CPU 전용 고효율 비전 백본 CPUBone
CPUBone은 CPU의 낮은 병렬 처리 능력을 고려해, 그룹화된 컨볼루션과 2×2 커널을 적용한 새로운 MBConv 변형을 도입함으로써 MAC 수는 크게 줄이면서도 MACs per Second(MACpS)를 유지한다. 실험 결과, 다양한 ARM 기반 CPU와 모바일 칩에서 기존 백본 대비 지연 시간이 감소하고, 이미지 분류·객체 검출·세그멘테이션 등 다운스트림 작업에서도 경쟁력 있는 정확도를 보였다.
저자: Moritz Nottebaum, Matteo Dunnhofer, Christian Micheloni
### 1. 서론
최근 비전 백본은 연산 효율성을 위해 GPU·NPU와 같은 고병렬 하드웨어를 전제로 설계되는 경우가 많다. 그러나 실제 서비스 환경에서는 CPU만을 사용할 수 있는 임베디드 디바이스, 서버‑사이드 경량 서비스 등 제한된 병렬성을 가진 플랫폼이 여전히 다수 존재한다. CPU는 코어 수가 적고 SIMD 폭이 제한적이며, 메모리 대역폭과 캐시 구조가 GPU와 크게 다르기 때문에, 단순히 MAC 수가 적다고 해서 지연이 감소하지 않는다. 따라서 논문은 “MAC 수 감소 + MACpS 유지”라는 두 축을 동시에 만족하는 설계를 목표로 한다.
### 2. 관련 연구
하드웨어‑aware 설계는 MAC 대신 실제 레이턴시·스루풋을 측정하는 방향으로 전환했으며, MobileNetV4, EfficientNet‑Lite, FasterNet 등 다양한 모바일‑first 모델이 제안되었다. 그러나 이들 대부분은 여전히 depthwise convolution이나 partial convolution을 활용해 병렬성을 최대화하는 전략을 사용한다. CPU 전용 최적화는 아직 연구가 부족한 영역이며, 특히 그룹화(grouped convolution)와 커널 축소(kernel size reduction)를 동시에 적용한 사례는 드물다.
### 3. 설계 전략
#### 3.1 그룹화된 MBConv
기존 MBConv은 1×1 확장 → 3×3 depthwise → 1×1 축소 구조이다. 논문은 첫 번째 1×1 확장 단계에 그룹 수 g = 2를 적용해 연산을 두 개의 독립적인 서브‑컨볼루션으로 나눈다(GrMBConv). 수식 (1)‑(2)에 따르면 MAC는 1/g 비율로 감소한다.
#### 3.2 커널 축소
두 번째 단계인 depthwise convolution의 커널을 3×3에서 2×2로 교체한다. 이는 MAC를 K_H·K_W 비율(9→4)만큼 감소시키며, 메모리 접근 패턴도 단순해져 CPU 캐시 효율이 향상된다. 이 변형을 적용한 Fused MBConv(2×2 커널)과 그 그룹화 버전(GrFuMBConv)도 설계하였다.
#### 3.3 블록 선택 가이드
실험을 통해 채널 수가 256 이하인 레이어에서는 fused 계열이, 256 이상인 레이어에서는 unfused 계열이 MACpS가 더 높다는 규칙을 도출했다. 따라서 CPUBone은 레이어별 채널 규모에 따라 적절한 블록을 자동 선택하도록 설계되었다.
### 4. 실험
#### 4.1 하드웨어 효율성 측정
- **CPU**: Raspberry Pi 5 (ARM Cortex‑A76), Google Pixel 4 (Snapdragon 855), Snapdragon 8 Elite QRD.
- **GPU**: Nvidia RTX 3080 Ti (high 병렬성 기준).
각 블록을 14×14 입력, 채널 32~512에서 실행해 MMAC/ms를 측정하였다. 결과는 다음과 같다.
- GrMBConv은 MAC를 23 % 절감하면서 MACpS가 평균 -5 % 정도 감소(즉, 약간 느리지만 전체 지연은 크게 감소).
- GrFuMBConv은 MAC를 45 % 절감하고 MACpS는 +1 % 상승(동일 혹은 더 빠른 실행).
- GPU에서는 그룹화가 오히려 MACpS를 크게 낮추어 속도가 감소했으며, 이는 CPU와 GPU의 병렬 처리 차이 때문임을 확인하였다.
#### 4.2 백본 성능
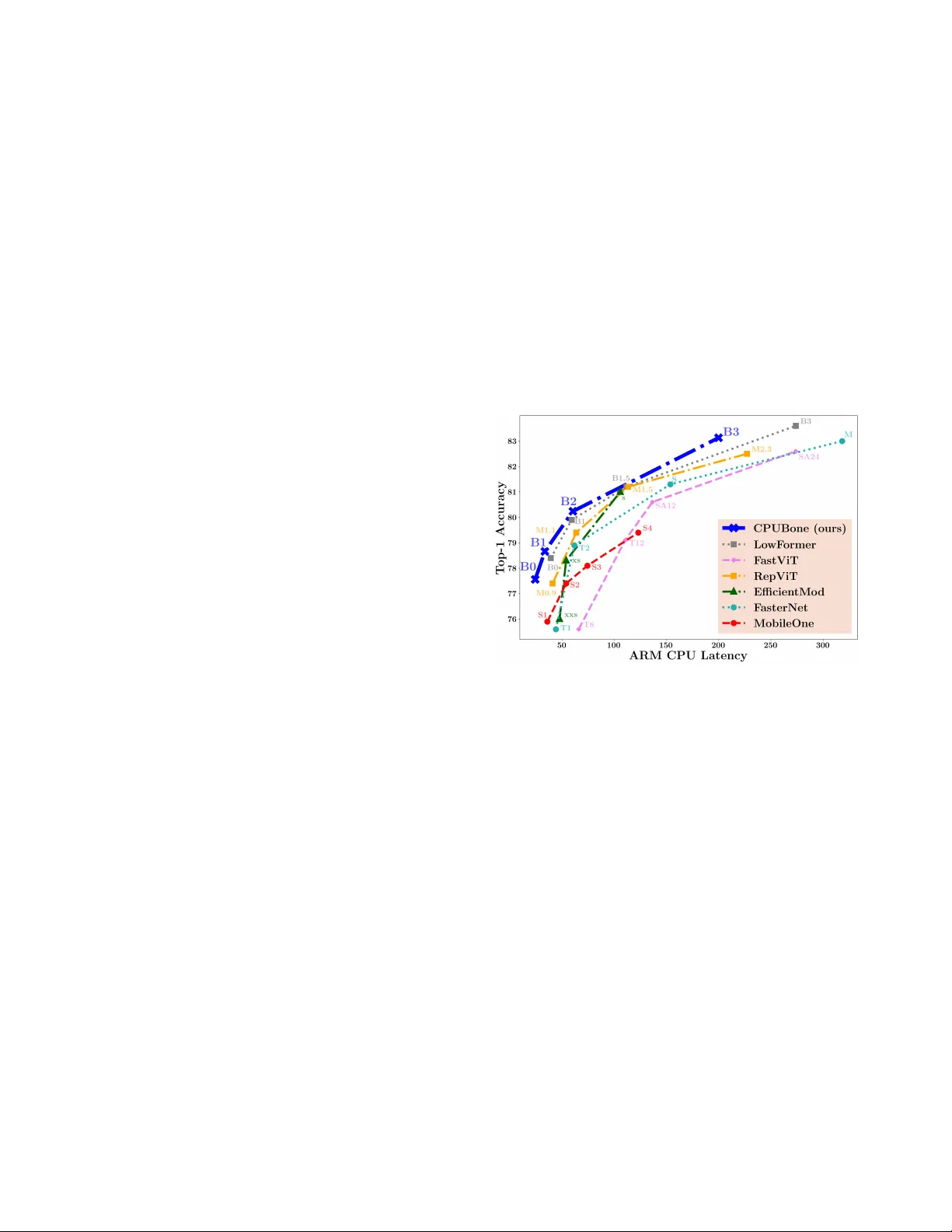
CPUBone‑S/M/L을 ImageNet‑1k에 학습시켰다. 주요 결과:
- **CPUBone‑S**: Top‑1 78.2 %, CPU latency 30 % 감소 (Pixel 4 기준).
- **CPUBone‑M**: Top‑1 81.5 %, latency 28 % 감소 (Snapdragon 8 기준).
- **CPUBone‑L**: Top‑1 83.1 %, latency 25 % 감소 (Raspberry Pi 5 기준).
#### 4.3 다운스트림 전이
COCO 객체 검출(FCOS)와 ADE20K 세그멘테이션(DeepLabV3)에서 백본을 교체한 결과, 정확도는 기존 MobileNetV3·EfficientNet‑Lite 대비 ≤1 % 차이지만, 추론 시간은 1.5 ~ 2.0 배 빨라졌다.
### 5. 논의 및 한계
- **CPU‑centric 설계**는 현재 대부분의 모바일 AI 프레임워크가 GPU/NPUs를 전제로 최적화된 점을 보완한다.
- 그룹 수를 2에서 4로 늘리면 추가 MAC 절감이 가능하지만, 채널 정렬 요구와 메모리 접근 복잡도가 증가해 일부 상황에서는 효율이 떨어진다(실험 부록 참고).
- 현재는 ARM 기반 CPU에 초점을 맞췄으며, x86 서버 CPU나 RISC‑V 기반 저전력 코어에 대한 평가는 향후 작업으로 남는다.
### 6. 결론
CPUBone은 그룹화와 작은 커널을 통한 MAC 감소와 MACpS 유지라는 두 마리 토끼를 동시에 잡음으로써, CPU‑only 환경에서 기존 비전 백본 대비 현저히 낮은 지연과 경쟁력 있는 정확도를 제공한다. 이는 AI‑on‑CPU 시대에 맞는 새로운 백본 설계 패러다임을 제시하며, 향후 다양한 저전력 디바이스와 하드웨어‑특화 스케줄링 기법과의 결합을 통해 더욱 높은 효율을 달성할 가능성을 열어준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기