유럽형 주권·고효율·오픈 LLM, EngGPT2의 모든 것
EngGPT2‑16B‑A3B는 16 억 파라미터 규모의 Mixture‑of‑Experts(모델)로, 2.5 조 토큰(≈25 % 이탈리아어)만으로 학습해 3 억 활성 파라미터만 사용해 추론한다. 8‑16 억 파라미터 밀집 모델과 동등한 MMLU‑Pro, GSM8K, IFEval, HumanEval 성능을 보이며, 추론 비용은 1/5~1/2 수준이다. 32 k 토큰 컨텍스트, 이탈리아·영어 이중 추론 모드, 터보‑리추링 등 유럽·이탈리아 특화 기능…
저자: G. Ciarfaglia, A. Rosanova, S. Cipolla
EngGPT2‑16B‑A3B는 유럽·이탈리아 시장을 겨냥한 주권형, 고효율, 오픈 소스 대형 언어 모델이다. 전체 파라미터는 16 억이지만, MoE(전문가 혼합) 구조를 통해 추론 시 활성 파라미터는 3 억에 불과해 메모리와 연산 비용을 크게 절감한다. 모델은 24 층 트랜스포머에 64 개의 전문가를 배치하고, 토큰당 8 개의 전문가를 동적 라우팅한다. 전문가의 크기는 Qwen3‑30B‑A3B와 GPT‑OSS‑20B 사이로, 충분한 표현력을 유지하면서도 파라미터 사용 효율을 높였다. 어텐션은 Grouped Query Attention(GQA)을 적용해 메모리 사용량을 최소화했으며, SwiGLU 활성화 함수와 RoPE, RMSNorm을 결합해 학습 안정성을 확보했다.
데이터 측면에서는 총 2.5 조 토큰(전체 토큰 대비 1/6~1/10)만 사용했으며, 이 중 25 %는 이탈리아어 데이터로 구성해 유럽·이탈리아어 특화 능력을 강화했다. 학습 파이프라인은 네 단계로 나뉜다. ① 프리트레이닝 단계에서는 대규모 원시 텍스트(책, 웹, 과학 논문, 코드 등)를 활용해 기본 언어 능력을 습득한다. ② 장기 컨텍스트 적응 단계에서는 32 k 토큰까지 확장된 시퀀스 길이를 학습해 긴 문서의 일관성과 정보 검색 능력을 강화한다. ③ 중간‑트레이닝 단계에서는 고품질 데이터와 수학·논리·코드 문제 해결 데이터셋을 중심으로 추론 능력을 집중 강화한다. ④ 포스트‑트레이닝 단계에서는 SFT와 정렬(Preference Optimization)을 통해 챗봇 형태의 대화 능력과 함수 호출, 도구 연동 기능을 부여한다.
학습 인프라는 128개의 노드(각 4 GPU, 총 512 GPU A100)로 구성됐으며, Megatron 프레임워크와 SmolLM3 기반 커스텀 코드를 사용해 텐서·파이프라인·데이터 병렬을 혼합했다. 전체 GPU 사용 시간은 약 250 000시간이며, 평균 Model FLOPs Utilization(MFU)은 21 %(피크 31 %)에 머물렀다. 이는 비용 효율성을 강조한 설계임을 보여준다. 장기 컨텍스트 단계는 2 000 GPU‑hour, 중간‑트레이닝은 12 000 GPU‑hour, 포스트‑트레이닝은 4 000 GPU‑hour를 소모했다. 총 FLOPs는 5.7 × 10²²에 달한다.
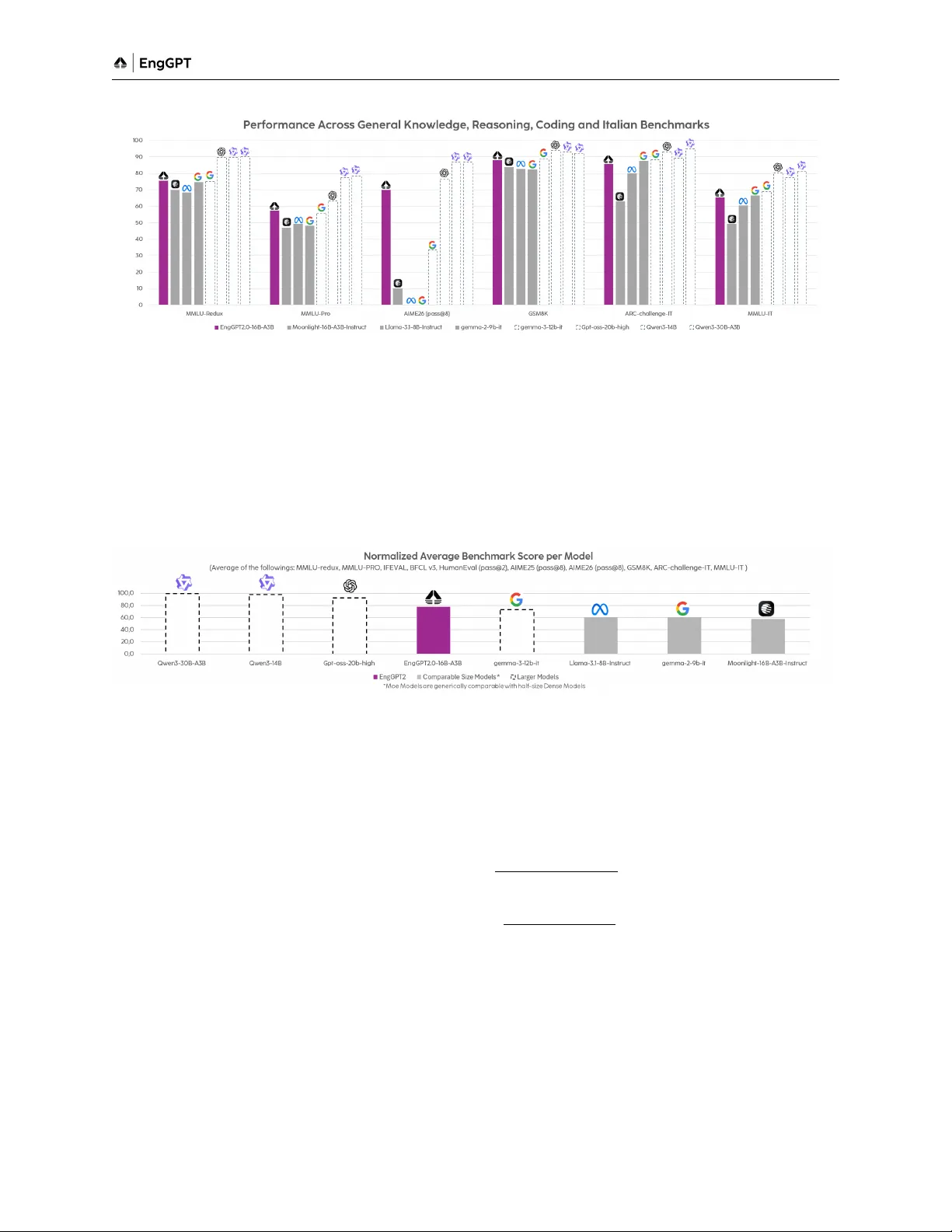
벤치마크에서는 MMLU‑Pro, GSM8K, IFEval, HumanEval에서 8‑16 B 밀집 모델 수준의 성능을 기록했으며, ‘Capability per Training Token’ 및 ‘Capability per Active Parameter’ 두 복합 지표에서도 대형 밀집 모델을 앞섰다. 특히 추론 비용은 동일 규모 밀집 모델 대비 1/5~1/2 수준이며, 3 B 활성 파라미터만 사용해도 동등한 성능을 보인다. 모델은 네 가지 추론 모드를 제공한다. ① 비추론 모드, ② 이탈리아어 추론, ③ 영어 추론, ④ 터보‑리추링(불릿 포인트 스타일)으로, 실시간 응답이 요구되는 서비스에 적합하도록 설계됐다.
EU AI Act와의 호환성도 강조한다. 훈련 FLOPs가 10²⁵ FLOPs 기준 이하이므로 ‘GP AI’ 등급에 해당하지만, 시스템 위험 보고 의무는 면제된다. 모델은 Hugging Face에 공개돼 투명성, 재현성, 규제 준수를 지원한다.
한계점으로는 낮은 MFU가 하드웨어 활용 효율을 저하시킬 가능성, 라우팅 오버헤드와 전문가 불균형으로 인한 지연, 이탈리아어 데이터 비중이 높아 다언어 일반화가 제한될 수 있음, 공개 벤치마크 외 실제 산업 현장 워크로드에 대한 평가 부족 등을 들 수 있다. 향후 연구에서는 MFU 향상, 라우팅 최적화, 다언어 데이터 확대, 실제 기업·공공 부문 적용 사례 분석이 필요하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기