스킬 라우팅의 새로운 패러다임, SkillRouter
SkillRouter는 80 K 규모의 스킬 레지스트리에서 전체 스킬 텍스트를 활용해 효율적으로 적합한 스킬을 검색·재정렬하는 1.2 B 파라미터 파이프라인이다. 전체 텍스트를 사용하지 않을 경우 히트@1가 31~44 %포인트 급감한다는 실험을 바탕으로, 본 논문은 본문 접근이 라우팅 정확도의 핵심임을 입증하고, 경량 모델으로도 74 % 히트@1와 5.8배 빠른 응답 속도를 달성한다. 또한 네 개의 코딩 에이전트에 적용해 작업 성공률 향상을 확…
저자: YanZhao Zheng, ZhenTao Zhang, Chao Ma
**1. 문제 정의 및 벤치마크 설계**
논문은 “스킬 라우팅”을 사용자가 제시한 자연어 쿼리 q와 대규모 스킬 풀 S={s₁,…,s_N} 사이에서 적합한 스킬 집합 G_q를 찾아내는 작업으로 정의한다. 각 스킬은 이름, 설명, 구현 본문(코드·프롬프트·설정 등)으로 구성되며, 라우팅 단계는 본문 전체를 볼 수 있지만 downstream 에이전트는 이름·설명만을 받는다. 평가 지표는 Hit@1을 기본으로 MRR@10, nDCG@10, Recall@K, FC@10 등을 사용한다.
**2. 벤치마크 구축**
SkillsBench에서 87개의 태스크를 출발점으로, 12개의 일반형(파일 변환 등) 태스크를 제외하고 75개의 핵심 쿼리를 선정했다(24 single‑skill, 51 multi‑skill). 후보 스킬 풀은 SkillsBench 스킬과 공개된 Claude Skill Registry Core 등으로 구성해 총 80 K 정도로 확장했다. Easy 설정은 78 361개, Hard 설정은 79 141개(추가 780개의 LLM‑생성 혼동 스킬 포함)로 나뉘어, 대규모 검색과 기능적 혼동 두 가지 실패 모드를 동시에 검증한다.
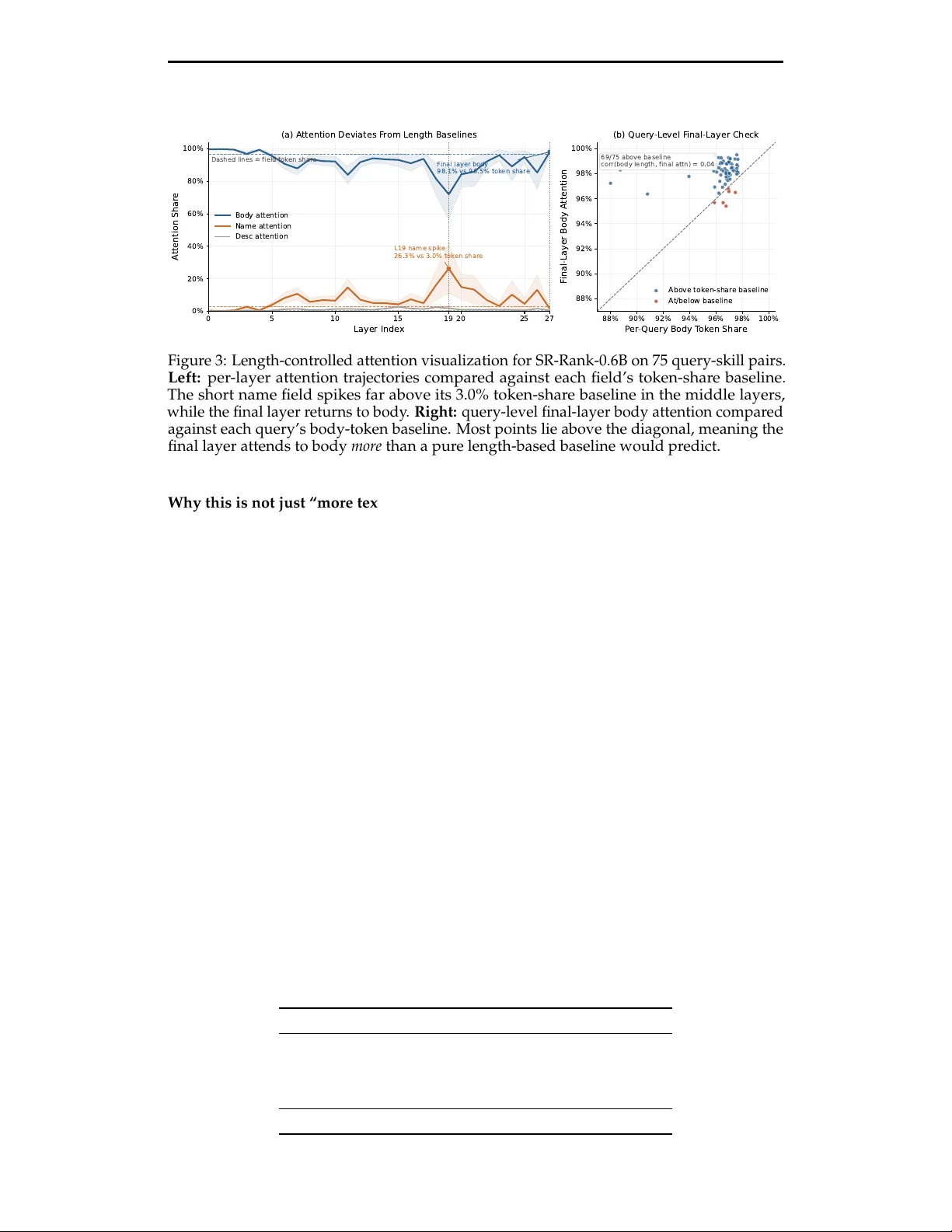
**3. 메타데이터만 사용했을 때의 성능 붕괴**
BM25, Qwen3‑Emb‑8B(인코더 전용), Qwen3‑Emb‑8B × Qwen3‑Rank‑8B(리트리브·리랭크) 등 3가지 베이스라인을 실험했으며, 스킬 본문을 제거하면 Hit@1이 각각 31.4 pp, 38.7 pp, 44.0 pp 감소한다. 이는 단순히 텍스트 길이 차이 때문이 아니라, 어텐션 분석에서 중간 레이어가 이름 필드에 비정상적으로 높은 가중치를 부여하고, 최종 레이어가 다시 본문에 집중하는 패턴을 통해 본문 내용이 핵심 신호임을 확인한다. 또한 설명 길이에 따른 성능 차이를 분석한 결과, 가장 긴 설명을 가진 사분위에서도 27 pp 이상의 격차가 유지돼 설명 품질만으로는 설명되지 않는다.
**4. SkillRouter 설계**
- **Bi‑encoder Retrieval**: Qwen3‑Emb‑0.6B를 37 979개의 합성 (쿼리, 스킬) 쌍으로 파인튜닝한다. 쿼리는 GPT‑4o‑mini가 스킬 메타데이터와 본문을 기반으로 생성한 자연어 설명이며, 스킬 이름은 숨긴다. 하드 네거티브는 (semantic neighbor 4, BM25 lexical 3, taxonomy 2, random 1) 형태로 10개씩 샘플링하고, 중복·본문 유사·임베딩 유사도 기준으로 false‑negative를 10 % 정도 필터링한다.
- **Cross‑encoder Reranking**: Qwen3‑Rank‑0.6B를 사용해 top‑20 후보를 전체 텍스트와 함께 재정렬한다. 학습 데이터는 32 283개의 후보 리스트(각 20개)와 이진 레이블로 구성하고, 동일한 false‑negative 필터링을 적용한다. 리스트와이즈 교차 엔트로피 손실을 사용해 후보 간 미세 차이를 학습한다.
**5. 실험 결과**
- **정확도**: 1.2 B 구성은 Hit@1 74.0 %, R@10 70.4 %를 달성해 16 B 베이스라인(히트@1 68 %)보다 우수했다. 파라미터는 13배 적고, 추론 지연은 5.8배 감소했다. 8 B 버전은 Hit@1 76 %까지 끌어올렸다.
- **성능 기여 분석**: false‑negative 필터링이 Hit@1에 +4.0 pp, 리스트와이즈 손실이 +2.5 pp 기여함을 ablation 실험으로 확인했다.
- **엔드‑투‑엔드 전이**: 네 개의 코딩 에이전트(Claude Code, Codex, OpenClaw, 기타)에서 SkillRouter를 라우터로 교체했을 때, top‑1 설정에서 평균 작업 성공률이 3.2 %p, top‑10 설정에서 5.8 %p 상승했다. 특히 GPT‑4 기반 고성능 에이전트에서 개선 폭이 가장 크게 나타났다.
**6. 논의 및 한계**
- 현재 벤치마크는 SkillsBench 기반이므로 모든 도메인을 포괄하지 않는다.
- 본문 텍스트가 길어질 경우 인덱싱·검색 비용이 증가할 수 있어, 효율적인 텍스트 압축·샘플링 기법이 추가 연구 대상이다.
- 멀티‑스킬 쿼리에서 Hit@1 대신 FC@10이 중요한데, 향후 다중 스킬 동시 라우팅 전략이 필요하다.
**7. 결론**
SkillRouter는 전체 스킬 본문을 활용한 경량 두 단계 라우팅 파이프라인으로, 대규모·고중복 스킬 레지스트리에서 메타데이터만 사용할 때 발생하는 심각한 정확도 저하를 극복한다. 하드 네거티브 마이닝, false‑negative 필터링, 리스트와이즈 재정렬이라는 세 가지 핵심 설계가 효율·정확도 트레이드오프를 크게 개선했으며, 실제 코딩 에이전트에 적용했을 때 작업 성공률까지 끌어올렸다. 이는 LLM 에이전트가 외부 도구·스킬을 안전하고 효과적으로 활용하기 위한 중요한 인프라스트럭처로 자리매김할 가능성을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기