A General Model for Deepfake Speech Detection: Diverse Bonafide Resources or Diverse AI-Based Generators
In this paper, we analyze two main factors of Bonafide Resource (BR) or AI-based Generator (AG) which affect the performance and the generality of a Deepfake Speech Detection (DSD) model. To this end, we first propose a deep-learning based model, ref…
Authors: Lam Pham, Khoi Vu, Dat Tran
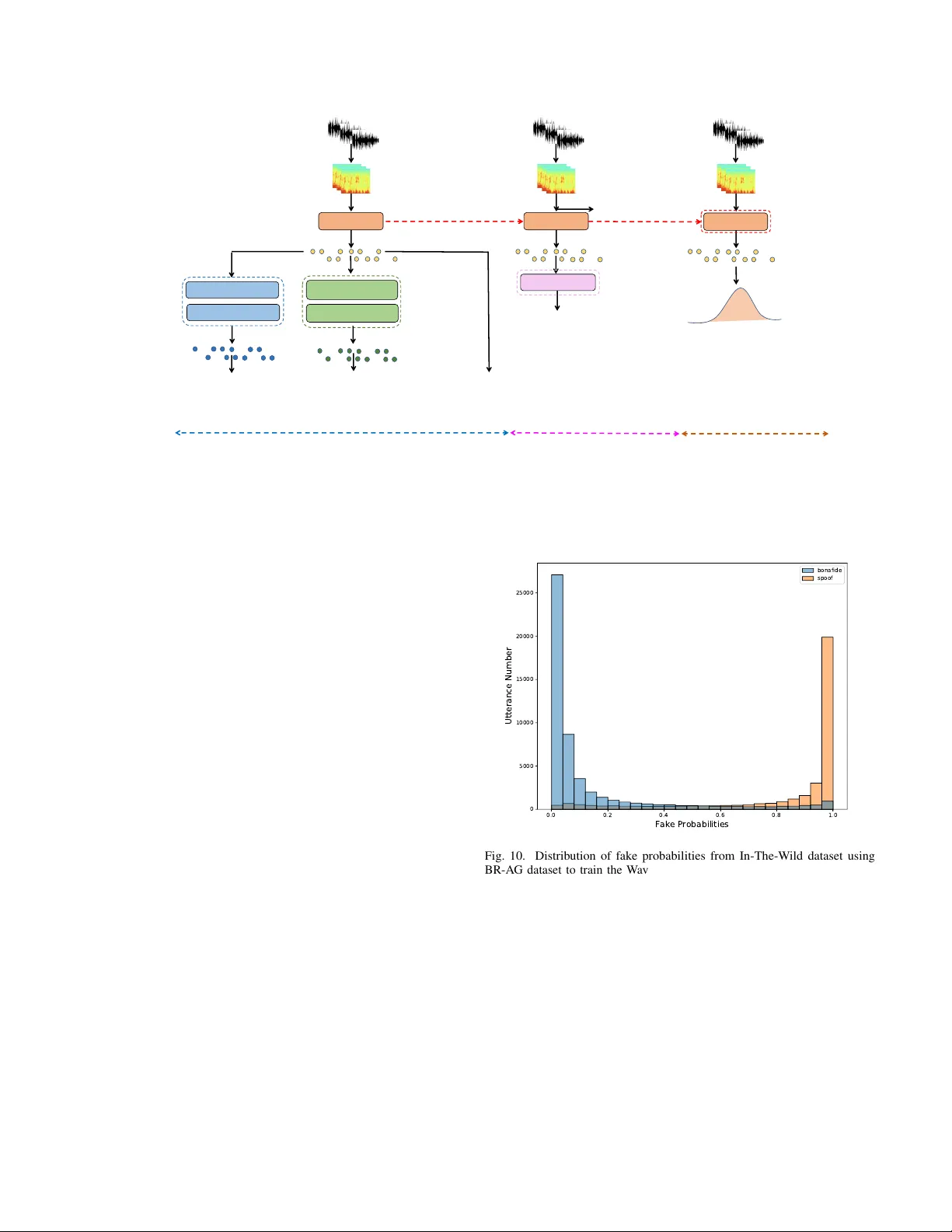
A General Model for Deepfak e Speech Detection: Di v erse Bonafide Resources or Di v erse AI-Based Generators Lam Pham 1 ∗ , Khoi V u 2 ∗ , Dat T ran 2 ∗ , David Fischinger 1 , Simon Freitter 1 , Marcel Hasenbalg 1 , Davide Antonutti 1 , Alexander Schindler 1 , Martin Boyer 1 , Ian McLoughlin 3 Abstract —In this paper , we analyze two main factors of Bonafide Resource (BR) or AI-based Generator (A G) which affect the performance and the generality of a Deepfake Speech Detection (DSD) model. T o this end, we first pr opose a deep-learning based model, referr ed to as the baseline. Then, we conducted experiments on the baseline by which we indicate how Bonafide Resource (BR) and AI-based Generator (A G) factors affect the threshold score used to detect fake or bonafide input audio in the inference process. Given the experimental r esults, a dataset, which re-uses public Deepfake Speech Detection (DSD) datasets and shows a balance between Bonafide Resource (BR) or AI-based Generator (A G), is proposed. W e then train various deep-lear ning based models on the proposed dataset and conduct cross-dataset evaluation on different benchmark datasets. The cross-dataset evaluation results pro ve that the balance of Bonafide Resources (BR) and AI-based Generators (A G) is the key factor to train and achiev e a general Deepfake Speech Detection (DSD) model. I . I N T RO D U C T I O N Over the past few years, generative AI presents an impressive de velopment due to remarkable adv ancements in deep-learning techniques. Regarding applying generati ve AI in audio domain, especially focusing on human speech, a wide range of high- quality applications such as media production, AI-based music composer , audio-based chatbot, etc. ha ve been introduced and used popularly . Howe ver , this also poses potential risks when generated human speech by AI-based generators is used for criminal purposes. T o address this concern, the audio forensic task of Deepf ake Speech Detection (DSD) has been raised and drawn much attention from the audio research community . Indeed, various public datasets from scientific papers and challenge competitions have been proposed for the DSD task recently (i.e., The survey paper [1] indicates that four DSD datasets each year ha ve been published from 2021). Gi ven the public datasets, a wide range of deep-learning based models hav e been proposed to detect the deepfake audio, referred to as DSD models. The state-of-the-art DSD models [2]–[4] hav e le veraged pre-trained deep neural networks which were trained on large-scale datasets of human speech for the up-stream task of Speech-to-T ext. Then, these pre-trained models are fine- tuned on the down-stream task of DSD. In particular , authors L. Pham, D. Fischinger, S. Freitter , M. Hasenbalg, D. Antonutti, A. Schindler, and M. Boyer are with Austrian Institute of T echnology , Austria. K. V u and D. Tran are with FPT University , V ietnam. I. McLoughlin is with Singapore Institute of T echnology , Singapore. (*) Main and equal contribution into the paper . 4- secon d Segments Pre - tra ined WavLM MLP . . . . Audio Embed ding p F p B Pre dict ed Pro babil iti es Fully Co nnected 01 ReLU Dro pout Fully Co nnected 02 ReLU Dro pout Fully Co nnected 03 Soft, max Thre shold Scor e Fig. 1. The proposed baseline architecture in [2] achiev ed the best performance by fintuning XLSR model, a variant of W ave2V ec2 [5] released by Meta. Meanwhile, authors in [3] lev eraged and finetuned W avLM [6] released by Microsoft. The authors in [4] made ef fort to benchmark a wide range of popular pre-trained models proposed for audio tasks. Howe ver , the state-of-the-art DSD models present two main concerns. First, these DSD models use Equal Error Rate (EER) with free threshold score as the main metric to compare the performance among proposed models. The EER scores are reported and treated as indi vidual values as they are computed from different testing datasets rather than on all testing datasets. For each EER v alue obtained from a specific testing dataset, there is a corresponding threshold score which is used to detect fak e or bonafile audio. These threshold scores may be significantly dif ferent from different testing datasets. Ho wev er, only one threshold score must be selected to detect fake or bonafile audio from an unseen data in the inference process. Therefore, if the threshold scores are much different from different testing datasets, it leads the overfitting issue and the DSD model is not general. In other words, proposed high- performance DSD models with low EER values ev aluated on individual testing datasets may be not really reliable if the corresponding threshold scores are not presented, compared, and analyzed. Ho wev er, the state-of-the-art DSD systems ha ve not reported or analyzed threshold scores across testing datasets. Second, during training a DSD model, Softmax-based layer is normally used to separate f ake and bonafide audio into two distributions with the boundary probability of 0.5. Howe ver , the unbalance issues of Bonafide Resource (BR) or AI-based Generators (A G) may lead the fake or bonafide distrib utions to mainly locate at the boundary (e.g., around the probability of 0.5). Therefore, increasing or decreasing the probability boundary (e.g., upper or lower than 0.5) helps to find the optimized boundary probability from which the EER and the corresponding threshold score are computed. Howe ver , none of research has analyzed the role of Bonafide Resource (BR) or AI-based Generators (A G) which may significantly af fect the final probability boundary . By addressing these concerns, we make the follo wing main contributions in this paper: • W e conduct extensi ve experiments to indicate the roles of Bonafide Resource (BR) and AI-based Generator (A G) which af fect a DSD model performance, the EER metric and the corresponding threshold score. • Giv en the e xperimental results, we propose a dataset for DSD task which re-uses public DSD datasets and shows a balance between Bonafide Resource (BR) and AI-based Generator (A G). • W ith the proposed dataset, we train various deep-learning based model for DSD task. The proposed models prov es general when we conduct cross-dataset ev aluation on different benchmark datasets and using a fixed threshold. I I . E V A L U A T I O N O F B O NA FI D E R E S O U R C E A N D A I - B A S E D G E N E R A T O R F AC T O R S A. Pr oposed Baseline Model T o ev aluate the role of Bonafide Resource (BR) and AI- Based Generator (A G) to affect the DSD model performance, we first propose a deep-learning based model which is referred to as the baseline in this paper . Inspired by lev eraging pre- trained models [2]–[4] from the state-of-the-art, we also use the pre-trained W avLM [6] model to construct the baseline. In particular , the baseline is shown in Fig. 1. First, 4-second audio segments are fed into the pre-trained W avLM [6] model which was trained on large-scale datasets for the task of Speech- to-T ext. By lev eraging the pre-trained W avLM model [6], audio embeddings (i.e., The audio embedding