Sommelier: Scalable Open Multi-turn Audio Pre-processing for Full-duplex Speech Language Models
As the paradigm of AI shifts from text-based LLMs to Speech Language Models (SLMs), there is a growing demand for full-duplex systems capable of real-time, natural human-computer interaction. However, the development of such models is constrained by …
Authors: Kyudan Jung, Jihwan Kim, Soyoon Kim
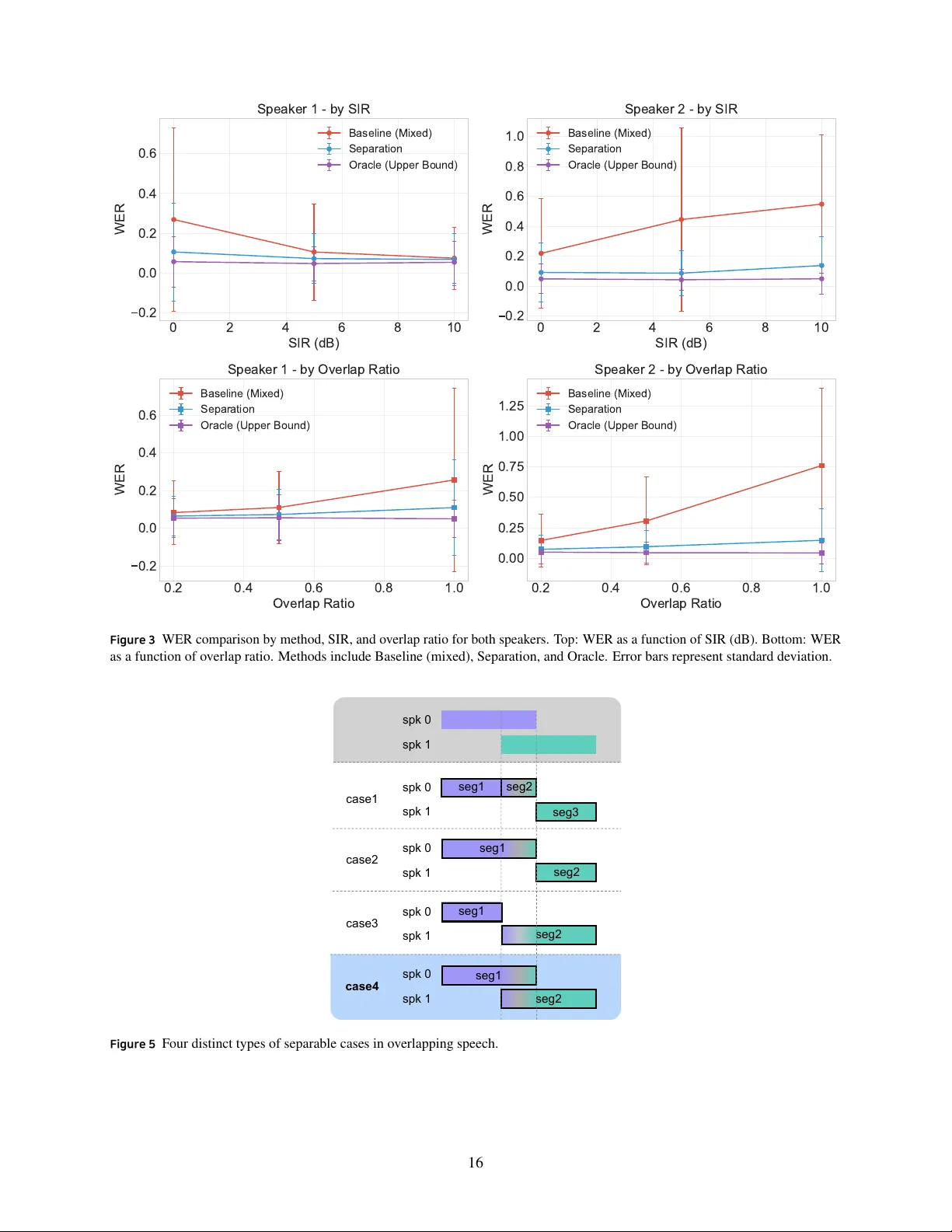
Sommelier: Scalable Open Multi-turn Audio Pre-processing for Full-duple x Speech Language Models Kyudan Jung 1 , 2 , ♣ , Jihwan Kim 1 , 2 , ♣ , Soyoon Kim 2 , Jeonghoon Kim 2 , Jaegul Choo 1 † , Cheonbok Park 1 , 2 † 1 KAIST AI, 2 N A VER Cloud † Corresponding authors As the paradigm of AI shifts from text-based LLMs to Speech Language Models (SLMs), there is a gro wing demand for full-duplex systems capable of real-time, natural human-computer interaction. Howe v er , the de velopment of such models is constrained by the scarcity of high-quality , multi-speaker con v ersational data, as existing lar ge-scale resources are predominantly single-speaker or limited in v olume. Addressing the complex dynamics of natural dialogue, such as overlapping and back-channeling remains a challenge, with standard processing pipelines suffering from diarization errors and ASR hallucinations. T o bridge this gap, we present a robust and scalable open-source data processing pipeline designed for full-duple x model. Correspondence: cbok.park@navercorp.com , jchoo@kaist.ac.kr Demo and C ode: sommelier.github.io 1 Introduction Recent advances in speech large language models (SLMs) ha ve ev olved from single short queries to multi-turn, open- ended con versations ( Xu et al. , 2025b ; Goel et al. , 2025 ). Y et most systems still operate in disjoint user and assistant turns through a cascaded ASR and TTS pipeline ( Y e et al. , 2025 ), which inherits latency , discards paralinguistic cues, and struggles with interruptions, overlapping speech, and backchanneling. Full-duplex system ( W ang et al. , 2024b ; Roy et al. , 2026 ) addresses these limitations by enabling the system to listen and speak simultaneously , supporting more fluid and human-like interaction. Progress tow ard full-duplex SLMs has been facing bottlenecked by the lack of high-quality con versational data suitable for duplex training. While Moshi ( Défossez et al. , 2024 ) lev erages millions of hours of unsupervised audio for pre- training, these sources are largely single-stream and provide limited supervision for o verlapping speech. Consequently , ov erlap robustness relies on relativ ely small high-fidelity conv ersational corpora such as Fisher ( Cieri et al. , 2004 ), which is unlikely to meet the scale and di versity required for supervised fine-tuning (SFT) ( Xu et al. , 2025b ). Curating full-duplex training data from in-the-wild recordings is challenging because real con versations contain frequent ov erlaps, backchannels, and acoustic clutter , which amplify diarization and transcription errors ( W ang et al. , 2024a ). In addition, long-form audio typically includes non-conv ersational or irrele vant regions (e.g., music, noise, long silences), requiring careful filtering and normalization while preserving speaker structure and multi-turn conte xt. Finally , processing web-scale audio demands high throughput to make large-scale curation feasible under practical compute budgets in the real industry . T o address these challenges, we propose an open, robust, and scalable speech pre-processing pipeline designed for full-duplex SLMs. Our contributions are as follo ws: • The first scalable pipeline for full-duplex SLMs: W e release a scalable pipeline for curating multi-turn con versa- tional speech suitable for full-duplex training, helping alle viate the community-wide data scarcity . • High-fidelity overlap processing: W e provide a detailed processing strategy that handles overlaps via rigorous diarization analysis and reduces ASR hallucinations using paralleled model ensembling and n-gram filtering. ♣ This work was done during the residenc y program at N A VER Cloud. 1 Audio Standardization VAD Speaker Diarization Ensemble ASR (a) less than 5m in BGM Detector Overlap Separation spk1 spk2 concat Speech Separation start time speaker raw audio language end time transcript_1 transcript_2 transcript_3 transcript_final (b) (c) (d) (e) (f) (g) Full - Duplex Speech Language Model Figure 1 The overall pipeline of the Sommelier con versational audio pre-processing. Blue boxes denote neural model-based components, and a green box represent a algorithmic component. • Proven efficac y on a full-duplex model: W e validate our pipeline by fine-tuning the full-duple x model Moshi on Sommelier -processed speech and analyze practical data requirements for stable full-duplex training. 2 Method In this section, we present Sommelier , a robust data processing pipeline designed to transform raw , in-the-wild con versational audio into high-quality training corpora for full-duplex Speech Language Models (SLMs). Unlike traditional ASR pipelines that prioritize clean, non-overlapping speech, our design philosoph y centers on preserving the chaotic yet rich dynamics of human dialogue, such as overlaps and backchannelings, while ensuring scalability for web-scale processing. The ov erall architecture, illustrated in Figure 1 , is built as a modular framework where each component can be toggled or reconfigured, allowing researchers to adapt the trade-off between data purity and con versational authenticity . Sommelier is designed to transform ra w audio into clean, well-structured data while preserving the semantic context. The process begins with standardization, bringing div erse audio formats into a unified representation. W e then segment the audio based on silence detection, follo wed by a V oice Activity Detection (V AD) model ( T eam , 2024 ) that further partitions the content into chunks of less than fiv e minutes, a practical constraint that prevents downstream models from running out of memory on lengthy recordings (§ 2.1 ). Speaker diarization (§ 2.2 ) follows, identifying who speaks when. Guided by these speaker boundaries, we separate and restore o verlapping speech regions (§ 2.3 ), with optional remov al of background noise and music (§ 2.4 )depending on the use case. Finally , an ensemble of three Automatic Speech Recognition (ASR) models (§ 2.5 ) generates text transcripts and captions, leveraging model di versity to improve robustness. Each module in the pipeline can be toggled on or off to suit specific requirements. Rather than stripping aw ay speech ov erlaps and backchannelings, interruptions, and simultaneous speech that characterize real dialogue, we preserve them. This allows the duple x speech language model to learn not just what people say , but how con versations actually unfold. 2.1 Audio Standardization Since collected radio and podcast data vary in format and v olume, we adopt the method of ( He et al. , 2024 ). Using the pydub 1 and librosa ( McFee , 2025 ) libraries, we con vert all audio to the standard format (16kHz, 16-bit, Mono) and perform loudness normalization to -20dBFS ( He et al. , 2024 ) as illustrated in Figure 1 (a). 1 https://github .com/jiaaro/pydub 2 candidate 1 candidate 2 𝑠𝑖 𝑚 ! = 𝑐𝑜𝑠𝑆𝑖𝑚 (𝐸 "#$%! , 𝐸 &'(! ) 𝑠𝑖 𝑚 ) = 𝑐𝑜𝑠𝑆𝑖𝑚 (𝐸 "#$%! , 𝐸 &'() ) 𝑎𝑟𝑔𝑚𝑎𝑥 ( 𝑠𝑖 𝑚 ! , 𝑠𝑖 𝑚 ) ) sep sep segment segment Speaker Emb Model 𝑟𝑒𝑓1 𝑟𝑒𝑓2 A B sep A sep B Speech Separat ion M odel (a) (b) Decision Non - overlapping speec h Figure 2 Illustration of the speech ov erlap separation process. (a) The process of calculating similarity to distinguish speaker identities using arbitrary independent speaker segments. (b) Separating overlapped re gions and making identity decisions for candidates based on the similarity calculated in (a). Finally , the separated segments are concatenated with the original segments. 2.2 V AD & Speaker Diarization T o prev ent out-of-memory issues with the diarization model, we split long audio files into units of less than 5 minutes as shown in Figure 1 (b). T o maintain con versational conte xt, we use a V AD model to cut the audio at silence intervals. For speaker diarization, as shown in Figure 1 (c), instead of the commonly used pyannote speaker-diarization-3.1 model ( Bredin , 2023 ), we adopted Sortformer ( Park et al. ) from NVIDIA. Section 3.2 presents a performance comparison between the two models, demonstrating Sortformer’ s superiority in robustly capturing very short utterances such as backchannelings. 2.3 Handling Overlapping Speech Con versational audio features frequent turn changes and short utterances ( W ang et al. , 2025b ). T o systematically handle massi ve-scale industrial speech data, we categorized overlapping scenarios into four distinct cases, as sho wn in Figure 5 . Case 1 segments based on the o verlap, yielding non-o verlapping segments b ut losing full utterance information. Cases 2 and Case 3 assign the overlapping speech to one side, which risks ASR errors where utterances mix or transcripts fail. Case 4 allows both se gments to contain the o verlap based on speak er identity , preserving full information despite sharing the ASR issues of Cases 2 and Case 3 . W e selected Case 4 as our baseline, incorporating a module that performs two-speaker separation ( Shin et al. , 2024 ) on the ov erlapped interv als. W e find that inputting only the duplicated part into separation model works better than using the entire segment. Before separating ov erlapped speech, we extract non-o verlapping parts longer than 2 seconds to generate embedding tuples ( e ref 1 , e ref 2 ) = ( M emb ( a 0 ) , M emb ( a 1 )) , where a denotes the audio segment and M represents the model. This process uses the speaker embedding model M emb as shown in Figure 2 (a). In parallel, the overlapped audio a ov er lap is fed into the speech separation model M sep to produce candidates a cand 1 and a cand 2 as shown in Fig- ure 2 (b). T o identify the speakers, we calculate the cosine similarity scores S 1 = sim ( M emb ( a cand 1 ) , e ref 1 ) and S 2 = sim ( M emb ( a cand 1 ) , e ref 2 ) . The candidate with the higher similarity is assigned to the corresponding speaker ( a i ), while the other candidate corresponds to the remaining speaker . Finally , we concatenate the non-ov erlapping parts with the separated segments to create single-speaker se gments as shown in Figure 1 (d). 3 Model Pause Handling Backchannel Smooth T urn T aking User Interruption Synthetic TOR ↓ Candor TOR ↓ TOR ↓ Freq ↑ JSD ↓ Candor TOR ↑ Latency ↓ TOR ↑ GPT -4o ↑ Latency ↓ Moshi 0.985 0.980 1.000 0.001 0.957 0.941 0.265 1.000 0.765 0.257 Moshi + Sommelier 1.000 1.000 0.291 0.052 0.630 1.000 0.344 0.858 3.684 1.065 T able 1 Full-Duplex-Bench 1.0 results for base Moshi and Moshi fine-tuned on 83 hours of Sommelier -processed data. Arrows indicate whether higher ( ↑ ) or lower ( ↓ ) v alues are better . 