BLOSSOM: Block-wise Federated Learning Over Shared and Sparse Observed Modalities
Multimodal federated learning (FL) is essential for real-world applications such as autonomous systems and healthcare, where data is distributed across heterogeneous clients with varying and often missing modalities. However, most existing FL approac…
Authors: Pranav M R, Jayant Ch, wani
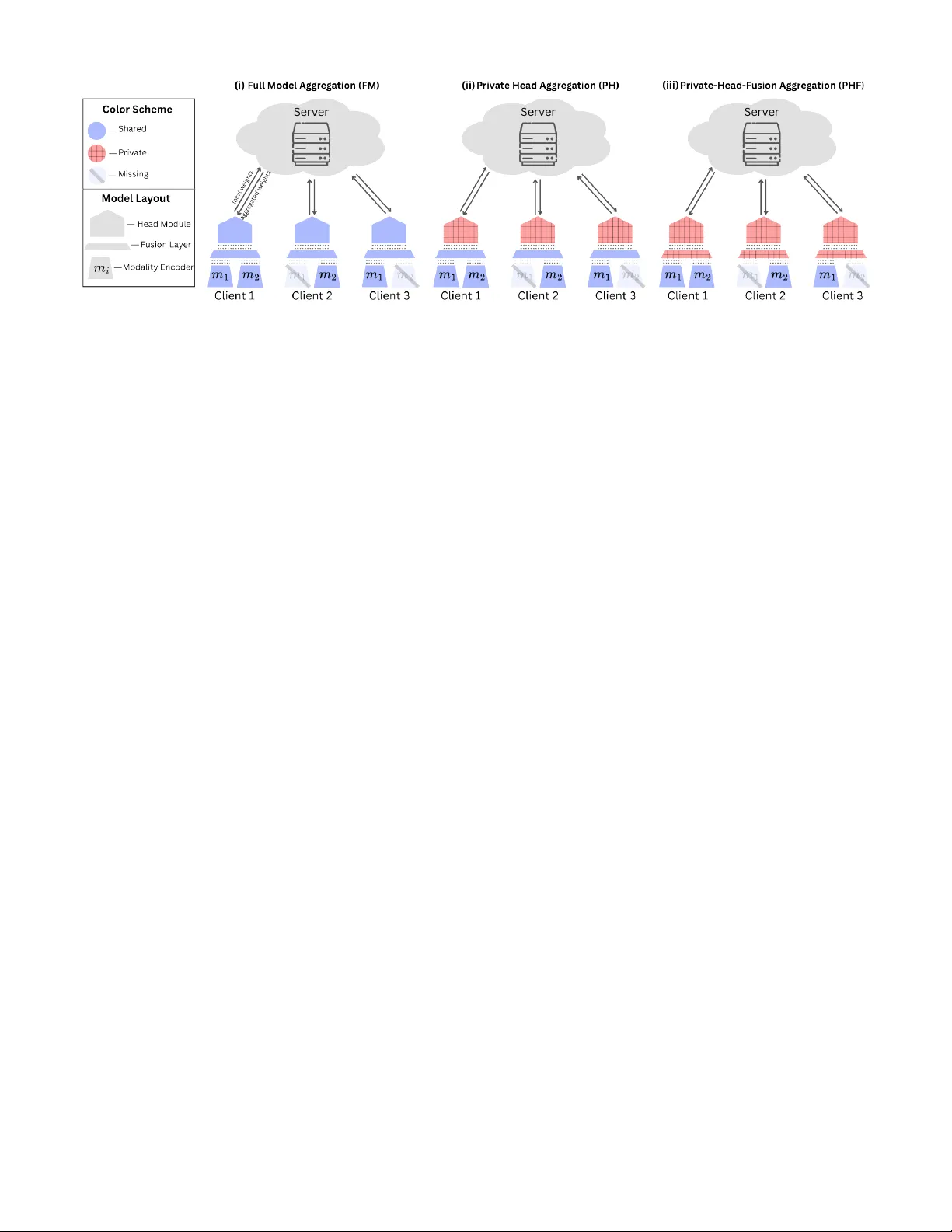
B L O S S O M : Block-wise Federated Learning Ov er Shared and Sparse Observ ed Modalities Pranav M R ∗ † , Jayant Chandwani ∗ † , Ahmed M. Abdelmoniem ‡ , Arnab K. Paul † † DaSH Lab, BITS Pilani, KK Birla Goa Campus, India ‡ Queen Mary University of London, United Kingdom { f20230340, f20230356, arnabp } @goa.bits-pilani.ac.in, ahmed.sayed@qmul.ac.uk Abstract —Multimodal federated learning (FL) is essential for real-w orld applications such as autonomous systems and health- care, where data is distributed across heterogeneous clients with varying and often missing modalities. However , most existing FL approaches assume unif orm modality availability , limiting their applicability in practice. W e introduce B L O S SO M , a task- agnostic framework for multimodal FL designed to operate under shared and sparsely observed modality conditions. B L OS S O M supports clients with arbitrary modality subsets and enables flexible sharing of model components. T o addr ess client and task heterogeneity , we pr opose a block-wise aggregation strategy that selectively aggregates shared components while keeping task-specific blocks private, enabling partial personalization. W e evaluate B L O SS O M on multiple diverse multimodal datasets and analyse the effects of missing modalities and personalization. Our results show that block-wise personalization significantly im- pro ves perf ormance, particularly in settings with severe modality sparsity . In modality-incomplete scenarios, B L O S S O M achieves an av erage performance gain of 18.7% over full-model aggregation, while in modality-exclusive settings the gain incr eases to 37.7%, highlighting the importance of block-wise learning for practical multimodal FL systems. I . I N T RO D U C T I O N Federated Learning (FL) [ 1 ] enables collaborative model train- ing across decentralized and priv acy-sensiti ve data sources without sharing raw data. By keeping data local and ex- changing only model updates, FL supports learning under strict pri vac y , legal, and operational constraints, making it well suited for domains such as healthcare [ 2 ], autonomous systems [ 3 ], and mobile sensing [ 4 ]. Many real-world applications are inherently multimodal especially in FL [ 5 ], relying on heterogeneous information sources such as vision, audio, text, and sensor signals. Le ver - aging multiple modalities typically yields stronger representa- tions by capturing complementary aspects of the underlying phenomena. In federated settings, howe ver , multimodality is further complicated by client heterogeneity: clients often col- lect dif ferent subsets of modalities due to hardware limitations, cost constraints, or deployment environments [ 6 ], [ 7 ]. Despite this, most FL research primarily addresses sta- tistical heterogeneity (Non-IID data distribution) [ 8 ] while implicitly assuming uniform modality availability . Even recent multimodal FL approaches frequently rely on full modality ∗ Pranav M R and Jayant Chandwani are the lead authors and contrib uted equally to this work. This work was supported in part by BITS Pilani CDRF grant C1/23/173, ANRF/SERB SRG grant SRG/2023/002445, and e6Data Inc. ov erlap or consider only limited forms of missing modalities; such as sample-le vel corruption or partial observations within a fixed modality set [ 6 ], which does not reflect real-world conditions. In practice, missing modalities arise in sev eral forms: (i) modality-complete , where all clients observe all modalities; (ii) modality-incomplete , where some modalities are missing for subsets of clients; and (iii) modality-e xclusive , where clients possess entirely disjoint modality sets. Existing methods typically handle only one of these scenarios, limiting their general applicability . T o address this gap, we propose B L O S S O M , a unified framew ork for robust multimodal FL under arbitrary modality av ailability . B L O S S O M decomposes a multimodal model into modality-specific encoders, a fusion module, and task-specific prediction heads. W e adopt a late-fusion design and introduce a block-wise aggregation strategy in which only modality encoders shared across clients are aggregated, allowing clients with disjoint modality sets to participate. T o mitigate performance degradation of clients with sparse or exclusi ve modalities, B L O S S O M incorporates partial per- sonalization [ 9 ] by maintaining priv ate task-specific heads per client, enabling shared representations to adapt to local data distributions. W e further study variants that also priv atize the fusion module, analysing the trade-offs between generalization and personalization under varying modality sparsity . W e ev aluate B L O S S O M across di v erse multimodal bench- marks spanning emotion recognition, human activity recogni- tion, healthcare, and multimedia tasks. Our results demonstrate consistent improv ements ov er standard FL baselines across modality-complete, incomplete, and exclusi ve settings, with an av erage gain of 19 . 8% across all our experiments. T o the best of our knowledge, this work constitutes the first systematic benchmarking study of partial personalization in multimodal FL under missing-modality settings. T o support reproducibility , we release B L O S S O M as an open-source frame work with publicly hosted experimental splits ( https://github .com/DaSH- Lab- CSIS/blossom ). I I . R E L A T E D W O R K A. Multimodal Learning Multimodal learning methods are commonly categorized into early and late fusion strategies [ 5 ]. Early fusion combines low- lev el features from all modalities into a joint representation and requires all modalities to be present during training and infer- ence. Late fusion processes each modality independently and Fig. 1: Illustration of the B L O S S O M framework under the three block-wise aggregation modes. integrates high-level representations at a later stage, making it more robust to missing-modality scenarios [ 10 ]. These distinctions are critical in federated settings with het- erogeneous modality av ailability across clients. Standard Fed- erated A veraging (FedA vg) [ 1 ] assumes homogeneous model architectures and synchronized parameter updates, and there- fore performs poorly under missing or asymmetric modality distributions. Multimodal FL addresses this by e xtending FL to clients observing dif ferent modality subsets, b ut introduces challenges such as incompatible parameter updates, restricted aggregation, and performance degradation under sparse or disjoint modality observations. B. Multimodal FL with Sparse Modalities Early multimodal FL approaches largely av oid explicit mul- timodal modeling under sparsity by decoupling modalities. Ensemble-based methods, such as FedMFS [ 11 ], train in- dependent unimodal models and combine predictions at in- ference time. While robust to missing modalities, the y can- not capture cross-modal interactions and incur high com- munication o verhead. KD-based approaches, ex emplified by CreamFL [ 12 ], enable cross-modal transfer via distillation b ut typically require a public dataset at the server , weakening federated priv acy guarantees. Both classes implicitly assume modality sufficiency , that each modality alone contains enough information to solve the task, an assumption inspired by classical multi-view learning [ 13 ] that often fails under sparse or heterogeneous modality av ailability . Representation learning approaches mo ve beyond unimodal decoupling by learning modality-specific latent embeddings, commonly via autoencoders [ 14 ], which are later fused for prediction. While this enables limited cross-modal interaction, recent studies show that autoencoder-based representations re- main vulnerable to gradient-based reconstruction attacks [ 15 ], raising priv acy concerns in federated settings. Fusion-based methods explicitly separate modality encoders from task-level components and combine them via late fusion, making them more suitable for heterogeneous federated en- vironments. Hybrid variants, such as Harmony [ 7 ], integrate ensemble-style training with fusion-based aggregation but rely on sufficient cross-client modality ov erlap and degrade under highly sparse regimes. FedMSplit [ 16 ] more directly targets missing-modality settings using graph-based aggregation over ov erlapping modality subsets; howe ver , its reliance on overlap limits applicability in modality-exclusi ve scenarios. Unlike prior work such as FedMultimodal [ 17 ] and FedM- Split, we focus on structural modality missingness , where clients lack specific modalities entirely rather than individual samples being partially observed. This client-lev el modality heterogeneity is formalized in Section IV . V ery recent work also considers fully missing client modalities [ 18 ], but most such methods rely on reconstructing absent modalities, which conflicts with federated priv acy constraints. C. P artial P ersonalization Partial personalization in FL refers to the joint training of shared global parameters and client-specific local parame- ters, where only the shared parameters are aggre gated across clients. In multimodal settings, personalization can be applied at either the encoder or task-head lev el. While encoder - lev el personalization improves local adaptation, it restricts cross-client representation sharing, which is undesirable when clients observe sparse or disjoint modality subsets. T ask-head- lev el personalization instead enables clients to adapt shared multimodal representations to local label distrib utions while preserving collaborativ e representation learning. Prior work on partial personalization analyses ho w sepa- rating shared and pri vate model components improves op- timization stability , con ver gence, and generalization under heterogeneous client data distributions [ 9 ]. Ho wev er , this line of work does not consider heterogeneity arising from missing or disjoint modalities across clients. I I I . M E T H O D O L O G Y A. Problem F ormulation W e consider a multimodal FL setting with C clients and M distinct modalities. Each client k observes data from a subset of modalities M k ⊆ M , and these subsets may vary arbitrarily across clients. W e focus on extremely sparse modality settings, where client modality subsets have little or no o verlap. W e additionally consider modality-insufficient scenarios, in which no single modality contains sufficient information to solve the task in isolation. B. Arc hitectur e of B L O S S O M W e use a late-fusion multimodal architecture as discussed in Section II-A where each modality is encoded separately and combined only at the fusion stage. As shown in Figure 1 , B L O S S O M is organized into three blocks: modality-specific encoders, a fusion module, and a task prediction head. Encoders produce latent modality repre- sentations, the fusion block integrates the representations from the modalities available at a client, and the head generates the final output. Missing modalities are handled by zeroing out the corresponding encoder outputs before fusion, as proposed by Pillutla et al. [ 9 ], preserving a fixed fusion architecture and input dimensionality . This block structure enables block-wise aggregation and partial personalization. W ithin this setup, we study two fusion methods: concatenation-based fusion (ConcatFusion), which merges modality embeddings by concatenation followed by a projec- tion layer , and attention-based fusion (AttentionFusion), which learns modality-dependent weights to combine embeddings adaptiv ely . Each fusion method is ev aluated under two partial- personalization configurations to compare robustness under sparse and heterogeneous modality av ailability . C. Block-wise F ederated Aggr e gation Aggregation Backbone: W e adopt FedA vg as the underlying aggregation primitiv e. It remains the most widely used and well-understood aggregation strategy in FL and serv es as a common baseline in multimodal FL studies. Furthermore, empirical findings reported in FedMultimodal [ 17 ] indicate that alternativ e federated optimizers (except FedOpt) yield only mar ginal performance dif ferences under comparable ar- chitectures and data partitions. This choice allows us to isolate and analyse the impact of block-wise aggregation and partial personalization without in- troducing confounding ef fects from more comple x serv er-side optimization schemes. Importantly , B L O S S O M is aggr e gation- strate gy agnostic : the proposed block-wise decomposition and selectiv e aggre gation mechanism can be readily combined with alternativ e federated optimizers (e.g., FedAdam, FedY ogi [ 19 ]) without requiring changes to the model architecture or training protocol. Block-wise Aggregation: W e implement block-wise federated aggregation through the server-side procedure specified in Algorithm 1 . Instead of aggregating model parameters as a single unit, the server aggregates each architectural block separately according to block type and modality av ailability . In particular , modality encoders are aggre gated only from clients that possess the corresponding modality (lines 11–14), while the fusion and head blocks are either aggregated or kept client- priv ate depending on the selected personalization mode (lines 15–25). This enables training with missing modalities and unev en modality overlap across clients. Algorithm 1 Block-wise Aggregation Strategy . 1: Input: Clients C , modalities M , aggre gation method A ( · ) 2: Hyperparameters: T , E , aggregation mode P ∈ { FM , PH , PHF } 3: Initialize: Global modality encoders { θ m } m ∈M , fusion block θ f , head block θ h 4: for each communication round t = 1 to T do 5: Server sends rele vant global blocks to participating clients 6: for each client c ∈ C in parallel do 7: Initialize local model using recei ved blocks 8: T rain local model on client data for E epochs 9: Send updated blocks to server 10: end for 11: for each modality m ∈ M do 12: Get encoder updates { θ c m } from clients with modality m 13: θ m ← A ( { θ c m } ) 14: end for 15: if P == FM then 16: Collect fusion updates { θ c f } and head updates { θ c h } 17: θ f ← A ( { θ c f } ) 18: θ h ← A ( { θ c h } ) 19: else if P == PH then 20: Collect fusion updates { θ c f } 21: θ f ← A ( { θ c f } ) 22: Keep θ h priv ate to each client 23: else if P == PHF then 24: Keep θ f and θ h priv ate to each client 25: end if 26: end f or 27: return updated global modality encoders { θ m } m ∈M Personalization Modes: The personalization behavior is con- trolled by the aggregation mode parameter P in Algorithm 1 . W e ev aluate three configurations: 1) Full model a ggr e gation (FM): all blocks are aggregated (lines 15–18); this matches the standard aggregation setting used in most prior multimodal FL works and serves as our primary reference configuration. 2) Private head (PH): modality encoders and the fu- sion block are aggregated, while the prediction head remains client-specific (lines 19–21); we denote this head-personalized configuration as PH for clarity . Prior work has explored comparable personalization patterns, though not under consistent naming. 3) Private head-fusion (PHF): only modality encoders are aggregated, while clients keep both the fusion and head blocks priv ate (lines 22–24); we refer to this encoder- only aggregation re gime as PHF , again as a naming con venience rather than a new personalization concept. I V . E X P E R I M E N TA L S E T U P Our framew ork is built on top of the Flower FL frame- work [ 26 ], with Hydra-based configuration management [ 27 ], enabling fle xible specification of datasets, tasks, modality av ailability patterns, and aggregation strategies. W e ev aluate B L O S S O M on a diverse suite of real-world multimodal tasks spanning human activity recognition, healthcare, multimedia classification, and emotion recognition, summarized in T able I . W e conduct all experiments using 10 clients, 60 communi- cation rounds, and 1 local epoch per round. F or all non-IID T ABLE I: Overvie w of multimodal datasets used to ev aluate B L O S S O M . T ask Datasets Modalities Featur es Models Metric HAR KU-HAR [ 20 ], UCI-HAR [ 21 ] Acc, Gyro Raw , Raw Con v1D+GR U, Con v1D+GR U F1 Healthcare PTB-XL [ 22 ] I-A VF , V1-V6 Raw , Raw Con v1D+GR U, Con v1D+GR U F1 Multimedia A V -MNIST [ 23 ] Image, Audio Raw , MelSpec Con v2D, Conv2D Accuracy Emotion Recognition MELD [ 24 ], IEMOCAP [ 25 ] Audio, T ext MelSpec, MobileBER T Conv1D+GR U, GR U Accuracy T ABLE II: Performance comparison of dif ferent aggregation modes. Dataset Modality Config ConcatFusion AttentionFusion IID NIID IID NIID FM PH PHF FM PH PHF FM PH PHF FM PH PHF KU-HAR 0–0–10 90.14 83.39 84.86 66.91 64.96 64.58 86.61 79.98 73.95 63.48 62.22 61.41 3–3–4 71.11 74.28 73.30 45.39 57.15 58.77 63.06 62.36 65.30 46.16 49.31 53.46 5–5–0 59.29 73.52 71.49 35.28 55.96 54.10 31.03 51.77 64.64 21.91 33.06 50.29 UCI-HAR 0–0–10 91.10 87.45 88.60 83.95 80.79 82.54 87.65 85.20 84.72 80.78 80.16 76.50 3–3–4 71.11 74.28 73.30 45.39 57.15 58.77 80.38 75.02 78.15 71.69 67.68 71.10 5–5–0 59.29 73.52 71.49 35.28 55.96 54.10 79.79 70.95 80.17 69.41 70.80 66.78 PTB-XL 0–0–10 66.13 63.59 63.78 55.91 55.31 55.76 64.32 63.41 60.77 54.25 55.11 53.83 3–3–4 41.24 59.90 60.20 38.97 51.60 52.10 37.10 42.18 56.66 35.16 41.71 50.84 5–5–0 24.49 58.17 58.19 28.28 49.95 49.51 36.80 44.14 55.47 38.71 34.10 48.79 A V -MNIST 0–0–10 99.83 99.78 99.68 99.75 99.57 99.42 99.81 99.45 98.58 99.58 99.08 98.58 3–3–4 82.34 96.26 98.77 82.92 96.48 98.41 84.45 96.36 98.41 94.31 97.58 97.05 5–5–0 84.94 97.18 98.43 78.97 97.18 97.88 81.08 94.14 98.12 92.98 78.58 96.19 MELD 0–0–10 61.09 61.68 61.55 62.28 81.18 82.21 59.66 61.10 61.60 59.91 82.07 81.47 3–3–4 55.93 57.62 57.75 59.97 80.38 81.33 57.48 57.02 58.09 54.95 81.29 81.50 5–5–0 55.32 55.25 54.69 56.41 81.03 79.80 53.94 54.72 55.23 59.69 80.83 80.97 IEMOCAP 0–0–10 67.09 64.55 63.92 64.38 75.82 75.93 67.86 64.26 60.34 61.61 73.79 72.77 3–3–4 56.72 54.68 55.65 56.18 71.89 70.72 56.75 54.42 52.95 59.96 69.78 70.86 5–5–0 50.68 49.69 50.63 51.41 69.90 70.19 52.56 50.18 49.68 53.17 67.92 69.39 (NIID) experiments, we use Dirichlet-based label partitioning ( α = 0 . 5 ). W e adopt a modality configuration notation of the form a–b–c, where a, b, and c denote the number of clients possessing modality 1 only , modality 2 only , and both modalities, respectiv ely . For example, 0–0–10 corresponds to a modality-complete setting where all clients observe both modalities, while configurations such as 3–3–4 and 5–5–0 introduce increasing lev els of missing modalities, analogous to missing-modality rates commonly used in prior work. Since we focus on structural missing modalities, each absent modality at a client is counted as a missing instance. Under this scheme, 0–0–10 corresponds to 0% missing modality rate, 3–3–4 to 30%, and 5–5–0 to 50%. This setting is substantially more challenging and realistic for FL because clients lack en- tire modalities, rather than the commonly studied sample-lev el missingness where clients still partially observe all modalities. V . E V A L U A T I O N A N D R E S U LT S The ev aluation of B L O S S O M addresses the following research questions: • T o what extent does partial personalization improve per- formance under (1) missing-modality conditions and (2) client-side label heterogeneity? (Section V -A ) • Between the PH and PHF personalization modes, which configuration yields better performance across v arying lev els of modality sparsity? (Section V -B ) • How does modality insufficienc y impact performance across different tasks? (Section V -C ) • Do modality-incomplete clients contribute positively to the final global model performance? (Section V -D ) • How does B L O S S O M compare to state-of-the-art multi- modal FL benchmarks? (Section V -E ) A. Impact of P artial P ersonalization T o quantify the impact of personalization, we define: PH Gain = S PH − S FM S FM × 100% , PHF Gain = S PHF − S FM S FM × 100% , Personalization Gain (PG) = max( PH Gain , PHF Gain ) , where S denotes the validation score of interest. In the modality-complete setting (0–0–10), FM slightly out- performs the personalized variants, with marginally neg ativ e gains ( P G > − 5% ). This outcome follows naturally because 0–0–10 reduces to a standard FL setup analogous to FedA vg, where structural heterogeneity is absent and personalization offers limited benefit. Performance in this regime aligns with established benchmarks for KU-HAR, UCI-HAR, PTB-XL, and MELD [ 17 ], and for IEMOCAP [ 28 ], validating our setup. 1) Missing Modalities: Under modality-incomplete (3–3–4) and modality-exclusi ve (5–5–0) settings, partial personaliza- tion yields substantial performance improvements. Both PH and PHF consistently outperform FM, with an av erage PG of 19 . 77% . The gain increases from 18 . 65% in the 3–3–4 case to 37 . 70% in the 5–5–0 setting, indicating that personalization benefits grow with increasing modality sparsity . 2) Label Heter ogeneity: Personalization gains further in- crease under label heterogeneity . In NIID settings, the average PG reaches 25 . 82% , compared to 13 . 71% in IID. The largest gains occur when both factors occur simultaneously , with PG of 25 . 32% for NIID 3–3–4 and 43 . 28% for NIID 5–5–0, highlighting the robustness of partial personalization under combined structural and distributional heterogeneity . Emotion T asks: For MELD and IEMOCAP , we observe large personalization gains under NIID splits ev en in modality- complete settings, likely due to strong label imbalance and emotional ambiguity that make personalized heads better suited for sparse local label distributions. Con versely , these are the only datasets where personalization causes perfor- mance drops under IID settings. W e hypothesize that for such complex tasks, access to the full global data distribution is more important than local adaptation, which becomes sample- inefficient under uniform data. For other tasks, block-wise aggregation mitigates this IID penalty . B. PH vs. PHF W e compare the two personalization modes, PH and PHF . Across all experiments, we observe an average PH Gain of 14 . 85% , while PHF Gain is higher at 18 . 82% , indicating a consistent advantage of personalizing the fusion module in addition to the task head. This difference is fusion-dependent. As sho wn in T able II , under ConcatFusion, PH Gain and PHF Gain are nearly iden- tical, with av erage gains of 20 . 82% and 20 . 87% , respectiv ely . In contrast, under AttentionFusion, PHF Gain substantially exceeds PH Gain, achie ving an average gain of 16 . 76% compared to 8 . 89% for PH. This behaviour arises from the nature of the fusion operator . ConcatFusion is a fixed operation, so personalizing it provides little improvement in gain. AttentionFusion, howe v er , is a learned module, and keeping it personalized allows clients to adapt the fusion process to their local modality av ailability and data distribution, leading to higher gains under both missing-modality and label-heterogeneous settings. Conse- quently , since attention-based fusion is widely used in practice and PHF Gain consistently matches or exceeds PH Gain, PHF represents a robust default choice for multimodal FL. C. Modality-insufficient tasks Some datasets in our e valuation are inherently modality- insufficient. PTB-XL is a representati ve case, as it consists of 12 ECG leads split into two sets of six treated as sep- arate modalities. A single set captures only partial cardiac information, leading to sev ere performance de gradation under missing-modality settings. KU-HAR e xhibits a similar trend. As reported in FedMultimodal, performance drops by up to 43% under a 50% missing modality rate, indicating that no single sensor stream is sufficient for reliable prediction. Accordingly , we observ e the lar gest personalization g ains on these datasets, with average PG of 80 . 12% for KU-HAR and 72 . 75% for PTB-XL. While PH and PHF perform similarly under ConcatFusion, under AttentionFusion PHF significantly outperforms PH, achieving gains of 41 . 47% on KU-HAR and 30 . 78% on PTB-XL in IID settings. These results indicate that for modality-insuf ficient tasks, personalizing the fusion module is particularly critical, as it helps mitigate the compounded ef fects of limited representa- tional capacity and client heterogeneity . D. Impact of Modality-Incomplete Clients Fig. 2: Modality-wise validation F1 across training rounds on PTB- XL under the 3–3–4 NIID setting. Colours indicate client modality av ailability (unimodal vs. multimodal), and line styles denote aggre- gation modes (FM, PH, PHF). An important question in structurally sparse multimodal fed- erated settings is whether modality-incomplete clients mean- ingfully contribute to global performance. W e in vestigate this using modality-wise validation F1 across training rounds on PTB-XL under the 3–3–4 client configuration, grouped by modality av ailability and aggregation strategy (Figure 2 ). PTB-XL is modality-insuf ficient by design, so performance depends on effecti ve cross-client modality sharing. W e high- light NIID results because the effect is easiest to observe here; howe ver , the same ordering holds across most datasets under both IID and NIID splits, with smaller gaps in the IID case. Performance differences are most pronounced for unimodal clients, where aggregation choice has the strongest impact. PHF consistently outperforms PH across rounds and often approaches FM scores for multimodal clients, with the lar gest gains visible for IT O A VF-only clients. In contrast, multi- modal clients remain relativ ely stable during training, with only minor differences between FM, PH, and PHF . Overall, this indicates that personalization substantially improves the usefulness of updates from modality-incomplete clients. T ABLE III: Relativ e performance degradation under varying miss- ing modality rates (IID, AttentionFusion). Lower is better . Dataset Modality Config (Missing Rate) FedMultimodal B L O S S O M (PHF) KU-HAR 3–3–4 (30%) 13.0% 11.7% 5–5–0 (50%) 43.0% 12.6% UCI-HAR 3–3–4 (30%) 4.6% 7.8% 5–5–0 (50%) 10.3% 5.4% PTB-XL 3–3–4 (30%) 14.0% 6.8% 5–5–0 (50%) 18.0% 8.7% MELD 3–3–4 (30%) 4.0% 5.7% 5–5–0 (50%) 6.7% 10.3% E. Comparison with F edMultimodal W e compare B L O S S O M against the state-of-the-art multimodal FL benchmark FedMultimodal on the four common datasets (KU-HAR, UCI-HAR, PTB-XL, and MELD). A V -MNIST and IEMOCAP are excluded, as they are not part of FedMulti- modal, and are used only for internal comparisons. As noted in Section II-B , most multimodal FL methods, including FedMultimodal, do not explicitly study settings with fully missing client modalities. In addition, FedMultimodal also uses a different partitioning scheme, which makes direct comparisons of absolute performance unreliable. W e therefore report relati ve percentage performance losses under missing- modality scenarios using corresponding missing rates from FedMultimodal (Section IV ) in T able III . For consistency with the original FedMultimodal setup, we restrict this comparison to the IID partition and the Atten- tionFusion configuration, which most closely matches their experimental setup. As shown in T able III , despite operating under a more challenging structural-missingness setting, our framew ork achieves lower relativ e degradation in most cases compared to FedMultimodal, indicating stronger robustness to modality sparsity . V I . C O N C L U S I O N W e introduced B L O S S O M , a frame work that addresses modal- ity scarcity and exclusivity in FL through a modular late- fusion architecture and block-wise aggregation strategy . Our ev aluation confirms that partial personalization crucially miti- gates performance degradation in modality-exclusi ve scenarios while balancing global knowledge sharing. Despite its ef fectiv eness, our study has limitations that guide future work. Computational constraints restricted experiments to specific modality configurations and client counts, lea ving broader scalability and low-participation scenarios unexplored. Additionally , while we ev aluated div erse domains, our datasets contain few modalities per client, necessitating validation in richer multimodal settings. T o facilitate further research, we release B L O S S O M as an open-source framework. Future work will lev erage the framew ork’ s modularity to explore heterogeneous task heads for multi-task learning and extend B L O S S O M to decentralized cross-silo en vironments. R E F E R E N C E S [1] H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, Communication-ef ficient learning of deep networks fr om decentralized data , 2023. [2] D. C. Nguyen et al., F ederated learning for smart healthcar e: A survey , 2021. [3] Y . Xianjia, J. P . Queralta, J. Heikkonen, and T . W esterlund, “Federated learning in robotic and autonomous systems, ” Procedia Computer Science , vol. 191, 2021. [4] W . Y . B. Lim et al., “Federated learning in mobile edge networks: A comprehensiv e survey, ” IEEE Communications Surveys and T utorials , vol. 22, 2020. [5] T . Baltru ˇ saitis, C. Ahuja, and L.-P . Morenc y, “Multimodal machine learning: A survey and taxonomy , ” IEEE T ransactions on P attern Analysis and Machine Intelligence , vol. 41, 2019. [6] H. Pan, X. Zhao, L. He, Y . Shi, and X. Lin, “A survey of multimodal federated learning: Background, applications, and perspectiv es, ” Mul- timedia Syst. , vol. 30, 2024. [7] X. Ouyang et al., “Harmony: Heterogeneous multi-modal federated learning through disentangled model training, ” in Pr oceedings of the 21st Annual International Conference on Mobile Systems, Applications and Services , 2023. [8] Q. Li, Y . Diao, Q. Chen, and B. He, F ederated learning on non-iid data silos: An experimental study , 2021. [9] K. Pillutla, K. Malik, A. Mohamed, M. Rabbat, M. Sanjabi, and L. Xiao, F ederated learning with partial model personalization , 2022. [10] W . Huang, D. W ang, X. Ouyang, J. W an, J. Liu, and T . Li, “Multi- modal federated learning: Concept, methods, applications and future directions, ” Information Fusion , vol. 112, 2024. [11] L. Y uan, D.-J. Han, V . P . Chellapandi, S. H. ˙ Zak, and C. G. Brinton, F edmfs: F ederated multimodal fusion learning with selective modality communication , 2024. [12] Q. Y u, Y . Liu, Y . W ang, K. Xu, and J. Liu, Multimodal federated learning via contrastive repr esentation ensemble , 2023. [13] Y . Y ang, K.-T . W ang, D.-C. Zhan, H. Xiong, and Y . Jiang, “Compre- hensiv e semi-supervised multi-modal learning, ” in Proceedings of the 28th International Joint Conference on Artificial Intelligence , 2019. [14] Y . Zhao, P . Barnaghi, and H. Haddadi, Multimodal federated learning on iot data , 2022. [15] K. Y ue, R. Jin, C.-W . W ong, D. Baron, and H. Dai, Gradient obfus- cation gives a false sense of security in federated learning , 2022. [16] J. Chen and A. Zhang, “Fedmsplit: Correlation-adaptiv e federated multi-task learning across multimodal split networks, ” in Pr oceedings of the 28th A CM SIGKDD Confer ence on Knowledge Discovery and Data Mining , 2022. [17] T . Feng et al., F edmultimodal: A benchmark for multimodal federated learning , 2023. [18] J. Geraghty , A. Hines, and F . Golpayegani, “Learning to associate: Multimodal inference with fully missing modalities, ” ACM T rans. Intell. Syst. T echnol. , vol. 16, 2025. [19] S. Reddi et al., Adaptive federated optimization , 2021. [20] N. Sikder and A.-A. Nahid, “Ku-har: An open dataset for hetero- geneous human activity recognition, ” P attern Recognition Letters , vol. 146, 2021. [21] D. Garcia-Gonzalez, D. Rivero, E. Fernandez-Blanco, and M. R. Lu- aces, “A public domain dataset for real-life human activity recognition using smartphone sensors, ” Sensors , vol. 20, 2020. [22] P . W agner et al., “PTB-XL, a large publicly av ailable electrocardiog- raphy dataset, ” Sci. Data , vol. 7, 2020. [23] V . V ielzeuf, A. Lechervy, S. P ateux, and F . Jurie, Centralnet: A multilayer approac h for multimodal fusion , 2018. [24] S. Poria, D. Hazarika, N. Majumder , G. Naik, E. Cambria, and R. Mihalcea, Meld: A multimodal multi-party dataset for emotion r ecognition in conversations , 2019. [25] C. Busso et al., “Iemocap: Interactive emotional dyadic motion capture database, ” Language Resour ces and Evaluation , vol. 42, 2008. [26] D. J. Beutel et al., Flower: A friendly federated learning resear ch framework , 2020. [27] O. Y adan, Hydra - a framework for ele gantly configuring comple x applications , 2019. [28] S. Padi, S. O. Sadjadi, D. Manocha, and R. D. Sriram, Multimodal emotion r ecognition using transfer learning from speaker r ecognition and bert-based models , 2022.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment