SkillRouter: Skill Routing for LLM Agents at Scale
Reusable skills let LLM agents package task-specific procedures, tool affordances, and execution guidance into modular building blocks. As skill ecosystems grow to tens of thousands of entries, exposing every skill at inference time becomes infeasibl…
Authors: YanZhao Zheng, ZhenTao Zhang, Chao Ma
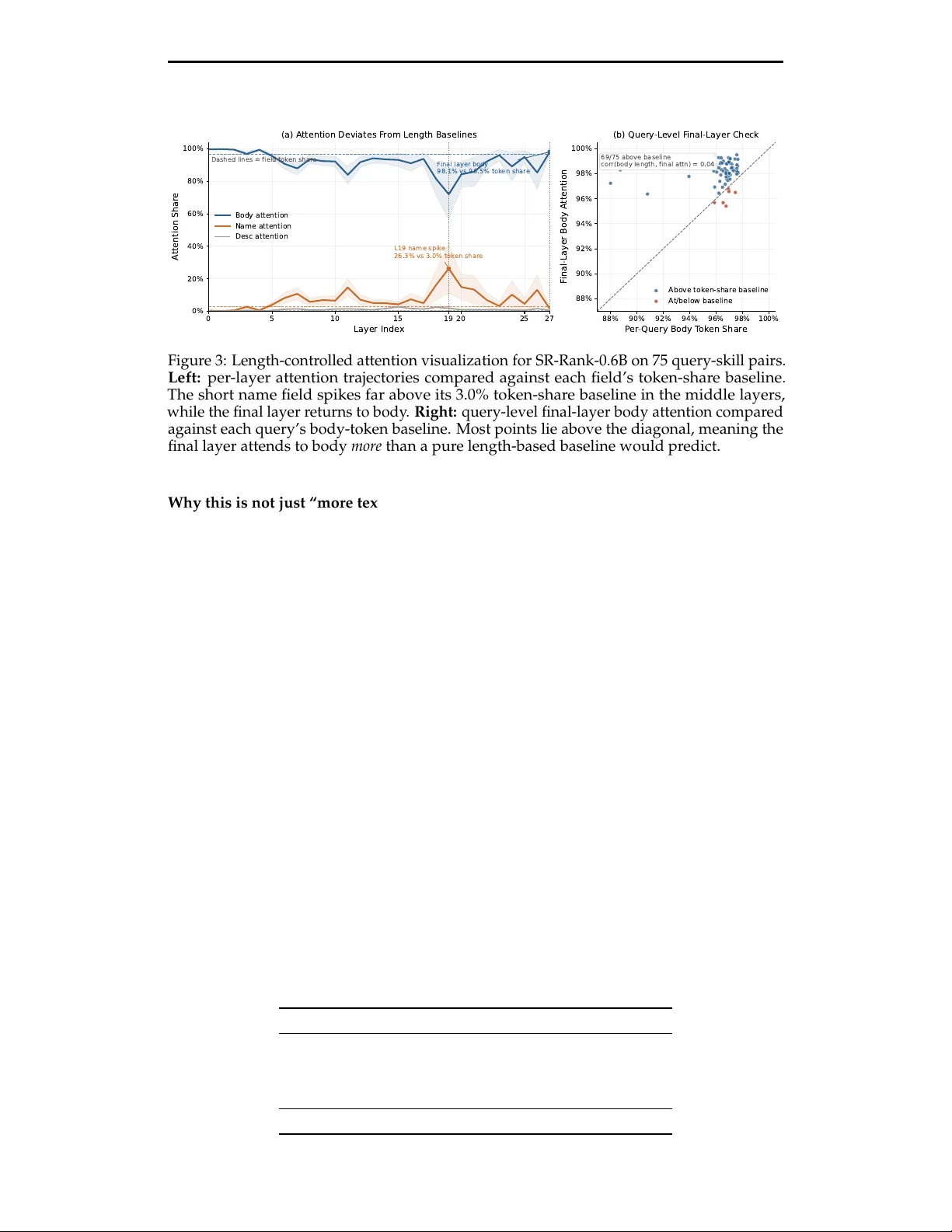
Preprint. Under review . SkillRouter: Skill Routing for LLM Agents at Scale Y anZhao Zheng ZhenT ao Zhang Chao Ma Y uanQiang Y u JiHuai Zhu W u Y ong T ianze Xu Baohua Dong ∗ Hangcheng Zhu Ruohui Huang Gang Y u Alibaba Group, Hangzhou, China zhengyanzhao.zyz, zhangzhentao.zzt, mc524716, yuyuanqiang.yyq, zhujihuai.zjh, wy517954, xutianze.xtz, baohua.dbh, linran.lr09, wentong, ruohai @alibaba-inc.com Abstract Reusable skills let LLM agents package task-specific procedur es, tool af- fordances, and execution guidance into modular building blocks. As skill ecosystems grow to tens of thousands of entries, exposing every skill at in- ference time becomes infeasible. This cr eates a skill-routing problem: given a user task, the system must identify relevant skills before downstream planning or execution. Existing agent stacks often rely on pr ogressive dis- closure, exposing only skill names and descriptions while hiding the full implementation body . W e examine this design choice on a SkillsBench- derived benchmark with approximately 80K candidate skills, targeting the practically important setting of large skill registries with heavy over- lap. Across repr esentative sparse, dense, and reranking baselines on this setting, hiding the skill body causes a 31–44 percentage point drop in routing accuracy , showing that full skill text is a critical routing signal in this setting rather than a minor metadata refinement. Motivated by this finding, we present S K I L L R O U T E R 1 , a compact 1.2B full-text r etrieve-and- rerank pipeline. S K I L L R O U T E R achieves 74.0% Hit@1 on our benchmark— the strongest average top-1 routing performance among the baselines we evaluate—while using 13 × fewer parameters and running 5.8 × faster than the strongest base pipeline. In a complementary end-to-end study across four coding agents, r outing gains transfer to impr oved task success, with larger gains for mor e capable agents. 1 Introduction Skills have emerged as a practical abstraction for extending LLM agents with reusable procedur es, tool knowledge, and execution guidance. Recent coding-agent products such as Claude Code, Codex, and OpenClaw expose reusable skills as a first-class capability ( Anthropic , 2025 ; OpenAI , 2025 ; OpenClaw , 2026 ). These systems r eflect the gr owing use of skill registries in r eal deployments. Presenting every skill to the agent is infeasible, so real systems need skill r outing : retrieving the right skill fr om a large pool given a user task. This setting has an important asymmetry: the routing component can inspect the full skill text, while the agent that eventually consumes the skill usually sees only its name and description. In deployed agent stacks, this upstream routing decision is a high-leverage bottleneck: once the wrong skill shortlist is surfaced, downstr eam planning and execution have little chance to recover . The question is therefore not only whether an agent can use a provided skill, but whether the system can find the right skill under severe pool-scale confusion. ∗ Corresponding author . 1 https://github.com/zhengyanzhao1997/SkillRouter 1 Preprint. Under review . Current agent frameworks implicitly treat metadata as sufficient for selection, yet this assumption has not been tested at realistic scale. Existing benchmarks such as SkillsBench ( Li et al. , 2026 ), T oolBench ( Qin et al. , 2023 ), and MetaT ool ( Huang et al. , 2024 ) study downstream tool use or tool-choice behavior , but they do not dir ectly evaluate lar ge-pool upstream skill routing under hidden implementations. On the retrieval side, prior work has studied reranking and context-aware r etrieval ( Zheng et al. , 2024 ; Y uan et al. , 2024 ), but typically on name-and-description metadata and in much smaller candidate pools. This leaves a gap between current benchmark practice and realistic agent deployment, wher e skill registries can be both large and highly overlapping. Our goal is not to claim that every skill-routing benchmark exhibits the same failur e mode, but to study the practically important setting of lar ge skill registries with heavy overlap, wher e many candidates can appear relevant for the same query . W e study skill r outing on a benchmark with ∼ 80K skills and 75 expert-verified SkillsBench- derived queries that instantiate this setting. Our central empirical finding is that, on this setting, full skill text is a critical routing signal: removing the body causes 31–44pp drops acr oss repr esentative sparse, dense, and reranking baselines, while length-controlled attention diagnostics and description-quality stratification argue against simple length-only or description-quality explanations. Motivated by this observation, we build S K I L L R O U T E R , a compact 1.2B full-text retrieve-and-rerank pipeline. The primary 1.2B configuration (0.6B encoder + 0.6B reranker) r eaches 74.0% Hit@1 and 70.4% R@10, compar ed with 68.0% Hit@1 for the strongest 16B base pipeline—achieving comparable or higher accuracy at 13 × fewer parameters and 5.8 × lower serving latency . An 8B scaled version reaches 76.0%. W e also validate transfer beyond retrieval metrics: in a complementary end-to-end study using the natural pool across four coding agents, S K I L L R O U T E R improves average task success over the strongest base router in both top-1 and top-10 settings, with the benefit being more pronounced for mor e capable agents. These downstream results should be r ead as end- to-end utility measur ements rather than dir ect pr oxies for exhaustive gold-skill r ecovery , since the agent consumes a bounded shortlist rather than the abstract annotated set. On a real-pool GPU benchmark the 1.2B pipeline serves queries at sub-second median latency . Because the benchmark contains many multi-skill queries, we use Hit@1 as the headline top-1 routing metric and r eport coverage metrics alongside it to characterize routing quality more completely . Our contributions are thr eefold: 1. On a new ∼ 80K-skill benchmark with expert-verified queries, Easy/Har d robustness tiers, and explicit single- versus multi-skill evaluation, we show that full skill text is a critical routing signal: removing the body causes 31–44pp dr ops acr oss r epresentative baselines, and length-controlled diagnostics and description-quality stratification ar gue against simple length-only or description-quality explanations. 2. W e pr esent S K I L L R O U T E R , a compact full-text retrieve-and-r erank pipeline built fr om standard IR components, and identify two training adaptations that are specifically necessary in homogeneous skill pools: false-negative filtering to handle near-duplicate skills, and listwise reranking loss to r esolve fine-grained candidate competition. 3. W e show that the routing gains transfer to a complementary end-to-end study using the natural pool across four coding agents, and we characterize the compact pipeline’s efficiency–accuracy tradeof f on a r eal-pool GPU serving benchmark. 2 Problem Definition and Benchmark T ask and metrics. W e study skill routing : given a task query q and a large skill pool S = { s 1 , . . . , s N } , retrieve the skill set G q ⊆ S needed to solve the task. Each skill contains a name , description , and full implementation body . This creates a hidden-body asymmetry : the routing system can inspect full skill text, while the downstream agent typically sees only metadata. W e report Hit@1 as the primary top-1 r outing metric, together with MRR@10, nDCG@10, Recall@ K ( K ∈ { 10, 20, 50 } ; average fraction of gr ound-truth skills r ecover ed), and FC@10 (fraction of queries whose full ground-truth skill set appears in the top 10). For multi-skill queries, Hit@1 is defined mechanically as whether any requir ed skill is ranked 2 Preprint. Under review . T able 1: Illustrative benchmark example. Hard distractors remain topically plausible but fail the requir ed function. T ype Name Description Ground tr uth speech-to-text T ranscribe audio/video locally with Whisper and return timestamped text. Pool distractor audio-transcriber General-purpose cloud transcription service for uploaded audio files. Hard distractor video-subtitle-sync Synchronize subtitle timing to video playback using audio cues. first. W e therefor e report Recall@ K and FC@10 to characterize shortlist and full-set coverage more dir ectly . Benchmark construction. W e build the benchmark from SkillsBench ( Li et al. , 2026 ), which provides expert-curated task–skill mappings. Starting from 87 SkillsBench tasks, we exclude 12 generic-only cases whose labels contain only file-type skills (e.g., pdf or xlsx ) and retain 75 core queries : 24 single-skill and 51 multi-skill . W e evaluate against an ∼ 80K-skill pool assembled from SkillsBench skills plus a large open-sour ce skill collection spanning 51 categories, drawn from Claude Skill Registry Core ( Majiayu000 , 2026 ). T o pr obe robustness, we r eport two tiers: Easy with 78,361 candidate skills, and Hard with 79,141 candidates after adding 780 LLM-generated distractor skills that are topically r elated but functionally distinct. All main r esults average Easy and Hard; Appendix A reports the exact cor e-query selection protocol and a metadata audit of the 80K pool, while Appendix B details distractor generation and repr esentative data examples. Why this benchmark is credible. SkillsBench is valuable here because its task–skill map- pings are expert curated rather than weakly inferr ed. Our core split keeps the 59 “clean” and 16 “mixed” tasks that contain at least one non-generic core skill, and excludes only the 12 generic-only tasks described above. The Easy/Hard split then isolates two dif ferent failure modes: standard large-pool retrieval in Easy , and confusion among plausible but functionally incorrect alternatives in Hard. T able 1 illustrates this design: the Hard distractor remains close enough to look r elevant under surface matching, but still fails the requir ed speech-to-text function. The Har d distractors ar e not random noise: they ar e generated to be same-domain, same-technology , or over-generalized alternatives that r emain superficially plausible for the query while failing the required function. W e therefore use Hard as a targeted str ess test for function-level confusion rather than as an estimate of exact distractor prevalence in natural r epositories. T ogether , expert curation, explicit core-query selection, large-pool evaluation, and functionally close distractors let us test both average routing quality and robustness to realistic confusion without changing the underlying ground-tr uth tasks. What this benchmark represents. SkillsBench-derived queries do not cover every skill- routing setting, but they do target the practically important setting of large skill registries with heavy overlap. The 75 core queries span 55 application domains across eight super- categories (scientific computing, engineering, security , media, data analytics, software de- velopment, document processing, and domain applications), with no single super-category exceeding 17% of queries; Appendix A gives the full diversity profile. This setting is com- mon in community skill ecosystems and internal tool catalogs, where many options can appear plausible for the same query while dif fering in supported formats, constraints, execution assumptions, or edge-case handling. Our benchmark is designed to capture this setting directly . 