DELTA: A DAG-aware Efficient OCS Logical Topology Optimization Framework for AIDCs
The rapid scaling of large language models (LLMs) exacerbates communication bottlenecks in AI data centers (AIDCs). To overcome this, optical circuit switches (OCS) are increasingly adopted for their superior bandwidth capacity and energy efficiency.…
Authors: Niangen Ye, Jingya Liu, Weiqiang Sun
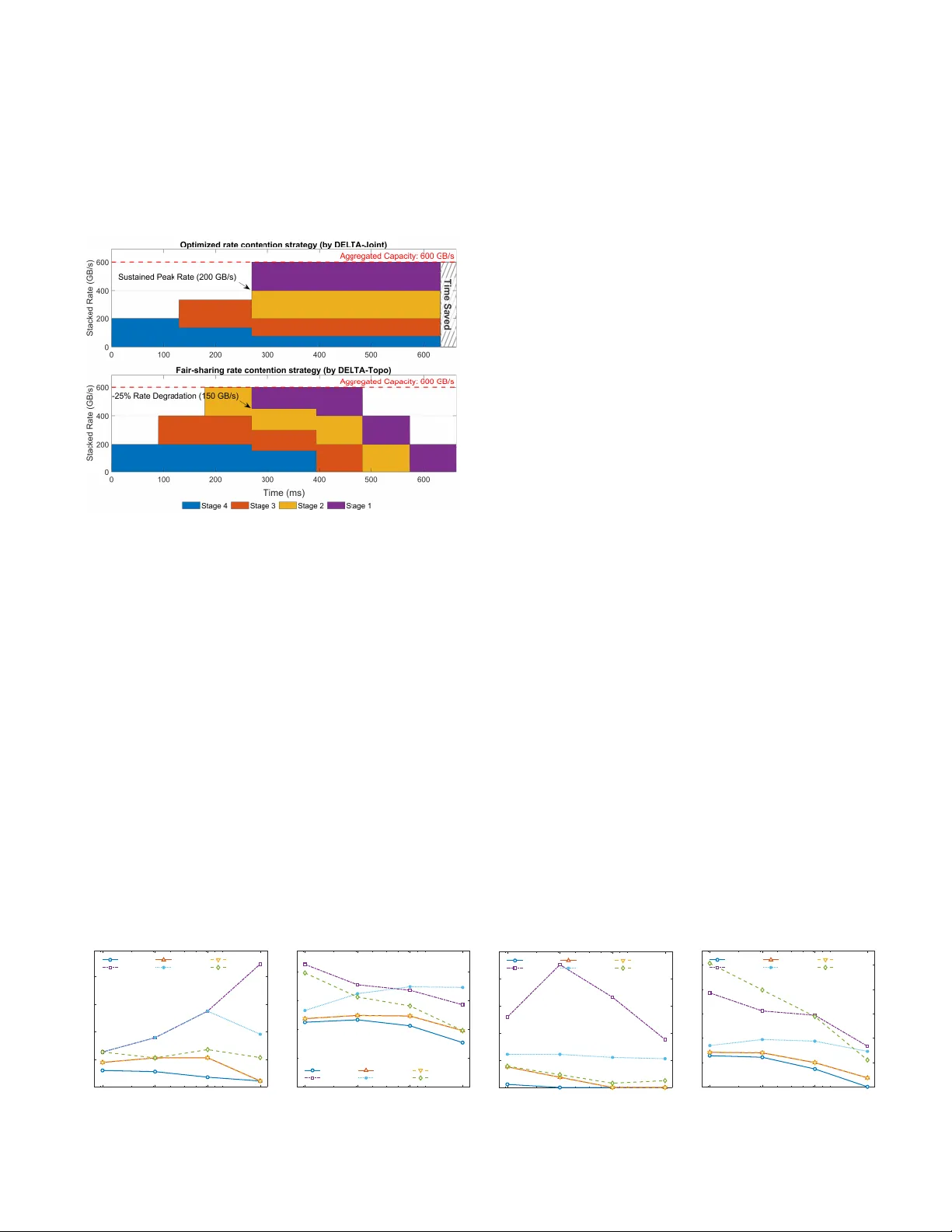
JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 1 DEL T A: A D A G-a ware Ef ficient OCS Logical T opology Optimization Frame w ork for AIDCs Niangen Y e, Jingya Liu, W eiqiang Sun, Senior Member , IEEE , and W eisheng Hu, Member , IEEE Abstract —The rapid scaling of large language models (LLMs) exacerbates communication bottlenecks in AI data centers (AIDCs). T o overcome this, optical circuit switches (OCS) are increasingly adopted for their superior bandwidth capacity and energy efficiency . However , their reconfiguration overhead precludes intra-iteration topology update, necessitating a priori engineering of a static topology to absorb time-varying LLM traffic. Existing methods engineer these topologies based on traffic matrices. However , this representation obscures the bursty concurrent band width demands dictated by parallelization strate- gies and fails to account f or the independent channels required for concurrent communication. T o address this, we propose DEL T A, an efficient logical topology optimization framework for AIDCs that leverages the computation-communication directed acyclic graph (DA G) to encode time-varying traffic patterns into a Mixed-Integer Linear Programming (MILP) model, while exploiting the temporal slack of non-critical tasks to sav e optical ports without penalizing iteration makespan. By pioneering a variable-length time interval formulation, DEL T A significantly reduces the solution space com- pared to the fixed-time-step formulation. T o scale to thousand- GPU clusters, we design a dual-track acceleration strategy that combines search space pruning (reducing complexity from quadratic to linear) with heuristic hot-starting. Evaluations on large-scale LLM workloads show that DEL T A reduces communi- cation time by up to 17.5% compar ed to state-of-the-art traffic- matrix-based baselines. Furthermore, the framework reduces op- tical port consumption by at least 20%; dynamically reallocating these surplus ports to band width-bottlenecked workloads reduces their performance gap relativ e to ideal non-blocking electrical networks by up to 26.1%, ultimately enabling most workloads to achieve near-ideal performance. Index T erms —AI data center , optical circuit switch, logical topology , mixed-integer linear programming. I . I N T R O D U C T I O N Driv en by the vision of Artificial General Intelligence (A GI) and the scaling laws of LLMs [1, 2], AIDCs are undergoing rapid expansion. Howe ver , the evolution of computational demand has outpaced the iteration of underlying network equipment, making communication an increasingly prominent bottleneck for cluster scaling [3 – 7]. Existing multi-tier electri- cal Clos networks that support massiv e GPU interconnections struggle to bridge this gap. Specifically , as endpoint GPU communication rates surge, relying exclusiv ely on electrical packet switches (EPS) not only introduces severe bottlenecks in power consumption [6, 8 – 11] and latency [10 – 12], but the frequent upgrades to match these endpoint rates also N. Y e, J. Liu, W . Sun, and W . Hu are with the State Key Laboratory of Photonics and Communications, Shanghai Jiao T ong Univ ersity , Shanghai, China. Corresponding author: W eiqiang Sun (E-mail: sunwq@sjtu.edu.cn). incur prohibitive infrastructure churn [13–15]. Consequently , the industry is introducing OCS—leveraging their low power , low latency , and data-rate transparency—to replace the EPS in original Core or Spine layers, dri ving the emergence of OCS-AIDCs that enable ef ficient inter-Pod optical connecti vity while retaining flexible intra-Pod electrical switching [13 – 18]. Howe ver , unlike the fle xible any-to-an y connectivity of EPS, the coarse-grained, point-to-point nature of OCS struggles to accommodate the dynamic communication patterns in LLM training. Furthermore, while an OCS can reconfigure optical circuits within tens of milliseconds [14, 15, 19], the subsequent initialization of associated components—such as transceiv ers, NICs, and EPSs (update the routing tables in order)—requires sev eral seconds [19 – 21]. Gi ven that mainstream LLM training iterations typically span only a fe w seconds [22 – 26], intra- iteration topology reconfiguration is impractical. Under this constraint, maintaining a static topology throughout an itera- tion is a pragmatic strategy for current deployments [15 – 18]. Consequently , a priori engineering of a logical topology (i.e., the number of optical circuits allocated between Pod pairs [13, 27, 28]) tailored to absorb time-v arying LLM traffic is critical for mitigating OCS-induced communication bottlenecks. While such a priori engineering is imperativ e, tailoring a rigid logical topology to accommodate the dynamic traffic patterns extends far beyond simple volume-based allocation deriv ed from the con ventional traffic-matrix representation. Simply encoding traffic features into an aggregated traffic ma- trix within an iteration obscures the bursty concurrent commu- nication demands dictated by parallelization strategies, thereby failing to account for the independent channels required for concurrent communication. T o capture these transient peaks, existing approaches often employ fine-grained temporal snap- shots of traffic. Y et, they typically revert to volume-based allocation within each time slice, aiming to driv e dynamic reconfigurations (e.g., MixNet [19] and other practices in cloud data centers [13, 21, 29 – 31])—a path precluded by the aforementioned reconfiguration overhead. Ultimately , solving such an engineering problem hinges on strategically encoding the temporal dynamics of LLM traffic into the optimization formulation of the logical topology . T o address this engineering problem and construct an op- timal logical topology , we propose DEL T A, a D A G-aware, efficient frame work for OCS logical topology optimization for AIDCs. W e first analyze the spatiotemporal characteristics of LLM training traffic to identify the specific opportunities and optimization challenges in mapping these dynamics to topology construction (Section II). T o address these chal- lenges, we introduce a computation-communication DA G of JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 2 LLM training that dynamically encodes the time-varying traf- fic patterns into the optimization formulation. This encoding allows the framework to exploit the full spectrum of traffic features while ensuring the resulting topology targets the exact bottlenecks go verning the training iteration time. Based on this D AG, we formulate DEL T A-Joint, an MILP model that jointly optimizes the topology and communication scheduling. Specifically , by pioneering a variable-length time interval formulation, DEL T A-Joint averts the dimensionality curse in- herent in con ventional fixed-time-step methods. Moreover , by exploiting the temporal slack of non-critical communication tasks, the model incorporates a lexicographic objectiv e to eliminate redundant port allocations without compromising the optimal iteration time (Section III). T o scale to large- scale clusters, we design a dual-track acceleration strategy (Section IV). Specifically , we employ a search space pruning technique that reduces the problem complexity from quadratic to linear , compressing the MILP solving time to minutes. In parallel, we develop DEL T A-Fast—a fast heuristic that yields high-quality topologies and provides a hot-start for the MILP , further accelerating MILP solving. Evaluations on large-scale training workloads (e.g., the 671B-parameter DeepSeek model) show that DEL T A reduces communication time by up to 17.5% compared to state-of- the-art traffic-matrix-based baselines. Furthermore, DEL T A reduces optical port consumption by at least 20% without penalizing iteration time. By reallocating these freed ports to bottlenecked workloads, DEL T A reduces their performance gap relativ e to ideal non-blocking electrical networks by up to 26.1%, enabling most workloads under optical switching to achiev e nearly the performance of ideal electrical networks. In summary , the ke y contrib utions of this work are threefold: • W e dynamically encode the time-varying traffic patterns of LLM training into the logical topology optimization formu- lation via a computation-communication DA G. This moves beyond traffic matrices, ensuring we fully exploit traffic characteristics while precisely targeting the bottlenecks that dictate iteration makespan. • W e significantly reduce the MILP solution space of DEL T A by pioneering a variable-length time interval formulation. Combined with search space pruning (reducing complexity from quadratic to linear) and heuristic hot-starting, we solve the MILP within minutes, e ven at a thousand-GPU scale. • W e integrate a resource-saving paradigm into DEL T A that exploits temporal slack in non-critical communication tasks to reduce optical port consumption without penalizing itera- tion time. Dynamically reallocating these freed ports enables most workloads under OCS to achieve performance nearly identical to ideal electrical networks. I I . B A C K G R O U N D A N D M O T I V A T I O N T o motiv ate the design of DEL T A, this section first charac- terizes the spatiotemporal traffic features of LLM training to identify topology optimization opportunities. W e then articu- late the algorithmic challenges in mapping these features to OCS configuration, followed by a revie w of related literature. A. F eatur es of LLM T raining T raffic and Opportunities in Optimizing Logical T opology for OCS-AIDC In contrast to the stochastic traffic patterns typical of cloud data centers, the communication within LLM training ex- hibits unique spatiotemporal characteristics driv en by parallel strategies, namely T ensor (TP), Pipeline (PP), Data (DP), and Expert (EP) parallelism. Fig. 1 profiles a GPT -7B training iteration, rev ealing three key traffic features and corresponding optimization opportunities for OCS logical topologies: 0 50 100 150 200 250 Time (ms) 1 2 3 4 5 6 7 8 GPU Index 1 2 3 4 1 1 5 2 2 6 3 3 7 4 4 8 5 5 6 6 7 7 8 8 1 2 3 4 1 1 5 2 2 6 3 3 7 4 4 8 5 5 6 6 7 7 8 8 1 1 2 2 3 3 4 1 1 4 2 2 5 5 3 3 6 6 4 4 7 7 5 5 8 8 6 6 7 7 8 8 1 1 2 2 3 3 4 1 1 4 2 2 5 5 3 3 6 6 4 4 7 7 5 5 8 8 6 6 7 7 8 8 1 1 2 2 3 1 1 3 2 2 4 4 3 3 5 5 4 4 6 6 5 5 7 7 6 6 8 8 7 7 8 8 1 1 2 2 3 1 1 3 2 2 4 4 3 3 5 5 4 4 6 6 5 5 7 7 6 6 8 8 7 7 8 8 1 1 1 2 2 2 3 3 3 4 4 4 5 5 5 6 6 6 7 7 7 8 8 8 1 1 1 2 2 2 3 3 3 4 4 4 5 5 5 6 6 6 7 7 7 8 8 8 1 2 3 4 5 6 7 8 1 2 3 4 5 6 7 8 1 2 3 1 4 2 5 3 6 4 7 5 8 6 7 8 1 2 3 1 4 2 5 3 6 4 7 5 8 6 7 8 1 2 1 3 2 4 3 5 4 6 5 7 6 8 7 8 1 2 1 3 2 4 3 5 4 6 5 7 6 8 7 8 1 2 3 4 5 6 7 8 1 2 3 4 5 6 7 8 Pod 1 Pod 2 Forward Backward PP Send PP Recv DP Comm. (a) Execution trace of 1F1B scheduling on the first DP replica under a TP=2/PP=4/DP=2 parallelism configuration with 8 micro-batches per GPU (TP communications are subsumed into the forward/backward blocks for visual brevity .) 0 50 100 150 200 250 Time (ms) 0 400 800 1200 1600 BW Demand (Gb/s) GPU3 GPU4 PP Pod 1 ! Pod 2 GPU1 GPU2 GPU3 GPU4 DP Pod 1 ! Pod 3 Stepped BW Demand Rectangular BW Demand Comp. Latency (b) Inter-pod bandwidth demand of Pod 1. Note the distinct profiles of PP (rectangular) and DP (stepped) bandwidth demand. Fig. 1: Spatiotemporal profiling of GPT -7B training schedule and traffic under ideal 400 Gb/s network (GPUs are deployed uniformly across 4 Pods). F1: Communication in LLM training features deter - ministic traffic demands gov erned by a computation- communication D A G. The model architecture and paralleliza- tion strategy jointly dictate the communication beha vior during training, determining both the physical properties of the traf fic and their causal dependencies. Consequently , the exact charac- teristics of communication tasks—including source-destination pairs, traffic volumes, and their temporal order—can be calcu- lated before execution. As illustrated by the 1F1B execution trace in Fig. 1a, the launch time and scheduling order of each task are fully determined as a function of the 1F1B schedule. Opportunity 1. This predictability in LLM traffic enables pr oactive topology engineering, allowing the pr e-allocation of network r esour ces to match the bandwidth demands of each communication task. F2: LLM training generates bursty traffic, whose peak demand is driven by the scale of parallelism-induced concurrent flows. In contrast to the smooth traffic patterns typical of traditional cloud computing, LLM training traffic is characterized by burstiness and concurrency in the temporal dimension. As illustrated in Fig. 1b, inter-pod communication bandwidth demand surges during specific training process phases. Specifically , the concurrent transmission of acti vations JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 3 and gradients between model layers (PP communication) from GPU 3 and GPU 4 demands an aggregated inter-pod bandwidth of 2 × 400 Gb/s. And parameter synchronization between replicas (DP communication) inv olves successive communication from GPU 3&4 and GPU 1&2, resulting in a maximum bandwidth demand of 4 × 400 Gb/s. Opportunity 2. This burst concurr ency implies that to alle- viate congestion, r esour ce allocation should prioritize pr ovi- sioning independent physical channels (i.e., OCS lightpaths) that matc h flow concurrency , rather than simply allocating r esour ces based solely on the aggr e gated traf fic matrices. F3: DP communication exhibits time-varying concur - rency and stepped bandwidth demand profiles. As illus- trated in Fig. 1a, in hybrid parallel training, the backward pass propagates in rev erse pipeline order , triggering gradient syn- chronization sequentially from the final stage back to the first. Consequently , the aggregated bandwidth demand manifests as a stepped en velope (Fig. 1b)—peaking exclusi vely during periods of flow overlap—rather than as a uniform rectangular burst typical of PP traffic. This intrinsic temporal staggering facilitates link time-multiplexing. Specifically: Opportunity 3. Suf ficiently staggering DP flows acr oss pipeline stages shrinks peak-concurrency intervals, allowing us to pr ovision fewer independent optical channels without exacerbating congestion. Opportunity 4. Furthermore , the temporal slack of earlier DP flows enables dynamic bandwidth r eallocation among overlapping DP tasks. Levera ging this slack helps accom- modate bandwidth-intensive workloads under stricter capacity constraints without pr olonging the global iteration makespan. B. Challenges of Optimizing Logical T opology for OCS-AIDC The transition from the any-to-an y connectivity of EPS (Fig. 2a) to the rigid point-to-point nature of OCS creates bottlenecks when destination-div ergent flo ws (e.g., orthogonal PP and DP traffic) compete for limited optical exit ports (Fig. 2b). Under such hardware constraints, topology construction is essentially a constrained resource allocation problem. While utilizing the aforementioned opportunities for this problem is promising, capturing these benefits is non-trivial due to two distinct challenges in encoding the dynamic LLM training traffic patterns into the optimization formulation. C1: Challenge in encoding shifting communication bottlenecks into the optimization for training iteration time reduction. In contrast to cloud data center workloads, where network throughput linearly correlates with application performance, the iteration time of LLM training is strictly determined by the most time-consuming sequence of causally chained computation and communication tasks (hereafter re- ferred to as the critical path). Consequently , accelerating a spe- cific communication flow yields no marginal gain if it resides outside this path. Compounding this issue, these bottlenecks are decision-dependent; optimizing one communication task can shift the critical path to a dif ferent sequence of tasks. Thus, a ke y challenge lies in mathematically encoding these shifting Spine-Leaf Spine-Leaf Core (EPS) Spine-Leaf Spine-Leaf Pod 1 Pod 2 Pod 3 Pod 4 GPUs (a) Any-to-an y inter -pod paths es- tablished by the EPS. Spine-Leaf Spine-Leaf Core (OCS) Spine-Leaf Spine-Leaf Pod 1 Pod 2 Pod 3 Pod 4 GPUs (b) Point-to-point inter-pod paths established by the OCS. Fig. 2: Comparison of inter-pod connection patterns estab- lished by OCS and EPS for the multi-pod LLM training setup in Fig. 1. bottlenecks into the topology optimization formulation, and ensuring the solver targets actual iteration-time reduction rather than merely maximizing aggregate network bandwidth. C2: Challenge in encoding diverse and decision- dependent communication demands into topology opti- mization. Encoding the time-varying bandwidth requirements of LLM workloads ( F2 and F3 ) into the optimization formu- lation presents two algorithmic hurdles. First, communication demands dri ven by different parallelization strategies exhibit distinct temporal behaviors, such as the stepped bandwidth demand en velopes of DP traf fic v ersus the uniform, rectangular demand of PP traffic. Constructing a topology solely based on a traffic matrix fails to capture these temporal dynam- ics, thereby missing the temporal multiplexing opportunities created by the pipeline-induced staggering of DP flows (i.e., failing to exploit O3 and O4 ). Second, a circular depen- dency exists between topology decisions and traffic profiles. Specifically , any adjustment to the logical topology inherently alters transmission rates, which in turn stretches or compresses the actual flow durations. This non-linear coupling in validates static optimization approaches, requiring a solver capable of dynamically tracking how topological decisions reshape the temporal demand landscape. C. Related W ork OCS in cloud data centers. Existing studies hav e proposed various topology construction methods for the deployment of OCS in cloud data centers [13, 21, 28 – 35]. For instance, [13, 21, 29–31] construct logical topologies by exploiting long- term traffic pattern prediction to optimize network throughput or link utilization. Meanwhile, w orks such as [28, 32 – 35] focus on developing algorithms with polynomial time complexity to compute logical topology mapping and reconfiguration schemes that satisfy the physical port mapping constraints of OCS and maximize network throughput. Ho wever , these approaches target traditional cloud computing environments featuring stochastic, slow-v arying traffic, prioritizing gen- eral network performance metrics ov er job-level ex ecution times. Consequently , they are ill-suited for the deterministic, JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 4 bursty traffic of LLM training, where minimizing the iteration makespan is the primary objective. Introducing OCS into AI data centers. Recent studies hav e begun integrating OCS into AI data centers to optimize AI workload training time while reducing network costs [16, 19, 36 – 43]. Early works [36, 37] optimized OCS reconfig- uration and multiplex ed the optical circuit by exploiting the interleav ed compute-communicate phases of distributed train- ing, but focused exclusiv ely on DP parameter synchronization. T o further accelerate this synchronization process, [38 – 40] jointly optimize the schedule of optical circuit and in-network computing resources. Ho wever , such DP-centric and hardware- dependent designs lack the generality required for modern LLM training. Other studies [19, 41, 42] explore architectures where GPUs are directly connected to OCS, reconfiguring the topology based on traffic pattern predictions to optimize the All-to-All or All-Reduce communications required for EP or TP/DP . Y et, this approach is incompatible with the prev ailing architectural paradigm of scaling clusters by interconnecting multiple pods via OCS. While the methods proposed in [16, 43] support OCS-based pod-le vel interconnection and are not restricted to specific workloads, their decision-making processes still rely on aggregated traffic matrices and fail to incorporate the iteration time of LLM training as an optimization objectiv e. Consequently , they do not resolve the previously mentioned challenges C1 and C2 , which may lead to sub-optimal topological decisions—a critical limitation that our work specifically aims to overcome. Computation-communication D A G-aware communica- tion optimization. Existing works [44–49] emphasize the importance of leveraging computation-communication depen- dencies to optimize communication in LLM training. Specifi- cally , studies such as [44 – 47] focus on the parameter synchro- nization phase in DP , utilizing priority-based scheduling for communication operations according to their dependency order to minimize synchronization stalls. For PP+DP hybrid paral- lelism, [48] groups and reorders the backward computation and corresponding gradient synchronization across different model layers; this removes a portion of DP communication from the critical path of the conv entional 1F1B scheduling, enabling it to overlap with the computations of other layers. Furthermore, T riRace [49], an asynchronous pipeline scheduling approach, reschedules the communication required for PP and DP by analyzing the critical path within the D A G, thereby reducing the bubble rate in PP . While the aforementioned works pri- marily exploit D AG dependencies to schedule communication ov er a fixed network topology , our approach integrates D A G dependencies into logical topology optimization, tailoring the topology configuration to accelerate the LLM training. I I I . C O M P U TA T I O N - C O M M U N I C AT I O N DA G - A W A R E O P T I M I Z A T I O N O F L O G I C A L T O P O L O G Y F O R O C S - A I D C This section details our approach to optimizing the logical topology for OCS-AIDCs. T o resolve the aforementioned chal- lenges, our core strategy is to dynamically encode the time- varying, decision-dependent traffic patterns of LLM training into the optimization space via a computation-communication D A G. Building upon this DA G, we formulate an MILP model structured around v ariable-length time intervals to efficiently solve this logical topology optimization problem. B1S1 B1S1 B1S2 B2S1 B1S2 B2S1 B1S3 B2S2 B3S1 B1S3 B2S2 B3S1 B1S4 B2S3 B3S2 B4S1 B2S3 B3S2 B4S1 B1S4 B1S4 B2S4 B1S3 B1S3 B3S3 B2S4 B2S4 B3S3 B1S2 B3S4 B1S2 B4S2 B2S3 B2S3 B4S2 B1S1 B4S3 B3S4 B3S4 B4S3 B2S2 B4S4 B2S2 B3S3 B3S3 B2S1 B4S4 B4S4 B0S4 B3S2 B3S2 B4S3 B4S3 B0S3 B3S1 B4S2 B4S2 B0S2 B4S1 B0S1 Comp. Forward Comp. Backward PP Comm. Forward PP Comm. Backward DP Comm. Wait Activation for Comm. Wait Activation for Comp. Wait Loss for Backward Processs Next Batch Release Resource Ready for Sync. Gradient (a) Complete computation-communication D AG of an LLM training iteration. B1S2 B2S2 B3S2 B1S3 B2S3 B4S2 B3S3 B0S4 B4S3 B0S3 B0S2 B0S1 Start / =7.5 / =43.3 / =7.5 / =34.5 / =57.4 / =48.6 / =48.6 / =71.6 / =21.6 / =21.6 / =21.6 / =21.6 / =30.4 / =43.3 / =20.3 / =0.0 / =14.2 / =27.0 / =16.3 Virtual Start PP Comm. Forward PP Comm. Backward DP Comm. Virtual Start Dependency Wait Loss for Backward Processs Next Batch Release Resource Ready for Sync. Gradient (b) Reduced inter-pod communication D A G with intra-pod tasks merged into directed edges representing rigid intervals δ (ms). Fig. 3: Complete computation-communication D A G and reduced inter-pod communication D A G of an LLM training iteration (setup identical to Fig. 1, but with 4 micro-batches). Node label “B b S s ” indicates the processing of micro-batch b at stage s . JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 5 A. Encoding LLM T raining T raffic Dynamics via the Computation-Communication DA G Fig. 3a illustrates the D A G corresponding to the LLM training iteration shown in Fig. 1a. For clarity , the micro- batch size is reset to 4, and each pair of synchronously ex ecuted PP send and receive tasks is consolidated into a single node. In this DA G, each computation or communica- tion task is represented as a node with a specific execution duration, and the directed edges enforce strict causal depen- dencies between tasks. Specifically , these dependencies fall into three categories: (1) data dependencies dictated by the computational graph of the LLM itself ( W ait Activation/Loss for Comm./Comp./Backwar d ); (2) scheduling dependencies gov erned by the micro-batch scheduling mechanism in PP ( GPU Pr ocess Next Batch and Release GPU Resource ); and (3) gradient dependencies induced by waiting for the backward pass of the final micro-batch to complete before gradient synchronization ( Ready for Sync. Gradient ). Crucially , once the model architecture and parallelization strategy are defined, this topology-agnostic D A G is determined. The cornerstone of our approach is encoding the time- varying traffic patterns via this computation-communication D A G. Specifically , we formulate the execution of a training iteration as a precedence-constrained scheduling problem to minimize the overall iteration makespan C . This makespan is strictly defined by the length of the critical path: C = X m ∈E crit τ m , (1) where E crit denotes the critical path of the DA G, and τ m represents the duration of individual tasks. Within this formu- lation, we treat the start and completion times of each task as decision variables bounded by the DA G’ s edges. The topology decisions dictate the bandwidth, which in turn determines the duration of individual tasks ( τ m ). Constrained by the causal dependencies defined by the DA G, any change in a task’ s duration cascades to its successors, thereby shifting the ov erall temporal distribution of traffic. By nativ ely encoding this topology-traffic coupling into the decision space via this D A G, our formulation intrinsically captures the decision- dependent communication demands (addressing C2 ), while simultaneously ensuring that minimizing the objective directly targets the exact communication bottlenecks governing the iteration makespan (addressing C1 ). Notably , in the logical topology optimization problem for OCS–AIDC, the design decisions affect only the durations of inter-pod communication tasks. Therefore, explicitly mod- eling intra-pod computation or communication tasks—whose ex ecution times are independent of the inter-pod topology—is redundant. T o reduce complexity , we perform graph reduction on Fig. 3a, yielding the reduced D A G shown in Fig. 3b. Specifically , for any two inter-pod communication tasks m pre and m that are separated solely by intra-pod tasks in the original D A G, the intermediate intra-pod tasks are equiv alently replaced by a weighted directed edge (we introduce a virtual inter-pod communication task occurring at t = 0 to handle the intra-pod tasks preceding the first inter -pod communication task in the same manner). The weight of this edge, denoted by δ m pre → m , equals the sum of the ex ecution times of these intra-pod tasks. Accordingly , C can be reformulated as: C = X m ∈E inter-pod crit τ m + X m pre ,m ∈ E inter-pod crit δ m pre → m , (2) where E inter-pod crit denotes the inter-pod tasks on E crit . Eq. (2) provides a reduced-complexity model for LLM training itera- tion time, which will be incorporated into the mathematical formulation of the topology optimization problem in the subsequent section. B. MILP F ormulation with V ariable-Length T ime Interval for Logical T opology Optimization Con ventional network optimization literature [39, 50 – 55] typically relies on fixed-time-step formulations to capture the bandwidth reallocation and rate variations induced by the dynamic arriv al and completion of communication tasks. Howe ver , this approach imposes a trade-off between temporal precision and computational efficienc y: coarse-grained dis- cretization obscures transient traffic variations, whereas fine- grained discretization inflates the decision space, rendering the model computationally intractable. Empirically , solving the fixed-time-step MILP (detailed in Appendix A) for small- scale workloads—where training iterations span only hundreds of milliseconds—still requires tens of hours at a 0.1-ms resolution, precluding its real-world application. T o overcome this computational bottleneck, we pioneer a variable-length time interval modeling approach inspired by the methodology of Discrete Event Simulation (DES), as illustrated in Fig. 4. In a DES paradigm, the system state—specifically , the task acti vation state ( y m,k ) and flo w rates (the ratio of data volume w m,k to interval duration ∆ k )—remains entirely static between state-transition ev ents, which in our context correspond to the initiation ( S m ) and completion ( C m ) of communication tasks. Therefore, instead of uniformly slicing the time horizon, we can derive the temporal discretization points ( t k ) solely from the occurrences of these ev ents, dynamically partitioning the timeline into a sequence of K variable-length intervals. 1 Lev eraging the stability within each of these K intervals allows a concise set of variables (e.g., y m,k , w m,k , and ∆ k ) to sufficiently characterize the entire temporal horizon, obviating the need to track the system at fixed, fine-grained time steps. This approach fundamentally decouples the problem size from temporal granularity , thereby av oiding the variable explosion inherent in high-resolution time slicing and significantly re- ducing the MILP solution space. The rigorous mathematical formulation is detailed below . Input Parameters: • P : The set of all Pods in the OCS-AIDC. 1 Theoretically , because each task contributes exactly two state-transition timestamps (initiation and completion), setting K ≤ 2 |M| − 1 (where M is the set of all tasks) guarantees capturing all state transitions. In practice, K is profiled from a baseline simulation and is typically much smaller , as synchronized tasks (e.g., equi valent communication tasks e xecuting concurrently within separate DP replicas in identical network en vironments) share identical event timestamps. JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 6 Fig. 4: Primary decision variables and their relationships within the variable-length time interval MILP formulation. • G : The set of all GPUs in the OCS-AIDC. • M : The set of inter-pod communication tasks in volv ed in a single training iteration. An element m ∈ M is defined by a 6-tuple m ≜ ( i m , j m , F m , V m , G src m , G dst m ) , representing the source Pod, destination Pod, number of concurrent flows (where communication between a pair of GPUs corresponds to one flow), data volume, source GPU set, and destination GPU set, respectiv ely . Notably , to reduce the problem scale, synchronous communication tasks triggered from multiple GPUs and sharing the identical source-destination Pod pair (e.g., PP/DP communication tasks from all GPUs within the same stage) are aggregated into a single communication task, with its flo w count accumulated accordingly . Note that O2 is exploited through the joint incorporation of F m and V m into the formulation, ensuring that resource allocation matches instantaneous flow concurrency rather than relying solely on data volume. • D : The set of temporal dependencies among communication tasks. The element ( m pre , m, δ m pre → m ) ∈ D indicates that the successor task m can only start after a rigid time interval of δ m pre → m following the completion of the predecessor task m pre . Note that incorporating the a priori knowledge of M and D exploits O1 for proactive topology engineering and O3 for DP flow-staggering-a ware topology optimization. • Φ src ( g ) , Φ dst ( g ) : The set of communication tasks originating from and destined for GPU g . • U p : The maximum number of av ailable OCS ports for the training job in Pod p , generally constrained to the number of allocated GPUs in that Pod for fairness purposes. • L i,j : The number of binary bits required to represent the maximum number of optical circuits between Pod i and Pod j , defined as ⌊ log 2 (min( U i , U j )) ⌋ + 1 . • B : The maximum network injection bandwidth of a single NIC, which is assumed to be identical to the bandwidth capacity of a single OCS port. • K : The maximum index of time interv als within the con- sidered time horizon. • M : A large positiv e constant. Unless otherwise specified, all indices i, j range over the set of P , g ranges over the set of G , k ranges over the set of { 1 , . . . , K } , and m belongs to the set of M . Decision V ariables: • x i,j : An integer v ariable denoting the number of optical circuits/ports allocated between Pod i and Pod j . • β i,j,b : A binary auxiliary variable that equals 1 if the b -th bit in the binary representation of x i,j is 1, and 0 otherwise. • t k : A continuous v ariable denoting the start time of the k -th time interval. • ∆ k : A continuous v ariable denoting the duration of the k -th time interval. • ρ i,j,b,k : A continuous auxiliary v ariable. If β i,j,b = 1 , this variable equals to ∆ k ; otherwise, it ev aluates to 0. • w m,k : A continuous variable indicating the data volume transmitted by task m during time interval k . Note that by formulating both w m,k and ∆ k as decision v ariables, the following MILP inherently exploits O4 to optimize the transmission rates of competing flo ws. • y m,k : A binary v ariable indicating whether task m is activ e during time interval k . • s f l ag m,k : A binary auxiliary v ariable indicating whether task m is initiated at time interval k . • S m , C m : Continuous variables denoting the start time and completion time of task m , respectively . • C : A continuous variable denoting the iteration time of LLM training. • u i,j,k : A continuous auxiliary variable denoting the refer- ence per-flo w data transmission volume across the aggre- gated optical circuits between Pod i and Pod j during the k -th time interv al. It facilitates the fair distrib ution (optional) of bandwidth across all active tasks sharing this inter-pod connection. Objective: The primary optimization objectiv e is to minimize the iteration time of the training task: min C. (3) T o conserve optical port resources by eliminating redundant allocations on non-critical paths (exploiting O4 ), an optional lexicographic objecti ve is introduced to minimize the total allocated ports. Letting C ∗ denote the optimal makespan obtained in Eq. (3), this secondary objectiv e is defined as: min X i ∈P X j ∈P ,j = i x i,j , s.t. C ≤ C ∗ . (4) Constraints: 1) T opology-Related Constraints: ( P j ∈P ,j = i x i,j ≤ U i , ∀ i. P i ∈P ,i = j x i,j ≤ U j , ∀ j . (5) Eq. (5) ensures that the total number of outgoing and incoming logical connections for any Pod is constrained by its av ailable transmission ports U i and receiving ports U j , respectively . x i,j = x j,i , ∀ i, j. (6) Eq. (6) ensures that every directed logical link is accompanied by a reciprocal circuit, satisfying the bidirectional connectivity required for practical network operation [28]. x i,j = L i,j − 1 X b =0 2 b · β i,j,b , ∀ i, j. (7) JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 7 Eq. (7) expands x i,j into its binary representation to facilitate the subsequent linearization of the bilinear term x i,j · ∆ k . Specifically , we adopt binary rather than unary expansion to reduce the dimensionality of b from U p down to log 2 U p . 2) Optical Circuit and NIC Capacity-Related Constraints: ρ i,j,b,k ≤ M · β i,j,b , ρ i,j,b,k ≤ ∆ k , ρ i,j,b,k ≥ ∆ k − M · (1 − β i,j,b ) , ∀ i, j, ∀ k , ∀ b ∈ { 0 , . . . , L i,j − 1 } . (8) Eq. (8) employs the Big-M method [56] to linearize the bilinear term β i,j,b · ∆ k . Specifically , the formulation con- strains ρ i,j,b,k to equal ∆ k when β i,j,b = 1 , and enforces ρ i,j,b,k = 0 when β i,j,b = 0 , thereby ensuring the equiv alence ρ i,j,b,k = β i,j,b · ∆ k . X m ∈M ( i,j ) w m,k ≤ B · L i,j − 1 X b =0 (2 b · ρ i,j,b,k ) , ∀ k , ∀ i, j. (9) Eq. (9) bounds the aggregated traffic rate in ∆ k by the total bandwidth of the allocated optical circuits from Pod i to Pod j . Here, M ( i,j ) denotes the set of tasks originating from Pod i and destined for Pod j . Note that the term P L i,j − 1 b =0 (2 b · ρ i,j,b,k ) is introduced to represent the binary expansion and linearization of the bilinear term x i,j · ∆ k . ( P m ∈ Φ src ( g ) w m,k F m ≤ B · ∆ k , ∀ k , ∀ g . P m ∈ Φ dst ( g ) w m,k F m ≤ B · ∆ k , ∀ k , ∀ g . (10) Eq. (10) ensures that the aggregated injection and reception data volume of each GPU during interval k must not ex- ceed the maximum data theoretically transferable by the NIC bandwidth B . This constraint assumes a one-to-one mapping between GPUs and NICs, regulating both the outgoing tasks in Φ src ( g ) and the incoming tasks in Φ dst ( g ) . 3) Data Conservation and T ask Activation Constraints: K X k =1 w m,k = V m , ∀ m. (11) Eq. (11) guarantees that the sum of the data transmitted by a task m across all time intervals exactly equals its predefined total data volume, V m . w m,k ≤ V m · y m,k , ∀ m, k . (12) Eq. (12) restricts a task to transmit data strictly during the time intervals in which it is active (i.e., y m,k = 1 ). If a task is inactiv e ( y m,k = 0 ), its transmission v olume w m,k is forcefully constrained to 0. ( s f lag m,k ≥ y m,k − y m,k − 1 , ∀ m, k ( setting y m, 0 = 0) . P K k =1 s f lag m,k = 1 , ∀ m. (13) Eq. (13) introduces s f l ag m,k to identify the activ ation e vent (rising edge) of task m . By limiting the total number of such ev ents to one, the constraint prev ents task suspension, ensuring that each task occupies a single, contiguous time block. 4) T emporal Boundary and Mapping Constraints: ∆ k = t k +1 − t k , ∀ k . (14) Eq. (14) defines the duration of the k -th time interval, ∆ k , as the difference between adjacent temporal points. ( S m ≤ t k + M · (1 − y m,k ) , ∀ m, k . C m ≥ t k +1 − M · (1 − y m,k ) , ∀ m, k . (15) Eq. (15) defines the temporal boundaries of task m based on its activ e intervals. By utilizing the Big-M method, it ensures that the interval [ S m , C m ] encompasses all time slots ∆ k where the task is scheduled to transmit ( y m,k = 1 ). 5) Inter-P od Communication D A G Constraints: S m ≥ C m pre + δ m pre → m , ∀ ( m pre , m, δ m pre → m ) ∈ D . (16) Eq. (16) guarantees that the execution order strictly adheres to the reduced inter-pod communication DA G. Specifically , it ensures that any subsequent task m is initiated only after the completion of its predecessor m pre and the subsequent elapse of the time interval δ m pre → m . 6) Flow F airness Constraints (Optional for Comparison): ( w m,k F m − u i,j,k ≤ M · (1 − y m,k ) , u i,j,k − w m,k F m ≤ M · (1 − y m,k ) , ∀ i, j, ∀ m ∈ M ( i,j ) , ∀ k . (17) Eq. (17) is an optional constraint that simulates con ventional fair -sharing mechanisms by compelling concurrently active tasks ( y m,k = 1 ) tra versing the same inter -pod connection to transmit an equal volume of data per flow ( u i,j,k ). It is introduced as a comparativ e baseline to quantify the perfor- mance gains of the optimized rate control strategy against the con ventional fair-sharing policy . 7) Objective Function Constraint: C ≥ C m , ∀ m. (18) Eq. (18) defines the LLM training iteration time C as the upper bound of all individual task completion times C m . Note that, rather than explicitly modeling C using the critical-path-based formulation in Eq. (2), Eq. (18) relies on the linear temporal constraints deriv ed from the DA G D (Eq. (16)) to express C in an MILP-tractable format. I V . A C C E L E R A T I O N O F M I L P S O LV I N G A N D D E S I G N O F H E U R I S T I C A L G O R I T H M S Despite the substantial simplification achieved through the reduced inter-pod communication DA G and variable-length time interv al modeling, directly solving the proposed MILP re- mains computationally intractable for LLM training workloads spanning multiple Pods and thousands of GPUs. T o overcome this, this section introduces a dual-track acceleration approach. First, we incorporate domain-specific strategies to reduce the MILP scale. In parallel, we dev elop a fast heuristic search al- gorithm for efficient hot-starting. Collectiv ely , these strategies guarantee rapid conv ergence to a high-quality solution within minutes, even at the thousand-GPU scale. JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 8 A. Strate gies for Accelerating MILP Solving The scale of the MILP is primarily governed by the task- time decision v ariables ( w m,k , y m,k , and s f lag m,k ), which exhibit a quadratic growth of O ( |M| 2 ) since the interval count K scales linearly with the task count |M| . In contrast, the scale of the topology and capacity v ariables ( x i,j , β i,j,b , ρ i,j,b,k , and u i,j,k ) is constrained. While the number of pos- sible pairs ( i, j ) is theoretically bounded by the square of the Pod count ( |P | 2 ), the sparsity of LLM communication pairs substantially reduces the actual number of instantiated spatial variables. Coupled with the logarithmic bound of the binary expansion index b , the total number of these variables scales at most linearly with the interv al count K (i.e., O ( |M| ) ). Consequently , the y constitute a negligible fraction of the model size. Therefore, our acceleration strategies specifically target the O ( |M| 2 ) variable explosion induced by the task- time variables. 1) Reducing T otal T ask Count by Isomorphism and Inde- pendence of DP Replicas: W e first project the multi-replica optimization problem onto a single-replica domain by lev eraging the isomorphism and independence of DP replicas to mitigate the O ( |M| 2 ) complexity associated with task-time v ariables. Specifically , when different DP replicas are deployed in identical network en vironments, their communication tasks are theoretically syn- chronized. By formulating the MILP for a single reference replica and mapping the resulting topology configurations and schedules across the others, the global task count |M| can be reduced to the scale of a single replica. Conv ersely , when DP replicas span heterogeneous networks, we exploit the decoupled nature of their ex ecution. Aside from parameter synchronization tasks, the operations within each replica are independent of the others. This allo ws the global optimization to be decomposed into parallel single-replica sub-problems. T o satisfy the DP synchronization barrier , the schedule of the bottleneck replica—which initiates the synchronization phase last—is established as the global temporal baseline to align the DP communication across all replicas. Ultimately , regardless of the deployment scenario, this methodology guarantees solution v alidity and global iteration time optimality while successfully reducing the dimensionality of task-time decision variables from a O ( |M| 2 ) complexity to a single-replica- related O ( |M single-replica | 2 ) scale. 2) Reducing searc h space by T ask-T ime Domain Pruning: T o further reduce computational complexity , we prune the search space of task-time related decision variables (i.e., w m,k , y m,k , and s f l ag m,k ). As illustrated by Fig. 5a, within the model and parallel configuration defined in Fig. 1a, each inter - pod communication task for each DP replica occupies only a small fraction of the total time intervals in practice. 2 Giv en these observations, it is reasonable to infer that the optimal solution of this MILP will exhibit a sparse structure for y m,k and its associated variables w m,k , s f l ag m,k . 2 It should be noted that because some inter-pod communication tasks overlap in time (as shown in Fig. 1a, e.g., the forward PP communications for micro-batches 4, 5, 6, 7, 8 on Stage 2 and Stage 3 completely overlap with the backward PP communications for micro-batches 2, 3, 4, 5, 6), the total number of time intervals K is less than 2 |M single-replica | − 1 . 10 20 30 40 50 60 70 Time Interval Index k 10 20 30 40 50 60 Task Index m Active Interval (a) Activ e intervals of tasks under a baseline network in practice. 10 20 30 40 50 60 70 Time Interval Index k 10 20 30 40 50 60 Task Index m Retained Interval Feasible Interval Infeasible Interval (b) Retained intervals refined by D A G and anchor-guided pruning. Fig. 5: search space reduction for MILP via index pruning (LLM training setup as in Fig. 1, but with 32 micro-batches). Specifically , the temporal dependencies defined by the set D impose strict boundaries on the feasible active intervals for communication tasks. Dictated by these dependencies, a task cannot be acti vated too early , as this would inevitably force its predecessors into inv alid time intervals (i.e., interval indices < 1 ). Conv ersely , giv en a total interval count K , a task cannot remain acti ve too late without pushing its subsequent tasks into in valid time intervals (i.e., indices > K ) (provided the assigned K accommodates the theoretical optimal solu- tion, pruning these states preserv es optimality). Lev eraging this property , we apply a topological sorting algorithm to D —computing the longest paths from the global source and sink nodes of the D A G to each task—to determine the earliest and latest allo wable interval indices for ev ery task. Conse- quently , the corresponding decision variables ( w m,k , y m,k , and s f lag m,k ) can be strictly constrained to 0 outside this feasible temporal window , thereby substantially reducing the search space. The pruning effect of this strategy on the m − k search space is illustrated by the light green regions in Fig. 5b. While the preceding topological sorting establishes bound- aries based on whole-graph-wide longest paths, relying solely on it yields overly conservati ve search spaces (detailed in Appendix B). From a local-task-centric perspectiv e, as ob- served from Fig. 3b and Fig. 5a, the dependencies in D strictly constrain the ex ecution of intermediate tasks: a task m cannot ov erlap with the state transitions of its prede- cessors or successors. Driv en by this strict causal ordering, an intermediate task typically monopolizes a complete time interval, leaving minimal room for shifts within the discrete interval sequence and rendering its activ e index range highly deterministic. Consequently , a lightweight baseline simula- tion (Fig. 5a) can approximate this range. Exploiting this predictability , we extract index bounds [ ˜ k start m , ˜ k end m ] for each intermediate task m from the profiling results (to accom- modate potential index encroachments among tasks sharing identical topological orders, we introduce a slight redundancy margin when calculating [ ˜ k start m , ˜ k end m ] ). By integrating these anchoring bounds with longest-path-deriv ed boundaries, we tightly confine the allowable acti ve indices, further pruning the m − k search space as illustrated by the dark green regions in Fig. 5b. The complete algorithm workflo w is presented in Alg. 1. Since most tasks are intermediate tasks (Fig. 3b), bounding their indices significantly tightens the entire MILP JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 9 scale. Through a cascade effect, this tightening further prunes the indices of DP tasks. Ultimately , the combined restriction on both intermediate and DP tasks reduces the scale of task- time decision variables from O ( |M| 2 ) to O ( |M| ) . Collectiv ely , by synergistically applying the aforementioned task reduction and search space pruning strategies, we guar- antee rapid con ver gence to a high-quality solution within minutes, even at the thousand-GPU scale. Algorithm 1 T askTimeInde xPruning Input: M , D , K , anchors ˜ k start m and ˜ k end m . Let M succ ≜ { m ∈ M | ∃ ( u, v , δ ) ∈ D } denote the subset of tasks that have successor tasks. Output: Pruned upper bounds U B ( · ) for decision v ariables. ▷ Step 1: Initialization & Anchoring 1: f or each m ∈ M do k min m ← 1 , k max m ← K 2: f or each m ∈ M succ do k min m ← ˜ k start m , k max m ← ˜ k end m 3: Compute in-degree deg in ( m ) and out-degree deg out ( m ) based on D . ▷ Step 2: F orward Bounds Propagation (Earliest Start) 4: Q ← { m ∈ M | deg in ( m ) = 0 } 5: while Q = ∅ do 6: u ← Q . pop () 7: for each ( u, v , δ ) ∈ D do 8: k min v ← max k min v , k min u + ( δ > 0 ? 2 : 1) 9: deg in ( v ) ← deg in ( v ) − 1 ; if deg in ( v ) == 0 then Q . push ( v ) 10: end for 11: end while ▷ Step 3: Backward Bounds Propagation (Latest End) 12: Q ← { m ∈ M | deg out ( m ) = 0 } 13: while Q = ∅ do 14: v ← Q . pop () 15: for each ( u, v , δ ) ∈ D do 16: k max u ← min k max u , k max v − ( δ > 0 ? 2 : 1) 17: deg out ( u ) ← deg out ( u ) − 1 ; if deg out ( u ) == 0 then Q . push ( u ) 18: end for 19: end while ▷ Step 4: V ariable Domain Pruning 20: f or each m ∈ M do 21: K in valid ← { 1 , . . . , k min m − 1 } ∪ { k max m + 1 , . . . , K } 22: for each k ∈ K in valid do U B ( y m,k ) , U B ( w m,k ) , U B ( s f lag m,k ) ← 0 23: end for 24: r eturn U B ( · ) B. Simulation-Based Heuristic Sear ch Algorithm Although the accelerated MILP in Section IV -A efficiently achiev es joint topology and flow-rate optimization, broader scenarios—like GPU-resource allocation co-optimization in multi-tenant clusters—demand frequent in vocations of the topology optimizer . T o this end, we propose a fast, simulation- based heuristic search algorithm (DEL T A-Fast). The key idea is to decouple the search space by offloading the constraint- solving process of the cumbersome task-time dimensions (i.e., y m,k , w m,k , and ∆ k ) to a lightweight DES engine, thereby av oiding computationally expensi ve joint searches across all variables. Specifically , an outer-loop genetic algorithm opti- mizes the logical topology ( x i,j ), while an inner-loop DES chronologically simulates tasks based on D A G dependencies. Through a single simulation pass, it implicitly determines valid values for these temporal and task-state variables, naturally satisfying all constraints. Although this decoupling sacrifices the dynamic joint optimization of flow rates (degenerating to a fair-sharing mechanism), it effecti vely mitigates compu- tational complexity , enabling the rapid generation of high- quality topology candidates for upper-le vel co-optimization framew orks. Furthermore, since the DES ex ecution trace is isomorphic to the MILP’ s event-dri ven formulation, the sim- ulated results seamlessly map to an initial feasible solution, providing an efficient hot-start for the MILP . T o further accel- erate the search process, we design DEL T A-Fast around two core components: a D AG-a ware search space pruning strategy and a domain-adapted genetic algorithm. 1) DA G-A war e sear ch space Pruning: T o prune the topology search space, we eliminate redundant capacity allocations by jointly exploiting physical and logical constraints. Physically , NIC-bound GPU data injection limits render any optical circuits ( x ij ) exceeding the maximum con- current inter-Pod flows redundant (exploiting O2 ). Logically , the DA G D explicitly prohibits temporally dependent inter- Pod tasks from executing concurrently . Moti vated by these observations, we propose Alg. 2 to estimate the maximum concurrent communication pairs per inter -pod connection to establish an upper bound for x ij : First, similar to Alg. 1, we use D and a coarse estimated iteration time upper bound ˆ T up to deriv e the earliest start time (EST m ) and latest completion time (LCT m ) for each task m (Line 2, detailed in Alg. 4 in Appendix C). Next, computing the transiti ve closure R of D identifies all dependency-linked, mutually exclusi ve task pairs (Line 3). Subsequently , for each inter-pod connection ( u, v ) , we merge and sort the temporal boundaries (EST and LCT) of all associated tasks into a discrete interval sequence T (Lines 5-6). Scanning each interv al, the algorithm extracts activ e tasks A to construct a conflict graph G , where tasks act as vertices, flo w counts as vertex weights, and mutual exclusi vity relations as edges (Lines 8-12). Since mutually exclusi ve tasks cannot run in parallel, the maximum concurrent flow per interval equals the Maximum W eight Independent Set (MWIS) of G . Finally , the peak MWIS across all intervals defines the tight capacity upper bound ¯ X u,v (Lines 13-14), significantly compressing the topology search space. 2) Simulation-Based Domain-Adapted Genetic Algorithm: T o ef ficiently na vigate the constrained topology search space and accelerate con vergence, we de velop a domain-adapted genetic algorithm that integrates a fast DES engine driv en by the reduced D A G D for rapid iteration time ev aluation, alongside a topology repair mechanism utilizing the capacity upper bounds ¯ X to restore the physical feasibility of in valid offspring. As illustrated in Alg. 3, after initializing a popula- tion of feasible topologies strictly bounded by physical port JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 10 Algorithm 2 XUpperBoundEstimation Input: M , D , estimated iteration time upper bound ˆ T up . Output: Upper bound matrix ¯ X for x ij . ▷ Step 1: Initialization & Prepr ocessing 1: Initialize ¯ X as a zero matrix for all pod pairs 2: [ EST , LCT ] ← CalT askT imeWindo ws ( M , D , ˆ T up ) 3: R ← T ransitiv eClosure ( D ) ▷ via matrix squaring ▷ Step 2: Capacity Bound Computation 4: f or each inter-pod connection ( u, v ) do 5: M u,v ← { m ∈ M | task m traverses ( u, v ) } 6: T ← Sort Unique ( { EST m , LCT m | m ∈ M u,v } ) 7: for k ← 1 to | T | − 1 do 8: t mid ← ( T [ k ] + T [ k + 1]) / 2 9: A ← { m ∈ M u,v | EST m ≤ t mid < LCT m } 10: if A = ∅ then 11: ▷ Construct the conflict graph for MWIS 12: G ← Graph ( V ertices = A , W eights = F m ∈A , Edges = R| A ) 13: c max ← SolveMWIS ( G ) ▷ Solve MWIS 14: ¯ X u,v ← max( ¯ X u,v , c max ) 15: end if 16: end for 17: end for 18: r eturn ¯ X limits U and capacity bounds ¯ X (Line 1, detailed in Alg. 5 in Appendix D), iteration time (fitness) is ev aluated in parallel via the D AG-a ware DES (Line 2), where the total allocated optical circuits can serve as a secondary fitness. Notably , this DES ev aluation can also be accelerated by exploiting the isomorphism and independence of DP replicas to reduce the scale of the simulated task. Follo wing standard crossov er and mutation (Lines 7-8), the RepairT opo function (Alg. 6 in Appendix D) calibrates the child’ s optical circuits to restore compliance with U and ¯ X (Line 9). Unrepairable children are replaced by newly generated feasible configurations to maintain population diversity (Lines 10-11). The remaining steps follow a standard genetic algorithm framework to update the population and track the global optimal logical topology X ∗ . Collectively , Alg. 3 ensures an efficient con vergence tow ard optimal, physically deployable logical topologies. V . E V A L U A T I O N S In this section, we ev aluate the performance of the proposed D A G-aware efficient logical topology optimization algorithm and compare it to e xisting solutions. All ev aluations are conducted on a commodity computing platform equipped with an Intel i5-13500H (2.6 GHz) CPU and 32 GB of RAM. A. Evaluation Setup 1) W orkloads: W e e valuate the logical topology opti- mization problem across four representativ e LLM training workloads (Megatron-177B, Mixtral-8X22B (MoE model), Megatron-462B, Deepseek-671B (MoE model)), with the e val- uation configurations provided in T able I. The parallel strategy Algorithm 3 SimBasedDomainAdaptedGA Input: Acti ve pod pairs E , port capacities U = [ U 1 , ..., U |P | ] , upper bounds ¯ X , GA parameters ( N pop , N gen ), M , D Output: Logical topology X ∗ 1: X ← FeasibleRandomInit ( E , U, ¯ X ) N pop i =1 2: Fitness ← ParallelEv alDES ( X , M , D ) 3: X ∗ , C ∗ max ← GetBestIndividual ( X , Fitness ) 4: f or g en = 1 . . . N gen do 5: X new ← RetainElites ( X , Fitness ) 6: while |X new | < N pop do 7: p 1 , p 2 ← T ournamentSelection ( X , Fitness ) 8: child ← Mutate ( Crossov er ( p 1 , p 2 )) 9: child, success ← RepairT opo ( chil d, E , U, ¯ X ) 10: if not success then chil d ← FeasibleRandomInit ( E , U, ¯ X ) 11: X new ← X new ∪ { child } 12: end while 13: X ← X new ; Fitness ← ParallelEv alDES ( X , M , D ) 14: if min( Fitness ) < C ∗ max then 15: X ∗ , C ∗ max ← GetBestIndividual ( X , Fitness ) 16: end if 17: end for 18: r eturn X ∗ configurations for these models are derived from the Megatron benchmarks [57 – 59]. T o emulate practical scheduling strate- gies that increase the number of micro-batches to mitigate pipeline bubbles, the number of micro-batches processed per GPU per iteration is set to 8 times the PP size. The com- munication demand traces are generated via simAI [60, 61]. Furthermore, to simulate the fragmented model deployment typical of multi-tenant clusters, we limit the number of GPUs per Pod to 16 per DP replica for the two smaller models and 32 for the two larger models. Notably , allocating more GPUs per Pod per replica (i.e., # of GPUs / Pod / Replica) would localize more communication tasks within a single Pod, inadvertently simplifying the optimization problem. Therefore, we restrict this capacity to ensure sufficient inter-pod tasks, thereby rigorously ev aluating the proposed algorithm’ s perfor- mance. Specifically , we restrict inter-pod communication to PP and DP , as standard practice confines the latency-sensitiv e and bandwidth-intensi ve EP and TP to intra-pod electrical networks. Unless otherwise specified, the sequence length for LLM training is set to 4096, and inter-pod bandwidth is set to 400 Gb/s/GPU. For fairness, we assume that the maximum number of OCS ports ( U p ) exclusiv ely allocated to a training job in each Pod is strictly bounded by the number of GPUs assigned to that job within the Pod. 2) Algorithms for Comparison: Our ev aluation includes six optimization algorithms: DEL T A-Joint, DEL T A-T opo, DEL T A-Fast, and three traffic-matrix-based baselines: Prop- Alloc (derived from SiP-ML [43]), Sqrt-Alloc (a modified Prop-Alloc proposed in this work), and Iter -Halve (derived from T opoOpt [16]). Specifically , DEL T A-Joint and DEL T A- T opo construct the logical topology by solving the MILP formulated in Section III-B, with the former additionally JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 11 T ABLE I: Evaluation configurations for the four representativ e LLMs. Model Name TP PP ETP EP # of GPUs # of GPUs / Pod / Replica # of Micro-batches Megatron-177B 8 6 - - 384 16 48 Mixtral-8X22B 2 8 1 8 128 16 64 Megatron-462B 8 16 - - 1024 32 128 Deepseek-671B 2 16 1 8 256 32 128 co-optimizing the flow rates. DEL T A-Fast is the heuristic algorithm detailed in Alg. 3. Regarding the baselines, Prop- Alloc treats all traffic demands as concurrent; to minimize the maximum transmission time, it mathematically corresponds to allocating links proportionally to the traffic volume. Sqrt-Alloc assumes that traffic demands originating from the same Pod to different destinations occur strictly sequentially (analogous to DP and PP communication within the same stage); accord- ingly , to minimize total transmission time, it allocates links in proportion to the square root of the traffic volume. Iter- Halve iterati vely assigns a logical link to the communication pair with the highest weight—initially set by the traffic ma- trix—and subsequently halves that weight for the next round of allocation. Unless otherwise specified, the execution time for all algorithms is capped at 600s. The MILPs are solved using Gurobi 13.0. T o maximize computational efficiency , our proposed DEL T A suite employs four-thread parallelization. 3) P erformance Metric: W e adopt Normalized Commu- nication T ime (NCT) as the primary metric, defined as the ratio of the inter-pod communication time on the critical path under the OCS architecture to that under an ideal non-blocking electrical network with zero packet-processing delay . This normalization provides a standardized baseline for e valuating algorithms across div erse model architectures. Furthermore, focusing on the critical path captures the communication bottleneck that governs the actual iteration makespan. B. P erformance Comparison on V arying Inter-pod Bandwidths Fig. 6 illustrates the NCT of the six ev aluated algorithms under varying inter-pod bandwidth capacities. As inter-pod bandwidth increases, the communication-to-computation time ratio drops, shortening the relativ e duration of concurrent inter - pod communication for DP . This mitigates the communication degradation caused by allocating fewer logical links than the maximum number of concurrent flows, thereby reducing the NCT across all algorithms. While all algorithms benefit from this trend, the proposed D A G-driv en DEL T A suite consistently outperforms traffic-matrix-based baselines. Specifically , across the four ev aluated LLMs, DEL T A-Joint achiev es maximum NCT reductions of 11.5%, 13.7%, 10.7%, and 17.5% (at bandwidths of 800, 1600, 200, and 800 Gb/s, respectiv ely) compared to the best-performing baselines. Generally , in next- generation network infrastructures with higher inter-pod band- widths, the NCT reductions achieved by DEL T A over the baselines become more substantial. W ithin the DEL T A suite, DEL T A-Joint achiev es the lowest NCT , confirming that topology and flo w-rate co-optimization can further reduce the time in the critical path compared to topology-only methods. Across the four LLMs, it yields maximum NCT reductions of 11.5%, 10.6%, 10.7%, and 10.7% (at 800, 1600, 200, and 1600 Gb/s, respectiv ely) ov er the topology-only DEL T A. Moreover , DEL T A-Fast performs identically to DEL T A-T opo across all ev aluated scenarios, validating the efficac y of the heuristic DEL T A-Fast. Notably , DEL T A-Joint enables a static optical topology to achiev e performance close to that of an ideal, non-blocking electrical switch (NCT = 1), without incurring the overhead of reconfigurations. Specifically , at an inter-pod bandwidth of 1600 Gb/s, DEL T A-Joint reduces the performance gap to the theoretical ideal to 1.2%, 12.7%, 0%, and 0% across the four ev aluated LLMs, respectiv ely , demonstrating the power of D A G-aware joint optimization. W e also note that at band- widths of 400 Gb/s or below , communication performance under a static topology remains limited for workloads such as Megatron-177B, Mixtral-8X22B, and Deepseek-671B. Ho w- ev er , this bottleneck can be effecti vely mitigated by reallocat- ing surplus optical ports sav ed from other workloads (with- out compromising their original NCTs) to these bandwidth- bottlenecked workloads, as demonstrated in Section V -D. Fig. 7 illustrates how DEL T A-Joint approaches the perfor- mance of an ideal non-blocking electrical switch through its optimized flow-rate control strategy . As shown in the figure, when bandwidth contention is induced by concurrent com- munication from multiple stages, DEL T A-Joint ensures that 200 400 800 1600 Bandwidth (Gb/s) 1 1.2 1.4 Norm. Communication Time DELTA-Joint Prop-Alloc DELTA-Topo Sqrt-Alloc DELTA-Fast Iter-Halve (a) Megatron-177B. 200 400 800 1600 Bandwidth (Gb/s) 1 1.2 1.4 1.6 1.8 Norm. Communication Time DELTA-Joint Prop-Alloc DELTA-Topo Sqrt-Alloc DELTA-Fast Iter-Halve (b) Mixtral-8X22B. 200 400 800 1600 Bandwidth (Gb/s) 1 1.2 1.4 1.6 1.8 2 Norm. Communication Time DELTA-Joint Prop-Alloc DELTA-Topo Sqrt-Alloc DELTA-Fast Iter-Halve (c) Megatron-462B. 200 400 800 1600 Bandwidth (Gb/s) 1 1.2 1.4 1.6 1.8 2 Norm. Communication Time DELTA-Joint Prop-Alloc DELTA-Topo Sqrt-Alloc DELTA-Fast Iter-Halve (d) Deepseek-671B. Fig. 6: Performance of D A G-driv en vs. traffic-matrix-dri ven topology optimization under varying inter-pod bandwidths. JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 12 the critical flow (Stage 1), which dictates the global iteration makespan, continuously transmits at its physical upper bound of 200 GB/s (i.e., the aggreg ated injection bandwidth of 4 NICs). In contrast, the con ventional fair -sharing strategy employed by DEL T A-T opo causes this critical flow to experi- ence a 25% rate degradation (from 200 to 150 GB/s) during contention periods. Fig. 7: Flo w-rate control results of DP communication for Megatron-462B (400 Gb). For clarity , the time axis is zeroed at the moment Stage 4 initiates DP communication. This sustained peak transmission in DEL T A-Joint is achiev ed by exploiting the temporal slack of non-critical tasks. During contention periods, DEL T A-Joint actively compresses the transmission rates of earlier-initiated flows (Stages 2 to 4) that possess temporal slack and dynamically reallocates the released bandwidth to Stage 1. Consequently , this flo w-control strategy effecti vely pre vents local congestion from delaying the critical task. C. P erformance Comparison on V arying Sequence Lengths Beyond bandwidth, variations in model hyperparameters (e.g., sequence length) also reshape the communication band- width demands during LLM training. Consequently , we further in vestigate the performance of topology optimization algo- rithms on varying sequence lengths, as shown in Fig. 8. As the sequence length increases, the DEL T A suite not only consistently outperforms the baseline algorithms but also exhibits a more consistent downw ard trend in NCT . Specifically , across the four ev aluated LLMs, DEL T A-Joint achiev es maximum NCT reductions of 15.8%, 9.8%, 11.6%, and 18.1% (at sequence lengths of 8192, 4096, 2048, and 16384, respectiv ely) compared to the best-performing base- lines. Moreover , consistent with previous ev aluations, DEL T A- Fast retains its performance parity with DEL T A-T opo. Funda- mentally , an increase in sequence length triggers a twofold shift in the communication characteristics of LLM training: on the one hand, prolonged computation intervals (caused by the expanded sequence length) facilitate enhanced staggering of DP traffic, thereby creating better link time-multiplexing opportunities and mitigating concurrency bottlenecks; on the other hand, the concurrent “rectangular” bandwidth demands of PP scale proportionally with the sequence length. Leverag- ing the D AG-a ware design, the DEL T A suite more effecti vely navigates the dynamics of these superimposing effects. Furthermore, when ev aluated against an ideal non-blocking electrical network, DEL T A-Joint exhibits a performance gap of 11.9%, 44.8%, 2.3%, and 25.6% across the four models at a sequence length of 2048. As the sequence scales to 16384, this gap narrows to 4.2%, 30.7%, 0%, and 0%, respectiv ely . As the context window of large language models continues to expand, this performance disparity is projected to become increasingly marginal. D. Reduction of Optical P ort Consumption and P erformance Gains via P ort Reallocation T o enhance the performance of bandwidth-bottlenecked workloads, we minimize the total number of allocated optical ports by exploiting temporal slack in communication tasks along non-critical paths, thereby liberating port resources for reallocation. As illustrated in Fig. 9, this optimization reduces the allocated port ratio to below 80% (except for DEL T A- Joint on Deepseek-671B at 81.3%) without prolonging the LLM training iteration time. The port reduction is most pronounced for the Megatron-462B model, which features a higher computation-to-communication ratio in its training; in this scenario, DEL T A-T opo and DEL T A-Joint further compress the port ratios to 68.8% and 60.9%, respectiv ely . Fig. 10 illustrates the reduced NCTs achieved by reallocat- ing these recov ered surplus ports to bandwidth-bottlenecked workloads. Specifically , Model T is ev aluated by deploying it with a rev ersed stage-to-Pod mapping relativ e to the original 2048 4096 8192 16384 Sequence Length 1 1.2 1.4 1.6 1.8 Norm. Communication Time DELTA-Joint Prop-Alloc DELTA-Topo Sqrt-Alloc DELTA-Fast Iter-Halve (a) Megatron-177B. 2048 4096 8192 16384 Sequence Length 1 1.2 1.4 1.6 1.8 Norm. Communication Time DELTA-Joint Prop-Alloc DELTA-Topo Sqrt-Alloc DELTA-Fast Iter-Halve (b) Mixtral-8X22B. 2048 4096 8192 16384 Sequence Length 1 1.2 1.4 1.6 1.8 2 Norm. Communication Time DELTA-Joint Prop-Alloc DELTA-Topo Sqrt-Alloc DELTA-Fast Iter-Halve (c) Megatron-462B. 2048 4096 8192 16384 Sequence Length 1 1.2 1.4 1.6 1.8 2 Norm. Communication Time DELTA-Joint Prop-Alloc DELTA-Topo Sqrt-Alloc DELTA-Fast Iter-Halve (d) Deepseek-671B. Fig. 8: Performance of D A G-driv en vs. traffic-matrix-dri ven topology optimization under varying sequence lengths. JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 13 Megatron-177B Mixtral-8X22B Megatron-462B Deepseek-671B Model 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% Allocated Port Ratio DELTA-Joint DELTA-Topo DELTA-Fast Fig. 9: Allocated port ratio compressed by DEL T A variants (400 Gb/s, 4096 sequence length). Model to absorb its released ports (serving as a controlled ev aluation scheme to isolate performance gains from broader multi-tenant co-scheduling complexities that lie beyond the scope of this work). Benchmarked against an ideal non- blocking electrical switch operating at 400 Gb/s with a se- quence length of 4096, this reallocation strategy significantly narrows the performance gaps for bandwidth-bottlenecked workloads. Specifically , the NCT ov erheads for Megatron- 177B, Mixtral-8x22B, and Deepseek-671B are substantially reduced from 11.0% to 2.2%, 46.5% to 20.4%, and 24.3% to 2.8%, respectively . This degree of optimization is unattainable for con ventional algorithms that construct the logical topology based solely on traffic matrices. Moreover , it highlights a promising strategy for multi-tenant AIDCs: when coupled with an appropriate job placement strategy , compressing the port allocation of bandwidth-insensitive workloads (e.g., Megatron-462B)—without inflating their iteration times—can be lev eraged to provision bandwidth-bottlenecked workloads, thereby enabling otherwise severely constrained workloads to approach the performance of ideal non-blocking electrical networks. Notably , for Megatron-177B and Mixtral-8x22B, DEL T A-Joint yields a slightly higher NCT than DEL T A-T opo because it releases fewer ports to preserve its original optimal performance; we leav e the in vestigation of these complex trade-offs to future work. NCT=1 Megatron-177B T Mixtral-8X22B T Megatron-462B T Deepseek-671B T Model 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 Norm. Communication Time DELTA-Joint DELTA-Topo DELTA-Fast Reduction Fig. 10: Reduced NCTs of bandwidth-bottlenecked workloads by reallocating surplus ports (400 Gb/s, 4096 sequence length). E. Execution T ime Analysis As detailed in Section IV -A, the algorithm’ s computational complexity is dominated by the total number of inter-pod communication tasks, denoted as |M| . The scale of |M| depends on two parameters: the PP size, which dictates the number of stages and proportionally scales both PP and DP task counts; and the number of micro-batches (hereafter , # of MBS), which scales the number of PP tasks linearly 3 . Since the configured PP size in T able I already reaches the recommended upper bound in the literature [57 – 59], and further scaling PP size is limited by pipeline bubble overheads, this ev aluation isolates the impact of scaling the # of MBS on execution time. Fig. 11 presents the execution times (including preprocess- ing time) of DEL T A-Fast, DEL T A-T opo, DEL T A-Joint, and DEL T A-Joint-HotStart under a varying # of MBS when op- timizing topologies for Megatron-462B and Deepseek-671B. Notably , 512 is the maximum configuration reported in [58], whereas typical deployments adopt 128 or 256. Benefiting from the acceleration strate gies in Section IV -B, DEL T A-F ast’ s ex ecution time exhibits only marginal growth as the # of MBS increases. Across all ev aluations, it con verges to a stable state (where the optimal solution remains unchanged for 200 consecutiv e iterations) within tens of seconds. In contrast, the time required for DEL T A-T opo and DEL T A-Joint to conv erge to the final solution (defined as the point where, after stabiliza- tion, the objective gap between consecuti ve feasible solutions remains belo w 0.01%) increases significantly with the # of MBS. The maximum execution times for the two algorithms reach 896s and 928s for Megatron-462B, and 2020s and 1526s for Deepseek-671B, respectiv ely . Howe ver , with the strategies in Section IV -A, the solving process can complete within 600s for a # of MBS up to 256. Crucially , the hot-start mechanism in DEL T A-Joint-HotStart drastically reduces ov erall ex ecution time (DEL T A-T opo-HotStart is omitted since DEL T A-Fast al- ready yields a near-optimal solution). Specifically , hot starting reduces this time by an average of 50.4% (up to 69.6%) for Megatron-462B, and 72.7% (up to 89.5%) for Deepseek- 671B, bringing the maximum execution times of DEL T A- Joint-HotStart down to 358s and 637s for the two models, respectiv ely . Gi ven that these ev aluations were performed on a consumer-grade laptop, the results strongly demonstrate the computational efficiency of the proposed algorithms. V I . C O N C L U S I O N W e propose DEL T A, a computation-communication D A G- aware, efficient logical topology optimization framework for OCS-AIDCs. By encoding dynamic LLM training traffic fea- tures via D A G into the optimization model, alongside variable- length time interval MILP modeling, search space pruning, and heuristic acceleration, DEL T A generates a high-quality logical topology within minutes. Furthermore, by exploiting temporal slack on non-critical communication tasks, DEL T A can reallocate optical ports without compromising iteration time, effecti vely boosting bandwidth-bottlenecked workloads. 3 Specifically , under the 1F1B scheduling scheme, after aggregating the communication tasks that concurrently start and finish at each stage, the number of PP tasks per model replica is 2 × ( PP size − 1) × ( # of MBS ) , while the number of DP tasks equals the PP size. JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 14 128 256 384 512 Number of Micro-batches 0 200 400 600 800 1000 Execution Time (s) DELTA-Fast DELTA-Topo DELTA-Joint DELTA-Joint-HotStart (a) Megatron-462B. 128 256 384 512 Number of Micro-batches 0 300 600 900 1200 1500 1800 2100 Computation Time (s) DELTA-Fast DELTA-Topo DELTA-Joint DELTA-Joint-HotStart (b) Deepseek-671B. Fig. 11: Execution time of the algorithms in DEL T A. In multi-job scenarios, the disparate iteration cycles of vari- ous workloads cause their traf fic overlaps to shift continuously , making accurate traffic prediction difficult. Moreov er , since a single makespan objectiv e cannot balance cluster through- put and fairness, a pragmatic solution to this complexity is to independently optimize the topology for each job using DEL T A and aggregate these decisions via job-specific weights. Consequently , determining these weights to achieve data- center-le vel operational optimality constitutes a ke y direction for future research. V I I . A C K N O W L E D G E M E N T S This work was supported in part by the National Ke y Research and Development Project of China under Grant 2024YFB2908301 and in part by the National Natural Science Foundation of China (NSFC) under Grant 62331017. (Corre- sponding author: W eiqiang Sun.) R E F E R E N C E S [1] J. Kaplan, S. McCandlish, T . Henighan, T . B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. W u, and D. Amodei, Scaling Laws for Neural Language Models , 2020. arXiv: 2001.08361 [cs] . [2] J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T . Cai, E. Rutherford, D. d. L. Casas, L. A. Hendricks, J. W elbl, A. Clark, et al., T raining Compute-Optimal Lar ge Language Models , 2022. arXi v: 2203. 15556 [cs] . [3] Z. Zhang, C. Chang, H. Lin, Y . W ang, R. Arora, and X. Jin, “Is Network the Bottleneck of Distributed T raining?” In Proceedings of the W orkshop on Network Meets AI & ML , ser . NetAI ’20, New Y ork, NY , USA: Association for Computing Machinery, 2020, pp. 8–13. [4] E. Erdil and D. Schneider-Joseph, Data movement limits to fr ontier model training , 2024. arXiv: 2411.01137 [cs] . [5] A. Gholami, Z. Y ao, S. Kim, C. Hooper, M. W . Mahoney , and K. Keutzer, “AI and Memory W all, ” IEEE Micro , vol. 44, no. 3, pp. 33–39, 2024, I S S N : 1937-4143. [6] K. Benyahya, A. G. Diaz, J. Liu, V . L yutsarev , M. Pantouvaki, K. Shi, S. Y . Siew, H. Ballani, T . Burridge, D. Cletheroe, et al., “Mosaic: Breaking the Optics versus Copper Trade-of f with a Wide-and-Slo w Architecture and MicroLEDs, ” in Proceedings of the ACM SIGCOMM 2025 Conference , ser . SIGCOMM ’25, New Y ork, NY , USA: Associa- tion for Computing Machinery , 2025, pp. 234–247. [7] Y . W ei, T . Hu, C. Liang, and Y . Cui, “Communication Optimization for Distributed Training: Architecture, Advances, and Opportunities, ” IEEE Network , vol. 39, no. 3, pp. 241–248, 2025, I S S N : 1558-156X. [8] K. Qian, Y . Xi, J. Cao, J. Gao, Y . Xu, Y . Guan, B. Fu, X. Shi, F . Zhu, R. Miao, et al., “ Alibaba HPN: A Data Center Network for Large Language Model Training, ” in Proceedings of the ACM SIGCOMM 2024 Conference , ser . ACM SIGCOMM ’24, New Y ork, NY , USA: Association for Computing Machinery , 2024, pp. 691–706. [9] W . Tian, H. Hou, H. Dang, X. Cao, D. Li, S. Chen, and B. Ma, “Progress in Research on Co-Packaged Optics, ” Micr omachines , vol. 15, no. 10, p. 1211, 2024, I S S N : 2072-666X. [10] Brad Smith, A New Era in Data Center Networking with NVIDIA Silicon Photonics-based Network Switching , 2025. [11] Ashkan Seyedi, Scaling AI F actories with Co-P ackaged Optics for Better P ower Efficiency , 2025. [12] E. Ding, C. Ouyang, and R. Singh, “Photonic Rails in ML Datacenters, ” in Pr oceedings of the 24th A CM W orkshop on Hot T opics in Networks , ser . HotNets ’25, New Y ork, NY , USA: Association for Computing Machinery , 2025, pp. 149–159. [13] L. Poutievski, O. Mashayekhi, J. Ong, A. Singh, M. T ariq, R. W ang, J. Zhang, V . Beaure gard, P . Conner, S. Gribble, et al., “Jupiter evolving: T ransforming google’ s datacenter network via optical circuit switches and software-defined networking, ” in Proceedings of the ACM SIG- COMM 2022 Confer ence , ser . SIGCOMM ’22, New Y ork, NY , USA: Association for Computing Machinery , 2022, pp. 66–85. [14] R. Urata, H. Liu, K. Y asumura, E. Mao, J. Berger, X. Zhou, C. Lam, R. Bannon, D. Hutchinson, D. Nelson, et al., Mission Apollo: Landing Optical Cir cuit Switching at Datacenter Scale , 2022. arXiv: 2208.10041. [15] H. Liu, R. Urata, K. Y asumura, X. Zhou, R. Bannon, J. Ber ger, P . Dashti, N. Jouppi, C. Lam, S. Li, et al., “Lightwa ve Fabrics: At-Scale Optical Circuit Switching for Datacenter and Machine Learning Systems, ” in Pr oceedings of the ACM SIGCOMM 2023 Confer ence , New Y ork NY USA: ACM, 2023, pp. 499–515. [16] W . W ang, M. Khazraee, Z. Zhong, M. Ghobadi, Z. Jia, D. Mudigere, Y . Zhang, and A. Kewitsch, “T opoOpt: Co-optimizing Network T opology and Parallelization Strategy for Distributed Training Jobs, ” in 20th USENIX Symposium on Networked Systems Design and Implementation, NSDI 2023, Boston, MA, April 17-19, 2023 , M. Balakrishnan and M. Ghobadi, Eds., USENIX Association, 2023, pp. 739–767. arXiv: 2202.00433. [17] N. Jouppi, G. Kurian, S. Li, P . Ma, R. Nagarajan, L. Nai, N. Patil, S. Subramanian, A. Swing, B. T owles, et al., “TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings, ” in Proceedings of the 50th Annual Interna- tional Symposium on Computer Ar chitectur e , ser . ISCA ’23, Ne w Y ork, NY , USA: Association for Computing Machinery , 17, 2023, pp. 1–14. [18] Y . Zu, A. Ghaffarkhah, H.-V . Dang, B. T owles, S. Hand, S. Huda, A. Bello, A. Kolbaso v , A. Rezaei, D. Du, et al., “Resiliency at Scale: Managing Google’ s TPUv4 Machine Learning Supercomputer , ” in 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24) , 2024, pp. 761–774. [19] X. Liao, Y . Sun, H. Tian, X. W an, Y . Jin, Z. W ang, Z. Ren, X. Huang, W . Li, K. F . Tse, et al., “MixNet: A Runtime Reconfigurable Optical- Electrical Fabric for Distributed Mixture-of-Experts Training, ” in Pr o- ceedings of the ACM SIGCOMM 2025 Conference , ser . SIGCOMM ’25, New Y ork, NY , USA: Association for Computing Machinery , 2025, pp. 554–574. [20] J. Zerwas, W . K ellerer, and A. Blenk, “What Y ou Need to Know About Optical Circuit Reconfigurations in Datacenter Networks, ” in 2021 33th International T eletraffic Congr ess (ITC-33) , 2021, pp. 1–9. [21] M. Zhang, J. Zhang, R. W ang, R. Govindan, J. C. Mogul, and A. V ahdat, Gemini: Practical Reconfigurable Datacenter Networks with T opology and T raffic Engineering , 2021. arXiv: 2110.08374 [cs] . [22] Nvidia, B. Adler, N. Agarwal, A. Aithal, D. H. Anh, P . Bhattacharya, A. Brundyn, J. Casper, B. Catanzaro, S. Clay, et al., Nemotr on-4 340B T echnical Report , 2024. arXiv: 2406.11704 [cs] . [23] Z. Jiang, H. Lin, Y . Zhong, Q. Huang, Y . Chen, Z. Zhang, Y . Peng, X. Li, C. Xie, S. Nong, et al., “MegaScale: Scaling Large Language Model T raining to More Than 10,000 GPUs, ” in 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24) , 2024, pp. 745–760. [24] C. Jin, Z. Jiang, Z. Bai, Z. Zhong, J. Liu, X. Li, N. Zheng, X. W ang, C. Xie, Q. Huang, et al., MegaScale-MoE: Lar ge-Scale Communication- Efficient T raining of Mixtur e-of-Experts Models in Production , 2025. arXiv: 2505.11432 [cs] . [25] W . Feng, Y . Chen, S. W ang, Y . Peng, H. Lin, and M. Y u, “Opti- mus: Accelerating large-scale multi-modal LLM training by bubble exploitation, ” in Pr oceedings of the 2025 USENIX Conference on Usenix Annual T echnical Conference , ser . USENIX A TC ’25, USA: USENIX Association, 2025, pp. 161–177. [26] M. Liang, H. T . Kassa, W . Fu, B. Coutinho, L. Feng, and C. Delimitrou, “Lumos: Efficient performance modeling and estimation for lar ge-scale LLM training, ” in Proceedings of Machine Learning and Systems , M. Zaharia, G. Joshi, and Y . Lin, Eds., vol. 7, MLSys, 2025. [27] S. Zhao, P . Cao, and X. W ang, “Understanding the Performance Guarantee of Physical T opology Design for Optical Circuit Switched Data Centers, ” Pr oc. A CM Meas. Anal. Comput. Syst. , vol. 5, no. 3, 42:1–42:24, 2021. JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 15 [28] X. Han, Y . Lv, W . Jiang, S. Zhang, Y . Mao, S. Zhao, Z. Liu, Z. Liu, P . Cao, X. Liu, et al., A Highly Scalable LLM Clusters with Optical Inter connect , 2025. arXiv: 2411.01503 [cs] . [29] M. Y . T eh, S. Zhao, and K. Bergman, METTEOR: Robust Multi-T raffic T opology Engineering for Commercial Data Center Networks , 2020. arXiv: 2002.00473 [cs] . [30] P . Cao, S. Zhao, M. Y . The, Y . Liu, and X. W ang, “TR OD: Evolving From Electrical Data Center to Optical Data Center, ” in 2021 IEEE 29th International Conference on Network Protocols (ICNP) , 2021, pp. 1–11. [31] M. Y . T eh, S. Zhao, P . Cao, and K. Bergman, “Enabling Quasi- Static Reconfigurable Networks W ith Robust T opology Engineering, ” IEEE/ACM T ransactions on Networking , vol. 31, no. 3, pp. 1056–1070, 2023, I S S N : 1558-2566. [32] S. Zhao, R. W ang, J. Zhou, J. Ong, J. C. Mogul, and A. V ahdat, “Minimal Rewiring: Efficient Liv e Expansion for Clos Data Center Networks, ” in 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19) , 2019, pp. 221–234. [33] K. Hanauer, M. Henzinger, S. Schmid, and J. Trummer , “Fast and Heavy Disjoint W eighted Matchings for Demand-A ware Datacenter T opologies, ” in IEEE INFOCOM 2022 - IEEE Confer ence on Computer Communications , 2022, pp. 1649–1658. [34] K. Hanauer, M. Henzinger , L. Ost, and S. Schmid, “Dynamic Demand- A ware Link Scheduling for Reconfigurable Datacenters, ” in IEEE IN- FOCOM 2023 - IEEE Conference on Computer Communications , 2023, pp. 1–10. [35] J. W ang, G. Zhao, H. Xu, and H. W ang, “Leaf: Improving QoS for Reconfigurable Datacenters with Multiple Optical Circuit Switches, ” in 2024 IEEE/ACM 32nd International Symposium on Quality of Service (IWQoS) , 2024, pp. 1–10. [36] L. Liu, H. Y u, G. Sun, H. Zhou, Z. Li, and S. Luo, “Online job scheduling for distributed machine learning in optical circuit switch networks, ” Knowledge-Based Systems , vol. 201–202, p. 106 002, 2020, I S S N : 0950-7051. [37] C. W ang, N. Y oshikane, F . Balasis, and T . Tsuritani, “OSDL: Dedicated optical slice provisioning in support of distributed deep learning, ” Computer Networks , vol. 214, p. 109 191, 2022, I S S N : 1389-1286. [38] X. Dong, H. Y ang, Y . Zhang, X. Xie, and Z. Zhu, “On Scheduling DML Jobs in All-Optical DCNs with In-Network Computing, ” in GLOBECOM 2024 - 2024 IEEE Global Communications Confer ence , 2024, pp. 5090–5095. [39] X. Xie, B. T ang, X. Chen, and Z. Zhu, “P4INC-A OI: All-Optical Inter- connect Empowered by In-Network Computing for DML W orkloads, ” IEEE T ransactions on Networking , pp. 1–16, 2025, I S S N : 2998-4157. [40] L. Liu, X. Xu, P . Zhou, X. Chen, D. Ergu, H. Y u, G. Sun, and M. Guizani, “PSscheduler: A parameter synchronization scheduling algorithm for distributed machine learning in reconfigurable optical networks, ” Neur ocomputing , vol. 616, p. 128 876, 2025, I S S N : 0925- 2312. [41] C. Shou, G. Liu, H. Nie, H. Meng, Y . Zhou, Y . Jiang, W . Lv, Y . Xu, Y . Lu, Z. Chen, et al., “InfiniteHBD: Building Datacenter- Scale High-Bandwidth Domain for LLM with Optical Circuit Switching T ransceivers, ” in Pr oceedings of the ACM SIGCOMM 2025 Conference , ser . SIGCOMM ’25, New Y ork, NY , USA: Association for Computing Machinery , 2025, pp. 1–23. [42] V . Addanki, “When Light Bends to the Collective Will: A Theory and V ision for Adapti ve Photonic Scale-up Domains, ” in Proceedings of the 24th ACM W orkshop on Hot T opics in Networks , ser . HotNets ’25, Ne w Y ork, NY , USA: Association for Computing Machinery, 2025, pp. 326– 334. [43] M. Khani, M. Ghobadi, M. Alizadeh, Z. Zhu, M. Glick, K. Bergman, A. V ahdat, B. Klenk, and E. Ebrahimi, “SiP-ML: High-bandwidth optical network interconnects for machine learning training, ” in Pr oceedings of the 2021 ACM SIGCOMM 2021 Conference , ser . SIGCOMM ’21, Ne w Y ork, NY , USA: Association for Computing Machinery, 2021, pp. 657– 675. [44] S. H. Hashemi, S. Abdu Jyothi, and R. Campbell, “TicT ac: Accelerating Distributed Deep Learning with Communication Scheduling, ” Proceed- ings of Machine Learning and Systems , vol. 1, pp. 418–430, 2019. [45] A. Jayarajan, J. W ei, G. Gibson, A. Fedorova, and G. Pekhimenko, “Priority-based Parameter Propagation for Distributed DNN Training, ” Pr oceedings of Machine Learning and Systems , vol. 1, pp. 132–145, 2019. [46] Y . Peng, Y . Zhu, Y . Chen, Y . Bao, B. Yi, C. Lan, C. W u, and C. Guo, “A generic communication scheduler for distributed DNN training acceleration, ” in Proceedings of the 27th ACM Symposium on Operating Systems Principles , ser . SOSP ’19, New Y ork, NY , USA: Association for Computing Machinery , 2019, pp. 16–29. [47] Y . Bao, Y . Peng, Y . Chen, and C. Wu, “Preemptiv e All-reduce Schedul- ing for Expediting Distrib uted DNN T raining, ” in IEEE INFOCOM 2020 - IEEE Conference on Computer Communications , 2020, pp. 626–635. [48] F . Li, S. Zhao, Y . Qing, X. Chen, X. Guan, S. W ang, G. Zhang, and H. Cui, “Fold3D: Rethinking and Parallelizing Computational and Communicational T asks in the T raining of Large DNN Models, ” IEEE T ransactions on P arallel and Distributed Systems , vol. 34, no. 5, pp. 1432–1449, 2023, I S S N : 1558-2183. [49] S. Li, K. Lu, Z. Lai, W . Liu, K. Ge, and D. Li, “A Multidimensional Communication Scheduling Method for Hybrid Parallel DNN Training, ” IEEE T ransactions on P arallel and Distributed Systems , vol. 35, no. 8, pp. 1415–1428, 2024, I S S N : 1558-2183. [50] S. Kandula, I. Menache, R. Schwartz, and S. R. Babbula, “Calendaring for wide area networks, ” in Proceedings of the 2014 ACM Conference on SIGCOMM , ser . SIGCOMM ’14, New Y ork, NY , USA: Association for Computing Machinery, 2014, pp. 515–526. [51] S. H. Mohamed, A. Hammadi, T . E. H. El-Gorashi, and J. M. H. Elmirghani, Optimizing Co-flows Scheduling and Routing in Data Centre Networks for Big Data Applications , 2020. arXiv: 2008.03497 [cs] . [52] J. Li, W . Shi, N. Zhang, and X. Shen, “Delay-A ware VNF Scheduling: A Reinforcement Learning Approach With V ariable Action Set, ” IEEE T ransactions on Cognitive Communications and Networking , vol. 7, no. 1, pp. 304–318, 2021, I S S N : 2332-7731. [53] B. Fatemipour, W . Shi, and M. St-Hilaire, “A Cost-Ef fective and Multi- Source-A ware Replica Migration Approach for Geo-Distributed Data Centers, ” in 2022 IEEE Cloud Summit , 2022, pp. 17–22. [54] T . W ang, S. Chen, Y . Zhu, A. T ang, and X. W ang, “LinkSlice: Fine- Grained Network Slice Enforcement Based on Deep Reinforcement Learning, ” IEEE Journal on Selected Areas in Communications , vol. 40, no. 8, pp. 2378–2394, 2022, I S S N : 1558-0008. [55] N. Diaz and N. Gautam, “Non-Periodic T raffic Allocation in Time- A ware TSN Networks, ” IEEE Access , vol. 13, pp. 187 758–187 773, 2025, I S S N : 2169-3536. [56] L. A. W olsey, Integ er Pr ogramming . John W iley & Sons, 2020. [57] D. Liu, Z. Y an, X. Y ao, T . Liu, V . Korthikanti, E. W u, S. Fan, G. Deng, H. Bai, J. Chang, et al., MoE P arallel F olding: Heter ogeneous P arallelism Mappings for Efficient Larg e-Scale MoE Model Tr aining with Megatr on Core , 2025. arXiv: 2504.14960 [cs] . [58] NVIDIA Corporation, P erformance Summary — NeMo Me gatr on-Bridge 0.2.0 documentation , 2025. [59] NVIDIA Corporation, Megatr on-LM and Me gatr on Cor e , 2026. [60] X. Li, H. Zhou, Q. Li, S. Zhang, and G. Lu, “AICB: A benchmark for e valuating the communication subsystem of LLM training clusters, ” BenchCouncil T ransactions on Benc hmarks, Standards and Evaluations , vol. 5, no. 1, p. 100 212, 2025, I S S N : 27724859. [61] X. W ang, Q. Li, Y . Xu, G. Lu, D. Li, L. Chen, H. Zhou, L. Zheng, S. Zhang, Y . Zhu, et al., “SimAI: Unifying Architecture Design and Per- formance T uning for Large-Scale Large Language Model Training with Scalability and Precision, ” in 22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25) , 2025, pp. 541–558. A P P E N D I X A M I L P F O R M U L AT I O N W I T H F I X E D - T I M E - S T E P F O R L O G I C A L T O P O L O G Y O P T I M I Z A T I O N Serving as a comparativ e baseline for the variable-length time interval MILP formulation, this appendix details the fixed-time-step counterpart, which formulates the topology optimization problem by discretizing the time horizon into uniform slices. T emporal Discretization: The considered time horizon is partitioned into a set of fixed-duration time slices, indexed by T = { 1 , 2 , . . . , T } , where the integer T denotes the total number of slices and each slice has a constant length ∆ t . Decision V ariables: • r m,t : A continuous v ariable denoting the instantaneous transmission rate of task m during time slice t . • y m,t : A binary variable indicating whether task m is activ e during time slice t . JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 16 • S m,t , C m,t : Binary auxiliary variables indicating the initia- tion and completion of task m at time slice t . • u i,j,t : A continuous auxiliary variable denoting the normal- ized fair-share reference rate across the aggregated optical circuits between Pod i and Pod j during time slice t . It facilitates the fair distribution (optional) of aggregated bandwidth across all activ e tasks sharing this inter-pod connection. • x i,j : An integer v ariable denoting the number of optical circuits/ports allocated between Pod i and Pod j . Unless otherwise specified, all indices i, j range over the set of P , g ranges ov er the set of G , t ranges over the set of T , and m belongs to the set of M . Objectives: The primary optimization objectiv e is to minimize the iteration time of the training task: min C. (19) A secondary objective minimizes total optical port con- sumption without increasing the optimal makespan C ∗ : min X i ∈P X j ∈P ,j = i x i,j , s.t. C ≤ C ∗ . (20) Constraints: 1) T opology-Related Constraints: P j ∈P ,j = i x i,j ≤ U i , ∀ i. P i ∈P ,i = j x i,j ≤ U j , ∀ j . x i,j = x j,i , ∀ i, j. (21) Eq. (21) defines the physical port limits and bidirectional symmetry , following the same logic as the main text. 2) Optical Cir cuit and NIC Capacity-Related Constraints: X m ∈M ( i,j ) r m,t ≤ x ij · B , ∀ t, ∀ i, j . (22) ( P m ∈ Φ src ( g ) r m,t F m ≤ B , ∀ t, g . P m ∈ Φ dst ( g ) r m,t F m ≤ B , ∀ t, g . (23) Eq. (22) and (23) bound the aggregated rates by the allocated logical link bandwidth and individual NIC injection/reception capacities, respectively . 3) T ask Lifecycle and Data T ransmission Constraints: X t S m,t = 1 , X t C m,t = 1 , ∀ m. (24) y m,t − y m,t − 1 = S m,t − C m,t , ∀ m, t. (25) T X t =1 ( r m,t · ∆ t ) ≥ V m , ∀ m. (26) r m,t ≤ y m,t · ( F m · B ) , ∀ m, t. (27) Eq. (24) and (25) enforce unique initiation and completion points, maintaining state continuity throughout the lifecycle of each task. Eq. (26) guarantees that the cumulative data volume transmitted satisfies the predefined demand V m . Furthermore, Eq. (27) explicitly couples the continuous transmission rate with the binary state, ensuring that transmission only occurs during activ e intervals ( y m,t = 1 ) while respecting the flow- lev el physical bandwidth limits. 4) Inter-P od Communication D A G Constraints: X t ( t · S m,t ) ≥ X t ( t · C m pre ,t ) + δ m pre → m ∆ t , ∀ ( m pre , m, δ ) ∈ D . (28) Eq. (28) guarantees that task execution strictly adheres to the precedence requirements defined in the reduced D A G D . 5) Flow F airness Constraints (Optional for Comparison): − M (1 − y m,t ) ≤ r m,t F m − u i,j,t ≤ M (1 − y m,t ) , ∀ t, ( i, j ) , m ∈ M ( i,j ) . (29) Eq. (29) uses the Big-M method to simulate con ventional fair -sharing mechanisms by equalizing the normalized rates of concurrent flows on the same link. 6) Objective Function Constraint: C ≥ t · C m,t , ∀ m, t. (30) Eq. (30) defines the global completion time as the en velope of all individual task completion times. A P P E N D I X B L I M I TA T I O N S O F T O P O L O G Y - S O RT I N G - B A S E D S E A R C H S PAC E P RU N I N G Relying exclusi vely on topological sorting for search space pruning is conservati ve. First, when two tasks (e.g., the B3S2 PPFwd and B1S3 PPBwd nodes in Fig. 3b) share the same topological order on D but exhibit different time intervals δ relativ e to their predecessors, the task subject to a longer delay should logically be activ ated in a later time interv al. Howe ver , because its earliest active index remains identical to that of the earlier task, topological sorting yields lower -bound (left- side) index redundancy (as shown by the left boundary of the feasible region for the fourth task in Fig. 5b). Second, consider a task serving as a common predecessor across multiple dependency branches (e.g., the B4S3 PPBwd node in Fig. 3b, which is a prerequisite for three different DP communication tasks). If its multiple successors hav e varying startup interval requirements, this predecessor should logically complete earlier to accommodate their distinct activ e intervals. Y et, when determining its latest active index, topological sort- ing adopts the pessimistic assumption that all successors might start and stop simultaneously (i.e., collectively occupying only a single time interval). This oversimplification generates upper-bound (right-side) index redundancy (as demonstrated by the right boundary of the feasible region for the fourth-to- last task in Fig. 5b). A P P E N D I X C S U P P L E M E N T A RY A L G O R I T H M S F O R S E A R C H S PAC E P RU N I N G This appendix details the Alg. 4 (CalT askT imeW indows) utilized in Alg. 1. Alg. 4 computes the Earliest Start Time JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 17 (EST) and Latest Completion T ime (LCT) for each task m ∈ M . The algorithm operates in three steps. First, it initializes the minimum physical duration τ m based on the task data volume V m and per-flow bandwidth B (Line 2). Second, a forward propagation traversal over the reduced computation- communication D A G D calculates the EST for each task by respecting all rigid dependenc y interv als δ (Line 6-13). Finally , backward propagation starting from the coarsely estimated upper bound on the iteration time ˆ T up yields the LCT (Lines 14-21). The effect of Alg. 4 is illustrated in Fig. 12. Algorithm 4 CalT askTimeW indows Input: M , D , Bandwidth B , Time upper bound ˆ T up . Output: EST , LCT. ▷ Step 1: Initialization & Minimum Duration Estimation 1: f or each m ∈ M do 2: τ m ← V m / ( F m · B ) ▷ Minimum physical duration 3: EST m ← 0 , LCT m ← ˆ T up 4: Compute in-degree deg in ( m ) and out-degree deg out ( m ) based on D . 5: end for ▷ Step 2: F orward Propagation (Earliest Start Time) 6: Q ← { m ∈ M | deg in ( m ) = 0 } 7: while Q = ∅ do 8: u ← Q . pop () 9: for each dependency ( u, v , δ ) ∈ D do 10: EST v ← max( EST v , EST u + τ u + δ ) 11: deg in ( v ) ← deg in ( v ) − 1 ; if deg in ( v ) == 0 then Q . push ( v ) 12: end for 13: end while ▷ Step 3: Backward Propagation (Latest Completion Time) 14: Q ← { m ∈ M | deg out ( m ) = 0 } 15: while Q = ∅ do 16: v ← Q . pop () 17: for each dependency ( u, v , δ ) ∈ D do 18: LCT u ← min( LCT u , LCT v − τ v − δ ) 19: deg out ( u ) ← deg out ( u ) − 1 ; if deg out ( u ) == 0 then Q . push ( u ) 20: end for 21: end while 22: r eturn EST , LCT = { EST m , LCT m | m ∈ M} Note that Fig. 12 and Fig. 5b exhibit similarly compact profiles, suggesting that an analogous approach could be employed to prune the search space for fixed-time-step MILP formulation. Howe ver , in our empirical ev aluations, even with a relatively coarse time resolution of 0.1 ms (compared to the millisecond-lev el duration of a single PP communication) and similar search space pruning techniques, solving the fixed-time-step MILP corresponding to a slightly large-scale problem still required tens of hours. 0 100 200 300 400 500 600 700 800 Time (ms) 0 10 20 30 40 50 60 Task Index m Task Time Window [EST LCT] Fig. 12: D A G-aware task time window estimation for search space pruning (LLM training setup as in Fig. 5). A P P E N D I X D S U B R O U T I N E S F O R D O M A I N - A DA P T E D G E N E T I C A L G O R I T H M This appendix details the initialization and repair subrou- tines used in Alg. 3 of the domain-adapted genetic algorithm. Alg. 5 (FeasibleRandomInit) constructs a valid initial logical topology X that adheres to both the physical port capacities U and the upper bounds ¯ X . First, it initializes the current port usage and calculates the unprocessed degrees for all pods to anticipate future connecti vity requirements (Lines 1-2). Second, it iterativ ely processes each active pod pair e ∈ E to determine the maximum allowable capacity by reserving ports for remaining connections and bounding it with ¯ X e (Lines 3-10). Finally , it uniformly samples a valid link capacity x e within the calculated limits and updates the ph ysical port usage for the corresponding endpoints (Lines 11-15). Algorithm 5 FeasibleRandomInit Input: Acti ve pod pairs (edges) E , port capacities U = [ U 1 , ..., U |P | ] , upper bounds ¯ X Output: A feasible logical topology X 1: Initialize port usage U used p ← 0 for all p ∈ P ▷ Initialize unprocessed degrees for future lookahead 2: Let D p ← |{ e ∈ E | e connects to p }| for all p ∈ P 3: f or each edge e = ( u, v ) ∈ E do 4: ▷ Update future degrees (remaining ports after current e ) 5: D u ← D u − 1 ; D v ← D v − 1 6: ▷ Calculate remaining valid ports 7: R u ← U u − U used u ; R v ← U v − U used v 8: ▷ Reserve ports for future connectivity 9: R ′ u ← R u − D u ; R ′ v ← R v − D v 10: ▷ Determine maximum allowable capacity and bound it 11: limit ← min( R ′ u , R ′ v , ¯ X e ) 12: limit ← max(1 , limit ) ▷ Ensure basic connectivity 13: ▷ Sample capacity and update usage 14: x e ∼ U { 1 , l imit } 15: U used u ← U used u + x e ; U used v ← U used v + x e 16: end for 17: r eturn X = { x e | e ∈ E } JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2021 18 T o address inv alid offspring generated during crossover and mutation, Alg. 6 (RepairT opo) restores compliance with all physical and logical constraints. First, a base trimming process enforces the capacity upper bounds ¯ X e and ensures connectivity for each active pod pair (Lines 1-3). Second, a port ov erflow reduction mechanism identifies ov erloaded pods and randomly decrements the capacity of their reducible edges until the physical port limits are met or no reducible edges remain (Lines 4-15). Finally , a verification step checks whether all port constraints U p are globally satisfied, returning the repaired topology and a boolean success flag (Lines 16-20). Algorithm 6 RepairT opo Input: Mutant/Crossov er topology X ′ , active pod pairs E , port capacities U = [ U 1 , ..., U |P | ] , upper bounds ¯ X Output: Repaired topology X ′ , boolean flag success indicat- ing repair status ▷ Step 1: Base T rimming 1: f or each e ∈ E do 2: x ′ e ← max 1 , min( x ′ e , ¯ X e ) ▷ Enforce bounds & connectivity 3: end for ▷ Step 2: Port Overflow Reduction 4: Compute current port usage U used p for all p ∈ P 5: while ∃ p ∈ P such that U used p > U p do 6: Let P over be the set of ov erloaded pods 7: Randomly select a pod p ∈ P over 8: E p ← { e ∈ E | e connects to p and x ′ e > 1 } 9: if E p = ∅ then 10: break ▷ Repair failed: overloaded but no reducible edges 11: end if 12: Randomly select a reducible edge e ∈ E p 13: x ′ e ← x ′ e − 1 14: Update U used locally for the endpoints of e 15: end while ▷ Step 3: Final V erification 16: if all U used p ≤ U p for p ∈ P then 17: retur n X ′ , T rue 18: else 19: retur n X ′ , False 20: end if
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment