이미지월드: 실세계 과제에 대한 설명 가능한 인간 평가 기반 이미지 생성 모델 스트레스 테스트
이미지월드는 3.6천 개의 조건 집합을 6가지 핵심 과제와 6가지 도메인에 걸쳐 구성한 대규모 벤치마크이다. 20 천 개의 세밀한 인간 라벨과 객체·세그먼트 수준 오류 태깅을 포함한 설명 가능한 평가 스키마를 제공해, 14개 이미지 생성·편집 모델을 종합적으로 비교한다. 주요 결과는 편집 과제가 가장 어려우며, 텍스트‑중심 도메인(스크린샷·인포그래픽)에서 성능이 크게 떨어진다는 점이다. 최신 VLM 기반 메트릭은 인간 순위와 높은 상관관계(Ke…
저자: Samin Mahdizadeh Sani, Max Ku, Nima Jamali
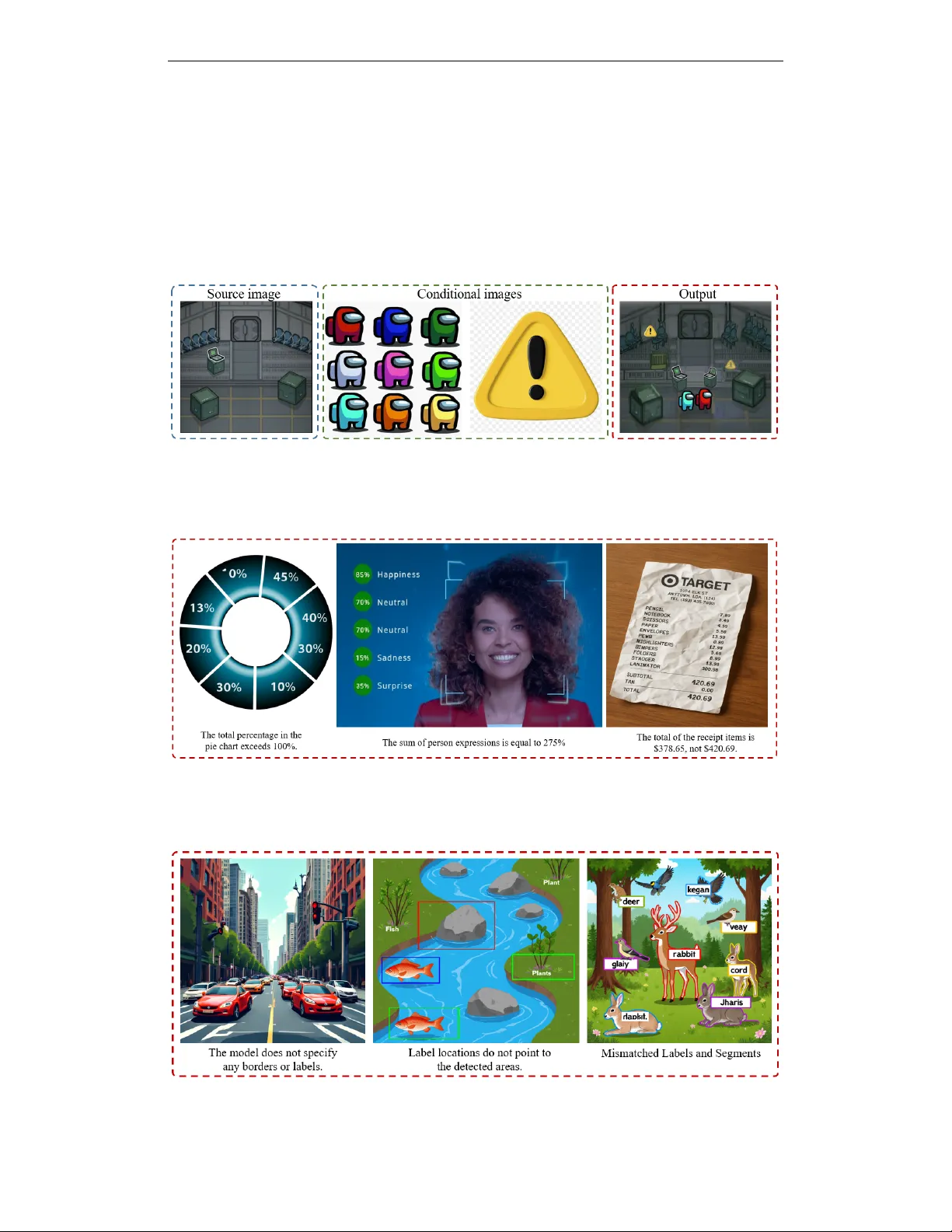
본 논문은 급속히 발전하고 있는 확산, 자동회귀, 하이브리드 이미지 생성 모델들을 실제 사용 환경에서 종합적으로 평가하기 위한 새로운 벤치마크 ‘ImagenWorld’를 제안한다. 기존 평가 자료들은 텍스트‑투‑이미지, 편집, 개인화 등 개별 과제에 국한되거나, 도메인 편향이 심하고, 점수만 제공해 실패 원인을 파악하기 어렵다는 한계를 가지고 있었다. 이를 극복하고자 저자들은 3,600개의 조건 집합을 6가지 핵심 과제(텍스트‑가이드 생성, 단일·다중 레퍼런스 생성, 텍스트‑가이드 편집, 단일·다중 레퍼런스 편집)와 6가지 도메인(예술작품, 포토리얼리즘, 정보 그래픽, 텍스트 그래픽, 컴퓨터 그래픽, 스크린샷)으로 체계화했다. 각 과제·도메인 조합당 100개의 샘플을 고르게 배치해 통계적 균형을 확보했으며, 전체 데이터는 인간이 직접 작성한 프롬프트와 레퍼런스·소스 이미지를 포함한다.
평가 프로토콜은 두 단계로 구성된다. 첫 번째 단계에서는 5점 리커트 척도로 ‘프롬프트 관련성’, ‘미학적 품질’, ‘내용 일관성’, ‘아티팩트’를 평가하고, 세 번째 단계에서는 객체 수준(예: 누락, 왜곡, 텍스트 오류)과 세그먼트 수준(예: 색상 불일치, 레이아웃 오류)으로 구체적인 오류를 라벨링한다. 라벨링은 3명의 독립 annotator가 수행하며, 오류 위치를 마스크 형태로 제공해 시각적 설명성을 높였다.
자동 평가로는 Gemini‑2.5‑Flash 기반 VIEScore를 활용해 인간과 동일한 네 가지 기준에 대한 점수를 산출했으며, CLIPScore와 LPIPS를 보조 메트릭으로 사용했다. VLM 기반 메트릭은 인간‑인간 순위와 Kendall τ 0.79까지 높은 상관관계를 보였으나, 세부 오류 유형을 식별하지 못한다는 한계가 있었다.
저자들은 14개의 최신 모델을 대상으로 실험을 진행했다. 여기에는 4개의 통합 생성·편집 모델(예: OpenAI, Google 최신 모델)과 10개의 전용 모델(예: Stable Diffusion, DALL·E 파생 모델) 등이 포함된다. 실험 결과는 다음과 같다. (1) 편집 과제에서 모델은 ‘전체 재생성’ 혹은 ‘전혀 변형하지 않음’이라는 두 극단적 실패 모드 중 하나에 치우치는 경향이 강했다. 이는 현재 아키텍처가 로컬 컨트롤을 정밀하게 수행할 메커니즘이 부족함을 의미한다. (2) 텍스트‑중심 도메인(스크린샷, 인포그래픽, 텍스트 그래픽)에서 전반적인 성능 저하가 관찰됐으며, Qwen‑Image는 텍스트‑중심 이미지에 특화된 합성 데이터로 사전 학습돼 유일하게 높은 점수를 기록했다. 이는 데이터 커리케이션이 성능 향상의 핵심 열쇠임을 시사한다. (3) 폐쇄형 상용 모델이 대부분의 과제에서 최고 성적을 보였지만, 오픈소스 모델은 텍스트‑투‑이미지 생성에서는 경쟁력을 유지하면서도 편집·다중 레퍼런스 조합에서는 아직 격차가 크다. 이는 오픈소스 커뮤니티가 대규모 데이터와 연산 자원은 확보했지만, 편집 제어와 멀티모달 통합에 대한 연구가 상대적으로 부족함을 반영한다. (4) VLM 메트릭은 순위 매기기에서는 인간 수준의 신뢰성을 보였지만, 객체·세그먼트 오류 라벨링을 제공하지 못한다는 점에서 인간 평가가 여전히 필수적이다.
논문은 세 가지 주요 기여를 강조한다. 첫째, 6×6 구조의 다중 과제·도메인 벤치마크를 제공해 모델 간 공정하고 포괄적인 비교가 가능하도록 했다. 둘째, 오류 유형을 구체적으로 라벨링하는 설명 가능한 인간 평가 스키마를 도입해, 모델이 왜 실패했는지를 정량·정성적으로 파악할 수 있게 했다. 셋째, VLM 기반 자동 평가와 인간 라벨을 결합한 하이브리드 파이프라인을 제시해, 대규모 실험을 효율화하면서도 설명 가능성을 유지하는 실용적인 방안을 제공한다.
결론적으로, ImagenWorld는 현재 이미지 생성·편집 모델의 한계를 명확히 드러내며, 특히 로컬 편집 제어와 텍스트‑중심 이미지 처리에서의 개선 필요성을 강조한다. 향후 연구는 (i) 로컬 제어를 위한 구조적 모듈(예: 마스크‑조건 확산, 레이어‑별 디코더) 개발, (ii) 텍스트‑중심 도메인에 특화된 데이터 증강 및 합성 파이프라인 구축, (iii) VLM을 활용한 자동 오류 라벨링 기술 고도화 등을 통해 모델의 견고성과 설명 가능성을 동시에 향상시킬 수 있을 것으로 기대한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기