AI 기반 자동 탐지 코드 생성 프레임워크 AVDA
AVDA는 Model Context Protocol(MCP)을 활용해 조직 내 기존 탐지 규칙·텔레메트리 스키마·코딩 가이드 등을 LLM에 제공함으로써 자동 탐지 코드 작성을 지원한다. Baseline, Sequential, Agentic 세 가지 워크플로우를 92개의 실제 탐지 사례와 11개 LLM에 적용해 평가했으며, Agentic이 전체 유사도 점수에서 19% 향상, Sequential이 비용 대비 87% 품질을 40배 낮은 토큰 사용량으…
저자: Fatih Bulut, Carlo DePaolis, Raghav Batta
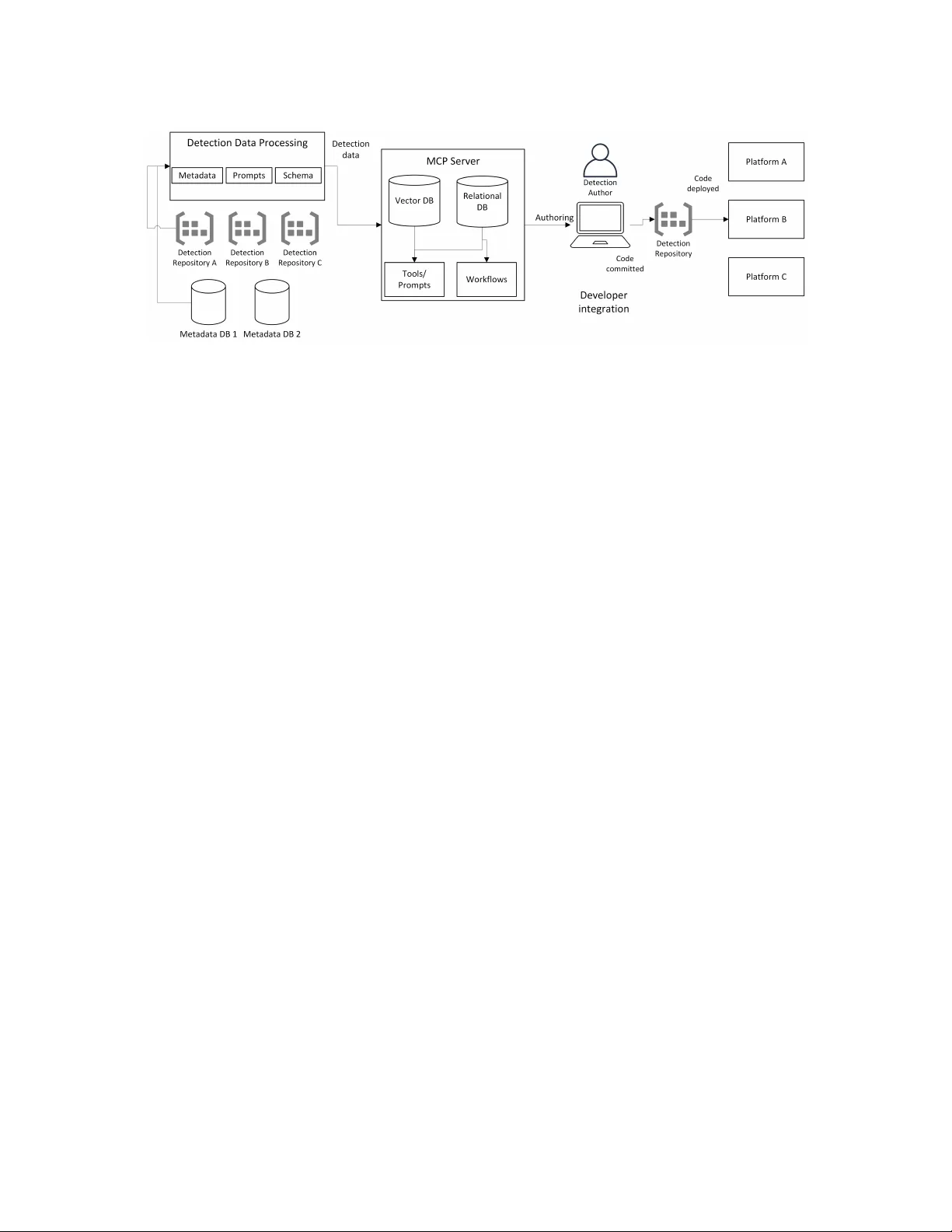
본 논문은 AI 기반 코드 생성 기술이 사이버보안 탐지 엔지니어링에 미치는 영향을 조사하고, 조직 내부의 탐지 지식(기존 탐지 규칙, 텔레메트리 스키마, 코딩 가이드)을 LLM에 통합하는 새로운 프레임워크 AVDA(Autonomous Vibe Detection Authoring)를 제안한다. AVDA는 Model Context Protocol(MCP)을 기반으로, 탐지 데이터 처리 레이어, MCP 서버, 저작 워크플로우, 개발자 통합 네 단계 아키텍처를 설계한다. 탐지 데이터 처리 레이어는 다양한 레포지토리와 위키에서 수집된 탐지 코드와 메타데이터를 정규화·파싱하고, LLM이 이해하기 쉬운 통합 스키마와 프롬프트 템플릿을 생성한다. 이 과정에서 벡터 데이터베이스(OpenAI text‑embedding‑3‑large)와 관계형 DB(SQLite)를 병행 사용해 의미 검색과 구조적 조회를 동시에 지원한다.
MCP 서버는 “도구”, “리소스”, “프롬프트”라는 세 가지 추상화를 제공한다. 도구는 semantic_search, search_by_mitre, get_telemetry_fields 등 탐지 포트폴리오 검색·스키마 조회·유사도 계산 기능을 포함한다. 이러한 도구들은 LLM이 외부 지식에 접근해 실시간으로 컨텍스트를 보강하도록 설계되었다.
AVDA는 세 가지 저작 워크플로우를 정의한다. Baseline은 LLM에 탐지 사양만 전달해 제로샷으로 코드를 생성한다. Sequential은 먼저 MCP 도구를 이용해 관련 탐지와 스키마를 검색·정리한 뒤, 그 정보를 프롬프트에 삽입해 한 번에 코드를 만든다. Agentic은 도구 호출·피드백 루프를 포함해, 생성된 코드가 스키마 검증을 통과하지 못하면 자동으로 재시도하고, 필요 시 추가 정보를 질의한다. Agentic은 “도구‑오리엔티드 에이전트” 형태로, 복잡한 오류 복구와 탐지 로직 최적화를 목표로 한다.
평가에는 92개의 실제 탐지 사례(5개 플랫폼, 3개 언어)와 11개의 최신 LLM(다양한 파라미터와 reasoning capability 포함)을 사용했으며, 총 5,796개의 탐지 코드를 생성했다. 품질 평가는 TTP 매칭, 구문 유효성, 제외 로직 일치, 코드 스타일 일관성 등 10가지 이진 메트릭과 embedding 기반 유사도 점수를 결합한 종합 점수로 수행했다. 결과는 다음과 같다.
- Agentic이 평균 유사도 0.447로 Baseline 대비 19% 향상, 가장 높은 품질을 달성.
- Sequential은 Agentic 품질의 87%를 유지하면서 토큰 사용량을 40배 절감, 비용 효율성에서 큰 장점.
- TTP 매칭 99.4%, 구문 유효성 95.9% 등 핵심 기능은 거의 완벽하지만, 제외 로직 일치율은 8.9%에 머물러 실제 운영 시 오탐 위험이 존재.
- 스키마 hallucination(존재하지 않는 필드 사용)과 스타일 위반이 소수 발생했으며, 이는 MCP 기반 실시간 검증으로 완화 가능.
전문가 검증 단계에서는 22개의 탐지를 무작위 추출해 인간 평가와 자동 평가지표를 비교했으며, Spearman ρ=0.64(p<0.002)라는 유의한 상관관계를 확인했다. 이는 제안된 자동 평가지표가 실무 판단을 충분히 대변한다는 증거다.
논문의 주요 기여는 다음과 같다.
1. 조직 컨텍스트를 LLM에 제공하는 MCP 기반 탐지 저작 프레임워크 AVDA 설계 및 구현.
2. Baseline, Sequential, Agentic 세 가지 워크플로우를 11개 모델·21개 설정으로 체계적으로 비교한 대규모 실증 연구.
3. 자동 평가지표와 전문가 평가 간의 통계적 상관관계를 입증해 평가 방법론의 신뢰성 확보.
4. 비용·품질·지연성 사이의 트레이드오프를 제시하고, 실무 적용을 위한 Sequential 워크플로우의 효율성을 강조.
한계점으로는 제외 로직 자동 생성의 낮은 정확도, 스키마 hallucination 위험, 그리고 현재는 탐지 코드 생성에 초점을 맞추어 탐지 성능(탐지율·오탐률) 자체는 평가하지 않은 점을 들 수 있다. 향후 연구에서는 멀티‑모델 앙상블, CI/CD 파이프라인과의 자동 테스트 연동, 그리고 실시간 로그 샘플링을 통한 검증 루프를 추가해 신뢰성을 높이고, 탐지 성능까지 포괄적으로 평가할 계획이다. AVDA는 AI‑assisted 탐지 엔지니어링의 실용적 전환점을 제공하며, 조직이 보안 규칙을 빠르고 일관되게 확장할 수 있는 기반을 마련한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기