Multi-Agent Dialectical Refinement for Enhanced Argument Classification
Argument Mining (AM) is a foundational technology for automated writing evaluation, yet traditional supervised approaches rely heavily on expensive, domain-specific fine-tuning. While Large Language Models (LLMs) offer a training-free alternative, th…
Authors: Jakub Bąba, Jarosław A. Chudziak
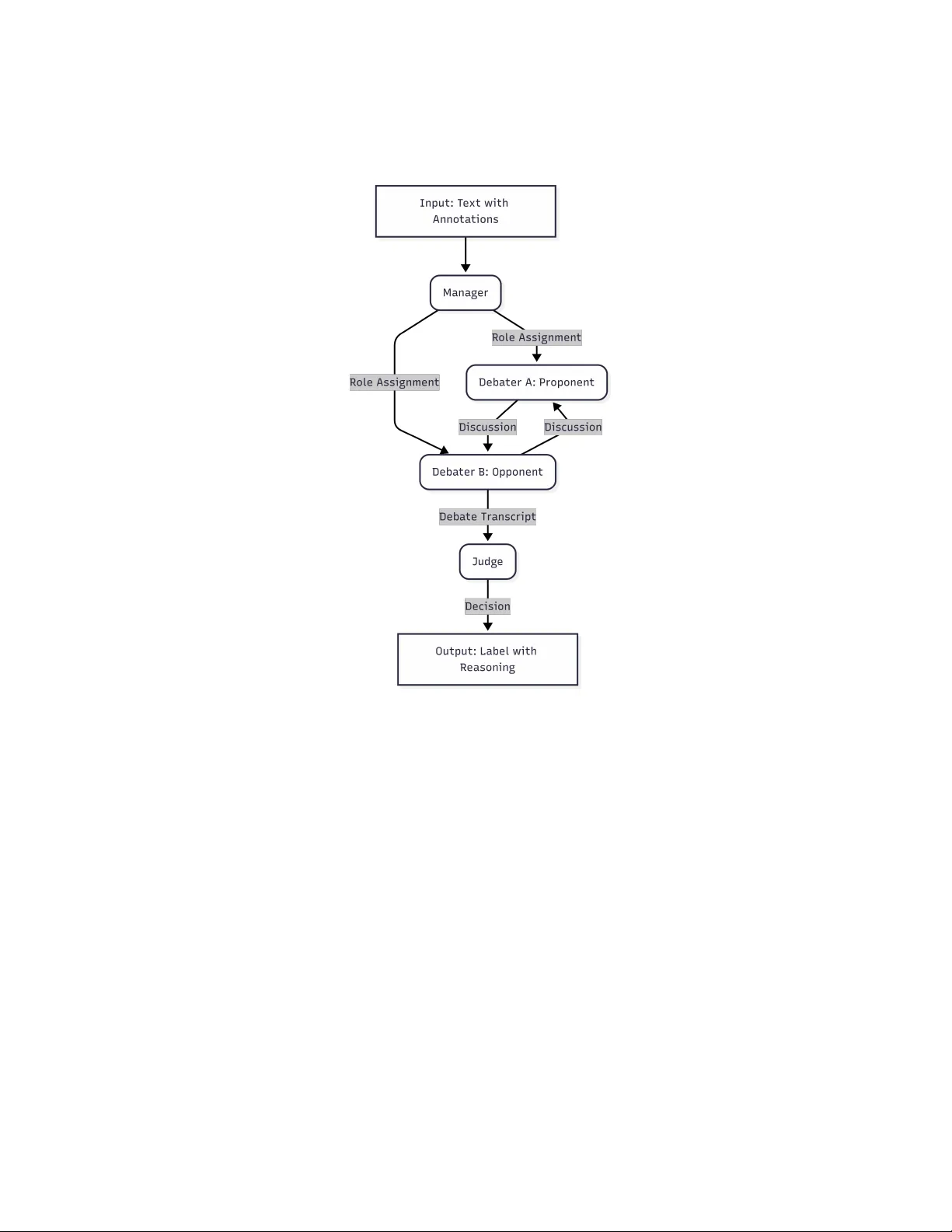
Multi-Agen t Dialectical Refinemen t for Enhanced Argumen t Classification Jakub Bąba [0009 − 0009 − 7000 − 4887] and Jarosła w A. Chudziak [0000 − 0003 − 4534 − 8652] F acult y of Electronics and Information T echnology , W arsa w Universit y of T ec hnology , Poland {jakub.baba.stud,jaroslaw.chudziak}@pw.edu.pl Abstract. Argumen t Mining (AM) is a foundational technology for au- tomated writing ev aluation, y et traditional sup ervised approac hes rely hea vily on exp ensive, domain-specific fine-tuning. While Large Language Mo dels (LLMs) offer a training-free alternative, they often struggle with structural ambiguit y , failing to distinguish b et ween similar comp onents lik e Claims and Premises. F urthermore, single-agent self-correction mech- anisms often suffer from sycophancy , where the mo del reinforces its o wn initial errors rather than critically ev aluating them. W e introduce MAD-A CC (Multi-Agen t Debate for Argument Comp onent Classifica- tion), a framework that leverages dialectical refinement to resolve clas- sification uncertaint y . MAD-ACC utilizes a Prop onent-Opponent-Judge mo del where agen ts defend conflicting interpretations of am biguous text, exp osing logical nuances that single-agent mo dels miss. Ev aluation on the UKP Studen t Essays corpus demonstrates that MAD-ACC ac hieves a Macro F1 score of 85.7%, significan tly outp erforming single-agent reason- ing baselines, without requiring domain-sp ecific training. Additionally , unlik e "black-box" classifiers, MAD-ACC’s dialectical approach offers a transparen t and explainable alternative by generating human-readable debate transcripts that explain the reasoning b ehind decisions. Keyw ords: Artificial In telligence · Natural Language Pro cessing · F or- mal Argumen tation · Argument Mining · Multi-Agent Systems · Large Language Mo dels. 1 In tro duction Argumen t Mining - the automated extraction and iden tification of argumentativ e structures from text - is a crucial field for high-lev el semantic and reasoning tasks. It enables systems to mov e b ey ond surface-level text ev aluation, such as grammar or sp elling chec king, tow ard deep logic analysis and automated writing ev aluation. Recen t dev elopmen ts in Large Language Models (LLMs) ha ve shifted the paradigms used in the field. Current state-of-the-art approaches primarily lever- age fine-tuned generativ e mo dels, achieving high accuracy on tasks such as com- p onen t classification and relation extraction. How ev er, the reliance on proper tuning of the sup ervised architecture remains c hallenging: it is computationally 2 J. Bąba and J. A. Ch udziak exp ensiv e, requires high-quality annotated corpora, and often results in rigid mo dels that struggle to generalize to new domains [24]. Con versely , training- free LLMs offer a flexible and cost-effective alternative, but they currently fail to bridge the p erformance gap with sup ervised baselines. Standard prompting approac hes often miss sp ecific details in Argument Mining, resulting in errors, esp ecially b et ween structurally similar comp onen ts. Moreov er, attempts to re- duce this via single-agent self-correction mechanisms often result in supp orting previously made mistakes instead of correcting them [6]. This raises the cen- tral question: can LLM-based systems improv e their p erformance in argumen t comp onen t classification by utilizing a m ulti-agent framework while a voiding the cost of sup ervised fine-tuning? T o address this question, we prop ose the MAD-ACC (Multi-Agent Debate for Argumen t Component Classification), a framework that form ulates argu- men t classification as a structured debate pow ered b y Prop onent, Opponent, and Judge agents. Through structured interaction, the mo del encourages ev al- uating comp eting classifications rather than self-refinement. This dynamic en- ables MAD-A CC to capture and expose logical nuances that are often o v er- lo ok ed b y single-pass mo dels. W e illustrate this capability through a case study in Section 3.3. W e show that MAD-ACC reduces the p erformance gap b etw een inference-only approaches and sup ervised mo dels, outp erforming all ev aluated single-pass and reasoning-augmented baselines on the UKP Student Essays cor- pus [26]. Moreo ver, MAD-ACC provides an additional contribution by improv- ing mo del transparency . Through rev ealing in termediate argumen ts in debate and final reasoning b ehind each decision, the framew ork offers insigh t into the decision-making pro cess, addressing a key limitation of black-box classifiers. 2 Related W ork The prop osed MAD-ACC sits at the intersection of computational argumen- tation and agentic artificial intelligence. T o contextualize our contribution, we surv ey the literature across the evolution of Argument Mining metho dologies, the applications of Large L anguage Mo dels to these tasks, and the emergence of Multi-Agen t Systems for reasoning. W e fo cus there on the paradigm shifts, from feature engineering to deep learning and generative inference. W e also review MAS approac hes, which motiv ate our idea of dialectical refinement. 2.1 Argumen t Mining Approac hes Argumen t Mining (AM) [16] is a researc h area within the field of Natural Lan- guage Pro cessing, fo cused on extracting and identifying structured reasoning from unstructured text. The field includes sev eral different subtasks, ranging from b oundary identification and relation extraction to the classification of the elemen ts. F oundational work in AM fo cused on providing annotation schemes and corp ora that allow ed for structuring and indexing retriev ed annotations. T o b enc hmark progress, the comm unity established v arious domain-sp ecific datasets. Multi-Agen t Dialectical Refinemen t for Enhanced Argument Classification 3 Among these, the UKP Argument Annotated Essays corpus [26] has emerged as a widely adopted standard for analyzing argumen tation in educational texts. Metho dologically , this area has exp erienced a notable shift. Early approaches relied primarily on manual feature engineering, t ypically combining Supp ort V ector Mac hines (SVMs) with carefully designed lexical and structural fea- tures [26, 12]. As deep learning techniques matured, the state-of-the-art shifted to ward neural architectures [7, 20]. T ransformer-based models such as BER T and RoBER T a hav e set new p erformance b enc hmarks [19]. Despite their strong accuracy , these sup ervised approac hes remain limited by their dependence on large-scale annotated data, suffering from p o or generalization when applied to out-of-domain text. 2.2 Large Language Mo dels in Argumen tation The rise of generative models has resulted in another shift, mo ving from e ncoder- only architectures to generative Large Language Mo dels (LLMs). This led to an exploration of the training-free capabilities, where mo dels such as GPT-4 [1] were ev aluated on argument mining tasks. Comprehensive ev aluations ha ve sho wn the p oten tial of LLMs [31, 5, 9], including the field of argument mining [22, 2]. One of the research directions to enhance LLM p erformance on argument mining w as chain-of-though t (CoT) prompting, a promising training-free technique that impro ves reasoning capabilities on complex tasks [28]. How ev er, the effectiveness of CoT v aries significan tly on the mo del size and task characteristics, with recent findings suggesting decreasing results for non-reasoning mo dels [18]. In resp onse to the limitations of prompting, recent state-of-the-art research fo cused on applying sup ervised strategies into LLM metho ds. Recent studies, in- cluding Cab essa et al. (2025) demonstrated that fine-tuning of the LLMs achiev es sup erior p erformance compared to the earlier b enc hmarks [4]. Beyond argument mining, fine-tuning has prov en to b e promising for enhancing reasoning capabili- ties across v arious NLP tasks [21, 3]. How ever, while these fine-tuned approaches curren tly define the standard, they reintroduce the issue of heavily relying on high-qualit y annotated data, limiting their usage in low-resource domains and languages, where suc h annotations are unav ailable. 2.3 LLM-based Multi-Agent Systems Multi-Agen t Systems (MAS), one of the recen tly emerging research directions [27], lev erage the concept of structured roles and collab oration to enhance problem solving. By distributing tasks across sp ecialized agents with distinct roles, p er- sonas, and sp ecific contexts, MAS framew orks often offer improv ed problem solving across diverse fields [14, 30]. These systems hav e demonstrated particular promise in domains such as legal reasoning and Natural Language pro cessing [10, 23]. A subset of this field is Multi-Agent Debate (MAD), a concept growing in Argumen t Mining and NLP . Distributing reasoning among sp ecialized agents engaged in structural discussion enables mo dels to refine through debate and 4 J. Bąba and J. A. Ch udziak critique [29, 13]. Recent research included different MAD frameworks and con- figurations across diverse NLP tasks [17, 8, 11]. A key recent work [15] utilized a debate framework to ev aluate implicit premises, outp erforming b oth neural baselines and single-agent LLMs. This effectively sho wed that agents can ac hieve b etter accuracy b y discussing and refining their answers based on opp osing opin- ions than b y rep eated generation. 3 Metho dology W e prop ose MAD-ACC (Multi-Agent Debate for Argument Comp onen t Clas- sification), a framework designed to resolv e ambiguities in the classification task without reliance on annotated training data. In our framew ork, we lev erage di- alog to adjudicate comp eting interpretations of structural relationships within argumen ts. 3.1 T ask F orm ulation W e formalize the Argumen t Component Classification (A CC) as a se- quence lab eling task. Let D = { t 1 , t 2 , . . . , t n } b e an argumentativ e do cument consisting of n argument comp onen ts. F or each target comp onen t t i , let C i de- note its con text window (e.g. whole do cument or surrounding paragraph). The ob jectiv e is to establish a mapping function Φ : ( t i , C i ) → y that assigns the correct lab el y ∈ Y , derived from the annotation sc heme defined by Stab and Gurevyc h [25]: Y = { MajorClaim , Claim , Premise } where classes are defined as follo ws: – MajorClaim : The ro ot node of the argumen t structure, represen ts cen tral thesis of the do cumen t. – Claim : An in termediate no de that receiv es supp ort, functions as the topic for eviden tiary statements. – Premise : A leaf no de that pro vides supp ort (example, evidence, reason) to Claim or another Premise. 3.2 The MAD-ACC F ramew ork W e formalize the MAD-ACC framework as a Multi-Agen t System (MAS) tuple S = ⟨A , P , T ⟩ , where: – A = { Mgr , Prop , Opp , Jud } is the set of Agen ts (Manager, Prop onen t, Op- p onen t, Judge). – P is the set of agent-specific system Prompts defining their roles. – T is the shared state (T ranscript) of the in teraction. The execution flow of the MAD-ACC framew ork is illustrated in Figure 1. It consists of three phases. Multi-Agen t Dialectical Refinemen t for Enhanced Argument Classification 5 Fig. 1. The MAD-ACC system ov erview. Probabilistic Initialization T o prop erly induce dialectical diversit y b etw een debaters, the Manager agent acts as a probabilistic filter. Giv en input x , it estimates the probabilit y distribution ov er the lab els: P ( y | x ) = Mgr ( x ) for y ∈ Y Let y top 1 , y top 2 ∈ Y b e the lab els with the highest probabilities. T o mitigate p osition and authorit y biases, system randomly assigns these lab els to the Pro- p onen t and Opp onen t , ensuring fairness of the debate for b oth Debaters . Dialectical In teraction The debate is mo deled as a sequence of message turns T = [ m 1 , m 2 , . . . , m k ] , where k is total num b er of turns. A t each turn i , an active agen t a ∈ { Prop , Opp } generates a message defending their y lab el, based on the input x and the con versation history T an apa rtment is more exp ensive . Ho wever, this is only partially true..." Mgr P ( Premise ) = 0 . 75 P ( Claim ) = 0 . 20 Prop Opp Argues Premise: "It states a fact. Supports topic." Argues Claim: "No, lo ok at ’Howev er’. It’s a Counter-Claim." Assign: Premise Assign: Claim Interaction Interaction Jud T ranscript V erdict: Agent B correctly identifies the argument structure. Final Lab el: CLAIM Fig. 2. Illustrativ e execution trace. Multi-Agen t Dialectical Refinemen t for Enhanced Argument Classification 7 The do cumen t examines the differences and trade-offs b et ween living in uni- v ersity dormitories and apartments. The target sen tence - "an ap artment is mor e exp ensive" - illustrates a case of classic claim am biguity . Semantically , the state- men t sounds as a factual observ ation ab out accommo dation costs. As a result, standard mo dels (and our Manager agent) frequently misclassify this comp o- nen t as a Pr emise , assuming it serves as a supp orting evidence rather than as a claim. Ho wev er, the debate exp oses the true structural role of the sentence in the do cumen t. Prop onen t initially argues for the Pr emise label, interpreting the sen tence as a previously stated observ ation. On the other side of the debate, Opp onen t identifies the structural function of the argumen t as a core economic argumen t in a section of text, directly supp orting text’s main thesis. The Op- p onen t shows that the subsequent statements refute this statement (e.g. "this is only p artial ly true" ), and as a result, it functions as a Claim . The Judge agen t, leveraging the hierarchical definitions, analyzes the debate transcript and adjudicates in fav or of the Opp onen t. The verdict relies on the direction of supp ort - since the comp onent w as recipient of the logic b ehind the whole paragraph, it hierarc hically functions as a Claim . This example highlights the core con tribution of our work: by forcing agents to debate the structure of the text, defending even unpopular lab els, MAD-ACC successfully finds the small details that other classification mo dels miss. 4 Exp erimen ts In this section, we present the ev aluation pro cess of the MAD-A CC framework. Our primary ob jective is to c heck if the proposed dialectical in teraction can efficien tly increase the p erformance of the training-free inference. W e detail the b enc hmark dataset and its preparation, the selection of baselines and the sp ecific configuration of multi-agen t arc hitecture used to v alidate our claims regarding accuracy and in terpretability . 4.1 Dataset F or our analysis, w e used the UKP Argumen t Annotated Essa ys v2 [26] corpus, a dataset containing 402 essays and 6089 statements. T o ensure strict comparabilit y with state-of-the-art sup ervised solutions, exp eriments w ere con- ducted based on the exact test split (80 essays with 1266 argumen t statements) established in prior literature [4]. No p ortion of the training split was used for prompt calibration or man ual tuning. Prior to pro cessing by the MAD-ACC framework, the corpus with the an- notations was formatted to enable easier LLM agent comprehension. F or each instance, the full essay was provided, with argumen t comp onen ts delimited by the tags. The target comp onent was marked as ... , while surrounding comp onen ts w ere mask ed as generic ... , without leak- ing the ground truth lab els. 8 J. Bąba and J. A. Ch udziak 4.2 Baselines W e ev aluate performance using Macro F1, W eigh ted F1 and class-sp ecific F1 scores for Ma jorClaim, Claim and Premise t yp es. T o v alidate the effectiveness of the multi-agen t framework, w e compare MAD-ACC against three different, single-agen t baselines: 1. V anilla: Represents standard usage of the LLMs. It utilizes the same mo del as the Manager agent ( Gemini 2.5 Flash ), with the direct classification prompt. 2. Chain-of-Though t (CoT): Utilizes standard Chain-of-Though t reasoning prompting with Gemini 2.5 Flash to assess if internal reasoning is sufficient. 3. Smart Reasoning: Uses the more capable Gemini 2.5 Pr o mo del with built-in reasoning and the exact same system definitions and rules as ones giv en to a Judge agent. It is designed to simulate Judge’s decision making pro cess without the b enefit of the debate conten t. A dditionally , we contextualize our results with the state-of-the-art sup ervised approac hes, sp ecifically fine-tuned LLMs [4]. While these metho ds currently de- fine the upp er b ound baseline, w e highligh t that they act as "black-box" solutions with limited explainability , whereas our framework prioritizes transparency and reasoning used b ehind decisions. 4.3 Exp erimen tal Setup F or this study , we set the debate length to 2 rounds (four total turns), allow- ing eac h agen t to present its initial argument and resp ond to the opponent’s coun terargument. This configuration reflects a trade-off b etw een argumen tative depth and efficiency: preliminary exp erimentation and manual insp ection indi- cated that a single round often fails to exp ose structural disagreements, while longer debates tend to introduce rep etitiv eness without yielding additional clas- sification b enefits. T o mitigate the p osition bias from the Judge agent, w e employ ed a random- ized stance assignment strategy . Prop onent and Opp onen t agents are randomly assigned to defend first and second most probable label, ensuring that the order of probabilities will not affect the final judgment. While the framework supp orts a confidence-based skip threshold, we treated all samples with the debate to rigorously ev aluate system’s ability to resolv e ambiguities in the corpus. W e used the Gemini 2.5 family of models. The Manager and the Judge agen ts used Gemini 2.5 Flash and Gemini 2.5 Pr o resp ectively; the Manager was designed to quickly filter the least probable lab el, while the Judge required higher capacit y to pro cess debate context. While the MAD-A CC framework is mo del- agnostic, w e prioritized establishing a strong baseline with Gemini and leav e the comparative analysis of other models, including open-source alternativ es , for future w ork. F or b oth agen ts, the temperature w as set to 0.0 to ensure deterministic outputs and consisten t scoring. The Debaters used Gemini 2.5 Flash mo del, with a temp erature of 0.7 , selected to ensure creativity through div erse reasoning paths during lab el defense. Multi-Agen t Dialectical Refinemen t for Enhanced Argument Classification 9 5 Results and Discussion In this section, w e present the empirical ev aluation of the MAD-ACC framework on the UKP Student Essa ys corpus. W e analyze the MAD-ACC p erformance against selected single-agent baselines and contextualize them with a sup ervised approac h. Subsequently , we conduct a qualitativ e analysis of selected examples based on the debate transcripts, to sho w the p o wer of our system in correct- ing logical errors through adversial reasoning, highlighting the in terpretability b enefits of our framework. 5.1 P erformance Analysis T able 1 summarizes the argument classification results on the UKP test set. The results show a clear p erformance hierarc hy . Context-free, general-purp ose inference baselines (Baselines A and B) achiev e Macro F1 scores of 78.5% and 79.2%, respectively . Single-agen t reasoning (Baseline C) achiev es a Macro F1 score of 84.9%, and MAD-ACC achiev es the highest training-free p erformance of 85.7%. Chain-of-Though t ac hieves slightly b etter performance than v anilla prompt- ing, how ev er b oth of the baselines hit the ceiling of approximately 80%. More- o ver, b oth of them mostly struggle with Claim comp onen ts (Claim F1 scores of 57.0% and 58.5%). This supp orts the theory of incorrect reliance on surface-level seman tics and often incorrectly connecting comp onents "sounding like opinions" with Claims. There is a ma jor improv emen t b etw een the first tw o baselines and the solu- tions equipp ed with base rules. Baseline C, equipp ed with reasoning and such kno wledge, impro ves consistently , particularly in Macro F1, and more impor- tan tly , Claim F1, which is up around +14 p ercen tage p oin ts . It suggests that mo ving the fo cus to resolving semantic ambiguities based on direction of supp ort substan tially improv es p erformance. Utilizing dialectical refinement in the pip eline resulted in MAD-ACC ac hiev- ing the b est results, b eating Baseline C b y 0.8% in Macro F1. Moreo ver, the MAD-ACC outp erformed strong single-agent baseline by another Claim F1 T able 1. Comparison of classification p erformance on UKP Student Essays. Metho d Ov erall Performance Class-wise F1-score Macr o F1 W-F1 MC Claim Pr emise Infer enc e-Only Baselines Baseline A (V anilla) 78.5 80.8 90.6 57.0 88.0 Baseline B (Chain-of-Thought) 79.2 81.2 91.4 58.5 87.8 Baseline C (Smart Reasoning) 84.9 86.1 92.2 72.5 90.1 MAD-A CC (Ours) 85.7 87.0 92.0 74.5 90.7 Sup ervise d Refer enc e Cab essa et al. (2025) 89.5 - - - - 10 J. Bąba and J. A. Ch udziak +2% , while keeping F1 scores for Premises and Ma jor Claims stable. This means that it MAD-ACC isn’t just moving classifications from Premises to Claims, but activ ely using debate to differentiate comp onents more effectively . 5.2 Comparison with State-of-the-Art T able 1 contextualizes our results against the sup ervised state-of-the-art [4]. While fine-tuned LLMs currently define the upp er b ound p erformance of 89.5% Macro F1 score, MAD-ACC reduces this gap with a comp etitive 85.7% without requiring an y training or parameter up dates. This result highlights a trade-off betw een Performanc e and Data Efficiency . Their SOT A mo del achiev ed b etter results, but fine-tuning relied on approxi- mately 80% of the corpus, whereas MAD-A CC op erates in a training-free setting. Ultimately , fine-tuning remains optimal for the cases where the cost of tuning is acceptable and annotated data is a v ailable. On the other side, the MAD- A CC framework presents a comp elling alternative for lo w-resource domains and cases where annotating large amounts of do cuments is imp ossible. W e note that while MAD-ACC eliminates training costs, the multi-agen t debate increases costs from token consumption compared to single-pass prompting. How ever, for low- resource domains, this trade-off is often preferable to data annotation costs. 5.3 Qualitativ e Analysis: Case Studies T o inv estigate the source of MAD-ACC p erformance gain, we analyzed exem- plary instances where the single-agent baseline (Baseline C) failed, but MAD- A CC lab eled the comp onent correctly by taking adv antage of reasoning from the debate transcript. Resolving T opic Sen tence Ambiguit y (Case 1) Single-pass mo dels often confuse the main argumen t with the evidence supporting it, esp ecially when the argumen t is descriptive. In Essa y 335, the baseline incorrectly classified the comp onen t "connecting p eople by email is easy and fast" as a Premise, under- estimating its role in the text. How ev er, the debate transcript shows that Agent B correctly identified it as one of the main arguments in the text, directly sup- p orting the main thesis of the essa y ( "IT disc overies ar e likely to have mor e disadvantages than b enefits and p e ople should know how to use their develop- ments pr op erly" ), and as a result, it w as correctly classified as a Claim. Hierarc hical Distinction (Case 2) These models also sometimes struggle with abstraction and hierarc hy . In Essay 169, the target sentence "Only b y de- v eloping students, can we ha ve a b etter academic field" was misclassified by a baseline as a Ma jorClaim. The debate pro cess correctly found and analyzed the dep endency c hain, realizing that while the sen tence w as abstract, it was a pillar for the main thesis of the text ( "pr ofessors should sp end mor e time on pr ep aring c ourses than r ese ar ch" ), and as a result, it was a Claim. Multi-Agen t Dialectical Refinemen t for Enhanced Argument Classification 11 T able 2. Qualitative comparison of Baseline C vs. MAD-ACC. The dialectical tran- script allows the Judge to resolv e structural am biguity where the single-agent fails. Case Type T ext & Context Dialectical Resolution (MAD- A CC) Case 1: T opic Sen tence (Essa y 335) T ar get: "connecting p eople by email is easy and fast" Pr e dictions: Baseline: Premise MAD-ACC: Claim A gent B A r gues (simplifie d): The target sentence is a Claim, as it is pre- sen ted as argument supp orting another idea that IT has benefits, which is a crucial comp onen t of the essay’s ov er- all thesis. At the same time, it acts as the core ideas of the paragraph, one of direct b enefits. V er dict: Judge accepts that the tar- get is one of the main arguments pre- sen ted in the paragraph and functions as a Claim. Case 2: Hierarc hy Resolution (Essa y 169) T ext: "Only by developing stu- den ts, can we hav e a b etter academic field" Pr e dictions: Baseline: Ma jorClaim MAD-ACC: Claim A gent A Ar gues (simplifie d): Th e target is a Main Argumen t and a Claim that supports the essay’s o verarc hing thesis, not the thesis itself. It provides the abstract principle explaining why professors should prioritize teaching. It connects directly to the Ma jorClaim b y justifying it, functioning as a supp ort rather than the ro ot no de. V er dict: Judge recognizes the target as a Claim as a high-lev el argumen t supp orting the Thesis. These examples demonstrate that the dialectical pro cess forces the system to thoroughly ev aluate the function of each comp onent and decide whether it supp orts a neighbor (Premise), the thesis (Claim) or acts as a main idea - and as a result, it supp orts resolving structural ambiguit y present in the baselines. 6 F uture W ork The results presented in this work suggest several promising directions for future researc h. Firstly , the framework’s cross-domain generalization capabilities should b e in vestigated. Since MAD-A CC do es not rely on domain-sp ecific annotated data, it is a strong candidate for application in other domains, esp ecially low-resource ones, including legal, p olitical, or biomedical text mining. F uture studies could ev aluate the usage of such a dialectical framew ork, esp ecially in the role of an assistan t suggesting initial annotations, with the p ow erful reasoning helping in v alidating these lab els. 12 J. Bąba and J. A. Ch udziak A second area of study is the extension of the approac h b eyond comp onen t classification. The framew ork could b e assessed on other tasks, suc h as Argument Relation Identification and Classification (ARI/ARC). By configuring agents to debate the existence and types of links (Supp ort/Attac k), subsequent research could mo ve tow ard full argument structure parsing. Finally , a critical direction for suc h agentic systems would b e to integrate them into real-world educational technologies. F uture w ork could deploy MAD- A CC within intelligen t educational systems, where the framework’s explainabil- it y and in terpretability could b e measured through p edagogical impact and user studies. Suc h studies could verify the v alue of the AI-generated dialectical an- notations in the pro cess of improving argumentativ e skills. 7 Conclusion In this w ork, w e presented the MAD-A CC , a m ulti-agent framework utiliz- ing dialectical refinement to improv e p erformance on the Argument Comp onent Classification task without relying on exp ensiv e fine-tuning on high-qualit y anno- tated data. By replacing static classification with a multi-agen t debate of con tra- dicting opinions, we addressed the limitations of single-agent LLMs, sp ecifically their tendency to mismatch the structural function of the argument based on a seman tic assertiveness. Our exp erimen ts on the UKP Student Essays corpus demonstrate that MAD- A CC achiev es a Macro F1 score of 85.7%, outp erforming all the baselines without task-sp ecific training. Notably , the framework effectively resolves the "Claim vs. Premise" ambiguit y , providing substan tial improv ement in the Claim F1 score. As demonstrated by the qualitative analysis in Section 5.3, the debate mec hanism successfully corrects errors where single agen ts misclassify topic sen tences or hierarc hy of the documents, based on the direction of supp ort. While state-of- the-art still holds a p erformance adv antage (89.5%), our metho dology provides a comp etitiv e, data-efficient alternative for low-resource domains. Bey ond quantitativ e p erformance, MAD-ACC adds a level of explainabilit y that is largely absent in traditional classifiers. The generated debate transcripts pro vide a transparent thought pro cess b ehind each decision, shifting the system from a blac k-b ox mo del to a to ol capable of justifying its conclusions to users. A ckno wledgemen t. The work rep orted in this paper w as supp orted b y the P olish National Science Centre under grant 2024/06/Y/HS1/00197. References 1. A chiam, J., Adler, S., Agarwal, S., Ahmad, L., Akk a ya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadk at, S., et al.: Gpt-4 technical rep ort. arXiv preprin t arXiv:2303.08774 (2023) Multi-Agen t Dialectical Refinemen t for Enhanced Argument Classification 13 2. Al Zubaer, A., Granitzer, M., Mitrović, J.: Performance analysis of large language mo dels in the domain of legal argument mining. F rontiers in Artificial Intelligence 6 , 1278796 (2023) 3. Bousselham, H., Mourhir, A., et al.: Fine-tuning gpt on biomedical nlp tasks: an empirical ev aluation. In: 2024 International Conference on Computer, Electrical & Comm unication Engineering (ICCECE). pp. 1–6. IEEE (2024) 4. Cab essa, J., Hernault, H., Mushtaq, U.: Argumen t mining with fine-tuned large language mo dels. In: Rambow, O., W anner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B.D., Sc ho ck aert, S. (eds.) Pro ceedings of the 31st International Confer- ence on Computational Linguistics. pp. 6624–6635. Asso ciation for Computational Linguistics, Abu Dhabi, UAE (Jan 2025), https://aclan thology .org/2025.coling- main.442/ 5. Chang, Y., W ang, X., W ang, J., W u, Y., Y ang, L., Zhu, K., Chen, H., Yi, X., W ang, C., W ang, Y., et al.: A survey on ev aluation of large language mo dels. ACM T ransactions on Intelligen t Systems and T echnology 15 (3), 1–45 (2024) 6. Chen, C.H., Huang, H.H., Chen, H.H.: Self-augmented preference alignment for sycophancy reduction in llms. In: Pro ceedings of the 2025 Conference on Empirical Metho ds in Natural Language Pro cessing. pp. 12390–12402 (2025) 7. Eger, S., Daxenberger, J., Gurevych, I.: Neural end-to-end learning for com- putational argumentation mining. In: Barzilay , R., Kan, M.Y. (eds.) Pro ceed- ings of the 55th Annual Meeting of the Asso ciation for Computational Linguis- tics (V olume 1: Long Papers). pp. 11–22. Association for Computational Lin- guistics, V ancouver, Canada (Jul 2017). h ttps://doi.org/10.18653/v1/P17-1002, h ttps://aclanthology .org/P17-1002/ 8. Estornell, A., T on, J.F., Y ao, Y., Liu, Y.: Acc-collab: An actor-critic approach to m ulti-agent llm collab oration (2025), 9. Gorur, D., Rago, A., T oni, F.: Can large language mo dels p erform relation-based argumen t mining? (2024), 10. Gorur, D., Rago, A., T oni, F.: Retriev al and argumentation enhanced multi-agen t llms for judgmental forecasting (2025), h 11. Gou, Z., Shao, Z., Gong, Y., Shen, Y., Y ang, Y., Duan, N., Chen, W.: Critic: Large language models can self-correct with to ol-interactiv e critiquing (2024), h 12. Hab ernal, I., Gurevych, I.: Argumentation mining in user-generated w eb discourse. Computational Linguistics 43 (1), 125–179 (Apr 2017). h ttps://doi.org/10.1162/COLI_a_00276, https://aclan thology .org/J17-1004/ 13. Harbar, Y., Chudziak, J.A.: Simulating o xford-style debates with llm-based multi- agen t systems. In: Nguy en, N.T., Matsuo, T., Gaol, F.L., Manolop oulos, Y., F ujita, H., Hong, T.P ., W o jtkiewicz, K. (eds.) Intelligen t Information and Database Sys- tems. pp. 286–300. Springer Nature Singapore, Singapore (2025) 14. K ostk a, A., Chudziak, J.A.: T ow ards cognitive synergy in llm-based m ulti- agen t systems: In tegrating theory of mind and critical ev aluation (2025), h 15. Ku, H.B., Shin, J., Lee, H.J., Na, S., Jeon, I.: Multi-agent LLM de- bate un veils the premise left unsaid. In: Chistov a, E., Cimiano, P ., Had- dadan, S., Lap esa, G., Ruiz-Dolz, R. (eds.) Pro ceedings of the 12th Argu- men t Mining W orkshop. pp. 58–73. Association for Computational Linguis- tics, Vienna, Austria (Jul 2025). https://doi.org/10.18653/v1/2025.argmining-1.6, h ttps://aclanthology .org/2025.argmining-1.6/ 14 J. Bąba and J. A. Ch udziak 16. La wrence, J., Reed, C.: Argument mining: A survey . Computational Lin- guistics 45 (4), 765–818 (Dec 2019). h ttps://doi.org/10.1162/coli_a_00364, h ttps://aclanthology .org/J19-4006/ 17. Liu, T., W ang, X., Huang, W., Xu, W., Zeng, Y., Jiang, L., Y ang, H., Li, J.: Group debate: Enhancing the efficiency of multi-agen t debate using group discus- sion. arXiv preprint arXiv:2409.14051 (2024) 18. Meinc ke, L., Mollick, E., Mollick, L., Shapiro, D.: Prompting science rep ort 2: The decreasing v alue of chain of thought in prompting. arXiv preprint (2025) 19. Mush taq, U., Cab essa, J.: Argumen t classification with b ert plus con textual, struc- tural and syntactic features as text. In: International Conference on Neural Infor- mation Pro cessing. pp. 622–633. Springer (2022) 20. Niculae, V., Park, J., Cardie, C.: Argument mining with structured SVMs and RNNs. In: Barzilay , R., Kan, M.Y. (eds.) Pro ceedings of the 55th Ann ual Meeting of the Asso ciation for Computational Linguistics (V olume 1: Long Papers). pp. 985– 995. Asso ciation for Computational Linguistics, V ancouver, Canada (Jul 2017). h ttps://doi.org/10.18653/v1/P17-1091, https://aclan thology .org/P17-1091/ 21. P areja, A., Nay ak, N.S., W ang, H., Killamsetty , K., Sudalaira j, S., Zhao, W., Han, S., Bhandwaldar, A., Xu, G., Xu, K., et al.: Unv eiling the secret recip e: A guide for sup ervised fine-tuning small llms. arXiv preprint arXiv:2412.13337 (2024) 22. P o joni, M.L., Dumani, L., Schenk el, R.: Argumen t-mining from po dcasts using c hatgpt. In: ICCBR W orkshops. pp. 129–144 (2023) 23. Sado wski, A., Chudziak, J.A.: On verifiable legal reasoning: A multi-agen t frame- w ork with formalized knowledge represen tations. In: Pro ceedings of the 34th ACM In ternational Conference on Information and Knowledge Management. pp. 2535– 2545. CIKM ’25, ACM (Nov 2025). https://doi.org/10.1145/3746252.3761057, h ttp://dx.doi.org/10.1145/3746252.3761057 24. Song, S., Xu, H., Ma, J., Li, S., Peng, L., W an, Q., Liu, X., Y u, J.: How to alleviate catastrophic forgetting in llms finetuning? hierarchical la yer-wise and elemen t-wise regularization (2025), 25. Stab, C., Gurevych, I.: Annotating argument comp onen ts and relations in p ersua- siv e essays. In: Pro ceedings of COLING 2014, the 25th International Conference on Computational Linguistics: T echnical Papers. pp. 1501–1510 (2014) 26. Stab, C., Gurevych, I.: P arsing argumentation structures in p ersuasiv e essays. Computational Linguistics 43 (3), 619–659 (2017) 27. T ran, K.T., Dao, D., Nguy en, M.D., Pham, Q.V., O’Sulliv an, B., Nguy en, H.D.: Multi-agen t collab oration mechanisms: A survey of llms (2025), h 28. W ei, J., W ang, X., Sch uurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language mo dels. A dv ances in Neural Information Pro cessing Systems 35 , 24824–24837 (2022) 29. W u, H., Li, Z., Li, L.: Can llm agents really debate? a controlled study of multi- agen t debate in logical reasoning (2025), 30. Zamo jsk a, M., Chudziak, J.A.: Games agents play: T ow ards transactional analysis in llm-based multi-agen t systems (2025), 31. Zhao, W.X., Zhou, K., Li, J., T ang, T., W ang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al.: A survey of large language models. arXiv preprint arXiv:2303.18223 1 (2) (2023)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment