모델프리 강화학습을 이용한 MITM 공격 탐지와 보안 강화
본 논문은 사이버‑물리 시스템에서 학습 기반 중간자 공격을 탐지하기 위해 기존 Bellman Deviation Detection(BDD) 프레임워크를 확장한다. 보상 함수를 현재‑다음 상태에 의존하도록 일반화하고, 적의 최적 시스템 식별 전략을 도출한 뒤, 탐지 시간 복잡도가 적의 학습 시간에 선형으로 비례함을 증명한다. 또한 비동기·간헐적 공격 상황에서도 검증 가능한 알고리즘을 제시한다.
저자: Rishi Rani, Massimo Franceschetti
본 논문은 사이버‑물리 시스템(CPS)에서 강화학습 기반 제어를 수행하는 에이전트가 학습 기반 중간자(MITM) 공격을 실시간으로 탐지할 수 있는 모델‑프리 프레임워크를 제안한다. 기존 연구에서는 공격자가 시스템 모델을 완전히 알거나, 단순 재생 공격을 수행하는 경우에 초점을 맞추었으며, 탐지 방법도 주로 모델 기반 혹은 워터마크 삽입 방식에 의존했다. 그러나 실제 환경에서는 공격자가 초기에는 시스템에 대한 지식이 없고, 관측을 통해 점진적으로 모델을 학습한다는 점을 간과했다. 저자는 이러한 현실을 반영하여, 에이전트와 적이 모두 강화학습을 수행하는 상황을 MDP(Markov Decision Process) 프레임워크 안에서 동시에 모델링한다.
**1. 문제 정의와 모델 확장**
기존 MDP 공격 모델은 보상이 현재 상태와 행동에만 의존한다고 가정했지만, 논문은 보상 함수를 r(x_t, u_t, x_{t+1}) 로 확장한다. 이는 전이 추정 오류가 보상 통계에 미치는 영향을 정량화할 수 있게 해준다. 또한, 보상 노이즈 w_t 를 i.i.d. 영 평균으로 두면서도 분산이 무한할 수 있다는 일반적인 가정을 채택해, 네트워크 지연·패킷 손실 등 현실적인 비정상 노이즈 상황에서도 알고리즘이 유효함을 보장한다.
**2. 에이전트와 적의 학습 과정**
에이전트는 모델‑프리 RL 알고리즘을 사용해 Q‑함수 \hat{Q} 를 학습한다. 학습 과정에서 얻은 추정 오차 \epsilon(t_a) 가 0 으로 수렴한다는 확률적 보장을 전제로 한다. 적은 초기 학습 단계에서 시스템 궤적 τ_b 를 관측하고 전이 행렬 \hat{P} 를 추정한다. 적의 학습 단계에서는 에이전트와 달리 제어 권한이 없으므로, \hat{P} 에 대한 수렴 보장은 가정하지 않는다.
**3. 최적 시스템 식별(SI) 전략**
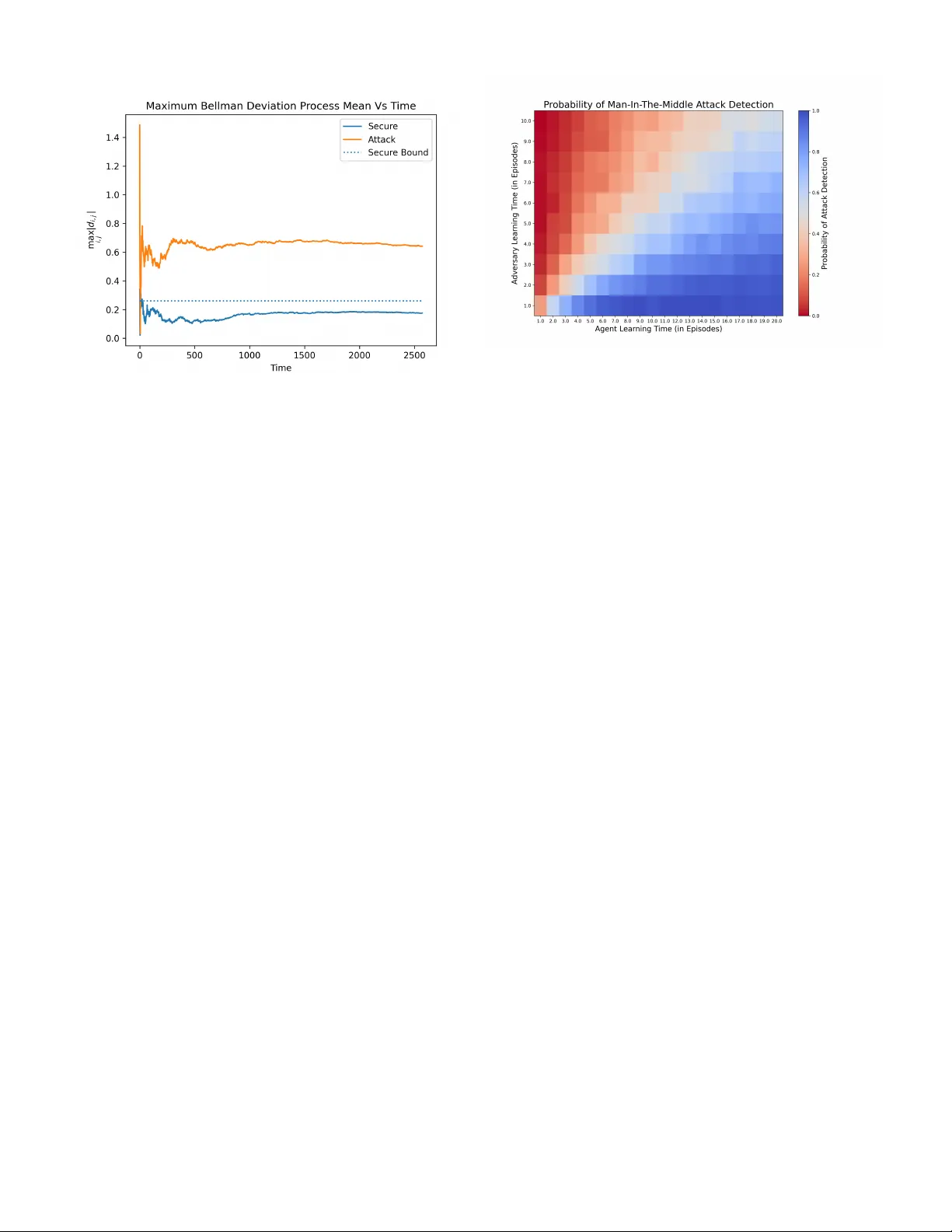
적의 목표는 공격 단계에서 에이전트가 탐지하기 어려운 최소값 편차(Φ_min)를 만들면서도, 목표 상태로 시스템을 유도하는 것이다. 이를 위해 적은 관측된 전이와 보상 데이터를 이용해 \hat{P} 를 선택한다. 논문은 이 SI 알고리즘이 “값 편차 최소화”라는 최적화 문제의 해이며, 이는 적이 만들 수 있는 가장 작은 탐지 가능 편차를 의미한다는 수학적 증명을 제공한다.
**4. Bellman Deviation Detection (BDD) 알고리즘**
BDD는 두 핵심 개념인 Bellman Deviation Process(BDP)와 그 평균(BDPM)을 이용한다. BDP는 각 (state, action) 쌍에 대해 \hat{Q}(i,j) - r_i,j - w_i,j(k) - γ\hat{V}(x_{i,j}(k)) 로 정의되며, 이는 TD 오차와 동일하다. BDPM은 해당 BDP들의 샘플 평균이며, 방문 횟수가 충분히 큰 쌍만을 남겨 노이즈 영향을 억제한다. 알고리즘은 다음 절차로 동작한다: (1) 공격 단계에서 수집된 궤적 τ_c 를 순회하며 BDP를 누적, (2) 각 (i,j) 에 대해 방문 횟수 T
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기