MolmoPoint 더 나은 포인팅을 위한 그라운딩 토큰
MolmoPoint은 좌표를 텍스트로 생성하는 대신 시각 토큰을 직접 선택하는 그라운딩 토큰 방식을 도입한다. <PATCH>, <SUBPATCH>, <LOCATION> 세 가지 특수 토큰을 순차적으로 발행해 coarse‑to‑fine 포인팅을 수행하고, Rotary Embedding과 no‑more‑points 클래스로 순서와 종료를 제어한다. 이미지, GUI, 비디오 등 다양한 도메인에서 기존 좌표 기반 VLM을 크게 앞서는 성능을 기록했으며…
저자: Christopher Clark, Yue Yang, Jae Sung Park
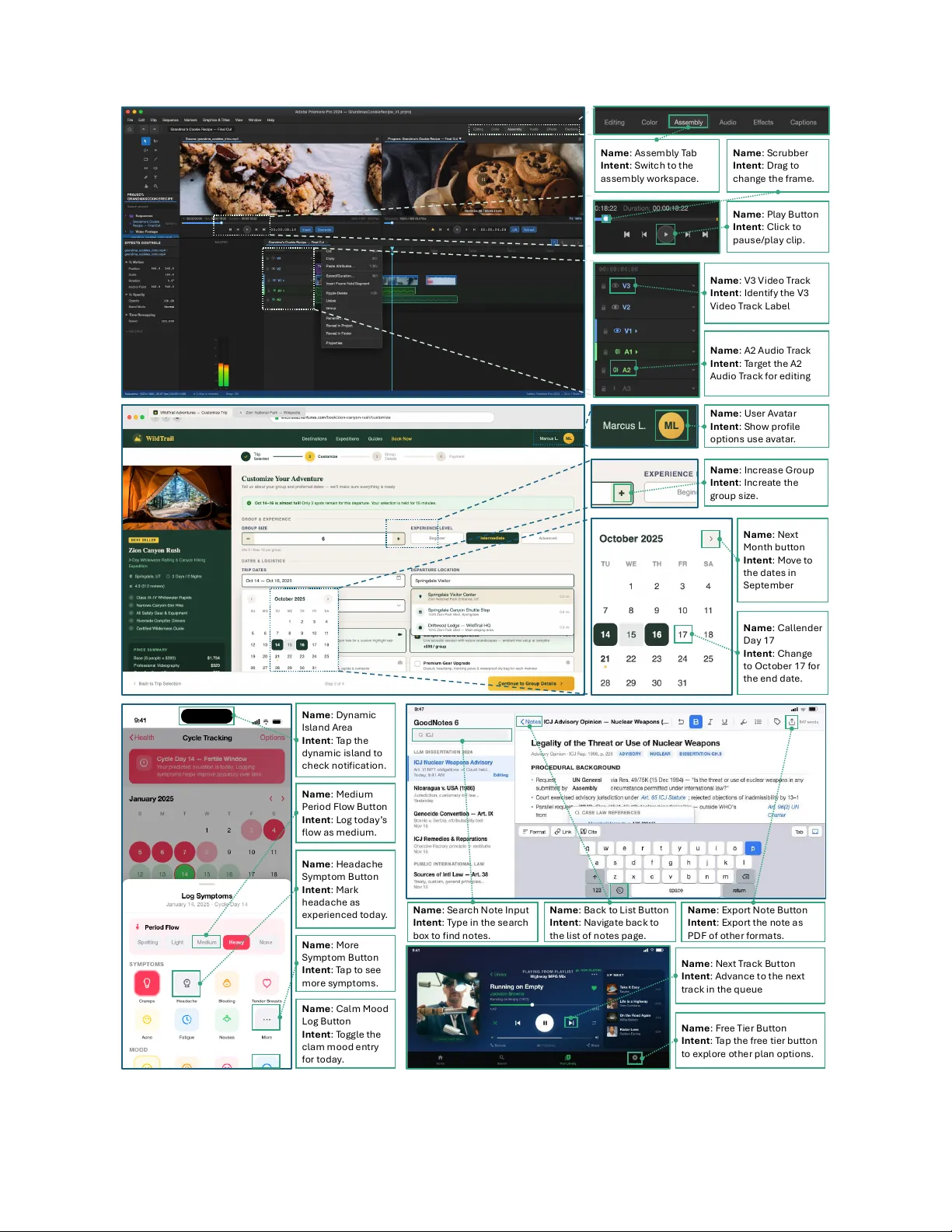
MolmoPoint 논문은 비전‑언어 모델(VLM)에서 기존에 사용되던 텍스트 좌표 생성 방식을 대체할 새로운 포인팅 메커니즘을 제안한다. 기존 VLM은 (x, y) 좌표를 문자열 혹은 이산화된 토큰 시퀀스로 출력했으며, 이는 좌표 체계 학습이라는 추가 부담과 고해상도 이미지에서 토큰 수 급증이라는 문제를 야기한다. MolmoPoint은 이러한 한계를 극복하기 위해 “그라운딩 토큰”이라는 특수 토큰을 도입한다. 모델이 토큰을 출력하면, 해당 토큰의 hidden state를 query 로 변환하고, 이미지 입력을 토큰화한 토큰들의 hidden state를 key 로 매핑해 dot‑product 스코어링을 수행한다. 가장 높은 스코어를 받은 이미지 토큰이 선택되며, 이는 coarse‑grained 패치를 의미한다. 선택된 패치 인덱스는 다음 토큰인 의 입력 임베딩에 포함되어 “이미 선택된 패치” 정보를 LLM에 전달한다.
< SUBPATCH > 단계에서는 가 선택한 coarse‑grained 토큰을 구성하는 4개의 ViT 패치(각 14×14 픽셀) 중 하나를 선택한다. 이 역시 query‑key 매칭을 통해 수행되며, 선택된 ViT 패치의 특징을 LLM 차원으로 투사해 토큰의 입력 임베딩에 삽입한다. 마지막으로 토큰은 3×3 그리드(9개 위치) 중 하나를 예측해 최종 좌표를 결정한다. 14×14 픽셀 패치 위에 3×3 그리드를 겹치면 평균 4.7픽셀 정도의 정밀도를 제공한다. 이 방식은 입력 이미지 해상도와 무관하게 일정한 정밀도를 유지한다는 장점이 있다.
포인팅 순서를 제어하기 위해 MolmoPoint은 Rotary Positional Embedding(RoPE)을 적용한다. 토큰이 이전에 선택한 이미지 토큰 위치를 회전 각도로 인코딩함으로써, “앞선 토큰보다 뒤쪽에 있는 토큰만 선택”하도록 모델을 유도한다. 이는 다중 포인트를 요구하는 작업이나 비디오 프레임 간 연속 포인팅에서 중요한 역할을 한다. 또한, 토큰이 “no‑more‑points” 클래스를 선택하도록 고정된 key 벡터를 추가함으로써, 불필요한 포인트 생성을 방지하고 출력 길이를 동적으로 제어한다.
학습은 기존 Molmo2 파이프라인을 그대로 사용하면서, 새로 도입된 토큰에 대한 별도 학습률과 그래디언트 클리핑을 적용한다. 손실은 기존 LLM 토큰 손실에 와 선택을 위한 cross‑entropy를 직접 더해준다. 데이터는 세 가지 도메인별로 구성했는데, 일반 이미지용 MolmoPoint‑8B, GUI 전용 MolmoPoint‑GUI‑8B, 비디오 전용 MolmoPoint‑Vid‑8B가 있다. 특히 GUI 도메인에서는 고해상도 스크린샷과 UI 요소를 자동으로 라벨링한 MolmoPoint‑GUISyn 데이터를 활용해 평균 54개의 포인트를 포함하는 밀집 라벨을 제공한다. 비디오 트래킹을 위해서는 인간 주석과 합성 트랙을 결합한 MolmoPoint‑Track 데이터를 구축했다.
성능 평가 결과는 다음과 같다. 이미지 포인팅 벤치마크 PointBench에서 MolmoPoint‑8B는 70.7% 정확도로 기존 최고 기록을 2~4 포인트 앞섰다. GUI 포인팅에서는 ScreenSpotPro에서 61.1%를 기록해 동일 규모 오픈 모델 중 최고를 달성했으며, OSWorldG에서도 유의미한 향상을 보였다. 비디오 포인팅에서는 인간 선호도 실험에서 59.1% 승률을 기록, 텍스트 좌표 기반 베이스라인을 크게 앞섰다. 트래킹에서는 Molmo2 대비 6.3%p(62.5 vs 56.7) 상승을 보이며, 새로운 데이터와 토큰 설계가 트래킹 정확도에도 긍정적 영향을 미쳤음을 입증한다. 또한 토큰 수 감소(좌표당 8→3)와 고해상도 일반화 능력 향상으로 추론 속도와 메모리 효율도 개선되었다.
결론적으로 MolmoPoint은 “시각 토큰을 직접 선택하는” 직관적 포인팅 메커니즘을 제시함으로써 VLM의 그라운딩 능력을 크게 향상시켰다. 좌표 학습 부담을 없애고, 토큰 기반 선택·정밀화·순서 제어를 통합함으로써 다양한 멀티모달 작업에 적용 가능한 범용 프레임워크를 제공한다. 향후 연구에서는 더 미세한 서브패치 분할, 다중 객체 관계 인코딩, 그리고 실제 로봇 제어와 같은 실시간 인터랙션 시나리오에의 적용이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기