KG-Hopper: Empowering Compact Open LLMs with Knowledge Graph Reasoning via Reinforcement Learning
Large Language Models (LLMs) demonstrate impressive natural language capabilities but often struggle with knowledge-intensive reasoning tasks. Knowledge Base Question Answering (KBQA), which leverages structured Knowledge Graphs (KGs) exemplifies thi…
Authors: Shuai Wang, Yinan Yu
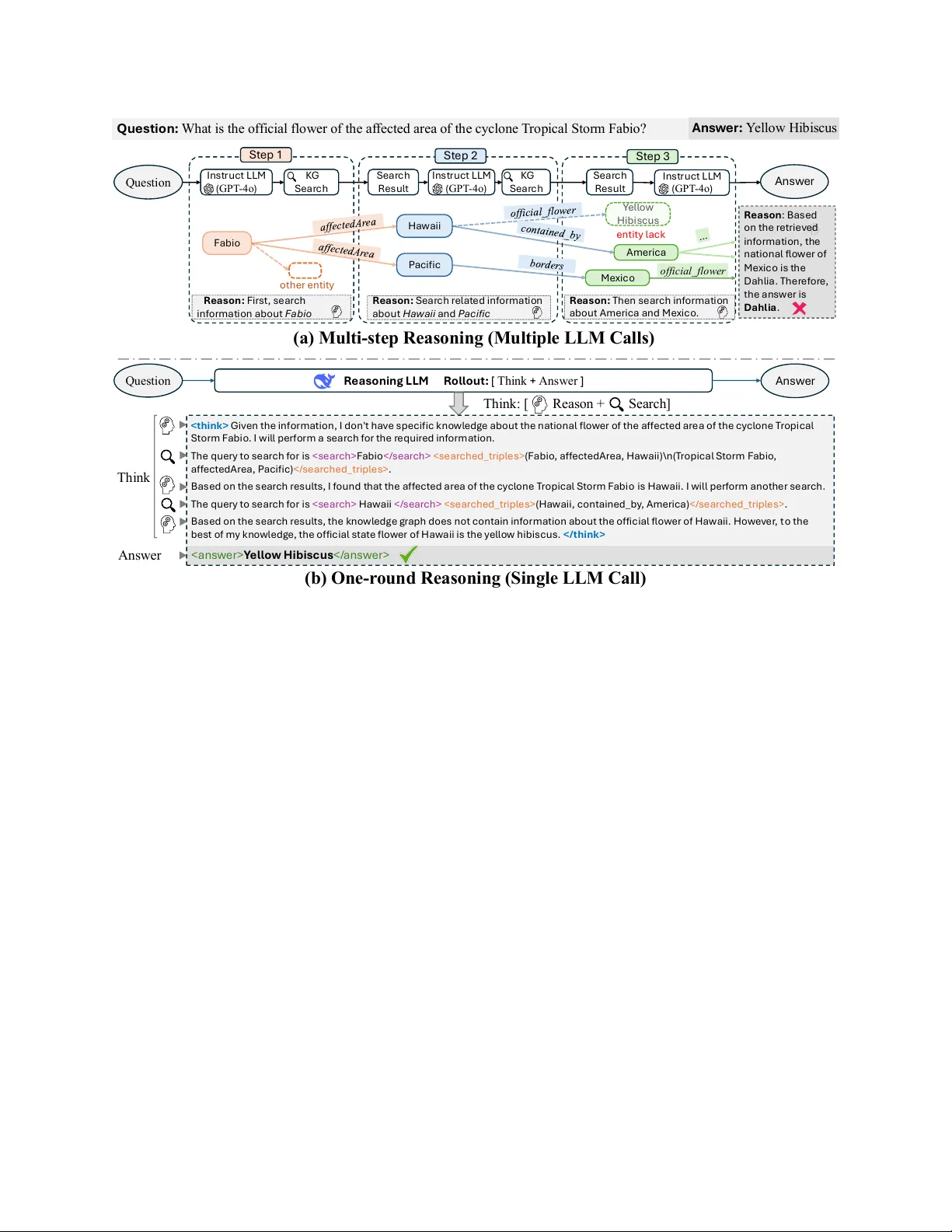
KG-Hopper: Empo wering Compact Open LLMs with Kno wledge Graph Reasoning via Reinforcement Learning Shuai W ang, Y inan Y u Department of Computer Science and Engineering Chalmers Univ ersity of T echnology and Univ ersity of Gothenbur g SE-41296 Gothenbur g, Sweden {shuaiwa, yinan}@chalmers.se Abstract —Large Language Models (LLMs) demonstrate impressi ve natural language capabilities but often struggle with knowledge-intensive reasoning tasks. Knowledge Base Question Answering (KBQA), which leverages structured Knowledge Graphs (KGs) exemplifies this challenge due to the need for accurate multi-hop r easoning. Existing approaches typically perform sequential reasoning steps guided by predefined pipelines, restricting flexibility and causing error cascades due to isolated reasoning at each step. T o address these limitations, we propose KG-Hopper , a novel Reinfor cement Learning (RL) framework that empowers compact open LLMs with the ability to perform integrated multi-hop KG reasoning within a single inference round. Rather than reasoning step-by-step, we train a Reasoning LLM that embeds the entire KG traversal and decision process into a unified “thinking” stage, enabling global reasoning over cross-step dependencies and dynamic path exploration with backtracking . Experimental r esults on eight KG reasoning benchmarks show that KG-Hopper , based on a 7B-parameter LLM, consistently outperforms larger multi-step systems (up to 70B) and achieves competitive performance with proprietary models such as GPT -3.5- T urbo and GPT -4o-mini, while remaining compact, open, and data-efficient. The code is publicly a vailable at: https: //github .com/W angshuaiia/KG- Hopper. Index T erms —LLM, knowledge graph, question answer - ing I . I N T R O D U C T I O N Large Language Models (LLMs) hav e achiev ed re- markable success across div erse domains but still exhibit notable shortcomings, such as hallucinations and factual inaccuracies, particularly in knowledge-intensi ve tasks. This is largely due to the implicit storage of knowl- edge within their model weights, making knowledge updates cumbersome and resource-intensive through fine- tuning. T o address this limitation, Retrie val-Augmented Generation (RA G) has emerged as an effecti ve strategy , enabling LLMs to dynamically access external knowledge during inference [1]. Among v arious external resources, Knowledge Graphs (KGs) stand out as structured and reliable knowledge bases, offering explicit, interpretable, and easily updateable knowledge beneficial in critical applications such as medicine and finance. Knowle dge Base Question Answering (KBQA), which aims to leverage structured knowledge from KGs to answer questions, often requires complex multi-hop rea- soning—trav ersing multiple interconnected relationships within a KG [2]. Current approaches typically follow step-by-step reasoning strategies, sequentially processing entities and relationships from a predefined pipeline. For example, as illustrated in Figure 1(a), answering the question "What is the official flower of the area af fected by T ropical Storm Fabio?" inv olves first identifying the af fected area and subsequently retrieving its of ficial flower . Howe ver , such rigid frameworks present critical drawbacks: • Limited Flexibility and Local Optima Suscep- tibility . T raditional methods sequentially aggreg ate information through individual inference steps guided by predefined reasoning paths. Consequently , these methods struggle to dynamically adjust when facing incomplete or misleading KG data. For instance, as shown in Figure 1(a), missing the critical entity "Y ellow Hibiscus" could mislead a multi-step method employing beam search into incorrectly choosing the national flower of Mexico, with limited capability for backtracking. • Error Cascading and Reasoning Bias. Stepwise methods inherently propagate errors from earlier steps. Incorrectly choosing a node, such as "Mexico" in Figure 1(a), directly influences subsequent reasoning steps. Additionally , treating each reasoning step inde- pendently neglects inter-step dependencies, causing biases and potential de viations from the original query intent. T o mitigate these limitations, two lines of research offer promising advances. First, Reinforcement learning (RL) have demonstrated its effecti veness in navigating discrete and combinatorial decision spaces, such as KG trav ersal by optimizing reasoning policies through o f f i c i a l _ f l o we r Q u es t i o n : W h a t is t h e o ffi ci al fl o w er of t h e af fect ed area of t h e cy cl o n e T ro p i cal St o r m Fab i o ? I n s t r u ct L L M ( G P T - 4o ) KG S e a r c h S e a r c h R e s u l t S e a r c h R e s u l t R e a s on : Firs t , s e a rch in f o rma t i o n a b o u t F a b i o Fa b io H a w a ii P a ci f ic Y e l l o w H ib i s cu s A meri ca M e x ic o R e a s on : S e a r c h re l a t e d in f o rm a t i o n a b o u t H a w a i i a n d P a c i fi c R e a s on : T h e n s e a rc h in f o rma t i o n a b o u t A m e rica a n d M e x ic o . e n t it y l a ck R e a s o n i n g L L M R o l l o ut : [ T hi nk + A ns w e r ] < t h i n k > G iv en t h e in f o r m a t io n , I d o n ' t h a v e s p ecif ic k n o w l ed g e a b o u t t h e n a t io n a l f l o w er o f t h e a f f ect ed a re a o f t h e cy cl o n e Tro p i ca l S t o rm Fa b i o . I w il l p e rf o r m a s e a rch f o r t h e r e q u ire d in f o rm a t io n . Th e q u e ry t o s e a rch f o r is < s e a rch > Fa b io < / s e a rch > < s e a rch e d _ t rip l e s > ( Fa b io , a f f ect ed A rea , H a w a ii ) \ n ( T ro p ica l S t o rm Fa b io , a f f e ct e d A re a , P a ci f ic ) < / s e a rch ed _ t rip l e s > . B a s e d o n t h e s e a rc h re s u l t s , I f o u n d t h a t t h e a f f e ct e d a re a o f t h e cy cl o n e T ro p ic a l S t o rm Fa b i o is H a w a ii. I w il l p e rf o rm a n o t h e r s e a rc h . T h e q u e ry t o s e a rc h f o r is < s e a rc h > H a w a ii < / s e a rc h > < s e a rch ed _ t rip l e s > ( H a w a ii , co n t a in e d _ b y , A m e ric a ) < / s e a rc h e d _ t rip l e s > . B a s e d o n t h e s e a rch re s u l t s , t h e k n o w l e d g e g ra p h d o e s n o t co n t a in in f o r m a t io n a b o u t t h e o f f ic ia l f l o w e r o f H a w a ii. H o w e v e r , t o t h e b e s t o f m y k n o w l e d g e , t h e o f f ic ia l s t a t e f l o w e r o f H a w a ii is t h e y e l l o w h ib is cu s . < / t h i n k > I n s t r u ct L L M ( G P T - 4o ) KG S e a r c h I n s t r u ct L L M ( G P T - 4o ) o t h e r en t it y R e a s on : B a s e d o n t h e re t rie v ed in f o rm a t i o n , t h e n a t io n a l f l o w er o f M ex ic o is t h e D a h l ia . Th e r e f o r e, t h e a n s w er is D a h l i a . S t e p 1 S t e p 2 S t e p 3 ( a ) Mu l t i - s t e p R e a s o n i n g ( M u l t i p l e LLM C a l l s ) ( b ) O n e - r o u n d R e a s o n i n g ( S i n g l e LLM C a l l ) Q ue s t i on A n s w e r A n s w e r Q ue s t i on < a n s w e r> Y e l l o w H i b i s c us < / a n s w e r> T h i n k A n s w er T h i n k : [ Reas o n + Sea rch ] A n s w er: Y el l o w H i b i s cu s Fig. 1: Multi-step vs one-round multi-hop reasoning ov er a knowledge graph: (a) multi-step reasoning and (b) our one-round reasoning. The multi-step pipeline in vokes multiple sequential LLM calls and fails due to the missing entity Y ellow Hibiscus , leading to an incorrect path. In contrast, our one-round approach performs the entire reasoning process within a single Reasoning LLM call, maintaining coherence and demonstrating robustness to incomplete knowledge. exploration and long-term rewards [3]–[5]. Second, recent work on Reasoning LLMs , such as ChatGPT -o1 [6] and DeepSeek-R1 [7], has significantly improved the reasoning capabilities of language models. These models perform a dedicated “thinking” phase before generating answers, where each token in the thought sequence can be viewed as a latent v ariable. Importantly , later tokens can re vise earlier ones, enabling self-reflection and correction within the reasoning process [8]. This iterativ e refinement mechanism aligns naturally with the multi-hop nature of complex KBQA tasks, allowing LLMs to reason more coherently and correct potential errors before answer generation. Building on these insights, we propose KG-Hopper , a nov el KBQA framework integrating the entire multi-hop reasoning process within a single LLM call, as depicted in Figure 1(b). Specifically , KG-Hopper leverages RL to enhance the reasoning capabilities of LLMs by training them to utilize KG retriev al tools effecti vely . KG-Hopper addresses pre vious limitations with the following adv antages: (1) By embedding the complete reasoning chain within a single inference step, KG- Hopper captures cross-step dependencies, mitigating local biases and ensuring coherent reasoning. (2) Integrating reasoning into the Reasoning LLM ’ s "thinking" phase allows flexible exploration and effecti ve backtracking, significantly reducing cascading errors without predefined reasoning patterns. (3) Our framework le verages RL to ex- plicitly guide and refine reasoning processes, substantially improving the model’ s performance in complex multi-hop scenarios. (4) It remains compact and deployable, using a 7B LLM to achiev e competitiv e results with much larger models. T o effecti vely train KG-Hopper , we initially generate cold-start data and employ Supervised Fine-T uning (SFT), enabling autonomous KG retriev al. W e subsequently strengthen multi-hop reasoning capabilities through tar- geted RL training, guided by carefully designed reward functions for retrieving and reasoning process. Addi- tionally , we mask the retrieved triples from KG to minimize external knowledge interference and employ history resampling to enhance training efficienc y . Our main contributions are as follows: • W e introduce a RL framew ork for LLM–KG integra- tion, combining structured re ward signals for retriev al and reasoning with masked supervision over KG content. T o the best of our knowledge, this is the first work to apply RL to enable end-to-end KG reasoning within LLMs. • W e propose a one-round KBQA frame work that performs multi-hop reasoning entirely within the “thinking” phase of a single LLM inference, enabling autonomous and iterative KG trav ersal without multi- step orchestration. • W e achiev e strong empirical results on eight KBQA benchmarks: our compact 7B-parameter model consis- tently outperforms multi-step methods using models up to 70B, and matches or exceeds the performance of proprietary models such as GPT -3.5-T urbo and GPT -4o-mini. I I . T A S K D E FI N I T I O N W e address the task of Kno wledge Base Question Answering (KBQA) over a kno wledge graph G = { ( e, r , e ′ ) | e, e ′ ∈ E , r ∈ R} , where each triple ( e, r , e ′ ) denotes a relation r between two entities e and e ′ . Giv en a natural language question q , along with an identified topic entity e t ∈ E mentioned in the question, the objecti ve is to infer the correct answer entity e a ∈ E by reasoning ov er the knowledge graph G . The answering process typically starts from the topic entity e t and in volves exploring the graph to identify the answer entity e a . In practice, large-scale knowledge graphs are often sparse and incomplete, making it difficult to locate the answer through simple one-hop queries. As a result, multi-hop reasoning is frequently required, where the answer entity e a may reside several hops away from the topic entity e t . I I I . M E T H O D Our approach leverages reinforcement learning to train LLMs for KG retrie val and reasoning. This section introduces two key components: the construction of a knowledge graph retriev al tool, and the RL framew ork for training LLMs to interact with the knowledge graph. A. Knowledge Graph Retrieval T ool Large-scale knowledge graphs are typically stored in graph databases and queried using SP ARQL for retriev al. Our retrie v al process starts from a topic entity and expands the search. Due to the vast number of triples connected to a single node, it is crucial to filter out irrelev ant information. T o address this, we adopt a two- stage strategy: first retrieving the set of directly connected edges (predicates) and then selecting the ones relev ant to the input query . Giv en a topic entity , our tool first retrie ves all pred- icates and corresponding object entities linked to it. For example, giv en the question “What books did J.K. Rowling write?” , the topic entity is J.K. Rowling . The follo wing SP ARQL query is issued to retrie ve all outgoing predicates and their objects: SELECT ?predicate ?object WHERE { ns:m.05b6w ?predicate ?object . } Here, ns:m.05b6w denotes the Freebase ID for J.K. Rowling, ?predicate retriev es all relations where she appears as the subject, and ?object returns the corresponding object entities. For example, the retriev ed predicates include: ns:book.author.works_written , ns:people.person.place_of_birth , ns:people.person.nationality . Based on the semantic rele vance to the question, the most related predicate, such as ns:book.author.works_written , is selected. This predicate indicates the books authored by the subject. Next, the tool issues another SP ARQL query to retriev e the tail entities (i.e., books) associated with the selected predicate: SELECT ?tailEntity WHERE { ns:m.05b6w ns:book.author.works_written ?tailEntity . } This query fetches all book entities linked to J.K. Rowl- ing through the works_written relation, effecti vely answering the question. In summary , the retriev al tool takes an entity as input and returns a set of relev ant triples from the kno wledge graph by identifying and filtering meaningful relations and associated entities. B. Cold Start T o av oid the unstable cold-start phase typically seen in early RL training. Specifically , we construct and collect a small set of CoT annotated data to fine-tune the base LLM, which is then used as the initial RL actor . The cold-start dataset is created with two primary objectiv es: (1) to demonstrate how the model should properly inv oke the knowledge graph retriev al tool; and (2) to enforce a consistent, structured format for answer generation. W e define a rule such that when the LLM generates the special tokens and , it triggers the KG retrieval tool to search the enclosed entity . The retrie ved triples are then wrapped with tags and appended to the current context, enabling the LLM to continue generation with access to the retrieved knowledge. T o collect cold start data, we use few-shot prompting with a long CoT example to elicit responses from a powerful LLM. W e then select examples that correctly in vok e KG queries and exhibit high readability . For instance, given the question: what timezone is Utah in? A preferred response would begin with an explicit motiv ation for search, such as: Given the information, I don’t have specific knowledge about Utah’s timezone. I will perform a sear ch for the r equir ed information. The query to searc h for is utah (Utah, timeZone, Mountain T ime Zone) . Based on the sear ch r esults, I found that Utah is in the Mountain T ime Zone. Mountain Standar d T ime W e select such examples, which exhibit clarity , ap- propriate tool in vocation, and well-structured reasoning, as the cold-start training data. Such structure is the desired output format of the LLM. The section encapsulates the full CoT reasoning process, including autonomous inv ocation of the KG tool ( ), retriev al results ( ), and intermediate de- ductions. The section then summarizes the reasoning into a final answer . This also represents the desired output format of the LLM. W e use the collected data to fine-tune the base LLM. During training, we mask the tokens within the to prev ent the model from being distracted by retriev ed knowledge. This encourages the model to generalize its reasoning strategy while preserving tool-use behaviors. The fine-tuned model is then further optimized via reinforcement learning. C. Reasoning-oriented Reinforcement Learning Gi ven the difficulty of obtaining sufficient high-quality long CoT reasoning data, we lev erage Reinforcement Learning with Human Feedback (RLHF) as a principled alternati ve to explicitly guide the model tow ard effecti ve multi-hop reasoning. W e design a composite re ward function to guide the model’ s beha vior throughout the reasoning process. The reward comprises four compo- nents: retriev al reward, format reward, reasoning reward, and final answer rew ard. • Retriev al Reward T o encourage the model to search for answers through the knowledge graph rather than relying solely on its internal knowledge, we provide a positive reward for each in vocation of the query tool. Howe ver , to prevent the model from overusing the tool solely for rew ard accumulation, we apply a cap on the maximum re ward. The retriev al reward is defined as: R search = min(0 . 5 · n, 0 . 8) (1) where n denotes the number of times the query tool is in voked. This design incentivizes query usage while discouraging excessi ve or redundant retriev als. • F ormat Reward T o enforce structured reasoning and tool usage, we define a format reward that requires the generated text to follow a predefined format. Specifically , the model must use the tags , , and appropriately . If all tags appear in the correct positions and order , a fixed rew ard is granted: R format = ( 0 . 5 if the format meets all requirements 0 otherwise (2) This constraint ensures that the model explicitly separates its reasoning, search actions, and final answer . • Reasoning Reward In multi-hop KG reasoning, an error at any intermediate step can lead to an incorrect final answer . T o mitigate this, we introduce a reward signal that directly ev aluates the quality of the rea- soning process itself, encouraging the model to make sound decisions at each step, rather than focusing solely on the final answer . The model is expected to adapt its behavior based on the informativeness of retriev ed triples. When the retriev ed information is suf ficient, the model should organize and synthesize it into a coherent answer . Otherwise, it should continue reasoning by selecting the next entity or relation to query . In cases where the KG lacks the necessary facts (e.g., due to incompleteness), the model is allowed to fall back on its internal kno wledge to infer a plausible answer . T o assess the quality of the model’ s reasoning behavior , we use an external LLM to ev aluate the full reasoning trace enclosed in the tag. The reasoning rew ard is computed as: R reason = f r ( reasoning process ) ∈ (0 , 1) (3) where f r denotes an external LLM, and a higher score indicates a more reasonable and logically valid reasoning trace. • Answer Reward Finally , we reward the model if it provides a correct answer . Since the generated answer may differ from the ground truth due to variati ons such as abbreviations or phrasing, we again use a separate LLM to perform semantic similarity assessment between the predicted answer and the ground truth ( LLM as Evaluator ). The final answer rew ard is defined as: R answer = f a ( predicted_answer , ground_truth ) ∈ { 0 , 1 } (4) where f a denotes an external LLM, and the predicted answer is extracted from the tag. A rew ard of 1 is given if the LLM determines the answer is semantically correct, and 0 otherwise. In the absence of ground truth, we directly use a (preferably larger) LLM with rich kno wledge as both the J udge and Evaluator , i.e., we rely on the LLM’ s internal knowledge to assess whether the predicted answer is correct. By combining the above four rew ard functions, the total rew ard provides comprehensi ve guidance to the model throughout the reasoning process, promoting structured, accurate, and knowledge-grounded answers, which can be represented as: R final = R search + R format + R reason + R answer (5) D. Optimization W e optimize the reasoning policy using Group Relative Policy Optimization (GRPO), which trains the LLM to maximize the expected reward of generated reasoning trajectories. Formally , the objectiv e is simplified as: θ ∗ = arg max θ E q ∼ π θ R final ( q ) , (6) where π θ denotes the LLM policy and R final ( q ) is the corresponding rew ard function. GRPO estimates relative advantages within sampled output groups to stabilize optimization and encourage higher-quality reasoning paths. Masking Retriev ed T riples. Retrie ved triples are provided as auxiliary context b ut are not expected to be generated by the model. W e therefore mask tokens enclosed by and during loss computation to pre vent the model from learning to reproduce retriev ed content. History Resampling f or Efficient T raining. In KBQA, simple one-hop queries often produce uniformly high rew ards, leading to near -zero normalized advantages and inefficient learning. Follo wing a history resampling strategy [9], we remov e one-hop questions after an initial training phase, encouraging the model to focus on multi- hop reasoning in a curriculum learning manner [10]. I V . E X P E R I M E N T S A. Datasets W e e valuate our approach on eight widely-used datasets for KBQA, lev eraging two large-scale general-purpose knowledge graphs: Freebase and W ikiData. Four of the datasets are based on the Freebase knowledge graph and are standard KBQA benchmarks: ComplexW ebQuestions (CWQ) [11], W ebQuestionsSP (W ebQSP) [12], W ebQues- tions [13], and GrailQA [14]. The other four datasets are grounded in the WikiData knowledge graph. Among them, QALD10-en [15] is a KBQA dataset, while T -REx [16] and Zero-Shot RE [17] are designed for slot filling tasks, and Creak [18] focuses on factual verification. Follo wing prior work [19]–[21], we use Hit@1 score as the ev aluation metric for both question answering and slot filling tasks, while accuracy is used to ev aluate performance on the Creak dataset. B. Implementation Details W e conduct experiments using two instruction-tuned language models as backbones: LLaMA-3.1-8B-Instruct and Qwen-2.5-7B. T o mitigate the unstable cold-start phase of reinforcement learning, we first construct a set of 500 high-quality examples to teach the models ho w to properly in voke the kno wledge retriev al tool. W e randomly sample 2,000 examples from 8 datasets for RL training. The scoring model f r for the reasoning process is Llama-3.3-70B, while the model f a used to determine whether the predicted answer matches the ground truth is Llama-3.2-3B. Starting from the second epoch, we apply a resampling strategy to dynamically filter out trivial questions and retain more informativ e ones for continued training. The training is performed on 8 NVIDIA A100 80G GPUs in total. For each input query , we generate 16 outputs (rollouts). W e train for 2 epochs with a batch size of 16 and a learning rate of 1 e − 6 . The rollout temperature is set to 1, the PPO clip ratio is 0.2, and the KL diver gence penalty coefficient is 1 e − 5 . C. Main Results W e design our experiments to explore the reasoning ef fectiv eness, training efficiency , and design trade-offs of our method KG-Hopper . KG-Hopper is designed as an open-source, compact, and flexible solution that promotes transparency in the training process and supports targeted modifications. Through our experiments, we in vestigate ho w RL contributes to efficient multi-hop KBQA. Results are reported in T able I. In terms of integration strategy , prompt-only LLMs, including strong proprietary models like GPT -4o, con- sistently underperform on multi-hop KBQA tasks. This highlights the limitations of relying solely on parametric knowledge and the lack of explicit, structured reasoning. Adding KG retriev al tools improves performance signifi- cantly (often by 10–30 Hits@1), but without any form of model-le vel adaptation, these systems exhibit fixed reasoning patterns and struggle to generalize beyond shallow queries. SFT on KG reasoning tasks further improv es results, especially for moderately complex questions. Howe ver , its imitation-based learning process tends to be brittle, it teaches the model to reproduce specific reasoning paths rather than adapti vely exploring alternativ es. Our RL-trained model, KG-Hopper, consis- tently outperforms SFT -based models of similar (7-8B) or larger size (13B, 70B) and matches or exceeds the performance of GPT -4o-mini + KG, particularly on more complex multi-hop reasoning tasks. D. Ablation a) RL vs SFT . How does reinforcement learning compare to SFT in the context of multi-hop KBQA performance? ( RQ1 ) T able II reports the Hits@1 scores across eight KBQA T ABLE I: Performance comparison (Hits@1). Results marked with ‘*’ are taken directly from the corresponding original papers. Bold numbers indicate the best performance , while underlined numbers denote the second-best. Method Size Freebase WikiData CWQ W ebQSP W ebQuestion GrailQA QALD10-en T -REx Zero-Shot RE Creak LLM Prompting Only Qwen-2.5-7B 7B 31.25 46.97 44.23 29.53 41.88 31.15 7.84 73.26 LLaMA-3.1-8B 8B 32.33 45.07 45.88 28.35 40.25 23.00 12.54 75.80 LLaMA-3.3-70B 70B 37.20 71.12 59.73 33.79 56.00 20.12 18.55 83.72 DeepSeek-R1-Distill-Llama-70B 70B 31.92 77.43 68.84 31.70 43.10 34.21 22.27 79.10 GPT -4o-mini – 42.32 65.97 57.26 36.22 51.98 26.90 18.85 83.72 GPT -4o – 41.77 72.55 64.79 35.01 56.20 44.46 48.20 90.70 KG-A ugmented LLMs without Fine-T uning Qwen-2.5-7B + KG 7B 44.82 72.60 56.33 41.10 56.54 64.21 70.32 79.04 LLaMA-3.1-8B + KG 8B 45.64 71.32 57.05 40.40 55.73 65.80 68.66 80.50 LLaMA-3.3-70B + KG 70B 44.00 81.90 72.60 57.70 71.78 65.42 80.42 87.04 DeepSeek-R1-Distill-Llama-70B + KG 70B 52.38 81.34 75.80 59.02 66.10 72.04 78.04 91.20 GPT -4o-mini + KG – 54.35 84.40 81.02 60.00 72.86 69.70 75.12 90.20 KG-CoT w/GPT 3.5-T urbo [20] – 51.6 ∗ 82.1 ∗ 66.5 ∗ - - - - - KG-A ugmented LLMs with Supervised Fine-T uning Interactiv e-KBQA w/LLaMA-7B [21] 7B 39.9 ∗ 43.57 ∗ - - - - - - KG-CoT w/LLaMA-7B [20] 7B 46.7 ∗ 72.4 ∗ - - - - - - Qwen-2.5-7B (SFT) + KG 7B 51.84 74.80 61.42 46.18 65.18 68.77 71.46 83.43 LLaMA-3.1-8B (SFT) + KG 8B 47.40 72.98 60.00 47.70 59.63 70.23 64.08 84.47 Interactiv e-KBQA w/LLaMA-13B [21] 13B 42.5 ∗ 54.86 ∗ - - - - - - KG-CoT w/LLaMA-13B [20] 13B 50.0 ∗ 74.6 ∗ - - - - - - KG-A ugmented LLMs with RL Fine-T uning KG-Hopper w/Qwen-2.5-7B (ours) 7B 61.07 83.20 66.90 50.10 74.28 72.14 78.64 91.82 datasets, comparing models trained with SFT and RL using two LLM backbones: Qwen-2.5-7B and LLaMA- 3.1-8B. In both cases, the RL-trained models consistently outperform their SFT counterparts, achieving gains of +4% to +10%. This performance gap can be attributed to the inherent misalignment issue [22] in SFT , where the model learns to produce fixed, pattern-based responses. Such rigidity often leads the model to rely on spurious correlations from training examples, which can interfere with its ability to reason based on its own kno wledge. In contrast, RL allo ws the model to adaptively coordi- nate with the retrie val module, perform more coherent multi-hop reasoning, and explicitly generate step-by-step solutions. Notably , the performance gains are especially signifi- cant on complex datasets such as CWQ and QALD10- en, with improvements of around 10%. These datasets demand longer reasoning chains and deeper trav ersal of the KG. The results illustrate the strength of RL in capturing long-horizon dependencies, an area where supervised fine-tuning falls short due to its imitation- based nature and limited exposure to div erse reasoning patterns. In addition to accuracy , RL achieves better performance with fewer annotated examples, since it learns from scalar rewards rather than full reasoning traces. This improv es data efficiency and generalization to unseen multi-hop patterns. b) RL Rewar d Design. W e analyze the impact of individual reward compo- nents in our RL framew ork for KBQA. Specifically , we address the following questions: Which components (retriev al, format, reasoning, or an- swer) contribute most to multi-hop KBQA performance? In particular , how do token-lev el action rew ards (i.e. retriev al reward and format rew ard) compare to global sequence-le vel re ward (i.e. reasoning and result reward)? ( RQ2 ) As shown in T able III, removing the reasoning rew ard leads to the lar gest performance drop across most datasets, indicating that sequence-lev el feedback is essential for acquiring robust, long-horizon reasoning capabilities. In contrast, the retriev al and format rewards yield smaller but consistent improvements, helping to regularize tool use and output structure. These two rew ards operate at the token le vel, primarily guiding the generation of literal tags (e.g., , ) to enforce structured output and tool in vocation. As such, these behaviors are ef fectiv ely learned through SFT – RL does not offer a clear ef ficiency advantage in this context. While token-le vel rew ards contribute to training stability and early con ver gence, their gains are marginal compared to the global benefits provided by reasoning- lev el supervision. For the final answer reward, can LLMs reliably serve as automated judges for final answers in RL? ( RQ3 ) Specifically , we compare two modes: (i) Ev aluator - only , where the LLM assesses the answer against a known ground truth, and (ii) Judge+Ev aluator , where no ground truth is provided and the LLM both infers a reference answer and ev aluates the model’ s output accordingly . Using GPT -4o in Judge+Ev aluator mode results in a noticeable performance drop, though it still performs better than removing answer rew ard entirely . This suggests LLMs can act as fallback e valuators when ground truth is unav ailable, but are less reliable than T ABLE II: Comparison of RL and SFT . (RQ1) Method Freebase WikiData CWQ W ebQSP W ebQuestion GrailQA QALD10-en T -REx Zero-Shot RE Creak Qwen-2.5-7B (SFT) + KG 51.84 74.80 61.42 46.18 65.18 68.77 71.46 83.43 Qwen-2.5-7B (RL) + KG 61.07 (+9.23) 83.20 (+8.40) 66.90 (+5.48) 50.10 (+3.92) 74.28 (+9.10) 72.14 (+3.37) 78.64 (+7.18) 91.82 (+8.39) LLaMA-3.1-8B (SFT) + KG 47.40 72.98 60.00 47.70 59.63 70.23 64.08 84.47 LLaMA-3.1-8B (RL) + KG 58.20 (+10.80) 76.90 (+3.92) 67.28 (+7.28) 55.41 (+7.71) 67.66 (+8.03) 74.20 (+3.97) 70.25 (+6.17) 88.31 (+3.84) T ABLE III: Ablation study of the RL training process. The table reports performance across different RL variants compared to the baseline Qwen-2.5-7B (RL) + KG model. Reported (+/–) values indicate the change in Hits@1 relativ e to the baseline. Method Freebase WikiData CWQ W ebQSP W ebQuestion GrailQA QALD10-en T -REx Zero-Shot RE Creak Qwen-2.5-7B (RL) + KG 61.07 83.20 66.90 50.10 74.28 72.14 78.64 91.82 reward signal ablation (RQ2) w/o Retrieval Reward 60.75 (-0.32) 82.38 (-0.82) 66.01 (-0.89) 49.71 (-0.39) 73.54 (-0.74) 72.81 (+0.67) 77.81 (-0.83) 91.62 (-0.20) w/o Format Reward 60.45 (-0.62) 83.63 (+0.43) 66.19 (-0.71) 49.97 (-0.13) 72.77 (-1.51) 72.10 (-0.04) 78.10 (-0.54) 91.30 (-0.52) w/o Reasoning Rew ard 57.94 (-3.13) 80.50 (-2.70) 64.42 (-2.48) 49.92 (-0.18) 71.69 (-2.59) 70.22 (-1.92) 75.75 (-2.89) 91.72 (-0.10) w/o Answer Rew ard 51.96 (-9.11) 75.68 (-7.52) 57.15 (-9.75) 42.19 (-7.91) 64.81 (-9.47) 68.87 (-3.27) 72.31 (-6.33) 82.06 (-9.76) without ground truth – LLM being Judge+Evaluator (RQ3) Evaluate Reward by GPT -4o 53.49 (-7.58) 77.07 (-6.13) 57.46 (-9.44) 47.46 (-2.64) 70.53 (-3.75) 69.31 (-2.83) 73.82 (-4.82) 89.23 (-2.59) without history resampling (RQ4) w/o History Resampling 57.83 (-3.24) 80.64 (-2.56) 67.19 (+0.29) 47.50 (-2.60) 72.16 (-2.12) 70.15 (-1.99) 77.39 (-1.25) 91.13 (-0.69) 0 50 100 150 200 250 T raining Steps 0.75 1.00 1.25 1.50 1.75 2.00 R ewar d W/ R esample W/O R esample 0 50 100 150 200 250 T raining Steps 500 1000 1500 2000 2500 R esponse L ength W/ R esample W/O R esample 0 50 100 150 200 250 T raining Steps 1 2 3 4 5 R etrieval Count W/ R esample W/O R esample Fig. 2: The RL training process under two settings: with and without history resampling ( RQ4 ). The figure shows how rew ard, response length, and retriev al count change over training steps. direct supervision. c) RL Sampling Efficiency . How ef fectiv e is history resampling in mitigating ov erfitting to trivial or overrepresented examples during RL training? ( RQ4 ) Figure 2 presents training trajectories for three ke y metrics: av erage reward, response length, and retriev al count [23], comparing models trained with and without history resampling. All metrics show a general upward trend over time, indicating learning progress. When history resampling is introduced at the start of the second epoch, a temporary dip in av erage rew ard is observed, reflecting the remov al of simpler, one-hop questions in fav or of more challenging multi- hop queries. As training proceeds, the model adapts to these harder examples, resulting in a steady recovery and continued rew ard improvement. Importantly , models trained with history resampling ex- hibit longer response lengths and higher retriev al counts, both indicativ e of more complex, multi-step reasoning. These results confirm that resampling ef fectiv ely shifts training focus tow ard higher-quality samples, improving the model’ s capacity for reasoning without being biased tow ard shallow patterns. V . R E L AT E D W O R K KBQA methods are broadly categorized as retrie val- based or semantic parsing-based. The former extract rele vant KG subgraphs, while the latter translate questions into executable queries [24], [25]. Reinforcement learning (RL) has been used to explore multi-hop paths [3], [26], though prior methods often struggle with efficiency and error accumulation. T o address this, recent works incorporate LLMs for sub-question decomposition or as priors for guiding RL [20], [27]. LLMs demonstrate stronger reasoning when prompted explicitly [28]–[30], and RL further enhances this via iterativ e reflection [7], [8]. While RL-augmented LLMs succeed in unstructured multi-hop retriev al [31], KG reasoning remains more constrained, requiring alignment to discrete graph paths. This limits the applicability of open-ended reasoning and calls for structural-aware LLM integration. V I . C O N C L U S I O N In this paper , we introduced KG-Hopper , a nov el RL- based framework designed to empo wer compact open LLMs with enhanced multi-hop reasoning capabilities ov er KGs. T o the best of our kno wledge, KG-Hopper is the first framework to apply reinforcement learning to enhance multi-hop knowledge graph reasoning in large language models. Beyond this, KG-Hopper integrates KG reasoning directly into the intrinsic "thinking" process of the reasoning LLM, enabling autonomous multi-hop trav ersal and answer generation within a single inference round. Specifically , we propose a two-stage training paradigm: we begin with cold-start data to teach basic KG retrie val skills, and then apply reinforcement learning to substantially improv e multi-hop reasoning capability . T o support this, we design tailored reward functions that explicitly guide retriev al and reasoning behaviors, intro- duce masking techniques to control exposure to retrie ved knowledge, and implement a history resampling strategy to improve training ef ficiency . Experimental results on eight benchmark datasets, along with comprehensiv e ablation studies, demonstrate the effecti veness of KG- Hopper in enabling efficient and robust KBQA. A C K N OW L E D G M E N T This work was partially funded by the Autonomous Systems and Software Program (W ASP), supported by the Knut and Alice W allenberg Foundation, and the Chalmers Artificial Intelligence Research Centre (CHAIR). R E F E R E N C E S [1] X. W ang, M. Costa, J. K ov acev a, S. W ang, and F . C. Pereira, “Plug- ging schema graph into multi-table qa: A human-guided frame- work for reducing llm reliance, ” arXiv pr eprint arXiv:2506.04427 , 2025. [2] S. W ang and Y . Y u, “iQUEST: An iterative question-guided framew ork for kno wledge base question answering, ” in Pr oceedings of the 63r d Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , Jul. 2025, pp. 15 616–15 628. [Online]. A vailable: https: //aclanthology .org/2025.acl- long.760/ [3] W . Xiong, T . Hoang, and W . Y . W ang, “Deeppath: A reinforcement learning method for knowledge graph reasoning, ” in Pr oceedings of the 2017 Conference on Empirical Methods in Natural Language Pr ocessing , 2017, pp. 564–573. [4] S. W ang, D. Parthasarathy , R. Feldt, and Y . Y u, “Domagent: Lev er- aging knowledge graphs and case-based reasoning for domain- specific code generation, ” arXiv pr eprint arXiv:2603.21430 , 2026. [5] X. V . Lin, R. Socher , and C. Xiong, “Multi-hop knowledge graph reasoning with reward shaping, ” in Pr oceedings of the 2018 Conference on Empirical Methods in Natural Language Pr ocessing , 2018, pp. 3243–3253. [6] A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky , A. Low , A. Helyar, A. Madry , A. Beutel, A. Carney et al. , “Openai o1 system card, ” arXiv preprint , 2024. [7] D. Guo, D. Y ang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P . W ang, X. Bi et al. , “Deepseek-r1: Incenti vizing reasoning capability in llms via reinforcement learning, ” arXiv preprint arXiv:2501.12948 , 2025. [8] F . Zhu, P . W ang, and Z. Sui, “Chain-of-thought tokens are computer program variables, ” arXiv preprint , 2025. [9] X. Zhang, J. W ang, Z. Cheng, W . Zhuang, Z. Lin, M. Zhang, S. W ang, Y . Cui, C. W ang, J. Peng et al. , “Srpo: A cross-domain implementation of large-scale reinforcement learning on llm, ” arXiv preprint arXiv:2504.14286 , 2025. [10] S. Narvekar , B. Peng, M. Leonetti, J. Sinapov , M. E. T aylor, and P . Stone, “Curriculum learning for reinforcement learning domains: A framework and surve y , ” Journal of Machine Learning Resear ch , vol. 21, no. 181, pp. 1–50, 2020. [11] A. T almor and J. Berant, “The web as a knowledge-base for answering complex questions, ” in Proceedings of the 2018 Confer ence of the North American Chapter of the Association for Computational Linguistics: Human Language T echnologies, V olume 1 (Long P apers) , 2018, pp. 641–651. [12] W .-t. Y ih, M. Richardson, C. Meek, M.-W . Chang, and J. Suh, “The value of semantic parse labeling for knowledge base question answering, ” in Pr oceedings of the 54th Annual Meeting of the Association for Computational Linguistics (V olume 2: Short P apers) , 2016, pp. 201–206. [13] J. Berant, A. Chou, R. Frostig, and P . Liang, “Semantic parsing on freebase from question-answer pairs, ” in Pr oceedings of the 2013 confer ence on empirical methods in natural language processing , 2013, pp. 1533–1544. [14] Y . Gu, S. Kase, M. V anni, B. Sadler , P . Liang, X. Y an, and Y . Su, “Beyond iid: three levels of generalization for question answering on knowledge bases, ” in Proceedings of the W eb Conference 2021 , 2021, pp. 3477–3488. [15] A. Perevalo v , D. Diefenbach, R. Usbeck, and A. Both, “Qald-9- plus: A multilingual dataset for question answering over dbpedia and wikidata translated by native speakers, ” in 2022 IEEE 16th International Confer ence on Semantic Computing (ICSC) . IEEE, 2022, pp. 229–234. [16] H. Elsahar , P . V ougiouklis, A. Remaci, C. Gravier , J. Hare, F . Laforest, and E. Simperl, “T -rex: A large scale alignment of natural language with knowledge base triples, ” in Pr oceedings of the Eleventh International Confer ence on Language Resour ces and Evaluation (LREC 2018) , 2018. [17] F . Petroni, A. Piktus, A. Fan, P . Lewis, M. Y azdani, N. De Cao, J. Thorne, Y . Jernite, V . Karpukhin, J. Maillard et al. , “Kilt: a benchmark for knowledge intensive language tasks, ” in Pr oceed- ings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language T echnologies , 2021, pp. 2523–2544. [18] Y . Onoe, M. J. Zhang, E. Choi, and G. Durrett, “Creak: A dataset for commonsense reasoning over entity knowledge, ” in Thirty-fifth Confer ence on Neural Information Processing Systems Datasets and Benchmarks T rack (Round 2) . [19] J. Sun, C. Xu, L. T ang, S. W ang, C. Lin, Y . Gong, L. Ni, H.- Y . Shum, and J. Guo, “Think-on-graph: Deep and responsible reasoning of large language model on knowledge graph, ” in The T welfth International Confer ence on Learning Representations , 2024. [20] R. Zhao, F . Zhao, L. W ang, X. W ang, and G. Xu, “KG-CoT: Chain- of-thought prompting of large language models over knowledge graphs for knowledge-aware question answering, ” in Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI-24) . International Joint Conferences on Artificial Intelligence, 2024, pp. 6642–6650. [21] G. Xiong, J. Bao, and W . Zhao, “Interactiv e-KBQA: Multi-turn interactions for knowledge base question answering with large language models, ” in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , L.-W . Ku, A. Martins, and V . Srikumar , Eds., Aug. 2024, pp. 10 561–10 582. [22] P . W ang, L. Li, Z. Shao, R. Xu, D. Dai, Y . Li, D. Chen, Y . W u, and Z. Sui, “Math-shepherd: V erify and reinforce llms step-by-step without human annotations, ” in Pr oceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , 2024, pp. 9426–9439. [23] H. Song, J. Jiang, Y . Min, J. Chen, Z. Chen, W . X. Zhao, L. Fang, and J.-R. W en, “R1-searcher: Incentivizing the search capability in llms via reinforcement learning, ” arXiv preprint , 2025. [24] H. Zhang, J. Cai, J. Xu, and J. W ang, “Complex question decomposition for semantic parsing, ” in Pr oceedings of the 57th Annual Meeting of the Association for Computational Linguistics , 2019, pp. 4477–4486. [25] Y . Gu and Y . Su, “ ArcaneQA: Dynamic program induction and contextualized encoding for kno wledge base question answer- ing, ” in Proceedings of the 29th International Confer ence on Computational Linguistics , N. Calzolari, C.-R. Huang, H. Kim, J. Pustejovsky , L. W anner, K.-S. Choi, P .-M. Ryu, H.-H. Chen, L. Donatelli, H. Ji, S. Kurohashi, P . Paggio, N. Xue, S. Kim, Y . Hahm, Z. He, T . K. Lee, E. Santus, F . Bond, and S.-H. Na, Eds., 2022, pp. 1718–1731. [26] R. Das, S. Dhuliawala, M. Zaheer , L. V ilnis, I. Durugkar, A. Krishnamurthy , A. Smola, and A. McCallum, “Go for a walk and arrive at the answer: Reasoning over paths in knowledge bases using reinforcement learning, ” in International Confer ence on Learning Representations , 2018. [27] Z. Zhang and W . Zhao, “ A collaborativ e reasoning framew ork powered by reinforcement learning and large language models for complex questions answering over knowledge graph, ” in Pro- ceedings of the 31st International Confer ence on Computational Linguistics , 2025, pp. 10 672–10 684. [28] S. W ang, Y . Y u, E. Barr, and D. Parthasarathy , “Llm-powered workflo w optimization for multidisciplinary software devel- opment: An automotiv e industry case study , ” arXiv preprint arXiv:2603.21439 , 2026. [29] J. W ei, X. W ang, D. Schuurmans, M. Bosma, F . Xia, E. Chi, Q. V . Le, D. Zhou et al. , “Chain-of-thought prompting elicits reasoning in large language models, ” Advances in neural information pr ocessing systems , vol. 35, pp. 24 824–24 837, 2022. [30] S. W ang, Y . Y u, R. Feldt, and D. Parthasarathy , “ Automating a complete software test process using llms: An automotive case study , ” in 2025 IEEE/ACM 47th International Conference on Softwar e Engineering (ICSE) . IEEE, 2025, pp. 373–384. [31] X. Li, J. Jin, G. Dong, H. Qian, Y . Zhu, Y . W u, J.-R. W en, and Z. Dou, “W ebthinker: Empowering large reasoning models with deep research capability , ” arXiv preprint , 2025.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment