특징 희소성을 활용한 초장문 트랜스포머 가속화
본 논문은 쿼리·키를 k‑희소 코드로 변환해 자기‑주의 연산을 Θ(n²d)에서 Θ(n²k²/d)로 감소시키는 Sparse Feature Attention(SFA)를 제안한다. 이를 효율적으로 구현하기 위해 FlashAttention을 확장한 IO‑aware 커널 FlashSFA를 설계했으며, GPT‑2와 Qwen‑3 사전학습에서 정확도는 유지하면서 최대 2.5배 속도 향상과 FLOPs·KV‑cache 50% 절감을 달성한다. 실험 결과는 특징 …
저자: Yan Xie, Tiansheng Wen, Tangda Huang
본 논문은 초장문 트랜스포머 모델이 직면한 O(n²d) 복잡도의 자기‑주의 연산을 피처 차원에서의 희소성을 활용해 근본적으로 경감하는 방법을 제시한다. 기존 연구들은 주로 시퀀스 차원(윈도우, 로컬 어텐션, 저‑랭크 근사, 토큰 프루닝)에서 연산을 줄였지만, 긴 컨텍스트에서 정확도 저하가 불가피했다. 저자들은 이러한 한계를 극복하기 위해 Sparse Feature Attention(SFA)라는 새로운 패러다임을 도입한다. SFA는 각 토큰의 쿼리(Q)와 키(K) 벡터를 행별 Top‑k 연산을 통해 k‑희소 코드로 변환한다. 즉, 각 토큰은 d 차원 중 가장 큰 절대값을 가진 k개의 차원만 활성화하고 나머지는 0으로 만든다. 이렇게 만든 ˜Q와 ˜K는 CSR/CSC 형식의 희소 행렬로 저장되며, 두 행렬의 곱 ˜Q·˜Kᵀ는 동일 차원을 공유하는 토큰 쌍에 대해서만 비제로 값을 만든다. 수식적으로는 sᵢⱼ = (1/√d) Σ_{u∈Sᵢ∩Sⱼ} ˜qᵢ,ᵤ·˜kⱼ,ᵤ 로 정의된다. 여기서 Sᵢ는 토큰 i의 활성 차원 집합이다.
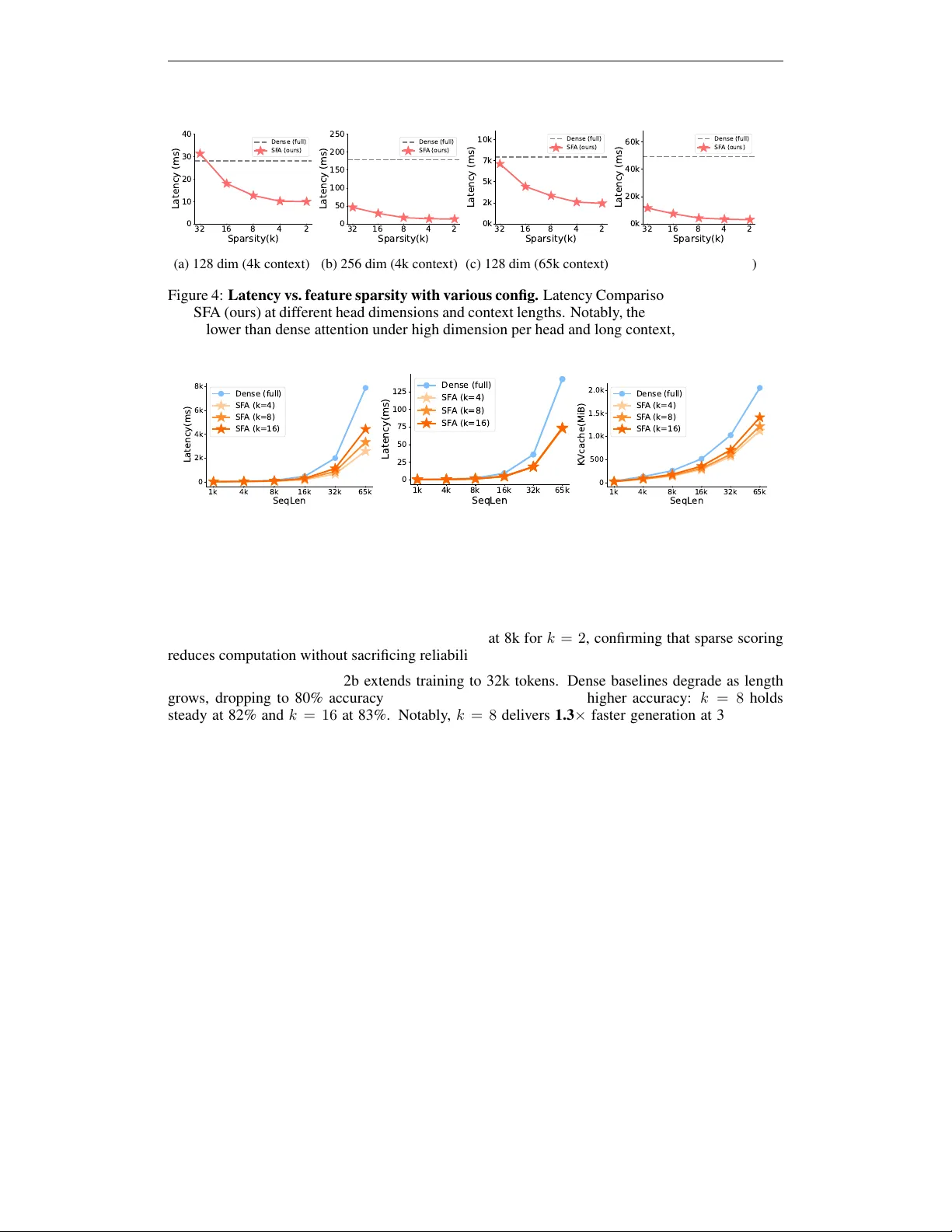
희소성에 따른 연산량을 기대값으로 분석하면 전체 연산은 Θ(n²k²/d) 로 감소한다. 예를 들어 d=128, k=16이면 1/64 수준, d=1024, k=32이면 1/1024 수준으로 연산이 감소한다. 이는 모델 차원이 클수록 더 큰 절감 효과를 기대할 수 있음을 의미한다. 또한, 저장 공간도 O(nk) 로 감소해 KV‑cache 메모리 사용량이 크게 줄어든다.
하지만 희소 행렬 곱을 수행하면서도 소프트맥스와 값(Value) 집계를 정확히 구현해야 하는데, 전체 n×n 스코어 행렬을 메모리에 저장하면 메모리 병목이 발생한다. 이를 해결하기 위해 저자들은 FlashAttention의 IO‑aware 타일링과 온라인 소프트맥스 방식을 차용한 FlashSFA 커널을 설계했다. FlashSFA는 쿼리와 키를 작은 타일(B_r, B_c) 단위로 읽어 들이고, 타일 내부에서 활성 차원 교집합을 탐색해 스코어를 즉시 온라인 소프트맥스에 전달한다. 이 과정에서 스코어 행렬을 전혀 메모리에 저장하지 않으며, 연산량은 타일 내 겹치는 차원 수에 비례한다. 따라서 메모리 I/O는 O(n) 수준으로 유지되면서도 연산 복잡도는 O(n²k²/d) 로 감소한다. 역전파에서는 Straight‑Through Estimator를 사용해 선택된 차원에만 그래디언트를 전달함으로써 학습 효율을 유지한다.
실험에서는 GPT‑2(124M, 350M)와 Qwen‑3‑0.6B 모델에 SFA(k=8,16)를 적용하고, 동일한 학습 설정에서 dense baseline와 차원 축소(d=32,64) baseline와 비교하였다. 퍼플렉시티와 PiQA, LAMBADA, ARC‑e/c, HellaSwag 등 다양한 벤치마크에서 SFA는 dense와 거의 동일한 성능을 보였으며, k=16일 때는 0.5% 이하의 차이만 나타났다. 반면 차원 축소 baseline는 퍼플렉시티가 20% 이상 상승하고, 특히 ARC‑c와 같은 어려운 과제에서 현저히 낮은 점수를 기록했다. 속도 측면에서는 128k 토큰 디코딩 시 2.0~2.5배 가속을 달성했고, FLOPs와 KV‑cache 메모리는 각각 45%와 41% 절감되었다. 합성 장거리 검색 벤치마크인 Needle‑in‑a‑Haystack에서도 SFA는 훈련 시 본 길이보다 긴 테스트 길이에서도 정확도를 유지해, 희소 피처가 장거리 의존성을 보존한다는 점을 입증했다.
또한, SFA는 토큰‑레벨 희소성 기법(예: 라우팅, 페이지 매김)과 독립적으로 동작하면서도 결합 가능함을 보였다. 즉, 기존 토큰 프루닝이나 로컬 어텐션과 함께 사용하면 전체 연산량을 더욱 크게 감소시킬 수 있다.
논문의 한계로는 고정된 k 값에 의존한다는 점과, 매우 작은 k에서는 표현력 손실이 발생할 가능성이 있다는 점을 들 수 있다. 향후 연구에서는 동적 k 조정, 학습 중 희소 패턴을 최적화하는 메타‑학습, 그리고 다른 효율화 기법과의 시너지 효과를 탐색할 여지가 있다. 전반적으로 본 연구는 피처 차원에서의 희소성을 통해 초장문 트랜스포머의 효율성을 크게 향상시키는 새로운 축을 제시했으며, 장거리 언어 모델링 및 검색 등 다양한 응용 분야에 실용적인 이점을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기