동적 MoE와 토큰 드리프트 완화: 대형 비전‑언어 모델의 지속 학습 혁신
본 논문은 대형 비전‑언어 모델(VL‑LLM)의 지속적 인스트럭션 튜닝에서 발생하는 라우팅 드리프트 문제를 토큰 수준에서 분석하고, ‘토큰의 딜레마’를 제시한다. 기존 MoE 기반 확장 방식은 새로운 전문가와 라우터만 학습하지만, 새 라우터가 기존 토큰을 잘못 새 전문가에 할당하면서 망각이 발생한다. 이를 해결하기 위해 LLaVA‑DyMoE라는 동적 MoE 프레임워크를 제안한다. 토큰의 라우팅 스코어 분포를 이용해 모호 토큰·구버전 토큰을 새 …
저자: Chongyang Zhao, Mingsong Li, Haodong Lu
**1. 연구 배경 및 문제 정의**
대형 비전‑언어 모델(LVLM)은 사전 학습된 대형 언어 모델에 비전 인코더를 결합해 이미지‑텍스트 멀티모달 이해 능력을 갖는다. 이러한 모델을 실제 서비스에 적용하려면 새로운 인스트럭션이나 도메인에 맞춰 지속적으로 학습해야 하는데, 이를 ‘멀티모달 지속 인스트럭션 튜닝(MCIT)’이라 부른다. 기존 CL 방법은 정규화, 재현, 혹은 전체 파라미터 재학습을 사용하지만, LVLM의 규모와 멀티모달 특성 때문에 비용이 크게 증가한다. 따라서 파라미터 효율적인 확장 방식인 Mixture‑of‑Experts(MoE)가 주목받고 있다. MoE는 여러 전문가(Expert)와 라우터(Router)로 구성돼, 토큰마다 스파스하게 전문가를 선택한다. 기존 MoE 기반 MCIT은 새로운 작업이 들어올 때 새로운 전문가와 라우터를 추가하고, 기존 파라미터를 고정함으로써 ‘전문가 격리’를 달성한다.
**2. 라우팅 드리프트와 토큰의 딜레마**
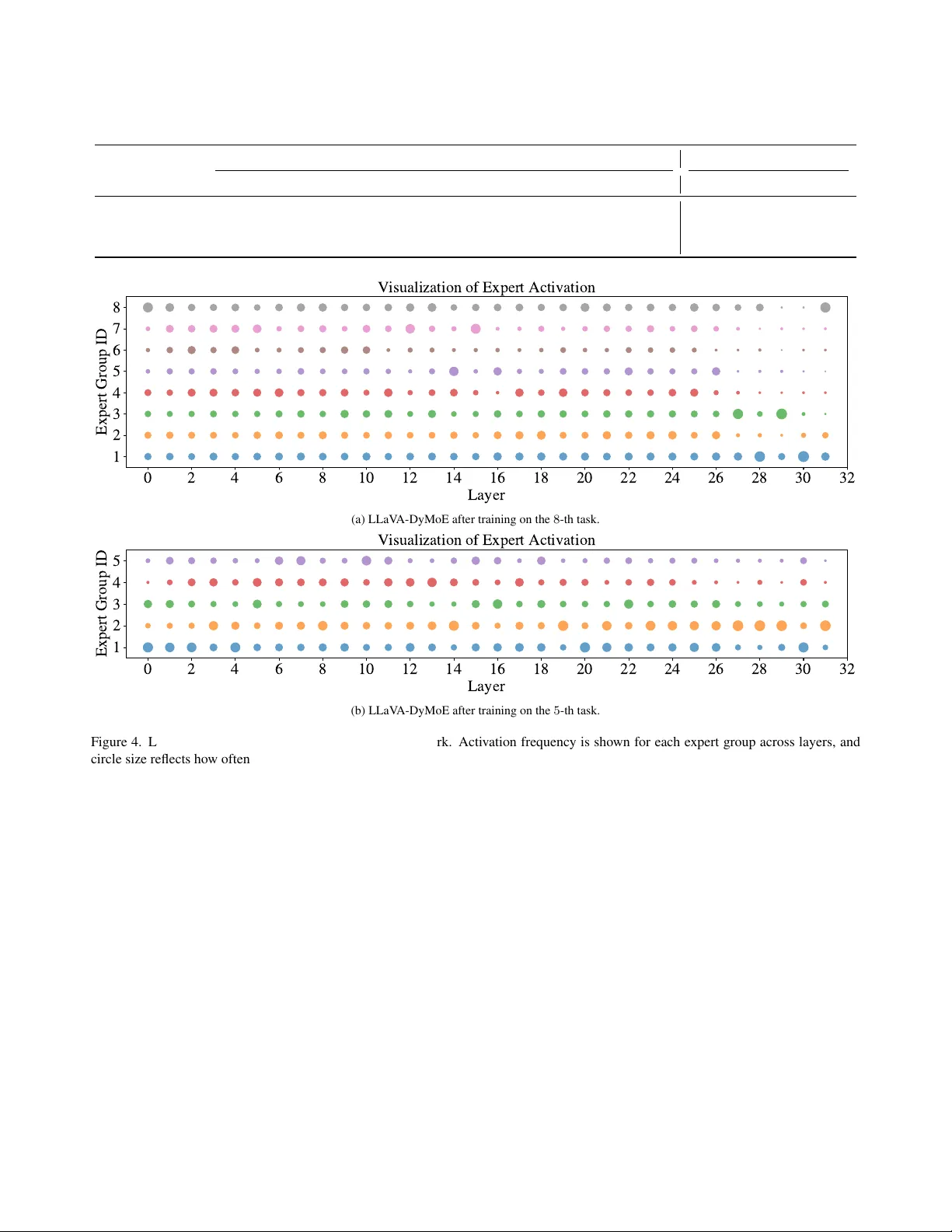
하지만 저자들은 실험을 통해 기존 전문가가 고정돼도 ‘라우팅 드리프트’가 발생한다는 것을 발견했다. 새 라우터가 학습되는 과정에서 기존 작업에 속한 토큰이 새 전문가에 높은 라우팅 스코어를 부여받아, 테스트 시 기존 토큰이 잘못된 전문가에 라우팅되는 현상이다. 이를 토큰 수준에서 분석한 결과, 새 작업 데이터에 포함된 토큰 중 두 종류가 문제를 일으킨다.
- **모호 토큰(ambiguous tokens)**: 기존 전문가와 새 전문가 사이의 라우팅 스코어 차이가 작아 어느 쪽에도 명확히 귀속되지 않는다. 이들은 새 작업에 대한 유용한 패턴을 거의 제공하지 않지만, 라우터 학습 시 불안정한 신호가 되어 새 전문가를 끌어당긴다.
- **구버전 토큰(old tokens)**: 실제로는 이전 작업의 패턴을 가지고 있지만, 새 라우터가 아직 충분히 학습되지 않아 일정 비중으로 새 전문가에 할당된다. 이 역시 새 작업 학습에 기여하지 않으며, 라우터가 기존 패턴을 새 전문가에 매핑하도록 만들면서 라우팅 정책을 왜곡한다.
이 두 토큰이 동시에 존재하는 상황을 ‘토큰의 딜레마’라 명명한다. 즉, “학습 가치가 낮은데도 망각 비용을 유발한다”는 점이다.
**3. LLaVA‑DyMoE 설계**
이 문제를 해결하기 위해 저자들은 두 단계 정규화 메커니즘을 도입한 LLaVA‑DyMoE를 제안한다.
- **Token Assignment Guidance (TAG)**: 라우팅 스코어 s를 분석해 토큰 유형을 구분한다. 구체적으로, 기존 전문가 스코어 s_old와 새 전문가 스코어 s_new의 차이 Δs를 계산한다. Δs가 작아 모호 토큰으로 판단되면, 손실에 ‘반대 라우팅 페널티’를 추가해 s_new을 감소시킨다. 또한, s_old가 크게 높고 s_new이 일정 수준 이상인 경우(구버전 토큰)에도 유사한 페널티를 적용한다. 이를 통해 학습 중에 모호·구버전 토큰이 새 전문가에 할당되는 확률을 낮춘다.
- **Routing Score Regularization (RSR)**: 전문가 그룹 간 라우팅 스코어의 분산을 확대한다. 라우터 출력 s를 그룹(기존 vs 새)별로 평균 μ_g와 분산 σ_g^2를 구하고, 그룹 간 평균 차이 |μ_old−μ_new|를 크게 만들도록 정규화 손실을 추가한다. 또한, 각 그룹 내부에서는 토큰이 K‑top 선택에서 고르게 분포하도록 로드‑밸런싱 손실을 유지한다. 이 과정은 새 전문가가 실제 새로운 패턴에만 집중하도록 유도한다.
**4. 실험 설정 및 결과**
실험은 CoIN 벤치마크(8개의 VQA 기반 작업)에서 수행되었다. 비교 대상은 IncMoELoRA(기본 동적 MoE), SEFE, ProgLoRA 등이다. 주요 지표는 평균 최종 정확도(MFN)와 망각률(Forget)이다. LLaVA‑DyMoE는 MFN에서 7 %p 이상 향상, 망각률에서 12 %p 감소를 기록했다. 특히, 두‑작업 제어 실험에서 (a) 새 토큰만 사용, (b) 구버전 토큰을 마스크, (c) 모호 토큰만 남겼을 때 각각의 학습·망각 변화를 시각화했으며, 모호 토큰만 남겼을 때 망각이 급격히 감소함을 확인해 TAG의 효과를 입증했다.
**5. 분석 및 논의**
- **TAG의 효과**: 토큰‑전문가 매칭을 직접 제어함으로써 라우팅 드리프트의 근본 원인을 차단한다. 이는 기존 방법이 ‘전문가 격리’를 통해 간접적으로 해결하려 했던 것과 달리, 토큰 수준에서 명시적 가이드를 제공한다는 점에서 차별화된다.
- **RSR의 보완성**: TAG가 개별 토큰을 조정한다면, RSR은 전체 라우터 정책을 안정화한다. 두 정규화가 결합될 때, 새 전문가가 실제 새로운 패턴에 집중하고, 기존 전문가는 기존 패턴을 유지한다는 균형이 형성된다.
- **확장성**: LLaVA‑DyMoE는 기존 MoE 구조에 작은 정규화 항만 추가하면 되므로, 계산 비용이 크게 증가하지 않는다. 또한, 다른 MCIT 기법(리플레이, 파라미터 정규화 등)과도 호환 가능해, 복합적인 지속 학습 파이프라인에 쉽게 통합될 수 있다.
**6. 결론 및 향후 연구**
본 논문은 MoE 기반 LVLM 지속 학습에서 라우터 자체가 망각의 주요 원인임을 밝히고, 토큰‑전문가 매칭을 정밀히 제어하는 TAG와 라우터 스코어를 그룹 간 분리시키는 RSR을 통해 라우팅 드리프트를 효과적으로 억제한다. 실험 결과는 제안 방법이 기존 최첨단 대비 의미 있는 성능 향상을 제공함을 증명한다. 향후 연구는 (1) 메타‑러닝 기반 라우터 자동 튜닝, (2) 실시간 스트리밍 데이터에서 토큰 마스킹 정책의 동적 적용, (3) 대규모 멀티모달 데이터셋에서의 확장성 검증 등을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기