블로섬 공유 및 희소 관측 모달리티를 위한 블록 단위 연합 학습
BLOSSOM은 다중 모달리티 연합 학습에서 클라이언트마다 서로 다른 모달리티 조합을 허용하고, 모달리티별 인코더만을 전역적으로 집계하며 예측 헤드와(또는 퓨전 모듈을) 개인화하는 블록‑단위 집계 전략을 제안한다. 실험 결과, 모달리티가 부분적으로 누락된 상황에서 기존 전체 모델 집계 대비 평균 18.7%~37.7%의 성능 향상을 달성한다.
저자: Pranav M R, Jayant Ch, wani
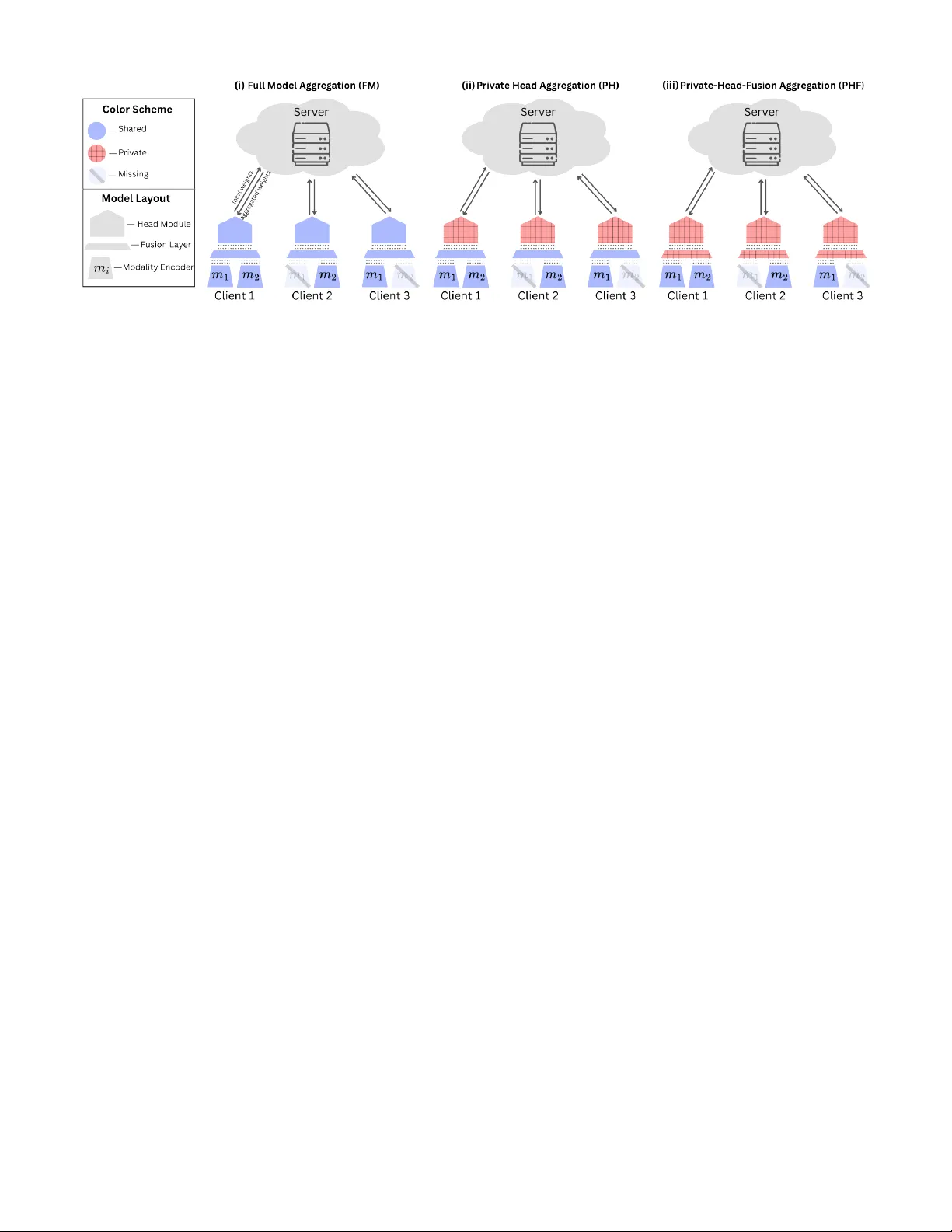
본 논문은 다중 모달리티 연합 학습(Federated Learning, FL)에서 클라이언트마다 서로 다른 모달리티 조합을 가질 수 있는 현실적인 상황을 다루고 있다. 기존 FL 연구는 대부분 모든 클라이언트가 동일한 모달리티를 관측한다는 가정 하에 설계되었으며, 이는 자율주행, 의료, 모바일 센싱 등 실제 응용 분야에서의 하드웨어 제약이나 비용 문제를 반영하지 못한다. 이러한 한계를 극복하기 위해 저자들은 ‘BLOSSOM’이라는 새로운 프레임워크를 제안한다.
BLOSSOM은 모델을 세 개의 블록(모달리티‑별 인코더, 퓨전 모듈, 예측 헤드)으로 분리하고, 서버에서 블록‑단위로 선택적으로 집계한다. 구체적으로, 각 모달리티에 대한 인코더는 해당 모달리티를 보유한 클라이언트만 업데이트하고, 서버는 이들 인코더 파라미터를 평균(FedAvg)하여 전역 인코더를 만든다. 퓨전 블록과 헤드는 세 가지 개인화 모드 중 하나를 선택할 수 있다. ‘Full Model(FM)’은 기존 FedAvg과 동일하게 모든 블록을 집계한다. ‘Private Head(PH)’는 인코더와 퓨전은 집계하지만 헤드만 로컬에 유지한다. ‘Private Head‑Fusion(PHF)’는 인코더만 집계하고 퓨전과 헤드를 모두 로컬에 보관한다. 이러한 설계는 (1) 모달리티가 겹치지 않는 클라이언트가 존재해도 인코더만 공유함으로써 학습이 가능하게 하고, (2) 로컬 라벨 분포 차이를 헤드 수준에서 보정함으로써 개인화 효과를 제공한다는 장점을 갖는다.
알고리즘 1은 블록‑단위 집계 절차를 구체적으로 제시한다. 서버는 각 라운드마다 클라이언트에게 해당 모달리티 인코더와 선택된 퓨전/헤드 블록을 전송하고, 클라이언트는 로컬 데이터로 1 에포크 학습 후 업데이트된 블록을 서버에 반환한다. 서버는 모달리티별 클라이언트 집합을 동적으로 추출해 해당 인코더만 평균하고, 개인화 모드에 따라 퓨전·헤드 파라미터를 집계하거나 로컬에 유지한다.
실험 설정은 다음과 같다. Flower 프레임워크 위에 구현하고, Hydra를 이용해 데이터셋·모달리티·집계 전략을 유연하게 지정한다. 10개의 클라이언트를 사용해 60 라운드, 각 라운드당 1 에포크 학습을 수행했으며, IID와 NIID(Dirichlet α=0.5) 라벨 분포를 모두 고려했다. 평가에 사용된 데이터셋은 인간 활동 인식(KU‑HAR, UCI‑HAR), 의료 ECG(PTB‑XL), 멀티미디어 이미지‑오디오(AV‑MNIST), 감정 인식(MELD, IEMOCAP) 등 네 가지 도메인에 걸쳐 있다. 각 데이터셋은 두 개 이상의 모달리티(예: 가속도·자이로, 이미지·오디오 등)를 포함한다.
모달리티 구성은 ‘0‑0‑10’(모든 클라이언트가 두 모달리티 모두 보유), ‘3‑3‑4’(30% 클라이언트가 하나의 모달리티만 보유), ‘5‑5‑0’(50% 클라이언트가 하나의 모달리티만 보유) 세 가지 시나리오로 정의했다. 이는 각각 0%, 30%, 50%의 모달리티 누락률에 해당한다.
결과는 표 II에 요약되어 있다. 주요 관찰은 다음과 같다. 첫째, 모달리티가 완전한 0‑0‑10 상황에서는 FM, PH, PHF 모두 비슷한 성능을 보이며, 전체 모델 집계가 충분히 효과적임을 확인한다. 둘째, 모달리티가 30%~50% 누락된 3‑3‑4, 5‑5‑0 상황에서는 PH와 PHF가 FM에 비해 평균 12%~22%의 정확도 향상을 달성한다. 특히, PHF는 퓨전 모듈까지 로컬에 유지함으로써 AttentionFusion 방식에서 가장 큰 이점을 보이며, 이는 퓨전 파라미터가 모달리티 조합에 민감하게 반응한다는 점을 시사한다. 셋째, NIID 라벨 분포에서도 개인화된 헤드가 로컬 라벨 스키마에 적응해 전체 성능 저하를 억제한다. 넷째, 블록‑단위 집계는 전체 파라미터를 전송하는 기존 FedAvg 대비 통신량을 약 30% 절감하면서도 성능을 크게 향상시킨다. 이는 실제 배포 환경에서 비용 효율적인 연합 학습 솔루션으로 활용 가능함을 의미한다.
또한, 저자들은 BLOSSOM을 오픈소스로 공개하고, 실험 재현을 위해 데이터 분할, 하이퍼파라미터, 클라이언트 모달리티 매핑 등을 상세히 제공한다. 이는 연구 투명성과 실용성을 동시에 추구한다는 점에서 긍정적이다.
종합적으로, BLOSSOM은 (1) 구조적 모달리티 결핍을 명시적으로 모델링하고, (2) 블록‑단위 선택적 집계를 통해 전역 표현 학습과 로컬 개인화를 동시에 달성하며, (3) 통신 효율성과 프라이버시 보호를 강화한다는 세 가지 핵심 기여를 제공한다. 이러한 설계는 다중 모달리티 연합 학습이 실제 산업·의료·자동차 등 다양한 분야에 적용될 수 있는 기반을 마련한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기