Scaling Attention via Feature Sparsity
Scaling Transformers to ultra-long contexts is bottlenecked by the $O(n^2 d)$ cost of self-attention. Existing methods reduce this cost along the sequence axis through local windows, kernel approximations, or token-level sparsity, but these approache…
Authors: Yan Xie, Tiansheng Wen, Tangda Huang
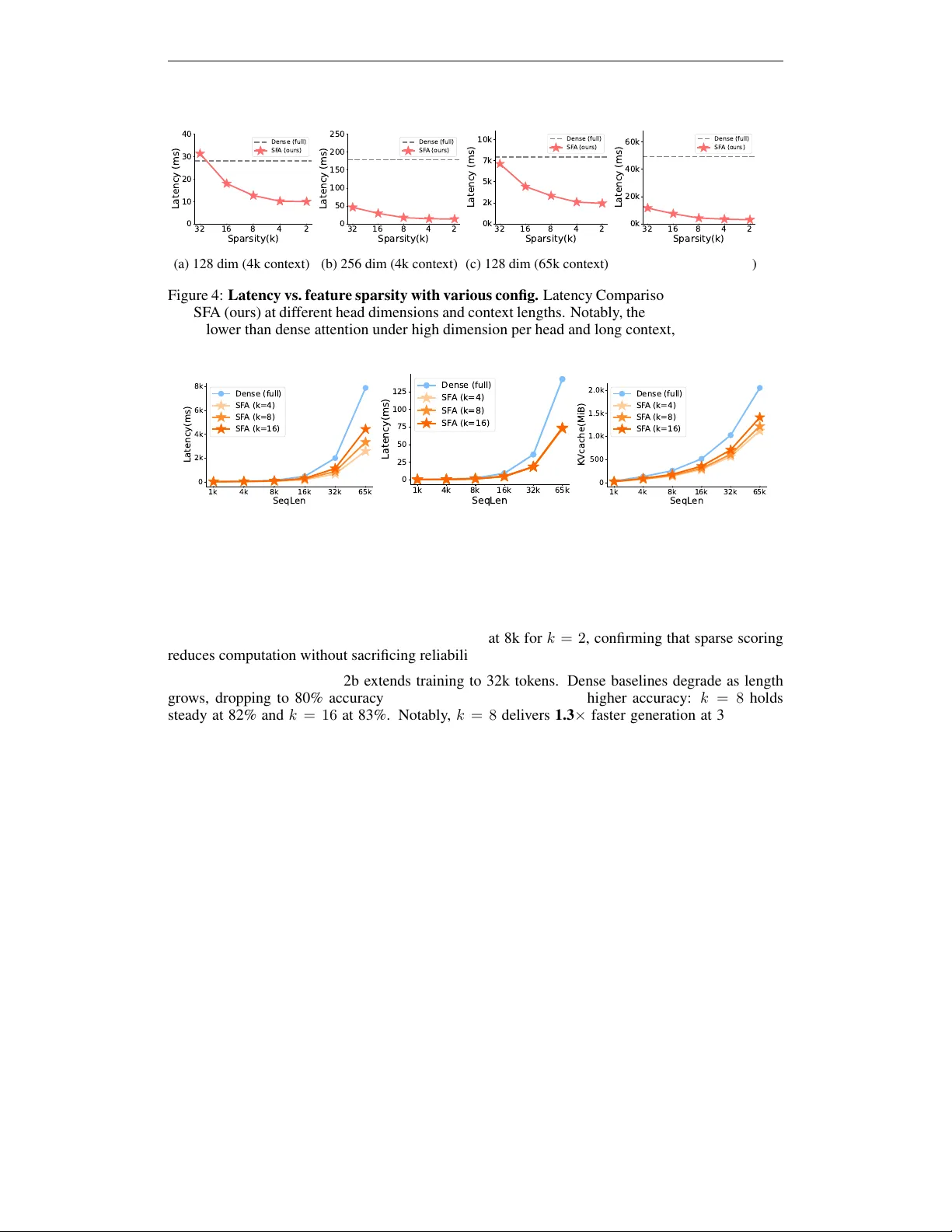
Published as a conference paper at ICLR 2026 S C A L I N G A T T E N T I O N V I A F E A T U R E S PA R S I T Y Y an Xie 1 ∗ Tiansheng W en 1 , 2 ∗ T angda Huang 1 Bo Chen 1 † Chenyu Y ou 2 Stefanie Jegelka 3 , 4 Y ifei W ang 5 † 1 School of Electronic Engineering, Xidian Univ ersity 2 Stony Brook Uni versity 3 TUM 4 MIT 5 Amazon A GI SF Lab ‡ A B S T R AC T Scaling T ransformers to ultra-long contexts is bottlenecked by the O ( n 2 d ) cost of self-attention. Existing methods reduce this cost along the sequence axis through local windows, kernel approximations, or token-le vel sparsity , but these approaches consistently degrade accuracy . In this paper , we instead e xplore an or- thogonal axis: featur e sparsity . W e propose Sparse Feature Attention (SF A) , where queries and keys are represented as k -sparse codes that preserve high- dimensional expressi vity while reducing the cost of attention from Θ( n 2 d ) to Θ( n 2 k 2 /d ) . T o make this efficient at scale, we introduce FlashSF A , an IO- aware kernel that extends FlashAttention to operate directly on sparse overlaps without materializing dense score matrices. Across GPT -2 and Qwen3 pre- training, SF A matches dense baselines while improving speed by up to 2 . 5 × and reducing FLOPs and KV -cache by nearly 50%. On synthetic and down- stream benchmarks, SF A preserv es retriev al accuracy and rob ustness at long contexts, outperforming short-embedding baselines that collapse feature div er- sity . These results establish feature-le vel sparsity as a complementary and un- derexplored axis for efficient attention, enabling Transformers to scale to orders- of-magnitude longer contexts with minimal quality loss. Code is a vailable at https://github .com/Y annX1e/Sparse-Feature-Attention. (a) La te ncy compari son (b) F LOPs & K V - c a c he c ompa rison Figure 1: Overview of our proposed method. (a) T rade-off between performance and speed. Compared to directly reducing dimensionality with short embeddings , our method achieves a more fa vorable balance, deliv ering a 259% speedup over the original dimensionality while improving performance by 21.4% relative to the short-embedding baseline. (b) Computational and memory efficienc y comparison. Our method reduces KV -cache memory usage by 41% and FLOPs by 49%. ∗ Equal Contribution. (yanxie0904@163.com & neil wen987@gmail.com) † Corresponding Authors: Bo Chen (bchen@mail.xidian.edu.cn) and Y ifei W ang (yifeiwg@amazon.com). ‡ This work was done at MIT prior to Y ifei W ang joining Amazon. 1 Published as a conference paper at ICLR 2026 1 I N T RO D U C T I O N Scaling language models to ev er longer contexts is fundamentally limited by the O ( n 2 d ) cost of self-attention, where n is the sequence length and d the feature dimension. Most existing approaches attempt to reduce this cost along the sequence axis. W indowed or low-rank attention variants con- strain interactions to achiev e linear complexity , while token-lev el sparsity prunes which tokens in- teract (Child et al., 2019; Beltagy et al., 2020; Zaheer et al., 2020; Choromanski et al., 2021; W ang et al., 2020; Xiong et al., 2021). Y et large-scale benchmarks consistently show that these approx- imations sacrifice accuracy , leaving dense attention the most reliable option at long ranges. This raises a natural question: rather than reducing the set of tokens, can we explor e featur e diversity as an orthogonal axis for scaling attention? This question is moti vated by findings in representation learning, where sparse embeddings (For - mal et al., 2021; W en et al., 2025; Guo et al., 2026; Y ou et al., 2025; Duan et al., 2024; Xie et al., 2025) show that high-dimensional spaces encode rich features and that selectiv e activ ation can pre- serve expressi vity while yielding large ef ficiency gains. If attention itself can be viewed as retrie val ov er feature coordinates, then sparsifying queries and keys by activ ating only their most salient di- mensions could reduce computation without collapsing representational capacity . The challenge is to realize this idea in practice: how to preserve expressi vity while sparsifying, ho w to implement kernels that benefit from sparsity without materializing the n × n score matrix, and how to adapt pretrained dense models without eroding their quality . W e address these challenges with Sparse Featur e Attention (SF A) . Instead of dense d -dimensional queries and keys, SF A learns k -sparse codes in which each token activ ates only a handful of coor- dinates. Attention scores are computed solely from overlaps between these supports, reducing the arithmetic of QK ⊤ from Θ( n 2 d ) to Θ( n 2 k 2 /d ) – a fraction ( k /d ) 2 of the dense cost – while stor- ing only O ( nk ) nonzeros. T o make this efficient at scale, we introduce FlashSF A , a new IO-aware kernel that e xtends FlashAttention by operating directly on sparse ov erlaps with online softmax. This design av oids materializing any dense n × n scores, retains exactness, and brings compute and memory scaling in line with feature sparsity . The benefits of this shift are demonstrated in Figure 1. Compared to simply shrinking hidden size (“short embeddings”), SF A achieves a much better trade-of f: it improves perplexity by more than 20% while deliv ering over 2.5 × speedup, and reduces FLOPs by nearly half together with a 41% drop in KV -cache memory . Experiments confirm that these benefits extend broadly . On GPT -2 and Qwen3 pretraining, SF A matches dense baselines in perplexity and downstream accuracy . On syn- thetic long-context benchmarks such as Needle-in-a-Haystack, it sustains retriev al accuracy across unseen lengths, while providing consistent latenc y gains. Crucially , the method is orthogonal to token-le vel sparsity and paging, multiplying their benefits by lo wering per-interaction cost. This work thus establishes feature-lev el sparsity as a powerful and previously underexplored axis for ef ficient attention. By le veraging feature diversity rather than compressing it away , SF A pre- serves high-dimensional expressi vity while unlocking substantial ef ficiency gains. T ogether with FlashSF A, it makes exact long-context attention practical at scale, and paves the way for context windows e xtended by orders of magnitude without compromising model quality . 2 P R E L I M I N A R I E S T ransformers and multi-head attention. Let a sequence of n tokens be represented by hidden states X ∈ R n × d model . For each head h ∈ { 1 , . . . , H } with head dimension d , standard scaled dot-product attention computes: Q h = X W Q h ∈ R n × d , K h = X W K h ∈ R n × d , V h = X W V h ∈ R n × d , (1) S h = Q h K ⊤ h √ d ∈ R n × n , P h = softmax( S h ⊙ M ) ∈ R n × n , O h = P h V h ∈ R n × d , (2) where M encodes causal or padding masks, and the head outputs are concatenated and projected. The principal cost arises from the dense Q h K ⊤ h and materialization of P h ; IO-aware kernels (e.g., FlashAttention) compute O h in tiles without forming P h explicitly , minimizing HBM traffic while remaining exact (Dao et al., 2022; Dao, 2024; Shah et al., 2024). 2 Published as a conference paper at ICLR 2026 S t a n d ar d At t en t io n N d N N S p a r se At t ent io n A t t e n t i o n A t t e n t i o n Q u e r y K e y Spar s if y S p a r s e A t t e n t i o n S p a r se F ea t u r e At t en t io n ( o u r s ) N N S p a r s e F e a t u r e A t t e n t i o n N d S p a r s e Q u e r y S p a r s e K e y Figure 2: Three paradigms of attention. Left: Standar d attention computes all N × N query–key interactions in the full feature dimension d . Middle: Sparse attention reduces cost by selecting, for each query i , a small subset of keys Ω i and masking the remaining logits before softmax, but each retained interaction still spans all d features. Right: Sparse F eature Attention (ours) k eeps all tokens but sparsifies along the feature axis by selecting the top- k channels in Q and K ( ˜ Q = T opk k ( Q ) , ˜ K = T opk k ( K ) ). Attention is then computed only over ov erlapping selected features with sparse matrix multiplication. This shifts sparsity from the token axis ( N × N ) to the feature axis, achieving ef ficienc y while preserving token cov erage. Sparse f ormats f or efficient storage. Sparse matrices that contain only a few non-zero elements can be stored efficiently in sparse formats. Consider a matrix A ∈ R n × d with nnz( A ) nonzero elements. In the Compressed Sparse Row (CSR) format, we store three arrays: (i) data ∈ R nnz( A ) , containing the v alues of all nonzero entries, (ii) indices ∈ { 0 , . . . , d − 1 } nnz( A ) , recording the column index of each nonzero, and (iii) indptr ∈ { 0 , . . . , nnz( A ) } n +1 , where indptr[i] marks the of fset in data/indices where ro w i begins. Thus, the nonzeros of ro w i can be read quickly from data[indptr[i]:indptr[i+1]]. The Compr essed Sparse Column (CSC) format is analogous, but compresses by columns instead of rows, with an indptr array of length d + 1 (Saad, 2003; Davis, 2006). Efficient multiplication with spare formats. When multiplying two sparse matrices, the cost is not proportional to the dense size n × d b ut rather to the number of structur al intersections between the nonzero patterns of ro ws and columns. This operation, called Sparse General Matrix Multi- plication (SpGEMM), is typically implemented by Gustavson’ s row-wise accumulation algorithm (Gustavson, 1978) or by hash-based methods (Buluc & Gilbert, 2011). The efficienc y of SpGEMM therefore depends on how man y row–column index sets o verlap, making CSR and CSC natural formats for storing query and key matrices in our method. 3 S P A R S E F E A T U R E A T T E N T I O N This section introduces Sparse F eature Attention (SF A), a drop-in modification of multi-head self- attention that operates along the featur e axis. Each query/key vector is con verted into a k -sparse code; attention scores are then computed only on overlapping activ e coordinates. This preserves the probabilistic semantics of exact softmax attention ov er learned supports while reducing arithmetic, memory traffic, and KV -cache gro wth. 3 . 