Secure Reinforcement Learning: On Model-Free Detection of Man in the Middle Attacks
We consider the problem of learning-based man-in-the-middle (MITM) attacks in cyber-physical systems (CPS), and extend our previously proposed Bellman Deviation Detection (BDD) framework for model-free reinforcement learning (RL). We refine the stand…
Authors: Rishi Rani, Massimo Franceschetti
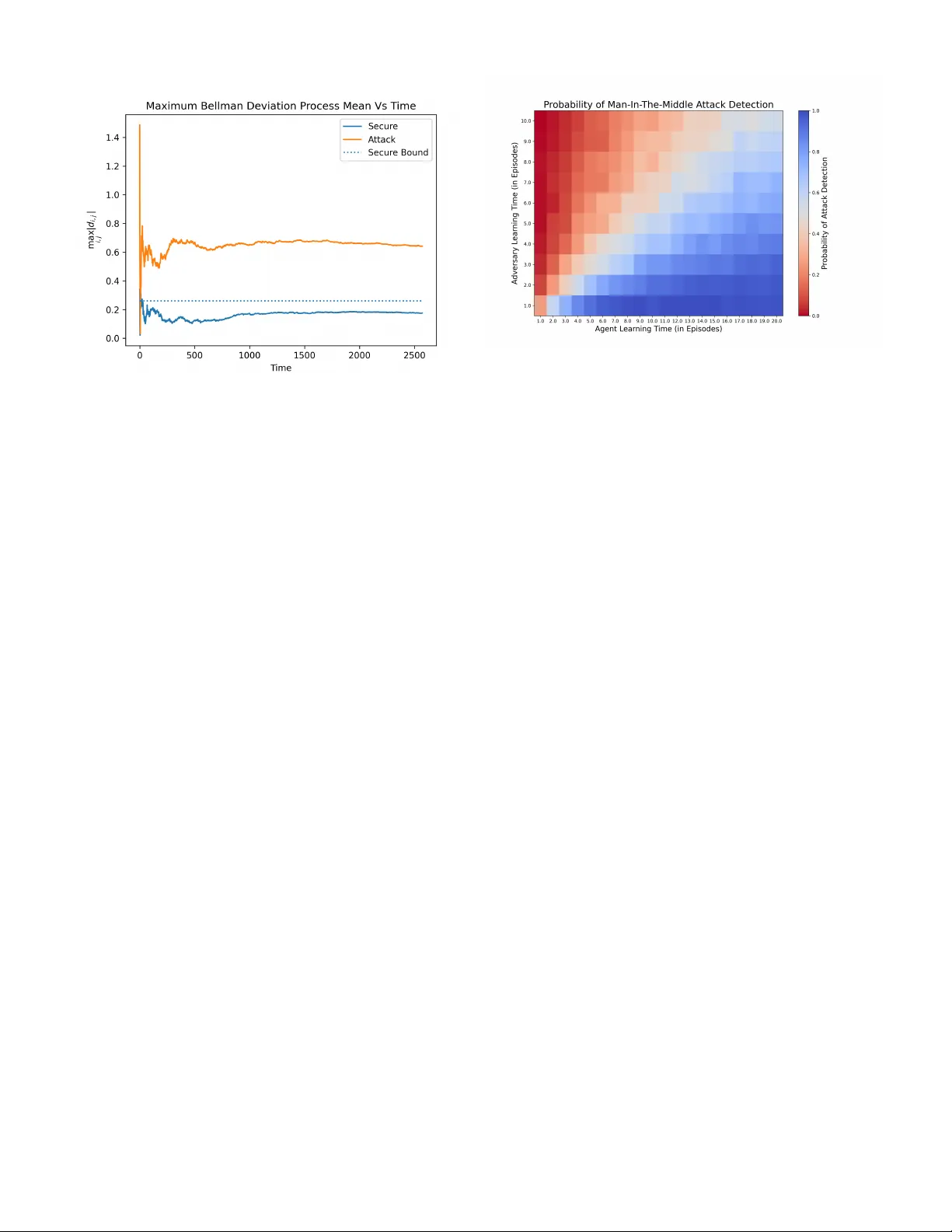
Secure Reinforcement Learning: On Model-Free Detection of Man in the Middle Attacks Rishi Rani, , Massimo Franceschetti, Abstract —W e consider the problem of lear ning-based man- in-the-middle (MITM) attacks in cyber -physical systems (CPS), and extend our pre viously proposed Bellman Deviation Detection (BDD) framework for model-free reinfor cement learning (RL). W e refine the standard MDP attack model by allowing the reward function to depend on both the current and subsequent states, ther eby capturing reward variations induced by errors in the adversary’ s transition estimate. W e also derive an optimal system-identification strategy for the adversary that minimizes detectable value deviations. Further , we prove that the agent’s asymptotic lear ning time r equired to secure the system scales as Θ( t b ) , wher e t b is the adv ersary’s lear ning time, and that this matches the optimal lo wer bound. Hence, the pr oposed detection scheme is order-optimal in detection efficiency . Finally , we extend the framework to asynchronous and intermittent attack scenarios, where reliable detection is preserved. Index T erms —Cyber -physical systems, learning based attacks, man-in-the-middle attacks, model-free reinf orcement learning, secure reinf orcement learning system identification. I . I N T RO D U C T I O N Recent advancements in wireless technology and computa- tional capabilities hav e made it possible to perform networked control in cyber-physical systems (CPS), enabling a wide range of applications such as cloud robotics, autonomous nav- igation, and industrial process management [1]. These systems are inherently online, making real-time decisions based on past observations in a closed-loop fashion. Howe ver , the distributed architecture of CPS introduces significant security vulnera- bilities, necessitating the development of secure and optimal control strategies. Security breaches in these systems can hav e catastrophic consequences, including attacks on financial sys- tems, hijacking of autonomous vehicles and unmanned aerial vehicles, or compromising life-critical infrastructure [2]–[4]. High-profile incidents such as the cyber-attacks on the Ukraine power grid, the German steel mill, the Australian se wage system, the Davis-Besse nuclear power plant, and the Stuxnet malware attack on the Iranian uranium enrichment f acility highlight the sev erity of these threats [5]. These ev ents have spurred extensi ve research into the pre vention of security breaches at a control-theoretic lev el [6]–[8]. W ithin this context, the “man-in-the-middle” (MITM) attack model is a significant concern in CPS. In such attacks, an adversary intercepts and manipulates sensor feedback signals sent from the physical plant to the legitimate agent, feed- ing spoofed signals that appear to indicate safe and stable operation. Meanwhile, the adversary also manipulates the control signal to steer the plant toward a catastrophic state. T o detect these attacks, the legitimate agent must continuously monitor plant outputs and search for statistical anomalies in the feedback. Con versely , the attacker aims to generate spoofed sensor data that is statistically indistinguishable from the legitimate signals while driving the system towards failure. T w o prominent MITM attack types hav e been studied in detail. The first, the r eplay attack , in volves the adversary recording system behavior over time and then replaying it periodically to decei ve the agent [9], [10]. This attack is easier to detect, as it does not require knowledge of system parameters. One countermeasure is to embed a watermark signal into the control input, making it undetectable to the adversary [11], [12]. The second, the statistical-duplicate attack , assumes the adversary has complete kno wledge of the system’ s dynamics and parameters, allowing them to construct trajectories statistically identical to the true system’ s behavior [11], [13], [14]. Detecting this attack is more com- plex due to the adversary’ s full system knowledge, requiring sophisticated detection techniques. T o counter this, agents can employ methods such as moving tar get [15]–[18], baiting [19], [20], or priv ate randomness through watermarking [14]. Another category of MITM attacks, learning-based attacks , arises from the broader field of learning-based control [21]– [23]. In this case, the adversary lacks initial knowledge of the system but can learn its dynamics over time through observation. This type of attack is more practical, as perfect knowledge of the system is unrealistic. Howe ver , once the ad- versary learns the system model, they can launch sophisticated deception schemes. Previous studies hav e used information- theoretic approaches to derive bounds on the probability of successful deception in scalar and vector linear time-in v ariant systems [24], as well as bounds on the agent’ s time and energy required to detect the attack with confidence [25]. In our previous work [26], [27], we extend the model of learning-based attacks to include the learning process of the agent itself. Specifically , we focus on a legitimate agent that performs model-free control through reinforcement learning (RL). In this setting, where the agent has no explicit system model, attack detection becomes particularly challenging. W e propose a no vel attack detection algorithm, the “Bellman De vi- ation Detection” (BDD) algorithm, which guarantees detection with high probability while av oiding false alarms, provided an “information advantage” condition is met. This condition links the error in the agent’ s Q-function to the adversary’ s error in modeling the system. Furthermore, our analysis provides insights into the information patterns required for successful detection. A. Contributions This paper extends our prior work on the Bellman Devi- ation Detection (BDD) algorithm for Markov decision pro- cesses [26]. Our main novel contributions are as follo ws: 1) Refined Problem Formulation. W e refine the standard MDP attack model by allowing the rew ard function to depend not only on the current state and action b ut also on the subsequent state. This captures the fact that, under a man-in-the-middle (MITM) attack, the re ward statistics can drift as a function of the underlying state transition model. Building on this more nuanced formulation, we deriv e a modified version of the original BDD algorithm that explicitly accounts for changes in the transition dynamics of the underlying system. 2) Adversary’ s Optimal System Identification. W e de vise a simple system-identification (SI) algorithm and prov e that it is optimal in terms of minimizing the deviation in value estimates that the agent uses to detect an attack. The resulting SI algorithm yields the system estimate that produces the smallest detectable trajectory deviations. 