is a vector - based presentation) e xtracted from this model present general acoustic features of human speech. Then audio embeddings are explored by a Multilayer Perceptron (MLP) which is performed by three Dense layers. During training the baseline, the pre- trained W avLM model is frozen. In other words, only trainable parameters of the MLP component is updated during the training process to adapt the DSD task. B. The Statistics of Public and Benchmark DSD Datasets W e now analyze the statistics of public and benchmark datasets proposed for the DSD task (i.e., Only English datasets are analyzed). T o this end, we present the public datasets for the DSD task in T able I which were also summarized in our previous work [1]. The T able I indicates an unbalanced issue between Bonafide Resource (BR) and AI-Based Generator (A G). Indeed, ASVspoof 2021 (DF task) [12] presents the largest number of A G (e.g., more than 100 T ext-to-Speech (TTS) and V oice Con version (VC)) but is limited by the number of speakers (e.g., 21 males and 27 females). In contrast, some datasets such as ASVspoof5 [25], W a veFake [13], LibriSe Real Speakers Fake Utterances Fake Speech Generators Real Speakers 106 246500 10 107 108978 19 48 163114 13 48 589221 100 107 41280 5 2 117985 6 500 25000 2 140 195541 7 ASVspoof 2015 ASVspoof 2019 ASVspoof 2021 LA ASVspoof 2021 DF VoC.v WaveFake FakeAVCeleb FoR Fig. 2. The statistics of DSD datasets in English V oc [20] le verage the Librispeech [21], a large-scale of human speech dataset, as the bonafide resource. This is effecti ve to construct a general human speech dataset with div erse speech characteristics such as gender , accent, loudness, speech flo w , etc. that reflects real-worl d conv ersations. Howe ver , these datasets present a limitation of A G and unbalanced issue between TTS and VC systems. Similarly , A V -Deepfake1M [22] presents a large number of fake utterances but fake utterances are generated from only 2 TTS systems. The Fig. 2 again indicates an unbalance issue among Bonafide Resource (BR), AI-Based Generators (A G), and the fake utterance number regarding proposed DSD datasets without using the Librispeech as the bonafide resource. C. Experimental Settings Giv en the DSD dataset concerns above, we no w setup an experiment to e valuate the roles of Bonafide Resource (BR) and AI-Based Generators (A G). First, ASVspoof 2019 (LA), ASVspoof 2021 (LA), and ASVspoof 2021 (DF) are grouped into one dataset with totally 53,552/861,304 of bonafide/fake utterances. W e gather these datasets as they use bonafide audio from a limited speaker volunteers but apply div erse AI-Based Generators (e.g., more than 100 generators). This data is referred to as the A G dataset Meanwhile, ASVspoof 2024 [25] train and dev elopment subsets are also grouped into one dataset with totally 50,131/273,176 of bonafide/fake utterances. As these datasets use di verse bonafide audio from Libreispeech [21], these are group together to present a div erse bonafide dataset, referred to as the BR dataset. Gi ven the BR dataset and the A G dataset as sho wn in T able II, we setup two test cases. In the first test case, we ev aluate the role of A G. W e use the A G dataset to train the baseline model. After the training process, we test the baseline model on the In-The-W ild [18] dataset. In the second test case, we ev aluate the role of BR. W e use the BR-dataset to train the T ABLE I P U BL I C A N D B E NC H M A RK D AT A S E TS P RO P O SE D F O R D E E PFA K E S P EE C H D E T EC T I O N ( D S D ) I N E N G L IS H Datasets Y ears Speakers Utt. No. Fake speech Real Speech (Male/Female) (Bonafide/Fake) Generators Resources ASVspoof 2015 [7](audio) 2015 45/61 16,651/246,500 10 (7 VC, 3 TTS) Speaker V olunteers FoR [8](audio) 2019 140 -/195541 7 TTS Kaggle [9] ASVspoof 2019 (LA task) [10](audio) 2019 46/61 12,483/108,978 19 (8VC, 11 TTS) Speaker V olunteers DFDC [11](video) 2020 3426 128,154/104,500 1 TTS Speak er V olunteers ASVspoof 2021 (LA task) [12](audio) 2021 21/27 18,452/163,114 13 TTS/VC Speaker V olunteers ASVspoof 2021 (DF task) [12](audio) 2021 21/27 22,617/589,212 100+ TTS/VC Speaker V olunteers W aveFak e [13](audio) 2021 0/2 -/117,985 6 TTS LJSPEECH [14], JSUT [15] FakeA VCeleb [16](video) 2022 250/250 570/25,000 2 TTS V ox-Celeb2 [17] In-the-Wild [18](video) 2022 58 19963/11816 n/a Self-collected V oc.v [19](audio) 2023 46/61 14,250/41,280 5 TTS ASVspoof 2019 LibriSeV oc [20](audio) 2023 n/a 13,201/79,206 6 TTS/VC Librispeech [21] A V -Deepfake1M [22], [23](video) 2023 2,068 286,721/860,039 2 TTS V oxceleb2 [17] MLAAD [24](audio) 2024 n/a -/76,000 54 TTS Librispeech [21] ASVspoof5 [25](audio) 2024 n/a 188,819/815,262 28 (15 TTS, 6 VC, 7 A T) Librispeech [21] T ABLE II P RO P OS E D D A T A S E T S TO B AL A N C E A I- B AS E D G E N ER ATO R A N D B O NA FI DE R E SO U R C E FA CT O RS Datasets Bonafide Utterances Fake Utterances A G dataset 53,552 861,304 BR dataset 50,131 273,176 BR-A G dataset 103,683 1,134,408 0.0 0.2 0.4 0.6 0.8 1.0 Fake Probabilities 0 5000 10000 15000 20000 25000 30000 35000 4-second Audio Segment Number bonafide spoof Fig. 3. Distribution of fake probabilities from In-The-W ild dataset using AG dataset to train the baseline model baseline model. Then, we test the baseline model on the In- The-W ild [18] dataset. W e select In-The-Wild [18] for testing in both test cases as this dataset has been widely used for cross- dataset ev aluation in the state-of-the-art papers and has not presented the A G or BR information. This dataset also presents v arious noise background, different audio quality which reflect real scenarios, and balance between 52,605 4-second bonafide segments and 35483 4-second fak e segments. The baseline model is constructed with Pytorch framework and is trained on GPU GeForce 12 GB. W e uses Adam [26] algorithm for optimization. The training process is stop after 30 epoch and uses a fixed learning rate of 1E-5. Notably , this experiment is for 4-second audio segment input. In other words, original audio utterances are split into 4-second audio segments before feeding into the model. Regarding ev aluating metrics, we present F1 score, Accuracy , AuC, and EER. The EER is accompanied with the threshold score. W e use the probability of 0.5 to compute Accuracy , F1 Score and AuC (i.e., if the fake probability is larger than 0.5, the input audio is referred to as fake). Meanwhile, we follow ASVspoof challenge to compute EER and the 8 6 4 2 0 2 Logarithmic Scores 0 500 1000 1500 2000 4-second Audio Segment Number Threshold: -1.38 bonafide spoof Fig. 4. Distribution of Logarit scores from In-The-Wild dataset using AG dataset to train the baseline model Fig. 5. Distribution of fake probabilities from In-The-Wild dataset using BR dataset to train the baseline model corresponding threshold basing on the Logarithmic scores. Particularly , the Logarithmic score is computed from fake and bonafide probabilities in the following equation: Log S core = log ( P B /P F ) 10 , (1) where P B and P F are the bonafide and fake probabilities, respectiv ely . D. Experimental Results and Discussion As Fig. 3 and Fig. 4 show , this indicates that the distribution of fak e probabilities (e.g., the output of Softmax layer) from fake audio locates near one when we train the baseline on 4 2 0 2 Logarithmic Scores 0 250 500 750 1000 1250 1500 1750 4-second Audio Segment Number Threshold: 1.45 bonafide spoof Fig. 6. Distribution of Logarit scores from In-The-Wild dataset using BR dataset to train the baseline model Bonafide Fake Bonafide Fake 54.3 45.7 4.5 95.5 Fig. 7. Confusion matrix (%) for In-The-W ild dataset using the AG dataset to train the baseline model (The boundary probability of 0.5) A G-dataset. Meanwhile, the distribution of fake probabilities from bonafide audio spreads from zero to near one. This leads the threshold of -1.38 when EER of 0.85 is computed. In other words, the f ake probability is significant larger than the bonafide probability (e.g., f ake probability is near one) to decide a fak e audio input if we use the threshold score of -1.38. In contrast, when we train the baseline on the BR-dataset, the distribution of fake probabilities from fake audio spread from zero to one while the fake probabilities from bonafide audio locate near zero. This leads the threshold v alue of 1.45 when the EER of 0.82 is computed. In other words, the fak e probability is significant smaller than bonafide probability (e.g., the fak e probability is near zero) to decide a fake audio input if we use the threshold score of 1.45 as the boundary . As a result, we conclude that if we train a model on either A G-dataset or BR-dataset and then use the threshold score accompanied with EER metric for the inference process, this leads the ov erfitting issue on the training dataset and may obtain significant misclassification on unseen data. Indeed, instead of using the threshold score from the EER metric, we use the probability of 0.5 (e.g., The output of Softmax layer) as the probability boundary to decide fak e or bonafide audio input, the confusion matrix shown in Fig. 7 and Fig. 8 indicate that Bonafide Fake Bonafide Fake 97.1 2.9 57.4 42.6 Fig. 8. Confusion matrix (%) for In-The-Wild dataset using the BR dataset to train the baseline model (The boundary probability of 0.5) the misclassification occurs on bonafide audio if training on A G dataset and on fake audio if training on BR dataset. I I I . P RO P O S E D D S D D A TA S E T , D S D M O D E L , A N D C RO S S - T E S T E V A L U A T I O N A. Pr oposed Dataset for DSD task Experimental results in the Section II-D indicate that the unbalance issue between Bonafide Resource (BR) and AI- Based Generators (AG) leads significantly dif ferent threshold scores. Consequently , a DSD model, which was trained on unbalance datasets of BR and A G, may be not general for unseen data in the inference process if using the threshold score from EER metric. In other words, individual EER scores and corresponding threshold scores ev aluated on independent testing datasets may not exactly reflect the generality of a DSD model. T o address these concerns, we proposed a DSD dataset which comprises both BR-dataset and A G-dataset. The dataset is referred to as the BR-A G dataset. As T able II sho ws, the BR-A G dataset comprises 103,683 bonafide utterances and 1,134,480 fake utterances. Regarding fake utterances, there are 462,354 utterances generated from T ext-to-Speech (TTS) systems and 672,126 utterances generated from V oice Conv ersion (VC) systems. B. Pr oposed a DSD model Giv en the proposed BR-A G dataset, we construct a DSD model which improves the proposed baseline architecture in Section II-A and re-uses the training strategy in our pre vious published work [27]. As Fig. 9 sho ws, training the proposed DSD models comprises three main stages. In the first stage, the pre-trained model is used as the backbone to extract audio embeddings. Then, the audio embeddings are explored by three heads, each of which is applied by one loss function. The first loss function is A-Softmax loss which is used to classify audio embeddings into three categories: bonafide, TTS (fak e audio generated from TTS systems), and VC (fake audio generated from VC systems). The second loss function is Contrastiv e Loss which is used to separate bonafide audio embeddings with fak e audio embeddings. The final loss function, Central Bonafid e loss (L3) Backb one . . . . Xb . . . . Bonafid e segmen t s N ( 𝜇, ∑ ) Backb one . . A- Sof tmax loss (L1) Contr astive loss (L2) . . FC – BN – GELU FC – Soft ma x . . FC – BN – GELU FC – BN – G ELU . . . . . . X . . . . . . . . Y Z . . . . Froz en 4- second segmen t s Contr astive Hea d Soft max Hea d Backb one . . . . X . . . . 4- second segmen t s FC – Softmax Entr opy loss Entr opy Hea d Trans f e r Stag e 1 Stag e 2 Stag e 3 Multipl e Cl asses & Multiple Los ses Trai ning Two - cla ss F in etu n in g Bonafid e Distr ibution Fig. 9. Our proposed model with three-stage training strategy for DSD task Loss, is used to condense the bonafide audio embeddings. The combination of theses three loss function is ef fective to separate distrib ution of f ake and bonafide audio embeddings far away . In the second stage, three heads in the first stage are removed. The backbone is connected to only one head with Binary-Cross-Entropy loss to learn two categories of fake and bonafide. In the final stage, bonafide utterances are fed into the backbone to extract bonafide audio embeddings. These audio embeddings are used to compute the bonafide distribution using Mahalanobis distribution. In the inference process, the unseen audio is first fed into the backbone to e xtract the audio embedding. The the audio embedding is compared with the bonafide distribution to decide whether the unseen audio is fake or bonafide. C. Experimental Settings T o e valuate the backbone in the proposed DSD model, we ev aluate three pre-trained models: Whisper-base model [28], W avLM-lar ge [6], and W ave2XLSR [5], which show the state-of-the-art results on the upstream task of Speech-T o- T ext. Reg arding testing datasets, we ev aluate dif ferent datasets of In-The-Wild [18], ASVspoof5 Evaluation Subset [29], and F akeA VCeleb [30]. The ASVspoof5 Evaluation [29] subset is selected as this dataset presents div erse bonafide resource and unseen fake generators compared with ASVspoof5 Dev elopment and T rain subset in BR-A G dataset. Meanwhile, FakeA VCeleb [30] is selected as this dataset uses the V ox- Celeb [17] as the bonafide resource which presents real- world conv ersation from a lar ge number of speakers. In this experiment, we report the Accuracy (Acc.), F1, and AuC scores using the the fixed probability of 0.5 as the boundary for all 0.0 0.2 0.4 0.6 0.8 1.0 Fake Probabilities 0 5000 10000 15000 20000 25000 Utterance Number bonafide spoof Fig. 10. Distribution of fake probabilities from In-The-Wild dataset using BR-A G dataset to train the W avLM-Lar ge-Finetune+MLP model ev aluating datasets. The other settings are re-used from the experiment in Section II-C D. Experimental Results and Discussion Compare among pre-trained models as sho wn in the lower part in the T able III, this indicates that finetuning the pre-trained W avLM-Lar ge with the three-stage training strategy is more effect than finetuning W av2V ec2.0-XLSR-53 and Whisper- based models. Finetuning the W avLM-Lar ge backbone also enhances the performance compared with freezing the W avLM- large backbone as sho wn in the baseline. T ABLE III E V A LU A T I ON O F T H E B R A N D A G FA CT O RS O N I N - T H E - W IL D D A TAS E T ( U S IN G P R OB AB I L I TY B O U ND ARY O F 0 . 5 ) Model T rain Data T est Data Acc. F1 A uC W avLM-Large frozen + MLP (baseline) AG dataset In-The-W ild 0.71 0.72 0.74 W avLM-Large frozen + MLP (baseline) BR dataset In-The-Wild 0.75 0.58 0.69 W avLM-Large frozen + MLP (baseline) BR-A G dataset In-The-Wild 0.80 0.72 0.82 W avLM-Large finetune + MLP BR-A G dataset In-The-Wild 0.87 0.79 0.83 Whisper-base finetune + MLP BR-AG dataset In-The-W ild 0.73 0.60 0.65 W av2V ec2-XLSR-53 finetune + MLP BR-A G dataset In-The-Wild 0.79 0.64 0.73 T ABLE IV C RO S S - D AT A S E T E V A LU A T I ON O F T H E B E ST M O DE L ( W A V L M - L A R G E FI N ET U N E + M L P ) U S I N G T H E B O U ND ARY P RO BA B I L IT Y O F 0 . 5 T est Dataset Accuracy F1 Score A uC In-The-W ild 0.87 0.79 0.83 ASVspoof5 Eva Subset 0.91 0.91 0.92 FakeA VCeleb 0.99 0.99 0.99 6 4 2 0 2 Logarithmic Scores 0 1000 2000 3000 4000 5000 Utterance Number Threshold: 0.19 bonafide spoof Fig. 11. Distribution of Logarithmic scores from In-The-Wild dataset using BR-A G dataset to train the W avLM-Lar ge-Finetune+MLP model Giv en the best model of W avLM-Large-Finetune+MLP , we ev aluate this proposed model on diff erent datasets. As the experimental results are sho wn in the T able IV, the proposed model achiev es accuracy scores of 0.87 and 0.91 on In- The-W ild and ASVspoof5 Evaluation Subset, respectiv ely . Significantly , the model achie ves a high performance on Fak eA VCeleb (i.e., All accuracy , F1, and AuC scores are 0.99). These results indicate that the proposed model is general on these three e valuating datasets as using the fixed boundary probability of 0.5. The Fig. 10 and Fig. 11, which present the distribution of fake probabilities and Logarithmic scores of In-The-W ild dataset using the best model of W avLM-Large-Finetune+MLP , also indicate that fake and bonafide distribution is well separated. I V . C O N C L U S I O N W e have presented a comprehensive analysis of Bonafide Resource (BR) and AI-Based Generators (A G) and indicated ho w these two factors affect the performance and the generality of a Deefake Speech Detection (DSD) model. Given the analysis, we successfully proposed the BR-A G dataset which is used to train and achie ve a general DSD model. Our proposed DSD model trained on the BR-A G dataset proves general on various benchmark DSD datasets and potential for real- work applications. Our future work will explore cross-language ev aluation. R E F E R E N C E S [1] L. Pham, P . Lam, D. T ran, H. T ang, T . Nguyen, A. Schindler, F . Skopik, A. Polonsky , and H. C. V u, “ A comprehensive surv ey with critical analysis for deepfake speech detection, ” Computer Science Review , vol. 57, p. 100757, 2025. [2] K.-H. Ng, T . Song, Y . WU, and Z. Xia, “Xlsr-mambo: Scaling the hybrid mamba-attention backbone for audio deepfake detection, ” arXiv preprint arXiv:2601.02944 , 2026. [3] D. Combei, A. Stan, D. Oneata, and H. Cucu, “W avlm model ensemble for audio deepfake detection, ” arXiv pr eprint arXiv:2408.07414 , 2024. [4] S. Dowerah, A. Kulkarni, A. Kulkarni, H. M. Tran, J. Kalda, A. Fe- dorchenko, B. Fauve, D. Lolive, T . Alum ¨ ae, and M. M. Doss, “Speech df arena: A leaderboard for speech deepfake detection models, ” arXiv pr eprint arXiv:2509.02859 , 2025. [5] A. Conneau, A. Baevski, R. Collobert, A. Mohamed, and M. Auli, “Unsu- pervised Cross-Lingual Representation Learning for Speech Recognition, ” in Pr oc. INTERSPEECH , 2021, pp. 2426–2430. [6] S. Chen et al. , “W avlm: Large-scale self-supervised pre-training for full stack speech processing, ” IEEE J ournal of Selected T opics in Signal Pr ocessing , vol. 16, no. 6, pp. 1505–1518, 2022. [7] Z. W u, T . Kinnunen, N. Evans, J. Y amagishi, C. Hanil c ¸ i, M. Sahidullah, and A. Sizov , “ Asvspoof 2015: the first automatic speaker verification spoofing and countermeasures challenge, ” in Proc. INTERSPEECH , 2015, pp. 2037–2041. [8] R. Reimao and V . Tzerpos, “For: A dataset for synthetic speech detection, ” in International Conference on Speech T echnology and Human-Computer Dialogue , 2019, pp. 1–10. [9] “ Audio source used to generate for dataset, ” https://www .kaggle.com/ datasets/percev alw/englishfrench- translations, 2018. [10] X. W ang et al. , “ Asvspoof 2019: A large-scale public database of synthesized, conv erted and replayed speech, ” Computer Speech & Language , vol. 64, p. 101114, 2020. [11] B. Dolhansky , J. Bitton, B. Pflaum, J. Lu, R. Ho wes, M. W ang, and C. C. Ferrer, “The deepfake detection challenge (DFDC) dataset, ” arXiv pr eprint arXiv:2006.07397 , 2020. [12] J. Y amagishi et al. , “ Asvspoof 2021: accelerating progress in spoofed and deepfake speech detection, ” in W orkshop-Automatic Speaker V erification and Spoofing Coutermeasur es Challenge (ASVspoof) , 2021. [13] J. Frank and L. Sch ¨ onherr , “W avef ake: A data set to facilitate audio deepfake detection, ” NeurIPS , 2024. [14] N. Kalchbrenner , E. Elsen, K. Simonyan, S. Noury , N. Casagrande, E. Lockhart, F . Stimberg, A. Oord, S. Dieleman, and K. Kavukcuoglu, “Efficient neural audio synthesis, ” in Proc. ICML , 2018, pp. 2410–2419. [15] R. Sonobe, S. T akamichi, and H. Saruwatari, “Jsut corpus: free large- scale japanese speech corpus for end-to-end speech synthesis, ” arXiv pr eprint arXiv:1711.00354 , 2017. [16] H. Khalid, S. T ariq, M. Kim, and S. S. W oo, “Fak eavceleb: A nov el audio-video multimodal deepfake dataset, ” in Thirty-fifth Conference on Neural Information Pr ocessing Systems Datasets and Benchmarks T rack (Round 2) , 2021. [17] J. S. Chung, A. Nagrani, and A. Zisserman, “V oxCeleb2: Deep Speaker Recognition, ” in Proc. INTERSPEECH , 2018, pp. 1086–1090. [18] N. M ¨ uller , P . Czempin, F . Diekmann, A. Froghyar , and K. B ¨ ottinger , “Does Audio Deepfake Detection Generalize?” in Proc. INTERSPEECH , 2022, pp. 2783–2787. [19] X. W ang and J. Y amagishi, “Spoofed training data for speech spoofing countermeasure can be efficiently created using neural vocoders, ” in Pr oc. ICASSP , 2023, pp. 1–5. [20] C. Sun, S. Jia, S. Hou, and S. Lyu, “ Ai-synthesized voice detection using neural vocoder artifacts, ” in Proc. IEEE/CVF Confer ence on Computer V ision and P attern Recognition , 2023, pp. 904–912. [21] V . Panayotov , G. Chen, D. Povey , and S. Khudanpur , “Librispeech: an asr corpus based on public domain audio books, ” in Proc. ICASSP , 2015, pp. 5206–5210. [22] Z. Cai, S. Ghosh, A. P . Adatia, M. Hayat, A. Dhall, and K. Stefanov , “ A v-deepfake1m: A large-scale llm-driven audio-visual deepfake dataset, ” arXiv pr eprint arXiv:2311.15308 , 2023. [23] “1m-deepfakes detection challenge, ” https://deepfakes1m.github .io/, 2023. [24] N. M. M ¨ uller , P . Kawa, W . H. Choong, E. Casanova, E. G ¨ olge, T . M ¨ uller , P . Syga, P . Sperl, and K. B ¨ ottinger , “Mlaad: The multi-language audio anti-spoofing dataset, ” in Proc. IJCNN , 2024, pp. 1–7. [25] “The asvspoof 2024 challenge, ” https://www .asvspoof.org/, 2024. [26] P . K. Diederik and B. Jimmy , “ Adam: A method for stochastic optimization, ” CoRR , vol. abs/1412.6980, 2015. [27] L. Pham, D. Tran, P . Lam, F . Skopik, A. Schindler , S. Poletti, D. Fischinger, and M. Boyer, “Din-cts: Low-complexity depthwise- inception neural network with contrastive training strategy for deepfake speech detection, ” arXiv preprint , 2025. [28] A. Radford et al. , “Robust speech recognition via large-scale weak supervision, ” in Proc. ICML , 2023, pp. 28 492–28 518. [29] T . B. Patel and H. A. Patil, “Combining evidences from mel cepstral, cochlear filter cepstral and instantaneous frequency features for detection of natural vs. spoofed speech. ” in Pr oc. INTERSPEECH , 2015, pp. 2062– 2066. [30] K. Prajwal, R. Mukhopadhyay , V . P . Namboodiri, and C. Jawahar , “ A lip sync expert is all you need for speech to lip generation in the wild, ” in Pr oc. ACM international conference on multimedia , 2020, pp. 484–492.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment