풀듀플렉스 음성 모델을 위한 대규모 멀티턴 오디오 전처리 파이프라인 Sommelier
** Sommelier는 겹치는 발화와 백채널 등 자연 대화의 복잡성을 보존하면서, 웹 규모의 멀티스피커 오디오를 전처리하는 오픈소스 파이프라인이다. 표준화·VAD·다중 화자 다이어리제이션·오버랩 분리·배경음악 제거·앙상블 ASR 등 7개의 모듈을 조합해 고품질 전처리 데이터를 생성하고, 이를 이용해 Moshi 기반 풀듀플렉스 SLM을 미세조정함으로써 백채널·중단 처리 능력이 크게 향상되었다. **
저자: Kyudan Jung, Jihwan Kim, Soyoon Kim
**
본 연구는 최근 텍스트 기반 대형 언어 모델(LLM)에서 음성 언어 모델(SLM)로 전환되는 흐름 속에서, 실시간 양방향 대화를 지원하는 풀듀플렉스 시스템 구축에 필요한 고품질 멀티스피커 대화 데이터를 효율적으로 확보하기 위한 전처리 파이프라인 ‘Sommelier’를 제안한다. 기존 대규모 음성 데이터는 대부분 단일 화자이거나 겹침을 충분히 포함하지 않아, 풀듀플렉스 SLM의 오버랩 강인성을 학습시키기에 부족했다. Sommelier는 다음과 같은 7개의 핵심 모듈로 구성된다.
1. **오디오 표준화** – pydub와 librosa를 이용해 모든 입력을 16 kHz, 16‑bit, Mono로 변환하고 -20 dBFS 라우드니스 정규화한다. 이는 이후 모델들의 입력 요구사항을 일관되게 맞추어 처리 효율을 높인다.
2. **VAD 및 청크 분할** – 최신 VAD 모델을 적용해 무음 구간을 탐지하고, 메모리 제한을 고려해 5 분 이하의 청크로 나눈다. 이는 장시간 녹음에서도 OOM 오류를 방지한다.
3. **화자 다이어리제이션** – 기존 pyannote‑3.1 대신 NVIDIA Sortformer를 채택했으며, 짧은 백채널(≤0.5 s)과 빠른 턴‑테이킹 상황에서 DER·JER이 크게 감소한다는 실험 결과를 제시한다.
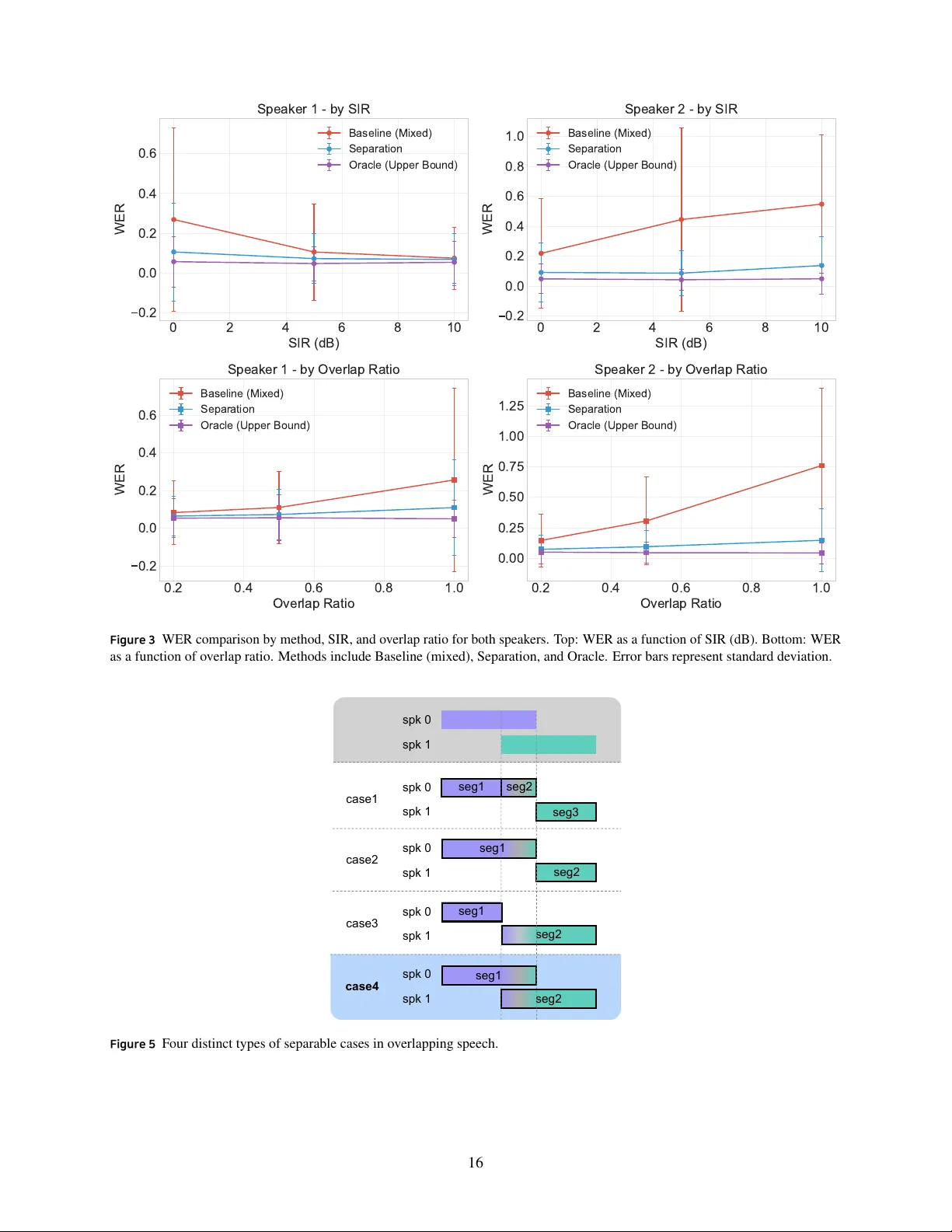
4. **오버랩 처리** – 겹침 상황을 4가지 케이스로 구분하고, 정보 손실이 최소인 Case 4를 기본으로 선택한다. 겹친 구간에 대해 두 화자 분리 모델을 적용하고, 사전에 추출한 비오버랩 구간의 스피커 임베딩과 코사인 유사도를 비교해 화자를 매핑한다. 이때 겹친 부분만을 입력함으로써 연산량을 크게 절감한다.
5. **배경음악 제거** – PANNS를 이용해 BGM 존재 확률을 추정하고, 0.3 이상일 경우 Demucs 모델을 적용한다. 전체 2 분 청크를 입력해 분리 성능을 최적화했으며, 고지연 SAM‑Audio는 배제하였다.
6. **앙상블 ASR** – Whisper, Whisper‑large‑v3, MoE 기반 모델 등 세 가지 SOT‑A 모델을 ROVER 방식으로 앙상블한다. 단어 수준 다수결을 통해 텍스트를 결정하고, 다수결에 못 미치는 경우 기본 Whisper 결과를 사용한다. 또한 15‑gram 반복 필터로 환각을 억제하고, Whisper를 이용해 정밀 타임스탬프를 추출한다.
7. **데이터 선택 및 포맷** – 풀듀플렉스 학습에 적합하도록 각 턴을 10 초 이하로 제한하고, 최소 3턴 이상 연속되는 구간만을 추출한다. 스테레오 채널에서는 왼쪽 채널에 화자 1, 오른쪽 채널에 화자 2를 배치한다.
실험에서는 Sommelier‑처리 데이터(≈83 시간)를 사용해 Moshi 기반 풀듀플렉스 SLM을 LoRA 방식으로 미세조정하였다. Full‑Duplex‑Bench 1.0 평가에서 백채널 응답, 부드러운 턴‑테이킹, 사용자 중단 처리 지표가 모두 크게 향상되었으며, 특히 지연(Latency)이 증가한 것은 모델이 실제로 사용자 입력을 인식하고 적절히 반응함을 의미한다. 다이어리제이션 평가에서는 Sortformer가 전역 DER 7.16%에서 짧은 구간(≤0.5 s) DER 0.006%까지 낮추어 기존 pyannote‑3.1 대비 우수함을 입증했다. 오버랩 분리 품질에서는 SIR, STOI, UTMOS 등에서 원본 대비 0.02~0.05 정도의 개선을 보였으며, 앙상블 ASR은 WER을 2.04%까지 낮추어 단일 Whisper 모델 대비 30% 이상 개선하였다. 파이프라인 전체의 처리 속도는 A100 GPU 기준으로 실시간에 근접하도록 최적화되었으며, 모든 모듈이 오픈소스로 공개돼 연구자와 기업이 손쉽게 확장·재현할 수 있다.
결론적으로 Sommelier는 풀듀플렉스 SLM 개발에 필요한 대규모 고품질 멀티턴 대화 데이터를 자동으로 구축할 수 있는 최초의 확장 가능한 오픈소스 솔루션이며, 실제 모델 성능 향상을 통해 향후 인간‑컴퓨터 상호작용의 자연스러움을 크게 높일 것으로 기대된다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기