3) Extension to Asynchr onous and Intermittent Attacks. The original BDD framew ork assumed a synchronous, phased attack schedule. Here, we generalize to a dy- namic attack model in which the adversary may attack asynchr onously and on an intermittent basis. W e show how to adapt the BDD algorithm to this setting and prov e that it still reliably detects attacks ev en when they occur sporadically . 4) Detection Complexity and Cost–T radeoff Analysis. W e compare the sample complexity—i.e., the learning time required by both the adversary (to mount an unde- tectable attack) and the agent (to detect it). By deriving a notion of asymptotic detection complexity , we prov e that the modified BDD algorithm remains order-optimal in the agent’ s learning time and matches the order of detection ef ficiency of model-based detectors. I I . M A T H E M AT I C A L P R E L I M I N A R I E S A N D N OTA T I O N A Markov Decision Process is defined by the quadruple ( X , U , P , R , γ ) , where X is the set of states with cardinality |X | = N and U is the set of actions with cardinality |U | = M . P is the transition probability matrix, R is the reward matrix and γ is the discount factor . The probabilistic transitions from state to state are Markov and are gi ven by Pr( x t +1 | x t , u t ) = p x t ,u t ≡ [ p x t ,u t ( x 1 ) , . . . , p x t ,u t ( x N )] , (1) and P = p x 1 ,u 1 . . . p x N ,u M , where the rows are index ed over all ( x, u ) ∈ X × U . Similarly , the re ward for each transition is giv en by r ( x t , u t , x t +1 ) = r x t ,u t ≡ [ r x t ,u t ( x 1 ) , . . . , r x t ,u t ( x N )] , (2) and R = r x 1 ,u 1 . . . r x N ,u M . The model-free control objecti ve is to learn a policy function π ( x ) : X → U such that the following discounted rew ard is maximized: π ∗ ( x ) = arg max π E " ∞ X t =0 γ t r ( x t , π ( x t ) , x t +1 ) # , x 0 ∈ X , (3) where the discount factor , γ , represents how much the future rew ard is discounted. This problem is termed the infinite time horizon discounted r ewar d pr oblem. This objective is achieved by learning the optimal Q-function of the problem, which is Q ∗ ( x, u ) = max π E " r ( x 0 , u 0 , x 1 ) + ∞ X t =1 γ t r ( x t , π ( x t ) , x t +1 ) # , (4) where x 0 = x and u 0 = u. The optimal Q-function relates to the optimal policy as π ∗ ( x ) = arg max u Q ∗ ( x, u ) , and the optimal value function, which describes the total accrued reward of an optimal trajec- tory , is defined as V ∗ ( x ) = max u Q ∗ ( x, u ) , (5) v = [ V ∗ ( x 1 ) , . . . , V ∗ ( x N )] , where v denotes the optimal value function as a v ector . Finally , we note that the optimal Q-function can be recursively written using the Bellman equation as Q ∗ ( x, u ) = X x ′ ∈X p ( x, u, x ′ ) r ( x, u, x ′ ) + γ max u ′ Q ∗ ( x ′ , u ′ ) (6) = X x ′ ∈X p ( x, u, x ′ ) ( r ( x, u, x ′ ) + γ V ∗ ( x ′ )) = p x,u r T x,u + γ v T . Throughout the paper , we describe vectors using boldface, and vectors are defined as ro w vectors by default (to align with MDP con ventions). Matrices are boldfaced and capitalized, and ∥ · ∥ 2 refers to the Euclidean norm. Finally , we say that an ev ent occurs with high probability (w .h.p.) if its probability p n tends to 1 as n → ∞ . Note that proofs of all theorems presented are deferred to the appendix. I I I . P RO B L E M S T A T E M E N T The system is modeled as a Marko v Decision Process (MDP) controlled by an agent receiving a reward corrupted by additi ve noise. The reward noise w t is assumed to be i.i.d. with zero mean; notably , we do not assume finite variance, (a) a (b) b Fig. 1. (a) Adversary Learning Phase: During this phase, the attacker eav esdrops and learns the system dynamics without altering the feedback signal to the agent. (b) Adversary Attack Phase: During this phase, the attacker intercepts the feedback loop and provides a falsified signal to the agent to induce a target policy or cause value deviation. allowing for hea vy-tailed distributions. While standard RL analyses often rely on finite-variance assumptions to inv oke the Central Limit Theorem, our framew ork is designed to be robust even when the v ariance is infinite. This represents an analytical strength rather than a limitation, as it ensures that the Bellman Deviation Detection (BDD) remains valid for a broader class of noise processes, including those with impul- siv e characteristics common in networked control systems. W e assume that the agent has learned an estimate of the optimal Q-function ˆ Q using a training trajectory τ a described as τ A = ( x 1 , u 1 , . . . x t a , u t a ) , (7) where t a is the agent training time. No additional assumption is made on τ a itself and the trajectory can be controlled by the agent. The agent has no information about the system model or reward function and uses a generalised learning algorithm with the following stochastic guarantee, | ˆ Q t a ( x, u ) − Q ∗ ( x, u ) | ≤ ϵ ( t a ) , w .h.p (8) and ∀ x ∈ X , u ∈ U s.t ϵ ( t a ) → 0 as t a → ∞ . As described in Fig. 1a, the adversary initially is in its learning phase where it observes a trajectory τ b and it learns the system giving it an estimate of the transition model ˆ P . During its learning phase the adversary has no control over its learning trajectory τ b , as it merely learns by observing and does not control the system. Therefore, no asymptotic con vergence guarantees are placed on its estimate ˆ P . In the attack phase (as described in Fig. 1b) the agent takes control of the system and feeds the agent a spoofed state feedback signal. This feedback signal is statistically consistent with its transition model estimate ˆ P . Note that ˆ P need not be an explicit estimate made by the adversary (for example the adversary may also use model-free learning), howe ver there exists an implicit statistical model it follows. The trajectory τ c formed during the attack phase is used by the agent to perform attack detection. The adversary in this phase steers the true system towards catastrophe and the agent is tasked with detecting the attack and declaring a breach. The adversary’ s strategy to lead the system to catastrophe does not af fect attack detection, namely the adversary’ s closed feedback with system is not of strict concern to the detection problem. Problem Statement: Giv en the agent has a learned estimate of the optimal Q-function ˆ Q ( · ) from the trajectory τ a and the adversary spoofs the system with a transition model estimate ˆ P , devise a detection algorithm that uses the trajectory during attack τ c and provides guarantees on attack detection as the trajectory length t c → ∞ . I V . A D E T E C T I O N A L G O R I T H M B A S E D O N “ B E L L M A N D E V I A T I O N ” In this section, we describe our proposed algorithm and prov e its stochastic guarantees. A. Algorithmic Description Before we describe the detection algorithm, we begin by defining the ke y quantities required for our analysis. The trajectory observed during an attack is a tuple of the form τ c = ( x 1 , u 1 , . . . , x t c , u t c ) . Let t c ( i, j ) be the number of times the state-action pair ( i, j ) is observed, and the sequences x i,j ( k ) and u i,j ( k ) represent the respecti ve states and actions that followed them each subsequent time. Similarly , let r i,j be the immediate reward doled out at that instant, and w i,j ( k ) be its associated white noise. Definition 1 (Bellman Deviation Process) . Let d i,j ( k ) = ˆ Q ( i, j ) − r i,j − w i,j ( k ) − γ ˆ V ( x i,j ( k )) (9) ∀ k ∈ [1 , t c ( i, j )] , be the Bellman deviation pr ocess. This sequence repr esents the deviations fr om Bellman-consistent behavior in the observed trajectory during the attack phase. The Bellman de viation process (BDP) is simply the empir- ical temporal difference (TD) error , separated by state-action pair , to form M × N dif ferent sequences, each representing the sequence of TD errors measured in the trajectory when the system transitioned through the respectiv e state-action pair . Definition 2 (Bellman Deviation Process Mean) . W e define ¯ d i,j = P t c ( i,j ) k =1 d i,j ( k ) t c ( i, j ) (10) to be the Bellman deviation pr ocess mean (BDPM). The (BDPM) is simply the sample mean of the BDP . T aking the sample mean reduces the ef fect of disturbances due to noise in rew ards and stochastic transitions, and is an effecti ve metric to detect de viations from Bellman-consistency . W e use bounds on the BDPM to determine if the system is under a MITM attack. A high BDPM would suggest that the system is under attack. Howe ver , to establish precise bounds on the de viation averages, we need to define an informati ve metric on the adversary’ s model error to characterize its detectability . Definition 3 (Minimum V alue Drift) . Given an MDP system ( X , U , P , R ) and the adversary’ s system model ˆ P , we can define its minimum value drift as Φ min = min i,j ∈X ×U | ˜ p i,j ( r i,j + γ v ) | (11) wher e v is a matrix with the optimal value r ow vector , and ˜ p i,j is the ( i, j ) indexed row fr om the adversary’ s model err or ˜ P = P − ˆ P . The abov e definition can be understood intuiti vely as a measure that tells us how easily we can observe statistical deviations in the system’ s trajectory during the attack phase. For example, if the system has Φ min = 0 , this implies that the value function gi ves us no information about the different trajectories, as there is no detectable minimum drift. Therefore, the minimum value drift measure is a k ey feature of the system and should be ev aluated when designing secure systems. W ith the above quantities defined, we are now ready to present the Bellman deviation detection algorithm (see Algo- rithm 1) and prove its correctness. In Algorithm 1, the division D T is an element-wise division of the two matrices. The algorithm essentially calculates the BDPMs ¯ d i,j , and prunes out the BDPMs that were not suffi- ciently averaged and have therefore not con verged yet. Then it takes the maximum absolute value among them and compares it with the security bound ξ = (1 + γ )¯ ϵ . If it exceeds this bound, a breach is declared. Note that the algorithm guarantees attack detection and no false alarms, with high probability , if and only if the information adv antage condition is met. The information advantage condition essentially compares the agent’ s information about the system to the adversary’ s by comparing their learning errors, and the above algorithm is only ef fectiv e if the agent has greater information about its en vironment than the adversary to av oid deception. It is fully prov en and described in the follo wing subsection. Remark 1. W e point out that the algorithm does not r equir e exact estimates of the err or bound of the Q-function ϵ ( t a ) , Algorithm 1 Bellman Deviation Detection Require: t c ≥ 0 , length( τ C ) = t c , γ ¯ ϵ ≥ max i,j | Q ( i, j ) − ˆ Q ( i, j ) | w .h.p. initialize D ← [ 0 ] initialize T ← [ 0 ] initialize n ← 1 while n ≤ t c do i ← τ C [ n ][0] j ← τ C [ n ][1] k ← τ C [ n + 1][0] // Accumulating the values of the BDP . D [ i, j ] ← ˆ Q ( i, j ) − r ( i, j, k ) − γ ˆ V ( k ) + D [ i, j ] T [ i, j ] ← T [ i, j ] + 1 n ← n + 1 end while // Pruning the BDPs whose means have not conver ged PR UNE ( D , T ) // Calculating BDPM by dividing by times visited D ← D T // Thr eshold larg est BDPM by security bound if max( | D | ) > (1 + γ )¯ ϵ then declare breach else declare no breach end if // This function prunes BDPs with unconver ged means, i.e., infr equently visited state-action pairs function PR UNE ( D , T ) initialize m = 1 2 ·|X ||U | for all ( i, j ) in X × U do if T [ i, j ] ≤ m · t c then DELETE ( D [ i, j ] , T [ i, j ]) end if end f or end function but rather an over estimate ( ¯ ϵ ). This allows for more practical scenarios where an exact value of the quantity would be unavailable and could be obtained thr ough bootstrap methods with certain confidence bounds. B. Corr ectness of the Algorithm In this section, we prove the correctness of the proposed algorithm. W e begin by proving an asymptotic upper bound on the BDPMs when no attack is underway . T o this end, we deri ve the asymptotic limit of the BDPMs under secure conditions. Theorem 1. In the absence of attacks, the BDPMs con verg e asymptotically as, ¯ d i,j → ˆ Q ( i, j ) − Q ∗ ( i, j ) + γ p i,j ( v − ˆ v ) T , (12) w .h.p. as t c ( i, j ) → ∞ , ∀ ( i, j ) ∈ X × U . W e now use the asymptotic limit to prove an asymptotic upper bound on the magnitude of the BDPM when no attack is underway . Theorem 2. In the case when no attack occurs, the magnitude of the BDPMs can be upper-bounded as, | ¯ d i,j | ≤ (1 + γ ) ϵ ( t a ) , w .h.p. as (13) t c ( i, j ) → ∞ , ∀ ( i, j ) ∈ X × U , wher e ϵ ( t a ) is the err or in the agent’ s estimate of the optimal Q-function. W e similarly derive the asymptotic limit of the BDPMs when an attack is underway . Theorem 3. Given that the system is under attack, the BDPMs asymptotically limit as follows, ¯ d i,j → ˆ Q ( i, j ) − Q ∗ ( i, j ) + γ ˆ p i,j ( v − ˆ v ) T + ˜ p i,j ( r i,j + γ v ) T (14) a.s. as t c ( i, j ) → ∞ , ∀ ( i, j ) ∈ X × U . Similarly , we now prove a theorem that lower -bounds the magnitude of the BDPMs when the system is under attack. Theorem 4. Given that the system is under attack, the magnitude of the BDPMs can be lower-bounded as follows, | ¯ d i,j | ≥ Φ min − (1 + γ ) ϵ ( t a ) , (15) ∀ ( i, j ) ∈ X × U , w .h.p. as t c ( i, j ) → ∞ . Giv en that we hav e shown that the absolute v alue of the BDPM is upper-bounded when the system is secure and lo wer- bounded when the system is under attack, we can no w deriv e conditions on when Algorithm 1 will be able to detect MITM attacks. Intuitiv ely , this happens when the safety upper bound is prov ably lower than the attack’ s lower bound, as formalized in the theorem below . Theorem 5. The information advantage condition, Φ min > 2 · (1 + γ )¯ ϵ, (16) is necessary and sufficient for Algorithm 1 to guarantee attack detection while avoiding false alarms with high pr obability as t c → ∞ , when the ag ent uses any arbitrary policy . Here , ¯ ϵ is an over -estimate of the agent’ s err or in the Q-function, such that ¯ ϵ ≥ ϵ ( t a ) . C. Optimal System Identification While discussing model-free techniques to detect man-in- the-middle attacks on a system, one critical aspect to consider is the effecti veness of the agent’ s detection scheme, which is dependent on how accurately the adversary estimates the system model. In this section, we propose a system identifica- tion algorithm that the adversary can use and prov e that it is optimal in terms of minimizing the de viation in the BDPM. Algorithm 2, which we refer to as the Sample Distribu- tion Estimation algorithm, estimates the transition probability matrix by observing a training trajectory τ B to generate a frequency tensor F . It then normalizes the entries of F to obtain the estimated transition probability matrix ˆ P . In Algorithm 2, τ B is a sequence of state-action pairs of length t b , and 0 represents a zero tensor of appropriate dimensions. The algorithm explicitly iterates through each state i ∈ X and action j ∈ U to compute the transition probabilities to each subsequent state k ∈ X . For state-action pairs ( i, j ) observed in the trajectory , the transition probability is calculated as the empirical frequency of moving to state k divided by the total number of times the pair ( i, j ) was visited. For unvisited state- action pairs, a uniform prior is assigned to ensure ˆ P remains a v alid stochastic matrix. Algorithm 2 Sample Distribution Estimation Require: t b ≥ 0 , | τ B | = t b Initialize F ∈ Z |X |×|U |×|X | ← 0 Initialize ˆ P ∈ R |X |×|U |×|X | ← 0 // Count observed transitions for n = 1 to t b − 1 do i ← τ B [ n ][0] j ← τ B [ n ][1] k ← τ B [ n + 1][0] F [ i, j, k ] ← F [ i, j, k ] + 1 end f or // Compute transition pr obabilities via explicit normaliza- tion for all i ∈ X do for all j ∈ U do S ← P k ′ ∈X F [ i, j, k ′ ] if S > 0 then for all k ∈ X do ˆ P [ i, j, k ] ← F [ i, j, k ] /S end f or else // Handle unvisited pairs with uniform prior ˆ P [ i, j, :] ← 1 / |X | end if end f or end f or retur n ˆ P T o prove the optimality of the abo ve simple statistical scheme, we must define the following key metric. Definition 4 (Asymptotic Bellman Deviation Process Gap) . The asymptotic Bellman deviation pr ocess gap (BDPG) is the differ ence between the asymptotic limits of the BDPMs when the system is secur e and when the system is under attack. Ther efore , lim t c ( i,j ) →∞ ˜ d i,j = lim t c ( i,j ) →∞ ¯ d attack i,j − ¯ d secur e i,j (17) = ˜ p i,j ( r i,j + γ v ) T , ∀ ( i, j ) ∈ X × U . W e can now show that Algorithm 2 is optimal in the sense of minimizing the Asymptotic BDPG given the adversary’ s learning trajectory τ b . In other words, we show that using Algorithm 2 minimizes the BDPG up to fundamental statistical limits. Theorem 6. The sample distribution algorithm described in Algorithm 2 is an efficient estimator for the asymptotic BDPG. That is, ˆ P satisfies the following, ˆ p i,j = arg min ˆ p i,j | τ b E | ( p i,j − ˆ p i,j )( r i,j + γ v ) T | 2 , (18) = arg min ˆ p i,j | τ b E h | ˜ d i,j | 2 i , ∀ ( i, j ) ∈ X × U . Finally , we pro ve that Algorithm 2 has the follo wing asymp- totic con vergence bounds. Theorem 7. The sample distribution algorithm described in Algorithm 2 assures that, | ˜ p i,j ( r i,j + γ v ) T | m.s − − → 0 , ∀ ( i, j ) ∈ X × U , (19) as t b ( i, j ) → ∞ , with a con verg ence rate of O 1 √ t b ( i,j ) , wher e m.s refer s to conver gence in the mean-squar ed sense and t b ( i, j ) is the number of times the ( i, j ) state-action pair occurr ed in the adversary’ s learning trajectory τ b . D. Extension to Dynamic Attacks The attack paradigm discussed in Section III assumes syn- chronous attacks. In this section, we extend the paradigm to include asynchronous and dynamic attacks, while requiring little to no modification to the proposed Bellman deviation detection algorithm. In the current paradigm, it is implicitly assumed that the ad- versary’ s attack phase begins simultaneously with the agent’ s detection phase. This “synchronous” assumption is unrealistic in real-world scenarios. Therefore, we extend the paradigm to account for cases where the adversary initiates the attack before or after the agent begins detection. If the attack begins before detection, the setting is effecti vely identical to the synchronous case from the agent’ s perspective. Thus, we focus on the case where the attack begins after detection, with a finite lag t L , and show that Algorithm 1 maintains the same asymptotic guarantees. Theorem 8. Given that the adversary’ s attac k begins any finite lag t L after the start of detection. The Bellman deviation sequence has identical asymptotic limits as, ¯ d i,j → ˆ Q ( i, j ) − Q ∗ ( i, j ) + γ p i,j ( v − ˆ v ) T , when secur e and ¯ d i,j → ˆ Q ( i, j ) − Q ∗ ( i, j ) + γ p i,j ( v − ˆ v ) T + ˜ p i,j ( r i,j + γ v ) T when under attack, w .h.p as t c ( i, j ) → ∞ , ∀ ( i, j ) ∈ X × U . Similarly , the information advantage condition remains un- changed as Φ min > 2 · (1 + γ )¯ ϵ. Ther efore , Algorithm 1 guarantees attac k detection while avoiding false alarms with high pr obability , as t c → ∞ even for asynchr onous attacks, when the information advantage condition is met. W e now extend the paradigm to include dynamic attacks, in which the adversary intermittently switches between attacking the system and allowing the agent to interact with the true en vironment. W e show that the Bellman deviation detection algorithm can be slightly modified to guarantee attack detec- tion w .h.p, and a low probability of false alarms. T o that end, we define the following key quantity for the adversary . Definition 5 (Adversary Attack Fraction) . The attack fraction ν is defined as the asymptotic fraction of time the adversary spends attac king the system, ν = lim t c →∞ P t c t =1 I a ( t ) t c , (20) wher e I a ( t ) is an indicator function that indicates if the adversary was attacking during time step t . W e now sho w that the proposed algorithm can be modified slightly while still providing identical asymptotic guarantees. Theorem 9. Given that the adversary performs a dynamic attack with an attack fraction of ν . The Bellman deviation sequence has the same asymptotic limits, ¯ d i,j → ˆ Q ( i, j ) − Q ∗ ( i, j ) + γ p i,j ( v − ˆ v ) T , when secur e and a slightly differ ent limit, ¯ d i,j → ˆ Q ( i, j ) − Q ∗ ( i, j ) + γ p i,j ( v − ˆ v ) T + ν · ˜ p i,j ( r i,j + γ v ) T (21) when under attack, w .h.p as t c ( i, j ) → ∞ , ∀ ( i, j ) ∈ X × U . Similarly , the information advantage condition is modified as, ν · Φ min > 2(1 + γ )¯ ϵ. (22) Ther efore , Algorithm 1 guarantees attac k detection while avoiding false alarms with high pr obability as t c → ∞ even for dynamic attacks when the information advantage condition is met. V . C O S T - T R A D E O FF A N D C O N V E R G E N C E A N A L Y S I S So far , all analyses of attack detection guarantees ha ve been limited to comparisons between the agent’ s and the adversary’ s error metrics. In this section, we formalize a method for analyzing detection ef ficiency in terms of the more tractable metric of learning times and provide guarantees on the detection efficienc y of the proposed BDD algorithm. T o that end, we first define the detection ef ficiency of an algorithm. Definition 6. (Detection Efficiency) Let M = ( X , U , P , R , γ ) be a Markov Decision Pr ocess. The detection efficiency E of a r einfor cement learning algorithm A is defined as the minimum number of samples t a ( t b , δ ) requir ed for the agent to learn a policy π t a such that the pr obability of detecting the adversary who had learned for t b samples is 1 − δ assuming both agent and adversary ar e sample efficient in learning. That is, t a ( t b , δ ) = min { t a | Pr( Attack Detection) ≥ 1 − δ } wher e π t a is the policy learned by the algorithm after t a samples, the term (Φ min > 2 · (1 + γ )¯ ϵ ) is the information advantage condition, Φ min is the minimum value drift and ϵ is the ag ent’ s err or in its Q-function. Thus, a detection algorithm with lower t a ( t b , δ ) is consid- er ed more detection efficient. There are fundamental information-theoretic limits on how efficient a detection algorithm can be. In the following lemma we derive an asymptotic universal lower bound on detection efficienc y of any detection algorithm. Lemma 1. The detection efficiency for any system M and any algorithm A is asymptotically lower-bounded linearly by Ω( t b ) , as t b → ∞ and δ → 0 . Finally we now deri ve the asymptotic detection efficiency of the proposed BDD framework, and provide guarantees on its required learning time to maintain an information advantage on an adversary . Theorem 10. The Bellman de viation detection algorithm (Algorithm 1) has an asymptotic detection efficiency bounded both below and above by Θ t b (1+ γ ) 2 (1 − γ ) 3 , as t b → ∞ and δ → 0 . Corollary 1. It follows fr om Lemma. 1 and Theorem 10 that the proposed BDD algorithm is linear and order -optimal in its learning time, showing that it is the same order of efficiency in t b as model-based detection schemes. V I . E X P E R I M E N T A L V A L I DAT IO N A. Markov Decision Pr ocess F ormulation W e consider a finite Markov Decision Process (MDP) that models a stochastic random walk in a discrete one- dimensional state space. The MDP is represented as a tuple M = ( S, A, P , R, γ ) , where: • State Space ( S ): The agent occupies a discrete state s ∈ S , where S = {− 5 , − 4 , . . . , 4 , 5 } . The boundary states s = − 5 and s = 5 are absorbing states. • Action Space ( A ): The agent can take actions a ∈ A = {− 1 , 0 , 1 } , corresponding to stepping left, staying in place, or stepping right, respectiv ely . • T ransition Dynamics ( P ): The transition probability function P ( s ′ | s, a ) defines the probability of transitioning to state s ′ giv en the current state s and action a . The dynamics follo w a stochastic motion model, P ( s ′ | s, a ) = 0 . 05 , s ′ = s + a − 2 0 . 15 , s ′ = s + a − 1 0 . 60 , s ′ = s + a 0 . 15 , s ′ = s + a + 1 0 . 05 , s ′ = s + a + 2 (23) where the state transitions are absorbed at the boundaries, such that if s ′ / ∈ S , the probability mass is assigned to the nearest valid state (i.e., − 5 or 5 ). • Reward Function ( R ): The agent receives a deterministic rew ard that decreases with the distance from the central state as, R ( s ) = 5 , s = 0 4 , s ∈ {− 1 , 1 } 3 , s ∈ {− 2 , 2 } 2 , s ∈ {− 3 , 3 } 1 , s ∈ {− 4 , 4 } 0 , s ∈ {− 5 , 5 } . (24) • Discount Factor ( γ ): The problem is formulated as an infinite-horizon discounted reward problem, where the agent maximizes the e xpected sum of discounted re wards, J = E " ∞ X t =0 γ t R ( s t ) # , γ ∈ [0 , 1] . (25) For our experiments, we set the discount factor to γ = 0 . 4 . This MDP captures the noisy motion of a drunkard who attempts to mov e in a chosen direction but may ov ershoot or undershoot due to randomness. The structure of the rew ard function suggests that the agent should attempt to reach or remain near the central state s = 0 , which provides the highest rew ard. Agent Description: The agent employs a traditional Q- learning algorithm as described in [28], with the learning rate α n ( i, j ) = 1 /n ( i, j ) and the ϵ -greedy exploration strategy , where, α n ( i, j ) is the learning rate for the n th step taken to learn Q ∗ ( i, j ) . The agent then uses the learned Q-function, ˆ Q ( · ) , to perform Bellman deviation detection as in Algo- rithm 1. Adversary Description: The adversary learns the system optimally by estimating the sample distribution as described in Algorithm 2. The adversary then uses the learned system estimate ˆ P to perform a MITM attack. B. Simulation W e first validate the correctness of the algorithm by simulat- ing single instances of the MITM attack problem. The agent is trained on 5 episodes (each 1000 samples long) and the adversary is trained on 1 episode of data, this raises the odds that the information advantage condition is met and that the agent will successfully detect an attack. W e now simulate two scenarios, one where the agent is not under attack and one where the adversary is performing a MITM attack. In both cases, the agent uses the proposed BDD algorithm to detect attacks by calculating the BDPM and comparing it to the security bound, gi ven by (1 + γ ) ϵ. W ith high probability , the agent successfully detects an attack and the plots of the maximum BDPMs are compared in Fig. 2. As predicted by Theorem 2, the absolute value of the maximum BDPM remains belo w the security bound when no attack occurs. Similarly , we observe that since the information advantage condition is met the absolute value of the maximum BDPM con ver ges to a value ov er the security bound, as a Fig. 2. This figure shows the absolute v alue of the maximum BDPM for the cases when an attack occurs (in orange) and when the system is secure (in blue). The security bound (in dotted blue) upper bounds the BDPM when no attack occurs and lower bounds the BDPM when attack occurs, if the information advantage condition is met. consequence of Theorem 4 and Theorem 5. This validates the correctness of Algorithm 1 in scenarios where the information advantage condition holds. T o verify Theorem 10, we conduct Monte Carlo simulations to show that the minimum agent learning time required to detect an attack grows linearly with the adversary’ s learning time, i.e., Θ( t b ) . T o this end, we simulate the MITM attack problem for varying amount of agent and adversary learning times, measured in number of episodes. 1000 trials are con- ducted for each configuration of agent and adversary learning times. W e then count the number of trials where the agent successfully detected the MITM attack underw ay and calculate the empirical probability of success. The results of the Monte- Carlo simulation are summarized in the heat map shown in Fig. 3. As we expect the probability of attack detection rises as the agent learning times grows with respect to the adversary’ s, represented by the blue region. Similarly the probability of attack detection falls as the adversary learning time grows greater with respect to the agent’ s, represented by the red region. Howe ver the most notable feature of the heat map is that regions of high and lo w detection probability are separated by a distinct linear contour - a structure that is nontri vial and theoretically significant. While the contour could have been nonlinear , it is in fact linear, as predicted by Theorem 10. This result validates that the proposed BDD algorithm has linear asymptotic detection efficienc y and hence order-ef ficient, as prov en in Theorem 10 and Corollary . 1. V I I . C O N C L U S I O N In this paper, we addressed the problem of securing rein- forcement learning agents against Man-in-the-Middle (MITM) attacks in a model-free setting. By refining the Bellman Fig. 3. This figure shows the probability of the agent detecting an attack, calculated based on 1000 trials for varying amounts of agent and adversary learning times. Deviation Detection (BDD) frame work to account for rew ard structures dependent on subsequent states, we captured the physical realities of control-loop interceptions where the ad- versary’ s estimation error manifests as system drift. W e further demonstrated the robustness of our frame work against dy- namic attack strategies, including asynchronous and intermit- tent interceptions, proving that reliable detection is preserved ev en when the adversary attempts to remain hidden through sporadic acti vity . Our theoretical analysis established that the agent’ s learning time to secure the system is order-optimal, matching the adversary’ s o wn learning time Θ( t b ) . More broadly , the results sho w that meaningful security guarantees can be obtained e ven when the legitimate con- troller is fully model-free and has access only to learned value information rather than an explicit plant model. This is important because most existing detection guarantees in cyber -physical security are deriv ed in model-based settings, where the defender is assumed to know or estimate the system dynamics directly . In contrast, our results show that attack detectability can still be characterized through Bellman- consistency de viations and that precise information-theoretic tradeoffs persist ev en in the absence of an explicit model. T o our knowledge, this is among the first frameworks to provide rigorous attack-detection guarantees, dynamic-attack extensions, and asymptotic ef ficiency guarantees for learning- based MITM attacks in model-free reinforcement learning. As such, the paper helps bridge the gap between classical control- theoretic security and modern learning-based control, showing that security guarantees need not disappear when control is performed through reinforcement learning. V I I I . F U T U R E W O R K While the present work establishes fundamental detectabil- ity limits and order -optimality for discrete MDPs, several promising directions remain. A primary objective is the ex- tension of the BDD framew ork to high-dimensional and con- tinuous state-spaces through the use of deep reinforcement learning and neural function approximators. Additionally , the application of this full framew ork to continuous-time linear systems, such as the Linear Quadratic Regulator (LQR) under model-free adaptive control, presents a significant open prob- lem. Another important direction is the study of a dual safety problem, where post-training model drift or en vironmental change must be detected online using only model-free v alue information. Establishing analogous detectability guarantees in that setting would broaden the scope of the present framework beyond adversarial interception and toward real-time safety certification for learning-based control systems. I X . C O R R E C T N E S S O F T H E B E L L M A N D E V I A T I O N D E T E C T I O N A L G O R I T H M A. Pr oof of Theor em 1 W e rearrange the terms of the Bellman equation (6) and subtract it from (10) to get: ¯ d i,j = P t c ( i,j ) k =1 ˆ Q ( i, j ) − r i,j ( x i,j ( k )) − w i,j ( k ) t c ( i, j ) (26) − γ P t c ( i,j ) k =1 ˆ V ( x i,j ( k )) t c ( i, j ) − Q ∗ ( i, j ) + p i,j ( r i,j + γ v ) T = P t c ( i,j ) k =1 ˆ Q ( i, j ) − Q ∗ ( i, j ) t c ( i, j ) − P t c ( i,j ) k =1 w i,j ( k ) t c ( i, j ) − P t c ( i,j ) k =1 r i,j ( x i,j ( k )) t c ( i, j ) − p i,j r T i,j ! − γ P t c ( i,j ) k =1 ˆ V ( x i,j ( k )) t c ( i, j ) − p i,j v T ! . The first term simplifies to ˆ Q ( i, j ) − Q ∗ ( i, j ) . The second and third terms, due to the Law of Large Numbers (LLN), almost surely conv erge to zero. The fourth term con verges to γ p i,j ( v − ˆ v ) T . Therefore, ¯ d i,j → ˆ Q ( i, j ) − Q ∗ ( i, j ) + γ p i,j ( v − ˆ v ) T . B. Pr oof of Theor em 2 Giv en that ¯ d i,j con verges as: ¯ d i,j → ˆ Q ( i, j ) − Q ∗ ( i, j ) + γ p i,j ( v − ˆ v ) T , we use the con ver gence bound on the Q-function from (8) to show that the first term inv olving ˆ Q ( i, j ) − Q ∗ ( i, j ) is bounded by ϵ t a from (8), and the second term, p i,j ( v − ˆ v ) T , can be bounded as follows. From (8), we know that ˆ V ( x ) − V ∗ ( x ) ≤ ϵ ( t a ) , ∀ x ∈ X , (27) and using this property , we get: γ p i,j ( v − ˆ v ) T ≤ γ X x ′ ∈X p ( i, j, x ′ ) ϵ ( t a ) = γ ϵ ( t a ) . (28) Therefore, by using the triangle inequality , we can get that: | ¯ d i,j | ≤ (1 + γ ) ϵ ( t a ) , w .h.p. as t c ( i, j ) → ∞ , ∀ ( i, j ) ∈ X × U . ■ C. Pr oof of Theor em 3 In a manner similar to the proof of Theorem 1, we subtract equation (6) from (10) and introduce additional terms: ¯ d i,j = P t c ( i,j ) k =1 ˆ Q ( i, j ) − r i,j ( x i,j ( k )) − w i,j ( k ) t c ( i, j ) (29) − γ P t c ( i,j ) k =1 ˆ V ( x i,j ( k )) t c ( i, j ) − Q ∗ ( i, j ) + r i,j + γ ˆ p i,j v T + γ ˜ p i,j v T = P t c ( i,j ) k =1 ˆ Q ( i, j ) − Q ∗ ( i, j ) t c ( i, j ) − P t c ( i,j ) k =1 w i,j ( k ) t c ( i, j ) − P t c ( i,j ) k =1 r i,j ( x i,j ( k )) t c ( i, j ) − p i,j r T i,j ! − γ P t c ( i,j ) k =1 ˆ V ( x i,j ( k )) t c ( i, j ) − ˆ p i,j v T ! + γ ˜ p i,j v T . The first term simplifies to ˆ Q ( i, j ) − Q ∗ ( i, j ) , the second term, due to the law of large numbers (LLN), almost surely con verges to 0 , the third term conv erges to ˜ p i,j r T i,j , and the fourth term conv erges to γ ˆ p i,j ( v − ˆ v ) T . Therefore, ¯ d i,j → ˆ Q ( i, j ) − Q ∗ ( i, j ) + γ ˆ p i,j ( v − ˆ v ) T + ˜ p i,j ( r i,j + γ v ) T . ■ D. Pr oof of Theor em 4 Giv en that ¯ d i,j con verges as ¯ d i,j → ˆ Q ( i, j ) − Q ∗ ( i, j ) + γ ˆ p i,j ( v − ˆ v ) T + ˜ p i,j ( r i,j + γ v ) T , we use the con vergence bound on the Q-function from (8) to show that the first term, inv olving ˆ Q ( i, j ) − Q ∗ ( i, j ) , is bounded by ϵ ( t a ) from (8). The second term, p i,j ( v − ˆ v ) T , can be bounded as follows. From (8), we know that ˆ V ( x ) − V ∗ ( x ) ≤ ϵ ( t a ) , ∀ x ∈ X , (30) and using the above property , we get γ ˆ p i,j ( v − ˆ v ) T ≤ γ X x ′ ∈X ˆ p ( i, j, x ′ ) ϵ ( t a ) = γ ϵ ( t a ) . (31) Finally , the third term can be bounded using rigorous matrix algebra and norm inequalities: ˜ p i,j ( r i,j + γ v ) T ≥ Φ min . (32) Therefore, using triangular inequalities, we prov e that | ¯ d i,j | ≥ Φ min − (1 + γ ) ϵ ( t a ) , w .h.p. as t c ( i, j ) → ∞ . ■ E. Pr oof of Theor em 5 From Theorem 2, | ¯ d i,j | ≤ (1 + γ ) ϵ ( t a ) ≤ (1 + γ )¯ ϵ (33) with high probability as t c → ∞ , since ¯ ϵ ≥ ϵ ( t a ) . Similarly , by Theorem 3, | ¯ d i,j | ≥ Φ min − (1 + γ ) ϵ ( t a ) ≥ Φ min − (1 + γ )¯ ϵ (34) with high probability as t c → ∞ . Therefore, we can guar- antee attack detection with no false alarms as t c → ∞ for Algorithm 1, if and only if Φ min − (1 + γ )¯ ϵ > (1 + γ ) ¯ ϵ. That is, when the lo wer bound on the largest BDPM during an attack exceeds the upper bound on all BDPMs during no attack. This allo ws us to detect an attack when the lo wer bound is exceeded. W e can now rewrite the above equation as Φ min > 2 · (1 + γ )¯ ϵ. Since asymptotic attack detection with no false alarms with high probability can be achieved by Algorithm 1 if and only if (16) is true, this proves that (16) is a necessary and sufficient condition. ■ X . O P T I M A L S Y S T E M I D E N T I FI C AT I O N A. Pr oof of Theor em 6 Notice that minimizing E | ( p i,j − ˆ p i,j )( r i,j + γ v ) T | 2 is equiv alent to finding the minimum v ariance unbiased estimator (MVUE) of p i,j ( r i,j + γ v ) T , which is a linear function of a row of P . Referring to Theorem 3 in [29], we know that any linear function on any row of P can be efficiently estimated by the same linear function ov er its sample distribution estimator ˆ P . Therefore, ˆ p i,j ( r i,j + γ v ) T is a MVUE of p i,j ( r i,j + γ v ) T . Hence, ˆ p i,j = arg min ˆ p i,j | τ b E h | ˜ d i,j | 2 i , ∀ ( i, j ) ∈ X × U . ■ B. Pr oof of Theor em 7 In Theorem 6, we proved that ˆ p i,j ( r i,j + γ v ) T esti- mated from Algorithm 2 is a MVUE, which implies that E ˜ p i,j ( r i,j + γ v ) T = 0 , since E ( ˆ p i,j − p i,j )( r i,j + γ v ) T = E ˜ p i,j ( r i,j + γ v ) T (35) = 0 . Similarly , the term ˜ p i,j ( r i,j + γ v ) T can have its variance bound using the Cauchy-Schwarz inequality as E | ˜ p i,j ( r i,j + γ v ) T | 2 ≤ E ∥ ˜ p i,j ∥ 2 · ∥ r i,j + γ v ∥ 2 . (36) Since E ∥ ˜ p i,j ∥ 2 = E " N X k =1 ˜ p 2 i,j,k # and E ˜ p 2 i,j,k = p i,j,k − p 2 i,j,k t b ( i, j ) , which can be deriv ed with elementary estimation theory . Hence, E | ˜ p i,j ( r i,j + γ v ) T | 2 → 0 , as t b ( i, j ) → ∞ , (37) with a con vergence rate of O 1 t b ( i,j ) . Since ˜ p i,j ( r i,j + γ v ) T has a mean of 0 and its variance con verges to 0, it con verges to 0 in the mean-squared sense (m.s.). Now , we prove its conv ergence rate by inv oking Cheby- shev’ s inequality as | ˜ p i,j ( r i,j + γ v ) T | ≤ K · E ∥ ˜ p i,j ∥ 2 1 / 2 · ∥ r i,j + γ v ∥ , w .h.p. , (38) for some large constant K . Since E ∥ ˜ p i,j ∥ 2 con verges to 0 as O 1 t b ( i,j ) , it follows that E ∥ ˜ p i,j ∥ 2 1 / 2 con verges to 0 as O 1 √ t b ( i,j ) . Using the above fact and (38), this proves that (19) also has a con vergence rate of O 1 √ t b ( i,j ) . ■ X I . E X T E N S I O N T O D Y N A M I C A T TAC K S A. Pr oof of Theor em 8 The fact that the asymptotic limit for the BDPM when no attack occurs is unchanged is trivially true. Since the start of the detection phase is of no consequence when no attack occurs. For the case of the asymptotic limit for the BDPM when an attack does occur, we decompose the BDPM series as follo ws, ¯ d i,j = P t c ( i,j ) k =1 d i,j ( k ) t c ( i, j ) , (39) = P t d − 1 k =1 d i,j ( k ) t c ( i, j ) + P t c ( i,j ) k = t d d i,j ( k ) t c ( i, j ) , = t d t c ( i, j ) · P t d − 1 k =1 d i,j ( k ) t d + t c ( i, j ) − t d t c ( i, j ) · P t c ( i,j ) k = t d d i,j ( k ) t c ( i, j ) − t d , where t d is the time when the detection phase starts. As t c ( i, j ) → ∞ , the two fractions con verge as t d t c ( i,j ) → 0 and t c ( i,j ) − t d t c ( i,j ) → 1 , thereby approaching the same limit as the asynchronous attack limit. Finally since asymptotic limits for both cases remain the same Theorem 5 similarly applies and we obtain the same information advantage condition. ■ B. Pr oof of Theor em 9 The fact that the asymptotic limit for the BDPM when no attack occurs is unchanged is trivially true. Since the start of the detection phase is of no consequence when no attack occurs. For the case of the asymptotic limit for the BDPM when an attack does occur, we start by defining the attack and safe duration sets. Let T a denote the set of time indices when an attack was occurring, i.e, t ∈ T a ⇐ ⇒ I a ( t ) = 1 . Similarly , let T s be the complementary set, i.e, t ∈ T s ⇐ ⇒ I a ( t ) = 0 . W e now , decompose the BDPM series, in the following manner , ¯ d i,j = P t c ( i,j ) k =1 d i,j ( k ) t c ( i, j ) , (40) = P k ∈T s d i,j ( k ) t c ( i, j ) + P k ∈T a d i,j ( k ) t c ( i, j ) , = |T s | t c ( i, j ) · P k ∈T s d i,j ( k ) t d + |T a | t c ( i, j ) · P k ∈T a d i,j ( k ) t c ( i, j ) − t d . Now , as t c ( i, j ) → ∞ , the two fractions con ver ge as |T s | t c ( i,j ) → 1 − ν and |T a | t c ( i,j ) → ν . Hence the BDPM when under a dynamic attack has asymptotic limits as follows, ¯ d i,j → (1 − ν )( ˆ Q ( i, j ) − Q ∗ ( i, j ) + γ p i,j ( v − ˆ v ) T ) (41) + ν ( ˆ Q ( i, j ) − Q ∗ ( i, j ) + γ p i,j ( v − ˆ v ) T + · ˜ p i,j ( r i,j + γ v ) T ) = ˆ Q ( i, j ) − Q ∗ ( i, j ) + γ p i,j ( v − ˆ v ) T + ν · ˜ p i,j ( r i,j + γ v ) T . Finally we apply Theorem 5 with the new asymptotic limits to obtain the information advantage condition under a dynamic attack as, ν · Φ min > 2(1 + γ )¯ ϵ. ■ X I I . C O S T T R A D E O FF A N D C O N V E R G E N C E A N A L Y S I S A. Pr oof of Lemma 1 By Theorem 7, after observing t b samples, the adversary can estimate each transition row with error of order ˜ p i,j ( r i,j + γ v ) T = O 1 p t b ( i, j ) ! . (42) Hence, the minimum detectable value drift generated by an optimally learning adversary can be as small as order t − 1 / 2 b . On the other hand, by the information advantage condition, reliable detection requires (1 + γ ) ϵ ( t a ) < Φ min 2 . (43) Therefore, if the adversary has learned for t b samples and induces a drift of order Φ min = O ( t − 1 / 2 b ) , the agent must achiev e value-estimation error ϵ ( t a ) = O ( t − 1 / 2 b ) (44) in order to detect the attack with probability tending to one. Finally , for model-free reinforcement learning in discounted MDPs, achie ving value error ϵ requires at least t a = Ω( ϵ − 2 ) (45) samples. Substituting ϵ = O ( t − 1 / 2 b ) yields t a = Ω( t b ) . (46) This prov es the claim. ■ B. Pr oof of Theor em 10 Giv en that the adversary had t b to learn a policy , the goal is to find an upper bound on the minimum number of samples needed to achieve information advantage as, Φ min > (1 + γ ) ϵ, min i,j ∈X ×U | ˜ p i,j ( r i,j + γ v ) | > (1 + γ ) ϵ. (47) Howe ver , in Theorem 7, we proved that | ˜ p i,j ( r i,j + γ v ) T | ∼ O 1 / p t b ( i, j ) and since min i,j t b ( i, j ) ∼ O t b |X ||U | . W e get, O p |X ||U | √ t b ! > (1 + γ ) ϵ. (48) Therefore, ϵ ∼ O √ |X ||U | √ t b (1+ γ ) . Howe ver , we kno w that the lower bound on the sample complexity of Q-learning for the infinite-horizon discounted-rew ard problem is t a ∼ Ω |X ||U | (1 − γ ) 3 ϵ 2 , and that model-free RL algorithms do indeed achiev e a sample complexity of t a ∼ Θ |X ||U | (1 − γ ) 3 ϵ 2 , (49) (refer to [30]). Therefore substituting (49) in (48), we finally get, t a ∼ Θ t b (1 + γ ) 2 (1 − γ ) 3 . ■ R E F E R E N C E S [1] B. Kehoe, S. Patil, P . Abbeel, and K. Goldberg, “ A survey of research on cloud robotics and automation, ” IEEE T ransactions on Automation Science and Engineering , vol. 12, no. 2, pp. 398–409, 2015. [2] D. I. Urbina, J. A. Giraldo, A. A. Cardenas, N. O. Tippenhauer , J. V alente, M. Faisal, J. Ruths, R. Candell, and H. Sandberg, “Lim- iting the impact of stealthy attacks on industrial control systems, ” in Proceedings of the 2016 ACM SIGSAC Confer ence on Computer and Communications Security , ser. CCS ’16. New Y ork, NY , USA: Association for Computing Machinery , 2016, p. 1092–1105. [3] S. M. Dibaji, M. Pirani, D. B. Flamholz, A. M. Annaswamy , K. H. Johansson, and A. Chakrabortty , “ A systems and control perspective of cps security , ” Annual Reviews in Contr ol , vol. 47, pp. 394–411, 2019. [4] M. Jamei, E. Stewart, S. Peisert, A. Scaglione, C. McP arland, C. Roberts, and A. McEachern, “Micro synchrophasor-based intrusion detection in automated distribution systems: T o ward critical infrastructure security , ” IEEE Internet Computing , vol. 20, no. 5, pp. 18–27, 2016. [5] H. Sandberg, S. Amin, and K. H. Johansson, “Cyberphysical security in networked control systems: An introduction to the issue, ” IEEE Control Systems Magazine , vol. 35, no. 1, pp. 20–23, 2015. [6] C.-Z. Bai, F . Pasqualetti, and V . Gupta, “Data-injection attacks in stochastic control systems: Detectability and performance tradeoffs, ” Automatica , vol. 82, pp. 251–260, 2017. [7] Y . Chen, S. Kar , and J. M. Moura, “Cyber physical attacks with control objectiv es and detection constraints, ” in 2016 IEEE 55th Conference on Decision and Control (CDC) , 2016, pp. 1125–1130. [8] T . R., C. Murguia, and J. Ruths, “Tuning windowed chi-squared detec- tors for sensor attacks, ” in 2018 Annual American Contr ol Conference (ACC) , 2018, pp. 1752–1757. [9] Y . Mo, S. W eerakkody , and B. Sinopoli, “Physical authentication of control systems: Designing watermarked control inputs to detect coun- terfeit sensor outputs, ” IEEE Control Systems Magazine , vol. 35, no. 1, pp. 93–109, 2015. [10] M. Zhu and S. Mart ´ ınez, “On the performance analysis of resilient networked control systems under replay attacks, ” IEEE T ransactions on Automatic Contr ol , vol. 59, no. 3, pp. 804–808, 2014. [11] P . Hespanhol, M. Porter , R. V asudevan, and A. Aswani, “Statistical watermarking for networked control systems, ” in 2018 Annual American Contr ol Conference (ACC) , 2018, pp. 5467–5472. [12] H. Liu, J. Y an, Y . Mo, and K. H. Johansson, “ An on-line design of physical watermarks, ” in 2018 IEEE Confer ence on Decision and Contr ol (CDC) , 2018, pp. 440–445. [13] R. S. Smith, “ A decoupled feedback structure for covertly appropriating networked control systems, ” IF AC Pr oceedings V olumes , vol. 44, no. 1, pp. 90–95, 2011, 18th IF A C W orld Congress. [14] B. Satchidanandan and P . R. Kumar , “Dynamic watermarking: Activ e defense of network ed cyber–ph ysical systems, ” Pr oceedings of the IEEE , vol. 105, no. 2, pp. 219–240, 2017. [15] S. W eerakkody and B. Sinopoli, “Detecting integrity attacks on control systems using a moving target approach, ” in 2015 54th IEEE Conference on Decision and Contr ol (CDC) , 2015, pp. 5820–5826. [16] A. Kanellopoulos and K. G. V amv oudakis, “ A moving target defense control framework for cyber -physical systems, ” IEEE Tr ansactions on Automatic Contr ol , vol. 65, no. 3, pp. 1029–1043, 2020. [17] Z. Zhang, R. Deng, D. K. Y . Y au, P . Cheng, and J. Chen, “ Analysis of moving tar get defense against false data injection attacks on po wer grid, ” IEEE T ransactions on Information F or ensics and Security , vol. 15, pp. 2320–2335, 2020. [18] P . Griffioen, S. W eerakkody , and B. Sinopoli, “ An optimal design of a moving target defense for attack detection in control systems, ” in 2019 American Control Conference (ACC) , 2019, pp. 4527–4534. [19] S. M. Dibaji, M. Pirani, D. B. Flamholz, A. M. Annaswamy , K. H. Johansson, and A. Chakrabortty , “ A systems and control perspective of cps security , ” Annual Reviews in Contr ol , vol. 47, pp. 394–411, 2019. [20] A. Hoehn and P . Zhang, “Detection of covert attacks and zero dynamics attacks in cyber -physical systems, ” in 2016 American Contr ol Confer- ence (ACC) , 2016, pp. 302–307. [21] J. F . Fisac, A. K. Akametalu, M. N. Zeilinger, S. Kaynama, J. Gillula, and C. J. T omlin, “ A general safety frame work for learning-based control in uncertain robotic systems, ” IEEE T ransactions on Automatic Control , vol. 64, no. 7, pp. 2737–2752, 2019. [22] F . Berkenkamp, M. Turchetta, A. Schoellig, and A. Krause, “Safe model- based reinforcement learning with stability guarantees, ” in Advances in Neural Information Pr ocessing Systems , I. Guyon, U. V . Luxbur g, S. Bengio, H. W allach, R. Fergus, S. V ishwanathan, and R. Garnett, Eds., vol. 30. Curran Associates, Inc., 2017. [23] S. T u and B. Recht, “Least-squares temporal difference learning for the linear quadratic regulator , ” in Pr oceedings of the 35th International Confer ence on Machine Learning , ser . Proceedings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80. PMLR, 10–15 Jul 2018, pp. 5005–5014. [24] M. J. Khojasteh, A. Khina, M. Franceschetti, and T . Javidi, “Learning- based attacks in cyber-ph ysical systems, ” IEEE T ransactions on Contr ol of Network Systems , vol. 8, no. 1, pp. 437–449, 2021. [25] A. Rangi, M. J. Khojasteh, and M. Franceschetti, “Learning based attacks in cyber physical systems: Exploration, detection, and control cost trade-offs, ” in Pr oceedings of the 3rd Conference on Learning for Dynamics and Control , ser . Proceedings of Machine Learning Research, A. Jadbabaie, J. L ygeros, G. J. Pappas, P . P . A. Parrilo, B. Recht, C. J. T omlin, and M. N. Zeilinger , Eds., vol. 144. PMLR, 07 – 08 June 2021, pp. 879–892. [26] R. Rani and M. Franceschetti, “Detection of man-in-the-middle attacks in model-free reinforcement learning, ” in Pr oceedings of The 5th Annual Learning for Dynamics and Control Conference , ser. Proceedings of Machine Learning Research, N. Matni, M. Morari, and G. J. Pappas, Eds., vol. 211. PMLR, 15–16 Jun 2023, pp. 993–1007. [Online]. A vailable: https://proceedings.mlr .press/v211/rani23a.html [27] ——, “Detection of man in the middle attacks in model-free reinforce- ment learning for the linear quadratic regulator , ” in 2024 American Contr ol Conference (ACC) , 2024, pp. 4038–4043. [28] C. J. W atkins and P . Dayan, “Q-learning, ” Machine learning , vol. 8, no. 3-4, pp. 279–292, 1992. [29] D. S. Bai, “Efficient estimation of transition probabilities in a markov chain, ” Ann. Statist. , vol. 3, no. 1, pp. 1305–1317, 1975. [30] J. He, D. Zhou, and Q. Gu, “Nearly minimax optimal reinforcement learning for discounted mdps, ” in Advances in Neural Information Pr ocessing Systems , M. Ranzato, A. Beygelzimer , Y . Dauphin, P . Liang, and J. W . V aughan, Eds., vol. 34. Curran Associates, Inc., 2021, pp. 22 288–22 300.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment