CausalEvolve: Towards Open-Ended Discovery with Causal Scratchpad
Evolve-based agent such as AlphaEvolve is one of the notable successes in using Large Language Models (LLMs) to build AI Scientists. These agents tackle open-ended scientific problems by iteratively improving and evolving programs, leveraging the pri…
Authors: Yongqiang Chen, Chenxi Liu, Zhenhao Chen
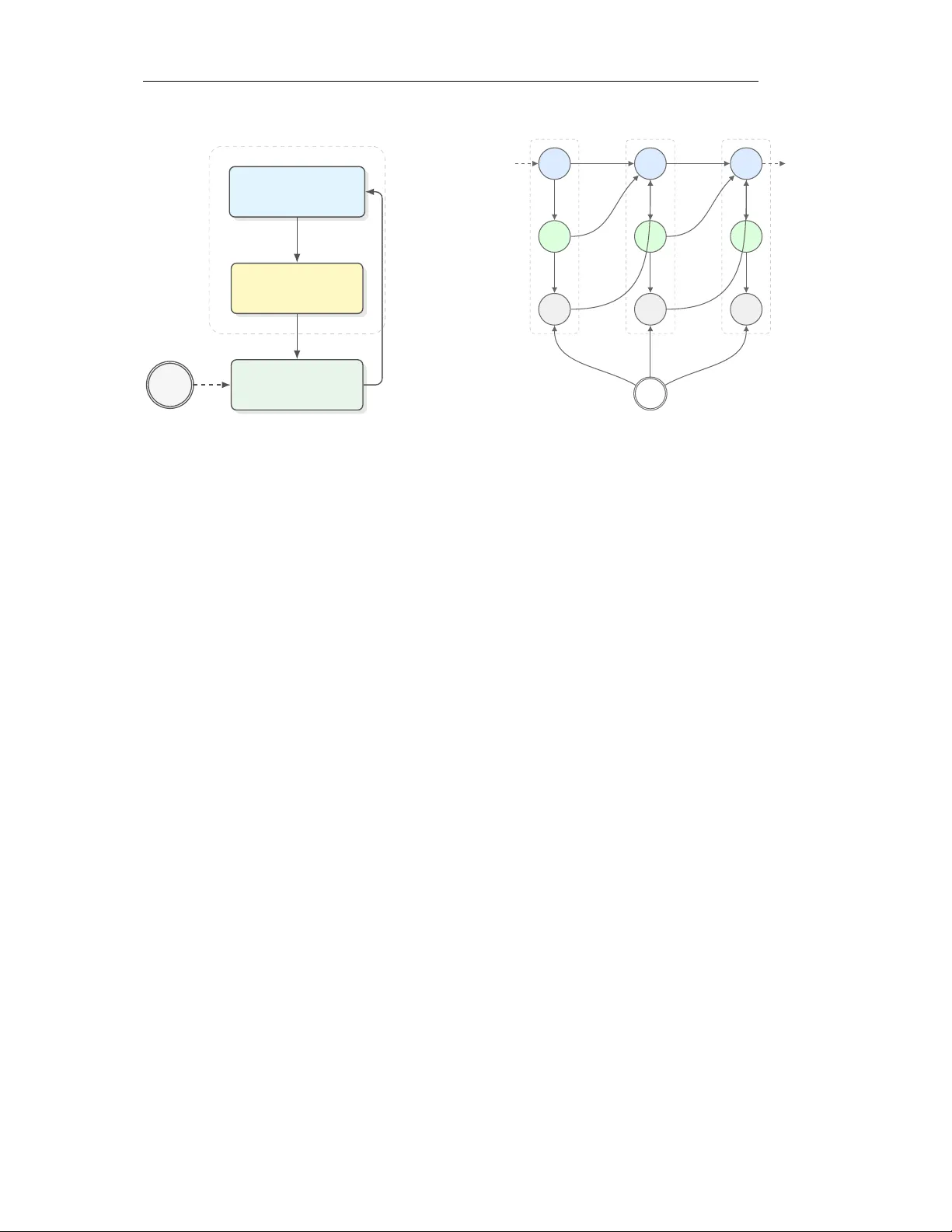
Preprint C AU S A L E V O L V E : T O W A R D S O P E N - E N D E D D I S C OV E RY W I T H C AU S A L S C R A T C H P A D Y ongqiang Chen ∗ 1 , 2 Chenxi Liu ∗ 3 Zhenhao Chen 1 T ongliang Liu 4 , 1 Bo Han 3 Kun Zhang 1 , 2 1 MBZU AI 2 Carnegie Mellon Uni versity 3 TMLR Group, Hong K ong Baptist University 4 SAIC Centre, The Univ ersity of Sydney yqchen24@gmail.com cscxliu@comp.hkbu.edu.hk A B S T R AC T Evolv e-based agent such as AlphaEvolv e is one of the notable successes in using Large Language Models (LLMs) to build AI Scientists. These agents tackle open-ended scientific problems by iterativ ely improving and ev olving programs, le veraging the prior knowledge and reasoning capabilities of LLMs. Despite the success, e xisting e volv e-based agents lack targeted guidance for e volution and ef fectiv e mechanisms for organizing and utilizing knowledge acquired from past ev olutionary experience. Consequently , they suffer from decreasing ev olution efficienc y and exhibit oscillatory behavior when approaching kno wn performance boundaries. T o mitigate the gap, we de velop CausalEvolve , equipped with a causal scratchpad that le verages LLMs to identify and reason about guiding f actors for ev olution. At the beginning, CausalEvolve first identifies outcome-level factors that offers complementary inspirations in improving the tar get objecti ve. During the ev olu- tion, CausalEvolve also inspects surprise patterns during the e volution and abducti ve reasoning to hypothesize ne w factors, which in turn of fer no vel directions. Through compre- hensiv e experiments, we show that CausalEvolve effecti vely improv e the ev olutionary efficienc y and discovers better solutions in 4 challenging open-ended scientific tasks. 1 I N T RO D U C T I O N As large language model (LLMs) demonstrate increasing capabilities in comple x and challenging reasoning tasks ( Guo et al. , 2025 ; Li et al. , 2025e ), the community seeks to build LLM-based agents to facilitate a number of downstream applications ( Plaat et al. , 2025 ). One of the most notable and promising applications is the AI Scientist agents ( ZHENG et al. , 2025 ), where the LLM-based agent is e xpected to automate the scientific discov ery process ranging from conducting literature surveys ( W an et al. , 2026 ), hypothesis generation ( Khemakhem et al. , 2020 ), data-driven analysis ( Chan et al. , 2024 ) to experiment design ( Li et al. , 2025c ), etc. In fact, when incorporated into the agentic frame work, LLMs ha ve demonstrated great promise. Lu et al. ( 2024 ); Gottweis et al. ( 2025 ); Mitchener et al. ( 2025 ) sho w that LLMs can come up with new research hypotheses and proposals based on the existing literature and automate the full scientific disco very pipeline ( Y amada et al. , 2025 ). Recent adv ances in using LLMs to assist with scientific discovery shows LLMs can accelerate the idea iteration and deep literature search ( Bubeck et al. , 2025 ; W oodruf f et al. , 2026 ). One of the most representati ve AI Scientist agents is the e volutionary coding agent, like AlphaEvolve ( Novik ov et al. , 2025 ; Lange et al. , 2025b ). In the iterati ve e volutionary frame work, LLMs demonstrate great capabilities in proposing, ev aluating, and refining iteratively better solutions to a number of scientific problems ( Sharma , 2025 ; Georgie v et al. , 2025 ; Cheng et al. , 2025 ). Despite the success, the e volution process in the e xisting ∗ These authors contributed equally . 1 Preprint framew orks is mainly driv en by the ev olution algorithm or deriv ed from correlational studies. In contrast, human scientists can design purposeful experiments and summarize scientific insights from observ ational data ( Kuhn & Ha wkins , 1963 ; Kaelbling et al. , 1998 ; Glymour ). The gap that emerges between the uncon- trolled ev olutionary process of evolv e-based agents and the guided discovery process of humans raises a challenging research question: How can we develop e volution-based agents to perform guided scientific discovery like humans? T o tackle the question, we resort to causality , which summarizes the practice of scientific discovery of humans ( Spirtes et al. , 2000b ; Pearl , 2009 ). Essentially , scientific discovery is about re vealing the underlying causal mechanism of the interested problem ( W allace , 1981 ; Glymour ). Hence, we can formulate the e volution- based scientific discov ery process as a Partially Observ able Marko v Decision Process (POMDP) ( Kaelbling et al. , 1998 ), where the agent needs to uncover the underlying causal mechanism through purposeful actions and interventions (Sec. 3 ). W ith the POMDP formulation, we demonstrate that accumulating and guiding the ev olution with causal knowledge is crucial to both the ef ficiency and effecti veness of the discov ery process. W ithout the incorporation of causality , the ev olution can easily oscillate or get stuck at local optimal solutions. T o this end, we dev elop a new ev olutionary AI Scientist framework, termed CausalEvolve , where we introduce a causal scratchpad to the e volution-based agent. The guidance provided by CausalEvolve is built upon the interv entional factors identified before and during the e volution process. As the e volution-based agent primarily focuses on optimizing a target objective, such as the objecti ve v alue of a combinatorial optimization problem or the accurac y of a machine learning problem ( Lange et al. , 2025b ), CausalEvolve first identifies a set of outcome-level factors to pro vide complementary vie ws of the target objecti ve. During the evolution, CausalEvolve lev erages a multi-arm bandit (MAB) to adaptiv ely determine the desired intervention with respect to a selected outcome-le vel factor . In addition, CausalEvolve also identifies pr ocedur e-level factors from the accumulated trials with LLMs ( Liu et al. , 2024 ). Intuiti vely , the procedure-le vel factors are useful interv entions to the solutions that explain the objecti ve v alue changes. For e xample, the optimization technique used to solve a combinatorial optimization problem. Nevertheless, some combinations of apparently useful f actors may lead to decreased scores, which we term as “surprise patterns”. Understanding and explaining the “surprise patterns” is critical to re veal ne w scientific insights ( W allace , 1981 ). Hence, CausalEvolve also performs abducti ve reasoning to come up with ne w factors and hypothesis that will be suggested to ev aluate in the future e xperiments to better explain all the observ ed patterns ( Douven , 2025 ). Empirically , we sho w that CausalEvolve significantly improv es the evolution efficienc y and achieves better results compared to the existing state-of-the-art ShinkaEvolve ( Lange et al. , 2025b ) across 4 open-ended discov ery problems. Our contributions can be summarized as follo ws: • W e propose a theoretical formulation of e volution-based open-ended discovery , and demonstrate the necessity of causality (Sec. 3 ); • W e propose a ne w frame work CausalEvolve to realize the accumulation and guidance of causal knowledge by identifying outcome-based and procedure-based f actors; • CausalEvolve is shown to improv e both the e volution efficienc y and effecti veness across 4 open-ended discov ery problems. 2 R E L A T E D W O R K AI Scientist Agents. W ith the significant adv ancement in LLM capacity and the de velopment of Agentic system, there is a rising number of w orks on developing agents for helping scientific discov eries ( Lu et al. , 2024 ; Y amada et al. , 2025 ; Gottweis et al. , 2025 ). One research line is to automating the pipelines in scientific 2 Preprint acti vities, including literature re view ( Huang et al. , 2025b ), hypothesis generation ( Li et al. , 2024a ; Y ang et al. , 2024 ; W ang et al. , 2024 ; Y ang et al. , 2025 ), hypothesis verification ( Li et al. , 2024b ; Huang et al. , 2025a ), and assistance in scientific reports ( Liang et al. , 2024 ). Another research line is to integrating the knowledge and reasoning ability of LLMs to conduct computational intensi ve ev olution or iteration on specific scientific problems ( Shojaee et al. , 2025 ; Romera-Paredes et al. , 2024 ; No vikov et al. , 2025 ; Sharma , 2025 ; Lange et al. , 2025a ). There are also works on automated tabular data analysis with machine learning workflo ws ( Zha et al. , 2023 ; Li et al. , 2023 ; Zhang et al. , 2023 ; Li et al. , 2025b ), or embodied agents that can conduct real-world experiments ( Roch et al. , 2020 ; Zhu et al. , 2022 ; T om et al. , 2024 ; Mandal et al. , 2025 ). The impact of these lines of work has been made on scientific fields includes chemistry ( Y ang et al. , 2026 ; Boiko et al. , 2023 ), earth science ( Feng et al. , 2025 ), and biology ( Swanson et al. , 2025 ; T ruhn et al. , 2026 ). Causality for Scientific Discov ery . There has been a long history for the discussions on how to understand world through observ ations ( Greenland et al. , 1999 ; Spirtes et al. , 2000a ; Pearl , 2009 ). One research line is causal discov ery for structured data, where algorithms are designed to learn directed acyclic graphs among the random v ariables as causal structure, including constrained-based methods ( Spirtes et al. , 1995 ; 2000a ), methods with constrained functional ( Shimizu et al. , 2006 ; Zhang & Hyv arinen , 2012 ; Hoyer et al. , 2008 ), non-stationarity ( Malinsky & Spirtes , 2019 ; Huang et al. , 2019 ; 2020 ; Liu & Kuang , 2023 ), the incorporation with multiple domain data ( Huang et al. , 2020 ; Y ang et al. , 2018 ; Brouillard et al. , 2020 ; Mooij et al. , 2020 ; Perry et al. , 2022 ), and handling latent v ariables with the pure children assumption ( Li et al. , 2025d ; Li & Liu , 2025 ). Recently , there are works to inte grating causality with lar ge language models. One direction is to empo wer the causal methods with the kno wledge of LLMs, which includes constructing priors based on v ariable descriptions ( Long et al. , 2023 ; Li et al. , 2024c ), adjusting the causal structure searching process ( Ban et al. , 2023 ; V ashishtha et al. , 2023 ; Jiralerspong et al. , 2024 ), constructing structured variables out of unstructured data ( Liu et al. , 2025 ; Li et al. , 2025a ), and finding valid adjustment sets for treatment effect estimation ( Dhawan et al. , 2024 ; Liu et al. , 2025 ; Sheth et al. ). Another direction is to empower LLM-based agent with causal tools for tabular data analysis ( Abdulaal et al. , 2023 ; Khatibi et al. , 2024 ; Shen et al. , 2024 ; W ang et al. , 2025a ; V erma et al. , 2025 ), rev ealing insights from data in an autonomous pipeline. 3 S C I E N T I FI C D I S C O V E RY V I A O B J E C T I V E O P T I M I Z A T I O N 3 . 1 F O R M U L AT I O N O F S C I E N T I FI C D I S C OV E RY Scientific discov ery aims to uncover the underlying scientific knowledge or the causal mechanisms from interactions with the world ( Kuhn & Hawkins , 1963 ), which can be formulated as a P artially Observed Markov Decision Process (POMDP) ( Kaelbling et al. , 1998 ). Scientific knowledge. The primary objecti ve of an AI Scientist is to uncov er the underlying scientific knowledge about the task-world, represented by a latent v ariable Θ sci ∈ Θ , where Θ may encode causal structure, mechanisms, inductiv e biases, constraints, etc. Specifically , Θ sci = θ sci can be parameterized as a Structural Causal Model (SCM) θ sci = ( G , F , P U ) ( Spirtes et al. , 2000a ), where G = ( V , E ) is a directed graph whose nodes V represent variables of interest and whose edges E encode direct causal dependencies; F = { f v } v ∈ V is a collection of structural equations v = f v (P a( v ) , u v ) , where P a( v ) denotes the parents of v in G and u v is an exogenous noise v ariable; P U is a distribution o ver the exogenous v ariables U = { u v } v ∈ V . POMDP process. Given θ sci , as shown in Fig. 1 , the AI Scientist agent, implemented via the e volutionary coding framework such as AlphaEvolve ( Noviko v et al. , 2025 ), will interact with the environment by proposing candidate programs p t ∈ P (at turn t ) to g ain observations, y t = F ( p t , θ sci ) , where F : P × Θ → R is the objecti ve that the agent aims to optimize. Then, the scientific discovery process can be formulated as a POMDP M = ( S, A, Ω , T , O , R, γ ) with a static hidden parameter as θ sci of the underlying scientific 3 Preprint The AI Scientist Agent Scratchpad Memory ( m t → m t +1 ) ”Integrate evidence” Propose Candidate Program ( p t ) ”T r iggers e xper iment” Observe Outcome ( y t ) ”Yielding outcome” θ sci Guide Execute Provide Evidence m t +1 p t +1 y t +1 m t p t y t m t +2 p t +2 y t +2 θ sci t t + 1 t + 2 · · · · · · Figure 1: The iterative scientific disco very loop. Left: Conceptual flow of the agent. The agent maintains a scratchpad memory ( m ), proposes a program ( p ), and observes the outcome ( y ) which is constrained by the unknown w orld state ( θ sci ). The outcome feeds back into the memory for the next step. Right: The diagram illustrates ho w the AI Scientist probes the unkno wn world state θ sci . By proposing a candidate program p t , the agent triggers an experiment yielding outcome y t . This observ ation provides evidence about θ sci , which is integrated into the agent’ s scratchpad memory m t +1 . Over time steps t, t + 1 , . . . , this recurrent process allows the agent to navig ate the performance landscape and con verge to wards optimal programs despite the static but unkno wn nature of θ sci . knowledge. The hidden state s t = θ sci is the scientific kno wledge θ sci that does not change ov er turns. The action is a t = p t representing the choice of which program to ev aluate. The observ ation o t = y t is the ev aluation outcome. The transition kernel T can be simply considered as identity , and the observation kernel is O ( o t | s t , a t ) = P ( y t | θ sci , p t ) . Gi ven a finite experiment b udget T , the agent chooses p 0 , . . . , p T − 1 and gain observ ations y 0 , . . . , y T − 1 , so as to find ˆ p = arg max p F ( p, θ sci ) and the scientific knowledge θ sci . Evaluation as interv ention on SCM. Gi ven the SCM parametrization of θ sci , we can consider that a program p ∈ P is encoded as a particular configuration of design variables X = x p . Then, F can be implemented as F ( p ; θ sci ) := E Y do( X = x p ) , θ sci , (1) i.e., the expected outcome under the intervention do( X = x p ) in the true causal model θ sci . T ypical implementations of F can be the objectiv e value of a combinatorial optimization problem, the efficienc y of a kernel program, or the performance of a machine learning model ( Novik ov et al. , 2025 ). Belief as a probability distrib ution ov er Θ . W e define b t as the agent’ s Bayesian belief after history h t = { ( p 0 , y 0 ) , . . . , ( p t − 1 , y t − 1 ) } , i.e. a probability distribution on Θ : b t ( B ) = Pr(Θ sci ∈ B | h t , e ) , B ⊆ Θ . (2) In the ideal Bayesian formalism, the belief b t ( θ ) is a sufficient statistic for decision-making ( Kaelbling et al. , 1998 ). In practice, the AI Scientist maintains an internal belief, which is usually implemented as memory m t = Φ( h t ) for some (possibly learnable) summarization function Φ ( Lange et al. , 2025a ), to represent the appr oximate r epr esentation of its kno wledge about θ sci and the landscape of F ( · ; θ sci ) . Each e valuation step ( p t , y t ) thus updates m t , which in turn updates the agent’ s effecti ve belief about θ sci . In this sense, each step r eveals part of the underlying scientific knowledge , which in turn determines the next action p t +1 . 4 Preprint 3 . 2 E S S E N T I A L I T Y O F C AU S A L K N OW L E D G E F O R A I S C I E N T I S T S If the objecti ve function F is static uni versally , then with more experiment turns, the optimized solution p t and the agent’ s rev ealed scientific kno wledge can also be applied universally . Howe ver , the observation from the ev aluation is usually only giv en by a proxy knowledge θ e about the scientific knowledge Θ sci at some specific en vironment e ∈ E . F or example, the performance of a machine learning model is usually assessed on finite samples from the test distribution, and there also exist distribution shifts from the test distribution when deploying the model in the real world ( Quinonero-Candela et al. , 2008 ). Different from Θ sci that characterizes the complete causal structure about the scientific problem, optimization under en vironment θ e may introduce some spurious correlations that maximize the objectiv e value F e ( Chen et al. , 2023 ). Therefore, without loss of generality , to retain the optimality of ˆ p beyond the source en vironment e src to some target e tgt , it is essential to rev eal the causal knowledge and answer causal questions for an AI Scientist. Definition 3.1 (Causal AI Scientist) . A Causal AI Scientist is an ag ent specified by: (i) a policy π t ( · | θ t , e src ) selecting p t , (ii) a counterfactual / e xplanatory operator CF , that answer interventional queries ( e, p ) via CF( θ t ; e, p ) as an “e xplanation” of predicted performance , where θ t is the knowledge r evealed at turn t . W ithout the revealing of the causal knowledge, the disco very process suffers from significant inefficienc y and suboptimality issues. W e discuss the two issues more concretely below . Evolutionary efficiency of Causal AI Scientist. W e begin by considering a static en vironment and finite P = { p 1 , . . . , p K } . For θ sci , we assume each program p has a kno wn feature vector x p ∈ R d with ∥ x p ∥ 2 ≤ 1 , and the unknown scientific parameter is a weight vector w ⋆ ∈ R d and F ( p ) = ⟨ x p , w ⋆ ⟩ . Each evaluation returns a noisy observation y t = F ( p t ) + ε t where ε t ∼ N (0 , σ 2 ) i.i.d. . A Causal AI Scientist in this en vironment can be implemented via estimating the w ⋆ and optimizing for ˆ p from the history . In addition, we also consider a black-box baseline that does not consider the interactions between the historical observations. It can be characterized as the following θ bb := n µ : P → R o where each program has an unrelated unknown mean F ( p ; µ ) = µ ( p ) , and y t = µ ( p t ) + ε t , where ε t is the same Gaussian noise. Theorem 3.2 (Informal) . Under the given en vir onment, ther e e xists a policy π causal such that with pr obability at least 1 − δ , F ( ˆ p ; θ sci ) obtains less than 2 ϵ err or than the optimal value, with O ( d log ( K )) turns; In contrast, the blac k-box baseline needs O ( K ) . The formal description of the sample ef ficiency issue and the proof are gi ven in Appendix B . Theorem 3.2 shows that, when K ≫ d , which is usually the case as the space for all programs is significantly lar ger than the underlying SCM, encoding (correct) causal structure yields an exponential (or at least multiplicati ve) gain in sample efficienc y under finite budgets. Generalizability of Causal AI Scientist. T o show the necessity of capturing θ sci , we hav e the following: Theorem 3.3. Consider the e src , e tgt ∈ E and θ 0 , θ 1 ∈ Θ such that F e src ( · | p, θ 0 ) = F e src ( · | p, θ 1 ) ∀ p ∈ P , and ∃ p, p ′ ∈ P s.t. F e tgt ( p ; θ 0 ) − F e tgt ( p ′ ; θ 0 ) ≥ ∆ and F e tgt ( p ′ ; θ 1 ) − F e tgt ( p ; θ 1 ) ≥ ∆ , for some ∆ > 0 , then for any policy π that can inter act only with e src , ther e exists i ∈ { 0 , 1 } such that for e very budget T , max p ∈P F e tgt ( p ; θ i ) − F e tgt ( ˆ p ; θ i ) ≥ ∆ / 2 . The formal description of the generalizability issue and the proof are gi ven in Appendix C . Intuitively , Theorem 3.3 imply that if the source en vironment does not distinguish the corresponding θ sci among { θ 0 , θ 1 } , then the solution ˆ p solved gi ven source en vironment is always suboptimal. In the real world, it is usually the case that two machine learning models will hav e similar performances under the public test benchmarks, but exhibit significantly dif ferent behaviors when generalizing to distrib utions from other en vironments. 5 Preprint 4 C AU S A L S C R A T C H PA D F O R E V O L U T I O N A RY C O D I N G A G E N T Giv en the limitations shown in Sec. 3.2 , it is essential to explicitly incorporate the causal knowledge into the ev olutionary process. Hence, we present CausalEvolve , which incorporates a causal scratchpad to identify critical factors and e xploit their causal relations with the objecti ve variables to guide the e volution process. Specifically , we consider incorporating the outcome-lev el factors and the procedure-lev el factors to tackle the efficienc y and the suboptimality issues, respectiv ely . 4 . 1 O U T C O M E - L E V E L F A C T O R Essentially , the underlying configurations of the program can be reflected and recognized from task-dependent, real-valued descriptors extracted from the observable outcomes of program ex ecution. As shown in Theo- rem 3.2 , intervening on the underlying configuration variables provides significantly higher sample ef ficiency . F actor construction. For a gi ven task, a set of outcome-based factors m := ( m 1 , m 2 , . . . , m K ) is specified by LLMs before the e volution. An LLM would be prompted with the basic task description, which is the same as the system prompt used in e volution, and the expected output of each program, e.g., a list of coordinates, or an n × n matrix. For each of the outcome-based factors, the LLM would define the factor name and also a excitable code that maps the program output to the factor value. W e list the outcome-based factors used in our tasks in Appendix D . Causal Planner with outcome-level factors. With outcome-based f actors m , we develop CausalPlanner . Specifically , we define the action space A := ∪ m ∈ m ( m, +1) , ( m, − 1) . When applying an action ( m, d ) , the existing programs would be sorted in descending order according to m × d , and then the inspiration programs would be selected from the top of them. In t -th generation, after generating each child program from its parent and the inspiration programs with action a ∈ A , the rew ard R a could be calculated. Let the y c be the child’ s main target that is to be maximized, and v t be the best-so-far value of the main target. W e define the re ward as R a := ( y c − τ · v t ) + , where τ ∈ (0 , 1) . W e introduce this discounter τ because improving the best-so-f ar result could be a rare ev ent, and therefore cannot be fairly estimated by only a fe w iterations. In practice, we alternate between exploration and exploitation: random actions are taken for K iterations, follo wed by choosing the currently best action for the next K iterations. 4 . 2 P R O C E D U R E - L E V E L F A C T O R S T o better capture important designs of the programs and uncover their associated causal kno wledge, we also introduce procedure-lev el factors identified from the programs. Factor construction. W e construct the procedure-le vel factors based on the COAT framew ork ( Liu et al. , 2025 ) that le verages LLMs to identify useful procedure factors from unstructured data. As LLMs are considered incapable of understanding causality , Liu et al. ( 2025 ) constructs feedback to regularize the identified factors by LLMs. Similarly , we prompt LLMs to identify factors that explain the performance differences of the performances of dif ferent programs. Then, CausalEvolve estimates an approximated av erage treatment ef fect of dif ferent factors with respect to the target objecti ve v alue to pro vide a holistic view of the usefulness of the identified procedure-le vel factors. Due to the limited sample size and the existence of hidden confounders, the estimated treatment effects may contain biases, while empirically , we do not need an accurate estimation, but order -preserved quantities to provide insights. Abductive reasoning . As mainly explaining the performance dif ferences is insufficient for re vealing all factors, we also incorporate a surprise detection module and le verage LLMs to perform abducti ve reasoning 6 Preprint on the potentially existing factors and hypotheses that explain the surprise patterns ( Douven , 2025 ). The detection of surprise patterns relies on the estimated treatment ef fects. Since the estimation can contain biases, we focus on detecting significant shifts in the estimated effects, including the signal in verses, i.e., a positively correlated factor produces neg ativ e effects, and significant quantity shifts, i.e., a minor correlated factor produces negati ve ef fects. By explaining the surprise patterns, we are able to find the underlying confounder and better rev eal the underlying θ sci . 5 E X P E R I M E N T S 5 . 1 E X P E R I M E N TA L S E T T I N G Baselines. W e mainly compare CausalEvolve with the state-of-the-art ev olve-based agent ShinkaEvolve ( Lange et al. , 2025a ) that produces the best or competitiv e results as AlphaEvolve ( Noviko v et al. , 2025 ) in an sample-efficient manner . As ShinkaEvolve also in- corporates a memory module to summarize the insights from h t , we also consider tw o additional v ariants, CausalPlanner with meta summary module from ShinkaEvolve , and COAT , to ablate the ef fects of two modules in CausalEvolve . For the LLMs, we fix to using Grok-4.1-fast-reasoning ( xAI , 2025 ) for fair comparisons. T asks. W e e valuate our frame work on four scientific discov ery tasks that require optimizing code for dif ferent objectiv es: Hadamard Matrix ( n = 29 ). The goal is to construct an n × n matrix H with entries in {± 1 } that maximizes the absolute determinant | det( H ) | . F or n = 29 , the best-kno wn solution achie ves | det( H ) | = 2 28 · 7 12 · 320 , which we use to normalize scores to [0 , 1] for comparability with prior work ( W ang et al. , 2025b ). This discrete optimization problem requires balancing matrix properties including row orthogonality , element balance, and determinant magnitude. Second A utocorrelation Inequality . W e seek a step function f : [ − 1 , 1] → R ≥ 0 (discretized into n = 256 steps) that minimizes the ratio R ( f ) = ∥ f ∗ f ∥ 2 2 ∥ f ∗ f ∥ 1 ∥ f ∗ f ∥ ∞ , where f ∗ f denotes linear autocon volution. The optimal value R ( f ) ≥ 1 . 1547 . . . remains an open conjecture. This continuous optimization task requires carefully shaping the function’ s smoothness, concentration, and sparsity . Circle Packing ( N = 26 ). The objectiv e is to place N circles with radii r i and centers C i = ( x i , y i ) in a unit square [0 , 1] 2 such that: (i) no circles ov erlap ( ∥ C i − C j ∥ ≥ r i + r j for all i = j ), (ii) all circles remain within the square ( r i ≤ C x i , C y i ≤ 1 − r i ), and (iii) the sum of radii P i r i is maximized. This geometric optimization task requires spatial reasoning about density , distribution, and boundary constraints. AIME Mathematical Pr oblem Solving. W e e valuate on the 2024 American In vitational Mathematics Examination (AIME), a challenging competition consisting of 15 problems requiring integer answers in [000 , 999] . The task is to build an LLM-based agent that solv es these problems efficiently . Performance is measured by accuracy , while auxiliary metrics track format compliance (e.g., \ boxed {} format), cost efficienc y , and stability across problems. Evaluation metrics. W e run every method using 3 random seeds ( 1 , 2 , 3 ) to accommodate the randomness. T o compare the efficiency and the optimality , we inspect the stepwise av eraged results as well as the best result from the 3 runs, at 4 intermediate steps. Gi ven the difficulty of different tasks, we inspect steps 50 , 100 , 150 , 200 for Second Autocorrelation Inequality and Circle Packing, steps 20 , 40 , 80 , 100 for Hadamard Matrix, and steps 20 , 40 , 60 , 80 for AIME agent. 7 Preprint T able 1: Main results across f our scientific discovery tasks. Performance is reported at training steps 1 through 4. F or each step, we report the mean performance (Mean) and the best-so-far value (Best). All tasks are maximization objectiv es. T ask Method Grok-4.1-FR Step 1 Step 2 Step 3 Step 4 Mean Best Mean Best Mean Best Mean Best Hadamard Matrix ( ↑ ) ShinkaEvolve 0.495 0.533 0.521 0.540 0.521 0.540 0.521 0.540 CausalPlanner (Meta) 0.556 0.573 0.567 0.573 0.567 0.573 0.567 0.573 COAT 0.503 0.519 0.514 0.543 0.521 0.552 0.532 0.561 CausalEvolve 0.542 0.574 0.550 0.574 0.563 0.576 0.568 0.576 Second A utocorr . Inequality ( ↑ ) ShinkaEvolve 0.723 0.724 0.729 0.739 0.735 0.749 0.737 0.751 CausalPlanner (Meta) 0.730 0.745 0.734 0.749 0.735 0.750 0.736 0.750 COAT 0.753 0.770 0.771 0.783 0.773 0.783 0.783 0.786 CausalEvolve 0.781 0.800 0.783 0.805 0.790 0.809 0.793 0.809 Circle Packing ( ↑ ) ShinkaEvolve 2.342 2.431 2.342 2.431 2.400 2.435 2.479 2.500 CausalPlanner (Meta) 2.348 2.541 2.358 2.541 2.456 2.541 2.456 2.541 COAT 2.183 2.261 2.238 2.292 2.436 2.560 2.456 2.568 CausalEvolve 2.106 2.295 2.216 2.370 2.385 2.516 2.476 2.564 AIME Agent ( ↑ ) ShinkaEvolve 33.33 33.33 34.44 36.67 34.44 36.67 34.44 36.67 CausalPlanner (Meta) 34.44 36.67 35.56 36.67 36.67 40.00 36.67 40.00 COAT 37.78 43.33 37.78 43.33 37.78 43.33 38.89 43.33 CausalEvolve 33.33 36.67 38.89 40.00 38.89 40.00 38.89 40.00 5 . 2 E X P E R I M E N TA L R E S U LT S The results of the experiments are giv en in T able 1 . From the results, we can find that across all tasks, CausalEvolve produce significantly better av eraged results than ShinkaEvolve across different tasks and steps, demonstrating the effecti veness of CausalEvolve . Notably , in AIME, CausalEvolve achiev es 38 . 89% results based on the same scaf folding agent as in ShinkaEvolve . While in the orig- inal paper of ShinkaEvolve , ev en with a more sophisticated ensemble of multiple frontier reasoning models, ShinkaEvolve can only achiev e a performance of 34 . 4% , demonstrating the effecti veness of CausalEvolve in breaking the state-of-the-art results in the open-ended discov ery . When comparing dif ferent variants and CausalEvolve , we can find that, across 4 tasks, CausalEvolve maintain the overall best performances, verifying that each module is essential to the success of CausalEvolve . Interestingly , in the majority of tasks, COAT can already produce an impressi ve best result, demonstrating the ef fectiveness of procedure-le vel factors for optimality . When comparing results with and without CausalPlanner , we can also find that with CausalPlanner , we can achieve better results already at early steps, demonstrating the effecti veness of outcome-based factors in sample ef ficiency . 6 C O N C L U S I O N S In this work, we studied the ev olutionary coding agent for scientific discovery . W ith the POMDP formulation of the discovery process, we demonstrate the necessity of incorporating causal knowledge. Then, we propose CausalEvolve that uses a causal scratchpad to identify and e xploit outcome-based and procedure-based factors and the associated causal kno wledge to guide the e volution process. Empirical results with 4 discov ery tasks verified the impro ved efficienc y and optimality of CausalEvolve . 8 Preprint A C K N O W L E D G M E N T S W e thank the revie wers for their constructiv e comments and suggestions. R E F E R E N C E S Ahmed Abdulaal, Nina Montana-Bro wn, Tiantian He, A yodeji Ijishakin, Iv ana Drobnjak, Daniel C Castro, Daniel C Alexander , et al. Causal modelling agents: Causal graph discov ery through synergising metadata- and data-dri ven reasoning. In The T welfth International Conference on Learning Repr esentations , 2023. (Cited on page 3 ) T aiyu Ban, L yuzhou Chen, Derui L yu, Xiangyu W ang, and Huanhuan Chen. Causal structure learning supervised by large language model. arXiv preprint , 2023. (Cited on page 3 ) Daniil A Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models. Natur e , 624(7992):570–578, 2023. (Cited on page 3 ) Philippe Brouillard, S ´ ebastien Lachapelle, Alexandre Lacoste, Simon Lacoste-Julien, and Alexandre Drouin. Differentiable causal discovery from interventional data. Advances in Neural Information Pr ocessing Systems , 33:21865–21877, 2020. (Cited on page 3 ) S ´ ebastien Bubeck, Christian Coester, Ronen Eldan, Timothy Gowers, Y in T at Lee, Alexandru Lupsasca, Mehtaab Sawhne y , Robert Scherrer , Mark Sellke, Brian K. Spears, Derya Unutmaz, K evin W eil, Steven Y in, and Nikita Zhi votovskiy . Early science acceleration experiments with gpt-5. ArXiv , abs/2511.16072, 2025. (Cited on page 1 ) Jun Shern Chan, Neil Chowdhury , Oliv er Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Ke vin Liu, Leon Maksin, T ejal Patwardhan, Lilian W eng, and Aleksander Madry . Mle-bench: Evaluating machine learning agents on machine learning engineering. 2024. URL 2410.07095 . (Cited on page 1 ) Y ongqiang Chen, W ei Huang, Kaiwen Zhou, Y atao Bian, Bo Han, and James Cheng. Understanding and improving feature learning for out-of-distrib ution generalization. In Advances in Neural Information Pr ocessing Systems , 2023. (Cited on page 5 ) Audrey Cheng, Shu Liu, Melissa Z. Pan, Zhifei Li, Bowen W ang, Alexander Krentsel, Tian Xia, Mert Cemri, Jongseok Park, Shuo Y ang, Jeff Chen, Lakshya A Agrawal, Aditya Desai, Jiarong Xing, Koushik Sen, Matei Zaharia, and Ion Stoica. Barbarians at the gate: How ai is upending systems research. ArXiv , abs/2510.06189, 2025. (Cited on page 1 ) Nikita Dhawan, Leonardo Cotta, Karen Ullrich, Rahul G Krishnan, and Chris J Maddison. End-to-end causal effect estimation from unstructured natural language data. Advances in Neural Information Pr ocessing Systems , 37:77165–77199, 2024. (Cited on page 3 ) Igor Douven. Abduction. In Edward N. Zalta and Uri Nodelman (eds.), The Stanfor d Encyclopedia of Philosophy . Metaphysics Research Lab, Stanford Univ ersity , Winter 2025 edition, 2025. (Cited on pages 2 and 7 ) Peilin Feng, Zhutao Lv , Junyan Y e, Xiaolei W ang, Xinjie Huo, Jinhua Y u, W anghan Xu, W enlong Zhang, Lei Bai, Conghui He, et al. Earth-agent: Unlocking the full landscape of earth observation with agents. arXiv pr eprint arXiv:2509.23141 , 2025. (Cited on page 3 ) Bogdan Georgie v , Javier G’omez-Serrano, T erence T ao, and Adam Zsolt W agner . Mathematical exploration and discov ery at scale. ArXiv , abs/2511.02864, 2025. (Cited on page 1 ) 9 Preprint Clark Glymour . An outline of the history of methods of discov ering causal- ity . URL https://www.cmu.edu/dietrich/philosophy/docs/glymour/ an- outline- of- the- history- of- methods- of- discovering- causality.pdf . Accessed: 2026-01-29. (Cited on page 2 ) Juraj Gottweis, W ei-Hung W eng, Alexander Daryin, T ao T u, Anil P alepu, Petar Sirk ovic, Artiom Myask ovsky , Felix W eissenberger , K eran Rong, Ryutaro T anno, et al. T owards an ai co-scientist. arXiv pr eprint arXiv:2502.18864 , 2025. (Cited on pages 1 and 2 ) Sander Greenland, Judea Pearl, and James M Robins. Causal diagrams for epidemiologic research. Epidemi- ology , 10(1):37–48, 1999. (Cited on page 3 ) Daya Guo, Dejian Y ang, Haowei Zhang, Junxiao Song, Ruo yu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi W ang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv pr eprint arXiv:2501.12948 , 2025. (Cited on page 1 ) Patrik Hoyer , Dominik Janzing, Joris M Mooij, Jonas Peters, and Bernhard Sch ¨ olkopf. Nonlinear causal discov ery with additi ve noise models. Advances in neural information pr ocessing systems , 21, 2008. (Cited on page 3 ) Biwei Huang, Kun Zhang, Mingming Gong, and Clark Glymour . Causal discov ery and forecasting in nonstationary en vironments with state-space models. In International confer ence on machine learning , pp. 2901–2910. Pmlr , 2019. (Cited on page 3 ) Biwei Huang, Kun Zhang, Jiji Zhang, Joseph Ramsey , Ruben Sanchez-Romero, Clark Glymour, and Bernhard Sch ¨ olkopf. Causal discov ery from heterogeneous/nonstationary data. Journal of Machine Learning Resear ch , 21(89):1–53, 2020. (Cited on page 3 ) K exin Huang, Y ing Jin, Ryan Li, Michael Y Li, Emmanuel Candes, and Jure Lesko vec. Automated hypothesis validation with agentic sequential f alsifications. In ICML , 2025a. (Cited on page 3 ) Y uxuan Huang, Y ihang Chen, Haozheng Zhang, Kang Li, Huichi Zhou, Meng Fang, Lin yi Y ang, Xiaoguang Li, Lifeng Shang, Songcen Xu, et al. Deep research agents: A systematic examination and roadmap. arXiv pr eprint arXiv:2506.18096 , 2025b. (Cited on page 3 ) Krittanut Jiralerspong et al. Ef ficient causal graph discovery using large language models. arXiv pr eprint arXiv:2402.01207 , 2024. (Cited on page 3 ) Leslie Pack Kaelbling, Michael L Littman, and Anthony R Cassandra. Planning and acting in partially observable stochastic domains. Artificial intelligence , 101(1-2):99–134, 1998. (Cited on pages 2 , 3 and 4 ) Elahe Khatibi, Mahyar Abbasian, Zhongqi Y ang, Iman Azimi, and Amir M Rahmani. Alcm: Autonomous llm-augmented causal discov ery framework. arXiv preprint , 2024. (Cited on page 3 ) Ilyes Khemakhem, Ricardo Monti, Diederik Kingma, and Aapo Hyv arinen. Ice-beem: Identifiable conditional energy-based deep models based on nonlinear ica. Confer ence and W orkshop on Neural Information Pr ocessing Systems , 33:12768–12778, 2020. (Cited on page 1 ) Thomas S. Kuhn and Da vid Hawkins. The structure of scientific re volutions. American Journal of Physics , 31:554–555, 1963. (Cited on pages 2 and 3 ) Robert Lange et al. T ow ards open-ended and sample-efficient program e volution. arXiv pr eprint arXiv:2509.19349 , 2025a. (Cited on pages 3 , 4 and 7 ) 10 Preprint Robert Tjarko Lange, Y uki Imajuku, and Edoardo Cetin. Shinkaev olve: T owards open-ended and sample- efficient program e volution. ArXiv , abs/2509.19349, 2025b. (Cited on pages 1 and 2 ) Hongxin Li, Jingran Su, Y untao Chen, Qing Li, and Zhao-Xiang Zhang. Sheetcopilot: Bringing software productivity to the ne xt level through lar ge language models. Advances in Neural Information Pr ocessing Systems , 36:4952–4984, 2023. (Cited on page 3 ) Jin Li, Shoujin W ang, Qi Zhang, Feng Liu, T ongliang Liu, Longbing Cao, Shui Y u, and F ang Chen. Re vealing multimodal causality with lar ge language models. In The Thirty-ninth Annual Conference on Neural Information Pr ocessing Systems , 2025a. (Cited on page 3 ) Jinyang Li, Nan Huo, Y an Gao, Jiayi Shi, Y ingxiu Zhao, Ge Qu, Bowen Qin, Y urong W u, Xiaodong Li, Chenhao Ma, et al. Are large language models ready for multi-turn tabular data analysis? In F orty-second International Confer ence on Machine Learning , 2025b. (Cited on page 3 ) Junyi Li, Y ongqiang Chen, Chenxi Liu, Qianyi Cai, T ongliang Liu, Bo Han, Kun Zhang, and Hui Xiong. Can large language models help experimental design for causal discov ery? ArXiv , abs/2503.01139, 2025c. URL . (Cited on page 1 ) Long Li, W eiwen Xu, Jiayan Guo, Ruochen Zhao, Xingxuan Li, Y uqian Y uan, Boqiang Zhang, Y uming Jiang, Y ifei Xin, Ronghao Dang, et al. Chain of ideas: Re volutionizing research via novel idea de velopment with llm agents. arXiv pr eprint arXiv:2410.13185 , 2024a. (Cited on page 3 ) Michael Y Li, V iv ek V ajipey , Noah D Goodman, and Emily B Fox. Critical: Critic automation with language models. arXiv pr eprint arXiv:2411.06590 , 2024b. (Cited on page 3 ) Peiwen Li, Xin W ang, Zeyang Zhang, Y uan Meng, F ang Shen, Y ue Li, Jialong W ang, Y ang Li, and W enwu Zhu. Realtcd: T emporal causal disco very from interventional data with large language model. In Pr oceedings of the 33r d A CM International Conference on Information and Knowledge Mana gement , pp. 4669–4677, 2024c. (Cited on page 3 ) Xiu-Chuan Li and T ongliang Liu. Efficient and trustworth y causal disco very with latent v ariables and complex relations. In The Thirteenth International Confer ence on Learning Repr esentations , 2025. (Cited on page 3 ) Xiu-Chuan Li, Jun W ang, and T ongliang Liu. Recov ery of causal graph in volving latent variables via homologous surrogates. In The Thirteenth International Confer ence on Learning Representations , 2025d. (Cited on page 3 ) Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Y uxuan Y ao, Haotian Xu, Junhao Zheng, Pei-Jie W ang, Xiuyi Chen, et al. From system 1 to system 2: A surve y of reasoning large language models. arXiv pr eprint arXiv:2502.17419 , 2025e. (Cited on page 1 ) W eixin Liang, Y uhui Zhang, Hancheng Cao, Binglu W ang, Daisy Y i Ding, Xinyu Y ang, Kailas V odrahalli, Siyu He, Daniel Scott Smith, Y ian Y in, et al. Can large language models provide useful feedback on research papers? a lar ge-scale empirical analysis. NEJM AI , 1(8):AIoa2400196, 2024. (Cited on page 3 ) Chenxi Liu and Kun K uang. Causal structure learning for latent intervened non-stationary data. In Interna- tional Confer ence on Machine Learning , pp. 21756–21777. PMLR, 2023. (Cited on page 3 ) Chenxi Liu, Y ongqiang Chen, T ongliang Liu, Mingming Gong, James Cheng, Bo Han, and Kun Zhang. Discov ery of the hidden world with lar ge language models. In A. Glober- son, L. Mackey , D. Belgrav e, A. Fan, U. Paquet, J. T omczak, and C. Zhang (eds.), Advances in Neural Information Pr ocessing Systems , volume 37, pp. 102307–102365. Curran Associates, Inc., 2024. URL https://proceedings.neurips.cc/paper_files/paper/2024/file/ b99a07486702417d3b1bd64ec2cf74ad- Paper- Conference.pdf . (Cited on page 2 ) 11 Preprint Chenxi Liu, Y ongqiang Chen, T ongliang Liu, Mingming Gong, James Cheng, Bo Han, and Kun Zhang. Discov ering and reasoning of causality in the hidden world with large language models, 2025. URL https://arxiv.org/abs/2402.03941 . (Cited on pages 3 and 6 ) Stephanie Long, Alexandre Pich ´ e, V alentina Zantedeschi, T ibor Schuster , and Alexandre Drouin. Causal discov ery with language models as imperfect experts. arXiv preprint , 2023. (Cited on page 3 ) Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob F oerster, Jef f Clune, and Da vid Ha. The ai scientist: T owards fully automated open-ended scientific discovery . arXiv pr eprint arXiv:2408.06292 , 2024. (Cited on pages 1 and 2 ) Daniel Malinsky and Peter Spirtes. Learning the structure of a nonstationary vector autoregression. In The 22nd International Confer ence on Artificial Intelligence and Statistics , pp. 2986–2994. PMLR, 2019. (Cited on page 3 ) Shubham Mandal et al. Artificially intelligent lab assistant for automated experimentation. Nature Communi- cations , 16:1234, 2025. (Cited on page 3 ) Ludovico Mitchener, Angela Y iu, Benjamin Chang, Mathieu Bourdenx, T yler Nadolski, Arvis Sulovari, Eric C. Landsness, D ´ aniel L. Barab ´ asi, Siddharth Narayanan, Nick y Ev ans, Shriya Reddy , Martha S. F oiani, Aizad Kamal, Leah P . Shri ver , Fang Cao, Asmama w T . W assie, Jon M. Laurent, Edwin Melville-Green, Mayk Caldas Ramos, Albert Bou, Kaleigh F . Roberts, Sladjana Zagorac, T imothy C. Orr , Miranda E. Orr , Ke vin J. Zwezdaryk, Ali E. Ghareeb, Laurie McCoy , Bruna Gomes, Euan A Ashley , Karen E. Duff, T onio Buonassisi, T om Rainforth, Randall J. Bateman, Michael Skarlinski, Samuel G. Rodriques, Michaela M. Hinks, and Andrew D. White. K osmos: An ai scientist for autonomous discovery . ArXiv , abs/2511.02824, 2025. (Cited on page 1 ) Joris M Mooij, Sara Magliacane, and T om Claassen. Joint causal inference from multiple contexts. Journal of machine learning r esear ch , 21(99):1–108, 2020. (Cited on page 3 ) Alexander No vikov , Ng ˆ an V ˜ u, Marvin Eisenberger , Emilien Dupont, Po-Sen Huang, Adam Zsolt W agner, Serge y Shirobokov , Borislav K ozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphae volv e: A coding agent for scientific and algorithmic discov ery . arXiv pr eprint arXiv:2506.13131 , 2025. (Cited on pages 1 , 3 , 4 and 7 ) Judea Pearl. Causality . Cambridge uni versity press, 2009. (Cited on pages 2 and 3 ) Ronan Perry , Julius V on K ¨ ugelgen, and Bernhard Sch ¨ olkopf. Causal disco very in heterogeneous en vironments under the sparse mechanism shift hypothesis. Advances in Neural Information Pr ocessing Systems , 35: 10904–10917, 2022. (Cited on page 3 ) Aske Plaat, Max van Duijn, Niki van Stein, Mike Preuss, Peter van der Putten, and Kees Joost Batenbur g. Agentic large language models, a surv ey . arXiv preprint , 2025. (Cited on page 1 ) Joaquin Quinonero-Candela, Masashi Sugiyama, Anton Schwaighofer , and Neil D Lawrence. Dataset shift in machine learning . Mit Press, 2008. (Cited on page 5 ) Lo ¨ ıc M. Roch et al. Chemos: An orchestration software to democratize autonomous discov ery . PLOS ONE , 15(4):e0229862, 2020. (Cited on page 3 ) Bernardino Romera-P aredes et al. Mathematical disco veries from program search with lar ge language models. Natur e , 625:468–475, 2024. (Cited on page 3 ) 12 Preprint Asankhaya Sharma. Opene volve: an open-source ev olutionary coding agent, 2025. URL https:// github.com/algorithmicsuperintelligence/openevolve . (Cited on pages 1 and 3 ) C Shen, Zhengzhang Chen, Dongsheng Luo, Dongkuan Xu, Haifeng Chen, and Jingchao Ni. Exploring multi-modal integration with tool-augmented llm agents for precise causal disco very . arXiv pr eprint arXiv:2412.13667 , 1(3), 2024. (Cited on page 3 ) Ivaxi Sheth, Zhijing Jin, Bryan W ilder, Dominik Janzing, and Mario Fritz. Can llms propose instrumental v ariables for causal reasoning? In NeurIPS 2025 W orkshop on CauScien: Uncovering Causality in Science . (Cited on page 3 ) Shohei Shimizu, Patrik O Hoyer , Aapo Hyv ¨ arinen, Antti Kerminen, and Michael Jordan. A linear non- gaussian acyclic model for causal disco very . Journal of Machine Learning Resear ch , 7(10), 2006. (Cited on page 3 ) Parshin Shojaee et al. Scientific equation discov ery via programming with large language models. arXiv pr eprint arXiv:2404.18400 , 2025. (Cited on page 3 ) Peter Spirtes, Christopher Meek, and Thomas Richardson. Causal inference in the presence of latent v ariables and selection bias. In Pr oceedings of the Eleventh confer ence on Uncertainty in artificial intelligence , pp. 499–506, 1995. (Cited on page 3 ) Peter Spirtes, Clark N Glymour, and Richard Scheines. Causation, pr ediction, and searc h . MIT press, 2000a. (Cited on page 3 ) Peter Spirtes, Clark N Glymour, and Richard Scheines. Causation, prediction, and sear ch . MIT press, 2000b. (Cited on page 2 ) K yle Swanson, W esley W u, Nash L Bulaong, John E Pak, and James Zou. The virtual lab of ai agents designs new sars-co v-2 nanobodies. Natur e , 646(8085):716–723, 2025. (Cited on page 3 ) Gary T om, Stefan P Schmid, Sterling G Baird, Y ang Cao, K ourosh Darvish, Han Hao, Stanley Lo, Sergio Pablo-Garc ´ ıa, Ella M Rajaonson, Marta Skreta, et al. Self-driving laboratories for chemistry and materials science. Chemical Revie ws , 124(16):9633–9732, 2024. (Cited on page 3 ) Daniel T ruhn, Shekoofeh Azizi, James Zou, Leonor Cerda-Alberich, F aisal Mahmood, and Jak ob Nikolas Kather . Artificial intelligence agents in cancer research and oncology . Natur e Reviews Cancer , pp. 1–14, 2026. (Cited on page 3 ) Siddharth V ashishtha et al. Causal ordering as a robust interface for integrating e xpert knowledge. Advances in Neural Information Pr ocessing Systems , 2023. (Cited on page 3 ) V ishal V erma, Saw al Acharya, Dev ansh Bhardwaj, Samuel Simko, Y ongjin Y ang, Anahita Haghighat, Dominik Janzing, Mrinmaya Sachan, Bernhard Sch ¨ olkopf, and Zhijing Jin. Causal AI scientist: Facilitating causal data science with large language models. In NeurIPS 2025 W orkshop on CauScien: Uncovering Causality in Science , 2025. URL https://openreview.net/forum?id=EDWTHMVOCj . (Cited on page 3 ) W .A. W allace. Causality and Scientific Explanation . Number v . 2 in Causality and Scientific Explanation. Univ ersity Press of America, 1981. ISBN 9780819114815. (Cited on page 2 ) Haiyuan W an, Chen Y ang, Junchi Y u, Meiqi Tu, Jiaxuan Lu, Di Y u, Jianbao Cao, Ben Gao, Jiaqing Xie, Aoran W ang, et al. Deepresearch arena: The first e xam of llms’ research abilities via seminar -grounded tasks. AAAI , 2026. (Cited on page 1 ) 13 Preprint Qingyun W ang, Doug Downe y , Heng Ji, and T om Hope. Scimon: Scientific inspiration machines optimized for nov elty . In Pr oceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pp. 279–299, 2024. (Cited on page 3 ) Xinyue W ang, Kun Zhou, W enyi W u, Har Simrat Singh, F ang Nan, Songyao Jin, Aryan Philip, Saloni Patnaik, Hou Zhu, Shiv am Singh, et al. Causal-copilot: An autonomous causal analysis agent. arXiv preprint arXiv:2504.13263 , 2025a. (Cited on page 3 ) Y iping W ang, Shao-Rong Su, Zhiyuan Zeng, Eva Xu, Liliang Ren, Xinyu Y ang, Zeyi Huang, Xuehai He, Luyao Ma, Baolin Peng, Hao Cheng, Pengcheng He, W eizhu Chen, Shuohang W ang, Simon Shaolei Du, and Y elong Shen. Thetae volve: T est-time learning on open problems. ArXiv , abs/2511.23473, 2025b. (Cited on page 7 ) David P . W oodruff, V incent Cohen-Addad, Lalit Jain, Jieming Mao, Song Zuo, Mohammad Rez Bateni, Simina Br ˆ anzei, Michael P . Brenner , Lin Chen, Y ing Feng, Lance Fortno w , Gang Fu, Ziyi Guan, Zahra Hadizadeh, Mohammad T aghi Hajiaghayi, Mahdi JafariRaviz, Adel Jav anmard, S. KarthikC., Ken ichi Kawarabayashi, Ravi K umar, Silvio Lattanzi, Euiwoong Lee, Y i Li, Ioannis Panageas, Dimitris P aparas, Benjamin Przybocki, Bernardo Subercaseaux, Ola Svensson, Shayan T aherijam, Xuan W u, Eylon Y ogev , Morteza Zadimoghaddam, Samson Zhou, and V ahab S. Mirrokni. Accelerating scientific research with gemini: Case studies and common techniques. ArXiv , abs/2602.03837, 2026. (Cited on page 1 ) xAI. Grok 4.1 fast and agent tools api, 2025. URL https://x.ai/news/grok- 4- 1- fast . Accessed: 2026-02-10. (Cited on page 7 ) Y utaro Y amada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster , Jeff Clune, and David Ha. The ai scientist-v2: W orkshop-le vel automated scientific discovery via agentic tree search. arXiv pr eprint arXiv:2504.08066 , 2025. (Cited on pages 1 and 2 ) Cheng Y ang, Jiaxuan Lu, Haiyuan W an, Junchi Y u, and Feiwei Qin. From what to wh y: A multi-agent system for evidence-based chemical reaction condition reasoning. ICLR , 2026. (Cited on page 3 ) Karren Y ang, Abigail Katcoff, and Caroline Uhler . Characterizing and learning equi valence classes of causal dags under interventions. In International Confer ence on Machine Learning , pp. 5541–5550. PMLR, 2018. (Cited on page 3 ) Zonglin Y ang, Xinya Du, Junxian Li, Jie Zheng, Soujan ya Poria, and Erik Cambria. Large language models for automated open-domain scientific hypotheses discov ery . In F indings of the Association for Computational Linguistics: A CL 2024 , pp. 13545–13565, 2024. (Cited on page 3 ) Zonglin Y ang, W anhao Liu, Ben Gao, T ong Xie, Y uqiang Li, W anli Ouyang, Soujanya Poria, Erik Cambria, and Dongzhan Zhou. Moose-chem: Large language models for rediscov ering unseen chemistry scientific hypotheses. In ICLR , 2025. (Cited on page 3 ) Liangyu Zha, Junlin Zhou, Liyao Li, Rui W ang, Qingyi Huang, Saisai Y ang, Jing Y uan, Changbao Su, Xiang Li, Aofeng Su, et al. T ablegpt: T owards unifying tables, nature language and commands into one gpt. arXiv pr eprint arXiv:2307.08674 , 2023. (Cited on page 3 ) Kun Zhang and Aapo Hyvarine n. On the identifiability of the post-nonlinear causal model. arXiv pr eprint arXiv:1205.2599 , 2012. (Cited on page 3 ) W enqi Zhang, Y ongliang Shen, W eiming Lu, and Y ueting Zhuang. Data-copilot: Bridging billions of data and humans with autonomous workflo w . arXiv pr eprint arXiv:2306.07209 , 2023. (Cited on page 3 ) 14 Preprint T ianshi ZHENG, Zheye Deng, Hong T ing Tsang, W eiqi W ang, Jiaxin Bai, Zihao W ang, and Y angqiu Song. From automation to autonomy: A survey on large language models in scientific discov ery . ArXiv , abs/2505.13259, 2025. (Cited on page 1 ) Qing Zhu, Fei Zhang, Y an Huang, Hengyu Xiao, LuY uan Zhao, XuChun Zhang, T ao Song, XinSheng T ang, Xiang Li, Guo He, et al. An all-round ai-chemist with a scientific mind. National Science Review , 9(10): nwac190, 2022. (Cited on page 3 ) 15 Preprint L L M U S E S TA T E M E N T From the research side, this work studies the use of LLMs for automated scientific discovery . From the paper writing side, we use LLMs to assist with improving the writing of this work. E T H I C S S TA T E M E N T W e study using LLMs to automate scientific discovery that will benefit the whole humanity and society . This work does not in volve human subjects or personally identifiable information beyond public benchmarks used under their licenses. A A D D I T I O N A L T E C H N I C A L D E TA I L S A . 1 N O TA T I O N T able 2: Notation used in the formulation and theorems. Symbol Meaning P Program / pipeline / model space (candidate designs) K Number of candidate programs, K := |P | (finite in Theorem 1) p ∈ P A program to ev aluate (action) X Design-v ariable space (encoding of programs) x p ∈ X Encoding of program p (e.g., design variables X = x p ) Θ Hypothesis space of scientific knowledge (e.g., SCMs / mechanisms) Θ sci Latent R V taking values in Θ (Bayesian vie w) θ ⋆ ∈ Θ True (fix ed but unknown) scientific kno wledge instance (realization) µ 0 Prior ov er Θ (i.e., Θ sci ∼ µ 0 ) E En vironment / protocol index set (ev aluation regimes, deployments) e ∈ E En vironment index; e src source, e tgt target F e ( p ; θ ) T rue performance in env e (scalar objecti ve) P e ( · | p, θ ) Observation model (lik elihood) for evaluator output in en v e y t Observed e valuator outcome at round t h t History { ( p 0 , y 0 ) , . . . , ( p t − 1 , y t − 1 ) } b t Bayesian belief/posterior ov er θ : b t ( · ) = Pr(Θ sci ∈ · | h t , e src ) T Evaluation b udget / horizon (number of program ev aluations) A . 2 R A N D O M V A R I A B L E , S PAC E , A N D R E A L I Z A T I O N ( T O A V O I D N O T AT I O N C O N F U S I O N ) W e use the following (standard) con vention. (i) Hypothesis space. Θ is a set that contains all candidate scientific-knowledge hypotheses. (ii) T rue but unknown instance. The real world is gov erned by a fixed but unkno wn θ ⋆ ∈ Θ . (iii) Bayesian view (optional but conv enient). A Bayesian agent models uncertainty by treating θ ⋆ as a realization of a latent random v ariable Θ sci with prior µ 0 , i.e. Θ sci ∼ µ 0 and θ ⋆ is one draw from it. The belief b t is simply the posterior distribution of Θ sci after seeing history h t . (iv) Does scientific knowledge change acr oss en vironments? In our formulation, the underlying scientific kno wledge θ ⋆ is static across rounds. Dif ferent en vironments e ∈ E represent dif ferent ev aluation/deployment protocols (distribution shifts, constraint changes, measurement noise, pri vate vs public tests, etc.). Formally , 16 Preprint The AI Scientist Agent Scratchpad Memory ( m t → m t +1 ) ”Integrate evidence” Propose Candidate Program ( p t ) ”T r iggers e xper iment” Observe Outcome ( y t ) ”Yielding outcome” θ sci Guide Execute Provide Evidence m t +1 p t +1 y t +1 m t p t y t m t +2 p t +2 y t +2 θ sci t t + 1 t + 2 · · · · · · Figure 2: The iterative scientific disco very loop. Left: Conceptual flow of the agent. The agent maintains a scratchpad memory ( m ), proposes a program ( p ), and observes the outcome ( y ) which is constrained by the unknown w orld state ( θ sci ). The outcome feeds back into the memory for the next step. Right: The diagram illustrates ho w the AI Scientist probes the unkno wn world state θ sci . By proposing a candidate program p t , the agent triggers an experiment yielding outcome y t . This observ ation provides evidence about θ sci , which is integrated into the agent’ s scratchpad memory m t +1 . Over time steps t, t + 1 , . . . , this recurrent process allows the agent to navig ate the performance landscape and con verge to wards optimal programs despite the static but unkno wn nature of θ sci . en vironments affect either the true performance map F e ( · ; θ ) and/or the observation kernel P e ( · | p, θ ) , while θ ⋆ itself remains the same hidden instance. A . 3 E V A L U A T O R A S A N O B S E RV ATI O N M O D E L ( C O V E R S D E T E R M I N I S T I C A N D S T O C H A S T I C E V A L U A T O R S ) Fix an en vironment e ∈ E . When the agent e valuates program p , it recei ves an observ ation y ∈ Y drawn from y ∼ P e ( · | p, θ ⋆ ) , where P e ( · | p, θ ) is a conditional distribution on Y . Deterministic evaluator . A deterministic ev aluator is the special case where there exists a function g e such that P e ( · | p, θ ) = δ g e ( p ; θ ) ( · ) , i.e., y = g e ( p ; θ ⋆ ) a.s. In many program-e volution settings, the e valuator is designed to deterministically check v alidity and compute an objectiv e score (e.g., via a verifier and a scoring routine). Stochastic/noisy evaluator . A common instantiation is additive noise: y = F e ( p ; θ ⋆ ) + ε, ε ∼ N (0 , σ 2 ) , but our proofs only rely on the specific Gaussian form in Theorem 1. 17 Preprint A . 4 B E L I E F A N D B AY E S U P D A T E : K E R N E L F O R M A N D U N D E R G R A D UAT E - F R I E N D LY S P E C I A L C A S E S Let h t = { ( p 0 , y 0 ) , . . . , ( p t − 1 , y t − 1 ) } be the history . The Bayesian belief (posterior) is b t ( B ) = Pr(Θ sci ∈ B | h t , e src ) , B ⊆ Θ . General Bayes update (ker nel form). After choosing p t and observing y t in e src , the posterior is b t +1 ( B ) = R B P e src ( dy t | p t , θ ) b t ( dθ ) R Θ P e src ( dy t | p t , θ ) b t ( dθ ) . (3) Finite hypothesis space (sum f orm). If Θ = { θ 1 , . . . , θ N } is finite and the likelihood has a pmf P e src ( y t | p t , θ i ) , then b t +1 ( θ i ) = b t ( θ i ) P e src ( y t | p t , θ i ) P N j =1 b t ( θ j ) P e src ( y t | p t , θ j ) . Continuous hypothesis space (density f orm). If P e src ( dy | p, θ ) has a density p e src ( y | p, θ ) , then b t +1 ( θ ) = b t ( θ ) p e src ( y t | p t , θ ) R Θ b t ( θ ′ ) p e src ( y t | p t , θ ′ ) dθ ′ . Deterministic evaluator (indicator/filter form). If y = g e src ( p ; θ ) deterministically , then the update becomes b t +1 ( dθ ) ∝ 1 { g e src ( p t ; θ ) = y t } b t ( dθ ) , i.e. the posterior is the prior restricted to hypotheses consistent with the observed outcome. B P RO O F O F T H E O R E M 3 . 2 ( S T A T I C S A M P L E - E FFI C I E N C Y G A P ) Throughout this section we fix a single static environment (drop e from notation), and assume P = { p 1 , . . . , p K } is finite. B . 1 P R OT O C O L A N D P E R F O R M A N C E C R I T E R I O N Experiment–then–commit protocol. A policy π interacts for T rounds. At each round t = 0 , . . . , T − 1 it selects a program p t ∈ P (possibly randomized) based on the past history h t , then observes y t ∈ R . After T ev aluations it outputs a final recommendation ˆ p ∈ P . Simple regr et. Let f ( p ) denote the true mean performance of program p in this en vironment. Define the (random) simple regret SR T := max p ∈P f ( p ) − f ( ˆ p ) . (4) ( ϵ, δ ) -correctness (unif orm). Fix ϵ > 0 and δ ∈ (0 , 1) . W e say a policy π is ( ϵ, δ ) -corr ect uniformly on a hypothesis class H if for ev ery instance in H , Pr SR T ≤ ϵ ≥ 1 − δ. “Uniformly” means the guarantee must hold for all instances in the class, not only on av erage. 18 Preprint B . 2 T W O H Y P O T H E S I S C L A S S E S (1) Structured (causal/scientific) linear class. Each program p has a kno wn feature vector x p ∈ R d with ∥ x p ∥ 2 ≤ 1 . The unknown instance is a weight vector w ⋆ ∈ R d and f ( p ) = ⟨ x p , w ⋆ ⟩ . (5) Observations follo w a Gaussian noise model y t = f ( p t ) + ε t , ε t ∼ N (0 , σ 2 ) i.i.d. (6) Assume there exist d basis programs p (1) , . . . , p ( d ) whose feature vectors are the standard basis: x p ( i ) = e i , i = 1 , . . . , d. (7) (2) Unstructured black-box class (baseline). The unknown instance is an arbitrary v ector of means µ = ( µ 1 , . . . , µ K ) ∈ R K , f ( p i ) = µ i , and observations are y t = µ I t + ε t , ε t ∼ N (0 , σ 2 ) i.i.d. , (8) where I t ∈ { 1 , . . . , K } is the index of the chosen program p t = p I t . Crucially , there is no assumed r elation between µ i and µ j for i = j . B . 3 F O R M A L S TA T E M E N T A N D P R O O F Theorem B.1 (F ormal version of Theorem 3.2 ) . F ix ϵ > 0 and δ ∈ (0 , 1 / 4) . 1. (Upper bound under the structured linear class). Under equation 5 –equation 7 and equation 6 , ther e exists a policy π lin such that Pr SR T ≤ 2 ϵ ≥ 1 − δ whenever T ≥ 2 d σ 2 ϵ 2 log 2 K δ . 2. (Lo wer bound for the unstructured black-box class). F or the black-box class equation 8 , any policy that is ( ϵ, δ ) -correct uniformly for all µ ∈ R K must satisfy T ≥ ( K − 1) σ 2 8 ϵ 2 log 1 2 δ . Pr oof. W e prove the tw o parts separately . Part (1): constructive upper bound (estimate w ⋆ then commit). Evaluate each basis program p ( i ) exactly n times (total T = nd ). Let y ( i ) 1 , . . . , y ( i ) n be the observations for basis i , and define ˆ w i := 1 n n X j =1 y ( i ) j . By equation 5 –equation 7 , f ( p ( i ) ) = w ⋆ i . By equation 6 , ˆ w i ∼ N ( w ⋆ i , σ 2 /n ) and these coordinates are independent. Define for any program p : b f ( p ) := ⟨ x p , ˆ w ⟩ , ˆ w = ( ˆ w 1 , . . . , ˆ w d ) . 19 Preprint Then b f ( p ) − f ( p ) = ⟨ x p , ˆ w − w ⋆ ⟩ ∼ N 0 , σ 2 n ∥ x p ∥ 2 2 , so since ∥ x p ∥ 2 ≤ 1 , Pr | b f ( p ) − f ( p ) | ≥ ϵ ≤ 2 exp − nϵ 2 2 σ 2 . Union bound ov er K programs gives Pr max p ∈P | b f ( p ) − f ( p ) | ≥ ϵ ≤ 2 K exp − nϵ 2 2 σ 2 . Choose n ≥ 2 σ 2 ϵ 2 log 2 K δ , so that with probability at least 1 − δ we hav e max p | b f ( p ) − f ( p ) | ≤ ϵ . Now output ˆ p := arg max p ∈P b f ( p ) . Let p ⋆ := arg max p f ( p ) . On the above high-probability e vent, f ( p ⋆ ) − f ( ˆ p ) ≤ f ( p ⋆ ) − b f ( p ⋆ ) + b f ( ˆ p ) − f ( ˆ p ) ≤ ϵ + ϵ = 2 ϵ. Thus Pr(SR T ≤ 2 ϵ ) ≥ 1 − δ for T = nd as stated. Part (2): lower bound f or the black-box class. W e construct K hard instances and lo wer bound an y uniformly ( ϵ, δ ) -correct policy . Let the programs be p 1 , . . . , p K . Define a base instance µ (0) ∈ R K : µ (0) 1 = 0 , µ (0) i = − 2 ϵ ( i = 2 , . . . , K ) . For each i ∈ { 2 , . . . , K } , define an alternative instance µ ( i ) : µ ( i ) 1 = 0 , µ ( i ) i = +2 ϵ, µ ( i ) j = − 2 ϵ ( j / ∈ { 1 , i } ) . Under µ (0) , the unique best program is p 1 , and choosing any p i with i ≥ 2 incurs regret 2 ϵ > ϵ . Under µ ( i ) , the unique best program is p i , and choosing p 1 incurs regret 2 ϵ > ϵ . Let P 0 be the distribution of the full transcript T := ( p 0: T − 1 , y 0: T − 1 , ˆ p ) under µ (0) , and P i the analogous distribution under µ ( i ) . Uniform ( ϵ, δ ) -correctness implies P 0 ( ˆ p = p 1 ) ≥ 1 − δ, P i ( ˆ p = p 1 ) ≤ δ ( i = 2 , . . . , K ) . Step 1: a KL lower bound fr om an event. For any e vent A and distributions P, Q , one has KL( P ∥ Q ) ≥ P ( A ) log P ( A ) Q ( A ) + (1 − P ( A )) log 1 − P ( A ) 1 − Q ( A ) . Apply it with A = { ˆ p = p 1 } , P = P 0 , Q = P i . Let p := P 0 ( A ) ≥ 1 − δ and q := P i ( A ) ≤ δ . F or δ ∈ (0 , 1 / 4) this yields KL( P 0 ∥ P i ) ≥ log 1 2 δ . (9) Step 2: compute KL( P 0 ∥ P i ) via number of pulls of arm i . Under µ (0) and µ ( i ) , the policy is identical; only observations when playing p i differ: y ∼ N ( − 2 ϵ, σ 2 ) under µ (0) , y ∼ N (+2 ϵ, σ 2 ) under µ ( i ) . 20 Preprint For Gaussians with equal v ariance, KL( N ( m 0 , σ 2 ) ∥N ( m 1 , σ 2 )) = ( m 0 − m 1 ) 2 2 σ 2 , so each pull of p i contributes KL (4 ϵ ) 2 2 σ 2 = 8 ϵ 2 σ 2 . Let N i be the (random) number of times p i is ev aluated in T rounds. Additi vity of log-likelihood ratios over independent Gaussian samples yields KL( P 0 ∥ P i ) = 8 ϵ 2 σ 2 E P 0 [ N i ] . (10) Step 3: conclude the lower bound on T . Combine equation 9 and equation 10 : E P 0 [ N i ] ≥ σ 2 8 ϵ 2 log 1 2 δ , i = 2 , . . . , K . Summing ov er i = 2 , . . . , K gives T = K X i =1 N i ≥ K X i =2 E P 0 [ N i ] ≥ ( K − 1) σ 2 8 ϵ 2 log 1 2 δ . This completes the proof. Remark (deterministic ev aluator). If σ = 0 , the structured linear class can recov er w ⋆ exactly from d basis ev aluations and achiev e SR T = 0 , while in the unstructured black-box class a uniform worst-case guarantee requires ev aluating all K programs at least once. Reference f or the black-box lower bound. The abov e is a standard change-of-measure/KL argument for best-arm identification in K -armed Gaussian bandits (e.g., see classical treatments of best-arm identification lower bounds). C P RO O F O F T H E O R E M 3 . 3 ( N O N - I D E N T I FI A B I L I T Y U N D E R E N V I R O N M E N T S H I F T S ) C . 1 S E T U P : S O U R C E I N T E R AC T I O N , T A R G E T E V A L UAT I O N , A N D TA R G E T R E G R E T The agent can only interact with the sour ce environment e src : y t ∼ P e src ( · | p t , θ ⋆ ) . After T rounds it outputs a final program ˆ p . Performance is judged in a tar get en vironment e tgt via F e tgt ( p ; θ ⋆ ) . Define the target (simple) re gret: GR T ( θ ⋆ ) := max p ∈P F e tgt ( p ; θ ⋆ ) − F e tgt ( ˆ p ; θ ⋆ ) . C . 2 F O R M A L S TA T E M E N T A N D P R O O F Theorem C.1 (Non-identifiability barrier under shifts) . F ix e src , e tgt ∈ E . Assume ther e exist two hypotheses θ 0 , θ 1 ∈ Θ such that: (Source indistinguishability) P e src ( · | p, θ 0 ) = P e src ( · | p, θ 1 ) , ∀ p ∈ P . (11) (T arget optimal action flips with margin ∆ ) ∃ p 0 , p 1 ∈ P and ∆ > 0 s.t. (12) p 0 ∈ arg max p ∈P F e tgt ( p ; θ 0 ) , p 1 ∈ arg max p ∈P F e tgt ( p ; θ 1 ) , F e tgt ( p 0 ; θ 0 ) − F e tgt ( p ; θ 0 ) ≥ ∆ , ∀ p = p 0 , F e tgt ( p 1 ; θ 1 ) − F e tgt ( p ; θ 1 ) ≥ ∆ , ∀ p = p 1 . (13) 21 Preprint Then for any policy π that can interact only with e src , ther e exists i ∈ { 0 , 1 } such that for e very budg et T , E GR T ( θ i ) ≥ ∆ / 2 . This impossibility holds whether the evaluator is stochastic or deterministic, since equation 11 is stated at the level of the full observation model P e src . Pr oof. Let P i be the distribution o ver the full transcript T := ( p 0: T − 1 , y 0: T − 1 , ˆ p ) when the true hypothesis is θ i and interaction is only with e src . By equation 11 , for any history and any chosen action p t , the conditional distribution of y t is identical under θ 0 and θ 1 . By induction on t , the entire transcript distrib ution is identical: P 0 = P 1 . In particular , the marginal distrib ution of the final output ˆ p is the same under θ 0 and θ 1 . Let this common distribution be denoted by Q on P . Now consider the e xpected target regret under θ 0 : by equation 13 , any output ˆ p = p 0 incurs regret at least ∆ under θ 0 : GR T ( θ 0 ) = F e tgt ( p 0 ; θ 0 ) − F e tgt ( ˆ p ; θ 0 ) ≥ ∆ · 1 { ˆ p = p 0 } . T aking expectation w .r .t. Q yields E [GR T ( θ 0 )] ≥ ∆ · (1 − Q ( ˆ p = p 0 )) . Similarly , E [GR T ( θ 1 )] ≥ ∆ · (1 − Q ( ˆ p = p 1 )) . Since Q ( ˆ p = p 0 ) + Q ( ˆ p = p 1 ) ≤ 1 , at least one of these probabilities is at most 1 / 2 , so at least one of the two expected re grets is at least ∆ / 2 : max { E [GR T ( θ 0 )] , E [GR T ( θ 1 )] } ≥ ∆ / 2 . This prov es the claim. C . 3 C O N C R E T E E X A M P L E S S A T I S F Y I N G T H E C O N D I T I O N S W e gi ve two illustrati ve e xamples where source data cannot distinguish tw o hypotheses, yet the target-optimal decision differs. Example 1: public test vs private (distrib ution shift / shortcut feature). Let θ ∈ { θ 0 , θ 1 } encode which feature is truly stable/causal. Programs correspond to two model families: p 0 uses a stable causal feature; p 1 uses a shortcut feature. In the source environment (public benchmark), the shortcut feature is perfectly correlated with labels, so both hypotheses yield the same ev aluator distribution for e very program, satisfying equation 11 . In the tar get environment (deplo yment/priv ate), the shortcut correlation breaks: under θ 0 , p 0 is uniquely optimal; under θ 1 , p 1 is uniquely optimal, with margin ∆ , satisfying equation 13 . No amount of interaction with e src can identify which world holds. 22 Preprint T able 3: Mathematical definitions of auxiliary metrics across tasks. All metrics are deterministic outcome- lev el functionals of the program outputs. For subset-defined metrics (e.g., large circle margin ), if the index set is empty , the metric value is defined as 0 . T ask Program Output A ux Metric Definition Hadamard Matrix H ∈ {± 1 } n × n binary matrix row orthogonality deviation 1 n ( n − 1) X i = j X k H ik H j k row sum variance V ar X j H ij element balance 1 n 2 X i,j 1 [ H ij = +1] log10 abs det log 10 | det( H ) | Second Autocorr Inequality f ∈ R n , f i ≥ 0 nonnegati ve discrete function smoothness score 1 n − 1 X i | f i +1 − f i | center concentration X | x i |≤ 0 . 5 f i / X i f i sparsity 1 n X i 1 [ f i < ε ] peak to average ratio max i f i / E [ f ] tail mass X | x i | > 0 . 5 f i / X i f i entropy − X i p i log p i , p i = f i / X j f j Circle Packing { ( C i , r i ) } N i =1 circle centers and radii density score X i πr 2 i / S 2 center spread index 1 N X i ∥ C i − ( S/ 2 , S/ 2) ∥ 2 radius std normalized Std( r ) / E [ r ] neighbor distance ratio 1 N X i min j = i ∥ C i − C j ∥ 2 / r i large circle margin 1 | I | X i ∈ I min( C x i , S − C x i , C y i , S − C y i ) − r i , I = { i : r i > E [ r ] } pairwise radii product sum X i
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment