ImagenWorld: Stress-Testing Image Generation Models with Explainable Human Evaluation on Open-ended Real-World Tasks
Advances in diffusion, autoregressive, and hybrid models have enabled high-quality image synthesis for tasks such as text-to-image, editing, and reference-guided composition. Yet, existing benchmarks remain limited, either focus on isolated tasks, co…
Authors: Samin Mahdizadeh Sani, Max Ku, Nima Jamali
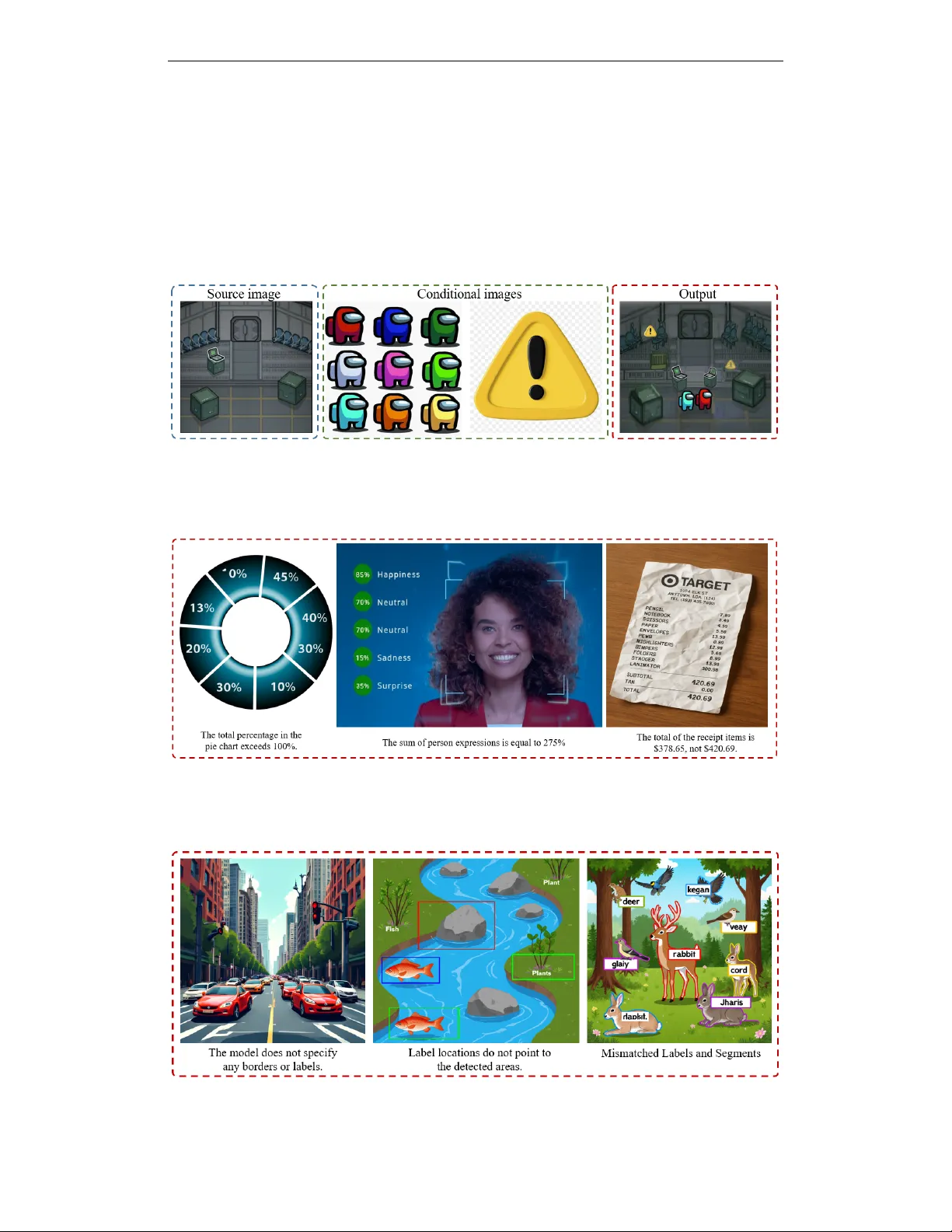
Published as a conference paper at ICLR 2026 I M A G E N W O R L D : S T R E S S - T E S T I N G I M A G E G E N E R A - T I O N M O D E L S W I T H E X P L A I N A B L E H U M A N E V A L U A - T I O N O N O P E N - E N D E D R E A L - W O R L D T A S K S †‡ Samin Mahdizadeh Sani ∗♠ , †‡ Max Ku ∗♠♡ , Nima Jamali ♠ , Matina Mahdizadeh Sani ♠ , Paria Khoshtab ♢ , W ei-Chieh Sun ♡ , Parnian F azel ♢ , Zhi Rui T am ♡ , Thomas Chong ♡ , Edisy Kin W ai Chan ♡ , Donald W ai T ong Tsang ♡ , Chiao-W ei Hsu ♡ , T ing W ai Lam ♡ , Ho Y in Sam Ng ♡ , Chiafeng Chu ♡ , Chak-W ing Mak ♡ , Keming W u ♢ , Hiu T ung W ong ♡ , Y ik Chun Ho ♡ , Chi Ruan ♠ , Zhuofeng Li ♢ , I-Sheng Fang ♡ , Shih-Y ing Y eh ♣♡ , Ho Kei Cheng ♡§ , † Ping Nie ♢ , ‡ W enhu Chen ♠ ♠ Univ ersity of W aterloo ♡ G-G-G ♣ Comfy Org § Univ ersity of Illinois Urbana-Champaign ♢ Independent https://tiger- ai- lab.github.io/ImagenWorld/ A B S T R AC T Adv ances in dif fusion, autore gressi ve, and hybrid models have enabled high-quality image synthesis for tasks such as text-to-image, editing, and reference-guided com- position. Y et, e xisting benchmarks remain limited, either focus on isolated tasks, cov er only narro w domains, or pro vide opaque scores without explaining failure modes. W e introduce ImagenW orld , a benchmark of 3.6K condition sets spanning six core tasks (generation and editing, with single or multiple references) and six topical domains (artw orks, photorealistic images, information graphics, textual graphics, computer graphics, and screenshots). The benchmark is supported by 20K fine-grained human annotations and an explainable ev aluation schema that tags localized object-level and segment-le vel errors, complementing automated VLM-based metrics. Our large-scale ev aluation of 14 models yields sev eral in- sights: (1) models typically struggle more in editing tasks than in generation tasks, especially in local edits. (2) models excel in artistic and photorealistic settings but struggle with symbolic and text-hea vy domains such as screenshots and informa- tion graphics. (3) closed-source systems lead ov erall, while targeted data curation (e.g., Qwen-Image) narro ws the gap in te xt-heavy cases. (4) modern VLM-based metrics achiev e K endall accuracies up to 0.79, approximating human ranking, but fall short of fine-grained, explainable error attribution. ImagenW orld provides both a rigorous benchmark and a diagnostic tool to advance rob ust image generation. 1 I N T RO D U C T I O N The rapid progress in generativ e image modeling, po wered by dif fusion (Rombach et al., 2022; Lipman et al., 2023), autoregressiv e (AR) (Y u et al., 2022; Tian et al., 2024), and hybrid architec- tures (OpenAI, 2025), has enabled systems capable of producing high-quality images under di v erse conditioning inputs. More recent work has begun to push to w ard broader functionality , dev eloping models that can handle multiple tasks—such as generation and editing—within a single frame- work (Deng et al., 2025; W u et al., 2025b; Chen et al., 2025a; Google, 2025), with early evidence of real-world applicability (Chen et al., 2025a). Howe v er , ev aluation has not kept pace with this modeling progress. Existing benchmarks are fragmented, often restricted to isolated tasks (e.g., text- to-image (Saharia et al., 2022; Y u et al., 2022), editing (Huang et al., 2023), or personalization (Peng et al., 2025; Li et al., 2023)) or biased tow ard narrow domains such as artworks (K u et al., 2024b) or textual graphics (T uo et al., 2024). As a result, it remains unclear how well these unified models generalize across the full spectrum of real-w orld use cases. T o address this gap, we introduce * Equal contribution † Project Lead ‡ Q samin.mahdizadeh@gmail.com; { m3ku, wenhu.chen } @uwaterloo.ca 1 Published as a conference paper at ICLR 2026 TOPIC Artwor ks Photor eal istic Image s In f ormation G raphic s T ex tual G raphic s Com puter G raphic s Sc reen shot s Dataset Cre ation Output im ag e 1 • Sup erm an • Cat • T ext • … Object Ex tr action Data set Evaluation Condition s et gen eration TASK T ex t - guided im age ge n erat ion Si n gle ref eren ce im age ge n erat ion M ul tipl e ref eren ce im age ge n erat ion T ex t - guided im age editing Si n gle ref eren ce im age editing M ul tipl e ref eren ce im age editing Imag e M odel 2 3 Se gment Ext rac tion Prom p t R elevanc e: 0 .7 5 Aesthetic Qu ality: 0 .7 5 C o nte nt C o h ere nce : 1 A rtif act: 1 Sc ore s: Object issues: Se gment issues: Ca t 6 Hum an Prom p t R elevanc e: 0 .7 0 A esthetic Q uali ty: 1 C o nte nt C o h ere nce : 1 A rtif act: 1 Sc ores: VLM Object an d Segme n t Ex tr action Figure 1: Overview of our dataset and e v aluation pipeline, co vering six content categories and six generation/editing tasks. Model outputs are assessed by both human annotators (explainable schema) and vision–language models (scores only). ImagenW orld , a large-scale, human-centric benchmark comprising 3.6K condition sets designed to systematically stress-test generati ve models. ImagenW orld unifies six representativ e task types and six topical domains, creating a di v erse testbed that mirrors the breadth of real-world image generation and editing. At its core, ImagenW orld relies on structured human e valuation, where annotators not only provide scores b ut also tag specific failure modes with textual descriptions and localized masks as illustrated in Figure 1. This schema yields explainable outcomes, rev ealing why models fail. T o complement human judgments, we also include VLM-as-a-judge metrics, enabling comparison between human and automatic e v aluators. T ogether , this design supports both rigorous benchmarking and forward-looking exploration of ho w e v aluation protocols can scale. By ev aluating a broad set of model families under a single protocol, ImagenW orld provides the most comprehensive picture to date of model performance and failure patterns across real-w orld generation and editing tasks. Our study cov ers 14 models in total, including 4 recent unified models capable of both generation and editing, and 10 task-specific models that serve as auxiliary baselines. W e uncover four key insights : (1) For editing tasks, we identify two distinct failure modes: (i) regenerating an entirely ne w image, and (ii) returning the input unchanged. Strikingly , models tend to exhibit one mode far more frequently than the other, suggesting a systematic bias in how they interpret editing instructions. This highlights a deeper limitation in current architectures: they lack fine-grained control mechanisms to modify localized regions without either o verhauling or ignoring the input. (2) All models struggle with te xt-related tasks such as information graphics, screenshots, and te xtual graphics. Howe ver , our results re veal an exception: Qwen-Image consistently outperforms other models on textual graphics. Notably , Qwen-Image employs a synthetic data curation pipeline explicitly tailored for text-heavy images, suggesting that targeted data augmentation may be a practical path to closing this gap. This highlights that the challenge is not purely architectural, but also fundamentally tied to data design. (3) While closed-source models consistently achiev e strong results across tasks, open-source models are primarily competitiv e in text-to-image generation, where abundant training data and community optimization hav e dri ven rapid progress. Their weaker performance in editing and multimodal composition highlights the need for further research and targeted data curation in these areas, be yond scale alone. (4) Beyond model performance, we find that modern VLM metrics achie ve K endall accuracies up to 0.79, closely matching or e ven e xceeding human–human agreement. This suggests that modern VLMs as a judge are reliable as scalable ev aluators for relati v e ranking in our context, b ut they f all short in the explainable paradigm, where humans remain indispensable for fine-grained tagging of specific failure modes. Our contributions are threefold: (1) we introduce ImagenW orld, a diverse benchmark that unifies six core tasks and six topical domains, enabling consistent cross-model and cross-task e valuation of generativ e image systems; (2) we conduct the first human study of its kind, looking into the failure modes, offering ne w insights and observed patterns. (3) we propose a schema for explainable human ev aluation, labeling object-le vel errors and segment-le v el errors to provide fine-grained, interpretable error attribution beyond scalar scores. By combining task di versity , model breadth, and diagnostic ev aluation depth, ImagenW orld establishes a unified and human-centric study to record our process tow ards the full control of creation and manipulation in images. 2 Published as a conference paper at ICLR 2026 2 R E L A T E D W O R K S Progr ess in Conditional and Multimodal Image Synthesis. The introduction of Latent Diffusion Models (LDMs) (Rombach et al., 2022) mark ed a turning point, leading to a flourishing ecosystem of conditional image synthesis systems (runwayml, 2023; stability .ai, 2023) spanning div erse tasks such as instruction-driv en editing (Brooks et al., 2023a; Huang et al., 2025), structural control (Zhang & Agrawala, 2023), and personalization (Ruiz et al., 2023; Y eh et al., 2024; Hu et al., 2024). While diffusion remains the dominant paradigm, alternative architectures are rapidly adv ancing. Autoregressi ve approaches (Y u et al., 2022; Tian et al., 2024) improve compositional reasoning and fidelity (Xiong et al., 2025), flo w-matching models (BlackForestLabs et al., 2025) le v erage ODE-nativ e properties for potentially faster sampling, and hybrid designs such as autoregressiv e LLMs with diffusion decoders (W u et al., 2024; OpenAI, 2025; Google, 2025) integrate nativ e image generation into con versational agents. T ogether , these families define the current landscape of multimodal conditional image synthesis, though their e valuation remains fragmented across tasks and settings. Our work takes these de velopments into account by systematically studying their strengths and weaknesses under a unified ev aluation frame work. Image Synthesis Assessments and Benchmarks. T raditional ev aluations of generativ e image models hav e relied on metrics such as FID (Heusel et al., 2017) and LPIPS (Zhang et al., 2018) for image fidelity , or CLIPScore (Hessel et al., 2021) for text–image alignment. More recent approaches, including VIEScore and VQAScore (Cho et al., 2023; Hu et al., 2023; Ku et al., 2024a; Lin et al., 2024; Niu et al., 2025), use vision language models (VLM) to better capture semantic relevance, though they introduce biases and often depend on proprietary models. Human preference–driven metrics such as Pick-a-Pic (Kirstain et al., 2023a), ImageRew ard (Xu et al., 2023), and HPS (Ma et al., 2025) emphasize aesthetics and subjecti ve preferences. Beyond indi vidual metrics, benchmarks like DrawBench (Saharia et al., 2022) and PartiPrompts (Y u et al., 2022) target text-to-image fidelity , while others focus on editing (Huang et al., 2023) or personalization (Peng et al., 2025; Li et al., 2023). More recent ef forts, including ImagenHub (K u et al., 2024b) and MMIG-Bench (Hua et al., 2025), extend be yond single tasks by cov ering multiple generation settings and inte grating both automatic and human ev aluation. Gecko (W iles et al., 2025) further scales this direction by introducing a large ev aluation suite that measures text-to-image alignment across di v erse human annotation templates and scoring setups. Open platforms like GenAI-Arena (Jiang et al., 2024) provide Elo-style rankings, but suf fer from topic bias in user-submitted prompts. Overall, existing protocols remain task-specific or opaque, limiting the interpretability and scalability . Beyond simply adding another dataset, our work offers a new perspectiv e: a unified benchmark across tasks and domains, complemented by structured, explainable human e v aluation that can also serve as a foundation for future VLM-based automatic ev aluators. T able 1 reflects how ImagenW orld differs from prior works. T able 1: Comparison with dif ferent ev aluation benchmarks on dif ferent properties. Method Generation & Editing Single Ref Guided Multi Ref Guided Human Rating T opic V ariety Explainable T race ImagenHub (Ku et al., 2024b) ✓ ✓ ✗ ✓ ✓ ✗ GenAI-Arena (Jiang et al., 2024) ✓ ✗ ✗ ✓ ✗ ✗ DreamBench++ (Peng et al., 2025) ✗ ✓ ✗ ✗ ✓ ✗ I 2 EBench (Ma et al., 2024) ✗ ✗ ✗ ✓ ✓ ✗ ICE-Bench (Pan et al., 2025) ✓ ✓ ✗ ✗ ✓ ✗ MMIG-Bench (Hua et al., 2025) ✗ ✓ ✗ ✓ ✓ ✓ Rich-HF (Liang et al., 2024) ✗ ✗ ✗ ✓ ✓ ✓ ImagenW orld (Ours) ✓ ✓ ✓ ✓ ✓ ✓ 3 T H E I M A G E N W O R L D B E N C H M A R K Problem F ormulation . T o capture practical usage scenarios, we unify multiple generation and editing tasks under a common instruction-dri ven framew ork: every task is conditioned on a natural language instruction t ins , optionally accompanied by auxiliary inputs such as a source image I src or a set of reference images I R . This unification reflects how real users typically interact with generati ve systems by providing instructions that guide the system to either create ne w images or edit e xisting ones. Building on this formulation, we categorize tasks into two groups: instruction-dri ven generation, 3 Published as a conference paper at ICLR 2026 T ask T e xt Ins tr u c tion S ou r c e I m age Im ag e Cond ition s S u c c e ss Case F ail u r e Cas e T I G ( CG ) Fo r est s ce n e s h o w in g b o u n d in g b o x e s ar o u n d an i m als s u c h as d ee r , r ab b its , an d b ir d s . − − SRI G (P) C T s ca n o f a b r ain u s i n g t h e r ef er en ce m a s k as th e an ato m ica l s h ap e. − M RIG ( S) Gen er ate a p et s im u lat io n g a m e in ter f ac e w it h p et ch ar ac ter d esig n s f r o m t h e f ir s t an d s ec o n d im a g e s an d th e h o m e d ec o r atio n s t y le f r o m t h e th ir d i m a g e. − T I E (T ) C h a n g e to p tex t to “ I f A I lear n s f r o m h u m a n s ” an d th e b o tto m tex t to “ W h o ’ s co a ch in g t h e co ac h ? ” − SRI E ( A) Re - co lo r t h e s t y l ized p o r tr ait in i m a g e 1 u s in g ex clu s i v el y t h e s p ec i f ic co lo r p alette p r esen ted i n i m a g e 2 . M RIE (I ) I n s tep 2 , u p d ate th e ad d ed p asta to r esem b le s p ag h e tti n o o d les as s h o w n i n i m ag e 2 . Fo r s tep s 1 an d 2 , r ef in e th e w a ter g r ap h ic, d ep ictin g it w it h th e w av e p atter n s t y le f o u n d in i m a g e 3 . Figure 2: Illustrativ e examples from our dataset, sho wing successful and f ailure cases for each task where the system synthesizes a ne w image without a source image, and instruction-dri v en editing, where the system modifies an existing source image I src while following the instruction. Formally: • T ext-guided Image Generation (TIG): Giv en an instruction t ins in natural language, the model synthesizes a new image y = f ( t ins ) . • Single Reference Image Generation (SRIG): Giv en an instruction t ins and a reference image I ref , the model generates a ne w image y = f ( I ref , t ins ) of the referenced entity (e.g., subject, object, or layout) in a different conte xt, pose, or en vironment. • Multiple Reference Image Generation (MRIG): Gi v en an instruction t ins and a set of reference images I R = { I 1 ref , I 2 ref , . . . } , the model synthesizes a ne w image y = f ( I R , t ins ) that composes multiple visual concepts from the instruction and references. • T ext-guided Image Editing (TIE): Given an instruction t ins and a source image I src , the model produces y = f ( t ins , I src ) by modifying I src according to the instruction while preserving its core structure. • Single Reference Image Editing (SRIE): Giv en an instruction t ins , a source image I src , and a reference image I ref , the model edits I src to y = f ( I ref , t ins , I src ) , adapting the reference entity to the specified instruction or style. • Multiple Reference Image Editing (MRIE): Gi ven an inst ruction t ins , a source image I src , and a set of reference images I R , the model edits I src to y = f ( I R , t ins , I src ) , aligning it with the visual attributes or semantics suggested by the instruction and references. Dataset Curation Pipeline. T o construct ImagenW orld, we curated a large-scale dataset through a combination of human annotation and automated refinement. Annotators wrote natural language prompts and paired them with corresponding reference or source images, ensuring that each instance aligned with one of the six benchmark tasks. T o reflect real-world applications, our dataset co vers six major topics: Artworks (A), Photorealistic Images (P), Information Graphics (I), T extual Graphics (T), Computer Graphics (CG) , and Screenshots (S) , each further di vided into fine- grained subtopics to guarantee div erse use cases. In total, our dataset contains 3.6K entries, with 100 samples for each task–topic combination. Figure 2 shows representati ve e xamples from our dataset (see Appendix A.6 for details). 4 Published as a conference paper at ICLR 2026 User Q uer y M odel Out put Ex pec ted A dd a chand el ier to th e ceiling of the roo m . Matc h the styl e and colo r sche me of the o riginal p ainting . Score s : Prom p t R elevanc e: 0 .7 5 A esthetic Q uali ty: 0 .7 5 C o nte nt C o h ere nce : 0 .7 5 A rtif acts: 1 Object Issues : A chand elier in the up p er - mid dl e sectio n, a p p ear ing to h ang f ro m th e ceiling Segm ent Issues : Figure 3: Examples include object-lev el issues, where expected objects are missing or distorted, and segment-le v el issues, where SoM partitions highlight specific regions with visual inconsistencies that affect e v aluation scores. 4 E V A L U A T I O N S E T U P Scoring Criteria. Our ev aluation relies on four criteria that measure Prompt Rele vance, Aesthetic Quality , Content Coherence, and Artifact, capturing complementary aspects of image generation and editing quality , similar to prior works (Xu et al., 2023; Ku et al., 2024b). Each criterion is rated on a 5-point Likert scale (1 = poor , 5 = e xcellent) and later rescaled to the range [0,1]. The definitions of the scoring dimensions are: • Prompt Rele vance: Measures whether the image faithfully reflects the instruction. • Aesthetic Quality : Evaluates the ov erall visual appeal and design (e.g., o vercro wded or poorly aligned elements, poor color schemes, inconsistent fonts). • Content Coherence : Assesses logical and semantic consistency (e.g., labels pointing to the wrong region, a chart titled “gro wth” sho wing decreasing values, or a figure labeled “P arts of a Flower” depicting tree anatomy). • Artifacts : Captures visual flaws and technical issues caused by generation errors (e.g., distorted or gibberish text, warped edges, e xtra limbs, unnatural eyes, or repeated patterns). Each criterion was e valuated both by human annotators and by automated scorers. Specifically , each image was rated by three annotators independently , while LLM-based scores were obtained using the Gemini-2.5-Flash model follo wing the VIEScore (Ku et al., 2024a) paradigm, which produces ratings aligned with the same four criteria. In addition, CLIPScore (Hessel et al., 2021) and LPIPS (Zhang et al., 2018) were computed as auxiliary automated metrics to assess image quality . Explainability via Object and Segment Issues. While many prior works focus on e v aluating image generation quality , few consider the e xplainability of e valuation scores (Chen et al., 2023; Ku et al., 2024a). T o improv e interpretability , we define two complementary error taxonomies: object-level issues in text and segment-lev el issues in image. In addition to assigning ratings on the four criteria, annotators were asked to identify which objects or re gions in the image ne gati vely influenced their scores. For object-level issues, the instruction together with any source or reference images from our dataset were gi ven to Gemini-2.5-Flash, and the model was queried to generate a list of objects expected to appear in the output image. Annotators revie wed this list and marked any objects that were missing, incorrectly rendered, or distorted. F or segment-le v el issues, each generated image was partitioned into regions using the Set-of-Mark (SoM) (Y ang et al., 2023), and annotators selected any segments that contained visual flaws or inconsistencies, thereby identifying specific areas of the image responsible for score deductions. Figure 3 illustrates examples of both object-level and segment-le vel annotations from our dataset. 5 Published as a conference paper at ICLR 2026 T able 2: T ask coverage and architectural categorization of the ev aluated models are shown in chronological order . W e classify multimodal large language models as a form of autoregressiv e model, and group flow matching within the diffusion f amily , following recent literature (Xiong et al., 2025; Chang et al., 2025). For closed-source models where architectural details are una vailable, we label them as Unknown. Model Architectur e TIG TIE SRIG SRIE MRIG MRIE InstructPix2Pix (Brooks et al., 2023b) Diffusion ✗ ✓ ✗ ✗ ✗ ✗ SDXL (Podell et al., 2023) Diffusion ✓ ✗ ✗ ✗ ✗ ✗ Infinity (Han et al., 2025) AR ✓ ✗ ✗ ✗ ✗ ✗ Janus Pro (Chen et al., 2025b) AR + Diffusion ✓ ✗ ✗ ✗ ✗ ✗ GPT -Image-1 (OpenAI, 2025) Unknown ✓ ✓ ✓ ✓ ✓ ✓ UNO (W u et al., 2025c) AR + Diffusion ✓ ✗ ✓ ✗ ✓ ✗ B AGEL (Deng et al., 2025) AR ✓ ✓ ✓ ✓ ✓ ✓ Step1X-Edit (Liu et al., 2025) AR + Diffusion ✗ ✓ ✗ ✗ ✗ ✗ IC-Edit (Zhang et al., 2025) Diffusion ✗ ✓ ✗ ✗ ✗ ✗ Gemini 2.0 Flash (W u et al., 2025c) Unknown ✓ ✓ ✓ ✓ ✓ ✓ OmniGen2 (W u et al., 2025b) AR + Diffusion ✓ ✓ ✓ ✓ ✓ ✓ Flux.1-Krea-dev (Lee et al., 2025) Diffusion ✓ ✗ ✗ ✗ ✗ ✗ Flux.1-K ontext-dev (BlackF orestLabs et al., 2025) Diffusion ✗ ✓ ✓ ✗ ✗ ✗ Qwen-Image (W u et al., 2025a) Diffusion ✓ ✗ ✗ ✗ ✗ ✗ Baselines. W e ev aluate ImagenW orld using models from three major architectural families: dif fusion models, autoregressi ve models, and hybrids that combine AR with dif fusion decoders. T able 2 lists the ev aluated models, their architectural families, and their task coverage. This set spans both unified models capable of all six tasks (GPT -Image-1 (Chen et al., 2025a), Gemini 2.0 Flash (Google, 2025), B A GEL (Deng et al., 2025), OmniGen2 (W u et al., 2025b)) and e xpert models specialized for subsets of tasks (W u et al., 2025a; BlackForestLabs et al., 2025; Liu et al., 2025; Han et al., 2025). This setup enables broad comparisons across architectures and between unified and expert approaches. 5 R E S U L T S A N D A N A L Y S I S W e summarize our quantitativ e findings in T able 3, which reports human ev aluation scores and VLM predictions across six tasks and four criteria. The subsections below analyze these results by task, topic, and ev aluation metric (see Appendix A.5 for statistical tests). 5 . 1 Q UA N T I TA T I V E A N A L Y S I S T ask Level. Across the six benchmark tasks, there is a clear gap between open- and closed-source models as reflected in Figure 4. GPT -Image-1 achiev es the strongest ov erall performance, outper- forming Gemini 2.0 Flash by about 0.1–0.2 points on a verage. This mar gin is particularly pronounced in editing tasks, where Gemini falls further behind. Despite this average gap, scale alone doesn’t determine success: sev eral open-source models (e.g., Flux-Krea-de v , Qwen-Image, Flux-1-Konte xt- Dev) outperform Gemini on text-guided generation and editing, showing that larger scale doesn’t always yield superior results. Howev er , none of the open-source unified models can catch up with close-source models, as seen in Figure 5. Beyond scale effects, the distribution of scores further highlights dif ferences in task dif ficulty: models consistently achie ve lo wer performance on editing tasks (TIE, SRIE, MRIE) than on their generation counterparts (TIG, SRIG, MRIG), with an av erage gap of roughly 0.1 This pattern suggest that while generation has benefited from scaling and improv ed reasoning integration, localized modification remains a major bottleneck. T opic Level. Performance also v aries substantially across topical domains. Figure 4 presents topic- le vel statistics (see Appendix A.4 for detailed results across the full model set). Among the six defined topics, Artworks (A) and Photorealistic Images (P) stand out as the most successful, with a verages approaching 0.78 and the best model (GPT -Image-1) reaching around 0.9 in both cate gories. This reflects notable progress in rendering high-fidelity content in naturalistic and stylistic domains. In contrast, structured and symbolic topics rev eal much larger gaps. T e xtual Graphics (T) and Computer Graphics (C) both av erage near 0.68, while Screenshots (S) and Information Graphics (I) remain the most challenging, with av erages closer to 0.55. Overall, these findings underscore persistent weaknesses in handling text-heavy and symbolic content, highlighting the need for targeted adv ances in these domains. W e also observe similar trend b ut more obvious g ap in unified models (Figure 5). 6 Published as a conference paper at ICLR 2026 T able 3: All e valuated models across six core tasks with bolded maxima for the four human metrics and ov erall in each task. ¯ O Human denotes the human-annotated ov erall av erage; ¯ O VLM is the VLM- predicted ov erall. α is Krippendorf f ’ s alpha for inter-rater reliability and ρ s is the Spearman’ s rank correlation for human-vlm alignment. Human Overalls Agreement Model Prompt ↑ Relev ance Aesthetic ↑ Quality Content ↑ Coherence Artifacts ↑ ¯ O Human ¯ O VLM α Kripp. ρ s Spear . T ext-guided Image Generation (TIG) GPT -Image-1 0.90 ± 0.14 0.92 ± 0.10 0.91 ± 0.13 0.92 ± 0.12 0.91 ± 0.10 0.92 ± 0.13 0.52 0.39 Qwen-Image 0.82 ± 0.22 0.92 ± 0.11 0.88 ± 0.17 0.85 ± 0.22 0.87 ± 0.15 0.86 ± 0.20 0.75 0.76 Flux.1-Krea-dev 0.77 ± 0.23 0.85 ± 0.16 0.84 ± 0.18 0.80 ± 0.22 0.82 ± 0.17 0.82 ± 0.23 0.67 0.79 Gemini-2.0-Flash 0.79 ± 0.21 0.78 ± 0.21 0.83 ± 0.19 0.79 ± 0.25 0.80 ± 0.19 0.82 ± 0.24 0.67 0.70 UNO 0.75 ± 0.21 0.77 ± 0.19 0.83 ± 0.17 0.76 ± 0.26 0.78 ± 0.18 0.72 ± 0.27 0.72 0.73 B A GEL 0.72 ± 0.24 0.80 ± 0.20 0.82 ± 0.21 0.73 ± 0.29 0.76 ± 0.21 0.75 ± 0.26 0.74 0.78 OmniGen2 0.67 ± 0.25 0.77 ± 0.23 0.78 ± 0.24 0.72 ± 0.32 0.74 ± 0.23 0.75 ± 0.27 0.71 0.80 Infinity 0.64 ± 0.30 0.74 ± 0.23 0.76 ± 0.24 0.69 ± 0.31 0.70 ± 0.24 0.73 ± 0.27 0.78 0.81 SDXL 0.55 ± 0.29 0.70 ± 0.25 0.70 ± 0.27 0.61 ± 0.31 0.64 ± 0.25 0.65 ± 0.30 0.75 0.79 Janus Pro 0.62 ± 0.30 0.62 ± 0.30 0.62 ± 0.30 0.60 ± 0.29 0.61 ± 0.29 0.54 ± 0.32 0.77 0.74 T ext-guided Image Editing (TIE) GPT -Image-1 0.77 ± 0.17 0.86 ± 0.15 0.86 ± 0.17 0.79 ± 0.22 0.82 ± 0.15 0.80 ± 0.28 0.65 0.58 Flux.1-K ontext-de v 0.52 ± 0.31 0.76 ± 0.22 0.75 ± 0.22 0.76 ± 0.26 0.70 ± 0.21 0.63 ± 0.32 0.68 0.71 Gemini-2.0-Flash 0.62 ± 0.29 0.68 ± 0.25 0.75 ± 0.24 0.70 ± 0.28 0.69 ± 0.23 0.64 ± 0.35 0.70 0.64 B A GEL 0.59 ± 0.28 0.64 ± 0.26 0.73 ± 0.23 0.70 ± 0.25 0.67 ± 0.22 0.59 ± 0.33 0.62 0.66 OmniGen2 0.38 ± 0.31 0.63 ± 0.29 0.67 ± 0.30 0.66 ± 0.31 0.58 ± 0.27 0.57 ± 0.32 0.77 0.72 IC-Edit 0.38 ± 0.28 0.54 ± 0.23 0.56 ± 0.22 0.52 ± 0.24 0.50 ± 0.22 0.49 ± 0.29 0.65 0.58 Step1xEdit 0.34 ± 0.28 0.46 ± 0.29 0.51 ± 0.29 0.51 ± 0.32 0.46 ± 0.26 0.43 ± 0.36 0.73 0.71 InstructPix2Pix 0.26 ± 0.24 0.48 ± 0.25 0.56 ± 0.26 0.51 ± 0.27 0.45 ± 0.22 0.41 ± 0.30 0.64 0.66 Single Reference Image Generation (SRIG) GPT -Image-1 0.79 ± 0.20 0.86 ± 0.16 0.86 ± 0.18 0.85 ± 0.18 0.84 ± 0.15 0.86 ± 0.18 0.61 0.48 Gemini-2.0-Flash 0.62 ± 0.26 0.65 ± 0.24 0.74 ± 0.24 0.69 ± 0.28 0.67 ± 0.22 0.70 ± 0.28 0.66 0.60 B A GEL 0.57 ± 0.24 0.67 ± 0.25 0.69 ± 0.24 0.64 ± 0.29 0.64 ± 0.22 0.65 ± 0.28 0.66 0.66 UNO 0.57 ± 0.25 0.62 ± 0.23 0.65 ± 0.23 0.59 ± 0.25 0.61 ± 0.21 0.60 ± 0.29 0.65 0.65 OmniGen2 0.41 ± 0.26 0.61 ± 0.24 0.65 ± 0.26 0.64 ± 0.28 0.58 ± 0.22 0.62 ± 0.30 0.65 0.74 Single Reference Image Editing (SRIE) GPT -Image-1 0.73 ± 0.22 0.80 ± 0.20 0.86 ± 0.17 0.80 ± 0.22 0.80 ± 0.16 0.76 ± 0.29 0.63 0.46 Gemini-2.0-Flash 0.44 ± 0.29 0.60 ± 0.24 0.69 ± 0.25 0.63 ± 0.26 0.59 ± 0.21 0.54 ± 0.32 0.64 0.66 B A GEL 0.35 ± 0.29 0.58 ± 0.25 0.62 ± 0.26 0.65 ± 0.27 0.55 ± 0.22 0.53 ± 0.32 0.56 0.60 OmniGen2 0.30 ± 0.27 0.60 ± 0.27 0.62 ± 0.28 0.62 ± 0.30 0.54 ± 0.24 0.54 ± 0.31 0.66 0.72 Multiple Reference Image Generation (MRIG) GPT -Image-1 0.80 ± 0.17 0.86 ± 0.15 0.86 ± 0.18 0.85 ± 0.17 0.84 ± 0.15 0.88 ± 0.16 0.51 0.39 Gemini-2.0-Flash 0.69 ± 0.25 0.72 ± 0.24 0.81 ± 0.20 0.72 ± 0.29 0.73 ± 0.22 0.68 ± 0.30 0.73 0.73 B A GEL 0.56 ± 0.26 0.63 ± 0.26 0.66 ± 0.26 0.60 ± 0.30 0.61 ± 0.24 0.59 ± 0.31 0.67 0.65 OmniGen2 0.47 ± 0.26 0.66 ± 0.22 0.66 ± 0.26 0.65 ± 0.28 0.61 ± 0.21 0.59 ± 0.28 0.66 0.70 UNO 0.53 ± 0.22 0.61 ± 0.20 0.67 ± 0.20 0.60 ± 0.22 0.60 ± 0.18 0.58 ± 0.25 0.58 0.54 Multiple Reference Image Editing (MRIE) GPT -Image-1 0.72 ± 0.19 0.82 ± 0.18 0.82 ± 0.20 0.80 ± 0.21 0.79 ± 0.17 0.75 ± 0.27 0.66 0.55 Gemini-2.0-Flash 0.49 ± 0.25 0.66 ± 0.21 0.69 ± 0.22 0.64 ± 0.25 0.62 ± 0.19 0.51 ± 0.31 0.62 0.56 OmniGen2 0.32 ± 0.20 0.56 ± 0.25 0.55 ± 0.28 0.60 ± 0.28 0.51 ± 0.22 0.45 ± 0.30 0.69 0.66 B A GEL 0.28 ± 0.22 0.44 ± 0.26 0.48 ± 0.29 0.51 ± 0.28 0.43 ± 0.23 0.38 ± 0.28 0.67 0.64 Evaluation Criteria. Across the four defined metrics, we observe distinct patterns in model beha vior from Figure 4. Prompt Relev ance sho ws the lar gest v ariability across tasks, peaking in TIG (0.72) but dropping to 0.46 in editing tasks on average, underscoring the difficulty of aligning edits with instructions. Aesthetic Quality and Content Coherence are more stable, with maximum task-lev el gaps of 0.17 and 0.16, respectiv ely . Both metrics (Aesthetic Quality/Content Coherence) achieve their highest values in Artworks (0.79/0.79) and Photorealistic Images (0.82/0.82) but decline in symbolic settings such as Screenshots (0.58/0.63) and Information Graphics (0.58/0.59). Artifact suppression appears more uniform at the task level (gap = 0.11), yet topic-level analysis rev eals clear asymmetry: non-symbolic content is largely free of distortions, whereas te xt-heavy cate gories frequently suffer from unreadable or corrupted elements. T aken together , these results show that instruction following is the primary bottleneck across tasks, while artifact control remains the central challenge in text-intensi ve domains, particularly Screenshots. 7 Published as a conference paper at ICLR 2026 P r ompt R elevance A esthetic Quality Content Coher ence Artifact Human Overall Metric I A S CG P T T opic 0.48 0.58 0.59 0.54 0.55 0.67 0.79 0.82 0.83 0.78 0.52 0.58 0.63 0.47 0.55 0.55 0.70 0.74 0.74 0.68 0.65 0.79 0.82 0.84 0.78 0.59 0.71 0.74 0.69 0.68 T opic × Metric (Human means) P r ompt R elevance A esthetic Quality Content Coher ence Artifact Human Overall Metric TIG TIE SRIG SRIE MRIG MRIE T ask 0.72 0.79 0.80 0.75 0.76 0.48 0.63 0.67 0.64 0.61 0.59 0.68 0.72 0.68 0.67 0.45 0.64 0.70 0.67 0.62 0.61 0.70 0.73 0.68 0.68 0.45 0.62 0.64 0.64 0.59 T ask × Metric (Human means) 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Mean scor e 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Mean scor e Figure 4: Mean human ev aluation scores across metrics by topic (left) and task (right). Figure 5: Overall human rating by task and topic for the four unified models that support all six tasks. 5 . 2 Q UA L I TA T I V E A NA LY S I S Quantitati ve metrics alone fail to capture common mistakes that become clear when e xamining outputs more closely . These mistakes manifest in sev eral recurring ways, as illustrated in Appendix A.3. Across tasks, models often skip parts of comple x and multi-step instructions (Figure 8) or produce unreadable and corrupted text (Figure 13), a problem that persists across nearly all te xt-hea vy domains. Numerical inconsistencies are also frequent in symbolic settings, such as pie chart percentages not summing to 100 or receipt totals not matching itemized v alues (Figure 9). Symbolic and structured domains add further challenges, including errors in understanding depth maps, frequent mismatches between chart legends and plotted data, and incomplete object detection in computer graphics where bounding boxes are poorly aligned with object boundaries (Figure 10). Editing tasks further expose critical weaknesses: models may alter the canv as, misplace objects, ne glect shadows and reflections, return the original input unchanged, or ev en generate a completely new image instead of applying the requested modification (Figure 11). In generation, systems sometimes collapse to near-duplicates of references, ignore one or more references, or produce distorted human figures. These recurring errors clarify why artifact suppression and fine-grained alignment remain ke y open problems, e ven for the strongest models. 5 . 3 H U M A N V S . V L M A S J U D G E T o assess the reliability of automatic ev aluation, we compare VLM-based judgments with human ratings across all four criteria. T able 4 reports fold-a veraged 1 rank correlations (Spearman), K endall’ s 1 Fold-a veraged results are computed using a leave-one-out procedure: each annotator (or the VLM) is compared against the mean of the other two, and results are a veraged across folds. 8 Published as a conference paper at ICLR 2026 T able 4: Fold-a veraged Spearman correlations, K endall’ s accurac y , and Bias (av erage signed dif fer- ence between VLM and human ratings) comparing VLM-based judgments with human ratings across all criteria. Metric Human–Human VLM–Human Spearman ρ Kendall Acc. Spearman ρ Kendall Acc. Bias Prompt Relev ance 0.67 ± 0.03 0.77 ± 0.01 0.70 ± 0.00 0.79 ± 0.00 − 0 . 07 ± 0 . 01 Aesthetic Quality 0.55 ± 0.01 0.73 ± 0.00 0.62 ± 0.01 0.76 ± 0.00 − 0 . 01 ± 0 . 01 Content Coherence 0.50 ± 0.01 0.71 ± 0.01 0.57 ± 0.01 0.74 ± 0.01 − 0 . 05 ± 0 . 01 Artifact 0.64 ± 0.01 0.76 ± 0.01 0.59 ± 0.01 0.75 ± 0.00 0 . 06 ± 0 . 00 Overall 0.68 ± 0.02 0.76 ± 0.01 0.72 ± 0.00 0.78 ± 0.00 − 0 . 02 ± 0 . 00 accuracy , and VLM bias (the av erage signed dif ference between VLM and human ratings). Overall, the VLM exhibits moderate to strong agreement with human raters across ev aluation dimensions, aligning well with human–human consistency . Spearman correlations between VLM and human ratings range from 0.57 for content coherence to 0.70 for prompt relev ance, closely matching and in some cases exceeding human–human correlations. Kendall’ s accuracy follo ws a similar trend, with values between 0.74 and 0.79, indicating that the VLM preserves the relati v e ranking of samples in line with human judgments. At the metric level, prompt relev ance shows the strongest alignment, suggesting that the VLM is particularly effecti ve at assessing semantic faithfulness to the input prompt. In contrast, for artifacts, VLM–human agreement lags behind human–human agreement, and the positiv e bias indicates that the VLM under-penalizes flaws such as unreadable text, boundary glitches, or misaligned layouts that humans consistently flag. T aken together , the results suggest that VLM-based ev aluation provides a reliable proxy for human scoring on high-level criteria such as prompt rele v ance and aesthetic quality , b ut human judgment remains crucial for more detailed criteria such as visual defects. 6 D I S C U S S I O N Figure 6: Percentage of cases where the model generating completely ne w image or simply return input in image editing tasks. T argeted data curation boosts domain-specific perf ormance. While GPT -Image-1 achiev es the strongest results across most domains, Qwen-Image demonstrates how deliberate data design can shift the balance in text-heavy scenarios. Unlike many models that struggle with textual content, Qwen-Image consistently outperforms ev en closed-source systems in artwork, photorealistic images, and especially textual graphics for text-guided generation (Figure 15). This advantage stems from a training pipeline enriched with synthetic te xt-rich samples and a progressive curriculum that gradually introduced increasingly complex layouts. T ogether with a balanced domain cov erage, these choices directly improv ed text rendering, making Qwen-Image particularly effecti ve in te xt-heavy tasks where most models perform poorly . Architectural pathways and training objecti ves influence editing tasks beha viours. The error rates in Figure 6 suggest that autoregressi v e–diffusion h ybrids such as OmniGen2 and Step1X-Edit are more likely to generate entirely ne w images when asked to edit ( 17 %), possibly reflecting their reliance on language-dri ven pathw ays that can ov erride source conditioning. In contrast, diffusion- 9 Published as a conference paper at ICLR 2026 only editors like IC-Edit (0.6%) and InstructPix2Pix (3.4%) rarely disregard the source image, consistent with their architectures being explicitly optimized for localized modifications (though this may come at the cost of limited task coverage). Interestingly , Flux.1 Konte xt, despite being diffusion-based, sho ws a higher rate of generating a ne w image (14.4%), likely due to its broader training scheme that mix es local edits, global edits, and reference-based composition. This unified in-context design impro ves v ersatility b ut makes the model less constrained to preserve the source image like InstructPix2Pix and IC-Edit. Future W ork. The structure of our dataset, which includes human scores, object-lev el tags, and full model outputs, points to several directions for future research. (1) The collected human scores can be used as preference data to train models that better align with human judgments, for example through preference optimization or ranking-based fine-tuning (W u et al., 2023; Liang et al., 2024). (2) The object-lev el tags pro vide a basis for diagnostic and self-correcti v e approaches, enabling models to generate object-aware refinements or produce correcti ve instructions (Chen et al., 2024; Chakrabarty et al., 2023). (3) The combination of fine-grained annotations and human ev aluations creates opportunities for dev eloping more interpretable metrics that capture object-le v el errors, compositional inconsistencies, and prompt–object mismatches more faithfully than existing automatic metrics (T an et al., 2024; Kirstain et al., 2023b). T aken together , we hope that these directions will support the dev elopment of more reliable, controllable, and human-aligned multimodal generation systems. 7 C O N C L U S I O N W e present ImagenW orld, a benchmark that unifies six generation and editing tasks across six topical domains, supported by 20K fine-grained human annotations. Unlike prior benchmarks, ImagenW orld introduces an explainable e valuation schema with object-le vel and segment-le v el issue labels, enabling interpretable diagnosis of model failures be yond scalar scores. Evaluating 14 models, we find consistent trends: models perform better on generation than on editing, struggle with symbolic and text-hea vy domains, and show a persistent gap between closed-source and open-source models. Our structured human annotations capture localized errors and re veal insights that modern VLM-based metrics miss. By combining broad task coverage with explainable labeling, ImagenW orld serves not only as a rigorous benchmark but also as a diagnostic tool, laying the groundw ork for more faithful and rob ust image generation systems. E T H I C S S T A T E M E N T The rapid adv ancement of image generation and editing technologies raises pressing safety and ethical concerns. T raditional photo manipulation tools such as Photoshop already enabled malicious uses, b ut modern AI-po wered systems dramatically lo wer the technical barrier , making realistic forgeries accessible to a much broader audience. This democratization amplifies risks of fraud and deception in e veryday conte xts: for example, a user might alter a photo of deli vered food to obtain fraudulent refunds, fabricate receipts for economic g ain, or generate fake identification documents. More broadly , the same capabilities can be misused for deepfake creation, leading to non-consensual imagery , political disinformation, or priv ac y violations. Such misuse threatens not only businesses and institutions but also public trust in digital media and the safety of indi viduals. As generative models continue to improv e in fidelity and controllability , it is critical to establish safeguards, encourage responsible deployment, and promote ethical practices. In releasing ImagenW orld, we will pro vide only sanitized data and annotations, exclude sensiti ve or personally identifiable content, and make all resources publicly av ailable to support transparent and responsible research. R E P RO D U C I B I L I T Y S TA T E M E N T All experiments were conducted with 8 NVIDIA A6000 GPUs using the ImagenHub (Ku et al., 2024b) inference library , into which we inte grated the latest models when not already included. w For f airness, all model implementations follo wed the default configurations recommended in their respectiv e papers or of ficial releases, and all open-source models were ev aluated under the same seed (42). Approximately $1,000 USD were spent on API access for closed-source models and 10 Published as a conference paper at ICLR 2026 VLM-based ev aluators. Code, dataset, and sanitized human annotations will be released on publicly accessible platforms (e.g., GitHub, HuggingFace). A C K N O W L E D G E M E N T W e extend our gratitude to Min-Hung Chen for v aluable feedback and insightful comments on this paper . W e also sincerely thank Y u-Y ing Chiu, Boris Leung, W yett Zeng, and Dongfu Jiang for their help with data creation and annotation setup. R E F E R E N C E S BlackForestLabs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, T im Dockhorn, Jack English, Zion English, Patrick Esser , Sumith Kulal, K yle Lacey , Y am Le vi, Cheng Li, Dominik Lorenz, Jonas M ¨ uller , Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer , and Luke Smith. Flux.1 kontext: Flow matching for in-context image generation and editing in latent space, 2025. URL . T im Brooks, Aleksander Holynski, and Ale xei A. Efros. Instructpix2pix: Learning to follow image editing instructions. In CVPR, 2023a. T im Brooks, Aleksander Holynski, and Ale xei A Efros. Instructpix2pix: Learning to follo w image editing instructions. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 18392–18402, 2023b. T uhin Chakrabarty , Kanishk Singh, Arkadiy Saak yan, and Smaranda Muresan. Learning to follo w object-centric image editing instructions faithfully . arXiv preprint arXi v:2310.19145, 2023. Ziyi Chang, George Alex Koulieris, Hyung Jin Chang, and Hubert P . H. Shum. On the design fundamentals of dif fusion models: A surve y , 2025. URL 04542 . Sixiang Chen, Jinbin Bai, Zhuoran Zhao, T ian Y e, Qingyu Shi, Donghao Zhou, W enhao Chai, Xin Lin, Jianzong W u, Chao T ang, Shilin Xu, T ao Zhang, Haobo Y uan, Y ikang Zhou, W ei Chow , Linfeng Li, Xiangtai Li, Lei Zhu, and Lu Qi. An empirical study of gpt-4o image generation capabilities, 2025a. URL . Xiaokang Chen, Zhiyu W u, Xingchao Liu, Zizheng Pan, W en Liu, Zhenda Xie, Xingkai Y u, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint arXi v:2501.17811, 2025b. Xinyan Chen, Jiaxin Ge, T ianjun Zhang, Jiaming Liu, and Shanghang Zhang. Learning from mistakes: Iterative prompt relabeling for te xt-to-image dif fusion model training. In Findings of the Association for Computational Linguistics: EMNLP 2024, pp. 2937–2952, 2024. Y ixiong Chen, Li Liu, and Chris Ding. X-iqe: explainable image quality ev aluation for text-to-image generation with visual large language models. arXi v preprint arXi v:2305.10843, 2023. Jaemin Cho, Y ushi Hu, Roopal Gar g, Peter Anderson, Ranjay Krishna, Jason Baldridge, Mohit Bansal, Jordi Pont-T uset, and Su W ang. Davidsonian scene graph: Improving reliability in fine-grained ev aluation for te xt-to-image generation. arXiv preprint arXi v:2310.18235, 2023. Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu W ang, Shu Zhong, W eihao Y u, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan. Emerging properties in unified multimodal pretraining. arXiv preprint arXi v:2505.14683, 2025. Google. Gemini 2.5: Pushing the frontier with adv anced reasoning, multimodality , long context, and next generation agentic capabilities, 2025. URL . Jian Han, Jinlai Liu, Y i Jiang, Bin Y an, Y uqi Zhang, Zehuan Y uan, Bingyue Peng, and Xiaobing Liu. Infinity: Scaling bitwise autoregressi ve modeling for high-resolution image synthesis. In Proceedings of the Computer V ision and Pattern Recognition Conference , pp. 15733–15744, 2025. 11 Published as a conference paper at ICLR 2026 Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Y ejin Choi. CLIPScore: a reference-free ev aluation metric for image captioning. In EMNLP, 2021. Martin Heusel, Hubert Ramsauer , Thomas Unterthiner , Bernhard Nessler , and Sepp Hochreiter . Gans trained by a two time-scale update rule con verge to a local nash equilibrium. Advances in neural information processing systems, 30, 2017. Hexiang Hu, K elvin Chan, Y u-Chuan Su, W enhu Chen, Y andong Li, Zhao Y ang, Xue Ben, Boqing Gong, W illiam W Cohen, Ming-W ei Chang, and Xuhui Jia. Instruct-imagen: Image generation with multi-modal instruction. arXiv preprint arXi v:2401.01952, 2024. Y ushi Hu, Benlin Liu, Jungo Kasai, Y izhong W ang, Mari Ostendorf, Ranjay Krishna, and Noah A Smith. Tif a: Accurate and interpretable text-to-image faithfulness ev aluation with question answering. In Proceedings of the IEEE/CVF International Conference on Computer V ision , pp. 20406–20417, 2023. Hang Hua, Ziyun Zeng, Y izhi Song, Y unlong T ang, Liu He, Daniel Aliaga, W ei Xiong, and Jiebo Luo. Mmig-bench: T ow ards comprehensiv e and explainable ev aluation of multi-modal image generation models, 2025. URL . Y i Huang, Jiancheng Huang, Y ifan Liu, Mingfu Y an, Jiaxi Lv , Jianzhuang Liu, W ei Xiong, He Zhang, Liangliang Cao, and Shifeng Chen. Diffusion model-based image editing: A survey . IEEE T ransactions on Pattern Analysis and Machine Intelligence , 47(6):4409–4437, June 2025. ISSN 1939-3539. doi: 10.1109/tpami.2025.3541625. URL http://dx.doi.org/10.1109/ TPAMI.2025.3541625 . Y uzhou Huang, Liangbin Xie, Xintao W ang, Ziyang Y uan, Xiaodong Cun, Y ixiao Ge, Jiantao Zhou, Chao Dong, Rui Huang, Ruimao Zhang, and Y ing Shan. Smartedit: Exploring complex instruction-based image editing with multimodal large language models, 2023. URL https: //arxiv.org/abs/2312.06739 . Dongfu Jiang, Max K u, T ianle Li, Y uansheng Ni, Shizhuo Sun, Rongqi Fan, and W enhu Chen. Genai arena: An open ev aluation platform for generativ e models, 2024. URL abs/2406.04485 . Y uval Kirstain, Adam Polyak, Uriel Singer , Shahbuland Matiana, Joe Penna, and Omer Levy . Pick-a- pic: An open dataset of user preferences for text-to-image generation. 2023a. Y uval Kirstain, Adam Polyak, Uriel Singer , Shahbuland Matiana, Joe Penna, and Omer Le vy . Pick- a-pic: An open dataset of user preferences for text-to-image generation. Advances in neural information processing systems, 36:36652–36663, 2023b. Max Ku, Dongfu Jiang, Cong W ei, Xiang Y ue, and W enhu Chen. VIEScore: T owards explainable metrics for conditional image synthesis ev aluation. In Lun-W ei Ku, Andre Martins, and V ivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers) , pp. 12268–12290, Bangkok, Thailand, August 2024a. Association for Computational Linguistics. doi: 10.18653/v1/2024.acl- long.663. URL https: //aclanthology.org/2024.acl- long.663/ . Max Ku, Tianle Li, Kai Zhang, Y ujie Lu, Xingyu Fu, W enwen Zhuang, and W enhu Chen. Ima- genhub: Standardizing the ev aluation of conditional image generation models. In The T welfth International Conference on Learning Representations , 2024b. URL https://openreview. net/forum?id=OuV9ZrkQlc . Sangwu Lee, Titus Ebbecke, Erwann Millon, Will Beddow , Le Zhuo, Iker Garc ´ ıa-Ferrero, Liam Esparraguera, Mihai Petrescu, Gian Saß, Gabriel Menezes, and V ictor Perez. Flux.1 krea [de v]. https://github.com/krea- ai/flux- krea , 2025. T ianle Li, Max K u, Cong W ei, and W enhu Chen. Dreamedit: Subject-driv en image editing. arXiv preprint arXiv:2306.12624, 2023. 12 Published as a conference paper at ICLR 2026 Y ouwei Liang, Junfeng He, Gang Li, Peizhao Li, Arseniy Klimovskiy , Nicholas Carolan, Jiao Sun, Jordi Pont-T uset, Sarah Y oung, Feng Y ang, et al. Rich human feedback for text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition , pp. 19401–19411, 2024. Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Dev a Ramanan. Evaluating te xt-to-visual generation with image-to-te xt generation, 2024. URL https://arxiv.org/abs/2404.01291 . Y aron Lipman, Ricky T . Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generativ e modeling, 2023. URL . Shiyu Liu, Y ucheng Han, Peng Xing, Fukun Y in, Rui W ang, W ei Cheng, Jiaqi Liao, Y ingming W ang, Honghao Fu, Chunrui Han, et al. Step1x-edit: A practical framew ork for general image editing. arXiv preprint arXi v:2504.17761, 2025. Y iwei Ma, Jiayi Ji, K e Y e, W eihuang Lin, Zhibin W ang, Y onghan Zheng, Qiang Zhou, Xiaoshuai Sun, and Rongrong Ji. I2ebench: A comprehensive benchmark for instruction-based image editing, 2024. URL . Y uhang Ma, Y unhao Shui, Xiaoshi W u, K eqiang Sun, and Hongsheng Li. Hpsv3: T owards wide- spectrum human preference score, 2025. URL . Y uwei Niu, Munan Ning, Mengren Zheng, W eiyang Jin, Bin Lin, Peng Jin, Jiaqi Liao, Chaoran Feng, Kunpeng Ning, Bin Zhu, and Li Y uan. W ise: A world kno wledge-informed semantic e v aluation for text-to-image generation, 2025. URL . OpenAI. Introducing 4o image generation. https://openai.com/index/ introducing- 4o- image- generation/ , March 2025. Image generation e xample from the official OpenAI announcement. Y ulin Pan, Xiangteng He, Chaojie Mao, Zhen Han, Zeyinzi Jiang, Jingfeng Zhang, and Y u Liu. Ice-bench: A unified and comprehensi ve benchmark for image creating and editing, 2025. URL https://arxiv.org/abs/2503.14482 . Y uang Peng, Y uxin Cui, Haomiao T ang, Zekun Qi, Runpei Dong, Jing Bai, Chunrui Han, Zheng Ge, Xiangyu Zhang, and Shu-T ao Xia. Dreambench++: A human-aligned benchmark for personalized image generation. In The Thirteenth International Conference on Learning Representations , 2025. URL https://dreambenchplus.github.io/ . Dustin Podell, Zion English, Kyle Lacey , Andreas Blattmann, T im Dockhorn, Jonas M ¨ uller , Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXi v:2307.01952, 2023. Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser , and Bj ¨ orn Ommer . High- resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10684–10695, 2022. Nataniel Ruiz, Y uanzhen Li, V arun Jampani, Y ael Pritch, Michael Rubinstein, and Kfir Aber- man. Dreambooth: Fine tuning te xt-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition , pp. 22500–22510, 2023. runwayml. Stable dif fusion inpainting, 2023. URL https://huggingface.co/runwayml/ stable- diffusion- inpainting . Chitwan Saharia, W illiam Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour , Raphael Gontijo Lopes, Burcu Karagol A yan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. Advances in Neural Information Processing Systems, 35:36479–36494, 2022. stability .ai. Stable diffusion xl, 2023. URL https://stability.ai/stable- diffusion . 13 Published as a conference paper at ICLR 2026 Zhiyu T an, Xiaomeng Y ang, Luozheng Qin, Mengping Y ang, Cheng Zhang, and Hao Li. Evalalign: Supervised fine-tuning multimodal llms with human-aligned data for ev aluating text-to-image models. arXiv preprint arXi v:2406.16562, 2024. Ke yu T ian, Y i Jiang, Zehuan Y uan, Bingyue Peng, and Liwei W ang. V isual autoregressiv e modeling: Scalable image generation via next-scale prediction, 2024. URL 2404.02905 . Y uxiang T uo, W angmeng Xiang, Jun-Y an He, Y ifeng Geng, and Xuansong Xie. Anyte xt: Multilingual visual text generation and editing, 2024. URL . Olivia W iles, Chuhan Zhang, Isabela Albuquerque, Ivana Kajic, Su W ang, Emanuele Bugliarello, Y asumasa Onoe, Pinelopi Papalampidi, Ira Ktena, Christopher Knutsen, Cyrus Rashtchian, Anant Nawalgaria, Jordi Pont-T uset, and Aida Nematzadeh. Re visiting text-to-image ev alu- ation with gecko: on metrics, prompts, and human rating. In The Thirteenth International Conference on Learning Representations , 2025. URL https://openreview.net/forum? id=Im2neAMlre . Chenfei W u, Jiahao Li, Jingren Zhou, Jun yang Lin, Kaiyuan Gao, Kun Y an, Sheng ming Y in, Shuai Bai, Xiao Xu, Y ilei Chen, Y uxiang Chen, Zecheng T ang, Zekai Zhang, Zhengyi W ang, An Y ang, Bowen Y u, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu W ei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang W u, Peng W ang, Shuting Y u, T ingkun W en, W ensen Feng, Xiaoxiao Xu, Y i W ang, Y ichang Zhang, Y ongqiang Zhu, Y ujia W u, Y uxuan Cai, and Zenan Liu. Qwen-image technical report, 2025a. URL 2508.02324 . Chenyuan W u, Pengfei Zheng, Ruiran Y an, Shitao Xiao, Xin Luo, Y ueze W ang, W anli Li, Xiyan Jiang, Y exin Liu, Junjie Zhou, Ze Liu, Ziyi Xia, Chaofan Li, Haoge Deng, Jiahao W ang, Kun Luo, Bo Zhang, Defu Lian, Xinlong W ang, Zhongyuan W ang, T iejun Huang, and Zheng Liu. Omnigen2: Exploration to advanced multimodal generation. arXi v preprint arXi v:2506.18871, 2025b. Shaojin W u, Mengqi Huang, W enxu W u, Y ufeng Cheng, Fei Ding, and Qian He. Less-to-more general- ization: Unlocking more controllability by in-conte xt generation. arXiv preprint , 2025c. Shengqiong W u, Hao Fei, Leigang Qu, W ei Ji, and T at-Seng Chua. Ne xt-gpt: Any-to-an y multimodal llm. In Proceedings of the International Conference on Machine Learning , pp. 53366–53397, 2024. Xiaoshi W u, Keqiang Sun, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score: Better aligning text-to-image models with human preference. In Proceedings of the IEEE/CVF International Conference on Computer V ision, pp. 2096–2105, 2023. Jing Xiong, Gongye Liu, Lun Huang, Chengyue W u, T aiqiang W u, Y ao Mu, Y uan Y ao, Hui Shen, Zhongwei W an, Jinfa Huang, Chaofan T ao, Shen Y an, Huaxiu Y ao, Lingpeng Kong, Hongxia Y ang, Mi Zhang, Guillermo Sapiro, Jiebo Luo, Ping Luo, and Ngai W ong. Autoregressi ve models in vision: A surve y , 2025. URL . Jiazheng Xu, Xiao Liu, Y uchen W u, Y uxuan T ong, Qinkai Li, Ming Ding, Jie T ang, and Y uxiao Dong. Imagerew ard: Learning and e valuating human preferences for te xt-to-image generation, 2023. Jianwei Y ang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v . arXiv preprint arXi v:2310.11441 , 2023. URL . Shih-Y ing Y eh, Y u-Guan Hsieh, Zhidong Gao, Bernard B W Y ang, Giyeong Oh, and Y anmin Gong. Navig ating text-to-image customization: From lycoris fine-tuning to model ev aluation, 2024. URL https://arxiv.org/abs/2309.14859 . Jiahui Y u, Y uanzhong Xu, Jing Y u K oh, Thang Luong, Gunjan Baid, Zirui W ang, V ijay V asude v an, Alexander K u, Y infei Y ang, Burcu Karagol A yan, Ben Hutchinson, W ei Han, Zarana Parekh, Xin Li, Han Zhang, Jason Baldridge, and Y onghui W u. Scaling autoregressiv e models for content-rich text-to-image generation, 2022. URL . 14 Published as a conference paper at ICLR 2026 Lvmin Zhang and Maneesh Agrawala. Adding conditional control to text-to-image dif fusion models. arXiv preprint arXi v:2302.05543, 2023. Richard Zhang, Phillip Isola, Ale xei A Efros, Eli Shechtman, and Oli ver W ang. The unreasonable effecti v eness of deep features as a perceptual metric. In CVPR, 2018. Zechuan Zhang, Ji Xie, Y u Lu, Zongxin Y ang, and Y i Y ang. In-context edit: Enabling instructional image editing with in-context generation in large scale dif fusion transformer , 2025. URL https: //arxiv.org/abs/2504.20690 . 15 Published as a conference paper at ICLR 2026 A A P P E N D I X A . 1 U S E O F L L M I N W R I T I N G W e used ChatGPT to improv e the writing, mainly on grammar fix. A . 2 H U M A N A N N O T A T I O N D E TA I L S During the annotation stage, we recruited 22 expert annotators, primarily graduate students fluent in English. Each annotator ev aluated approximately 500–1,000 images, with each annotation taking 30–90 seconds. T o reduce fatigue and ensure consistent quality , we restricted annotators to a maximum of 200 samples per week. The entire process was conducted using Label Studio, which provided a user-friendly interface. Potential object-lev el and segment-lev el issues were pre-listed using a vision–language model (VLM) and Set-of-Marks (SOM), allowing annotators to simply select them via checkboxes. For cases where the VLM and SOM failed to capture issues, annotators could switch to a manual mode to input text or create bounding boxes. The full annotation process spanned two months, during which all data were collected. Belo w we present the guidelines for annotators, and Figure 7 illustrates the annotation interface. Annotation Guidelines: Prompt Rele vance Definition: Whether the image accurately reflects or responds to the prompt. Ask yourself: Does the image actually follow the instructions or topic in the prompt? Common issues: – Prompt: “Explain the water c ycle. ” → Image sho ws the food chain. – Prompt: “Slide about diabetes symptoms. ” → Image sho ws a kidne y structure. – Prompt: “Compare apples and oranges. ” → Image compares apples and bananas. Rating (1–5): 1. Completely unrelated to the prompt. 2. Mostly incorrect; v ague connections with many mismatches. 3. Partially rele v ant; ke y ideas present but with errors/omissions. 4. Mostly accurate; follo ws the prompt with minor issues. 5. Fully aligned with the prompt; clear , focused, and complete. Aesthetic Quality / V isual A ppeal Definition: Whether the image is visually appealing, clean, and easy to interpret. Ask yourself: Is this image pleasant to look at, readable, and professionally designed? Common issues: – T ext too small/hard to read or blending into the background. – Cluttered or misaligned layout. – Poor color combinations; inconsistent fonts or spacing. Rating (1–5): 1. V isually poor; unattractive, hard to read, or confusing. 2. Belo w av erage; noticeable design flaws, poor readability . 3. Decent; generally readable with minor layout/design issues. 4. Clean and aesthetically good; fe w flaws. 5. Polished and visually excellent. 16 Published as a conference paper at ICLR 2026 Content Coherence Definition: Whether the content is logically consistent and fits together meaningfully . Ask yourself: Does ev erything in the image belong together and make sense as a whole? Common issues: – Labels pointing to the wrong part (e.g., “li ver” pointing to lungs). – Chart sho ws decreasing values titled “gro wth o ver time. ” – T itle: “Parts of a Flo wer” b ut the figure shows tree anatomy . Rating (1–5): 1. Internally inconsistent or nonsensical; contradictory parts. 2. Some logic present, but components are confusing/mismatched. 3. Mostly coherent, with noticeable mismatches or awkw ard parts. 4. Logically sound ov erall; only minor inconsistencies. 5. Completely coherent and internally consistent. Artifacts / V isual Errors Definition: Whether the image has visual flaws due to generation errors (e.g., distortions, glitches). Ask yourself: Are there technical visual issues like melting edges, strange text, or broken parts? Common issues: – Gibberish or distorted text (e.g., “#di%et@es” instead of “diabetes”). – W arped borders, duplicated textures, or glitched areas. – Extra limbs, broken symmetry , ov er-smoothed or pix elated regions. Rating (1–5): 1. Se vere artifacts that ruin the image. 2. Major flaws that are clearly noticeable. 3. Minor artifacts; image remains usable. 4. Mostly clean; very subtle fla ws if any . 5. No visible artifacts. Issue T agging – Object-le vel issues (model output): Select any item that has issues. If none apply , choose “None of the objects hav e issues. ” – Segmentation issues (segmentation map): Select any index with issues. If none apply , choose “None. ” – Other issues: If your score is not 5/5 and the issue is not cov ered abov e, briefly describe it here. Important: Selecting “None” may mean either (i) there is no issue, or (ii) your issue is not listed. In the latter case, provide a brief e xplanation under “Other issues. ” If your score is not full (5/5), you must either select a corresponding issue or provide a short e xplanation. s 17 Published as a conference paper at ICLR 2026 Figure 7: Label Studio interface: annotators read the prompt, inspect the image, rate four criteria (1–5), and flag VLM/SoM-suggested object- and segment-le vel issues. 18 Published as a conference paper at ICLR 2026 A . 3 E X A M P L E S O F FA I L U R E S A . 3 . 1 M O D E L FA I L S T O P R E C I S E LY F O L L O W I N S T RU C T I O N S . Prompt: Edit image 1. Replace the top-left crate with the yello w warning sign from image 3. Place the pink crewmate (from the center of image 2) and the yellow crewmate (from the bottom right of image 2) standing side-by-side on the central doorway in image 1. Ensure all new elements are integrated with correct perspecti ve, lighting, and scale. Figure 8: Instruction-following problem: The model placed red and green crewmates instead of pink and yellow , and the yellow sign’ s position does not match the request. A . 3 . 2 N U M E R I C A L I N C O N S I S T E N C I E S Figure 9: Examples of numerical inconsistencies. A . 3 . 3 S E G M E N T S A N D L A B E L I N G I S S U E S Figure 10: Examples of labeling issues. 19 Published as a conference paper at ICLR 2026 A . 3 . 4 G E N E R AT E N E W I M AG E I N E D I T I N G Figure 11: Examples of generating a new image when the task is editing. 20 Published as a conference paper at ICLR 2026 A . 3 . 5 P L O T S A N D C H A RT E R R O R S Figure 12: Examples of plots and diagram issues. A . 3 . 6 U N R E A D A B L E T E X T Figure 13: Examples of text issues. A . 3 . 7 E R R O R M A S K S T A T I S T I C S Figure 14: Distribution of error pix el proportions across the dataset. Histograms illustrate the fraction of error pixels relati ve to total mask pixels, excluding masks with none or all pixels marked as errors. 21 Published as a conference paper at ICLR 2026 A . 4 T A S K A N D T O P I C S TA T I S T I C S Model Artworks Computer Graphics Information Graphics Photorealistic Images Screenshots T extual Graphics T ext-guided Image Generation GPT -Image-1 0.95 ± 0.06 0.90 ± 0.09 0.81 ± 0.13 0.96 ± 0.06 0.93 ± 0.09 0.92 ± 0.08 Qwen-Image 0.97 ± 0.03 0.81 ± 0.14 0.79 ± 0.18 0.97 ± 0.07 0.73 ± 0.14 0.94 ± 0.11 Flux.1-Krea-dev 0.92 ± 0.06 0.75 ± 0.18 0.67 ± 0.22 0.94 ± 0.08 0.73 ± 0.12 0.88 ± 0.13 Gemini 2.0 Flash 0.87 ± 0.09 0.73 ± 0.20 0.61 ± 0.26 0.94 ± 0.09 0.75 ± 0.12 0.88 ± 0.14 UNO 0.89 ± 0.08 0.73 ± 0.16 0.62 ± 0.21 0.86 ± 0.13 0.64 ± 0.13 0.92 ± 0.09 B A GEL 0.95 ± 0.04 0.66 ± 0.19 0.66 ± 0.23 0.91 ± 0.09 0.62 ± 0.17 0.79 ± 0.17 Infinity 0.93 ± 0.08 0.69 ± 0.18 0.56 ± 0.27 0.85 ± 0.15 0.44 ± 0.12 0.76 ± 0.22 OmniGen2 0.86 ± 0.11 0.77 ± 0.19 0.52 ± 0.29 0.89 ± 0.11 0.52 ± 0.13 0.87 ± 0.13 SDXL 0.90 ± 0.10 0.43 ± 0.27 0.55 ± 0.25 0.82 ± 0.14 0.57 ± 0.18 0.57 ± 0.19 Janus Pro 0.87 ± 0.13 0.49 ± 0.27 0.42 ± 0.29 0.81 ± 0.23 0.50 ± 0.22 0.60 ± 0.27 T ext-guided Image Editing GPT -Image-1 0.86 ± 0.09 0.90 ± 0.12 0.69 ± 0.19 0.88 ± 0.09 0.73 ± 0.13 0.86 ± 0.12 Flux.1-K ontext-de v 0.73 ± 0.14 0.83 ± 0.14 0.50 ± 0.23 0.76 ± 0.12 0.56 ± 0.20 0.82 ± 0.17 Gemini 2.0 Flash 0.72 ± 0.16 0.75 ± 0.21 0.50 ± 0.23 0.83 ± 0.17 0.51 ± 0.19 0.83 ± 0.18 B A GEL 0.64 ± 0.20 0.86 ± 0.14 0.45 ± 0.22 0.71 ± 0.16 0.61 ± 0.18 0.73 ± 0.21 OmniGen2 0.74 ± 0.13 0.72 ± 0.23 0.40 ± 0.21 0.81 ± 0.14 0.36 ± 0.22 0.48 ± 0.24 IC-Edit 0.59 ± 0.20 0.57 ± 0.24 0.35 ± 0.18 0.55 ± 0.21 0.39 ± 0.18 0.56 ± 0.21 Step1X-Edit 0.53 ± 0.26 0.39 ± 0.30 0.19 ± 0.15 0.65 ± 0.19 0.47 ± 0.20 0.50 ± 0.20 InstructPix2Pix 0.49 ± 0.22 0.53 ± 0.23 0.32 ± 0.16 0.52 ± 0.25 0.48 ± 0.19 0.36 ± 0.18 Single Reference Image Generation GPT -Image-1 0.95 ± 0.08 0.86 ± 0.13 0.72 ± 0.18 0.87 ± 0.10 0.83 ± 0.14 0.81 ± 0.15 B A GEL 0.83 ± 0.17 0.76 ± 0.23 0.57 ± 0.19 0.67 ± 0.16 0.52 ± 0.19 0.52 ± 0.19 Gemini 2.0 Flash 0.77 ± 0.19 0.73 ± 0.19 0.52 ± 0.19 0.81 ± 0.19 0.56 ± 0.18 0.66 ± 0.20 UNO 0.78 ± 0.20 0.65 ± 0.20 0.49 ± 0.19 0.68 ± 0.20 0.56 ± 0.15 0.49 ± 0.19 OmniGen2 0.78 ± 0.16 0.68 ± 0.18 0.43 ± 0.19 0.66 ± 0.17 0.41 ± 0.20 0.50 ± 0.16 Single Reference Image Editing GPT -4o 0.79 ± 0.16 0.79 ± 0.18 0.80 ± 0.17 0.89 ± 0.08 0.63 ± 0.15 0.86 ± 0.11 Gemini 2.0 Flash 0.59 ± 0.19 0.63 ± 0.22 0.39 ± 0.14 0.64 ± 0.20 0.39 ± 0.14 0.63 ± 0.19 B A GEL 0.54 ± 0.24 0.53 ± 0.22 0.50 ± 0.26 0.68 ± 0.19 0.47 ± 0.17 0.58 ± 0.19 OmniGen2 0.62 ± 0.17 0.57 ± 0.23 0.27 ± 0.14 0.57 ± 0.23 0.27 ± 0.14 0.47 ± 0.20 Multiple Reference Image Generation GPT -Image-1 0.96 ± 0.03 0.81 ± 0.12 0.66 ± 0.17 0.86 ± 0.07 0.83 ± 0.12 0.92 ± 0.10 Gemini 2.0 Flash 0.91 ± 0.12 0.71 ± 0.20 0.53 ± 0.17 0.85 ± 0.15 0.54 ± 0.15 0.86 ± 0.15 OmniGen2 0.80 ± 0.14 0.62 ± 0.18 0.46 ± 0.15 0.69 ± 0.17 0.40 ± 0.18 0.68 ± 0.17 B A GEL 0.79 ± 0.17 0.49 ± 0.22 0.47 ± 0.16 0.80 ± 0.17 0.42 ± 0.20 0.71 ± 0.17 UNO 0.70 ± 0.12 0.66 ± 0.14 0.41 ± 0.13 0.63 ± 0.14 0.51 ± 0.15 0.71 ± 0.20 Multiple Reference Image Editing GPT -Image-1 0.85 ± 0.11 0.85 ± 0.10 0.69 ± 0.20 0.92 ± 0.05 0.81 ± 0.12 0.62 ± 0.18 Gemini 2.0 Flash 0.76 ± 0.16 0.58 ± 0.17 0.62 ± 0.25 0.70 ± 0.13 0.56 ± 0.16 0.50 ± 0.16 OmniGen2 0.66 ± 0.13 0.53 ± 0.18 0.44 ± 0.22 0.68 ± 0.19 0.32 ± 0.15 0.41 ± 0.15 B A GEL 0.53 ± 0.23 0.50 ± 0.20 0.41 ± 0.23 0.59 ± 0.15 0.21 ± 0.11 0.32 ± 0.16 T able 5: T opic-wise performance across six tasks. Bolded entries are the per-topic best within each task. 22 Published as a conference paper at ICLR 2026 Figure 15: Best-performing model per task×topic across all of our 14 baselines. A CG I P S T A verage TIG TIE SRIG SRIE MRIG MRIE A verage Closed A verage Scor e by T ask × T opic A CG I P S T A verage TIG TIE SRIG SRIE MRIG MRIE A verage Open A verage Scor e by T ask × T opic A CG I P S T A verage TIG TIE SRIG SRIE MRIG MRIE A verage (Closed Open) 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Scor e 0.10 0.05 0.00 0.05 0.10 0.15 0.20 0.25 = Closed Open (vmin=-0.1) Figure 16: Best-performing model per task×topic for closed-source (left) and open-source (middle) models based on human ov erall scores; the ∆ panel (right) shows ∆ = Closed − Open. A CG I P S T TIG TIE SRIG SRIE MRIG MRIE GPT Image 0.95 GPT Image 0.90 GPT Image 0.81 GPT Image 0.96 GPT Image 0.93 GPT Image 0.92 GPT Image 0.86 GPT Image 0.90 GPT Image 0.69 GPT Image 0.88 GPT Image 0.73 GPT Image 0.86 GPT Image 0.95 GPT Image 0.86 GPT Image 0.72 GPT Image 0.87 GPT Image 0.83 GPT Image 0.81 GPT Image 0.79 GPT Image 0.79 GPT Image 0.80 GPT Image 0.89 GPT Image 0.63 GPT Image 0.86 GPT Image 0.96 GPT Image 0.81 GPT Image 0.66 GPT Image 0.86 GPT Image 0.83 GPT Image 0.92 GPT Image 0.85 GPT Image 0.85 GPT Image 0.69 GPT Image 0.92 GPT Image 0.81 GPT Image 0.62 Closed Best Model by T ask × T opic A CG I P S T TIG TIE SRIG SRIE MRIG MRIE Qwen Image 0.97 Qwen Image 0.81 Qwen Image 0.79 Qwen Image 0.97 Flux.1 Kr ea dev 0.73 Qwen Image 0.94 Omni Gen2 0.74 BA GEL 0.86 Flux K onte xt dev 0.50 Omni Gen2 0.81 BA GEL 0.61 Flux K onte xt dev 0.82 BA GEL 0.83 BA GEL 0.76 BA GEL 0.57 UNO 0.68 UNO 0.56 BA GEL 0.52 Omni Gen2 0.62 Omni Gen2 0.57 Omni Gen2 0.65 BA GEL 0.68 BA GEL 0.47 BA GEL 0.58 Omni Gen2 0.80 UNO 0.66 BA GEL 0.47 BA GEL 0.80 UNO 0.51 UNO 0.71 Omni Gen2 0.66 Omni Gen2 0.53 Omni Gen2 0.44 Omni Gen2 0.68 Omni Gen2 0.32 Omni Gen2 0.41 Open Best Model by T ask × T opic A CG I P S T TIG TIE SRIG SRIE MRIG MRIE -0.02 +0.08 +0.02 0.00 +0.20 -0.02 +0.12 +0.04 +0.19 +0.08 +0.12 +0.04 +0.11 +0.10 +0.15 +0.18 +0.27 +0.29 +0.17 +0.22 +0.15 +0.20 +0.16 +0.28 +0.16 +0.16 +0.19 +0.06 +0.32 +0.20 +0.18 +0.33 +0.25 +0.24 +0.49 +0.21 (Closed Open) 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Scor e 0.1 0.0 0.1 0.2 0.3 = Closed Open (vmin=-0.1) Figure 17: A verage human score per task×topic for closed-source (left) and open-source (middle) models; the ∆ panel (right) shows ∆ = Clos ed − Open. 23 Published as a conference paper at ICLR 2026 A . 5 S TA T I S T I C A L S I G N I FI C A N C E A N A LY S I S W e conduct statistical significance tests to quantify the robustness of the performance differences reported in the paper . All analyses operate on human ratings, where each human score denotes the av erage of the three independent annotators for a given (task id, model) pair . The tests are performed on a per-item basis. Paired two-sided t -tests are used when comparing two models (or model families) ev aluated on the same instances, while W elch’ s t -test is used when comparing two disjoint groups of items (e.g., generation vs. editing tasks). I. GPT -Image-1 vs. Gemini 2.0 Flash. W e compare GPT -Image-1 and Gemini across all task instances. GPT -Image-1 receives significantly higher ratings o verall compared to Gemini 2.0 Flash. • Overall : n = 1080 , mean diff = 0 . 5961 , std = 0 . 7706 , t = 25 . 42 , p = 4 . 3 × 10 − 112 . II. Closed vs. Open Model Families. W e compare the family-wise means of closed-source models with open-source ones using a paired test across tasks. • Overall : n = 1080 , mean diff = 0 . 6821 , std = 0 . 5840 , t = 38 . 38 , p = 6 . 6 × 10 − 204 . III. Generation vs. Editing T asks (Unified Models). T o assess task difficulty , we compare human ratings on generation and editing tasks ov er our unified models: { Bagel, Gemini 2.0 Flash, GPT - Image-1, OmniGen2 } . • Overall : generation ( n = 2158 , mean = 3 . 9152 ), editing ( n = 2160 , mean = 3 . 5244 ), t = 13 . 71 , p = 6 . 6 × 10 − 42 . IV . Symbolic vs. Non-Symbolic T opics. W e compare human ratings on symbolic and text-heavy do- mains (Information Graphics, Screenshots) against non-symbolic domains (Artworks, Photorealistic Images). • Overall : non-symbolic ( n = 2159 , mean = 4 . 1067 ), symbolic ( n = 2157 , mean = 3 . 1905 ), t = 34 . 26 , p = 7 . 3 × 10 − 227 . • Artifacts : non-symbolic ( n = 2159 , mean = 4 . 3522 ), symbolic ( n = 2157 , mean = 3 . 0163 ), t = 46 . 23 , p < 10 − 196 . V . Human vs. VLM-as-Judge Agr eement. W e compare Gemini’ s automatic scores with human- mean ratings for all 6,469 (task id, model) instances. • Prompt Rele vance : mean diff = − 0 . 2704 , std = 1 . 0185 , t = − 21 . 35 , p = 8 . 4 × 10 − 98 . • Aesthetic Quality : mean diff = − 0 . 0529 , std = 1 . 0135 , t = − 4 . 20 , p = 2 . 7 × 10 − 5 . • Content Coherence : mean diff = − 0 . 2069 , std = 1 . 2741 , t = − 13 . 06 , p = 1 . 7 × 10 − 38 . • Artifacts : mean diff = +0 . 2220 , std = 1 . 1207 , t = 15 . 93 , p = 4 . 2 × 10 − 56 . • Overall : mean diff = − 0 . 0770 , std = 0 . 8516 , t = − 7 . 28 , p = 3 . 9 × 10 − 13 . 24 Published as a conference paper at ICLR 2026 A . 6 D A T A S E T D E TA I L S Figure 18: T opic distribution for the entire dataset Figure 19: W ord cloud of subtopics across the entire dataset, with word size proportional to frequenc y 25 Published as a conference paper at ICLR 2026 T ask T opic Subtopics (Count) TIG A Collage (26), Cultural/heritage art (9), Digital arts (15), Glitch Art (3), Pixel Art (5), Pop art (5), Stylized art (11), T raditional art (11), oil paintings (16) CG 3D renders (17), CAD models (13), Depth maps (11), Facial estimation and analysis (3), Game assets (8), Object detection visuals (11), Semantic or Instance segmentation (16), T exture Map (8), T exture maps (1), VFX and P articles (12) I Diagrams, charts, and graphs (25), Icons and symbols (26), Maps (17), UI mockups (21), V isual instructions and manuals (11) P Astronomical images (18), Long exposure (7), Medical Images (1), Medical images (21), Microscopic imagery (20), Minimalist Designs (5), Photography (28), Retro Futurism (2) S Games (19), Receipts (35), Software interfaces (19), W ebsites (27) T ASCII Art (6), Branding and visual identity (7), Calligraphy (6), Comics (13), Concrete Poetry (3), Graffiti (T ext-based) (9), Illuminated Manuscripts (9), Memes (11), Posters (12), T extile Art with T e xt (6), T extual T attoos (7), T ypog- raphy (6), W ord Clouds (5) SRIG A Collage (16), Cultural or Heritage art (14), Digital arts (24), Portraits (1), Styl- ized art (32), T raditional art (14) CG 3D renders (12), CAD models (12), Depth maps (13), Facial estimation and analysis (13), Game Assets (1), Game assets (12), Object detection visuals (13), Semantic or Instance segmentation (13), VFX and P articles (12) I Diagrams, charts, and graphs (25), Icons and symbols (21), Maps (14), UI mockups (20), V isual instructions and manuals (20) P Astronomical images (28), Medical images (22), Microscopic imagery (23), Photography (27) S Games (24), Receipts (18), Software interfaces (28), W ebsites (30) T Branding and visual identity (11), Comics (15), Memes (25), Newspaper (3), Posters (22), T ypography (22), W ebsite (2) MRIG A Collage (13), Cultural or Heritage art (23), Digital arts (29), Stylized art (19), T raditional art (16) CG 3D renders (12), CAD models (11), Depth maps (13), Facial estimation and analysis (10), Game assets (11), Object detection visuals (23), Semantic or Instance segmentation (10), VFX and P articles (10) I Diagrams, charts, and graphs (38), Icons and symbols (15), Maps (18), UI mockups (18), V isual instructions and manuals (11) P Astronomical images (6), Microscopic imagery (13), Photography (81) S Games (24), Receipts (23), Software interfaces (31), W ebsites (22) T Branding and visual identity (24), Comics (15), Memes (16), Posters (23), T ypography (18), T ypography-not-english (5) T able 6: Subtopics across generation tasks (TIG, SRIG, MRIG). 26 Published as a conference paper at ICLR 2026 T ask T opic Subtopics (Count) TIE A Animation (2), Blueprint (1), Ceramic art (1), Collage (4), Conceptual art (1), Cropping (1), Cubism (3), Cultural or Heritage art (4), Digital art (8), Digital arts (2), Expressionism (4), Fauvism (2), Futurism (4), Graffiti (1), Graffiti art (1), Hand drawn blueprint (1), Impressionism (4), Medie v al art (1), Neoclassicism (2), Oil Painting (1), Painting (8), Paintings (3), Pixel art (4), Pix el arts (2), Pop art (3), Post-Impressionism (2), Renaissance (6), Renaissance arts (1), Romanticism (4), Sketches (2), Statue (5), Surrealism (3), T raditional art (4), T raditional arts (1), V ector art (3), V ector arts (1) CG 3D renders (10), CAD models (10), Depth maps (10), Facial estimation and analysis (10), Game assets (10), Mesh Processing (5), Object detection visuals (10), Physics Simulation (5), Semantic or Instance segmentation (10), Shader Programming (5), Skeletal Animation and Rigging (5), VFX and Particles (5), V olume Rendering (5) I Diagrams, charts, and graphs (61), Exploded V ie ws (5), Exploded views (2), Floor Plan (8), Icons and symbols (8), Maps (5), T ables (6), UI mockups (5) P Astronomical images (21), Medical images (15), Microscopic imagery (20), Photography (45) S Game Screenshots (1), Games (26), Mobile software interfaces (7), QR codes (11), Receipts (3), Software interfaces (50), W ebsites (14) T Branding and visual identity (27), Comics (15), Memes (26), Posters (16), T ypography (16) SRIE A Collage (20), Cultural or Heritage art (19), Digital arts (20), Stylized art (20), T raditional art (21) CG 3D renders (11), CAD models (6), Depth maps (13), Facial estimation and analysis (13), Game assets (13), Image T ransformation (15), Object detection visuals (18), Semantic or Instance segmentation (11) I Diagrams, charts, and graphs (30), Icons and symbols (20), Maps (26), UI mockups (24) P Astronomical images (30), Medical images (23), Microscopic imagery (20), Photography (27) S Games (25), Receipts (25), Software interfaces (25), W ebsites (25) T Branding and visual identity (22), Comics (22), Memes (20), Posters (16), T ypography (20) MRIE A Collage (20), Cultural or Heritage art (12), Digital arts (9), Oil painting (12), Pop art (14), Portraits (10), Stylized art (9), T raditional art (14) CG 3D Character Integration (1), 3D renders (7), Augmented Reality or Computer V ision V isualization (1), CAD models (1), Computer Animation (1), Com- puter Animation or Stylized Rendering (1), Depth maps (10), Game assets (9), Geometric Modeling or Stylized Rendering (1), Global Illumination (2), Non-Photorealistic Rendering (1), Object detection visuals (23), Scene Editing (1), Semantic or Instance segmentation (19), Stylized Rendering (1), Stylized Rendering or 3D renders (4), Stylized Rendering or Computer Animation (2), Stylized Rendering or V isual Effects (1), UI Design or Stylized Rendering (1), VFX and Particles (13) I Diagrams, charts, and graphs (23), Icons and symbols (22), Maps (25), UI mockups (23), V isual instructions and manuals (8) P Astronomical images (15), Medical images (15), Microscopic imagery (10), Scenic Nature Parks (19), Urban & Street Photography (16), W ildlife & Nature Photography (25) S Chat and Social Messaging (14), Forms and Authentication (9), Games (14), Online Meeting Interfaces (11), QR Code (14), Receipts (15), Software interfaces (11), Software interfaces - f arsi (1), W ebsites (11) T Advertisements (1), Book (1), Branding and visual identity (12), Card (1), Comics (9), Flyers (2), Fonts (1), Magazine (2), Meme (1), Memes (18), Menu (4), Newspaper (2), Ne wspapers (1), Nutrition Fact (1), Poster (2), Posters (15), Products (1), Signs (5), Subtitle (1), T ypography (20) T able 7: Subtopics across editing tasks (TIE, SRIE, MRIE). 27 Published as a conference paper at ICLR 2026 A . 7 A U T O M A T E D E V A L U A T I O N S LLM-based Embedding & perceptual Model Prompt relev ance Aesthetic quality Content Coherence Artifact Overall CLIP LPIPS T ext-guided Image Generation GPT -4o 0.89 ± 0.20 0.95 ± 0.12 0.91 ± 0.23 0.96 ± 0.13 0.93 ± 0.13 0.25 ± 0.12 N/A Qwen-Image 0.79 ± 0.29 0.93 ± 0.17 0.86 ± 0.28 0.88 ± 0.24 0.87 ± 0.20 0.24 ± 0.12 N/A Flux.1-Krea-dev 0.74 ± 0.30 0.89 ± 0.20 0.82 ± 0.33 0.89 ± 0.25 0.84 ± 0.23 0.24 ± 0.12 N/A Janus Pro 0.40 ± 0.31 0.52 ± 0.34 0.60 ± 0.41 0.58 ± 0.38 0.52 ± 0.32 0.23 ± 0.10 N/A Gemini 2.0 Flash 0.79 ± 0.27 0.86 ± 0.23 0.84 ± 0.31 0.83 ± 0.29 0.83 ± 0.23 0.24 ± 0.11 N/A B A GEL 0.65 ± 0.33 0.83 ± 0.24 0.76 ± 0.37 0.81 ± 0.29 0.76 ± 0.26 0.24 ± 0.12 N/A UNO 0.61 ± 0.31 0.80 ± 0.25 0.79 ± 0.34 0.80 ± 0.30 0.75 ± 0.25 0.24 ± 0.11 N/A OmniGen2 0.62 ± 0.31 0.81 ± 0.26 0.74 ± 0.38 0.81 ± 0.33 0.74 ± 0.27 0.24 ± 0.12 N/A Infinity 0.58 ± 0.33 0.79 ± 0.27 0.76 ± 0.36 0.76 ± 0.33 0.72 ± 0.28 0.24 ± 0.11 N/A SDXL 0.49 ± 0.33 0.72 ± 0.31 0.71 ± 0.39 0.72 ± 0.35 0.66 ± 0.30 0.24 ± 0.11 N/A Janus Pro 0.40 ± 0.31 0.52 ± 0.34 0.60 ± 0.41 0.58 ± 0.38 0.52 ± 0.32 0.23 ± 0.10 N/A T ext-guided Image Editing GPT -4o 0.77 ± 0.31 0.81 ± 0.30 0.79 ± 0.35 0.84 ± 0.32 0.80 ± 0.28 0.25 ± 0.10 0.54 ± 0.15 Flux.1-K ontext-de v 0.52 ± 0.38 0.66 ± 0.34 0.67 ± 0.41 0.76 ± 0.36 0.65 ± 0.31 0.25 ± 0.10 0.52 ± 0.18 B A GEL 0.56 ± 0.37 0.61 ± 0.35 0.68 ± 0.39 0.70 ± 0.37 0.64 ± 0.32 0.25 ± 0.09 0.33 ± 0.23 Gemini 2.0 Flash 0.57 ± 0.37 0.61 ± 0.36 0.63 ± 0.42 0.68 ± 0.40 0.62 ± 0.34 0.25 ± 0.09 0.39 ± 0.23 OmniGen2 0.34 ± 0.35 0.56 ± 0.35 0.61 ± 0.43 0.72 ± 0.39 0.56 ± 0.32 0.25 ± 0.09 0.42 ± 0.25 IC-Edit 0.25 ± 0.34 0.50 ± 0.35 0.63 ± 0.41 0.66 ± 0.40 0.51 ± 0.30 0.25 ± 0.09 0.23 ± 0.19 InstructPix2Pix 0.16 ± 0.27 0.45 ± 0.35 0.58 ± 0.43 0.61 ± 0.43 0.45 ± 0.30 0.25 ± 0.09 0.27 ± 0.19 Step1X-Edit 0.35 ± 0.34 0.44 ± 0.37 0.46 ± 0.43 0.53 ± 0.42 0.44 ± 0.34 0.25 ± 0.09 0.36 ± 0.27 Single Reference Image Generation GPT -Image-1 0.77 ± 0.28 0.91 ± 0.16 0.88 ± 0.24 0.93 ± 0.20 0.88 ± 0.17 0.15 ± 0.09 0.73 ± 0.08 Gemini 2.0 Flash 0.61 ± 0.32 0.73 ± 0.35 0.73 ± 0.38 0.77 ± 0.35 0.69 ± 0.28 0.17 ± 0.10 0.59 ± 0.16 B A GEL 0.51 ± 0.30 0.68 ± 0.32 0.65 ± 0.42 0.73 ± 0.37 0.64 ± 0.30 0.17 ± 0.10 0.68 ± 0.17 UNO 0.40 ± 0.30 0.65 ± 0.27 0.66 ± 0.40 0.73 ± 0.37 0.61 ± 0.29 0.16 ± 0.10 0.66 ± 0.14 OmniGen2 0.41 ± 0.33 0.63 ± 0.35 0.64 ± 0.42 0.74 ± 0.37 0.61 ± 0.31 0.17 ± 0.11 0.53 ± 0.24 Single Reference Image Editing GPT -Image-1 0.75 ± 0.30 0.80 ± 0.29 0.78 ± 0.35 0.84 ± 0.32 0.79 ± 0.27 0.24 ± 0.10 0.66 ± 0.12 Gemini 2.0 Flash 0.40 ± 0.35 0.55 ± 0.35 0.59 ± 0.42 0.67 ± 0.39 0.55 ± 0.32 0.24 ± 0.10 0.59 ± 0.16 OmniGen2 0.30 ± 0.30 0.59 ± 0.34 0.58 ± 0.43 0.70 ± 0.40 0.54 ± 0.30 0.24 ± 0.11 0.69 ± 0.11 B A GEL 0.31 ± 0.33 0.56 ± 0.35 0.59 ± 0.42 0.67 ± 0.38 0.53 ± 0.30 0.24 ± 0.10 0.57 ± 0.16 Multiple Reference Image Generation GPT -Image-1 0.69 ± 0.31 0.75 ± 0.30 0.73 ± 0.37 0.80 ± 0.33 0.74 ± 0.29 0.16 ± 0.10 0.72 ± 0.07 UNO 0.35 ± 0.24 0.64 ± 0.27 0.62 ± 0.39 0.73 ± 0.36 0.59 ± 0.26 0.13 ± 0.09 0.73 ± 0.09 Gemini 2.0 Flash 0.35 ± 0.30 0.49 ± 0.35 0.50 ± 0.42 0.59 ± 0.41 0.48 ± 0.32 0.17 ± 0.10 0.69 ± 0.09 OmniGen2 0.26 ± 0.28 0.51 ± 0.34 0.45 ± 0.42 0.63 ± 0.40 0.46 ± 0.30 0.16 ± 0.11 0.72 ± 0.09 B A GEL 0.23 ± 0.28 0.39 ± 0.34 0.36 ± 0.40 0.49 ± 0.40 0.37 ± 0.29 0.14 ± 0.09 0.70 ± 0.09 Multiple Reference Image Editing GPT -Image-1 0.69 ± 0.31 0.75 ± 0.30 0.73 ± 0.37 0.80 ± 0.33 0.74 ± 0.29 0.16 ± 0.10 0.72 ± 0.07 Gemini 2.0 Flash 0.35 ± 0.30 0.49 ± 0.35 0.50 ± 0.42 0.59 ± 0.41 0.48 ± 0.32 0.17 ± 0.10 0.69 ± 0.09 OmniGen2 0.26 ± 0.26 0.51 ± 0.34 0.45 ± 0.42 0.63 ± 0.40 0.46 ± 0.30 0.16 ± 0.11 0.73 ± 0.07 B A GEL 0.23 ± 0.24 0.39 ± 0.34 0.36 ± 0.40 0.49 ± 0.40 0.37 ± 0.29 0.16 ± 0.10 0.70 ± 0.09 T able 8: Automatic e valuations on all entries in our dataset 28 Published as a conference paper at ICLR 2026 LLM-based Embedding & perceptual Model Prompt relev ance Aesthetic quality Content Coherence Artifact Overall CLIP LPIPS T ext-guided Image Generation GPT -Image-1 0.88 ± 0.22 0.95 ± 0.13 0.91 ± 0.23 0.96 ± 0.13 0.92 ± 0.13 0.24 ± 0.12 N/A Qwen-Image 0.77 ± 0.31 0.93 ± 0.17 0.87 ± 0.28 0.89 ± 0.24 0.86 ± 0.20 0.23 ± 0.12 N/A Flux.1-Krea-dev 0.72 ± 0.31 0.88 ± 0.21 0.80 ± 0.35 0.89 ± 0.26 0.82 ± 0.23 0.23 ± 0.12 N/A Gemini 2.0 Flash 0.78 ± 0.28 0.85 ± 0.23 0.82 ± 0.31 0.83 ± 0.29 0.82 ± 0.24 0.24 ± 0.12 N/A B A GEL 0.62 ± 0.34 0.83 ± 0.23 0.74 ± 0.37 0.82 ± 0.30 0.75 ± 0.26 0.23 ± 0.12 N/A OmniGen2 0.62 ± 0.33 0.81 ± 0.25 0.73 ± 0.37 0.82 ± 0.31 0.75 ± 0.27 0.22 ± 0.12 N/A UNO 0.57 ± 0.32 0.79 ± 0.26 0.75 ± 0.37 0.78 ± 0.31 0.72 ± 0.27 0.23 ± 0.12 N/A Infinity 0.58 ± 0.32 0.80 ± 0.26 0.76 ± 0.36 0.75 ± 0.34 0.73 ± 0.27 0.22 ± 0.11 N/A SDXL 0.48 ± 0.33 0.72 ± 0.32 0.71 ± 0.39 0.71 ± 0.36 0.65 ± 0.30 0.23 ± 0.11 N/A Janus Pro 0.41 ± 0.30 0.55 ± 0.33 0.62 ± 0.41 0.60 ± 0.37 0.54 ± 0.32 0.22 ± 0.10 N/A T ext-guided Image Editing GPT -Image-1 0.77 ± 0.31 0.81 ± 0.30 0.79 ± 0.35 0.85 ± 0.31 0.80 ± 0.28 0.24 ± 0.10 0.55 ± 0.15 Gemini 2.0 Flash 0.59 ± 0.37 0.62 ± 0.37 0.66 ± 0.41 0.68 ± 0.40 0.64 ± 0.35 0.24 ± 0.10 0.42 ± 0.23 Flux.1-K ontext-de v 0.48 ± 0.36 0.66 ± 0.35 0.64 ± 0.42 0.75 ± 0.37 0.63 ± 0.32 0.24 ± 0.10 0.52 ± 0.19 B A GEL 0.51 ± 0.37 0.57 ± 0.37 0.65 ± 0.41 0.64 ± 0.39 0.59 ± 0.33 0.24 ± 0.10 0.35 ± 0.25 OmniGen2 0.34 ± 0.36 0.58 ± 0.35 0.63 ± 0.43 0.74 ± 0.38 0.57 ± 0.32 0.25 ± 0.10 0.41 ± 0.26 IC-Edit 0.23 ± 0.32 0.48 ± 0.35 0.60 ± 0.40 0.64 ± 0.41 0.49 ± 0.29 0.24 ± 0.09 0.23 ± 0.18 Step1X-Edit 0.34 ± 0.35 0.43 ± 0.38 0.45 ± 0.45 0.52 ± 0.43 0.43 ± 0.36 0.24 ± 0.09 0.39 ± 0.30 InstructPix2Pix 0.14 ± 0.25 0.41 ± 0.35 0.52 ± 0.43 0.58 ± 0.44 0.41 ± 0.30 0.24 ± 0.09 0.26 ± 0.19 Single Reference Image Generation GPT -Image-1 0.73 ± 0.28 0.91 ± 0.16 0.87 ± 0.24 0.92 ± 0.22 0.86 ± 0.18 0.16 ± 0.10 0.73 ± 0.18 Gemini 2.0 Flash 0.58 ± 0.33 0.72 ± 0.35 0.74 ± 0.38 0.76 ± 0.35 0.70 ± 0.28 0.16 ± 0.10 0.59 ± 0.16 B A GEL 0.49 ± 0.30 0.68 ± 0.32 0.65 ± 0.42 0.73 ± 0.37 0.65 ± 0.28 0.16 ± 0.10 0.69 ± 0.17 OmniGen2 0.41 ± 0.33 0.63 ± 0.35 0.64 ± 0.42 0.74 ± 0.37 0.62 ± 0.30 0.17 ± 0.11 0.55 ± 0.24 UNO 0.38 ± 0.29 0.64 ± 0.32 0.65 ± 0.40 0.73 ± 0.37 0.60 ± 0.29 0.15 ± 0.10 0.68 ± 0.14 Single Reference Image Editing GPT -4o 0.67 ± 0.30 0.77 ± 0.29 0.78 ± 0.35 0.84 ± 0.32 0.76 ± 0.29 0.24 ± 0.10 0.65 ± 0.13 OmniGen2 0.29 ± 0.31 0.58 ± 0.34 0.58 ± 0.43 0.70 ± 0.40 0.54 ± 0.31 0.24 ± 0.10 0.69 ± 0.11 B A GEL 0.38 ± 0.35 0.54 ± 0.36 0.60 ± 0.42 0.65 ± 0.38 0.53 ± 0.32 0.24 ± 0.10 0.56 ± 0.17 Gemini 2.0 Flash 0.42 ± 0.36 0.52 ± 0.37 0.59 ± 0.42 0.68 ± 0.40 0.51 ± 0.32 0.24 ± 0.10 0.59 ± 0.16 Multiple Reference Image Generation GPT -Image-1 0.79 ± 0.25 0.91 ± 0.17 0.90 ± 0.25 0.93 ± 0.21 0.88 ± 0.16 0.14 ± 0.09 0.73 ± 0.08 Gemini 2.0 Flash 0.59 ± 0.31 0.70 ± 0.30 0.70 ± 0.39 0.74 ± 0.37 0.68 ± 0.30 0.14 ± 0.09 0.74 ± 0.09 OmniGen2 0.40 ± 0.28 0.64 ± 0.28 0.58 ± 0.40 0.74 ± 0.38 0.59 ± 0.28 0.13 ± 0.10 0.72 ± 0.09 B A GEL 0.47 ± 0.26 0.61 ± 0.33 0.61 ± 0.41 0.68 ± 0.39 0.59 ± 0.31 0.14 ± 0.09 0.74 ± 0.08 UNO 0.35 ± 0.25 0.65 ± 0.26 0.62 ± 0.39 0.72 ± 0.36 0.58 ± 0.25 0.13 ± 0.09 0.74 ± 0.08 Multiple Reference Image Editing GPT -Image-1 0.67 ± 0.31 0.77 ± 0.30 0.73 ± 0.36 0.82 ± 0.32 0.75 ± 0.28 0.16 ± 0.10 0.72 ± 0.08 Gemini 2.0 Flash 0.36 ± 0.30 0.51 ± 0.35 0.53 ± 0.42 0.62 ± 0.41 0.51 ± 0.31 0.17 ± 0.10 0.69 ± 0.09 OmniGen2 0.23 ± 0.23 0.50 ± 0.34 0.42 ± 0.42 0.64 ± 0.41 0.45 ± 0.30 0.15 ± 0.11 0.73 ± 0.07 B A GEL 0.23 ± 0.25 0.40 ± 0.33 0.37 ± 0.39 0.52 ± 0.40 0.38 ± 0.28 0.16 ± 0.10 0.70 ± 0.09 T able 9: Automatic e valuations on our human-annotated subset 29 Published as a conference paper at ICLR 2026 A . 8 P R O M P T T E M P L A T E S Prompt T emplate for Image Generation & Editing Y ou are an expert visual generation assistant. T ask: { T ASK N AME } T ask Definition: { T ASK DEFINITION } V isual Domain: { TOPIC N AME } User Objectiv e: { USER PR OMPT } Attached Images: { IMG LIST } (None for T ext-guided image generation) Please generate an image that fulfills the user’ s objecti ve, adheres to the task definition, and fits within the specified visual domain. T ASK N AME: • T ext-guided Image Generation • T ext-guided Image Editing • Single Reference-guided Image Generation • Single Reference-guided Image Editing • Multiple References-guided Image Generation • Multiple References-guided Image Editing T ASK DEFINITION: • T ext-guided Image Generation: Generate a completely new image based only on a descrip- tiv e text prompt. No source or reference images are provided. • T ext-guided Image Editing: Edit an existing image using a descripti ve te xt prompt. Decide what to modify in the image based on the prompt. No mask or marked region is gi v en. • Single Reference-guided Image Generation: Create a new image by combining visual cues from one reference image with instructions from a descriptiv e text prompt. • Single Reference-guided Image Editing: Edit an existing image using both a reference image and a text prompt. Use the reference image to guide the style or content of the edits. • Multiple References-guided Image Generation: Generate a new image using se v eral refer- ence images along with a text prompt. The new image should reflect visual elements from the references and follow the prompt’ s description. • Multiple References-guided Image Editing: Modify an existing image using multiple reference images and a descriptiv e text prompt. The edits should be guided by both the style or content of the references and the instructions in the prompt. TOPIC N AME: • Information Graphics • Artworks • Screenshots • Computer Graphics • Photorealistic Images • T extual Graphics 30 Published as a conference paper at ICLR 2026 Prompt T emplate for Image Evaluation Y ou are an expert AI image evaluator . Y our task is to rate a generated image based on a provided te xt prompt and any reference images. Use the following guidelines for your assessment. Provide a rating from 1 to 5 for each criterion. Do NO T include any additional text or e xplanations in your response. The response MUST be a single JSON object. Quality Assessment • Prompt Rele vance Definition: Whether the image accurately reflects or responds to the prompt. Rating Guide (1–5): 1 – Completely unrelated to the prompt. 2 – Mostly incorrect; some vague connections b ut man y mismatches. 3 – Partially rele v ant; ke y ideas are present but with errors or omissions. 4 – Mostly accurate; follows the prompt well with minor issues. 5 – Fully aligned with the prompt; clear , focused, and complete. • Aesthetic Quality / V isual A ppeal Definition: Whether the image is visually appealing, clean, and easy to interpret. Rating Guide (1–5): 1 – V isually poor; unattractive, hard to read or confusing. 2 – Below a v erage; noticeable design flaws, poor readability . 3 – Decent; generally readable but has minor layout/design issues. 4 – Clean and aesthetically good; professional feel with few fla ws. 5 – Beautiful, polished, and visually excellent. • Content Coherence Definition: Whether the content in the image is logically consistent and fits together meaningfully . Rating Guide (1–5): 1 – Internally inconsistent or nonsensical; parts contradict each other . 2 – Some logic, but confusing or mismatched components. 3 – Mostly coherent, though there are noticeable mismatches or awkward parts. 4 – Logically sound ov erall, with only minor inconsistencies. 5 – Completely coherent and internally consistent. • Artifacts / V isual Errors Definition: Whether the image has visual fla ws due to generation errors (e.g., distortions, glitches). Rating Guide (1–5): 1 – Sev ere artifacts that ruin the image. 2 – Major flaws that are clearly noticeable. 3 – Some minor artifacts, b ut the image remains usable. 4 – Mostly clean; only very subtle fla ws if any . 5 – Perfectly clean; no visible artifacts at all. Expected Output (single JSON object): { "prompt_relevance": , "aesthetic_quality": , "content_coherence": , "artifacts": } 31
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment