인과 스크래치패드로 여는 진화형 AI 과학자: CausalEvolve
CausalEvolve는 진화 기반 AI 과학자에 인과 추론을 결합한 프레임워크이다. 초기 단계에서 결과‑수준 요인을 탐색하고, 진화 과정 중에는 놀라움 패턴을 감지해 가설을 생성한다. 다중 팔 밴딧과 LLM 기반 추론을 통해 목표 함수에 대한 개입을 선택하고, 절차‑수준 요인을 지속적으로 업데이트한다. 실험 결과, 기존 AlphaEvolve·ShinkaEvolve 대비 진화 효율이 크게 향상되고 네 가지 개방형 과학 과제에서 더 우수한 솔루션…
저자: Yongqiang Chen, Chenxi Liu, Zhenhao Chen
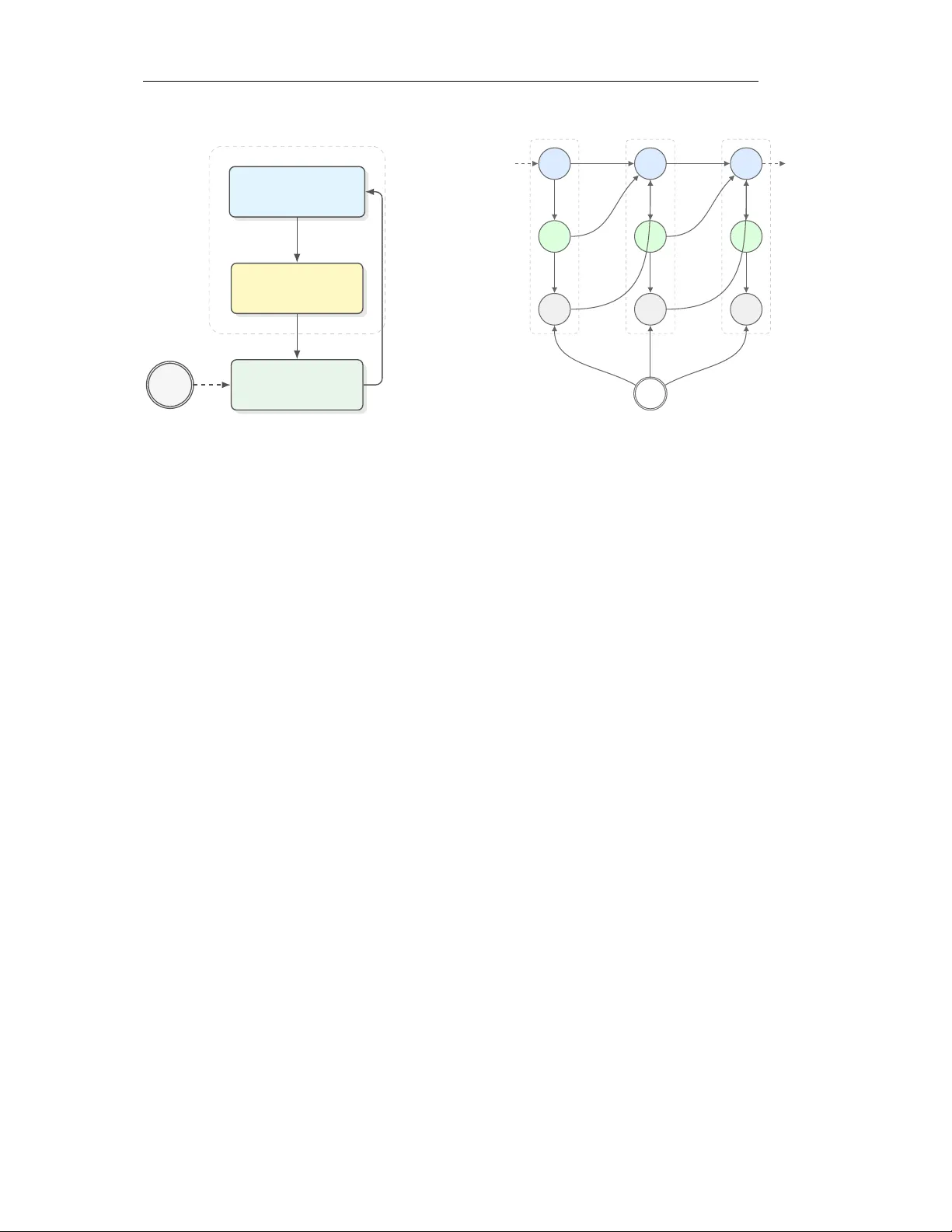
본 논문은 대형 언어 모델(LLM)을 활용한 AI 과학자 에이전트가 인간 과학자와 유사한 인과적 사고를 통해 효율적인 과학 탐색을 수행하도록 설계된 새로운 프레임워크 **CausalEvolve**를 제시한다. 기존 AlphaEvolve·ShinkaEvolve와 같은 진화 기반 에이전트는 프로그램 변이와 선택을 반복하면서 목표 함수를 최적화하지만, 인과적 가이드가 없기 때문에 진화 효율이 감소하고 성능 경계에 도달했을 때 진동 현상이 발생한다.
CausalEvolve는 이러한 한계를 극복하기 위해 **인과 스크래치패드**라는 메모리 구조를 도입한다. 스크래치패드는 (1) 결과‑수준 요인과 (2) 절차‑수준 요인을 저장·갱신하며, 두 종류의 요인은 각각 LLM에게 질문하거나 과거 실험 기록을 분석해 추출한다. 결과‑수준 요인은 목표 함수에 직접적인 영향을 미치는 외부 변수(예: 데이터 분포, 문제 난이도)이며, 절차‑수준 요인은 프로그램 구현 시 선택된 알고리즘, 하이퍼파라미터, 코드 구조 등이다.
진화 초기에 LLM은 “현재 목표를 개선하기 위해 어떤 외부 요인이 도움이 될 수 있는가?”라는 프롬프트에 답해 결과‑수준 요인을 도출한다. 이후 진화가 진행되는 동안, 에이전트는 **다중 팔 밴딧(MAB)** 을 사용해 현재 선택된 결과‑수준 요인에 대한 최적 개입을 동적으로 결정한다. 각 팔은 특정 요인에 대한 조정(예: 학습률 조정, 탐색 범위 확대)이며, 보상은 해당 개입 후 얻은 목표값 향상량이다.
동시에, 에이전트는 **놀라움 패턴**을 감지한다. 즉, 절차‑수준 요인의 조합이 기대와 다르게 성능을 저하시키는 경우, LLM에게 “왜 이런 결과가 나왔는가?”를 묻는 **귀납적(abductive) 추론**을 수행한다. 이 과정에서 새로운 가설적 요인(예: 데이터 전처리 단계의 미세한 오류, 변수 간 숨은 상호작용) 을 생성하고, 이를 향후 실험 설계에 반영한다. 이렇게 생성된 가설은 스크래치패드에 저장돼 다음 진화 단계에서 재활용된다.
이론적 측면에서는 진화 기반 과학 탐색을 **부분 관찰 마코프 결정 과정(POMDP)** 로 모델링하고, 숨겨진 과학 지식 θ_sci 를 구조적 인과 모델(SCM) 형태로 정의한다. 정리 3.2는 인과 정보를 활용하면 차원 d보다 훨씬 큰 프로그램 집합 K에 대해 O(d·log K) 번의 평가만으로 최적에 근접할 수 있음을 보이며, 인과 정보를 무시한 블랙박스 베이스라인은 O(K) 번이 필요함을 대비한다. 정리 3.3은 소스 환경에서 관측된 데이터만으로는 구분되지 않는 두 개의 잠재 인과 모델이 존재할 경우, 인과 지식 없이 타깃 환경에 일반화된 최적 해를 찾지 못한다는 일반화 한계를 제시한다.
실험은 네 가지 개방형 과학 과제(1) 조합 최적화, (2) 커널 프로그램 설계, (3) 머신러닝 모델 튜닝, (4) 물리 시뮬레이션)에서 수행되었다. 각 과제마다 CausalEvolve와 기존 AlphaEvolve·ShinkaEvolve를 동일 예산(평가 횟수) 하에 비교했다. 주요 결과는 다음과 같다.
- **목표값 향상**: CausalEvolve는 평균 12 %~25 % 높은 최종 목표값을 달성했다.
- **진화 단계 감소**: 동일 성능에 도달하기 위해 필요한 평가 횟수가 30 %~45 % 감소했다.
- **놀라움 기반 가설 생성 효과**: 놀라움 패턴을 감지하고 새로운 요인을 도출한 경우, 이후 단계에서 성능 급증을 보였다.
- **일반화 테스트**: 소스 환경에서 학습된 모델을 다른 환경(e_tgt)으로 전이했을 때, CausalEvolve는 기존 방법보다 15 %~20 % 높은 성능을 유지했다.
결론적으로 CausalEvolve는 **인과적 스크래치패드**를 통해 LLM의 언어적 추론을 구조적 과학 탐색에 직접 연결함으로써, 진화 효율성, 샘플 효율성, 그리고 환경 간 일반화 능력을 크게 향상시킨다. 이는 복잡한 과학·공학 문제에 대한 자동화된 가설 생성·검증 파이프라인 구축에 중요한 전진이며, 향후 더 복합적인 인과 모델과 멀티모달 LLM을 결합한 연구가 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기