3 Preprint. Under review . 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 A vg Hit@1 (cor e; Easy + Har d) BM25 (Sparse) Qwen3-Emb-8B Qwen3-Emb-8B x Qwen3-R ank-8B +31.3pp +38.7pp +44.0pp (a) Body R emoval on the Main Benchmark Name+Desc only F ull skill te xt Body Name Desc 0% 20% 40% 60% 80% 100% Shar e 96.5% 3.0% 0.5% 72.0% 26.3% 1.8% 98.1% 1.5% 0.4% Short name field spik es 3.0% tok ens -> 26.3% (b) L ength-Contr olled A ttention Summary T ok en shar e Layer 19 Layer 27 Figure 1: Full skill text is a critical routing signal. Left: A veraged over the paper ’s Easy and Hard tiers, removing body r educes Hit@1 by 31.4pp for BM25, 38.7pp for Qwen3-Emb- 8B, and 44.0pp for Qwen3-Emb-8B × Qwen3-Rank-8B. Right: Length-controlled attention diagnostics argue against a simple length-only explanation: although the body field occupies 96.5% of skill tokens, the short name field peaks at 26.3% attention in layer 19 despite covering only 3.0% of tokens, while the final layer returns to 98.1% body attention. 3 What Signals Drive Skill Selection? Current agent frameworks typically expose only a skill’s name and description, implicitly assuming that metadata is suf ficient for selection. W e test this assumption on the paper ’s main benchmark setting, reporting the Easy/Hard average used elsewhere in the main text. Figure 1 (left) uses three r epresentative baselines aligned with the main tables: BM25, the strongest encoder -only base model (Qwen3-Emb-8B), and the strongest base retrieve- and-rerank pipeline (Qwen3-Emb-8B × Qwen3-Rank-8B). Appendix T able 9 reports the full encoder-only nd/full br eakdown for BM25, Qwen3-Emb-0.6B, and Qwen3-Emb-8B on the same 75 core queries. W e also analyze cross-encoder attention, controlling for field length, to test whether the reranker is simply following field length in the final decision. Body removal collapses performance across method families. Figure 1 (left) r eports 31.4– 44.0pp Hit@1 drops for the three r epresentative baselines. On the paper ’s main Easy/Hard average, BM25 falls fr om 31.4% to 0.0%, Qwen3-Emb-8B dr ops from 64.0% to 25.3%, and Qwen3-Emb-8B × Qwen3-Rank-8B drops from 68.0% to 24.0%. Appendix T able 9 shows the same encoder-only pattern for Qwen3-Emb-0.6B, which dr ops fr om 56.0% to 18.7% on the same benchmark. This collapse is therefor e not tied to a single model choice: acr oss sparse r etrieval, encoder -only retrieval, and r eranking, r emoving the body removes a critical routing signal and sharply degrades top-rank performance. Length-controlled attention supports the same story . Raw attention mass is length- confounded because, in the 75 analyzed query-skill pairs, the body , name, and description fields account for 96.5%, 3.0%, and 0.5% of skill tokens, r espectively . W e therefor e do not interpret the 91.7% aggregate body attention in isolation. Instead, the informative signal is the layer -wise redistribution of attention acr oss fields. If the reranker were r esponding mainly to field length, attention would stay close to the token-share baseline throughout the network. It does not: the name field covers only 3.0% of skill tokens yet rises to 26.3% attention at layer 19, befor e the final layer returns to 98.1% body attention. Final-layer body attention exceeds the body’s token share on 69/75 queries and is effectively uncor- related with absolute body length ( r = 0.04). These diagnostics argue against a simple longer-text explanation, although they do not eliminate all possible length-mediated ef- fects. Appendix C reports the full layer-wise and query-level diagnostics underlying this body → name → body trajectory . As a further contr ol, Appendix D stratifies the nd → full gap by GT description length and finds that the gap remains lar ge ( ≥ 27pp) even for the quartile of skills with the longest descriptions, arguing against a description-quality confound. 4 Preprint. Under review . Figure 2: S K I L L R O U T E R pipeline. A bi-encoder r etrieves top-20 candidates from the full ∼ 80K pool; a cr oss-encoder reranks them. Both stages use full skill text, motivated by the body-access finding in Section 3 . Implication. T aken together , these r esults indicate that full skill text is a critical routing signal for reliable r outing in this setting, in both retrieval and r eranking. This observation directly motivates the design of S K I L L R O U T E R in the next section. 4 SkillRouter: A Compact Full-T ext Pipeline Our pipeline uses standard retrieve-and-rerank components—bi-encoder retrieval with InfoNCE, cross-encoder r eranking with listwise cr oss-entr opy—and we make no claim to architectural novelty . The contribution is instead the empirical finding that motivates this design (Section 3 ), and the identification of two training adaptations that ar e specifically necessary in homogeneous skill pools: false-negative filtering to handle near -duplicate skills that corrupt contrastive learning, and listwise reranking to r esolve fine-grained distinctions among topically similar candidates. Neither component is new in isolation; what we show is that, in this setting, these choices are essential (Section 5.3 ) and that the r esulting compact pipeline is effective on the ef ficiency–accuracy fr ontier . Motivated by Section 3 , S K I L L R O U T E R is a full-text two-stage pipeline: a bi-encoder first retrieves a short candidate list fr om the ∼ 80K pool, and a cross-encoder then r eranks those candidates using the complete skill body . Our primary configuration uses a 0.6B encoder and a 0.6B reranker , for 1.2B parameters total. Figure 2 summarizes the training setup and the two-stage inference path. Bi-encoder retrieval. W e fine-tune Qwen3-Emb-0.6B ( Zhang et al. , 2025 ) on 37,979 syn- thetic (query , skill) pairs. Skills are sampled from the ∼ 80K community pool with stratified sampling to ensure category diversity . For each sampled skill, we generate a synthetic user query using an LLM (GPT -4o-mini) prompted with the skill’s metadata and body content (Appendix E , T able 15 ). The prompt instructs the model to pr oduce a r ealistic task descrip- tion without revealing the skill name, so that generated queries reflect functional need rather than lexical identity . The training and evaluation skill pools are fully disjoint, ensuring the encoder learns transferable routing patterns rather than memorizing benchmark skills. W e optimize the retriever with in-batch InfoNCE over the full skill text. At inference time, the encoder embeds the full skill inventory offline and retrieves only the top-20 candidates, giving the second stage a narrow but still diverse decision set. 5 Preprint. Under review . Hard negative mining. In practice, a single user r equest may match dozens of superfi- cially relevant skills—e.g., multiple “git” or “docker ” management tools—while only one provides the specific capability needed. Random negatives cannot teach the encoder to make these fine-grained distinctions. Each query is paired with 10 negatives from four complementary sources: semantic neighbors (4 per query) r etrieved by the base encoder ’s embeddings, lexical matches (3) via BM25 scoring, taxonomy distractors (2) from the same skill category , and random negatives (1) from a different category . This mixture forces the en- coder to distinguish semantically close alternatives, lexical confounders, and same-category distractors simultaneously—precisely where full skill body access becomes operationally essential. Appendix E provides the full mining procedur e. False negative filtering. Because the hard negatives above ar e mined fr om a pool where the same capability is often independently implemented by differ ent authors under different names, the mined candidate set inevitably includes skills that ar e functionally equivalent to the gr ound truth. T reating these as negatives corrupts the contrastive signal. W e apply a three-layer filter: name deduplication, body-text overlap (trigram Jaccard > 0.6), and embedding similarity ( > 0.92), removing approximately 10% of mined negatives. Section 5.3 shows that this filtering contributes +4.0pp Hit@1. Cross-encoder reranking. The retriever supplies the top-20 candidates to a fine-tuned Qwen3-Rank-0.6B ( Zhang et al. , 2025 ), which scores each query–skill pair using the full flattened skill text. T raining uses 32,283 candidate lists retrieved by SR-Emb-0.6B, each containing 20 skills with binary relevance labels; the same false-negative filtering pipeline as the encoder stage is applied. W e adopt listwise cross-entr opy rather than pointwise binary classification, since reranking in homogeneous skill pools requires relative comparison among close alternatives. Section 5.3 shows that listwise training is essential, outperforming the pointwise variant by 30.7pp Hit@1. Why listwise reranking matters. Once the r etriever has narr owed the pool to 20 candi- dates, the r emaining skills are often all topically plausible. The reranker ’s job is ther efore not to decide whether a candidate is relevant in isolation, but to choose the best candidate among many near neighbors. This makes listwise supervision a natural fit: the model is trained to compar e candidates against one another rather than assign loosely calibrated independent scores. Implementation details. The retriever and reranker are both trained on a single GPU. At inference time, all skills are pre-embedded offline; a live query requir es one encoder forward pass, approximate near est-neighbor sear ch, and r eranking of only 20 candidates. Appendix G shows why we use top-20 candidates: it preserves most available recall head- room while avoiding the extra noise intr oduced by larger windows. Appendix H reports the serving benchmark for this online path on the real pool. Prompt templates, loss definitions, and training hyperparameters ar e in Appendix F . This division of labor is important for practicality: the encoder handles large-pool recall, while the reranker spends its full-text capacity where fine-grained distinctions among similar candidates matter most. 5 Experiments 5.1 Setup All results use the benchmark in Section 2 : 75 core queries over an ∼ 80K skill pool, evaluated on both Easy and Har d tiers and averaged unless otherwise noted. Our primary metric is Hit@1, with MRR@10 as a secondary ranking metric. For multi-skill queries, we additionally report Recall@ K and FC@10 as coverage metrics: R@10 serves as the main shortlist-coverage metric, while FC@10 provides a stricter full-coverage view . All models in the main results use full skill text; the nd-versus-full comparisons are summarized in Section 3 . Unless otherwise stated, rerankers operate on the encoder ’s top-20 candidate list. 6 Preprint. Under review . T able 2: Encoder-only r etrieval results on the 80K skill-r outing benchmark. The tuned 0.6B encoder (highlighted) outperforms the 13 × larger base encoder , showing that task-specific training compensates for scale in this setting. A vg = Easy/Hard average. R@20 reflects candidate coverage for downstream r eranking. Model T ype Params Easy Hit@1 Hard Hit@1 A vg Hit@1 A vg MRR@10 A vg R@20 BM25 Sparse retrieval – .347 .280 .314 .365 .365 BGE-Large-v1.5 T raditional encoder 335M .613 .587 .600 .653 .668 gemini-embedding-001 Proprietary encoder – .613 .560 .587 .650 .687 text-embedding-3-large Proprietary encoder – .640 .600 .620 .658 .664 Qwen3-Emb-0.6B Base encoder 0.6B .587 .533 .560 .638 .637 Qwen3-Emb-8B Base encoder 8B .653 .627 .640 .698 .726 SR-Emb-0.6B Our compact encoder 0.6B .667 .640 .654 .723 .754 SR-Emb-8B Scaled encoder 8B .693 .667 .680 .731 .777 Input formats. Each skill contains three fields: name , description , and body . W e use full to denote the concatenation of all three fields, and nd for name+description only . Throughout the paper , “full” denotes this concatenation after model-specific truncation at each model’s input limit rather than the unbounded raw document. All tuned models are trained and evaluated with full inputs. W e additionally evaluate nd configurations for r epr esentative baselines to isolate the effect of body access. Encoder baselines. W e compare four encoder families: • Sparse retrieval: BM25 ( Robertson & Zaragoza , 2009 ) over the full skill text. • T raditional open bi-encoders: E5-Large-v2 ( W ang et al. , 2022 ), GTE-Large-v1.5 ( Li et al. , 2023 ), and BGE-Large-v1.5 ( Xiao et al. , 2024 ). • Decoder-based encoders: Qwen3-Emb-0.6B, Qwen3-Emb-8B ( Zhang et al. , 2025 ), and NV -Embed-v2 ( Lee et al. , 2024 ). • Proprietary APIs: OpenAI text-embedding-3-large ( OpenAI , 2024b ) and Gemini gemini-embedding-001 ( Google , 2025 ). Reranker baselines and our systems. For reranking we evaluate Qwen3 base r erankers ( Zhang et al. , 2025 ) and listwise LLM-as-judge baselines, all operating on the encoder ’s top-20 candidate list. Our own systems include SR-Emb-0.6B / SR-Rank-0.6B as the primary compact pipeline, plus 8B scaling variants to test recipe transfer . The benchmark stresses both stages thr ough scale, overlap, and lexical mismatch: encoders must r etrieve through category overlap and many plausible alternatives, while rerankers must sort highly similar candidates within the top-20 window . What the main tables do and do not claim. The main-text result tables restore the encoder - only and end-to-end views separately , while still keeping only repr esentative systems rather than every encoder × reranker combination. The full grids remain in Appendix I . For multi- skill queries, Hit@1 retains this any-hit-at-rank-1 definition, so we pair it with coverage metrics in the calibration analysis below and limit claims accordingly . 5.2 Main Results Fine-tuning is more valuable than scale alone. T able 2 shows that, among encoder-only systems, SR-Emb-0.6B reaches 65.4% average Hit@1, improving by +9.4pp over the same- size Qwen3-Emb-0.6B base model and still edging past Qwen3-Emb-8B at 64.0% despite a 13 × parameter gap. This indicates that, in this setting, skill-r outing data and task-specific negatives can compensate for a 13 × parameter gap. The retriever also gives the reranker useful headroom. SR-Emb-0.6B reaches 75.4% average R@20, exceeding Qwen3-Emb-8B at 72.6%. This matters because reranking can only help when the correct skill enters the candidate window at all. The encoder improvements are ther efore not just better top-1 ranking, but also better candidate coverage for the second stage. 7 Preprint. Under review . T able 3: End-to-end retrieve-and-r erank results (top-20 candidates). The compact 1.2B tuned pipeline (highlighted) reaches the highest Hit@1 among non-scaling configurations, exceeding the 16B base pipeline at 13 × fewer parameters. A vg = Easy/Hard average. Encoder Reranker Params Easy Hit@1 Hard Hit@1 A vg Hit@1 A vg MRR@10 A vg R@10 Qwen3-Emb-0.6B Qwen3-Rank-0.6B 1.2B .653 .627 .640 .684 .604 Qwen3-Emb-8B Qwen3-Rank-0.6B 8.6B .613 .547 .580 .672 .694 Qwen3-Emb-8B Qwen3-Rank-8B 16B .680 .680 .680 .745 .692 SR-Emb-0.6B Qwen3-Rank-0.6B 1.2B .720 .693 .707 .769 .724 SR-Emb-0.6B Qwen3-Rank-8B 8.6B .720 .707 .714 .776 .727 SR-Emb-0.6B SR-Rank-0.6B 1.2B .760 .720 .740 .791 .704 SR-Emb-8B SR-Rank-8B 16B .787 .733 .760 .808 .719 The compact pipeline matches or exceeds the strongest base system at 13 × fewer pa- rameters. T able 3 shows that our primary 1.2B pipeline, SR-Emb-0.6B × SR-Rank-0.6B, reaches 74.0% average Hit@1, compared with 68.0% for the 16B strongest base pipeline (Qwen3-Emb-8B × Qwen3-Rank-8B). It also improves by +10.0pp over the same-size 1.2B base configuration and by +8.6pp over encoder-only retrieval with the same tuned encoder . The gain remains positive on both Easy (+8.0pp) and Har d (+4.0pp). Combined with the serving results in Section 5.5 —5.8 × lower latency and 15.8% less GPU memory—the com- pact pipeline occupies a favorable position on the ef ficiency–accuracy frontier . Appendix J shows the same dir ectional pattern on matched query sets—acr oss 150 query-tier evalua- tions, the primary pipeline impr oves over the str ongest base pipeline in 18 cases and trails it in 9. Base rerankers help, but tuned reranking helps more. The strongest base pipeline already improves on encoder -only r etrieval, confirming that r eranking is useful when the corr ect skill is present in the candidate window . However , the tuned 1.2B pipeline reaches 74.0% compared with 71.4% for a configuration that pairs SR-Emb-0.6B with the larger Qwen3- Rank-8B base r eranker , and 68.0% for the full 16B base pipeline. The pattern is consistent with task-specific adaptation in both stages contributing to the overall gain. Appendix K gives the query-level pipeline decomposition that illustrates where the reranker helps most. LLM judges are not competitive in this setting. Appendix I includes OpenAI GPT -4o- mini and GPT -5.4-mini ( OpenAI , 2024a ; 2026 ) as listwise judges over the same candidate lists. Under the same SR-Emb-0.6B candidate lists and with full body text available, the strongest judge (GPT -4o-mini) reaches 67.3% average Hit@1, compar ed with 70.7% for the compact cross-encoder baseline (SR-Emb-0.6B × Qwen3-Rank-0.6B) and 74.0% for the full S K I L L R O U T E R pipeline. The judge rows also pr ovide only a top-1 choice rather than a scored full reranking. This reinforces the value of a compact specialized reranker when routing must be both accurate and operationally efficient. The recipe also scales to 8B. Applying the same training recipe to both stages yields 76.0% Hit@1 with SR-Emb-8B × SR-Rank-8B. The scaled result is stronger overall, but the 1.2B system remains the most practical compact configuration and alr eady captur es most of the gain. 5.3 Metric Calibration and Key Ablations Hit@1 gains should be read as top-1 routing gains. The primary pipeline improves Hit@1 on both single-skill and multi-skill queries, and the same directional gain holds on Easy and Hard in Appendix I . T able 4 complements this result by showing how top-1 routing, shortlist coverage, and strict full coverage relate to one another on multi-skill queries. The strongest base pipeline r emains better on strict multi-skill FC@10 (.382 vs. .353), so our main claim is strongest top-1 routing rather than uniformly better exhaustive set recovery . W e therefor e use Hit@1 as the headline metric, with R@10 and FC@10 reported as complementary coverage context. 8 Preprint. Under review . T able 4: Single- vs. multi-skill calibration for two base pipelines and our primary 1.2B pipeline. Hit@1 reflects top-1 routing, R@10 reflects shortlist coverage, and FC@10 r eflects strict full coverage for multi-skill queries. Pipeline Single Multi Hit@1 R@10 FC@10 Hit@1 R@10 FC@10 Qwen3-Emb-0.6B × Qwen3-Rank-0.6B .625 .708 .708 .647 .556 .324 Qwen3-Emb-8B × Qwen3-Rank-8B .667 .812 .812 .686 .636 .382 SR-Emb-0.6B × SR-Rank-0.6B .729 .875 .875 .745 .624 .353 T able 5: Key ablations. False-negative filtering contributes +4.0pp encoder Hit@1; listwise reranking is essential, outperforming the pointwise variant by +30.7pp. T op: encoder variants. Bottom: reranker variants using SR-Emb-0.6B as the r etriever . Component V ariant Hit@1 MRR@10 R@10 Encoder training SR-Emb-0.6B Clean negatives .653 .723 .688 SR-Emb-0.6B Raw negatives .613 .692 .672 Reranker training SR-Emb-0.6B Encoder-only (no r eranking) .653 .723 .688 SR-Emb-0.6B × Qwen3-Rank-0.6B Base reranker .707 .769 .724 SR-Emb-0.6B × SR-Rank-0.6B (PW) Pointwise BCE fine-tuning .433 .578 .573 SR-Emb-0.6B × SR-Rank-0.6B (L W) Listwise CE fine-tuning .740 .791 .704 T wo training choices are essential. T able 5 shows that two training choices ar e essential. False-negative filtering contributes +4.0pp Hit@1, +3.1pp MRR@10, and +1.6pp R@10 to the encoder , showing that near-duplicate skills otherwise corrupt both top-rank quality and shortlist usefulness. For reranking, listwise training is decisive on top-rank quality: the pointwise variant collapses to 43.3% Hit@1, 57.8% MRR@10, and 57.3% R@10, while the listwise model reaches 74.0% Hit@1, 79.1% MRR@10, and 70.4% R@10. FC@10 and additional coverage analyses are reported separately in T able 4 and T able 22 . This pattern is consistent with our setting, wher e the reranker must choose among many semantically close candidates rather than score each candidate independently . What the calibration changes in the claim. The main takeaway is that S K I L L R O U T E R de- livers the strongest top-1 routing performance in our evaluation, while the calibration table provides additional coverage context for multi-skill queries rather than a dir ect downstream- use proxy . This is why we keep Hit@1 as the headline routing metric and report R@10 and FC@10 alongside it in the calibration analysis; the next subsection then shows how these routing gains transfer to dir ect execution. 5.4 Downstream End-to-End Agent Evaluation Routing gains transfer to direct agent execution. T able 6 reports a complementary end- to-end study using the natural pool , not a replay of the Easy/Har d benchmark tiers. W e evaluate four coding agents on the 75-task core set using the same execution harness, but retrieved skills ar e supplied fr om the natural pool, i.e., the non-synthetic benchmark pool without Hard-tier distractors: Kimi-K2.5 ( Kimi T eam , 2026 ), glm-5 ( Z.AI , 2026 ), Claude Sonnet 4.6, and Claude Opus 4.6 ( Anthr opic , 2026 ). All four agents run inside the Claude Code harness, and for retrieved-skill conditions the harness injects each r etrieved skill’s name and description into the agent context. Conditioned on the exposed skill package, the downstream task setup and success criteria otherwise follow SkillsBench ( Li et al. , 2026 ). Across both top-1 and top-10 r etrieved-skill settings, S K I L L R O U T E R improves average task success over the str ongest base router . W ith the four-agent average, average success rises 9 Preprint. Under review . T able 6: Direct end-to-end agent evaluation on the 75-task core set using skills retrieved from the natural pool (the non-synthetic benchmark pool without Har d-tier distractors). Each task is evaluated three times per condition; results average over all trials and four coding agents under the same execution harness with a 1200 s timeout. Gold skills are oracle upper bounds for context. Skill Condition Router / Source T op- K Single Success Multi Success Overall Success No skills None – 12.50% 16.01% 14.89% Gold skills Oracle ground-truth GT 30.90% 33.50% 32.67% Retrieved skills Qwen3-Emb-8B × Qwen3-Rank-8B 1 26.74% 25.33% 25.78% Retrieved skills SkillRouter (SR-Emb-0.6B × SR-Rank-0.6B) 1 29.86% 26.47% 27.56% Retrieved skills Qwen3-Emb-8B × Qwen3-Rank-8B 10 20.49% 27.78% 25.45% Retrieved skills SkillRouter (SR-Emb-0.6B × SR-Rank-0.6B) 10 26.04% 28.60% 27.78% from 25.78% to 27.56% (+1.78pp) in the top-1 setting and fr om 25.45% to 27.78% (+2.33pp) in the top-10 setting. Recovery relative to oracle skills. Relative to the no-skill baseline (14.89%), S K I L L R O U T E R recovers about 71% of the no-skill → gold-skill uplift in the top-1 setting and 73% in top- 10, compar ed with 61% and 59% for the base r outer . Both top-1 and top-10 yield similar overall success ( ∼ 27.56–27.78%), suggesting that beyond a certain retrieval quality thr eshold, expanding the shortlist provides diminishing r eturns as additional candidates incr ease the agent’s downstream selection bur den. Routing gains are larger for more capable agents. The four-agent average masks a sys- tematic interaction with model strength. Claude Sonnet 4.6 and Opus 4.6, whose gold-skill success rates average 39.34%, show consistently positive S K I L L R O U T E R deltas across both top-1 and top-10 (average + 3.22pp). By contrast, glm-5 and Kimi-K2.5, whose gold-skill rates average 26.00%, show mixed directional effects (average + 0.89pp). This pattern is consistent with a ceiling on r outing utility: weaker agents may lack the ability to exploit correctly r outed skills, so improved routing yields diminished r eturns. Appendix M r eports the full per-agent br eakdowns, and Appendix M.1 gives representative cases illustrating routing mechanisms and limitations. 5.5 Serving Efficiency The compact pipeline remains operationally lightweight on the real pool. Appendix H reports the full GPU serving benchmark on the real pool. On that benchmark, SR-Emb- 0.6B runs at 19.8 ms median latency and 50.5 queries/s, while the full 1.2B S K I L L R O U T E R pipeline runs at 495.8 ms median latency and 1.83 queries/s. Relative to the strongest 16B base pipeline (Qwen3-Emb-8B × Qwen3-Rank-8B), which requir es 2.90 s median latency and 0.323 queries/s, the compact pipeline is 5.8 × faster at median latency , 11.3 × lower in benchmark compute footprint (GPU-sec / 1K queries), and uses 15.8% less peak GPU memory—while achieving higher Hit@1 (74.0% vs. 68.0%) with 13 × fewer parameters. Ap- pendix L also provides repr esentative success and failure cases that illustrate the remaining routing limits. 6 Related W ork LLM agents increasingly depend on large tool and skill collections. Prior work has studied tool invocation and retrieval in settings ranging from small fixed tool sets to large API repositories ( Schick et al. , 2023 ; Shen et al. , 2023 ; Qin et al. , 2023 ; Patil et al. , 2023 ; Du et al. , 2024 ; Y uan et al. , 2024 ; Zheng et al. , 2024 ). However , these systems typically retrieve fr om much smaller pools, emphasize tool usage rather than upstream routing, or operate mainly on metadata. Our setting is harder in exactly the setting that modern skill ecosystems cr eate: large skill r egistries with heavy overlap, wher e many candidates can appear r elevant for the same query . 10 Preprint. Under review . Our system design follows the standard retrieve-and-rerank paradigm from neural IR ( Karpukhin et al. , 2020 ; Izacard et al. , 2022 ; Xiong et al. , 2021 ; W ang et al. , 2022 ; Li et al. , 2023 ; Xiao et al. , 2024 ; Nogueira & Cho , 2019 ; Sun et al. , 2023 ), but our setting differs in two ways: skills are structur ed multi-field objects with severe inter -skill homogeneity , and our evaluation explicitly studies how routing quality changes when models have access to the full body rather than only the name and description. Our benchmark is built on SkillsBench ( Li et al. , 2026 ), but shifts the focus from downstr eam tool use to lar ge-scale skill r etrieval. Methodologically , our contribution is therefor e not a new r eranking ar chitecture, but an end-to-end full-text routing recipe and benchmark setup tailored to homogeneous skill pools where false negatives and listwise competition dominate. 7 Conclusion W e study skill routing at realistic registry scale and show empirically that full skill text provides a critical r outing signal in large skill r egistries with heavy overlap. On our ∼ 80K- skill benchmark, r emoving body text causes 31–44pp drops across repr esentative sparse, dense, and reranking baselines on the paper ’s main benchmark setting, while a compact 1.2B full-text retrieve-and-r erank pipeline reaches 74.0% Hit@1 and 70.4% R@10—matching or exceeding the strongest 16B base pipeline at 5.8 × lower latency; an 8B scaled variant reaches 76.0% Hit@1. The accompanying ablations further show that false-negative filtering and listwise reranking loss are essential in homogeneous skill pools. Beyond retrieval metrics, the r outing gains also transfer to direct task execution acr oss four coding agents, although the downstream top-10 results suggest that exhaustive gold-set recovery and end-to-end package utility are related but non-identical objectives under bounded agent attention. The compact 1.2B pipeline serves queries at 495.8 ms median latency on the real-pool GPU benchmark. More broadly , the paper ar gues that upstream r outing deserves to be treated as a first-class systems problem for LLM agents: once r egistries become large and overlapping, routing systems can benefit substantially from using richer skill information for downstream execution. The body-access finding likely generalizes beyond skill routing to other structur ed-retrieval settings wher e agent-consumed objects carry rich implementation detail—such as API r outing, plugin selection, and tool-use or chestration. In this view , skill routing is an instance of structur ed document retrieval with downstr eam agent consumption, and the gap between metadata-only and full-text r outing may widen further as registries continue to gr ow . Limitations. The benchmark contains 75 queries derived from a single sour ce benchmark, so broader cr oss-benchmark validation r emains necessary . Our claim should therefor e be interpreted as applying to lar ge skill registries with heavy overlap, rather than to every possible skill-routing setting. In smaller tool catalogs, or in settings wher e candidates are alr eady easy to separate from concise metadata, metadata-only r outing may be more competitive than it is her e. Because most queries are multi-skill, we report additional coverage metrics alongside Hit@1 to characterize routing quality more fully . Our direct downstream evaluation remains limited to four coding agents, skills retrieved from the natural pool rather than the synthetic Hard tier , and a single execution budget. In particular , FC@10 and end-to-end top-10 success should not be read as interchangeable quantities: the former measures exhaustive r ecovery of the annotated gold set, whereas the latter measur es the usefulness of the bounded exposed package under fixed agent budgets. A natural next step is to study how r outing quality interacts with agent capability more systematically , including whether the diminishing r eturns observed for weaker agents can be mitigated by agent-side disambiguation or r etrieval depth. Finally , the length-controlled attention diagnostics and description-quality stratification (Appendix D ) argue against simple length- only or description-quality explanations, but they do not constitute a complete causal isolation of all possible length-mediated effects. References Anthropic. Claude Code overview . https://code.claude.com/docs , 2025. 11 Preprint. Under review . Anthropic. Models overview . https://platform.claude.com/docs/en/about- claude/ models/overview , 2026. Y u Du, Fangyun W ei, and Hongyang Zhang. Anytool: Self-reflective, hierar chical agents for large-scale api calls. In Proceedings of the 41st International Conference on Machine Learning , 2024. https://openreview.net/forum?id=qFILbkTQWw . Google. Gemini embedding model. https://ai.google.dev/gemini- api/docs/embeddings , 2025. Y ue Huang, Jiawen Shi, Y uan Li, Chenrui Fan, Siyuan W u, Qihui Zhang, Y ixin Liu, Pan Zhou, Y ao W an, Neil Zhenqiang Gong, and Lichao Sun. Metatool benchmark for large language models: Deciding whether to use tools and which to use. arXiv preprint , 2024. Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Ar- mand Joulin, and Edouar d Grave. Unsupervised dense information r etrieval with con- trastive learning. T ransactions on Machine Learning Research , 2022. Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell W u, Ser gey Edunov , Danqi Chen, and W en-tau Y ih. Dense passage retrieval for open-domain question answer- ing. In Proceedings of EMNLP , 2020. Kimi T eam. Kimi k2.5: Scaling reinforcement learning with llms. arXiv pr eprint arXiv:2602.02276 , 2026. Chankyu Lee, Rajarshi Roy , Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and W ei Ping. Nv-embed: Improved techniques for training llms as generalist embedding models. arXiv preprint , 2024. ICLR 2025 Spotlight. Xiangyi Li, W enbo Chen, Y imin Liu, Shenghan Zheng, Xiaokun Chen, Y ifeng He, Y ubo Li, Bingran Y ou, Haotian Shen, Jiankai Sun, Shuyi W ang, Binxu Li, Qunhong Zeng, Di W ang, Xuandong Zhao, Y uanli W ang, Roey Ben Chaim, Zonglin Di, Y ipeng Gao, Junwei He, Y izhuo He, Liqiang Jing, Luyang Kong, Xin Lan, Jiachen Li, Songlin Li, Y ijiang Li, Y ueqian Lin, Xinyi Liu, Xuanqing Liu, Haoran L yu, Ze Ma, Bowei W ang, Runhui W ang, T ianyu W ang, W engao Y e, Y ue Zhang, Hanwen Xing, Y iqi Xue, Steven Dillmann, and Han-chung Lee. Skillsbench: Benchmarking how well agent skills work across diverse tasks, 2026. Zehan Li, Xin Zhang, Y anzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. T owards general text embeddings with multi-stage contrastive learning. arXiv preprint arXiv:2308.03281 , 2023. Majiayu000. Claude Skill Registry Core. https://github.com/majiayu000/ claude- skill- registry- core , 2026. GitHub repository; accessed March 30, 2026. Rodrigo Nogueira and Kyunghyun Cho. Passage re-ranking with bert. arXiv preprint arXiv:1901.04085 , 2019. OpenAI. Gpt-4o mini model. https://platform.openai.com/docs/models/gpt- 4o- mini , 2024a. OpenAI. New embedding models and api updates. https://openai.com/blog/ new- embedding- models- and- api- updates , 2024b. OpenAI. Codex — AI coding partner from OpenAI. https://openai.com/codex/ , 2025. OpenAI. Gpt-5.4 mini model. https://developers.openai.com/api/docs/models/gpt- 5. 4- mini , 2026. OpenClaw. Skills - OpenClaw. https://docs.openclaw.ai/tools/skills , 2026. Shishir G Patil, T ianjun Zhang, Xin W ang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis. arXiv preprint , 2023. 12 Preprint. Under review . Y ujia Qin, Shihao Liang, Y ining Y e, Kunlun Zhu, Lan Y an, Y axi Lu, Y ankai Lin, Xin Cong, Xiangru T ang, Bill Qian, et al. T oolllm: Facilitating large language models to master 16000+ real-world apis. arXiv preprint , 2023. Stephen Robertson and Hugo Zaragoza. The pr obabilistic relevance framework: Bm25 and beyond. Foundations and T rends in Information Retrieval , 3(4):333–389, 2009. T imo Schick, Jane Dwivedi-Y u, Roberto Dess ` ı, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer , Nicola Cancedda, and Thomas Scialom. T oolformer: Language models can teach themselves to use tools. arXiv preprint , 2023. Y ongliang Shen, Kaitao Song, Xu T an, Dongsheng Li, W eiming Lu, and Y ueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face. Advances in Neural Information Processing Systems , 2023. W eiwei Sun, Lingyong Y an, Xinyu Ma, Shuaiqiang W ang, Pengjie Ren, Zhumin Chen, Dawei Y in, and Zhaochun Ren. Is chatgpt good at sear ch? investigating large language models as re-ranking agents. arXiv preprint , 2023. Liang W ang, Nan Y ang, Xiaolong Huang, Binxing Jiao, Linjun Y ang, Daxin Jiang, Rangan Majumder , and Furu W ei. T ext embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533 , 2022. Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighof f, Defu Lian, and Jian-Y un Nie. C-pack: Packed resour ces for general chinese embeddings. In Proceedings of the 47th International ACM SIGIR Confer ence on Resear ch and Development in Information Retrieval , 2024. Lee Xiong, Chenyan Xiong, Y e Li, Kwok-Fung T ang, Jialin Liu, Paul Bennett, Junaid Ahmed, and Arnold Overwijk. Approximate near est neighbor negative contrastive learning for dense text retrieval. In Proceedings of ICLR , 2021. Lifan Y uan, Y angyi Chen, Xingyao W ang, Y i R. Fung, Hao Peng, and Heng Ji. Craft: Customizing llms by cr eating and r etrieving from specialized toolsets. In Proceedings of ICLR , 2024. Z.AI. Chat completion - overview . https://docs.z.ai/api- reference/llm/ chat- completion , 2026. Y anzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Y ang, Pengjun Xie, An Y ang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 em- bedding: Advancing text embedding and reranking thr ough foundation models. arXiv preprint arXiv:2506.05176 , 2025. https://qwenlm.github.io/blog/qwen3- embedding/ . Y uanhang Zheng, Peng Li, W ei Liu, Y ang Liu, Jian Luan, and Bin W ang. T oolrerank: Adaptive and hierarchy-awar e reranking for tool retrieval. In Proceedings of LREC-COLING , pp. 16263–16273, 2024. A Evaluation Details Single- vs. multi-skill queries. Of the 75 cor e queries, 24 ar e single-skill queries (exactly one gr ound-truth skill) and 51 are multi-skill queries (two or more gr ound-truth skills requir ed to complete the task). Metric computation for multi-skill queries. For queries with multiple ground-tr uth skills G q = { g 1 , . . . , g m } , we define Hit@1 as the indicator of whether any ground-truth skill appears at rank 1. MRR@10 uses the highest-ranked ground-truth skill’s recipr ocal rank. Recall@ K measures the fraction of ground-truth skills that appear in the top- K results: R@ K = | G q ∩ top- K | / | G q | . FC@10 (Full Coverage at 10) is the strictest metric: it equals 1 only when all gr ound-truth skills for a query appear in the top 10. W e therefore use R@10 and FC@10 to complement this any-hit criterion. 13 Preprint. Under review . T able 7: Metadata audit for the 78,361-skill Easy pool. Descriptions are usually present, but they are far mor e compr essed than bodies. Statistic V alue Descriptions empty 0.12% Descriptions < 10 words 18.66% Descriptions < 25 words 59.22% Median description length 21 words Median body length 704 words P90 body length 1,991 words Core-query selection protocol. The underlying relevance file contains 87 SkillsBench- derived tasks. W e define the reported 75-query core benchmark as the subset with at least one non-generic core skill ( core gt ids non-empty), which yields 59 clean tasks and 16 mixed tasks. The r emaining 12 tasks are generic only : their labels contain only auxiliary file-type skills such as pdf , docx , pptx , or xlsx , so they ar e excluded fr om tier-specific routing metrics. Metadata richness in the 80K pool. The poor nd results are not explained by missing descriptions alone. In the Easy pool, descriptions ar e almost always present (only 0.12% empty), but they ar e much shorter than full skill bodies: the median description length is 21 words, versus 704 words for the body . T able 7 summarizes the resulting field-length distribution. Query diversity . T able 8 summarizes the diversity profile of the 75 core queries. The queries span 55 application domains, which we group into eight super -categories for read- ability; the distribution is relatively balanced, with no single super-category exceeding 17% of queries. W ithin these domains, 244 unique topic tags cover ar eas from seismology and quantum simulation to BGP r outing and video dubbing. The difficulty distribution is intentionally skewed toward non-trivial tasks (medium 60%, hard 35%, easy 5%), consistent with the benchmark’s focus on large-pool routing where easy cases are less informative. Among the 51 multi-skill queries, prior analysis identifies thr ee str uctural types: comple- mentary/pipeline tasks (43%) where skills form sequential stages, substitute/overlap tasks (25%) where multiple skills serve similar functions, and mixed tasks (32%) combining both patterns. This structural variation exer cises different aspects of r outing quality: pipeline queries stress r ecall (all stages must be found), while substitute queries stress precision (the best alternative must be ranked first). T able 8: Diversity profile of the 75 cor e benchmark queries. Dimension V alue Application domains 55 (8 super-categories) Unique topic tags 244 Difficulty split easy 4 / medium 45 / har d 26 Single / multi-skill 24 / 51 GT skills per query 1–7 (mean 2.75) Multi-skill types pipeline 43% / substitute 25% / mixed 32% Instruction length 36–586 words (median 169) Encoder-only nd/full detail for the body-access study . T able 9 r eports the complete encoder-only nd/full comparison r eferenced in Section 3 . All numbers use the same bench- mark pool and the same 75 cor e queries as the main text. Easy and Hard are the two evaluation tiers reported in the main paper . 14 Preprint. Under review . T able 9: Encoder-only nd/full detail on the same benchmark pool and 75 core queries used in the main text. Easy and Hard are the two evaluation tiers r eported in the main paper . Model Input Easy Hit@1 Hard Hit@1 A vg Hit@1 BM25 nd .000 .000 .000 BM25 full .347 .280 .314 Qwen3-Emb-0.6B nd .227 .147 .187 Qwen3-Emb-0.6B full .587 .533 .560 Qwen3-Emb-8B nd .307 .200 .253 Qwen3-Emb-8B full .653 .627 .640 B Benchmark Data Hard tier distractor generation. The Hard tier augments the Easy pool with 780 LLM- generated distractor skills. For each ground-truth skill, we prompt GPT -4o-mini to generate 3–5 plausible-but-incorrect skills using three distractor strategies: same-domain-different- problem (same technical domain but solves a different task), same-tech-different-use (same technology stack but differ ent application), and over-generalized (broader version that lacks the specific capability needed). W e use these distractors as a targeted robustness stress test for function-level confusion, not as an estimate of their exact prevalence in natural repositories. T able 10 shows the generation prompt. Pool deduplication and canonicalization. The 80K pool is deduplicated by skill ID only . Exact duplicate IDs ar e r emoved as data-cleaning artifacts, but same-name overlaps with ground-tr uth skills are intentionally r etained to preserve r ealistic near -duplicate confusion rather than construct an artificially conflict-fr ee catalog. T able 10: Distractor skill generation prompt for the Har d evaluation tier . System: Y ou are a skill document writer for a coding agent platform. Y ou produce SKILL.md-style documents that are plausible but address a DIFFERENT problem than the r eference skill. Each distractor must look like a real, useful skill document but must NOT solve the same task as the refer ence. User: I have a ground-truth skill used for the task(s): Reference skill (name: , category: ): Generate HARD distractor skills. Each distractor must be a complete SKILL.md document that looks relevant to someone searching for this skill, but actually solves a differ ent pr oblem. Use these distractor strategies (one per distractor): same-domain-diff-problem, same-tech-diff-use, over-generalized For EACH distractor , output a JSON object with fields: distractor type , name , description , body (400–1200 words). Data examples. T able 11 shows representative examples from the Easy and Hard tiers, illustrating the differ ence between a ground-truth skill, a pool skill (natural distractor), and an LLM-generated distractor . C Detailed Attention Analysis T able 12 summarizes the raw per -layer attention distribution for SR-Rank-0.6B. Because raw attention mass is length-confounded, T able 13 compares the same traces against field token-share baselines. Figure 3 then gives the two most useful visual views of the same 15 Preprint. Under review . T able 11: Representative data examples fr om the Easy and Hard tiers. Ground-tr uth skills appear in both tiers; LLM-generated distractors are added only in the Har d tier to incr ease inter-skill confusion. T ype Name Description Body (truncated) Ground-truth skill (pr esent in both Easy and Hard) GT speech-to-text T ranscribe audio files using Whisper Converts audio/video files to text using Ope- nAI Whisper model. Supports chunked pro- cessing for long files, multiple output formats (txt, srt, vtt)... Natural pool skill (present in both Easy and Hard — fr om community) Pool audio-transcriber Audio transcription service A general-purpose audio transcription skill using cloud APIs. Sends audio to external service, returns JSON transcript with times- tamps... LLM-generated distractor (added in Hard tier only) Distractor video-subtitle-sync Synchronize subtitles with video Adjusts subtitle timing to match video play- back. Parses SR T files, detects audio cues for alignment, handles frame-rate conversion... evidence: a layer-wise trajectory against token-share baselines and a query-level final-layer check. T able 12: Raw attention distribution across skill fields by layer gr oup and key individual layers (SR-Rank-0.6B, 28 layers × 16 heads, 75 queries). Layer (Group) Name Desc Body Layer groups (averaged) Early (0–6) 2.3% 0.3% 97.3% Middle (7–20) 9.6% 1.4% 89.0% Late (21–27) 7.5% 0.8% 91.7% Key individual layers Layer 0 0.3% 0.1% 99.6% Layer 11 14.6% 1.4% 84.0% Layer 19 26.3% 1.8% 72.0% Layer 27 1.5% 0.4% 98.1% Overall 7.3% 1.0% 91.7% T able 13: Length-controlled attention diagnostics for the same 75 query-skill pairs. If attention were explained mainly by field length, per-layer attention would r emain close to field token share. Field T oken Share Overall Attn. Layer 19 Layer 27 Name 3.0% 7.3% 26.3% 1.5% Desc 0.5% 1.0% 1.8% 0.4% Body 96.5% 91.7% 72.0% 98.1% 16 Preprint. Under review . 0 5 10 15 19 20 25 27 Layer Inde x 0% 20% 40% 60% 80% 100% A ttention Shar e L19 name spik e 26.3% vs 3.0% tok en shar e F inal layer body 98.1% vs 96.5% tok en shar e Dashed lines = field tok en shar e (a) A ttention Deviates F r om L ength Baselines Body attention Name attention Desc attention 88% 90% 92% 94% 96% 98% 100% P er - Query Body T ok en Shar e 88% 90% 92% 94% 96% 98% 100% F inal-Layer Body A ttention 69/75 above baseline cor r(body length, final attn) = 0.04 (b) Query -L evel F inal-Layer Check Above tok en-shar e baseline A t/below baseline Figure 3: Length-controlled attention visualization for SR-Rank-0.6B on 75 query-skill pairs. Left: per-layer attention trajectories compared against each field’s token-share baseline. The short name field spikes far above its 3.0% token-share baseline in the middle layers, while the final layer returns to body . Right: query-level final-layer body attention compared against each query’s body-token baseline. Most points lie above the diagonal, meaning the final layer attends to body more than a pur e length-based baseline would pr edict. Why this is not just “more text.” The aggregate 91.7% body attention in T able 12 should be interpreted r elative to the fact that the body field alr eady occupies 96.5% of skill tokens in these analyzed pairs. A pure longer -text explanation would ther efore pr edict attention to stay near the token-share baseline across layers. Instead, T ables 12 – 13 and Figure 3 show a structur ed body → name → body trajectory: the short name field spans only 3.0% of tokens but receives 26.3% attention at layer 19, while the final layer r eturns to 98.1% body attention. The easiest way to read Figur e 3 is ther efor e: the left panel shows that attention does not simply track field length through the network, and the right panel shows that this final-layer r eturn to body is not driven by a handful of outlier queries. At the query level, final-layer body attention exceeds the body’s token share on 69 of 75 queries and is effectively uncorrelated with absolute body length ( r = 0.04). These diagnostics argue against a trivial length effect and support the interpretation that the reranker uses name for intermediate alignment and body for the final relevance judgment, while still falling short of a complete causal isolation of all length-mediated effects. D Description-Quality Stratification A natural concern is that the nd → full gap reported in Section 3 could be driven by poor GT skill descriptions: if descriptions were more detailed, metadata-only r outing might suffice. T o test this, we stratify the 148 matched Easy+Medium queries by the wor d count of their GT skill’s description, dividing the 188 GT skills with extractable descriptions into four quartiles (Q1 ≤ 19 words, Q2 20–27, Q3 28–35, Q4 > 35). T able 14 reports the nd vs. full Hit@1 per quartile for the strongest base encoder (Qwen3-Emb-8B) on the 80K v3 pool. T able 14: nd vs. full Hit@1 stratified by GT description word count. The gap remains large ( ≥ 27pp) in every quartile, including Q4 wher e descriptions ar e longest. Baseline: Qwen3- Emb-8B, 80K v3 pool, Easy+Medium averaged. Quartile N Full Hit@1 ND Hit@1 Gap (pp) Q1 ( ≤ 19w) 26 53.8% 26.9% +26.9 Q2 (20–27w) 40 80.0% 30.0% +50.0 Q3 (28–35w) 38 65.8% 26.3% +39.5 Q4 ( > 35w) 44 52.3% 20.5% +31.8 Overall 148 63.5% 25.7% +37.8 17 Preprint. Under review . The gap does not decrease monotonically with description length: Q4 (longest descriptions, > 35 words) still shows a +31.8pp gap, and Q2 exhibits the largest gap (+50.0pp). This pattern argues against a description-quality confound and supports the interpretation that body text provides r outing signal that descriptions—regar dless of their length or detail—cannot substitute. E T raining Data Construction This appendix provides the full details of training data construction for both stages of the S K I L L R O U T E R pipeline, complementing the summary in Section 4 . E.1 Query Generation Section 4 summarizes the 37,979 synthetic (query , skill) training pairs; here we provide the generation details. Skills ar e drawn fr om 51 categories with stratified sampling. The generated queries have a mean length of 160 wor ds. T able 15 shows the pr ompt template used with GPT -4o-mini. T able 15: Query generation prompt template (simplified). The LLM receives the skill’s metadata and produces a r ealistic task description without mentioning the skill name. System: Y ou are an experienced user of AI assistants. Y ou write clear , realistic task requests that describe what you need to accomplish. User: Given the following skill specification, write a realistic task description that someone would ask an AI assistant to help with. The task should naturally r equire the capabilities described in this skill. Skill name: Category: Description: Skill body: Requirements: (1) Describe a concrete scenario with specific inputs/outputs. (2) Include enough detail that the skill would be clearly useful. (3) Do NOT mention the skill name “ ” anywhere in the task. Output ONL Y the task description. E.2 Hard Negative Mining Effective contrastive learning requir es informative negatives that are challenging but not false positives. W e employ a multi-sour ce mining strategy that pr oduces 10 negatives per query from four complementary sour ces: • Semantic negatives (4 per query): W e pre-compute embeddings for all skills using the base Qwen3-Emb-0.6B model, retrieve the top-50 most similar skills by cosine similar- ity , and sample 4 non-positive skills from this set. These are the hardest negatives— semantically close but functionally distinct. • Lexical negatives (3 per query): BM25 scoring over skill text (name + description + body) on the same top-50 candidate set, capturing term-overlap confounders that semantic search may miss. • T axonomy negatives (2 per query): randomly sampled from the same category as the positive skill but with a differ ent name, pr oviding same-domain distractors. • Random negatives (1 per query): uniformly sampled from a differ ent category , serving as easy negatives for calibration. E.3 False Negative Filtering As described in Section 4 , the mined negatives ar e post-pr ocessed with a thr ee-layer filter . The per-layer r emoval counts ar e: 18 Preprint. Under review . 1. Name deduplication : removing negatives that share the same name as any ground-truth skill for the query (24,879 pairs removed). 2. Body overlap : removing negatives whose body text has trigram Jaccard similarity > 0.6 with a ground-tr uth skill’s body (13,860 pairs removed). 3. Embedding similarity : removing negatives with cosine similarity > 0.92 to a gr ound- truth skill’s embedding, catching semantic duplicates missed by lexical matching (326 pairs removed). In total, 39,065 false negative pairs are r emoved (approximately 10% of all mined negative pairs). E.4 Reranker T raining Data For each of the 32,283 training queries, we retrieve the top-20 candidates using the trained SR-Emb-0.6B encoder . Each candidate list contains 20 skills with binary r elevance labels (positive or negative), forming one training gr oup for listwise cr oss-entr opy optimization. The same three-layer false negative filtering described above is applied to the reranker training data. F Model Input T emplates and T raining Details W e document the exact input formats, field truncation rules, loss functions, and selected training settings used for the reported models. Bi-encoder (query side). Following Qwen3-Emb’s instruction-pr efixed encoding format: Instruct: Given a task description, retrieve the most relevant skill document that would help an agent complete the task Query: Before tokenization, the raw query text is tr uncated to 1,500 characters. Bi-encoder (skill side). Skills are encoded as plain concatenated text without instr uction prefix: | | Before tokenization, description is truncated to 300 characters and body to 2,500 charac- ters. During encoder training, each query / positive / negative input is tokenized with a maximum length of 2,048 tokens. Cross-encoder reranker (flattened full-text format). Following the Qwen3-Rank input convention ( Zhang et al. , 2025 ): : Given a task description, judge whether the skill document is relevant and useful for completing the task : : | | Before prompt construction, description is truncated to 500 characters and body to 2,000 characters. T okenized reranker inputs use a maximum length of 4,096 tokens. LLM-as-judge (GPT -4o-mini / GPT -5.4-mini). W e evaluate OpenAI GPT -4o-mini and GPT -5.4-mini ( OpenAI , 2024a ; 2026 ) as listwise judges. Both LLM judges operate in listwise mode: they receive the full list of top- K candidates at once and select the single most relevant skill. System prompt: 19 Preprint. Under review . T able 16: Selected training hyperparameters for the reported SkillRouter models. Character caps are applied befor e tokenization. Model Objective Input / prompt Field caps Max len Epoch Batch GA LR SR-Emb-0.6B In-batch InfoNCE ( τ = 0.05) Query instruction prefix; skill = name | description | body query 1500 chars; desc 300 chars; body 2500 chars 2048 1 8 4 2 × 10 − 5 SR-Rank-0.6B Listwise CE ( τ = 1.0) flattened full-text query-document prompt over top- 20 candidates desc 500 chars; body 2000 chars 4096 1 1 listwise group 16 1 × 10 − 5 You are an expert at matching tasks to reusable skill definitions. Given a task query and a numbered list of candidate skills, identify the SINGLE most relevant skill that best solves the task. Respond with ONLY the number (e.g. ‘3’) of the best matching skill, nothing else. User message: The query text followed by a numbered list of candidates, each formatted as: [1] Name: Description: Body: [2] Name: ... The selected skill is placed at rank 1; all other candidates retain their original encoder ordering. For LLM-judge experiments, each candidate uses the same field caps as the reranker: description is truncated to 500 characters and body to 2,000 characters before prompt constr uction. Loss definitions. The reported SR-Emb-0.6B model uses in-batch InfoNCE: L enc = − 1 B B ∑ i = 1 log exp ( sim ( q i , s + i ) / τ ) ∑ j exp ( sim ( q i , s j ) / τ ) (1) where τ = 0.05 and sim ( · , · ) is cosine similarity over normalized embeddings. The reported SR-Rank-0.6B model uses listwise cr oss-entropy over the top- K candidate set: L L W = − log exp ( f ( q , s + ) / τ ) ∑ K j = 1 exp ( f ( q , s j ) / τ ) (2) where f ( q , s ) is the reranker score and τ = 1.0 in training. For the pointwise ablation only , we instead use binary cross-entr opy: L PW = − 1 K K ∑ j = 1 y j log σ ( f j ) + ( 1 − y j ) log ( 1 − σ ( f j )) . (3) T raining hyperparameters. All reported training runs use a single NVIDIA H20 GPU (96GB). Unless otherwise noted, both reported models use AdamW with weight decay 0.01, a cosine learning-rate schedule with 5% warmup, BF16 mixed pr ecision, and gradient checkpointing. T able 16 summarizes the selected training settings for the reported models, and both reported models ar e described using a 1-epoch training configuration. G T op- K Candidate Ablation W e ablate the number of candidates ( K ∈ { 10, 20, 50 } ) passed from the encoder to the reranker . T able 17 r eports Hit@1 for three rerankers across both tiers. Figure 4 shows Recall@ K candidate coverage for three encoder r etrievers, with star markers at K = 20 indi- cating the corresponding end-to-end pipeline Hit@1. 20 Preprint. Under review . T able 17: Hit@1 as a function of top- K candidates for reranking. Encoder = SR-Emb-0.6B. Across the r eported Easy/Hard comparisons, K = 20 consistently matches or exceeds the alternatives. Easy Hard A vg Reranker @10 @20 @50 @10 @20 @50 @20 SR-Rank-0.6B (FT) .747 .760 .733 .720 .720 .707 .740 Qwen3-Rank-0.6B .720 .720 .667 .693 .693 .640 .707 Qwen3-Rank-8B .693 .720 .707 .680 .707 .707 .714 1 10 20 50 K 0.45 0.50 0.55 0.60 0.65 0.70 0.75 0.80 0.85 R ecall@K P ipeline Hit@1: 76.0% top-20 reranker (a) Easy 1 10 20 50 K P ipeline Hit@1: 72.0% top-20 reranker (b) Har d Qwen3-0.6B base Qwen3-8B base SR -Emb-0.6B (Ours) Figure 4: Recall@ K candidate coverage for three encoder r etrievers on Easy and Hard. Star markers at K = 20 indicate the corr esponding end-to-end pipeline Hit@1 for each encoder - reranker pair . T aken together , T able 17 and Figure 4 motivate our choice of K = 20. Figure 4 shows that K = 20 already captures most of the available candidate coverage for all three retrievers. T able 17 then shows that moving to K = 50 does not improve downstr eam Hit@1 and often hurts it, particularly for the fine-tuned SR-Rank-0.6B ( − 2.0pp average), whereas K = 10 leaves less reranking headr oom. H Serving Efficiency T able 18 reports the GPU serving benchmark on the r eal pool. These measurements cover the online query path only: one encoder forward pass, approximate near est-neighbor retrieval, and top-20 reranking when applicable. They exclude one-time model loading, of fline pool embedding, and index construction costs. I Extended Main-T ext T ables T able 19 and T able 20 pr ovide the full encoder-only and end-to-end result grids that were compressed into r epresentative main-text tables for the COLM submission. T able 21 r eports the stratified r obustness summary , and T able 22 gives the full multi-metric reranker-loss ablation. J Paired Headline Comparison Key observations. T able 23 compares the primary 1.2B pipeline against the strongest retained 16B base pipeline on matched query sets. S K I L L R O U T E R achieves higher Hit@1 on both Easy (+8.0pp) and Hard (+4.0pp), with a combined +6.0pp delta. Across 150 matched 21 Preprint. Under review . T able 18: Real-pool GPU serving benchmark. GPU-sec / 1K queries is a benchmark compute- footprint measure rather than a dollar -cost estimate. System p50 (ms) p95 (ms) Throughput (q/s) Dominant Stage Peak GPU Mem (MB) GPU-sec / 1K queries SR-Emb-0.6B 19.8 20.8 50.50 encoder 9363.90 19.80 SR-Emb-0.6B × SR-Rank-0.6B 495.8 871.4 1.83 rerank forward 18975.58 546.96 Qwen3-Emb-8B 60.4 81.3 18.69 encoder 22539.28 53.51 Qwen3-Emb-8B × Qwen3-Rank-8B 2900.1 5676.5 0.323 rerank forward 22539.28 6189.86 T able 19: Full encoder retrieval results on the 80K skill pool. All models use full skill text as input. Easy Hard A verage (Easy + Hard) Model T ype Params Hit@1 R@20 Hit@1 R@20 Hit@1 MRR@10 nDCG@10 R@10 R@20 R@50 BM25 Sparse – .347 .376 .280 .354 .314 .365 .276 .321 .365 .433 gemini-embedding-001 Propri. – .613 .689 .560 .685 .587 .650 .575 .629 .687 .774 text-embedding-3-large Propri. – .640 .676 .600 .652 .620 .658 .557 .609 .664 .709 E5-Large-v2 Encoder 335M .507 .594 .493 .594 .500 .565 .494 .553 .594 .622 BGE-Large-v1.5 Encoder 335M .613 .677 .587 .658 .600 .653 .522 .608 .668 .743 GTE-Large-v1.5 Encoder 434M .573 .706 .520 .686 .547 .631 .542 .630 .696 .750 Qwen3-Emb-0.6B Decoder 0.6B .587 .645 .533 .628 .560 .638 .526 .595 .637 .733 NV -Embed-v2 Decoder 7B .440 .565 .413 .559 .427 .508 .410 .504 .562 .649 Qwen3-Emb-8B Decoder 8B .653 .736 .627 .716 .640 .698 .581 .659 .726 .790 SR-Emb-0.6B Decoder 0.6B .667 .762 .640 .745 .654 .723 .616 .688 .754 .814 SR-Emb-8B Decoder 8B .693 .785 .667 .769 .680 .731 .623 .692 .777 .851 query-tier evaluations, S K I L L R O U T E R impr oves over the base pipeline in 18 cases and trails it in 9, showing a consistent directional advantage at 13 × fewer parameters. K Additional Pipeline Diagnostics Reranker contribution decomposition. Across 150 Easy+Har d evaluations, the r eranker fixes 19 cases (12.7%) wher e the encoder misses rank 1 but still r etrieves the corr ect skill into the top-20 window , while degrading only 6 cases (4.0%). The net gain is therefor e +8.7pp Hit@1, from 65.3% to 74.0%. The remaining 33 misses are mainly recall failur es or cases that requir e multi-hop pr erequisite infer ence. L Case Studies W e present six r epresentative cases analyzing the behavior of the S K I L L R O U T E R pipeline. The main text focuses on aggregate results; her e we provide six detailed success and failure cases. Case 1: Encoder advantage (video-tutorial-indexer). Query: Extract chapter timestamps from a local tutorial video. GT Skill: speech-to-text (Whisper-based audio transcription). Analysis: Base encoders are misled by surface keyword “video” and r etrieve video editing tools. Qwen3-Emb-0.6B base ranks GT at position 25; Qwen3-Emb-8B at position 6. SR-Emb- 0.6B learns the indirect mapping “video + timestamps → speech-to-text” and retrieves GT at rank 1. This demonstrates that fine-tuning captures reasoning shortcuts that model scale alone cannot provide. Case 2: Reranker rescue (simpo-code-reproduction). Query: Reproduce a research paper ’s loss function and set up the development environment. GT Skill: nlp-research-repo-package-installment (Python environment setup). Analysis: All encoders miss this subtle match (SR-Emb-0.6B: rank 13; base encoders: rank > 50). Since rank 13 is within the top-20 window , the cross-encoder reranker identifies the alignment between “setup the environment” and the skill’s dependency installation instructions, pr omoting GT to rank 1. 22 Preprint. Under review . T able 20: Full encoder × reranker results (top-20 candidates). LLM judges only provide a top-1 choice, so only Hit@1 is reported for those r ows. Easy Hard A verage (Easy + Hard) Encoder Reranker Rank Input Hit@1 MRR Hit@1 MRR Hit@1 MRR@10 nDCG@10 R@10 Encoder-only (no reranking) Qwen3-Emb-0.6B – – .587 .658 .533 .618 .560 .638 .526 .595 Qwen3-Emb-8B – – .653 .709 .627 .687 .640 .698 .581 .659 SR-Emb-0.6B – – .667 .735 .640 .710 .654 .723 .616 .688 Reranker with nd input (no body) Qwen3-Emb-8B Qwen3-Rank-8B nd .293 .437 .187 .348 .240 .392 .357 .530 Qwen3-Emb-0.6B Qwen3-Rank-0.6B nd .360 .455 .173 .328 .267 .392 .374 .524 Qwen3-Emb-8B Qwen3-Rank-0.6B nd .293 .451 .133 .318 .213 .385 .385 .603 Qwen3-Emb-8B GPT -4o-mini nd .213 – .173 – .193 – – – Qwen3-Emb-0.6B GPT-4o-mini nd .253 – .160 – .207 – – – Qwen3-Emb-8B GPT -5.4-mini nd .347 – .267 – .307 – – – Qwen3-Emb-0.6B GPT-5.4-mini nd .373 – .293 – .333 – – – Reranker with full input — base models Qwen3-Emb-8B GPT -4o-mini full .667 – .627 – .647 – – – Qwen3-Emb-0.6B GPT-4o-mini full .560 – .547 – .554 – – – Qwen3-Emb-8B GPT -5.4-mini full .627 – .560 – .594 – – – Qwen3-Emb-0.6B GPT-5.4-mini full .573 – .547 – .560 – – – Qwen3-Emb-0.6B Qwen3-Rank-0.6B full .653 .695 .627 .673 .640 .684 .558 .604 Qwen3-Emb-8B Qwen3-Rank-0.6B full .613 .697 .547 .647 .580 .672 .588 .694 Qwen3-Emb-8B Qwen3-Rank-8B full .680 .745 .680 .744 .680 .745 .623 .692 SR-Emb-0.6B + reranker (full input) SR-Emb-0.6B GPT -5.4-mini full .667 – .653 – .660 – – – SR-Emb-0.6B GPT -4o-mini full .693 – .653 – .673 – – – SR-Emb-0.6B Qwen3-Rank-0.6B full .720 .780 .693 .758 .707 .769 .649 .724 SR-Emb-0.6B Qwen3-Rank-8B full .720 .781 .707 .771 .714 .776 .649 .727 SR-Emb-0.6B SR-Rank-0.6B full .760 .809 .720 .773 .740 .791 .640 .704 Scaling variants (8B components) SR-Emb-0.6B SR-Rank-8B full .787 .831 .707 .778 .747 .804 .655 .707 SR-Emb-8B SR-Rank-8B full .787 .827 .733 .789 .760 .808 .666 .719 T able 21: Stratified robustness summary for the strongest 8B base pipeline and the primary 1.2B pipeline. Pipeline Easy Hard Single Multi Multi FC@10 Qwen3-Emb-0.6B × Qwen3-Rank-0.6B .653 .627 .625 .647 .324 Qwen3-Emb-8B × Qwen3-Rank-8B .680 .680 .667 .686 .382 SR-Emb-0.6B × SR-Rank-0.6B .760 .720 .729 .745 .353 Case 3: Encoder advantage (workflow-automation). Query: Automate a multi-step CI/CD pipeline with conditional stage execution. GT Skill: github-actions-workflow (GitHub Actions Y AML generation). Analysis: Base encoders retrieve generic automation skills (“task-scheduler ”, “cron- manager ”). SR-Emb-0.6B captures the “CI/CD + conditional” → “GitHub Actions” map- ping, ranking GT at position 1 vs. position 8 for Qwen3-Emb-8B. The skill body explicitly describes conditional workflow syntax, which the fine-tuned model has learned to associate with CI/CD queries. Case 4: Reranker rescue (data-format-conversion). Query: Convert a legacy XML configu- ration to modern TOML format with schema validation. GT Skill: config-format-converter (multi-format config file conversion). Analysis: The encoder retrieves XML-focused and TOML-focused tools separately but misses the unified converter (SR-Emb-0.6B: rank 11). The reranker , thr ough cross-attention over the body’s supported format list (XML, Y AML, JSON, TOML, INI), identifies the correct multi-format skill and promotes it to rank 1. Case 5: Pointwise loss degradation (api-documentation). Query: Generate REST API documentation from OpenAPI spec with interactive examples. GT Skill: openapi-doc-generator (Swagger/OpenAPI documentation tool). 23 Preprint. Under review . T able 22: Full reranker-loss ablation. Encoder = SR-Emb-0.6B, top-20 candidates. L W = listwise cross-entr opy; PW = pointwise binary cr oss-entropy; base = untuned. Easy Hard A verage Reranker Loss Hit@1 MRR R@10 Hit@1 MRR R@10 Hit@1 MRR R@10 FC@10 SR-Rank-0.6B (L W) L W .760 .809 .720 .720 .773 .688 .740 .791 .704 .520 Qwen3-Rank-0.6B base .720 .780 .736 .693 .758 .712 .707 .769 .724 .527 Qwen3-Rank-8B base .720 .781 .732 .707 .771 .722 .714 .776 .727 .527 SR-Rank-0.6B (PW) PW .453 .592 .576 .413 .564 .569 .433 .578 .573 .320 Encoder-only (no reranking) .667 .735 .696 .640 .710 .673 .654 .723 .688 .480 T able 23: Matched-query headline comparison between the strongest retained base pipeline and our primary 1.2B pipeline. W in/loss counts report discordant query-tier instances where one system succeeds at rank 1 and the other does not. T ier Base Hit@1 S K I L L R O U T E R Hit@1 ∆ Hit@1 SR-only Base-only Easy .680 .760 +.080 9 3 Hard .680 .720 +.040 9 6 Combined .680 .740 +.060 18 9 Analysis: SR-Emb-0.6B correctly retrieves GT at rank 1. However , SR-Rank-0.6B (PW) degrades it to rank 18, while SR-Rank-0.6B (L W) maintains rank 1. The pointwise model assigns similar scores ( ∼ 0.52) to all API-related candidates, effectively randomizing the order . This case exemplifies why pointwise scoring fails in homogeneous candidate pools. Case 6: System limitation (invoice-fraud-detection). Query: Analyze invoice images to detect potential fraud patterns (duplicate amounts, suspicious vendor names). GT Skill: pdf-table-extractor (structured data extraction fr om PDF/images). Analysis: All methods fail. The connection between “invoice fraud detection” and “PDF table extraction” r equires multi-hop reasoning: fraud analysis → structur ed data needed → invoices are PDFs → table extraction. No retrieval method in our pipeline captur es this chain. The top results are fraud-detection analytics tools and image classifiers, none of which provide the prerequisite data extraction step. This case illustrates one important source of the remaining miss rate in our curr ent evaluation: retrieval-based pipelines still struggle on tasks that r equire multi-hop pr erequisite infer ence. M Downstream Evaluation Details W e report the full direct execution results underlying the averaged main-text table. All runs use the same execution harness on the 75-task core set with a 1200 s timeout. This appendix reports the same complementary end-to-end study using the natural pool described in the main text, not a tier-matched continuation of the Easy/Hard retrieval benchmark. Retrieved skills come from the natural pool, i.e., the non-synthetic benchmark pool without Hard-tier distractors. Once the exposed skill package is fixed, the downstr eam execution protocol otherwise follows SkillsBench ( Li et al. , 2026 ), including task setup and success validation. The four evaluated agents are Kimi-K2.5 ( Kimi T eam , 2026 ), glm-5 ( Z.AI , 2026 ), Claude Sonnet 4.6, and Claude Opus 4.6 ( Anthropic , 2026 ). M.1 Representative Downstream Cases These cases illustrate how routing quality affects end-to-end agent execution. They are mechanism illustrations drawn from the 3-trial evaluation, not statistical pr oofs. Case A (positive): Semantic distractor avoidance (software-dependency-audit). Query: Audit project dependencies for known vulnerabilities, extract CVSS scor es, and pr oduce a 24 Preprint. Under review . T able 24: Per-query Hit@1 decomposition: SR-Emb-0.6B encoder-only vs. the full SR-Emb- 0.6B × SR-Rank-0.6B pipeline. Easy Hard All Category n % n % n % Both correct 47 62.7 45 60.0 92 61.3 Reranker fixed 10 13.3 9 12.0 19 12.7 Reranker degraded 3 4.0 3 4.0 6 4.0 Both missed 15 20.0 18 24.0 33 22.0 Encoder Hit@1 50 66.7 48 64.0 98 65.3 Pipeline Hit@1 57 76.0 54 72.0 111 74.0 T able 25: Direct end-to-end agent success rates (%) by model and skill condition. Each task is evaluated three times per condition. Retrieved skills use the natural pool, i.e., the non-synthetic benchmark pool without Hard-tier distractors. Model Skill Condition Router / Source T op- K Single Multi Overall Kimi-K2.5 No skills None – 12.50 9.15 10.22 Gold skills Oracle ground-truth GT 20.83 25.49 24.00 Retrieved skills Qwen3-Emb-8B × Qwen3-Rank-8B 1 20.83 11.76 14.67 Retrieved skills SkillRouter 1 20.83 16.34 17.78 Retrieved skills Qwen3-Emb-8B × Qwen3-Rank-8B 10 16.67 21.57 20.00 Retrieved skills SkillRouter 10 19.44 17.65 18.22 glm-5 No skills None – 11.11 12.42 12.00 Gold skills Oracle ground-truth GT 37.50 23.53 28.00 Retrieved skills Qwen3-Emb-8B × Qwen3-Rank-8B 1 36.11 19.61 24.89 Retrieved skills SkillRouter 1 36.11 16.99 23.11 Retrieved skills Qwen3-Emb-8B × Qwen3-Rank-8B 10 19.44 21.57 20.89 Retrieved skills SkillRouter 10 30.56 22.22 24.89 Claude Sonnet 4.6 No skills None – 13.89 22.22 19.56 Gold skills Oracle ground-truth GT 40.28 43.79 42.67 Retrieved skills Qwen3-Emb-8B × Qwen3-Rank-8B 1 31.94 34.64 33.78 Retrieved skills SkillRouter 1 36.11 37.25 36.89 Retrieved skills Qwen3-Emb-8B × Qwen3-Rank-8B 10 33.33 38.56 36.89 Retrieved skills SkillRouter 10 36.11 42.48 40.44 Claude Opus 4.6 No skills None – 12.50 20.26 17.78 Gold skills Oracle ground-truth GT 25.00 41.18 36.00 Retrieved skills Qwen3-Emb-8B × Qwen3-Rank-8B 1 18.06 35.29 29.78 Retrieved skills SkillRouter 1 26.39 35.29 32.44 Retrieved skills Qwen3-Emb-8B × Qwen3-Rank-8B 10 12.50 29.41 24.00 Retrieved skills SkillRouter 10 18.06 32.03 27.56 CSV report. Gold skills: cvss-score-extraction , trivy-offline-vulnerability-scanning , vulnerability-csv-reporting . Retrieval: The baseline top-1 retrieves dependency-security (a community-contributed skill about general dependency security), while S K I L L R O U T E R top-1 r etrieves trivy-offline-vulnerability-scanning (a gold skill providing the specific offline scanning workflow). Result: Baseline top-1 scores 0/12 acr oss all four agents; S K I L L R O U T E R top-1 scor es 12/12. Every agent transitions fr om complete failure to complete success when the correct skill is r outed. This is the most dramatic case in the dataset and illustrates how semantically similar but functionally distinct skills can completely block downstr eam execution when the wrong one is selected. Case B (positive): Surface-matching trap (video-tutorial-indexer). Query: Index a video tutorial by extracting and timestamping its spoken content. Gold skill: speech-to-text . Retrieval: The baseline top-1 retrieves video-explorer (matching the surface keyword 25 Preprint. Under review . “video”), while S K I L L R O U T E R retrieves speech-to-text (matching the required function: transcription). Result: Baseline top-1 scores 0/12; S K I L L R O U T E R top-1 scor es 9/12 (glm-5 3/3, Kimi-K2.5 2/3, Opus 3/3, Sonnet 1/3). The baseline retriever matches on the task’s surface topic (video) rather than its functional requir ement (audio transcription), a failur e mode that the trained router avoids. Case C (negative): Specialized multi-skill domains (hvac-control). Query: Design and tune a model-predictive HV AC controller with safety interlocks. Gold skills: excitation-signal-design , first-order-model-fitting , imc-tuning-rules , safety-interlocks , scipy-curve-fit . Retrieval: The baseline top-1 retrieves first-order-model-fitting (a gold skill); S K I L L - R O U T E R top-1 r etrieves simulation-metrics (a related but non-gold control-engineering skill). In the top-10 setting, the baseline recovers all 5 gold skills, while S K I L L R O U T E R recovers only 1. Result: Baseline top-1 scores 8/12; S K I L L R O U T E R top-1 scores 4/12. This case illustrates where the compact r outer falls short: in highly specialized multi-skill engineering domains requiring pr ecise vocabulary matching acr oss multiple sub-disciplines, the 16B baseline’s deeper domain repr esentation pr oduces substantially better retrieval. 26
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment