denote the function map- ping a page image to its preliminar y textual tran- scription. The output of this stage for a docu- ment D is the sequence of page-lev el transcriptions T D = ⟨ OCR ( p 1 ) , OCR ( p 2 ) , . . . , OCR ( p n ) ⟩ . Processing the documents with a specialised model allows us to achiev e high transcription qual- ity and successfully preserves reading order , as demonstrated in the following example: - 26 - # ATTI PARLAMENTARI - CAMERA DEI DEPUTATI - SESSIONE DEL 1874. ministrazione delle finanze, quanto in quella fatta dalla Corte dei conti, come cioe’ fra i risultati che io enunciai il 15 marzo 1874, quando presentai la situazione del Tesoro, vale a dire due mesi e mezzo soltanto dopo che l’ esercizio 1873 era finito, fra questi risultati che io prevedeva ed annunciava alla Camera, e quelli definitivi del resoconto medesimo, vi passi una differenza minima. 3.3. Semantic Labelling This stage involv es the employment of Qwen- VL2.5-72B , a large-scale vision-language model, to perform transcription refinement, te xtual seg- mentation, element type classification, and speaker identification. For each page p i , the model receives three inputs: (i) the page image, (ii) a structured prompt that specifies the annotation schema and task requirements, and (iii) the preliminary OCR transcription OCR ( p i ) . The prompt instructs the model to segment the page content into discret e elements, representing a segmented te xtual unit, each characterised by three attributes: • type : a categorical label that indicates the role of the element on the page. The type is drawn from the set of labels: page-header , section- header , te xt, note, footno te, table. Elements la- belled as te xt represent the main content of the report, i.e. the speeches, and are those that are typically assigned to speakers. The note type designates parenthetical remarks within the main te xt that record non-verbal events or reactions during the session (e.g., Hilarity , The Chamber approv es ); • content : the v erbatim transcription of the ele- ment, preser ving original punctuation and or - thograph y . Line-brok en sentences within a single element are asked to be reconstructed as continuous te xt; • speak er : the name of the person speaking, in- cluding their institutional role if explicitly men- tioned. For elements that do not constitute speeches (headers, footno tes, notes, tables) or that repor t neutral content such as article te xt being read aloud, this field is set to "none". When a speech continues from a previous el- ement on the same page without an e xplicit speaker indication, the model is instructed to infer the speaker from context. If inference is not possible (e.g., te xt continuing from a previ- ous page), the field is mar k ed as "unknown". T o guide the model’s behaviour on challeng- ing cases, the prompt includes a synthetic e xam- ple, which aggregat es multiple difficult scenarios: te xt continuation from previous pages, speaker role annotations, parenthetical notes interrupting speeches, footnot e refer ences, and section tran- sitions. This one-shot example demonstrates the e xpected output format and handling of edge cases. The model is instructed to return its output in JSON format, producing for each page a seq uence of annotated elements, E p i = ⟨ e 1 , e 2 , . . . , e m ⟩ , where each element e j = ( type j , content j , speaker j ) . The following example shows the beginning of a structured output produced by the semantic la- belling stage: { "speaker": "none", "type": "page-header", "content": "- 26 -" }, { "speaker": "none", "type": "page-header", "content": "ATTI PARLAMENTARI - CAMERA DEI DEPUTATI - SESSIONE DEL 1874." }, { "speaker": "unknown", "type": "text", "content": "ministrazione delle finanze, quanto in quella fatta dalla Corte dei conti, come cioe’ fra i risultati che io enunciai il 15 marzo 1874, quando presentai la situazione del Tesoro, vale a dire due mesi e mezzo soltanto dopo che l’esercizio 1873 era finito, fra questi risultati che io prevedeva ed annunciava alla Camera, e quelli definitivi del resoconto medesimo, vi passi una differenza minima." } In this ex ample, the third element is a speech frag- ment whose speaker is mark ed as "unknown" . The text begins without any speaker heading, in- dicating that the speech star ted on a preceding page. Because the model processes each page independently , it has no access to the previous page’ s conte xt and therefor e cannot determine the identity of the speaker . Such cases are resolv ed in the subsequent phase. 3.4. Document Post-Processing The outputs from the vision-language model un- dergo a post-processing phase to address ar tef acts arising from page-lev el processing and to resolv e cross-page dependencies. This stage per forms the following operations. Hyphenation Resolution . Words hyphenat ed at line or column break s are rejoined by detect- ing and removing mid-word hyphens followed by whitespace patterns indicative of line continuation. Cross-Page Element Merging . Elements trun- cated at page boundaries are identified and merged with their continuations on subsequent pages. This is achieved by detecting incom plet e sent ences (lacking terminal punctuation) at page endings and matching them with elements marked as continu- ations (speaker "unknown" with type "text") at the beginning of subsequent pages. Role Extraction . Institutional roles embedded within speaker names or element content are ex- tracted and normalised. When a speaker is identi- fied with an accom pan ying role, the role is parsed and separated by a comma from the speaker name. Speaker Continuity Inference . For elements where the speaker could not be det ermined dur - ing page-level processing (mar k ed as "unknown"), we implement a backward-looking inference mech- anism. The algorithm trav erses the document in reading order , propagating speaker attribution from the most recent explicitly identified speaker until a discontinuity marker is encountered. A disconti- nuity marker is represent ed by the appearance of a new section header , indicating a thematic break in proceedings. This ensures that speeches span- ning multiple pages are correctly attributed to their speakers while respecting the logical structure of parliamentary proceedings. The output of this stage is a document- lev el sequence of processed elements: ˆ D = ⟨ ˆ e 1 , ˆ e 2 , . . . , ˆ e k ⟩ . Figure 3 illustrat es the effect of post-processing on the running e xample. The speech fragment on page 26, originally mar k ed with an "unknown" speaker , is merged with the incomplete element at the end of page 25: the hyphenated word is rejoined, the content is concatenat ed, and the speaker identity is propagated from the preceding conte xt. Before Post-Processing End of page 25: speaker : "MINGHETTI, PRESIDENTE DEL CONSIGLIO, MINISTRO PER LE FINANZE" content : "[...] nella relazione della am-" Start of page 26: speaker : "unknown" content : "ministrazione delle finanze, [...] vi passi una differenza minima." ⇓ After Post-Processing Merged element: speaker : "MINGHETTI, PRESIDENTE DEL CONSIGLIO, MINISTRO PER LE FINANZE" content : "[...] nella relazione della amministrazione delle finanze, [...] vi passi una differenza minima." Figure 3: Effect of post-processing on a cross- page speech fragment. Highlighted regions show speaker inference ( unknown → resolv ed ); un- derlined text shows hyphenation resolution. 3.5. Entity Retriev al T o enable linking of extract ed speakers to authorita- tive records, we retriev e from the Italian Chamber of Deputies knowledge base all individuals who held parliamentary positions on the date of each session. The knowledge base, accessible via a SP ARQL endpoint 2 , contains structured information about deputies, government members, parliamentary of- ficers, and members of institutional organs. F or a session occurring on date d , we e xecut e a series of SP ARQL queries to retrie ve the set of activ e en- tities P d = P dep d ∪ P gov d ∪ P org d ∪ P off d , where P dep d denot es deputies, P gov d gov ernment members, P org d members of parliamentar y organs, and P off d parlia- mentary officers active on date d . For each entity p ∈ P d , we retriev e: the unique URI ser ving as the canonical identifier , the full name, surname, given name, and the set of institu- tional roles held on the rele vant date. This knowl- edge base is linked to Wikidata, enabling subse- quent enrichment with additional biographical and political information such as par ty affiliation and demographic attributes. On No vember 27th 1874, we hav e 557 active parliamentarians. For each entity , we retrie ve the URI, name, and roles: { "uri": "http://dati.camera.it/ocd/persona.rdf/ pr3028", "fullname": "MARCO MINGHETTI", "name": "MARCO", "surname": "MINGHETTI", "dep": true, "gov": [ "MINISTRO: MINISTERO DELLE FINANZE", "PRESIDENTE: PRESIDENZA DEL CONSIGLIO" ], "org": [], "off": [] } 3.6. Speaker Matching The final stage establishes correspondences be- tween extract ed speaker names and knowledge base entities. Given the historical nature of the corpus and the variety of conventions used to iden- tify speakers in parliamentar y proceedings, a sim- ple string matching approach prov es insufficient. Speaker names ma y appear as surnames only , as full names, with abbreviat ed giv en names, or solely by institutional role (e.g., PRESIDENT , MIN- IS TER OF THE INTERIOR ). F ur thermore, multiple individuals may share the same surname within a single legislature. W e theref ore im plement a multi- strat egy matching pipeline that applies increasingly sophisticated matching criteria. The pipeline pro- cesses each unique speaker name extracted from a document and attempts to link it to entities in P d . Generic Speaker Filtering . Cer tain speak er designations refer to collective or anonymous voices (e.g., V OICES , A DEPUTY ) and are ex- cluded from entity linking by pattern matching. Role-Based Identification . When a speaker is identified solely by institutional role, the syst em queries the entity set for individuals holding that role on the session date. A special case handles the 2 https://dati.camera.it/sparql session president ( PRESIDENT ): the document’s first page typically contains a heade r followed by the presiding officer’s name, which is extract ed and used to disambiguate among members of the Pre- siding Committee . Name Matching with Fuzzy Strategies . For speakers identified by name, the syst em applies a cascade of fuzzy matching algorithms with decreas- ing stringency . The matching process employs mul- tiple similarity metrics, including token-based ratios, par tial matching, and token set comparisons, ap- plied iter atively to both surnames and full names. Candidate entities are those exceeding a config- urable similarity threshold. Disambiguation . When multiple candidate enti- ties remain af ter initial matching, a disambiguation cascade is applied: 1. score-based ranking: candidates are ranked by their fuzzy matching scores; if a single can- didate achie ves the highest score, it is se- lected; 2. role matching: if the speaker’s role w as e x- tracted, candidates whose roles match the ex- tracted role are prioritised; 3. full name similarity : remaining ties are bro- ken by com puting similarity betw een the can- didate ’s full name and the extract ed speaker name; 4. abbreviat ed name handling: for speaker names containing initials (e.g., "G. ROSSI"), the system generat es abbreviated forms of candidate names and compares them; 5. conte xtual mention: candidat es whose full names appear elsewhere in the document text are fav oured; 6. weighted edit distance: a weighted Lev en- shtein distance is computed, assigning low er substitution costs to vo wel-vo wel substitutions to account for spelling v ariations common in historical documents. If disambiguation succeeds, the speaker is linked to the entity’s URI; other wise, all high-scoring can- didates are retained as potential matches. In a second pass, unresolv ed speakers are compared against successfully resolved speakers from the same document. If an unresolved speaker name e xhibits high similarity to a resolved one, the linking from the resolv ed speak er is propagated. The output of the complete pipeline is a JSON file for each session document, containing the se- quence of annotated elements with speaker entity URIs where linking succeeded. This structured representation enables direct integration with the parliamentar y knowledge base and, through its link - age to Wikidata, facilitates enrichment with politi- cal par ty affiliations, biographical data, and cross- ref erences to ext ernal resources for comprehensive political discourse analysis. { "speaker": "MINGHETTI, PRESIDENTE DEL CONSIGLIO, MINISTRO PER LE FINANZE", "type": "text", "content": "In questa occasione credo che la Camera sara’ contenta di sentire quello che gia’ vedra’ distintamente tanto nella relazione della amministrazione delle finanze, quanto in quella fatta dalla Corte dei conti, come cioe’ fra i risultati che io enunciai il 15 marzo 1874, quando presentai la situazione del Tesoro, vale a dire due mesi e mezzo soltanto dopo che l’esercizio 1873 era finito, fra questi risultati che io prevedeva ed annunciava alla Camera, e quelli definitivi del resoconto medesimo , vi passi una differenza minima.", "speaker_uri": "http://dati.camera.it/ocd/ persona.rdf/pr3028", "wikidata_uri": "Q597155" } 4. Evaluation T o assess the effectiveness of the proposed pipeline, we conduct a comparativ e ev aluation against IPSA ( Frasnelli and P almero Aprosio , 2024 ), a previously published syst em for Italian parliamentary corpus construction. W e ev aluate both the OCR transcription q uality and the speaker tagging accuracy using the benchmark dataset re- leased by the authors. 4.1. Evaluation Setup Benchmark Dataset . The ev aluation relies on the benchmark dataset released alongside IPSA. The dataset consists of 60 scanned parliamentary pages paired with manual transcriptions, which ser v e as the ground truth for OCR e valuation. These pages span the period from 1848 to 1996 and cov er documents from both the Camera dei Deputati and the Senato della Repubblica across multiple legislatures. F or the speaker tagging task, annotations are a vailable for 58 of these 60 pages. W e retrie ved the page images and refer ence anno- tations from the authors’ reposit or y and processed the same page images through our pipeline. Metrics . We adopt Word Error Rat e (WER) and Character Error Rate (CER) for OCR quality as- sessment. Both metrics quantify the edit distance between the predicted transcription and the ground truth: WER = S + D + I N , CER = S + D + I N (1) where S denotes the number of substitutions, D the number of deletions, I the number of inser tions, and N the total number of words (for WER) or char - acters (for CER) in the ground truth. Lower values indicate higher transcription quality . For the tagging task, we repor t Precision, Recall, and F1 score. A true positive corresponds to a cor - rectly identified speaker -entity link, a false positive to an incorrect identification, and a false negative to a missed identification. Experimental Configuration . We employ ed dots.ocr 3 for the initial OCR processing, and then Qwen-VL2.5-72B 4 with 8-bit quantisation to enable semantic inference. The experiments were run on a Nvidia H100 NVL 94 GB graphics card. 4.2. OCR Evaluation T able 1 presents the OCR evaluation results on the 60 benchmar k pages, comparing the T esseract baseline used in IPSA against the two stages of our pipeline: (i) dots.ocr alone, and (ii) dots.ocr follow ed by Qwen-VL transcription refinement. Method CER WER T esseract (IPSA) 0.030 0.071 dots.ocr 0.031 0.050 dots.ocr + Qwen- VL 0.009 0.024 T able 1: OCR evaluation results on the 60-page benchmark. Lower values indicate better per for - mance. The results indicate that when applied in isola- tion, dots.ocr achiev es a comparable CER to T esseract (0.031 vs. 0.030) while yielding a notable improv ement at the word level, reducing WER by appro ximately 30% (from 0.071 to 0.050). The in- tegration of Qwen-VL for transcription refinement delivers substantial gains: the complete pipeline achiev es an error reductions of approximat ely 70% in CER and 66% in WER compared to the T esser - act baseline. 4.3. T agging Evaluation T able 2 presents the speaker tagging evaluation re- sults, com paring the rule-based approach of IPSA against our pipeline. The released benchmark provides only page im- ages without the relative session metadata. Since our pipeline requires this information, in par ticular the session date for Senate document, in order to retrie ve the set of active parliamentarians, we re- strict our evaluation to the 29 Chamber of Deputies 3 https://github.com/rednote- hilab/dots. ocr 4 https://huggingface.co/RedHatAI/Qwen2. 5- VL- 72B- Instruct- FP8- dynamic pages for which the date could be reliably extracted from the filename. Method Precision Recall F1 IPSA (Global) 0.939 0.880 0.909 Ours (Global) 0.885 0.970 0.925 IPSA (Pre- WW2) 0.953 0.850 0.898 Ours (Pre-WW2) 0.883 0.970 0.924 IPSA (Pos t-WW2) 0.916 0.942 0.929 Ours (Post-WW2) 0.892 0.971 0.930 T able 2: Speak er tagging evaluation results. Our pipeline achiev es a higher global F1 score, driven by substantially higher Recall, while the IPSA baseline retains an advantage in Precision. The lower precision of our method is par tly explained by a systematic difference in segmentation granularity : when a speech is interrupt ed by a parenthetical note (e.g., The Chamber appro v es ), our pipeline splits the surrounding te xt into two distinct speech elements, whereas the ground truth treats it as a single continuous speech. This produces a higher number of predicted speech segments and, conse- quently , additional false positives. A notable finding is that our pipeline exhibits no significant per formance gap between the Pre- WW2 and Post- WW2 subsets, whereas the IPSA base- line shows a marked sensitivity to document q ual- ity across historical periods. This degradation is consistent with the lower typographic quality of Pre- WW2 documents, which exhibit great er variability in print clarity , adversely affecting both OCR accuracy and the reliability of the downstr eam tagging task. The stability in performance of our VLM-based ap- proach suggests that the superior transcription qual- ity does not merely benefit the exploitation of the te xt itself, but also carries ov er to subsequent tasks, keeping them uneffected by the degradation inher - ent in older source documents. 4.4. Limitations Sev eral factors limit the direct comparability of tag- ging per formance between our pipeline and the IPSA baseline and ma y par tially account for ob- ser v ed differences. As noted abov e, the absence of session dat e me tadata in Senate document filenames restrict ed the tagging evaluation to the Chamber of Deputies subset. For these pages, the date was extract ed from the filename and used to quer y the set of active parliamentarians. In a full- corpus processing scenario, session dates would be readily available from the document metadata, remo ving this constraint entirely . F ur thermore, the fragmented nature of the bench- mark, consisting of isolat ed pages rather than complete documents, prev ents our pipeline from demonstrating its full capabilities in cross-page speaker inf erence. In a standard workflow , a speech that begins on a previous page and con- tinues onto the current one would be attributed to the correct speaker through the Speaker Continuity Inference mechanism. In the benchmark setting, howe ver , no previous page is av ailable, and the ground truth accordingly leav es the first speech un- labelled when no explicit speaker heading appears on the page. Our syst em is therefore evaluat ed without ex ercising one of its core design strengths. A related limitation concerns the identification of the presiding officer . In a complete document, the President of the session is explicitly named on the first page, allowing our system to propagate this identity throughout subsequent pages. Because benchmark pages are processed in isolation with- out access to this introductory conte xt, our method must approximate the presiding officer based solely on the legislature, a heuristic that is prone to er- ror when mid-term changes in presidency occur or when a Vice President substitutes for the main President. Finally , while our approach requires signifi- cantly higher computational resources, necessi- tating GPUs for Visio n-Language Model inference, we argue that this cost is justified by the superior quality of the final output, which is crucial for en- abling accurate downstream NLP tasks such as topic modelling or sentiment analysis. 5. Conclusion In this paper , we present ed a pipeline for automatic transcription, semantic segmentation, and entity linking of Italian parliamentary speeches based on Vision-Language Models. The proposed approach combines a specialised OCR model ( dots.ocr ) with a large-scale VLM ( Qwen2.5-VL-72B ) to jointly per form te xt extraction, element classifica- tion, and speaker identification, followed by entity retrie val from the Chamber of Deputies knowledge base and a multi-strategy fuzzy matching proce- dure for linking speakers to records. Evaluation against the IPS A benchmark demon- strated that the VLM-based pipeline achieves sub- stantial improvements in transcription q uality , with relativ e error reductions of approximat ely 70% in Character Error Rate and 66% in Word Error Rate compared to the T esseract baseline. The results of the speaker tagging showed competitive per- formance, with our met hod achieving higher F1 scores than the baseline across all temporal sub- sets. Notably , the pipeline exhibited consistent per - formance in both pre- and post-WW2 documents, suggesting robustness to the considerable variation in source document quality across historical peri- ods. The ev aluation on isolated benchmark pages represents a conser vativ e estimate of performance, as the pipeline’s cross-page inference mechanisms could not be fully e xploited in this setting. W e are currently preparing the public release of a dataset spanning from 1848 to 1948 extract ed with the proposed approach. The released data will include OCR transcriptions, structural anno- tations, and speaker -entity links in a structured, machine-readable format. Processing complete documents rather than isolat ed pages improv es speaker tagging accuracy , as the syst em can fully exploit cross-page inference mechanisms such as session president identification and speaker conti- nuity propagation. The link to external knowledge bases, such as Wikidata, opens the possibility of en- riching the corpus with structured metadata, includ- ing par ty affiliations and demographic attributes, enabling richer downstream analyses in political science and computational social science. Acknowledgements Computational resources pro vided by IND AC O Core facility , which is a project of High Performance Computing at the Univ ersity of MIL AN http:// www.unimi.it Bibliographical References Shuai Bai, Keqin Chen, X uejing Liu, Jialin W ang, W enbin Ge, Sibo Song, Kai Dang, P eng Wang, Shijie Wang, Jun T ang, Humen Zhong, Y uanzhi Zhu, Mingkun Y ang, Zhaohai Li, Jianqiang W an, P engfei Wang, W ei Ding, Zheren F u, Yiheng Xu, Jiabo Y e, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Y ang, Haiy ang Xu, and Jun- yang Lin. 2025. Qwen2.5-vl technical repor t . Noman Islam, Zeeshan Islam, and Nazia Noor . 2017. A sur ve y on optical character recognition syst em. arXiv preprint . Y umeng Li, Guang Y ang, Hao Liu, Bowen Wang, and Colin Zhang. 2025. dots.ocr : Multilin- gual document lay out parsing in a single vision- language model . Linke Ouyang, Y uan Qu, Hongbin Zhou, Jia wei Zhu, Rui Zhang, Qunshu Lin, Bin W ang, Zhiyuan Zhao, Man Jiang, Xiaomeng Zhao, Jin Shi, F an W u, Pei Chu, Minghao Liu, Zhenxiang Li, Chao X u, Bo Zhang, Bo tian Shi, Zhongying T u, and Conghui He. 2025. Omnidocbench: Benchmarking diverse pdf document parsing with comprehensive annotations. In Proceed- ings of the IEEE/CVF Conference on Computer Vision and P atter n Recognition (CVPR) , pages 24838–24848. R. Smith. 2007. An ov er view of the tesseract ocr engine . In Ninth International Confer ence on Doc- ument Analysis and Recognition (ICD AR 2007) , volume 2, pages 629–633. Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shi- jian Lu. 2024. Vision-language models for vision tasks: A sur vey . IEEE T rans. on Patt ern Analy sis and Machine Intellig ence , 46(8):5625–5644. Language Resource References Alzetta, Chiara and Montemagni, Simonetta and Sar tor , Mar ta and V enturi, Giulia. 2024. P arlamint-it : an 18-karat UD treebank of Italian parliamentary speeches . Springer Science and Business Media LL C. Cominetti, Federica and Gregori, Lorenzo and Lom- bardi V allauri, Edoardo and Panunzi, Alessandro. 2024. IMP A QT S: a multimodal corpus of par - liamentary and other political speeches in Italy (1946-2023), annot ated with implicit strat egies . ELRA and ICCL. Cov a, Joshua. 2025. A new database for Italian parliamentary speeches: introducing the ItaP arl- Corpus dataset . Erjav ec, T omaž and Ogrodniczuk, Maciej and Osenov a, P ety a and Ljubešić, Nikola and Simov , Kiril and Pančur , Andrej and Rudolf, Michał and K opp, Matyáš and Barkarson, Starkaður and Ste- ingrímsson, Steinþór and undefinedöltekin, unde- finedağrı and de Does, Jesse and Depuydt, Ka- trien and Agnoloni, T ommaso and V enturi, Giulia and Pérez, María Calzada and de Macedo, Lu- ciana D. and Nav arretta, Costanza and Luxardo, Giancarlo and Coole, Matthew and Ra yson, Paul and Morkevičius, V aidas and Krilavičius, T omas and Dar ´ gis, Rober ts and Ring, Orsolya and van Heusden, Ruben and Mar x, Maar ten and Fišer , Darja. 2022. The P arlaMint corpora of parliamen- tary proceedings . Springer Science and Busi- ness Media LL C. F rasnelli, V alentino and Palmero Aprosio, Alessio. 2024. Ther e’s Somet hing New about the Italian P arliament : The IPS A Corpus . ELRA and ICCL. Rauh, Christian and Schwalbach, Jan. 2020. The P arlSpeech V2 data set : Full-t e xt corpora of 6.3 million parliamentary speeches in the ke y legisla- tiv e chambers of nine representativ e democra- cies . Harvard Dataverse.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment