AVDA: Autonomous Vibe Detection Authoring for Cybersecurity
With the rapid advancement of AI in code generation, cybersecurity detection engineering faces new opportunities to automate traditionally manual processes. Detection authoring - the practice of creating executable logic that identifies malicious act…
Authors: Fatih Bulut, Carlo DePaolis, Raghav Batta
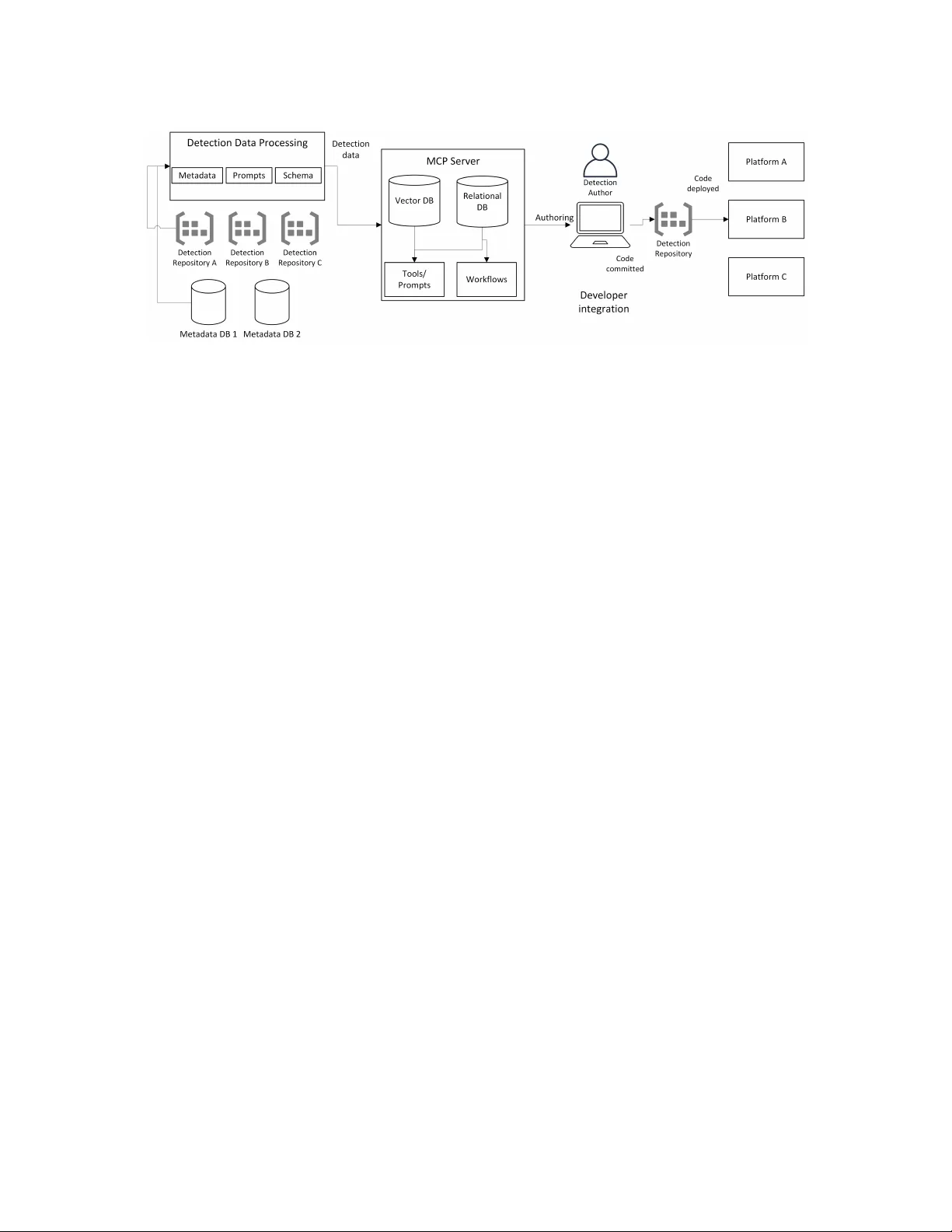
A VD A: A utonomous Vibe Detection A uthoring for Cyb ersecurity Fatih Bulut Microsoft USA mbulut@microsoft.com Carlo DePaolis Microsoft USA mdepaolis@microsoft.com Raghav Batta Microsoft USA raghavbatta@microsoft.com Anjali Mangal Microsoft USA anjalimangal@microsoft.com Abstract With the rapid advancement of AI in code generation, cybersecu- rity detection engineering faces new opportunities to automate traditionally manual processes. Detection authoring—the practice of creating executable logic that identies malicious activities from security telemetry—is hindered by fragmented code across repos- itories, duplication, and limited organizational visibility . Current workows remain heavily manual, constraining both coverage and velocity . In this paper , w e introduce A VD A, a framework that lever- ages the Model Context Protocol (MCP) to automate detection authoring by integrating organizational context—existing detec- tions, telemetry schemas, and style guides—into AI-assisted code generation. W e evaluate three authoring strategies—Baseline, Se- quential, and Agentic—across a diverse corpus of production de- tections and state-of-the-art LLMs. Our results show that A gentic workows achiev e a 19% improvement in o verall similarity score over Baseline approaches, while Sequential workows attain 87% of Agentic quality at 40 × lower token cost. Generated detections excel at T TP matching (99.4%) and syntax validity (95.9%) but struggle with exclusion parity (8.9%). Expert validation on a 22-detection subset conrms strong Spearman correlation between automated metrics and practitioner judgment ( 𝜌 = 0 . 64 , 𝑝 < 0 . 002 ). By inte- grating seamlessly into standard de veloper environments, A VD A provides a practical path toward AI-assisted detection engineering with quantied trade-os between quality , cost, and latency . CCS Concepts • Security and privacy → Software security engineering . Ke y words Cybersecurity , Detection Engineering, Articial Intelligence A CM Reference Format: Fatih Bulut, Carlo DePaolis, Raghav Batta, and Anjali Mangal. 2026. A VDA: A utonomous Vibe Detection Authoring for Cyberse curity . In 34th ACM Joint European Software Engineering Conference and Symposium on the Founda- tions of Software Engineering (FSE Companion ’26), July 05–09, 2026, Montreal, This work is licensed under a Creative Commons Attribution-NonCommercial- NoDerivatives 4.0 International License. FSE Companion ’26, Montreal, QC, Canada © 2026 Copyright held by the owner/author(s). ACM ISBN /2026/07 https://doi.org/10.1145/3803437.3805261 QC, Canada. A CM, New Y ork, NY, USA, 11 pages. https://doi.org/10.1145/ 3803437.3805261 1 Introduction Articial Intelligence ( AI) and Machine Learning (ML) have long played a pivotal role in cybersecurity , enabling capabilities such as anomaly detection, entity extraction, and intrusion detection. Re- cent br eakthroughs—particularly the emergence of Large Language Models (LLMs) and agentic workows—have opened new avenues for innovation. Advances in code generation, exemplied by tools such as GitHub Copilot [ 7 ], OpenAI Codex [ 13 ], and Anthropic’s Claude Code [ 3 ], have transformed software engineering practices by enabling automated, context-aware code synthesis. The term vibe coding, coined by Andrej Karpathy in Februar y 2025, describes a development style in which pr ogrammers express intent in natural language and rely on AI systems to generate im- plementation details through iterative , conversational interaction rather than manual coding. A VD A extends this paradigm to cyb er- security detection engine ering: authors describe threats in natural language and leverage AI-assiste d workows to produce e xe cutable detection logic, hence “Vibe Detection Authoring. ” Detection engineering, a cornerstone of modern cyberse curity , has evolved fr om ad hoc rule creation into a structured discipline that mirrors the software development lifecycle. Contemporar y detection-as-code practices [ 17 ] emphasize version control, testing, and continuous integration, aligning detection development with established engineering principles. Detection artifacts var y widely in language, format, and complexity—from simple atomic rules ex- pressed in standardized query languages to sophisticated behavioral analytics. Critically , detection authoring is fundamentally a code generation task: authors translate threat concepts into executable logic tailored to spe cic platforms and telemetry schemas. This makes detection engineering a natural candidate for LLM-assisted automation. Despite the maturation of detection-as-code practices, detec- tion development remains challenging. As enterprise attack sur- faces expand through cloud adoption and heter ogene ous security ecosystems, detection workows often become fragmented across multiple repositories and platforms. This fragmentation introduces duplication, inconsistency , and signicant manual o verhead, ulti- mately limiting both visibility and coverage. Traditional authoring workows—identifying protection gaps, drafting detection logic, performing unit tests, and validating against real-world data—are resource-intensive and do not scale with the velocity of mo dern FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada Bulut et al. threats. In large enterprises operating across multiple vendors, over- lapping rules and blind spots are common, increasing maintenance burden and reducing organizational resilience. The advent of state-of-the-art LLMs presents an opportunity to address these challenges. Recent innovations such as the Model Context Protocol (MCP) [ 2 ] enable seamless context sharing across tools and environments, facilitating interoperability between AI as- sistants and organizational knowledge bases. MCP allows detection authors to query existing detection portfolios, retrieve telemetry schemas, and generate platform-specic co de—all within a unied interface. Coupled with widespread adoption of developer tools such as Visual Studio Code, these advancements create an opportu- nity to streamline detection authoring through AI-driven automa- tion. In this pap er , we introduce A VD A, a framework designed to auto- mate detection authoring workows by integrating LLM-base d code generation with organizational context. A VDA le verages MCP to provide detection authors with access to existing dete ctions, schema information, and platform-specic style guides during the author- ing process. By embedding AI assistance directly into developer environments, A VDA reduces duplication, impro ves consistency , and accelerates the development of high-quality dete ctions while preserving human oversight. W e evaluate A VD A across three authoring strategies—Baseline (zero-shot generation), Sequential (retrieval-augmented genera- tion), and Agentic (iterative tool-orchestrated reasoning)—using 92 production detections spanning 5 platforms and 3 languages. Our evaluation encompasses 11 mo dels and 21 congurations across multiple LLM families, including reasoning-capable mo dels at var y- ing reasoning eort levels, producing 5,796 generated detection artifacts. Results demonstrate that Agentic workows achiev e the highest overall similarity score (mean 0.447), representing a 19% im- provement ov er Baseline approaches. Sequential workows oer a practical alternative, achie ving 87% of Agentic quality at 40 × lower token cost. Expert validation on a 22-detection subset conrms strong correlation between automated metrics and practitioner judgment (Spearman 𝜌 = 0 . 64 , 𝑝 < 0 . 002 ), establishing the reliabil- ity of our evaluation framework. Our contributions are as follows: • A VDA Framework: A retrieval-augmented dete ction au- thoring system that leverages the Model Context Protocol (MCP) to integrate organizational context—including e xist- ing dete ctions, telemetry schemas, and style guides—into AI-assisted code generation within standard developer tools. • Comprehensive Empirical Evaluation: A systematic com- parison of Baseline, Se quential, and Agentic workows across 11 models, 21 congurations, and 92 production detections spanning 5 platforms and 3 languages, quantifying trade-os between quality (19% improvement for Agentic) and cost (40 × token overhead). W e identify that generated detections excel at T TP matching (99.4%) and syntax validity (95.9%) but struggle with exclusion parity (8.9%). • V alidated Evaluation Methodology: An automated eval- uation framework combining LLM-as-a-judge semantic as- sessment with embedding-based similarity , validated against expert ratings on a 22-detection subset with statistically sig- nicant correlation ( 𝜌 = 0 . 64 , 𝑝 < 0 . 002 ), enabling scalable quality assessment for AI-generated detections. • Practical Guidance for Practitioners: Empirical insights on model selection (reasoning-capable models outp erform), workow trade-os (Sequential as cost-eective alternative), and failure modes (schema hallucination, missing exclusion logic), informing adoption of AI-assiste d detection authoring in enterprise settings. The remainder of this paper is organize d as follows. Section 2 re- views related work, providing context for existing appr oaches and their limitations. Section 3 describes the system design of A VD A, detailing its architecture and integration with developer tools. Se c- tion 4 presents our evaluation methodology and results. Section 5 discusses key ndings, limitations, and lessons learned. Finally , Section 6 concludes the pap er and outlines directions for future research. 2 Related W ork Recent advances in large language models have prompted explo- ration of AI-assisted security dete ction authoring. Schwartz et al. [ 15 ] describe a system that extracts generic-signature detection rules from cloud-focused cyb er threat intelligence (CTI) reports, converting unstructured CTI into sigma rules and Splunk queries via LLM pipeline. In contrast, A VD A targets platform-specic detec- tion authoring across heterogeneous environments (K QL, Python, Scala), compares three increasingly autonomous workows (base- line, sequential, agentic), and evaluates detection quality through ten binary semantic criteria enabling diagnostic analysis of individ- ual failure modes. RuleGenie [ 16 ] has explored LLM-aided optimiza- tion of existing detection rule sets. It uses embeddings and chain- of-thought reasoning to identify redundant SIEM rules and rec- ommend consolidations. While complementary to our generation- focused approach, such optimization would be applied after A VDA produces candidate detections. GRIDAI [ 9 ] proposes a multi-agent LLM framework for generating and repairing network intrusion detection rules. Their system comprises multiple agents. While GRID AI addresses network-layer intrusion detection from trac samples, our work targets any type of detection authoring from natural language descriptions. Similar to [ 16 ], GRID AI’s key contri- bution is reducing ruleset redundancy by repairing existing rules for attack variants; in contrast, A VDA focuses on comparing workow automation levels (baseline, sequential RA G, and agentic) to deter- mine optimal LLM orchestration strategies for enterprise security platforms. The authors in [ 11 ] investigate small language models for K QL quer y generation in SOC workows, similar to [ 19 ], demon- strating that ne-tuned mo dels can match larger models on narro w domains, though their evaluation focuses on query correctness rather than comprehensive detection quality metrics. While their work targets query generation for log analysis and threat hunting, A VDA addresses detection authoring —generating executable rules that run continuously in production environments. Both systems share a schema-aware retrieval component, but A VDA explores varying autonomy levels (baseline, sequential, agentic) and gen- erates complex multi-language detections (K QL, Python/PySpark, Scala) rather than KQL queries alone . A VDA: A utonomous Vibe Dete ction Authoring for Cybersecurity FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada The Detection as Code (DaC) movement applies software engi- neering practices to detection life cycle management [ 17 ]. Industry surveys indicate that while 63% of security teams aspire to adopt DaC practices, only 35% have implemente d them, citing challenges in version control, automated testing, and environment drift. Palan- tir’s Alerting and Detection Strategy (ADS) framework [ 14 ] ex- emplies mature DaC practices with structured do cumentation, mandatory pe er review , and version-controlled pipelines. Sublime Security’s Automated Detection Engineer (ADÉ) [ 5 , 18 ] represents an industry deployment of LLM-driven detection author- ing, evaluating generated rules across detection accuracy , robust- ness, and economic cost, with production deployments reporting high precision comparable to human-authored rules. Bertiger et al. [ 5 ] present an evaluation framework introducing a holdout-based methodology that compares LLM-generated rules against human- authored baselines using expert-inspired metrics. NL2KQL [ 19 ] provides a benchmark for security log quer y generation evaluating both syntactic and semantic correctness, but b enchmarks using synthetic datasets may not reect production complexity . The Model Context Protocol (MCP) [ 2 ] provides an open stan- dard for connecting AI applications to external systems, enabling tool-augmented LLM workows by standar dizing data source ac- cess and multi-turn context retrieval. Recent work distinguishes between sequential workows that chain tool invocations without dynamic adaptation and agentic systems that incorporate fee dback loops for iterative renement [ 1 ]. Structured workows often out- perform autonomous agents on deterministic tasks, while agents ex- cel when problems require exploration or error r e covery—detection authoring exhibits characteristics of both. A VDA dierentiates itself from prior work by combining: (1) sup- port for heterogeneous enterprise environments spanning multiple languages (Python/PySpark, KQL, Scala) and multiple platforms; (2) MCP-grounded tool access for schema validation and telemetry introspection; (3) a systematic comparison of Baseline, Sequen- tial, and Agentic worko ws across 11 state-of-the-art models and reasoning congurations; and (4) rigorous evaluation against 92 production detections validated by expert correlation. 3 System Design Figure 1 illustrates the A VDA ar chite cture, which comprises four main components: (1) a Detection Data Processing layer that ingests and normalizes detection artifacts fr om organizational repositories; (2) an MCP Server that exposes tools for semantic search, schema introspection, and code generation; (3) A uthoring W orkows that orchestrate LLM interactions in baseline, sequential, or agentic modes; and (4) Developer Integration that embe ds these capabilities into standard IDE and CI/CD environments. The design prioritizes three obje ctives: scalability across large detection portfolios, in- teroperability across heterogeneous platforms, and automation of repetitive authoring tasks while preserving human oversight. 3.1 Detection Data Processing This layer ingests and normalizes detection artifacts from heteroge- neous sources. It processes two primary inputs: (i) detection code from organizational repositories, treated as the canonical source of T able 1: MCP tools exposed by A VDA. Category T ool Description Retrieval semantic_search V ector similarity search over detec- tion embeddings search_by_mitre Retrieve detections by MI TRE A T T&CK technique or tactic search_by_platform Filter dete ctions by platform and language get_content Fetch full source code and metadata by ID Schema get_telemetry_fields List elds for a telemetry table get_supported_actions Return actions for a telemetry table get_actions_and_tables Enumerate action–table mappings get_best_table Recommend table for a detection ac- tion Similarity get_similar Find detections by cosine similarity get_details Retrieve extended metadata and mappings truth, and (ii) metadata from wikis and platform catalogs, which is often incomplete or inconsistent. T o standardize these artifacts, the system applies platform-spe cic parsers augmented by LLM-based canonicalization for schema align- ment. A unied schema captures key elds including: • detection_id , name , description — unique identier and documentation • platform , language — execution environment (e.g., XDR/PyS- park, Sentinel/KQL) • mitre_tactics , mitre_techniques — A T T&CK mappings for coverage analysis and search • data_sources — telemetry tables and signals consumed • original_content — raw detection code for retrieval and comparison • repository , file_path — provenance for lineage tracking Missing metadata (e.g., MI TRE mappings) is inferred from code analysis and related documentation. The system also auto-generates two assets consumed by the MCP server: (i) prompt templates encoding platform conventions and style guides, and (ii) context schemas summarizing available tables, columns, and join patterns derived from existing detections. Outputs are persisted in two complementary stores: a vector database (using OpenAI’s text-embedding-3-large ) for semantic search and similarity queries, and a relational database (SQLite) for structured metadata, lineage tracking, and audit operations. This dual-store architecture supports both exploratory retrieval and deterministic lookups required by the MCP tools. 3.2 MCP Ser ver and T ool Suite The Model Context Protocol (MCP) [ 2 ] provides a standardized interface for LLM agents to interact with external tools and data sources. A VDA implements an MCP server that exposes organiza- tional detection knowledge through three abstraction types: tools (executable functions), resources (data access), and prompts (reusable templates). T able 1 summarizes the tools expose d by A VDA, organized into three categories: FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada Bulut et al. Figure 1: A VDA architecture. Detection artifacts ow from organizational repositories through the Data Processing layer , which populates vector and relational stores. The MCP Server exposes these assets to LLM-powered authoring workows via standardized tools. Detection authors interact through IDE extensions or CLI, with generated code following standard DevOps pipelines to deployment. • Retrieval T ools: Enable semantic and structured search across the detection portfolio, supporting lters by platform, MI TRE technique, and language. • Schema T ools: Provide access to telemetr y schemas, includ- ing available tables, elds, and supported detection actions for each platform. • Similarity T ools: Identify related detections using v e ctor similarity , supporting deduplication and exemplar-based gen- eration. This tool suite represents the minimal foundation used in our evaluations. The MCP architecture is intentionally e xtensible, al- lowing organizations to add domain-specic tools as dete ction engineering needs evolve. Examples of additional tools that could enhance the workow include: querying IOC feeds and threat ac- tor proles to enrich detection context; e xe cuting queries against sample datasets or replay logs to validate logic b efore deployment; identifying gaps in MI TRE A T T&CK coverage or overlapping de- tections across the portfolio; integrating with CI/CD systems to lint, test, and promote detections through staging environments; and retrieving historical alert data to inform tuning decisions and exclusion logic. 3.3 A uthoring W orkows A VDA supports three authoring workows that repr esent increas- ing levels of tool integration and autonomy . These workows are central to our evaluation (Section 4). Baseline. The simplest appr oach provides the LLM with a de- tection specication (target T TP, platform, language and natural language description) without access to MCP tools. This zero-shot generation serves as a lower bound, isolating the model’s intrinsic capability from retrieval augmentation. Sequential. This workow follows a deterministic pipeline that mirrors structured human practice: (1) Extract detection metadata (MI TRE te chniques, platform, keywords) via LLM preprocessing (2) Query the vector database via semantic_search to retrieve the top-10 similar detections (3) Retrieve full content for the top-3 results via get_content (4) Generate detection code using retriev e d exemplars as ground- ing context The sequential approach provides r etrieval-augmented generation (RA G) with predictable cost and latency . Agentic. This workow adopts a ReA ct-style paradigm [ 21 ] where the LLM iteratively reasons, invokes to ols, observes re- sults, and renes its approach. At each iteration, the agent receives the full conversation history—including prior tool calls and their outputs—and autonomously decides which tool to invoke ne xt. The agent may call semantic_search to nd similar detections, re- trieve their content via get_content , quer y telemetry schemas with get_telemetry_fields , or explore MI TRE mappings—all without predetermined ordering. This exploratory loop continues until the agent determines it has sucient context to generate the nal dete ction code, or until reaching a maximum of 150 itera- tions. While more capable for complex or ambiguous detection requirements, this approach exhibits higher token consumption and latency variability due to the multi-turn reasoning overhead. Figure 2 illustrates the three workows. The choice of workow involves trade-os b etween quality , cost, and predictability that we quantify in Section 4. 3.4 Developer Integration A VDA integrates with developer workows through multiple entry points. The primary interface is an MCP-enabled extension for Visual Studio Code, allowing authors to invoke tools, generate detections, and validate outputs without leaving the editor’s chat window . This integration lev erages the MCP client capabilities built into modern AI coding assistants. Beyond the IDE, A VD A aligns with standard DevOps practices. Generated detections follow the conventional pipeline: edit → com- mit → pull r e quest → CI checks → review → deploy . MCP tools can programmatically create pull requests with structur e d summaries, reducing review ov erhead while preserving human approval gates. A VDA: A utonomous Vibe Dete ction Authoring for Cybersecurity FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada Baseline Sequential Agentic Detection Desc. LLM Generate Detection Code Single call, no tools Detection Desc. Extract Keywords Semantic Search T op-10 Get Content T op-3 Examples Generate w/ Context Detection Code Detection Desc. Agent (Reason) T ool? MCP T ools Observe Done? Detection Code yes yes no no (max 150) Figure 2: Comparison of detection authoring workows. A continuous improvement loop complements authoring. Feed- back from automated che cks (syntax validation, schema compli- ance) and human r eviews is captured and incorporated into prompt templates, enabling iterative renement of generation quality over time. 4 Evaluation W e evaluate A VDA across multiple dimensions: detection code quality , workow eciency , and model performance characteris- tics. Our primar y goal is to assess how closely generate d detections align with ground-truth implementations in terms of both semantic delity (functional correctness and intended behavior) and syntac- tic similarity (structural corr esp ondence). T o enable repr o ducible evaluation at scale , A VD A employs an automated composite metric that combines LLM-based semantic judgment with emb edding sim- ilarity and surface-level syntactic measur es; we detail this metric and validate it against expert ratings in §4.2 and RQ1. Specically , we address the following r esearch questions: • RQ1 (Expert V alidation): How well do automated metrics align with security practitioner ratings? • RQ2 (W orkow Comparison): What are the performance dierences among Baseline, Sequential, and Agentic approaches? • RQ3 (Criterion Analysis): Which LLM-as-a-Judge criteria have the highest and lo west pass rates, and how does tool- assisted retrieval aect them? • RQ4 (Reasoning Eort): How do high, me dium, and low reasoning tiers compare? • RQ5 (T op-5 Leaderboard): What model–approach combi- nations occupy the T op-5 positions? • RQ6 (T oken Eciency): How do workows compare in token consumption? • RQ7 (Platform & Language): How do scores vary across platforms and languages? • RQ8 (Model Timeline): Do new er model releases yield better detection quality? T able 2: Evaluation dataset summary . Characteristic V alue T otal detections 92 Platforms 5 Languages 3 MI TRE tactics covered 14 MI TRE techniques covered 66 Lines of code (range) 12–3,280 Lines of code (median) 94 Expert-validated subset 22 4.1 Experimental Setup W e evaluate A VD A on a curated corpus of 92 pr oduction detections sourced from ve Microsoft detection platforms: two public plat- forms (Microsoft Sentinel and Microsoft Defender XDR) and three internal security platforms (referred to as Internal Platforms A, B, and C in subsequent tables to preserve condentiality). The corpus spans three languages—PySpark (Python) (43%), KQL (35%), and Scala (22%)—reecting the heterogeneous tooling found in enter- prise security operations. Detections are approximately balanced across platforms (20 per platform), with XDR contributing 12 de- tections. All evaluation detections were strictly withheld fr om the MCP server’s retrieval indices to eliminate data leakage. Although there may be publicly available do cumentation for Sentinel and XDR that may have inuenced pretraining of frontier models, none of the 92 evaluation detections w ere exposed during generation via MCP tools, ensuring a clean separation between training and test conditions. T able 2 summarizes the evaluation corpus. The selecte d detec- tions span all 14 MI TRE A T T&CK [10] tactics and 66 unique te ch- niques. Complexity varies—from simple 12-line to 3,280-line multi- stage detection pipelines (mean: 286 LoC)—ensuring the e valuation captures a broad spectrum of authoring challenges repr esentative of enterprise-scale detection engineering. FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada Bulut et al. A VDA’s preprocessing pipeline ingested 10,127 detection arti- facts from 9 dier ent detection platforms to construct a rich con- textual foundation comprising schemas, exemplars, and platform- specic style guides. The 92 evaluation detections were explicitly held out from this corpus to pr event data leakage. For expert vali- dation (§4.4, RQ1), we selected a stratied subset of 22 detections spanning 13 of the 14 MI TRE A T T&CK tactics to ensure diverse coverage. W e compare three authoring workows representing increasing levels of sophistication and autonomy: baseline, sequential, and agentic. T o ensure pr ompt fairness, platform-spe cic prompt styles encoded as MCP prompts are excluded from our evaluation. Addi- tionally , only two of the ve platforms (XDR and P latform B) expose schema information through MCP tools, enabling us to evaluate the eectiveness of including runtime schema access in the agentic workow . 4.2 Metrics Our evaluation framework centers on two complementary dimen- sions: semantic similarity , which captur es functional correctness, and syntactic similarity , which measures structural resemblance. T ogether , these dimensions provide a holistic view of detection quality . Semantic Similarity . W e employ two complementar y approaches. First, an LLM-as-a-judge protocol uses GPT -4.1 (temperature 𝜏 = 0 ) to assess functional equivalence b etween generated and gold- standard detections [ 22 ]. Rather than soliciting a single holistic score—which can be unreliable—we decompose evaluation into ten binary criteria (T able 3), each answered True/False . The LLM-judge score is computed as: 𝑆 LLM = 1 𝑛 𝑛 𝑖 = 1 𝑐 𝑖 , 𝑐 𝑖 ∈ { 0 , 1 } (1) where 𝑛 = 10 is the numb er of criteria and 𝑐 𝑖 indicates whether criterion 𝑖 is satised. Second, we compute embedding similarity using cosine similarity between vector representations from OpenAI’s text-embedding-3- large model: 𝑆 embed = v 𝑔 · v 𝑟 ∥ v 𝑔 ∥ ∥ v 𝑟 ∥ (2) where v 𝑔 and v 𝑟 are the embedding vectors of the generated and reference detections, respectively . Syntactic Similarity . W e evaluate structural resemblance using two surface-level metrics. First, ROUGE-L F1 measures the longest common subsequence (LCS) between generated and r eference code: 𝑆 ROUGE-L = ( 1 + 𝛽 2 ) · 𝑃 lcs · 𝑅 lcs 𝑅 lcs + 𝛽 2 · 𝑃 lcs , 𝑃 lcs = | LCS | | 𝑔 | , 𝑅 lcs = | LCS | | 𝑟 | (3) where | 𝑔 | and | 𝑟 | are the lengths of the generated and reference sequences, and 𝛽 = 1 for balanced F1. Second, normalized Lev enshtein similarity quanties edit dis- tance: 𝑆 Lev = 1 − Lev ( 𝑔, 𝑟 ) max ( | 𝑔 | , | 𝑟 | ) (4) T able 3: Evaluation Questions for LLM-as-a-Judge Question Description Q1 (ttp_match) Does the candidate detection target the exact same T TP as the Gold detection? Q2 (logic_equivalence) Is the candidate’s core detection logic (lters, joins, aggr e- gations) functionally equivalent to the Gold detection? Q3 (schema_accuracy) Does the candidate use the correct tables/elds without hallucinations? Q4 (syntax_validity) Is the candidate syntactically valid for the target lan- guage/platform? Q5 (indicator_alignment) Does the candidate check for the same key indicators/sig- nals as Gold? Q6 (exclusion_parity ) Does the candidate implement the same (or stronger) exclusion logic to control false positives? Q7 (robustness) Is the candidate equally resilient to common evasions (case, encoding, minor variations)? Q8 (data_source_correct) Does the candidate pull from the correct data source for this detection? Q9 (output_alignment) Does the candidate emit results to the expected destina- tion (e.g., Alerts table) with requir e d elds? Q10 (library_usage) Does the candidate leverage the correct platform-specic libraries/functions required for this detection? where Lev ( 𝑔, 𝑟 ) is the minimum number of single-character edits (insertions, deletions, substitutions) to transform 𝑔 into 𝑟 [ 8 , 20 ]. These metrics capture surface-level similarity without implying functional correctness—important be cause semantically equivalent detections may dier substantially in formatting, variable naming, or stylistic conventions. Composite Scores. W e aggregate individual metrics into comp os- ite scores: 𝑆 syntactic = 0 . 5 × 𝑆 ROUGE-L + 0 . 5 × 𝑆 Lev (5) 𝑆 semantic = 0 . 8 × 𝑆 LLM + 0 . 2 × 𝑆 embed (6) 𝑆 overall = 0 . 8 × 𝑆 semantic + 0 . 2 × 𝑆 syntactic (7) The syntactic score equally weights ROUGE-L and Levenshtein as b oth measure surface-level similarity with no strong prior for one over the other . Within the semantic score, we weight the LLM-judge at 0.8 because its criterion-base d decomposition directly evaluates functional properties (T TP matching, schema accuracy , logic equiva- lence) and enables diagnostic analysis of failure modes, whereas em- bedding similarity provides a complementary but less interpretable holistic signal. The overall 80/20 semantic-syntactic weighting pri- oritizes functional behavior over textual resemblance; w e validate this choice empirically in RQ1. Scope and Limitations. Our evaluation measures alignment with human-authored gold-standard detections without runtime execu- tion . This design enables scalable evaluation across 92 detections with dierent model congurations and workows, but means scores reect authoring proximity rather than veried correctness. In practice, generated detections serve as high-delity starting points that engine ers rene—a workow validated by expert as- sessment (RQ1). A VDA: A utonomous Vibe Dete ction Authoring for Cybersecurity FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada 4.3 Models W e evaluate 11 mo dels spanning 21 congurations: 5 chat/comple- tion models (GPT -4.1, GPT -4.1-mini, GPT -4o, GPT -4o-mini, GPT -5.1- chat) and 6 reasoning models (GPT -5, GPT -5-mini, GPT -5.1, o1, o3, o3-pro). Chat models use their default conguration, while reason- ing mo dels are tested at three reasoning-eort levels corr esp onding to the API parameter: low (minimal chain-of-thought), medium (balanced reasoning depth), and high (extended thinking); o3-pr o supports only high. All generations use temperature 𝜏 = 0 for reproducibility . Agen- tic workows are capped at 150 iterations to bound runtime. Across 92 dete ctions, 21 congurations, and 3 workows, we produce 5,796 generated detections for evaluation. 4.4 Results T o ground our automate d metrics in practitioner judgment, we rst validate the comp osite overall score against expert ratings on a 22-detection subset, then report ndings across the full corpus. RQ1: Does the overall score reect expert judgment? How well do automated metrics align with security practi- tioner ratings? Because obtaining expert ratings is time-consuming and costly , we validate our metrics on a held-out subset of 22 detections. For each generated detection, multiple security practitioners rate d the eort required to transform the artifact into the gold-standard detection on a 0–10 scale (0 = substantial eort; 10 = ready to deploy). W e averaged the expert ratings and compared them against the automated composite score. W eight Calibration. The composite overall score combines se- mantic and syntactic similarity with congurable weights. T o select appropriate weights, we evaluated weightings from 0.0 to 1.0 in 0.2 increments (T able 4). The 60/40 semantic-syntactic weighting maximizes Sp earman correlation ( 𝜌 = 0 . 65 ), whereas 80/20 matches the lowest mean absolute error (MAE = 0.11 vs. 0.16) while retaining syntactic signal. Given the marginal dierence in rank correlation ( Δ 𝜌 = 0 . 01 , not statistically signicant at 𝑛 = 22 ) and the domain consideration that functional correctness should dominate surface- level similarity in detection quality , we select the 80/20 weighting. V alidation Results. With the 80/20 weighting, the overall scor e shows strong, statistically signicant correlation with expert ratings (Spearman 𝜌 = 0 . 64 , 𝑝 < 0 . 002 ; Pearson 𝑟 = 0 . 63 , 𝑝 < 0 . 002 ), with a mean absolute error of 0.11 on a normalized 0–1 scale. Detections that score highly under the automated composite tend to require minimal expert eort, while lower composite scores correspond to artifacts needing substantial revision. While the weight selection and validation use the same expert sample, the stability of corr elations across the 0.6–0.8 range ( 𝜌 = 0 . 64 – 0 . 65 ) suggests the result is not an artifact of overtting to this particular weighting. This agreement justies using the composite overall metric as a scalable proxy for human evaluation in the remaining research questions. T able 4: W eight sensitivity analysis: expert correlation by weighting. Semantic Syntactic Spearman 𝜌 MAE 0.0 1.0 0.35 0.37 0.2 0.8 0.60 0.29 0.4 0.6 0.58 0.22 0.6 0.4 0.65 0.16 0.8 0.2 0.64 0.11 1.0 0.0 0.62 0.11 RQ2: How do authoring workows compar e? What are the performance dierences among Baseline, Sequential, and Agentic approaches? T able 5: Overall score by authoring approach. Approach Mean Median Std Dev Agentic 0.447 0.419 0.180 Sequential 0.388 0.356 0.150 Baseline 0.375 0.328 0.160 T able 5 reports overall scores across the three authoring ap- proaches, averaged ov er all mo del congurations. The Agentic workow yields the highest similarity (0.447 mean), outperform- ing both Sequential (RAG-augmented) and Baseline (zero-shot) ap- proaches by 15% and 19% respectively . Sequential provides a modest gain over Baseline ( +3.5%), indicating that retrieval-augmented gen- eration improves alignment even without full agentic reasoning. Median similarity follows the same pattern, conrming that gains are not driven by outliers. W e observe greater score variability under the Agentic approach. W e attribute this to the multi-turn, tool-orchestrated nature of agentic worko ws and the inherent nondeterminism of LLM gener- ations, which can amplify disp ersion across diverse detection tasks and schemas. RQ3: What are the strengths and weaknesses by eval- uation criterion? Which LLM-as-a-Judge criteria have the highest and lowest pass rates, and how does tool-assisted retrieval aect them? T able 6 reports pass rates for each evaluation criterion, disaggre- gated by workow . The Agentic Only column isolates runs using the Re Act-based workow; Schema-Enabled Platforms further restricts to the two platforms (XDR and Platform B) where schema-r etrieval tools are enabled. Universal strengths. T TP matching and syntax validity excee d 95% across all conditions, conrming that mo dels reliably map threat descriptions to A T T&CK techniques and produce code judge d to be syntactically valid. FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada Bulut et al. Criterion All Agentic Agentic+Schema (%) (%) (%) T TP Match 99.4 99.3 ( − 0.2) 99.6 ( +0.1) Syntax V alidity 95.9 95.6 ( − 0.3) 96.3 ( +0.4) Library Usage 61.9 72.7 ( +10.8) 77.8 ( +15.9) Data Source Correct 31.7 43.4 (+11.7) 45.7 ( +13.9) Indicator Alignment 30.8 29.6 ( − 1.2) 18.8 ( − 12.0) Robustness 23.7 27.5 (+3.8) 17.4 ( − 6.2) Logic Equivalence 18.4 18.5 (+0.2) 9.1 ( − 9.3) Output Alignment 18.4 29.1 ( +10.7) 32.4 ( +14.0) Schema Accuracy 17.6 24.6 (+7.1) 21.4 ( +3.8) Exclusion Parity 8.9 10.7 ( +1.8) 3.6 ( − 5.3) T able 6: Evaluation criteria pass rates by workow and plat- form scope. Deltas computed from unrounded values. Agentic gains. T ool-assisted retrieval yields substantial im- provements on schema-sensitiv e criteria: librar y usage (+10.8 pp), data-source selection (+11.7 pp), and output alignment ( +10.7 pp). These gains amplify further when schema tools are available, with schema-enabled platforms reaching +15.9 pp on library usage and +14.0 pp on output alignment. Persistent challenges. Exclusion parity remains the weakest criterion ( <11%), indicating that models rarely replicate the precise exclusion logic of reference detections. Logic equivalence and indica- tor alignment also decline in the schema-enabled subset, suggesting that richer schema context can bias models toward platform idioms at the expense of exact semantic delity to the reference . These patterns conrm that agentic r etrieval most benets cri- teria requiring platform-sp ecic knowledge (schemas, tables, li- braries), while criteria dependent on preser ving reference semantics (exclusions, logic structure) require additional grounding strategies. RQ4: What is the eect of reasoning eort? How do high, medium, and low reasoning tiers compare? T able 7: Overall similarity by reasoning tier . Reasoning All All Agentic Agentic Tier Mean Median Mean Median High 0.442 0.408 0.501 0.480 Medium 0.420 0.372 0.473 0.437 Low 0.410 0.367 0.438 0.394 T able 7 reports o verall similarity by r easoning tier , disaggr egate d by workow . Across all approaches, the high tier achieves 0.442 mean similarity , with diminishing returns at lower tiers—the gap narrows from high → medium (0.022) to medium → low (0.010). The Agentic w orkow amplies reasoning tier eects substan- tially . High-tier Agentic runs reach 0.501 mean similarity—a 13% improvement over the all-approaches high tier (0.442). The tier sep- aration also widens: high → medium spans 0.028 and medium → low spans 0.035, indicating that reasoning eort compounds with tool- assisted retrieval. The medium tier oers a favorable quality–cost trade-o for b oth workows: it captures most high-tier gains while incurring lo wer token consumption and latency . For Agentic deployments, medium- tier reasoning achieves 94% of high-tier p erformance (0.473 vs. 0.501), making it a practical default where throughput requirements constrain reasoning budget. RQ5: Which congurations achiev e top performance? What model–approach combinations occupy the T op-5 posi- tions? T able 8: T op-5 leaderboard by model, reasoning tier , and ap- proach. Rank Model Tier Approach Mean Me dian 1 gpt-5 medium Agentic 0.578 0.545 2 gpt-5.1 high Agentic 0.575 0.549 3 gpt-5-mini high Agentic 0.553 0.541 4 gpt-5.1 medium Agentic 0.547 0.520 5 gpt-5 high Agentic 0.545 0.526 T able 8 reports the top ve performing congurations. All ve are Agentic workows, with the GPT -5 family claiming three of the top ve positions. Notably , medium reasoning tier appears in both #1 and #4 positions, while high tier occupies the remaining slots—reinforcing that medium oers competitive quality at lower cost. While high reasoning generally outperforms medium on ag- gregate (RQ4), the emergence of GPT -5 Medium as the top-ranking conguration (#1) highlights a nuance in reasoning dynamics: for certain detection tasks, maximal reasoning eort can occasionally induce “reasoning drift” or o ver-complication that diverges from the gold-standard’s detection logic, whereas medium eort oers an optimal balance. The tight clustering of scores (0.545–0.578) across GPT -5 and GPT -5.1 families indicates that model selection within the frontier tier matters less than workow choice ( Agentic) and reasoning conguration. Crucially , these results are achieved without executing the gener- ated code, iterative renement via execution feedback, or automated validation . The current MCP tool suite lacks ecacy tools—such as query e xe cution against sample telemetry or unit test runners—that would enable agents to self-correct. Generated detections therefore represent rst-draft artifacts that detection authors rene , rather than production-ready rules. The scores reported here reect align- ment with gold-standard detections at the authoring stage; extend- ing the tool suite with execution-based feedback loops represents a natural next step to close the gap b etween draft and deployable code. RQ6: What are the cost–quality trade-os? How do work- ows compare in token consumption? A VDA: A utonomous Vibe Dete ction Authoring for Cybersecurity FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada The Agentic workow consumes r oughly two orders of magni- tude more tokens than Baseline (using median token counts: ~80 × Baseline), reecting the multi-turn Re Act pattern [ 21 ] and r ep eated tool invocations. Sequential occupies a middle ground—about 2 × Baseline at the median—oering retrieval-augmented generation with predictable cost. T oken variance is highest for Agentic, ex- hibiting a heavy-tailed distribution as planning depth varies sub- stantially with detection complexity . Sequential achieves 87% of Agentic quality (RQ2) at ~40 × lower median token cost, making it suitable for routine detection author- ing where throughput and cost eciency are priorities. However , reaching the top-tier performance obser ved in RQ5—where the b est congurations exceed 0.57 score— requires the Agentic workow . For complex detections involving unfamiliar schemas, novel threat patterns, or multi-stage logic, the added quality premium and access to iterativ e tool-assisted renement justify the resource investment. RQ7: How do scores var y across platforms and lan- guages? Does detection complexity explain performance dif- ferences? T able 9: Overall similarity by platform. Platform All Agentic A vg LoC Internal Platform A 0.488 0.511 (+0.023) 60 Sentinel 0.458 0.500 (+0.042) 93 XDR 0.402 0.411 (+0.008) 64 Internal Platform B 0.346 0.438 ( +0.092) 986 Internal Platform C 0.322 0.362 ( +0.040) 139 T able 10: Overall similarity by language. Language All Agentic A vg LoC Scala 0.488 0.511 ( +0.023) 60 KQL 0.437 0.467 (+0.029) 82 Python 0.334 0.400 ( +0.066) 562 T ables 9 and 10 reveal variation across platforms and languages, with an inverse relationship between dete ction complexity and similarity scores. Internal Platform A (Scala, 60 LoC mean) and Sentinel (KQL, 93 LoC) achieve the highest scores, while Internal Platform B (Python, 986 LoC) and Internal P latform C (Python, 139 LoC) score lowest. This pattern admits two complementary explanations. First, longer detections are harder to reproduce : Python-based platforms encode multi-stage detection pipelines with extensive preprocess- ing, feature engineering, and aggr egation logic that models struggle to replicate exactly . Second, simpler quer y languages constrain vari- ance : KQL and Scala detections follow mor e stereotype d patterns with fewer degrees of freedom, making semantic alignment easier . Notably , the Agentic workow provides the largest gains pre- cisely where overall scores are lowest: Internal Platform B impr oves by +0.092 and Python by +0.066, compared to +0.023 for Internal Platform A. This suggests that tool-assisted retrieval dispropor- tionately benets complex detections, where schema lookups and similar-detection examples help models navigate platform-sp ecic idioms that would otherwise require extensive implicit knowledge. RQ8: How does model performance evolv e over time? Do newer model releases yield better detection quality? Figure 3: Best-performing conguration per model o ver time (A gentic workow). Figure 3 plots the best-p erforming conguration for each model family under the Agentic worko w against release date. A strong positive correlation b etween release date and detection quality emerges ( 𝑟 = 0 . 75 , Pearson): models released in mid-2024 (gpt- 4o, gpt-4o-mini) achieve mean similarity scores below 0.35, while frontier models from late 2025 ( gpt-5, gpt-5.1) exceed 0.57—a 68% relative impro vement over 18 months. Three distinct capability tiers are visible. Early chat models (gpt- 4o family) establish a baseline around 0.30. The April 2025 cohort (gpt-4.1, o3) marks a step-change, with o3-high reaching 0.49. The A ugust–November 2025 releases (gpt-5, gpt-5.1) consolidate gains above 0.55, suggesting that detection authoring b enets from ad- vances in both reasoning depth and instruction following. Notably , GPT -5.1 (0.575) does not surpass GPT -5 (0.578) despite being released three months later . This aligns with observations in other works [ 4 , 6 ], where GPT -5.1 similarly trails GPT -5 by a small margin. Op enAI has indicate d that GPT -5.1 prioritizes inference speed and cost eciency over raw capability gains, representing a trade-o between quality and operational eciency rather than a strict successor [12]. 5 Discussion This section reects on the strengths and limitations of our ap- proach, interprets the impact of schema availability on detection quality , and outlines directions for future work. The Impact of Schema A vailability . A critical component of our evaluation was the selective enabling of MCP schema tools for specic platforms (XDR and P latform B). This experimental condi- tion allows us to isolate the impact of retrieval-augmented context on generation quality . The results demonstrate a sharp distinction FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada Bulut et al. between “structural” and “logical” correctness. For the schema- enabled platforms, metrics that rely on exact knowledge retrieval showed signicant gains over the all-approach average: Library Usage improved by 15.9 percentage points (77.8% vs 61.9%), Data Source Correctness by 14.0 p ercentage points (45.7% vs 31.7%), and Output Alignment by 14.0 percentage points (32.4% vs 18.4%). This validates the core premise of A VDA: providing agents with tool-based access to schemas directly mitigates hallucinations in table selection. However , Schema Accuracy (21.4%) remained low even with tools available. This suggests that while agents success- fully identify the broad components ( correct table, correct libraries), they still struggle with the ne-graine d precision of specic eld names within complex, production-grade schemas—likely due to context window constraints or retrie val precision limits. The “Tribal Knowledge” Gap. While structural metrics im- proved with tools, semantic metrics like Exclusion Parity (3.6%) and Logic Equivalence (9.1%) remained the most challenging cri- teria, particularly in the schema-aware subset. This highlights a fundamental limitation: detection logic often relies on “tribal knowl- edge”—unwritten environmental context (e.g., “server X is a benign scanner”)—rather than documented schemas. The availability of a database schema does not help an agent infer that a specic IP range should be excluded from a dete ction. This nding reinforces that AI can act as a pow erful accelerator for drafting the skeleton and syntax of a dete ction, but human engineers remain essential for injecting environment-specic context and robust exclusion logic. Model Selection Trade-os. Our evaluation rev eals clear per- formance stratication across model families. Reasoning-capable models (GPT -5, GPT -5.1, o3-pro) consistently outperform chat/- completion models, with GPT -5 achieving the top composite score (0.578) at medium reasoning eort. The medium reasoning tier oers a favorable quality–cost balance, closing most of the gap to high-eort congurations while reducing token consumption (RQ6). Notably , smaller models struggle to follow complex instruc- tions in the Agentic workow , where accumulated context degrades instruction adherence. Practitioners should select models based on detection complexity and latency requirements. Challenges and Operational Trade-os. Despite promising results, several challenges remain. First, LLM-driven generation exhibits variability , particularly in Agentic workows where multi- turn nondeterminism amplies output dispersion. Second, the Agen- tic approach introduces signicant operational o verhead. Agents accumulate large volumes of intermediate context, leading to con- text windo w exhaustion on models and signicantly higher latency compared to single-shot inference. This necessitates a tiered de- ployment strategy: utilizing cost-eective Sequential w orkows for standard detection drafting, while reser ving resource-intensive Agentic workows for comple x, novel threat scenarios where the 19% quality gain justies the computational cost. Scope and Future Directions. Our evaluation reects deliber- ate design choices that balance depth with breadth, while identi- fying opportunities for extension. W e focused on OpenAI models given their widespread adoption in enterprise settings; the MCP- based ar chite cture is pr ovider-agnostic by design, enabling straight- forward extension to other frontier models (Anthropic, Google, Meta) as future work. Our evaluation measures authoring prox- imity to gold-standard detections rather than runtime ecacy—a practical choice that enabled systematic comparison acr oss 5,796 generated artifacts. Complementary runtime validation using syn- thetic attack replay would bridge this gap, measuring true positive rates and analyst triage burden in controlled environments. The 92-detection corpus spans ve platforms and three languages, pro- viding meaningful diversity in syntax, semantics, and telemetry schemas; cross-organizational validation would further establish generalizability of coding conventions and e xclusion patterns. Fi- nally , expert validation on a 22-detection subset—while constrained by practitioner availability—yielded statistically signicant correla- tion, conrming that automated metrics reliably reect practitioner judgment. Expanding expert coverage and incorporating feedback loops for iterative renement repr esent natural extensions of this work. 6 Conclusion This paper presented A VDA, an agentic framework for automating security detection authoring. A VDA leverages AI-assisted metadata extraction from organizational detection artifacts and operational- izes this knowledge through MCP-based tool orchestration. By in- tegrating directly into developer workows via Visual Studio Code and GitHub Copilot, A VDA enables detection authors to generate high-quality detections without disrupting established practices. W e evaluated three authoring workows—Baseline, Sequential, and Agentic—across 92 detections, 11 models, and 21 congurations, producing 5,796 generated artifacts. K ey ndings include: (1) expert validation conrms strong correlation between automated metrics and practitioner judgment ( 𝜌 = 0 . 64 , 𝑝 < 0 . 002 ); (2) the Agentic workow achiev es 19% higher overall similarity than Baseline but consumes more tokens; (3) r easoning-capable models (GPT -5, o3- pro) consistently outperform non-reasoning models; and (4) the medium reasoning tier oers a favorable quality–cost balance. While agentic workows demonstrate superior accuracy , the trade-os in latency and resource consumption underscore the need for cost-aware deployment strategies. Future work will extend beyond static code generation to runtime validation, incorporating synthetic telemetry replay and controlled execution in production environments to bridge the gap between authoring quality and operational ecacy . References [1] Anthropic. 2024. Building Eective Agents. https://www .anthropic.com/ engineering/building- eective- agents. [2] Anthropic. 2025. Model Context Protocol Specication. https:// modelcontextprotocol.io/. [3] Anthropic. 2026. Claude Co de: Agentic Coding in Terminal, IDE, and W eb. https://claude.com/product/claude- code. Accessed: 2026-01-16. [4] Julien Benchek, Rohit Shetty , Benjamin Hunsberger, Ajay Arun, Zach Richards, Brendan Foody , Osvald Nitski, and Bertie Vidgen. 2025. The AI Consumer Index (A CE). arXiv:2512.04921 [cs.AI] https://ar xiv .org/abs/2512.04921 [5] Anna Bertiger, Bobby Filar, Aryan Luthra, Stefano Meschiari, Aiden Mitchell, Sam Scholten, and Vivek Sharath. 2025. Evaluating LLM Generated Detection Rules in Cybersecurity . arXiv:2509.16749 [cs.CR] https://arxiv .org/abs/2509.16749 [6] A vik Dutta, Harshit Nigam, Hosein Hasanbeig, Arjun Radhakrishna, and Sumit Gulwani. 2026. An Empirical Investigation of Robustness in Large Language Models under T abular Distortions. arXiv:2601.05009 [cs.AI] https://arxiv .org/ abs/2601.05009 [7] GitHub. 2026. GitHub Copilot: Y our AI Pair Programmer . https://github.com/ features/copilot. Accessed: 2026-01-16. [8] C. Gravino. 2021. Using the Normalized Levenshtein Distance to Analyze Rela- tionship between Faults and Local V ariables with Confusing Names: A further A VDA: A utonomous Vibe Dete ction Authoring for Cybersecurity FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada Investigation (S). International Conferences on Software Engine ering and Knowl- edge Engineering 2021 (2021), 550–553. doi:10.18293/seke2021- 124 [9] Jiarui Li, Y uhan Chai, Lei Du, Chenyun Duan, Hao Yan, and Zhaoquan Gu. 2025. GRIDAI: Generating and Repairing Intrusion Detection Rules via Collaboration among Multiple LLM-based Agents. arXiv:2510.13257 [cs.CR] https://ar xiv .org/ abs/2510.13257 [10] MI TRE Corporation. 2026. MI TRE A T T&CK. https://attack.mitre.org/. Accessed: 2026-01-21. [11] Saleha Muzammil, Rahul Reddy, Vishal Kamalakrishnan, Hadi Ahmadi, and W ajih Ul Hassan. 2025. T owards Small Language Models for Security Query Generation in SOC W orkows. arXiv:2512.06660 [cs.CR] https://ar xiv .org/abs/ 2512.06660 [12] OpenAI. 2025. GPT -5.1 Instant and GPT-5.1 Thinking System Card Adden- dum. https://cdn.openai.com/pdf/4173ec8d- 1229- 47db- 96de- 06d87147e07e/5_1_ system_card.pdf . Accessed: 2026-01-21. [13] OpenAI. 2026. OpenAI Codex. https://openai.com/index/openai- codex/. Ac- cessed: 2026-01-16. [14] Palantir T echnologies. 2017. Alerting and Dete ction Strategy Framework. https: //github.com/palantir/alerting- detection- strategy- framework. Accessed: 2026- 01-21. [15] Y uval Schwartz, Lavi Benshimol, Dudu Mimran, Yuval Elovici, and Asaf Shabtai. 2024. LLMCloudHunter: Harnessing LLMs for Automated Extraction of Detection Rules from Cloud-Base d CTI. arXiv:2407.05194 [ cs.CR] https://arxiv .org/abs/ 2407.05194 [16] Akansha Shukla, Parth Atulbhai Gandhi, Y uval Elovici, and Asaf Shabtai. 2025. RuleGenie: SIEM Detection Rule Set Optimization. arXiv:2505.06701 [cs. CR] https://arxiv .org/abs/2505.06701 [17] Splunk. 2025. What Is Detection as Co de (DaC)? Benets, T ools, and Real-W orld Use Cases. https://www.splunk.com/en_us/blog/learn/detection- as- co de.html. [18] Sublime Security. 2025. More than “plausible nonsense”: A rigorous eval for ADÉ, our security coding agent. https://sublime.security/blog/more- than- plausible- nonsense- a- rigorous- eval- for- ade- our- security- coding- agent/. [19] Xinye Tang, Amir H. Abdi, Jeremias Eichelbaum, Mahan Das, Alex Klein, Ni- hal Irmak Pakis, William Blum, Daniel L Mace, T anvi Raja, Namrata Padman- abhan, and Y e Xing. 2025. NL2KQL: From Natural Language to Kusto Query . arXiv:2404.02933 [cs.DB] [20] Keiichiro T ashima, Hirohisa Aman, Sousuke Amasaki, T omoyuki Y okogawa, and Minoru Kawahara. 2018. Fault-Prone Java Method Analysis Focusing on Pair of Local V ariables with Confusing Names. In 2018 44th Euromicro Conference on Software Engine ering and Advanced Applications (SEAA) . 154–158. doi:10.1109/ SEAA.2018.00033 [21] Shunyu Y ao, Jerey Zhao, Dian Y u, Nan Du, Izhak Shafran, Karthik Narasimhan, and Y uan Cao. 2023. Re Act: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629 [cs.CL] [22] Lianmin Zheng, W ei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao W u, Y onghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT -Bench and Chatbot Arena. arXiv:2306.05685 [cs.CL] https://arxiv .org/abs/2306.05685
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment