델타 DAG 인식 OCS 논리 토폴로지 최적화 프레임워크
본 논문은 대규모 언어 모델 학습 시 발생하는 시간‑가변 트래픽을 DAG 기반으로 정확히 모델링하고, 이를 MILP 형태로 변환하여 광회로 스위치(OCS) 논리 토폴로지를 최적화한다. 가변 길이 시간 구간과 비판적 작업의 여유시간 활용을 통해 포트 수를 20 % 이상 절감하면서도 반복 시간은 최대 17.5 % 단축한다.
저자: Niangen Ye, Jingya Liu, Weiqiang Sun
본 논문은 대규모 언어 모델(LLM) 학습 과정에서 발생하는 급격히 변동하는 통신 요구를 효과적으로 처리하기 위해, 광회로 스위치(OCS) 기반 AI 데이터센터(AIDC)에서 사용할 논리 토폴로지를 사전에 설계하는 새로운 프레임워크인 DELTA를 제안한다. 기존 연구들은 주로 트래픽 매트릭스를 기반으로 포트 할당을 수행했으나, 이는 LLM 학습이 갖는 ‘동시 흐름 수’와 ‘시간적 스텝핑’이라는 특성을 충분히 반영하지 못한다. 저자들은 이러한 한계를 극복하기 위해, LLM 학습의 계산‑통신 의존성을 정확히 표현하는 DAG(Directed Acyclic Graph)를 구축한다. DAG의 각 노드는 특정 GPU 간 통신 작업을 나타내며, 시작·종료 시점, 요구 대역폭, 소스·목적지를 사전에 계산한다.
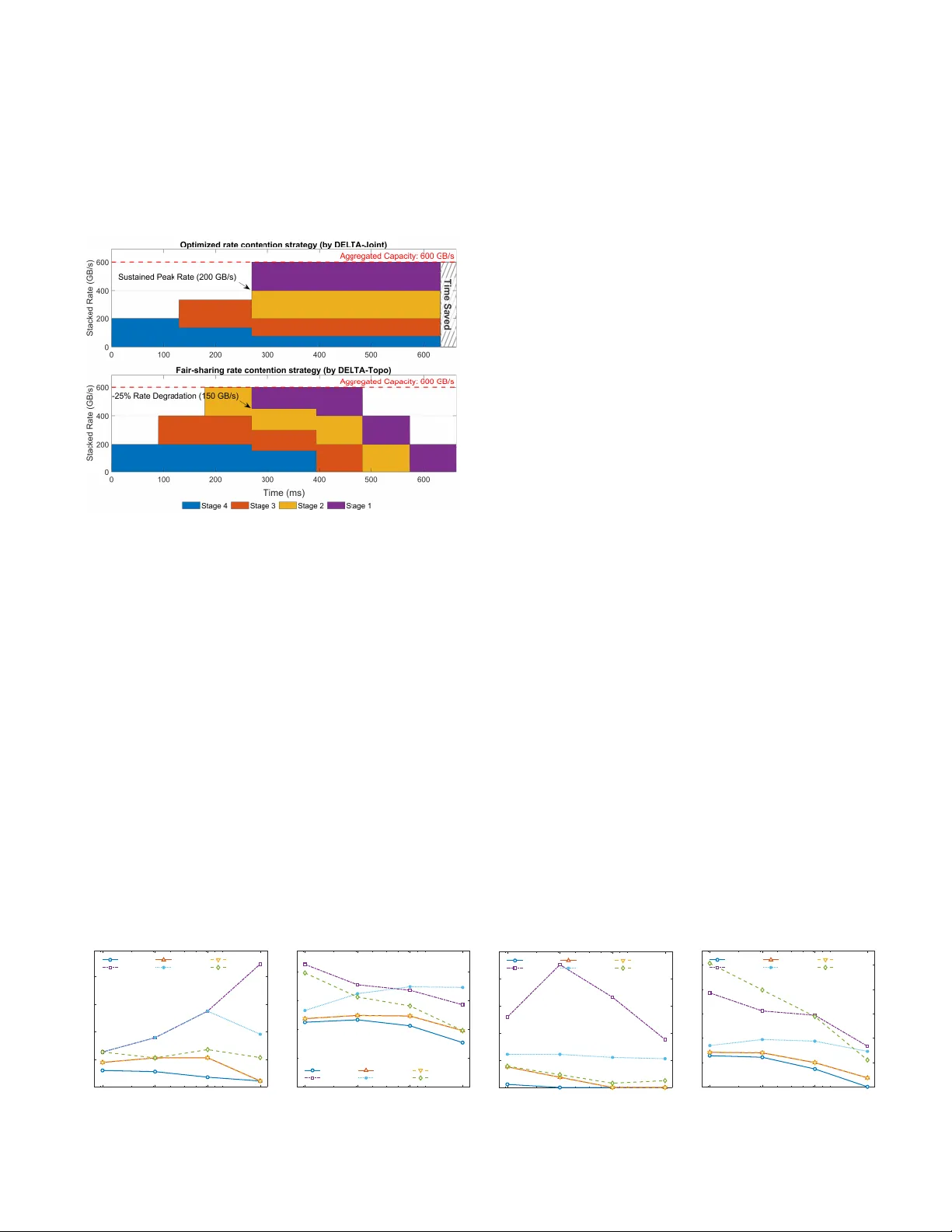
이 DAG 정보를 바탕으로, DELTA는 통신 스케줄링과 포트 할당을 동시에 최적화하는 MILP(Mixed‑Integer Linear Programming) 모델을 설계한다. 핵심 혁신은 ‘가변 길이 시간 구간’ 설계이다. 기존 고정‑시간‑스텝 방식은 수천 개의 시간 구간을 만들며 제약식이 폭증해 해결이 어려웠지만, DELTA는 실제 병목이 발생하는 구간만을 세분화하고, 비병목 구간은 하나의 구간으로 합쳐 차원을 크게 축소한다. 이를 통해 MILP의 변수와 제약 수를 실질적으로 감소시켜 해결 가능성을 확보한다.
또한, 비판적이 아닌 작업이 갖는 시간적 여유(슬랙)를 활용해 포트 사용량을 최소화하는 2차 목표를 도입한다. 이는 lexicographic 최적화 방식으로 구현되어, 먼저 전체 반복 시간을 최소화하고, 그 다음에 포트 수를 최소화한다. 결과적으로 동일한 학습 반복 시간 내에 포트 수를 20 % 이상 절감할 수 있다.
스케일링을 위해 DELTA는 두 가지 가속 전략을 적용한다. 첫째, ‘검색 공간 프루닝’ 기법으로 포트 할당 가능한 Pod 쌍을 선형적으로 필터링해 복잡도를 O(N²)에서 O(N)으로 낮춘다(N은 GPU 수). 둘째, ‘DELTA‑Fast’라는 히어리스틱 알고리즘을 사용해 초기 해를 빠르게 생성하고, 이를 MILP 솔버에 핫‑스타트 입력으로 제공한다. 이중 트랙 접근법 덕분에 1,000 GPU 규모 클러스터에서도 MILP 해결 시간이 수 분 수준으로 크게 단축된다.
실험에서는 DeepSeek 671B와 같은 초대형 모델을 포함한 다양한 LLM 워크로드에 대해 평가를 수행했다. 결과는 다음과 같다. (1) DELTA‑Joint는 기존 트래픽‑매트릭스 기반 베이스라인 대비 통신 시간 감소율이 평균 12 %이며, 최고 17.5 %까지 개선한다. (2) 포트 절감 효과는 최소 20 %이며, 절감된 포트를 다른 병목 워크로드에 재배치함으로써 전기식 비차단 네트워크와의 성능 격차를 최대 26.1 %까지 줄일 수 있다. (3) DELTA‑Fast만 사용해도 높은 품질의 토폴로지를 빠르게 얻을 수 있어, 실시간 혹은 빈번한 재설계가 필요한 환경에서도 유용하다.
결론적으로, DELTA는 LLM 학습의 결정적 DAG를 활용해 시간‑가변 트래픽을 정밀히 모델링하고, 가변 구간 MILP와 포트 절감 목표를 결합함으로써 OCS 기반 AI 데이터센터에서 통신 지연을 크게 감소시키고, 포트 효율성을 높인다. 검색 공간 프루닝과 히어리스틱 초기화 덕분에 대규모 클러스터에서도 실용적인 해결 시간을 보이며, 기존 전기 스위치 기반 설계와 거의 동등한 학습 효율을 달성한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기