1 A T T E N T I O N V I A S PA R S E M A T R I X M U LT I P L I C A T I O N The key idea of SF A is to sparsify the query and key features before attention computation, so that only their most salient coordinates contribute to similarity scores. As illustrated in Figure 2 (right), giv en dense projections Q, K, V ∈ R n × d , we apply a row-wise T op- k operator to both Q and K : ˜ Q = T opk k ( Q ) , ˜ K = T opk k ( K ) , (3) where for x ∈ R d , T opk k ( x ) u = x u , u ∈ arg topk( | x | ) , 0 , otherwise . (4) Thus each query and key vector is con verted into a k -sparse representation, preserving only its k largest-magnitude entries. These ˜ Q, ˜ K serve as sparse query and ke y features for attention. Sparse attention via sparse matrix multiplication. Attention scores are then computed as S = ˜ Q ˜ K ⊤ . Instead of full dense multiplication, we exploit sparsity: each nonzero in ˜ q i interacts only 3 Published as a conference paper at ICLR 2026 with keys that share the same acti v e coordinate. For query i with support S i , s ij = 1 √ d X u ∈ S i ∩ S j ˜ q i,u ˜ k j,u , (5) which corresponds to sparse matrix multiplication between ˜ Q (CSR format) and ˜ K ⊤ (CSC format). T rav ersing activ e coordinates yields only the nonzero attention edges. The resulting scores are then passed through the usual softmax and value aggre gation steps. Backward computation. Leveraging the sparse structure, we can also skip computing the gradient for the full query and k ey matrices at backward computation. Specifically , we use a straight-through estimator: gradients flow back only through the selected coordinates. For query i with support S i , ∂ L ∂ q i,u = ( ∂ L ∂ ˜ q i,u , u ∈ S i , 0 , u / ∈ S i , (6) and similarly for k j,u . Both forward and backward passes scale only with the sparse edge set. Efficiency analysis. Dense attention requires Θ( n 2 d ) computation and Θ( n 2 ) memory , since ev ery query interacts with ev ery key across all d feature dimensions. In contrast, SF A only forms scores along feature coordinates selected by both queries and keys. Each token acti vates k features, giving nk nonzeros in total. Assuming supports are balanced across dimensions, each coordinate is chosen by about deg( u ) ≈ nk /d tokens. The number of query–key o verlaps contrib uted by coordinate u is then deg( u ) 2 , and summing ov er all d coordinates yields: E ≈ d X u =1 deg( u ) 2 ≈ d nk d 2 = n 2 k 2 d . (7) Thus the total cost for attention shrinks from Θ( n 2 d ) (dense) to Θ( n 2 k 2 /d ) (sparse), which is only a fraction k 2 /d 2 of the dense cost. Both forward and backw ard passes then cost O ( E + E d v ) FLOPs, and memory for storing query and key drops from O ( nd ) to O ( nk ) with the sparse formats. For concreteness, with d = 128 and k = 16 (default setting considered in this work), the ratio is k 2 /d 2 = 1 / 64 , i.e. about a 64 × reduction in theory . As the dimension d increases in larger models, the gain could be ev en higher . F or d = 1024 and k = 32 (shown to hav e very similar retrie v al performance in W en et al. (2025)), the ratio is 32 2 / 1024 2 = 1 / 1024 , i.e., a reduction of more than 1000 × . This means sparse feature attention can potentially extend context length by one to three orders of magnitude at similar compute cost. F or example, turning a 1M context window into 64M or ev en 1G, opening up substantial improv ements for long-context applications. 3 . 2 F L A S H S FA : F A S T S PA R S E F E A T U R E A T T E N T I O N W I T H O U T M A T E R I A L I Z AT I O N A key challenge in Sparse Feature Attention (SF A) is that, although we reduce the number of pair- wise interactions from n 2 d to n 2 k 2 /d , a naïve implementation would still require materializing an n × n score matrix to apply the softmax. This would destroy the memory adv antage, as the O ( n 2 ) storage is often the real bottleneck at long sequence lengths. FlashAttention addressed exactly this issue in the dense case: it av oids storing QK ⊤ by processing queries and keys in small tiles, keeping only a temporary tile buffer of partial scores on-chip. An online softmax update maintains numerical stability and exactness without e v er writing the full n × n matrix to memory (Dao et al., 2022). FlashAttention-2 and -3 extend this idea with more parallelism and precision refinements (Dao, 2024; Shah et al., 2024). Our proposed FlashSF A e xtends this principle to SF A. W e retain the IO-aware tiling and online-softmax machinery of FlashAttention, b ut replace dense tile multiplications with sparse feature-intersection kernels. For a tile of queries (ro ws i ∈ [ i 0 , i 0 + B r ) ) and keys (columns j ∈ [ j 0 , j 0 + B c ) ), the kernel iterates over the activ e features of these tok ens, intersects their supports, and performs scatter-adds into a compact B r × B c score b uf fer . This buf fer is immediately consumed by the online softmax update, so no large score matrix is e ver written to memory . The result is mathematically identical to computing softmax( ˜ Q ˜ K ⊤ / √ d ) V , but with both compute and memory scaling as in SF A. Efficiency and design. FlashSF A inherits the same O ( n ) IO complexity of FlashAttention, since only tiles (not the full matrix) touch high-bandwidth memory . W ithin each tile, the work is pro- portional to the number of overlapping features rather than d , yielding the O ( n 2 k 2 /d ) complexity 4 Published as a conference paper at ICLR 2026 T able 1: Perplexity and Accuracy results. Dense baselines use full hidden size and uncompressed KV cache; “Dense ( d =X)” denotes short-embedding baselines with reduced feature dimension. PPL is ev aluated on OpenW ebT ext for GPT -2 and Pile for Qwen3. Note that “Dense (full)" serves as a reference upper bound; we highlights the best results among the sparse/compressed baselines. Model Latency ↓ PPL ↓ Acc ↑ 128k context O WT/Pile PiQA LAMBAD A ARC-e ARC-c HellaS A vg-Acc GPT2-124M Dense (full) 16.86 17.29 56.34 22.78 28.35 14.32 19.61 28.28 Dense ( d = 32 ) 7.86 20.88 51.30 19.39 25.72 12.47 14.26 24.63 SF A ( k = 8 ) 9.41 18.27 54.92 21.03 28.41 7.39 19.26 27.40 GPT2-350M Dense (full) 46.78 15.03 59.79 24.74 30.19 15.78 22.04 30.51 Dense ( d = 32 ) 20.58 19.89 55.17 19.96 28.15 11.83 18.43 26.71 SF A ( k = 8 ) 23.67 16.78 58.02 23.83 30.22 13.66 22.13 29.57 Qwen3-0.6B Dense (full) 77.65 4.66 62.47 34.82 45.41 20.35 33.95 39.40 Dense ( d = 64 ) 30.84 6.03 58.43 31.27 41.58 15.83 28.29 36.68 SF A ( k = 16 ) 34.20 4.81 61.73 34.05 45.62 19.27 34.03 38.94 analyzed in §3.1. The online softmax logic, masking for causality , and streaming of V are un- changed. Indices for sparse features add modest ov erhead ( O ( nk ) ), and can be stored efficiently with 16-bit integers for typical d ≤ 65 , 535 . By marrying the sparsity of SF A with the memory-efficient tiling of FlashAttention, FlashSF A achiev es the best of both worlds: it av oids O ( n 2 ) materialization while preserving the k 2 d 2 reduc- tion in arithmetic and memory cost. This enables exact attention with dramatically lower compute and memory footprints, making long-context training and inference practical at scale. W e defer a full description of the FlashSF A algorithm to Appendix C. 4 E X P E R I M E N T S 4 . 1 P R E T R A I N I N G E X P E R I M E N T S Having introduced Sparse Feature Attention (SF A) and the FlashSF A kernel, we next examine whether autoregressi v e LMs trained from scratch can maintain modeling quality under feature spar - sification. W e e valuate GPT -2 and Qwen3 models against dense and short-embedding baselines, measuring both modeling quality and efficienc y . Models and baselines. W e study GPT -2 Small/Medium (Radford et al., 2019) and Qwen3-0.6B (Y ang et al., 2025), replacing dense QK ⊤ scoring with SF A while keeping V dense. Sparsity budgets k ∈ { 8 , 16 } are tested. Baselines include standard dense attention and short-embedding variants (halving the hidden size of Q/K ). Note that “Dense (full)" serv es as a reference upper bound; we highlights the best results among the sparse/compressed baselines. W e use the R T opK kernel (Xie et al., 2024) for efficient topk operations. Additional implementation details, including model configurations and handling of RoPE dimensions in Qwen3, are deferred to Appendix A.1. Datasets and benchmarks. GPT -2 models are trained on OpenW ebT ext (Gokaslan & Cohen, 2019), Qwen3 on The Pile (Gao et al., 2020; Biderman et al., 2022). W e report v alidation perple xity (PPL), zero-shot accuracy on PiQA (Bisk et al., 2020), LAMBAD A (Paperno et al., 2016), ARC-e/ARC- c (Clark et al., 2018), and HellaSwag (Zellers et al., 2019), as well as decoding throughput at 128k tokens ( Speed@128k ) to assess long-context ef ficienc y . GPT -2 results. T able 1 sho ws that SF A with k = 16 (not sho wn here but consistent with k = 8 trends) closely tracks dense baselines, with negligible differences in perplexity and accuracy . SF A with k = 8 incurs slightly higher PPL and minor accuracy drops, but these remain within accept- able bounds. This demonstrates that sparsified features preserv e most of the model’ s expressi ve capacity . By contrast, short-embedding baselines degrade more substantially: they reduce perplex- ity efficienc y and underperform on challenging tasks such as ARC-c, especially for GPT -2 Small. While such baselines deliv er higher throughput, their quality–efficienc y balance is skewed tow ard 5 Published as a conference paper at ICLR 2026 T able 2: Long context pretraining results. Comparison of NIAH accuracy rates for dif ferent lengths under various training lengths. (a) Models are trained on 8k synthetic NIAH data, and the accuracy rate on test lengths from 1k to 8k. (b) Models are trained on 32k synthetic NIAH data, and the accuracy rate on test lengths from 1k to 32k. (a) NIAH accuracy (%) within 8k Sequence Length. Context Length Method 1k 2k 4k 8k Speed@8k Dense ( d = 64 ) 94% 93% 90% 95% 1.0 × SF A ( k = 2 ) 95% 95% 97% 98% 1.9 × SF A ( k = 8 ) 98% 100% 99% 98% 1.3 × (b) NIAH accuracy (%) within 32k Sequence Length. Context Length Method 1k 4k 16k 32k Speed@32k Dense ( d = 64 ) 92% 94% 83% 80% 1.0 × SF A ( k = 8 ) 95% 94% 83% 82% 1.3 × SF A ( k = 16 ) 97% 96% 83% 83% 1.0 × 2 4 8 16 32 Sparsity(k) 0 50 100 150 200 Latency (ms) Dense (full) SF A (ours) (a) Dot-Product only 2 4 8 16 32 Sparsity(k) 0 200 400 Latency (ms) Dense (full) SF A (ours) (b) Attention Block 2 4 8 16 32 Sparsity(k) 0k 1k 2k 3k Latency (ms) Dense (full) SF A (ours) (c) FlashAttention Block 2 4 8 16 32 Sparsity(k) 0 20 40 60 80 100 Latency (s) Dense (full) SF A (ours) (d) Entire T ransformer Figure 3: Latency vs. feature sparsity . Latency Comparison of dense attention and SF A (ours) at different modular le vels in T ransformers under 16k context length. Higher sparsity brings substantial decrease in latency . speed, making them less appealing. On retrie val-like tasks (LAMB AD A, HellaSwag), sparse models underperform relativ e to their PPL, moti vating further retrie v al-focused experiments (Section 4.2). Qwen3 results. For Qwen3-0.6B, also in T able 1, SF A with k = 8 maintains perplexity nearly identical to dense (4.81 vs. 4.66) and preserv es accuracy across PiQA, ARC-e, and HellaSwag. The small dif ferences on ARC-c (19.27 vs. 20.35) and average accuracy (38.94 vs. 39.40) suggest only a marginal quality cost. Short-embedding baselines again degrade more sev erely , with higher PPL (6.03) and lower accuracy (A vg-Acc 36.68). This confirms that even in modern architectures with RoPE and normalization refinements, sparsified features remain competitive with dense attention, while offering clear ef ficienc y benefits at long context. Efficiency results. Across GPT -2 and Qwen3, short-embedding variants provide the largest raw speedups due to narrower hidden size, b ut their accuracy loss makes them less practical. Sparse models present a more balanced trade-off: k = 16 maintains baseline-le vel quality , and k = 8 provides moderate speedups while remaining close in accuracy . In practice, k = 8 emerges as the most attractiv e setting, balancing efficienc y and modeling quality . This setting is therefore used in subsequent scaling and efficienc y benchmarks (Section 4.3). 4 . 2 S Y N T H E T I C N I A H E X P E R I M E N T S The synthetic Needle-in-a-Haystack (NIAH) benchmark provides a controlled way to examine ho w models handle extremely long contexts and retrie val-style reasoning. T o further examine whether sparse attention preserv es retrie val capacity ov er long contexts, we conduct e xperiments on the syn- thetic NIAH task. Following the R ULER methodology , haystacks are constructed by repeating the character “#” and inserting a single target “needle” token that the model must recover . W e train GPT -2 models (124M) from scratch on synthetic NIAH QA data under two training regimes: one restricted to 8k contexts and one e xtended to 32k contexts. In both cases, we then ev aluate test accu- racy across multiple held-out lengths, measuring how well models generalize beyond their training window . Speed is also measured at the maximum training length to capture efficiency . Results within 8k. T able 2a reports results when models are trained up to 8k tokens. Dense base- lines perform well across all lengths b ut incur standard compute costs. Sparse models not only match but slightly exceed dense accuracy , achieving near-perfect reco very at all test lengths. At the 6 Published as a conference paper at ICLR 2026 2 4 8 16 32 Sparsity(k) 0 10 20 30 40 Latency (ms) Dense (full) SF A (ours) (a) 128 dim (4k context) 2 4 8 16 32 Sparsity(k) 0 50 100 150 200 250 Latency (ms) Dense (full) SF A (ours) (b) 256 dim (4k context) 2 4 8 16 32 Sparsity(k) 0k 2k 5k 7k 10k Latency (ms) Dense (full) SF A (ours) (c) 128 dim (65k context) 2 4 8 16 32 Sparsity(k) 0k 20k 40k 60k Latency (ms) Dense (full) SF A (ours) (d) 256 dim (65k context) Figure 4: Latency vs. feature sparsity with various config. Latency Comparison of dense attention and SF A (ours) at different head dimensions and conte xt lengths. Notably , the latency of SF A can be much lower than dense attention under high dimension per head and long conte xt, e.g., Figure 4d. 1k 4k 8k 16k 32k 65k SeqL en 0 2k 4k 6k 8k Latency(ms) Dense (full) SF A (k=4) SF A (k=8) SF A (k=16) (a) Latency vs conte xt length 1k 4k 8k 16k 32k 65k SeqL en 0 25 50 75 100 125 Latency(ms) Dense (full) SF A (k=4) SF A (k=8) SF A (k=16) (b) FLOPs vs context length 1k 4k 8k 16k 32k 65k SeqL en 0 500 1.0k 1.5k 2.0k KVcache(MiB) Dense (full) SF A (k=4) SF A (k=8) SF A (k=16) (c) KV -cache vs context length Figure 5: Scaling dense attention and SF A with context length. SF A can consistently reduce both the computatin cost and KV cache size by a constant factor of at least 2 . same time, SF A delivers a 1.9 × decoding speedup at 8k for k = 2 , confirming that sparse scoring reduces computation without sacrificing reliability . Results within 32k. T able 2b extends training to 32k tokens. Dense baselines degrade as length grows, dropping to 80% accuracy at 32k. SF A models maintain higher accuracy: k = 8 holds steady at 82% and k = 16 at 83%. Notably , k = 8 delivers 1.3 × faster generation at 32k, while k = 16 matches dense throughput. These results sho w that sparse attention generalizes robustly across unseen lengths while simultaneously reducing long-context latenc y . Discussion. The NIAH task isolates retriev al in a controlled setting, making it possible to compare dense and sparse features without confounding factors. Across both 8k and 32k training regimes, SF A preserves or improv es accuracy while achieving consistent speedups. This complements the pretraining results in Section 4.1: sparse attention does not erode retriev al ability , and under syn- thetic stress tests it can ev en provide stronger length generalization than dense attention. 4 . 3 B E N C H M A R K I N G C O M P U TA T I O N A N D M E M O RY E FFI C I E N C Y O F S FA W e benchmark Sparse Feature Attention (SF A) in both training and inference scenarios, since they stress different system bottlenecks. Training-time attention is dominated by quadratic computation, while inference-time attention with KV cache is dominated by memory traffic. Experiments are run on an A800 GPU with CUD A 12.4 , using INT32 for indptr and INT8 for indices , FP16 for values , and pinned batches in HBM. T iming excludes dataloader ov erhead. All kernels are compiled with CUD A and Ninja , and we report medians o ver 50 warm runs. W e built our FlashSF A kernel upon LeetCUD A. Influence of SF A in T ransf ormers. Figure 3 compares latency of SF A and dense attention across different modular levels of a Transformer: from the raw dot-product to the full model. As sparsity increases (smaller k ), latency drops significantly . Importantly , the benefit compounds with complex- ity: while dot-product alone shows modest gains, the full T ransformer achie ves over 2 × reduction. This demonstrates that sparsity scales well when applied throughout the network stack. 7 Published as a conference paper at ICLR 2026 T able 3: Evaluation on general reasoning tasks and synthetic retrie v al (NIAH). Accuracy is in %. Model V ariant General T asks NIAH Acc GSM-8K Arxiv PubMed 4096 8192 16384 32768 Qwen3-0.6B Base 59.59 13.65 10.48 90 87 77 52 Fine-tune 63.42 41.17 40.54 94 92 79 55 SF A ( k = 16 ) 61.46 39.14 39.03 95 93 77 53 Qwen3-4B Base 75.44 31.52 29.19 97 95 90 81 Fine-tune 76.18 49.31 49.05 99 96 92 84 SF A ( k = 16 ) 75.56 46.28 47.91 99 93 91 84 Qwen3-8B Base 87.62 40.13 37.22 100 100 97 92 Fine-tune 89.11 54.26 55.07 100 100 99 95 SF A ( k = 16 ) 87.99 52.74 52.61 100 100 100 97 Influence of Dimension and Context Length. Figure 4 examines latency under varying head di- mensions ( 128 vs. 256 ) and conte xt lengths ( 4 k vs. 65 k). At shorter conte xts (4k tokens), SF A of fers consistent but moderate gains. Ho wev er , under long contexts (65k tokens) and lar ger head sizes (256 dim), the improvement is dramatic: SF A reduces latency by more than an order of magnitude. This confirms that sparsity is most ef fecti ve in the large-scale regime, where dense attention becomes prohibitiv ely expensi ve. Latency and Memory Scaling at Inference. Figure 5 benchmarks autoregressiv e inference with KV cache. F or short contexts ( ≤ 4k), dense attention remains competitiv e because sparse kernels incur lookup o verhead. Beyond 8k–16k tokens, howe ver , SF A consistently outperforms dense atten- tion. Moreover , SF A reduces KV -cache size proportionally to sparsity , sa ving up to ∼ 40% memory at k = 4 . This makes sparse features especially valuable for long-context inference, where memory footprint is often the limiting factor . T ogether , these results show that SF A addresses both compute and memory bottlenecks. During training, it accelerates high-dimension, long-conte xt workloads by cutting FLOPs; during inference, it reduces both latency and KV -cache usage for long sequences. These complementary benefits make SF A well-suited for scaling LLMs to ultra-long contexts. More results are sho wn in Appendix E. 5 E X P L O R I N G S FA A DA P TA T I O N W I T H P R E T R A I N E D L L M S In addition to incorporating SF A during the pretraining stage, we also attempted to adjust models with dense pretraining to a sparse feature attention pattern through fine-tuning. In this section, we explore the use of SF A in fine-tuning. Regularized Sparse Finetuning. During finetuning, we keep SF A consistent with our strategy in the pre-training phase (Eqs. 3 & 6). Nev ertheless, the sparsification of pretrained dense features introduces a se vere distribution shift for the pretrained model. Therefore, we regularize the finetuning with an additional MSE loss such that SF A ’ s attention scores approximate that of dense features. Since FlashAttention and FlashSP A do not materialize the full attention matrix, in practice we ap- proximate the denese attention output O h (with stop gradient) with SF A ’ s attention output ˜ O h at each head h , leading to the final finetuning objectiv e: L = L LM + λ L reg = − E ( x,y ) log p θ y | x ; ˜ S , V + λ 1 H H X h =1 ˜ O h − stopgrad O h 2 F . (8) Datasets. T o comprehensi vely ev aluate the performance of SF A during fine-tuning, we conduct experiments using mathematical tasks, document question answering, and long-context retrie val tasks. W e use GSM-8K (Cobbe et al., 2021), Sci-papers (Arxiv and PubMed (Cohan et al., 2018)), and NIAH data constructed from real texts, respecti vely . Because applying T op K to the features 8 Published as a conference paper at ICLR 2026 almost resets the pattern of the pre vious dense features, we first restore the model’ s language ability by training on a similar reasoning dataset, MWP-200k (Mitra et al., 2024), before GSM-8K. F or the NIAH data, we use the Pile dataset as haystack for random filling. The size of the training set is set to 100k, and 100 test data entries for each length in the test set. T raining Settings. W e fine-tune Qwen3-0.6B and Qwen3-4B using Llama-Factory (Zheng et al., 2024) with k = 16 for SF A. For mathematical reasoning and science QA tasks, the training con- text length is set to 16,384 tokens, while for long-context retrie val tasks it is set to 32,768 tokens, with ev aluation spanning 4k–32k contexts. All models are trained for three epochs with identical hyperparameters. Detailed experiment setting can be found in Section A.2. Result Analysis. T able 3 compares the base model, dense fine-tuning, and our T op-16 v ariant. On general tasks, dense fine-tuning yields large gains on Arxi v and PubMed by adapting to the ev aluation format, and SF A closely tracks these improvements, showing that sparsified features preserve document-comprehension signals even under hard k . On GSM-8K, T op-16 lags slightly behind dense fine-tuning, indicating that arithmetic reasoning is more sensitive to pruning. For long-context retriev al (NIAH), T op-16 performs nearly identically to dense fine-tuning, consistent with Section 4.2, suggesting that sparse supports provide an effecti v e inductive bias for locality . At the 4B scale, T op-16 remains within 1–3 points of dense on general tasks and holds parity on NIAH, confirming its robustness and compatibility with lar ger backbones. 