EngGPT2: Sovereign, Efficient and Open Intelligence
EngGPT2-16B-A3B is the latest iteration of Engineering Group's Italian LLM and it's built to be a Sovereign, Efficient and Open model. EngGPT2 is trained on 2.5 trillion tokens - less than Qwen3's 36T or Llama3's 15T - and delivers performance on key…
Authors: G. Ciarfaglia, A. Rosanova, S. Cipolla
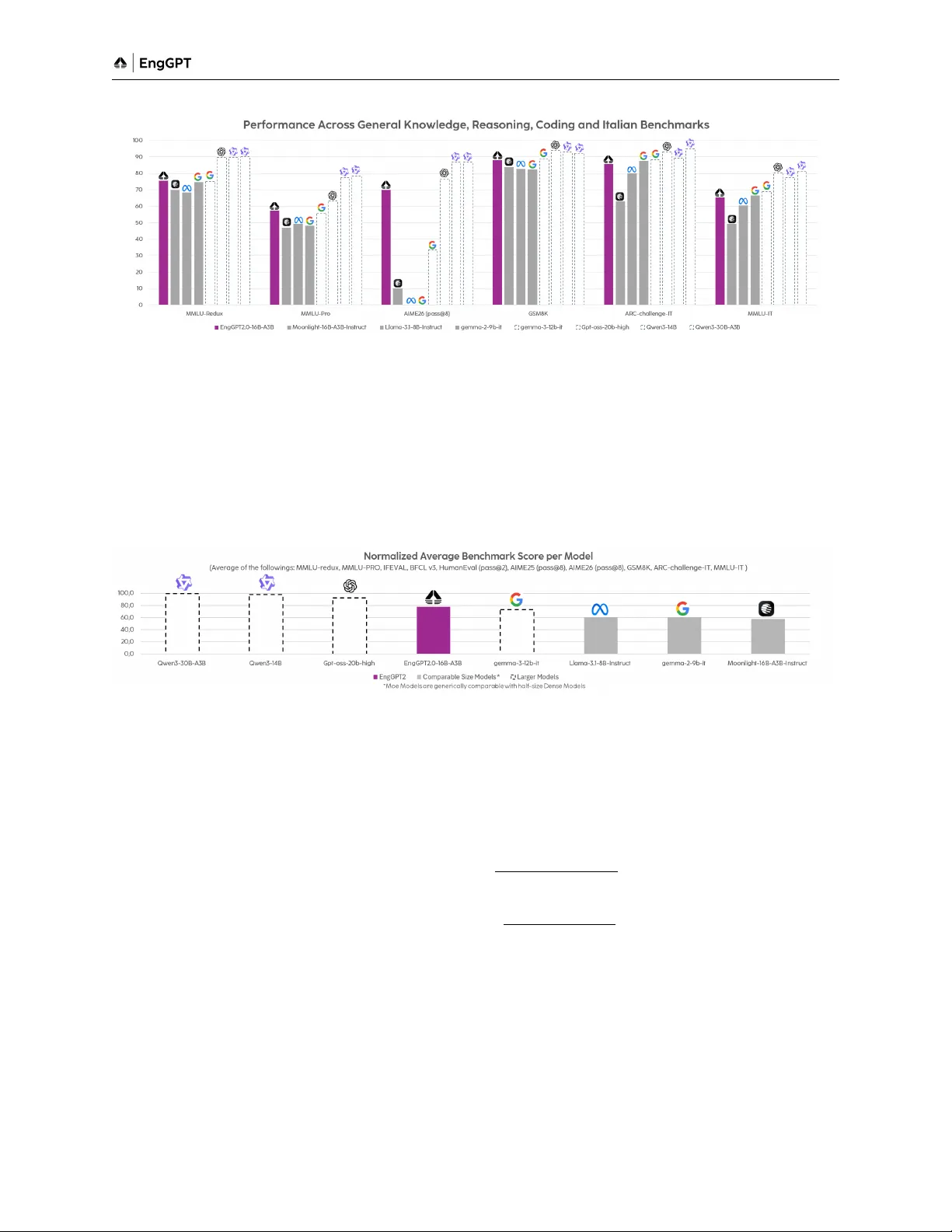
E N G G P T 2 : S OV E R E I G N , E FFI C I E N T A N D O P E N I N T E L L I G E N C E Ciarfaglia G. Rosanova A. Cipolla S. Bartoli J . ∗ Di Domenico A. ∗ Fioroni C. ∗ Fontana A. ∗ Scoleri M. R. ∗ Mone M. I. Franchi D. Del Gaudio M. C. Leodori A. Cinti F . Capozzi M. Baston C. Picariello F . Gabusi M. Bonura S. Morreale V . Bailo I. EngGPT T eam @ Engineering Group A B S T R AC T EngGPT2-16B-A3B 1 is the latest iteration of Engineering Group’ s Italian LLM and it’ s b uilt to be a So vereign, Ef ficient and Open model. EngGPT2 is trained on 2.5 trillion tokens, less than Qwen3’ s 36T or Llama3’ s 15T , and deliv ers performance on key benchmarks, including MMLU-Pro, GSM8K, IFEv al and HumanEval, comparable to dense models in the 8B–16B range, while requiring one-fifth to half of the inference power , and between one-tenth to one-sixth of the training data and consequent needed training po wer . Designed as a trained-from-scratch Mixture-of-Experts (MoE) architecture, EngGPT2 features 16 billion parameters with 3 billion acti ve per inference, with expert sizes positioned between those used in GPT -OSS and Qwen3. Approximately 25% of its training corpus consists of Italian-language data, to deliv er strong capabilities for European and Italian NLP tasks among models of similar scale. This efficienc y aims to position EngGPT2 as a key contrib utor to the growing portfolio of open-weight European models, combining performance and ef ficiency with full alignment to the EU AI Act. EngGPT2 is also a single model capable of multiple reasoning modes: non-reasoning, reasoning in Italian or English, and turbo-reasoning (a concise, b ullet-point style reasoning a v ailable in both languages designed for real-time reasoning use cases). EngGPT2 aims to set a ne w standard for resource-conscious, high-performance LLMs tailored to European and Italian contexts. Figure 1: Comparison of model evaluation and efficiency . T op: model comparison under the Cost of Intelligence framew ork. Bottom: EngGPT2 average e valuation comparison ag ainst main open-weight comparable size models. ∗ Equal contributions. Names are listed in alphabetical order . 1 https://huggingface.co/engineering-group/EngGPT2-16B-A3B ©Engineering Ingegneria Informatica S.p.A. All rights reserv ed. This document is provided for informational and research purposes only . EngGPT2 T echnical Report 1 Introduction 1.1 Context and Scope Europe is steadily strengthening its capabilities in large language models, e ven if it still lags behind the major innov ation hubs in the United States and China. In recent years, a small but growing set of national initiativ es, driv en by both industry and academia, has emer ged to dev elop open, re gion - focused foundation models. Although still limited in scale, these efforts mark an important starting point for building a European ecosystem committed to responsible, safe, and v alue - aligned AI de velopment. As this ecosystem tak es shape, generativ e AI is rapidly becoming a strategic asset for both public administrations and priv ate enterprises. Cultiv ating strong local expertise is essential: technological sov ereignty , sustained innov ation, and seamless regulatory compliance all depend on Europe’ s ability to design, operate, and gov ern AI systems within its own principles, standards, and le gal framew orks. W ithin this context, Engineering Group contrib utes not only as a technology integrator but as a true solutions builder , combining deep consulting e xpertise with engineering e xcellence to guide org anizations in defining, designing, and deploying the AI solutions best suited to their specific needs. Our close collaboration with public institutions and industrial partners giv es us direct insight into emer ging requirements and real - world operational constraints. This vantage point reinforces the importance of maintaining full control o ver the entire de velopment pipeline, from initial design to deployment, and of in vesting in internal capabilities to b uild, adapt, and continuously refine customized AI systems rather than relying solely on off-the-shelf models. In this spirit, we introduce EngGPT 2, our Large Language Model designed to strengthen Engineering’ s technological stack and to contribute to the broader European ef fort to build a so vereign and open AI ecosystem. Compliance with the EU AI Act is a foundational pillar of this sovereign and open approach. W e adopt rigorous transparency practices, including comprehensi ve technical documentation and the publication of the model on the Hugging F ace Hub, to support transparency , accountability , and regulatory compliance. Beyond sov ereignty and openness, EngGPT 2 strongly emphasizes ef ficiency , le veraging adv anced architectural choices such as mixture - of - experts (MoE), dual - reasoning flows, and nati ve agentic integrations. These techniques enable significant performance gains, both in speed and in cost of operation, while supporting scalable, adaptable configurations tailored to enterprise and public - sector en vironments. Through this work, we aim to deliv er not only adv anced technological solutions but also a concrete contrib ution to a sov ereign, efficient, and future-ready European AI landscape. 1.2 EngGPT 2 Overview W e introduce EngGPT2 - 16B - A3B, a highly sparse, medium - scale Mixture of Experts (MoE) language model designed as a flexible and ef ficient foundation for research and adv anced downstream applications. Engineered to balance computational efficienc y with strong general - purpose reasoning, EngGPT2 - 16B - A3B supports a wide spectrum of capabilities, including structured reasoning, domain adaptation, tool - augmented workflo ws, controlled generation, and general con versational proficienc y . The EngGPT2 - 16B - A3B release provides full insight into its de velopment pipeline, cov ering architectural decisions, data preparation, training dynamics, and ev aluation methodology across the entire lifecycle of the model. The project is centered on the principle that efficient parameter utilization through sparse expert-based architectures can deliv er competiti ve performance while maintaining computational tractability [ 1 ]. Unlike dense models that activ ate all parameters during inference, the proposed MoE architecture enables selecti ve activ ation of a subset of specialized sub-models (experts) on a per -token basis, thereby reducing computational o verhead while maintaining expressi ve capacity . This approach aligns with recent industry adv ances demonstrating that carefully designed sparse models can achiev e performance parity with significantly larger dense systems while incurring substantially lower training and inference costs [2, 3, 4, 5, 6]. The architecture is inspired by Qwen3 [ 5 ] and GPT -OSS [ 6 ]. From Qwen3, we adopt hybrid attention and Grouped- Query Attention (GQA) for memory-ef ficient inference and sparse MoE routing enabling scalable parameters [ 5 ]. GPT -OSS influences the design with fewer , larger experts for an ef ficient MoE setup [ 6 ]. The tokenizer dra ws from Mistral [ 7 ], chosen for its strong multilingual support, especially ef fectiv e with Italian and other Romance and Germanic languages. The training process is structured around four distinct but interconnected phases, each with specific objectives and methodological approaches: 1. Pr e-training: Language F oundation 2 EngGPT2 T echnical Report The model begins by learning fundamental language skills through self-supervised learning on lar ge, div erse, and mostly raw te xt datasets. This phase emphasizes English and Italian to support multilingual generalization. Data from v arious public sources such as books, web corpora, scientific documents, and code are carefully curated to build a broad and div erse knowledge base. This foundational phase establishes the core language understanding that subsequent training phases cannot fully replicate. 2. Long-Context Adaptation: Extended Context Pretraining Before entering the mid-training stage, the model undergoes a dedicated phase aimed at adapting it to substantially extended conte xt windows. This phase le verages targeted datasets with long documents to teach the model to maintain coherence, stability , and effecti ve information retrie val ov er long sequences. The objectiv e is to ensure reliable handling of contexts up to 32768 tokens and be yond. 3. Mid-T raining: Consolidation and Capability Enhancement This intermediate training stage focuses on consolidating knowledge and enhancing capabilities. T raining centers on high-quality , carefully curated datasets that emphasize data quality ov er volume, tar geting improve- ments in reasoning and linguistic precision. Logical, mathematical, and problem-solving skills are intensified by integrating specialized reasoning datasets, aiming to boost the model’ s capacity in these areas. 4. P ost-T raining: Alignment and Instruction Following The final phase transitions the model into a chat-oriented, instruction-follo wing system through supervised fine-tuning (SFT) and alignment techniques. Model mer ging is also applied to combine the strengths of SFT and alignment models. During this phase, the chat-template is formalized, and compatibility with function calling and the MCP server is ensured, enabling adv anced agent-oriented interactiv e capabilities. The entire training pipeline was ex ecuted on an HPC infrastructure, scaling up to 128 nodes, each equipped with 4 NVIDIA A100 GPUs. Our training pipeline leverages the Megatron frame work [ 8 ], a highly optimized and scalable system for training large transformer models across multiple GPUs via a combination of tensor, pipeline, and data parallelism. Building upon Megatron, we use custom code deri ved from the SmolLM3 project [ 9 ], which incorporates modular enhancements and optimizations tailored for sparse Mixture of Experts (MoE) architectures. This hybrid framew ork allo ws efficient large-scale training while supporting advanced features such as long context windo ws, expert routing, and seamless inte gration with downstream fine-tuning and alignment workflo ws. On standard benchmarks, our model deliv ers performance that is fully comparable to dense baseline models of similar size. Beyond absolute benchmark scores, our model distinguishes itself e ven more clearly when metrics are normalized for training ef ficiency and inference cost. T o capture these aspects, we define two composite metrics: one measuring capability per unit of training signal, and another measuring capability per activ e parameter at inference time. Under both normalizations, the model consistently outperforms larger dense baselines when compared at equi valent units of training or inference compute. These normalized perspecti ves highlight the core strength of our approach: deli vering superior capability for a giv en compute budget, rather than merely achie ving good absolute scores. The technical report is structured to comprehensiv ely document the project and includes the following chapters: • Architectur e : Describes the design principles and structural characteristics of the EngGPT 2 model, outlining the rationale behind its core architectural choices. • Evaluation Framework : Presents the general methodology used to assess the model across training phases, clarifying the ev aluation principles and comparison criteria. • Pre-T raining : Summarizes ho w the foundational training of EngGPT 2 w as conducted, outlining the multi- stage process, dataset mixture, and general training dynamics that shaped the base model. • Long-Context Adaptation : Explains the dedicated phase used to e xtend the model’ s ef fectiv e context windo w , describing how EngGPT 2 w as adapted to handle significantly longer sequences. • Mid-T raining : Describes the intermediate refinement stage focused on consolidating model behav- ior—particularly reasoning—under controlled conditions and preparing the model for subsequent alignment phases. • Post-T raining : Outlines the steps performed after mid-training, including supervised fine-tuning, preference optimization, and the introduction of structured reasoning and interaction formats that enable final deployment capabilities. • Final Benchmarking and Comparativ e Analysis : Reports ho w the finished model was e valuated against reference baselines. • Conclusion : Summarizes the ov erall findings of the project and highlights the overarching direction for future model dev elopment. 3 EngGPT2 T echnical Report • Legal Notice : Outlines the copyright terms, usage restrictions, disclaimers, and legal conditions governing the distribution and use of this document. 1.3 T raining Compute Assessment and GP AI Classification The full training pipeline required approximately 250,000 GPU hours, for an estimated total cost of C500,000, assuming an av erage cost of C2 per GPU hour . Pre-training represented the most computationally intensi ve stage, accounting for roughly 235,000 A100 GPU hours. This phase ran for approximately 23 days, scaling up to a maximum of 128 nodes (512 GPUs). The observed a verage Model FLOPs Utilization (MFU) was around 21%, with peak values reaching 31% during the most efficient segments of the run. The long-context training phase required approximately 2,000 GPU hours and was completed in about 20 hours, using up to 128 nodes (512 GPUs). Due to increased sequence lengths and reduced parallel efficienc y , the average MFU during this phase was lo wer , at approximately 14%. The mid-training phase consumed roughly 12,000 GPU hours over a period of 7 days, operating on a reduced configuration of 16 nodes (64 GPUs). The av erage MFU observed in this stage was approximately 8%, reflecting additional computational ov erhead introduced by data-dependent processing and masking strategies, which reduce peak hardware utilization in fa vor of improv ed training dynamics. Finally , the post-training stages, including fine-tuning and post-training alignment, accounted for approximately 4,000 GPU hours. These activities spanned around 10 days and were executed using variable configurations ranging from 4 to 16 nodes. The MFU during post-training is highly variable across dif ferent phases but consistently remains well belo w 10%. This is e xpected, as post-training workloads are not compute-bound: they in volve autore gressiv e generation, frequent synchronization, e valuation steps, and small batch sizes , all of which naturally lead to low hardw are utilization. T o estimate the computational footprint of our training pipeline, we assumed a peak performance of 312 TFLOPS per NVIDIA A100 GPU (FP16). F or each phase of training, we computed an average ef fecti ve throughput by multiplying this peak value by the empirically observ ed GPU utilization rate. Specifically , we used 65.52 TFLOPS (21% of peak) for the pre - training phase, 43.68 TFLOPS (14%) for long - context training, 25 TFLOPS (8%) for mid - context training. For each phase, the total computational cost w as obtained by multiplying the corresponding av erage TFLOPS by the total number of GPU - hours, con verted into seconds (i.e., GPU - hours × 3600). This yields a total of 5 . 5 × 10 10 TFLOPs for pre - training, 3 . 1 × 10 8 TFLOPs for long - context training, 1 . 1 × 10 9 TFLOPs for mid - context training. The post - training stage consisted of multiple sub - phases with dif ferent measured MFU v alues; therefore, we directly report the aggre gated computational cost across the 4000 GPU - hours, which amounts to 3 . 6 × 10 8 TFLOPs in total. Summing across all training phases, the total cumulativ e compute amounts to 5 . 7 × 10 22 FLOPs. Our model qualifies as a GP AI model under the European AI Act framew ork, as outlined in [ 10 ]. Ho wev er , it is not subject to the obligations related to system risk reporting, since its cumulativ e training compute of 5 . 7 × 10 22 FLOPs is well below the 10 25 FLOPs threshold specified in the regulation. 4 EngGPT2 T echnical Report 2 Architectur e Our model le verages a Mixture-of-Experts (MoE) transformer architecture with 24 layers. Each layer contains 64 experts, with 8 experts acti vated per tok en through dynamic routing. No parameters are shared across experts, which promotes greater specialization. The attention system uses Grouped Query Attention (GQA) [ 11 ], and each layer incorporates SwiGLU activ ations [12], Rotary Positional Embeddings (RoPE) [13], and RMSNorm [14] with pre-normalization to ensure training stability and effecti ve representation. Figure 2: Model e xpert size comparison In our design, the individual e xperts are con- figured with hidden size H and MoE interme- diate size m , chosen to lie between Qwen3- 30B-A3B [ 5 ] and Openai-gpt-oss-20b [ 6 ]. This decision is driven by the need to main- tain a minimum of approximately 3B acti ve parameters per forward pass, ensuring suf- ficient model capacity for high-quality rea- soning, while keeping the total model size manageable within our training budget con- straints. By selecting intermediate-sized ex- perts, we strike a balance between ef ficiency and expressi veness, allowing the model to perform ef fectiv ely without incurring exces- siv e computational or memory costs. Finally , we sought to identify a Mixture-of-Experts configuration that is original and uniquely tai- lored to our model. In Figure 2, we illustrate a visual comparison of dif ferent model expert sizes. See T able 1 and T able 2 for further details about the model’ s architecture. The model’ s tokenizer employs a vocab ulary size that is expanded to 131084 tokens. Be- yond the standard v ocabulary , it incorporates 12 additional specialized tokens specifically designed to support reasoning and tool-calling capabilities. Featur e V alue Featur e V alue Number of Layers 24 Num attention heads 32 T otal number of experts 64 Num ke y value heads 4 Experts activ ated/token 8 Context length 32768 V ocabulary size 131084 T able 1: Architectural Parameters Model # Params (T otal / Activ e) Single Expert Size H/m % Active Params Layers Experts (T otal / Activ ated) Heads (Q /KV) V ocab size EngGPT2-16B-A3B 16B / 3B 9.3M 2880 / 1080 20 . 27% 24 64 / 8 32 / 4 131084 Qwen3-30B-A3B 30B / 3B 4.7M 2048 / 768 10 . 98% 48 128 / 8 32 / 4 151936 Openai-gpt-oss-20B 21B / 3.6B 24.9M 2880 / 2880 17 . 30% 24 32 / 4 64 / 8 201088 T able 2: MoE Comparison 5 EngGPT2 T echnical Report 3 Evaluation Framework Our ev aluation methodology provides a comprehensiv e, phase-aware assessment of the model’ s capabilities, combining standardized benchmark measurements with tar geted analyses tailored to the objecti ves of each stage of the training pipeline. The approach prioritizes reproducibility , comparability with prior w ork, and a clear separation between capabilities acquired during base pre-training and behaviors introduced through subsequent alignment and refinement stages. Quantitati ve ev aluation is primarily conducted using the lm-e valuation-harness frame work [ 15 ], ensuring consistent and robust measurement across a broad range of academic and open-source language model benchmarks. Function-calling performance is assessed through the BFCL V3 suite using the Ev alScope framew ork [ 16 ]. All experiments are ex ecuted under controlled and fully documented serving configurations to guarantee transparency and replicability . The ev aluation frame work spans the entire training lifecycle, with a lev el of depth proportional to the model’ s maturity at each phase. During early pre-training checkpoints and intermediate refinement stages, the assessment is intentionally limited to a core subset of ke y performance indicators (KPIs). These metrics are selected to v alidate training stability , verify correct optimization dynamics, and monitor the progressi ve emergence of tar get capabilities. At this stage, the objectiv e is not comparativ e benchmarking, but controlled v alidation of training quality and trajectory . A complete and systematic benchmarking analysis is presented in section 8. This section provides an extensi ve compar - ati ve ev aluation that integrates standardized benchmark suites with qualitative and capability-oriented assessments. The analysis cov ers general kno wledge, instruction following a nd alignment, code generation, mathematical and logical reasoning, Italian-language performance, and function-calling capabilities. It also includes direct comparisons with architectures of comparable parameter scale as well as with larger baseline models, offering both an assessment of competitiv eness within the same model class and an ev aluation of efficienc y and performance trade-offs relativ e to more computationally demanding systems. 3.1 Evaluation A pproach During pre-training, e valuation focuses on tracking learning progression and con vergence dynamics through founda- tional benchmarks that measure intrinsic language modeling quality , general kno wledge acquisition and long-context understanding. These assessments are primarily intended to monitor capability growth and conv ergence dynamics rather than to provide competiti ve comparisons. Post-training e valuation, by contrast, is oriented to ward final-model assessment and e xternal benchmarking. At this stage, the model is e valuated on a broader and more usage-oriented suite of benchmarks cov ering knowledge, structured reasoning, instruction following, code generation, multilingual performance, and tool-calling ability . These results are used both to measure downstream readiness and to enable direct comparison against peer models. Multilin- gual ev aluation—particularly for Italian—is treated as an integral component of the final assessment, ensuring that deployment-oriented performance is v alidated beyond English-only benchmarks. When benchmarking against e xternal models, we systematically re-ev aluated all systems under two distinct serving configurations to ensure strict and transparent comparability . First, all models were e valuated using a fully standardized generation setup, with identical sampling hyperparameters (temperature, top-p, top-k, and min-p) applied across all systems. This unified configuration eliminates variability introduced by decoding strategies and ensures that performance differences reflect intrinsic model capability rather than sampling artifacts. Second, whenever of ficially recommended or best-performing serving configurations were provided in the respectiv e model documentation, we additionally report results obtained under those optimal settings. This dual ev aluation protocol—standardized configuration for controlled comparison and optimal configuration for capability estimation—ensures both methodological fairness and practical relev ance, reducing ev aluation bias while preserving fidelity to each model’ s intended deployment regime. T o better contextualize raw benchmark results with respect to efficienc y , we introduce two additional composite metrics that are of particular interest to our use case. The first metric captures a normalized av erage performance score, computed as the mean of the selected KPIs after normalization, di vided by the total number of training tokens. This metric is intended to approximate performance per unit of training signal, highlighting ho w ef fectiv ely the model con verts training data into do wnstream capability . The second metric follo ws a similar aggre gation strategy b ut normalizes the a veraged KPI score by the number of acti ve parameters at inference time, rather than by total model size. This metric is especially rele vant for MoE architectures, as it directly reflects the effecti ve inference footprint and provides a more faithful measure of performance-to-compute efficienc y than raw parameter counts. 6 EngGPT2 T echnical Report T aken together , these metrics allow us to mo ve beyond absolute benchmark scores and e xplicitly capture the trade-off between capability and cost. Under both normalizations, our model consistently achiev es performance le vels that are close to those of larger dense baselines, while requiring significantly fewer training tokens and substantially fe wer activ e parameters during inference. This results in mark edly lower training costs and reduced inference latenc y and compute consumption, without a proportional degradation in accurac y or reasoning quality . 3.2 Benchmark suite W e ev aluate core linguistic, reasoning, and task-oriented capabilities through a div erse suite of benchmarks co vering general knowledge, instruction following, code generation, mathematical reasoning, multilingual performance, and function-calling ability . • General Knowledge: W e assess broad factual knowledge and domain-specific e xpertise using MMLU [ 17 ], MMLU-Pro [ 18 ], and MMLU-Redux [ 19 ]. These datasets span a wide range of academic disciplines and difficulty le vels, enabling a holistic ev aluation of factual recall, professional-le vel kno wledge, and robustness across subject domains. • Instruction F ollowing / Alignment: Instruction-following beha vior and alignment with user intent are e valuated using IFEv al [ 20 ]. W e report loose prompt accuracy , which measures the model’ s ability to correctly interpret instructions, adhere to structural constraints, and produce outputs aligned with formatting and semantic requirements. This benchmark is particularly relev ant for real-world deployment scenarios in volving structured prompts and constrained outputs. • Code Generation: Programming and code synthesis capabilities are ev aluated using HumanEval [ 21 ]. W e report pass@2, which estimates the probability that at least one of two generated samples passes all unit tests. This metric reflects realistic code-generation workflo ws where multiple candidate solutions may be sampled. • Reasoning: For e valuating mathematical and logical reasoning skills, we employ high-lev el math benchmarks including AIME25 [ 22 ], AIME26 [ 23 ], GSM8K [ 24 ]. Each AIME year includes Part I and P art II, for a total of 30 problems. For each problem, we compute pass@8, providing a robust estimate of reasoning reliability under stochastic decoding. • Italian Language: T o assess multilingual capabilities—particularly for deployment in the Italian market—we include Italian-adapted benchmarks: ARC-Challenge-IT [ 25 ] and MMLU-IT [ 26 ]. These benchmarks e valuate knowledge recall across a broad range of subjects, problem-solving and analytical reasoning e xpressed in Italian, and robustness in handling domain-specific terminology and culturally grounded content. This ensures that performance is not disproportionately optimized for English and that quality , precision, and instruction adherence are preserved in Italian-language deployment scenarios. • Function Calling: The ability to correctly inv oke external tools and APIs is ev aluated using the Berkeley Function-Calling Leaderboard (BFCL v3) [ 27 ], assessed via the Ev alScope framew ork [ 16 ]. The benchmark cov ers AST -based ev aluation (both non-live and li ve), rele vance detection, and multi-turn interaction scenarios, providing a comprehensi ve assessment of the model’ s ability to interface with structured APIs in realistic deployment settings. 3.3 Evaluation Pr otocol for Final Benchmarking All post-training ev aluations are conducted e xclusiv ely in generati ve mode, where the model produces free-form outputs until EOS token is generated or a maximum length limit is reached (35000 tokens or the model’ s maximum context window if lo wer for reasoning models). This setup dif fers from the multiple-choice ev aluation used during pretraining and better reflects real world do wnstream usage including open-ended reasoning, instruction following, structured and long-form generation. Evaluations are performed in the appropriate zero-shot, ensuring methodological adherence and comparability across models. For each model–benchmark pair, we verified that ev aluation metrics accurately captured the intended answers by aligning extraction rules and stop sequences with the task format, v alidating answer normalization procedures, and checking for truncation or misparsing. T o ensure strict cross-model comparability , we ev aluate all models using the same generation hyperparameters adopted for EngGPT2-16B-A3B: temperature = 0.6, top-p = 0.95, top-k = 20, and min-p = 0. In addition, to ensure that the reported results reflect each model’ s maximum achiev able capability under realistic serving conditions, we also ev aluate ev ery model in its best-performing configuration, as detailed in Appendix E. This dual reporting strategy (optimal configuration vs. standardized configuration) provides both a fair estimate of maximum practical capability and a controlled comparison under identical sampling conditions. 7 EngGPT2 T echnical Report W e aim to benchmark EngGPT2 - 16B - A3B against models of comparable size. Within this category , the closest MoE reference is Moonlight - 16B - A3B - Instruct [ 28 ], which matches both the architectural class and the ov erall parameter scale. Be yond Moonlight, ho wev er , few MoE models exist in this size range, limiting direct comparisons within the MoE family . Gi ven the scarcity of similarly sized MoE baselines, we adopt a heterogeneous selection strategy that incorporates dense models of approximately 8B parameters as our primary “comparable - sized” baselines. This approach is supported by evidence—most notably [ 5 ]—showing that MoE architectures often achie ve performance comparable to dense models with roughly half as many parameters. In that study , for example, Qwen3 - 30B - A3B deliv ers results close to the dense Qwen3 - 14B, reinforcing the validity of comparing EngGPT2 - 16B - A3B with dense models in the 8B range. Follo wing this rationale, our comparable-sized baselines include Llama-3.1-8B-Instruct [29] and gemma-2-9b-it [30]. T o contextualize performance beyond this range, we further include a set of lar ger dense and MoE models. Here, our se- lection is again deliberate: among the many a v ailable options, we specifically choose Qwen3 - 14B and Qwen3 - 30B - A3B, as their relationship has been well-studied and provides a clear and meaningful MoE-vs-dense comparison point, con- sistent with the observ ations from [ 5 ]. Alongside these, we include gemma - 3 - 12b - it [ 31 ] and GPT - OSS - 20B[ 6 ]. This broader set enables us to characterize ho w EngGPT2 - 16B - A3B scales relati ve to both lar ger dense architectures and substantially larger MoE systems, while maintaining conceptual coherence across the chosen baselines. 8 EngGPT2 T echnical Report 4 Pre-T raining The pre-training stage forms the cornerstone of EngGPT’ s linguistic and multilingual foundation. It was structured as a three-phase process, each serving distinct objecti ves and e xecuted under strict computational b udget constraints, limiting total training to approximately 2.5 trillion tokens. The first phase also served as a w armup and baseline step, providing an initial model for v alidating the entire mid- and post-training pipelines. • Phase 1: W armup and Initial Model (600B tokens): Establishes a stable baseline checkpoint and verifies the reliability of the end-to-end training infrastructure. • Phase 2: Main Scale-up (1.5T tokens): Expands corpus coverage and consolidates the model’ s core linguistic capabilities. • Phase 3: High-Quality Refinement (400B tokens): Focuses on curated, high-quality datasets to strengthen reasoning, coding, and domain precision before transitioning to mid-training. This phased strategy enabled efficient utilization of av ailable GPU-hour allocations while ensuring a robust baseline for downstream v alidation and development. 4.1 Pre-T raining Data The pre-training corpus was constructed by combining se veral large-scale, publicly av ailable datasets cov ering web text, educational material, mathematical content, code, PDF documents, and synthetic data. Specifically , we leveraged FineW eb-2, FineW eb-Edu, FineMath, FinePDFs, StarcoderData, and Nemotron-Pretraining-SFT -v1. The composition of the data mixture across the different training stages is reported in T able 3. Each dataset was used in accordance with its respectiv e license terms. The training corpus includes a combination of datasets released under open licenses and/or datasets gov erned by usage-restricted agreements, as well as curated collections of permissiv ely licensed or open-access content. Where datasets included heterogeneous sources (e.g., code or web data collections), additional filtering and selection procedures were applied to retain only content compliant with the applicable licensing terms. A detailed description of each dataset, including data sources, scale, filtering strategies, and priv acy considerations, is provided in Appendix A. All pre-training data underwent standardized preparation and tokenization pipelines executed directly on the HPC infrastructure. Specifically , tokenization and preprocessing were performed lev eraging Megatron’ s nativ e data utilities combined with the Datatrov e library for efficient sharded data handling. The tok enizer is inspired from Mistral[ 7 ], chosen for its prov en multilingual performance and strong encoding ef ficiency across Italian, English, French, Spanish, and German. This tokenizer supports substantial v ocabulary o verlap across Romance and Germanic languages, reducing fragmentation and improving cross-lingual generalization. Data ingestion, shuffling, and packing workflo ws were orchestrated to ensure uniform token distribution and consistent throughput across hundreds of data-parallel work ers. The result was a reproducible and scalable pre-training pipeline capable of handling multi-terabyte tokenized datasets while maintaining data determinism required for checkpoint reproducibility . Rather than designing an ad-hoc data cleaning pipeline, we relied on the data curation, filtering, deduplication, and PII mitigation procedures provided by the original dataset creators, which include language identification, quality scoring, near-duplicate remo val, decontamination against standard e valuation benchmarks, and license compliance checks. This choice allows us to b uild upon well-established and transparent preprocessing pipelines while ensuring reproducibility and legal clarity . In addition to standard data cleaning procedures, we implemented a dedicated copyright-filtering pipeline to mitigate the inclusion of protected material. This pipeline combines rule-based heuristics, pattern matching to assign each record a composite cop yright risk score. Records e xceeding a predefined risk threshold are automatically excluded from the final corpus. By integrating multiple signals into a unified scoring framew ork, this approach enables systematic identification and remov al of documents likely to contain copyrighted content, thereby reducing potential infringement and improving the o verall compliance of the dataset. This procedure is further e xplained in Appendix B. 2 Data gov erned by the NVIDIA Data Agreement for Model Training (https://huggingface.co/datasets/n vidia/Nemotron-Pretraining-Dataset-sample/raw/main/LICENSE.md) 3 The dataset was filtered to retain only content from repositories identified as open-access / permissively licensed, in accordance with the dataset’ s documentation and licensing guidelines (https://huggingface.co/datasets/bigcode/the-stack) 9 EngGPT2 T echnical Report Dataset License Stage 1 (600B token) Stage 2 (1.5T token) Stage 3 (400B token) Fineweb-edu (english) odc-by 52% 48% 21% Fineweb2 - ita odc-by 23% 12% 15% Finepdf - ita odc-by 0% 5% 5% Fineweb2 - rom lang odc-by 12% 12% 6% Finemath odc-by 1% 3% 0% Nemotron-Pr etraining (SFT -v1 - Math) NVIDIA 2 0% 4% 17% StarCoder Misc 3 12% 7% 12% Nemotron-Pr etraining (SFT -v1 - Code) NVIDIA 2 0% 4% 10% Nemotron-Pr etraining (SFT -v1 - General) NVIDIA 2 0% 5% 14% T able 3: Pretrain datasets. The listed datasets are subject to different licensing regimes, including open license, usage-restricted agreements and curated collections of permissiv ely licensed content. 4.2 Pre-T raining Stages The entire pre-training process was carried out on an HPC infrastructure, with each node equipped with four NVIDIA A100 GPUs, using the Me gatron frame work to support lar ge - scale distributed transformer training [ 32 ]. The system employed a hybrid parallelization strategy combining tensor , data, pipeline, and expert parallelism, with a pipeline parallelism degree of 2 and an expert parallelism de gree of 4. This configuration ensured that expert layers remained primarily contained within the nodes of four GPUs, reducing inter - node communication o verhead and stabilizing ov erall throughput. Parallel folding w as enabled across all stages [ 33 ], contributing to a sustained peak Model FLOPs Utilization (MFU) of approximately 31%, which represented a well - balanced equilibrium between computational efficienc y and training stability for this hardware configuration. All pre - training stages were executed as independent training runs, each reinitialized with specific optimization schedules, parallel configurations, and e xpert - routing parameters tailored to the progression of the model’ s learning dynamics. Across all stages, training was performed on sequences of 4096 tok ens. 4.2.1 Stage 1 - W armup and Initial Model The first stage served as both a system warmup and the creation of an initial stable checkpoint. It w as executed on 64 nodes (256 NVIDIA A100 GPUs) and consisted of 75,776 optimization steps, targeting approximately 600 billion training tokens. This phase adopted a warmup - and - decay learning - rate schedule, beginning at 1 . 89 × 10 − 7 and increasing linearly to 1 . 2 × 10 − 4 , after which the learning rate gradually decayed over the remainder of the training. During the initial 19,076 steps, the global batch size (GBS) was set to 1,024, supporting a smooth w armup of both model dynamics and distributed infrastructure. After the warmup, the GBS w as increased to 2,048. Gradient accumulation be gan at 8 and was later increased to 16 to handle the higher ef fectiv e batch size without exceeding memory limits. From a performance perspectiv e, Stage 1 achiev ed an average throughput of 70.74 TFLOPs/GPU, corresponding to an MFU of 22.6%. The ef fectiv e training time—excluding o verheads—was approximately 8 days. Beyond throughput metrics, this stage validated the stability of lar ge - scale distributed training, ensured proper expert - routing behavior , and produced the foundational checkpoint used in subsequent pre - training phases. The load balancing loss coefficient for this phase was set to 1 × 10 − 2 , promoting uniform expert utilization during the early stages of learning. 10 EngGPT2 T echnical Report 4.2.2 Stage 2 - Main Scale-up The second stage marked the main scale - out effort of pre - training, shifting focus tow ard broad multilingual generalization and long - horizon optimization stability . T raining was reinitialized on an expanded configuration of 128 nodes (512 GPUs), for a total of 182,212 optimization steps, processing approximately 1.5 trillion tokens. In contrast to Stage 1, this phase employed a constant learning rate of 1 × 10 − 4 , maintaining consistent gradient dynamics over a prolonged training window . The global batch size was fix ed at 2,048, and gradient accumulation remained at 8 across the entire run. T o improve expert uniformity in the larger - scale setup, the load balancing loss coefficient w as reduced to 5 × 10 − 3 , which resulted in smoother routing behavior and reduced expert - specific variance. A verage throughput during Stage 2 reached 63 TFLOPs/GPU (MFU 20.2%), aligning with expectations for a model of this size operating on the increased GPU count. The stage deli vered the b ulk of the model’ s representational capacity , forming the core of pre-training before refinement. 4.2.3 Stage 3 - High-Quality Refinement The third stage focused on refinement, domain specialization, and preparation for mid - training. Lik e Stage 2, it was ex ecuted on 128 nodes (512 GPUs), comprising 63,578 optimization steps and processing approximately 400 billion tokens. This phase adopted a linear learning - rate decay schedule, starting from 1 × 10 − 4 and decreasing to 4 . 52 × 10 − 10 , enabling increasingly stable and fine - grained updates as training approached its endpoint. The global batch size was again set to 2,048, with gradient accumulation maintained at 8. The load balancing loss coefficient was further reduced to 1 × 10 − 3 , encouraging more adapti ve expert specialization while mitigating routing imbalance during the final training phase. A verage throughput during Stage 3 was 65.9 TFLOPs/GPU, corresponding to an MFU of 21.1%. This final pre - training stage emphasized curated, high - quality sources—particularly code, mathematics, and structurally rich language datasets—to enhance reasoning accuracy , symbolic manipulation, and structured task performance before transitioning into mid-training. 4.2.4 Throughput Dynamics acr oss Stages The throughput profile across the three pre - training stages (see Figure 3) reflects the combined ef fects of gradient - accumulation settings, GPU scaling, and learning - rate schedules. The initial portion of the curve — corre- sponding to Stage 1 — displays a distincti ve two - regime beha vior . During the earliest steps, throughput is noticeably lo wer and more volatile, primarily due to the use of a gradient accumulation factor of 8, which limits the effecti ve batch size and results in more frequent synchronization across the 256 - GPU configuration. In this period, the training system is also still settling in: expert routing, activ ation patterns, and pipeline stage utilization are stabilizing, all of which contribute to the mark ed fluctuations visible in the early segment of the graph. Figure 3: Throughput during the first three stages of pre-training. 11 EngGPT2 T echnical Report As Stage1 progresses and the gradient accumulation is increased to 16, throughput improves significantly . This transition is clearly visible in the chart, where throughput rises into a more stable and higher - performance band. The larger ef fecti ve batch size reduces communication ov erhead relativ e to compute time, allowing GPUs to operate with improv ed efficienc y . Once this higher accumulation setting is in place, the remainder of Stage1 sho ws a more consistent throughput profile. The first vertical dashed line marks the transition to Stage2. Here, the throughput stabilizes into a sustained plateau, reflecting the move to 512 GPUs and the use of a fixed gradient accumulation of 8 throughout the entire stage. Despite the lower accumulation factor relati ve to the latter part of Stage1, the throughput does not degrade significantly; the larger number of GPUs and the uniform training configuration help maintain a consistent efficiency lev el. The constant learning rate used in Stage2 further contributes to the steady beha vior observed, minimizing optimizer - induced variability . The second dashed line marks the start of Stage3. As expected, the throughput pattern remains very similar to Stage2, since both stages use the same number of nodes (512 GPUs), identical parallelism configuration, and the same gradient accumulation factor . The only notable difference stems from the linear decay of the learning rate, which introduces mild fluctuations in the early portion of Stage3 but does not fundamentally alter the throughput regime. Once the decay stabilizes, throughput returns to the familiar band established during Stage2. 4.3 Pre-T raining Evaluation During the initial stages of pre-training, the model’ s progression was continuously monitored through a combination of capability-oriented and intrinsic ev aluation signals. In particular , across the first three pre-training phases, we tracked performance on MMLU as an external proxy for the emergence of general kno wledge. MMLU was selected for this purpose, as it provides a task-lev el assessment of knowledge integration and multi-domain reasoning that is not directly captured by intrinsic language modeling metrics such as perple xity . As shown in Figure 4, MMLU accuracy at early checkpoints w as close to random-choice performance (approximately 25%), reflecting the limited task-specific competence of the model at this stage. W ith continued training, MMLU performance increased steadily , reaching approximately 55% by the end of the third pre-training phase, indicating substantial gains in general kno wledge acquisition and reasoning potential as the model was exposed to increasing amounts of training data. Figure 4: MMLU accuracy and perple xity across the first three pre-training phases as a function of the number of processed training tok ens. MMLU e valuation is conducted on a fixed subset of the benchmark to monitor the emer gence of general knowledge throughout training. English perple xity is measured on a fixed subset of W ikiT ext-2, while Italian perplexity is computed on a fix ed subset of a curated W ikimedia-based Italian corpus, following the same e v aluation protocol used for English. The decreasing perple xity trend reflects progressiv ely improved predicti ve performance on held-out data. 12 EngGPT2 T echnical Report In parallel, we monitored language modeling quality through perple xity measurements, follo wing the standard e valuation procedure described in the Hugging Face T ransformers documentation [ 34 ]. F or the English language, perplexity was ev aluated on the WikiT ext-2 dataset [ 35 ], while Italian perplexity was measured on a curated W ikimedia-based Italian corpus [36]. Both English and Italian perplexity exhibited a consistent downw ard trend across training checkpoints, reflecting improv ed predictiv e accuracy of the underlying language model distrib ution. The concurrent reduction in perplexity and increase in MMLU accurac y pro vide complementary e vidence that the model is simultaneously improving its token-le vel language modeling performance and its higher -lev el knowledge and reasoning capabilities. 13 EngGPT2 T echnical Report 5 Long-Context Adaptation As part of our ongoing model dev elopment efforts, we conducted a dedicated long - context training phase aimed at significantly extending the ef fectiv e context windo w of our language model. The primary objective w as to enhance the model’ s ability to capture long - range dependencies, maintain coherence across multi - page documents, and perform complex tasks such as document-le vel summarization and multi-step reasoning o ver extended inputs. Figure 5: R ULER long-context ev aluation across increas- ing context lengths. Comparison between the final pre- training checkpoint (post stage 3) and the long-context- adapted model on the RULER benchmark. Both models are extended beyond 64k tokens using Y ARN to enable ev aluation at long context lengths. Results are reported as av erage accuracy across the R ULER task suite for context sizes ranging from 4k to 64k tokens. This long - context adaptation initiative was designed to scale the model’ s recepti ve field up to 65,536 tokens, enabling improv ed cross - paragraph reasoning and more robust global information integration. T o achie ve this, we lev eraged the Megatron-LM frame work, which provides optimized support for large - scale transformer training through a combination of expert parallelism, pipeline parallelism, and context-a ware partitioning strategies. A ke y focus of the adaptation w as ensuring computational stability at very long sequence lengths. This required adjustments to positional encoding mechanisms and at- tention scaling strategies to preserve gradient quality and maintain throughput. Ov erall, the long - context training stage strengthens the model’ s performance in long - form generation scenarios, increasing robustness and coher- ence across extended inputs. 5.1 Long-Context Adaptation Data The allenai/dolmino-mix-1124 dataset is a lar ge-scale En- glish text corpus designed for adv anced language model training [ 37 ]. It contains a mixture of high-quality data sources—including web pages from DCLM, curated text like FLAN and W ikipedia dumps, STEM research con- tent, StackExchange posts, and multiple synthetic math- ematical subsets—totaling 50B tokens with div erse lin- guistic and factual content. The mixture strategy balances general web text with structured and domain-specific material, making it well suited for training long-conte xt language models that benefit from both broad world knowledge and specialized reasoning samples. This dataset is released under an open data license (ODC-BY). 5.2 Long-Context Adaptation Stage The long - context adaptation stage introduced se veral architectural and training - lev el configurations to support signifi- cantly extended sequence lengths while maintaining high training ef ficiency . During this phase, the model was trained using a sequence length of 32,768 tokens, balancing memory feasibility with the progressive extension of long - range attention capacity . T raining employed a global batch size of 128, ensuring adequate gradient signal accumulation while preserving stability across distributed w orkers. T o enable ef ficient training at these sequence lengths, we introduced a context parallelism factor of 8, allowing the attention computation for long sequences to be partitioned across multiple devices without exceeding memory constraints. This context - parallel setup was combined with the existing pipeline parallelism of 2 and expert parallelism of 4, achieving an ef fective distrib ution across compute nodes while maintaining high training throughput. This adaptation phase was conducted on a subset of the full training corpus using 128 compute nodes (512 GPUs), cov ering roughly half of the total dataset due to time and budget constraints. 5.3 Long-Context Adaptation Evaluation T o assess the effectiv eness of the long-context adaptation phase, we e valuate the model’ s ability to process and reason ov er extended input sequences using the R ULER benchmark [ 38 ]. R ULER provides a comprehensi ve frame work for 14 EngGPT2 T echnical Report long-context e valuation, spanning 13 tasks grouped into four categories that probe retrie val, reasoning, aggre gation, and robustness under increasing conte xt lengths. W e compare the final checkpoint obtained at the end of pre-training (post stage 3) with the model after the dedicated long-context adaptation phase. F or both models, the context window is e xtended beyond 64k tokens using Y ARN [ 39 ], ensuring support for at least 64k-token sequences. The pre-training checkpoint is extended using a Y ARN scaling factor of 16, while the long-context-adapted model employs a Y ARN scaling factor of 2. Evaluation is conducted across multiple context lengths (4k, 8k, 16k, 32k and 64k tokens). Results, summarized in Figure 5, show that while the pre-trained model exhibits a sharp degradation in performance as context length increases, the long-context-adapted model maintains substantially higher accurac y across all ev aluated settings. These results indicate that positional extension alone, ev en when applied uniformly across models, is insuf ficient to preserve performance under long-context re gimes. In contrast, tar geted long-context adaptation leads to significantly improv ed robustness and scalability , enabling the model to effecti vely utilize e xtended context windo ws and mitigate the performance degradation observ ed in the pre-trained baseline. Despite the clear impro vements ov er the pre - training baseline, the o verall performance remains relati vely limited. It is likely that a more prolonged or extensiv e long - context adaptation phase would have allowed the model to better consolidate the skills required for very long input sequences. In future work, we intend to e xtend this training phase to further enhance the model’ s robustness and ef fectiv eness in long-context settings. 6 Mid-T raining The mid-training phase represents an intermediate consolidation step in the training pipeline, positioned between the initial large-scale training and the subsequent alignment and instruction-focused stages. Its goal is to refine the internal representations of the model under more controlled conditions, impro ving stability and preparing the model for later optimization stages, with a specific focus on reasoning structure. Mid-training was conducted as a single lar ge-scale run starting from a model checkpoint already supporting e xtended context lengths. Rather than introducing long-context capabilities, this phase aimed at consolidating and stabilizing the model behavior in this regime, preparing it for downstream alignment and instruction-tuning stages. The training w as executed using the Megatron-LM frame work, selected for its nati ve support for large-scale distrib uted training, expert parallelism, and ef ficient ex ecution on HPC systems. 6.1 Mid-T raining Data The dataset used for mid-training consists of a compact mixture of publicly av ailable post-training and structured reasoning corpora. The selection was designed to enable controlled model adaptation, with particular emphasis on con versational structure and explicitly represented reasoning traces. T o preserve distributional consistency , only languages already present in the pre-training corpus were selected. All samples were filtered to ensure correct language attribution, v alid reasoning annotations, and consistent structural formatting. Special care was taken to enforce a clear separation between intermediate reasoning steps and final answers. Samples failing to meet the required structural or linguistic constraints were excluded. Data preparation follo wed a unified internal pipeline that produced fully pre-templated and serialized training sequences using the project-specific chat template. The corpus is restricted to samples containing structured reasoning segments, in which assistant responses explicitly encode intermediate reasoning traces delimited by dedicated tags (e.g., ... ). This deterministic templating strategy directly materializes conv ersational context and reasoning structure within the training sequences. Such explicit formatting ensures stable separation between reasoning traces and final outputs, guarantees deterministic tokenization required by Megatron-LM, and maintains methodological consistency between mid-training data and subsequent reasoning-enabled ev aluation. Information about the datasets employed in the Mid-T raining phase is summarized in T able 4. 6.2 Mid-T raining Stage T raining was performed on 16 nodes (64 GPUs total), with a global batch size of 128 and a sequence length of 32,768 tokens. The training objective w as defined in terms of total token b udget, targeting approximately 100 billion tokens, corresponding to around 3 million training samples. The run progressed for approximately 7 days, accumulating close to 25,000 training iterations, corresponding to an estimated compute usage of 12,000 GPU-hours. Loss v alues during this 4 The dataset is largely open-licensed; samples with more restricti ve terms were e xcluded from our training subset. 15 EngGPT2 T echnical Report Dataset Licence T oken Composition (45B token) Llama-Nemotron-P ost-T raining-Dataset_reasoning_r1 cc-by-4.0 4 42% OpenThoughts3-1.2M Apache-2.0 12% Dolci-ThinK-SFT -32B odc-by 46% T able 4: Mid-T rain datasets stage remained stable and well-behav ed, con verging from around 0.82 to ward 0.74, while the auxiliary load-balancing loss remained close to 1.0, indicating stable expert utilization throughout the run. Memory usage and parameter norms remained constant, confirming numerical stability o ver extended training. Multiple checkpoints were sav ed along the training trajectory . These checkpoints constitute the definiti ve mid-training outputs and are used both for subsequent ev aluation and as initialization points for downstream alignment and instruction-tuning phases. 6.3 Mid-T raining Evaluation The ev aluation of the mid-training phase is designed to assess the consolidation and stability of reasoning capabilities across checkpoints generated within the same optimization trajectory , rather than to measure absolute task performance or establish leaderboard-lev el results. In contrast to pre-training ev aluation, which tracks the emergence of general knowledge and foundational reasoning skills, mid-training e valuation focuses on v erifying that continued optimization preserves pre viously acquired capabilities and improv es reasoning consistency . Evaluation w as conducted on a selected set of intermediate checkpoints extracted from the mid-training run. These checkpoints represent dif ferent stages of the same optimization trajectory and enable controlled comparison of incre- mental capability consolidation. In line with the pre-training ev aluation protocol, assessment continues to rely on MMLU accuracy as a representati ve benchmark for general kno wledge and multi-domain reasoning. Ho wev er , at this stage e v aluation is performed in reasoning-enabled mode, acti vating structured reasoning traces through the mid training chat template. This ensures continuity with earlier capability tracking while specifically monitoring the stabilization and consolidation of explicit reasoning beha vior under extended-context conditions. Results are reported in terms of relati ve deltas across checkpoints, emphasizing progressi ve consolidation rather than isolated peak performance. Step MMLU ∆ 12288 65.68 +11.01 16800 67.02 +1.33 20800 67.02 +0.00 23841 68.46 +1.44 T able 5: MMLU accuracy across mid-training checkpoints. The results reported in T able 5 show a steady improv ement in MMLU accuracy across checkpoints, indicating progressiv e consolidation of general reasoning capabilities. Performance increases consistently without late-stage degradation, suggesting stable optimization dynamics. Overall, mid-training strengthens broad reasoning competence and provides stable checkpoints suitable for downstream alignment and instruction-tuning. 16 EngGPT2 T echnical Report 7 Post-T raining The post - training pipeline is or ganized as a coherent sequence of refinement steps that progressi vely consolidate the model’ s instruction - following capabilities, alignment quality , and functional performance. Beginning from the selected mid - training checkpoint, the pipeline combines supervised fine - tuning, preference - based optimization, and model souping. First, the model undergoes SFT to acquire strong instruction-follo wing and con versational capabilities. Next, we apply Anchored Preference Optimization (APO) [ 40 ], an of f-policy v ariant of Direct Preference Optimization (DPO) [ 41 ], following the approach adopted in SmolLM2 [ 42 ] and SmolLM3 [ 9 ], to further align the model. Finally , we perform model merging through a model soup strategy , combining the SFT and aligned checkpoints to integrate their complementary strengths into a single, more robust and stable final model. The core objective of post - training was to produce a model with a well - defined chat template and strong instruction - following capabilities, while supporting both reasoning and non - reasoning interaction modes. The model also pro vides nati ve support for function calling compliant with the Model Conte xt Protocol (MCP), ensuring structured, interoperable, and predictable tool-usage behaviors. For reasoning - enabled interactions, the system supports both Italian and English. This multilingual reasoning capability is acti vated through dedicated control tokens embedded in the chat template, allo wing explicit selection of the target reasoning language. In addition to standard chain - of - thought traces, the model introduces a synthetic, compressed reasoning modality (“turbo”), also controlled via dedicated tokens, designed to provide concise intermediate reasoning signals while reducing verbosity and computational o verhead. All post-training stages were ex ecuted as full-parameter optimization runs, utilizing between 4 and 32 compute nodes equipped with 4×A100 GPUs each. The training stack lev eraged DeepSpeed ZeRO - 3 [ 43 , 44 ] for efficient memory partitioning and large - scale model parallelism, while the TRL library [ 45 ] was used to implement both supervised fine - tuning and preference - based optimization. Model souping w as performed using mergekit [ 46 ], integrated as the final consolidation step of the post-training workflo w . 7.1 SFT Stage The first post-training stage consists of Supervised Fine-T uning (SFT) for instruction alignment. In this phase, the model is trained on an instruction-follo wing dataset, formatted using a custom con versational chat template. The template is inspired by the Qwen schema [5] and further adapted to match the target interaction style and system constraints. This stage plays a foundational role in the o verall pipeline, as it is where the final chat template is introduced and stabilized. Alongside standard instruction tuning, SFT is used to explicitly teach the model the structure and semantics of the con versational format, including system, user , and assistant roles, as well as the handling of control tokens. Overall, the SFT stage focuses on grounding the model in high-quality instructional behavior , enforcing consistent response formatting, and ensuring robust adherence to user intent across both reasoning and non-reasoning interaction modes. The resulting SFT checkpoint serv es as the initialization point for all subsequent post-training stages. From an operational standpoint, the SFT phase was ex ecuted using a multi - node distrib uted setup consisting of 4 compute nodes equipped with a total of 16 NVIDIA A100 GPUs. Training was performed ov er 5 full epochs with a gradient accumulation step (GA) set to 1, resulting in an effecti ve global batch size (GBS) of 16. The optimization schedule follo wed a cosine - decay learning - rate policy , starting from an initial value of 2 × 10 − 5 and progressi vely annealing to a minimum of 2 × 10 − 6 , which was reached to ward the final portion of training. 7.1.1 Reasoning Mode During the SFT stage, a set of dedicated control tokens is introduced to e xplicitly regulate reasoning beha vior during training and inference. The model supports two inference re gimes: non-reasoning mode and reasoning mode. When reasoning is enabled ( enable_thinking = true ), the reasoning configuration is controlled through the following tok ens: • Reasoning Structure Internal reasoning content is encapsulated between the tokens and , which delimit inter - mediate reasoning from the final answer . • Language Control The opening token is preceded by a reasoning language specifier: – /reasoning_en 17 EngGPT2 T echnical Report Dataset #T okens (M) Mode T ask T ype Policies Alignment 5.3 RI, RE, NR Policies; Safety Metrics Alignment 31.4 RE, NR Metrics General Purpose 23.6 RE, NR Creativ e Writing; T ext Process- ing;Information Extraction; Struc- tured Output; SQL-like Genera- tion; Code Generation; Code Mi- gration; Code Related Generation; ActLike; Data Mng; Agentic Or- chestration; Misc Mathematical Problems 11.3 RE Math Reasoning Capabilities 186.7 RE Problem Solving; Code Genera- tion; Code Related Generation Italian Reasoning 144.1 RI Problem Solving; Code Genera- tion; Code Related Generation T urbo Reasoning 8.3 R TI, R TE Problem Solving; Code Genera- tion; Code Related Generation T ool Calling 9.3 RE, NR T ool Calling Data Handling 35.9 NR, RE Data Management Document Understanding 0.2 RE, NR Information Extraction T able 6: T raining dataset mixture used for the SFT stage. – /reasoning_ita enabling reasoning traces in English or Italian. • T urbo Mode When a synthetic and compressed reasoning mode is desired, an additional /turbo token is inserted between the language token and the tag. This acti v ates a shorter and less verbose reasoning trace, reducing computational ov erhead while preserving the same structural format. When reasoning is disabled ( enable_thinking = false ), the model preserv es the structural tags ), the internal reasoning language may follow the language of the user prompt rather than the explicitly selected reasoning_lang parameter . In particular , under compressed reasoning, the model tends to align the reasoning language with the prompt language, even when a dif ferent reasoning language is specified at inference time. This indicates that, in turbo mode, prompt-le vel language signals can dominate over auxiliary control tokens. As a result, structural compliance is preserved, but semantic language control behaves as a soft conditioning mechanism rather than a strict constraint. Importantly , this phenomenon appears to be specific to turbo reasoning and is not observed in full - reasoning mode. A plausible explanation is that the turbo - reasoning component was fine - tuned on a comparativ ely smaller SFT dataset than the one used for full reasoning, which may limit its robustness and lead to the observ ed behavior . When the prompt language and the requested reasoning language are aligned, behavior remains stable and predictable. T able 12: Reasoning Efficienc y T rade-off Benchmark A vg T okens (Reasoning) A vg T okens (T urbo) Perf . Drop (%) T okens Drop (%) MMLU-Pro 2990 249 16.0 91.67 MMLU-Redux 1245 132 12.9 89.40 AIME25 20061 746 43.3 96.28 AIME26 19590 1753 60.0 91.05 GSM8K 731 122 13.6 83.31 T able 12 quantifies the efficienc y trade-off introduced by compressed reasoning. Across all benchmarks, turbo mode substantially reduces the number of generated reasoning tokens, with a verage reductions ranging from approximately 83% to ov er 96% relativ e to full reasoning traces. This compression translates into significantly lower inference cost and latency , particularly on tasks where full reasoning produces long intermediate chains. The performance impact of this reduction varies depending on the complexity of the benchmark. Knowledge-oriented and shorter reasoning tasks such as GSM8K and MMLU-Redux exhibit relati vely moderate performance degradation (13–16%), indicating that many reasoning steps can be compressed without fully compromising answer accuracy . In contrast, tasks requiring deeper symbolic reasoning, such as the AIME benchmarks, experience a lar ger performance drop under turbo mode. In these settings, full reasoning traces can e xceed 20k tokens on av erage, and aggressi ve compression limits the model’ s ability to externalize long multi-step reasoning chains. 26 EngGPT2 T echnical Report Overall, the results indicate that turbo reasoning substantially reduces the number of generated reasoning tokens across benchmarks, typically by close to an order of magnitude, while retaining reasonable performance on several tasks. These observations suggest that compressed reasoning can represent a practical deployment option when inference cost or latency are primary considerations, whereas full reasoning remains preferable for workloads that require deeper and more reliable multi-step reasoning. 9 Conclusion In this technical report, we hav e presented EngGPT 2, a Mixture - of - Experts language model featuring 16B total parameters and 3B activ e per token. The architecture is designed to maximize compute, training, and inference efficienc y , deliv ering competitiv e performance while operating with a fraction of the data and acti ve parameters used by larger international models. Despite being trained on a comparativ ely modest corpus of 2.5T tokens, EngGPT 2 consistently matches or surpasses dense models in the 8B–16B parameter class across a broad range of benchmarks, with ev en stronger relativ e performance when normalized by training tokens or acti ve inference compute. The model supports multiple inference modes, including standard non - reasoning responses, full structured reasoning in Italian and English, and a compressed “turbo” reasoning modality optimized for lo w - latency , low - verbosity applications. In addition, EngGPT 2 incorporates nativ e tool - calling aligned with modern interoperability standards and uses a carefully engineered chat template that ensures deterministic formatting, explicit control signals, and reliable behavior across interaction modes. Evaluation results confirm that EngGPT 2 achie ves solid performance in general knowledge (MMLU - Pro, MMLU - Redux), mathematical reasoning (AIME, GSM8K), code generation (HumanEv al), and multilingual tasks (MMLU - IT , ARC - Challenge - IT). In Italian - centric e valuation in particular , EngGPT 2 establishes a ne w competitiv e baseline among open - weight European models of comparable ef fectiv e scale. Normalized analyses highlight what we consider the principal strength of this model family: high capability per unit of compute, demonstrating that sparse architectures and ef ficient training pipelines can serv e as robust foundations for scalable and sustainable European LLM dev elopment. EngGPT 2 represents a significant step to ward a family of open, efficient, and regulation - aligned European large language models. With this w ork, we aim to contrib ute to a broader ecosystem of trustw orthy AI systems de veloped according to European values and operational requirements, and to establish a strong, sustainable foundation for future advancements. Looking ahead, we ackno wledge that the model’ s performance on long - context tasks remains limited and w ould hav e benefited from a more e xtended training schedule. Similarly , the Supervised Fine - T uning phase was likely too short and disproportionately focused on reasoning capabilities, resulting in comparativ ely weaker performance in tool calling and coding. Strengthening these tw o areas will therefore be a primary objecti ve for upcoming releases. In parallel, we intend to scale both the size of the model and the volume of training tokens to further enhance overall capacity and robustness. W e are also activ ely experimenting with RL VR, with the expectation that an additional reinforcement - learning stage may yield further gains in reasoning stability , controllability , and downstream task performance. 27 EngGPT2 T echnical Report 10 Legal Notice © Engineering Ingegneria Informatica S.p.A. All rights reserv ed. This document is made publicly av ailable for informational and research purposes. The content may be cited, provided that proper attribution is gi ven to Engineering Ingegneria Informatica S.p.A. No part of this document may be reproduced, modified, or distrib uted for commercial purposes without prior written authorization from Engineering Ingegneria Informatica S.p.A., unless otherwise e xplicitly permitted. This document is provided “as is” and for informational purposes only . Engineering Ingegneria Informatica S.p.A. makes no representations or warranties, express or implied, regarding the accuracy , completeness, or fitness for a particular purpose of the information contained herein. The content of this document does not constitute any contractual obligation or commitment. 28 EngGPT2 T echnical Report A Details on Pretraining Datasets This appendix summarizes the datasets used for pre-training, describing their sources, scale, licensing conditions, and the data curation pipelines adopted by the original dataset authors. A.1 FineW eb-2 FineW eb-2 [ 49 ] is sourced from 96 snapshots of Common Cra wl collected between summer 2013 and April 2024, comprising approximately 8TB of compressed data, corresponding to roughly 3 trillion tokens across 5 billion documents in ov er 1,000 languages. F or our experiments, we selected fiv e Romance and Germanic languages: German, French, Italian, Portuguese, and Spanish. The dataset is released under the Open Data Commons Attribution (ODC-By) license, which permits both research and commercial use subject to the T erms of Use of Common Crawl. The raw web data was processed to e xtract and filter text from Common Crawl W ARC files, with language-specific deduplication and quality filters applied to ensure high-quality training data. For all the FineW eb-related data, the processing pipeline includes anonymization of e-mail addresses and public IP addresses. Ho wev er , gi ven the web-sourced nature of the dataset, personally identifiable information such as names and phone numbers may still be present, and the authors provide an opt-out form for PII remo val requests. A.2 FineW eb-Edu W e incorporated educational content from FineW eb-Edu [ 50 ], a curated subset of high-quality educational webpages. FineW eb-Edu is derived from FineW eb through an educational quality classification pipeline: a regression model w as trained on 450,000 annotations from Llama3-70B-Instruct assigning educational scores from 0 to 5 to web documents. Applying a threshold of 3, this filtering procedure retained 1.3 trillion tokens while remo ving approximately 92% of the original dataset. W e selected data from Common Cra wl snapshots CC-MAIN-2021 through CC-MAIN-2025, lev eraging the temporal breadth to capture e volving educational content. The dataset is released under the Open Data Commons Attribution (ODC-By) license, with usage also subject to CommonCra wl’ s T erms of Use. A.3 FineMath T o enhance mathematical reasoning capabilities, we incorporated FineMath [51], a specialized dataset of high-quality mathematical educational content extracted from CommonCrawl. FineMath is curated using a two-tier quality filtering approach: a re gression classifier trained on 1 million annotated web samples assigns educational scores from 0 to 5, ev aluating pages based on logical reasoning clarity and step-by-step solution quality . This process results in 34 billion tokens across 21.4 million documents in FineMath-3+, with the option to use the higher -quality FineMath-4+ subset containing 9.6 billion tokens across 6.7 million documents. The dataset underwent additional processing to ensure data quality: documents were deduplicated using MinHash-LSH, filtered to remove non-English content via FineW eb’ s language classification pipeline, and contamination was addressed by removing samples with 13-gram overlaps against test sets from GSM8k, MA TH, MMLU, and ARC, with detailed decontamination logs made publicly a vailable. The dataset is released under the Open Data Commons Attrib ution License (ODC-By) v1.0, subject to CommonCra wl’ s T erms of Use. A.4 FinePDFs T o complement web-derived and educational datasets, we incorporated Italian-language content from FinePDFs [ 52 ], the largest publicly av ailable corpus built entirely from PDF documents. FinePDFs spans 475 million documents in 1,733 languages, totaling approximately 3 trillion tokens e xtracted from Common Cra wl. PDFs of fer distinct adv antages ov er HTML sources by capturing higher-quality , domain-specific content, particularly in legal, academic, and technical domains. The dataset processing pipeline employs a sophisticated two-path extraction strate gy: a text-based e xtraction path using Docling for embedded text, and a GPU-accelerated OCR path using RolmOCR for image-only pages, with an XGBoost-based OCR routing classifier determining the optimal processing path for each document. Language classification was performed using Google/Gemma-3-27b-it on a 20,000-sample subset per language to identify and filter non-Italian content, accounting for code-switching phenomena. Documents were further deduplicated using MinHash-LSH. The dataset undergoes PII anonymization by replacing email addresses and public IP addresses via rege x pattern matching; ho wev er , as with other web-sourced datasets, some personally identifiable information may remain and remov al can be requested via the provided opt-out form. FinePDFs is released under the Open Data Commons Attribution License (ODC-By) v1.0, with usage also subject to CommonCra wl’ s T erms of Use. 29 EngGPT2 T echnical Report A.5 StarcoderData T o enhance code generation capabilities, we incorporated a subset of StarcoderData [ 53 ], a specialized pretraining dataset consisting of 783 GB of code across 86 programming languages, complemented by 54 GB of GitHub Issues, 13 GB of Jupyter Notebooks, and 32 GB of GitHub commits, totaling approximately 250 billion tokens. Unlike web-deriv ed datasets, StarcoderData is sourced directly from GitHub repositories through The Stack v1.2, a collection of permissi vely licensed public repositories with copyleft licenses (MPL, EPL, LGPL) excluded and opt-out requests processed through February 9, 2023. The dataset under goes extensi ve multi-stage processing: data cleaning combines heuristic filtering and manual inspection, including exclusion of unsupported configuration and programming languages, heuristic filtering of GitHub issues and commits, near-deduplication, and language-specific filtering, with additional exclusion of malicious code. A key dif ferentiator is the comprehensi ve PII remov al approach: in collaboration with T oloka, personally identifiable information including names, passwords, and email addresses is remo ved from the training data, supplemented by a dedicated PII dataset for training and e valuating PII remov al models. The dataset maintains strict license compliance through provenance tracking and pro vides attribution tools such as integration with VS Code to enable dev elopers to verify generated code against the training data. The Stack is regularly updated to process validated data remo val requests, ensuring ongoing respect for contrib utors’ opt-out preferences. A.6 Nemotron-Pr etraining-SFT -v1 T o further enhance instruction-following and reasoning capabilities, we incorporated Nemotron-Pretraining-SFT -v1 [ 54 ], NVIDIA ’ s synthetic instruction-tuned dataset designed for supervised fine-tuning. Unlike datasets deriv ed from natural web sources, Nemotron-SFT -v1 comprises synthetically generated examples across code, mathematics, general knowledge QA, and fundamental reasoning tasks. STEM data was expanded from high-quality math and science seeds using multi-iteration generation with Qwen3 and DeepSeek models, producing varied and challenging multiple-choice questions with step-by-step solutions, while academic QA pairs were synthesized from comple x undergraduate and graduate-lev el texts. Additional SFT -style data cov ering code, math, MMLU-style general QA, and fundamental reasoning was generated using DeepSeek-V3 and Qwen3 for logical, analytical, and reading comprehension questions. The dataset is gov erned by the NVIDIA Data Agreement for Model T raining, with the important caveat that any AI model trained with this data that is distributed or made publicly a v ailable becomes subject to redistribution and usage requirements under the Qwen License Agreement and DeepSeek License Agreement. 30 EngGPT2 T echnical Report B Pretraining Data Filtering In this section, we describe the filtering procedures and methodologies applied during the pre - training phase of EngGPT 2, with the objectiv e of ensuring transparency , accountability , and compliance with the EU AI Act. Since the detailed composition of data sources and collection methodologies is documented in a separate chapter , the present section focuses solely on: • filtering techniques applied to web-scale pre-training corpora • the additional safeguards designed to minimize the ingestion of copyrighted material • the implementation of opt-out mechanisms for future model training. These processes constitute a core component of EngGPT 2’ s compliance posture, demonstrating that Engineering has undertaken reasonable and demonstrable ef forts to use only data that can be lawfully processed for LLM training. B.1 Baseline Filtering Pipeline EngGPT 2 benefits from an initial preprocessing layer already applied by the dataset pro viders, which includes standard quality and safety filtering steps such as deduplication, language identification, and boilerplate removal. This baseline provides an initial le vel of dataset cleaning before the application of copyright-specific safe guards. B.2 EngGPT 2 Copyright-Focused Filtering Pipeline T o strengthen compliance with the AI Act’ s transparency and intellectual - property obligations, we designed and ex ecuted an additional filtering pipeline applied on top of pre-train datasets, targeting specifically copyrighted and editorial content. This pipeline combines rule-based heuristics, pattern matching, and machine-learning classification, producing a risk score used to exclude high-risk records. The main components are as follows. Domain Lev el Copyright Exclusion List A curated domain blacklist was constructed co vering digital magazines, news outlets, ebook repositories, publishers and editorial platforms, as well as academic and scientific publishers. Any URL belonging to a listed domain is remov ed during preprocessing; see T able 13 for a non-exhausti ve list of such domains. Category Link List Media & News European Newspapers Directory – Bro wse National & Regional Ne ws by Country 5 Academic sciencedirect.com, nature.com, tandfonline.com Broadcasting rai.it, bbc.co.uk, zdf.de, rtve.es Legal wolterskluwer .it, chbeck.de, dalloz.fr Literary mondadori.it, hachette.fr , penguin.co.uk Professional ipsoa.it, de jure.it, beck-online.de T able 13: URL List Editorial Pattern Detection Man y copyrighted works e xhibit identifiable editorial markers. Using lexical rules and NLP heuristics, we exclude records containing chapter mark ers (e.g., “Chapter 3”, “V olume I”), book - specific structures (preface, ackno wledgements, table of contents), formal article headings used by newspapers or journals, explicit page numbering sequences typical of scanned or reprinted works. 5 https://newspapers-europe.eu/ 31 EngGPT2 T echnical Report Copyright Notice & Legal Boiler plate Detection W e emplo y a set of regular e xpressions and pattern - based detectors to remov e records containing e xplicit copyright symbols (©, ®, ™), “ All rights reserved” disclaimers, license statements, publication notices, and legal disclaimers, standard boilerplate te xt commonly found in copyrighted books or journals. Composite Copyright Risk Score Each record receiv es a risk score combining some of the previous signals: domain blacklist match, editorial pattern detection, le gal boilerplate markers and ISBN/DOI patterns. Records e xceeding the risk threshold are remov ed from the pre-training corpus. B.3 Results The cop yright-aware pipeline was applied to the full dataset and the process resulted in a substantial reduction of content with high likelihood of being cop yrighted, systematic exclusion of entire cate gories of editorial and scientific content, and improv ed dataset transparency , auditability , and traceability through a fully reproducible preprocessing procedure. Metric P ercentage Clean Records 76 . 26% Flagged records ( ≥ 1 signal) 23 . 74% High-risk records ( ≥ 0 . 5 signal) 1 . 65% T able 14: Copyright Filtering Statistics The most frequent infringement categories were Media & Ne ws ( 7 . 88% ), Broadcasting ( 6 . 27% ), ISBN markers ( 5 . 85% ), and Copyright boilerplate ( 5 . 16% ), confirming that the pipeline ef fectiv ely targets editorial and protected sources. T wo alternativ e risk thresholds were e valuated to balance cov erage and precision. With a threshold of 0.3, 18.8% of the corpus is excluded, capturing a broader range of potentially copyrighted content. With a threshold of 0.4, 5.9% of the corpus is excluded, resulting in a more conservati ve, higher - precision filtering strategy . Both configurations are reported for transparency , enabling downstream policy decisions without altering the underlying technical pipeline. Overall, the proposed filtering frame work represents a key technical contrib ution of EngGPT 2 toward responsible and compliant large-scale language model training. By integrating baseline quality controls with a dedicated copyright- aware pipeline, EngGPT 2 establishes a transparent, auditable, and reproducible methodology for dataset construction. This approach demonstrates that regulatory requirements under the EU AI Act can be operationalized through concrete engineering solutions, enabling scalable model de velopment while significantly reducing exposure to cop yrighted and editorial content. B.4 Opt-Out Procedur es T o respect data subject rights and ensure compliance with the AI Act and EU copyright regulations, we implemented an opt-out procedure. If you think that we inadvertently used your cop yrighted data, send us an email to enggpt- team@eng.it. W e will promptly exclude the rele vant data from future model iterations. 32 EngGPT2 T echnical Report C Reasoning T emplate Examples This appendix reports illustrative examples of the reasoning templates used during training and inference across all supported configurations. C.1 Full Reasoning (English) /reasoning_en Step-by-step reasoning in English... Final answer. C.2 Full Reasoning (Italian) /reasoning_ita Ragionamento passo per passo in italiano... Risposta finale. C.3 T urbo Reasoning (English) /reasoning_en /turbo Compressed reasoning trace in English... Final answer. C.4 T urbo Reasoning (Italian) /reasoning_ita /turbo Ragionamento sintetico in italiano... Risposta finale. C.5 Non-Reasoning Mode When reasoning is disabled ( enable_thinking = false ), structural tags are preserved for formatting consistency , but no intermediate reasoning content is generated. Final answer only. 33 EngGPT2 T echnical Report D SFT Data Details This appendix pro vides a detailed ov erview of the task taxonomy used to describe the functional coverage of the T raining Dataset. The taxonomy is not intended as a normativ e constraint on dataset construction; rather, it serv es as a unifying abstraction that highlights the breadth of behaviors, competencies, and interaction patterns represented across the mixture. The taxonomy or ganizes tasks into a structured hierarchy consisting of: Primary task families, capturing broad functional domains (e.g., reasoning, instruction following, transformation, creativ e generation). High - lev el categories, representing coherent groups of beha viors within each family . Sub - tasks, reflecting concrete interaction types and data patterns observed across the corpus. This framework enables a systematic interpretation of dataset content and supports clearer comparisons across modalities and data sources. A detailed breakdown of the taxonomy—including all primary families, categories, and sub - tasks—is presented in T able 15. This structure is intended to help conte xtualize how the dataset mixture supports the model’ s broad beha vioral capabilities and generalization properties. Category T ask T ype Sub-T asks T ext Creative Writing storytelling; talk about a theme; email writing; trip planner; dialog generation; QA generation; document generation; brainstorming T ext Processing rephrase; summarization; translation; NER; text filtering; text masking; text classification; focus shift; style adaptation; text expansion; te xt projection Information Extraction grounded QA; not-grounded QA; ke yword extraction; keyphrase extraction; needleHaystack Structured Output json-like output; markdo wn output Code Code Generation python; ja vascript; etc. Code Migration language-to-language migration; frame work migration; v ersion upgrade; code refactoring; legac y code modernization; dependenc y replacement Code Related Generation code documentation; inline comments generation; test case gener- ation; unit/integration tests creation; bug e xplanation; code revie w & suggestions SQL-like Generation query generation; query reformulation; query classification Instruction Follo wing ActLike act-like personas; act-like with style constraints; act-like tool of classification; act-like a console; act-like a tool Alignment Policies safety polic y enforcement; content moderation; self-awareness handling; refusal & self-completion; chit-chat handling; prompt injection detection; jailbreak resistance Metrics KPI-style Data Data Management table QA; time series analysis Problem Solving Problem Solving math; logic; puzzles; science problems; medical questions; etc. Agentic AI T ool Calling tool selection; tool calling; parameter extraction; multi-tool chain- ing; tool error handling; tool output interpretation Agentic Orchestration intent classification; agent selection; task decomposition; plan generation; multi-agent coordination; reflection & self-correction; memory usage & retriev al Misc Misc miscellaneous T able 15: T ask taxonomy . 34 EngGPT2 T echnical Report E Evaluation Configuration Parameters The configurations used for the ev aluation comparison are reported below . For a strict cross-model comparison, all models were ev aluated using the same generation hyperparameters: temperature = 0.6, top-p = 0.95, top-k = 20, and min-p = 0. In addition, each model was ev aluated in its best-performing configuration to ensure that the reported results reflect the maximum achiev able capability under realistic serving conditions. When supported, reasoning mode was enabled during ev aluation, and the official serving configurations pro vided in the model documentation were adopted. References to the corresponding documentation for each best-performing configuration are also provided. The complete set of serving parameters is reported in T able 16. T emperature T op_p T op_k Min_p EngGPT2-16B-A3B 0.6 0.95 20 0 Qwen3-14B 6 0.6 0.95 20 0 Qwen3-30B-A3B 7 0.6 0.95 20 0 Gpt-oss-20b-high 8 1 1 0 – Llama-3.1-8B-Instruct 9 0.6 0.9 – – gemma-2-9b-it 10 1 – – – gemma-3-12b-it 11 1 0.95 64 0 Moonlight-16B-A3B-Instruct 12 0.6 0.95 20 0 T able 16: Optimal serving parameters and reference sources for all ev aluated models, as used in the final ev aluation. If no value is reported for a gi ven parameter , the default setting from the lm-e valuation-harness frame work was used. 6 https://huggingface.co/Qwen/Qwen3-14B#best-practices 7 https://huggingface.co/Qwen/Qwen3-30B-A3B#best-practices 8 https://unsloth.ai/docs/models/gpt-oss-how-to-run-and-fine-tune#recommended-settings 9 https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct. W e ev aluated the new model v ersion: Llama-3.1-8B-Instruct [55]. 10 https://huggingface.co/google/gemma-2-9b#adv anced-usage 11 https://unsloth.ai/docs/models/gemma-3-how-to-run-and-fine-tune#recommended-inference-settings 12 No official docs 35 EngGPT2 T echnical Report F Acknowledgments Part of this w ork is framed within the Project "A V ANT" – Project no. IPCEI-CL_0000005 - Application protocol no. 108421 of 14/05/2024 - CUP B89J24002920005 - Grant decree no. 1322 of August 8, 2024 - financed by the European Union – NextGenerationEU (IPCEI Funding). References [1] Noam Shazeer , Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geof frey Hinton, and Jef f Dean. Out- rageously large neural netw orks: The sparsely-gated mixture-of-e xperts layer . arXiv preprint , 2017. [2] T aishi Nakamura, T akuya Akiba, Kazuki Fujii, Y usuke Oda, Rio Y okota, and Jun Suzuki. Drop-upcycling: T raining sparse mixture of experts with partial re-initialization, 2025. [3] Houyi Li, Ka Man Lo, Ziqi W ang, Zili W ang, W enzhen Zheng, Shuigeng Zhou, Xiangyu Zhang, and Daxin Jiang. Can mixture-of-experts surpass dense llms under strictly equal resources?, 2025. [4] Changxin Tian, K unlong Chen, Jia Liu, Ziqi Liu, Zhiqiang Zhang, and Jun Zhou. T ow ards greater leverage: Scaling laws for ef ficient mixture-of-experts language models, 2025. [5] An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv , et al. Qwen3 technical report. arXiv pr eprint arXiv:2505.09388 , 2025. [6] Sandhini Agarw al, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Y u Bai, Bowen Baker , Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card. arXiv pr eprint arXiv:2508.10925 , 2025. [7] Mistral AI and NVIDIA. Mistral-Nemo-Base-2407. https://huggingface.co/mistralai/ Mistral- Nemo- Base- 2407 , 2024. Hugging Face model card. [8] Mohammad Shoeybi, Mostof a Patw ary , Raul Puri, Patrick LeGresley , Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053 , 2019. [9] Hugging Face. Smollm3: smol, multilingual, long-context reasoner . Hugging F ace Blog , 2025. [10] Eu artificial intelligence act: Up-to-date dev elopments and analyses. https://artificialintelligenceact. eu/ , 2026. Accessed: 2026-03-12. [11] Joshua Ainslie, James Lee-Thorp, Michiel De Jong, Y ury Zemlyanskiy , Federico Lebrón, and Sumit Sanghai. Gqa: T raining generalized multi-query transformer models from multi-head checkpoints. In Pr oceedings of the 2023 Confer ence on Empirical Methods in Natural Languag e Pr ocessing , pages 4895–4901, 2023. [12] Y ann N. Dauphin, Angela Fan, Michael Auli, and Da vid Grangier . Language modeling with gated conv olutional networks, 2017. [13] Jianlin Su, Y u Lu, Shengfeng Pan, Ahmed Murtadha, Bo W en, and Y unfeng Liu. Roformer: Enhanced transformer with rotary position embedding, 2023. [14] Zixuan Jiang, Jiaqi Gu, Hanqing Zhu, and David Z. P an. Pre-rmsnorm and pre-crmsnorm transformers: Equiv alent and efficient pre-ln transformers, 2023. [15] Lintang Sutawika, Hailey Schoelk opf, Leo Gao, Baber Abbasi, Stella Biderman, Jonathan T ow , Charles Lov ering, Jason Phang, Anish Thite, Thomas W ang, et al. Eleutherai/lm-ev aluation-harness: v0. 4.9. Zenodo , 2025. [16] ModelScope T eam. EvalScope Documentation: BFCL V3 Evaluation. https://evalscope.readthedocs. io/en/v1.0.0/third_party/bfcl_v3.html , 2024. Accessed: 2025. [17] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massiv e multitask language understanding. arXiv pr eprint arXiv:2009.03300 , 2020. [18] Y ubo W ang, Xueguang Ma, Ge Zhang, Y uansheng Ni, Abhranil Chandra, Shiguang Guo, W eiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. Advances in Neural Information Pr ocessing Systems , 37:95266–95290, 2024. [19] Aryo Pradipta Gema, Joshua Ong Jun Leang, Giwon Hong, Alessio Dev oto, Alberto Carlo Maria Mancino, Rohit Saxena, Xuanli He, Y u Zhao, Xiaotang Du, Mohammad Reza Ghasemi Madani, et al. Are we done with mmlu? In Pr oceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Languag e T echnologies (V olume 1: Long P apers) , pages 5069–5096, 2025. 36 EngGPT2 T echnical Report [20] Jeffre y Zhou, T ianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Y i Luan, Denny Zhou, and Le Hou. Instruction-following e valuation for large language models. arXiv preprint , 2023. [21] Mark Chen, Jerry T worek, Hee woo Jun, Qiming Y uan, Henrique Ponde De Oliv eira Pinto, Jared Kaplan, Harri Edwards, Y uri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating lar ge language models trained on code. arXiv pr eprint arXiv:2107.03374 , 2021. [22] AIME. Aime problems and solutions 2025. https://artofproblemsolving.com/wiki/index.php/AIME_ Problems_and_Solutions , 2025. [23] AIME. Aime problems and solutions 2026. https://artofproblemsolving.com/wiki/index.php/AIME_ Problems_and_Solutions , 2026. [24] Karl Cobbe, V ineet Kosaraju, Mohammad Ba varian, Mark Chen, Hee woo Jun, Lukasz Kaiser , Matthias Plappert, Jerry T worek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math w ord problems. arXiv pr eprint arXiv:2110.14168 , 2021. [25] Multilingual arc (italian subset). https://huggingface.co/datasets/alexandrainst/m_arc . Italian subset of the multilingual ARC (AI2 Reasoning Challenge) dataset, accessed via Hugging Face. [26] Meta AI. Llama 3.1 8b instruct ev aluations: Multilingual mmlu (italian subset). https://huggingface. co/datasets/meta- llama/Llama- 3.1- 8B- Instruct- evals . Italian subset of the Multilingual MMLU benchmark included in the Llama 3.1 8B Instruct ev aluation suite on Hugging Face. [27] Huanzhi Mao, Fanjia Y an, Charlie Cheng-Jie Ji, Jason Huang, V ishnu Suresh, Y ixin Huang, Xiaowen Y u, Joseph E. Gonzalez, and Shishir G. Patil. BFCL V3: Multi-T urn & Multi-Step Function Calling. https: //gorilla.cs.berkeley.edu/blogs/13_bfcl_v3_multi_turn.html , 2024. Accessed: 2025. [28] Jingyuan Liu, Jianlin Su, Xingcheng Y ao, Zhejun Jiang, Guokun Lai, Y ulun Du, Y idao Qin, W eixin Xu, Enzhe Lu, Junjie Y an, Y anru Chen, Huabin Zheng, Y ibo Liu, Shaowei Liu, Bohong Y in, W eiran He, Han Zhu, Y uzhi W ang, Jianzhou W ang, Mengnan Dong, Zheng Zhang, Y ongsheng Kang, Hao Zhang, Xinran Xu, Y utao Zhang, Y uxin W u, Xinyu Zhou, and Zhilin Y ang. Muon is scalable for llm training, 2025. [29] Aaron Grattafiori, Abhiman yu Dubey , Abhinav Jauhri, Abhinav Pandey , Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur , Alan Schelten, Alex V aughan, et al. The llama 3 herd of models. arXiv pr eprint arXiv:2407.21783 , 2024. [30] Gemma T eam, Mor gane Riviere, Shreya P athak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size. arXiv pr eprint arXiv:2408.00118 , 2024. [31] Gemma T eam. Gemma 3. 2025. [32] Mohammad Shoeybi, Mostof a Patw ary , Raul Puri, Patrick LeGresley , Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism, 2020. [33] Dennis Liu, Zijie Y an, Xin Y ao, T ong Liu, V ijay K orthikanti, Evan W u, Shiqing Fan, Gao Deng, Hongxiao Bai, Jianbin Chang, Ashwath Aithal, Michael Andersch, Mohammad Shoeybi, Jiajie Y ao, Chandler Zhou, David W u, Xipeng Li, and June Y ang. Moe parallel folding: Heterogeneous parallelism mappings for efficient lar ge-scale moe model training with megatron core, 2025. [34] Hugging Face. Perplexity of fixed-length models. https://huggingface.co/docs/transformers/ perplexity , 2024. Accessed 2026. [35] Salesforce Research. W ikitext-2 dataset. https://huggingface.co/datasets/Salesforce/wikitext/ viewer/wikitext- 2- raw- v1 , 2017. Accessed 2026. [36] Matteo Rinaldi. W ikimedia italian corpus. https://huggingface.co/datasets/mrinaldi/abcdefg/tree/ main/wikimedia_it , 2023. Accessed 2026. [37] Allen Institute for AI. Dolmino mix 1124. https://huggingface.co/datasets/allenai/ dolmino- mix- 1124 , 2025. Hugging Face dataset. A technical manuscript is forthcoming. [38] Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Y ang Zhang, and Boris Ginsb urg. Ruler: What’ s the real context size of your long-context language models? arXiv pr eprint arXiv:2404.06654 , 2024. [39] Bowen Peng, Jeffre y Quesnelle, Honglu Fan, and Enrico Shippole. Y arn: Efficient context windo w extension of large language models. arXiv preprint , 2023. [40] Karel D’Oosterlinck, W innie Xu, Chris Develder , Thomas Demeester, Amanpreet Singh, Christopher Potts, Douwe Kiela, and Shikib Mehri. Anchored preference optimization and contrastive revisions: Addressing underspecification in alignment, 2024. 37 EngGPT2 T echnical Report [41] Rafael Rafailo v , Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Y our language model is secretly a rew ard model. Advances in neural information pr ocessing systems , 36:53728–53741, 2023. [42] Loubna Ben Allal, Anton Lozhko v , Elie Bakouch, Gabriel Martín Blázquez, Guilherme Penedo, Lewis T unstall, Andrés Marafioti, Hynek Kydlí ˇ cek, Agustín Piqueres Lajarín, V aibha v Sriv astav , et al. Smollm2: When smol goes big–data-centric training of a small language model. arXiv pr eprint arXiv:2502.02737 , 2025. [43] S. Rajbhandari, J. Rasley , O. Ruwase, and Y . He. ZeR O: Memory optimizations toward training trillion parameter models. In Pr oc. of the Int’l Conf. for High P erformance Computing, Networking, Storag e, and Analysis (SC) 2020 . IEEE/A CM, 2020. [44] J. Ren, S. Rajbhandari, R. Y azdani Aminabadi, O. Ruwase, S. Y ang, M. Zhang, D. Li, and Y . He. ZeR O-offload: Democratizing billion-scale model training. CoRR , abs/2101.06840, 2021. [45] Leandro v on W erra, Y ounes Belkada, Le wis T unstall, Edward Beeching, T ristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. TRL: T ransformers Reinforcement Learning, 2020. [46] Charles Goddard, Shamane Siriwardhana, Malikeh Ehghaghi, Luke Me yers, Vladimir Karpukhin, Brian Benedict, Mark McQuade, and Jacob Solawetz. Arcee’s MergeKit: A toolkit for merging lar ge language models. In Franck Dernoncourt, Daniel Preo¸ tiuc-Pietro, and Anastasia Shimorina, editors, Pr oceedings of the 2024 Confer ence on Empirical Methods in Natural Language Pr ocessing: Industry T rac k , pages 477–485, Miami, Florida, US, Nov ember 2024. Association for Computational Linguistics. [47] DeepSeek-AI. Deepseek-r1: Incenti vizing reasoning capability in llms via reinforcement learning, 2025. [48] Jiafan He, Huizhuo Y uan, and Quanquan Gu. Accelerated preference optimization for large language model alignment. arXiv pr eprint arXiv:2410.06293 , 2024. [49] HuggingFaceFW . fineweb-2 (revision 1fbf94b). https://huggingface.co/datasets/HuggingFaceFW/ fineweb- 2 , 2024. [50] HuggingFaceFW . fineweb-edu (re vision 22b0aca). https://huggingface.co/datasets/HuggingFaceFW/ fineweb- edu , 2024. [51] Hugging F ace TB Research. finemath (re vision a0422cd). https://huggingface.co/datasets/ HuggingFaceTB/finemath , 2024. [52] Hynek Kydlí ˇ cek, Guilherme Penedo, and Leandro v on W erra. Finepdfs. https://huggingface.co/datasets/ HuggingFaceFW/finepdfs , 2025. [53] BigCode. Starcoderdata. https://huggingface.co/datasets/bigcode/starcoderdata , 2025. [54] NVIDIA Research. Nvidia nemotron nano 2: An accurate and efficient hybrid mamba-transformer reasoning model, 2025. [55] Meta AI. Llama 3.1 8b instruct. https://huggingface.co/meta- llama/Llama- 3.1- 8B- Instruct . Of fi- cial model repository on Hugging Face. 38
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment