On Token's Dilemma: Dynamic MoE with Drift-Aware Token Assignment for Continual Learning of Large Vision Language Models
Multimodal Continual Instruction Tuning aims to continually enhance Large Vision Language Models (LVLMs) by learning from new data without forgetting previously acquired knowledge. Mixture of Experts (MoE) architectures naturally facilitate this by i…
Authors: Chongyang Zhao, Mingsong Li, Haodong Lu
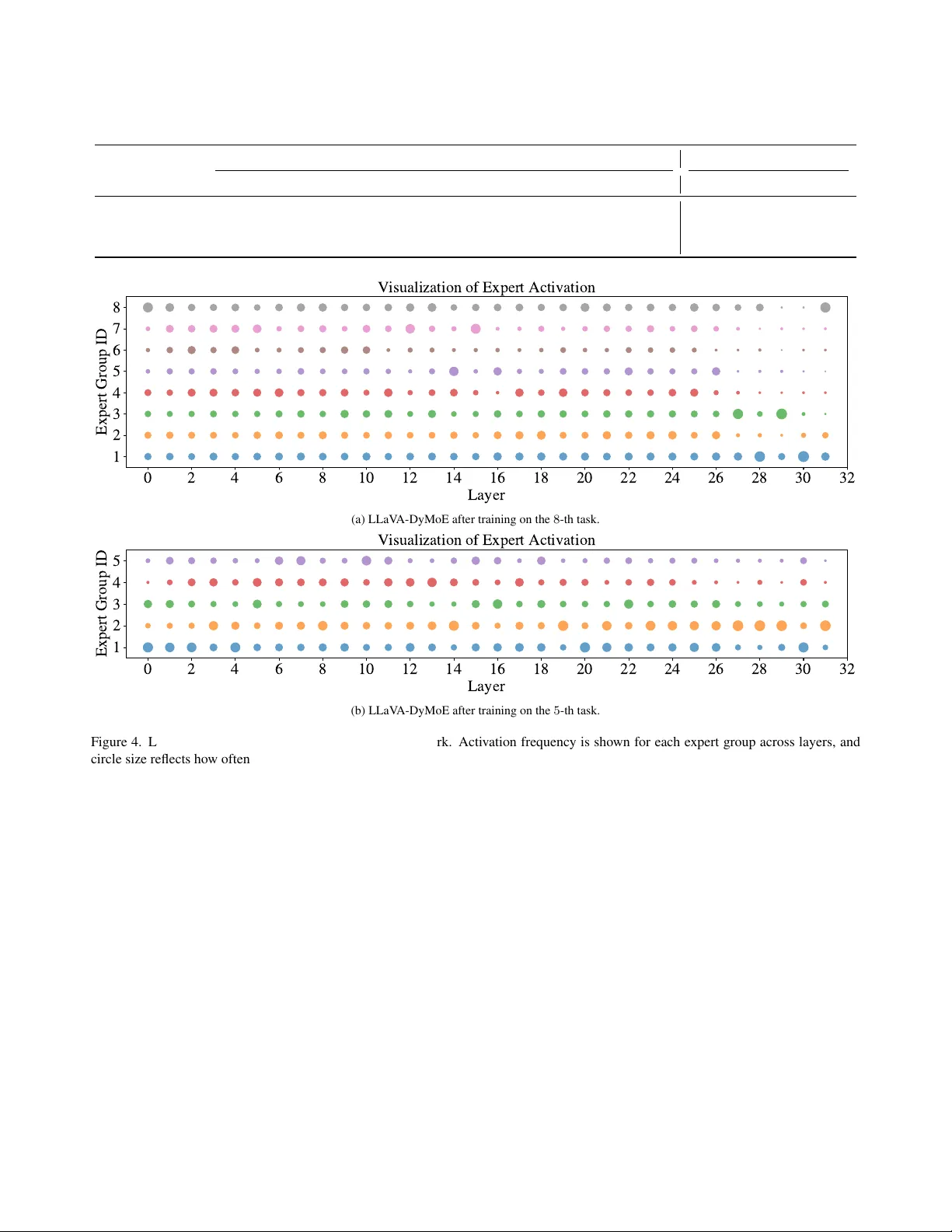
On T oken’ s Dilemma: Dynamic MoE with Drift-A ware T ok en Assignment f or Continual Learning of Lar ge V ision Language Models Chongyang Zhao Mingsong Li Haodong Lu Dong Gong * Uni versity of Ne w South W ales (UNSW Sydney) { chongyang.zhao, dong.gong } @unsw.edu.au Abstract Multimodal Continual Instruction T uning aims to continu- ally enhance Lar ge V ision Language Models (L VLMs) by learning fr om new data without for getting pr eviously ac- quir ed knowledg e. Mixture of Experts (MoE) ar chitectur es naturally facilitate this by incr ementally adding new ex- perts and expanding r outers while keeping the e xisting ones fr ozen. However , despite expert isolation, MoE-based con- tinual learners still suffer fr om forg etting due to r outing- drift: old-task tokens become mistakenly attracted to newly added experts, degr ading performance on prior tasks. W e analyze the failure mode at the token level and r eveal the to- ken’ s dilemma: ambiguous and old tokens in new-task data offer minimal learning benefit yet induce forgetting when r outed to new experts, due to their ambiguous r outing as- signment during training. Motivated by this, we propose LLaV A-DyMoE, a dynamic MoE frame work that incremen- tally expands the MoE with drift-awar e token assignment. W e characterize token types via their r outing scor e dis- tributions and apply tar geted r e gularization. Specifically , a token-level assignment guidance steers ambiguous and old tokens away fr om new experts to preserve established r outing patterns and alleviate r outing-drift, while comple- mentary r outing score r egularizations enfor ce expert-gr oup separation and pr omote new-expert specialization. Exten- sive e xperiments demonstrate that our LLaV A-DyMoE ef- fectively mitigates r outing-drift-induced for getting, achiev- ing over a 7% gain in mean final accuracy and a 12% re- duction in forg etting compared to baselines. The pr oject page is zhaoc5.github.io/DyMoE . 1. Introduction Large V ision Language Models (L VLMs) [ 3 , 12 , 38 , 64 ] hav e recently achie ved remarkable performance across a wide range of vision-language tasks [ 2 , 37 , 44 ] by extend- ing Large Language Models (LLMs) [ 28 , 59 , 60 ] to pro- * D. Gong is the corresponding author . MFN SQA VQA Te xt ImgNet GQA V izWiz REF VQA v2 VQA OCR LoRA MoELoRA EWC LwF IncLoRA O-LoRA IncMoELoRA LLaV A-DyMoE (Ours) Figure 1. Performance comparison on the CoIN benchmark, sho w- ing per-task final accurac y and mean final accuracy (MFN). cess multimodal information. Central to their success is a two-phase dev elopment pipeline: pre-training for vision- language alignment, follo wed by instruction tuning to adapt the model to specific domains and tasks. While these models are trained on fixed datasets and remain largely static, ne w instruction-following requirements often arise dynamically in real-world applications. This motiv ates continual learning capabilities that allow the model to as- similate new knowledge while preserving performance on previously learned tasks, overcoming catastrophic forget- ting [ 17 , 30 , 36 ]. As naiv ely retraining on a combined set of old and new data is resource-intensiv e, Multimodal Continual Instruc- tion T uning (MCIT) [ 5 , 7 , 8 , 23 , 73 ] has emerged to address this need, aiming to incrementally instruction-tune L VLMs on new tasks while maintaining proficiency on previously learned ones. Common strategies include regularization- based methods [ 8 , 23 , 31 , 46 ], which impose parameter constraints to pre vent for getting, and rehearsal-based meth- ods [ 32 , 43 , 73 ], which rely on replaying old data. Howe ver , these approaches often introduce non-trivial computational ov erhead or storage constraints. An attractiv e alternativ e is to isolate task-specific parameters via parameter -efficient tuning (PEFT) approaches [ 8 , 16 , 24 , 75 ]. Among these, the Mixture of Experts (MoE) paradigm [ 16 , 65 , 69 , 73 , 74 ] has become a prev alent solution owing to its dynamic modular architecture, superior scalability , and inference efficiency . 1 This modular structure inherently facilitates flexible expert allocation and parameter isolation across tasks, which is crucial for mitigating catastrophic forgetting. Despite these advantages, existing MoE-based MCIT approaches still exhibit significant forgetting. Training a fixed-size MoE without parameter isolation across shared experts and routers leads to inter-task interference and de- graded knowledge retention [ 7 ]. Some works [ 20 , 25 , 73 , 81 ] address this by incrementally expanding model ex- perts while freezing previous ones, and introducing task- specific routers to identify tasks and assign experts accord- ingly . Howe ver , reliable task identification may require heavy computation and can become unreliable when tasks are di verse and complex. Moreo ver , task-lev el expert as- signment reduces the combinatorial fle xibility of MoE, sac- rificing its inherent token-le vel routing adaptability . In this paper , we introduce LLaV A-DyMoE, a Dynamic MoE framework with Drift-A ware T oken Assignment for continual learning of L VLMs. Unlike prior works that by- pass routing instability via task-specific routing [ 20 , 25 , 73 ], we focus on directly addressing the underlying token-lev el cause of forgetting during dynamic MoE expansion. Even with old experts and their router parameters frozen, training the ne wly added components on new-task data still causes forgetting: the updated routing parameters distort the as- signment of old-task tokens to their established experts. This distortion constitutes routing-drift , a corruption of the router’ s learned polic y for old tasks that driv es catastrophic forgetting at the token lev el. W e analyze how routing- drift arises during training of newly added components and rev eal that not all tokens in the new-task data contribute equally (Sec. 3.3 and Fig. 2 ). Beyond new tokens that carry genuinely no vel patterns, we identify two types that pose a forgetting risk: ambiguous tok ens , which exhibit simi- lar routing af finity for both old and new expert groups; and old tokens , whose patterns closely resemble old tasks yet receiv e non-negligible new-e xpert weight from the under- optimized router . Both types of fer minimal benefit for ne w- task learning, yet when routed to ne w experts, they inad- vertently train the new router to attract old-task patterns— causing old-task tokens to be mis-routed at inference time and inducing forgetting. This is the token’ s dilemma : min- imal learning value, yet a direct forgetting cost when left unguided; compounded by the inherent ambiguity of their routing and expert assignment. Motiv ated by this analysis, LLaV A-DyMoE mitigates forgetting in dynamic MoE expansion through a two- fold regularization comprising T oken Assignment Guidance (T A G) and Routing Score Regularization (RSR). T AG iden- tifies token types from their routing scores and guides their assignment by adjusting routing scores during training, di- rectly tackling the tokens’ dilemma and steering ambigu- ous tokens away from ne w experts. As a complemen- tary soft regularization, RSR encourages exclusi ve token- to-group routing and promotes new-expert specialization on genuinely new-task tokens. Extensive experiments on the CoIN benchmark [ 7 ] across eight VQA-based tasks demon- strate the effecti veness of LLaV A-DyMoE, achieving over a 7% gain in MFN and a 12% reduction in forgetting com- pared to baseline methods. Moreov er , LLaV A-DyMoE is orthogonal to and com- patible with existing MCIT paradigms, including data- based methods [ 8 , 51 , 73 ] and task-specific routing ap- proaches [ 20 , 72 , 73 , 81 ], and can be combined with them for further performance gains. Our main contributions are summarized as follo ws: • W e identify the token-le vel cause of r outing-drift : the to- ken’ s dilemma . Through controlled analysis, we sho w that ambiguous tok ens and old tokens in new-task data of- fer minimal new-task benefit yet induce forgetting when routed to new experts. Ambiguous tokens are especially challenging, as their ambiguous af finity makes them dif- ficult to identify and prone to unstable routing. (Sec. 3.3 ) • Motiv ated by this, we introduce LLaV A-DyMoE, a two- fold regularization framework. It comprises a T oken As- signment Guidance (T A G) mechanism that identifies and redirects ambiguous tok ens a way from new experts, and a Routing Score Regularization (RSR) that encourages ex- clusiv e token-to-group routing and promotes new-expert specialization. (Sec. 3.4 ) • Extensive experiments demonstrate that our method sig- nificantly outperforms baseline methods, achieving a su- perior balance between knowledge retention and new-task acquisition. (Sec. 4 ) 2. Related W ork Continual Learning (CL) inv estigates methods for train- ing models on non-stationary data distributions, typically presented as a sequence of tasks, with the primary goal of ov ercoming catastrophic forgetting [ 14 , 30 , 49 , 62 , 71 , 80 ]. CL methods can be broadly categorized by their core strat- egy to mitigate catastrophic forgetting. Rehearsal-based methods [ 4 , 6 , 39 , 49 , 50 , 52 , 57 ] store and generate a small subset of pre vious samples or features during train- ing on ne w tasks, thereby approximating the data distri- bution of the past. Regularization-based methods [ 1 , 27 , 30 , 36 , 45 , 76 , 78 , 79 ] mitigate catastrophic forgetting by penalizing updates to parameters deemed critical for performance on pre vious tasks. Architecture-based meth- ods [ 35 , 40 , 41 , 55 , 61 , 68 , 70 – 72 ] allocate new parameters for each task, either by physically expanding the netw ork or by functionally isolating parameter subsets via masking. Continual Learning for L VLMs and LLMs. Continu- ally expanding the capabilities of LLMs [ 28 , 59 , 60 ] and L VLMs [ 3 , 12 , 38 , 64 ] presents unique challenges, as the immense computational cost of retraining makes continual 2 instruction tuning a necessity . In the vision-language do- main, recent ef forts [ 5 , 7 , 18 , 20 , 23 , 25 , 46 , 65 , 77 ] focus on continual instruction-tuning L VLMs with sequential tasks, av oiding the expensiv e process of retraining from scratch. MoELoRA [ 7 ] proposes the CoIN benchmark and adopts the framework of Mixture of Experts (MoE) with LoRA e x- perts. SEFE [ 8 ] incrementally learns new LoRA matrices and regularizes key parameter updates to retain prior knowl- edge. ProgLoRA [ 73 ] proposes a progressi ve LoRA pool that mitigates task interference by isolating kno wledge in separate LoRA blocks. In the language domain, similar ef- forts have been applied to either re gularize learning [ 48 , 63 ] or expand the capacity of the model [ 48 ]. Mixture of Experts (MoE) with LoRA. The MoE paradigm enhances model capacity by replacing the T rans- former’ s dense feed-forward layer with multiple expert subnetworks and a routing network [ 13 , 16 , 21 , 33 , 56 , 69 ]. This frame work dynamically routes each input to a sparse subset of experts, employing auxiliary load- balancing losses [ 16 ] to ensure balanced expert utiliza- tion. This paradigm has been adopted in conjunction with LoRA [ 24 ] for standard fine-tuning [ 10 , 15 , 34 ] and for con- tinual learning [ 7 , 72 ], where low-rank adapters are treated as experts. Our formulation adopts this MoE with LoRA paradigm, where we add ne w LoRA e xperts for each task to expand the kno wledge base of the foundation model. 3. Methodology: LLaV A-DyMoE with Drift- A ware T oken Assignment 3.1. Problem Setup Continual Learning aims to enable models to continually acquire new knowledge without catastrophic forgetting. W ithin the broader CL paradigm, Multimodal Continual In- struction T uning (MCIT) enables Large V ision-Language Models (L VLMs) to incrementally adapt to new tasks and maintain strong performance on previously learned tasks, without full retraining. Let {D 1 , ..., D t , ..., D T } denote the training data of a sequence of T tasks arriving as a stream. The dataset D t = { X } S t for the t -th task consists of S t samples. Each sample is a multimodal instruction-response triplet X = ( x v , x q , x a ) . Here, x v , x q , and x a denote the image, instruction, and answer tokens, respectively . W e fo- cus on the MCIT setting [ 7 ] based on LLaV A [ 38 ]. 3.2. Dynamic MoE Layers MoE Layers with LoRA. Giv en a pre-trained LLaV A, learning on new instruction tuning tasks is achieved through fine-tuning with LoRA [ 24 ]. A LoRA module parame- terizes a low-rank update to a pre-trained weight matrix W l,m 0 ∈ R d out × d in (at layer l , module m in the T ransformer of LLaV A) by introducing two factors B l,m ∈ R d out × r and A l,m ∈ R r × d in , such that ∆ W l,m = B l,m A l,m , where r ≪ min( d in , d out ) . The updated weight matrix is then de- fined as: W l,m = W l,m 0 + ∆ W l,m = W l,m 0 + B l,m A l,m . Instead of relying on a single continually trained LoRA adapter or merging task-specific adapters into the back- bone, we de velop an MoE architecture with LoRA mod- ules as experts to augment each module with weight matrix W l,m 0 in the pre-trained LLM of LLaV A. An MoE layer is composed of multiple experts { e l,m i () } N i =1 and a router R l,m () : R d in → R N to assign each input token representa- tion to specific experts. Each expert e i () is a LoRA module parameterized by ( A l,m i , B l,m i ) . Giv en an input multimodal token’ s representation h l,m ∈ R d in , the output h l,m out is com- puted as: h l,m out = W l,m 0 h l,m + X N i =1 w i B l,m i A l,m i h l,m , w i = w ′ i / X N i =1 w ′ i , w ′ i = exp( s i ) 1 [ i ∈ TopK K ( s )] , (1) where B l,m i A l,m i h l,m = e i ( h l,m ) , s = R l,m ( h l,m ) is the logits vector produced by the router , TopK K ( s ) denotes the set comprising the indices of the K highest affinity scores among all N experts, 1 () is the indicator function, s i and w i are the i -th elements of s and w , respectively . The router assigns the token to the corresponding K experts with top- K highest scores. The resulting routing weight w is sparse, indicating that only K out of N gate v alues are nonzero. This sparsity property encourages the tokens to be assigned to specialized experts at each layer . Dynamic MoE with incrementally added experts. W e implement dynamic MoE (DyMoE) with LoRA experts, in- crementally adding ne w e xperts and e xpanding the router as each new task arri ves. In MCIT , when the t -th task ( t > 1 ) arriv es, we assume existing experts E t − 1 with a router pro- ducing scores w t − 1 , s t − 1 ∈ R |E t − 1 | , index ed by S t − 1 . For a new task t , we add N t new experts E t, new = { e l,m i } N t i =1 and expand the router to produce N t new output routing scores w t, new , s t, new ∈ R N t . All old existing parameters are frozen; only the ne wly added experts E t, new and their associ- ated router parameters are trained, while input tokens from task t can be routed to both old frozen experts E t − 1 and new trainable experts E t, new . After adding and training ne w ex- perts, the expert set and router output are expanded: E t = E t − 1 ∪ E t, new , w t = [ w t − 1 ; w t, new ] , and s t = [ s t − 1 ; s t, new ] , and the index set is updated as S t = S t − 1 ∪ S t, new . For getting as routing-drift in DyMoE. During training, newly added experts and their router parameters are updated while existing e xperts remain frozen, allo wing ne w-task to- kens to reuse previously learned knowledge and keeping ex- perts isolated across tasks. Howe ver , despite this isolation, DyMoE still exhibits catastrophic forgetting in MCIT due to r outing-drift . After updating the new router parameters, old-task tokens may be mis-routed to newly added experts that were nev er trained on them, resulting in performance 3 50 100 150 200 250 Training Step 68 70 72 74 76 78 80 82 T ask 1 (SQA) Accuracy (%) T ask 1 (SQA) T ask 2 (TextVQA) Only Retain New T okens Default Training 44 46 48 50 52 54 T ask 2 (T extVQA) Accuracy (%) (a) Only retain new tok ens 50 100 150 200 250 Training Step 68 70 72 74 76 78 80 82 T ask 1 (SQA) Accuracy (%) T ask 1 (SQA) T ask 2 (TextVQA) Mask Out Old T okens Default Training 46 48 50 52 54 T ask 2 (T extVQA) Accuracy (%) (b) Mask out old tokens 50 100 150 200 250 Training Step 0 10 20 30 40 50 60 70 80 T ask 1 (SQA) Accuracy (%) T ask 1 (SQA) T ask 2 (TextVQA) Only Retain Ambiguous T okens − 1 0 1 2 3 4 5 6 7 8 T ask 2 (T extVQA) Accuracy (%) (c) Only retain ambiguous tokens Figure 2. Routing-drift analysis in a controlled two-task learning experiment. After learning on the 1st task (SQA), we conduct the 2nd task (T extVQA) training using the baseline (default training) and three different token masking strategies based on token type. Throughout the training stages, we evaluate forgetting (decrease in task 1 accuracy) and new-task learning (improvement of task 2 accuracy). Polynomial regression-fitted curv es are used for better visualization and readability of performance changes. The baseline (default training) refers to a scenario where each input token is assigned to all experts (including old frozen and new learnable ones). W e then examine the role of each token group based on its routing score: (a) W e only retain the contribution of tokens that have high af finity to the new expert group (termed “new tokens”). (b) W e mask out the contribution of tokens with a high affinity to the old expert group (termed “old tokens”). (c) W e only retain the contribution of tok ens with a small affinity dif ference between the old and new e xpert group (termed “ambiguous tokens”). degradation on old tasks, i.e . , for getting . 3.3. T oken’ s Dilemma: Analyses on Routing-drift Associated with T oken Assignment Although many CL and MCIT methods with incremen- tally added network components [ 9 , 61 , 73 , 77 , 81 ] at- tempt to handle or bypass the for getting caused by routing- drift, they typically rely on auxiliary mechanisms, such as task-specific router predictors or auxiliary regularizers. In- stead, we aim to inv estigate and tackle the inherent cause of routing-drift in the dynamic MoE expansion process. W e analyze how routing-drift is caused at the token le vel when only newly added parameters are updated on ne w-task data while old parameters remain frozen. Even when trained only on new-task tokens, the newly added router parame- ters can still attract old-task tokens ( i.e . , high routing scores s t, new ) and route them to new experts. Since MoE routers operate on and are also trained by individual token-expert assignments, we ask: how does token assignment during new-task tr aining lead to r outing confusion? W e inv estigate how different tokens from ne w-task data are assigned to experts during training and ho w this finally influences routing and performance on both tasks in testing. T o closely examine the token–router dynamics when train- ing ne wly added experts and router parameters, we conduct a controlled two-task experiment at the second incremental step (Fig. 2 ). When the second ( i.e. , new) task arri ves, only the ne wly added LoRA experts and router are updated in a default way ( i.e. , basic IncMoELoRA; Sec. 3.2 ), and we measure accuracy on both new and old tasks as indicators of new-kno wledge acquisition and forgetting. During training, each token is assigned to all experts (including old frozen ones and ne w learnable ones) according to routing scores s = [ s old , s new ] . Since routing-drift occurs with old-task tokens attracted by newly trained components, e ven when training only on new-task tokens, we hypothesize that dif- ferent tokens exhibit varying degrees of ne w patterns—not all new-task tok ens carry genuinely new patterns—and that freely assigning all of them to both old and ne w e xperts dur- ing training causes routing confusion between tasks. Af- ter inv estigating the token-expert assignment pattern, we dynamically categorize new-task tokens into three groups based on the relativ e dominance of s new vs. s old in their rout- ing scores s = [ s old , s new ] : new , old , and ambiguous tok ens. W e analyze how each token type influences forgetting and new-task learning (Fig. 2 ), yielding three k ey observ ations. Observation 1 : New tokens (with high affinity to the new expert group) primarily drive new-task kno wledge acquisi- tion and cause less forgetting. As sho wn in Fig. 2 (a), train- ing only on new tokens yields strong new-task performance with minimal forgetting, as these tokens carry patterns dis- tinct from old tasks and are naturally routed to newly added experts, lea ving the old router policy uncorrupted. Observation 2 : Old tokens contribute less to new-task learning. Masking them from accessing ne wly added pa- rameters yields similar new-task performance and forget- ting as the baseline (Fig. 2 (b)), suggesting they are best han- dled by old frozen experts and do not need to contribute to new-task learning. When assigned small b ut non-negligible weight toward new experts (by an under-optimized router), this inadvertently biases the new router to ward old-task pat- terns, causing routing-drift despite limited learning value. Observation 3 : Ambiguous tokens offer minimal ne w-task learning benefit while posing a direct forgetting risk. Iden- tified by their small af finity dif ference between old and new expert groups, these tokens capture ambiguous patterns across tasks. Their ambiguity makes them particularly dif- ficult to handle correctly . As shown in Fig. 2 (c), training solely on these tokens neither improv es new-task acquisi- tion nor preserves old-task performance, confirming their minimal learning value and direct for getting risk. These controlled e xperiments rev eal ho w different tok en 4 LLaV A - DyMo E … Ta s k t Expansion … 🔥 o ld grou p new grou p ❌ ✅ Pretrai ned We i g h t Router 🔥 … ? ? … RMS Norm Multi - head Attentio n MLP RMS Norm Language Model ×"𝐿 ×"𝐿 Vi s i o n Encoder VL Adapter Te x t To k e n i z e r … What is th e object in the imag e? Dri vin g we ll t ake s prac ti ce, follow ing trait in herited or acquired? Darn el ca n d riv e a car. A. acqu ired B. inhe rit ed Ta s k 1 Ta s k t … Tr an s f o r m er Block Figure 3. Ov erview of our LLaV A-DyMoE method, which applies a dynamic MoE with LoRA experts to each layer of the language backbone in LLaV A. It is a two-fold regularization approach designed to resolve routing-drift-induced for getting, based on our analysis of different token types in Sec. 3.3 . The right panel illustrates this high-level approach: as new tasks (T ask t ) arrive, the router and experts expand, creating a frozen “ old group ” and a trainable “ new group ”. Our T oken Assignment Guidance (T A G) pre vents routing-drift (red dashed arrow) by directing tokens to appropriate expert–router groups, complemented by our Routing Score Regularization (RSR) that encourage exclusi ve token-to-group routing and new-expert specialization. Our method regularizes the router behavior during training and imposes no constraints at inference, allowing seamless combination with other continual learning methods. types af fect new-task learning and contrib ute to routing- drift, exposing the link between the plasticity–stability dilemma in CL and the token’ s dilemma : the inherent as- signment ambiguity and trade-off between learning new tasks and inducing routing-drift. Building on this insight, we design regularization strategies for DyMoE that iden- tify token types and guide their assignment during training, enabling us to lev erage all tokens while mitigating routing- drift-induced forgetting. 3.4. Drift-A ware T oken Assignment Regularization f or Alleviating F orgetting T o resolve routing-drift-induced forgetting in DyMoE for MCIT , we design a two-fold re gularization approach in our proposed LLaV A-DyMoE. As analyzed in Sec. 3.3 , differ - ent new-task tokens from new component training affect new-task learning and old-task forgetting differently . Mo- tiv ated by this, our proposed re gularization guides token routing between old frozen and newly added experts dur - ing training to mitigate routing-drift, which relies solely on tokens’ routing scores without additional assumptions. The re gularization operates on intermediate token represen- tations across all MoE layers. The two-fold regularization comprises T oken Assignment Guidance (T A G) and Rout- ing Score Regularization (RSR). T AG identifies tok en types from their routing scores and guides their assignment by adjusting routing scores during training, shaping the router to avoid drift. It directly tackles the tokens’ dilemma and specifically handles ambiguous tokens. As a complemen- tary soft regularization, RSR directly regularizes the routing score values to enforce discrepanc y and specialty . 3.4.1. T oken Assignment Guidance (T A G) During training, router behavior in MoE is iterati vely up- dated through backpropagation, and the token assignments made by an under-optimized router directly affect the sub- sequent learning of both experts and routers, influencing whether the model dev elops the desired expert specializa- tions and routing patterns [ 66 , 67 , 69 ]. As routers and ex- perts are jointly trained, under -optimized routing weights may generate misleading gradients through token-expert as- signment, contaminating the training of both. Our analysis in Sec. 3.3 shows that dif ferent tokens influence training dif- ferently w .r .t. old and new expert groups: new tokens carry clear new patterns and route naturally to new experts; old tokens gravitate toward old experts b ut their residual affin- ity for new experts should be suppressed to prevent routing corruption; ambiguous tokens exhibit uncertain routing be- tween both groups and require careful handling. T A G dy- namically identifies token types via their routing score am- biguity w .r .t. old and new expert groups and guides their assignment during training to mitigate routing-drift. T oken assignment ambiguity w .r .t. router -expert gr oup. In LLaV A-DyMoE, when a ne w task t arri ves in MCIT , we add new experts together with their router parameters, re- sulting in two router–e xpert groups: the old group S t − 1 (also denoted S t, old ) and the new group S t, new . For the representation of a giv en token at any layer , we denote the router logits ov er all experts as s t = [ s t − 1 ; s t, new ] ∈ R |E t | . W e extract the confidence score from each expert group by taking the maximum logit within that group: c old = max( s t − 1 ) , c new = max( s t, new ) . (2) W e quantify token assignment ambiguity by the relati ve dif- 5 ference between the two group-wise confidence scores: D rel = | c new − c old | max( | c new | , | c old | ) + ϵ , (3) where ϵ is a small constant ( e.g . , 1 e − 9 ) for numerical sta- bility . D rel characterizes the token type. By introducing the ambiguity hyperparameter τ , a token ( i.e. , intermediate representation) is identified as ambiguous if D rel ≤ τ , in- dicating no clear routing preference between old and ne w expert groups. T oken assignment guidance. The T A G mechanism routes a token to new e xpert group S t, new only if it meets tw o con- ditions simultaneously: (1) it is not ambiguous ( D rel > τ ), and (2) it is new-dominant ( c new > c old ). W e formalize this decision with a binary mask M new ∈ { 0 , 1 } : M new = 1 (( c new > c old ) ∧ ( D rel > τ )) , where 1 () is the indicator function, M old = 1 − M new . This ensures that any token which is old-dominant ( c old ≥ c new ) or ambiguous ( D rel ≤ τ ) is automatically assigned to the safe old expert group. T A G applies the mask to produce the final logits s ′ t ∈ R |E t | that are passed to the Softmax function. For expert i , the final routing score s ′ t,i is defined as: s ′ t,i = ( s t,i , if m t,i = 1 , −∞ , otherwise , (4) where m t,i = 1 ( i ∈ S t − 1 ) M old + 1 ( i ∈ S t, new ) M new . T A G routes lo w-ambiguity tokens according to their inherent- pattern-decided routing preference: new tokens to new ex- perts to promote ne w-task learning, and old tokens to old experts with their residual af finity for new experts sup- pressed. Considering their low benefit for learning new knowledge (Sec. 3.3 ), high-ambiguity tokens are routed safely to old experts to pre vent potential forgetting, when no additional prior knowledge is gi ven. 3.4.2. Routing Score Regularization (RSR) As a complement to T AG, we introduce Routing Score Re g- ularization (RSR) to directly regularize the routing score weights. RSR comprises two terms: (1) an exclusi vity loss ( L exc ) that enforces clean separation between old and new expert groups; and (2) a specialization loss ( L spe ) that pro- motes new-expert utilization and specialization to enhance new-task learning. Giv en a token representation at a specific layer , we define the collectiv e gate output, i.e. , the total routing probabil- ity mass assigned to each expert group, in terms of routing weights w i (from Eq. ( 1 )) as: g old = X i ∈S t − 1 w i , g new = X i ∈S t, new w i . (5) Exclusivity loss. This loss enforces clean routing separa- tion by prev enting a tok en from strongly activ ating both ex- pert groups simultaneously , directly working on the routing scores. Minimizing the product of their collecti ve gate out- puts encourages e xclusiv e routing to one group, reinforcing the conditional routing decision of T A G: L exc = g old g new . (6) Specialization loss. Complementing T A G and L exc that mitigate routing-drift and forgetting for stability , we in- troduce the specialization loss L spe to promote and bal- ance plasticity by encouraging higher routing weight to- ward new experts. W e first define a soft target y which is close to 1 if no old experts are selected by the router ( i.e. , ˜ g old = max { w i } i ∈S t − 1 is close to zero): y ≜ 1 − ˜ g old . Relying on ˜ g old , y approaches 1 , reflecting the varying ac- tivity le vel of old e xperts. L spe is formulated as a BCE loss between the collective ne w expert routing weight g new and target y to encourage usage of new experts: L spe = − y log g new − (1 − y ) log 1 − g new . (7) L spe works in synergy with L exc and T AG to balance new- task learning and forgetting mitigation. 3.5. T raining of LLaV A-DyMoE T raining objectives. Our total training objectiv e is a weighted combination of the primary task-learning loss, a standard auxiliary load balancing loss for MoE, and our pro- posed routing regularization terms: L = L NTP + λ L aux + α ( L exc + L spe ) , (8) where L NTP is the standard instruction-tuning loss ( e.g . , au- toregressi ve cross-entropy), and λ and α are scalar hyper- parameters. W e adopt the standard auxiliary load balancing loss ( L aux ) [ 16 ] to ensure balanced utilization, applied to the set of newly added experts. W e use a unified hyperparame- ter α to control the contributions of the two complementary regularization losses, L exc and L spe . Integration with other methods. Our LLaV A-DyMoE, which focuses on rectifying micro-lev el token routing- drift, is inherently orthogonal to and compatible with other macro-lev el MCIT paradigms. It is also compatible with data-based approaches [ 8 , 49 , 73 ], as LLaV A-DyMoE en- hances the router’ s robustness in handling the mixed stream of old and new data, regardless of its source. Our method can also be seamlessly inte grated into architectures that em- ploy task-lev el routing methods [ 20 , 73 , 81 ]. These methods first decide which group of experts to activ ate at a task lev el, while our LLaV A-DyMoE then optimizes the token assign- ment within that activ ated group, mitigating the intra-group routing drifts we identified. These combinations offer the potential for further enhanced performance. 6 T able 1. Comparison with continual learning models on the CoIN benchmark. Method Accuracy on Each T ask (%) Aggregate Results (%) SQA VQA T ext ImgNet GQA V izW iz REF VQA v2 VQA OCR MFN ↑ MAA ↑ BWT ↑ LoRA 52.56 48.12 39.27 44.47 37.46 1.22 56.10 55.11 41.79 43.99 -23.12 MoELoRA [ 7 ] 72.01 46.89 44.75 42.79 28.22 3.31 55.74 57.72 43.93 43.92 -22.18 EWC [ 54 ] 59.11 47.21 39.88 45.12 35.33 2.72 56.29 41.21 40.86 43.75 -21.76 L WF [ 36 ] 62.32 48.66 51.45 45.84 43.76 0.24 54.96 44.63 43.98 44.89 -19.69 IncLoRA 73.33 44.32 54.59 44.07 25.93 4.49 54.91 58.55 45.02 43.12 -23.21 O-LoRA [ 63 ] 75.61 49.98 78.24 44.18 30.70 4.66 55.51 57.37 49.53 46.65 -17.54 IncMoELoRA 68.43 50.31 68.42 47.97 39.46 4.56 57.31 60.95 49.68 49.50 -16.67 LLaV A-DyMoE (Ours) 76.25 53.86 95.80 48.40 52.35 9.25 58.30 62.00 57.03 57.70 -4.67 T able 2. Ablations on main components. Configuration Aggregate Results (%) MFN ↑ MAA ↑ BWT ↑ IncMoELoRA 49.68 49.50 -16.67 + L aux 50.76 51.17 -15.44 + T AG 54.44 52.18 -7.04 + L exc 55.18 54.38 -6.83 + L spe (Ours) 57.03 57.70 -4.67 T able 3. Ablations on ambiguity threshold. τ Aggregate Results (%) MFN ↑ MAA ↑ BWT ↑ 10% 56.87 57.23 -4.94 20% 57.03 57.70 -4.67 30% 56.27 55.65 -5.21 50% 55.32 53.51 -5.54 T able 4. Ablations on loss weights α . α Aggregate Results (%) MFN ↑ MAA ↑ BWT ↑ 1e-2 55.43 57.73 -5.81 5e-3 56.87 57.50 -5.32 1e-3 57.03 57.70 -4.67 5e-4 56.32 57.63 -4.94 4. Experiments 4.1. Experimental Setup Datasets. W e ev aluate our method on the CoIN [ 7 ] benchmark, which encompasses a series of eight VQA tasks. These tasks include ScienceQA (SQA) [ 42 ], T extVQA [ 58 ], ImageNet [ 53 ], GQA [ 26 ], V izW iz [ 22 ], RefCOCO (REF) [ 29 ], VQA v2 [ 19 ], and OCR-VQA [ 44 ]. Each task varies in terms of the number of data samples, stylistic features, and domain characteristics. The training set comprises a total of 569k samples, while the testing set contains 261k samples. Evaluation metrics. W e adopt the metrics introduced in CoIN [ 7 , 8 ], which measure the discrepancy between the model’ s output and the ground truth. Specifically , we re- port: (1) Mean Final Accuracy MFN = 1 T P T i =1 A T ,i , as- sessing the a verage accuracy across all tasks after the com- plete incremental training sequence, where A T ,i represents the accuracy on task i after learning on the final task T ; (2) Mean A verage Accuracy MAA = 1 T P T j =1 1 j P j i =1 ( A j,i ) , representing the mean of the av erage accuracies on all learned tasks after each incremental training step; and (3) Backward T ransfer BWT = 1 T P T i =1 ( A T ,i − A i,i ) , assess- ing the degree of for getting. Implementation details. In our experiments, we utilize the pre-trained, instruction-untuned LLaV A-v1.5-7B [ 38 ] as the backbone model for continual learning. The model in- tegrates V icuna [ 11 ] as its language backbone and a pre- trained CLIP V iT -L/14 visual encoder [ 47 ] to extract visual embeddings. Only the newly added modules are trainable, while the other components remain frozen throughout the continual learning process. Please refer to the Appendix for details on the network architectures, hyperparameters, and implementation settings. 4.2. Main Results W e ev aluate the proposed method on the CoIN [ 7 ] bench- mark, as presented in T able 1 . Pre vious methods that con- tinually train a static model without expanding ne w param- eters for new tasks, e.g., LoRA, MoELoRA [ 7 ], EWC [ 54 ], and L WF [ 36 ], show significant forgetting and inferior ac- curacy as the kno wledge obtained from previous tasks gets repeatedly ov erwritten. T o mitigate such overwriting, new modules are expanded to e xplicitly capture this new knowledge. W e conduct base- line experiments with IncLoRA (adding ne w LoRA mod- ules for each task), and O-LoRA [ 63 ], which further adds orthogonal regularization to the LoRA weight matrix to help mitigate forgetting by regularizing parameter updates in orthogonal directions. T o ensure that LoRA experts learned from previous tasks can be reused while new task knowledge can be absorbed without e xcessiv e overwriting, we further implement the per -task e xpansion baseline in the MoE frame work (IncMoELoRA), where ne w LoRA experts are added for each new task. This baseline exhibits com- parable to or better performance than O-LoRA without any regularization techniques. Howe ver , it suffers from ambigu- ous token-e xpert assignment (see Fig. 2 ), where ambiguous cross-task tokens activate and train newly added e xperts, largely hindering old e xpert utilization on these tokens. Our proposed method significantly outperforms these 7 T able 5. LLaV A-DyMoE is compatible with data-based continual learning strategies. Method Accuracy on Each T ask (%) Aggregate Results (%) SQA VQA T ext ImgNet GQA VizW iz REF VQA v2 VQA OCR MFN ↑ MAA ↑ BWT ↑ None MoELoRA [ 7 ] 72.01 46.89 44.75 42.79 28.22 3.31 55.74 57.72 43.93 43.92 -22.18 O-LoRA [ 63 ] 75.61 49.98 78.24 44.18 30.70 4.66 55.51 57.37 49.53 46.65 -17.54 + ASD [ 8 ] SEFE [ 8 ] 75.35 58.66 83.10 54.25 48.85 16.75 65.35 66.25 58.57 63.04 -10.45 LLaV A-DyMoE (Ours) 74.60 55.24 93.80 53.45 55.00 25.50 63.95 62.85 60.55 62.26 -4.75 + Replay ProgLoRA [ 73 ] 74.84 51.83 83.90 49.93 53.87 31.19 62.71 64.44 59.09 62.38 -6.59 LLaV A-DyMoE (Ours) 75.55 56.88 96.50 54.75 55.90 29.15 63.65 64.25 62.08 61.93 -1.55 methods through our token-le vel routing re gularization. This enforces the assignment of ambiguous cross-task to- kens to old, frozen experts, bringing impro vements of 7.35%, 8.20%, and 12.00% on MFN, MAA, and BWT , re- spectiv ely . W e provide qualitati ve studies in the Appendix. 4.3. Ablation Study The effect of main components. In T able 2 , we ablate the effects of each component of our method. Starting from our implemented baseline (IncMoELoRA), adopting a standard auxiliary load balancing loss ( L aux ) yields a slight perfor - mance improvement by balancing the expert usage for the new incoming task. Notably , the proposed T AG module, which applies group-wise routing guidance based on token assignment ambiguity , significantly improves the final ac- curacy and mitigates forgetting. This is because T AG pre- vents ambiguous tokens from contributing to the learning of the new task (aligned with our observ ations in Sec. 3.3 ). Building on the T A G mechanism, we further regularize the raw router logits. Adding L exc , which re gularizes the ac- tiv ations of ambiguous tokens on new task routers, brings a further improv ement. Finally , to ensure effecti ve learn- ing on the new task, we enforce the utilization of new task routers on (potentially) ne w task-specific tokens through L spe . This component largely improves new task learning while maintaining low forgetting, bringing the full model’ s performance to the state-of-the-art lev el. The effect of ambiguity threshold τ for token assignment routing guidance. W e ablate the effects of different am- biguity thresholds in T able 3 , where we sweep the thresh- old over { 10% , 20% , 30% , 50% } . The ambiguity threshold controls the token-e xpert assignment to the old and ne w groups of experts. A higher ambiguity threshold encour- ages ambiguous tokens to be assigned to frozen old ex- perts, which helps mitigate forgetting (as these experts do not contrib ute to the learning of the new router and ex- perts) b ut could limit learning on ne w tasks, and vice versa. Through our experiments, we find that controlling the ambi- guity threshold between 10% and 20% brings the best trade- off between learning ne w tasks and for getting old tasks. Us- ing a larger ambiguity threshold hinders effecti ve learning on the new task, as shown by the decreased MFN and MAA. The effect of token assignment regularization weighting factor α . W e conduct an ablation study on the hyperparam- eter α , which controls the unified weighting of our proposed regularization losses ( L exc and L spe ). As shown in T able 4 , we ev aluate model performance by sweeping α across the values { 1e-2 , 5e-3 , 1e-3 , 5e-4 } . The results indicate that our proposed method is relativ ely robust to the choice of this weighting factor , and we adopt α = 1e-3 by default. 4.4. Discussion Study of complementary data-based techniques. Our proposed method is orthogonal to and compatible with data-based techniques. As shown in T able 5 , incorpo- rating these techniques with our method yields consistent improv ements across metrics, demonstrating their comple- mentary nature. W e first compare against SEFE [ 8 ], which adopts the ASD data paradigm and achie ves a BWT of - 10.45%. By complementing this same ASD paradigm with our proposed LLaV A-DyMoE, for getting is significantly mitigated, improving the BWT to -4.75%. W e e valuate against replay-based methods. When combined with a stan- dard replay buffer [ 51 ] (using a buffer size comparable to ProgLoRA [ 73 ]), our approach again outperforms the com- petitor: LLaV A-DyMoE with a small replay b uffer achieves a BWT of -1.55%, substantially better than ProgLoRA ’ s - 6.59%, while also attaining a higher mean final accuracy . 5. Conclusion W e analyze routing-drift in dynamic MoE expansion and trace its cause to the token lev el: ambiguous and old to- kens in new-task data offer minimal learning value yet cor- rupt the router’ s policy for old tasks when left unguided. W e propose LLaV A-DyMoE, comprising a T oken Assign- ment Guidance mechanism that detects and redirects high- drift tokens, and complementary routing losses that enforce expert-group separation. Experiments sho w that LLaV A- DyMoE effecti vely mitigates routing-drift. As it targets the inherent routing mechanism, it is complementary to exist- ing MCIT paradigms for further gains. Limitations and future work. Future work could further in vestigate the scalability of our approach on larger -scale models and in more realistic scenarios. 8 Acknowledgments This work was partially supported by the ARC DECRA Fel- lowship (DE230101591), the ARC Discovery Project Grant (DP260103379), and the NVIDIA Academic Grant Pro- gram. References [1] Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny , Marcus Rohrbach, and Tinne T uytelaars. Memory aware synapses: Learning what (not) to forget. In Pr oceedings of the Eur opean confer ence on computer vision (ECCV) , pages 139–154, 2018. 2 [2] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: V isual question answering. In Pr oceedings of the IEEE international conference on computer vision , pages 2425– 2433, 2015. 1 [3] Shuai Bai, Keqin Chen, Xuejing Liu, Jialin W ang, W enbin Ge, Sibo Song, Kai Dang, Peng W ang, Shijie W ang, Jun T ang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 , 2025. 1 , 2 [4] Pietro Buzzega, Matteo Boschini, Angelo Porrello, Davide Abati, and Simone Calderara. Dark experience for gen- eral continual learning: a strong, simple baseline. Advances in neural information processing systems , 33:15920–15930, 2020. 2 [5] Meng Cao, Y uyang Liu, Y ingfei Liu, T iancai W ang, Ji- ahua Dong, Henghui Ding, Xiangyu Zhang, Ian Reid, and Xiaodan Liang. Continual llav a: Continual instruction tuning in large vision-language models. arXiv preprint arXiv:2411.02564 , 2024. 1 , 3 [6] Arslan Chaudhry , Marcus Rohrbach, Mohamed Elhoseiny , Thalaiyasingam Ajanthan, Puneet K Dokania, Philip HS T orr , and Marc’Aurelio Ranzato. On tiny episodic memo- ries in continual learning. arXiv pr eprint arXiv:1902.10486 , 2019. 2 [7] Cheng Chen, Junchen Zhu, Xu Luo, Heng T Shen, Jingkuan Song, and Lianli Gao. Coin: A benchmark of continual instruction tuning for multimodel large language models. Advances in Neural Information Pr ocessing Systems , 37: 57817–57840, 2024. 1 , 2 , 3 , 7 , 8 , 13 , 14 , 18 [8] Jinpeng Chen, Runmin Cong, Y uzhi Zhao, Hongzheng Y ang, Guangneng Hu, Horace Ho Shing Ip, and Sam Kwong. Sefe: Superficial and essential forgetting eliminator for mul- timodal continual instruction tuning. In ICML , 2025. 1 , 2 , 3 , 6 , 7 , 8 [9] W uyang Chen, Y anqi Zhou, Nan Du, Y anping Huang, James Laudon, Zhifeng Chen, and Claire Cui. Lifelong language pretraining with distribution-specialized e xperts. In Interna- tional Conference on Mac hine Learning , pages 5383–5395. PMLR, 2023. 4 [10] Zeren Chen, Ziqin W ang, Zhen W ang, Huayang Liu, Zhenfei Y in, Si Liu, Lu Sheng, W anli Ouyang, Y u Qiao, and Jing Shao. Octavius: Mitigating task interference in mllms via lora-moe. arXiv preprint , 2023. 3 [11] W ei-Lin Chiang, Zhuohan Li, Ziqing Lin, Y ing Sheng, Zhanghao W u, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Y onghao Zhuang, Joseph E Gonzalez, et al. V icuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality . See https://vicuna. lmsys. or g (accessed 14 April 2023) , 2(3):6, 2023. 7 , 13 [12] Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Nov een Sachdev a, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with adv anced reasoning, multimodality , long context, and next generation agentic capabilities. arXiv pr eprint arXiv:2507.06261 , 2025. 1 , 2 [13] Damai Dai, Chengqi Deng, Chenggang Zhao, RX Xu, Huazuo Gao, Deli Chen, Jiashi Li, W angding Zeng, Xingkai Y u, Y u W u, et al. Deepseekmoe: T owards ultimate expert specialization in mixture-of-experts language models. arXiv pr eprint arXiv:2401.06066 , 2024. 3 [14] Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Ale ˇ s Leonardis, Gregory Slabaugh, and T inne T uytelaars. A continual learning survey: Defying for- getting in classification tasks. IEEE transactions on pattern analysis and machine intelligence , 44(7):3366–3385, 2021. 2 [15] Shihan Dou, Enyu Zhou, Y an Liu, Songyang Gao, Jun Zhao, W ei Shen, Y uhao Zhou, Zhiheng Xi, Xiao W ang, Xiaoran Fan, et al. Loramoe: Alle viate world knowledge forgetting in large language models via moe-style plugin. arXiv pr eprint arXiv:2312.09979 , 2023. 3 [16] William Fedus, Barret Zoph, and Noam Shazeer . Switch transformers: Scaling to trillion parameter models with sim- ple and ef ficient sparsity . J ournal of Machi ne Learning Re- sear ch , 23(120):1–39, 2022. 1 , 3 , 6 [17] Robert M French. Catastrophic forgetting in connectionist networks. T r ends in cognitive sciences , 3(4):128–135, 1999. 1 [18] Chendi Ge, Xin W ang, Zeyang Zhang, Hong Chen, Jiapei Fan, Longtao Huang, Hui Xue, and W enwu Zhu. Dynamic mixture of curriculum lora experts for continual multimodal instruction tuning. arXiv preprint , 2025. 3 [19] Y ash Goyal, T ejas Khot, Douglas Summers-Stay , Dhruv Ba- tra, and Devi Parikh. Making the v in vqa matter: Elev ating the role of image understanding in visual question answer- ing. In Pr oceedings of the IEEE conference on computer vision and pattern r ecognition , pages 6904–6913, 2017. 7 , 13 [20] Haiyang Guo, Fanhu Zeng, Ziwei Xiang, Fei Zhu, Da- Han W ang, Xu-Y ao Zhang, and Cheng-Lin Liu. Hide- llav a: Hierarchical decoupling for continual instruction tun- ing of multimodal large language model. arXiv preprint arXiv:2503.12941 , 2025. 2 , 3 , 6 , 15 [21] Y ongxin Guo, Zhenglin Cheng, Xiaoying T ang, Zhaopeng T u, and T ao Lin. Dynamic mixture of experts: An auto- tuning approach for ef ficient transformer models. arXiv pr eprint arXiv:2405.14297 , 2024. 3 [22] Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. 9 V izwiz grand challenge: Answering visual questions from blind people. In Proceedings of the IEEE confer ence on computer vision and pattern r ecognition , pages 3608–3617, 2018. 7 , 13 [23] Jinghan He, Haiyun Guo, Ming T ang, and Jinqiao W ang. Continual instruction tuning for large multimodal models. arXiv pr eprint arXiv:2311.16206 , 2023. 1 , 3 [24] Edward J Hu, Y elong Shen, Phillip W allis, Zeyuan Allen- Zhu, Y uanzhi Li, Shean W ang, Lu W ang, and W eizhu Chen. LoRA: Low-rank adaptation of large language models. In In- ternational Confer ence on Learning Representations , 2022. 1 , 3 [25] Tian yu Huai, Jie Zhou, Xingjiao W u, Qin Chen, Qingchun Bai, Ze Zhou, and Liang He. Cl-moe: Enhancing multi- modal large language model with dual momentum mixture- of-experts for continual visual question answering. In Pr o- ceedings of the Computer V ision and P attern Recognition Confer ence , pages 19608–19617, 2025. 2 , 3 [26] Drew A Hudson and Christopher D Manning. Gqa: A ne w dataset for real-world visual reasoning and compositional question answering. In Pr oceedings of the IEEE/CVF con- fer ence on computer vision and pattern reco gnition , pages 6700–6709, 2019. 7 , 13 [27] Saurav Jha, Dong Gong, and Lina Y ao. Clap4clip: Contin- ual learning with probabilistic finetuning for vision-language models. Advances in neural information processing systems , 37:129146–129186, 2024. 2 [28] Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Dev endra Singh Chaplot, Die go de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lam- ple, Lucile Saulnier, L ´ elio Renard Lav aud, Marie-Anne Lachaux, Pierre Stock, T e ven Le Scao, Thibaut Lavril, Thomas W ang, Timoth ´ ee Lacroix, and W illiam El Sayed. Mistral 7b . arXiv preprint , 2023. 1 , 2 [29] Sahar Kazemzadeh, V icente Ordonez, Mark Matten, and T amara Berg. ReferItGame: Referring to objects in pho- tographs of natural scenes. In Proceedings of the 2014 Con- fer ence on Empirical Methods in Natur al Language Pr ocess- ing (EMNLP) , pages 787–798, Doha, Qatar , 2014. Associa- tion for Computational Linguistics. 7 , 13 [30] James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel V eness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, T iago Ramalho, Agnieszka Grabska- Barwinska, et al. Overcoming catastrophic forgetting in neu- ral networks. Pr oceedings of the national academy of sci- ences , 114(13):3521–3526, 2017. 1 , 2 [31] Mingrui Lao, Nan Pu, Y u Liu, Zhun Zhong, Erwin M Bakker , Nicu Sebe, and Michael S Le w . Multi-domain life- long visual question answering via self-critical distillation. In Pr oceedings of the 31st A CM International Confer ence on Multimedia , pages 4747–4758, 2023. 1 [32] Stan W eixian Lei, Difei Gao, Jay Zhangjie W u, Y uxuan W ang, W ei Liu, Mengmi Zhang, and Mike Zheng Shou. Symbolic replay: Scene graph as prompt for continual learn- ing on vqa task. In Pr oceedings of the AAAI Conference on Artificial Intelligence , pages 1250–1259, 2023. 1 [33] Dmitry Lepikhin, HyoukJoong Lee, Y uanzhong Xu, Dehao Chen, Orhan Firat, Y anping Huang, Maxim Krikun, Noam Shazeer , and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv pr eprint arXiv:2006.16668 , 2020. 3 [34] Dengchun Li, Yingzi Ma, Naizheng W ang, Zhengmao Y e, Zhiyuan Cheng, Y inghao T ang, Y an Zhang, Lei Duan, Jie Zuo, Cal Y ang, et al. Mixlora: Enhancing large language models fine-tuning with lora-based mixture of experts. arXiv pr eprint arXiv:2404.15159 , 2024. 3 [35] Xilai Li, Y ingbo Zhou, Tianfu W u, Richard Socher, and Caiming Xiong. Learn to grow: A continual structure learn- ing framework for ov ercoming catastrophic forgetting. In International conference on machine learning , pages 3925– 3934. PMLR, 2019. 2 [36] Zhizhong Li and Derek Hoiem. Learning without forgetting. IEEE transactions on pattern analysis and machine intelli- gence , 40(12):2935–2947, 2017. 1 , 2 , 7 [37] Tsung-Y i Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll ´ ar , and C La wrence Zitnick. Microsoft coco: Common objects in context. In Eur opean conference on computer vision , pages 740–755. Springer , 2014. 1 [38] Haotian Liu, Chunyuan Li, Qingyang W u, and Y ong Jae Lee. V isual instruction tuning. Advances in neural information pr ocessing systems , 36:34892–34916, 2023. 1 , 2 , 3 , 7 , 13 [39] David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. Advances in neu- ral information pr ocessing systems , 30, 2017. 2 [40] Haodong Lu, Chongyang Zhao, Jason Xue, Lina Y ao, Kris- ten Moore, and Dong Gong. Adaptive rank, reduced for - getting: Knowledge retention in continual learning vision- language models with dynamic rank-selectiv e lora. arXiv pr eprint arXiv:2412.01004 , 2024. 2 [41] Haodong Lu, Chongyang Zhao, Jason Xue, Lina Y ao, Kris- ten Moore, and Dong Gong. Little by little: Continual learn- ing via incremental mixture of rank-1 associati ve memory experts. arXiv preprint , 2025. 2 [42] Pan Lu, Swaroop Mishra, T ony Xia, Liang Qiu, Kai-W ei Chang, Song-Chun Zhu, Oyvind T afjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. In The 36th Confer ence on Neural Information Pr ocessing Systems (NeurIPS) , 2022. 7 , 13 [43] Imad Eddine Marouf, Enzo T artaglione, St ´ ephane Lath- uili ` ere, and Joost V an De W eijer . Ask and remember: A questions-only replay strategy for continual visual question answering. In Pr oceedings of the IEEE/CVF International Confer ence on Computer V ision , pages 18078–18089, 2025. 1 [44] Anand Mishra, Shashank Shekhar , Ajeet Kumar Singh, and Anirban Chakraborty . Ocr -vqa: V isual question answering by reading text in images. In 2019 international conference on document analysis and recognition (ICD AR) , pages 947– 952. IEEE, 2019. 1 , 7 , 13 [45] Cuong V Nguyen, Y ingzhen Li, Thang D Bui, and Richard E T urner . V ariational continual learning. arXiv pr eprint arXiv:1710.10628 , 2017. 2 10 [46] Jingyang Qiao, Zhizhong Zhang, Xin T an, Y anyun Qu, Shouhong Ding, and Y uan Xie. Large continual instruction assistant. arXiv preprint , 2024. 1 , 3 [47] Alec Radford, Jong W ook Kim, Chris Hallacy , Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry , Amanda Askell, P amela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. In International conference on machine learning , pages 8748–8763. PmLR, 2021. 7 , 13 [48] Anastasia Razdaibiedina, Y uning Mao, Rui Hou, Madian Khabsa, Mike Le wis, and Amjad Almahairi. Progressiv e prompts: Continual learning for language models. arXiv pr eprint arXiv:2301.12314 , 2023. 3 [49] Sylvestre-Alvise Rebuf fi, Alexander K olesnikov , Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. In Proceedings of the IEEE con- fer ence on Computer V ision and P attern Recognition , pages 2001–2010, 2017. 2 , 6 [50] Matthew Riemer , T im Klinger, Djallel Bouneffouf, and Michele Franceschini. Scalable recollections for continual lifelong learning. Pr oceedings of the AAAI confer ence on artificial intelligence , 33(01):1352–1359, 2019. 2 [51] David Rolnick, Arun Ahuja, Jonathan Schw arz, Timothy Lil- licrap, and Gregory W ayne. Experience replay for continual learning. Advances in neural information pr ocessing sys- tems , 32, 2019. 2 , 8 , 15 [52] Mohammad Rostami, Soheil K olouri, and Praveen K Pilly . Complementary learning for o vercoming catas- trophic forgetting using experience replay . arXiv pr eprint arXiv:1903.04566 , 2019. 2 [53] Olga Russako vsky , Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy , Aditya Khosla, Michael Bernstein, Alexander C. Ber g, and Li Fei-Fei. ImageNet Large Scale V isual Recognition Chal- lenge. International J ournal of Computer V ision (IJCV) , 115 (3):211–252, 2015. 7 , 13 [54] Jonathan Schwarz, W ojciech Czarnecki, Jelena Luketina, Agnieszka Grabska-Barwinska, Y ee Whye T eh, Razvan Pas- canu, and Raia Hadsell. Progress & compress: A scalable framew ork for continual learning. In International confer- ence on mac hine learning , pages 4528–4537. PMLR, 2018. 7 [55] Joan Serra, Didac Suris, Marius Miron, and Alexandros Karatzoglou. Ov ercoming catastrophic forgetting with hard attention to the task. In International conference on machine learning , pages 4548–4557. PMLR, 2018. 2 [56] Noam Shazeer , Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffre y Hinton, and Jeff Dean. Outra- geously large neural networks: The sparsely-gated mixture- of-experts layer . arXiv preprint , 2017. 3 [57] Hanul Shin, Jung Kwon Lee, Jaehong Kim, and Jiwon Kim. Continual learning with deep generati ve replay . Advances in neural information pr ocessing systems , 30, 2017. 2 [58] Amanpreet Singh, V iv ek Natarjan, Meet Shah, Y u Jiang, Xinlei Chen, Dhruv Batra, De vi Parikh, and Marcus Rohrbach. T owards vqa models that can read. In Pr oceed- ings of the IEEE Confer ence on Computer V ision and P attern Recognition , pages 8317–8326, 2019. 7 , 13 [59] Qwen T eam. Qwen2.5: A party of foundation models, 2024. 1 , 2 [60] Hugo T ouvron, Louis Martin, Ke vin Stone, Peter Albert, Amjad Almahairi, Y asmine Babaei, Nikolay Bashlyko v , Soumya Batra, Prajjwal Bhar gav a, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv pr eprint arXiv:2307.09288 , 2023. 1 , 2 [61] Huiyi W ang, Haodong Lu, Lina Y ao, and Dong Gong. Self- expansion of pre-trained models with mixture of adapters for continual learning. In Pr oceedings of the Computer V ision and P attern Recognition Conference , pages 10087–10098, 2025. 2 , 4 [62] Liyuan W ang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensiv e survey of continual learning: theory , method and application. IEEE T ransactions on P attern Analysis and Machine Intelligence , 2024. 2 [63] Xiao W ang, T ianze Chen, Qiming Ge, Han Xia, Rong Bao, Rui Zheng, Qi Zhang, T ao Gui, and Xuan-Jing Huang. Or- thogonal subspace learning for language model continual learning. In F indings of the Association for Computational Linguistics: EMNLP 2023 , pages 10658–10671, 2023. 3 , 7 , 8 [64] Xinlong W ang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Y ufeng Cui, Jinsheng W ang, Fan Zhang, Y ueze W ang, Zhen Li, Qiying Y u, et al. Emu3: Next-token prediction is all you need. arXiv preprint , 2024. 1 , 2 [65] Ziqi W ang, Chang Che, Qi W ang, Y angyang Li, Zenglin Shi, and Meng W ang. Smolora: Exploring and defying dual catastrophic for getting in continual visual instruction tuning. In Pr oceedings of the IEEE/CVF International Conference on Computer V ision , pages 177–186, 2025. 1 , 3 [66] Y ujie W ei, Shiwei Zhang, Hangjie Y uan, Y ujin Han, Zhekai Chen, Jiayu W ang, Difan Zou, Xihui Liu, Y ingya Zhang, Y u Liu, et al. Routing matters in moe: Scaling diffusion transformers with explicit routing guidance. arXiv pr eprint arXiv:2510.24711 , 2025. 5 [67] Y uan Xie, Shaohan Huang, Tian yu Chen, and Furu W ei. Moec: Mixture of expert clusters. In Pr oceedings of the AAAI Confer ence on Artificial Intelligence , pages 13807– 13815, 2023. 5 [68] Shipeng Y an, Jiangwei Xie, and Xuming He. Der: Dy- namically expandable representation for class incremental learning. In Pr oceedings of the IEEE/CVF conference on computer vision and pattern r ecognition , pages 3014–3023, 2021. 2 [69] Longrong Y ang, Dong Shen, Chaoxiang Cai, Fan Y ang, T ingting Gao, Di ZHANG, and Xi Li. Solving token gradi- ent conflict in mixture-of-experts for large vision-language model. In The Thirteenth International Conference on Learning Repr esentations , 2025. 1 , 3 , 5 [70] Fei Y e and Adrian G Bors. Self-evolv ed dynamic expan- sion model for task-free continual learning. In Pr oceedings of the IEEE/CVF International Conference on Computer V i- sion , pages 22102–22112, 2023. 2 [71] Jaehong Y oon, Eunho Y ang, Jeongtae Lee, and Sung Ju Hwang. Lifelong learning with dynamically expandable net- works. arXiv pr eprint arXiv:1708.01547 , 2017. 2 11 [72] Jiazuo Y u, Y unzhi Zhuge, Lu Zhang, Ping Hu, Dong W ang, Huchuan Lu, and Y ou He. Boosting continual learning of vision-language models via mixture-of-experts adapters. In Pr oceedings of the IEEE/CVF Conference on Computer V i- sion and P attern Recognition , pages 23219–23230, 2024. 2 , 3 , 15 [73] Y ahan Y u, Duzhen Zhang, Y ong Ren, Xuanle Zhao, Xiuyi Chen, and Chenhui Chu. Progressi ve lora for multimodal continual instruction tuning. In Findings of the Associa- tion for Computational Linguistics: ACL 2025 , pages 2779– 2796, 2025. 1 , 2 , 3 , 4 , 6 , 8 , 15 [74] T ed Zadouri, Ahmet ¨ Ust ¨ un, Arash Ahmadian, Beyza Ermis, Acyr Locatelli, and Sara Hooker . Pushing mixture of ex- perts to the limit: Extremely parameter efficient moe for in- struction tuning. In The T welfth International Confer ence on Learning Repr esentations , 2024. 1 [75] Fanhu Zeng, Fei Zhu, Haiyang Guo, Xu-Y ao Zhang, and Cheng-Lin Liu. Modalprompt: T owards efficient mul- timodal continual instruction tuning with dual-modality guided prompt. arXiv preprint , 2024. 1 [76] Friedemann Zenke, Ben Poole, and Surya Ganguli. Contin- ual learning through synaptic intelligence. In International confer ence on machine learning , pages 3987–3995. PMLR, 2017. 2 [77] Duzhen Zhang, Y ong Ren, Zhong-Zhi Li, Y ahan Y u, Jiahua Dong, Chenxing Li, Zhilong Ji, and Jinfeng Bai. Enhanc- ing multimodal continual instruction tuning with branchlora. arXiv pr eprint arXiv:2506.02041 , 2025. 3 , 4 [78] Gengwei Zhang, Liyuan W ang, Guoliang Kang, Ling Chen, and Y unchao W ei. Slca: Slow learner with classifier align- ment for continual learning on a pre-trained model. In Pr oceedings of the IEEE/CVF International Confer ence on Computer V ision , pages 19148–19158, 2023. 2 [79] Junting Zhang, Jie Zhang, Shalini Ghosh, Da wei Li, Serafet- tin T asci, Larry Heck, Heming Zhang, and C-C Jay Kuo. Class-incremental learning via deep model consolidation. In Pr oceedings of the IEEE/CVF winter confer ence on applica- tions of computer vision , pages 1131–1140, 2020. 2 [80] Chongyang Zhao and Dong Gong. Learning mamba as a continual learner: Meta-learning selectiv e state space models for efficient continual learning. arXiv pr eprint arXiv:2412.00776 , 2024. 2 [81] Hengyuan Zhao, Ziqin W ang, Qixin Sun, Kaiyou Song, Y ilin Li, Xiaolin Hu, Qingpei Guo, and Si Liu. Llav a-cmoe: T o- wards continual mixture of experts for large vision-language models. arXiv preprint , 2025. 2 , 4 , 6 , 15 12 On T oken’ s Dilemma: Dynamic MoE with Drift-A ware T ok en Assignment f or Continual Learning of Lar ge V ision Language Models Supplementary Material A. Additional Experiment Details A.1. More Implementation Details In our experiments, we utilize the pre-trained, instruction- untuned LLaV A-v1.5 [ 38 ] as the backbone model for con- tinual learning. The model employs V icuna [ 11 ] as its lan- guage backbone and a pre-trained CLIP V iT -L/14 visual encoder [ 47 ] for visual feature e xtraction. During contin- ual learning, only the newly added modules are trainable, while all other components remain frozen. In the default setting, 16 rank-4 LoRA experts are added when each new task starts, and K = 16 is applied for top-K routing ov er all trained experts. Different configurations are ev aluated in ablation studies. The same configurations are also applied to the baseline model IncMoELoRA in e xperiments. All ex- periments are conducted on a compute node equipped with four NVIDIA H100 GPUs. Follo wing the official LLaV A- v1.5 configuration, we adopt a global batch size of 128 and a learning rate of 2 × 10 − 4 . W e set the warmup ratio to 0.03 and use the AdamW optimizer for training. The model is trained in PyT orch with BF16 precision and DeepSpeed ZeR O-2. W e set the weights of the load balancing, exclu- sivity , and specialization losses to 1 × 10 − 3 . For all com- pared methods, we follow the default configurations from their original papers. Other remaining settings are consis- tent with those specified for LLaV A-v1.5 [ 38 ]. A.2. Details of Datasets The eight tasks in the CoIN [ 7 ] benchmark are as follows: ScienceQA (SQA) [ 42 ] is a multimodal science question- answering dataset designed to assess models’ reasoning ov er integrated visual and te xtual information. The training set contains 12,726 samples (6,218 image–text and 6,508 text-only), and the test set includes 4,241 samples (2,017 image–text and 2,224 te xt-only). T extVQA [ 58 ] focuses on text recognition within visual question-answering. It features real-world images with di- verse textual content. The training set includes 34,602 image–text samples, and the test set comprises 5,000 im- age–text samples. ImageNet [ 53 ] is a large-scale benchmark for image classi- fication. The training set contains 129,833 image–text sam- ples, and the test set includes 5,050 image–text samples. GQA [ 26 ] emphasizes real-world visual reasoning, requir- ing understanding of object relationships and multi-step in- ference based on both synthetic and real images with scene graphs. The training and test sets include 72,140 and 12,578 T able 6. Performance under v arying task orders. T ask Order Aggregate Results (%) MFN ↑ MAA ↑ BWT ↑ Origin 57.03 57.70 -4.67 Rev erse 56.67 57.34 -4.71 Alphabet 56.44 56.98 -4.92 image–text samples, respecti vely . V izWiz [ 22 ] is designed for visual question-answering in assistiv e contexts for visually impaired users. It provides 20,523 training samples and 4,319 test samples, all in the image–text modality . Grounding (Ref) [ 29 ] e valuates grounding of natural- language expressions in images. It contains image–text pairs requiring models to predict bounding box es aligned with textual descriptions. The training set includes 55,885 samples, and the test set includes 30,969 samples. VQA v2 [ 19 ], a visual question-answering benchmark, fea- tures balanced answer distributions and broad topical cov- erage. It provides 82,783 training samples and 214,354 test samples, all in the image–text modality . OCR VQA [ 44 ] integrates OCR with visual question- answering to assess models’ ability to extract and rea- son over textual content in images. The dataset includes 165,348 training samples and 99,926 test samples, all im- age–text. B. More Experiments B.1. Experiments on Different T ask Orders T o assess order sensitivity , we trained our method under multiple task orderings on the eight CoIN datasets. W e conduct experiments using three task orderings: “Origin”, the original task ordering proposed in the CoIN bench- mark; “Reverse”, the reversed version of the original or- dering; and “ Alphabet”, where tasks are ordered alphabet- ically . As summarized in T able 6 , our method exhibits ex- cellent stability across different task orderings; the amount of forgetting remains consistently low with minimal varia- tion across orderings. Without techniques like experience replay , our proposed token-le vel expert assignment regular- ization within this incremental MoE with LoRA approach consistently learns new task knowledge with minimal for- getting, regardless of the task ordering. This is because our method effecti vely prev ents ambiguous tokens from con- 13 T able 7. Performance under distinct training instruction types. Instruction Aggregate Results (%) MFN ↑ MAA ↑ BWT ↑ Origin 57.03 57.70 -4.67 Div erse 56.90 57.44 -5.12 10T ype 56.77 57.25 -4.87 tributing to the learning of new routers and experts, ensuring that effecti ve new knowledge is absorbed into the new ex- perts without any assumptions about the incoming order of the data. B.2. Experiments on Distinct T raining Instruction T ypes T o v alidate the reliability of our proposed method against distinct instruction templates, we conduct e xperiments with different template types, reported in T able 7 . There are three types of instruction templates in the CoIN benchmark [ 7 ]. Follo wing the default setting, the experiments in the main paper are based on the “Origin” type. W e further conduct experiments with the other two types of instruction tem- plates, Div erse and 10T ype, in [ 7 ]: 1) Di verse: Distinct in- struction templates tailored to different tasks. 2) 10T ype: Randomly sampled from 10 distinct instruction templates. (Details can be found in T able 16 .) The results show that forgetting and accuracy on all three metrics are nearly iden- tical across instruction types, indicating the method’ s sta- bility . This result is significant, as it indicates that our method’ s token-lev el routing mechanism is not ov erfitting to superficial, task-specific prompt formats. B.3. Ablation Studies on MoE Configurations In this section, we validate the proposed method on dif- ferent MoE configurations, including the top-K v alue, the number of experts, and the expert capacity , and show the results in T able 8 , 9 , and 10 . Experiments with baseline IncMoELoRA are conducted as a reference. The ablation studies demonstrate that the proposed method performs ro- bustly across different MoE configurations and consistently deliv ers improv ements. Ablations on top-K value. First, we conduct an ablation study on the top-K v alue, comparing top-8 and top-16 ov er all experts. As shown in T able 8 , the overall performance is relati vely insensitive to the choice of top-K, and under both configurations our LLaV A-DyMoE consistently out- performs the baseline method, demonstrating the effecti ve- ness of the proposed approach. Ablations on expert number . Second, we conduct an ab- lation study on the number of ne wly added experts, com- paring 8 and 16 e xperts per task. In the 8-expert setting, we T able 8. Ablations on top-K v alue. T op-K Method Aggregate Results (%) MFN ↑ MAA ↑ BWT ↑ 8 IncMoELoRA 48.55 49.87 -16.28 LLaV A-DyMoE 56.89 57.71 -5.12 16 IncMoELoRA 49.68 49.50 -16.67 LLaV A-DyMoE 57.03 57.70 -4.67 T able 9. Ablations on expert number . Expert Number Method Aggregate Results (%) MFN ↑ MAA ↑ BWT ↑ 8 IncMoELoRA 48.39 50.62 -17.93 LLaV A-DyMoE 56.97 58.37 -5.78 16 IncMoELoRA 49.68 49.50 -16.67 LLaV A-DyMoE 57.03 57.70 -4.67 T able 10. Ablations on expert capacity . Expert Capacity Method Aggregate Results (%) MFN ↑ MAA ↑ BWT ↑ 1 IncMoELoRA 48.23 49.14 -15.79 LLaV A-DyMoE 56.78 57.34 -4.13 2 IncMoELoRA 49.08 49.25 -16.58 LLaV A-DyMoE 56.91 57.48 -4.62 4 IncMoELoRA 49.68 49.50 -16.67 LLaV A-DyMoE 57.03 57.70 -4.67 increase the parameters of each expert to maintain a compa- rable total capacity . As sho wn in T able 9 , LLaV A-DyMoE consistently outperforms the baseline under both configura- tions, demonstrating its effecti veness. Ablations on expert capacity . Furthermore, we conduct an ablation study on the impact of expert capacity by varying the LoRA experts’ rank to 1, 2, and 4. As shown in T able 10 , models with larger expert capacity achie ve better perfor - mance, and across all capacity settings LLaV A-DyMoE consistently outperforms the baseline, further demonstrat- ing the effecti veness of the proposed approach. Overall, these ablations sho w that LLaV A-DyMoE is ro- bust to v ariations in the MoE configuration: it consistently outperforms the baseline across dif ferent choices of top-K, number of experts, and e xpert capacity . B.4. Experiments with Different Backbone Sizes Besides the 7B model, we further validate our method us- ing the larger 13B LLaV A backbone, as shown in T able 11 . 14 T able 11. Performance across dif ferent model sizes. Size Method Accuracy on Each T ask (%) Aggr egate Results (%) SQA VQA T ext ImgNet GQA V izWiz REF VQA v2 VQA OCR MFN ↑ MAA ↑ BWT ↑ 7B IncMoELoRA 68.43 50.31 68.42 47.97 39.46 4.56 57.31 60.95 49.68 49.50 -16.67 LLaV A-DyMoE (Ours) 76.25 53.86 95.80 48.40 52.35 9.25 58.30 62.00 57.03 57.70 -4.67 13B IncMoELoRA 68.75 51.69 85.80 48.10 40.20 6.55 58.85 64.60 53.07 53.20 -14.23 LLaV A-DyMoE (Ours) 78.75 56.24 96.05 55.85 53.20 13.85 64.05 65.15 60.39 61.25 -4.64 T able 12. LLaV A-DyMoE is compatible with task-lev el routing methods. Method Accuracy on Each T ask (%) Aggregate Results (%) SQA VQA T ext ImgNet GQA V izWiz REF VQA v2 VQA OCR MFN ↑ MAA ↑ BWT ↑ LLaV A-DyMoE 76.25 53.86 95.80 48.40 52.35 9.25 58.30 62.00 57.03 57.70 -4.67 + T ask Router 78.18 53.36 95.63 54.63 53.92 24.46 59.54 60.40 60.02 60.78 -1.73 T able 13. LLaV A-DyMoE is compatible with data-based contin- ual learning strategies. T able 5 in the main paper shows that the proposed token assignment regularization can work with replay techniques. This table shows the performance across different re- play buf fer sizes, with ProgLoRA [ 73 ] (containing replay) as a reference. Replay Size Method Aggregate Results (%) MFN ↑ MAA ↑ BWT ↑ 200 ProgLoRA 59.09 62.38 -6.59 LLaV A-DyMoE 62.08 61.93 -1.55 500 ProgLoRA 59.14 62.74 -6.47 LLaV A-DyMoE 62.55 62.17 -1.00 1000 ProgLoRA 59.66 63.23 -6.21 LLaV A-DyMoE 63.19 62.95 -0.64 Scaling to a larger and stronger backbone model yields im- prov ed continual learning performance while preserving a low forgetting rate. LLaV A-DyMoE demonstrates robust scalability , effecti vely le veraging the increased capacity to achiev e a higher MFN of 60.39% while maintaining a con- sistently lo w forgetting rate (-4.64%). This confirms that our drift-aw are token assignment mechanism remains ef fec- tiv e regardless of the underlying model size. B.5. Additional Results on Data-based Strategies The proposed drift-aware token assignment regularization in LLaV A-DyMoE is orthogonal and compatible with data- based strategies such as replay and data augmentation. By focusing on the core router training, our method can im- prov e performance when combined with these techniques. In the main paper , we have pro vided the experiments in T a- ble 5 . In this section, we provide additional details on the results of replay techniques under different replay buf fer sizes. W e compare our method, LLaV A-DyMoE equipped with a standard replay buf fer [ 51 ], against ProgLoRA [ 73 ]. This configuration serves as a basic replay-based v ariant of our dynamic MoE architecture. Follo wing ProgLoRA, we vary the buf fer size (200, 500, 1000) to match comparable replay budgets. As shown in T able 13 , LLaV A-DyMoE con- sistently achieves competitiv e or better performance across different replay b uffer sizes. B.6. Compatibility with Additional T ask-specific Router Our LLaV A-DyMoE, which focuses on rectifying micro- lev el token routing drifts, is inherently orthogonal to and compatible with macro-lev el MCIT paradigms based on task-specific routing. In particular, our method can be seamlessly integrated into architectures that employ task- lev el routing strategies [ 20 , 72 , 73 , 81 ]. These approaches first decide which group of experts to acti vate at the task lev el, while LLaV A-DyMoE then optimizes the token as- signments within the selected group, mitigating the intra- group routing drifts we identified and thus providing com- plementary benefits. T o verify this compatibility , we equip LLaV A-DyMoE with a task-specific router . In this setup, the task router de- termines which experts are activ ated for each task, while our dynamic MoE component can further re gularize token-lev el routing. As shown in T able 12 , this combination yields im- prov ed performance over vanilla LLaV A-DyMoE, demon- strating that LLaV A-DyMoE can provide additive gains when integrated with task-specific routing methods. B.7. LLaV A-DyMoE with Expert Pruning W e ev aluate the performance of LLaV A-DyMoE under dif- ferent MoE configurations. In particular , we inv estigate ex- pert pruning, which removes potentially unnecessary ex- 15 T able 14. Performance of LLaV A-DyMoE with expert pruning. Method Accuracy on Each T ask (%) Aggregate Results (%) SQA VQA T ext ImgNet GQA V izWiz REF VQA v2 VQA OCR MFN ↑ MAA ↑ BWT ↑ LLaV A-DyMoE 76.25 53.86 95.80 48.40 52.35 9.25 58.30 62.00 57.03 57.70 -4.67 + Pruning 1 / 8 76.04 53.91 96.10 48.16 52.51 9.27 58.21 61.79 57.00 57.62 -4.63 + Pruning 1 / 4 75.59 53.79 95.11 47.78 52.51 9.26 57.94 61.39 56.67 57.37 -4.48 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 Layer 1 2 3 4 5 6 7 8 Expert Group ID Visualization of Expert Activation (a) LLaV A-DyMoE after training on the 8 -th task. 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 Layer 1 2 3 4 5 Expert Group ID Visualization of Expert Activation (b) LLaV A-DyMoE after training on the 5 -th task. Figure 4. Layer-wise expert acti vation on the CoIN benchmark. Activ ation frequency is shown for each expert group across layers, and circle size reflects how often an e xpert is activ ated. perts from the MoE. T able 14 reports the performance of LLaV A-DyMoE after pruning either 1 / 8 or 1 / 4 of the ex- perts with the lowest acti vation frequencies following the training of each task. The results show that our method re- mains robust even with expert pruning. Note that we apply only a simple, naiv e pruning strategy , which leads to a slight performance drop. Although pruning is not the main fo- cus of this work, this experiment demonstrates the potential of our proposed techniques to remain ef fectiv e under more complex MoE training pipelines. B.8. V isualization of Expert Activ ation In Fig. 4 , we present layer-wise expert activ ation frequen- cies of LLaV A-DyMoE across the eight tasks in the CoIN benchmark. For clarity , the activ ation frequencies of ne wly added experts for each task are merged into one single ex- pert group. The routing scores are aggregated as the expert activ ation strength. The visualization shows that all e xperts are acti vated with varying strengths, exhibiting diverse uti- lization patterns across layers. B.9. Qualitative Result Examples W e provide a qualitativ e comparison in Fig. 5 by randomly sampling data from previous tasks (ScienceQA and Im- ageNet) after the model has finished training on the fi- nal task. As illustrated, LLaV A-DyMoE successfully re- tains fine-grained kno wledge that the baseline often forgets. Specifically , the IncMoELoRA baseline tends to regress to coarse-grained or incorrect labels, such as simplifying a “Bernese mountain dog” to a generic “Dog”, or confusing a “Sloth bear” with a visually similar “Otter”. In contrast, our method accurately recalls specific species and reason- 16 What i s th e o bje ct i n t he im age ? IncM oEL oR A : D og ❌ LLa VA - Dy M o E : B e r n e s e m o u n t a i n d o g ✅ Gr o u n d T r u t h : B e r n e s e m o u n t a i n d o g What i s th e o bje ct in t he ima ge ? IncM oEL oR A : D esk ❌ LLa VA - Dy M o E : C o m p u t e r ❌ Gr o u n d T r u t h : Mo u s e Wh a t i s t h e o b j e c t i n t h e i m a g e ? In c M o E L o R A : O tte r ❌ LLa VA - Dy M o E : S l o t h b e a r ✅ Gr o u n d T r u t h : S l o t h b e a r A tomat o pl ant c an grow seeds . Which part of the tomato plant makes the se eds? A. t he fruit; B. the flowers . IncM oEL oR A : A ❌ LLa VA - Dy M o E : B ✅ Gr o u n d T r u t h : B What i s th e c api tal of Lou is ian a ? A . F rankfort; B. Salem ; C. Baton Rouge; D. New Orleans IncM oEL oR A : C ✅ LLa VA - Dy M o E : C ✅ Gr o u n d T r u t h : C Wh i c h c o u n t r y i s h i g h l i g h t e d ? A. An t i g u a and B ar buda; B . S a i n t K i t t s a n d N ev i s ; C . G r en a d a ; D . S a i n t L u c i a . In c M o E L o R A : B ❌ LLa VA - Dy M o E : D ✅ Gr o u n d T r u t h : D Figure 5. Comparisons between baseline IncMoELoRA and LLaV A-DyMoE on cases after training on the final task. The first column shows cases from ScienceQA, the second column sho ws cases from ImageNet. T able 15. T raining time of LLaV A-DyMoE during sequential training. Method T raining Time on Each T ask (min) A verage SQA VQA T ext ImgNet GQA V izW iz REF VQA v2 VQA OCR IncMoELoRA 7.4 13.6 92.4 123.4 14.9 99.6 105.0 137.1 74.18 LLaV A-DyMoE (Ours) 7.4 14.6 95.5 127.6 15.8 103.2 109.6 145.7 77.43 ing details, such as identifying the correct biological part of a “T omato” plant. While complex scenes with small objects remain challenging for both models (e.g., the ambiguous Mouse case), our approach exhibits improved knowledge retention compared to the baseline across div erse domains. B.10. Efficiency The proposed drift-aware token assignment regularization is applied during training with minor additional computa- tions. T o validate the ef ficiency , we report the training time of the baseline (IncMoELoRA) and our LLaV A-DyMoE in T able 15 . Our method incurs only a small training-time ov erhead of 4.4% (from 74.18 minutes to 77.43 minutes), while leaving inference ef ficiency unaffected. C. Ethical and Social Impacts This work advances MCIT by effecti vely enabling L VLMs to incrementally perform instruction tuning on new tasks while maintaining proficiency on previously learned ones. A ke y social benefit of our proposed LLaV A-DyMoE is its emphasis on parameter and inference efficienc y . By utiliz- ing a sparse MoE architecture, we minimize the compu- tational energy required for long-term learning compared to dense retraining methods, aligning with the goals of Green AI. Regarding ethical considerations, we note that our model builds upon the pre-trained LLaV A backbone and standard datasets within the open-source CoIN benchmark. As with general data-driv en L VLMs, our model naturally reflects the data distributions and characteristics of these foundational resources. While our current work focuses on optimizing knowledge retention and plasticity , we encour- age future research to continue exploring safety alignment and fairness as integral components of the continual learn- ing process for real-world applications. 17 T able 16. The list of instruction templates for each task [ 7 ]. T ask Original Div erse 10T ype SQA Answer with the option’ s letter from the given choices directly Answer with the option’ s letter from the given choices directly Answer with the option’ s letter from the given choices directly Select the correct answer from the given choices and respond with the letter of the chosen option Determine the correct option from the provided choices and reply with its corresponding letter Pick the correct answer from the listed options and provide the letter of the selected option Identify the correct choice from the options below and respond with the letter of the correct option From the given choices, choose the correct answer and respond with the letter of that choice Choose the right answer from the options and respond with its letter Select the correct answer from the provided options and reply with the letter associated with it From the given choices, select the correct answer and reply with the letter of the chosen option Identify the correct option from the choices provided and respond with the letter of the correct option From the given choices, pick the correct answer and respond by indicating the letter of the correct option VQA T ext Answer the question using a single word or phrase Capture the essence of your response in a single word or a concise phrase Answer the question with just one word or a brief phrase Use one word or a concise phrase to respond to the question Answer using only one word or a short, descriptiv e phrase Provide your answer in the form of a single word or a brief phrase Use a single word or a short phrase to respond to the question Summarize your response in one word or a concise phrase Respond to the question using a single word or a brief phrase Provide your answer in one word or a short, descripti ve phrase Answer the question with a single word or a brief, descriptiv e phrase Capture the essence of your response in one word or a short phrase Capture the essence of your response in a single word or a concise phrase ImgNet Answer the question using a single word or phrase Express your answer in a single word or a short, descriptive phrase Express your answer in a single word or a short, descriptiv e phrase Provide your answer using a single word or a brief phrase Describe the content of the image using one word or a concise phrase Respond to the question with a single word or a short, descriptiv e phrase Classify the image content using only one word or a brief phrase Give your answer in the form of a single w ord or a concise phrase Use a single word or a short phrase to categorize the image content Express your answer with one word or a short, descriptiv e phrase Identify the type of content in the image using one word or a concise phrase Summarize your response in a single word or a brief phrase Use one word or a short phrase to classify the content of the image GQA Answer the question using a single word or phrase Respond to the question briefly , using only one word or a phrase Respond to the question with a single word or a short phrase Respond to the question using only one word or a concise phrase Answer the question with a single word or a brief phrase Respond with one word or a short phrase Provide your answer in the form of a single word or a concise phrase Respond to the question with just one word or a brief phrase Answer the question using a single word or a concise phrase Provide your response using only one word or a short phrase Respond to the question with a single word or a brief phrase Respond to the question using just one word or a concise phrase Answer the question with one word or a short phrase VizW iz Answer the question using a single word or phrase Provide a succinct response with a single word or phrase Answer the question using only one word or a concise phrase Respond to the question using only one word or a concise phrase Respond to the question with a single word or a brief phrase Provide your answer using just one word or a short phrase Respond with one word or a concise phrase Answer the question with just one word or a brief phrase Use a single word or a short phrase to answer the question Provide your answer in the form of one word or a brief phrase Reply to the question using one word or a concise phrase Answer with a single word or a short phrase Use one word or a brief phrase to answer the question REF Please provide the bounding box coordinate of the region this sentence describes Please provide the bounding box coordinate of the region this sentence describes Identify and provide the bounding box coordinates that match the description giv en in this sentence Extract and provide the bounding box coordinates based on the region described in the sentence Please provide the bounding box coordinate of the region this sentence describes Find and provide the bounding box coordinates for the region mentioned in the sentence Provide the coordinates of the bounding box that correspond to the region described in the sentence Give the bounding box coordinates as described in the sentence Determine and provide the bounding box coordinates based on the description in the sentence Identify and provide the coordinates of the bounding box described in the sentence Provide the coordinates for the bounding box based on the region described in the sentence Extract and provide the coordinates for the bounding box described in the sentence Identify and give the coordinates of the bounding box as described by the sentence VQA v2 Answer the question using a single word or phrase Answer the question using a single word or phrase Answer the question using a single word or phrase Answer the question with a single word or a brief phrase Use one word or a short phrase to respond to the question Answer the question using just one word or a concise phrase Provide your answer to the question using only one word or a brief phrase Respond to the question with a single word or a short phrase Use a single word or phrase to answer the question Provide an answer using only one word or a brief phrase Answer the question succinctly with one word or a brief phrase Answer the question with just one word or a short phrase Respond to the question using a single word or a concise phrase VQA OCR Answer the question using a single word or phrase Condense your answer for each question into a single word or concise phrase Answer with the option’ s letter from the given choices directly Select the correct answer from the given choices and respond with the letter of the chosen option Determine the correct option from the provided choices and reply with its corresponding letter Pick the correct answer from the listed options and provide the letter of the selected option Identify the correct choice from the options below and respond with the letter of the correct option From the given choices, choose the correct answer and respond with the letter of that choice Choose the right answer from the options and respond with its letter Select the correct answer from the provided options and reply with the letter associated with it From the given choices, select the correct answer and reply with the letter of the chosen option Identify the correct option from the choices provided and respond with the letter of the correct option From the given choices, pick the correct answer and respond by indicating the letter of the correct option 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment