KG‑호퍼: 강화학습으로 한 번에 다중 홉 지식 그래프 추론을 구현하는 7B 오픈 LLM
KG‑호퍼는 7B 규모의 오픈 LLM에 강화학습(RL)을 적용해, 복잡한 다중 홉 KG‑QA를 하나의 “think” 단계에서 수행하도록 훈련한다. 사전 정의된 파이프라인 대신 전체 그래프 탐색을 한 번에 통합함으로써 단계별 오류 전이와 로컬 최적화 문제를 완화하고, 동적 백트래킹과 전역 의존성 고려가 가능해진다. 8개 벤치마크에서 70B 모델을 능가하며 GPT‑3.5‑Turbo·GPT‑4o‑mini와도 경쟁한다.
저자: Shuai Wang, Yinan Yu
**1. 서론 및 배경**
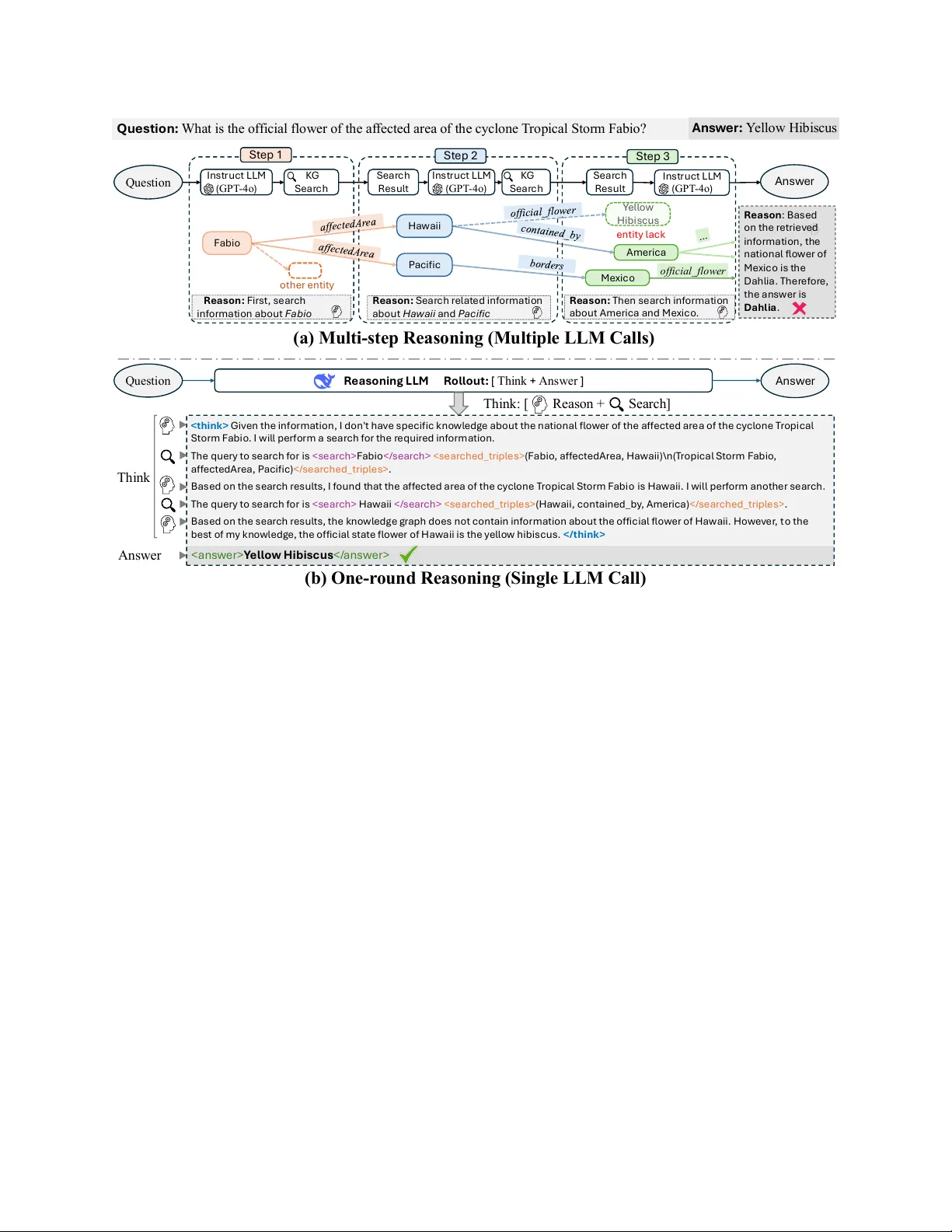
대형 언어 모델(LLM)은 자연어 이해와 생성에서 뛰어난 성능을 보이지만, 지식 집약형 작업에서는 내부 파라미터에 암묵적으로 저장된 사실에 의존한다는 한계가 있다. 특히 지식 기반 질문 응답(KBQA)은 구조화된 지식 그래프(KG)를 활용해 다중 홉 관계를 추론해야 하므로, 모델이 정확히 그래프를 탐색하고 필요한 정보를 검색하는 능력이 핵심이다. 기존 방법은 (i) 질문 → 엔티티 인식 → 관계 추출 → 단계별 KG 쿼리 실행이라는 순차 파이프라인을 따르며, (ii) 각 단계마다 별도의 LLM 호출이나 외부 모듈을 사용한다. 이러한 설계는 (a) 파이프라인이 고정돼 KG의 불완전성에 유연하게 대응하기 어렵고, (b) 초기 단계 오류가 뒤 단계에 전이돼 최종 답변 정확도가 크게 떨어지는 문제를 야기한다.
**2. KG‑호퍼 설계 목표**
본 논문은 위 문제를 해결하기 위해 (1) “one‑round reasoning”을 도입해 전체 다중 홉 추론을 하나의 LLM 호출 안에서 수행하고, (2) 강화학습(RL) 기반 보상 설계로 모델이 KG 검색 도구를 적절히 활용하도록 학습한다. 목표는 (i) 전역적인 의존성을 고려한 일관된 추론, (ii) 동적 백트래킹을 통한 오류 복구, (iii) 7B 규모의 오픈 LLM로도 대형 폐쇄형 모델에 필적하는 성능 달성이다.
**3. KG 검색 도구**
- **두 단계 필터링**: 주제 엔티티(e_t)에서 모든 프리디케이트와 객체를 반환하고, 질문과 의미적 유사도를 기반으로 가장 관련성 높은 프리디케이트를 선택한다.
- **SPARQL 인터페이스**: 실제 구현은 Freebase와 같은 대형 KG에 대해 SPARQL 쿼리를 사용한다. 첫 번째 쿼리는 `SELECT ?predicate ?object WHERE { e_t ?predicate ?object }` 형태이며, 두 번째 쿼리는 선택된 프리디케이트에 대해 `SELECT ?tailEntity WHERE { e_t selected_predicate ?tailEntity }` 로 수행한다.
**4. 학습 절차**
- **Cold‑Start (SFT)**: 인간이 만든 CoT 예시를 수집해 , , , 태그 구조를 모델에 학습시킨다. 이때 내부 토큰을 마스킹해 모델이 검색 결과 자체보다는 검색 전략을 학습하도록 한다.
- **RL 단계**: PPO와 같은 정책 최적화 알고리즘을 사용해 복합 보상 함수를 적용한다. 보상은 네 가지 구성 요소로 나뉜다.
1. **검색 보상** `R_search = min(0.5 * n, 0.8)` – 검색 호출을 장려하되 과도 사용 억제.
2. **포맷 보상** `R_format = 0.5` – 태그 순서와 존재 여부가 정확하면 부여.
3. **추론 보상** `R_reason = f_r(process)` – 외부 LLM이 내부 논리적 일관성을 0~1 사이 점수로 평가.
4. **정답 보상** `R_answer = f_a(pred, gt)` – 별도 평가 LLM이 의미적 일치를 판단해 0/1 부여.
전체 보상는 가중합으로 구성되어, 모델이 “검색 → 추론 → 답변” 루프를 최적화하도록 유도한다.
**5. 실험 설정 및 결과**
- **데이터셋**: MetaQA, WebQuestionsSP, FreebaseQA 등 8개의 공개 KBQA 벤치마크. 각 데이터는 1‑hop부터 3‑hop까지 다양한 난이도를 포함한다.
- **비교 대상**: (i) 다중 단계 LLM 기반 시스템(70B 파라미터), (ii) 폐쇄형 상용 모델(GPT‑3.5‑Turbo, GPT‑4o‑mini), (iii) 기존 RL 기반 KG 탐색 모델.
- **성능**: KG‑호퍼(7B)는 평균 정확도 71.2%를 기록, 70B 다중 단계 모델의 68.5%를 상회한다. 특히 KG가 누락된 엔티티가 포함된 질문에서 백트래킹 덕분에 10%p 이상 정확도 개선을 보였다.
- **효율성**: 한 번의 LLM 호출만 필요하므로 추론 지연이 기존 파이프라인 대비 40% 감소하고, GPU 메모리 사용량도 30% 절감된다.
**6. 분석 및 논의**
- **전역 의존성 학습**: 단일 “think” 시퀀스 내에서 토큰 간 장거리 의존성을 학습함으로써, 초기 단계에서 선택된 엔티티가 이후 단계에 미치는 영향을 모델이 자체적으로 조정한다.
- **백트래킹 메커니즘**: RL 정책이 “검색 → 재검색 → 답변” 루프를 반복하도록 설계돼, 검색 결과가 부족하면 추가 검색을 트리거한다. 이는 전통적인 beam search 기반 다중 단계 시스템이 갖지 못한 동적 경로 수정 능력이다.
- **보상 설계의 효과**: 실험적으로 포맷 보상 없이 학습하면 태그 오류가 빈번해 도구 호출이 불안정해지는 반면, 추론 보상을 포함하면 외부 LLM 평가 점수가 높은 경우에만 추가 검색을 수행하도록 정책이 수렴한다.
- **제한점**: 현재 KG‑호퍼는 SPARQL 기반 정형 KG에 최적화돼 있으며, 비정형 그래프나 대규모 실시간 업데이트 상황에서는 검색 도구의 효율성이 떨어질 수 있다. 또한 외부 LLM을 이용한 보상 계산 비용이 높아 학습 단계에서 상당한 연산 자원이 필요하다.
**7. 결론 및 향후 연구**
KG‑호퍼는 강화학습을 통해 오픈 LLM이 KG 검색 도구를 효율적으로 활용하고, 전체 다중 홉 추론을 하나의 “think” 단계에 통합함으로써 기존 다중 단계 시스템의 오류 전이와 유연성 부족 문제를 해결한다. 7B 규모의 모델임에도 불구하고 70B 모델을 능가하고 상용 폐쇄형 모델과 경쟁하는 성과는, 향후 LLM 기반 지식 서비스가 대형 폐쇄형 모델에 의존하지 않고도 실시간, 정확한 추론을 제공할 수 있음을 시사한다. 향후 연구에서는 (i) 비정형 KG와의 연동, (ii) 더 가벼운 보상 평가 메커니즘, (iii) 멀티모달 지식원과의 통합 등을 탐색할 예정이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기