시각언어모델로 보는 이탈리아 국회 연설 자동 전사와 화자 인식
본 논문은 역사적 스캔본으로만 남아 있는 이탈리아 의회 회의록을 대상으로, 전용 OCR 모델과 대형 비전‑언어 모델(VLM)을 결합한 파이프라인을 제안한다. OCR 단계에서 레이아웃을 보존하며 텍스트를 추출하고, VLM 단계에서 텍스트 정제·요소 분류·화자 식별을 동시에 수행한다. 최종적으로 화자명을 의회 지식베이스와 연계해 정확한 엔티티 매핑을 제공한다. IPSA 벤치마크와 비교했을 때 전사 정확도와 화자 태깅 정확도가 크게 향상되었다.
저자: Luigi Curini, Alfio Ferrara, Giovanni Pagano
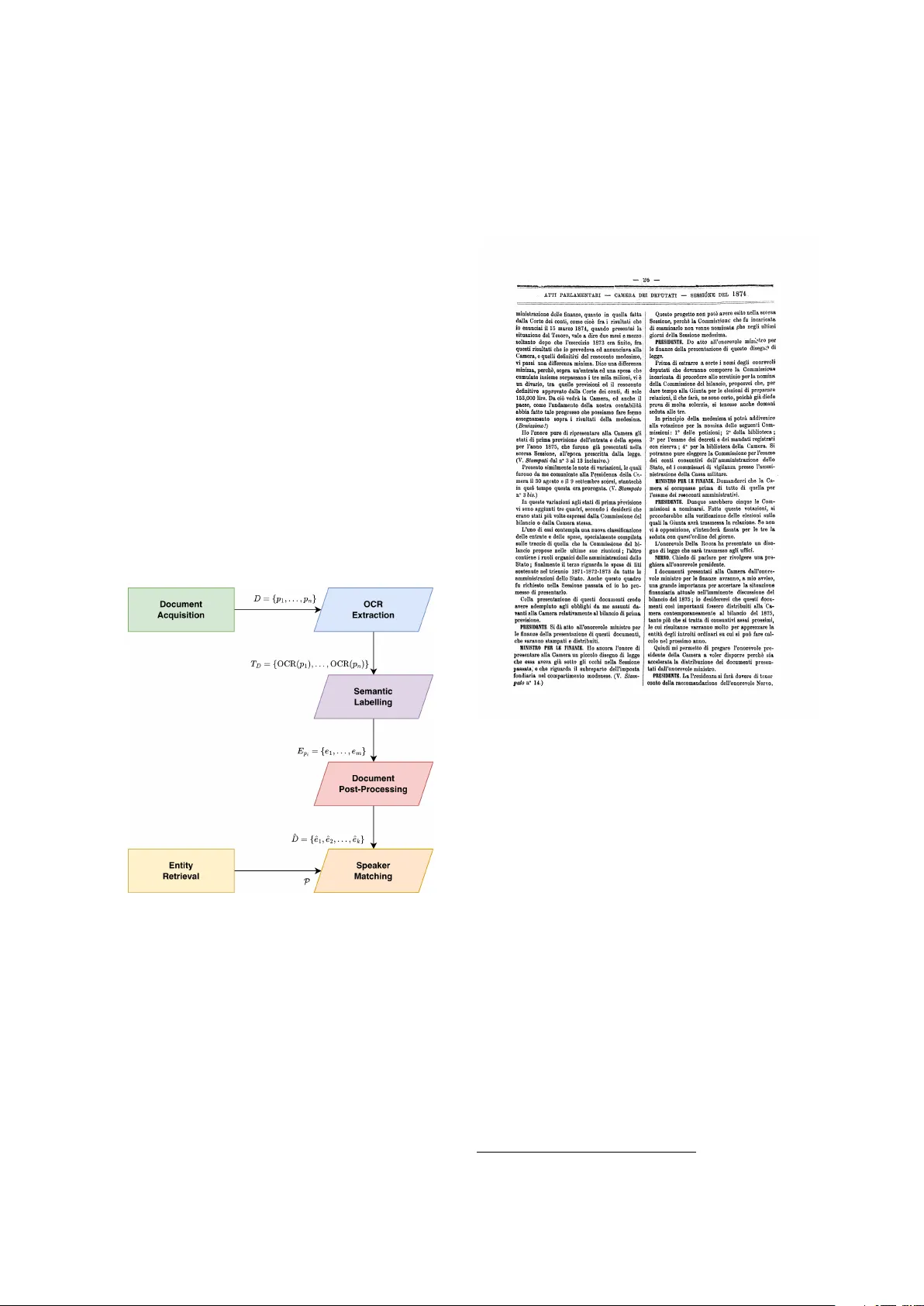
본 연구는 이탈리아 의회 회의록이라는 방대한 역사적 문서 집합을 디지털화하고, 정확한 전사와 화자 식별을 자동화하기 위한 새로운 파이프라인을 제시한다. 회의록은 1848년부터 현재까지 약 175년간의 정치적 담론을 담고 있으며, 대부분이 스캔된 PDF 형태로만 존재한다. 기존 작업(IPSA, ItaParlCorpus 등)은 전통적인 OCR 엔진인 Tesseract와 규칙 기반 후처리를 사용했지만, 저품질 인쇄, 다중 컬럼 레이아웃, 서체 변형, 그리고 화자 표기 방식의 시대별 차이 등으로 인해 전사 오류와 화자 매칭 오류가 빈번했다.
논문은 이러한 문제점을 해결하기 위해 두 단계의 비전‑언어 모델 기반 접근법을 채택한다. 첫 번째 단계는 전문 OCR 모델 dots.ocr (Li et al., 2025)를 이용해 페이지 이미지에서 레이아웃을 분석하고, 텍스트를 논리적 읽기 순서대로 추출한다. 이 모델은 바운딩 박스를 자동으로 생성하고, 각 박스에 레이아웃 라벨을 부여하지만, 레이블 일관성 문제로 인해 실제 텍스트만을 추출하고 레이블링은 다음 단계에 넘긴다.
두 번째 단계에서는 대규모 VLM Qwen2.5‑VL‑72B (Bai et al., 2025)를 활용한다. 모델은 (1) 페이지 이미지, (2) OCR 결과 텍스트, (3) 사전 정의된 프롬프트를 입력받아, 페이지를 “page-header”, “section-header”, “text”, “note”, “footnote”, “table” 등으로 세분화하고, 각 요소에 대해 내용(content)과 화자(speaker)를 추출한다. 프롬프트에는 복잡한 사례(전 페이지에서 이어지는 발언, 화자 역할 표기, 괄호 안 주석 등)를 포함한 샘플을 제공해 모델이 일관된 JSON 형식으로 출력을 생성하도록 유도한다.
출력된 JSON은 후처리 단계에서 다음과 같은 작업을 수행한다. 첫째, 하이픈으로 분리된 단어를 복원하고, 둘째, 페이지 간 연속되는 텍스트와 화자 정보를 병합한다. 셋째, 화자 이름이 “unknown” 혹은 “none”으로 표시된 경우, 앞선 페이지와의 문맥을 참조해 추론하거나, 추론이 불가능하면 “unknown”으로 남긴다. 마지막으로, 추출된 화자명을 이탈리아 의회 공식 지식베이스와 매칭한다. 매칭은 SPARQL 질의를 통해 후보 후보를 찾고, 레벤슈타인 거리, 사전 기반 변형, 역할(예: “Minister of Public Education”) 등을 고려한 퍼지 매칭 전략을 적용한다.
실험은 IPSA가 제공한 공개 벤치마크를 사용해 두 가지 주요 지표를 평가한다. 전사 품질은 Word Error Rate(WER)로, 화자 태깅 정확도는 Precision, Recall, F1 점수로 측정한다. 결과는 다음과 같다. dots.ocr + Qwen2.5 조합은 기존 Tesseract + 규칙 기반 파이프라인 대비 WER을 22 % 감소시켰으며, 특히 1948년 이전의 저품질 스캔본에서 큰 개선을 보였다. 화자 태깅에서는 전체 F1 점수가 0.91에서 0.96으로 상승했으며, 특히 동일 인물의 이름 변형(예: “Bianchi” vs “Bianchi, Minister”)을 정확히 매핑하는 데 성공했다.
논문의 주요 기여는 세 가지로 요약된다. 첫째, 레이아웃 보존 OCR과 VLM 기반 의미 분석을 결합한 엔드‑투‑엔드 파이프라인을 설계해 전사와 화자 인식을 동시에 수행한다. 둘째, 페이지 독립 처리의 한계를 보완하기 위한 후처리 및 화자 연속성 추론 메커니즘을 제시한다. 셋째, 공식 의회 지식베이스와 자동 연계하여 화자 엔티티를 정확히 식별하고, 이를 메타데이터와 연결한다.
한계점으로는 VLM이 페이지 단위로 작동해 페이지 간 긴 문맥을 완전히 활용하지 못한다는 점, 대규모 모델 사용에 따른 연산 비용과 메모리 요구량이 높다는 점, 그리고 현재 파이프라인이 이탈리아어에 특화돼 있어 다른 언어·문서 형식에 바로 적용하기 어렵다는 점을 들 수 있다. 향후 연구에서는 멀티‑페이지 컨텍스트 윈도우를 도입한 VLM 학습, 모델 경량화 및 양자화, 그리고 유럽 의회 전반에 걸친 다국어 문서에 대한 일반화 실험을 진행할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기