2.4 Background Music Removal In addition to multi-speaker overlaps, the div erse nature of industrial audio sources introduces another challenge. Audio from radio broadcasts or dramas contains background music (BGM), which may be undesirable for training speech language models. W e employ P ANNs ( Kong et al. , 2020 ) (Pre-trained Audio Neural Networks) to estimate the probability of background music presence in each segment. If the probability exceeds a threshold of 0.3, we apply the Demucs ( Rouard et al. , 2023 ; Défossez , 2021 ) model to e xtract the v ocal track. Since music remov al can degrade speech quality , we selectively apply it only to se gments identified by P ANNs, minimizing unnecessary processing as sho wn in Figure 1 (e) and (f). W e find that feeding the entire audio context into Demucs yields substantially better separation performance than processing short segments in isolation. Therefore, we input full two-minute audio chunks into the model and subsequently extract only the required portions from the separated output. W e also considered SAM-Audio ( Shi et al. , 2025 ) for music remov al but excluded it due to its high inference latenc y (R TF 0.73 on A100), which limits its scalability for large datasets. 2.5 Ensemble-based ASR High-quality ASR is essential for constructing lar ge-scale datasets, as it generates the text labels necessary for model training. Howe ver , relying on a single model, ev en SOT A architectures like Whisper ( Radford et al. , 2022a ), poses significant risks. These models are prone to hallucinations, particularly in silent or noisy se gments, where they often generate repetitive or nonsensical text ( K oenecke et al. , 2024b ; Bara ´ nski et al. , 2025 ; Mansoor et al. , 2025 ). Such artifacts introduce noise into the training signal, causing the do wnstream model to mimic these pathological behaviors. T o mitigate this, we employ a Recognizer Output V oting Error Reduction (R O VER) ( Fiscus , 1997 ) ensemble strategy combining outputs from three distinct SO T A models as sho wn in Figure 1 (g). W e align transcripts at the word le vel and apply a prioritized majority voting scheme: a word is accepted if predicted by at least two models; otherwise, we default to the prediction of our primary backbone, Whisper, to maintain consistency . Residual hallucinations are further pruned using a RepetitionFilter that discards samples with excessi ve n-gram ( n = 15 ) repetitions (count ≥ 5 ) ( Udandarao et al. , 2025 ). Concurrently , we extract word-le vel timestamps via Whisper . Precision in temporal alignment is critical for modern streaming speech language models (as detailed in Section 3.1 ), which typically require strict synchronization between audio and text tokens. 3 Experiments In this section, we validate the indi vidual components of our proposed pipeline. First, we examine the practical utility of our approach by fine-tuning Moshi using the dataset preprocesed by our proposed pipeline (§ 3.1 ). W e then quantitativ ely ev aluate the diarization accuracy (§ 3.2 ), the audio quality following overlap separation (§ 3.3 ), and the accuracy of the ensemble-based ASR (§ 3.4 ). Furthermore, to provide a comprehensiv e analysis, we discuss the pipeline’ s latency (§ 3.5 ). 3.1 Effectiveness of Sommelier-Processed Data for Full-Duplex Models T o validate the ef fectiveness of our proposed Sommelier pipeline, we examine whether training a full-duple x model on the data processed by this pipeline yields performance improvements. T o this end, we performed LoRA fine-tuning on 4 Model DER (%) JER (%) DER ( ≤ 1.0s, %) DER (turn, %) pyannote3.1 8.40 17.68 20.21 0.051 sortformer_v1 7.16 14.69 16.87 0.006 T able 2 Diarization model ablation on V oxConv erse ( Chung et al. , 2020 ) (common subset, ≤ 4 speak ers). Lo wer is better for DER/JER and R TF . SIR OVL WER (%) ↓ STOI ↑ UTMOS ↑ Ori Sep Orc Ori Sep Orc Ori Sep Orc 0 dB 0.2 10.5 6.1 4.8 .961 .982 1.00 3.04 3.53 3.88 0.5 13.9 7.9 5.8 .888 .969 1.00 2.27 3.32 3.87 1.0 48.9 15.6 5.3 .778 .913 1.00 1.70 3.02 3.84 5 dB 0.2 11.3 7.6 5.3 .961 .978 1.00 3.06 3.47 3.87 0.5 18.8 7.1 4.3 .887 .971 1.00 2.34 3.39 3.91 1.0 52.5 9.1 4.0 .761 .936 1.00 1.79 3.12 3.91 10 dB 0.2 12.6 7.0 5.6 .961 .980 1.00 3.26 3.60 3.98 0.5 29.7 10.1 5.2 .877 .956 1.00 2.58 3.21 3.86 1.0 51.0 13.8 4.8 .754 .919 1.00 2.17 3.01 3.92 T able 3 Speech quality for separated o verlapped speech across metrics for Ori ginal audio, source Sep arated, and Or a c le (pre-synthesis speech quality). moshiko-pytorch-bf16 ( Défossez et al. , 2024 ) and e v aluated its duplex performance using the Full-Duple x-Bench ( Lin et al. , 2025b , a ). Dataset. W e find that long turn-taking in the training data for Moshi, specifically when a single speaker holds the floor for too long (more than a minute), leads to unstable loss reduction and degrades performance, causing the model to become unresponsiv e. Consequently , we selected segments from the Sommelier -processed data where each turn lasted no more than 10 seconds. W e defined a valid region as a sequence of at least three consecutiv e turns, truncating the region if an utterance exceeding 10 seconds appeared. Additionally , we assigned only a single speaker to the left channel of the stereo training data. W e confirmed that these selection criteria significantly impact the training dynamics. The model configuration is detailed in Appendix D . Results. As sho wn in T able 1 , ev aluation on Full-Duplex-Bench 1.0 demonstrated performance impro vements across Backchanneling, Smooth T urn-T aking, and User Interruption handling. Regarding P ause Handling, howe ver , we observe that the model performs comparably to base Moshi, exhibiting similar limitations. W e hypothesize that this stems from the Moshi architecture or the absence of prompt audio, as proposed in Personaplex ( Roy et al. , 2026 ). Regarding latenc y , the base model exhibited notably short latencies simply because it failed to eng age in backchanneling or interruption handling, reflecting suboptimal behavior where the model continued speaking regardless of user input. In contrast, after fine-tuning with Sommelier-processed data, the increased latency can be interpreted positi vely , as it indicates that the model is no w actively processing user input and preparing appropriate responses for backchannels and interruptions. Detailed descriptions of the benchmark metrics are provided in Appendix D . 3.2 Diarization Model Choice Using Pyannote 3.1 has been widely regarded as the def ault for diarization models, a trend followed by recent w orks such as He et al. ( 2024 ) . In this study , howe ver , we compare the performance of Sortformer ( Park et al. ), which is adopted in our pipeline, against the Pyannote 3.1 ( Bredin , 2023 ; Plaquet and Bredin , 2023 ) baseline. Metrics. W e ev aluate speaker diarization quality using DER (Diarization Error Rate) and JER (Jaccard Error Rate). DER measures the fraction of speaker time that is incorrectly attributed, typically aggregating missed speech , false alarm speech , and speaker confusion within a tolerance collar . JER measures the average Jaccard distance between the reference and hypothesis speak er segments, and is kno wn to be more sensiti ve to boundary quality and se gmentation consistency . T o stress-test challenging regimes, we additionally compute DER on short-duration speech by restricting ev aluation to reference segments shorter than a threshold ( ≤ 0.5 s and ≤ 1.0 s), and DER on turn-taking r e gions by 5 Dataset Model WER (%) Time (s) LibriSpeech T est Clean Whisper 3 . 63 ± 9 . 37 0.39 MoE (Ours) 2 . 04 ± 6 . 50 1.40 LibriSpeech T est Other Whisper 6 . 26 ± 11 . 63 0.35 MoE (Ours) 3 . 92 ± 8 . 92 1.27 TEDLIUM3 T est Whisper 12 . 19 ± 12 . 31 0.36 MoE (Ours) 10 . 66 ± 11 . 73 1.33 T able 4 Ev aluation results on LibriSpeech (Clean/Other) and TEDLIUM3. Whisper refers Whisper-large-v3 model. restricting ev aluation to temporal windows around speaker change points (speaker alternations within a small gap). All metrics are reported on the V oxCon verse ( Chung et al. , 2020 ) common subset containing recordings with at most four speakers. Results and analysis. T able 2 demonstrates that Sortformer consistently outperforms the Pyannote 3.1 baseline across global metrics on the V oxConv erse benchmark. More importantly , the gains are most pronounced in regimes critical for con versational modeling. Sortformer exhibits superior rob ustness in handling short utterances and rapid turn-taking, effecti vely reducing errors in brief interjections and speaker boundaries. These results confirm that Sortformer is better suited for processing highly interactiv e, overlapping dialogue than standard baselines. 3.3 Speech Quality of Overlap Separation Processing ov erlapped speech is a critical step in constructing training datasets for full-duplex con versational mod- els ( Défossez et al. , 2024 ). This is because full-duplex training requires speech segments to ov erlap freely , as in natural human con versations, while maintaining source-separated audio streams for each speaker . Giv en two speech segments a i and a j that are sequentially overlapped, where a i starts at t start , a j ends at t end , and the ov erlap occurs from t 1 to t 2 , we e v aluate speech quality for each diarized speaker’ s utterance interval: [ t start , t 2 ] for speaker1 and [ t 1 , t end ] for speaker2 . Dataset. T o simulate div erse real-world ov erlap conditions, we synthesized 900 samples of two speaker mixtures from the LibriSpeech ( Panayoto v et al. , 2015 ) test utterance by v arying Signal-to-Interference Ratio (SIR ∈ { 0 , 5 , 10 } dB) and overlap ratio ( ρ ∈ { 0 . 2 , 0 . 5 , 1 . 0 } ), forming nine different conditions. W e also mix silence-trimmed sources to achiev e the target ov erlap precisely . Metrics. Evaluation is conducted across three conditions: (1) Original , which directly extracts time segments from the mixed signal, (2) Sep , which applies SepReformer ( Shin et al. , 2024 )-based separation with speaker identity matching (see Section 2.3 ), and (3) Oracle , which uses clean source signals as an upper bound. Ground-truth diarization timestamps from data synthesis are used across all conditions to ensure fair e v aluation of overlapped re gions. W e assess intelligibility using W ord Error Rate (WER), acoustic quality using SI-SDR and STOI, and perceptual naturalness using UTMOS ( Saeki et al. , 2022 ). Results and Analysis. The quantitative analysis presented in T able 3 rev eals that while v ariations in the Signal-to- Interference Ratio (SIR) ha ve a limited impact on performance, the overlap ratio serves as the critical determinant of task difficulty . As the ov erlap ratio increases, the baseline model suffers significant degradation; ho wever , our proposed method (Sep) consistently outperforms the baseline across all experimental conditions, demonstrating robust separation capabilities e ven in highly overlapped scenarios. Most notably , in terms of perceptual quality (UTMOS ( Saeki et al. , 2022 )), the proposed method achie ves scores closely approximating the Oracle upper bound. This result strongly suggests that our model not only improv es intelligibility but also preserves speech naturalness effecti vely , thereby guaranteeing the generation of high-quality samples suitable for use as training data. More detailed results and analysis are provided in Appendix B . 6 Stage Processing Time (s) RTF Audio Duration 120.00 – V AD + Sortformer 1.91 0.0159 SepReformer Separation 0.15 0.0013 ASR ensemble 13.91 0.1159 FlowSE Denoising 4.99 0.0416 T otal 20.95 0.1746 T able 5 Processing time breakdo wn for the proposed pipeline on a 120-second audio sample. 3.4 ASR Ensemble Performance W e compare the performance of the Whisper model against our proposed three-model ensemble method utilizing R O VER Fiscus ( 1997 ). Metrics. T o ev aluate ASR performance, we measure the W ord Error Rate (WER) using the LibriSpeech ( Panayoto v et al. , 2015 ) test dataset (clean and other splits) and the TEDLIUM3 ( Hernandez et al. , 2018 ) test set. Since LibriSpeech test-other and TEDLIUM3 contain noisy conditions, these datasets allow us to assess the model’ s robustness against real-world scenarios. Results and Analysis. The comparison results between the standalone Whisper Large v3 and the ensemble (Whisper + Canary + Parakeet ( Sekoyan et al. , 2025 )) are presented in T able 4 . In terms of WER, the proposed approach demonstrated a significant improvement of approximately 37%, reducing the error rate from 6.26% to 3.92% compared to the single Whisper-large-v3 baseline. This gap was particularly evident in noisy data, demonstrating improv ed recognition accuracy in se gments containing low v olume or BGM. Regarding inference time, the ensemble approach required approximately three times longer than the baseline. This latency is primarily attrib uted to the inference speed of Canary , the slo west model among the three, rather than sequential ex ecution. Additionally , the concurrent loading and inference of three models may introduce slight overhead. Qualitativ ely , we observed hallucinations in the Whisper outputs, such as repetiti ve generation (e.g., “Y eah., Y eah., Y eah... ” ). W e confirmed that our method successfully corrected these errors by selecting the accurate transcript provided by Canary (e.g., “Y eah, big decision for Dan” ). 3.5 Latenc y Data preprocessing is a computationally intensiv e task He et al. ( 2024 ); Dua et al. ( 2025 ). Thus, minimizing latency in this phase is critical. As shown in T able 5 , running a single process on an A100 (80GB) yields a total Real-Time F actor (R TF) of 0.1746. Excluding the optional FlowSE Denoising step further reduces the R TF to 0.133, with the primary bottleneck occurring in the ASR stage. Giv en the peak memory usage of 23GB, it is possible to allocate three concurrent processes on a single GPU, which effecti vely lowers the R TF to 0.0443 per GPU. Consequently , processing 10,000 hours of audio using eight A100 GPUs would take approximately 55 hours, demonstrating the practical feasibility of our approach. 4 Conclusion W e presented Sommelier , the first scalable, open-source pipeline for full-duplex SLMs. Our pipeline combines rigorous diarization, ov erlap handling, and ensemble-based ASR to improv e ov erall transcript quality . W e validated the ov erall utility of the Sommelier pipeline by fine-tuning Moshi on Sommelier -processed speech. W e release our pipeline to support reproducible industrial research and to accelerate progress tow ard natural, real-time human–AI interaction. Limitations A limitation of our pipeline is its exclusi ve focus on processing speech data. While optimized for con versational dialogue, it does not e xplicitly account for non-speech acoustic e vents or general sound scenes, limiting its scope compared to 7 omni-modal audio approaches. Although our overlap separation module effecti vely disentangles simultaneous speakers from single-stream recordings, the resulting audio fidelity is ine vitably slightly inferior to datasets that are originally recorded with distinct, isolated channels (Oracle), as the artificial separation process may introduce minor acoustic artifacts. Ethical Considerations W e dev eloped the Sommelier pipeline with a strict adherence to open-source compliance and intellectual property rights. All software components, libraries, and pre-trained models integrated into our framework are gov erned by commercially permissi ve licenses, primarily MIT and Creativ e Commons (CC), allowing for broad academic and industrial application without legal ambiguity . Furthermore, the podcast audio samples featured on our project demonstration page were exclusi vely selected from sources explicitly released under CC licenses. W e have rigorously v erified the usage terms of these recordings to ensure that no copyrighted material is infringed upon and that the original creators’ rights are respected. Beyond licensing compliance, we acknowledge the broader implications of releasing tools for high-fidelity speech processing. While our goal is to adv ance full-duplex interaction, we recognize that high-quality con versational datasets can potentially be misused for non-consensual v oice cloning or deepfake generation. W e urge the research community to utilize this pipeline responsibly , ensuring that any pri vate data processed is done so with appropriate consent and priv acy safeguards in place. Acknowledgments W e would like to e xpress our deepest gratitude to T aehong Moon. References Inclusion AI, Bowen Ma, Cheng Zou, Canxiang Y an, Chunxiang Jin, Chunjie Shen, Dandan Zheng, Fudong W ang, Furong Xu, GuangMing Y ao, et al. Ming-flash-omni: A sparse, unified architecture for multimodal perception and generation. arXiv preprint arXiv:2510.24821 , 2025. Mateusz Bara ´ nski, Jan Jasi ´ nski, Julitta Bartolewska, Stanisła w Kacprzak, Marcin W itko wski, and K onrad K ow alczyk. Inv estigation of whisper asr hallucinations induced by non-speech audio. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 1–5. IEEE, 2025. Zalán Borsos, Raphaël Marinier, Damien V incent, Eugene Kharitonov , Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier T eboul, David Grangier , Marco T agliasacchi, and Neil Zeghidour . Audiolm: a language modeling approach to audio generation, 2023. . Hervé Bredin. pyannote.audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe. In Pr oc. INTERSPEECH 2023 , 2023. Guoguo Chen, Shuzhou Chai, Guan-Bo W ang, Jiayu Du, W ei-Qiang Zhang, Chao W eng, Dan Su, Daniel Pove y , Jan Trmal, Junbo Zhang, Mingjie Jin, Sanjeev Khudanpur, Shinji W atanabe, Shuaijiang Zhao, W ei Zou, Xiangang Li, Xuchen Y ao, Y ongqing W ang, Zhao Y ou, and Zhiyong Y an. Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio. In Interspeech 2021 . ISCA, 2021. doi: 10.21437/interspeech.2021- 1965. http://dx.doi.org/10.21437/Interspeech. 2021- 1965 . Y unfei Chu, Jin Xu, Xiaohuan Zhou, Qian Y ang, Shiliang Zhang, Zhijie Y an, Chang Zhou, and Jingren Zhou. Qwen-audio: Adv ancing univ ersal audio understanding via unified large-scale audio-language models, 2023. . Y unfei Chu, Jin Xu, Qian Y ang, Haojie W ei, Xipin W ei, Zhifang Guo, Y ichong Leng, Y uanjun Lv , Jinzheng He, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen2-audio technical report, 2024. . Joon Son Chung, Jaesung Huh, Arsha Nagrani, T riantafyllos Afouras, and Andrew Zisserman. Spot the con versation: speaker diarisation in the wild. 2020. Christopher Cieri, David Graff, Owen Kimball, Dave Miller , and Kevin W alker . Fisher english training speech part 1 transcripts. Linguistic Data Consortium, 2004. https://catalog.ldc.upenn.edu/LDC2004T19 . LDC2004T19. 8 Alexandre Défossez. Hybrid spectrogram and wa veform source separation. In Pr oceedings of the ISMIR 2021 W orkshop on Music Sour ce Separation , 2021. Karan Dua, Puneet Mittal, Ranjeet Gupta, and Hitesh Laxmichand P atel. Speechweave: Div erse multilingual synthetic text & audio data generation pipeline for training text to speech models. In Pr oceedings of the 63r d Annual Meeting of the Association for Computational Linguistics (V olume 6: Industry T rac k) , page 718–737. Association for Computational Linguistics, 2025. doi: 10.18653/v1/2025.acl- industry .51. http://dx.doi.org/10.18653/v1/2025.acl- industry.51 . Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer , Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Ze ghidour . Moshi: a speech-text foundation model for real-time dialogue, 2024. . Jonathan G Fiscus. A post-processing system to yield reduced word error rates: Recognizer output voting error reduction (rov er). In 1997 IEEE W orkshop on Automatic Speech Recognition and Understanding Proceedings , pages 347–354. IEEE, 1997. John J. Godfrey and Edward Holliman. Switchboard-1 release 2. Linguistic Data Consortium (LDC), 1993. https://www.ldc. upenn.edu/ . LDC Catalog No.: LDC97S62. DOI: https://doi.org/10.35111/sw3h- rw02 . Arushi Goel, Sreyan Ghosh, Jaehyeon Kim, Sonal Kumar , Zhifeng K ong, Sang gil Lee, Chao-Han Huck Y ang, Ramani Duraiswami, Dinesh Manocha, Rafael V alle, and Bryan Catanzaro. Audio flamingo 3: Advancing audio intelligence with fully open large audio language models, 2025. . Haorui He, Zengqiang Shang, Chaoren W ang, Xuyuan Li, Y icheng Gu, Hua Hua, Liwei Liu, Chen Y ang, Jiaqi Li, Peiyang Shi, et al. Emilia: An extensi ve, multilingual, and diverse speech dataset for lar ge-scale speech generation. In 2024 IEEE Spoken Language T echnology W orkshop (SLT) , pages 885–890. IEEE, 2024. François Hernandez, V incent Nguyen, Sahar Ghannay , Natalia T omashenko, and Y annick Estève. TED-LIUM 3: T wice as Much Data and Corpus Repartition for Experiments on Speaker Adaptation , page 198–208. Springer International Publishing, 2018. ISBN 9783319995793. doi: 10.1007/978- 3- 319- 99579- 3_21. http://dx.doi.org/10.1007/978- 3- 319- 99579- 3_21 . Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow , Akila W elihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint , 2024. Kyudan Jung, Seungmin Bae, Nam Joon Kim, Hyun Gon Ryu, and Hyuk-Jae Lee. Improving asr performance with ocr through using word frequency difference. In 2024 International Conference on Electr onics, Information, and Communication (ICEIC) , pages 1–4, 2024a. doi: 10.1109/ICEIC61013.2024.10457220. Kyudan Jung, Nam-Joon Kim, Hyongon Ryu, Sieun Hyeon, Seung jun Lee, and Hyeok jae Lee. T exbleu: Automatic metric for ev aluate latex format, 2024b. . Allison K oenecke, Anna Seo Gyeong Choi, Katelyn X. Mei, Hilke Schellmann, and Mona Sloane. Careless whisper: Speech-to-text hallucination harms. In The 2024 A CM Confer ence on F airness, Accountability , and T ranspar ency , F AccT ’24, page 1672–1681. A CM, June 2024a. doi: 10.1145/3630106.3658996. http://dx.doi.org/10.1145/3630106.3658996 . Allison K oenecke, Anna Seo Gyeong Choi, Katelyn X Mei, Hilke Schellmann, and Mona Sloane. Careless whisper: Speech-to-text hallucination harms. In Pr oceedings of the 2024 ACM Confer ence on F airness, Accountability , and T ranspar ency , pages 1672–1681, 2024b. Qiuqiang Kong, Y in Cao, T urab Iqbal, Y uxuan W ang, W enwu W ang, and Mark D Plumbley . Panns: Large-scale pretrained audio neural networks for audio pattern recognition. IEEE/ACM T ransactions on Audio, Speech, and Language Processing , 28: 2880–2894, 2020. Shashidhar G Koolagudi and K Sreenivasa Rao. Emotion recognition from speech: a re view . International journal of speech technology , 15(2):99–117, 2012. Keon Lee, Dong W on Kim, Jaehyeon Kim, Seungjun Chung, and Jaew oong Cho. Ditto-tts: Diffusion transformers for scalable text-to-speech without domain-specific factors, 2025. . Guan-T ing Lin, Shih-Y un Shan Kuan, Qirui W ang, Jiachen Lian, Tingle Li, and Hung-yi Lee. Full-duplex-bench v1. 5: Evaluating ov erlap handling for full-duplex speech models. arXiv pr eprint arXiv:2507.23159 , 2025a. Guan-T ing Lin, Jiachen Lian, T ingle Li, Qirui W ang, Gopala Anumanchipalli, Ale xander H Liu, and Hung-yi Lee. Full-duplex-bench: A benchmark to ev aluate full-duplex spoken dialogue models on turn-taking capabilities. arXiv pr eprint arXiv:2503.04721 , 2025b. Harras Mansoor , Umer Abdullah, Shahryar Adil, Akhtar Jamil, Alaa Ali Hameed, and Faezeh Soleimani. Mitigating hallucinations in speech recognition systems for noisy data. In 2025 IEEE 4th International Conference on Computing and Machine Intelligence (ICMI) , pages 1–5. IEEE, 2025. Brian McFee. librosa/librosa: 0.11.0, March 2025. https://doi.org/10.5281/zenodo.15006942 . V ersion 0.11.0. 9 V assil Panayotov , Guoguo Chen, Daniel Pove y , and Sanjeev Khudanpur . Librispeech: An asr corpus based on public domain audio books. In 2015 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pages 5206–5210, 2015. doi: 10.1109/ICASSP .2015.7178964. T aejin Park, Ivan Medennikov , Kunal Dhawan, W eiqing W ang, He Huang, Nithin Rao Koluguri, Krishna C Puvvada, Jagadeesh Balam, and Boris Ginsbur g. Sortformer: A novel approach for permutation-resolved speaker supervision in speech-to-te xt systems. In F orty-second International Conference on Machine Learning . Guilherme Penedo, Hynek K ydlí ˇ cek, Anton Lozhko v , Margaret Mitchell, Colin A Raf fel, Leandro V on W erra, Thomas W olf, et al. The fineweb datasets: Decanting the web for the finest text data at scale. Advances in Neural Information Pr ocessing Systems , 37: 30811–30849, 2024. Alexis Plaquet and Hervé Bredin. Powerset multi-class cross entrop y loss for neural speaker diarization. In Proc. INTERSPEECH 2023 , 2023. Alec Radford, Jong W ook Kim, T ao Xu, Greg Brockman, Christine McLea ve y , and Ilya Sutske ver . Robust speech recognition via large-scale weak supervision, 2022a. . Alec Radford, Jong W ook Kim, T ao Xu, Greg Brockman, Christine McLea ve y , and Ilya Sutske ver . Robust speech recognition via large-scale weak supervision, 2022b. . Simon Rouard, Francisco Massa, and Alexandre Défossez. Hybrid transformers for music source separation. In ICASSP 23 , 2023. Rajarshi Roy , Jonathan Raiman, Sang-gil Lee, T eodor-Dumitru Ene, Robert Kirby , Sungwon Kim, Jaehyeon Kim, and Bryan Catanzaro. Personaplex: V oice and role control for full duplex con versational speech models. 2026. Paul K. Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chaumont Quitry , Peter Chen, Dalia El Badawy , W ei Han, Eugene Kharitonov , Hannah Muckenhirn, Dirk P adfield, James Qin, Danny Rozenber g, T ara Sainath, Johan Schalkwyk, Matt Sharifi, Michelle T admor Ramanovich, Marco T agliasacchi, Alexandru Tudor , Mihajlo V elimirovi ´ c, Damien V incent, Jiahui Y u, Y ongqiang W ang, V icky Zayats, Neil Zeghidour , Y u Zhang, Zhishuai Zhang, Lukas Zilka, and Christian Frank. Audiopalm: A large language model that can speak and listen, 2023. . T akaaki Saeki, Detai Xin, W ataru Nakata, T omoki Koriyama, Shinnosuke T akamichi, and Hiroshi Saruw atari. Utmos: Utokyo-sarulab system for voicemos challenge 2022. arXiv preprint , 2022. Monica Sekoyan, Nithin Rao Koluguri, Nune T adev osyan, Piotr Zelasko, Tra vis Bartley , Nikolay Karpov , Jagadeesh Balam, and Boris Ginsbur g. Canary-1b-v2 & parakeet-tdt-0.6b-v3: Efficient and high-performance models for multilingual asr and ast, 2025. https://arxiv.org/abs/2509.14128 . Bowen Shi, Andros Tjandra, John Hof fman, Helin W ang, Y i-Chiao W u, Luya Gao, Julius Richter , Matt Le, Apoorv Vyas, Sanyuan Chen, Christoph Feichtenhofer , Piotr Dollár , W ei-Ning Hsu, and Ann Lee. Sam audio: Segment anything in audio, 2025. https://arxiv.org/abs/2512.18099 . Ui-Hyeop Shin, Sangyoun Lee, T aehan Kim, and Hyung-Min Park. Separate and reconstruct: Asymmetric encoder-decoder for speech separation. Advances in Neural Information Pr ocessing Systems , 37:52215–52240, 2024. Luca Soldaini, Rodney Kinne y , Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur , Ben Bogin, Khyathi Chandu, Jennifer Dumas, Y anai Elazar, et al. Dolma: An open corpus of three trillion tokens for language model pretraining research. In Pr oceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: long papers) , pages 15725–15788, 2024. N A VER Cloud HyperCLO V A X T eam. Hyperclov a x 32b think, 2026a. . N A VER Cloud HyperCLO V A X T eam. Hyperclov a x 8b omni, 2026b. . Silero T eam. Silero vad: pre-trained enterprise-grade voice activity detector (vad), number detector and language classifier. https://github.com/snakers4/silero- vad , 2024. An varjon T ursunov , Soonil Kwon, and Hee-Suk Pang. Discriminating emotions in the valence dimension from speech using timbre features. Applied Sciences , 9(12):2470, 2019. V ishaal Udandarao, Zhiyun Lu, Xuankai Chang, Y ongqiang W ang, V iolet Z. Y ao, Albin Madapally Jose, Fartash Faghri, Josh Gardner , and Chung-Cheng Chiu. Data-centric lessons to improve speech-language pretraining, 2025. 20860 . Helin W ang, Jiarui Hai, Dading Chong, Karan Thakkar , T iantian Feng, Dongchao Y ang, Junhyeok Lee, Thomas Thebaud, Laure- ano Moro V elazquez, Jesus V illalba, et al. Capspeech: Enabling downstream applications in style-captioned text-to-speech. arXiv pr eprint arXiv:2506.02863 , 2025a. 10 Jinhan W ang, Long Chen, Aparna Khare, Anirudh Raju, Pranav Dheram, Di He, Minhua W u, Andreas Stolcke, and V enkatesh Ravichandran. Turn-taking and backchannel prediction with acoustic and large language model fusion. In ICASSP 2024-2024 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pages 12121–12125. IEEE, 2024a. Peng W ang, Songshuo Lu, Y aohua T ang, Sijie Y an, W ei Xia, and Y uanjun Xiong. A full-duplex speech dialogue scheme based on large language models, 2024b. . Y iyang W ang, Chen Chen, Tica Lin, V ishnu Raj, Josh Kimball, Alex Cabral, and Josiah Hester. Companioncast: A multi-agent con versational ai framework with spatial audio for social co-viewing e xperiences, 2025b. . Maurice W eber, Dan Fu, Quentin Anthony , Y onatan Oren, Shane Adams, Anton Alexandrov , Xiaozhong L yu, Huu Nguyen, Xiaozhe Y ao, V irginia Adams, et al. Redpajama: an open dataset for training large language models. Advances in neural information pr ocessing systems , 37:116462–116492, 2024. Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin W ang, Y ang Fan, Kai Dang, Bin Zhang, Xiong W ang, Y unfei Chu, and Junyang Lin. Qwen2.5-omni technical report, 2025a. . Jin Xu, Zhifang Guo, Hangrui Hu, Y unfei Chu, Xiong W ang, Jinzheng He, Y uxuan W ang, Xian Shi, T ing He, Xinfa Zhu, Y uanjun Lv , Y ongqi W ang, Dake Guo, He W ang, Linhan Ma, Pei Zhang, Xinyu Zhang, Hongkun Hao, Zishan Guo, Baosong Y ang, Bin Zhang, Ziyang Ma, Xipin W ei, Shuai Bai, Keqin Chen, Xuejing Liu, Peng W ang, Mingkun Y ang, Dayiheng Liu, Xingzhang Ren, Bo Zheng, Rui Men, Fan Zhou, Bo wen Y u, Jianxin Y ang, Le Y u, Jingren Zhou, and Junyang Lin. Qwen3-omni technical report, 2025b. . Canxiang Y an, Chunxiang Jin, Dawei Huang, Haibing Y u, Han Peng, Hui Zhan, Jie Gao, Jing Peng, Jingdong Chen, Jun Zhou, Kaimeng Ren, Ming Y ang, Mingxue Y ang, Qiang Xu, Qin Zhao, Ruijie Xiong, Shaoxiong Lin, Xuezhi W ang, Y i Y uan, Y ifei W u, Y ongjie L yu, Zhengyu He, Zhihao Qiu, Zhiqiang Fang, and Ziyuan Huang. Ming-uniaudio: Speech llm for joint understanding, generation and editing with unified representation, 2025. . Y ifan Y ang, Zheshu Song, Jianheng Zhuo, Mingyu Cui, Jinpeng Li, Bo Y ang, Y exing Du, Ziyang Ma, Xunying Liu, Ziyuan W ang, Ke Li, Shuai Fan, Kai Y u, W ei-Qiang Zhang, Guoguo Chen, and Xie Chen. Gigaspeech 2: An ev olving, large-scale and multi-domain asr corpus for lo w-resource languages with automated crawling, transcription and refinement, 2025. https: //arxiv.org/abs/2406.11546 . Hanrong Y e, Chao-Han Huck Y ang, Arushi Goel, W ei Huang, Ligeng Zhu, Y uanhang Su, Sean Lin, An-Chieh Cheng, Zhen W an, Jinchuan Tian, et al. Omnivinci: Enhancing architecture and data for omni-modal understanding llm. arXiv pr eprint arXiv:2510.15870 , 2025. Binbin Zhang, Hang Lv , Pengcheng Guo, Qijie Shao, Chao Y ang, Lei Xie, Xin Xu, Hui Bu, Xiaoyu Chen, Chenchen Zeng, Di W u, and Zhendong Peng. W enetspeech: A 10000+ hours multi-domain mandarin corpus for speech recognition, 2022. https://arxiv.org/abs/2110.03370 . 11 Appendix W e provide detailed supplementary materials or ganized as follo ws: • Appendix A revie ws related work on full-duplex models, large-scale speech datasets, and speech preprocessing techniques. • A ppendix B presents additional experimental results regarding o verlap separation. • A ppendix C illustrates specific cases for handling backchanneling and overlapping speech. • A ppendix D details supplementary results from the fine-tuning experiments. • A ppendix E describes the techniques employed for audio captioning. • A ppendix F provides examples of data processed by Sommelier . A Related Works In this section, we provide a comprehensiv e ov ervie w of the research landscape relev ant to our work. W e begin by tracing the ev olution of Speech Language Models from cascaded pipelines to end-to-end architectures, with a particular focus on the recent shift to ward full-duplex interaction (§ A.1 ). W e then critically examine the current landscape of large-scale speech datasets, identifying their structural limitations for modeling naturalistic con versational dynamics (§ A.2 ). Finally , we survey the automated pipelines used for speech data curation, discussing ke y technical challenges such as speaker diarization errors and transcription hallucinations that our work aims to address (§ A.3 ). A.1 Speech Language Models and Full-Duplex Interaction The landscape of spoken language understanding has undergone a fundamental transformation, moving away from cascaded systems towards end-to-end modeling. T raditional con versational agents relied on a cascade pipeline of Automatic Speech Recognition (ASR), Lar ge Language Models (LLM), and T ext-to-Speech (TTS) ( Lee et al. , 2025 ; Jung et al. , 2024a ). While effecti ve for distinct tasks, this modular approach ine vitably suf fers from error propagation and the loss of paralinguistic features such as emotion, prosody , and intonationp. T o address these limitations, End- to-End Speech Language Models (SLMs), such as AudioLM ( Borsos et al. , 2023 ) and AudioPaLM ( Rubenstein et al. , 2023 ), were introduced to process acoustic tokens directly , preserving the rich nuances of speech. Building on this foundation, recent multimodal models like Qwen-Audio Chu et al. ( 2023 , 2024 ), Qwen-Omni Xu et al. ( 2025a , b ), HyerCLO V A-X-8B-Omni ( T eam , 2026b , a ) and Audio Flamingo Chu et al. ( 2024 ); Goel et al. ( 2025 ) have demonstrated exceptional capabilities in understanding and reasoning across both text and audio modalities, ef fectiv ely bridging the gap between sound processing and language comprehension. Despite these advancements, a critical frontier remains in achieving natural, real-time human-computer interaction. While earlier models primarily operated on a turn-based (half-duplex) mechanism, recent de velopments like Moshi Défossez et al. ( 2024 ) and GPT -4o Hurst et al. ( 2024 ) aim to realize full-duple x communication, where listening and speaking occur simultaneously . This shift necessitates models to master complex con versational dynamics, including the ability to handle ov erlapping speech, process back-channeling (e.g., rapid affirmations), and predict turn-taking opportunities seamlessly . Howe ver , training such full-duplex systems presents a significant challenge: it requires high-quality , multi-stream data that captures these intricate acoustic intersections. The scarcity of such datasets in the current research landscape creates a bottleneck, limiting the ability of current models to generalize to the chaotic and fluid nature of real-world dialogue. A.2 Large-Scale Speech Datasets Existing speech datasets, despite their increasing volume, remain suboptimal for training full-duplex models that require rich interactional dynamics. T raditional ASR benchmarks like LibriSpeech ( Panayoto v et al. , 2015 ) and GigaSpeech ( Chen et al. , 2021 ) are dominated by scripted read speech or solitary monologues, failing to capture the 12 dynamic and interactiv e spontaneity of human dialogue. While con versational datasets such as Fisher ( Cieri et al. , 2004 ) and Switchboard ( Godfrey and Holliman , 1993 ) offer multi-speaker interactions, they are sev erely limited by their archaic telephony quality (8kHz), narro w bandwidth, and relati vely small scale (typically a fe w thousand hours), which is insufficient for modern large-scale pre-training Radford et al. ( 2022b ); Xu et al. ( 2025b ). While recent web-scale initiativ es like W enetSpeech ( Zhang et al. , 2022 ) and Emilia He et al. ( 2024 ) have successfully aggregated massiv e datasets, their pipelines are heavily optimized for single-stream speech, thereby neglecting the concurrent dynamics required for full-duplex interaction. Crucially , their pre-processing pipelines treat overlapping speech as noise to be excised or ignored rather than a feature to be modeled. This structural limitation results in data that lacks the distinct multi-stream separation and essential acoustic collisions required for learning true full-duplex interaction. A.3 Automated Speech Data Processing Pipelines While open-source data processing pipelines have become the bedrock of Large Language Model (LLM) research, ex emplified by transparent frame works like Dolma ( Soldaini et al. , 2024 ), RedPajama ( W eber et al. , 2024 ), and FineW eb ( Penedo et al. , 2024 ), the domain of speech processing remains significantly opaque. Although model weights for Speech Language Models (SLMs) are frequently released, the intricate “data recipes” required to curate high-quality pre-training corpora remain proprietary “black boxes, ” impeding the community’ s ability to reproduce results or impro ve upon existing strate gies. This lack of standardized, open pipelines is particularly critical when addressing the technical demands of full-duplex communication. Current methodologies rely heavily on tools designed for single-stream processing ( Dua et al. , 2025 ; Y ang et al. , 2025 ), which are ill-suited for capturing the concurrent dynamics of human dialogue. For instance, while speaker diarization is a prerequisite for multi-turn modeling, standard tools like Pyannote ( Bredin , 2023 ; Plaquet and Bredin , 2023 ) often struggle in the complex acoustic en vironments of in-the-wild web videos. Crucially , these tools frequently misinterpret the overlaps and rapid turn-taking , essential features of full-duplex interaction, as segmentation errors or noise, thereby degrading the structural inte grity of the con versational data. Furthermore, the reliance on ASR models for transcription introduces the risk of hallucinations. Models like Whis- per ( Radford et al. , 2022b ), though po werful, are prone to generating repetitiv e loops or nonsensical te xt during silence or non-speech interv als, a critical instability highlighted in recent studies such as Car eless Whisper ( Koenecke et al. , 2024a ). Existing pipelines lack the rob ustness to filter these hallucinations or handle the multi-stream nature of duple x speech, underscoring the urgent need for a transparent, hallucination-aware processing framew ork tailored for con versational AI. B Detail of Overlapping disentangle experiments This section presents detailed experimental results on the efficac y of our overlap separation module. W e ev aluated performance across varying Signal-to-Interference Ratios (SIR) and Overlap Ratios using four key metrics: W ord Error Rate (WER), Scale-In variant Signal-to-Distortion Ratio (SI-SDR), Short-T ime Objective Intelligibility (STOI), and UTMOS. The results, summarized in T ables 6 through 8 , demonstrate that applying the separation module (‘Sep’) consistently improv es signal quality compared to the baseline (‘Base’). Notably , the performance gain is significantly larger for Speaker 2 (the interfering or secondary speaker) than for Speaker 1 (the primary speaker), particularly in challenging conditions with high ov erlap ratios as shown in Figure 3 . B.1 Analysis of Results Asymmetric Gains (Spk1 vs. Spk2) Across all metrics, the gap between the ‘Base’ and ‘Sep’ conditions is most dramatic for Speaker 2. For instance, in the 0,dB SIR and 1.0 overlap condition, the WER for Speaker 2 improves drastically from 0.444 to 0.138 (T able 6 ), whereas Speaker 1 sees a relati vely smaller , though still significant, improv ement. This suggests that our module is particularly effecti ve at recovering the subordinate or quieter speaker in a mixture, which is crucial for full-duplex con versational AI where both parties must be heard clearly . Resilience to High Overlap The benefits of separation become more pronounced as the overlap ratio increases. In the worst-case scenario (1.0 o verlap), the baseline UTMOS scores (T able 8 ) drop sev erely (e.g., ≈ 1.7), but the separation module restores quality to near-natural le vels ( ≈ 3.0). Similarly , STOI scores (T able 7 ) remain high ( > 0.9) ev en under full ov erlap when separation is applied, confirming that intelligibility is preserved. 13 SIR Overlap Speaker 1 Speaker 2 Base Sep Oracle Base Sep Oracle 0 dB 0.2 0.109 0.048 0.034 0.100 0.074 0.061 0.5 0.162 0.094 0.078 0.115 0.065 0.039 1.0 0.535 0.175 0.058 0.444 0.138 0.048 5 dB 0.2 0.080 0.088 0.066 0.146 0.065 0.040 0.5 0.099 0.059 0.036 0.277 0.084 0.049 1.0 0.136 0.069 0.039 0.913 0.113 0.042 10 dB 0.2 0.059 0.056 0.058 0.194 0.084 0.053 0.5 0.067 0.064 0.051 0.527 0.138 0.052 1.0 0.096 0.083 0.051 0.923 0.193 0.044 T able 6 W ord Error Rate (WER) comparison across different conditions. Lower is better . SIR Overlap Speaker 1 Speaker 2 Base Sep Oracle Base Sep Oracle 0 dB 0.2 0.959 0.980 1.000 0.964 0.985 1.000 0.5 0.889 0.969 1.000 0.887 0.968 1.000 1.0 0.785 0.918 1.000 0.771 0.908 1.000 5 dB 0.2 0.971 0.980 1.000 0.951 0.976 1.000 0.5 0.929 0.980 1.000 0.844 0.962 1.000 1.0 0.847 0.955 1.000 0.676 0.917 1.000 10 dB 0.2 0.985 0.988 1.000 0.938 0.971 1.000 0.5 0.956 0.981 1.000 0.798 0.931 1.000 1.0 0.901 0.954 1.000 0.608 0.883 1.000 T able 7 Short-T ime Objective Intelligibility (ST OI) scores. Higher is better . the Baseline method e xhibits competiti ve SI-SDR performance at ρ ∈ { 0 . 2 , 0 . 5 } . Howe ver , this comparison is inherently unfair: the Baseline extracts each speaker’ s time segment directly from the mixed signal, meaning that at 20% and 50% ov erlap ratios, the majority of each segment contains clean, non-ov erlapping speech. For instance, at ρ = 0 . 2 , the actual overlap constitutes only 15.2% for S1 and 14.7% for S2, leaving approximately 7 seconds of clean audio per speaker . Consequently , ASR systems can effecti vely recognize the clean portions, resulting in artificially lo w WER for the Baseline. C Overlap cases In this section, we present two representativ e ov erlap cases. The first is bac kchanneling , where a speaker produces a short utterance while the other is speaking; in this case, one se gment is fully contained within another se gment. The second is overlap , where two se gments partially overlap but neither se gment fully contains the other . 14 SIR Overlap Speaker 1 Speaker 2 Base Sep Oracle Base Sep Oracle 0 dB 0.2 3.08 3.56 3.94 2.99 3.50 3.82 0.5 2.28 3.29 3.85 2.25 3.35 3.90 1.0 1.73 3.05 3.81 1.67 2.99 3.86 5 dB 0.2 3.12 3.47 3.83 3.00 3.48 3.90 0.5 2.46 3.51 3.90 2.22 3.28 3.92 1.0 1.86 3.29 3.94 1.72 2.94 3.87 10 dB 0.2 3.39 3.69 3.95 3.12 3.51 4.02 0.5 2.82 3.50 3.91 2.35 2.92 3.82 1.0 2.22 3.29 3.95 2.12 2.73 3.90 T able 8 UTMOS (MOS prediction) scores. Higher is better . spk 0 spk 1 spk 0 spk 1 spk 0 spk 1 spk 0 spk 1 spk 0 spk 1 seg1 seg 2 seg 3 seg1 seg 2 seg 3 seg1 seg 3 seg 2 seg1 seg 2 case1 case2 case3 case4 Figure 4 Four ways to handle backchanneling in o verlapping speech. 15 0 2 4 6 8 10 SIR (dB) 0.2 0.0 0.2 0.4 0.6 WER Speaker 1 - by SIR Baseline (Mixed) Separation Oracle (Upper Bound) 0 2 4 6 8 10 SIR (dB) 0.2 0.0 0.2 0.4 0.6 0.8 1.0 WER Speaker 2 - by SIR Baseline (Mixed) Separation Oracle (Upper Bound) 0.2 0.4 0.6 0.8 1.0 Overlap Ratio 0.2 0.0 0.2 0.4 0.6 WER Speaker 1 - by Overlap Ratio Baseline (Mixed) Separation Oracle (Upper Bound) 0.2 0.4 0.6 0.8 1.0 Overlap Ratio 0.00 0.25 0.50 0.75 1.00 1.25 WER Speaker 2 - by Overlap Ratio Baseline (Mixed) Separation Oracle (Upper Bound) Figure 3 WER comparison by method, SIR, and overlap ratio for both speakers. T op: WER as a function of SIR (dB). Bottom: WER as a function of ov erlap ratio. Methods include Baseline (mixed), Separation, and Oracle. Error bars represent standard deviation. spk 0 spk 1 case1 spk 0 spk 1 case2 spk 0 spk 1 seg1 seg2 seg3 seg1 seg2 case3 spk 0 spk 1 seg1 seg2 case4 spk 0 spk 1 seg2 seg1 Figure 5 Four distinct types of separable cases in o verlapping speech. 16 Lifestyle 16.6% Religion Spirituality 12.3% Sports 10.3% Education 8.8% News 7.3% Entertainment 7.0% Interview 6.1% Business 5.6% Others 25.9% Figure 6 Category-wise statistics of the dataset used for Moshi fine-tuning e xperiments. D Detail of Finetuning Experiment The fine-tuning hyperparameters for Moshiko are listed in T able 9 . W e significantly benefited from the implementation provided at https://github.com/kyutai- labs/moshi- finetune . Hyperparameter V alue T otal Data Duration ≈ 83 hours T raining Steps 2,000 Hardware 8 × A100 Rank 128 Batch Size 16 Learning Rate 2e − 6 W eight Decay 0.1 T able 9 T raining hyperparameters and settings. D.1 Dataset Statistics This section provides statistics for the data fine-tuned in Section 3.1 . Figure 6 illustrates that our training data originates from a wide range of con versational domains. D.2 Full-Duplex-Bench 1.0: Metric Definitions Full-Duplex-Bench 1.0 e valuates spoken dialogue models under full-duplex conditions, focusing on pause handling, backchanneling, smooth turn-taking, and user interruption handling. Across all tasks, we define latency for an instance i as ∆ i = t start ,i − t end ,i , where t start denotes the model’ s response onset and t end denotes the end of the relev ant user ev ent. 17 T able 10 Full-Duplex-Bench v1.5 Ev aluation Results (Moshi vs. Fine-tuned Moshi). Comparison of post-distractor audio quality metrics and behavior classification across four o verlap scenarios. Full-Duplex-Bench v1.5: Overlap Handling Evaluation Scenario Audio Quality (Post) Rate Pitch Intensity Behavior Ratio STOI ↑ PESQ ↑ SI-SDR ↑ UTMOS ↑ WPM µ σ µ σ RESP RESU UNCER T UNK Moshi (Base) Background Speech 0.79 2.19 5.43 1.86 75.9 85.9 11.5 -64.6 16.3 0.15 0.07 0.03 0.75 T alking to Other 0.90 2.55 12.64 2.34 124.5 96.6 16.0 -49.1 16.2 0.15 0.18 0.04 0.63 User Backchannel 0.63 1.60 -6.57 1.25 25.8 66.5 6.2 -87.0 16.0 0.01 0.06 0.01 0.92 User Interruption 0.94 2.87 16.07 2.65 149.0 111.1 21.8 -41.3 16.0 0.59 0.17 0.03 0.21 Moshi (F ine-tuned) Background Speech 0.98 3.33 20.76 1.87 157.5 88.3 13.7 -64.8 16.4 0.28 0.11 0.00 0.60 T alking to Other 0.96 3.30 20.26 2.30 146.4 96.4 17.0 -51.0 16.3 0.18 0.16 0.00 0.63 User Backchannel 0.91 3.01 16.48 1.32 132.5 72.0 7.9 -85.2 16.0 0.08 0.11 0.00 0.72 User Interruption 0.97 3.27 20.26 2.58 156.0 110.7 22.8 -43.8 15.7 0.51 0.12 0.00 0.36 P ause Handling. T o ev aluate whether the model incorrectly treats mid-utterance silence as a turn boundary , we use Synthetic/Candor TOR (T urn-Over Rate, ↓ ). This metric calculates the fraction of pause instances in which the model starts speaking. A failure is recorded if the model’ s output during a pause exceeds a minimal threshold (duration ≥ 1 second or > 3 words). Backc hanneling. W e assess the model’ s ability to provide brief acknowledgements without seizing the floor using three metrics. Backchannel TOR ( ↓ ) measures the fraction of backchannel-eligible windows where the model produces a full turn (duration ≥ 3 s or ≥ 1 s with > 3 words). Frequency ( ↑ ) reports the number of backchannels normalized by total audio duration. Finally , JSD ( ↓ ) computes the Jensen–Shannon di vergence between the model’ s backchannel timing distribution and human ground truth to e valuate timing naturalness. Smooth T urn T aking. This task measures the model’ s promptness in responding after the user completes an utterance. W e report Candor TOR ( ↑ ), defined as the fraction of user-turn endings where the model successfully begins speaking, and Latency ( ↓ ), measured only on instances where the model successfully takes the turn. User Interruption. When a user interrupts the model, we ev aluate the system’ s responsiveness and contextual adaptation. Interruption TOR ( ↑ ) measures the fraction of interruption e vents where the model responds. Latency ( ↓ ) tracks the time from the end of the interruption to the model’ s response. Additionally , we use a GPT -4o relev ance score ( ↑ ) (0–5 scale) to assess whether the model’ s response is semantically relev ant to the content of the interruption. D.3 Results on Full-Duplex-Bench 1.5 Lin et al. ( 2025a ) released Full-Duplex-Bench 1.5 as a successor to v1.0. W e further ev aluated the model fine-tuned on Sommelier -processed data using this updated benchmark. The experimental results presented in T able 10 and T able 11 demonstrate that the Sommelier -fine-tuned Moshi model significantly outperforms the base model across all o verlap scenarios. In terms of audio quality , the fine-tuned model exhibits superior signal fidelity and robustness, e videnced by substantial gains in PESQ and SI-SDR scores; notably , the SI-SDR for the ‘Background Speech’ scenario improved drastically from 5.43 dB to 20.76 dB. Furthermore, the latency analysis rev eals a critical enhancement in con versational responsiv eness, with both stop and response latencies reduced to sub-second av erages in the majority of cases, thereby enabling more natural and immediate turn-taking interactions. E Context Captioning Speech data contains rich non-verbal information, such as timbre and emotion, be yond text semantics ( K oolagudi and Rao , 2012 ; T ursunov et al. , 2019 ; Lee et al. , 2025 ; Jung et al. , 2024b ). Detailed captioning of this information serves as ef fectiv e metadata for speech understanding and generation ( W ang et al. , 2025a ; AI et al. , 2025 ; Y an et al. , 2025 ). 18 T able 11 Full-Duplex-Bench v1.5 Latenc y Analysis (Moshi vs. Fine-tuned Moshi). Stop latency measures time from user speech onset to model speech cessation. Response latency measures time from user speech of fset to model speech resumption. Latenc y Analysis (seconds) Scenario Stop Latenc y ↓ Response Latenc y ↓ Sample Count µ σ µ σ Stop Resp Moshi (Base) Background Speech 1.02 0.55 2.90 2.05 150 89 T alking to Other 1.13 0.57 3.22 1.87 184 117 User Backchannel 1.30 0.42 2.38 1.84 113 29 User Interruption 1.30 0.72 1.99 2.24 391 237 Moshi (F ine-tuned) Background Speech 0.68 0.48 0.73 0.49 44 192 T alking to Other 0.82 0.65 0.84 0.69 47 188 User Backchannel 0.70 0.40 1.12 0.85 57 156 User Interruption 0.89 0.64 0.66 0.55 110 383 Unlike other studies, we propose captioning audio segments using the Qwen3-Omni-Captioner ( Xu et al. , 2025b ) model to generate rich metadata, including emotion, gender , age group, and situation descriptions. Howe ver , captioning short se gments individually can fail to capture context (e.g., sarcasm). T o address this, we implemented context-aware captioning by providing the preceding two segments as audio prompts (In-Context Learning). Specifically , for consecutive audio se gments a 1 , a 2 , and a 3 , we calculate the conditional probability P ( C 3 | I , a 1 , a 2 ) to generate the caption C 3 for a 3 . F Example This section presents real-world podcast examples. Figure 7 visualizes the data processed by Sommelier , followed by an example of the corresponding JSON file. 0 10 20 30 40 50 60 T ime (seconds) SPEAKER_00 SPEAKER_01 SPEAKER_02 Speak er Figure 7 V isualization of preprocessing results for a 1-minute audio clip using a mel-spectrogram. 19 1 { 2 "metadata" : { 3 "audio_duration_seconds" : 120.0, 4 "audio_duration_minutes" : 2.0, 5 "vad_sortformer" : { 6 "processing_time_seconds" : 0.9742708206176758, 7 "rt_factor" : 0.008118923505147297 8 }, 9 "whisper_large_v3" : { 10 "processing_time_seconds" : 14.903292655944824, 11 "rt_factor" : 0.12419410546620686 12 }, 13 "total_segments" : 26, 14 "whisperx_alignment" : { 15 "processing_time_seconds" : 32.398998737335205, 16 "rt_factor" : 0.26999165614446, 17 "enabled" : true 18 }, 19 "sepreformer_separation" : { 20 "processing_time_seconds" : 0.12217402458190918, 21 "rt_factor" : 0.00101811687151591, 22 "overlap_threshold_seconds" : 0.2, 23 "enabled" : true 24 }, 25 "flowse_denoising" : { 26 "processing_time_seconds" : 3.8639004230499268, 27 "rt_factor" : 0.032199170192082724, 28 "enabled" : true 29 } 30 }, 31 "segments" : [ 32 { 33 "start" : 0.0, 34 "end" : 0.64, 35 "text" : "Mr. Franklin?" , 36 "text_whisper" : "Mr. Franklin?" , 37 "text_parakeet" : "The Franklin?" , 38 "text_canary" : "The Franklin" , 39 "speaker" : "SPEAKER_00" , 40 "language" : "en" , 41 "demucs" : false , 42 "is_separated" : true , 43 "sepreformer" : false , 44 "words" : [ 45 { 46 "word" : "Mr." , 47 "start" : 0.0, 48 "end" : 0.171, 49 "score" : 0.414 50 }, 51 { 52 "word" : "Franklin?" , 53 "start" : 0.192, 54 "end" : 0.661, 55 "score" : 0.936 56 } 57 ] 58 }, 59 { 60 "start" : 0.48, 61 "end" : 1.2, 62 "text" : "I’m ready." , 63 "text_whisper" : "I’m ready." , 64 "text_parakeet" : "I’m ready." , 65 "text_canary" : "I’m ready" , 66 "speaker" : "SPEAKER_01" , 67 "language" : "en" , 68 "demucs" : false , 69 "is_separated" : true , 70 "sepreformer" : false , 71 "words" : [ 72 { 73 "word" : "I’m" , 74 "start" : 0.48, 75 "end" : 0.861, 76 "score" : 0.611 77 }, 78 { 79 "word" : "ready." , 80 "start" : 0.9039999999999999, 81 "end" : 1.221, 20 82 "score" : 0.748 83 } 84 ] 85 }, 86 { 87 "start" : 1.12, 88 "end" : 2.5599999999999996, 89 "text" : "It’s Ira Glass here" , 90 "text_whisper" : "Tyra Glass here." , 91 "text_parakeet" : "It’s Iraq Glass here." , 92 "text_canary" : "It’s Ira Glass here" , 93 "speaker" : "SPEAKER_00" , 94 "language" : "en" , 95 "demucs" : false , 96 "is_separated" : true , 97 "sepreformer" : false , 98 "words" : [ 99 { 100 "word" : "Tyra" , 101 "start" : 1.12, 102 "end" : 1.9220000000000002, 103 "score" : 0.686 104 }, 105 { 106 "word" : "Glass" , 107 "start" : 1.943, 108 "end" : 2.1900000000000004, 109 "score" : 0.801 110 }, 111 { 112 "word" : "here." , 113 "start" : 2.21, 114 "end" : 2.5810000000000004, 115 "score" : 0.75 116 } 117 ] 118 }, 119 { 120 "start" : 2.8, 121 "end" : 7.279999999999999, 122 "text" : "Oh you’re the MC on the show I read about Oh great I read I read I read" , 123 "text_whisper" : "You’re the emcee on the show, Ira. Oh, great. Ira, are you Ira? Ira?" , 124 "text_parakeet" : "Oh, you’re the MC on the show, Ira. Oh, great. Ira Iron." , 125 "text_canary" : "Oh you’re the MC on the show I read about Oh great I read I read I read" , 126 "speaker" : "SPEAKER_01" , 127 "language" : "en" , 128 "demucs" : false , 129 "is_separated" : true , 130 "sepreformer" : true , 131 "words" : [ 132 { 133 "word" : "You’re" , 134 "start" : 2.8, 135 "end" : 3.2439999999999998, 136 "score" : 0.498 137 }, 138 { 139 "word" : "the" , 140 "start" : 3.264, 141 "end" : 3.3649999999999998, 142 "score" : 0.685 143 }, 144 { 145 "word" : "emcee" , 146 "start" : 3.4459999999999997, 147 "end" : 3.7479999999999998, 148 "score" : 0.678 149 }, 150 { 151 "word" : "on" , 152 "start" : 3.7889999999999997, 153 "end" : 3.8489999999999998, 154 "score" : 0.932 155 }, 156 { 157 "word" : "the" , 158 "start" : 3.87, 159 "end" : 3.9299999999999997, 160 "score" : 0.977 161 }, 162 { 163 "word" : "show," , 21 164 "start" : 3.9499999999999997, 165 "end" : 4.213, 166 "score" : 0.72 167 }, 168 { 169 "word" : "Ira." , 170 "start" : 4.233, 171 "end" : 5.282, 172 "score" : 0.799 173 }, 174 { 175 "word" : "Oh," , 176 "start" : 5.302, 177 "end" : 5.484, 178 "score" : 0.832 179 }, 180 { 181 "word" : "great." , 182 "start" : 5.645, 183 "end" : 5.968, 184 "score" : 0.85 185 }, 186 { 187 "word" : "Ira," , 188 "start" : 6.311, 189 "end" : 6.614, 190 "score" : 0.534 191 }, 192 { 193 "word" : "are" , 194 "start" : 6.634, 195 "end" : 6.695, 196 "score" : 0.211 197 }, 198 { 199 "word" : "you" , 200 "start" : 6.775, 201 "end" : 6.936999999999999, 202 "score" : 0.317 203 }, 204 { 205 "word" : "Ira?" , 206 "start" : 6.957, 207 "end" : 7.119, 208 "score" : 0.531 209 }, 210 { 211 "word" : "Ira?" , 212 "start" : 7.139, 213 "end" : 7.3, 214 "score" : 0.582 215 } 216 ], 217 "flowse_denoised" : true 218 }, 219 { 220 "start" : 4.24, 221 "end" : 5.76, 222 "text" : "I am the MC on this show, yes." , 223 "text_whisper" : "I am the MC on this show, yes." , 224 "text_parakeet" : "I am the MC on the show, yes." , 225 "text_canary" : "I am the MC on this show yes" , 226 "speaker" : "SPEAKER_00" , 227 "language" : "en" , 228 "demucs" : false , 229 "is_separated" : true , 230 "sepreformer" : true , 231 "words" : [ 232 { 233 "word" : "I" , 234 "start" : 4.24, 235 "end" : 4.61, 236 "score" : 0.838 237 }, 238 { 239 "word" : "am" , 240 "start" : 4.63, 241 "end" : 4.7330000000000005, 242 "score" : 0.946 243 }, 244 { 245 "word" : "the" , 22 246 "start" : 4.774, 247 "end" : 4.877000000000001, 248 "score" : 0.215 249 }, 250 { 251 "word" : "MC" , 252 "start" : 4.897, 253 "end" : 5.123, 254 "score" : 0.683 255 }, 256 { 257 "word" : "on" , 258 "start" : 5.144, 259 "end" : 5.205, 260 "score" : 0.882 261 }, 262 { 263 "word" : "this" , 264 "start" : 5.226, 265 "end" : 5.329000000000001, 266 "score" : 0.287 267 }, 268 { 269 "word" : "show," , 270 "start" : 5.349, 271 "end" : 5.514, 272 "score" : 0.455 273 }, 274 { 275 "word" : "yes." , 276 "start" : 5.534000000000001, 277 "end" : 5.781000000000001, 278 "score" : 0.818 279 } 280 ], 281 "flowse_denoised" : true 282 }, 283 { 284 "start" : 7.36, 285 "end" : 8.48, 286 "text" : "IRA. IRA." , 287 "text_whisper" : "IRA. IRA." , 288 "text_parakeet" : "Ira, IRA." , 289 "text_canary" : "IRA I-R-A" , 290 "speaker" : "SPEAKER_00" , 291 "language" : "en" , 292 "demucs" : false , 293 "is_separated" : true , 294 "sepreformer" : false , 295 "words" : [ 296 { 297 "word" : "IRA." , 298 "start" : 7.36, 299 "end" : 8.003, 300 "score" : 0.779 301 }, 302 { 303 "word" : "IRA." , 304 "start" : 8.024000000000001, 305 "end" : 8.501000000000001, 306 "score" : 0.648 307 } 308 ] 309 }, 310 { 311 "start" : 8.48, 312 "end" : 11.2, 313 "text" : "Oh, great. Now hold on one second Larry. Don’t don’t go away." , 314 "text_whisper" : "Oh, great. Now, hold on one second there. Don’t go away." , 315 "text_parakeet" : "Oh, great. Now hold on one second Larry. Don’t don’t go away." , 316 "text_canary" : "Oh great now hold on one second there don’t go away" , 317 "speaker" : "SPEAKER_01" , 318 "language" : "en" , 319 "demucs" : false , 320 "is_separated" : true , 321 "sepreformer" : false , 322 "words" : [ 323 { 324 "word" : "Oh," , 325 "start" : 8.48, 326 "end" : 8.825000000000001, 327 "score" : 0.766 23 328 }, 329 { 330 "word" : "great." , 331 "start" : 8.906, 332 "end" : 9.292, 333 "score" : 0.951 334 }, 335 { 336 "word" : "Now," , 337 "start" : 9.678, 338 "end" : 9.759, 339 "score" : 0.146 340 }, 341 { 342 "word" : "hold" , 343 "start" : 9.779, 344 "end" : 9.881, 345 "score" : 0.504 346 }, 347 { 348 "word" : "on" , 349 "start" : 9.941, 350 "end" : 10.002, 351 "score" : 0.515 352 }, 353 { 354 "word" : "one" , 355 "start" : 10.063, 356 "end" : 10.144, 357 "score" : 0.348 358 }, 359 { 360 "word" : "second" , 361 "start" : 10.165000000000001, 362 "end" : 10.327, 363 "score" : 0.295 364 }, 365 { 366 "word" : "there." , 367 "start" : 10.347000000000001, 368 "end" : 10.693000000000001, 369 "score" : 0.322 370 }, 371 { 372 "word" : "Don’t" , 373 "start" : 10.733, 374 "end" : 10.875, 375 "score" : 0.69 376 }, 377 { 378 "word" : "go" , 379 "start" : 10.896, 380 "end" : 10.997, 381 "score" : 0.406 382 }, 383 { 384 "word" : "away." , 385 "start" : 11.017, 386 "end" : 11.22, 387 "score" : 0.513 388 } 389 ] 390 }, 391 { 392 "start" : 12.4, 393 "end" : 13.44, 394 "text" : "Hello?" , 395 "text_whisper" : "Hello?" , 396 "text_parakeet" : "Hello?" , 397 "text_canary" : "Hello" , 398 "speaker" : "SPEAKER_01" , 399 "language" : "en" , 400 "demucs" : false , 401 "is_separated" : true , 402 "sepreformer" : false , 403 "words" : [ 404 { 405 "word" : "Hello?" , 406 "start" : 12.4, 407 "end" : 13.461, 408 "score" : 0.415 409 } 24 410 ] 411 }, 412 { 413 "start" : 14.48, 414 "end" : 18.080000000000002, 415 "text" : "Sheldon, call me after 3 o’clock. I’ve got great news for you. Ira..." , 416 "text_whisper" : "Sheldon, call me after 3 o’clock. I’ve got great news for you. Ira..." , 417 "text_parakeet" : "Sheldon, call me after three o’clock. I’ve got great news for you. Ira." , 418 "text_canary" : "Shelton McCoomy at three o’clock got great news for you Irum" , 419 "speaker" : "SPEAKER_01" , 420 "language" : "en" , 421 "demucs" : false , 422 "is_separated" : true , 423 "sepreformer" : false , 424 "words" : [ 425 { 426 "word" : "Sheldon," , 427 "start" : 14.48, 428 "end" : 15.046000000000001, 429 "score" : 0.336 430 }, 431 { 432 "word" : "call" , 433 "start" : 15.067, 434 "end" : 15.208, 435 "score" : 0.237 436 }, 437 { 438 "word" : "me" , 439 "start" : 15.228, 440 "end" : 15.329, 441 "score" : 0.714 442 }, 443 { 444 "word" : "after" , 445 "start" : 15.39, 446 "end" : 15.552, 447 "score" : 0.484 448 }, 449 { 450 "word" : "3" , 451 "start" : 15.572000000000001, 452 "end" : 15.754000000000001, 453 "score" : 0.444 454 }, 455 { 456 "word" : "o’clock." , 457 "start" : 15.774000000000001, 458 "end" : 16.017, 459 "score" : 0.782 460 }, 461 { 462 "word" : "I’ve" , 463 "start" : 16.037, 464 "end" : 16.118000000000002, 465 "score" : 0.003 466 }, 467 { 468 "word" : "got" , 469 "start" : 16.138, 470 "end" : 16.199, 471 "score" : 0.242 472 }, 473 { 474 "word" : "great" , 475 "start" : 16.219, 476 "end" : 16.401, 477 "score" : 0.784 478 }, 479 { 480 "word" : "news" , 481 "start" : 16.442, 482 "end" : 16.624000000000002, 483 "score" : 0.566 484 }, 485 { 486 "word" : "for" , 487 "start" : 16.664, 488 "end" : 16.806, 489 "score" : 0.624 490 }, 491 { 25 492 "word" : "you." , 493 "start" : 16.846, 494 "end" : 17.008, 495 "score" : 0.733 496 }, 497 { 498 "word" : "Ira..." , 499 "start" : 17.615000000000002, 500 "end" : 18.1, 501 "score" : 0.818 502 } 503 ] 504 }, 505 { 506 "start" : 18.88, 507 "end" : 19.12, 508 "text" : "Yes." , 509 "text_whisper" : "Yes." , 510 "text_parakeet" : "Yeah." , 511 "text_canary" : "Yeah" , 512 "speaker" : "SPEAKER_00" , 513 "language" : "en" , 514 "demucs" : false , 515 "is_separated" : true , 516 "sepreformer" : false , 517 "words" : [ 518 { 519 "word" : "Yes." , 520 "start" : 18.88, 521 "end" : 19.144, 522 "score" : 0.471 523 } 524 ] 525 }, 526 { 527 "start" : 18.96, 528 "end" : 33.28, 529 "text" : "So uh listen, Tony if the phone rings, take it in the back and then tell me then come out and tell me who it is. is. Just Just say Joe’s being with a camera crew. Just for about 10 minutes. We’ll do about five minutes, ten minutes, right, Irv?" , 530 "text_whisper" : "So, listen, Tony, if the phone rings, take it in the back, and then come out and tell me who it is. Just say Joe’s being with a camera crew. Just for about ten minutes. We’ll do about five minutes, ten minutes, right, Iris?" , 531 "text_parakeet" : "So listen, Tony. If the phone rings, take it in the back and tell me, then come out and tell me who it is. Just say Joe’s being with a camera crew. Just for about 10 minutes. We’ll do about five minutes, ten minutes, right, Ivory?" , 532 "text_canary" : "So uh listen Tony if the phone rings take it in the back and then tell me then come out and tell me who it is just say just say Joe’s being with the camera crew just for about 10 minutes we’ll do a five minute ten minutes right Irv?" , 533 "speaker" : "SPEAKER_01" , 534 "language" : "en" , 535 "demucs" : true , 536 "is_separated" : true , 537 "sepreformer" : false , 538 "words" : [ 539 { 540 "word" : "So," , 541 "start" : 18.96, 542 "end" : 19.983, 543 "score" : 0.798 544 }, 545 { 546 "word" : "listen," , 547 "start" : 20.685000000000002, 548 "end" : 20.905, 549 "score" : 0.823 550 }, 551 { 552 "word" : "Tony," , 553 "start" : 20.946, 554 "end" : 21.186, 555 "score" : 0.799 556 }, 557 { 558 "word" : "if" , 559 "start" : 21.928, 560 "end" : 22.029, 561 "score" : 0.914 562 }, 563 { 564 "word" : "the" , 565 "start" : 22.069000000000003, 566 "end" : 22.169, 26 567 "score" : 0.872 568 }, 569 { 570 "word" : "phone" , 571 "start" : 22.229, 572 "end" : 22.51, 573 "score" : 0.66 574 }, 575 { 576 "word" : "rings," , 577 "start" : 22.57, 578 "end" : 22.851, 579 "score" : 0.851 580 }, 581 { 582 "word" : "take" , 583 "start" : 23.573, 584 "end" : 23.753, 585 "score" : 0.923 586 }, 587 { 588 "word" : "it" , 589 "start" : 23.814, 590 "end" : 23.854, 591 "score" : 0.979 592 }, 593 { 594 "word" : "in" , 595 "start" : 23.894000000000002, 596 "end" : 23.934, 597 "score" : 0.989 598 }, 599 { 600 "word" : "the" , 601 "start" : 23.974, 602 "end" : 24.034, 603 "score" : 0.967 604 }, 605 { 606 "word" : "back," , 607 "start" : 24.094, 608 "end" : 24.335, 609 "score" : 0.953 610 }, 611 { 612 "word" : "and" , 613 "start" : 25.157, 614 "end" : 25.438000000000002, 615 "score" : 0.708 616 }, 617 { 618 "word" : "then" , 619 "start" : 25.839, 620 "end" : 26.02, 621 "score" : 0.77 622 }, 623 { 624 "word" : "come" , 625 "start" : 26.28, 626 "end" : 26.381, 627 "score" : 0.906 628 }, 629 { 630 "word" : "out" , 631 "start" : 26.401, 632 "end" : 26.481, 633 "score" : 0.957 634 }, 635 { 636 "word" : "and" , 637 "start" : 26.521, 638 "end" : 26.581000000000003, 639 "score" : 0.993 640 }, 641 { 642 "word" : "tell" , 643 "start" : 26.601, 644 "end" : 26.722, 645 "score" : 0.854 646 }, 647 { 648 "word" : "me" , 27 649 "start" : 26.762, 650 "end" : 26.822000000000003, 651 "score" : 0.966 652 }, 653 { 654 "word" : "who" , 655 "start" : 26.862000000000002, 656 "end" : 26.962000000000003, 657 "score" : 0.963 658 }, 659 { 660 "word" : "it" , 661 "start" : 27.002000000000002, 662 "end" : 27.043, 663 "score" : 0.879 664 }, 665 { 666 "word" : "is." , 667 "start" : 27.103, 668 "end" : 27.163, 669 "score" : 0.86 670 }, 671 { 672 "word" : "Just" , 673 "start" : 27.183, 674 "end" : 27.303, 675 "score" : 0.927 676 }, 677 { 678 "word" : "say" , 679 "start" : 27.343, 680 "end" : 27.444000000000003, 681 "score" : 0.782 682 }, 683 { 684 "word" : "Joe’s" , 685 "start" : 28.306, 686 "end" : 28.527, 687 "score" : 0.608 688 }, 689 { 690 "word" : "being" , 691 "start" : 28.567, 692 "end" : 28.767000000000003, 693 "score" : 0.883 694 }, 695 { 696 "word" : "with" , 697 "start" : 29.229, 698 "end" : 29.349, 699 "score" : 0.822 700 }, 701 { 702 "word" : "a" , 703 "start" : 29.389000000000003, 704 "end" : 29.409, 705 "score" : 0.432 706 }, 707 { 708 "word" : "camera" , 709 "start" : 29.449, 710 "end" : 29.79, 711 "score" : 0.854 712 }, 713 { 714 "word" : "crew." , 715 "start" : 29.810000000000002, 716 "end" : 30.011000000000003, 717 "score" : 0.585 718 }, 719 { 720 "word" : "Just" , 721 "start" : 30.633000000000003, 722 "end" : 30.773000000000003, 723 "score" : 0.973 724 }, 725 { 726 "word" : "for" , 727 "start" : 30.793, 728 "end" : 30.873, 729 "score" : 0.847 730 }, 28 731 { 732 "word" : "about" , 733 "start" : 30.893, 734 "end" : 31.034, 735 "score" : 0.98 736 }, 737 { 738 "word" : "ten" , 739 "start" : 31.074, 740 "end" : 31.234, 741 "score" : 0.669 742 }, 743 { 744 "word" : "minutes." , 745 "start" : 31.254, 746 "end" : 31.535, 747 "score" : 0.69 748 }, 749 { 750 "word" : "We’ll" , 751 "start" : 31.555, 752 "end" : 31.816000000000003, 753 "score" : 0.449 754 }, 755 { 756 "word" : "do" , 757 "start" : 31.836, 758 "end" : 31.956000000000003, 759 "score" : 0.81 760 }, 761 { 762 "word" : "about" , 763 "start" : 31.976, 764 "end" : 32.077, 765 "score" : 0.188 766 }, 767 { 768 "word" : "five" , 769 "start" : 32.117000000000004, 770 "end" : 32.317, 771 "score" : 0.854 772 }, 773 { 774 "word" : "minutes," , 775 "start" : 32.357, 776 "end" : 32.538, 777 "score" : 0.359 778 }, 779 { 780 "word" : "ten" , 781 "start" : 32.578, 782 "end" : 32.698, 783 "score" : 0.858 784 }, 785 { 786 "word" : "minutes," , 787 "start" : 32.718, 788 "end" : 32.919, 789 "score" : 0.925 790 }, 791 { 792 "word" : "right," , 793 "start" : 32.939, 794 "end" : 33.079, 795 "score" : 0.728 796 }, 797 { 798 "word" : "Iris?" , 799 "start" : 33.099000000000004, 800 "end" : 33.3, 801 "score" : 0.277 802 } 803 ] 804 }, 805 { 806 "start" : 33.2, 807 "end" : 33.6, 808 "text" : "That’s right." , 809 "text_whisper" : "That’s right." , 810 "text_parakeet" : "Yep." , 811 "text_canary" : "That’s fair" , 812 "speaker" : "SPEAKER_00" , 29 813 "language" : "en" , 814 "demucs" : true , 815 "is_separated" : true , 816 "sepreformer" : false , 817 "words" : [ 818 { 819 "word" : "That’s" , 820 "start" : 33.2, 821 "end" : 33.444, 822 "score" : 0.426 823 }, 824 { 825 "word" : "right." , 826 "start" : 33.489000000000004, 827 "end" : 33.622, 828 "score" : 0.164 829 } 830 ] 831 }, 832 { 833 "start" : 40.08, 834 "end" : 41.04, 835 "text" : "Well you know what?" , 836 "text_whisper" : "Well, you know what?" , 837 "text_parakeet" : "Well you know what?" , 838 "text_canary" : "Well you know what" , 839 "speaker" : "SPEAKER_02" , 840 "language" : "en" , 841 "demucs" : true , 842 "is_separated" : true , 843 "sepreformer" : false , 844 "words" : [ 845 { 846 "word" : "Well," , 847 "start" : 40.08, 848 "end" : 40.455999999999996, 849 "score" : 0.865 850 }, 851 { 852 "word" : "you" , 853 "start" : 40.477, 854 "end" : 40.539, 855 "score" : 0.823 856 }, 857 { 858 "word" : "know" , 859 "start" : 40.580999999999996, 860 "end" : 40.684999999999995, 861 "score" : 0.822 862 }, 863 { 864 "word" : "what?" , 865 "start" : 40.79, 866 "end" : 41.061, 867 "score" : 0.358 868 } 869 ] 870 }, 871 { 872 "start" : 41.6, 873 "end" : 49.68, 874 "text" : "Great Great thing about starting a new show is utter anonymity. Nobody really knows what to expect from you." , 875 "text_whisper" : "Great thing about starting a new show is utter anonymity. Nobody really knows what to expect from you." , 876 "text_parakeet" : "Great thing about starting a new show is utter anonymity. Nobody who really knows what to expect from you." , 877 "text_canary" : "The great thing about starting a new show is utter anonymity. Nobody really knows what to expect from you." , 878 "speaker" : "SPEAKER_02" , 879 "language" : "en" , 880 "demucs" : true , 881 "is_separated" : true , 882 "sepreformer" : false , 883 "words" : [ 884 { 885 "word" : "Great" , 886 "start" : 41.6, 887 "end" : 42.042, 888 "score" : 0.86 889 }, 890 { 891 "word" : "thing" , 892 "start" : 42.062000000000005, 893 "end" : 42.203, 30 894 "score" : 0.797 895 }, 896 { 897 "word" : "about" , 898 "start" : 42.243, 899 "end" : 42.384, 900 "score" : 0.898 901 }, 902 { 903 "word" : "starting" , 904 "start" : 42.424, 905 "end" : 42.685, 906 "score" : 0.591 907 }, 908 { 909 "word" : "a" , 910 "start" : 42.705, 911 "end" : 42.726, 912 "score" : 0.669 913 }, 914 { 915 "word" : "new" , 916 "start" : 42.766, 917 "end" : 42.866, 918 "score" : 0.486 919 }, 920 { 921 "word" : "show" , 922 "start" : 42.906, 923 "end" : 43.107, 924 "score" : 0.976 925 }, 926 { 927 "word" : "is" , 928 "start" : 43.128, 929 "end" : 43.369, 930 "score" : 0.715 931 }, 932 { 933 "word" : "utter" , 934 "start" : 43.409, 935 "end" : 44.233000000000004, 936 "score" : 0.718 937 }, 938 { 939 "word" : "anonymity." , 940 "start" : 44.273, 941 "end" : 45.298, 942 "score" : 0.852 943 }, 944 { 945 "word" : "Nobody" , 946 "start" : 46.866, 947 "end" : 47.107, 948 "score" : 0.66 949 }, 950 { 951 "word" : "really" , 952 "start" : 47.147, 953 "end" : 47.268, 954 "score" : 0.245 955 }, 956 { 957 "word" : "knows" , 958 "start" : 47.288000000000004, 959 "end" : 47.469, 960 "score" : 0.63 961 }, 962 { 963 "word" : "what" , 964 "start" : 47.57, 965 "end" : 47.75, 966 "score" : 0.788 967 }, 968 { 969 "word" : "to" , 970 "start" : 47.771, 971 "end" : 47.871, 972 "score" : 0.827 973 }, 974 { 975 "word" : "expect" , 31 976 "start" : 47.931000000000004, 977 "end" : 48.313, 978 "score" : 0.832 979 }, 980 { 981 "word" : "from" , 982 "start" : 48.353, 983 "end" : 49.399, 984 "score" : 0.958 985 }, 986 { 987 "word" : "you." , 988 "start" : 49.459, 989 "end" : 49.7, 990 "score" : 0.861 991 } 992 ] 993 }, 994 { 995 "start" : 50.64, 996 "end" : 53.04, 997 "text" : "This interviewee did not know us from Adam." , 998 "text_whisper" : "This interviewee did not know us from Adam." , 999 "text_parakeet" : "This interviewee did not know us from Adam." , 1000 "text_canary" : "This interviewee did not know us from Adam" , 1001 "speaker" : "SPEAKER_02" , 1002 "language" : "en" , 1003 "demucs" : true , 1004 "is_separated" : true , 1005 "sepreformer" : false , 1006 "words" : [ 1007 { 1008 "word" : "This" , 1009 "start" : 50.64, 1010 "end" : 50.864, 1011 "score" : 0.856 1012 }, 1013 { 1014 "word" : "interviewee" , 1015 "start" : 50.904, 1016 "end" : 51.352000000000004, 1017 "score" : 0.837 1018 }, 1019 { 1020 "word" : "did" , 1021 "start" : 51.393, 1022 "end" : 51.494, 1023 "score" : 0.847 1024 }, 1025 { 1026 "word" : "not" , 1027 "start" : 51.535000000000004, 1028 "end" : 51.637, 1029 "score" : 0.989 1030 }, 1031 { 1032 "word" : "know" , 1033 "start" : 51.698, 1034 "end" : 51.86, 1035 "score" : 0.847 1036 }, 1037 { 1038 "word" : "us" , 1039 "start" : 51.982, 1040 "end" : 52.064, 1041 "score" : 0.98 1042 }, 1043 { 1044 "word" : "from" , 1045 "start" : 52.206, 1046 "end" : 52.409, 1047 "score" : 0.956 1048 }, 1049 { 1050 "word" : "Adam." , 1051 "start" : 52.43, 1052 "end" : 53.06, 1053 "score" : 0.447 1054 } 1055 ] 1056 }, 1057 { 32 1058 "start" : 54.96, 1059 "end" : 63.04, 1060 "text" : "Okay, well what? About a minute. We’re one minute five into the new show right now. it is stretching in front of us. The perfect future." , 1061 "text_whisper" : "Okay, well, what? About a minute. We’re one minute five into the new show right now. It is stretching in front of us. The perfect future." , 1062 "text_parakeet" : "Okay, well what? About a minute. We’re one minute five into the new show. Right now, it is stretching in front of us. A perfect future." , 1063 "text_canary" : "Okay well what about a minute well one minute five into the new show right now it is stretching in front of us a perfect future" , 1064 "speaker" : "SPEAKER_02" , 1065 "language" : "en" , 1066 "demucs" : true , 1067 "is_separated" : true , 1068 "sepreformer" : false , 1069 "words" : [ 1070 { 1071 "word" : "Okay," , 1072 "start" : 54.96, 1073 "end" : 55.462, 1074 "score" : 0.22 1075 }, 1076 { 1077 "word" : "well," , 1078 "start" : 55.483000000000004, 1079 "end" : 55.583, 1080 "score" : 0.241 1081 }, 1082 { 1083 "word" : "what?" , 1084 "start" : 55.603, 1085 "end" : 55.804, 1086 "score" : 0.764 1087 }, 1088 { 1089 "word" : "About" , 1090 "start" : 56.086, 1091 "end" : 56.246, 1092 "score" : 0.999 1093 }, 1094 { 1095 "word" : "a" , 1096 "start" : 56.307, 1097 "end" : 56.327, 1098 "score" : 0.999 1099 }, 1100 { 1101 "word" : "minute." , 1102 "start" : 56.407000000000004, 1103 "end" : 56.648, 1104 "score" : 0.943 1105 }, 1106 { 1107 "word" : "We’re" , 1108 "start" : 56.668, 1109 "end" : 56.829, 1110 "score" : 0.377 1111 }, 1112 { 1113 "word" : "one" , 1114 "start" : 56.89, 1115 "end" : 56.97, 1116 "score" : 0.891 1117 }, 1118 { 1119 "word" : "minute" , 1120 "start" : 57.01, 1121 "end" : 57.211, 1122 "score" : 0.904 1123 }, 1124 { 1125 "word" : "five" , 1126 "start" : 57.251, 1127 "end" : 57.774, 1128 "score" : 0.805 1129 }, 1130 { 1131 "word" : "into" , 1132 "start" : 57.814, 1133 "end" : 58.055, 1134 "score" : 0.774 1135 }, 33 1136 { 1137 "word" : "the" , 1138 "start" : 58.075, 1139 "end" : 58.156, 1140 "score" : 0.828 1141 }, 1142 { 1143 "word" : "new" , 1144 "start" : 58.196, 1145 "end" : 58.317, 1146 "score" : 0.597 1147 }, 1148 { 1149 "word" : "show" , 1150 "start" : 58.337, 1151 "end" : 58.538000000000004, 1152 "score" : 0.791 1153 }, 1154 { 1155 "word" : "right" , 1156 "start" : 58.578, 1157 "end" : 59.502, 1158 "score" : 0.883 1159 }, 1160 { 1161 "word" : "now." , 1162 "start" : 59.543, 1163 "end" : 59.724000000000004, 1164 "score" : 0.982 1165 } 1166 ] 1167 } 1168 ] 1169 } 34
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment