CPUBone: Efficient Vision Backbone Design for Devices with Low Parallelization Capabilities
Recent research on vision backbone architectures has predominantly focused on optimizing efficiency for hardware platforms with high parallel processing capabilities. This category increasingly includes embedded systems such as mobile phones and embe…
Authors: Moritz Nottebaum, Matteo Dunnhofer, Christian Micheloni
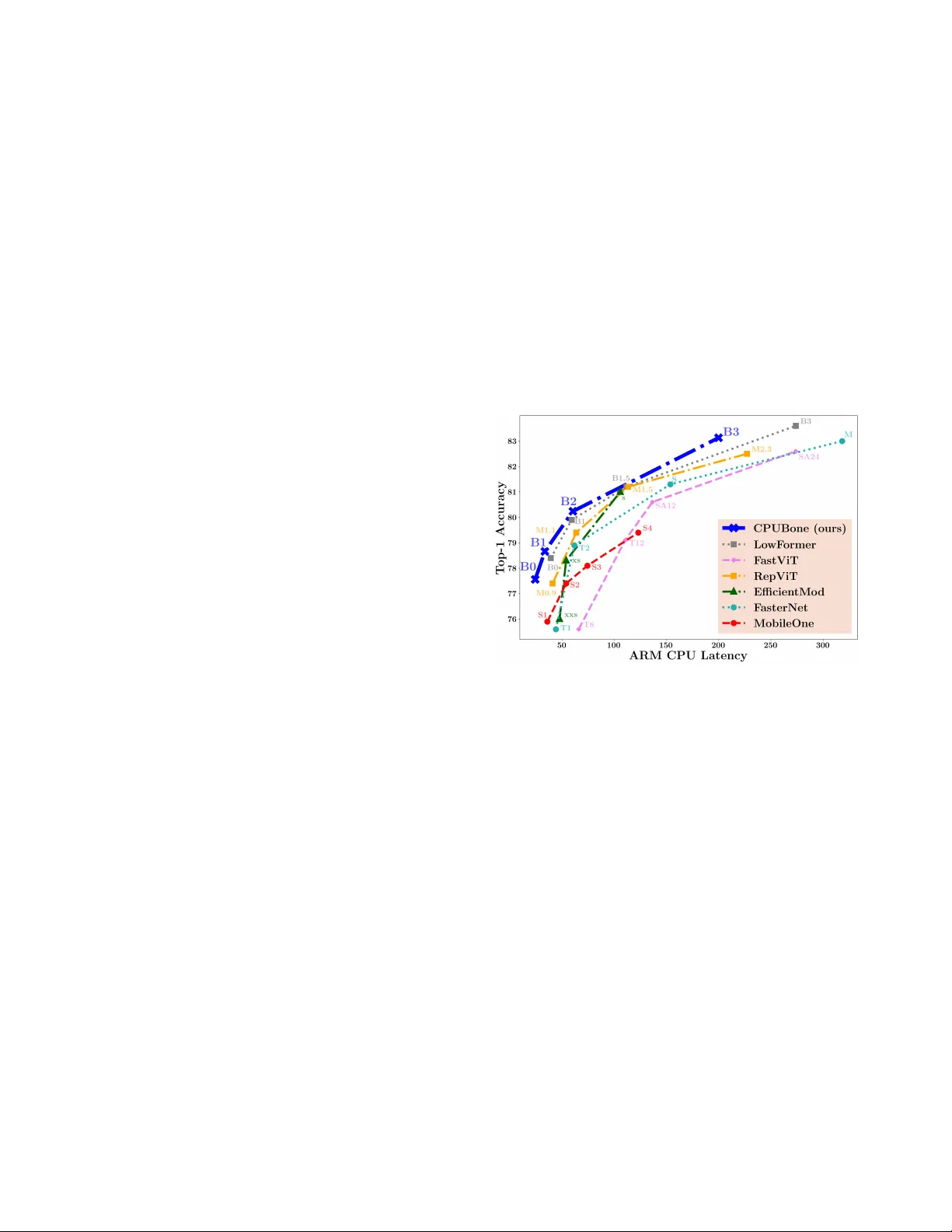
CPUBone: Efficient V ision Backbone Design f or Devices with Low Parallelization Capabilities Moritz Nottebaum 1 nottebaum.moritz@spes.uniud.it Matteo Dunnhofer 1,2 matteo.dunnhofer@uniud.it Christian Micheloni 1 christian.micheloni@uniud.it 1 Uni versity of Udine, Italy 2 Y ork Uni versity , Canada Abstract Recent r esearc h on vision backbone ar chitectur es has pre- dominantly focused on optimizing efficiency for har dwar e platforms with high par allel pr ocessing capabilities. This cate gory increasingly includes embedded systems suc h as mobile phones and embedded AI accelerator modules. In contrast, CPUs do not have the possibility to parallelize op- erations in the same manner , wher efor e models benefit fr om a specific design philosophy that balances amount of oper- ations (MA Cs) and hardwar e-efficient execution by having high MACs per second (MACpS). In pursuit of this, we in- vestigate two modifications to standar d con volutions, aimed at r educing computational cost: gr ouping con volutions and r educing kernel sizes. While both adaptations substantially decr ease the total number of MACs r equired for inference , sustaining low latency necessitates pr eserving hardwar e- efficiency . Our experiments acr oss diverse CPU devices confirm that these adaptations successfully r etain high har dware-ef ficiency on CPUs. Based on these insights, we intr oduce CPUBone, a new family of vision bac kbone mod- els optimized for CPU-based infer ence. CPUBone achieves state-of-the-art Speed-Accuracy T rade-offs (SA Ts) acr oss a wide rang e of CPU devices and effectively transfers its ef- ficiency to downstr eam tasks such as object detection and semantic se gmentation. Models and code are available at https://github .com/altair199797/ CPUBone . 1. Introduction The design of vision backbone architectures has advanced significantly in recent years [ 1 , 2 , 26 , 30 , 33 ], with increas- ing emphasis on improving the Speed-Accuracy Trade-of f (SA T) of models. Howe ver , numerous publications ha ve shown that relying solely on the number of multiply and ac- cumulate (MAC) operations is insufficient to assess model Figure 1. Comparison of ARM CPU latency and ImageNet top- 1 accurac y of recent image classification architectures, includ- ing our proposed CPUBone models. Markers refer to different model sizes within each architecture family . CPUBone consis- tently achie ves lo wer latenc y at comparable accurac y , highlighting its CPU-optimized design. efficienc y [ 22 , 24 , 29 ], as execution performance varies sub- stantially across hardware architectures due to differences in design and computational characteristics [ 22 , 24 ]. As a result, recent vision backbone architectures often target op- timization for specific de vice classes, tailoring their designs to the characteristics and constraints of particular hardware subsets [ 4 , 20 , 28 , 30 ]. Howe ver , the majority of these backbone architectures are still designed to exploit high degrees of computational parallelism to enhance runtime efficienc y [ 28 – 30 ]. This trend is dri ven by the fact that, beyond Graphics Processing Units (GPUs), embedded systems such as mobile phones and AI modules like NVIDIA Jetson devices have increas- ingly demonstrated substantial parallel processing capabil- ities – often matching or exceeding traditional GPUs in in- ference latency for various vision backbone architectures [ 28 ]. On the other side, Central Processing Units (CPUs) – which remain widely used [ 9 , 31 ] in many practical and resource-constrained scenarios – operate under fundamen- tally different architectural constraints [ 2 ]. In contrast to GPUs, CPUs of fer limited parallelism, wherefore existing models optimized for devices with high parallelization ca- pabilities [ 2 , 28 , 29 ] often fail to translate their efficienc y to CPU-based systems [ 20 ]. This is largely due to the ex- cessiv e number of MA C operations, which become a per- formance bottleneck under the CPU’ s limited concurrency [ 2 ]. T o address this gap, we propose CPUBone (Section 4 ), a nov el architecture family of vision backbone models specif- ically designed to optimize performance on CPUs by mini- mizing MA C count, while maintaining a hardware-ef ficient ex ecution of the MA C operations. Follo wing [ 2 ], we mea- sure hardware-efficienc y for ex ecution time by counting how many MA Cs are processed per second and will further abbreviate this metric by MA CpS ( MA C s p er s econd). A key component of CPUBone is a modification of the mobile inv erted bottleneck block (MBConv) [ 25 ], whose ef- ficiency benefits on CPU-based systems are demonstrated in Section 3 . CPUBone models consistently achiev e state-of- the-art results in the SA T across a variety of CPU devices and maintain their ef fectiv eness when applied to down- stream tasks such as object detection and semantic se gmen- tation. Our contributions can be summarized as follo ws: • W e introduce two ne w MBCon v variants that achieve both reduced MAC count and hardware-ef ficient execu- tion (high MA CpS): Grouped Fused MBCon v (GrFuMB- Con v) block and Grouped MBCon v (GrMBCon v) block. • W e conduct a comprehensive analysis of hardware- efficienc y (MA CpS) on both CPUs and GPU for the pro- posed MBCon v variants, and further inv estigate the effect of reducing con v olutional kernel sizes from 3 × 3 to 2 × 2 . • W e present the vision backbone family CPUBone, which achiev es state-of-the-art SA Ts on CPU-based devices. 2. Related W ork 2.1. Hardwar e-aware Architectur e Design Recent studies have shifted from using theoretical oper - ation counts (e.g., MACs) to wards direct measurements of latency and throughput to e valuate ex ecution efficiency [ 1 , 5 , 29 ]. This transition reflects the growing recognition that a model’ s efficienc y can v ary substantially across hard- ware platforms, as hardware characteristics strongly influ- ence ex ecution behaviour [ 22 , 24 ]. Consequently , many works have explored hardware-aware model design, adapt- ing architectures to specific devices or classes of hardware to maximize practical performance [ 2 , 30 ]. While models such as FasterNet [ 2 ] and EfficientMod [ 20 ] achie ve competitiv e performance across multiple hard- ware categories – particularly GPU throughput/latency and CPU latency – there has been an increasing trend to- wards optimizing architectures primarily for mobile devices [ 24 , 29 , 30 ]. For instance, MobileNetV4 [ 24 ] e valuates per- formance across a wide range of mobile devices, whereas RepV iT [ 30 ], next to reporting GPU throughput, focuses on device-specific latency ev aluation on the iPhone 12. Other architectures, such as SHV iT [ 35 ], concentrate on through- put optimization, howe ver on CPU and GPU devices. On the other side MobileOne [ 29 ] demonstrates that hardware- aware design can simultaneously benefit mobile phones, CPUs, and GPUs, highlighting the potential of flexible, multi-platform efficient architectures. W e, howe ver , focus our study specifically on CPU de vices, which are inherently limited in their parallelization capabil- ities [ 17 ] and differ substantially in that reg ard from GPUs and embedded AI accelerators (e.g. Nvidia Jetson de vices), that feature significantly more compute cores. Additionally , unlike many mobile chips, CPUs usually lack an integrated neural processing unit (NPU) and are unable to match the low-latenc y performance of modern mobile devices [ 35 ]. Overall, these factors make hardware-aware architecture de- sign uniquely challenging on CPUs. 2.2. Efficient Micro Design Many state-of-the-art vision backbone architectures adopt relativ ely simple macro designs while relying on sophis- ticated micro-architectural blocks to achie ve high perfor- mance [ 2 , 11 , 25 , 27 , 30 ]. Among the most widely used are the MBCon v block [ 25 ] and the ResNet bottleneck block [ 11 ]. Recently , Chen et al. [ 2 ] introduced the Partial Con- volution (PCon v), which has a reduced MA C count com- pared to a standard con volution, as it only conv olves ov er a portion of the channels, and is followed by lightweight pointwise conv olutions. Next to a low MA C count, they demonstrate ef ficient ex ecution with high MA CpS on GPU, Intel CPU and ARM CPU platforms. On the other side, the RepV iT -block [ 30 ] adopts the MetaFormer structure [ 34 ], with a lightweight depthwise conv olution as token mixer , achieving state-of-the-art results on the iPhone 12. Instead of using depthwise con volutions (RepV iT [ 30 ]) or processing only a portion of the channels (PCon v [ 2 ]), we reduce the MA C count of con volutions by increasing the groups parameter and reducing the k ernel size. Similarly to [ 2 ], we analyze ho w these adaptations influence MA CpS on CPU and GPU devices. 3. CPU-Efficient Design Strategies A high MAC count can significantly hinder fast execution on de vices with limited parallelization capabilities, such as CPUs. T o ov ercome this we propose two adaptations to the Figure 2. Design of MBConv variants, including the two pro- posed Grouped MBCon v (GrMBCon v) and Grouped Fused MB- Con v (GrFuMBConv). In both grouped variants, the first conv o- lution is configured with g r oups = 2 . All variants expand the channel dimension in the first con volution by the expansion factor (set to four in this figure) and reduce it again by the expansion fac- tor in the last con volution. standard configuration of con volutions: setting g r oups = 2 and reducing the k ernel size from the common 3 × 3 k ernel [ 33 ] to a 2 × 2 kernel. Overview of Grouped Con volutions. The number of g r oups in a conv olutional layers is a decisiv e parameter , as it has a strong influence on the MA C count of the con volu- tion. When gr oups = 1 , e very output feature map is a com- bination of all input feature maps, while when g r oups = C in (where C in is the number of input channels), the con- volutions becomes depthwise (DWCon v). Depthwise con- volutions process each input channel independently to pro- duce the corresponding output channel. On the other side, for values between 1 and C in , the con volution is divided into g r oups separate ungrouped sub-conv olutions, where each sub-con volution processes a disjoint subset of the channels of size C in /g r oups . Input channel dimension and output channel dimension always must both be divisible by g r oups . In the following sub-sections, we first quantify how grouping and a smaller kernel size reduce the MA C count compared to a standard ungrouped 3 × 3 con volution (see Subsection 3.1 ). W e then analyze whether these reductions affect hardware-ef ficiency – specifically , how they affect MA CpS (see Section 3.2 ). Grouping for MBCon v Block. In order to narrow down the configuration space we specifically analyze ho w the hardware-ef ficiency changes, when setting g r oups = 2 in the first con volution of the mobile in verted bottleneck (MB- Con v) block [ 25 ] and the fused mobile in verted bottleneck (FuMBCon v) block [ 10 ]. W e chose both blocks, as they are popular components in vision backbones, due to their high efficienc y [ 1 , 22 , 26 ]. The grouped variants are denoted as Grouped MBCon v (GrMBCon v) and Grouped Fused MB- Con v (GrFuMBCon v), as illustrated in Figure 2 . 3.1. Effect of Groups and K ernel Size on MA C Count Grouping . The MA C count ( M ) of a single conv olution with no bias is giv en by M = K H × K W × C in × C out × H out × W out g r oups , (1) where C out is the output channel dimension, K H the height of the kernel and K W the width of the kernel. By treating all variables except g r oups in Equation ( 1 ) as constants, we can transform it and get a clearer understanding how the g r oups parameter influences MAC count: M ∝ 1 g r oups . (2) Equation ( 2 ) shows that the MA C count ( M ) is inv ersely proportional to the number of groups. Therefore by increas- ing the number of groups to two, we halve the number of MA C operations required for execution. W e can no w apply Equation ( 1 ) to calculate how much less MA Cs the grouped MBCon v variants have, compared to their ungrouped coun- terpart, leaving aside normalization and activ ation functions (see supplementary material for e xact calculation). The Gr- FuMBCon v block has 45% less MA Cs than the FuMBConv , independent of the channel dimension. The GrMBCon v has 23% less MA Cs than the MBCon v block, a veraged o ver the fiv e channel dimensions featured in T able 1 . Ker nel Size. By treating all variables in Equation ( 1 ) un- related to the kernel size as constants, we obtain: M ∝ K H × K W . (3) From this we can see, that the MA C count of a con volu- tion is also proportional to the product of the kernel di- mensions. Consequently , reducing the kernel size directly lowers computational cost; for instance replacing a 3 × 3 kernel ( K 2 = 9 ) with a 2 × 2 kernel ( K 2 = 4 ) de- creases the MA C count of the conv olution by approximately (1 − 4 / 9) ∼ 56% . Similarly to grouping, we also apply the reduced 2 × 2 kernel to the FuMBConv and GrFuMBCon v block. While the total MAC of the FuMBCon v is reduced by exactly 50%, the GrFuMBCon v block has approximately 46% less MA Cs, compared to a 3 × 3 kernel (see supplemen- tary material for exact calculation). 3.2. Hardwar e-Efficiency Analysis While grouping and a smaller kernel size significantly re- duce the MA C count of a conv olution, it is not clear , if this advantage also translates to a significant reduction of latency . This is due to factors like degree of parallelism and memory access costs [ 2 , 22 , 24 ]. This phenomena can for Grouping Experiment Channel Dimension Device V ariant 32 64 128 256 512 A vg. MBCon v 7.8 13.3 21.4 26.4 26.2 19.0 Pi5 CPU Gr MBCon v 6.3 10.6 16.7 22.1 23.3 15.8 (-16%) (MMA Cs/ms) Fu MBCon v 40.6 45.3 40.7 32.4 24.5 36.7 GrFu MBCon v 31.0 42.1 44.4 34.7 30.4 36.5 (-0%) MBCon v 51.0 59.8 60.9 53.4 44.5 53.9 Pixel 4 CPU Gr MBCon v 45.3 56.7 59.2 58.3 45.9 53.1 (-1%) (MMA Cs/ms) Fu MBCon v 67.3 63.0 53.2 39.9 34.1 51.5 GrFu MBCon v 64.3 65.6 61.6 43.2 36.2 54.2 (+5%) MBCon v 78.0 111.6 124.5 129.0 126.4 113.9 Snapdragon 8 CPU Gr MBCon v 66.3 105.9 120.7 125.0 125.3 108.6 (-5%) (MMA Cs/ms) Fu MBCon v 121.4 128.8 133.4 130.3 115.4 125.9 GrFu MBCon v 114.0 129.4 133.8 125.1 113.9 123.2 (-2%) MBCon v 34.2 112.3 428.6 1747.3 3494.0 1163.3 TIT AN R TX GPU Gr MBCon v 25.0 88.4 308.8 1260.6 2679.1 872.4 (-25%) (MMA Cs/ms) Fu MBCon v 185.1 622.6 2394.6 3612.2 3849.0 2132.7 GrFu MBCon v 96.8 330.3 1307.3 2963.3 3878.9 1715.3 (-20%) T able 1. Execution efficienc y of MACs, measured in MMACs/ms, for the four MBConv variants (MBCon v , GrMBConv , FuMBCon v and GrFuMBCon v) for different channel dimensions. Bold entries indicate whether the grouped or ungrouped v ariant has higher MA CpS. example be observed for D WConvs [ 22 ], which hav e con- siderably lower MACpS compared to ungrouped conv olu- tions ( g r oups = 1 ). Therefore, it is crucial to analyze how grouping or smaller kernel sizes af fect MACpS. Execution Time Measurement. In order to quantify hardware-ef ficiency in execution (MACpS), we need to measure latency . W e feature several CPU devices for this: the CPU of the Raspberry Pi 5, the CPU of the Google Pixel 4, and the CPU of the Snapdragon 8 Elite QRD. W e fur- ther compare these results with latency measurements on a device with high parallelization capability – the Nvidia TI- T AN R TX GPU. Latency is always measured with a batch size of 1. 3.2.1. Effect of Grouping on Hard ware-Efficiency Setting. In T able 1 , we compare the MA CpS of the MB- Con v and FuMBCon v block with their grouped counterparts (GrMBCon v and GrFuMBCon v). W e do so by measuring the number of MMACs (million MACs) each architectural block executes per millisecond (MMAC/ms). While we fix the operating resolution to 14 × 14 , we feature fi ve dif ferent input channel dimensions (32, 64, 128, 256 and 512) and an expansion factor of 4 (see Figure 2 ). Observation 1. Across all CPU devices and channel di- mensions, GrMBCon v have on av erage 5% lower MA CpS compared to MBConv , while having 23% less MACs. On the other side, GrFuMBCon v hav e 1% higher MACpS than FuMBCon v , while having 45% less MA Cs. Observation 2. A veraged across all CPU devices, the fused variants (FuMBCon v and GrFuMBCon v) have ap- proximately 25% lower MACpS, when the channel dimen- sion is ≥ 256 , compared to < 256 , while the unfused v ari- ants (MBCon v and GrMBCon v) have 27% higher MA CpS. Howe ver , for channel dimensions belo w 256, the fused vari- ants achie ve 70% higher MA CpS than the unfused v ariants. This behaviour was previously observed by [ 22 ], though only on devices with higher parallelization capabilities. Operating Resolution. W e repeated the experiment for additional input resolutions ( 7 × 7 , 28 × 28 and 56 × 56 ) on ARM CPU (see supplementary material), yielding a similar result as in T able 1 . Across the resolutions, GrMBCon vs hav e 18% lower MACpS than MBCon v , while GrFuMB- Con vs have 2% lo wer MA CpS than FuMBConvs. Effect on GPU . In T able 1 we also feature the same ex- periment on GPU (Nvidia T itan R TX), howe ver both obser- vations do not hold on GPU anymore. The GrMBCon v has on average 23% less MACs, howe ver on GPU it also has 25% lower MA CpS, making the GrMBConv block slower on average. Similarly , the GrFuMBCon v has on av erage 20% lower MA CpS than the FuMBCon v , making it still faster howe ver due to having approximately half the MA C count. Additionally , similarly to what we observed on the CPU devices, the fused MBCon v variants (GrFuMBCon v & FuMBCon v) remain considerably more hardware-ef ficient (higher MACpS) than their unfused counterpart (GrMB- Con v & MBConv), especially for channel dimensions be- low 256. They execute up to 5 × more MA Cs in the same time. W e also repeated the same experiments for differ - ent resolutions (see supplementary material), leading to the same conclusion. Higher Groups parameter . So far we hav e only consid- ered gr oups = 2 , howe ver we also repeated the experiment on an ARM CPU with g r oups = 4 (see supplementary ma- terial). The av eraged result we discussed with g r oups = 2 are largely similar for g r oups = 4 , howev er the fused v ari- ants (GrFuMBCon v & FuMBCon v) exhibit a dif ferent be- haviour . For channel dimensions belo w 128, GrFuMBCon v has 20% lower MA CpS, when g r oups = 4 , compared to g r oups = 2 . Howe ver for channel dimensions ov er 128, they ha ve 36% higher MA CpS. Conclusion. The grouped variants achie ve similar MA CpS compared to their ungrouped counterparts (ob- servation 1), while featuring a considerably lower MA C count, leading to improved execution time. Ho wev er, on ARM CPU we observe, that the GrMBCon v’ s hardware- efficienc y degrades significantly (-16% MA CpS) compared to the MBCon v block, making it ne vertheless faster , as it has 23% less MA Cs. Additionally in order to optimize hardware efficienc y , fused variants (FuMBCon v and GrFuMBCon v) are better suited for layers with fewer than 256 channels, while unfused variants (MBCon v and GrMBCon v) perform best with channel dimensions of 256 or more (observation 2). Dwise Channel Dimension Resol. T ype 128 256 512 1024 A vg. 7×7 nmk 0.75 0.78 0.78 0.80 0.78 smk 0.66 0.70 0.70 0.73 0.70 14×14 nmk 1.26 1.28 1.27 1.24 1.26 smk 1.13 1.15 1.16 1.08 1.13 28×28 nmk 1.97 1.82 1.64 1.64 1.77 smk 1.73 1.50 1.26 1.19 1.42 T able 2. Execution ef ficiency e xperiment on ARM CPU on the ef- fect of kernel size reduction for depthwise con volutions, by mea- suring MMA Cs/ms. Resol. refers to operating resolution, T ype refers to the kernel size ( nmk = 3 × 3 , smk = 2 × 2 ). Bold entries indicate whether nmk or smk variant has higher MA CpS. 3.3. Effect of Kernel Reduction on Hard ware- Efficiency Setting. As shown before Subsection 3.1 , reducing the kernel size considerably reduces the MA C count. Ho wev er , similarly to grouping, we need to ensure that the MA CpS do not deteriorate. In order to hav e a comprehensiv e anal- ysis, also fitting to the previous grouping analysis and to our macro architecture, we feature three different kind of con volutions or blocks: Depthwise conv olutions (as cen- tral part of the MBConv block, see Figure 2 ), the FuM- BCon v block (see Figure 2 ) and the GrFuMBCon v block, Ungrouped Groups=2 Resol. T ype Channel Dim. Channel Dim. 128 256 A vg. 128 256 A vg. 7×7 nmk 39.36 28.63 33.99 37.88 32.42 35.15 smk 41.21 33.13 37.17 36.11 36.42 36.27 14×14 nmk 40.90 33.45 37.17 44.56 35.21 39.88 smk 46.94 36.01 41.48 43.86 40.58 42.22 28×28 nmk 40.70 29.23 34.96 47.45 36.37 41.91 smk 42.95 31.60 37.28 46.67 38.02 42.35 T able 3. Execution efficienc y experiment on ARM CPU on the effect of kernel size reduction. W e test the GrFuMBCon v (Groups=2) and FuMBConv (Ungrouped) block by measuring MMA Cs/ms. Resol. refers to operating resolution, T ype refers to the kernel size ( nmk = 3 × 3 , smk = 2 × 2 ). Bold entries indicate whether nmk or smk variant has higher MA CpS. with g roups = 2 . Both MBCon v versions feature an ex- pansion factor of 4. For depthwise con volutions we span channel dimensions from 128 to 1024, because this is the usual range occurring in the later stages of vision backbones [ 1 , 22 , 28 , 35 ]. On the other side, for the FuMBCon v and GrFuMBCon v , we only test for channel dimensions 128 and 256, as our previous analysis in Subsection 3.2.1 as well as [ 22 ] conclude that a channel dimension higher than 256 for fused MBConv versions results in a considerable reduction of MA CpS, wherefore we deem it less relev ant. In T able 2 and 3 we compare two settings of kernel sizes: nmk, re- ferring to 3 × 3 kernel and smk, referring to 2 × 2 kernel. All results are measured on the ARM CPU of the Raspberry Pi5, featuring a batch size of 1. Observation 1. While for the depthwise con volutions (see T able 2 ) the reduction of the kernel size leads to a small reduction of MA CpS (-10%), for the FuMBCon v and the GrFuMBCon v ( g roups = 2 ) block (see T able 3 ) the hardware-ef ficiency increases on average. Since the kernel size reductions approximately halve the MA C count for the tested MBCon v variants (as mentioned in Subsection 3.1 ), they lead to a considerable latenc y improvement. Observation 2. The absolute magnitude of MACpS for the depthwise conv olution (T able 2 ) is considerably lo wer than for the ungrouped or g roups = 2 conv olutions (see T able 3 ). The latter two hav e approximately 40 × higher MA CpS, compared to the depthwise conv olution. A simi- lar g ap can also be seen, when repeating the experiments on GPU (see supplementary material). Since depthwise con- volutions exhibit low MACpS on de vices with both low and with high parallelization capability , degree of parallelism is not the main factor , influencing the hardware-ef ficiency of depthwise conv olutions. W e believ e memory access cost is mainly responsible for that. Model Params MA Cs Pi5 CPU Pixel 7 Pro CPU Intel CPU T op-1 (M) (M) (ms) ↓ (ms) ↓ (ms) ↓ (%) EffF ormerV2-S0 [ 14 ] 3.5 400 36.3 39.4 7.9 73.7 GhostNetV2 x1.0 [ 27 ] 6.2 183 35.2 5.8 9.0 75.3 FastV iT -T8 [ 30 ] 3.6 705 65.9 44.0 10.6 75.6 MobileV iG-T i [ 21 ] 5.3 661 48.2 45.2 9.2 75.7 EfficientMod-xxs [ 20 ] 4.7 579 47.5 25.3 9.2 76.0 FasterNet-T1 [ 2 ] 7.6 850 32.8 24.4 6.3 76.2 RepV iT -M0.9 [ 30 ] 5.1 816 40.8 35.1 10.2 77.4 CPUBone-B0 (ours) 10.4 519 24.2 13.8 6.9 77.6 EffF ormerV2-S1 [ 14 ] 6.1 650 57.4 54.6 10.9 77.9 MobileV iG-S [ 21 ] 7.3 983 73.9 69.5 13.0 78.2 EfficientMod-xs [ 20 ] 6.6 773 53.8 28.1 11.5 78.3 LowF ormer-B0 [ 22 ] 14.1 944 39.1 20.8 9.4 78.4 CPUBone-B1 (ours) 12.4 746 33.5 18.6 9.4 78.7 FasterNet-T2 [ 2 ] 15.0 1910 61.7 28.5 10.1 78.9 MobileOne-S4 [ 29 ] 14.8 2978 122.9 43.6 13.3 79.4 RepV iT -M1.1 [ 30 ] 8.2 1338 63.5 48.7 12.0 79.4 LowF ormer-B1 [ 22 ] 17.9 1410 59.1 30.6 13.2 79.9 CPUBone-B2 (ours) 23.9 1354 60.3 32.4 16.1 80.3 EffF ormerV2-S2 [ 14 ] 12.6 1250 102.3 91.5 18.9 80.4 FastV iT -SA12 [ 28 ] 10.9 1943 136.4 86.2 20.0 80.6 LowF ormer-B15 [ 22 ] 33.9 2573 111.6 56.8 22.8 81.2 FasterNet-S [ 2 ] 31.1 4560 153.6 70.7 20.6 81.3 BiFormer -T [ 37 ] 13.1 2200 523.9 578.6 178.0 81.4 Resnet101 [ 11 ] 44.5 7801 293.8 115.6 30.8 81.9 RepV iT -M2.3 [ 30 ] 22.9 4520 227.0 148.0 37.7 82.5 FasterNet-M [ 2 ] 53.5 4370 318.1 151.5 41.6 83.0 CPUBone-B3 (ours) 40.7 4054 199.8 83.1 34.1 83.1 FasterNet-L [ 2 ] 93.5 7760 644.8 290.1 65.5 83.5 MIT -EfficientV iT -B3 [ 1 ] 49.0 3953 340.2 98.2 44.1 83.5 LowF ormer-B3 [ 22 ] 57.1 6098 273.8 124.0 44.4 83.6 BiFormer -S [ 37 ] 26.0 4500 1134.1 1290.0 391.0 83.8 T able 4. Performance on ImageNet-1K validation set. Evaluation resolution is 224×224, except for FastV iT models who operate on 256x256. Besides MobileV ig [ 21 ], no distillation nor pretraining is used for fair comparison. Models are sorted and grouped by top-1 accuracy . The highest top-1 accuracy in each group is bold. Effect on GPU . Similarly to how grouping reduces MA CpS on GPU, reducing the kernel size deteriorates per- formance completely on GPU. T o show that we repeat the same experiments of T ables 2 and 3 on the Nvidia TI- T AN R TX GPU (see supplementary material). For depth- wise conv olutions, the MA CpS reduces by 80% approxi- mately , making the smaller kernel version slower than the one with the original 3 × 3 kernel. Similarly , the FuM- BCon v and the GrFuMBCon v block approximately hav e 50% lo wer MA CpS. Consequently , reducing the kernel size consistently leads to higher execution time on GPU, even though less MA Cs need to be executed. Conclusion. Reducing the kernel size of a con volution from 2 × 2 to 3 × 3 , leads to a reduction of MA Cs by approx- imately 50%. On CPU, this advantage is retained, as the MA CpS remain similar (depthwise) or e ven improve (FuM- BCon v & GrFuMBCon v). Howe ver on GPU, similarly to grouping, reducing the kernel size leads to minimal latency benefits or ev en an increase in latency , as the MA CpS dete- riorates. 4. CPUBone The macro architecture of CPUBone is inspired by Low- Former [ 22 , 23 ], as it represents one of the most recent vi- sion backbone approaches incorporating MBCon v blocks as a main component. Following [ 22 , 23 ], we also integrate LowF ormer Attention in the final two stages of CPUBone. Howe ver , based on the findings in Section 3 , we exclu- Figure 3. CPUBone macro architecture design. Attention refers to Low- Former Attention [ 22 ]. Stage B0 B1 B2 B3 0 C=16, N=0, GrFu C=16, N=0, GrFu C=20, N=0, GrFu C=32, N=1, GrFu 1 C=32, N=0, GrFu C=32, N=0, GrFu C=40, N=0, GrFu C=64, N=1, GrFu 2 C=64, N=0, GrFu C=64, N=0, GrFu C=80, N=0, GrFu C=128, N=2, GrFu 3 C=128, N= 3 , GrFu C=128, N= 5 , GrFu C=160, N= 6 , GrFu C=256, N= 6 , Gr 4 C=256, N= 4 , Gr C=256, N= 5 , Gr C=320, N= 6 , Gr C=512, N= 6 , Gr T able 5. Specification of CPUBone architecture versions B0-B3. C, N, Gr and GrFu stand for channel dimension, the number of layers, GrMBCon v and GrFuMBCon v . Number of layer higher than two, are bold. Backbone Pi5 CPU Lat. mIoU (ms) (%) ResNet50 [ 11 ] 940.0 36.7 PVTv2-B0 [ 32 ] 587.7 37.2 CPUBone-B0 (ours) 131.5 37.9 FastV iT -SA12 [ 28 ] 603.9 38.0 CPUBone-B1 (ours) 189.9 39.2 RepV iT -M1.1 [ 30 ] 468.9 40.6 FastV iT -SA24 [ 28 ] 1161.5 41.0 EdgeV iT -XS [ 5 ] 461.5 41.4 F A T -B0 [ 8 ] 763.3 41.5 CPUBone-B2 (ours) 338.2 42.1 PVTv2-B1 [ 32 ] 1296.4 42.5 LowF ormer-B2 [ 22 ] 808.1 42.8 F A T -B1 [ 8 ] 1102.1 42.9 CPUBone-B3 (ours) 1181.6 44.1 Figure 4. Results on semantic segmentation, using Se- mantic FPN [ 13 ], trained and evaluated on ADE20K [ 36 ]. Backbone latency is measured under resolution 512 × 512 . Models are grouped by mIoU. Best value in each group is made bold. siv ely use the grouped MBConv variants (GrMBCon v and GrFuMBCon v), applying the fused version when the input channel dimension is below 256 and the unfused version otherwise. W e further only reduce the kernel size to 2 × 2 in the last two stages of CPUBone, where the bulk of com- putation is concentrated. W e believe higher kernel size is especially important in earlier layers to have a higher re- ceptiv e field and consequently better accuracy . In contrast to the LowF ormer architecture, we also omit the transpose con volution in the LowF ormer Attention and replace it with nearest neighbour upsampling. W e ablate this decision in Subsection 5.3 . In total, we feature four model v ariants with increasing model size: CPUBone-B0, B1, B2 and B3. The ov erall architecture is illustrated in Figure 3 and specifics to each model variant are listed in T able 5 . 5. Experiments 5.1. ImageNet Classification Settings. W e perform image classification experiments on ImageNet-1K [ 7 ], which consists of 1.28M training and 50K validation across for 1000 categories. All CPUBone models were trained from scratch using mostly the same setting as [ 1 , 22 ] and featuring an input resolution of 224 for ev aluation. W e train for a total of 320 epochs using AdamW [ 19 ] optimizer , including 20 warm-up epochs with a linear schedule. W e employ cosine decay [ 18 ] as learning rate scheduler . For CPUBone-B0 and B1, we use a base learn- ing rate of 10 − 3 and a batch size of 512. For CPUBone-B2, the batch size is increased to 1024. For CPUBone-B3, we use a batch size of 2400 and raise the base learning rate to 3 × 10 − 3 . Results. In T able 4 we compare the CPUBone models to recent vision backbones. W e compare model efficiency by measuring latency on the ARM CPU of the Raspberry Pi5, the CPU of the Pixel Pro 7 and the Intel(R) Xeon(R) W -2125 CPU, with a batch size of 1. Regarding results, CPUBone-B0 is faster than almost all models with a lower accuracy in T able 4 . EffF ormerV2-S0 [ 14 ] for example has a 50% higher Pi5 latency , a 300% higher Pixel 7 Pro CPU latency , but a 3.9% lower accuracy , than CPUBone-B0. On the other side, FasterNet-T1 [ 2 ], an architecture partially designed for CPU latency , achieves a slightly lower Intel CPU latency than CPUBone-B0, howe ver its Pi5 CPU la- tency is 33% higher, its Pixel 7 Pro CPU latency is 76% higher and its top-1 accuracy is 1.4% lower . On the other end of the spectrum regarding model size CPUBone-B3 is considerably faster than RepV iT -M2.3 [ 30 ] on all three CPU devices, while being 0.6% more accurate on ImageNet [ 7 ]. Overall, CPUBone models consistently achieve effi- cient performance across various model sizes and a div erse set of CPU platforms. 5.2. Downstr eam T asks T o assess transferability of CPUBone backbones to down- stream tasks, we integrate the pretrained models into object detection and semantic segmentation frameworks. Exper- iments are performed on COCO 2017 [ 15 ] and ADE20K [ 36 ] using the MMDetection [ 3 ] and MMSegmentation [ 6 ] toolkits. W e use RetinaNet [ 16 ] for detection and Semantic FPN [ 13 ] for segmentation. Results are depicted in T ables 4 and 7 . Pi5 CPU latency refers to backbone latency mea- sured under resolution 512 × 512. Semantic Segmentation. For semantic se gmentation, we train the models for 40K iterations with a batch size of 32, Model version Params MACs Pi5 CPU Lat. Pixel 4 CPU Pixel 7 Pro CPU Lat. Intel CPU Lat. T op-1 (M) (M) (ms) (ms) (ms) (ms) (%) Just original MBCon vs 13.3 758 48.6 25.4 20.1 12.63 78.5 (-0.2%) Using transpose 14.4 840 39.7 26.3 20.3 10.73 78.9 (+0.2%) Groups=8 11.0 560 28.7 21.2 16.0 8.8 78.0 (-0.7%) Groups=4 11.5 622 29.6 21.9 17.9 9.0 78.4 (-0.3%) B0-plain 14.1 944 39.1 29.6 20.8 9.4 78.4 (-0.3%) Baseline (B1) 12.4 746 33.5 23.8 18.6 9.4 78.7 T able 6. Ablation study of CPUBone-B1, featuring singular changes. W e also include B0-plain, an ablation to CPUBone-B0. Backbone Pi5 CPU Lat. AP (ms) (%) MobileNetV3 [ 12 ] 158.0 29.9 MNv4-Con v-M [ 24 ] 299.5 32.6 PVTv2-B0 [ 32 ] 587.7 37.2 CPUBone-B0 (ours) 131.5 37.5 LowF ormer-B0 [ 22 ] 226.9 38.6 EdgeV iT -XXS [ 5 ] 281.0 38.7 CPUBone-B1 (ours) 189.9 39.0 LowF ormer-B1 [ 22 ] 313.2 39.4 F A T -B0 [ 8 ] 763.3 40.4 CPUBone-B2 (ours) 338.2 40.4 EdgeV iT -XS [ 5 ] 461.5 40.6 PVTv2-B1 [ 32 ] 1296.4 41.2 LowF ormer-B2 [ 22 ] 808.1 41.4 F A T -B1 [ 8 ] 1102.1 42.5 CPUBone-B3 (ours) 1181.6 42.9 T able 7. Results on object detection using RetinaNet head [ 16 ]. Backbone latency is measured under resolution 512 × 512 . Models are grouped by AP . Best value in each group is made bold. following the protocols in [ 8 , 20 , 28 , 30 ]. Regarding results, CPUBone consistently achieves lower latency and higher mIoU across a wide range of model sizes (see T able 4 ). CPUBone executes up to 3 × faster than comparable models with similar or lower mIoU. Object Detection. W e train all models for 12 epochs us- ing the standard 1× schedule, following the setup in [ 1 , 8 ]. Similarly to semantic segmentation, CPUBone is able to outperform all compared models with a similar AP (see T a- ble 7 ) and ex ecutes up to 4 × faster than comparable models with a similar or lower AP . 5.3. Ablation Study T o verify that our design choices yield a CPU-optimal model, we perform the following ablations on CPUBone- B1 in T able 6 : setting groups=4 instead of two in all MB- Con v blocks, setting groups=8 instead of two in all MB- Con v blocks, featuring just original MBCon vs [ 25 ] instead of grouped or fused variants and using transpose conv olu- tions in LowFormer Attention [ 22 ], as originally designed, instead of nearest neighbour upsampling. Finally , we also ablate CPUBone-B0 in B0-plain , where we revert each of our contributions: grouping, reduced kernel size, and the re- placement of the transpose conv olution with nearest neigh- bour upsampling. B0-plain does have a increased accuracy , compared to CPUBone-B0, howe ver when we directly compare it to CPUBone-B1, it not only is considerably slo wer on all de- vices, but also has a lo wer top-1 accuracy . Groups=4 or Groups=8 on the other side, improve latency due to a lower MAC count, howe ver lead to a considerable reduction in accuracy . Higher group numbers further lead to an increasingly declining hardware-efficienc y . On the ARM CPU, the Groups=4 model sho ws a 5% reduction in MA CpS, while Groups=8 sho ws a 13% reduction relativ e to the baseline. Further , we can see that the efficienc y ben- efit on Intel CPU is minimal for those models. Our baseline (B1) with gr oups set to two is therefore a good balance be- tween MA C count and hardware-efficienc y (MACpS). Using transpose con volutions in Lo wFormer Attention im- prov es accuracy by 0.2%, but it increases latency consider- ably on all CPU devices. On ARM CPU it further leads to 5% lower MA CpS, compared to the Baseline. Just original MBCon v blocks instead of GrMBCon v or GrFuMBCon v blocks lead to a significantly lower accu- racy and degrades latency on all devices. This is the case, ev en though it has a similar MA C count as our Baseline B1, demonstrating the enormous hardware-efficienc y benefit of our design by optimizing MA CpS. 6. Conclusion In this work, we in vestigated strategies for CPU-efficient model design. W e pointed out, that a major limitation for CPUs is their low parallelization capability , making them less suited for models with a high MAC count. A common approach to efficient model design is the use of depthwise con volutions. While they feature a comparably low MAC count, they also suffer from low MA CpS, ev en on CPU de- vices. T o address this, we proposed two alternative design adaptations for standard con volutions: setting the number of groups to two and reducing the kernel size. W e explic- itly computed the MAC reduction for both modifications and verified experimentally that the hardware-ef ficiency of the con volution, measured in MA CpS, is maintained dur- ing e xecution on CPU. Building on these insights, we intro- duced CPUBone, a new vision backbone architecture fam- ily , specifically optimized for CPU-based inference. At its core, the Grouped Fused MBCon v (GrFuMBConv) block effecti vely combines low MA C count and high MACpS. CPUBone consistently outperforms existing models across a wide range of CPU devices and effecti vely transfers its efficienc y to downstream tasks such as object detection and semantic segmentation. Acknowledgements. This research has been funded by the European Union, NextGenerationEU – PNRR M4 C2 I1.1, RS Micheloni. Progetto PRIN 2022 PNRR - “Track- ing in Egovision for Applied Memory (TEAM)” Code P20225MSER 001 Code CUP G53D23006680001. Mat- teo Dunnhofer recei ved funding from the European Union’ s Horizon Europe research and innovation programme un- der the Marie Skłodowska-Curie grant agreement n. 101151834 (PRINNEVO T CUP G23C24000910006). W e also acknowledge ISCRA for aw arding this project access to the LEONARDO supercomputer , owned by the EuroHPC Joint Undertaking, hosted by CINECA (Italy). References [1] Han Cai, Junyan Li, Muyan Hu, Chuang Gan, and Song Han. Efficientvit: Lightweight multi-scale attention for high- resolution dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer V ision , pages 17302– 17313, 2023. 1 , 2 , 3 , 5 , 6 , 7 , 8 [2] Jierun Chen, Shiu-hong Kao, Hao He, W eipeng Zhuo, Song W en, Chul-Ho Lee, and S-H Gary Chan. Run, don’t walk: Chasing higher flops for faster neural networks. In Pr oceed- ings of the IEEE/CVF Conference on Computer V ision and P attern Reco gnition , pages 12021–12031, 2023. 1 , 2 , 3 , 6 , 7 [3] Kai Chen, Jiaqi W ang, Jiangmiao Pang, Y uhang Cao, Y u Xiong, Xiaoxiao Li, Shuyang Sun, W ansen Feng, Ziwei Liu, Jiarui Xu, Zheng Zhang, Dazhi Cheng, Chenchen Zhu, T ian- heng Cheng, Qijie Zhao, Buyu Li, Xin Lu, Rui Zhu, Y ue W u, Jifeng Dai, Jingdong W ang, Jianping Shi, W anli Ouyang, Chen Change Loy , and Dahua Lin. MMDetection: Open mmlab detection toolbox and benchmark. arXiv preprint arXiv:1906.07155 , 2019. 7 [4] Y inpeng Chen, Xiyang Dai, Dongdong Chen, Mengchen Liu, Xiaoyi Dong, Lu Y uan, and Zicheng Liu. Mobile- former: Bridging mobilenet and transformer . In Pr oceedings of the IEEE/CVF confer ence on computer vision and pattern r ecognition , pages 5270–5279, 2022. 1 [5] Zekai Chen, Fangtian Zhong, Qi Luo, Xiao Zhang, and Y an- wei Zheng. Edgevit: Efficient visual modeling for edge com- puting. In International Confer ence on W ireless Algorithms, Systems, and Applications , pages 393–405. Springer, 2022. 2 , 7 , 8 [6] MMSegmentation Contrib utors. MMSegmentation: Openmmlab semantic segmentation toolbox and benchmark. https : / / github . com / open - mmlab/mmsegmentation , 2020. 7 [7] Jia Deng, W ei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE confer ence on computer vision and pattern r ecognition , pages 248–255. Ieee, 2009. 7 [8] Qihang Fan, Huaibo Huang, Xiaoqiang Zhou, and Ran He. Lightweight vision transformer with bidirectional interac- tion. Advances in Neural Information Processing Systems , 36, 2023. 7 , 8 [9] Goutam Y elluru Gopal and Maria A Amer . Separable self and mixed attention transformers for efficient object track- ing. In Pr oceedings of the IEEE/CVF winter confer ence on applications of computer vision , pages 6708–6717, 2024. 2 [10] Suyog Gupta and Mingxing T an. Efficientnet-edgetpu: Cre- ating accelerator-optimized neural networks with automl. https://ai.googleblog .com/2019/08/efficientnetedgetpu- cr eating.html , 2019. 3 , 1 [11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Pr oceed- ings of the IEEE conference on computer vision and pattern r ecognition , pages 770–778, 2016. 2 , 6 , 7 [12] Andrew Howard, Mark Sandler , Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing T an, W eijun W ang, Y ukun Zhu, Ruoming Pang, V ijay V asudev an, et al. Searching for mo- bilenetv3. In Proceedings of the IEEE/CVF international confer ence on computer vision , pages 1314–1324, 2019. 8 [13] Alexander Kirillov , Ross Girshick, Kaiming He, and Piotr Doll ´ ar . Panoptic feature pyramid networks. In Pr oceedings of the IEEE/CVF confer ence on computer vision and pattern r ecognition , pages 6399–6408, 2019. 7 [14] Y an yu Li, Ju Hu, Y ang W en, Georgios Ev angelidis, Kamyar Salahi, Y anzhi W ang, Sergey T ulyakov , and Jian Ren. Re- thinking vision transformers for mobilenet size and speed. In Pr oceedings of the IEEE/CVF International Confer ence on Computer V ision , pages 16889–16900, 2023. 6 , 7 [15] Tsung-Y i Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Dev a Ramanan, Piotr Doll ´ ar , and C La wrence Zitnick. Microsoft coco: Common objects in context. In Computer V ision–ECCV 2014: 13th European Confer ence, Zurich, Switzerland, September 6-12, 2014, Pr oceedings, P art V 13 , pages 740–755. Springer , 2014. 7 [16] Tsung-Y i Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll ´ ar . Focal loss for dense object detection. In Pr o- ceedings of the IEEE international confer ence on computer vision , pages 2980–2988, 2017. 7 , 8 [17] Alejandro L ´ opez-Ortiz, Alejandro Salinger, and Robert Su- derman. T ow ard a generic hybrid cpu-gpu parallelization of divide-and-conquer algorithms. In 2013 IEEE International Symposium on P arallel & Distributed Processing , W ork- shops and Phd F orum , pages 601–610. IEEE, 2013. 2 [18] Ilya Loshchilov and Frank Hutter . Sgdr: Stochas- tic gradient descent with warm restarts. arXiv pr eprint arXiv:1608.03983 , 2016. 7 [19] Ilya Loshchilov and Frank Hutter . Decoupled weight decay regularization. arXiv pr eprint arXiv:1711.05101 , 2017. 7 [20] Xu Ma, Xiyang Dai, Jianwei Y ang, Bin Xiao, Y inpeng Chen, Y un Fu, and Lu Y uan. Efficient modulation for vision net- works. arXiv pr eprint arXiv:2403.19963 , 2024. 1 , 2 , 6 , 8 [21] Mustafa Munir, William A very , and Radu Marculescu. Mo- bilevig: Graph-based sparse attention for mobile vision ap- plications. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) W ork- shops , pages 2211–2219, 2023. 6 [22] Moritz Nottebaum, Matteo Dunnhofer , and Christian Mich- eloni. Lowformer: Hardware efficient design for con volu- tional transformer backbones. In 2025 IEEE/CVF W inter Confer ence on Applications of Computer V ision (W ACV) , pages 7008–7018. IEEE, 2025. 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 [23] Moritz Nottebaum, Matteo Dunnhofer , and Christian Mich- eloni. Beyond macs: Hardware efficient architecture design for vision backbones, 2026. 6 [24] Danfeng Qin, Chas Leichner , Manolis Delakis, Marco Fornoni, Shixin Luo, Fan Y ang, W eijun W ang, Colby Ban- bury , Chengxi Y e, Berkin Akin, et al. Mobilenetv4: uni versal models for the mobile ecosystem. In Eur opean Conference on Computer V ision , pages 78–96. Springer , 2024. 1 , 2 , 3 , 8 [25] Mark Sandler , Andrew Ho ward, Menglong Zhu, Andrey Zh- moginov , and Liang-Chieh Chen. Mobilenetv2: In verted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern reco gni- tion , pages 4510–4520, 2018. 2 , 3 , 8 , 1 [26] Mingxing T an and Quoc Le. Efficientnetv2: Smaller models and faster training. In International confer ence on machine learning , pages 10096–10106. PMLR, 2021. 1 , 3 [27] Y ehui T ang, Kai Han, Jianyuan Guo, Chang Xu, Chao Xu, and Y unhe W ang. Ghostnetv2: Enhance cheap operation with long-range attention. Advances in Neural Information Pr ocessing Systems , 35:9969–9982, 2022. 2 , 6 [28] Pav an Kumar Anasosalu V asu, James Gabriel, Jeff Zhu, On- cel Tuzel, and Anurag Ranjan. Fastvit: A fast hybrid vision transformer using structural reparameterization. In Pr oceed- ings of the IEEE/CVF International Conference on Com- puter V ision , pages 5785–5795, 2023. 1 , 2 , 5 , 6 , 7 , 8 [29] Pav an Kumar Anasosalu V asu, James Gabriel, Jeff Zhu, Oncel T uzel, and Anurag Ranjan. Mobileone: An im- prov ed one millisecond mobile backbone. In Pr oceedings of the IEEE/CVF confer ence on computer vision and pattern r ecognition , pages 7907–7917, 2023. 1 , 2 , 6 [30] Ao W ang, Hui Chen, Zijia Lin, Jungong Han, and Guiguang Ding. Repvit: Revisiting mobile cnn from vit perspecti ve. In Pr oceedings of the IEEE/CVF Confer ence on Computer V i- sion and P attern Recognition (CVPR) , pages 15909–15920, 2024. 1 , 2 , 6 , 7 , 8 [31] Ao W ang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jun- gong Han, et al. Y olov10: Real-time end-to-end object de- tection. Advances in Neural Information Pr ocessing Systems , 37:107984–108011, 2024. 2 [32] W enhai W ang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, T ong Lu, Ping Luo, and Ling Shao. Pvt v2: Improved baselines with pyramid vision transformer . Computational V isual Media , 8(3):415–424, 2022. 7 , 8 [33] Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Y uan, and Lei Zhang. Cvt: Introducing con- volutions to vision transformers, 2021. 1 , 3 [34] W eihao Y u, Mi Luo, Pan Zhou, Chenyang Si, Y ichen Zhou, Xinchao W ang, Jiashi Feng, and Shuicheng Y an. Metaformer is actually what you need for vision. In Pr oceedings of the IEEE/CVF confer ence on computer vision and pattern r ecognition , pages 10819–10829, 2022. 2 [35] Seokju Y un and Y oungmin Ro. Shvit: Single-head vision transformer with memory efficient macro design. arXiv pr eprint arXiv:2401.16456 , 2024. 2 , 5 [36] Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler , Adela Barriuso, and Antonio T orralba. Scene parsing through ade20k dataset. In Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , 2017. 7 [37] Lei Zhu, Xinjiang W ang, Zhanghan K e, W ayne Zhang, and Rynson WH Lau. Biformer: V ision transformer with bi-level routing attention. In Pr oceedings of the IEEE/CVF con- fer ence on computer vision and pattern r ecognition , pages 10323–10333, 2023. 6 CPUBone: Efficient V ision Backbone Design f or Devices with Low Parallelization Capabilities Supplementary Material 7. Additional Details to CPU-Efficient Design Strategies 7.1. MA C calculations W ith Equation ( 1 ) we can calculate the MACs of a conv olu- tion with no bias. This further allows us to compute the re- duction in MA Cs of the grouped MBCon v v ariants (GrMB- Con v & GrFuMBCon v) compared to their ungrouped coun- terparts (MBCon v & FuMBCon v), which we needed in Subsection 3.2.1 . As well as calculate how the reduction of the kernel size from 3 × 3 to 2 × 2 affects MACs of the whole FuMBCon v and GrFuMBCon v block, which we need in Subsection 3.3 . For MA C calculations, we leav e out any batch normalization and activ ation functions of the MBCon v blocks [ 25 ], due to having a minor influence on the MA C count. W e further assume for simplicity , that the input channel dimension ( C in ) and the output channel di- mension ( C out ) are the same, that the expansion factor is 4 and the stride is 1. 7.1.1. FuMBCon v vs. GrFuMBCon v Follo wing Equation ( 1 ), the MACs of the fused MBCon v block ( M f mb ) or the GrFuMBConv block can be computed as M f mb = K H × K W × C in × C in × H out × W out g r oups + C in × C in × 4 × H out × W out , (4) where the first part refers to the standard con volution and the second part to the pointwise con volution (see Figure 2 ). By pulling out common multiplicativ e factors, Equation ( 4 ) can be simplified as: M f mb =( C in × C in × 4 × H out × W out ) × ( K H × K W g r oups + 1) , (5) where the term of the pointwise con volution is reduced to a single number in the second bracket. The only distinc- tion between FuMBConv [ 10 ] and GrFuMBCon v in Equa- tion ( 4 ) lies in the g roups parameter . Therefore, Equation ( 5 ) allo ws us to compute the proportion of MA Cs that Gr- FuMBCon v requires relativ e to FuMBCon v . When having a kernel of size 3 × 3 (and g r oups = 1 for the FuMBConv and g r oups = 2 for the GrFuMBConv , while all other pa- rameters are the same), the MA C count of GrFuMBConv divided by FuMBCon v is: = ( C in × C in × 4 × H out × W out ) ( C in × C in × 4 × H out × W out ) × (3 × 3 2 + 1) (3 × 3 1 + 1) , (6) which can be further simplified to: = 1 1 × 5 . 5 10 = 0 . 55 . (7) Consequently , the GrFuMBCon v always has 45% less MA Cs than its ungrouped counterpart (when they only dif- fer in the g r oups paramter), independent of the channel di- mension. 7.1.2. MBCon v vs GrMBConv The original MBConv block [ 25 ] consists out of two point- wise con volutions and one depthwise con volution (see Fig- ure 2 ). Following Equation ( 1 ), we can calculate the MAC count of the MBCon v ( M mb ) and GrMBCon v block (only differing in the gr oups parameter) as follows: M mb = C in × C in × 4 × H out × W out g r oups + C in × 4 × K H × K W × H out × W out + C in × C in × 4 × H out × W out . (8) Similarly to what we did in Equation ( 5 ), we can simplify Equation ( 8 ) by pulling out the commmon multiplicative factors, lea ving us with this: M mb = C in × 4 × H out × W out × ( C in g r oups + K H × K W + C in ) . (9) Similarly to Equation ( 6 ), we can now easily compute the relativ e MA C count of GrMBConv , compared to MBConv , by dividing the number of MA Cs of GrMBCon v ( g r oups = 2 ) with the MA C count of MBConv (with kernel size set to 3 × 3 for both): = C in × 4 × H out × W out C in × 4 × H out × W out × ( C in 2 + 3 × 3 + C in ) ( C in 1 + 3 × 3 + C in ) , (10) which can be further simplified to: = 1 1 × ( C in 2 + 9 + C in ) ( C in 1 + 9 + C in ) = (1 . 5 × C in + 9) (2 × C in + 9) = 1 . 5 2 × C in + 6 C in + 4 . 5 . (11) Equation ( 11 ) above sho ws us, that the relati ve MA C count of GrMBCon v di vided by MBCon v , depends on the channel dimension. Howe ver it further shows that with increasing C in , it conv erges to 1 . 5 / 2 = 0 . 75 , meaning the grouped MBCon v v ariant has 25% less MA Cs than its ungrouped counterpart. For the channel dimensions in T able 1 , namely 32, 64, 128, 256 and 512, the relative MACs in percent- age rounded accordingly are, respectively: 78.1%, 76.6%, 75.8%, 75.4%, 75.2%. The av erage is 76.2%. 7.1.3. Impact of Ker nel Size Reduction on MA C Count for GrFuMBCon v and FuMBCon v In Subsection 3.3 we compared how a reduction of the ker - nel size from 3 × 3 to 2 × 2 af fects MACpS for the depth- wise con volution, the FuMBConv and the GrFuMBCon v with g r oups = 2 . In Subsection 3.1 we calculated for con- volutions in general, how the reduced kernel affects MA C count, leading to approximately 56% always. Therefore the MA C count of the depthwise con volution is reduced by 56%, when reducing the kernel size. Howe ver , the FuMB- Con v block and GrFuMBCon v block also include an addi- tional pointwise con volution, whose kernel is not reduced, making the calculation a bit more complicated. Howe ver , we need the MA C count of the full MBConv blocks, since we also tested the full MBCon v block in Subsection 3.3 . Starting from Equation ( 5 ), which describes the MAC count of the GrFuMBCon v or the FuMBConv , we can di- vide the MA Cs of the 2 × 2 FuMBCon v by the 3 × 3 FuM- BCon v block to obtain the percentage reduction (similarly to what we did in Equation ( 6 )): = ( C in × C in × 4 × H out × W out ) ( C in × C in × 4 × H out × W out ) × 2 × 2 1 + 1 3 × 3 1 + 1 = 1 1 × 5 10 = 0 . 5 . (12) Consequently , the kernel reduction does exactly halve the MA C count of the FuMBCon v block. By doing the same thing now for the GrFuMBCon v block, we yield: = ( C in × C in × 4 × H out × W out ) ( C in × C in × 4 × H out × W out ) × 2 × 2 2 + 1 3 × 3 2 + 1 = 1 1 × 3 5 . 5 = 0 . 54 , (13) meaning for the GrFuMBCon v block the kernel reduction leads to approximately 46% less MA Cs. 7.2. K ernel Experiment GPU In T able 8 & 9 , we repeat the experiments of Subsection 3.3 from table 2 & 3 , but on GPU instead of the ARM CPU of the Raspberry Pi5. T able 8 & 9 show an extreme deteriora- tion of the MACpS, when reducing the k ernel of a conv olu- tion from 3 × 3 to 2 × 2 . Especially for depthwise con volu- tions, this change leads to a higher execution time than com- pared to the original 3 × 3 kernel. For FuMBConv and Gr- FuMBCon v , the MA CpS also decrease significantly; how- ev er , both variants retain at least a similar latency compared to the original 3 × 3 kernel. While the y achie ve roughly half the MA Cs, the corresponding reduction in MACpS offsets the expected ef ficiency gain, ef fectively nullifying it. Dwise GPU Channel Dimension Resol. T ype 128 256 512 1024 A vg. 7×7 nmk 6.6 13.1 26.5 52.4 24.7 smk 1.2 2.3 4.7 9.3 4.4 14×14 nmk 26.4 52.7 103.8 205.3 97.0 smk 4.7 9.0 18.7 36.3 17.2 28×28 nmk 103.2 203.5 300.3 308.0 228.7 smk 18.1 35.7 71.5 68.9 48.5 T able 8. Execution efficiency experiment on GPU on the effect of kernel size reduction for depthwise con volutions, by measuring MMA Cs/ms. Resol. refers to operating resolution, T ype refers to the kernel size ( nmk = 3 × 3 , smk = 2 × 2 ). Bold entries indicate whether nmk or smk variant has higher MA CpS. Same as T able 2 , b ut on GPU. GPU Ungrouped Groups=2 Resol. T ype Channel Dim. Channel Dim. 128 256 A vg. 128 256 A vg. 7×7 nmk 661.6 1075.7 868.6 355.1 893.7 624.4 smk 284.4 882.9 583.6 145.3 627.2 386.2 14×14 nmk 2374.3 3545.5 2959.9 1422.6 3026.8 2224.7 smk 1081.8 2021.3 1551.5 627.0 1671.9 1149.4 28×28 nmk 4892.2 5385.9 5139.0 4068.5 4785.6 4427.0 smk 2333.9 2669.0 2501.5 2000.5 2538.2 2269.3 T able 9. Execution efficiency experiment on GPU on the effect of kernel size reduction. W e test the GrFuMBCon v (Groups=2) and FuMBConv (Ungrouped) block by measuring MMA Cs/ms. Resol. refers to operating resolution, T ype refers to the kernel size ( nmk = 3 × 3 , smk = 2 × 2 ). Bold entries indicate whether nmk or smk variant has higher MACpS. Same as T able 3 , but on GPU. 7.3. Grouping ARM CPU - additional Resolutions T able 10 shows a similar experiment as T able 1 , howe ver we focus only on ARM CPU, but feature the additional Grouping=2 Experiment ARM CPU Channel Dimension Resolution V ariant 32 64 128 256 512 A vg . MBCon v 4.1 8.5 14.9 22.4 23.5 14.7 7x7 Gr MBConv 3.7 6.5 11.6 17.7 19.5 11.8 (-19%) (MMA Cs/ms) Fu MBConv 25.5 36.3 38.7 27.8 24.3 30.5 GrFu MBCon v 14.7 28.3 37.2 32.3 26.5 27.8 (-8%) MBCon v 7.8 13.3 21.4 26.4 26.2 19.0 14x14 Gr MBCon v 6.3 10.6 16.7 22.1 23.3 15.8 (-16%) (MMA Cs/ms) Fu MBConv 40.6 45.3 40.7 32.4 24.5 36.7 GrFu MBCon v 31.0 42.1 44.4 34.7 30.4 36.5 (-0%) MBCon v 11.7 18.6 22.5 26.3 26.9 21.2 28x28 Gr MBCon v 9.4 14.8 18.1 21.3 26.8 18.1 (-14%) (MMA Cs/ms) Fu MBConv 53.2 54.6 41.2 30.0 25.9 41.0 GrFu MBCon v 45.5 53.4 44.1 37.5 29.2 41.9 (+2%) MBCon v 8.4 12.8 19.1 22.7 30.8 18.8 56x56 Gr MBCon v 7.2 9.9 14.3 18.4 25.4 15.0 (-20%) (MMA Cs/ms) Fu MBConv 42.3 37.5 31.7 24.4 23.2 31.8 GrFu MBCon v 35.3 37.3 34.8 27.2 24.0 31.7 (-0%) T able 10. Execution efficienc y of MACs, measured in MMA Cs/ms on the ARM CPU of the Raspberry Pi5, for the four MBConv v ariants (MBCon v , GrMBConv , FuMBCon v and GrFuMBCon v) for dif ferent channel dimensions and operating resolutions. Bold entries indicate whether the grouped or ungrouped variant has higher MACpS. All grouped variants hav e g r ou ps = 2 . It is similar to T able 1 , but for resolutions 7 × 7 , 14 × 14 , 28 × 28 and 56 × 56 and only on ARM CPU. resolutions 7 × 7 , 28 × 28 and 56 × 56 . The numbers are mostly very similar to 1 , independent of the resolu- tions. Ho we ver the GrMBCon v consistently underperforms on ARM CPU, compared to the other CPU devices fea- tured in T able 1 (Snapdragon 8 Elite CPU, Google Pixel 4 CPU). The FuMBCon v block howe ver consistently shows high MA CpS, only on resolution 7 × 7 it f alls off a bit. 7.4. Grouping 4 on ARM CPU In T able 11 we repeat the experiment of T able 1 for addi- tional resolutions ( 7 × 7 , 14 × 14 , 28 × 28 and 56 × 56 ) and on the ARM CPU, b ut for g r oups = 4 instead of gr oups = 2 . The av eraged numbers with g r oups = 4 (T able 11 ) are very similar to g r oups = 2 (T able 1 ), howe ver the distribution ov er the channels is different: For channel dimensions be- low 128, GrFuMBCon v with g r oups = 4 has 20% lower MA CpS, compared to g r oups = 2 . Ho wever for chan- nel dimensions over 128, they hav e 36% higher MACpS. Consequently , depending on the channel dimension, either g r oups = 2 (below 128) or g r oups = 4 (over 128) is more hardware ef ficient. 7.5. Grouping GPU - additional Resolutions In T able 12 we repeat the experiment of T able 1 for addi- tional resolutions ( 7 × 7 , 14 × 14 , 28 × 28 and 56 × 56 ) on the Nvidia TIT AN R TX GPU. W e observe that at lower resolutions, the grouped variants perform worse, likely due Grouping=4 Experiment ARM CPU Channel Dimension Resolution V ariant 32 64 128 256 512 A vg. MBConv 4.1 8.5 14.9 22.4 23.5 14.7 7x7 Gr MBConv 3.1 5.4 10.2 17.4 19.9 11.2 (-23%) (MMACs/ms) Fu MBConv 25.5 36.3 38.7 27.8 24.3 30.5 GrFu MBConv 10.2 18.5 31.4 34.9 32.0 25.4 (-16%) MBConv 7.8 13.3 21.4 26.4 26.2 19.0 14x14 Gr MBConv 5.6 9.2 16.1 22.1 28.1 16.2 (-14%) (MMACs/ms) Fu MBConv 40.6 45.3 40.7 32.4 24.5 36.7 GrFu MBConv 24.8 36.4 43.2 41.4 39.8 37.1 (+1%) MBConv 11.7 18.6 22.5 26.3 26.9 21.2 28x28 Gr MBConv 8.4 13.0 17.1 23.6 36.6 19.7 (-7%) (MMACs/ms) Fu MBConv 53.2 54.6 41.2 30.0 25.9 41.0 GrFu MBConv 36.7 47.1 49.5 50.5 45.7 45.9 (+12%) MBConv 8.4 12.8 19.1 22.7 30.8 18.8 56x56 Gr MBConv 6.3 8.9 14.2 21.6 33.8 17.0 (-9%) (MMACs/ms) Fu MBConv 42.3 37.5 31.7 24.4 23.2 31.8 GrFu MBConv 31.3 30.8 39.7 43.4 39.5 36.9 (+16%) T able 11. Execution efficienc y of MACs, measured in M MA Cs/ms on the ARM CPU of the Raspberry Pi5, for the four MBCon v vari- ants (MBCon v , GrMBConv , FuMBConv and GrFuMBConv) for different channel dimensions and operating resolutions. Bold en- tries indicate whether the grouped or ungrouped v ariant has higher MA CpS. It is similar to T able 1 , b ut for resolutions 7 × 7 , 14 × 14 , 28 × 28 and 56 × 56 , only on ARM CPU and all grouped variants hav e g r oups = 4 instead of g r oups = 2 of T able 1 . to reduced opportunities for parallelizing the conv olutional operations. From T able 12 we can conclude, that grouping con volutions does not fully translate lower MA C count to a similarly low latenc y on GPU. Grouping=2 Experiment GPU Channel Dimension Resolution V ariant 32 64 128 256 512 A vg . MBCon v 8.6 31.7 114.4 474.0 1746.1 475.0 7x7 Gr MBConv 5.6 20.4 82.4 328.4 1094.9 306.3 (-35%) (MMA Cs/ms) Fu MBConv 45.6 182.4 672.7 1089.9 1309.8 660.1 GrFu MBCon v 23.5 85.6 342.2 878.4 1264.3 518.8 (-21%) MBCon v 34.2 112.3 428.6 1747.3 3494.0 1163.3 14x14 Gr MBCon v 25.0 88.4 308.8 1260.6 2679.1 872.4 (-25%) (MMA Cs/ms) Fu MBConv 185.1 622.6 2394.6 3612.2 3849.0 2132.7 GrFu MBCon v 96.8 330.3 1307.3 2963.3 3878.9 1715.3 (-19%) MBCon v 140.0 530.1 1865.3 3053.0 4114.5 1940.6 28x28 Gr MBCon v 96.7 384.0 1350.1 2395.3 3769.6 1599.1 (-17%) (MMA Cs/ms) Fu MBConv 752.8 3043.4 4882.2 5472.1 5676.0 3965.3 GrFu MBCon v 395.0 1452.0 4237.8 4839.3 5703.9 3325.6 (-16%) MBCon v 524.9 1503.4 2518.9 3820.4 4717.1 2617.0 56x56 Gr MBCon v 379.8 1048.2 1953.9 3171.3 4416.1 2193.8 (-16%) (MMA Cs/ms) Fu MBConv 2930.6 4971.6 6183.8 7226.3 7576.2 5777.7 GrFu MBCon v 1402.0 3654.2 5068.1 6606.4 7288.1 4803.8 (-17%) T able 12. Execution efficienc y of MA Cs, measured in MMACs/ms on the Nvidia TIT AN R TX GPU, for the four MBConv variants (MBCon v , GrMBConv , FuMBCon v and GrFuMBCon v) for dif ferent channel dimensions and operating resolutions. Bold entries indicate whether the grouped or ungrouped variant has higher MACpS. All grouped variants hav e g r ou ps = 2 . It is similar to T able 1 , but for resolutions 7 × 7 , 14 × 14 , 28 × 28 and 56 × 56 and only on GPU.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment