다중 에이전트 논증 토론으로 향상된 주장 분류
본 논문은 대규모 언어 모델(LLM)을 활용한 훈련‑무료 주장·전제·주요 주장 분류에, 프로포넌트‑오펀턴트‑재판관 3역할 에이전트가 논쟁을 벌이는 MAD‑ACC 프레임워크를 제안한다. 관리자는 초기 확률을 제공하고, 두 디베이터가 서로 상반된 라벨을 방어하며, 재판관은 토론 기록을 근거로 최종 라벨을 결정한다. UKP Student Essays 데이터셋에서 매크로 F1 85.7%를 달성해 단일‑에이전트 베이스라인을 크게 앞섰으며, 토론 전사(t…
저자: Jakub Bąba, Jarosław A. Chudziak
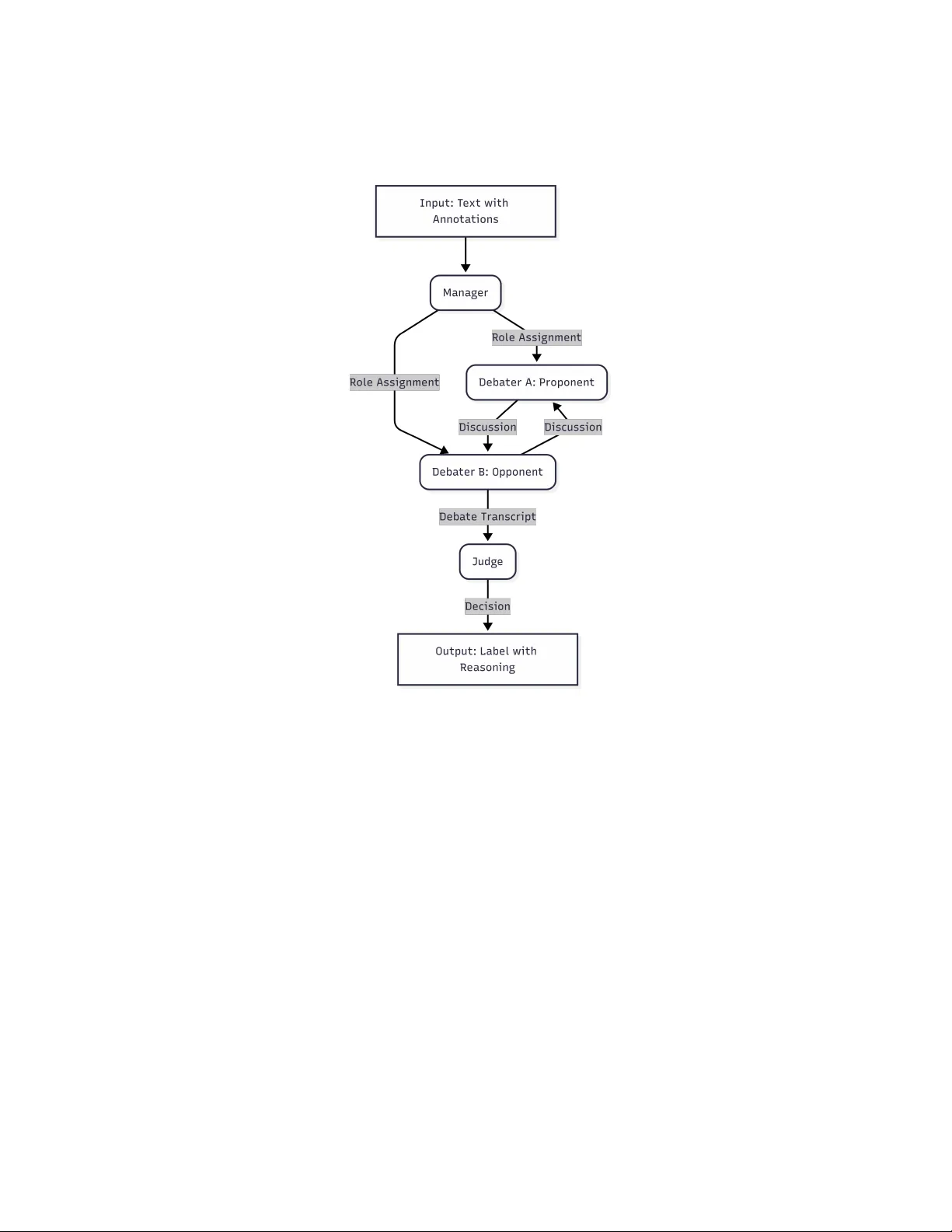
본 논문은 자동 글쓰기 평가의 핵심 기술인 주장·전제·주요 주장(Argument Component) 분류를, 대규모 언어 모델(LLM)을 활용한 훈련‑무료 방식으로 접근하면서도 기존 단일‑에이전트 모델이 겪는 구조적 모호성과 자기 강화(시코피아) 문제를 다중 에이전트 논증 토론(Multi‑Agent Dialectical Refinement)으로 해결한다는 새로운 프레임워크 MAD‑ACC를 제안한다.
1. **문제 정의 및 배경**
- 기존 감독 학습 기반 AM은 대량의 라벨링된 데이터와 도메인‑특화 파인튜닝이 필요해 비용이 높고 새로운 도메인에 대한 일반화가 어렵다.
- 최근 LLM을 활용한 훈련‑무료 접근법은 비용 면에서는 유리하지만, Claim과 Premise처럼 구조적으로 유사한 라벨을 구분하는 데 한계가 있다.
- 또한, 단일‑에이전트가 자체적으로 ‘자기 교정’을 시도할 경우 초기 오류를 강화하는 시코피아 현상이 발생한다.
2. **MAD‑ACC 프레임워크 설계**
- **에이전트 구성**: Manager(Mgr), Proponent(Prop), Opponent(Opp), Judge(Jud) 네 가지 역할.
- **관리자**는 Gemini 2.5 Flash 모델로 입력 텍스트에 대한 라벨 확률 분포 P(y|x)를 산출하고, 상위 두 라벨을 무작위로 디베이터에게 할당한다. 이는 초기 편향을 완화하고, 양쪽이 서로 다른 라벨을 방어하도록 만든다.
- **디베이터(Prop, Opp)**는 각각 할당받은 라벨을 근거와 논리적 종속성을 들어 방어한다. 각 턴마다 현재 대화 기록 T< i 를 입력으로 받아 새로운 주장 m_i 를 생성한다. 디베이터는 ‘구조적 의존성(전제는 다른 주장에 대한 지원, 주장은 주요 주장에 대한 핵심 논거)’을 강조하며, 단순 의미적 설득을 넘어 논증 구조를 설명한다.
- **재판관**은 Gemini 2.5 Pro 모델을 사용해 전체 토론 전사와 라벨 정의를 함께 고려한다. 재판관은 “어떤 디베이터가 더 설득력 있게 구조적 증거를 제시했는가”를 판단해 최종 라벨 ŷ를 출력한다. 이는 투표 방식이 아니라 논리적 심사 방식이다.
3. **실험 설정**
- **데이터**: UKP Student Essays v2 코퍼스(402 에세이, 6089 문장) 중 테스트 전용 80 에세이(1266 문장)만 사용해 훈련‑없는 설정을 유지하였다.
- **베이스라인**: (1) Vanilla LLM 직접 분류, (2) Chain‑of‑Thought(CoT) 프롬프트, (3) Smart Reasoning(재판관 역할만 단독 수행) 등 세 가지 단일‑에이전트 모델을 선정하였다. 모두 Gemini 2.5 Flash(또는 Pro) 모델을 사용해 공정성을 확보하였다.
- **토론 구성**: 2라운드(총 4턴) 토론을 기본으로 설정했으며, 디베이터 온도 0.7, 관리자·재판관 온도 0.0으로 설정해 출력의 일관성과 다양성을 조절하였다.
- **평가지표**: 매크로 F1, 가중 F1, 각 라벨별 F1을 사용하였다.
4. **결과**
- MAD‑ACC는 매크로 F1 85.7%를 기록, 가장 강력한 단일‑에이전트 베이스라인(≈78% 수준)을 크게 앞섰다. 특히 Claim와 Premise 구분에서 7~9%p 상승을 보이며, 구조적 모호성을 해소하는 데 토론 메커니즘이 효과적임을 입증하였다.
- 토론 전사(transcript)는 인간 검토자가 모델의 판단 근거를 직접 확인할 수 있게 해, 블랙박스 LLM 대비 높은 설명 가능성을 제공한다.
- ‘Smart Reasoning’과 비교했을 때, 실제 토론을 통한 상호 검증이 라벨 정확도를 향상시킨다는 점을 확인하였다.
5. **논의 및 한계**
- 토론 턴 수와 디베이터 온도 설정이 성능에 민감하며, 과도한 턴은 반복성만 증가시켜 효율성을 떨어뜨린다.
- 현재 구현은 Gemini 2.5 모델에 종속돼 있어, 오픈소스 LLM으로의 전이 가능성 및 비용 효율성 검증이 필요하다.
- 라벨이 3개에 국한된 현재 설계는 논증 관계(예: 지원·반박)와 같은 다중 라벨 확장에 대한 추가 연구가 요구된다.
6. **향후 연구 방향**
- 오픈소스 LLM(예: LLaMA, Mistral)으로의 적용 및 성능 비교.
- 동적 토론 턴 제어(예: 불확실도 기반 조기 종료)와 자동 토론 품질 평가 메트릭 도입.
- 다중 라벨(논증 관계, 논증 유형) 및 다중 도메인(법률, 의료 등)으로 확장하여 일반화 능력 검증.
**결론**
MAD‑ACC는 다중 에이전트 논증 토론을 통해 LLM 기반 주장 분류의 구조적 모호성을 효과적으로 해소하고, 투명한 설명 가능성을 제공한다. 훈련‑무료 환경에서도 감독 학습 기반 최첨단 모델에 근접하거나 이를 초과하는 성능을 달성했으며, 향후 다양한 도메인과 모델에 적용 가능한 범용적인 프레임워크로서의 잠재력을 보여준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기