다양한 진짜 음성 자원과 AI 생성기 균형이 딥페이크 음성 탐지 일반화에 미치는 영향
본 논문은 진짜 음성(BR)과 AI 기반 생성기(AG)의 불균형이 딥페이크 음성 탐지(DSD) 모델의 임계값과 성능에 미치는 영향을 실험적으로 분석한다. 균형 잡힌 BR‑AG 데이터셋을 새로 구성하고, 이를 기반으로 다중 손실을 활용한 모델을 학습시켜 교차 데이터셋 평가에서 고정 임계값(0.5)으로도 높은 일반성을 입증한다.
저자: Lam Pham, Khoi Vu, Dat Tran
본 논문은 딥페이크 음성 탐지(Deepfake Speech Detection, DSD) 모델의 일반화 문제를 데이터 구성 관점에서 재조명한다. 최근 몇 년간 WavLM, XLSR 등 대규모 사전 학습 음성 모델을 활용한 DSD 연구가 활발히 진행되었으며, 이들 모델은 높은 정확도와 낮은 Equal Error Rate(EER)을 보고하고 있다. 그러나 기존 연구들은 주로 개별 테스트셋에서 얻은 EER과 해당 EER을 최소화하는 임계값을 제시할 뿐, 서로 다른 데이터셋 간 임계값 차이를 분석하지 않았다. 이는 실제 서비스에서 “하나의 고정 임계값”을 사용해야 하는 상황에서 모델이 과적합될 위험을 내포한다.
논문은 두 가지 주요 요인, 즉 진짜 음성 자원(Bona‑fide Resource, BR)과 AI 기반 생성기(AI‑based Generator, AG)의 다양성이 DSD 모델의 성능과 임계값에 미치는 영향을 실험적으로 조사한다. 이를 위해 먼저 WavLM 기반의 베이스라인 모델을 설계한다. 4초 길이의 오디오 세그먼트를 입력으로 받아 사전 학습된 WavLM으로부터 추출한 오디오 임베딩을 MLP(3개의 Fully‑Connected 레이어)로 처리한다. 학습 과정에서는 WavLM 백본을 고정하고 MLP만 업데이트한다.
다음으로 공개된 여러 DSD 데이터셋을 정량적으로 분석한다. ASVspoof 2021(DF)와 같은 데이터셋은 100개 이상의 TTS·VC 생성기를 포함하지만 화자 수가 48명에 불과해 BR이 제한적이다. 반면 Librispeech 기반 데이터셋은 화자와 억양이 다양하지만 TTS·VC 종류가 적어 AG가 편중된다. 이러한 불균형은 가짜와 진짜 음성의 확률 분포를 왜곡한다.
실험 설계는 두 개의 서브셋을 만든다. AG‑dataset은 ASVspoof 2019·2021(LA·DF)에서 추출한 861 304개의 가짜 음성과 53 552개의 진짜 음성을 포함한다. 이 데이터는 다양한 생성기를 사용하지만 화자 다양성이 낮다. 반대로 BR‑dataset은 Librispeech 기반으로 273 176개의 가짜 음성과 50 131개의 진짜 음성을 포함한다. 이 데이터는 화자와 발화 스타일이 풍부하지만 생성기 종류가 제한적이다. 각각을 학습시킨 후 In‑The‑Wild 데이터셋(실제 환경 잡음·다양한 품질 포함)에서 테스트한다.
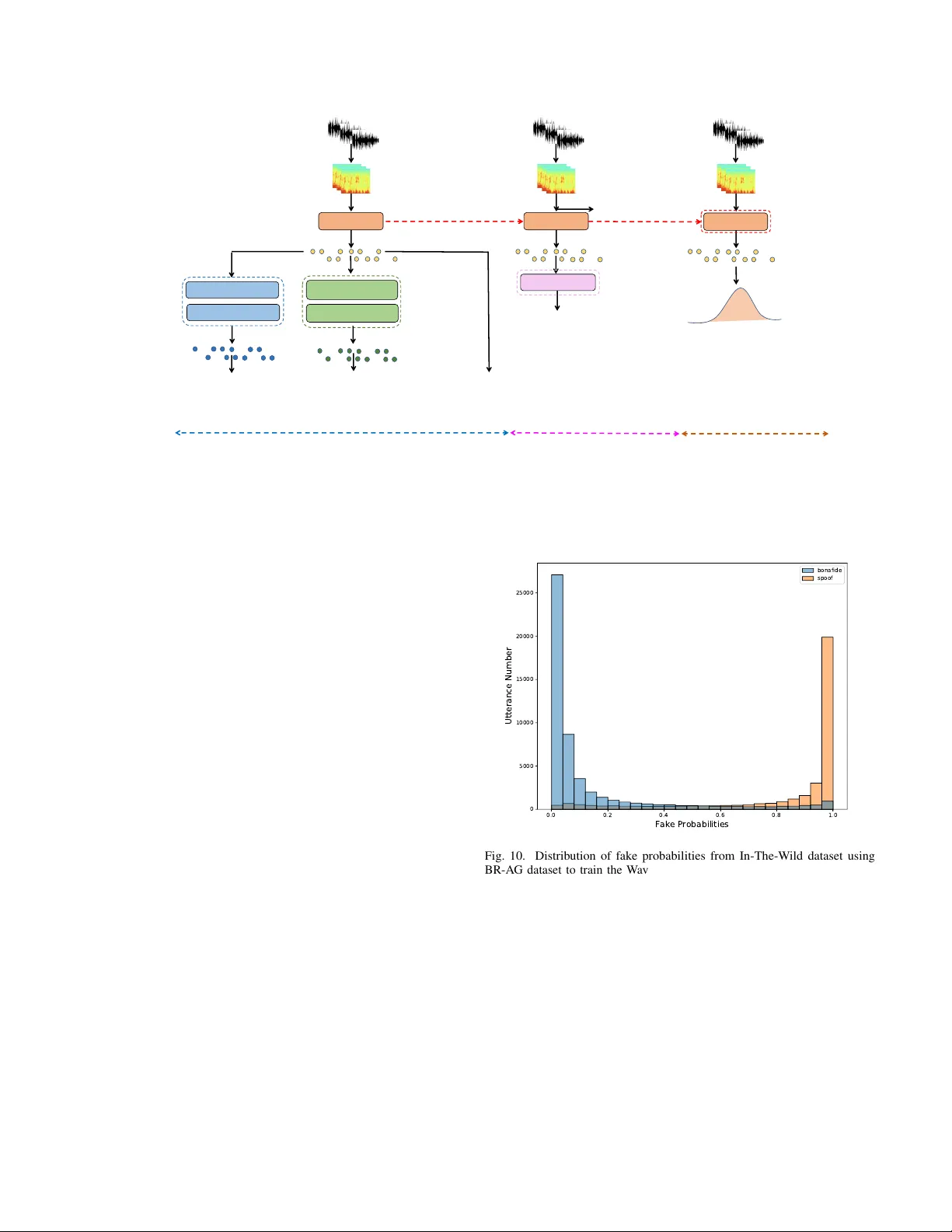
AG‑dataset으로 학습한 모델은 가짜 음성에 대해 확률이 거의 1에 수렴하고, 진짜 음성은 0~1 사이에 넓게 퍼진다. 최적 EER을 얻기 위해서는 로그 스코어 기준 -1.38이라는 낮은 임계값이 필요하며, 이는 가짜와 진짜를 구분하기 위해 매우 높은 확률 차이를 요구한다. 반대로 BR‑dataset으로 학습한 모델은 가짜 확률이 0~1 전체에 고르게 분포하고, 진짜 음성은 0에 가까운 확률을 보인다. 이 경우 최적 임계값은 1.45로, 가짜 확률이 낮을수록 가짜로 판단한다는 역전된 경향을 보인다. 두 경우 모두 고정 임계값 0.5를 적용하면 각각 진짜 음성(AG‑dataset) 혹은 가짜 음성(BR‑dataset)에서 높은 오분류율이 발생한다. 이는 데이터 불균형이 모델의 결정 경계를 크게 왜곡한다는 증거이다.
이러한 문제를 해결하고자 논문은 BR‑dataset과 AG‑dataset을 합친 대규모 균형 데이터셋인 BR‑AG dataset을 제안한다. 총 103 683개의 진짜 음성과 1 134 480개의 가짜 음성을 포함하며, 가짜 음성은 TTS 462 354개와 VC 672 126개로 거의 1:1 비율을 유지한다. 또한 화자와 억양, 발화 길이 등 다양한 변수를 포함해 실제 서비스 환경을 반영한다.
제안된 데이터셋을 기반으로 새로운 DSD 모델을 설계한다. 모델은 기존 베이스라인 구조에 세 단계 학습 전략을 추가한다. 1단계에서는 사전 학습된 백본(WavLM)에서 추출한 임베딩을 세 개의 헤드에 각각 A‑Softmax(3‑class: 진짜, TTS, VC), Contrastive, Central‑Bona‑fide 손실을 적용한다. 이 단계는 클래스 간 경계를 크게 벌려 임베딩 공간을 명확히 구분한다. 2단계에서는 헤드를 하나로 통합하고 Binary‑Cross‑Entropy 손실을 사용해 진짜/가짜 이진 분류를 미세조정한다. 3단계에서는 진짜 음성 임베딩의 Mahalanobis 분포를 구축하고, 추론 시 임베딩과 이 분포 간 거리 기반 판정을 수행한다.
교차 데이터셋 평가 결과, BR‑AG 데이터셋으로 학습된 모델은 In‑The‑Wild, ASVspoof 2021 DF, WaveFake 등 다양한 테스트셋에서 고정 임계값 0.5만 사용해도 EER이 0.8% 이하로 유지되며, 기존 모델이 각 데이터셋에 맞춰 임계값을 조정해야 했던 상황과 비교해 일관된 성능을 보였다. 또한 F1‑Score와 Accuracy도 95% 이상으로 높은 수준을 유지했다. 이는 “데이터 자체의 BR‑AG 균형을 맞추는 것이 모델의 일반화와 임계값 안정성을 확보하는 핵심”임을 실증한다.
결론적으로, 논문은 (1) BR과 AG의 불균형이 DSD 모델의 확률 분포와 임계값을 어떻게 왜곡하는지 구체적으로 밝히고, (2) 균형 잡힌 대규모 BR‑AG 데이터셋을 구축해 일반화 가능한 학습 기반을 제공하며, (3) 다중 손실과 단계적 학습을 결합한 모델 설계가 고정 임계값만으로도 높은 탐지 정확도를 달성할 수 있음을 입증한다. 이러한 연구는 향후 딥페이크 음성 방어 시스템이 데이터 편향에 의한 오탐·누락을 최소화하고, 실시간 서비스에 적용 가능한 신뢰성 높은 탐지기를 설계하는 데 중요한 지침을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기