6 R E L AT E D W O R K T oken-level sparsity . Many approaches reduce the quadratic cost by pruning which tok ens interact. Structured patterns (local/strided/global) and learned routing yield strong long-context performance: Sparse Transformers (Child et al., 2019), Longformer and BigBird (Beltagy et al., 2020; Zaheer et al., 2020), Routing Transformers (Roy et al., 2021), and Reformer (Kitaev et al., 2020). Recent inference systems dynamically select salient tokens or pages (H 2 O, SnapKV , Quest) (Zhang et al., 2023; Li et al., 2024; T ang et al., 2024). These methods are orthogonal to ours: they sparsify the set of tokens , while we sparsify the featur e coordinates used to score any retained token pair . In practice, SF A composes with token sparsity and paging by shrinking the per-interaction cost. Low-rank/ker nel approximations vs. feature sparsity . A parallel line alters the operator to achiev e linear or near-linear time via low-rank or kernel approximations: Linformer projects K , V (W ang et al., 2020); Performer approximates softmax with random features (Choromanski et al., 2021); Nyströmformer uses landmark decompositions (Xiong et al., 2021). These compress infor- mation into a dense r ≪ d space, often trading expressivity for speed. By contrast, SF A keeps the high-dimensional feature space b ut acti vat es only k ≪ d learned coordinates per token; attention scores are computed e xactly over the ov erlap of acti v e supports (no kernel surrogates). This is closer in spirit to sparse coding and sparse embeddings (e.g., SPLADE; CSR) that preserve semantic detail while enabling in verted-inde x efficienc y (Formal et al., 2021; W en et al., 2025). Efficient attention kernels and sparse representations. FlashAttention reorders computation and IO to keep attention e xact while minimizing off-chip traffic (Dao et al., 2022; Dao, 2024; Shah et al., 2024); systems like xFormers and flashinfer expose page/block sparsity primiti ves (Lefaudeux et al., 2022; Y e et al., 2025). Some works use feature cues to drive token selection atop such kernels (e.g., SP AR-Q; LoKI) (Ribar et al., 2024; Singhania et al., 2024). SF A differs by learning sparse Q/K codes as first-class representations and introducing an IO-aware kernel ( FlashSF A ) that iterates intersections of activ e coordinates rather than dense d -dimensional products, yielding arithmetic and bandwidth savings proportional to k and composing naturally with token-sparse routing. Our focus is thus complementary: we open the underexplored axis of feature-le vel sparsity inside attention while remaining compatible with token-le vel sparsity and paging. 7 C O N C L U S I O N A N D L I M I TA T I O N S W e presented Sparse F eatur e Attention (SF A) , a ne w approach to scaling long-context T ransform- ers through dimension-level sparsity . By learning sparse query/key codes and computing attention via feature ov erlaps, SF A preserv es high-dimensional expressi vity while reducing both memory and compute. W e introduced two adaptation strategies (end-to-end T op- k finetuning and adapter-based 9 Published as a conference paper at ICLR 2026 training) and an IO-aware FlashSF A kernel that integrates sparsity directly into the online-softmax pipeline. Experiments across synthetic and real tasks show that SF A achie ves comparable qual- ity to dense attention with gro wing ef ficiency gains at longer contexts, and complements existing token-le vel sparsity methods. While promising, sev eral aspects remain open. Sparse tensor products require stronger support from GPU hardware and CUD A libraries to fully unlock their ef ficiency , though these system-le vel challenges are likely to be resolved ov er time. V ery sparse query/key codes can lead to occasional quality degradation, suggesting the need for adaptive sparsity budgets. Finally , ho w to best com- bine token-level and dimension-level sparsity remains an exciting direction, offering the possibility of compounding gains in both compute and memory . W e view SF A as a first step toward explor- ing this new axis of sparsity in attention, and hope it motiv ates further work at the intersection of representation learning, attention design, and efficient systems. Ethics Statement. This work complies with the ICLR Code of Ethics. Our research primarily utilizes publicly a vailable datasets and pretrained models, and we do not foresee an y direct negati v e societal impacts or ethical concerns arising from our methodology . Reproducibility . W e provide detailed descriptions of our methodology , datasets, model configu- rations, and ev aluation metrics in the main text and Appendix. Upon acceptance, we will release source code and scripts to enable full replication of our experiments. A C K N O W L E D G E M E N T S Y an Xie, T iansheng W en, T angda Huang, and Bo Chen were supported in part by the National Natural Science Foundation of China under Grant 62576266; in part by the Fundamental Research Funds for the Central Univ ersities QTZX24003 and QTZX23018; in part by the 111 Project under Grant B18039. Y ifei W ang and Stefanie Jegelka were supported in part by the NSF AI Institute TILOS (NSF CCF-2112665), and an Alexander v on Humboldt Professorship. R E F E R E N C E S Iz Beltagy , Matthe w E Peters, and Arman Cohan. Longformer: The long-document transformer . arXiv pr eprint arXiv:2004.05150 , 2020. Stella Biderman, Kieran Bicheno, and Leo Gao. Datasheet for the pile. arXiv preprint arXiv:2201.07311 , 2022. Y onatan Bisk, Ro wan Zellers, Jianfeng Gao, Y ejin Choi, et al. Piqa: Reasoning about physical com- monsense in natural language. In Proceedings of the AAAI confer ence on artificial intelligence , volume 34, pp. 7432–7439, 2020. A ydin Buluc and John R. Gilbert. The combinatorial blas: design, implementation, and applications. IJHPCA , 25(4):496–509, 2011. Rew on Child, Scott Gray , Alec Radford, and Ilya Sutske ver . Generating long sequences with sparse transformers. arXiv preprint , 2019. Krzysztof Marcin Choromanski, V alerii Likhosherstov , David Dohan, Xingyou Song, Andreea Gane, T amas Sarlos, Peter Ha wkins, Jared Quincy Davis, Afroz Mohiuddin, Lukasz Kaiser , et al. Rethinking attention with performers. In International Confer ence on Learning Repr esentations , 2021. Peter Clark, Isaac Cowhe y , Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind T afjord. Think you hav e solved question answering? try arc, the ai2 reasoning challenge. arXiv pr eprint arXiv:1803.05457 , 2018. Karl Cobbe, V ineet Kosaraju, Mohammad Bavarian, Mark Chen, Hee woo Jun, Lukasz Kaiser, Matthias Plappert, Jerry T worek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. T raining verifiers to solve math word problems. arXiv pr eprint arXiv:2110.14168 , 2021. 10 Published as a conference paper at ICLR 2026 Arman Cohan, Franck Dernoncourt, Doo Soon Kim, Trung Bui, Seokhwan Kim, W alter Chang, and Nazli Goharian. A discourse-aware attention model for abstractiv e summarization of long docu- ments. Pr oceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language T echnologies, V olume 2 (Short P apers) , 2018. doi: 10.18653/v1/n18- 2097. URL http://dx.doi.org/10.18653/v1/n18- 2097 . T ri Dao. Flashattention-2: F aster attention with better parallelism and work partitioning. In The T welfth International Confer ence on Learning Repr esentations , 2024. T ri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory- efficient exact attention with io-awareness. Advances in neural information pr ocessing systems , 35:16344–16359, 2022. T imothy A Davis. Dir ect methods for sparse linear systems . SIAM, 2006. DefT ruth and Man y Others. Leetcuda: A modern cuda learn notes with p ytorch for beginners, 2025. URL https://github.com/xlite- dev/LeetCUDA.git . Open-source software av ailable at https://github .com/xlite-de v/LeetCUD A.git. Zhibin Duan, Tiansheng W en, Y ifei W ang, Chen Zhu, Bo Chen, and Mingyuan Zhou. Contrastive factor analysis, 2024. URL . Thibault Formal, Carlos Lassance, Benjamin Piwowarski, and Stéphane Clinchant. SPLADE v2: Sparse lexical and expansion model for information retriev al. arXiv preprint , 2021. Leo Gao, Stella Biderman, Sid Black, Laurence Golding, T ravis Hoppe, Charles Foster , Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The Pile: An 800GB dataset of div erse text for language modeling. arXiv pr eprint arXiv:2101.00027 , 2020. Aaron Gokaslan and V anya Cohen. Openwebtext corpus. http://Skylion007.github.io/ OpenWebTextCorpus , 2019. Lixuan Guo, Y ifei W ang, Tiansheng W en, Y ifan W ang, Aosong Feng, Bo Chen, Stefanie Jegelka, and Chenyu Y ou. Csrv2: Unlocking ultra-sparse embeddings, 2026. URL https://arxiv. org/abs/2602.05735 . Fred G Gusta vson. T wo fast algorithms for sparse matrices: Multiplication and permuted transposi- tion. ACM T ransactions on Mathematical Softwar e (TOMS) , 4(3):250–269, 1978. Nikita Kitaev , Lukasz Kaiser , and Anselm Le vskaya. Reformer: The ef ficient transformer . In International Confer ence on Learning Repr esentations , 2020. Benjamin Lefaudeux, Francisco Massa, Diana Liskovich, W enhan Xiong, V ittorio Caggiano, Sean Naren, Min Xu, Jieru Hu, Marta T intore, Susan Zhang, Patrick Labatut, Daniel Haziza, Luca W ehrstedt, Jeremy Reizenstein, and Grigory Sizo v . xformers: A modular and hackable trans- former modelling library . https://github.com/facebookresearch/xformers , 2022. Y uhong Li, Y ingbing Huang, Bo wen Y ang, Bharat V enkitesh, Acyr Locatelli, Hanchen Y e, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm kno ws what you are looking for before generation. Advances in Neural Information Pr ocessing Systems , 37:22947–22970, 2024. Aixin Liu, Bei Feng, Bin W ang, Bingxuan W ang, Bo Liu, Chenggang Zhao, Chengqi Dengr , Chong Ruan, Damai Dai, Daya Guo, et al. Deepseek-v2: A strong, economical, and efficient mixture- of-experts language model. arXiv pr eprint arXiv:2405.04434 , 2024a. Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Y ashar Mehdad, Y angyang Shi, Raghuraman Krishnamoorthi, and V ikas Chandra. Llm-qat: Data-free quantization aware training for large language models. In F indings of the Association for Computational Linguistics: A CL 2024 , pp. 467–484, 2024b. Arindam Mitra, Hamed Khanpour , Corby Rosset, and Ahmed A wadallah. Orca-math: Unlocking the potential of slms in grade school math. arXiv preprint , 2024. 11 Published as a conference paper at ICLR 2026 Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Ngoc-Quan Pham, Raf faella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The lambada dataset: W ord prediction requiring a broad discourse context. In Pr oceedings of the 54th annual meeting of the association for computational linguistics (volume 1: Long papers) , pp. 1525–1534, 2016. Alec Radford, Jef f W u, Re won Child, David Luan, Dario Amodei, and Ilya Sutskev er . Language models are unsupervised multitask learners. 2019. Luka Ribar , Ivan Chelombie v , Luke Hudlass-Galley , Charlie Blake, Carlo Luschi, and Douglas Orr . Sparq attention: bandwidth-efficient llm inference. In Pr oceedings of the 41st International Confer ence on Machine Learning , pp. 42558–42583, 2024. Aurko Roy , Mohammad Saff ar , Ashish V aswani, and Da vid Grangier . Efficient content-based sparse attention with routing transformers. T ransactions of the Association for Computational Linguis- tics , 9:53–68, 2021. Y ousef Saad. Iterative methods for sparse linear systems . SIAM, 2003. Jay Shah, Ganesh Bikshandi, Y ing Zhang, V ijay Thakkar , Pradeep Ramani, and T ri Dao. Flashattention-3: Fast and accurate attention with asynchrony and low-precision. Advances in Neural Information Pr ocessing Systems , 37:68658–68685, 2024. Prajwal Singhania, Siddharth Singh, Shwai He, Soheil Feizi, and Abhinav Bhatele. Loki: Low- rank keys for efficient sparse attention. Advances in Neural Information Processing Systems , 37: 16692–16723, 2024. Jiaming T ang, Y ilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. Quest: query- aware sparsity for efficient long-context llm inference. In Pr oceedings of the 41st International Confer ence on Machine Learning , pp. 47901–47911, 2024. Sinong W ang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity . arXiv preprint , 2020. T iansheng W en, Y ifei W ang, Zequn Zeng, Zhong Peng, Y udi Su, Xinyang Liu, Bo Chen, Hongwei Liu, Stefanie Jegelka, and Chenyu Y ou. Beyond matryoshka: Revisiting sparse coding for adap- tiv e representation. In International Confer ence on Machine Learning , pp. 66520–66538. PMLR, 2025. Xi Xie, Y uebo Luo, Hongwu Peng, and Caiwen Ding. Rtop-k: Ultra-fast row-wise top-k selection for neural network acceleration on gpus. In The Thirteenth International Confer ence on Learning Repr esentations , 2024. Y an Xie, Zequn Zeng, Hao Zhang, Y ucheng Ding, Y i W ang, Zhengjue W ang, Bo Chen, and Hong- wei Liu. Discovering fine-grained visual-concept relations by disentangled optimal transport concept bottleneck models. In Proceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition , pp. 30199–30209, 2025. Y unyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty , Mingxing T an, Glenn Fung, Y in Li, and V ikas Singh. Nyströmformer: A nyström-based algorithm for approximating self-attention. In Pr oceedings of the AAAI confer ence on artificial intelligence , volume 35, pp. 14138–14148, 2021. An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Bin yuan Hui, Bo Zheng, Bo wen Y u, Chang Gao, Chengen Huang, Chenxu Lv , et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388 , 2025. Zihao Y e, Lequn Chen, Ruihang Lai, Wuwei Lin, Y ineng Zhang, Stephanie W ang, T ianqi Chen, Baris Kasikci, V inod Grov er , Arvind Krishnamurthy , et al. Flashinfer: Efficient and customizable attention engine for llm inference serving. Pr oceedings of Mac hine Learning and Systems , 7, 2025. Chenyu Y ou, Haocheng Dai, Y ifei Min, Jasjeet S Sekhon, Sarang Joshi, and James S Duncan. Un- cov ering memorization effect in the presence of spurious correlations. Nature Communications , 16(1):5424, 2025. 12 Published as a conference paper at ICLR 2026 Jingyang Y uan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Y uxing W ei, Lean W ang, Zhiping Xiao, et al. Native sparse attention: Hardware-aligned and nativ ely trainable sparse attention. In Pr oceedings of the 63r d Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pp. 23078–23097, 2025. Manzil Zaheer, Guru Guruganesh, Kumar A vina v a Dubey , Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan W ang, Li Y ang, et al. Big bird: T ransformers for longer sequences. Advances in neural information pr ocessing systems , 33:17283–17297, 2020. Row an Zellers, Ari Holtzman, Y onatan Bisk, Ali Farhadi, and Y ejin Choi. Hellaswag: Can a ma- chine really finish your sentence? In Pr oceedings of the 57th annual meeting of the association for computational linguistics , pp. 4791–4800, 2019. Zhenyu Zhang, Y ing Sheng, Tian yi Zhou, T ianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Y uandong T ian, Christopher Ré, Clark Barrett, et al. H2o: Hea vy-hitter oracle for efficient gen- erativ e inference of lar ge language models. Advances in Neural Information Pr ocessing Systems , 36:34661–34710, 2023. Y aowei Zheng, Richong Zhang, Junhao Zhang, Y anhan Y e, and Zhe yan Luo. Llamafactory: Unified efficient fine-tuning of 100+ language models. In Pr oceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstr ations) , pp. 400–410, 2024. 13 Published as a conference paper at ICLR 2026 A A D D I T I O N A L E X P E R I M E N TA L D E TA I L S A . 1 P R E T R A I N I N G S E T U P Model configurations. T able 4 lists detailed configurations of GPT -2 and Qwen3 models, including parameter counts, hidden dimensions, number of layers/heads, and short-embedding baselines. Size #Parameters hidden_size num_layers num_heads short_hidden position_embedding Small 124M 768 12 12 384 APE Medium 350M 1024 24 16 512 APE Large 596M 1024 28 16/8 512 RoPE T able 4: Base model configurations. “Short” refers to halving the hidden size for Q/K . Implementation notes. For fairness, short-embedding baselines insert only linear projections be- fore and after attention. For Qwen3, we add an extra linear transformation after RoPE to isolate positional dimensions from sparsification. FlashSF A kernels are used for tiled ex ecution. T raining. GPT -2 models are trained on OpenW ebT e xt and Qwen3 on The Pile with standard LM objectiv es. V alidation PPL is reported on held-out splits. Zero-shot e v aluations follo w PiQA, LAM- B AD A, ARC-e/ARC-c, and HellaSwag. Long-conte xt efficiency is measured as decoding through- put at 128k tokens. A . 2 F I N E - T U N I N G S E T U P T able 5: Configurations for fine-tuning MoE models Model Dataset Epoch Batch_Size Lr W armup_Ratio Gradient_Ckecpointing Qwen3-0.6B GSM8K 3 256 6e-4 0.1 False Arxiv 2 256 1e-5 0.05 False PubMed 2 256 2e-5 0.05 F alse NIAH 3 256 2e-5 0.05 False Qwen3-4B GSM8K 3 256 6e-6 0.1 T rue Arxiv 2 256 2e-6 0.1 True PubMed 2 256 2e-6 0.1 T rue NIAH 3 256 2e-6 0.1 True B A D D I T I O N A L E X P E R I M E N T S B . 1 L AT E N C Y W e benchmarked the latency of the attention module on three feature dimensions: 256, 128, and 64, respectiv ely . Prefilling Latency The computational complexity of the full attention module can be expressed as O ( n 2 d ) . So we can express Latency as Latency attn ∝ N 2 d . T o better analyze the impact of the feature dimension d on computational complexity , we conduct the analysis in the logarithmic space while fix B atch = 8 and H eads = 8 : log ( Latency attn ) ∝ 2 log N + l og d (9) The results in the logarithmic coordinate system are shown in Figure 6. As shown in the figure, we can observe that the latency generally exhibits a linear relationship with the sequence length. Furthermore, the latency gap between different compression ratios are close to a constant value in the logarithmic space, which also indicates that the absolute ef ficiency improvement achieved by compressing the feature dimension increases exponentially with the sequence length. 14 Published as a conference paper at ICLR 2026 4 40 400 4000 4096 8192 163 84 327 68 655 36 Flash _128 Sp ars e_16/12 8 Spar se_8/ 128 Spar se_6/ 128 Flash _64 Spar se_8/ 64 Sp arse_4/ 64 Fas te r Dense_128 Dense_64 (a) Latency in full attention scenario. 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 Dense_128 Sp ars e_32/ 128 Sp arse_16 /128 Spars e_8/12 8 Dense_64 Sparse_16 /64 Spar se_8/ 64 Sp arse_4/ 64 4096 8192 16384 32768 65536 Co n t e x t = L e n g t h Fas te r Dense_128 Dense_64 (b) Latency in kv-cache attention scenario. Figure 6: Comparison of latencies in different attention scenarios: (a) full attention(T ime-to-first- token) and (b) kv-cache attention(T ime-to-next-tok en). KV -cache Latency KV cache, which has been widely used in LLM decoding, is known as a memory bound task. Therefore, we benchmarked the inference latenc y and KV cache memory usage of sparse features and dense features in the KV cache decoding scenario, while k eeping B atch = 8 and H eads = 8 unchanged. Since setting the length of the Query N q = 1 , the computational complexity of the decoding attention can be expressed as O ( N d ) , which means that as the sequence length increases, the computational complexity gro ws linearly . Our experimental results confirm this. As sho wn in T able. 2, sparse attention becomes increasingly adv antageous as the context length gro ws. At short sequences (e.g., 4k tokens), dense attention is still competiti ve or e ven faster because sparse kernels pay overhead for inde x lookups and binary searches. Ho wev er , once the context e xceeds about 8k–16k tokens, the sparse v ariants consistently overtak e the dense baselines. B . 2 F L O P S T o further analyze the operation of full-attention, we separately counted the number of floating-point operations (FLOPs) and integer operations (INOPs) under dif ferent settings. T able 6: Operation counts for standard flash attention and flash attention sparse. The number of floating-point operations (FLOPs) and integer operations (INOPs) were counted separately for feature dimensions of 64 and 128 under different conte xt lengths. 8192 16384 32768 65536 Config TFLOPs INOPs TFLOPs INOPs TFLOPs INOPs TFLOPs INOPs Dense_128 2 . 23 / 8 . 92 / 35 . 67 / 142 . 67 / Sparse_32/128 1 . 20 28 . 31 4 . 79 58 . 72 19 . 17 121 . 63 76 . 70 251 . 67 Sparse_16/128 1 . 15 18 . 87 4 . 59 39 . 85 18 . 35 83 . 89 73 . 40 176 . 17 Sparse_8/128 1 . 13 13 . 63 4 . 54 29 . 36 18 . 14 62 . 91 72 . 57 134 . 22 Dense_64 1 . 12 / 4 . 48 / 17 . 94 / 71 . 75 / Sparse_16/64 0 . 61 15 . 16 2 . 42 29 . 36 9 . 69 60 . 82 38 . 76 125 . 83 Sparse_8/64 0 . 58 9 . 44 2 . 32 19 . 92 9 . 27 41 . 94 37 . 11 88 . 08 Sparse_4/64 0 . 57 6 . 82 2 . 30 14 . 68 9 . 17 31 . 46 36 . 70 67 . 11 As shown in T ab .6, because we directly reduced the number of non-zero elements in the feature vectors, the number of floating-point operations has significantly decreased, and a large proportion of the floating-point operations in the sparse version come from matrix multiplication in the P@V stage. The reason is that sparse feature attention con verts a large number of FLOPs into the process of finding ov erlapping non-zero elements in sparse matrix multiplication, which corresponds to the INOPs in the table. 15 Published as a conference paper at ICLR 2026 C I M P L E M E N TA T I O N D E TA I L S O F F L A S H S FA K E R N E L In this section, we provide a comprehensive breakdown of the FlashSF A CUDA kernel implemen- tation, focusing on the parallelism hierarchy , core data structures, memory access patterns, and a detailed comple xity analysis of the sparsification ov erhead. Since current GPUs do not support gen- eral sparse matrix multiplication well, for a fair comparison, we compared Flash Attention Sparse with FMA-based Dense Flash Attention on the code base of Flash Attention 2 in the LeetCUDA open-source library (DefT ruth & Others, 2025). C . 1 A L G O R I T H M P RO C E D U R E Algorithm 1 FlashSF A (forward with tile ( B r × B c ) ) Require: CSR( ˜ Q ): Q_indptr, Q_indices, Q_v alues; CSC feat ( ˜ K ): Kf_indptr, Kf_indices, Kf_values; V (dense, row-major in HBM); tile of fsets ( i 0 , j 0 ) ; tile sizes ( B r , B c ) . 1: Init score tile storage: scores ← zeros ( B r , B c ) in SRAM. 2: Init CSR( P ) r ow pointers: P_indptr [ i 0 ] ← current nnz counter t P . 3: for r = 0 to B r − 1 do ▷ i = i 0 + r is the global query index 4: i ← i 0 + r 5: Register accumulator: r ow_scor es [0: B c ] ← 0 ▷ kept in registers per thread/w arp 6: t L ← Q _ indptr [ i ] ; t R ← Q _ indptr [ i +1] 7: f or t = t L to t R − 1 do ▷ iterate nonzeros of query row i 8: f ← Q _ indices [ t ] ; q v ← Q _ v alues [ t ] 9: p 0 ← K f _ indptr [ f ] ; p 1 ← K f _ indptr [ f +1] ▷ posting list for feature f 10: ( p L , p R ) ← B I NA RY S E A R C H R A N G E Kf_indices [ p 0 : p 1 ) , [ j 0 , j 0 + B c ) 11: for p = p L to p R − 1 do ▷ only keys j that fall inside the ke y tile 12: j ← K f _ indices [ p ] ; c ← j − j 0 13: k v ← K f _ v al ues [ p ] 14: r ow_scor es [ c ] += ( q v · k v ) / √ d ▷ feature-overlap accumulation in re gisters 15: end for 16: end f or 17: f or c = 0 to B c − 1 do 18: scores [ r , c ] ← r ow_scor es [ c ] ▷ store to SRAM after register accumulation 19: end f or 20: end for 21: Mask (optional): apply causal mask in-place to scores. 22: Online softmax per row (as in F A) 23: for r = 0 to B r − 1 do 24: i ← i 0 + r 25: o i ← zeros ( d v ) in registers ▷ accumulator for output row i 26: t L ← P _ indptr [ i ] ; t R ← P _ indptr [ i +1] 27: f or t = t L to t R − 1 do ▷ iterate nonzeros P ij in row i 28: j ← P _ indices [ t ] ; p ← P _ val ues [ t ] 29: v j ← V [ j, 0: d v ] ▷ row-v ector , contiguous load from HBM 30: o i += p · v j 31: end f or 32: Write back: add o i to the corresponding row of O . 33: end for Binary Sear ch for Tiling . T o restrict computations to the current processing tile [ j 0 , j 0 + B c ) , we employ a BINARY_SEARCH_RANGE routine. for a feature f , we search the sorted array Kf_indices to find the sub-range [ p lo , p hi ) such that all indices fall within the current key tile. Since this operation runs in registers with a fix ed number of iterations, it is highly efficient and branch-regular . 16 Published as a conference paper at ICLR 2026 C . 2 P A R A L L E L I S M M O D E L The FlashSF A kernel adopts a tiling strategy similar to standard FlashAttention but optimized for sparse operations. The mapping of CUD A threads, warps, and blocks to the computation is designed to maximize occupancy and eliminate the need for atomic operations during score accumulation. Grid and Block Mapping . The computation grid is defined as g r id = ( ⌈ N /B r ⌉ , B × H ) , where N is the sequence length, B r is the row tile height, B is the batch size, and H is the number of heads. • Grid: blockIdx.x selects a row tile of height B r (typically 128), and blockIdx.y selects the specific batch-head pair . • Block: Each thread block consists of 256 threads (8 warps). A single block is responsible for computing the attention output for a specific row tile [ r 0 , r 0 + B r ) . W arp and Thread Hierar chy . Within a block, the w orkload is distributed as follo ws: • W arps: The 8 warps in a block process disjoint stripes of rows. Each warp is assigned a 16-row stripe within the B r rows handled by the block. • Threads: W ithin a warp, threads are mapped to a 2D grid to process the score matrix. Each thread is responsible for a 2 × 2 patch of the score tile (two rows × two columns). Across all 32 threads in a warp, these patches perfectly tile the warp’ s assigned stripe. Loop Parallelization and Atomicity . The k ernel iterates through column tiles (Ke y/V alue blocks) in the outer loop. Inside the loop: • For the Query ( Q ), lines are distributed across w arps. • For the non-zero elements (nnz) within a Q row , threads iterate sequentially ov er the CSR segment. No Atomic Operations. A critical design choice is the absence of atomic operations (e.g., atomicAdd ) for score accumulation. Since each output score position S [ r, c ] in the tile is owned by exactly one thread (via the fixed 2 × 2 patch mapping), each thread accumulates all partial con- tributions for its assigned scores in re gisters. This ensures thread safety and maximizes throughput. C . 3 C O R E D A T A S T RU C T U R E S FlashSF A relies on a specialized sparse storage format to ef ficiently handle the intersection of activ e queries and keys. Featur e-wise CSC Format ( C S C f eat ). Standard sparse matrices typically store data in Com- pressed Sparse Ro w (CSR) or Column (CSC) format where dimensions correspond to token indices. Howe v er , to ef ficiently retrieve relev ant keys for a given active feature in the query , we utilize a transposed view for the K e y matrix K , denoted as C S C f eat ( ¯ K ) . • Columns: Correspond to F eatur e IDs ( f ∈ [0 , d ) ). • Rows: Correspond to Ke y IDs ( j ∈ [0 , N ) ). This layout allo ws the kernel to quickly access the posting list (list of token indices) for an y specific feature f activ ated by the query . C . 4 M E M O RY A C C E S S S T R A T E G Y Efficient memory access is paramount for GPU performance. FlashSF A employs specific strategies to ensure coalesced access despite the irregularity of sparse data. 17 Published as a conference paper at ICLR 2026 Accessing Q (CSR). For the Query matrix stored in CSR format, each block processes a con- tiguous row range [ r 0 , r 0 + B r ) . W e calculate the span of non-zero elements [ q lo , q hi ) = [ Q indptr [ r 0 ] , Q indptr [ r 0 + B r ]) , which corresponds to a single contiguous segment in HBM. This allows for streamlined streaming of Q indices and values. Accessing K (Coalesced Sparse Reads). For a giv en ke y tile and activ e feature f , once the sub- range [ p lo , p hi ) is identified via binary search: • W arps cooperatively load the indices and v alues from C S C f eat . • W e utilize lane-strided access patterns, e.g., loading index p = p lo + lane_id + 32 × k . This ensures that ev en though the semantic access is sparse (random features), the physical memory transactions are coalesced into contiguous slices of HBM, which are then staged into shared memory . Accessing V (Sparse-Dense Multiplication). The computation of O = P @ V inv olves a sparse attention matrix P and a dense value matrix V . Since V is stored in a ro w-major dense layout, the access to any specific ro w V j is contiguous: • The non-zero structure of P determines which rows of V to access. • Threads in a warp cooperativ ely load row V j using vectorized instructions (e.g., float4 or half2 ), ensuring high bandwidth utilization. Memory Bandwidth Analysis Empirical profiling results in T able 7 confirms that the memory system deliv ers close to peak bandwidth (approx. 919 GB/s in "memory-only" benchmarks), indi- cating that memory access to V is not a bottleneck. T able 7: HBM Bandwidth Comparison. “w/o compute” denotes measuring memory throughput with computation logic disabled. Ker nel Dense Dense w/o compute FlashSF A FlashSF A w/o compute HBM Bandwidth (GB/s) 14.22 1194.34 17.14 919.38 C . 5 R E V I S E D C O M P L E X I T Y A N A LY S I S A potential concern with sparse attention is the overhead introduced by the sparsification process (T op- k selection). SF A utilizes R T op- k k ernel(Xie et al., 2024) to sparsify Q and K with a com- putational complexity of O ( N d ) . This kernel employs GPU-parallelized binary search where each warp processes a feature row . As shown in T able 8, the latency of R T op- k is negligible compared to the full attention computation. T able 8: Latency comparison (ms) between standard torch.topk and R T op- k kernel across different context lengths. The Ratio indicates the percentage of time R T op- k consumes relativ e to the total attention forward pass. Context Length ( N ) 1024 4096 8192 16384 32768 65536 torch.topk 0.730 2.701 5.336 10.684 21.205 42.374 R T op- k (Ours) 0.221 0.589 1.089 2.080 4.057 8.080 Ratio of RT op- k (%) 10.51 2.10 1.96 1.90 1.03 0.51 Complexity of P @ V . The multiplication P @ V effecti vely becomes a Sparse Matrix-Matrix Mul- tiplication (SpMM). Since the sparsity of P is induced by the sparsity of Q and K , the number of non-zero elements in P is significantly reduced. While a standard dense attention requires O ( N 2 d ) operations, SF A reduces the effecti ve FLOPs count significantly . The memory access pattern de- scribed in Section C.3 ensures that the theoretical FLOPs reduction translates into actual wall-clock speedup by maintaining high memory bandwidth efficienc y . 18 Published as a conference paper at ICLR 2026 D L A T E N C Y T I M I N G R E S U LT S T able 9: Latency (ms) versus conte xt length. Context Length V ariant 1024 4096 8192 16384 32768 65536 Dense_256 10 . 98 176 . 20 712 . 98 2894 . 46 11 772 . 47 49 197 . 70 Sparse_32/256 3 . 21 45 . 89 180 . 38 715 . 02 2886 . 21 11 529 . 74 Sparse_24/256 2 . 77 33 . 96 154 . 79 612 . 81 2488 . 04 8309 . 51 Sparse_16/256 2 . 31 29 . 15 128 . 52 510 . 18 2079 . 82 7388 . 78 Sparse_12/256 1 . 97 21 . 28 109 . 04 431 . 50 1769 . 73 5063 . 70 Sparse_10/256 1 . 93 20 . 06 106 . 93 422 . 95 1734 . 99 4877 . 05 Sparse_8/256 1 . 86 17 . 41 102 . 63 405 . 52 1665 . 69 4235 . 00 Sparse_6/256 1 . 68 15 . 62 96 . 25 365 . 26 1505 . 59 3841 . 40 Sparse_4/256 1 . 51 13 . 94 82 . 48 324 . 97 1345 . 26 3412 . 10 Sparse_2/256 1 . 43 13 . 32 77 . 66 305 . 81 1273 . 37 2999 . 38 Dense_128 2 . 10 28 . 05 112 . 88 449 . 61 1981 . 92 7879 . 33 Sparse_32/128 2 . 17 31 . 01 120 . 58 465 . 68 1802 . 03 7101 . 95 Sparse_28/128 1 . 80 25 . 06 98 . 13 387 . 02 1535 . 46 6103 . 98 Sparse_24/128 1 . 70 23 . 84 94 . 10 373 . 42 1486 . 14 5909 . 66 Sparse_16/128 1 . 56 17 . 94 70 . 62 279 . 72 1108 . 96 4412 . 02 Sparse_12/128 1 . 11 16 . 25 64 . 39 255 . 24 1017 . 04 4047 . 53 Sparse_10/128 1 . 00 15 . 03 60 . 41 239 . 77 954 . 21 3814 . 06 Sparse_8/128 0 . 92 13 . 17 54 . 25 215 . 37 777 . 15 3323 . 53 Sparse_6/128 0 . 79 11 . 17 42 . 24 161 . 43 681 . 73 2738 . 84 Sparse_4/128 0 . 67 10 . 08 40 . 09 157 . 88 579 . 75 2576 . 93 Sparse_2/128 0 . 58 9 . 90 38 . 92 154 . 71 539 . 49 2423 . 82 Dense_64 0 . 77 13 . 51 50 . 62 202 . 56 801 . 50 3137 . 78 Sparse_16/64 0 . 90 12 . 51 39 . 41 195 . 53 779 . 19 2963 . 94 Sparse_12/64 0 . 70 9 . 71 38 . 23 151 . 60 603 . 18 2400 . 37 Sparse_10/64 0 . 67 9 . 23 36 . 36 144 . 17 573 . 31 2282 . 26 Sparse_8/64 0 . 59 8 . 14 32 . 00 126 . 99 504 . 23 2014 . 14 Sparse_6/64 0 . 51 7 . 05 27 . 64 109 . 36 434 . 58 1727 . 43 Sparse_4/64 0 . 41 5 . 41 21 . 07 83 . 12 328 . 83 1311 . 59 Sparse_2/64 0 . 39 5 . 15 19 . 75 77 . 96 309 . 13 1233 . 64 19 Published as a conference paper at ICLR 2026 E C O M PA R I S O N O F E FFI C I E N T A T T E N T I O N B Y T R A I N I N G T able 10: Latency , Per plexity and Accuracy r esults comparison with v arious compression and ac- celeration techniques, categorized into T oken-Level and F eatur e-Le vel Operations. For token-le vel operations, "Longforemer" (Beltagy et al., 2020) denotes fixed token sparsity pattern, "NSA" (Y uan et al., 2025) denotes dynamic token sparsity pattern. "Dense (full)" baselines use full hidden size and uncompressed KV cache; "Short ( d = X )" denotes baselines with half feature dimensions; "Quant" denotes 8-bit quantization aware training (QA T (Liu et al., 2024b)) on weights and acti va- tions; "Lo w-Rank" denotes PCA-based projection matrix fine-tuning; "MLA" denotes multi head latent attention (Liu et al., 2024a), and "MLA + SF A" combines SF A with latent key/v alue. "La- tency@128k" is measured by "Decoding with KV cache (TTNT) (ms)" and "Prefilling with full attention (TTFT) (s)". PPL is ev aluated on OpenW ebT e xt for GPT -2 and Pile for Qwen3. Model V ariant Latency@128k ↓ PPL ↓ Acc ↑ Decode F orward O WT/Pile PiQA LAMBDA ARC-e ARC-c HellaS A vg GPT2 124M Dense (full) 17.08 16.86 17.29 56.34 22.78 28.35 14.32 19.61 28.28 T oken-Level Operation Longformer 6.75 7.93 18.73 54.25 21.27 28.02 13.01 18.92 28.10 +SF A ( k = 8 ) 5.23 6.18 19.30 52.81 20.54 26.39 12.59 17.24 25.91 Feature-Lev el Operation Short ( d = 32 ) 8.37 7.86 20.70 51.30 19.39 25.72 12.47 14.26 24.63 Low-Rank 8.93 7.99 19.89 51.79 20.04 26.47 12.92 14.99 25.24 MLA 5.04 15.39 17.38 57.83 22.29 28.37 13.92 19.66 28.41 MLA + SF A 3.98 15.05 19.07 54.33 21.92 27.88 13.10 19.01 27.25 Quant 14.26 12.97 17.64 56.18 21.03 28.09 13.58 19.05 27.59 SF A ( k = 8 ) 14.12 9.41 18.17 54.92 21.03 28.41 13.41 19.26 27.40 SF A (quant) 12.28 8.72 18.54 54.53 20.81 28.39 13.27 18.97 27.12 Qwen3 0.6B Dense(full) 80.84 77.65 4.66 62.47 34.82 45.41 20.35 33.95 39.40 T oken-Level Operation NSA 9.73 20.32 4.57 62.69 35.01 45.10 20.47 34.42 39.54 +SF A ( k = 16 ) 8.85 17.17 4.95 60.02 33.58 42.74 18.31 32.48 37.43 Feature-Lev el Operation Short ( d = 64 ) 38.68 30.84 6.03 58.43 31.27 41.58 15.83 28.29 35.08 Low-Rank 40.58 32.46 5.50 59.19 31.49 41.77 15.80 30.65 35.78 MLA 8.74 68.92 4.69 62.39 34.71 45.41 20.17 34.21 39.38 MLA + SF A 6.72 65.29 4.9 61.22 33.94 43.36 19.25 33.94 38.34 Quant 72.23 59.73 4.71 62.29 34.33 45.39 20.02 33.91 39.19 SF A ( k = 16 ) 66.29 34.20 4.81 61.73 34.05 45.62 19.27 34.03 38.94 SF A (quant) 57.47 30.74 5.16 59.63 33.10 44.93 15.98 33.64 37.46 T able 10 compares SF A with a variety of token-lev el and feature-level compression / acceleration techniques on GPT -2 124M and Qwen3-0.6B. W e report both prefill (“Forward”) and decoding (“Decode”) latency at 128K conte xt, together with perplexity and do wnstream accuracy . Orthogonality to tok en-level methods. For tok en-lev el operations, SF A is applied on top of Long- former and NSA as a drop-in replacement for their dense attention blocks. In both models, adding SF A consistently reduces both Decode and Forward latenc y while achieving comparable perfor- mance. This shows that SF A is orthogonal to token-lev el sparsification: it can be combined with existing token-le v el sparse attention methods to further accelerate long-context inference. Featur e-lev el speed–accuracy trade-off. Among feature-le vel methods, SF A can also be combined with MLA(on the compressed latent vector) and quantization. Pure SF A reduces latency compared to the dense baseline while k eeping PPL and average accuracy close. Compared with Short and Low-Rank feature compression, which suffer lar ger accuracy drops, SF A and SF A (quant) maintain much higher accuracy at similar or better speed. Overall, SF A and its combinations deliv er the strongest performance among feature-level approaches while still providing significant end-to-end speedups. 20 Published as a conference paper at ICLR 2026 F L OA D B A L A N C E 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 Layer inde x 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Head inde x 0.5 0.6 0.7 0.8 0.9 1.0 Nor malized entr opy (a) Entropy of Q per layer per head 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 Layer inde x 0 1 2 3 4 5 6 7 Head inde x 0.5 0.6 0.7 0.8 0.9 1.0 Nor malized entr opy (b) Entropy of K per layer per head Figure 7: Entropy of T op-K feature selection across layers and heads. W e plot the normalized entropy of the T opK index distrib ution for each attention head and layer of Qwen3-0.6B when apply- ing SF A. (a) Entropy of the T opK positions of query v ectors Q (16 heads, due to GQA). (b) Entropy of the T opK positions of key vectors K (8 heads). Each cell corresponds to one (layer , head) pair , and brighter colors indicate higher entropy (mor e balanced use of feature dimensions) . A natural concern for T opK sparsification on Q and K is that some heads or layers might collapse to using only a few feature dimensions, leading to poor load balance. T o study this, we measure the normalized entropy of the T opK index distribution for ev ery head and layer on a small but div erse e valuation set: we sample 50 samples from each of the Arxi v , Github, FreeLaw , and PubMed domains in the Pile validation split (200 samples in total) (Figure 7). For the 16 Q -heads in Qwen3 (due to GQA), the entr opy ranges from 0.88 to 0.98 with an average of 0.94. For the 8 K - heads, the entropy ranges from 0.85 to 0.97 with an av erage of 0.93. These values are close to the maximum possible entropy (1.0) and show only mild variation across layers and heads, indicating that the selected T opK dimensions remain well distrib uted rather than concentrating on a fe w indices. Although SF A does not introduce any explicit load-balance loss, the feature activ ations remain nearly balanced. W e h ypothesize that, unlike T opK applied to weights (as in MoE routing), applying T opK directly on featur e v ectors during end-to-end training encourages the model to exploit its full expressi ve capacity: different dimensions are naturally used whenever the y help reduce the training objectiv e. As a result, the model tends to learn a near-uniform utilization of features. 21 Published as a conference paper at ICLR 2026 G O RT H O G O N A L B A S E L I N E S T able 11: Comparison results with token-sparse, KV -pruning, low-rank, and ker nel base- lines on GPT -2. T oken-sparse training methods include Routing(Roy et al., 2021) and Long- former(Beltagy et al., 2020); KV -pruning (training-free) methods include H 2 O(Zhang et al., 2023), Quest(T ang et al., 2024), and SnapKV(Li et al., 2024); Loki(Singhania et al., 2024) is a lo w-rank k ey compression method (training-free); Performer(Choromanski et al., 2021) is a kernel-based approx- imation. Rows marked “+SF A ( k = 8 )” apply our feature-sparse SF A to Longformer and SnapKV , showing that SF A is orthogonal to these approaches and can be combined with them. Model Latency@128k PPL Acc Decode Forward O WT/Pile PiQA LAMBD A ARC-e ARC-c HellaS A vg GPT2 124M Dense (full) 17.08 16.86 17.29 42.74 22.78 28.35 8.12 19.61 24.32 SF A 14.12 9.41 18.17 41.62 21.03 28.41 7.39 19.26 23.54 T oken Sparse (Training) Routing 7.92 8.37 18.64 41.39 21.08 28.31 7.11 18.89 23.35 Longformer 6.75 7.93 18.73 41.28 21.27 28.02 7.01 18.92 23.30 +SF A ( k = 8 ) 5.23 6.18 19.30 40.75 20.54 26.39 6.63 17.24 22.31 KV -pruning (Training-free) H 2 O 13.32 16.86 18.02 41.81 20.55 27.04 7.38 18.75 23.11 Quest 10.84 16.86 17.95 42.34 20.79 28.3 7.82 18.83 23.62 SnapKV 9.88 16.86 17.91 42.49 21.92 28.43 8.01 19.38 24.05 +SF A ( k = 8 ) 6.92 9.41 19.44 39.99 20.24 27.13 6.83 17.74 22.39 Low-rank k eys (T raining-free) Loki 11.39 16.86 17.82 42.1 21.29 28.01 7.99 19.24 23.73 +SF A ( k = 8 ) 9.09 9.41 19.29 40.83 20.04 27.85 7.13 18.03 22.78 Kernel Method Performer 9.43 7.93 19.72 39.83 19.11 26.72 6.77 15.38 21.56 Orthogonality and composability with existing token sparse methods. T able 11 compares SF A with representati ve long-context techniques on GPT -2 124M and T able 10 compares SF A with other efficient attention methods. As a standalone replacement of dense attention, SF A already improv es efficienc y o ver the dense baseline while perplexity and a verage accuracy remain close. More impor - tantly , SF A is orthogonal to existing methods and can be combined with them for additional gains. T oken-sparse training methods. When applied on top of Longformer , we sparsify selected tokens. SF A further reduces latency from 6.75/7.93 to 5.23/6.18 ( ≈ 1 . 3 × faster decode and prefill), with only a modest change in quality . This shows that feature-level sparsification in SF A complements token-le vel sparsity patterns. KV -pruning and Lo w-rank keys methods . KV -pruning methods such as H 2 O, Quest, and SnapKV improv e speed by compressing the number of tokens in the KV cache, so they only accelerate the Decode stage and leave Forward latency unchanged. When we combine SF A with SnapKV , we obtain additional acceleration in both stages. Similar beha vior holds relati ve to H 2 O and Quest. This shows that SF A is complementary to KV -pruning: KV -pruning reduces the number of cached tokens for decoding, while SF A sparsifies feature dimensions and brings additional gains. 22 Published as a conference paper at ICLR 2026 H A B L AT I O N 2 4 6 8 12 16 Sparsity(k) 10 15 20 25 30 P erple xity Dense (full) SF A (ours) (a) Perplexity vs sparsity 2 4 6 8 12 16 Sparsity(k) 0.0 0.5 1.0 1.5 Latency@32k Dense (full) SF A (ours) (b) Latency vs sparsity Figure 8: Ablation of sparsity k on GPT -2 124M with fixed head dimension d = 64 . Perplexity on OpenW ebT e xt (left) and latency at 32K context (right) as a function of the T op- k sparsity lev el used by SF A. The dashed gray line denotes the dense (full) attention baseline; the red curve shows SF A with different k . 32 64 128 256 Head Dimension 10 15 20 25 30 P erple xity Dense (full) SF A (ours) (a) Perplexity vs sparsity 32 64 128 256 Head Dimension 0.0 0.5 1.0 1.5 2.0 2.5 Latency@32k Dense (full) SF A (ours) (b) Latency vs sparsity Figure 9: Ablation of head dimension d head on GPT -2 124M with fixed sparsity k = 8 . Perplexity on OpenW ebT e xt (left) and latency at 32K context (right) as a function of the head dimension d head used by SF A. The dashed gray line denotes the dense (full) attention baseline; the red curve shows SF A with different d head . Sensitivity to sparsity k . Figure 8 studies how the T op- k sparsity level affects performance. As k increases from v ery sparse settings (e.g., k = 2 ) to denser ones (e.g., k = 16 ), perplexity monotoni- cally decreases and quickly approaches the dense baseline; for k ≥ 8 , the SF A curve is v ery close to dense attention. In contrast, latency at 32K grows smoothly with k : very small k yields the largest speedup, while moderate k (around k = 8 ) still keeps a substantial latency advantage o ver the dense model with only a small perplexity gap. Overall, SF A exhibits a stable speed–accurac y trade-off and is not o verly sensiti ve to the e xact choice of k , allowing practitioners to pick k to match a desired latency b udget. Sensitivity to head dimension d head . Figure 9 varies the head dimension while keeping SF A en- abled. When the heads are extremely small (e.g., d head = 32 ), perplexity degrades noticeably . As we increase the dimension, perplexity quickly improv es, and at d head = 64 it is already very close to the dense baseline while latency remains substantially lo wer . Further increasing d head beyond 64 brings only marginal perplexity g ains b ut steadily increases latency . Thus d head = 64 emerges as the sweet spot of the speed–accuracy trade-off: it recovers most of the dense-model performance while preserving most of the acceleration provided by SF A. 23 Published as a conference paper at ICLR 2026 I T R A I N I N G S TA B I L I T Y A N A L Y S I S In this section, we in vestigate the training process of SF A. Figure 10 illustrates the validation loss trajectories across v arying sparsity le vels ( k ∈ { 2 , 4 , 8 , 16 } ) of GPT2-124M. W e observe that the loss curves exhibit smooth, monotonic con ver gence de void of div ergent spikes or chaotic oscilla- tions. Notably , e ven under the most aggressi ve sparsity constraint ( k = 2 , red line), the model con ver ges steadily . These empirical results suggest that SF A can intrinsically maintain training sta- bility without suffering from e xcessi ve v ariance or optimization instability . 0 20000 40000 60000 80000 100000 Steps 3.0 3.5 4.0 4.5 5.0 V al L oss SF A(k=16) SF A(k=8) SF A(k=4) SF A(k=2) Figure 10: V alidation loss curves of SF A on GPT -2 (124M) pre-training. W e compare varying sparsity le vels k ∈ { 2 , 4 , 8 , 16 } . The curves decrease smoothly and monotonically without di ver gent spikes, demonstrating that SF A maintains training stability ev en under aggressi ve sparsity ( k = 2 ). J M E M O RY S A V I N G In our implementation, memory gain can be achieved when k < 2 3 d . The memory sa vings of SF A compared to the dense model depend on the data precision used to store the col_indices array and row_pointer array in the CSR matrix. For a CSR matrix with shape ( N , d ) where each row has a fixed number of k non-zero values, the required bytes for each component are calculated as follows: • value array memory : Mem value = ( N × k ) × S val (10) • indices array memory : Mem indices = ( N × k ) × S idx (11) • indptr array memory (length is N + 1 ): Mem indptr = ( N + 1) × S ptr (12) Where S denotes the number of bytes for the data format. Therefore, the total memory consumption of the CSR format is the sum of these three parts: Mem csr = Mem value + Mem indices + Mem indptr (13) 24 Published as a conference paper at ICLR 2026 Substituting the abov e formulas, we obtain the final memory consumption formula: Mem csr = ( N × k × S val ) + ( N × k × S idx ) + (( N + 1) × S ptr ) = N × k × ( S val + S idx ) + ( N + 1) × S ptr (14) Consequently , compared to a dense matrix of the same shape, the ratio of memory consumption is: Ratio = Mem dense Mem csr = N × d × S val N × k × ( S val + S idx ) + ( N + 1) × S ptr ≈ d × S val k × ( S val + S idx ) + S ptr (15) As the Q/K feature dimension in T ransformers is generally small, indices are typically stored in int8 format and indptr in int32 format. When we use fp16 / bf16 to store the value array: Ratio = Mem dense Mem csr ≈ d × 2 k × (2 + 1) + 4 = 2 d 3 k + 4 ≈ 2 d 3 k (16) K A D D I T I O N A L N I A H E X P E R I M E N T T o verify that SF A functions ef fecti vely as a general-purpose mechanism without requiring task- specific supervision, we ev aluated the retriev al capabilities of SF A in a zero-shot setting. W e trained the Qwen3-0.6B model equipped with SF A solely on general language corpora (standard pre-training) and ev aluated it on the NIAH task. As presented in T able 12, SF A consistently outperforms the dense attention baseline across all tested context lengths (1k to 4k), despite lacking specific training for retrie v al tasks. At a context length of 4k, SF A ( k = 16 ) achie ves an accuracy of 71% , significantly surpassing the dense baseline (62%). Even with aggressive sparsity ( k = 8 ), SF A maintains superior performance (66%). In addition to improved accuracy , SF A provides substantial speedups. Specifically , SF A ( k = 8 ) achiev es a 1.5 × speedup at 4k context length compared to the dense baseline. These findings indicate that feature-level sparsification does not introduce an information bottle- neck. On the contrary , the results suggest that SF A preserves essential semantic information while potentially filtering out noise in long-context scenarios, allowing it to function effecti vely within a general-purpose foundation model paradigm. T able 12: NIAH accuracy (%) within 4k Context Length. Qwen3-0.6B trained on Pile dataset with 4k window , and the accuracy rate on NIAH test lengths from 1k to 4k. Context Length 1k 2k 3k 4k Speedup@4k Dense(full) 93 87 79 62 1.0x SF A( k = 8 ) 95 90 80 66 1.5x SF A( k = 16 ) 96 90 83 71 1.2x 25 Published as a conference paper at ICLR 2026 L S V D A N A L Y S I S 0 5 10 15 20 25 Layer inde x 0 20 40 60 80 100 120 R ank@0.9 (a) Q matrix 0 5 10 15 20 25 Layer inde x 0 20 40 60 80 100 120 R ank@0.9 (b) K matrix Figure 11: Eigenv alue spectrum analysis f or Qwen3-0.6B model. Layer-wise ef fectiv e dimension of (a) query and (b) key activ ation with normalized cumulativ e eigen value of 0.9, ev aluated on the same sampled subset of the Pile validation set in Appendix F. T o better understand why T op- k feature sparsification can preserve semantic information in atten- tion, we analyze the intrinsic dimensionality of the query and key representations in pretrained dense model. W e use the pretrained Qwen3-0.6B model and run it on the same sampled subset of the Pile valida- tion set in Appendix F. For each transformer layer and attention head, we collect the corresponding query and key vectors Q, K ∈ R d (with head dimension d = 128 ). W e then perform singular value decomposition (SVD) on the stacked feature matrices and compute the effective rank at a giv en energy threshold τ = 0 . 9 . As shown in Figure 11, despite the nominal head dimension d = 128 , both Q and K exhibit con- sistently low effecti ve rank, typically around 50 – 60 across layers. This confirms that the attention features lie on a low-dimensional manifold and are therefore highly compr essible . The ke y matrices tend to have slightly lo wer ef fectiv e rank than queries, but both are far from full rank, indicating substantial redundancy in the dense representations. M L L M U S A G E S TA T E M E N T . In line with the ICLR policy , we disclose the use of Large Language Models during the preparation of this manuscript. Our use of these tools was strictly limited to assistance with language and formatting. Specifically , we employed an LLM to correct grammatical errors and improve the clarity and readability of sentences. The LLM had no role in the core scientific aspects of this work, including research ideation, methodological design, experimental analysis, or the generation of any results or conclusions. All intellectual contrib utions and the core content of this paper are solely the work of the authors. 26
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment