MolmoPoint: Better Pointing for VLMs with Grounding Tokens
Grounding has become a fundamental capability of vision-language models (VLMs). Most existing VLMs point by generating coordinates as part of their text output, which requires learning a complicated coordinate system and results in a high token count…
Authors: Christopher Clark, Yue Yang, Jae Sung Park
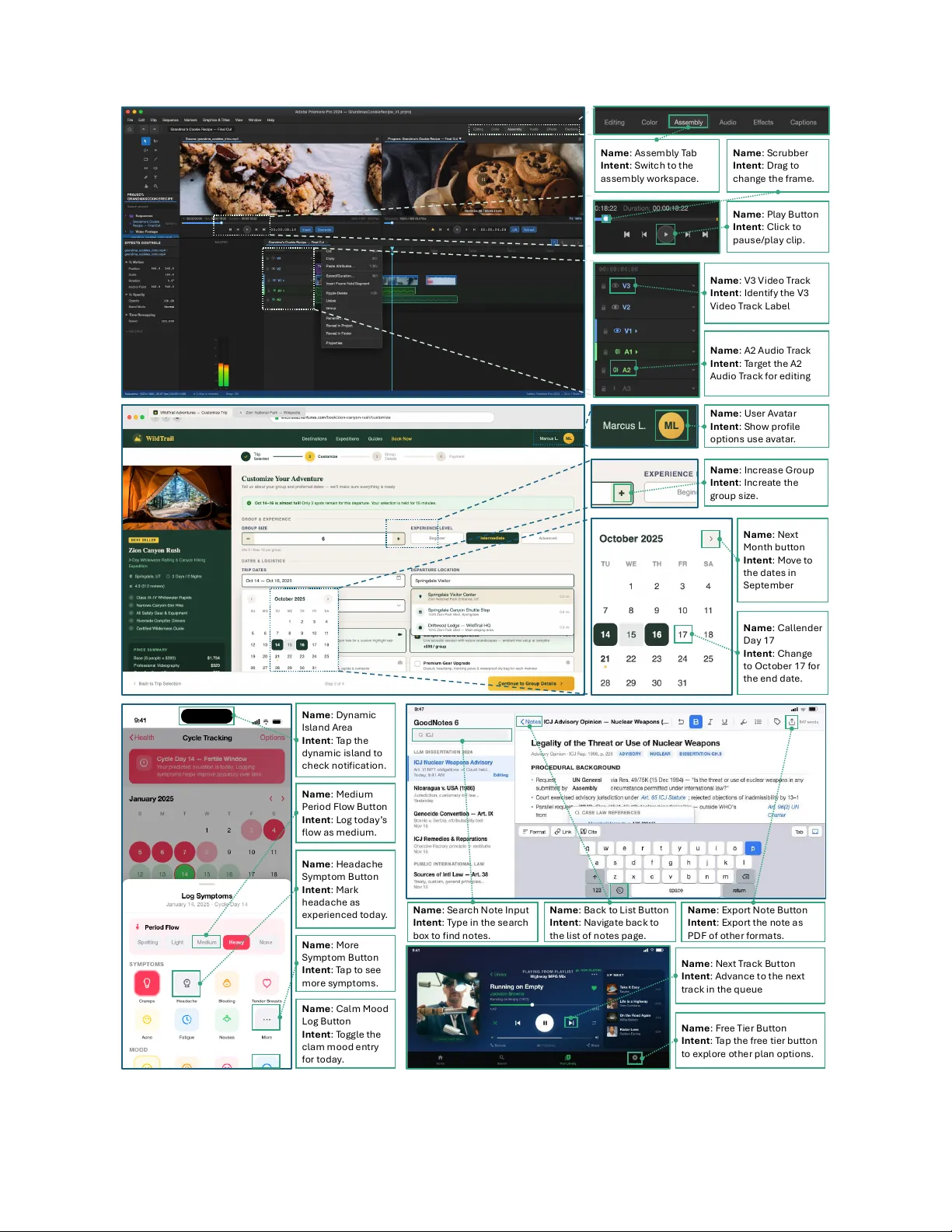
MolmoPoint Better Pointing for VLMs with Grounding Tokens Christopher Clark ♥ 1 Yue Yang ♥ 1 Jae Sung Park ♥ 1 Zixian Ma 1 , 2 Jieyu Zhang 1 , 2 Rohun Tripathi 1 Mohammadreza Salehi 1 , 2 Sangho Lee 1 Taira Anderson 1 Winson Han 1 Ranjay Krishna ♥ 1 , 2 1 Allen Institute for AI, 2 Univ ersit y of W ashington ♥ ma rks core con tributors Models: MolmoPoint-8B MolmoPoint-GUI-8B MolmoPoint-Vid-8B Data: MolmoPoint-GUISyn MolmoPoint-TrackAny MolmoPoint-TrackSyn Code: https://github.com/allenai/molmo2 https://github.com/allenai/MolmoPoint-GUISyn Demos: MolmoPoint-8B MolmoPoint-GUI-8B Contact: molmo@allenai.org Abstract Grounding has become a fundamental capability of vision-language models (VLMs). Most existing VLMs p oin t by generating co ordinates as part of their text output, whic h requires learning a complicated co ordinate system and results in a high tok en coun t. Instead, w e propose a more intuitiv e p oin ting mec hanism that directly selects the visual tokens that con tain the target concept. Our mo del generates a special p oin ting tok en that cross-attends to the input image or video tokens and selects the appropriate one. T o make this mo del more fine-grained, w e follo w these pointing tok ens with an additional sp ecial token that selects a fine-grained subpatc h within the initially selected region, and then a third token that sp ecifies a lo cation within that subpatc h. W e further show that p erformance impro v es by generating points sequen tially in a consistent order, encoding the relativ e p osition of the previously selected point, and including a special no-mor e-p oints class when selecting visual tok ens. Using this metho d, w e set a new state-of-the-art on image p oin ting (70.7% on Poin tBenc h), set a new state-of-the-art among fully open mo dels on GUI p oin ting (61.1% on ScreenSpotPro), and improv e video p oin ting (59.1% h uman preference win rate vs. a text coordinate baseline) and tracking (+6.3% gain on Molmo2T rack). W e additionally show that our metho d achiev es m uc h higher sample efficiency and discuss the qualitativ e differences that emerge from this design change. 1 Introduction Grounding through p oin ting is a key capability for vision-language mo dels (VLMs). P oin ting has direct applications to robotics, where p oin ts hav e been shown to b e an effectiv e wa y for VLMs to build plans for grasping or navigation [ 37 , 66 , 86 ]. Computer user agents hav e increasingly used p oin ting to determine how to in teract with graphical user in terfaces (GUIs) [ 69 , 100 , 58 , 74 ]. Poin ting can also be used with chain-of-though t to improv e performance on tasks lik e counting [ 22 , 19 ], and it can b e used to refer back to visual input when comm unicating with users to pro vide clearer and more interpretable resp onses. VLMs t ypically p oin t in one of tw o wa ys: b y directly generating text co ordinates [ 22 , 84 , 28 ], or by generating sp ecial tokens that corresp ond to discretized co ordinate bins [ 46 , 14 ]. Instead, as shown in Figure 1 , we 1 M o l m o P o i n t "po i nt t o t he r i ght br a k e l i ght o f t he l e f t m o st c a r " Figure 1 Overview of MolmoPoint . T o point, our mo del scores coarse-grained image patc hes using the LLM’s hidden states, then scores fine-grained subpatches from the highest scoring patc h using ViT image features, and then selects a p oin t within the highest scoring subpatc h. prop ose to use gr ounding tokens that directly select visual tokens from the input video or image. T o predict a p oin t, the model emits three sp ecial grounding tok ens, , , and , that generate a p oin t in a coarse-to-fine manner. The tok en is used to select a coarse-grained patch in the input image (or video) b y attending to the hidden states of the LLM’s visual tokens. The tok en selects a subpatc h within that patc h b y attending to the ViT features of finer-grained patches within that patch. Finally , the tok en selects a p oin t within the subpatch. When used as input, the tok en and tok en use em beddings derived from the selected patch and subpatch. This allo ws the mo del to carry forw ard location information as it generates future tokens. T o give the mo del additional aw areness of what it has already p ointed to, w e apply rotary embeddings (RoPE) [ 64 ] when selecting a patc h to encode how far candidate patches are from the patc h selected b y the pr evious tok en. This enco ding makes it easier for the model to generate consisten t, ordered p oin ts and av oid double-p ointing. W e also allow tok ens to emit a no-more-p oin ts class instead of selecting a token to indicate that the mo del should stop p oin ting. W e show that this preven ts degenerate b eha vior where the mo del generates an excessiv e n um ber of p oin ts. Our approach has several practical adv an tages. First, the mo del no longer needs to learn or memorize a co ordinate system, whic h w e show mak es learning faster and improv es generalization across image resolutions unseen during training. Second, it reduces the num ber of output tokens required to represent each p oin t, lo w ering the deco ding cost and impro ving inference latency . Third, it more tightly couples visual recognition and pointing: if the model has already encoded an ob ject, action, or part in the hidden state of a visual token, it b ecomes trivial to p oin t to th a t conten t by generating a query vector that matches its embedding. W e sho w that this leads to stronger p oin ting p erformance and sho ws signs of impro ving transfer to tasks b ey ond grounding. T o explore this approach, we train three mo dels: (1) MolmoPoint-8B : a general-purp ose image and video VLM follo wing the Molmo2 pip eline, (2) MolmoPoint-GUI-8B : a mo del sp ecialized for GUI p oin ting, and (3) MolmoPoint-Vid-8B : a ligh ter-w eight mo del sp ecialized for video p oin ting. T o train MolmoPoin t-GUI-8B, w e construct MolmoPoint-GUISyn , a new synthetic dataset of high-resolution GUI grounding examples by extending the code-guided data generation method of CoSyn [ 90 ]. T o impro v e trac king in MolmoPoin t-8B, w e also contribute MolmoPoint-Track , a dataset of human-annotated and synthetic trac ks for broader ob ject and scene co v erage. W e ev aluate these mo dels across man y p oin ting tasks. F or natural images, MolmoPoin t-8B sets a new SoT A on Poin tBench [ 16 ] and PixMo-Poin ts [ 22 ], b eating the previous metho ds b y 2 points and 4 p oin ts, resp ectively . F or GUI pointing, w e find MolmoPoin t-GUI-8B ac hiev es o ver 5 points better on ScreenSpotPro [ 39 ] and 4 p oin ts b etter on OSW orldG [ 81 ] compared to a baseline using text coordinates, and is SoT A among mo dels of 2 a similar size that ha ve open data. F or video pointing, MolmoP oint-8B shows a several-point gain on coun ting metrics and better human preference scores compared to Molmo2, despite b eing trained on the same data, and MolmoPoin t-Vid-8B further improv es these metrics. F or video tracking, MolmoP oint-8B reac hes 62.5 on J & F vs 56.7 for Molmo2 and shows large gains from b oth our new data and mo del design. W e also show that our approach impro ves training and sample efficiency and has notable qualitative effects on the p oin ting b eha vior. W e will release our mo dels, code, and data. 2 Related Work Generating Coordinates. Generating text coordinates or discrete tokens for grounding is an old approac h for VLMs [ 71 , 14 , 46 , 45 ]. Large-scale p oin ting datasets such as PixMo-Poin ts [ 22 ] hav e allo w ed VLMs to handle pointing across a wide range of ob jects and images [ 22 ], and man y recent VLMs ha ve adopted this capabilit y [ 28 , 84 , 44 , 93 , 72 , 8 ]. MolmoP oin t-8B sho ws that using grounding tok ens can provide a stronger and more efficien t w a y to learn this skill. GUI Grounding. Man y recent w orks hav e developed mo dels that use pointing to interact with graphical user in terfaces [ 74 , 76 , 42 ]. Existing metho ds often try to improv e p erformance b y enhancing data generation [ 58 , 80 , 24 , 15 ] or b y using reinforcement learning [ 69 , 100 , 94 , 67 ]. Other w orks hav e improv ed GUI grounding through agentic, m ulti-step strategies suc h as zooming in and cropping the input screenshot [ 100 , 96 ], although this comes at the exp ense of higher compute costs. Our w ork sho ws that impro ving the p oin t representation can also significan tly enhance GUI grounding. GUI Grounding Datasets. Existing GUI grounding datasets hav e b een built b oth purely syn thetically [ 90 , 88 , 29 , 77 , 29 ] and with humans [ 32 , 11 , 24 ]. Our MolmoPoin t-GUISyn differs in that it focuses on high-resolution images and greater diversit y across op erating systems, w ebsites, softw are, apps, resolutions, and asp ect ratios. MolmoP oin t-GUISyn also pro vides extremely dense annotations (54 points per image on av erage), making it v ery efficient to train on using message-tr e es to group all annotations for an image in to a single training sequence [ 19 ]. Video Grounding. Op en-v o cabulary video grounding is still generally done by sp ecialized mo dels [ 82 , 7 , 41 , 2 ], with only a few VLMs supp orting this capabilit y [ 19 , 28 ]. W e b eliev e that grounding should not b e limited to images, which is partly why w e build on top of the Molmo2 mo dels that support video p oin ting. Our results suggest that tok en referencing can help in this domain as well. Grounding Tokens. Grounding tokens ha ve b een used for tasks suc h as image segmentation [ 8 , 35 , 7 , 59 ] or depth estimation [ 36 , 9 ]. These metho ds t ypically employ a pre-trained deco der that constructs the grounded output from tokens. In contrast, our method deco des grounding tok ens through light weigh t pro jectors on top of the hidden states, remo ving the need for pre-trained deco ders. More similar to our work, PaDT [ 65 ] adds tokens to the mo del’s vocabulary using hidden states of input vision tok ens, which allo ws generated tok ens to similarly cross-attend to the input visual tok ens. Ho wev er, their approac h uses a separate deco der to obtain bounding b o xes or other grounding information from those tok ens, whereas our metho d uses the spatial lo cation of visual tok ens, along with refinemen t with additional tok ens, to p oin t. Our metho d also applies this approac h to videos and GUIs. GUI-A ctor [ 76 ] also allo ws cross-attention betw een a sp ecial tok en and visual patc hes; how ever, it do es not add refinement stages to allo w high-precision p oin ting and only applies their metho ds to GUIs and single p oin ts. 3 Method Our approac h trains the mo del to point b y directly selecting whic h visual token con tains the target ob ject and then refining that lo cation b y generating additional tokens. W e describ e it in more detail below. 3 V L M V i T l i n e a r l i n e a r l i n e a r l i n e a r l i n e a r R o P E R o P E U s K p K s Q p Q s i m a g e p o o l e d q u e st i o n < P A T C H > < S U B P A T C H > < L O C A T I O N> Figure 2 Pointing with grounding tokens . Keys are built from image tok ens and ViT patch features, and queries are built from the tok en and tok en hidden states, to score patc hes and subpatc hes. The tok en predicts the final output p oin ts within the highest scoring subpatc h . 3.1 Patch Selection First, we add a sp ecial tok en to the mo del’s vocabulary . When this token is generated, a query v ector is built from its hidden state: q p = W pq Norm ( h p ) Here W pq is a learned parameter with shap e M × D , h p is the hidden state of the tok en with shap e D × 1 , Norm is a lay er norm lay er, D is the mo del’s hidden size, and M is a hyper-parameter. W e also generate k ey v ectors for eac h tok en that embeds visual input as: K p = W pk Norm ( H i ) where W pk is another learned parameter with shap e M × D , H i are the hidden states of the tok ens with shap e D × I , and I is the n um b er of image tok ens. Finally , we score eac h image token as s p = K ⊤ p q p / √ M The score v ector s p has shap e I × 1 . During training, we compute the loss of this selection process as: L p = cross_en tropy ( softmax ( s p ) , t p ) where t p is the ground truth target tok en. L p is added directly to the tok en-level loss from the LLM before that loss is a v eraged b y the num b er of tok ens. During inference, we select the highest scoring token p ∗ = argmax ( s p ) . During training, we instead use p ∗ = t p . Then, when tok en is an input, w e add the input embedding of the tok en that w as selected to its embedding: q p + E i [ ∶ , p ∗ ] , where E i are input embeddings of the tok ens. This is imp ortan t so the mo del is a ware of whic h token it pointed to. During training, we sort ground truth p oin ts so that the tok ens the tok ens select are ordered based on where they app ear in the input sequence. W e mask out tok ens that come b efore previously selected tok ens during b oth training and inference to enforce this pattern. 4 3.2 Location Refinement In most VLMs, image tokens are constructed by p ooling m ultiple patches from the underlying ViT. F or example, in Molmo2 mo dels, eac h tok en is built from 4 ViT patches that eac h co v er 14x14 pixels, so it represen ts a 28x28 pixel area. This is to o coarse-grained, so we refine that location by adding additional tok ens after the tok en. After a tok en, our mo del also emits a tok en that selects one of the ViT patc hes that w ere p ooled to build p ∗ . This is done through dot-pro duct scoring as b efore. The hidden state of the tok en h s is pro jected to create a query vector q s , and key v ectors K s are built by pro jecting the ViT features for the subpatches U s , where U s is a T × K matrix, K is the num b er of subpatc hes, and T is the dimensionality of the ViT. W e similarly use the ground-truth subpatch lo cation to compute a loss L s for this comp onen t during training and select a subpatch index s ∗ . When a tok en is used as input, its embedding is built from the hidden state of the selected ViT patc h: q s + W se U s [ ∶ , s ∗ ] where W se with shap e D × T pro jects the ViT patc h feature to the LLM’s dimension. Adding this em b edding indicates to the LLM whic h subpatc h w as selected and gives the mo del access to the unp ooled features of the selected patc h, which we find imp ortan t when trying to further refine the lo cation. This giv es us a 14x14 resolution, whic h can still b e too coarse-grained. T o pro duce a precise point, w e emit a final tok en. The hidden state of the tok en is used to predict one of 9 lo cations within the subpatch (arranged in a 3x3 grid) using a single linear lay er. With 14x14 ViT patches, this results in a precision of ab out 4.7 pixels. Unlike p oin ting with text co ordinates, this metho d main tains a 4-pixel resolution regardless of input size, p oten tially enabling fine-grained p oin ting even with ultra-HD images. 3.3 Rotary Embedding W e add rotary em b eddings to b etter encode how tok ens are p ositioned relative to the previously selected tok en. This is imp ortan t to help the m odel follow the sorted order of p oin ts or to track what frames the previous p oin ts were generated for when doing video pointing. This is implemen ted b y rotating the token key and query v ectors: s p = Rot ( K p , p i ) ⊤ Rot ( q p , p q )/ √ M Where p i con tains the tok en p osition [ 0 , 1 , 2 , ...., I ] and p q is the image p osition selected by the previous tok en, or 0 if there is no such token. 3.4 No-More-Points Class One issue with this approac h is that if the mo del c ho oses to generate a tok en, it is forced to select a p oin t, even if none of the scores in s p are high. W e observe that this can sometimes lead to degenerate output, where the mo del generates an excessiv e num b er of points. T o solv e this, w e add a sp ecial no-mor e-p oints class with a fixed k ey em b edding that the tok en can attend to, meaning w e ha v e: K p = [ W pk Norm ( h i ) ; h done ] Where h done is a learned M × 1 v ector. W e use a p osition of 0 for h done when applying rotary em b eddings. If the no-more-points class is selected, the model is preven ted from generating a tok en and stops p oin ting. 4 Training and Inference W e train three mo dels using this prop osed metho d. W e present high-lev el details of how they are trained but lea v e the sp ecifics to the appendix. 5 B B O X E x t r a c t o r LLM < H T M L > a s c r e e n s h o t o f A uto C A D N a m e : Mea s u r e B u t t o n I nt e nt : Us e t h e m ea s u r e t o o l t o ca lc u la t e len g t h . N a m e : A d d Pi ck P o i n t s I nt e nt : A d d m o r e p i c k p o i n t s t o t h e h a t ch a r ea . N a me : C a n c el It em I nt e nt : U s e C a n ce l t o d i s ca r d t h e h a t ch . Figure 3 Overview of the generation of MolmoPoint-GUISyn. W e prompt an LLM to generate the HTML for the screenshot and extract all b ounding b o xes of its UI elements. Then w e use LLMs to annotate each b ounding b o x with its interaction inten ts. 4.1 Implementation During pre-pro cessing, we map input p oin ts to the corresp onding target tok en index, ViT patch index, and location index, and use those triples as additional input to the model. Our text input for p oin ts follo ws the Molmo2 [ 19 ] format, but replaces the string co ordinates with the grounding tok ens, including an additional tok en at the end of each list of p oin ts that is assigned the no-more-p oin ts class. This reduces the n um b er of tokens per co ordinate from 8 (6 digits and 2 spaces) to 3. F or video, we also remo ve the text timestamps used by Molmo2 since they can b e reco vered based on which tok en w as selected, further reducing the tok en coun t. As with Molmo2, w e also give an integer ob ject ID for each point, but place it after the co ordinates instead of b efore. F ollowing Molmo2, w e use a separate learning rate and gradient norm for the new p oin ting parameters. In general, w e set the learning rate to matc h that used for the image-text connector parameters. W e set M = 512 for all experiments. In all training runs, we use pac king and message-trees to support training on m ultiple examples p er sequence [ 19 ]. 4.2 Inference During inference, w e cac he the k eys of the image tok ens and ViT patches during prefilling. This adds additional memory o v erhead, but the lo w-dimensionality of the k eys means this uses roughly the same memory as the cac hed k eys and v alues for 1-2 LLM lay ers, and it is only required for the image tokens. W e constrain the mo del to generate a tok en and tok en after each tok en, and to only select tok ens that are the same, or after, any tok en it has already selected in the input sequence, so output p oin ts are ordered correctly . W e also preven t the mo del from generating m ultiple p oin ts with the same tok en and ViT subpatch since we observ e that this is almost alw a ys a case of the model p oin ting to the same thing twice. If the mo del selects the no-more-points class, w e constrain the mo del to generate the "> tok en, whic h ends a list of p oin ts in the Molmo2 p oin ting format. T o con v ert the selected patc hes back in to co ordinates, w e retain a map of tok en_id → co ordinates for every ViT patc h during pre-pro cessing and com bine it with the lo cation predictions to get the output point. 4.3 Models MolmoPoint-8B. W e conduct a full end-to-end training run following the pip eline of Molmo2-8B. W e use a larger batch size of 160 to b etter utilize the hardware we ha v e av ailable and low er the num b er of training steps from 30000 to 22,000 to comp ensate. T o improv e trac king, we also incorp orate MolmoP oint-T rack, a new dataset of human-annotated and syn thetic tracks (see below). W e also slightly adjust the training mixture to b etter exploit the impro v ed learning efficiency of the p oin ting data (see the app endix for details). 6 Ann o tate Poi n t T r ac ks fo r Input Ob j ect Blu e uniform player s Red -painted fing er nai ls . Gol d f ish lef t of o ra n g e fish Mo to r cy c les be hin d re d motorc ycle 1. Tr a cks are a nnota t ed at 2 FPS 2. Ma rk fr a me occluded if o b ject n o t visib le Mo lm o2 VideoPoint Re fe r r ing Expression Mult i - Sh o t Chan ges P ar t-L evel Objects … … … … t = 0. 0s t = 0. 5s t = 2. 5s t = 3. 0s t = 0. 0s t = 0. 5s t = 1. 5s t = 2. 0s t = 0. 0s t = 0. 5s t = 2. 5s t = 3. 0s t = 1. 0s t = 1. 5s t = 3. 5s t = 4. 0s Figure 4 MolmoPoint-TrackAny: human-annotated point-to-track extension. Annotators are giv en a text query and an ob ject of in terest, and pro vide p oin t tracks while marking frames as o ccluded when the ob ject is not visible. MolmoPoint-GUI-8B. The image p ointing data in the Molmo2 mixture do es not contain many instruc- tional/GUI examples. T o train a mo del b etter optimized for this task, we build MolmoPoin t-GUISyn, a co de-guided syn thetic GUI instructional dataset (see b elo w for details), and fine-tune on it for 2000 steps with a batc h size of 128 while increasing the image resolution to 48 crops p er image. MolmoPoint-Vid-8B. As with Molmo2, w e observe that MolmoP oint-8B underp erforms the sp ecialized mo dels on video grounding. W e therefore also train a sp ecialized video grounding mo del by finetuning MolmoP oint-8B after the pre-training stage on just video-pointing data for 6000 steps with a batch size of 64 and a max of 128 frames. W e then fine-tune it for another 800 steps with a max of 384 frames to supp ort longer videos. 4.4 MolmoPoint-GUISyn As shown in Figure 3 , w e extend the co de-guided synthetic data generation framework (CoSyn) [ 90 ] to screenshot generation, in which we prompt the language mo del to generate HTML code that mimics digital en vironmen ts for w eb, desktop, and mobile. Given access to the underlying HTML code in each screenshot, w e use the Pla ywrigh t library with custom Ja v aScript to automatically extract b ounding boxes for all elemen ts in the screenshot. W e then feed the b ounding box information to the language model to generate 5 p oin ting instructions p er elemen t that a user may ask when interacting with it. In total, w e syn thesize 36K screenshots, with 2M densely annotated p oin ts and ov er 10M p oin ting instructions. Qualitative examples of this data are pro vided in Figure 8 in the app endix. 4.5 MolmoPoint-Track Existing tracking datasets with referring expressions, such as Molmo2-VideoT rack [ 19 ], were collected by expanding trac ks for a fixed set of ob jects, resulting in limited scene and ob ject div ersity . Here, we con tribute MolmoP oin t-T rack, consisting of (1) MolmoPoint-TrackAny , human-annotated tracks on videos with an y ob jects and (2) MolmoPoint-TrackSyn , synthetic tracks with diverse motion and o cclusion patterns. F or MolmoP oin t-T rackAn y, we extend Molmo2-VideoP oint annotations into full trac ks via human annotation (Figure 4 ). F or MolmoPoin t-T rackSyn, we generate multi-ob ject trac king videos in Blender with complex o cclusion and motion dynamics, paired with automatically generated referring queries (Figure 7 ). See App endix 11 for c ollection details and qualitative examples. 5 Results 5.1 Image Pointing W e show results on natural image p ointing in T able 1 and T able 2 . MolmoPoin t-8B is state-of-the-art on P oin tBenc h [ 16 ], surpassing Molmo2 by almost 2 p oin ts, including a 5 p oin t gain in reasoning and spatial reasoning. On PixMo-Poin ts [ 22 ] MolmoPoin t-8B surpasses Molmo2 b y 4 points. Molmo2 and MolmoP oint-8B 7 Table 1 Point-Bench results. Baseline scores taken from the Poin t-Bench leaderb oard. Qwen3-VL-235B-A22B-Instruct and VisionReasoner-7B scores were taken from P oivre [ 87 ], which did not include sub-category scores. Model Aff. Spat. Reason Steer. Count. Avg Human 92.3 83.6 87.8 86.3 95.6 89.1 API call only Gemini-Rob otics-ER-1.5 [ 1 ] 69.7 69.7 60.1 67.5 68.5 67.1 Gemini-2.5-Pro [ 20 ] 72.7 70.3 71.0 41.0 59.2 62.8 Open weights P oivre-7B [ 87 ] - - - - - 67.5 Qw en2.5-VL-32B-Instuct [ 83 ] 76.8 60.0 54.4 46.5 57.1 59.0 Qw en2.5-VL-72B-Instuct [ 83 ] 76.8 60.0 54.4 46.5 57.1 59.0 Qw en3VL [ 84 ] 81.3 65.6 60.6 23.5 61.2 58.5 Qw en3-VL-235B [ 84 ] - - - - - 58.3 Fully open VisionReasoner-7B [ 44 ] - - - - - 64.7 Molmo-7B-D [ 22 ] 82.8 67.7 70.5 28.5 58.7 61.6 Molmo-72B [ 22 ] 87.9 70.3 69.4 37.0 54.6 63.8 Molmo-7B-O [ 22 ] 84.9 63.1 63.2 45.5 59.7 63.3 Molmo2-4B[ 19 ] 82.3 71.8 72.0 41.0 71.4 67.7 Molmo2-8B[ 19 ] 84.8 71.3 71.5 44.5 71.4 68.7 Molmo2-O-7B[ 19 ] 81.8 69.7 69.4 39.0 72.4 66.5 MolmoPoint MolmoP oint-8B 85.9 76.9 77.2 39.0 74.5 70.7 used the same data and training procedure, so these results sho w that using grounding tok ens significantly b oosts p oin ting capabilities on natural images. 5.2 GUI Pointing W e show results on ScreenSp ot-V2 [ 39 ], ScreenSpot-Pro [ 39 ], and OSW orldG [ 81 ]. In addition to other mo dels, we also compare to a baseline, Molmo2-GUI-8B, built b y fine-tuning Molmo2-8B on the same data MolmoP oin t-GUI-8B was trained on. The Molmo2 data mixture do es not contain instruction-point pairs, so MolmoPoin t-8B sometimes do es not p oin t when given them as input. T o fix this, we use constrained deco ding for both the Molmo2 mo dels and MolmoP oin t-8B (but not MolmoPoin t-GUI-8B) to force the mo del to generate exactly one point. W e also show results with test-time-sc aling where w e increase the n umber of crops during test time to 64. W e find that test-time scaling breaks models that use text co ordinates, dropping p erformance to < 10% , presumably due to the mo del not kno wing how to map the larger n umber of patches to text co ordinates. Therefore, we do not use it for other models. Results are sho wn in T able 3 . Compared to Molmo2, MolmoP oint-8B is even on ScreenSpot-V2 but shows significan t impro vemen ts on ScreenSp otPro and OSW orldG, again showing the b enefit of our pointing metho d. Fine-tuning with instruction-image data mak es MolmoPoin t-GUI-8B SoT A among fully op en mo dels on all tasks. Open-weigh t mo dels UI-V enus and MAI-UI show b etter results, likely b ecause b oth mo dels utilize large-scale proprietary data collection efforts as w ell as more elab orate training pipelines that include RL. W e observe a gap of 2 to 9 points b et ween MolmoPoin t-GUI-8B and the baseline that uses text coordinates on ScreenSp otPro, sho wing that our mo del design is critical for this high p erformance. W e h yp othesize that the large gap of 9 points in ScreenSpotPro might be due to grounding tokens ha ving a particularly high impact when dealing with high-resolution input. 8 Table 2 PixMo-Points results. MolmoPoin t-8B surpasses even proprietary models. W e collect results for GPT-5.2, Gemini-3, and Qw en3-VL ourselves. Metric API-only Open-weights Fully-open Ours GPT-5.2 Gemini3-Pro Qwen3-VL-8B Qwen3-VL-4B Molmo-7B-D Molmo-72B Molmo-7B-O Molmo2-4B Molmo2-8B Molmo2-O-7B MolmoPoint- 8B Recall 31.0 77.3 54.3 45.1 76.4 74.9 74.4 83.3 85.5 83.1 90.4 Precision 32.9 81.3 53.5 44.2 76.2 74.9 74.6 85.1 86.4 83.7 89.3 F1 31.6 77.8 53.4 43.7 75.7 74.5 74.0 83.4 85.2 82.7 89.2 Table 3 GUI grounding results. MolmoPoin t-GUI-8B is our GUI sp ecialized mo del finetuned on MolmoPoin t-GUISyn (Syn thetic GUI dataset) we constructed. Molmo2-GUI-8B also fine-tunes on MolmoPoin t-GUISyn but without our tok en referencing mec hanism. (64crops) denotes our test-time scaling for inference with more image crops. The best p erformance of ful ly op en mo dels is bold . Scores with * are from ev aluations in [ 69 , 58 ]. Model ScreenSpot-V2 ScreenSpot-Pro OSWorldG API call only Claude 3.7 [ 3 ] 87.6 27.7 - Op enAI CUA [ 55 ] 87.9 23.4 - Gemini-3-Pro [ 28 ] 93.7 72.7 35.5 Open weights Holo2-8B [ 21 ] 93.2 58.9 70.1 UI-T ARS 1.5-7B [ 58 ] 94.2 61.6 64.2 ∗ UI-V enus-1.5-8B [ 69 ] 95.9 68.4 69.7 Qw en3-VL-8B [ 6 ] 92.1 ∗ 52.7 ∗ 57.5 ∗ MAI-UI-8B [ 100 ] 95.2 65.8 60.1 Fully open GUI-A ctor [ 76 ] 90.9 41.8 - JEDI-7B [ 80 ] 91.7 50.2 54.1 GroundCUA-7B [ 24 ] 89.3 50.2 67.2 Op enCUA-7B [ 74 ] 92.3 50.0 55.3 GT A1-7B [ 89 ] 92.4 50.1 60.1 Molmo2-8B[ 19 ] 89.5 30.4 54.1 Molmo2-GUI-8B 88.8 52.3 66.1 MolmoPoint MolmoP oint-8B 89.8 36.4 54.9 MolmoP oint-8B (64crops) 89.8 39.4 56.5 MolmoP oint-GUI-8B 93.4 60.2 70.0 MolmoP oint-GUI-8B (64crops) 93.9 61.1 70.0 5.3 Video Pointing W e ev aluate video p oin ting on BURST-VideoCount [ 5 ], Molmo2-VideoCoun t, and Molmo2-VideoPoin t [ 19 ]. F or the counting datasets, we rep ort accuracy as well as close acc uracy , which measures if the num b er of p oin ts is almost correct (computed as ∣ pr ed − gt ∣ ≤ ∆ , where ∆ = 1 + ⌊ 0 . 05 × g t ⌋ ). F or Molmo2-VideoP oint, w e rep ort F1, recall, and precision metrics when matching points to ground-truth segmen tation masks. Baseline n um b ers come from Molmo2 [ 19 ]. F or MolmoP oint-8B, w e see an improv ement on b oth Burst-V C and Molmo2-VC compared to Molmo2-8B, 9 Table 4 Video counting and pointing results. MolmoPoin t-8B scores highest on BURST-VC and MolmoPoin t-8B-VP and second highest on MolmoP oint-8B-V C’s close accuracy , sligh tly behind Gemini 2.5 Pro. Best op en mo del results are bold . BURST VC (test) [ 5 ] Molmo2-VC Molmo2-VP Model A cc. Close acc. Acc. Close acc. F1 Recall Precision API call only GPT-5 [ 56 ] 43.1 73.7 35.8 50.3 4.1 4.4 4.2 GPT-5 mini [ 56 ] 46.0 73.0 29.8 49.3 2.2 2.2 2.2 Gemini 3 Pro [ 28 ] 44.0 71.7 37.1 53.1 20.0 27.4 19.8 Gemini 2.5 Pro [ 20 ] 41.6 70.0 35.8 56.5 13.0 14.5 13.6 Gemini 2.5 Flash [ 20 ] 38.7 70.0 31.9 48.2 11.1 11.2 12.2 Claude Sonnet 4.5 [ 4 ] 42.4 72.6 27.2 45.1 3.5 3.7 4.3 Open weights Qw en3-VL-4B [ 6 ] 38.9 74.7 25.3 44.3 0.0 0.0 0.0 Qw en3-VL-8B [ 6 ] 42.0 74.4 29.6 47.7 1.5 1.5 1.5 Fully open Molmo2-4B 61.5 76.1 34.3 56.1 39.9 42.7 39.4 Molmo2-8B 60.8 75.0 35.5 53.3 38.4 39.3 38.7 Molmo2-O-7B 61.6 76.0 33.2 50.5 35.8 35.8 37.9 MolmoPoint MolmoP oint-8B 61.6 76.9 35.6 54.6 36.2 35.7 37.8 MolmoP oint-Vid-8B 62.0 76.3 36.0 58.7 38.8 39.8 38.8 although w e also see a drop in Molmo2-VP . T o get a more definitive result, w e conduct a human preference ev aluation using predictions from b oth mo dels on 470 video p oin ting queries (See app endix for details). W e find 152 ties, 130 wins for Molmo2, and 188 wins for MolmoPoin t-8B. Excluding ties, MolmoPoin t-8B has a 59.1% win rate, showing humans prefer MolmoP oint-8B’s output. MolmoPoin t-Vid-8B sees a more consistent gain, including a full 5 p oin t gain on Molmo2-VC close, surpassing Gemini 3 Pro. 5.4 Tracking Results W e ev aluate MolmoPoin t-8B on the tracking b enc hmarks in tro duced in Molmo2 [ 19 ]. T able 5 presen ts results on academic b enc hmarks and T able 6 rep orts results on MolmoP oint-8B-T rack across video domains. F ollo wing [ 2 , 19 ], Jaccard and F-measure ( J & F ), which measures segmentation quality , is computed by passing MolmoP oin t-8B p oin ts as input to SAM2 [ 60 ] to obtain segmen tation masks. F1 and HOT A [ 48 ] ev aluate point accuracy directly , where F1 measures whether predicted p oin ts fall within the ground-truth segmen tation and HOT A further accoun ts for asso ciation consistency across frames. Ov erall, MolmoPoin t-8B shows substantial gains o ver Molmo2-8B across trac king benchmarks. Notable impro v emen ts come from the multi-ob ject tracking dataset as MolmoP oin t-8B reaches 63.5 vs. 62.3 and 72.2 vs. 70.8 J & F on Me ViS v alid and v alid-u splits [ 23 ]. On Molmo2-T rack, the gains are consistent across all video domains, with o v erall impro v emen ts of +5.7 J & F , +3.1 F1 and +2.5 HOTA . W e susp ect our grounding tok ens enable b etter grounding and instance-lev el identification in trac king as well. One exception is Reason V OS [ 7 ] whic h targets queries that require semantic reasoning rather than precise spatial grounding, th us grounding tok ens pro vide few er b enefits here. Tracking Ablations T o disentangle our mo deling and data contributions, w e conduct ablations that sequentially remo ve grounding tok ens and MolmoPoin t-T rac k. Due to computation constraints, all ablation models are trained for 5K steps on hea vily upsampled trac king data. As shown in T able 7 , b oth contribute meaningfully to tracking qualit y . 10 Table 5 Tracking Results on Academic Benchmark . J & F measures the segmentation mask qualit y of ob ject tracks. F1 measures whether p oin ts fall in the mask, and HOT A [ 48 ] further accoun ts for consistent ID associations. MeViS [ 23 ] MeViS [ 23 ] Ref-YT-VOS [ 61 ] Ref-Davis [ 34 ] ReasonVOS [ 7 ] v alid v alid-u v alid v alid test Model J & F J & F F1 HOT A J & F F1 HOT A J & F F1 HOT A J & F F1 HOT A API call only GPT-5 [ 56 ] 23.4 26.5 17.3 14.0 30.9 21.0 18.4 25.2 17.0 11.6 24.7 13.6 10.7 GPT-5 mini [ 56 ] 15.7 15.4 8.5 6.8 16.2 7.4 6.2 8.4 3.4 2.3 14.6 4.2 3.4 Gemini 3 Pro [ 28 ] 42.5 51.1 42.3 36.0 55.0 49.1 45.5 66.6 60.8 55.7 52.6 48.5 42.1 Gemini 2.5 Pro [ 20 ] 40.7 52.8 41.2 35.0 45.1 44.5 40.5 45.6 62.7 56.6 44.0 50.2 42.4 Gemini 2.5 Flash [ 20 ] 27.6 31.8 24.0 19.9 36.0 32.8 30.0 31.6 36.7 30.0 26.5 25.8 21.0 Open weights only Qw en3-VL-4B [ 84 ] 29.7 30.6 23.3 18.7 32.1 29.0 26.5 44.4 33.1 26.9 26.5 17.0 13.5 Qw en3-VL-8B [ 84 ] 35.1 34.4 30.1 23.8 48.3 42.1 37.6 41.0 41.6 33.2 24.9 22.3 17.5 Specialized open models VideoLISA [ 7 ] 44.4 53.2 – – 63.7 – – 68.8 – – 47.5 – – VideoGLaMM [ 59 ] 45.2 50.6 – – 66.8 – – 69.5 – – 33.9 – – Sa2V A-8B [ 92 ] 46.9 57.0 – – 70.7 – – 75.2 – – 55.5 – – Sa2V A-Qwen3-VL-4B [ 92 ] 36.7 57.1 – – 68.1 – – 76.0 – – 50.0 – – Fully open Molmo [ 22 ] + SAM 2 [ 60 ] 46.9 51.5 53.8 – 64.6 71.1 – 65.2 74.5 – 45.7 50.3 – VideoMolmo-7B [ 2 ] 53.9 57.0 59.4 – 67.3 73.7 – 72.5 75.4 – 51.1 50.3 – Molmo2-4B 63.3 70.0 75.5 72.4 70.2 80.4 78.8 73.5 83.1 81.1 61.9 66.5 64.0 Molmo2-8B 62.3 70.8 75.9 72.6 70.2 78.7 77.3 72.7 81.3 78.7 65.8 70.8 68.6 Molmo2-O-7B 58.4 69.7 76.1 72.3 67.9 77.7 76.1 70.4 79.2 76.0 62.6 67.5 65.1 MolmoPoint MolmoP oint-8B 63.5 72.2 77.0 73.8 70.5 81.9 80.5 73.6 84.1 82.2 64.7 68.8 67.0 Table 6 Results on Molmo2Track benchmark by video domain . Overall rep orts the accuracy across all samples. Animals Person Sports Dancers Misc Overall Model J & F F1 HOT A J & F F1 HOT A J & F F1 HOT A J & F F1 HOT A J & F F1 HOT A J & F F1 HOT A API call only GPT-5 [ 56 ] 41.4 20.6 20.3 16.5 4.5 4.2 14.4 2.0 2.5 33.8 11.7 11.5 14.6 2.2 1.6 23.5 7.5 7.5 GPT-5 mini [ 56 ] 21.7 7.8 8.0 8.6 1.6 1.5 10.7 0.6 0.8 15.6 2.1 2.0 13.5 0.6 0.4 12.7 2.1 2.1 Gemini 3 Pro [ 20 ] 70.4 62.3 60.0 44.5 30.7 29.2 23.4 10.3 8.8 55.6 44.3 37.8 35.3 18.3 14.4 44.6 32.2 29.1 Gemini 2.5 Pro [ 20 ] 69.3 56.8 53.2 50.0 33.6 31.9 29.7 10.8 8.9 55.9 39.4 32.2 34.7 17.6 18.3 47.9 31.2 27.8 Gemini 2.5 Flash [ 20 ] 58.0 46.6 44.4 38.9 21.4 20.1 13.2 6.2 5.5 48.0 29.0 25.1 21.9 5.7 4.6 36.2 21.8 19.8 Open models Qwen3-VL-4B [ 84 ] 57.2 11.5 12.3 35.1 12.0 11.2 3.8 0.4 0.4 34.6 6.9 5.7 17.5 6.2 4.2 28.5 7.2 6.7 Qwen3-VL-8B [ 84 ] 63.8 52.3 50.2 35.4 20.3 18.9 5.2 1.7 1.4 31.3 19.0 16.7 16.3 6.2 4.2 28.7 18.0 16.5 Specialized open models VideoLISA [ 7 ] 67.8 – – 35.8 – – 32.9 – – 53.6 – – 25.8 – – 43.3 – – VideoGLaMM [ 59 ] 63.9 – – 26.2 – – 34.3 – – 46.0 – – 22.3 – – 37.9 – – Sa2V A-8B [ 92 ] 74.3 – – 45.5 – – 30.7 – – 53.3 – – 49.1 – – 46.9 – – Sa2V A-Qwen3-VL-4B [ 92 ] 73.3 – – 48.6 – – 31.6 – – 50.1 – – 31.4 – – 46.7 – – SAM 3 [ 10 ] 41.1 – – 35.2 – – 43.3 – – 29.2 – – 36.8 – – 36.3 – – Molmo [ 22 ] + SAM 2 [ 60 ] 71.8 76.0 – 52.7 7.0 – 52.8 2.6 – 51.7 7.55 – 40.9 37.5 – 54.2 14.0 – VideoMolmo-7B [ 2 ] 68.4 69.5 – 51.1 6.3 – 43.2 2.1 – 53.8 7.2 – 39.9 30.8 – 51.3 12.7 – Fully Open Molmo2-4B 81.0 83.0 83.7 43.7 48.3 47.7 59.7 53.1 54.3 60.4 64.4 64.4 43.1 35.1 31.3 56.7 57.5 57.6 Molmo2-8B 80.1 82.0 83.0 43.1 47.9 48.0 59.8 53.3 54.8 59.9 63.9 63.5 41.6 31.5 29.7 56.2 57.1 57.5 Molmo2-O-7B 80.1 81.9 82.8 41.5 45.5 45.4 54.1 47.6 48.6 57.7 61.0 60.3 45.0 37.6 34.7 53.7 54.2 54.2 MolmoPoint MolmoPoin t-8B 81.9 84.4 85.8 56.9 51.2 50.9 63.6 56.9 57.7 61.8 65.6 64.2 49.1 45.7 43.1 62.5 60.2 60.0 11 Table 7 Tracking ablations on Molmo2Track . W e consecutiv ely remo ve grounding tok ens and the newly introduced MolmoP oint-T rack data. Model Animals Person Sports Dancers Misc Overall F1 HOT A F1 HOT A F1 HOT A F1 HOT A F1 HOT A F1 HOT A MolmoPoin t-8B-Ablation 83.4 85.3 49.2 49.1 56.5 57.6 64.9 63.7 47.5 44.5 59.3 59.3 w/o grounding tokens 80.7 81.8 44.4 44.5 49.4 51.4 62.9 62.9 37.9 35.5 54.7 55.3 w/o MolmoPoint-T rack 80.0 81.0 43.5 43.8 49.4 50.5 61.8 61.6 30.3 28.1 53.8 54.2 Remo ving grounding tok ens leads to a drop of 4.6 F1 and 4.0 HOTA o v erall, suggesting grounding tok ens are particularly b eneficial for trac king a diverse set of ob ject t yp es. F urther remo ving MolmoPoin t-T rac k yields additional losses, most notably on Misc ( -7.6 F1 ), confirming that the expanded data cov erage addresses gaps where the original training data had limited represen tation. 5.5 MultiTask Results T o ev aluate how w ell MolmoPoin t-8B works as a general-purp ose VLM, T able 8 rep orts a v erage p erformance on 11 image benchmarks [ 33 , 51 , 52 , 53 , 63 , 30 , 78 , 95 , 47 , 8 , 22 ], 3 m ulti-image b enc hmarks [ 70 , 54 , 26 ], 6 short-video b enc hmarks [ 79 , 57 , 38 , 62 , 31 , 43 ], and 7 long video b enc hmarks [ 25 , 75 , 101 , 73 , 49 , 50 ] following the ev aluation proto col Molmo2. F ull details are in the app endix. Ov erall, w e see only small c hanges compared to Molmo2-8B: a small gain on images, a small loss on multi- images and short videos, and no difference on long videos. Since the data and training proto col are mostly unc hanged betw een the t wo models, b etter transfer from image p oin ting data to image tasks migh t explain the gain in images. Although some in terference b et ween grounding and QA might likewise explain the drop in short videos. W e do observe another sign of p ositiv e transfer during pre-training, where captioning p erformance is slightly better for MolmoPoin t-8B after pre-training (55.6 vs 55.9 F1 on the Molmo captioning metric [ 22 ]). Ho w ev er, in either case, the effect is small. 5.6 Modeling Ablations Mo deling ablations are shown in T able 9 . Due to limited compute resources, we do ablations with a ligh ter- w eigh t training pipeline that starts from a pre-trained captioning mo del (without an y p oin ting capabilities) and then fine-tunes on the image and video p oin ting data from the Molmo2 data mixture. W e train for 6000 steps with a batch size of 64. F or video input, we observ e that mo dels can produce degenerate outputs with an excessive n umber of p oints. T o capture this, we add an over c ount metric, defined as how often predictions are > 10 p oin ts and >= t wice the n umber of ground truth p oin ts. Remo ving rotary em b eddings decreases performance a bit on images and has a more significan t effect on video. Remo ving the no-more-points tok en hurts performance and more than doubles the amoun t of ov ercounting. Randomizing the order of the p oin ts shows a significan t drop for video, but a surprising gain on Poin tBench. W e hypothesize that this might impro v e p erformance b y allowing models to generate p oin ts in an “easiest p oin t first" order [ 12 ], but more work will be needed to take adv antage of this without degrading video. 5.7 Sample Efficiency Figure 5 (left) sho ws p erformance when fine-tuning a base captioning mo del on a small n umber of p oin ting examples. Mo dels were tuned for 6 ep ochs to ensure they were fully saturated. MolmoPoin t-8B initially p erforms w orse, likely due to needing to learn new parameters from scratch, but quic kly improv es to a 20 p oin t gain when using 8192 examples (the full pointing dataset has close to half a million examples). Figure 5 (righ t) sho ws MolmoPoin t reaches p eak performance faster during pre-training. Both of these results show that grounding tok ens mak e p oin ting easier and more efficient to learn than text coordinates. 12 Table 8 Image and video QA results . A veraged results on the QA benchmarks in [ 19 ], see the app endix for details. Some results w ere computed b y [ 19 ]. Model Image Avg. Multi-Image Avg. Short Video Avg. Long Video Avg. API call only GPT-5[ 56 ] 83.7 72.1 73.1 76.3 GPT-5 mini[ 56 ] 81.9 68.2 66.8 69.8 Gemini 3 Pro[ 28 ] 86.2 81.9 71.0 78.8 Gemini 2.5 Pro[ 20 ] 81.3 72.4 71.1 80.4 Gemini 2.5 Flash[ 20 ] 79.3 68.3 67.0 74.5 Claude Sonnet 4.5[ 4 ] 76.3 59.5 62.8 66.4 Open weights In tern VL3.5-4B[ 72 ] 77.2 53.5 62.0 56.5 In tern VL3.5-8B[ 72 ] 78.2 54.9 63.0 57.1 Qw en3-VL-4B[ 6 ] 78.4 57.6 63.7 62.7 Qw en3-VL-8B[ 6 ] 81.2 56.3 65.3 63.5 Key e-VL-1.5-8B[ 85 ] 79.8 52.1 60.1 60.4 GLM-4.1V-9B[ 68 ] 77.0 67.4 64.2 60.5 MiniCPM-V-4.5-8B[ 91 ] 77.7 47.3 62.1 60.1 Eagle2.5-8B[ 13 ] 81.2 52.0 67.0 65.2 Fully open PLM-3B[ 18 ] 75.9 40.6 66.3 53.5 PLM-8B[ 18 ] 78.7 35.7 68.5 56.2 LLaV A-Video-7B[ 97 ] - - 59.4 56.2 VideoChat-Flash-7B[ 40 ] - - 66.4 58.1 Molmo2-4B[ 19 ] 80.4 57.8 69.3 64.5 Molmo2-8B[ 19 ] 81.7 56.4 69.9 64.1 Molmo2-O-7B[ 19 ] 79.7 53.5 68.1 59.2 MolmoPoint MolmoP oint-8B 82.2 56.0 69.5 64.2 Table 9 Ablations . Results when removing rotary em b eddings, the no-more-points class, or the constraint that the p oin ts m ust be generated in sorted order. Model PixMoPoint PointBench Molmo2-VC F1 Avg. Correct Close Overcount ↓ Molmo2-P-Ablation 85.2 67.8 58.0 36.6 3.6 w/o rotary 84.5 67.6 56.8 33.0 4.5 w/o no-more-p oin ts 84.7 66.6 52.3 32.8 10.3 w/o p oin t sorting 83.6 71.2 40.0 24.4 3.2 5.8 Qualitative results Despite being trained on the same data, w e observ e significant qualitative differences b et ween MolmoPoin t-8B and Molmo2-8B. MolmoP oint-8B is less likely to pro duce degenerate output on videos, is b etter at finding small ob jects, and can b e more precise when p oin ting. How ever, w e observe that it occasionally pro duces off-b y-one errors when coun ting high-frequency ob jects. Figure 6 demonstrates qualitative examples to compare Molmo2 and Molmo2-P in video p oin ting, high-resolution GUI grounding, and multi-ob ject pointing. 13 Figure 5 Sample efficiency . Left: Performance when using a v ery limited num b er of p oin ting training examples. Righ t: Poin ting performance during full-scale pre-training. 1024 2048 4096 8192 0 10 20 30 40 50 60 70 80 Number of T raining Examples PixMo-Points F1 0% 20% 40% 60% 80% 100% 50 60 70 80 90 Percent through Pre-T raining PixMo-Points F1 MolmoPoint Molmo2 6 Conclusion W e ha v e sho wn that using grounding tok ens significan tly improv es p oin ting across multiple domains. The impro v emen ts in sample efficiency and training sp eed sho w this metho d would be esp ecially helpful in low- resource settings. F uture work could extend this approach to include other mo dalities, suc h as p oin ting to text tok ens to highligh t imp ortan t parts of the text or p oin ting to audio tokens to reference a sound. Acknowledgements This w ork w ould not b e possible without the supp ort of our colleagues at Ai2. • W e thank David Albright, Cailin Brashear, Crystal Nam, Kyle Wiggers, and Will Smith for their important w ork for the MolmoP oin t-8B public release. • W e thank other members of the PRIOR team for providing advice and feedback on v arious asp ects of MolmoP oin t-8B. • W e thank the Prolific team for their supp ort and our annotators on Prolific for providing us with high-qualit y data that is crucial to MolmoP oin t-8B. This material is based up on w ork supp orted b y the National Science F oundation under A ward No. 2413244. 14 Figure 6 Qualitative examples . T op, Molmo2 generates lines of incorrect p oin ts in m ultiple video frames. Middle, Molmo2 is unable to lo calize the “x” exactly (zo omed images are close-ups of the same point). Bottom left, MolmoPoin t- 8B finds the second, partly occluded saddle. Bottom righ t, MolmoP oint-8B misses one of the plates. The middle row sho ws results from MolmoPoin t-GUI-8B and Molmo2-GUI-8B, and the others sho w MolmoPoin t-8B and Molmo2-8B. 15 References [1] A. Abdolmaleki, S. Ab eyru wan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, A. Balakrishna, N. Batchelor, A. Bewley , J. Bingham, M. Blo esc h, et al. Gemini rob otics 1.5: Pushing the frontier of generalist robots with adv anced em b odied reasoning, thinking, and motion transfer. arXiv pr eprint arXiv:2510.03342 , 2025. [2] G. S. Ahmad, A. Heakl, H. Gani, A. Shak er, Z. Shen, F. S. Khan, and S. Khan. Videomolmo: Spatio-temp oral grounding meets pointing. arXiv pr eprint arXiv:2506.05336 , 2025. [3] An thropic. The claude 3 mo del family: Opus, sonnet, haiku, 2024. URL https://www- cdn.anthropic.com/ de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf . [4] An thropic. Claude sonnet 4.5 system card, 2025. URL https://assets.anthropic.com/m/12f214efcc2f457a/ original/Claude- Sonnet- 4- 5- System- Card.pdf . [5] A. Athar, J. Luiten, P . V oigtlaender, T. Kh urana, A. Da v e, B. Leib e, and D. Ramanan. Burst: A b enc hmark for unifying ob ject recognition, segmentation and trac king in video. In W ACV , 2023. [6] S. Bai, Y. Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y. Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y. Sun, J. T ang, J. T u, J. W an, P . W ang, P . W ang, Q. W ang, Y. W ang, T. Xie, Y. Xu, H. Xu, J. Xu, Z. Y ang, M. Y ang, J. Y ang, A. Y ang, B. Y u, F. Zhang, H. Zhang, X. Zhang, B. Zheng, H. Zhong, J. Zhou, F. Zhou, J. Zhou, Y. Zhu, and K. Zhu. Qwen3-vl technical rep ort. arXiv pr eprint arXiv:2511.21631 , 2025. [7] Z. Bai, T. He, H. Mei, P . W ang, Z. Gao, J. Chen, L. Liu, Z. Zhang, and M. Z. Shou. One tok en to seg them all: Language instructed reasoning segmentation in videos. In NeurIPS , 2024. [8] L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnik o v, X. W ang, D. Salz, M. Neumann, I. Alab dulmohsin, M. T schannen, E. Bugliarello, T. Unterthiner, D. Keysers, S. K oppula, F. Liu, A. Grycner, A. Gritsenko, N. Houlsby , M. Kumar, K. Rong, J. Eisenschlos, R. Kabra, M. Bauer, M. Bošnjak, X. Chen, M. Minderer, P . V oigtlaender, I. Bica, I. Balazevic, J. Puigcerver, P . Papalampidi, O. Henaff, X. Xiong, R. Soricut, J. Harmsen, and X. Zhai. PaliGemma: A versatile 3B VLM for transfer. arXiv pr eprint arXiv:2407.07726 , 2024. [9] M. Bigv erdi, Z. Luo, C.-Y. Hsieh, E. Shen, D. Chen, L. G. Shapiro, and R. Krishna. Perception tokens enhance visual reasoning in multimodal language mo dels. In Pr o ce e dings of the Computer Vision and Pattern R e c o gnition Confer enc e , pages 3836–3845, 2025. [10] N. Carion, L. Gustafson, Y.-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ry ali, K. V. Alw ala, H. Khedr, A. Huang, et al. Sam 3: Segment anything with concepts. arXiv pr eprint arXiv:2511.16719 , 2025. [11] Y. Chai, S. Huang, Y. Niu, H. Xiao, L. Liu, D. Zhang, P . Gao, S. Ren, and H. Li. Amex: Android multi-annotation exp o dataset for mobile gui agen ts, 2024. URL . [12] H. Chang, H. Zhang, L. Jiang, C. Liu, and W. T. F reeman. Maskgit: Masked generative image transformer. In CVPR , 2022. [13] G. Chen, Z. Li, S. W ang, J. Jiang, Y. Liu, L. Lu, D.-A. Huang, W. Byeon, M. Le, M. Ehrlic h, T. Lu, L. W ang, B. Catanzaro, J. Kautz, A. T ao, Z. Y u, and G. Liu. Eagle 2.5: Bo osting long-con text p ost-training for fron tier vision-language mo dels. In NeurIPS , 2025. [14] T. Chen, S. Saxena, L. Li, D. J. Fleet, and G. Hin ton. Pix2seq: A language modeling framework for ob ject detection. arXiv pr eprint arXiv:2109.10852 , 2021. [15] K. Cheng, Q. Sun, Y. Chu, F. Xu, L. Y anT ao, J. Zhang, and Z. W u. Seeclic k: Harnessing gui grounding for adv anced visual gui agents. In Pr oc e edings of the 62nd A nnual Me eting of the Asso ciation for Computational Linguistics (V olume 1: L ong Pap ers) , pages 9313–9332, 2024. [16] L. Cheng, J. Duan, Y. R. W ang, H. F ang, B. Li, Y. Huang, E. W ang, A. Eftekhar, J. Lee, W. Y uan, et al. P ointarena: Probing m ultimo dal grounding through language-guided p oin ting. arXiv pr eprint arXiv:2505.09990 , 2025. [17] W.-L. Chiang, L. Zheng, Y. Sheng, A. N. Angelop oulos, T. Li, D. Li, H. Zhang, B. Zhu, M. Jordan, J. E. Gonzalez, and I. Stoica. Chatb ot arena: An open platform for ev aluating LLMs b y h uman preference. In ICML , 2024. 16 [18] J. H. Cho, A. Madotto, E. Mavroudi, T. Afouras, T. Nagara jan, M. Maaz, Y. Song, T. Ma, S. Hu, H. Rasheed, P . Sun, P .-Y. Huang, D. Boly a, S. Jain, M. Martin, H. W ang, N. Ravi, S. Jain, T. Stark, S. Mo on, B. Dama v andi, V. Lee, A. W estbury , S. Khan, P . Krähenbühl, P . Dollár, L. T orresani, K. Grauman, and C. F eich tenhofer. P erceptionlm: Op en-access data and mo dels for detailed visual understanding. arXiv preprint , 2025. [19] C. Clark, J. Zhang, Z. Ma, J. S. Park, M. Salehi, R. T ripathi, S. Lee, Z. Ren, C. D. Kim, Y. Y ang, et al. Molmo2: Op en weigh ts and data for vision-language models with video understanding and grounding. arXiv pr eprint arXiv:2601.10611 , 2026. [20] G. Comanici, E. Bieber, M. Schaek ermann, I. Pasupat, N. Sac hdev a, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, et al. Gemini 2.5: Pushing the frontier with adv anced reasoning, multimodality , long con text, and next generation agen tic capabilities. arXiv pr eprint arXiv:2507.06261 , 2025. [21] H. Company . Holo2 - op en foundation mo dels for navigation and computer use agen ts, 2025. URL https: //huggingface.co/collections/Hcompany/holo2 . [22] M. Deitke, C. Clark, S. Lee, R. T ripathi, Y. Y ang, J. S. P ark, M. Salehi, N. Muennighoff, K. Lo, L. Soldaini, J. Lu, T. Anderson, E. Bransom, K. Ehsani, H. Ngo, Y. Chen, A. P atel, M. Y atsk ar, C. Callison-Burc h, A. Head, R. Hend rix, F. Bastani, E. V anderBilt, N. Lambert, Y. Chou, A. Chheda, J. Sparks, S. Skjonsberg, M. Schmitz, A. Sarnat, B. Bischoff, P . W alsh, C. Newell, P . W olters, T. Gupta, K.-H. Zeng, J. Borchardt, D. Groeneveld, C. Nam, S. Lebrech t, C. Wittlif, C. Schoenick, O. Mic hel, R. Krishna, L. W eihs, N. A. Smith, H. Ha jishirzi, R. Girshic k, A. F arhadi, and A. Kembha vi. Molmo and pixmo: Op en w eights and open data for state-of-the-art vision-language mo dels. In CVPR , 2025. [23] H. Ding, C. Liu, S. He, X. Jiang, and C. C. Lo y . Mevis: A large-scale b enc hmark for video segmen tation with motion expressions. In ICCV , 2023. [24] A. F eizi, S. Nay ak, X. Jian, K. Q. Lin, K. Li, R. A wal, X. H. Lù, J. Obando-Ceron, J. A. Ro driguez, N. Chapados, D. V azquez, A. Romero-Soriano, R. Rabbany , P . T aslakian, C. Pal, S. Gella, and S. Ra jeswar. Grounding computer use agen ts on h uman demonstrations. arXiv pr eprint arXiv:2511.07332 , 2025. [25] C. F u, Y. Dai, Y. Luo, L. Li, S. Ren, R. Zhang, Z. W ang, C. Zhou, Y. Shen, M. Zhang, et al. Video-mme: The first-ev er comprehensive ev aluation b enc hmark of multi-modal llms in video analysis. In CVPR , 2025. [26] X. F u, Y. Hu, B. Li, Y. F eng, H. W ang, X. Lin, D. Roth, N. A. Smith, W.-C. Ma, and R. Krishna. Blink: Multimo dal large language models can see but not perceive. In ECCV , 2024. [27] T. Ge, X. Chan, X. W ang, D. Y u, H. Mi, and D. Y u. Scaling synthetic data creation with 1,000,000,000 p ersonas. arXiv pr eprint arXiv:2406.20094 , 2024. [28] Go ogle. Gemini 3 Pro model card, 2025. URL https://storage.googleapis.com/deepmind- media/ Model- Cards/Gemini- 3- Pro- Model- Card.pdf . [29] B. Gou, R. W ang, B. Zheng, Y. Xie, C. Chang, Y. Sh u, H. Sun, and Y. Su. Navigating the digital world as h umans do: Universal visual grounding for GUI agents. In The Thirte enth International Confer enc e on L e arning R epr esentations , 2025. URL https://openreview.net/forum?id=kxnoqaisCT . [30] Y. Goy al, T. Khot, D. Summers-Stay , D. Batra, and D. Parikh. Making the V in V QA matter: Elev ating the role of image understanding in visual question answering. In CVPR , 2017. [31] W. Hong, Y. Cheng, Z. Y ang, W. W ang, L. W ang, X. Gu, S. Huang, Y. Dong, and J. T ang. Motionbench: Benc hmarking and impro ving fine-grained video motion understanding for vision language mo dels. In CVPR , 2025. [32] R. Kap oor, Y. P . Butala, M. Russak, J. Y. K oh, K. Kam ble, W. AlShikh, and R. Salakh utdinov. Omniact: A dataset and benchmark for enabling m ultimo dal generalist autonomous agen ts for desktop and w eb. In Eur op e an Confer enc e on Computer Vision , pages 161–178. Springer, 2024. [33] A. Kem bhavi, M. Salv ato, E. Kolv e, M. Seo, H. Ha jishirzi, and A. F arhadi. A diagram is w orth a dozen images. In ECCV , 2016. [34] A. Khorev a, A. Rohrbach, and B. Sc hiele. Video ob ject segmen tation with language referring expressions. In ACCV , 2018. 17 [35] X. Lai, Z. Tian, Y. Chen, Y. Li, Y. Y uan, S. Liu, and J. Jia. Lisa: Reasoning segmen tation via large language mo del. In Pr oc e e dings of the IEEE/CVF c onfer enc e on c omputer vision and p attern r e c o gnition , pages 9579–9589, 2024. [36] J. Lee, J. Duan, H. F ang, Y. Deng, S. Liu, B. Li, B. F ang, J. Zhang, Y. R. W ang, S. Lee, W. Han, W. Pumaca y , A. W u, R. Hendrix, K. F arley , E. V anderBilt, A. F arhadi, D. F ox, and R. Krishna. Molmoact: A ction reasoning mo dels that can reason in space. arXiv pr eprint arXiv:2508.07917 , 2025. [37] J. Lee, J. Duan, H. F ang, Y. Deng, S. Liu, B. Li, B. F ang, J. Zhang, Y. R. W ang, S. Lee, et al. Molmoact: A ction reasoning mo dels that can reason in space. arXiv pr eprint arXiv:2508.07917 , 2025. [38] K. Li, Y. W ang, Y. He, Y. Li, Y. W ang, Y. Liu, Z. W ang, J. Xu, G. Chen, P . Luo, et al. Mvb enc h: A comprehensiv e multi-modal video understanding benchmark. In CVPR , 2024. [39] K. Li, Z. Meng, H. Lin, Z. Luo, Y. Tian, J. Ma, Z. Huang, and T.-S. Chua. Screensp ot-pro: Gui grounding for professional high-resolution computer use. In MM , 2025. [40] X. Li, Y. W ang, J. Y u, X. Zeng, Y. Zhu, H. Huang, J. Gao, K. Li, Y. He, C. W ang, Y. Qiao, Y. W ang, and L. W ang. Video c hat-flash: Hierarchical compression for long-context video modeling. arXiv pr eprint arXiv:2501.00574 , 2024. [41] Y. Li, J. Zhang, X. T eng, H. Zhang, X. Liu, and L. Lan. Refsam: Efficiently adapting segmenting an ything mo del for referring video ob ject segmen tation. Neural Networks , 2025. [42] K. Q. Lin, L. Li, D. Gao, Z. Y ang, S. W u, Z. Bai, W. Lei, L. W ang, and M. Z. Shou. Showui: One vision- language-action mo del for gui visual agen t, 2024. URL . [43] Y. Liu, S. Li, Y. Liu, Y. W ang, S. Ren, L. Li, S. Chen, X. Sun, and L. Hou. T emp compass: Do video llms really understand videos? In ACL , 2024. [44] Y. Liu, T. Qu, Z. Zhong, B. Peng, S. Liu, B. Y u, and J. Jia. Visionreasoner: Unified visual p erception and reasoning via reinforcemen t learning. arXiv pr eprint arXiv:2505.12081 , 2025. [45] J. Lu, C. Clark, R. Zellers, R. Mottaghi, and A. Kembha vi. Unified-io: A unified model for vision, language, and m ulti-mo dal tasks. arXiv pr eprint arXiv:2206.08916 , 2022. [46] J. Lu, C. Clark, S. Lee, Z. Zhang, S. Khosla, R. Marten, D. Hoiem, and A. Kembha vi. Unified-io 2: Scaling autoregressiv e multimodal mo dels with vision language audio and action. In CVPR , 2024. [47] P . Lu, H. Bansal, T. Xia, J. Liu, C. Li, H. Ha jishirzi, H. Cheng, K.-W. Chang, M. Galley , and J. Gao. Math Vista: Ev aluating mathematical reasoning of foundation mo dels in visual contexts. In ICLR , 2024. [48] J. Luiten, A. Osep, P . Dendorfer, P . T orr, A. Geiger, L. Leal-T aixé, and B. Leibe. Hota: A higher order metric for ev aluating multi-ob ject tracking. IJCV , 2021. [49] W. Ma, W. Ren, Y. Jia, Z. Li, P . Nie, G. Zhang, and W. Chen. Video ev al-pro: Robust and realistic long video understanding ev aluation. arXiv pr eprint arXiv:2505.14640 , 2025. [50] K. Mangalam, R. Akshulak o v, and J. Malik. Egosc hema: A diagnostic b enc hmark for very long-form video language understanding. In NeurIPS T r ack on Datasets and Benchmarks , 2023. [51] A. Masry , D. Long, J. Q. T an, S. Joty , and E. Ho que. ChartQA: A b enc hmark for question answ ering about c harts with visual and logical reasoning. In A CL , 2022. [52] M. Mathew, D. Karatzas, and C. Jaw ahar. Do cVQA: A dataset for V QA on do cumen t images. In W ACV , 2021. [53] M. Mathew, V. Bagal, R. Tito, D. Karatzas, E. V alven y , and C. Ja w ahar. InfographicV QA. In W ACV , 2022. [54] F. Meng, J. W ang, C. Li, Q. Lu, H. Tian, J. Liao, X. Zhu, J. Dai, Y. Qiao, P . Luo, K. Zhang, and W. Shao. Mmiu: Multimo dal m ulti-image understanding for ev aluating large vision-language models. In ICLR , 2025. [55] Op enAI. Collab orativ e user agreement, 2024. URL https://openai.com/policies/service- terms/ . Accessed: 2025-03-01. [56] Op enAI. GPT-5 system card, 2025. URL https://openai.com/index/gpt- 5- system- card/ . [57] V. Patraucean, L. Smaira, A. Gupta, A. Recasens, L. Markeev a, D. Banarse, S. Koppula, M. Malinowski, Y. Y ang, C. Do ersc h, et al. Perception test: A diagnostic b enc hmark for multimodal video mo dels. NeurIPS , 2023. 18 [58] Y. Qin, Y. Y e, J. F ang, H. W ang, S. Liang, S. Tian, J. Zhang, J. Li, Y. Li, S. Huang, et al. Ui-tars: Pioneering automated gui in teraction with nativ e agents. arXiv pr eprint arXiv:2501.12326 , 2025. [59] H. Rasheed, M. Maaz, S. Sha ji, A. Shak er, S. Khan, H. Cholakk al, R. M. An wer, E. Xing, M.-H. Y ang, and F. S. Khan. Glamm: Pixel grounding large multimodal model. In Pr o c ee dings of the IEEE/CVF Confer enc e on Computer Vision and Pattern R ec o gnition , pages 13009–13018, 2024. [60] N. Ravi, V. Gab eur, Y.-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. Rädle, C. Rolland, L. Gustafson, E. Mintun, J. Pan, K. V. Alwala, N. Carion, C.-Y. W u, R. Girshick, P . Dollár, and C. F eich tenhofer. Sam 2: Segment an ything in images and videos. In ICLR , 2025. [61] S. Seo, J.-Y. Lee, and B. Han. Urvos: Unified referring video ob ject segmen tation netw ork with a large-scale b enc hmark. In ECCV , 2020. [62] Z. Shangguan, C. Li, Y. Ding, Y. Zheng, Y. Zhao, T. Fitzgerald, and A. Cohan. T omato: Assessing visual temp oral reasoning capabilities in multimodal foundation mo dels. In ICLR , 2025. [63] A. Singh, V. Natarjan, M. Shah, Y. Jiang, X. Chen, D. P arikh, and M. Rohrbac h. T ow ards VQA mo dels that can read. In CVPR , 2019. [64] J. Su, M. Ahmed, Y. Lu, S. Pan, W. Bo, and Y. Liu. Roformer: Enhanced transformer with rotary p osition em b edding. Neur o c omputing , 2024. [65] Y. S u, H. Zhang, S. Li, N. Liu, J. Liao, J. P an, Y. Liu, X. Xing, C. Sun, C. Li, et al. Patc h-as-deco dable-tok en: T ow ards unified multi-modal vision tasks in mllms. arXiv pr eprint arXiv:2510.01954 , 2025. [66] Q. Sun, P . Hong, T. D. P ala, V. T oh, U.-X. T an, D. Ghosal, and S. P oria. Emma-x: An em b odied m ultimo dal action mo del with grounded chain of though t and lo ok-ahead spatial reasoning. In A CL , 2025. [67] J. T ang, Y. Xia, Y.-F. W u, Y. Hu, Y. Chen, Q. Chen, X. Xu, X. W u, H. Lu, Y. Ma, S. Lu, and Q. Chen. Lp o: T ow ards accurate gui agen t in teraction via lo cation preference optimization. ArXiv , abs/2506.09373, 2025. URL https://api.semanticscholar.org/CorpusID:279306118 . [68] V. T eam, W. Hong, W. Y u, X. Gu, G. W ang, G. Gan, H. T ang, J. Cheng, J. Qi, J. Ji, L. Pan, S. Duan, W. W ang, Y. W ang, Y. Cheng, Z. He, Z. Su, Z. Y ang, Z. P an, A. Zeng, B. W ang, B. Chen, B. Shi, C. P ang, C. Zhang, D. Yin, F. Y ang, G. Chen, J. Xu, J. Zhu, J. Chen, J. Chen, J. Chen, J. Lin, J. W ang, J. Chen, L. Lei, L. Gong, L. Pan, M. Liu, M. Xu, M. Zhang, Q. Zheng, S. Y ang, S. Zhong, S. Huang, S. Zhao, S. Xue, S. T u, S. Meng, T. Zhang, T. Luo, T. Hao, T. T ong, W. Li, W. Jia, X. Liu, X. Zhang, X. Lyu, X. F an, X. Huang, Y. W ang, Y. Xue, Y. W ang, Y. W ang, Y. An, Y. Du, Y. Shi, Y. Huang, Y. Niu, Y. W ang, Y. Y ue, Y. Li, Y. Zhang, Y. W ang, Y. W ang, Y. Zhang, Z. Xue, Z. Hou, Z. Du, Z. W ang, P . Zhang, D. Liu, B. Xu, J. Li, M. Huang, Y. Dong, and J. T ang. Glm-4.5v and glm-4.1v-thinking: T ow ards v ersatile m ultimo dal reasoning with scalable reinforcemen t learning. arXiv pr eprint arXiv:2507.01006 , 2025. [69] V. T eam, C. Gao, Z. Gu, Y. Liu, X. Qiu, S. Shen, Y. W en, T. Xia, Z. Xu, Z. Zeng, B. Zhou, X. Zhou, W. Chen, S. Dai, J. Dou, Y. Gong, Y. Guo, Z. Guo, F. Li, Q. Li, J. Lin, Y. Zhou, L. Zh u, L. Chen, Z. Guo, C. Meng, and W. W ang. Ui-ven us-1.5 technical rep ort. arXiv pr eprint arXiv:2602.09082 , 2026. [70] F. W ang, X. F u, J. Y. Huang, Z. Li, Q. Liu, X. Liu, M. D. Ma, N. Xu, W. Zhou, K. Zhang, et al. Muirb enc h: A comprehensiv e b enc hmark for robust multi-image understanding. In ICLR , 2025. [71] P . W ang, A. Y ang, R. Men, J. Lin, S. Bai, Z. Li, J. Ma, C. Zhou, J. Zhou, and H. Y ang. Ofa: Unifying arc hitectures, tasks, and modalities through a simple sequence-to-sequence learning framework. In International c onfer enc e on machine le arning , pages 23318–23340. PMLR, 2022. [72] W. W ang, Z. Gao, L. Gu, H. Pu, L. Cui, X. W ei, Z. Liu, L. Jing, S. Y e, J. Shao, et al. Intern vl3.5: Adv ancing op en-source m ultimo dal models in versatilit y , reasoning, and efficiency . arXiv pr eprint arXiv:2508.18265 , 2025. [73] W. W ang, Z. He, W. Hong, Y. Cheng, X. Zhang, J. Qi, M. Ding, X. Gu, S. Huang, B. Xu, et al. Lvb enc h: An extreme long video understanding benchmark. In ICCV , 2025. [74] X. W ang, B. W ang, D. Lu, J. Y ang, T. Xie, J. W ang, J. Deng, X. Guo, Y. Xu, C. H. W u, Z. Shen, Z. Li, R. Li, X. Li, J. Chen, B. Zheng, P . Li, F. Lei, R. Cao, Y. F u, D. Shin, M. Shin, J. Hu, Y. W ang, J. Chen, Y. Y e, D. Zhang, D. Du, H. Hu, H. Chen, Z. Zhou, H. Y ao, Z. Chen, Q. Gu, Y. W ang, H. W ang, D. Y ang, V. Zhong, F. Sung, Y. Charles, Z. Y ang, and T. Y u. Op encua: Op en foundations for computer-use agen ts. arXiv pr eprint arXiv:2508.09123 , 2025. 19 [75] H. W u, D. Li, B. Chen, and J. Li. Longvideob enc h: A b enc hmark for long-con text in terleav ed video-language understanding. In NeurIPS , 2024. [76] Q. W u, K. Cheng, R. Y ang, C. Zhang, J. Y ang, H. Jiang, J. Mu, B. P eng, B. Qiao, R. T an, et al. Gui-actor: Co ordinate-free visual grounding for gui agen ts. arXiv pr eprint arXiv:2506.03143 , 2025. [77] Z. W u, Z. W u, F. Xu, Y. W ang, Q. Sun, C. Jia, K. Cheng, Z. Ding, L. Chen, P . P . Liang, et al. Os-atlas: A foundation action model for generalist gui agents. arXiv pr eprint arXiv:2410.23218 , 2024. [78] xAI. RealW orldQA. https://huggingface.co/datasets/xai- org/RealworldQA , 2024. Accessed: 2024-09-24. [79] J. Xiao, X. Shang, A. Y ao, and T.-S. Ch ua. Next-qa: Next phase of question-answ ering to explaining temporal actions. In CVPR , 2021. [80] T. Xie, J. Deng, X. Li, J. Y ang, H. W u, J. Chen, W. Hu, X. W ang, Y. Xu, Z. W ang, Y. Xu, J. W ang, D. Sahoo, T. Y u, and C. Xiong. Scaling computer-use grounding via user in terface decomposition and synthesis. arXiv pr eprint arXiv:2505.13227 , 2025. [81] T. Xie, J. Deng, X. Li, J. Y ang, H. W u, J. Chen, W. Hu, X. W ang, Y. Xu, Z. W ang, Y. Xu, J. W ang, D. Sahoo, T. Y u, and C. Xiong. Scaling computer-use grounding via user in terface decomposition and synthesis. arXiv pr eprint arXiv:2505.13227 , 2025. [82] C. Y an, H. W ang, S. Y an, X. Jiang, Y. Hu, G. Kang, W. Xie, and E. Gavv es. Visa: Reasoning video ob ject segmen tation via large language models. In ECCV , 2024. [83] A. Y ang, B. Y ang, B. Hui, B. Zheng, B. Y u, C. Zhou, C. Li, C. Li, D. Liu, F. Huang, G. Dong, H. W ei, H. Lin, J. T ang, J. W ang, J. Y ang, J. T u, J. Zhang, J. Ma, J. Xu, J. Zhou, J. Bai, J. He, J. Lin, K. Dang, K. Lu, K. Chen, K. Y ang, M. Li, M. Xue, N. Ni, P . Zhang, P . W ang, R. Peng, R. Men, R. Gao, R. Lin, S. W ang, S. Bai, S. T an, T. Zhu, T. Li, T. Liu, W. Ge, X. Deng, X. Zhou, X. Ren, X. Zhang, X. W ei, X. Ren, Y. F an, Y. Y ao, Y. Zhang, Y. W an, Y. Chu, Y. Liu, Z. Cui, Z. Zhang, and Z. F an. Qw en2 technical report. arXiv pr eprint arXiv:2407.10671 , 2024. [84] A. Y ang, A. Li, B. Y ang, B. Zhang, B. Hui, B. Zheng, B. Y u, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. W ei, H. Lin, J. T ang, J. Y ang, J. T u, J. Zhang, J. Y ang, J. Y ang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Y ang, L. Y u, L. Deng, M. Li, M. Xue, M. Li, P . Zhang, P . W ang, Q. Zh u, R. Men, R. Gao, S. Liu, S. Luo, T. Li, T. T ang, W. Yin, X. Ren, X. W ang, X. Zhang, X. Ren, Y. F an, Y. Su, Y. Zhang, Y. Zhang, Y. W an, Y. Liu, Z. W ang, Z. Cui, Z. Zhang, Z. Zhou, and Z. Qiu. Qwen3 technical rep ort. arXiv pr eprint arXiv:2505.09388 , 2025. [85] B. Y ang, B. W en, B. Ding, C. Liu, C. Chu, C. Song, C. Rao, C. Yi, D. Li, D. Zang, et al. Kw ai key e-vl 1.5 tec hnical rep ort. arXiv pr eprint arXiv:2509.01563 , 2025. [86] J. Y ang, C. K. F u, D. Shah, D. Sadigh, F. Xia, and T. Zhang. Bridging p erception and action: Spatially-grounded mid-lev el representations for robot generalization. arXiv pr eprint arXiv:2506.06196 , 2025. [87] W. Y ang and Z. Huang. Poivre: Self-refining visual p oin ting with reinforcement learning. arXiv pr eprint arXiv:2509.23746 , 2025. [88] Y. Y ang, Y. W ang, D. Li, Z. Luo, B. Chen, C. Huang, and J. Li. Aria-ui: Visual grounding for gui instructions. arXiv pr eprint arXiv:2412.16256 , 2024. [89] Y. Y ang, D. Li, Y. Y ang, Z. Luo, Y. Dai, Z. Chen, R. Xu, L. Pan, C. Xiong, and J. Li. Grp o for gui grounding done right, 2025. URL https://huggingface.co/HelloKKMe/GTA1- 7B . [90] Y. Y ang, A. Patel, M. Deitke, T. Gupta, L. W eihs, A. Head, M. Y atsk ar, C. Callison-Burch, R. Krishna, A. Kembha vi, et al. Scaling text-ric h image understanding via co de-guided syn thetic multimodal data generation. In ACL , 2025. [91] T. Y u, Z. W ang, C. W ang, F. Huang, W. Ma, Z . He, T. Cai, W. Chen, Y. Huang, Y. Zhao, B. Xu, J. Cui, Y. Xu, L. Ruan, L. Zhang, H. Liu, J. T ang, H. Liu, Q. Guo, W. Hu, B. He, J. Zhou, J. Cai, J. Qi, Z. Guo, C. Chen, G. Zeng, Y. Li, G. Cui, N. Ding, X. Han, Y. Y ao, Z. Liu, and M. Sun. Minicpm-v 4.5: Co oking efficient mllms via architecture, data, and training recipe. arXiv pr eprint arXiv:2509.18154 , 2025. [92] H. Y uan, X. Li, T. Zhang, Z. Huang, S. Xu, S. Ji, Y. T ong, L. Qi, J. F eng, and M.-H. Y ang. Sa2v a: Marrying sam2 with llav a for dense grounded und erstanding of images and videos. arXiv preprint , 2025. [93] W. Y uan, J. Duan, V. Blukis, W. Pumaca y , R. Krishna, A. Murali, A. Mousa vian, and D. F ox. Rob opoint: A vision-language mo del for spatial affordance prediction for robotics. In CoRL , 2024. 20 [94] X. Y uan, J. Zhang, K. Li, Z. Cai, L. Y ao, J. Chen, E. W ang, Q. Hou, J. Chen, P .-T. Jiang, and B. Li. Enhancing visual ground ing for gui agents via self-evolutionary reinforcement learning. ArXiv , abs/2505.12370, 2025. URL https://api.semanticscholar.org/CorpusID:278739769 . [95] X. Y ue, Y. Ni, K. Zhang, T. Zheng, R. Liu, G. Zhang, S. Stevens, D. Jiang, W. Ren, Y. Sun, C. W ei, B. Y u, R. Y uan, R. Sun, M. Yin, B. Zheng, Z. Y ang, Y. Liu, W. Huang, H. Sun, Y. Su, and W. Chen. MMMU: A massiv e multi-discipline multimodal understanding and reasoning b enc hmark for exp ert AGI. In CVPR , 2024. [96] B. Zhang, B. Zhang, B. W ang, W. Zheng, Y. Cheng, L. T ang, Y. Y an, J. Zhou, and J. Lu. Manicog: T raining-free impro vemen t for gui grounding via manipulation c hains. 2026. [97] Y. Zhang, J. W u, W. Li, B. Li, Z. Ma, Z. Liu, and C. Li. Llav a-video: Video instruction tuning with synthetic data. TMLR , 2025. [98] Y. Zhang, L. Zhang, R. Ma, and N. Cao. T exverse: A univ erse of 3d ob jects with high-resolution textures. arXiv pr eprint arXiv:2508.10868 , 2025. [99] Y. Zhao, A. Gu, R. V arma, L. Luo, C.-C. Huang, M. Xu, L. W right, H. Sho janazeri, M. Ott, S. Sh leifer, et al. Pytorc h fsdp: Exp eriences on scaling fully sharded data parallel. arXiv pr eprint arXiv:2304.11277 , 2023. [100] H. Zhou, X. Zhang, P . T ong, J. Zhang, L. Chen, Q. K ong, C. Cai, C. Liu, Y. W ang, J. Zhou, and S. Hoi. Mai-ui tec hnical rep ort: Real-w orld centric foundation gui agents. arXiv pr eprint arXiv:2512.22047 , 2025. [101] J. Zhou, Y. Shu, B. Zhao, B. W u, Z. Liang, S. Xiao, M. Qin, X. Y ang, Y. Xiong, B. Zhang, et al. Mlvu: Benc hmarking multi-task long video understanding. In CVPR , 2025. 21 Table 10 Updated top-level sampling rates . F or MolmoPo int-8B we sligh tly reduce the sampling rates on p oin ting tasks since w e observ e faster conv ergence of these tasks. Each of these categories consists of its own sub-mixture of datasets. W e lea ve the sampling ratios within those submixtures unc hanged. See [ 19 ] for the full list. Dataset Group MolmoPoint-8B Molmo2 Captioning/Long QA 15.0 13.6 Image QA 25.0 22.7 Video QA 20.0 18.2 Image Poin ting 7.0 9.1 Video Poin ting 11.0 13.6 Video T rac king 12.0 13.6 NLP 10.0 9.1 Appendix This app endix incl udes the following sections: • § 7 - T raining Details • § 8 - VideoP oin t Human Ev al • § 9 - Multi-T ask Results • § 10 - MolmoP oin t-GUISyn Details • § 11 - MolmoP oin t-T rac k Details 7 Training Details Our training pip eline largely follows Molmo2, with a few differences to account for the hardware we ha ve a v ailable, impro v e efficiency , and take adv antage of the increased learning sp eed when using grounding tok ens. W e also expand the tracking data from Molmo2 to improv e trac king robustness. W e discuss the training c hanges b elo w, see Section 11 for details on the tracking data. Pre-training. W e improv e packing efficiency by allo wing up to 16 images p er input sequence. W e reduce the total n umber of training steps from 32k to 23k to k eep the n um b er of examples seen unchanged. W e use a learning rate of 1e − 4 with a w arm up of 200 for the p oin ting parameters. SFT. W e sligh tly t weak the mixture rates of Molmo2 because preliminary exp erimen ts show ed that grounding tasks conv erged significantly faster when using grounding tokens. W e do this b y adjusting the top-level sampling rates used in the Molmo2 training pip eline; see T able 10 . W e also train for 22k steps with a batch size of 160 instead of 30k steps with a batch size of 128, which reduces the n umber of examples seen by about 8.3%. W e still use a learning rate of 1e − 4 for the p oin ting parameters. Long-context SFT. W e train with a batc h size of 160 instead of 128, and w e train with a maxim um of 384 frames and 16384 tok ens p er training example, follo wing Molmo2. Specialized models. Both MolmoPoin t-Vid-8B and MolmoPoin t-GUI-8B used the same optimizer settings as the SFT mo del. W e train MolmoPoin t-GUI-8B for 2000 steps with a batc h size of 128 and a maximum of 48 crops p er image on MolmoPoin t-GUISyn. W e train MolmoPoin t-Vid-8B using the same pre-training stage, and then training on just the Video P oin t dataset group from Molmo2 for 6000 steps and a batc h size of 64, and then for another 800 steps with a maxim um of 384 frames. Training times . F ull training times are shown in T able 11 . All training was done on B200 GPUs. F ollowing Molmo2, w e use PyT orc h with T orch’s F ully Sharded Data Parallel (FSDP) 2 [ 99 ] for distributed training 22 Table 11 Training times . Columns sho w the mo del, the training phase, gpu counts, training hours, total GPU hours, batc h size, the estimated n um b er of multi-modal inputs that w ere seen (separately coun ting inputs that w ere pac k ed together), and the estimated num b er of training annotations that were seen (separately coun ting annotations that w ere merged in to message trees). Model phase Hardware GPUs hours GPU hr. batch steps mm. annotations MolmoP oint-8B Pretrain B200 32 10.3 330 128 23k 4.6m 14m MolmoP oint-8B SFT B200 80 86.4 6.9k 160 22k 13m 49m MolmoP oint-8B SFT-LC B200 80 36.2 2.9k 160 2k 2.2m 7.5m MolmoP oint-GUI-8B SFT B200 32 9.4 300 128 2k 360k 11m MolmoP oint-Vid-8B Pretrain H100 32 10.1 323 128 23k 3.5m 6.6m MolmoP oint-Vid-8B SFT B200 32 13.7 437 64 6k 1.4m 5.1m MolmoP oint-Vid-8B SFT-LC B200 32 12.5 400 64 800 170k 270k and the Automatic Mixed Precision (AMP) module 1 for mixed precision training. W e do not use sequence- parallelism since w e found that a long-con text mo del can fit on the B200 GPUs with just FSDP . 8 VideoPoint Human Evaluation W e perform an internal h uman preference ev aluation with tw o annotators (tw o of the authors) on the video p oin ting outputs of tw o mo dels – MolmoPoin t-8B and the text co ordinate baseline. W e first manually design the test set by selecting 271 challenging video-query pairs from Molmo2-VideoCoun tEv al [ 19 ] and writing 199 new queries for the videos in Molmo2-VideoCaptionEv al, resulting in a total of 470 examples in this human preference ev aluation dataset. W e develop a simple annotation interface to collect pair-wise preferences on this ev aluation dataset following standard practice [ 17 ], where the ordering of mo dels a and b is randomized, and four choices are allow ed: mo del a is b etter; mo del b is b etter; b oth are go od; or b oth are bad. After collecting all preferences, we then compute the win rate of MolmoPoin t-8B against the baseline, excluding ties (i.e., b oth go o d or both bad). 9 Multi-Task Results W e present the full set of video results in T able 12 . Comparing Molmo2 and MolmoPoin t-8B on video QA, we see mixed outcomes on the long-video QA b enc hmarks (ML VU (+2.2), Video-MME-SUB (+1.1), VideoEv alPro (-2.4)) and on short-video temp oral understanding b enc hmarks (T empCompass (+1.0), T omato (-2.3)), with results b eing ab out the same elsewhere. W e do not see a clear pattern in these results and conclude that the mo dels perform very similarly . The full set of image b enc hmarks is shown in T able 13 . Compared to Molmo2, we see notable gains on some high-res/OCR-tasks (InfoQa (+2.9), Ai2D (+0.8), ChartQA (+0.8)) and a sligh t drop in coun ting benchmarks (Coun tBenc h (-0.8), PixMoCoun t (-0.9)). The consisten t gain on high-res/OCR tasks suggests that grounding tok ens impro ved transfer from the p oin ting training datasets to these tasks, which con tinues the theme of impro ving high-res OCR-hea vy tasks that we observ e with GUI p oin ting. W e attribute the slight drop in coun ting to the o ccasional off-b y-one errors we observ e when coun ting high-frequency ob jects (see Figure 6 in the main pap er). There is a significant drop in video captioning p erformance. How ev er, when we chec k image-captioning p erformance, we see the opposite: 54.47 for MolmoP oin t-8B vs 53.62 for Molmo2, using the F1 captioning metric from [ 22 ]. This again suggests that the w ay grounding tok ens affect video and image p erformance differs. 1 https://docs.pytorch.org/docs/stable/amp.html 23 Table 12 Video benchmark results for a range of proprietary APIs, op en-w eight baselines, fully-op en baselines, Molmo2, and MolmoPoin t-8B across video understanding, captioning, and coun ting benchmarks. The b est-performing op en-w eight mo del is in bold , and the second-b est is underlined . F or MolmoPoin t-8B, w e rep ort PerceptionT est v al since the test server is no longer operational. Model NextQA test [ 79 ] PerceptionTest test [ 57 ] MVBench test [ 38 ] Tomato test [ 62 ] MotionBench v al [ 31 ] TempCompass test MCQ [ 43 ] Video-MME test [ 25 ] Video-MME-Sub test [ 25 ] LongVideoBench v al [ 75 ] MLVU test MCQ [ 101 ] LVBench test [ 73 ] VideoEvalPro test [ 49 ] Ego Schema test [ 50 ] Molmo2 Caption test F1 Score Molmo2 Count v al accuracy Short QA avg. Long QA avg. Average API call only GPT-5 [ 56 ] 86.3 79.4 74.1 53.0 65.4 80.4 83.3 86.9 72.6 77.7 65.2 68.8 75.6 50.1 35.8 73.1 76.3 70.6 GPT-5 mini [ 56 ] 83.2 72.0 66.5 44.1 59.9 74.9 77.3 82.3 69.7 69.1 54.7 60.1 70.9 56.6 29.8 66.8 69.8 65.0 Gemini 3 Pro [ 28 ] 84.3 77.6 70.4 48.3 62.6 82.8 88.6 87.5 75.9 75.7 77.0 78.0 68.9 36.0 37.1 71.0 78.8 70.0 Gemini 2.5 Pro [ 20 ] 85.3 78.4 70.6 48.6 62.0 81.9 87.8 87.8 76.8 81.5 75.7 78.4 72.2 42.1 35.8 71.1 80.4 71.2 Gemini 2.5 Flash [ 20 ] 81.8 74.7 67.0 39.1 59.3 80.2 84.2 84.2 73.1 75.1 64.9 69.6 70.2 46.0 31.9 67.0 74.5 66.7 Claude Sonnet 4.5 [ 4 ] 79.2 64.3 62.1 39.6 58.5 72.8 74.2 80.5 65.1 64.0 50.5 50.5 73.1 26.0 27.2 62.8 66.4 59.6 Open weights Intern VL3.5-4B [ 72 ] 80.3 68.1 71.2 26.8 56.5 68.8 65.4 68.6 60.8 52.0 43.2 46.5 58.9 7.7 26.3 62.0 56.5 53.4 Intern VL3.5-8B [ 72 ] 81.7 72.7 72.1 24.6 56.6 70.3 66.0 68.6 62.1 53.2 43.4 48.1 58.6 7.8 26.1 63.0 57.1 54.1 Qwen3-VL-4B [ 84 ] 81.4 70.7 68.9 31.8 58.6 70.8 69.3 74.0 62.8 58.4 56.2 49.8 68.4 25.2 25.3 63.7 62.7 58.1 Qwen3-VL-8B [ 84 ] 83.4 72.7 68.7 35.7 56.9 74.3 71.4 75.2 62.4 57.6 58.0 50.3 69.8 26.7 29.6 65.3 63.5 59.5 Keye-VL-1.5-8B [ 85 ] 75.8 64.2 56.9 33.0 55.1 75.5 73.0 76.2 66.0 53.8 42.8 54.9 56.3 25.4 27.2 60.1 60.4 55.7 GLM-4.1V-9B [ 68 ] 81.3 74.2 68.4 30.0 59.0 72.3 68.2 75.6 65.7 56.6 44.0 51.1 62.6 18.4 26.6 64.2 60.5 56.9 MiniCPM-V-4.5-8B [ 91 ] 78.8 70.9 60.5 29.8 59.7 72.7 67.9 73.5 63.9 60.6 50.4 54.9 49.6 29.3 26.3 62.1 60.1 56.6 Eagle2.5-8B [ 13 ] 85.0 81.0 74.8 31.0 55.7 74.4 72.4 75.7 66.4 60.4 50.9 58.6 72.2 22.8 28.9 67.0 65.2 60.7 Fully open PLM-3B [ 18 ] 83.4 79.3 74.7 30.9 60.4 69.3 54.9 59.4 57.9 48.4 40.4 46.2 66.9 12.3 24.4 66.3 53.5 53.9 PLM-8B [ 18 ] 84.1 82.7 77.1 33.2 61.4 72.7 58.3 65.4 56.9 52.6 44.5 47.2 68.8 10.9 26.6 68.5 56.2 56.2 LLaV A-Video-7B [ 97 ] 83.2 68.8 58.6 24.9 54.2 66.6 63.3 69.7 58.2 52.8 44.2 47.8 57.3 19.9 21.4 59.4 56.2 52.7 VideoChat-Flash-7B [ 40 ] 85.5 76.5 74.0 32.5 60.6 69.4 65.3 69.7 64.7 56.0 48.2 51.2 51.3 14.8 21.6 66.4 58.1 56.1 Molmo2-4B 85.5 81.3 75.1 39.8 61.6 72.8 69.6 75.7 68.0 63.0 53.9 59.9 61.2 39.9 34.3 69.3 64.5 62.8 Molmo2-8B 86.2 82.1 75.9 39.6 62.2 73.4 69.9 75.8 67.5 60.2 52.8 60.4 62.0 43.2 35.5 69.9 64.1 63.1 Molmo2-O-7B 84.3 79.6 74.8 36.2 60.6 73.0 64.9 69.2 63.7 55.2 49.6 55.1 56.8 40.1 33.2 68.1 59.2 59.7 MolmoPoint MolmoPoin t-8B 86.3 82.3 ∗ 75.2 37.3 61.4 74.4 69.6 76.9 67.3 62.4 52.5 58.0 63.0 40.3 35.6 69.5 64.2 63.5 10 MolmoPoint-GUISyn Details W e show the data generation pip eline of MolmoPoin t-GUISyn in Figure 3 . The input to the pip eline is a natural language query , e.g., “a screenshot of AutoCAD”, which will b e paired with a randomly selected p ersona from PersonaHub [ 27 ] (e.g., a Sci-fi novelist )to diversify its con ten t and st yle. W e systematically construct a comprehensiv e list of queries b y considering screenshot types (desktop, w eb, mobile), task domains (different w ebsites, Apps, soft w are), platforms (Windows, macOS, iOS, Android, etc.), asp ect ratios (4:3, 16:9, etc.), resolutions (720p, 1080p, 4K, etc.), and stages during a task (early , middle, end). W e randomly sample and combine those fields to construct inputs that span a broad range of scenarios in the digital w orld. W e feed the query into our prompt template, and an LLM outputs the corresp onding HTML code to render the screenshot. W e run customized Ja v aScript on the HTML co de to extract the bounding b o xes for all visible elemen ts in the screenshot. Each bounding b o x contains the syn thetic lab el from its naming attributes in HTML, the corresp onding lines of co de for this element, the (x, y) center, and the (width, height) of the box. 24 Table 13 Image benchmark results for a range of proprietary APIs, op en-w eight baselines, and MolmoPoin t-8B across a range of image understanding and coun ting b enc hmarks. The result of the best-p erforming open-weigh t mo del is in bold , and the second best is underlined. Model AI2D test [ 33 ] ChartQA test [ 51 ] DocVQA test [ 52 ] InfoQA test [ 53 ] TextVQA v al [ 63 ] VQA v2.0 v al [ 30 ] RWQA [ 78 ] MMMU v al [ 95 ] MathVista testmini [ 47 ] CountBench [ 8 ] PixMoCount test [ 22 ] MuirBench [ 70 ] MMIU [ 54 ] Blink v al [ 26 ] Img QA avg. MultiImg QA avg. Average API call only GPT-5 [ 56 ] 89.5 83.8 88.9 83.0 78.7 79.7 80.8 81.8 82.7 90.8 67.2 78.6 71.0 66.5 82.5 72.1 80.2 GPT-5 mini [ 56 ] 86.7 82.1 86.7 82.2 79.1 72.1 77.0 78.7 79.2 87.1 74.4 71.4 64.5 68.7 80.5 68.2 77.8 Gemini 2.5 Pro [ 20 ] 94.3 77.8 91.5 82.0 70.3 67.1 77.4 79.6 84.6 90.8 73.8 74.5 68.9 73.7 80.8 72.4 79.0 Gemini 2.5 Flash [ 20 ] 95.9 76.8 91.1 80.9 73.0 69.4 74.5 79.0 81.2 86.7 63.9 73.5 61.2 70.2 79.3 68.3 76.9 Claude Sonnet 4.5 [ 4 ] 91.5 80.2 91.7 65.9 67.2 77.0 61.1 77.8 73.1 87.3 58.3 59.6 54.1 64.8 75.6 59.5 72.1 Open weights only Intern VL3.5-4B [ 72 ] 82.6 86.0 92.4 78.0 77.9 78.1 66.3 66.6 77.1 82.2 62.4 53.1 49.2 58.1 77.2 53.5 72.1 Intern VL3.5-8B [ 72 ] 84.0 86.7 92.3 79.1 78.2 79.5 67.5 73.4 78.4 79.6 61.9 55.8 49.4 59.5 78.2 54.9 73.2 Qwen3-VL-4B [ 84 ] 84.1 85.0 95.3 80.3 81.0 81.7 70.9 67.4 73.7 85.5 58.0 63.8 43.2 65.8 78.4 57.6 74.0 Qwen3-VL-8B [ 84 ] 85.7 85.2 96.1 83.1 82.8 82.3 71.5 69.6 77.2 90.4 65.0 64.4 35.3 69.1 80.8 56.3 75.6 Keye-VL-1.5-8B [ 85 ] 89.5 85.0 93.4 74.9 81.5 79.3 73.5 71.4 81.2 81.6 57.4 51.2 50.3 54.9 79.0 52.1 73.2 GLM-4.1V-9B [ 68 ] 87.9 70.0 93.3 80.3 79.6 68.3 70.7 68.0 80.7 88.0 60.7 74.7 62.4 65.1 77.0 67.4 75.0 MiniCPM-V-4.5-8B [ 91 ] 86.5 87.4 94.7 73.4 82.2 64.1 72.1 67.7 79.9 83.9 62.8 53.3 46.5 42.0 77.7 47.3 71.2 Eagle2.5-8B [ 13 ] 84.5 87.5 94.1 80.4 83.7 82.4 76.7 55.8 67.8 90.2 66.9 61.8 48.4 45.8 79.1 52.0 73.3 Fully open PLM-3B [ 18 ] 90.9 84.3 93.8 74.6 84.3 84.4 72.4 41.2 59.1 87.1 63.0 25.7 40.6 55.4 75.9 40.6 68.3 PLM-8B [ 18 ] 92.7 85.5 94.6 80.0 86.5 85.6 75.0 46.1 59.9 91.8 68.0 23.5 27.4 56.0 78.7 35.7 69.5 Molmo2-4B 95.6 86.1 87.8 78.6 85.0 86.6 75.4 50.9 56.7 93.9 88.1 60.5 55.5 57.5 80.4 57.8 75.6 Molmo2-8B 95.8 86.0 93.2 80.1 85.7 87.0 77.6 53.0 58.9 93.7 88.5 63.7 54.2 51.3 81.7 56.4 76.3 MolmoPoin t-8B-O-7B 93.7 84.9 90.4 77.9 84.7 86.6 73.6 45.8 54.2 95.1 88.9 58.4 51.7 50.5 79.7 53.5 74.1 MolmoPoint MolmoPoin t-8B 96.4 86.8 93.8 83.0 86.0 87.2 77.4 53.7 59.4 92.9 87.6 62.5 54.6 50.8 82.2 56.0 76.6 W e feed this information back to the LLM to annotate each element with a natural language name (e.g., “Measure Button”) and 5 differen t in ten ts that a real user might ask when interacting with this elemen t. W e use claude-sonnet-4.6 as our co ding LLM to generate MolmoP oint-GUISyn, whic h costs ab out $0.2 p er example, with an a verage of 54 p oin ting annotations. Figure 8 demonstrates the qualitativ e examples from MolmoP oin t-GUISyn. 11 MolmoPoint-Track Details Here, we detail the data generation pip eline for MolmoP oint-T rack, whic h comprises t w o complementary data sources: (1) MolmoPoin t-T rackAn y, h uman-annotated tracks co v ering a broad range of vide os and ob ject categories, and (2) MolmoPoin t-T rackSyn, synthetically generated ob ject tracks featuring complex occlusion patterns and motion dynamics. 11.1 MolmoPoint-TrackAny: Human Annotated Tracks T o extend trac king annotations b ey ond existing datasets, we develop a h uman-in-the-lo op pip eline for annotating ob ject trac ks in real videos. Annotating point trac ks from scratch is both costly and difficult to qualit y-con trol; for multi-ob ject scenes, annotators must iden tify unique instances, track them simultaneously , and handle highly v ariable workloads across videos. How ever, if the ob jects of in terest and their coun t are kno wn in adv ance, the task simplifies to tracking a single designated ob ject at a time. Sp ecifically , we lev erage the Molmo2-VideoPoin t data, which already provides distinct iden tities for each text query , and extend single-frame p oin ts into full trac ks. Figure 4 illustrates the o v erall data generation pip eline. Eac h annotation task pro vides the annotator with the video, the input p oin t for the ob ject of interest, and all 25 … red too lbo xes routers with dual anten n a s ca p-wearing fi g ures Stati c Ca m e r a Dynamic Came ra bas k ets t = 0. 0s t = 0 .5s t = 1. 5s t = 2. 0s t = 0. 0s t = 0 .5s t = 1. 5s t = 2. 0s … … … t = 3. 0s t = 3 .5s t = 4. 5s t = 5. 0s t = 0. 0s t = 0. 5s t = 4.5 s t = 5. 0s Figure 7 Examples from MolmoPoint-TrackSyn data. Ob ject tracks, text queries, and videos are generated syn thetically with static and dynamic camera viewpoints. other annotated p oin ts for context. Annotators trac k one ob ject at a time while viewing the surrounding p oin ts, which helps prev ent duplicate trac ks for the same instance, particularly in am biguous cases in v olving shot c hanges or visually similar ob jects. By reducing the cognitive load to single-ob ject tracking, annotators no longer need to join tly iden tify and track multiple ob jects. In the end, our annotation consists of 13K videos with 17K text queries and an av erage of 6.7 unique ob jects per video, accompanied b y div erse tracks with re-iden tification in shot c hanges, part-lev el ob jects, and complex referring expressions. 11.2 MolmoPoint-TrackSyn: Synthetic Object Tracks and Videos W e generate synthetic multi-ob ject trac king videos in Blender using tw o pip elines: a static-camera pip eline and a moving-camera pipeline (see Figure 7 for examples). In b oth cases, eac h video is rendered with configurable duration, frame rate, resolution, and physically based rendering settings, and the pip eline outputs RGB frames together with p er-instance binary masks derived from Blender’s ob ject-index pass. The static-camera v ersion uses a fixed camera pose and samples ob ject tra jectories relativ e to a camera-a ware frustum, while the mo ving-camera v ersion extends this setup with a smo othly animated camera and frame-dep enden t wa yp oin t planning so that visibilit y constraints are enforced with resp ect to the camera motion at each wa yp oin t. After generation with div erse motion patterns, the frames are then enco ded uniformly in to videos as 6 fps. In b oth pip elines, 3D assets are sampled from T exV erse [ 98 ] after automatic caption-based filtering with GPT. The filter keeps only indep enden tly track able ob jects and remo v es scenes, backgrounds, abstract assets, o v ersized context assets, and collections of unrelated ob jects, while also assigning noun-only semantic categories to retained assets. F or eac h video, we first build category-specific p ools from the filtered assets, randomly c ho ose 1–3 categories, allo cate the requested num b er of ob jects across these categories, and then sample distinct assets accordingly . This category-based sampling encourages seman tic div ersit y within each sequence while a v oiding duplicate ob ject identities. After selection, assets are imp orted, merged if needed, normalized to a target scale, cen tered, and placed on the ground plane. The scene is rendered with randomized ligh ting and camera parameters. Ob ject motion is generated b y sampling wa yp oin t-based tra jectories under camera-aw are visibility constraints, so ob jects can b e forced to sta y visible or mov e off-screen for selected time spans. The moving-camera pipeline further animates the camera along a smo oth tra jectory and recomputes visibility constraints with resp ect to the camera p ose ov er time. F or eac h sequence, we render R GB frames and p er-instance segmen tation masks, then con v ert the masks in to frame-wise trac king annotations with consistent ob ject iden tities across time. After syn thesizing the videos, w e automatically generate language queries from the selected ob ject captions asso ciated with each sequence. F or every video, we collect the source captions of all sampled ob jects and prompt GPT to produce 0–3 referring queries, where eac h query m ust describ e a group con taining at least t w o ob jects. The query generator is constrained to pro duce concise group-level noun phrases rather than en umerations, a v oid explicit coun ts, and av oid references to ob ject parts, scenes, camera state, or temporal ev en ts. It ma y use either shared fine-grained t yp es (e.g., the to olboxes) or higher-lev el categories (e.g., the v ehicles) when grouping ob jects. The resulting queries are then matched back to ob ject identities and stored 26 together with the video path and frame-wise tracking annotations, yielding language-conditioned m ulti-ob ject trac king examples. After generating the segmentation masks, w e extract the center of the largest connected comp onen t to obtain the p oin t tracks. Overall, w e ha v e 76k unique queries for 25k videos as our training data, with an av erage of 3.3 unique ob jects p er video. 27 N a m e : A s s em b l y T a b I nt e nt : S w i t c h t o t h e as s em b l y w o r k s p ace. N a m e : V 3 V i d e o T r a ck I nt e nt : I d en t i f y t h e V 3 V i d eo T r a ck L a b el N a m e : A 2 A u d i o T r a ck I nt e nt : T a r g et t h e A 2 A u d i o T r a ck f o r ed i t i n g N a m e : S c r u b b er I nt e nt : D r a g t o c h an g e t h e f r am e . N a m e : Pl a y B u t t o n I nt e nt : C li ck t o p au s e/ p l a y c l i p . N a m e : U s er A v a t a r I nt e nt : S h o w p r o f i l e o p t i o n s u s e a v a t a r . N a m e : I n c r ea s e G r o u p I nt e nt : I n c r ea t e t h e g r o u p s i z e. N a m e : N ex t Mo n t h b u t t o n I nt e nt : Mo v e t o t h e d a t es i n S ep t e m b er N a m e : C a l l en d er Da y 1 7 I nt e nt : C h a n g e t o O ct o b er 1 7 f o r t h e en d d a t e. N a m e : Dy n a m i c Is la n d A r ea I nt e nt : T a p t h e d y n a m i c i s lan d t o ch eck n o t i f i ca t i o n . N a m e : Med i u m Per i o d Fl o w B u t t o n I nt e nt : L o g t o d a y ’ s f l o w a s m ed i u m . N a m e : H ea d a c h e S y m p t o m B u t t o n I nt e nt : Ma r k h ea d a ch e a s ex p er i en ced t o d a y . N a m e : Mo r e S y m p t o m B u t t o n I nt e nt : T a p t o s ee m o r e s y m p t o m s . N a m e : C a l m Mo o d L o g B u t t o n I nt e nt : T o g g l e t h e cl a m m o o d e n t r y f o r t o d a y . N a m e : S e a r c h N o t e I n p u t I nt e nt : T y p e i n t h e s e a r ch b o x t o f i n d n o t es . N a m e : B a ck t o L i s t B u t t o n I nt e nt : N a v i g a t e b a c k t o t h e l i s t o f n o t es p a g e. N a m e : E x p o r t N o t e B u t t o n I nt e nt : E x p o r t t h e n o t e a s PD F o f o t h e r f o r m a t s . N a m e : N ex t T r a ck B u t t o n I nt e nt : A d v an c e t o t h e n ex t t r a ck i n t h e q u eu e N a m e : Fr ee T i e r B u t t o n I nt e nt : T a p t h e f r ee t i er b u t t o n t o ex p l o r e o t h e r p l a n o p t i o n s . Figure 8 Qualitative examples of MolmoPoint-GUISyn. W e demonstrate GUI grounding examples for desktop, web, and mobile screenshots. 28
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment